



OpenStack Multi-site, Multi-clouds, and Distributed Clouds
Table of Contents
One OpenStack cloud is rarely enough. Most organizations that deploy one OpenStack cloud will, at some point, at least think about deploying a second. Some organizations will not only want to depoy a couple clouds, but maybe 10, or 20, or 50…or even more. In some industries, such as telecommunications, organizations may want to deploy hundreds of OpenStack instances. And, as unbelievable as it sounds, some use cases require thousands. But what are the options available when deploying more than one OpenStack cloud? How would we deploy 2, 10, or 100+ clouds?
In this post I will go over some options and their pros and cons, as well as consider some of the features and architectural changes OpenStack may need to implement in order to meet the requirements of use cases such as massively distributed clouds.
I should also mention that this post is based on a talk I did at the 2017 Boston OpenStack summit with two colleagues, Adrien Lebre and Chaoyi Huang. Adrien is the chair of the “Fog, Edge, and Massively Distributed Working Group” and Chaoyi works on the Tricircle and Kingbird projects and is active in many areas of Network Function Virtualization (NFV). I learned a lot from the two of them while putting together the presentation. I won’t link to the video here, because I’m not a huge fan of being recorded, but a simple Youtube search will find it. :)
Definitions
Terminology for multiple OpenStack clouds is difficult. Some people use different terms for the same thing, and use the same terms for different things. I’ll make a couple of definitions, but be aware that other people might not use them the same way I do, or might disagree with my choices.
Regions/Multi-region: When I talk about multi-region, I essentially mean that the OpenStack Keystone database is shared in some fashion.
Mult-site: I define multi-site as having multiple OpenStack clouds, but no shared Keystone.
Fog/Edge/Massively Distributed: I will use these interchangeably. Essentially it means that we have many small “data centers” (which may not be datacenters at all) and there will be only a few hypervisors located there–the OpenStack control plane will be remote, ie. in a different datacenter. This is for use cases like retail and such where an organization has thousands of locations, and many one or two hypervisors in each location.
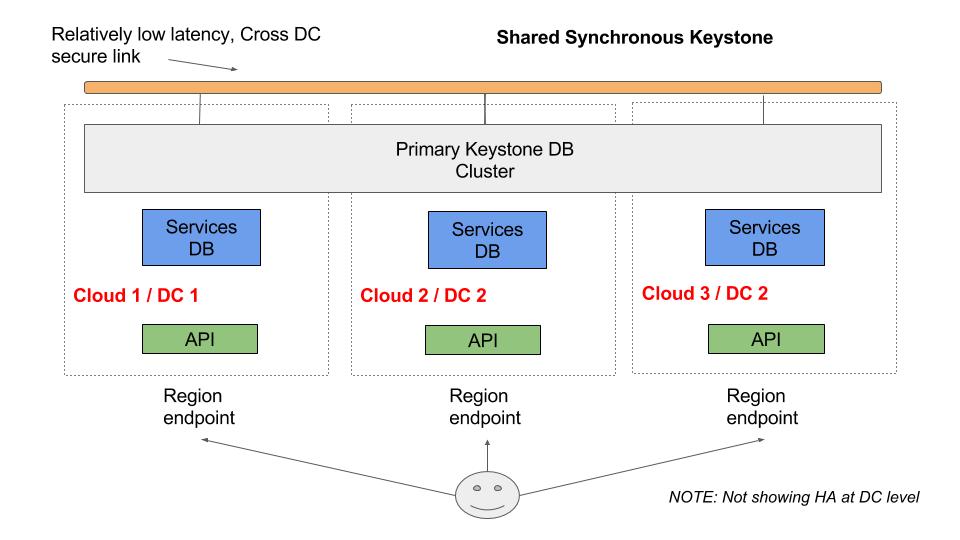
OpenStack Regions - The Historical Method
I used to work at a public cloud in Canada which was based on OpenStack. We planned on having two OpenStack regions in Canada, one in Vancouver and one in Toronto. OpenStack regions are a good way to manage authentication and authorization for two or three OpenStack clouds (or more, depending on your risk profile). The fact that I mention authorization (authz) and authentication (authn) is important, because in general this is all regions provide–shared identity. Only Keystone (and potentially Glance and Horizon) are suited for being shared across regions. Most of the other services, such as Nova and Neutron, will have completely separate installations in each region, and are not shared.
We’ve established that with regions we share Keystone in some fashion. In the image above, we can see a simplistic diagram of a Keystone that is shared across datacenters of a secure, private link. Each datacenter has MySQL Galera nodes that are part of a Galera cluster that exists across multiple datacenters.
To share the Keystone across mutliple datacenters you have three main options:
Centralized Keystone DB: In this model there is only one centralized Keystone database, and the other regions access the database directly via the WAN link; they have no local Keystone DB.
Asyncronous Keystone DB: Here you would have database instances in each region/DC, but only one would be the “master” version (ie. read/write) and the other regions would have their DBs asynchronously updated by the master, ie. they would be secondary databases.
Syncronous (Clustered) Keystone DB: Using MySQL/MaraiDB Galera clustering, the Keystone database would be synchronously shared across all regions. This is the model that is usually given as an example of regions.
All of these options have pros and cons. Asynchronous is probably the most scalable model, but overall my opinion is that none of these are all that useful. Essentially regions, as I define them, are no longer a good option.
The reality is that all a shared Keystone model buys you is shared authz/authn. We still have all kinds of other issues to deal with, from keys to images to determining how to share Neutron tenant networks across clouds. There are things that every OpenStack multi-cloud deployer wants, and regions don’t help with any of that. Further to this, using a shared Keystone has some additional cons, such as operational complexity, and the fact that the Keystone version would probably have to be the same across all clouds, making upgrades slightly more difficult.
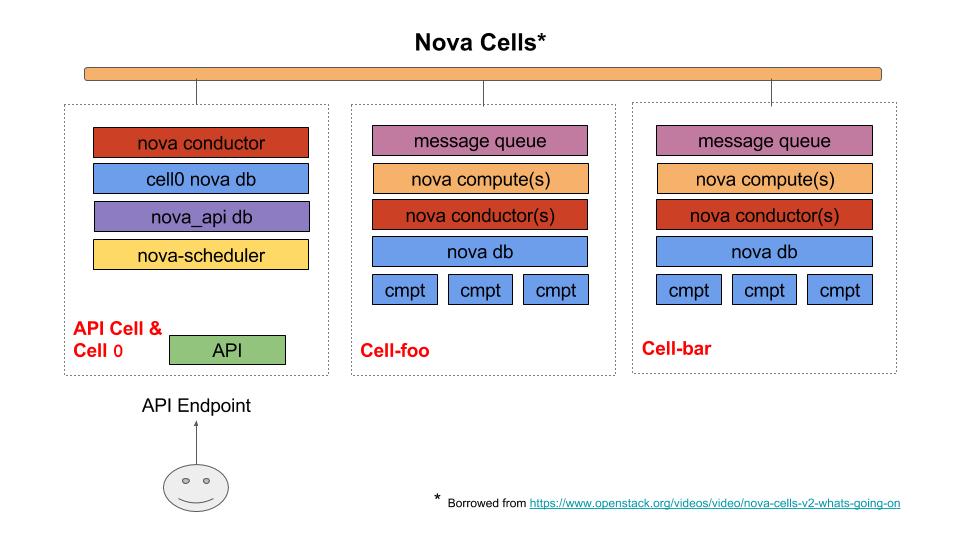
Nova Cells V2
Nova has had a cell model (V1) for quite some time. Essentially it allows the creation of reduced (Nova) failure domains and allows for better scalability. In V2 this is accomplished by adding a nova_api DB to the control plan, and a nova DB in the cell. Also each Cell has its own messaging queue (aka RabbitMQ). However, V1 is not widely used, and in fact I was recently at a OpenStack summit where Nova developers mentioned that they are surprised V1 even works.
However, V2 is is now default in OpenStack Ocata+. If you deploy Ocata you will have one cell. However, Cells V2 is not yet done, and in fact you can’t add additional cells. Right now you can have as many cells as you want as long as it’s one. This is expected to change in Pike or Queens. The point is that V2 will now be widely used, and at some point will be usable, and will enable Nova to be highly scalable.
Unfortunately, this is just for Nova. I would love to see a similar model applied to all major OpenStack projects. But even if they all decided they wanted to do that, it would probably take a couple years for the changes to make their way into the releases.
I’d also like to mention that, at least when Cells V2 is production ready, using it in combination with something like routed provider networks would be extremely powerful. I would consider routed provider networks complimentary to cells. Imagine doing Nova Cells V2 on a per rack basis, and also routed provider networks.
Shared LDAP
I should note that Keystone can authenticate to a LDAP backend, and that backend could be shared/synced across many clouds. Often this is done with Active Directory (which I know nothing about). But, of course, this just provides shared authn.
Shared-Nothing Multi-cloud
Mirantis has a good blog post on shared-nothing OpenStack multi-cloud. On first blush, it seems overly simplistic. We just deploy a bunch of completely separate clouds.
The reality is that you can’t just stop there. In a multi-cloud deployment with shared-nothing we are going to have to rely on some kind of 3rd party abstraction layer that sits above the clouds and manages users, groups, keys, images, etc. There is a lot of work required to implement that kind of model, as at least the 3rd party “cloud broker” must be implemented or developed. But, as Mirantis mentions, there are a lot of pros to using this model.
Realistically, if you are deploying 10s or 100s of clouds, this is probably the only model that will work (at least at this time).
ETSI MANO
Over the last year or so I have been doing a lot of work within the realm of “Network Function Virtualization” (NFV). The European Telecommunications Standards Institution (ETSI) has defined some NFV components. One of those complements is the “Management and Orchestration” (MANO) system. I’m sure there is a proper, specific definition for MANO, but I tend to see it as an amorphous blob that can take any shape and perform any function (ie. the ultimate lock-in).
There are several MANO vendors and open source projects. Suffice it to say that overall it seems like the MANO layer would not mind taking complete control of all OpenStack clouds. I’m not so sure that is a good idea, and may not be in OpenStack’s best interest. However, that doesn’t mean it’s not the best solution for telecommunications companies, such as AT&T. That said, MANO systems won’t be able to do absolutely everything without some help from additional projects, especially around networking.
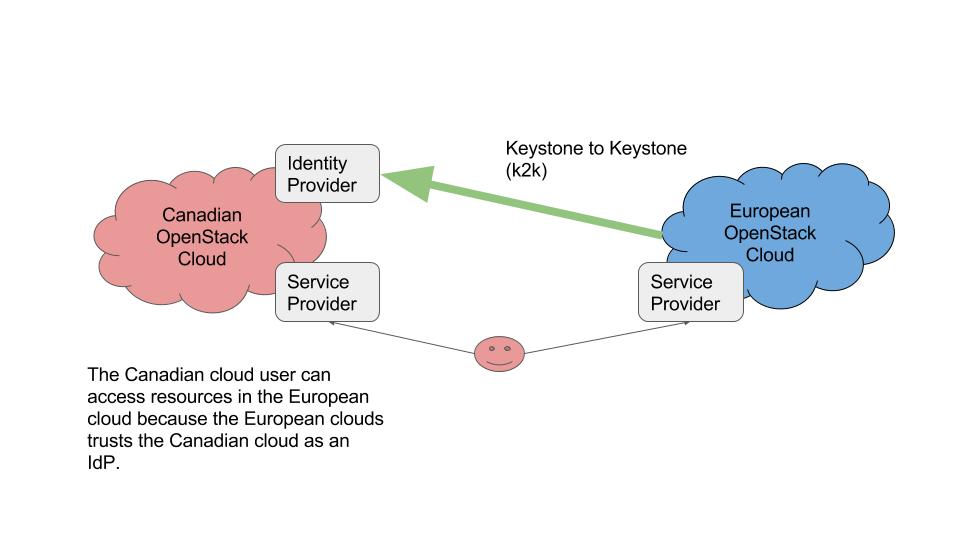
OpenStack Federation
Federation is a powerful technology that essentially allows one cloud to trust the users of another. The canonical use case for federation is when non-profit or academic institutions would like to enable their cloud users to utilize resources in another organizations cloud (and potentially vice-versa). Further to this, it could also be used as a form of centralized identity.
For this blog post I just want to go over some potential solutions, and don’t want to go in depth into any of the solutions in particular. In future blog posts I hope to go into federation more deeply.
Tricircle and Kingbird
There are a couple of projects I would like to mention that could be used to help deploy multiple clouds. As mentioned, it’s often desirable to have networking in OpenStack understand multi-cloud. Tricircle helps with this. Further, as mentioned, even if we used regions, we would still have to manage keys, images, and such. This is where Kingbird enters the picture.
I can’t comment much more on either of those projects as I have not used them. But, suffice it to say that they are in active development and are very important for organizations such as telecommunications companies who would like to deploy tens or hundreds of clouds.
Fog, Edge, and Massively distributed
As previously mentioned, there are use cases, such as retail stores with a couple hypervisors in each store, which we would consider as requiring some kind of massively distributed deployment model. This model does not currently exist, but there is a working group within the OpenStack community that is defining the surrounding use-cases, and over time will begin to define a recommended implementation.
It’s also fairly apparent to me that the OpenStack Foundation would like to see this use case supported. It is going to take a considerable amount of work to enable this use case, but over the next few releases I would expect to see it being earnestly discussed and worked on at some level. I’m excited to see increasing interest in the edge model, as to enable it we’ll have to make substantial changes to OpenStack.
Conclusion
OpenStack has some fairly rich authn/authz models. Unfortunately, my go to multi-cloud model of yesteryear, regions, doesn’t work (IMHO) when you have more than a handful of clouds, and doesn’t provide all that many features anyways. NFV deployments, and deployments requiring massively distributed hypervisors, won’t be able to use regions (not that they would help anyways), so we have to look at other models, some of which don’t yet exist.
Likely we will require a combination of tools such as software defined networking, perhaps Tricircle, Kingbird and massively distributed in order to deploy and operate large numbers of clouds. Generally speaking the telecommunications industry is going to drive these requirements as they are the ones that need thousands of tiny clouds or hundreds of small/medium ones.
It’s an exciting time in OpenStack, partially because I’m not sure what is going to happen. Will OpenStack pivot to support large NFV deployments? I think they will have to in order to continue to grow, assuming that is a goal. If not, then it is hard to say. Perhaps I’m just in denial that OpenStack just has to be able to provide shared-nothing clouds and some magical MANO or other higher layer abstraction along with SDN solutions and a couple cell-like models will be enough. What’s more, there does seem to be a lot of interest in creating an Open Source MANO solution, for example ONAP.