



Virtual NSX-t and TKGI Lab
Table of Contents
I used to do a lot of work in the telecom field, especially around Network Function Virtualization (NFV) and I’ve deployed several Software Defined Networks (SDN) into production. I’ve even seen a few good ones come into existence, and then sometimes disappear.
Now that I work at VMware in the Tanzu group, I work with VMware’s SDN system NSX-t and, of course, Kubernetes. One way that VMware can provide customers with k8s is via Tanzu Kubernetes Grid Integrated Edition (TKGI) which was previously called the Pivotal Container Service, or PKS. IMHO, TKGI works best with NSX-t. Networking is key to running k8s effectively.
NSX-t, TKGI, k8s…these are all complicated technologies. There is just no way around it. The best way to learn how it all works is to deploy it. Currently I have what I consider to be a simpler virtual lab setup of NSX-t and TKGI deployed as virtual infrastructure, meaning that the ESXI hosts are virtual machines.
tl;dr
This isn’t really a prescriptive document, it’s more like a bunch of notes on some things I did to build this lab. On one hand it seems complex due to the use of a virtual vcenter and esxi nodes, but ultimately this is the simplest deployment of NSX-t and TKGI on vSphere that is possible. It’s really not that challenging and I actually ran into ZERO issues. I didn’t have one single problem getting this working (unless I’ve just missed something, lol). That said, I’ve been running NSX-t and TKGI in my lab for quite a while. For this deployment I was looking at NSX-t 2.5 and EPMC, neither of which I’ve deployed previously.
Lab Design
The point of this particular lab is to create similar environment as to what would be deployed in a TKGI + NSX-t + vSphere proof of concept. This means that:
- Only 2 nics are used on the ESXI hosts
- There is no high availability at all, especially with regards to network traffic
- Trying to deploy the least amount of resources
- The EPMC system is used to abstract away the deployment of ops manager and bosh, and the initial setup of TKGI -> NSX-t connectivity
Virtual ESXI
Thank goodness for the fact that you can run ESXI hosts as virtual machines. This makes it a lot easier to build up lab infrastructure for learning how it all works and deploying it in many different ways. William Lam’s virtual ESXI content library is a godsend and allows me to build all kinds of fun infrastructure. having only recently been introduced to vSphere it’s taken me a while to get to the point where I’m building virtual clusters.
I’ve got three virtual, nested, esxi nodes in a vSphere cluster.
$ govc find . -type h
/Datacenter/host/Cluster/10.0.1.237
/Datacenter/host/Cluster/10.0.1.238
/Datacenter/host/Cluster/10.0.1.239
These are the resources they have:
$ govc host.info /Datacenter/host/Cluster/10.0.1.237
Name: 10.0.1.237
Path: /Datacenter/host/Cluster/10.0.1.237
Manufacturer: VMware, Inc.
Logical CPUs: 16 CPUs @ 2000MHz
Processor type: Intel(R) Xeon(R) CPU E5-2650 0 @ 2.00GHz
CPU usage: 7694 MHz (24.0%)
Memory: 65534MB
Memory usage: 39759 MB (60.7%)
Boot time: 2020-05-10 01:32:26.217102 +0000 UTC
State: connected
And these are all the vms that have been created for a full TKGI deployment, with one cluster deployed.
$ govc find . -type m
/Datacenter/vm/pks_vms/vm-6dbd0bf0-9b12-40fd-bd06-05898d3f6a18
/Datacenter/vm/pks_vms/vm-05632c06-2abd-4997-a7db-d5366f798281
/Datacenter/vm/pks_templates/sc-a0414145-7c72-4991-9c87-1539fe36efe6
/Datacenter/vm/pks_vms/vm-d341f649-fe5b-4487-9702-18ea60c265c9
/Datacenter/vm/pks_vms/vm-422cbe25-f60d-4ae4-a2bb-2254f9dcf1eb
/Datacenter/vm/pks_vms/vm-1456f8d2-24c3-4790-a622-9e9c6ef579e0
/Datacenter/vm/opsman-WnmxrhR3zg
/Datacenter/vm/pks-management-console-1.7.0-rev.1-978372
/Datacenter/vm/pks_vms/vm-3b5fbbc7-bc27-43b7-a40b-4c2984419b3b
/Datacenter/vm/pks_templates/sc-6f5a71cb-5949-4697-9245-418ece3d0182
/Datacenter/vm/nsx-unified-appliance-2.5.1.0.0.15314292
/Datacenter/vm/pks_vms/vm-7fd9e63c-3276-439e-a358-e074d0f4d453
/Datacenter/vm/pks_vms/vm-fbc5e464-56cf-4eca-aad6-0e46f1bb3144
/Datacenter/vm/pks_templates/sc-8caf221d-a04c-4f48-8747-f7cead82e788
/Datacenter/vm/nsx-edge1
As you can see, there is an ops manager instance, a nsx manager, and an nsx edge instance. As well, there is a bosh director as well, and finally a TGKI management console (here called “pks-management-console”).
There is a lot of abstraction going on here, e.g. EPMC deploys Ops Manager, which deploys the Bosh Director, which deploys the TKGI API, which deploys the TGKI clusters.
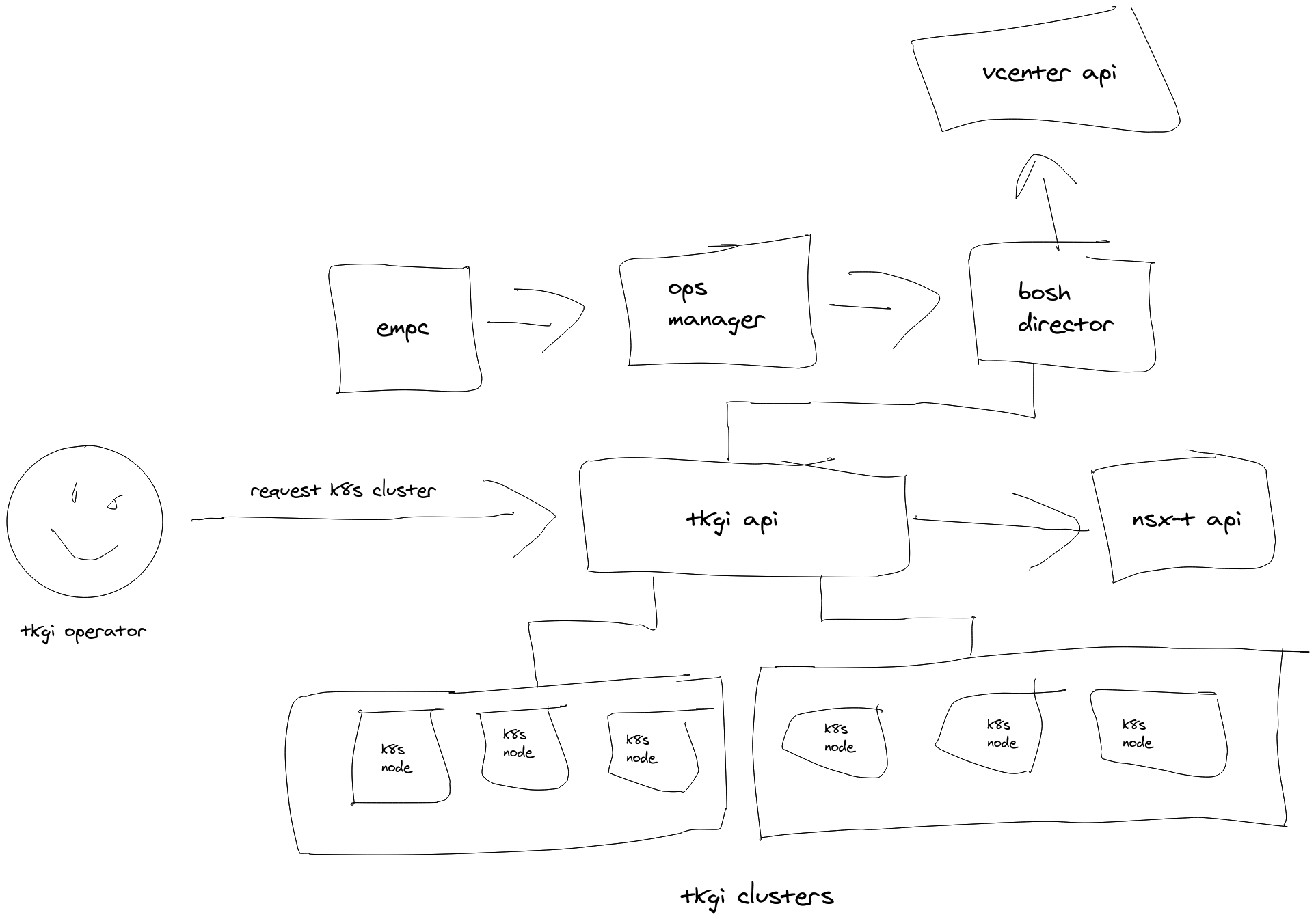
One of the most important features of TKGI is that it is a k8s cluster life cycle manager, it can deploy and manage N k8s clusters.
Enabling Nested Networking
There are a lot of ways to approach this setup. I took this approach
for h in $(govc find . -type h | grep -v nested); do \
govc host.portgroup.add -vswitch vSwitch0 -vlan 4095 -host=$h NestedVLANTrunk; \
done
to add a VLAN trunk that the nested esxi hosts would have access to to get trunk VLAN traffic, i.e. see more than one VLAN on a virtual nic.
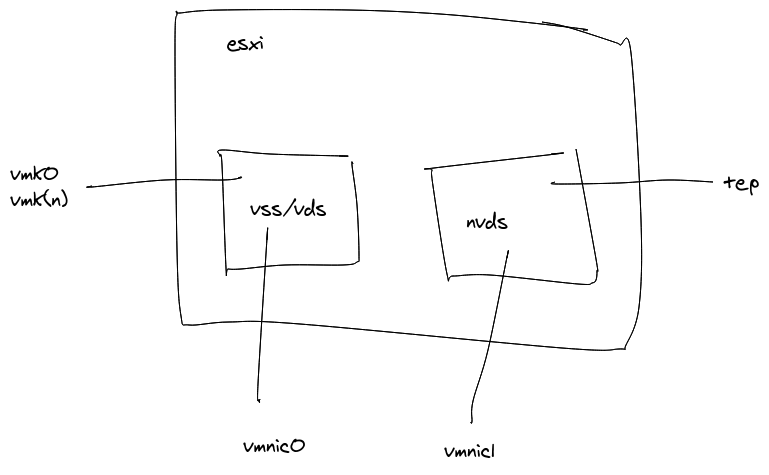
In the image below the nested esxi vm has two nics, one on the NestedVLANTrunk and one on “nested-pks-poc-nsx-tep” which is a physical VLAN in the underlying physical network, but one specifically setup for the nsx tep traffic. So this design only has 2 nics, which is nice, and what would typically be done in a physical proof of concept.
Then in the nested vcenter there are more networks defined, which are VLANS available on the NestedVLANTrunk interface. The initial VSS based networks were migrated onto VDS. So there is the “VM Network” (also VLAN101), and a network for “vmotion” as well. And, of course, the “nsx-uplink” and “nsx-tep” networks. Again, these are all physical VLANs in this lab, and are presented to the virtual vsphere system, in this case via the VLAN trunk and the distributed port group.
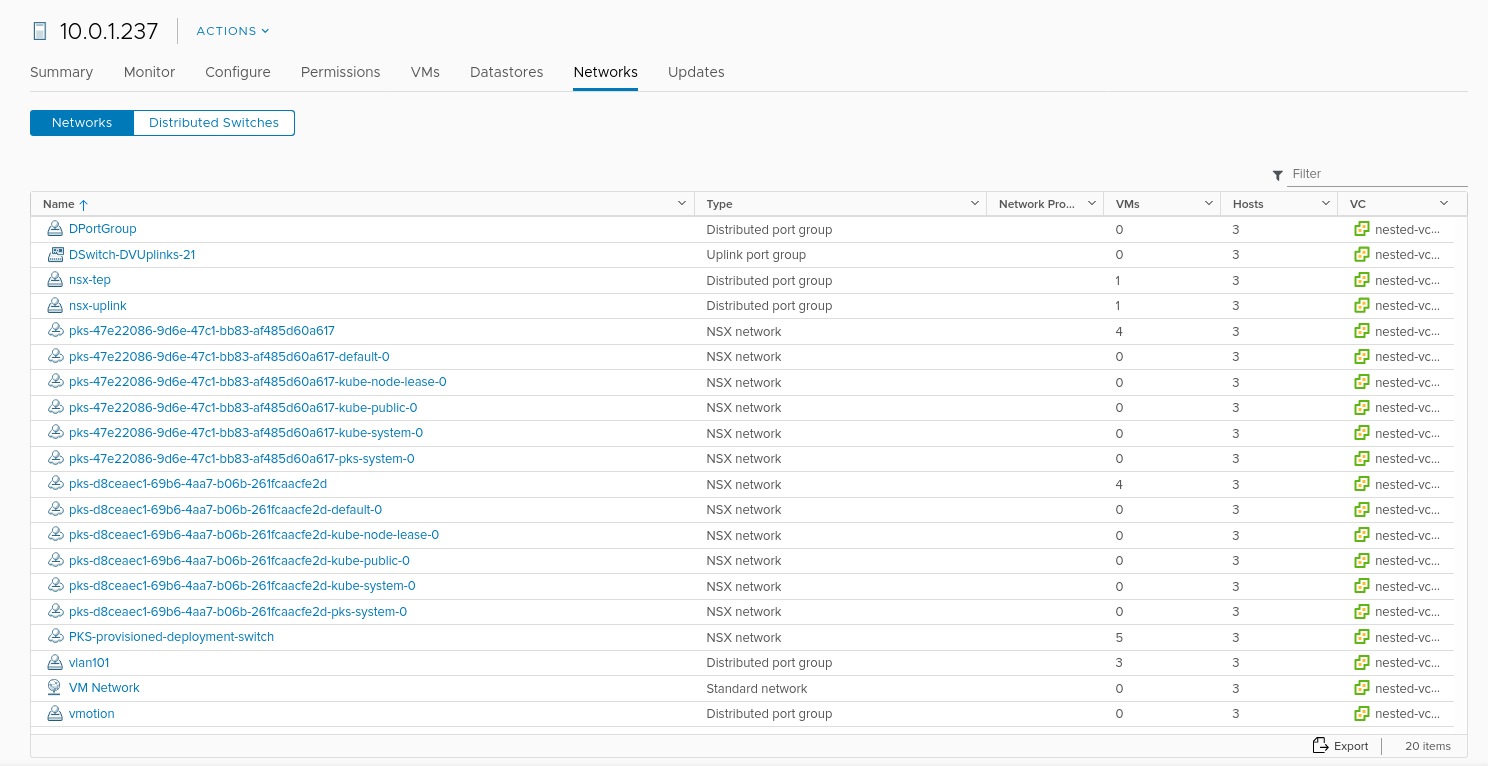
I suppose it’s a bit confusing that I’m using VSS in the physical hosts and VDS in the virtual ones, but that’s what I did.
Also, and this is important, promiscuous networking must be enabled in the er…physical virtual switch in the physical esxi nodes. As well note that the MTU is set to 1600.
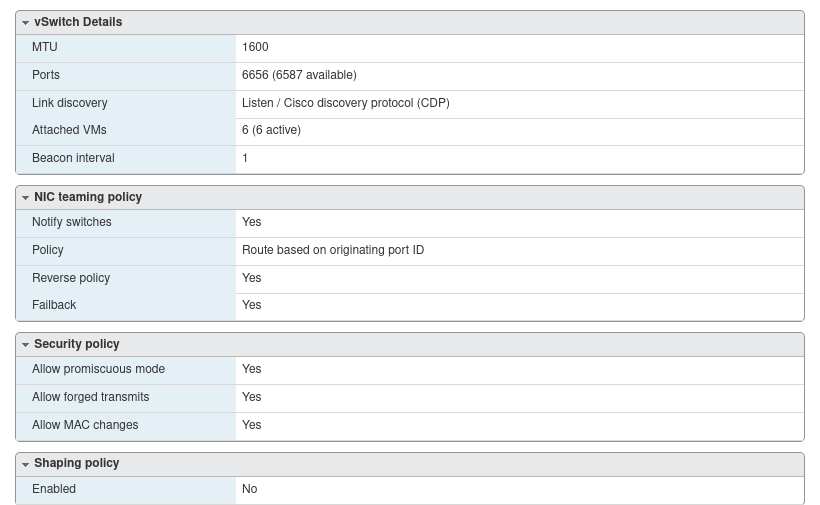
Also the DVS in the nested VCSA has a 1600 MTU.
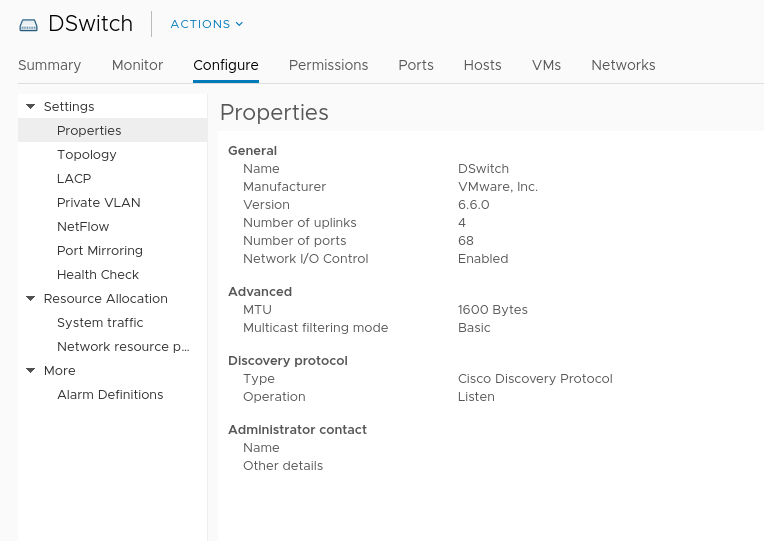
NSX-t Configuration
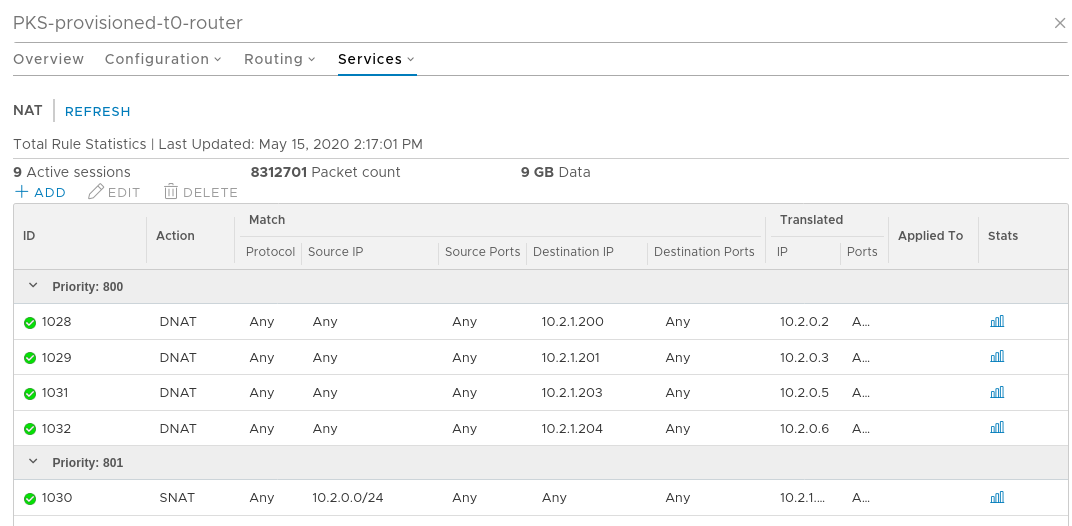
The configuration for this lab is bog standard, 2 NIC setup. The topology is the standard, most commonly used NAT model.
Everything is NATed. The T0 router has several DNAT and SNAT configurations.
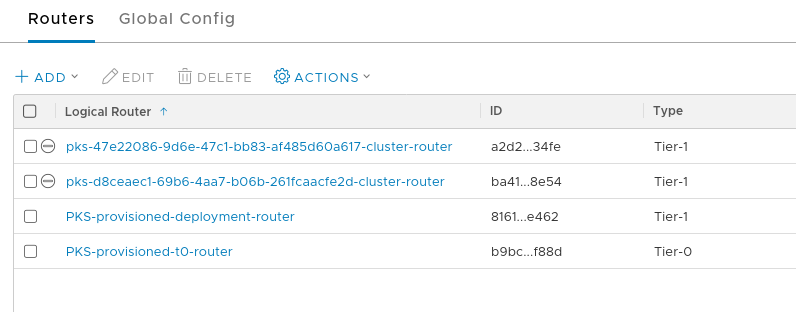
With TKGI 1.7, each k8s cluster gets its own T1 router. Right now there are 2 k8s clusters.
I created 3 VLANs in the physical network for this lab. There is also the “VM Network” which is 10.1.0.0/24 and has most management interfaces. Note that I just use /24s because it’s my lab.
name vlan range
nested-pks-poc-vmotion 119 10.0.19.0/24
nested-pks-nsx-tep 120 10.0.20.0/24
nested-pks-nsx-uplink 121 10.0.21.0/24
My habit, though it is a ridiculously sized network, is to set a static route for my NSX T0 routers and give them a /16. Within that /16 I’ve designated a couple /24s for use by NSX, most importantly the 10.2.1.0/24 range which is floating IPs for load balancers, etc. Because I’m using a simple static route there’s no need for BGP setup.
10.2.0.0/16 static route pointed to T0 router at 10.0.21.100
10.2.0.0/24 deployment range
10.2.1.0/24 floating ips
10.2.0.0/24 is the deployment range, and that is where things like ops manager and bosh director end up.
EPMC
EPMC is a great tool that helps to abstract away the complexity of the underlying TKGI deployment, especially around ops manager, bosh, and NSX-t networking configuration. And what’s more, it allows operators to download the configuration as a set of files. EPMC has a familiar, wizard like interface to take operators through configuration all the TKGI components. Though note that NSX-t has to be in place already, but not configured for TKGI.
Below is a screenshot of the network configuration as set up in EPMC.
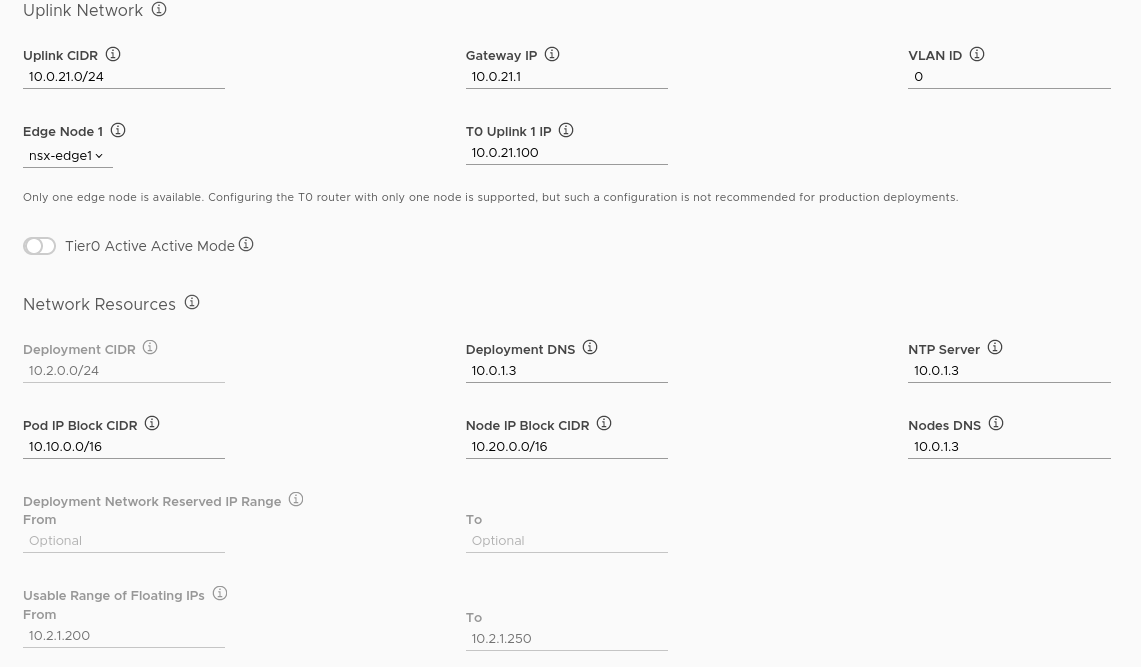
As mentioned, you can download the configuration file which is powerful, as you can reuse it.
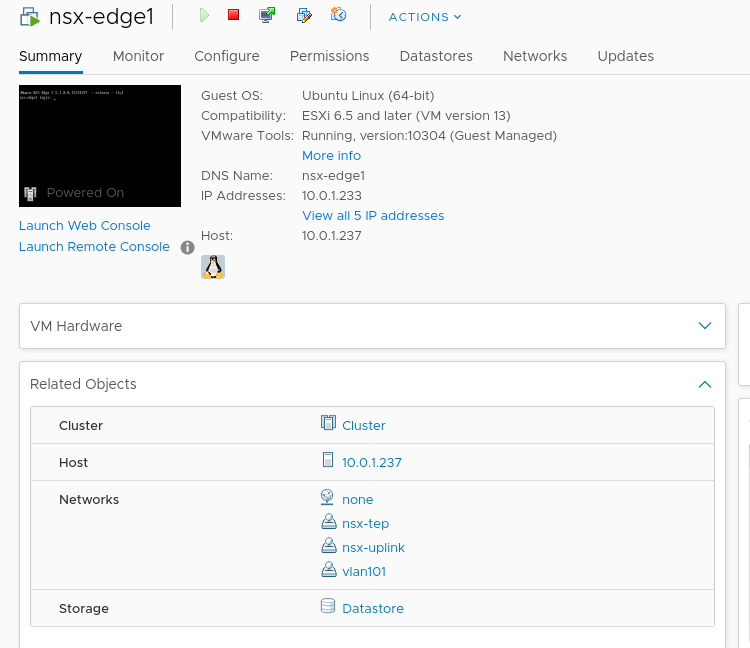
NSX Edges
When NSX-t is deployed it needs at least one edge node.
One of the more challenging things to understand about deploying NSX is that the ESXI nodes are (usually) physical, and the edge nodes virtual, but, in this design, they all need to be able to access TEP interface IPs…they need that reachability. Layer 2 is not required for this reachability, but in the case of this particular design, the edge nodes have an interface on the TEP VLAN and vnic1 on the ESXI nodes is also connected to that same VLAN as an access port, i.e. it looks like VLAN 0 to them. Please note that NSX-t is extremely flexible, and this design is the most basic.
This blog post describes a couple of different ways to deploy nsx edges. Typically 4 nics are expected. This particular deployment is the one they have a not so subtle warning about:
In a Collapsed Compute and Edge Cluster topology, compute host is prepared for NSX-T which implies that this host has N-VDS installed and is also configured with a Tunnel End point. This deployment option is NOT recommended on a host with two pNICs. The simple reason being, this host has two virtual switches now, a VSS/VDS and a N-VDS, each consuming one pNIC. So, there is no redundancy for either of the virtual switches. A host with 4 pNICs or more is recommended in this deployment option. NSX-T Edge VM deployment or configuration doesn’t change from option 1 as the Edge VM still leverages the VSS/VDS portgroups.
But that’s fine for this lab because it’s not meant for production.
So the nsx edge, a virtual machine, has 3 nics in use:
- Access to the TEP network
- Access to the uplink network
- A management interface
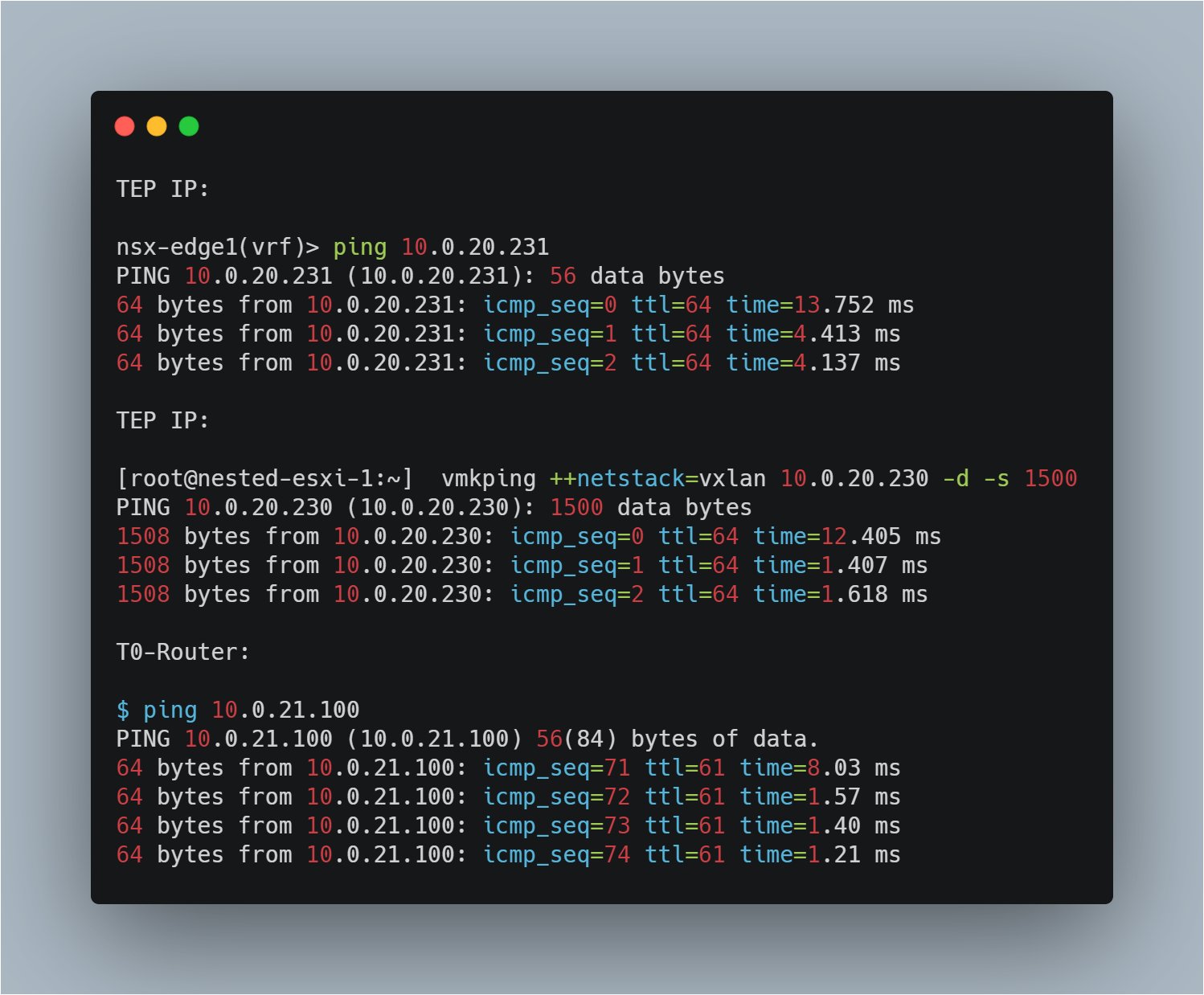
Pings
Can’t network without pings. :)
Conclusion
So there you have it, a somewhat haphazard tour of a virtual, 2 nic TKGI + NSX-t deployment. You could do this on a single ESXI host.