



Fine Tuning LLMs: Part 1 - Just Getting Started
Table of Contents
There are a few ways we can customise a Large Language Model (LLM), and one of those ways is to fine-tune it.
But why fine-tune an LLM?
Large language models (LLMs) like GPT-3 and Llama have shown immense promise for natural language generation. With sufficient data and compute, these models can produce remarkably human-like text. However, off-the-shelf LLMs still have limitations. They may generate text that is bland, inconsistent, or not tailored to your specific needs. This is where finetuning comes in. Finetuning is the process of taking a pre-trained LLM and customizing it for a specific task or dataset. With finetuning, you can steer the LLM towards producing the kind of text you want. - https://medium.com/@dave-shap/a-pros-guide-to-finetuning-llms-c6eb570001d3
As well I just want to make a little disclaimer here on decisions I’ve made. :)
DISCLAIMER
Please note that what I’ve done here is really a personal experiment in fine-tuning an LLM. There’s no particular rhyme or reason to the infrastructure and other choices I’ve made. I’m using a particular GPU supplier. I’m using a certain Python notebook. I’ve made some choices that might actually make things more difficult, or that might not make sense to an experienced fine-tuner. Also, in this post, I’m not tuning with a specific set of data or goal in mind. I’m just trying out a set of basic tools.
Happy hacking!
Quick Fine Tuning Example
Steps:
- Get a GPU from somewhere (I’m using brev.dev)
- Create an instance with proper CUDA and pytorch versioning
- Build a data set to fine-tune with (or use an existing one), NOTE: This step I will build on in later posts
- Use a Unsloth iPython notebook
- Step through the provided notebook and create a fine-tuned LLM
GPU Instance
First, we need a GPU.
NOTE: The easiest thing to do would just be to use Google Colab and the notebook that Unsloth links to; that would be super easy. Google Colab is a free cloud service to run Jupyter Notebooks and provides access to GPUs. But I’m not using Colab for…some reason. You might want to. Keep that in mind!
I’m using brev.dev to get access to a GPU instance, but there are tons of “GPU Brokers” out there.
NOTE: I have no relationship with brev.dev, I just randomly started using the service. I can’t tell you if it’s good or not, but the combination of the provider plus the docker image for CUDA + pytorch is working for me. Plus if you leave the GUI console for long enough, a cute DVD-style screen saver comes on. lol!
Here I’m creating a small NVIDIA 4090 instance. Other much larger GPUs are available from brev.dev and other providers.
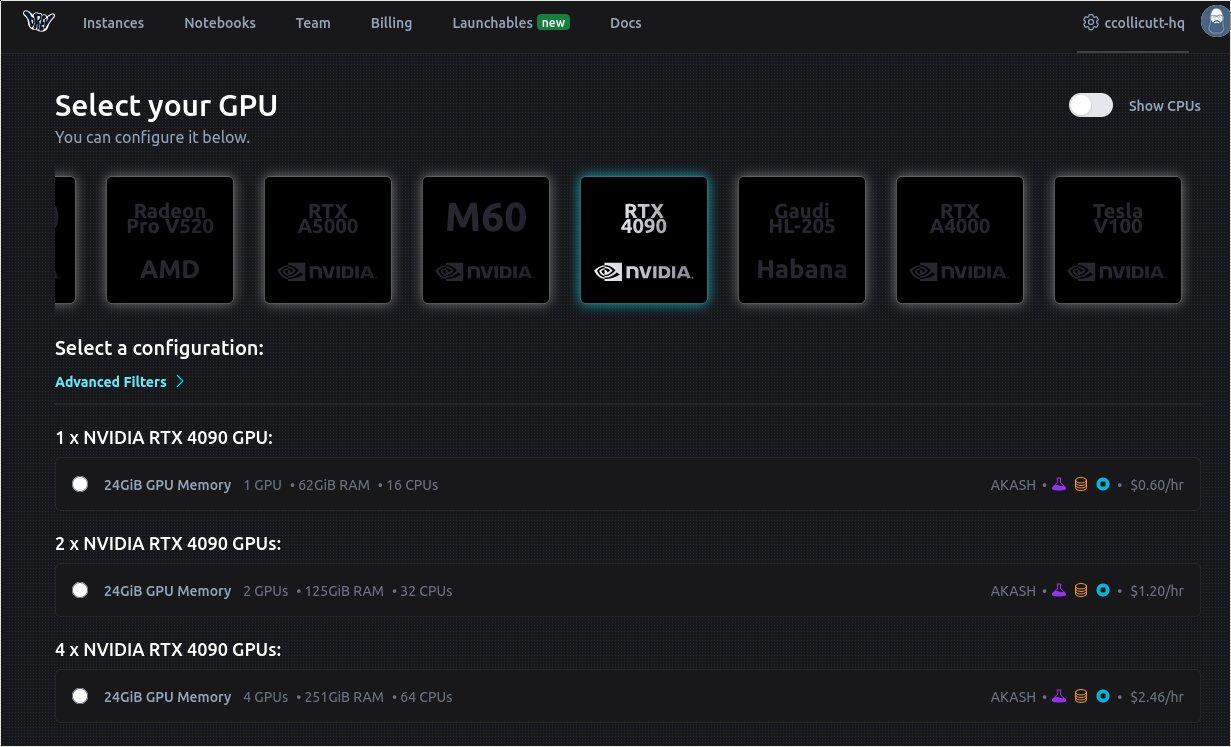
Note that I’m using the “advanced container settings” and selecting the docker.io/pythorch/pytorch:2.2.0-cuda12.1-cudnn8-runtime image. This is key because I’ve had lots of problems matching up these versions, especially on my home workstation where I have a NVIDIA 3090.
I find versioning CUDA and Pytorch challenging so this is a really nice feature of brev.dev, though it’s really just about dialing in the right image/settings/etc.
Once the instance is running there is an option to connect to a notebook.
And now we can use the notebook.

Or you can login with the the brev shell. Here my instance is brilliantly named “aaa”.
$ brev shell aaa
⢿ waiting for SSH connection to be available Agent pid 9158
Warning: Permanently added '[provider.pdx.nb.akash.pub]:31314' (ED25519) to the list of known hosts.
Welcome to Ubuntu 22.04.3 LTS (GNU/Linux 5.15.0-101-generic x86_64)
* Documentation: https://help.ubuntu.com
* Management: https://landscape.canonical.com
* Support: https://ubuntu.com/advantage
This system has been minimized by removing packages and content that are
not required on a system that users do not log into.
To restore this content, you can run the 'unminimize' command.
➜ verb-workspace
Connection to provider.pdx.nb.akash.pub closed.
Unsloth Notebook
Next I’ll upload the unsloth conversational notebook, which I obtained by opening the Colab notebook and downloading the file, then uploading it into the brev.dev instance’s notebook.
NOTE: There are a lot of notebooks for getting started training Llama3 out there. For example brev.dev has some too. As well, unsloth provides some via huggingface.
Unsloth - https://github.com/unslothai/unsloth
Unsloth is a lightweight library for faster LLM fine-tuning which is fully compatible with the Hugging Face ecosystem (Hub, transformers, PEFT, TRL). The library is actively developed by the Unsloth team (Daniel and Michael) and the open source community. The library supports most NVIDIA GPUs–from GTX 1070 all the way up to H100s–, and can be used with the entire trainer suite from the TRL library (SFTTrainer, DPOTrainer, PPOTrainer). At the time of writing, Unsloth supports the Llama (CodeLlama, Yi, etc) and Mistral architectures. - https://huggingface.co/blog/unsloth-trl
I’m using the conversational notebook they link to in their README. That will bring you to a
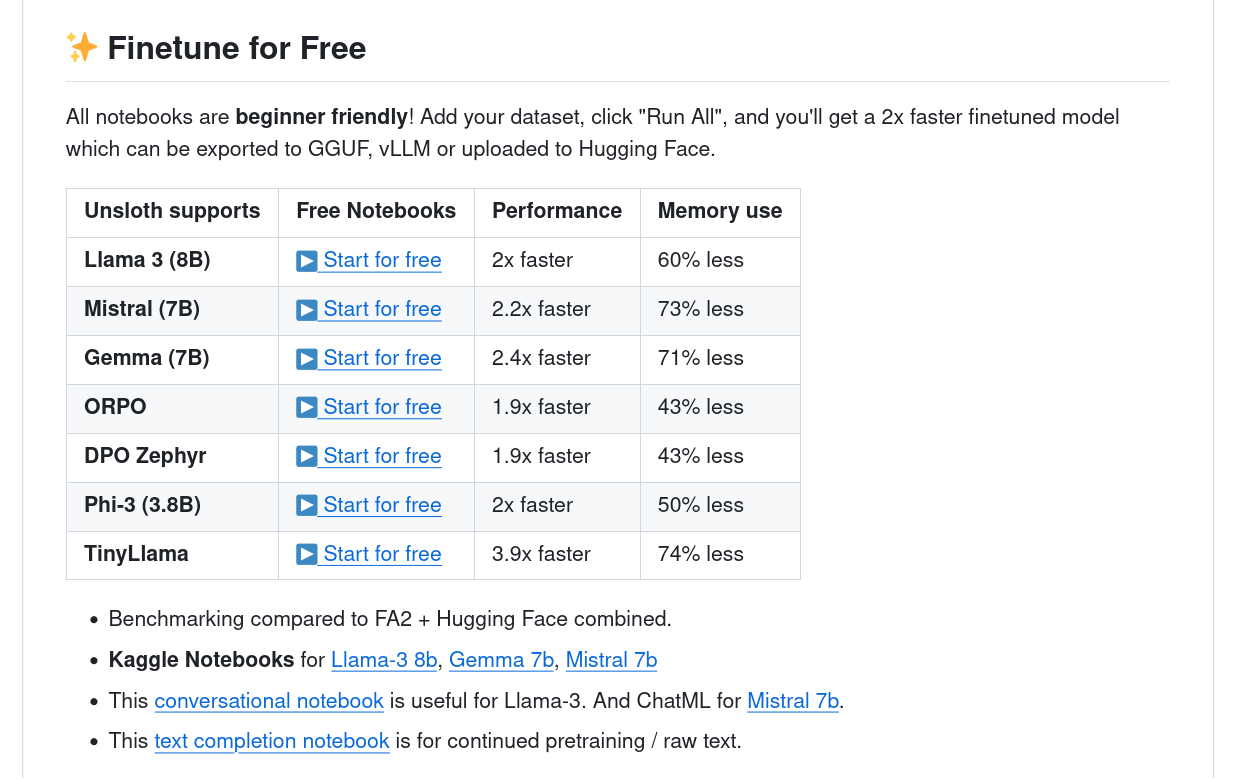
Train the Model
Now we can simply step through the notebook and train an example model.
After stepping through the cells, we come to the training cell.
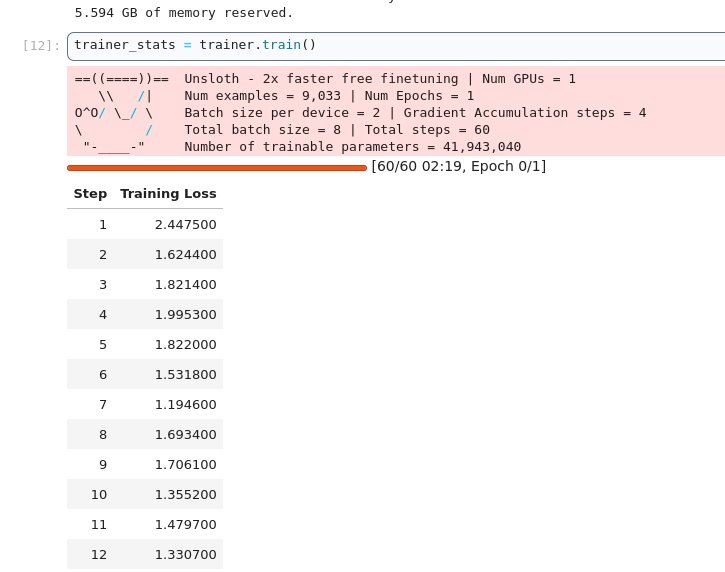
And we can see the memory usage.
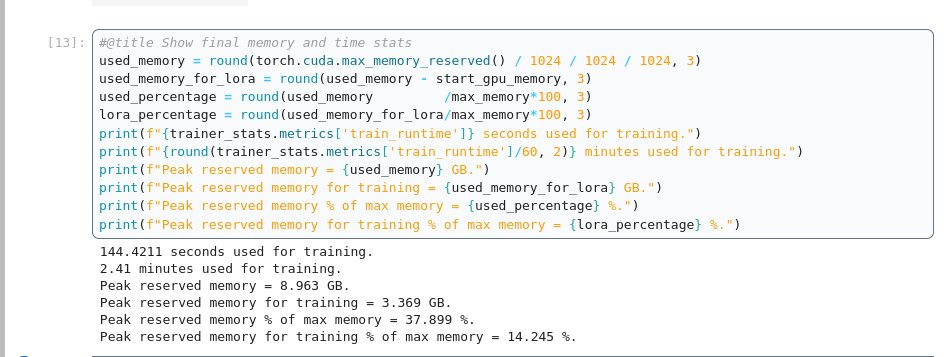
If you continue through the notebook you can save the model in various ways, upload it to hugging face, etc.
Conclusion
The technical part of fine-tuning a model is fairly straightforward from a user perspective if you know a bit of Python and understand the concept of a Jupyter notebook and have one to follow through with. Really this blog post is just connecting some dots, like GPU providers and Python notebooks. However, navigating through a notebook and understanding exactly what it does are two different things. Also, once you start understanding the fine tuning process, it becomes a matter of what data we put in and what results we get out. That is the real work. This is just a basic skeleton, but everyone needs a first step!
PS.
One of the things I love about LLMs right now is just how messy the technology landscape is. There is so much going on, so many niche technologies, libraries, chunks of code, websites, notebooks, on and on. It’s an amazing time.