serverascode.com rss feed2023-12-18T18:55:31+00:00http://serverascode.com/curtisgithubcurtis@serverascode.comMy Cyberpunk Weekend - Part 3: Using Docker and GPUs2023-12-18T00:00:00+00:00http://serverascode.com/2023/12/18/cyberpunk-weekend-3<h1 id="my-cyberpunk-weekend---part-3-using-docker-and-gpus">My Cyberpunk Weekend - Part 3: Using Docker and GPUs</h1>
<p>I’m working on running LocalAI. But I feel like running that out of Docker.</p>
<p>So how to use a GPU with Docker (on Linux).</p>
<p>First, need the <code class="language-plaintext highlighter-rouge">nvidia-docker2</code> driver. Otherwise you get an error like this:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>docker: Error response from daemon: could not select device driver "" with capabilities: [[gpu]].
</code></pre></div></div>
<p>So install that.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>sudo apt install nvidia-docker2
</code></pre></div></div>
<p>I had a fun thing to fix in that I had added some things to the “daemon.json” so had to fix that.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ sudo dpkg --configure -a
Setting up nvidia-docker2 (2.13.0-1) ...
Configuration file '/etc/docker/daemon.json'
==> File on system created by you or by a script.
==> File also in package provided by package maintainer.
What would you like to do about it ? Your options are:
Y or I : install the package maintainer's version
N or O : keep your currently-installed version
D : show the differences between the versions
Z : start a shell to examine the situation
The default action is to keep your current version.
*** daemon.json (Y/I/N/O/D/Z) [default=N] ? D
--- /etc/docker/daemon.json 2023-04-10 15:23:11.735382489 -0400
+++ /etc/docker/daemon.json.dpkg-new 2023-03-31 09:10:49.000000000 -0400
@@ -1,4 +1,8 @@
{
- "registry-mirrors": ["http://10.8.24.123"],
- "insecure-registries": ["https://some.registry"]
+ "runtimes": {
+ "nvidia": {
+ "path": "nvidia-container-runtime",
+ "runtimeArgs": []
+ }
+ }
}
</code></pre></div></div>
<p>Next, I have two NVIDIA GPUS, one old one and one newer, better one, the 3090, which is what I want to be using for LLMs.</p>
<p>So, locally I have two, as shown below.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ nvidia-smi
Mon Dec 18 11:35:39 2023
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 470.223.02 Driver Version: 470.223.02 CUDA Version: 11.4 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA GeForce ... Off | 00000000:06:00.0 Off | N/A |
| 0% 32C P8 12W / 350W | 10MiB / 24268MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 1 NVIDIA GeForce ... Off | 00000000:07:00.0 N/A | N/A |
| 44% 71C P0 N/A / N/A | 2574MiB / 3015MiB | N/A Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 1445 G /usr/lib/xorg/Xorg 4MiB |
| 0 N/A N/A 3231 G /usr/lib/xorg/Xorg 4MiB |
+-----------------------------------------------------------------------------+
</code></pre></div></div>
<p>But we can specify to use “device=0” only in the container, so we should only see one GPU.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ docker run -it --gpus "device=0" nvidia/cuda:11.4.3-base-ubuntu20.04 nvidia-smi
Mon Dec 18 16:33:29 2023
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 470.223.02 Driver Version: 470.223.02 CUDA Version: 11.4 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA GeForce ... Off | 00000000:06:00.0 Off | N/A |
| 0% 32C P8 10W / 350W | 10MiB / 24268MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
+-----------------------------------------------------------------------------+
</code></pre></div></div>
<p>BOOM!</p>
<p>One of the hard parts is figuring out what tag to use on the NVIDIA image. They are all listed here:</p>
<ul>
<li><a href="https://gitlab.com/nvidia/container-images/cuda/blob/master/doc/supported-tags.md">https://gitlab.com/nvidia/container-images/cuda/blob/master/doc/supported-tags.md</a></li>
</ul>
<p>Examples:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>11.4.3-base-ubuntu20.04 (11.4.3/ubuntu20.04/base/Dockerfile)
11.4.3-cudnn8-devel-ubuntu20.04 (11.4.3/ubuntu20.04/devel/cudnn8/Dockerfile)
11.4.3-cudnn8-runtime-ubuntu20.04 (11.4.3/ubuntu20.04/runtime/cudnn8/Dockerfile)
11.4.3-devel-ubuntu20.04 (11.4.3/ubuntu20.04/devel/Dockerfile)
11.4.3-runtime-ubuntu20.04 (11.4.3/ubuntu20.04/runtime/Dockerfile)
</code></pre></div></div>
<p>Note that these will change over time, of course. But if Docker reports it can’t find the tag, it’s likely because the tag is wrong, or has changed.</p>
My Cyberpunk Weekend - Part 2: The Llama2023-12-10T00:00:00+00:00http://serverascode.com/2023/12/10/cyberpunk-weekend-2<h1 id="my-cyberpunk-weekend---part-2-the-llama">My Cyberpunk Weekend - Part 2: The Llama</h1>
<p>Well, last week I picked up the 3090 GPU. This week I need to try to use it. That is not an easy feat because “drivers.”</p>
<p>My good old workstation is on Ubuntu 20.04. I should probably upgrade. I should probably not use this machine for AI work. But, I am.</p>
<p>Currently I’m using the nvidia-driver-470 that I’ve had for a while, as though it’s some sort of cherished antique that I’ll hand down to my children. I do remember it being a pain to get working, back when I only had one GPU.</p>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="nv">$ </span>dpkg <span class="nt">--list</span> | <span class="nb">grep </span>nvidia-driver
ii nvidia-driver-460 470.223.02-0ubuntu0.20.04.1 amd64 Transitional package <span class="k">for </span>nvidia-driver-470
ii nvidia-driver-470 470.223.02-0ubuntu0.20.04.1 amd64 NVIDIA driver metapackage
</code></pre></div></div>
<p>But to use a llamafile I need the right CUDA toolkit and driver match up. At first I installed 12.3, but then realized that’s not the driver I have. Need to match those up.</p>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="nv">$ </span>./llava-v1.5-7b-q4-server.llamafile <span class="nt">--n-gpu-layers</span> 35
building ggml-cuda with nvcc <span class="nt">-arch</span><span class="o">=</span>native...
nvcc fatal : Unsupported gpu architecture <span class="s1">'compute_30'</span>
/usr/local/cuda-12.3/bin/nvcc: returned nonzero <span class="nb">exit </span>status
building nvidia compute capability detector...
cudaGetDeviceCount<span class="o">()</span> failed: CUDA driver version is insufficient <span class="k">for </span>CUDA runtime version
error: compute capability detector returned nonzero <span class="nb">exit </span>status
</code></pre></div></div>
<p>Driver:</p>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="nv">$ </span>nvidia-smi | <span class="nb">grep </span>CUDA
| NVIDIA-SMI 470.223.02 Driver Version: 470.223.02 CUDA Version: 11.4 |
</code></pre></div></div>
<p>I didn’t want to break my workstation and thus for now wanted to stay on the 470 driver. So I installed the 11.4 CUDA toolkit.</p>
<p>First I purged the 12.3 CUDA toolkit:</p>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="nv">$ </span>dpkg <span class="nt">-l</span> | <span class="nb">grep</span> <span class="nt">-E</span> <span class="s2">"cuda|cublas|cufft|cufile|curand|cusolver|cusparse|gds-tools|npp|nvjpeg|nsight|nvvm"</span>
<span class="nv">$ </span><span class="c"># review that list</span>
<span class="nv">$ </span><span class="c"># now remove</span>
<span class="nb">sudo </span>apt-get <span class="nt">--purge</span> remove <span class="s2">"*cuda*"</span> <span class="s2">"*cublas*"</span> <span class="s2">"*cufft*"</span> <span class="s2">"*cufile*"</span> <span class="s2">"*curand*"</span> <span class="se">\</span>
<span class="s2">"*cusolver*"</span> <span class="s2">"*cusparse*"</span> <span class="s2">"*gds-tools*"</span> <span class="s2">"*npp*"</span> <span class="s2">"*nvjpeg*"</span> <span class="s2">"nsight*"</span> <span class="s2">"*nvvm*"</span>’’’
</code></pre></div></div>
<blockquote>
<p>NOTE: This requires setting up the NVIDIA repo! Not shown here.</p>
</blockquote>
<p>Then I installed the 11.4 CUDA toolkit:</p>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="nv">$ </span><span class="nb">sudo </span>apt-get <span class="nb">install </span>cuda-toolkit-11-4
</code></pre></div></div>
<p>Added this to my path:</p>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="nv">$ </span>which nvcc
/usr/local/cuda-11.4/bin/nvcc
</code></pre></div></div>
<p>Next I tried to run the llamafile again:</p>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="nv">$ </span>./llava-v1.5-7b-q4-server.llamafile <span class="nt">--n-gpu-layers</span> 35
building ggml-cuda with nvcc <span class="nt">-arch</span><span class="o">=</span>native...
nvcc fatal : Value <span class="s1">'native'</span> is not defined <span class="k">for </span>option <span class="s1">'gpu-architecture'</span>
/usr/local/cuda-11.4/bin/nvcc: returned nonzero <span class="nb">exit </span>status
building nvidia compute capability detector...
building ggml-cuda with nvcc <span class="nt">-arch</span><span class="o">=</span>compute_86...
NVIDIA cuBLAS GPU support successfully loaded
ggml_init_cublas: GGML_CUDA_FORCE_MMQ: no
ggml_init_cublas: CUDA_USE_TENSOR_CORES: <span class="nb">yes
</span>ggml_init_cublas: found 2 CUDA devices:
Device 0: NVIDIA GeForce RTX 3090, compute capability 8.6
Device 1: NVIDIA GeForce GTX 660 Ti, compute capability 3.0
cuBLAS error 3 at /home/curtis/.llamafile/ggml-cuda.cu:6091
current device: 1
</code></pre></div></div>
<p>But it was using the wrong card. I believe the error was due to using the old 660Ti and trying to compile for it using CUDA 11.4.</p>
<p>Setting <code class="language-plaintext highlighter-rouge">CUDA_VISIBLE_DEVICES=0</code> fixed that:</p>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="nv">$ </span><span class="nb">env</span> | <span class="nb">grep </span>CUDA
<span class="nv">CUDA_VISIBLE_DEVICES</span><span class="o">=</span>0
<span class="nv">$ </span>./llava-v1.5-7b-q4-server.llamafile <span class="nt">--n-gpu-layers</span> 35
NVIDIA cuBLAS GPU support successfully loaded
ggml_init_cublas: GGML_CUDA_FORCE_MMQ: no
ggml_init_cublas: CUDA_USE_TENSOR_CORES: <span class="nb">yes
</span>ggml_init_cublas: found 1 CUDA devices:
Device 0: NVIDIA GeForce RTX 3090, compute capability 8.6
<span class="o">{</span><span class="s2">"timestamp"</span>:1702258585,<span class="s2">"level"</span>:<span class="s2">"INFO"</span>,<span class="s2">"function"</span>:<span class="s2">"main"</span>,<span class="s2">"line"</span>:2650,<span class="s2">"message"</span>:<span class="s2">"build info"</span>,<span class="s2">"build"</span>:1500,<span class="s2">"commit"</span>:<span class="s2">"a30b324"</span><span class="o">}</span>
<span class="o">{</span><span class="s2">"timestamp"</span>:1702258585,<span class="s2">"level"</span>:<span class="s2">"INFO"</span>,<span class="s2">"function"</span>:<span class="s2">"main"</span>,<span class="s2">"line"</span>:2653,<span class="s2">"message"</span>:<span class="s2">"system info"</span>,<span class="s2">"n_threads"</span>:6,<span class="s2">"n_threads_batch"</span>:-1,<span class="s2">"total_threads"</span>:12,<span class="s2">"system_info"</span>:<span class="s2">"AVX = 1 | AVX2 = 1 | AVX512 = 0 | AVX512_VBMI = 0 | AVX512_VNNI = 0 | FMA = 1 | NEON = 0 | ARM_FMA = 0 | F16C = 1 | FP16_VA = 0 | WASM_SIMD = 0 | BLAS = 0 | SSE3 = 1 | SSSE3 = 1 | VSX = 0 | "</span><span class="o">}</span>
Multi Modal Mode Enabledclip_model_load: model name: openai/clip-vit-large-patch14-336
clip_model_load: description: image encoder <span class="k">for </span>LLaVA
clip_model_load: GGUF version: 3
clip_model_load: alignment: 32
clip_model_load: n_tensors: 377
clip_model_load: n_kv: 19
clip_model_load: ftype: q4_0
SNIP!
</code></pre></div></div>
<p>That’s about as far as I’m getting this weekend.</p>
<p>Here’s a fun command to watch the GPU:</p>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code>nvidia-smi <span class="nt">--query-gpu</span><span class="o">=</span>timestamp,name,pci.bus_id,driver_version,pstate,pcie.link.gen.max,pcie.link.gen.current,temperature.gpu,utilization.gpu,utilization.memory,memory.total,memory.free,memory.used <span class="nt">--format</span><span class="o">=</span>csv <span class="nt">-l</span> 5
</code></pre></div></div>
My Cyberpunk Weekend - Part 1: The Video Card (Or Neural Core, Take Your Pick)2023-12-04T00:00:00+00:00http://serverascode.com/2023/12/04/cyberpunk-weekend<h1 id="my-cyberpunk-weekend---part-1-the-video-card-or-neural-core-take-your-pick">My Cyberpunk Weekend - Part 1: The Video Card (Or Neural Core, Take Your Pick)</h1>
<p>There are a couple of ways to think about this post:</p>
<p>Option 1 (boring):</p>
<blockquote>
<p><em>I bought a video card and installed it in my computer.</em></p>
</blockquote>
<p>Option 2 (cheesy cliché cyberpunk; more fun):</p>
<blockquote>
<p><em>In the gray low-rent business suburbs on the edge of the city, where the air hums with the buzz of a thousand illicit transactions, I found myself trudging through a seedy strip mall, its flickering signs casting long shadows over an assortment of massage parlors. Here, amid the cacophony of distant traffic and the murmur of hushed conversation, lay my destination: a dubious, fly-by-night eBay store. The place was a cybernetic bazaar, a maze of used technology and questionable merchandise covered in handwritten labels. Navigating the cramped aisles, I sought a particular treasure–a used AI processor, a critical component for powering my large language model efforts. The store’s operators, engaged in a rapid exchange in a language completely foreign to me, barely acknowledged my presence as their faces, etched with lines of weary experience, hesitated for a brief moment before extracting the neural core straight from the guts of a humming, overworked system host. The device, a relic of technological ambition, was burning hot and singed their fingertips, but not enough to deter them from accepting the cash I offered.</em></p>
</blockquote>
<p>LOL. I’m not sure which one is better. I’ll let you decide.</p>
<h2 id="generative-artificial-intelligence">Generative Artificial Intelligence</h2>
<p>Like most people, I have been surprised by the big changes in Artificial Intelligence (AI) over the last few years…surprised, caught off guard, out of the “know” and out of the loop.</p>
<p>Also, like many people, I’ve been a big user of generative AI, but I don’t have a good understanding of how it works. I hope to change that. I want to be able to run Large Language Models (LLMs) locally, so first, I needed to get a video card–a GPU–capable of running these models.</p>
<h2 id="its-just-a-video-card">It’s Just a Video Card?</h2>
<p>It’s kind of amazing that I can use the phrase “video card” in connection with AI; that there’s any connection between the two at all. What’s a video card for? Connecting to a monitor. Playing video games. But for AI? It’s a bit of a stretch, but it’s true.</p>
<p>So my first step was to find the right video card, the right graphics processing unit (GPU), to work with AI. After a bit of research it seemed like my best bet, the best value card, was to find a used NVIDIA 3090, mostly because it has 24GB of memory and is a good price at this time.</p>
<p>There were a lot of comments and thoughts on sites like Reddit with this kind of advice:</p>
<blockquote>
<p><em>The 3090 is the best bang for your buck. It comes with 24gb of nvram in a single consumer card with a built-in cooling solution and plugs right into your home rig. It lets you run 33b GPTQ models without fuss.</em></p>
</blockquote>
<h2 id="kijiji---the-canadian-craigslist">Kijiji - The Canadian Craigslist</h2>
<p>Living in Toronto has some advantages in that you can find anything you need used–it’s out there, you just have to search and wait. It’s kind of like what I imagine living in a big city in China would be like - everything is available, you just have to go out and find it, maybe meet some interesting people along the way.</p>
<p>In Canada we have a site called Kijiji (not even sure how to spell it) which is like Craigslist–but a Canadian Craigslist–so I started looking for a used NVIDIA 3090 GPU with 24GB of memory.</p>
<p>Of course, there are all kinds of problems with buying a used video card on Kijiji, or anything else for that matter, but I was willing to take the risk in this case. Plus, it can be fun if you don’t mind possibly losing the money on a bad purchase. I’ve bought quite a few things on Kijiji and never had a problem, it’s really about finding the right person to buy from, like anything else in life. I’ve never been ripped off, but you will find some difficult people. I have a whole story about buying a canoe on Kijiji, but that’s for another time. Of course, you always want to keep your wits about you and meet in a public place.</p>
<p>I set up a search on Kijiji and there are usually a few 3090s for sale, usually around $1000 to $1200. Then I saw a post from a local person, just a few blocks away in fact, who was selling one for $700. “Quick sale,” the ad said. I contacted them, but I wasn’t quick enough, and they sold it in a couple of hours before I could get over there.</p>
<p>Eventually, I saw another ad for a used 3090 that had been pulled from a Dell Alienware workstation for $800 (Canadian) and contacted them about it. They said to give them a few hours notice before coming by to pick it up. Seemed like a good deal, so I said I’d give it a shot. Presumably, if it was from an Alienware computer, it was probably used for gaming, not crypto mining, which is a positive. On the other hand, the people selling it probably knew the value if they were going to part it out, i.e., sell the Alienware box as pieces instead of the entire thing, which means they are professional in some respect.</p>
<p>A day or two later I went to pick it up. Their store was in a strip mall surrounded by massage parlors, which seemed a little seedy at first because there were more than one, but next to the computer store was a regular car dealership, so I figured it couldn’t be that bad. I pulled open the door to the shop, which was so jammed I was not sure I could get it open, and walked into a room completely filled with old computers and a couple of people working feverishly testing them and putting large strips of tape with non-English words on them. Stacks and stacks of computers, half of them falling over.</p>
<p>I told them I was there for the video card and they asked me to wait a few minutes and showed me the card, which looked to be in perfect condition. I asked them if they would benchmark it for me, i.e. put it in a computer and run some tests. They hummed and hawed, but finally agreed to do it. He put it in a computer and ran Furmark and it seemed to work fine. To be honest, I don’t know that much about graphics cards or how they’re supposed to work, I mostly just watched the temperature and made sure the card was working. While the benchmark was running, they were talking to each other in a language I didn’t recognize, so I was never sure exactly what they were saying to each other. Sadly I only speak one language. But they were busy, which means they don’t have time to mess around with people. Frankly, they seemed like exactly the kind of place where you’d buy a used video card pulled from a high-end workstation.</p>
<p>During the benchmark, the temperature of the card went up quite a bit, I think around 85 degrees, but I wasn’t surprised. I asked them where they sold all these computers, the ones stacked around the place, and the elderly gentleman gruffly gave me a one-word answer: “ebay.” Then he went to pull out the card, but didn’t let it cool down and almost burned his fingers, which was a bit worrying; you’d think he’d know it was hot. I sure did.</p>
<p>In the end, I paid them $800 cash and took the card home. Surprisingly, they gave me a 30-day warranty card.</p>
<p>It felt very much like a William Gibson-esque cyberpunk experience, and I was happy to have the card.</p>
<h2 id="power">Power</h2>
<p>In preparation for getting this card, I did some research on maybe building a whole new computer. It was around Black Friday time, so there were a lot of deals. I could have just bought a whole new workstation, but my current one is only a few years old and works just fine. Also, while there was a lot of stuff on sale, there were no good CPUs available; they were all out of stock. Theoretically, I could put the 3090 in my current computer, it would be louder, which is annoying since the computer is in my office, and I would need a new power supply and have to replace it myself, but it should work and it would save some money as well. So for now, I’m just using my existing Linux workstation to host the 3090.</p>
<p>These 3090s can draw up to about 350 watts, which is quite a bit of power. So I had to get a properly sized power supply, as my current workstation only has a 550 watt power supply. I would need a lot more than that, at least 1000 watts. So I started looking for a bigger power supply. I ended up buying a refurbished Corsair RM1000x for $150 from Canada Computers. It’s one of the last remaining computer stores in Toronto. That and Memory Express, which doesn’t even have a Toronto location. <a href="https://www.canadacomputers.com/">Canada Computers</a> is about the best place we have to buy computer parts.</p>
<h2 id="installation">Installation</h2>
<p><img src="/img/cyberpunk-1-3090.png" alt="3090 card" /></p>
<p>I’m a bit of an odd person in that I have a lot of computers, like a lot, so much that I won’t write it down here. It’s just part of what I do for a living, and if you do it for long enough they start to accumulate. However, and I suppose this is the odd part, I don’t particularly like computer hardware, especially desktop computers. I don’t mind network switches for some reason, and rackmount computers, well, they’re okay (albeit desktops in another form). But everything else…not much fun. A lot of people take a considerable pride in their workstation setup, LED lights and all that, but that is not for me. With that in mind, I wasn’t super happy about having to change the power supply and open up the computer and move things around, but I did it. It took me a couple of hours, but I did it.</p>
<p>Honestly, the new power supply went in really easily. There was a <a href="https://www.youtube.com/watch?v=yafbKAuyntw&ab_channel=TheProvokedPrawn">Youtube video</a> that showed my exact power supply and a similar 3090, so that made me feel better about the power swap. I just had to pull three wires and put the new power supply in.</p>
<p>However, my motherboard is a little unusual in that if you use the second M2 slot, the second PCIe slot is disabled, which is where I would put the 3090. I assumed that my NVMe card was in the first slot, so I installed the card and rebooted. But I couldn’t see the 3090 from Linux. Looking at the motherboard again, I realized that the technician who built my computer had put the NVMe card in the second slot, probably to get it farther away from the GPU so it wouldn’t be affected by the card’s heat. As soon as I moved the NVMe card to the first M2 slot, the second PCIe slot was enabled and I could see the 3090!</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ nvidia-smi -L | grep 3090
GPU 0: NVIDIA GeForce RTX 3090
</code></pre></div></div>
<p>As you can see, I have an old 660ti as the video card that is connected to my monitors, and the 3090 is the second card. Nice to see the 24GB of memory, which is the whole point of all this “cyberpunk” work!</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ nvidia-smi
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 470.223.02 Driver Version: 470.223.02 CUDA Version: 11.4 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA GeForce ... Off | 00000000:06:00.0 Off | N/A |
| 0% 30C P8 8W / 350W | 10MiB / 24268MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 1 NVIDIA GeForce ... Off | 00000000:07:00.0 N/A | N/A |
| 34% 53C P8 N/A / N/A | 976MiB / 3015MiB | N/A Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 1417 G /usr/lib/xorg/Xorg 4MiB |
| 0 N/A N/A 2346 G /usr/lib/xorg/Xorg 4MiB |
+-----------------------------------------------------------------------------+
</code></pre></div></div>
<h2 id="cooling">Cooling</h2>
<p>I assume I’ll have to find ways to cool this chassis once I start putting the 3090 through its paces.</p>
<h2 id="drivers">Drivers</h2>
<p>Because I had the 660ti installed already, I didn’t have to add any additional drivers to get the 3090 to show up. Finally a nice piece of luck!</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ dpkg --list | grep nvidia-kernel
ii nvidia-kernel-common-470 470.223.02-0ubuntu0.20.04.1 amd64 Shared files used with the kernel module
ii nvidia-kernel-source-470 470.223.02-0ubuntu0.20.04.1 amd64 NVIDIA kernel source package
</code></pre></div></div>
<h2 id="conclusion">Conclusion</h2>
<p>So far, I’ve spent about $1000 CDN on this, which isn’t too bad. It remains to be seen if my older computer is up to the task of running the 3090; that it doesn’t get too hot and too loud; that I don’t end up buying a new computer anyway after all this power supply swapping. I might end up doing that if, for example, I decide I want to run multiple GPUs (two 3090s would be optimal) and/or reduce the noise, because I could put the second computer in the basement with all the other computers where I can’t hear it, and leave my trusty old relatively quiet workstation in my office.</p>
Restarting Kubernetes Pods When There Are New Secrets With Reloader2023-11-23T00:00:00+00:00http://serverascode.com/2023/11/23/reloader-kubernetes<h1 id="restarting-kubernetes-pods-when-there-are-new-secrets-with-reloader">Restarting Kubernetes Pods When There Are New Secrets With Reloader</h1>
<p>I will tell you a secret—no, a story. Say, at some point, I had a Kubernetes webhook admission controller that I wrote and deployed, and then the TLS certificate was automatically (nice!) renewed by cert-manager, but the pod wasn’t restarted, so it still had the old certificate, and now all Kubernetes deployments failed. That is indeed a story, perhaps a sad one. I had this shiny new cert, but no one was using it. Say I wanted to fix that. One way would be with <a href="https://github.com/stakater/Reloader">Reloader</a>.</p>
<h2 id="reloader">Reloader</h2>
<blockquote>
<p><em>Reloader can watch changes in ConfigMap and Secret and do rolling upgrades on Pods with their associated DeploymentConfigs, Deployments, Daemonsets Statefulsets and Rollouts.</em> - <a href="https://github.com/stakater/Reloader">Reloader</a></p>
</blockquote>
<h2 id="install-reloader">Install Reloader</h2>
<p>First add the repo.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ helm repo add stakater https://stakater.github.io/stakater-charts
$ helm repo update
</code></pre></div></div>
<p>Create a namespace.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ k create ns reloader
namespace/reloader created
$ kn reloader
✔ Active namespace is "reloader"
</code></pre></div></div>
<p>Install reloader.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ helm install reloader stakater/reloader
NAME: reloader
LAST DEPLOYED: Thu Nov 23 09:36:22 2023
NAMESPACE: reloader
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
- For a `Deployment` called `foo` have a `ConfigMap` called `foo-configmap`. Then add this annotation to main metadata of your `Deployment`
configmap.reloader.stakater.com/reload: "foo-configmap"
- For a `Deployment` called `foo` have a `Secret` called `foo-secret`. Then add this annotation to main metadata of your `Deployment`
secret.reloader.stakater.com/reload: "foo-secret"
- After successful installation, your pods will get rolling updates when a change in data of configmap or secret will happen.
</code></pre></div></div>
<p>Now we’ve got pods.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ k get pods
NAME READY STATUS RESTARTS AGE
reloader-reloader-64df699b8d-tm5rn 1/1 Running 0 3m4s
</code></pre></div></div>
<p>Nice and easy. Thanks Helm!</p>
<h2 id="simple-test">Simple Test</h2>
<p>Create a secret.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>kubectl create secret generic foo-secret --from-literal=key1=bar
</code></pre></div></div>
<p>Create a cert-manager certificate. (Of course you need cert-manager installed.)</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>kubectl apply -f - <<EOF
apiVersion: cert-manager.io/v1
kind: Certificate
metadata:
name: foo-certs
namespace: foo
spec:
secretName: foo-certs
issuerRef:
name: kubeadm-ca
kind: ClusterIssuer
duration: 24h # Validity period of the certificate
renewBefore: 12h
commonName: foo.foo.svc.cluster.local
dnsNames:
- foo.foo.svc.cluster.local
- foo.foo.svc
EOF
</code></pre></div></div>
<p>Use that secret in a deployment. Note the annotation for Reloader. We’re mounting the secret in <code class="language-plaintext highlighter-rouge">/etc/foo</code> and certificates <code class="language-plaintext highlighter-rouge">/etc/certs</code>.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>kubectl apply -f - <<EOF
apiVersion: apps/v1
kind: Deployment
metadata:
name: foo
labels:
app: foo
annotations:
secret.reloader.stakater.com/reload: "foo-secret,foo-certs"
spec:
replicas: 1
selector:
matchLabels:
app: foo
template:
metadata:
labels:
app: foo
spec:
containers:
- name: my-container
image: nginx
volumeMounts:
- name: secret-volume
mountPath: "/etc/foo"
readOnly: true
- name: certs
mountPath: "/etc/certs"
readOnly: true
volumes:
- name: secret-volume
secret:
secretName: foo-secret
- name: certs
secret:
secretName: foo-certs
EOF
</code></pre></div></div>
<p>Recreate the secret and check the logs of reloader.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ kubectl create secret generic foo-secret --from-literal=key1=foo --dry-run=client -o yaml | kubectl apply -f -
Warning: resource secrets/foo-secret is missing the kubectl.kubernetes.io/last-applied-configuration annotation which is required by kubectl apply. kubectl apply should only be used on resources created declaratively by either kubectl create --save-config or kubectl apply. The missing annotation will be patched automatically.
secret/foo-secret configured
</code></pre></div></div>
<p>Reloader logs. It has noticed the secret update and restarted the pod.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ k logs -n reloader reloader-reloader-64df699b8d-tm5rn
time="2023-11-23T14:36:25Z" level=info msg="Environment: Kubernetes"
time="2023-11-23T14:36:25Z" level=info msg="Starting Reloader"
time="2023-11-23T14:36:25Z" level=warning msg="KUBERNETES_NAMESPACE is unset, will detect changes in all namespaces."
time="2023-11-23T14:36:25Z" level=info msg="created controller for: configMaps"
time="2023-11-23T14:36:25Z" level=info msg="Starting Controller to watch resource type: configMaps"
time="2023-11-23T14:36:25Z" level=info msg="created controller for: secrets"
time="2023-11-23T14:36:25Z" level=info msg="Starting Controller to watch resource type: secrets"
time="2023-11-23T15:18:53Z" level=info msg="Changes detected in 'foo-secret' of type 'SECRET' in namespace 'foo', Updated 'foo' of type 'Deployment' in namespace 'foo'"
</code></pre></div></div>
<p>New pod should be starting.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ k get pods
NAME READY STATUS RESTARTS AGE
foo-5c67d96557-s6cj2 1/1 Running 0 18s
foo-75cb458f7d-xcszx 1/1 Terminating 0 2m30s
</code></pre></div></div>
<p>Now it’s got the new secret.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ k exec -it foo-5c67d96557-s6cj2 -- cat /etc/foo/key1
foo
</code></pre></div></div>
<p>Boom.</p>
<h2 id="certificates">Certificates</h2>
<p>Above we crated a certificate with only 24 hours of validity that should renew after 12 hours. So when it’s renewed, there will be a new version of the secret, and reloader will restart the pod. Let’s see.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ k logs -n reloader reloader-reloader-7f4859f649-6cvqt
time="2023-11-23T16:03:57Z" level=info msg="Environment: Kubernetes"
time="2023-11-23T16:03:57Z" level=info msg="Starting Reloader"
time="2023-11-23T16:03:57Z" level=warning msg="KUBERNETES_NAMESPACE is unset, will detect changes in all namespaces."
time="2023-11-23T16:03:57Z" level=info msg="created controller for: configMaps"
time="2023-11-23T16:03:57Z" level=info msg="Starting Controller to watch resource type: configMaps"
time="2023-11-23T16:03:57Z" level=info msg="created controller for: secrets"
time="2023-11-23T16:03:57Z" level=info msg="Starting Controller to watch resource type: secrets"
time="2023-11-23T16:06:18Z" level=info msg="Changes detected in 'foo-secret' of type 'SECRET' in namespace 'foo', Updated 'foo' of type 'Deployment' in namespace 'foo'"
time="2023-11-24T04:44:56Z" level=info msg="Changes detected in 'foo-certs' of type 'SECRET' in namespace 'foo', Updated 'foo' of type 'Deployment' in namespace 'foo'"
</code></pre></div></div>
<p>Looking at cert-manager logs we see:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>I1124 04:44:56.006536 1 trigger_controller.go:194] "cert-manager/certificates-trigger: Certificate must be re-issued" key="foo/foo-certs" reason="Renewing" message="Renewing certificate as renewal was scheduled at 2023-11-24 04:44:56 +0000 UTC"
SNIP!
I1124 04:44:56.636293 1 conditions.go:263] Setting lastTransitionTime for CertificateRequest "foo-certs-jk5sq" condition "Ready" to 2023-11-24 04:44:56.636261134 +0000 UTC m=+4380108.430326366
</code></pre></div></div>
<p>Right, so the secret was updated. Let’s see if the pod was restarted.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ k get pods
NAME READY STATUS RESTARTS AGE
foo-746699dd7-kr99d 1/1 Running 0 6h43m
$ k describe pod foo-746699dd7-kr99d | grep -i started
Started: Thu, 23 Nov 2023 23:44:59 -0500
</code></pre></div></div>
<p>That time converts to 04:44:59 UTC, which is when the secret was updated. So it was restarted. This is great, so when a new certificate is issued, the pod will be restarted and mount the new secret and have access to the new certificate and key.</p>
<p>There’s a reloader annototioant as well.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ k get pods -oyaml | grep reloader
reloader.stakater.com/last-reloaded-from: '{"type":"SECRET","name":"foo-certs","namespace":"foo","hash":"94af434fda756e922affdd1c43d723b26f196f3e","containerRefs":["my-container"],"observedAt":1700801096}'
</code></pre></div></div>
<h2 id="conclusion">Conclusion</h2>
<p>Personally, I would think that this kind of thing would be automatic, but it’s not. So this is a good way to make sure that your pods are restarted when there are new secrets.</p>
<p>Kubernetes is a framework, and you have to pull in a lot of “libraries,” such as Reloader.</p>
Understanding Kubernetes Pod Security: runAsNonRoot and runAsUser2023-09-02T00:00:00+00:00http://serverascode.com/2023/09/02/runasnonroot-vs-runasuser<h1 id="understanding-kubernetes-pod-security-runasnonroot-and-runasuser">Understanding Kubernetes Pod Security: runAsNonRoot and runAsUser</h1>
<p>Security is a prime concern when deploying applications in a Kubernetes cluster. One of the security aspects in Kubernetes is controlling who can run what and as whom within a Pod. Kubernetes provides two important fields in the Security Context to achieve this: runAsNonRoot and runAsUser. While they might seem similar at first glance, they serve different purposes. This blog post aims to demystify these settings and help you make the right choice for your applications.</p>
<h2 id="nginx-images">nginx images</h2>
<p>I have to wonder what percentage of containers are just nginx instances that are there to test something out. Nginx is an easy image to deploy because you can just do:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>kubectl run nginx --image=nginx
</code></pre></div></div>
<p>And you have a running nginx instance.</p>
<p>However, that default nginx image will run as root (if your cluster allows that).</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ k exec -it nginx -- cat /proc/1/status | grep "Name\|Uid"
Name: nginx
Uid: 0 0 0 0
</code></pre></div></div>
<p>There is an nginx unprivileged image that will run as a non-root user; it runs as user 101. I would definitely recommend using this image if you are just testing something out. It’s a few more letters to type, but it’s worth it.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>kubectl run nginx-unprivileged --image=nginxinc/nginx-unprivileged
</code></pre></div></div>
<p>Inspecting the images…</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ docker image inspect nginx | jq '.[0].Config.User'
""
$ docker image inspect nginxinc/nginx-unprivileged | jq '.[0].Config.User'
"101"
</code></pre></div></div>
<p>Here’s the nginx user in the unprivileged image:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ k exec -it runasnonroot-and-runasuser -- grep nginx /etc/passwd
nginx:x:101:101:nginx user:/nonexistent:/bin/false
</code></pre></div></div>
<p><br /></p>
<h2 id="differences-between-runasnonroot-and-runasuser">Differences Between runAsNonRoot and runAsUser</h2>
<table>
<thead>
<tr>
<th> </th>
<th>runAsNonRoot</th>
<th>runAsUser</th>
</tr>
</thead>
<tbody>
<tr>
<td><strong>Purpose</strong></td>
<td>Ensure container doesn’t run as root</td>
<td>Specify the exact UID for container</td>
</tr>
<tr>
<td><strong>Settings</strong></td>
<td>true/false</td>
<td>Numeric UID</td>
</tr>
<tr>
<td><strong>Flexibility</strong></td>
<td>Less flexible</td>
<td>More flexible</td>
</tr>
<tr>
<td><strong>Specificity</strong></td>
<td>General: just not root</td>
<td>Very specific: exact UID</td>
</tr>
<tr>
<td><strong>Root Allowed</strong></td>
<td>No</td>
<td>Yes, if specified</td>
</tr>
</tbody>
</table>
<p><br /></p>
<h2 id="runasnonroot">runAsNonRoot</h2>
<p>The runAsNonRoot field specifies that the container must not run as the root user. Setting this to true enforces that the container should be executed as a non-root user. If the container image specifies a user as root or numerically as 0, the container won’t start. It’s a way to ensure that your application doesn’t unintentionally run with more permissions than it needs.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: Pod
metadata:
name: non-root-pod
spec:
securityContext:
runAsNonRoot: true
containers:
- name: my-container
image: nginxinc/nginx-unprivileged
EOF
</code></pre></div></div>
<p>Check the id of the user running the container:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ kubectl exec -it non-root-pod -- id
uid=101(nginx) gid=101(nginx) groups=101(nginx)
</code></pre></div></div>
<p>But if we run the plain nginx image, it will fail:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: Pod
metadata:
name: non-root-pod-plain
spec:
securityContext:
runAsNonRoot: true
containers:
- name: my-container
image: nginx
EOF
</code></pre></div></div>
<p>Note that the container is not running:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ k get pods
NAME READY STATUS RESTARTS AGE
non-root-pod 1/1 Running 0 112s
non-root-pod-plain 0/1 CreateContainerConfigError 0 5s
</code></pre></div></div>
<p>And the reason is:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ k describe pod non-root-pod-plain | grep Error
Reason: CreateContainerConfigError
Warning Failed 1s (x5 over 42s) kubelet Error: container has runAsNonRoot and image will run as root (pod: "non-root-pod-plain_runasnonroot(c5764bbb-c1cf-47b1-9606-3a3a49ebf666)", container: my-container)
</code></pre></div></div>
<p><br /></p>
<h2 id="runasuser">runAsUser</h2>
<p>On the other hand, runAsUser specifies which UID (User ID) the container process should run as. Unlike runAsNonRoot, this allows you to specify the exact UID of the user, including root if you explicitly set it to 0.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: Pod
metadata:
name: specific-user-pod-nginx-priviliged
spec:
securityContext:
runAsUser: 1001
containers:
- name: my-container
image: nginxinc/nginx-unprivileged
EOF
</code></pre></div></div>
<p>Check the id of the user running the container:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ kubectl exec -it specific-user-pod-nginx-priviliged -- id
uid=1001 gid=0(root) groups=0(root)
</code></pre></div></div>
<p>But if we run the plain nginx image, it will fail:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: Pod
metadata:
name: specific-user-pod-nginx-plain
spec:
securityContext:
runAsUser: 1001
containers:
- name: my-container
image: nginx
EOF
</code></pre></div></div>
<p>Note that the container is not running:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ k get pod specific-user-pod-nginx-plain
NAME READY STATUS RESTARTS AGE
specific-user-pod-nginx-plain 0/1 CrashLoopBackOff 1 (10s ago) 16s
</code></pre></div></div>
<p><br /></p>
<h2 id="both-runasnonroot-and-runasuser">Both runAsNonRoot and runAsUser</h2>
<p>You can also use both runAsNonRoot and runAsUser together. In this case, runAsUser specifies the UID to use, and runAsNonRoot ensures that UID is not root.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: Pod
metadata:
name: runasnonroot-and-runasuser
spec:
securityContext:
runAsUser: 1001
runAsNonRoot: true
containers:
- name: my-container
image: nginxinc/nginx-unprivileged
EOF
</code></pre></div></div>
<p>Check the id of the user running the container:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ k exec -it runasnonroot-and-runasuser -- id
uid=1001 gid=0(root) groups=0(root)
$ k get pods runasnonroot-and-runasuser
NAME READY STATUS RESTARTS AGE
runasnonroot-and-runasuser 1/1 Running 0 22s
</code></pre></div></div>
<p>And nginx is indeed running as user 1001:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ k exec -it runasnonroot-and-runasuser -- cat /proc/1/status | grep "Name\|Uid"
Name: nginx
Uid: 1001 1001 1001 1001
</code></pre></div></div>
<blockquote>
<p>NOTE: PID 1 is the first process that runs in any operating system or containerized environment. When a container starts, it launches a single process with a PID (Process ID) of 1 within the isolated namespace of that container.</p>
</blockquote>
<p><br /></p>
<h2 id="nginx-plain-as-non-root-with-runasuser">nginx plain as non-root with runAsUser</h2>
<p>Will it blend?</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: Pod
metadata:
name: nginx-plain-runasnonroot-and-runasuser
spec:
securityContext:
runAsUser: 1001
runAsNonRoot: true
containers:
- name: my-container
image: nginx
EOF
</code></pre></div></div>
<p>No.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ k get pod nginx-plain-runasnonroot-and-runasuser
NAME READY STATUS RESTARTS AGE
nginx-plain-runasnonroot-and-runasuser 0/1 CrashLoopBackOff 1 (7s ago) 12s
</code></pre></div></div>
<p><br /></p>
<h2 id="use-cases">Use Cases</h2>
<ul>
<li>
<p>runAsNonRoot: Use this setting when you want a general assurance that none of the containers in the Pod are running as root, without caring which user they run as.</p>
</li>
<li>
<p>runAsUser: Use this when you need more control over the exact user that runs the container process, such as for compliance with internal security policies that require specific UIDs for different types of applications. As well, some images require a specific UID to run properly.</p>
</li>
</ul>
<h2 id="conclusion">Conclusion</h2>
<p>While runAsNonRoot and runAsUser both provide ways to control the user running a container, they serve different needs. runAsNonRoot is a more generalized setting to prevent root access, while runAsUser gives you fine-grained control over the user ID. Knowing when to use each can improve the security posture of your Kubernetes applications.</p>
<p>That said, both runAsUser and runAsNonRoot can co-exist. When they do, runAsUser specifies which UID to use, and runAsNonRoot ensures that UID is not root.</p>
<p>In normal, production systems one would never run a container as root so the image would, based on your organizations policies and image build process, have a user setup and the Kubernetes manifest would have runAsNonRoot set to true.</p>
Why My Flask App Refused to Crash: Understanding PID 1 in Containers and Kubernetes2023-09-02T00:00:00+00:00http://serverascode.com/2023/09/02/pid-one-gunicorn-kubernetes<h1 id="why-my-flask-app-refused-to-crash-understanding-pid-1-in-containers-and-kubernetes">Why My Flask App Refused to Crash: Understanding PID 1 in Containers and Kubernetes</h1>
<p>You’ve just deployed your Python Flask app on Kubernetes. You’re using Gunicorn as your WSGI server, and you’re trying to test how the container would behave if the app crashed. But wait! You find out that the container never crashes. Why not? Oh, Gunicorn is being helpful–it keeps restarting the application.</p>
<p>OK, maybe this isn’t “you” it’s “me”. I was trying to build a demo app that showed crash loop backoff in Kubernetes, and I couldn’t get the container to crash.</p>
<p>Because pid 1 is Gunicorn, not the app itself.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ k exec -it crash-only-backend-0 -- cat /proc/1/status | grep "Name\|Uid"
Name: gunicorn-run.sh
Uid: 10001 10001 10001 10001
</code></pre></div></div>
<p>Let’s dive into why this happens and the importance of understanding PID 1 in containers.</p>
<h2 id="what-the-heck-is-gunicorn">What the Heck is Gunicorn?</h2>
<blockquote>
<p>Gunicorn ‘Green Unicorn’ is a Python WSGI HTTP Server for UNIX. It’s a pre-fork worker model. The Gunicorn server is broadly compatible with various web frameworks, simply implemented, light on server resources, and fairly speedy. - <a href="https://gunicorn.org/">Gunicorn</a></p>
</blockquote>
<h2 id="what-is-a-wsgi-server">What is a WSGI Server?</h2>
<p>A Web Server Gateway Interface (WSGI) server is a web server that implements the WSGI specification. The WSGI specification is a Python standard that describes how a web server communicates with web applications.</p>
<h2 id="why-does-flask-need-a-wsgi-server">Why Does Flask Need a WSGI Server?</h2>
<p>Flask is a micro web framework written in Python. It’s a WSGI application, which means it needs a WSGI server to run.</p>
<blockquote>
<p>“Production” means “not development”, which applies whether you’re serving your application publicly to millions of users or privately / locally to a single user. Do not use the development server when deploying to production. It is intended for use only during local development. It is not designed to be particularly secure, stable, or efficient. - <a href="https://flask.palletsprojects.com/en/2.3.x/deploying/">Flask</a></p>
</blockquote>
<h2 id="what-is-pid-1">What is PID 1?</h2>
<p>In Unix-based systems, the process ID (PID) is a unique identifier for each running process. The very first process that runs when a system starts is the init system with PID 1. The init process has special responsibilities, like adopting orphaned child processes and handling signals.</p>
<h2 id="gunicorn-and-pid-1">Gunicorn and PID 1</h2>
<p>When you run a container, the process you start becomes PID 1 within that container. In the case of my Flask app, Gunicorn becomes PID 1.</p>
<blockquote>
<p>NOTE: Why not just run Flask directly? Because Gunicorn is a production-ready WSGI server that can handle multiple requests concurrently.</p>
</blockquote>
<h2 id="why-doesnt-the-container-crash">Why Doesn’t the Container Crash?</h2>
<p>If your Flask app (running as a Gunicorn worker) crashes, Gunicorn will restart it. Since Gunicorn is PID 1, the container will remain alive as long as Gunicorn does. This is why even if your Flask app encounters an error, the container doesn’t crash.</p>
<h2 id="the-kubernetes-perspective">The Kubernetes Perspective</h2>
<p>In a Kubernetes cluster, the kubelet will restart a crashed container based on its <code class="language-plaintext highlighter-rouge">restartPolicy</code>. However, if Gunicorn (PID 1) doesn’t crash, Kubernetes won’t know that something is wrong with your Flask app. This could lead to misleading metrics and logs, affecting your debugging and monitoring efforts.</p>
<h2 id="killing-pid-1">Killing Pid 1</h2>
<p>In the app I still wanted to use gunicorn which means to demonstrate an app crashing and Kubernetes restarting the container, I needed to kill gunicorn. I needed to kill PID 1.</p>
<p>Here’s what I ended up with inside the app:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>def random_crash():
if random.randint(1, 100) > 94:
logger.error("<<<< Crashing... >>>>")
# gunicorn will restart the process, which is pretty cool, but for this
# app we want to purposely crash the whole container, so we kill the
# parent process which is gunicorn
os.kill(os.getppid(), 9)
</code></pre></div></div>
<blockquote>
<p>NOTE: I’m purposely trying to crash the container to demonstrate crashLoopBackoff. As well, I’m not using <code class="language-plaintext highlighter-rouge">sys.exit()</code> because that would just exit the flask process, not the container. (Which, by the way, is what I originally did and why I couldn’t get the container to crash.)</p>
</blockquote>
<h2 id="conclusion">Conclusion</h2>
<p>Understanding PID 1 in containers is crucial for debugging, process management, and robustness, especially when deploying applications on Kubernetes.</p>
<p>To many, this is elementary…even downright obvious. But I’ve been doing this for a while and I still learned something when building this little demo app. As well, while researching this I found a fair bit of confusion around using gunicorn in containers.</p>
<p>Let me know if you have any questions or comments!</p>
Three Steps to a Default Secure Kubernetes2023-08-12T00:00:00+00:00http://serverascode.com/2023/08/12/three-steps-to-a-default-secure-kubernetes<h1 id="three-steps-to-a-default-secure-kubernetes">Three Steps to a Default Secure Kubernetes</h1>
<p>Kubernetes is a framework. We don’t usually describe it as a framework, but it is. IMHO, it’s a library we can use to deploy applications and imprint our organization’s policies and requirements on top of. That’s what makes it valuable, not the fact that it can create a container.</p>
<p>Because it’s a basic framework, a set of lego blocks, it’s not designed to be secure “out of the box.” We’ve got to make it as secure as we need it to be.</p>
<h2 id="note-not-a-panacea">NOTE: Not a Panacea</h2>
<p>This post is an exploration of some things we could do to make Kubernetes more secure by default. Like what are a couple minimal steps we could take that have a large return on investment. It’s not meant to meet every organization’s requirements or be the end-all-be-all of security. It’s meant as an exploration of a secure starting point that could potentially work for everyone and every Kuberenetes.</p>
<p>In fact I should say here that I’ve already had people give me diffrent opinions on these settings. For example for network policies here I’m thinking more of lateral movement, but many organizations would prefer to stop outbound access. It really depends on your organization’s requirements.</p>
<h2 id="1---pod-security-standards">1 - Pod Security Standards</h2>
<p>First, if you’re not familiar with Pod Security Standards, it’s not a bad idea to <a href="https://serverascode.com/2023/08/02/making-pod-security-standards-default.html">go read up on them</a>, but suffice it to say let’s make sure every namespace has the following label.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>kubectl label namespace <NAMESPACE> pod-security.kubernetes.io/enforce=restricted
</code></pre></div></div>
<p>Which means:</p>
<ul>
<li>Limit types of volumes</li>
<li>Don’t run as root user</li>
<li>No privilege escalation</li>
<li>Seccomp profile set to “RuntimeDefault” or “Localhost”</li>
<li>Drop all capabilities except perhaps add NET_BIND_SERVICE</li>
</ul>
<p>Here’s an example of running the nginx unprivileged container.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: Pod
metadata:
name: nginx-meets-pod-security-standards
namespace: enforcing
spec:
containers:
- image: nginxinc/nginx-unprivileged
name: nginx
securityContext:
allowPrivilegeEscalation: false
capabilities:
drop:
- ALL
runAsNonRoot: true
seccompProfile:
type: RuntimeDefault
EOF
</code></pre></div></div>
<p>That’s a pretty good start!</p>
<h2 id="2---network-policies">2 - Network Policies</h2>
<p>Historically, in Kubernetes, the connectivity was based on a giant, flat layer 3 network, which means every pod had an IP address and could talk to every other pod in the cluster. Obviously this doesn’t really work in enterprise environments, so Kubernetes added the ability to create <a href="https://kubernetes.io/docs/concepts/services-networking/network-policies/">Network Policies</a>.</p>
<p>Here let’s create a default policy to ensure that pods in a namespace can talk to one another, but cannot talk to pods OUTSIDE of their namespace. This is super basic, but I like it as a starting point. Note that services would still be accessible, just not pods directly.</p>
<p>Here’s an example:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: namespace-only
spec:
podSelector: {} # Selects all pods in the namespace
policyTypes:
- Ingress
- Egress
ingress:
- from:
- podSelector: {} # Allow pods in the same namespace to talk to one another
egress:
- to:
- ipBlock:
cidr: 0.0.0.0/0 # Allow egress to any destination
</code></pre></div></div>
<p>Obviously this can be taken a lot further, especially with a CNI that provides extra capabilities.</p>
<h2 id="3-runtime-threat-detection">3: Runtime Threat Detection</h2>
<p>The last step is to make sure that we’re monitoring our Kubernetes clusters for runtime threats. While we have a good baseline of security, something will always get through, no matter what we do. Any adversary worth their salt will find a way in, or mistakes will be made, etc. So we need to be able to detect them when they do. The only way to do that is to monitor the runtime environment.</p>
<p>We can do that in a couple of ways, one is to use Sysdig Secure, which is a commercial <a href="https://sysdig.com/learn-cloud-native/cloud-security/cloud-native-application-protection-platform-cnapp-fundamentals/">CNAPP (Cloud Native Application Protection Platform)</a> that has a decade of history in runtime protection. The other is to use Falco, which is an open source project that is part of the CNCF. Sysdig as a company supports the Falco project.</p>
<h3 id="3a---sysdig-secure">3a - Sysdig Secure</h3>
<p>Sysdig Secure is a security platform which has a decade of history in runtime protection.</p>
<p>It’s easy to sign up for a <a href="https://sysdig.com/start-free/">free trial</a> at Sysdig.</p>
<p>Then, install the agent into Kubernetes clusters with Helm:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>helm repo add sysdig https://charts.sysdig.com
helm repo update
helm install sysdig-agent --namespace sysdig-agent --create-namespace \
--set global.sysdig.accessKey=<ACCESS_KEY> \
--set global.sysdig.region=<SAAS_REGION> \
--set nodeAnalyzer.secure.vulnerabilityManagement.newEngineOnly=true \
--set global.kspm.deploy=true \
--set nodeAnalyzer.nodeAnalyzer.benchmarkRunner.deploy=false \
--set nodeAnalyzer.nodeAnalyzer.hostScanner.deploy=true
--set global.clusterConfig.name=<CLUSTER_NAME> \
sysdig/sysdig-deploy
</code></pre></div></div>
<p>Done!</p>
<h3 id="3b---falco">3b - Falco</h3>
<p><a href="https://falco.org/">Falco</a> is an open source project that is part of the CNCF. It’s a runtime threat detection engine that can be used to detect threats in Kubernetes clusters. Sysdig as a company supports the Falco project.</p>
<blockquote>
<p>Falco is a cloud native runtime security tool for Linux operating systems. It is designed to detect and alert on abnormal behavior and potential security threats in real-time.
At its core, Falco is a kernel monitoring and detection agent that observes events, such as syscalls, based on custom rules. Falco can enhance these events by integrating metadata from the container runtime and Kubernetes. The collected events can be analyzed off-host in SIEM or data lake systems. - <a href="https://falco.org/">Falco</a></p>
</blockquote>
<p>Installing Falco into Kubernetes is easy, just use Helm:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>helm repo add falcosecurity https://falcosecurity.github.io/charts
helm repo update
helm install falco falcosecurity/falco
</code></pre></div></div>
<p>Done!</p>
<h2 id="automation">Automation</h2>
<p>I would prefer that this all be done automatically. Because Kubernetes is a framework there are ways to make these kinds of security settings default, including the concepts of building operators and admission controllers. That would be my next step, to set up some tooling that would automatically apply these settings to every cluster, to every namespace, and to every pod.</p>
<p>So, look forward to a future blog post on that!</p>
<h2 id="conclusion">Conclusion</h2>
<p>I want to be clear that the point here is to create something that is simple and at the same time really improves the default security of Kubernetes–like what’s the best bang for the buck we can get in terms of security.</p>
<p>In this blog post we’ve seen how to create a higher level of default security for Kubernetes, and we looked at how to use Sysdig Secure and Falco to monitor the runtime environment for threats.</p>
<p>Ultimately, this post is an exploration of how to configure a Kubernetes cluster so that it is much more secure “by default.” There’s no need to have Kubernetes be so wide open.</p>
<p>PS. I’ve included an optional section discussing Buildpacks and how they can be used to create more secure container images.</p>
<h2 id="optional-buildpacks-and-paketo">OPTIONAL: Buildpacks and Paketo</h2>
<h3 id="background">Background</h3>
<p>Often people are surprised to find out that there is more than one way to build a container image. I mean, what’s a container image: it’s just a fancy tar file. There are many ways one can make a fancy tar file.</p>
<p>One way is <a href="https://buildpacks.io/">buildpacks</a>. I’ve written about them <a href="https://serverascode.com/2019/12/16/buidpack-pack.html">before</a>. <a href="https://paketo.io/">Paketo</a> is a set of buildpacks that are designed to be used with Kubernetes.</p>
<p>For the purposes of this blog post, the point of Vuildpacks is that they are a way to build a container image that is more secure by default. For example, buildpacks don’t run as root. If we just get rid of that one thing, we’ve made our container images more secure.</p>
<p>The value of Buildpacks:</p>
<ul>
<li>Security - Buildpacks run as non-root by default.</li>
<li>Advanced Caching - Robust caching is used to improve performance.</li>
<li>Auto-detection -Images can be built directly from application source without additional instructions.</li>
<li>Bill-of-Materials - Insights into the contents of the app image through standard build-time SBOMs in CycloneDX, SPDX and Syft JSON formats.</li>
<li>Modular / Pluggable- Multiple buildpacks can be used to create an app image.</li>
<li>Multi-language - Supports more than one programming language family.</li>
<li>Multi-process - Image can have multiple entrypoints for each operational mode.</li>
<li>Minimal app image - Image contains only what is necessary.</li>
<li>Rebasing - Instant updates of base images without re-building.</li>
<li>Reproducibility - Reproduces the same app image digest by re-running the build.</li>
<li>Reusability - Leverage production-ready buildpacks maintained by the community.</li>
</ul>
<h3 id="paketo">Paketo</h3>
<p><a href="https://paketo.io/">Paketo</a> is a set of buildpacks that are designed to be used with Kubernetes.</p>
<p>First off this is a Python app and I’m using gunicorn, so we have a Procfile. This is really the only difference I have between a Dockerfile based image and a buildpack based image. Instead of a Dockerfile I have a Procfile, and the Procfile only describes the command to run the app, nothing else.</p>
<blockquote>
<p>Procfiles define processes from your application’s code and contains one process per line.</p>
</blockquote>
<p>Here’s the example Procfile:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ cat Procfile
web: gunicorn app:app
</code></pre></div></div>
<p>Now we can build the image with a straight forward command.</p>
<blockquote>
<p>NOTE: This assumes, of course, the pack CLI is installed.</p>
</blockquote>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>pack build somepythonflaskapp \
--buildpack paketo-buildpacks/python \
--builder paketobuildpacks/builder:base
</code></pre></div></div>
<p>And deploy it into Kubernetes, port-forward to the service, and finally curl the app.</p>
<blockquote>
<p>NOTE: This app is setup to report the user it’s running as.</p>
</blockquote>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ curl localhost:8000
Application is running as user: cnb
</code></pre></div></div>
<p>Above we can see the app, which is configured to return the user it’s running as, is reporting that it is running as user “cnb” aka not root, aka Cloud Native Buildpacks. Done by default. Nice.</p>
Making Pod Security Standards the Default in Kubernetes2023-08-02T00:00:00+00:00http://serverascode.com/2023/08/02/making-pod-security-standards-default<h1 id="making-pod-security-standards-the-default-in-kubernetes">Making Pod Security Standards the Default in Kubernetes</h1>
<p>In my opinion, the default level of security in Kubernetes is not enough. There’s some work that needs to be done to bring it up to some, perhaps arbitrary, level of security. This post is part of an exploration of that area.</p>
<p>We used to have something called Pod Security Policies that we could use to increase the level of security, like reduce some exposure, but that model was <a href="https://kubernetes.io/blog/2021/04/06/podsecuritypolicy-deprecation-past-present-and-future/">deprecated</a>. Now we have something called Pod Security Standards. These are a set of recommendations for securing pods and are managed by the Pod Security Admission Controller which is part of Kubernetes. However, by default, no Pod Security Standards are configured, enforcing, etc…but what if we want them enforcing by default on a newly created namespace?</p>
<h2 id="one-model-mutating-requests-using-kyverno">One Model: Mutating Requests Using Kyverno</h2>
<p>One way to accomplish this is to use Kyverno, which, among its features, is the ability to mutate Kubernetes requests in, what I think, is a pretty straight forward fashion. For example, it can add a label to a namespace, such as specifying a Pod Security Standard. Thus, following this model, we can force every new namespace to require a certain security posture by default.</p>
<p>Another way to do this would be to set up a mutating admission controller. Probably other methods as well. (Let me know!!!)</p>
<p>I like “mutating” things because it really means having Kubernetes do the work for us. I like making Kubernetes do work for me instead of the other way around. :)</p>
<h3 id="install-kyverno">Install Kyverno</h3>
<ul>
<li>Install Kyverno</li>
</ul>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ helm install kyverno kyverno/kyverno -n kyverno --create-namespace
NAME: kyverno
LAST DEPLOYED: Wed Aug 2 07:47:18 2023
NAMESPACE: kyverno
STATUS: deployed
REVISION: 1
NOTES:
Chart version: 3.0.4
Kyverno version: v1.10.2
Thank you for installing kyverno! Your release is named kyverno.
The following components have been installed in your cluster:
- CRDs
- Admission controller
- Reports controller
- Cleanup controller
- Background controller
⚠️ WARNING: Setting the admission controller replica count below 3 means Kyverno is not running in high availability mode.
💡 Note: There is a trade-off when deciding which approach to take regarding Namespace exclusions. Please see the d
</code></pre></div></div>
<p>Done.</p>
<h3 id="make-the-restricted-pod-security-standard-the-default">Make the Restricted Pod Security Standard the Default</h3>
<p>Kyverno can mutate a request to create a namespace and add a label to it. In this case we’re telling it to add the label <code class="language-plaintext highlighter-rouge">pod-security.kubernetes.io/enforce: restricted</code> so that the pod security admission controller will enforce the Pod Security Standards on the namespace, in this case it will “enforce” the “restricted” profile.</p>
<h3 id="configuring-kyverno-to-add-the-label-to-namespaces">Configuring Kyverno to Add the Label to Namespaces</h3>
<ul>
<li>Add the ClusterPolicy to Kyverno</li>
</ul>
<blockquote>
<p>NOTE: In the “real world” we’d probably want to exclude some namespaces, but, again, only new namespaces will be affected by this policy.</p>
</blockquote>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>cat <<EOF | kubectl apply -f -
apiVersion: kyverno.io/v1
kind: ClusterPolicy
metadata:
name: add-ns-label
spec:
rules:
- name: add-ns-label
match:
resources:
kinds:
- Namespace
mutate:
patchStrategicMerge:
metadata:
labels:
pod-security.kubernetes.io/enforce: restricted
EOF
</code></pre></div></div>
<p>Verify:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ k get clusterpolicy add-ns-label
NAME BACKGROUND VALIDATE ACTION READY AGE MESSAGE
add-ns-label true Audit True 7h1m Ready
</code></pre></div></div>
<p>Good.</p>
<h2 id="create-a-namespace-and-test">Create a Namespace and Test</h2>
<ul>
<li>Create a new namespace (the name doesn’t matter)</li>
</ul>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>kubectl create ns enforcing
</code></pre></div></div>
<ul>
<li>Review that the label was added by Kyverno mutating the request for a namespace</li>
</ul>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ k get ns enforcing -oyaml
apiVersion: v1
kind: Namespace
metadata:
annotations:
policies.kyverno.io/last-applied-patches: |
add-ns-label.add-ns-label.kyverno.io: added /metadata/labels/pod-security.kubernetes.io~1enforce
creationTimestamp: "2023-08-02T11:50:14Z"
labels:
kubernetes.io/metadata.name: enforcing
pod-security.kubernetes.io/enforce: restricted
name: enforcing
resourceVersion: "11055"
uid: ce552efc-172e-4aa6-bc6d-13179f73372c
spec:
finalizers:
- kubernetes
status:
phase: Active
</code></pre></div></div>
<p>This label was added by Kyverno. This means the pod security admission controller will enforce the restricted Pod Security Standard in this namespace.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>pod-security.kubernetes.io/enforce: restricted
</code></pre></div></div>
<ul>
<li>Create an “insecure” pod in the namespace, just any old pod will do…</li>
</ul>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>kubectl run nginx --image=nginx -n enforcing
</code></pre></div></div>
<p>E.g. output:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ k run nginx --image=nginx -n enforcing
Error from server (Forbidden): pods "nginx" is forbidden: violates PodSecurity "restricted:latest": allowPrivilegeEscalation != false (container "nginx" must set securityContext.allowPrivilegeEscalation=false), unrestricted capabilities (container "nginx" must set securityContext.capabilities.drop=["ALL"]), runAsNonRoot != true (pod or container "nginx" must set securityContext.runAsNonRoot=true), seccompProfile (pod or container "nginx" must set securityContext.seccompProfile.type to "RuntimeDefault" or "Localhost")
</code></pre></div></div>
<p>The pod was not allowed to be created because it did not meet the Pod Security Standard.</p>
<ul>
<li>Create a pod that meets the Pod Security Standard for the “restricted” profile</li>
</ul>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: Pod
metadata:
name: nginx-meets-pod-security-standards
namespace: enforcing
spec:
containers:
- image: nginxinc/nginx-unprivileged
name: nginx
securityContext:
allowPrivilegeEscalation: false
capabilities:
drop:
- ALL
runAsNonRoot: true
seccompProfile:
type: RuntimeDefault
EOF
</code></pre></div></div>
<p>Ok, that worked.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ k get pods
NAME READY STATUS RESTARTS AGE
nginx-meets-pod-security-standards 1/1 Running 0 6h26m
</code></pre></div></div>
<ul>
<li>Connect to nginx running in the pod by port forwarding</li>
</ul>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>kubectl port-forward pod/nginx-meets-pod-security-standards 8080:8080 -n enforcing
</code></pre></div></div>
<ul>
<li>Curl it</li>
</ul>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ curl localhost:8080
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
html { color-scheme: light dark; }
body { width: 35em; margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif; }
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
</code></pre></div></div>
<p>Works!</p>
<h2 id="what-is-the-pod-security-standard-restricted-profile">What is the Pod Security Standard “Restricted” Profile?</h2>
<p>The Pod Security Standard “restricted” profile is defined in the <a href="https://kubernetes.io/docs/concepts/security/pod-security-standards/">Pod Security Standards</a> and is, er, the most restrictive profile.</p>
<ul>
<li>Limit types of volumes</li>
<li>Don’t run as root user</li>
<li>No privilege escalation</li>
<li>Seccomp profile set to “RuntimeDefault” or “Localhost”</li>
<li>Drop all capabilities except perhaps add <code class="language-plaintext highlighter-rouge">NET_BIND_SERVICE</code></li>
</ul>
<h2 id="conclusion">Conclusion</h2>
<p>No one should run vanilla, default Kubernetes in production. No one should run root user pods. I mean we’re mostly running web services here, they can listen on port 8080 and don’t really need much in the way of permissions. Definitely our namespaces should have security limitations that are only reduced later on if they need to be.</p>
<p>Using Kyverno to do this is one way, there are others.</p>
<p>Ultimately, the way to secure general purpose CPUs is to limit what the workloads can do with them.</p>
<h2 id="references">References</h2>
<ul>
<li><a href="[https://www.jrcomplex.fi/securing-containers-in-kubernetes-with-seccomp/">https://www.jrcomplex.fi/securing-containers-in-kubernetes-with-seccomp/</a></li>
<li><a href="[https://kubernetes.io/docs/concepts/security/pod-security-standards/">https://kubernetes.io/docs/concepts/security/pod-security-standards/</a></li>
<li><a href="https://kubernetes.io/docs/tasks/configure-pod-container/migrate-from-psp/">https://kubernetes.io/docs/tasks/configure-pod-container/migrate-from-psp/</a></li>
</ul>
Chain-Link - A Chain of Services in Kubernetes2023-07-30T00:00:00+00:00http://serverascode.com/2023/07/30/chain-link-kubernetes-python-application<h1 id="chain-link---a-chain-of-services-in-kubernetes">Chain-Link - A Chain of Services in Kubernetes</h1>
<h2 id="tldr">tl;dr</h2>
<p>I built an app called <a href="https://github.com/ccollicutt/chain-link">chain-link</a> that will create a “chain” of apps in Kubernetes of an arbitrary length. It’s written in Python.</p>
<p>While the point of this all is the app, what I learned most about what writing the CLI portion: the <code class="language-plaintext highlighter-rouge">chain-link-cli</code>. There’s actually way more code there (for better or worse) to deploy and manage the app than there is in the app itself.</p>
<h2 id="what-is-it">What is it?</h2>
<p>I wanted to do some work with a simple Python application that could allow creating a set of services that would form a chain that could be visualized in some kind of program (in this case it ended up being Zipkin, but it could be anything that can show traces).</p>
<p>I wanted it to do a few things:</p>
<ul>
<li>Support traces</li>
<li>Create a “chain” of services of an arbitrary length</li>
<li>Randomly insert some sleep time into the chain</li>
<li>Write a CLI that could be used to create and manage the chain</li>
<li>Deploy a loadgenerator to activate the chain</li>
<li>Deploy a tool that can visualize the chain through the traces it generates</li>
</ul>
<h2 id="how-does-it-work">How does it work?</h2>
<p>The app is written in Python and uses Flask. The app itself is pretty basic. It just looks at the generated list of services and forwards the request to the next service in the chain. It also adds some headers to the request to help with tracing.</p>
<p>This is what the pods look like in the cluster once they’re deployed:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ k get pods
NAME READY STATUS RESTARTS AGE
chain-link-deployment-0-855875c8d5-rz8wd 1/1 Running 2 (47d ago) 96d
chain-link-deployment-1-6cc5965f45-ch8cj 1/1 Running 6 (5d5h ago) 96d
chain-link-deployment-2-65dd5b4878-tnq2r 1/1 Running 6 (5d5h ago) 96d
chain-link-deployment-3-7bf888dddb-lwwdr 1/1 Running 6 (5d5h ago) 96d
chain-link-deployment-4-6c47c7dcb5-4sf4v 1/1 Running 2 (47d ago) 96d
chain-link-deployment-5-85655c8d4f-2z2r6 1/1 Running 6 (5d5h ago) 96d
loadgenerator 1/1 Running 0 23m
zipkin-deployment-69c4598df6-js95l 1/1 Running 209 (16m ago) 99d
</code></pre></div></div>
<p>Each deployment is a separate “app” that the overall service chain is composed of. (Now that I write “service chain” this reminds me of my telecom days.)</p>
<h2 id="what-does-it-look-like-in-zipkin">What does it look like in Zipkin?</h2>
<p><img src="/img/chain-link-zipkin1.png" alt="Zipkin" />
<img src="/img/chain-link-zipkin2.png" alt="Zipkin" /></p>
<h2 id="the-cli">The CLI</h2>
<p>Here’s the CLI help:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ ./chain-link-cli
WARNING Using existing config file: /home/curtis/.config/chain-link/chain-link-cli.conf
usage: chain-link-cli [-h] [--instances NUM_INSTANCES]
[--namespace NAMESPACE]
[--chain-link-image IMAGE_NAME]
[--sleep-time SLEEP_TIME] [-d] [-v]
[--config-file CONFIG_FILE]
{deploy,validate,generate,dry-run} ...
Deploy the chain-link application to a Kubernetes cluster
positional arguments:
{deploy,validate,generate,dry-run}
deploy Deploy chain-link to Kubernetes
validate Validate chain-link configuration
generate Generate chain-link kubernetes yaml
dry-run Generate chain-link kubernetes yaml
options:
-h, --help show this help message and exit
--instances NUM_INSTANCES
Number of instances to deploy
--namespace NAMESPACE
Namespace to deploy to
--chain-link-image IMAGE_NAME
ChainLink image to deploy
--sleep-time SLEEP_TIME
Time to sleep between loadgenerator requests
-d, --info Print lots of infoging statements
-v, --verbose Be verbose
--config-file CONFIG_FILE
Specify the path to the config file
</code></pre></div></div>
<p>As you can see there are a few subcommands, like deploy, validate, etc.</p>
<p>Here’s validate:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ ./chain-link-cli validate
WARNING Using existing config file: /home/curtis/.config/chain-link/chain-link-cli.conf
INFO Using the following configuration...
INFO Number of instances: 6
INFO Namespace: chain-link-2
INFO ChainLink image: ghcr.io/ccollicutt/chain-link:latest
INFO Loadgenerator sleep time: 60
INFO Validating chain-link configuration...
INFO Validating deployments...
INFO Deployments ready
INFO Validating pods...
INFO Pods ready
INFO All objects ready
</code></pre></div></div>
<p>All the config files are generated and placed in <code class="language-plaintext highlighter-rouge">~/.config/chain-link/manifests</code>:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ ls ~/.config/chain-link/manifests/
chain-link-2-namespace.yaml
chain-link-deployment-0-deployment.yaml
chain-link-deployment-1-deployment.yaml
chain-link-deployment-2-deployment.yaml
chain-link-deployment-3-deployment.yaml
chain-link-deployment-4-deployment.yaml
chain-link-deployment-5-deployment.yaml
chain-link-service-0-service.yaml
chain-link-service-1-service.yaml
chain-link-service-2-service.yaml
chain-link-service-3-service.yaml
chain-link-service-4-service.yaml
chain-link-service-5-service.yaml
chain-link-services-configmap.yaml
loadgenerator-pod.yaml
zipkin-deployment-deployment.yaml
zipkin-service-service.yaml
</code></pre></div></div>
<p>There’s a config file there too:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ cat ~/.config/chain-link/chain-link-cli.conf
[DEFAULT]
instances = 6
namespace = chain-link-2
chain_link_image = ghcr.io/ccollicutt/chain-link:latest
sleep_time = 60
</code></pre></div></div>
<p>There’s about 800 lines of Python for the CLI:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ wc -l *.py
95 arg_parser.py
569 chainlink.py
80 cli_manager.py
82 config.py
0 __init__.py
25 log_utils.py
36 utils.py
887 total
</code></pre></div></div>
<p>Versus 170 or so for the app itself.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ wc -l app.py
169 app.py
</code></pre></div></div>
<p>I need to do some research and see if there are some higher level abstractions in Python that can help reduce the number of lines in the CLI.</p>
<h2 id="why-a-python-cli-and-not-helm">Why a Python CLI and not Helm?</h2>
<p>YAML isn’t a programming language. Obviously you can do a lot “more” with Kubernetes using a real programming language. But of course, no one writes a Python CLI for every app they deploy to Kubernetes–that would make no sense.</p>
<p>I mean, it would make more sense to do this in Helm if I thought other people would actually use it. But I don’t expect anyone ever would. This app was really just a learning experience for me, and part of the learning experience I wanted was to create a CLI that could manage the app for me in Kubernetes.</p>
<p>Ultimately, I might prefer to use Python to manage Kubernetes environments. Then again, Helm’s ability to manage upgrades would be required in production. This is something I need to look into–how tools like Helm are looking at the state of a k8s app. Plus whatever other tooling exists–for example Pulumi (which I have never used).</p>
<h2 id="conclusion">Conclusion</h2>
<p>I learned a lot about Python and Kubernetes writing this application and the associated CLI. I’m sure there are tons of bugs, and there is, embarrassingly, little testing. That’s something I learned I need to improve on: testing.</p>
<p>For this app I just started writing, and this is what I ended up with. Is the end result perfect? No. Was the process of learning great? It sure was.</p>
blockfriday - Blocking Kubernetes Deployments with an Admission Controller2023-07-29T00:00:00+00:00http://serverascode.com/2023/07/29/blockfriday-kubernetes-admission-controller<p><em>Creating new deployments on a Friday is NOT allowed.</em></p>
<h1 id="blockfriday---blocking-kubernetes-deployments-with-an-admission-controller">blockfriday - Blocking Kubernetes Deployments with an Admission Controller</h1>
<p>Would you create a Kubernetes Admission Controller to block deployments on a Friday and use it in production? No. But you could, create one, say, as an example admission controller.</p>
<p>So that is precisely what I have done, created a very, very (very) simple admission controller, written in Go, that blocks NEW Kubernetes deployments on a Friday. I call it <a href="https://github.com/ccollicutt/blockfriday">blockfriday</a>.</p>
<h2 id="whats-an-admission-controller">What’s an Admission Controller?</h2>
<p>An admission controller is a piece of software that can intercept requests to the Kubernetes API server and either allow or deny them. Or well, more specifically the Kubernetes API will forward requests to the admission controller for validation. You can use them to enforce policies, like “no deployments on a Friday” or “all deployments must have a label of app: foo”. Using admission controllers you can apply “policy as code” to your Kubernetes cluster. (Note that there are a lot of admission controllers out there. This is just one example.)</p>
<h2 id="how-does-it-work">How does it work?</h2>
<p>This admission controller is a simple Go program, about 200 lines of code, that runs in a pod in the cluster. Once a ValidatingWebhookConfiguration is created which points to this service, the kube-api will send requests to the admission controller for validation. The admission controller will then either allow or deny the request.</p>
<p>This is the main piece of code that does the work:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>if isTodayFriday() {
klog.Infof("Denying the request to create a new Deployment on Friday. Deployment: %s, Namespace: %s", deploymentName, namespace)
return makeAdmissionResponse(admissionReview.Request.UID, false, "Creating new Deployments on Fridays is not allowed.")
}
</code></pre></div></div>
<p>Ultimately, it’s a lot of setup to simply do the above. (Of course there are likely better ways to do this, presumably using Open Policy Agent, aka OPA, but the point here is to <em>write</em> an admission controller.)</p>
<h2 id="but-first-certificates">But First: Certificates</h2>
<p>Honestly, the certificate portion of this admission controller was harder than writing the actual code.</p>
<p>In the case of blockfriday:</p>
<ul>
<li>I’m using cert-manager to, uh, manage certificates</li>
<li>The cluster as deployed with kubeadm, so there is a CA in /etc/kubernetes/pki/ca.crt</li>
<li>I use that CA as part of a Cluster Issuer</li>
<li>When deploying the admission controller, I use the Cluster Issuer to create a certificate for the admission controller</li>
<li>The admission controller mounts that certificate (which has a cert and a key) in /cert and uses it</li>
<li>The ValidatingWebhookConfiguration has a CA bundle that cert-manager injects (magically) for me based on the certificate that cert-manager created (nice), and then the kube-api can talk to the admission controller (though it would already be able to because I’m using the CA that kubeadm deployed, but you get my drift)</li>
</ul>
<h2 id="once-its-deployed">Once it’s Deployed</h2>
<p>Once the admission controller has been setup (certs, deployment, validatingwebhookconfiguration) it will block new deployments on a Friday.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ date +%A
Friday
$ k create -f test/deployment.yaml
Error from server: error when creating "test/deployment.yaml": admission webhook "blockfriday.serverascode.com" denied the request: Creating new Deployments on Fridays is not allowed.
</code></pre></div></div>
<p>Now we’re blockin’ Fridays!</p>
<p>Checkout the code <a href="https://github.com/ccollicutt/blockfriday">here</a>.</p>
Cert Manager's CA Injector and Validating Webhooks2023-07-28T00:00:00+00:00http://serverascode.com/2023/07/28/cert-manager-ca-injector<p><em>The racoons are injecting the CA bundle, of course.</em></p>
<h1 id="cert-managers-ca-injector-and-validating-webhooks">Cert Manager’s CA Injector and Validating Webhooks</h1>
<p>I’ve been working on a simple validating webhook for Kubernetes. More on that later. However, one of the things that you need to provide when you create the Kubernetes manifest for a validating webhook is the CA bundle that the kube-api can use to validate the webhook. But…where does that come from? How do we get it into the manifest?</p>
<p>Here’s the Kubernetes docs example of a validating webhook:</p>
<div class="language-yaml highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="na">apiVersion</span><span class="pi">:</span> <span class="s">admissionregistration.k8s.io/v1</span>
<span class="na">kind</span><span class="pi">:</span> <span class="s">ValidatingWebhookConfiguration</span>
<span class="na">metadata</span><span class="pi">:</span>
<span class="na">name</span><span class="pi">:</span> <span class="s2">"</span><span class="s">pod-policy.example.com"</span>
<span class="na">webhooks</span><span class="pi">:</span>
<span class="pi">-</span> <span class="na">name</span><span class="pi">:</span> <span class="s2">"</span><span class="s">pod-policy.example.com"</span>
<span class="na">rules</span><span class="pi">:</span>
<span class="pi">-</span> <span class="na">apiGroups</span><span class="pi">:</span> <span class="pi">[</span><span class="s2">"</span><span class="s">"</span><span class="pi">]</span>
<span class="err"> </span><span class="na">apiVersions</span><span class="pi">:</span> <span class="pi">[</span><span class="s2">"</span><span class="s">v1"</span><span class="pi">]</span>
<span class="err"> </span><span class="na">operations</span><span class="pi">:</span> <span class="pi">[</span><span class="s2">"</span><span class="s">CREATE"</span><span class="pi">]</span>
<span class="err"> </span><span class="na">resources</span><span class="pi">:</span> <span class="pi">[</span><span class="s2">"</span><span class="s">pods"</span><span class="pi">]</span>
<span class="err"> </span><span class="na">scope</span><span class="pi">:</span> <span class="err"> </span><span class="s2">"</span><span class="s">Namespaced"</span>
<span class="na">clientConfig</span><span class="pi">:</span>
<span class="err"> </span><span class="na">service</span><span class="pi">:</span>
<span class="err"> </span><span class="na">namespace</span><span class="pi">:</span> <span class="s2">"</span><span class="s">example-namespace"</span>
<span class="err"> </span><span class="na">name</span><span class="pi">:</span> <span class="s2">"</span><span class="s">example-service"</span>
<span class="err"> </span><span class="na">caBundle</span><span class="pi">:</span> <span class="s"><CA_BUNDLE></span>
<span class="s">admissionReviewVersions</span><span class="pi">:</span> <span class="pi">[</span><span class="s2">"</span><span class="s">v1"</span><span class="pi">]</span>
<span class="na">sideEffects</span><span class="pi">:</span> <span class="s">None</span>
<span class="na">timeoutSeconds</span><span class="pi">:</span> <span class="m">5</span>
</code></pre></div></div>
<p>Note the <code class="language-plaintext highlighter-rouge">CA_BUNDLE</code> value.</p>
<p>OK, so I have to provide that. But…I guess I just create that manually? At first I was doing the below.</p>
<blockquote>
<p>NOTE: In my homelab I use the kubeadm generated certs, which live in <code class="language-plaintext highlighter-rouge">/etc/kubernetes/pki/</code>. You probably aren’t doing that–the point is that you need to get the CA bundle from somewhere.</p>
</blockquote>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="nb">cat</span> /etc/kubernetes/pki/ca.crt | <span class="nb">base64</span> | <span class="nb">tr</span> <span class="nt">-d</span> <span class="s1">'\n'</span>
</code></pre></div></div>
<p>This is a huge pain. You’d have to do this manually every time you create a validating webhook. Why? I was thinking that there must be a better way…and then magically, I stumbled on it. Perhaps everyone else knows about this, but I didn’t, I had to dig a bit.</p>
<h2 id="cert-manager-ca-injector">Cert Manager CA Injector</h2>
<p>I stumbled on the <a href="https://cert-manager.io/docs/concepts/ca-injector/">Cert Manager docs for CA Injection</a>.</p>
<p>The example they give is this:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>apiVersion: v1
kind: Namespace
metadata:
name: example1
---
apiVersion: admissionregistration.k8s.io/v1
kind: ValidatingWebhookConfiguration
metadata:
name: webhook1
annotations:
cert-manager.io/inject-ca-from: example1/webhook1-certificate
webhooks:
- name: webhook1.example.com
admissionReviewVersions:
- v1
clientConfig:
service:
name: webhook1
namespace: example1
path: /validate
port: 443
sideEffects: None
---
apiVersion: cert-manager.io/v1
kind: Certificate
metadata:
name: webhook1-certificate
namespace: example1
spec:
secretName: webhook1-certificate
dnsNames:
- webhook1.example1
issuerRef:
name: selfsigned
---
apiVersion: cert-manager.io/v1
kind: Issuer
metadata:
name: selfsigned
namespace: example1
spec:
selfSigned: {}
</code></pre></div></div>
<p>Note the annotation:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code> annotations:
cert-manager.io/inject-ca-from: example1/webhook1-certificate
</code></pre></div></div>
<p>Once that annotation is there, and of course cert-manager is deployed and issuers configured, etc, the CA bundle can automatically be injected.</p>
<h2 id="conclusion">Conclusion</h2>
<p>Here it is in a real deployment (<em>I’ve removed most of the actual bundle for brevity</em>):</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ k get validatingwebhookconfigurations.admissionregistration.k8s.io blockfriday -oyaml | grep -i cabundle
caBundle: LS0tLS1CRU <SNIP!>
</code></pre></div></div>
<p>This really made my life easier.</p>
<p>PS. If anyone has any other insights into better ways to do this, please let me know.</p>
Command Collections/Groups in Bash Scripts2023-03-31T00:00:00+00:00http://serverascode.com/2023/03/31/using-bash-script-command-groups<h1 id="command-collectionsgroups-in-bash-scripts">Command Collections/Groups in Bash Scripts</h1>
<p>I work a lot with Kubernetes. So I need to have Kubernetes clusters. The way that I have usually been building them is with the Killer.sh training courses scripts, which can be found here:</p>
<ul>
<li><a href="https://github.com/killer-sh/cks-course-environment/tree/master/cluster-setup/latest">https://github.com/killer-sh/cks-course-environment/tree/master/cluster-setup/latest</a></li>
</ul>
<p>I decided to take that script and update it and change it around a bit for my liking.</p>
<p>The changes I’ve made can be found here:</p>
<ul>
<li><a href="https://github.com/ccollicutt/install-kubernetes">https://github.com/ccollicutt/install-kubernetes</a></li>
</ul>
<p>One of the things I found that I liked when writing this script is Bash command grouping.</p>
<h2 id="bash-command-collectionsgrouping">Bash Command Collections/Grouping</h2>
<p>From the <a href="https://www.gnu.org/software/bash/manual/html_node/Command-Grouping.html">bash docs</a>:</p>
<blockquote>
<p>Bash provides two ways to group a list of commands to be executed as a unit. When commands are grouped, redirections may be applied to the entire command list. For example, the output of all the commands in the list may be redirected to a single stream.</p>
</blockquote>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>{ list; }
</code></pre></div></div>
<p>Here’s a snippet of the install Kubernetes script where I use a grouping.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>...
### install containerd from binary over apt installed version
function install_containerd(){
echo "Installing containerd"
{
wget -q https://github.com/containerd/containerd/releases/download/v${CONTAINERD_VERSION}/containerd-${CONTAINERD_VERSION}-linux-amd64.tar.gz
tar xvf containerd-${CONTAINERD_VERSION}-linux-amd64.tar.gz
systemctl stop containerd
mv bin/* /usr/bin
rm -rf bin containerd-${CONTAINERD_VERSION}-linux-amd64.tar.gz
systemctl unmask containerd
systemctl start containerd
} 3>&2 >> $LOG_FILE 2>&1
}
...
</code></pre></div></div>
<p>It’s a function that downloads the latest binary of containerd and installs it. Hacky, sure. But it’s what I want to have done.</p>
<p>But what you can see here is that all the commands are wrapped into a command group, ie. with the <code class="language-plaintext highlighter-rouge">{}</code>. This is useful because I can control the output of those commands from one place, where you see the:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code> } 3>&2 >> $LOG_FILE 2>&1
</code></pre></div></div>
<p>(More on the above later.)</p>
<p>Basically I can take all the output of all the commands, there’s seven commands, and manage it with one command, as opposed to tagging a redirection onto each line. I think this is really useful. To create functions and put related commands into command groups. It made it a lot easier for me to understand this script.</p>
<h2 id="outputting-to-a-log-file">Outputting to a log file</h2>
<p>What I wanted to do is have the script have a verbose flag. If that’s not set, then don’t output anything other than some basic information, like the below.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>sudo ./install-kubernetes.sh -c -v
Starting install...
==> Logging all output to /tmp/install-kubernetes-XceXczAOta/install.log
Checking Linux distribution
Disabling swap
Removing packages
...
Configuring control plane node...
Initializing the Kubernetes control plane
Configuring kubeconfig for root and ubuntu users
Installing Calico CNI
==> Installing Calico tigera-operator
==> Installing Calico custom-resources
Waiting for nodes to be ready...
==> Nodes are ready
Install complete!
</code></pre></div></div>
<p>But if verbose is set, then show all the output of all the commands.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>...
### Log file ###
E: Unable to locate package kubelet
E: Unable to locate package kubeadm
E: Can't select installed nor candidate version from package 'kubectl' as it has neither of them
E: Unable to locate package kubernetes-cni
E: No packages found
Reading package lists...
Building dependency tree...
Reading state information...
The following packages will be REMOVED:
moby-buildx moby-cli moby-compose moby-containerd moby-engine moby-runc
0 upgraded, 0 newly installed, 6 to remove and 13 not upgraded.
After this operation, 401 MB disk space will be freed.
(Reading database ...
(Reading database ... 5%
(Reading database ... 10%
(Reading database ... 15%
(Reading database ... 20%
...
</code></pre></div></div>
<p>Do that that, I sent all the output to a log file. And if verbose is set, then cat the contents of that file.</p>
<p>But I ran into one problem where because I was doing the command grouping, I couldn’t cat the file.</p>
<p>The error I received:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>cat: $LOG_FILE: input file is output file
</code></pre></div></div>
<p>So I went to stack overflow and ended up here:</p>
<ul>
<li><a href="https://unix.stackexchange.com/questions/448323/trap-and-collect-script-output-input-file-is-output-file-error">https://unix.stackexchange.com/questions/448323/trap-and-collect-script-output-input-file-is-output-file-error</a></li>
</ul>
<p>Which gives a fix:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>#!/bin/bash
...
exit_handler () {
# 1. Make standard output be the original standard error
# (by using fd 3, which is a copy of original fd 2)
# 2. Do the same with standard error
# 3. Close fd 3.
exec >&3 2>&3 3>&-
cat "$logfile"
curl "some URL" -F "file=@$logfile"
}
...
</code></pre></div></div>
<p>This kind of hackery makes the script a bit harder to understand, but I still want it to work this way. Have functions, in the functions group commands, and then output the log file if the verbose flag is set. This definitely accomplishes that goal.</p>
<h2 id="conclusion">Conclusion</h2>
<p>I’m a big fan of command grouping and functions in Bash. Of course Bash has been used like this for years, decades, longer…I’m not sure why I haven’t used them as much before. I still have a lot to learn about Bash. The learning never stops. For whatever reason, I really like this particular model of scripting.</p>
<ul>
<li>Use functions</li>
<li>Put commands into command groups</li>
<li>Control the output into a log file</li>
<li>If verbose flag, cat the log file</li>
</ul>
<p>Let me know if you have any thoughts on this model. Thanks!</p>
Using AWS Nuke2023-01-16T00:00:00+00:00http://serverascode.com/2023/01/16/using-aws-nuke<h1 id="using-aws-nuke">Using AWS Nuke</h1>
<p>I recently set up a second AWS account just to use for testing. I have a primary account, but I want one that I can easily wipe out absolutely everything in, specifically using AWS Nuke.</p>
<h1 id="what-is-aws-nuke">What is AWS Nuke?</h1>
<p><a href="https://github.com/rebuy-de/aws-nuke">AWS Nuke</a> is a CLI applicaiton that can wipe out everything in an AWS account, if you want it to.</p>
<p>What does it do? It removes everything from your AWS account. And I quote:</p>
<blockquote>
<p>Remove all resources from an AWS account.</p>
</blockquote>
<p>Big red warning light:</p>
<blockquote>
<p>NOTE: Of course, using AWS Nuke can be extremely…dangerous. You could wipe out everything in your account. AWS Nuke tries to be as safe as possible, but the point is to use it to delete everything.</p>
</blockquote>
<h2 id="installation">Installation</h2>
<p>I downloaded the <a href="https://github.com/rebuy-de/aws-nuke/releases">latest release</a>, untarred it and insatlled the binary in my local bin.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ which aws-nuke
/home/curtis/bin/aws-nuke
</code></pre></div></div>
<p>Help:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ aws-nuke -h
A tool which removes every resource from an AWS account. Use it with caution, since it cannot distinguish between production and non-production.
Usage:
aws-nuke [flags]
aws-nuke [command]
Available Commands:
completion Generate the autocompletion script for the specified shell
help Help about any command
resource-types lists all available resource types
version shows version of this application
SNIP!!
</code></pre></div></div>
<h2 id="usage">Usage</h2>
<p>The most important thing is the config file and below is a configuration file I’ve used.</p>
<p>Notes on the configuration file example:</p>
<ul>
<li>I’m just looking at us-east-1 for now (and global, i.e. IAM)</li>
<li>I don’t want AWS Nuke to remove the “curtis” user, or their key</li>
<li>Also filter out the MFA configuration for that user (though I don’t believe Nuke can remove it)</li>
</ul>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>regions:
- us-east-1
- global
account-blocklist:
- "REDACTEDID_ACCOUNT_NOT_TO_NUKE" # personal i.e. prod account
accounts:
# awstesting account to run nuke in
"REDACTEDID_ACCOUNT_TO_NUKE":
filters:
IAMUser:
- "curtis"
IAMUserPolicyAttachment:
- "curtis -> AdministratorAccess"
IAMUserAccessKey:
- "curtis -> REDACTEDKEY1"
IAMVirtualMFADevice:
- "arn:aws:iam::REDACTEDID2:mfa/googleauth"
</code></pre></div></div>
<p>Otherwise, we’re going to remove everything from that account that we can, except the “curtis” user.</p>
<h2 id="alias-accounts">Alias Accounts</h2>
<p>AWS Nuke wants you to alias accounts. It’s going to try to save you from deleting production by looking for the letters “prod” in the account alias.</p>
<blockquote>
<p>“To avoid just displaying a account ID, which might gladly be ignored by humans, it is required to actually set an Account Alias for your account. Otherwise aws-nuke will abort.” - AWS Nuke documentation</p>
</blockquote>
<ul>
<li>For my testing account, I gave it this alias.</li>
</ul>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>aws iam create-account-alias --profile awstesting --account-alias awstesting
</code></pre></div></div>
<ul>
<li>To validate…</li>
</ul>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ aws iam list-account-aliases --profile awstesting
{
"AccountAliases": [
"awstesting"
]
}
</code></pre></div></div>
<p>Now I can use AWS Nuke.</p>
<h2 id="example-use">Example Use</h2>
<p>Let’s create a user in the AWS Account I want to run Nuke in, i.e. I want this new account to be <em>removed</em> by AWS Nuke.</p>
<p>First, validate I’m using my testing account.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ export AWS_PROFILE=awstesting
$ aws sts get-caller-identity
{
"UserId": "REDACTED",
"Account": "REDACTED",
"Arn": "arn:aws:iam::REDACTED:user/curtis"
}
</code></pre></div></div>
<ul>
<li>Next, create a user that will be removed by AWS nuke</li>
</ul>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>aws iam create-user --user-name nukeme
</code></pre></div></div>
<ul>
<li>Now list users in the account, there should be only two…</li>
</ul>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>aws iam list-users
</code></pre></div></div>
<p>E.g. output:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ aws iam list-users
{
"Users": [
{
"Path": "/",
"UserName": "curtis",
"UserId": "REDACTED",
"Arn": "arn:aws:iam::REDACTED:user/curtis",
"CreateDate": "2023-01-13T15:14:00Z"
},
{
"Path": "/",
"UserName": "nukeme",
"UserId": "REDACTED",
"Arn": "arn:aws:iam::REDACTED:user/nukeme",
"CreateDate": "2023-01-16T16:28:15Z"
}
]
}
</code></pre></div></div>
<ul>
<li>Run AWS Nuke in <strong>dry-run</strong> mode</li>
</ul>
<blockquote>
<p>NOTE: Without a specific option, which I won’t show here, AWS Nuke will always run in <strong>dry-run</strong> mode.</p>
</blockquote>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>aws-nuke -c aws-nuke.yaml --profile awstesting
</code></pre></div></div>
<p>It will ask you to type in the alias of the account.</p>
<p>If you want to actually <strong>for real</strong> delete everything, you will need to add the no dry run option, and you’ll be asked to type in the account profile name twice.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ aws-nuke -c aws-nuke.yaml --profile awstesting -q
aws-nuke version v2.21.2 - Fri Dec 9 20:36:12 UTC 2022 - e76d21c263477ebd6648fae19f9e539049ad2b51
Do you really want to nuke the account with the ID REDACTED and the alias 'awstesting'?
Do you want to continue? Enter account alias to continue.
> awstesting
SNIP!!
2023/01/16 13:19:18 This operation, ListFleets, has been deprecated
global - IAMUser - nukeme - [Name: "nukeme"] - would remove
Scan complete: 67 total, 1 nukeable, 66 filtered.
The above resources would be deleted with the supplied configuration. Provide --no-dry-run to actually destroy resources.
</code></pre></div></div>
<ul>
<li>Run it again, but with the option to <em>really delete everything</em></li>
</ul>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ aws-nuke -c aws-nuke.yaml --profile awstesting -q --no-dry-run
aws-nuke version v2.21.2 - Fri Dec 9 20:36:12 UTC 2022 - e76d21c263477ebd6648fae19f9e539049ad2b51
Do you really want to nuke the account with the ID REDACTED_ACCOUNT_TO_NUKE and the alias 'awstesting'?
Do you want to continue? Enter account alias to continue.
> awstesting
SNIP!!
Do you really want to nuke these resources on the account with the ID REDACTED_ACCOUNT_TO_NUKE and the alias 'awstesting'?
Do you want to continue? Enter account alias to continue.
> awstesting
global - IAMUser - nukeme - [Name: "nukeme"] - triggered remove
Removal requested: 1 waiting, 0 failed, 66 skipped, 0 finished
global - IAMUser - nukeme - [Name: "nukeme"] - waiting
Removal requested: 1 waiting, 0 failed, 66 skipped, 0 finished
global - IAMUser - nukeme - [Name: "nukeme"] - removed
Removal requested: 0 waiting, 0 failed, 66 skipped, 1 finished
Nuke complete: 0 failed, 66 skipped, 1 finished.
</code></pre></div></div>
<p>Goodbye new account!</p>
<h2 id="conclusion">Conclusion</h2>
<p>So far I like AWS Nuke. I had tested out some Fargate workloads and removed them, but they had left a NAT Gateway running, which AWS Nuke found. As we all know, those NAT gateways cost a lot of money. I’m really thankful tools like this exist.</p>
Jenkins and Kubernetes: Getting the plugin working2022-12-22T00:00:00+00:00http://serverascode.com/2022/12/22/jenkins-kubernetes-plugin-agent<h1 id="jenkins-and-kubernetes-getting-the-plugin-working">Jenkins and Kubernetes: Getting the plugin working</h1>
<p>I wanted to try out using Kubernetes from Jenkins, and that is what this post is about.</p>
<p>I have a Jenkins instance running on a host, specifically it is NOT running in Kubernetes. But I want that instance of Jenkins to talk to a Kubernetes cluster and use it as a “cloud”, where I’m using the term “cloud” in Jenkins parlance.</p>
<h2 id="tldr">tl;dr</h2>
<ol>
<li>Install the <a href="https://plugins.jenkins.io/kubernetes/">Jenkins Kubernetes plugin</a></li>
<li>Set up the Kubernetes namespace, service account, and roles/bindings</li>
<li>Create a long lived token for the service account</li>
<li>Add a “cloud” to Jenkins pointing to the Kubernetes cluster, using the token as authentication</li>
</ol>
<h2 id="caveat">Caveat</h2>
<p>This is all just running in my homelab, where security isn’t as big an issue as it would be in a real world situation. Keep that in mind! There’s likely a lot that could be improved here from a security perspective.</p>
<h2 id="install-the-kubernetes-plugin">Install the Kubernetes Plugin</h2>
<p>Given this Jenkins instance is just in my homelab, I just click buttons. If I want a plugin, I just install it from the GUI. It’s fun to just click around for once. :)</p>
<p><img src="/img/jenkins-k8s-plugin1.jpg" alt="Jenkins Kubernetes plugin install" /></p>
<h2 id="set-up-kubernetes-for-use-by-jenkins">Set up Kubernetes for use by Jenkins</h2>
<blockquote>
<p>NOTE: Here I assume you have a Kubernetes cluster available.</p>
</blockquote>
<p>First, create a namespace for Jenkins to use.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ kubectl create ns jenkins-agent
</code></pre></div></div>
<p>Then create a service account in that namespace with the proper role and rolebinding.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>apiVersion: v1
kind: ServiceAccount
metadata:
name: jenkins-admin
namespace: jenkins-agent
---
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: jenkins
namespace: jenkins-agent
labels:
"app.kubernetes.io/name": 'jenkins'
rules:
- apiGroups: [""]
resources: ["pods"]
verbs: ["create","delete","get","list","patch","update","watch"]
- apiGroups: [""]
resources: ["pods/exec"]
verbs: ["create","delete","get","list","patch","update","watch"]
- apiGroups: [""]
resources: ["pods/log"]
verbs: ["get","list","watch"]
- apiGroups: [""]
resources: ["secrets"]
verbs: ["get"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: jenkins-role-binding
namespace: jenkins-agent
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: jenkins
subjects:
- kind: ServiceAccount
name: jenkins-admin
namespace: jenkins-agent
</code></pre></div></div>
<p>Now create a token.</p>
<blockquote>
<p>NOTE, from the Kubernetes docs: If you want to obtain an API token for a ServiceAccount, you create a new Secret with a special annotation, kubernetes.io/service-account.name.</p>
</blockquote>
<p>Apply this YAML.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>apiVersion: v1
kind: Secret
type: kubernetes.io/service-account-token
metadata:
name: jenkins-admin-token
annotations:
kubernetes.io/service-account.name: "jenkins-admin"
</code></pre></div></div>
<p>Get the token from the secret that was created and decode it from base64. It will be used to configure the Kubernetes cloud in Jenkins as a “secret text” credential type.</p>
<h2 id="add-a-kubernetes-cloud">Add a Kubernetes “cloud”</h2>
<p>Go to “Dashboard -> Manage Jenkins -> Configure Clouds” and add a new Kubernetes cloud.</p>
<p><img src="/img/jenkins-k8s-plugin2.jpg" alt="Jenkins Kubernetes plugin install" /></p>
<p>Now configure that cloud instance.</p>
<p>Set the URL of the Kubernetes API endpoint.</p>
<p>Create the credential from here as well. Use the token we set up in Kubernetes and create a “secret text” credential.</p>
<p><img src="/img/jenkins-k8s-plugin3.jpg" alt="Jenkins Kubernetes plugin install" /></p>
<h2 id="create-a-pipeline">Create a Pipeline</h2>
<p>Create a new pipeline of “freestyle” type.</p>
<p><img src="/img/jenkins-k8s-plugin4.jpg" alt="Jenkins Kubernetes plugin install" /></p>
<p>Restrict where it can be run to the name you gave the Kubernetes cloud instance in Jenkins. In this case I called my “c2-kubernetes.”</p>
<p>Here’s the cloud configuration where I’ve configured the name “c2-kubernetes.”</p>
<p><img src="/img/jenkins-k8s-plugin5.jpg" alt="Jenkins Kubernetes plugin install" /></p>
<p>Here’s the job configuration. Note that it says “1 cloud” which refers to the Kubernetes cloud we just added.</p>
<p><img src="/img/jenkins-k8s-plugin6.jpg" alt="Jenkins Kubernetes plugin install" /></p>
<p>I created a simple job that just echos some output.</p>
<p><img src="/img/jenkins-k8s-plugin7.jpg" alt="Jenkins Kubernetes plugin install" /></p>
<p>If you run that job now you’ll see a container get built in the Kubernetes cluster. It won’t take long to run.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ k get pods
NAME READY STATUS RESTARTS AGE
c2-kubernetes-58rlp 1/1 Terminating 0 11s
</code></pre></div></div>
<p>Here’s the console output of that Jenkins job.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>Started by user admin
Running as SYSTEM
Agent c2-kubernetes-58rlp is provisioned from template c2-kubernetes
---
apiVersion: "v1"
kind: "Pod"
metadata:
labels:
jenkins: "slave"
jenkins/label-digest: "396f736cb86bcc043738aedb977de7d31c574611"
jenkins/label: "c2-kubernetes"
name: "c2-kubernetes-58rlp"
namespace: "jenkins-agent"
spec:
containers:
- env:
- name: "JENKINS_SECRET"
value: "********"
- name: "JENKINS_AGENT_NAME"
value: "c2-kubernetes-58rlp"
- name: "JENKINS_NAME"
value: "c2-kubernetes-58rlp"
- name: "JENKINS_AGENT_WORKDIR"
value: "/home/jenkins/agent"
- name: "JENKINS_URL"
value: "http://jenkins.example.com:8080/"
image: "jenkins/inbound-agent:4.11-1-jdk11"
name: "jnlp"
resources:
limits: {}
requests:
memory: "256Mi"
cpu: "100m"
volumeMounts:
- mountPath: "/home/jenkins/agent"
name: "workspace-volume"
readOnly: false
hostNetwork: false
nodeSelector:
kubernetes.io/os: "linux"
restartPolicy: "Never"
volumes:
- emptyDir:
medium: ""
name: "workspace-volume"
Building remotely on c2-kubernetes-58rlp (c2-kubernetes) in workspace /home/jenkins/agent/workspace/test-kubernetes-cloud
[test-kubernetes-cloud] $ /bin/sh -xe /tmp/jenkins17424164001143670183.sh
+ echo hi c2-kubernetes
hi c2-kubernetes
Finished: SUCCESS
</code></pre></div></div>
<h2 id="conclusion">Conclusion</h2>
<p>This took a bit of testing to get right, but not that much work. I kinda like Jenkins in my homelab because I can just poke around at it and not worry too much about how replicable it all is. Jenkins is pretty good from that perspective, just install plugins, configure things manually, update plugins. Sometimes it’s nice just to do ClickOps.</p>
<p>I’ve got a fair bit more to understand about this plugin though. There’s a lot more work to be done around Pod Templates…but that’s for another day. At least at this point Jenkins can create jobs in the Kubernetes cluster.</p>
<h2 id="resources">Resources</h2>
<ul>
<li><a href="https://devopscube.com/jenkins-build-agents-kubernetes/">How to Setup Jenkins Build Agents on Kubernetes Pods</a></li>
</ul>
<h2 id="issue---tcpslaveagentlistener">ISSUE - tcpSlaveAgentListener</h2>
<p>I had one issue with the container not completing properly because it couldn’t connect to Jenkins. Note the “tcpSlaveAgentListener” issue.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ k logs c2-kubernetes-xnb6n
Dec 21, 2022 11:28:49 PM hudson.remoting.jnlp.Main createEngine
INFO: Setting up agent: c2-kubernetes-xnb6n
Dec 21, 2022 11:28:49 PM hudson.remoting.jnlp.Main$CuiListener <init>
INFO: Jenkins agent is running in headless mode.
Dec 21, 2022 11:28:50 PM hudson.remoting.Engine startEngine
INFO: Using Remoting version: 4.11
Dec 21, 2022 11:28:50 PM org.jenkinsci.remoting.engine.WorkDirManager initializeWorkDir
INFO: Using /home/jenkins/agent/remoting as a remoting work directory
Dec 21, 2022 11:28:50 PM org.jenkinsci.remoting.engine.WorkDirManager setupLogging
INFO: Both error and output logs will be printed to /home/jenkins/agent/remoting
Dec 21, 2022 11:28:50 PM hudson.remoting.jnlp.Main$CuiListener status
INFO: Locating server among [http://jenkins.example.com:8080/]
Dec 21, 2022 11:28:50 PM hudson.remoting.jnlp.Main$CuiListener error
SEVERE: http://jenkins.example.com:8080/tcpSlaveAgentListener/ is invalid: 404 Not Found
java.io.IOException: http://jenkins.example.com:8080/tcpSlaveAgentListener/ is invalid: 404 Not Found
at org.jenkinsci.remoting.engine.JnlpAgentEndpointResolver.resolve(JnlpAgentEndpointResolver.java:219)
at hudson.remoting.Engine.innerRun(Engine.java:724)
at hudson.remoting.Engine.run(Engine.java:540)
</code></pre></div></div>
<p>I had to go into the Jenkin’s configuration and give the agent a port. As soon as I set that the containers were able to connect.</p>
<p><img src="/img/jenkins-k8s-plugin8.jpg" alt="Jenkins Kubernetes plugin install" /></p>
Things I learned: Computer Security Acronyms2022-11-08T00:00:00+00:00http://serverascode.com/2022/11/08/security-acronyms<h1 id="things-i-learned-computer-security-acronyms">Things I learned: Computer Security Acronyms</h1>
<h2 id="tldr">tl;dr</h2>
<ul>
<li>I recently starting working in security again, at a great company called <a href="https://sysdig.com/">Sysdig</a></li>
<li>I think the security industry has really been improving as of late…more work to be done, but I see progress</li>
<li>I need to learn what a lot of security related acronyms mean</li>
<li><a href="https://cloud.withgoogle.com/cloudsecurity/podcast/ep94-meet-cloud-security-acronyms-with-anna-belak/">Here’s a good podcast on security acronyms</a></li>
<li><a href="https://venturebeat.com/security/gartner-research-finds-no-single-tool-protects-app-security/">Categorization and definitions are ongoing</a></li>
</ul>
<h2 id="background">Background</h2>
<p>I started my career in security. That was a long time ago, back when Sun Microsystems was still around and quite popular. You know, before the Dotcom boom. What I remember from that time was 1) I managed a Checkpoint Firewall running on a Sun Microsystems box with 16 interfaces, and when you went to compile the rules often the whole box would crash (not good) and 2) security was just a person that said “NO”…regardless of what the question was, the answer was typically, if not always, no.</p>
<p>(ASIDE: I recently bought a <a href="https://www.redbubble.com/i/t-shirt/Sun-Microsystem-T-Shirt-by-SebastianHapy/109917061.FB110?ref=product-title">Sun Microsystems</a> shirt off of Redbubble. Well before I wrote this post. Not completely sure why…but I digress.)</p>
<p>To me, the failing firewall wasn’t as difficult as saying no. At the time, I didn’t have a lot of experience and made many mistakes, had the wrong (perhaps bad) attitude, but even then, saying no so often was hard on me. I didn’t see a good path forward in this part of the industry. It felt like the security world was failing, and eventually I stopped working strictly security focussed jobs and moved into open source infrastructure.</p>
<h2 id="security-is-improving">Security is Improving</h2>
<p>Over the last few years I think things have improved in security. It might not seem like it, from a high level, but I see the ecosystem doing a lot of great things. We’re getting to the point where we’re doing a lot of work to shift security left, moving security more towards development practices, and, for example, starting to try to understand what software makes up our applications (SBOMs and the like). This is good progress. Lots more still to be done, and maybe it can never be “done done”, but good progress nonetheless.</p>
<p>I recently came back to the security world, and started working at a great organization called <a href="https://sysdig.com/">Sysdig</a>–a company that is doing some great work to shift security left while still watching right (i.e. runtime) and was built from the ground up for modern workloads and modern infrastructure.</p>
<p>After a long time off from full time security work there are many newly invented acronyms that I need to learn, which is the real point of this post.</p>
<h2 id="acronyms">Acronyms</h2>
<p>Here’s a few that I’ve come across so far.</p>
<blockquote>
<p>NOTE: I should say that it’s quite possible I’ve got some things wrong. Let me know if I do. I’ll try to keep this up to date.</p>
</blockquote>
<p>GRC - Governance, Risk and Compliance</p>
<p>CIEM - Cloud Infrastructure Entitlements Management</p>
<p>KSPM - Kubernetes Security Posture Management</p>
<p>CSPM - Cloud Security Posture Management</p>
<p>SOAR - Security Orchestration Automation and Response</p>
<p>SIEM - Security Information and Event Management</p>
<p>CNAPP - Cloud Native Application Protection Platform</p>
<p>XDR - eXtended Detection and Response</p>
<p>CWPP - Cloud Workload Protection Platform</p>
<p>CASB - Cloud Access Security Broker</p>
<p>RASP - Runtime Application Self-Protection</p>
<p>SAST - Static Application Security Testing</p>
<p>DAST - Dynamic Application Security Testing</p>
<p>IAST - Interactive Application Security Testing</p>
<p>IOC - Indicator of Compromise</p>
<p>TDR - Threat Detection and Response</p>
<p>TI - Threat Intelligence</p>
<p>CVSS - Common Vulnerability Scoring System</p>
<p>DART - Detection and Response Team</p>
<p>CDR - Cloud Detection and Response</p>
<p>VM - Vulnerability Management (not Virtual Machine)</p>
<p>MDR - Managed Detection and Response</p>
<p>CMDB - Configuration Management Database</p>
<p>DLP - Data Loss Prevention</p>
<h2 id="cloud-security-podcast-with-anna-belak">Cloud Security Podcast with Anna Belak</h2>
<p>To get better insight into security acronyms than I can provide, have a listen to this podcast:</p>
<ul>
<li><a href="https://cloud.withgoogle.com/cloudsecurity/podcast/ep94-meet-cloud-security-acronyms-with-anna-belak/">EP94 Meet Cloud Security Acronyms with Anna Belak</a></li>
</ul>
<h2 id="conclusion">Conclusion</h2>
<p>Technology is complicated. We need ways to simplify and understand what all this complex technology does, what it means, and how it works. This is why organizations like Gartner exist. They create functional areas and categories such as “Cloud Security and Posture Management” to help reduce the cognitive load of the vast, vast security ecosystem. In a lot of ways they provide an important function.</p>
<p>However, I think it’s paramount to understand that these acronyms and categories are not static, and in some cases not even accurate as to what end users need or are already doing. These acronyms change over time. They come into existence, and they disappear. Sometimes they are popular, other times not so much. They are adjusted over time. They merge and they split apart. I expect that we will see considerable change in these major categories, especially the ones that exist in fast moving areas like modern applications and public clouds as we, as an industry, better understand what problems we have and how best to solve them. On the one hand this might be obvious, but on the other sometimes we put too much faith in these categories.</p>
Homelab - Hardware and Layout2022-06-06T00:00:00+00:00http://serverascode.com/2022/06/06/homelab<h1 id="homelab---hardware-and-layout">Homelab - Hardware and Layout</h1>
<p>I’ve got (what I think) is a fairly substantial, though definitely aging, homelab. I thought I’d write a bit of a post on what it consists of.</p>
<h2 id="hardware">Hardware</h2>
<p>Current setup:</p>
<ul>
<li>3x ESXI hosts - each are a 1U Supermicro server with 192GB memory on a X9DRI-LN4F+ motherboard</li>
<li>1x Network storage server - A 2U Supermicro, 64GB of memory, X9DRI-LN4F+ motherboard</li>
<li>Intel Xeon CPU E5-2650 2.00GHz CPUs (old!)</li>
<li>1x Mikrotik 24 port CRS326-24S+2Q+RM</li>
<li>1x Mikrotik 24 port CRS326-24G-2S+RM</li>
<li>Battery backup - Cyberpower 1500VA</li>
<li>Firewall - Protectli Vault 6 Port running OpenBSD</li>
</ul>
<p>Extra hardware:</p>
<ul>
<li>Juniper EX3300</li>
<li>Many server components: disks, motherboards, memory, etc</li>
</ul>
<h2 id="storage-server">Storage Server</h2>
<p>This is an Ubuntu 18.04 server using ZFS on linux, with four mirrored spinning disks and a zlog disk. Brilliantly and originally I’ve named the zpool tank.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ zpool status
pool: tank
state: ONLINE
scan: scrub repaired 0B in 23h24m with 0 errors on Sun May 8 23:48:18 2022
config:
NAME STATE READ WRITE CKSUM
tank ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
wwn-0x5000cca221c07016 ONLINE 0 0 0
wwn-0x5000cca221c8e492 ONLINE 0 0 0
mirror-1 ONLINE 0 0 0
wwn-0x5000cca221c8e026 ONLINE 0 0 0
wwn-0x5000cca221db40d0 ONLINE 0 0 0
logs
wwn-0x55cd2e404c0f5d34 ONLINE 0 0 0
</code></pre></div></div>
<p>Also I have a NVMe disk that has 1.8T of storage, which is setup with XFS. I’ve called this one Mammoth. I’m surprised this drive is still working as it’s just a Western Digital Blue disk that I thought would quickly wear out, but it’s still going strong. I put it into a generic PCI adapter and it’s been working well…so far (though again, I expect it to fail at some point).</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ mount | grep xfs
/dev/nvme0n1 on /mammoth/1 type xfs (rw,relatime,attr2,inode64,noquota)
</code></pre></div></div>
<p>The ZFS and XFS storage is exported via NFS to the ESXI hosts.</p>
<h2 id="esxi-hosts">ESXI Hosts</h2>
<p>Not much special here, just some older 1U nodes. vCenter is running as a VM on these hosts. The E5-2650 CPUs likely won’t work with vSphere 8.</p>
<p>Each node also has a 1TB SSD drive in it, but I don’t use these much. If I’m doing a nested deployment of vSphere, I’ll put the nested, virtualized ESXI hosts on these disks, and manually distribute them across the three hosts, but otherwise I don’t currently use them.</p>
<p>Initially I used inexpensive flash USB drives to run the ESXI OS, but that <a href="https://kb.vmware.com/s/article/82515">stopped working</a> and I had to install ESXI onto local drives, which right now are spinning disks that I had been using when I was testing out VSAN.</p>
<h2 id="networking">Networking</h2>
<h3 id="mikrotik">Mikrotik</h3>
<p>At this time, for the lab, I’m using Mikrotik network switches, mostly because they are extremely low power and incredibly quiet. Two switches is like 1/3 the watts of another vendor’s single switch.</p>
<p>I have several other switches that could be in place, for example a Juniper EX3300 with 24x 1GB ports and 4x 10GB ports, but while it has better performance, it’s louder and adds another amp of power usage.</p>
<blockquote>
<p>NOTE: Please take a look at the <a href="https://mikrotik.com/product/CRS326-24G-2SplusRM#fndtn-testresults">performance testing</a> for Mikrotik switches and note the switching performance. They might not work for you. :)</p>
</blockquote>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>[admin@MikroTik] > /system resource print
uptime: 4w2h33m31s
version: 6.42.12 (long-term)
build-time: Feb/12/2019 08:23:13
factory-software: 6.41
free-memory: 480.5MiB
total-memory: 512.0MiB
cpu: ARMv7
cpu-count: 1
cpu-frequency: 800MHz
cpu-load: 0%
free-hdd-space: 3896.0KiB
total-hdd-space: 16.0MiB
write-sect-since-reboot: 53897
write-sect-total: 102370
bad-blocks: 0%
architecture-name: arm
board-name: CRS326-24G-2S+
platform: MikroTik
</code></pre></div></div>
<p>The 1GB switch is doing all the routing, the VLAN gateways live here. As well, it does DHCP for the services that need it.</p>
<p>Configuring the Mikrotiks is a bit unusual compared to other major switch vendors, e.g. Juniper. There’s no commit/rollback model.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>[admin@MikroTik] > /interface bridge port print
Flags: X - disabled, I - inactive, D - dynamic, H - hw-offload
# INTER... BRIDGE HW PVID PR PATH-COST INTERNA... HORIZON
0 H ;;; defconf
ether1 bridge yes 1 0x 10 10 none
SNIP!
</code></pre></div></div>
<p>The bridge model is a bit unusual as well, note the “HW: yes” column.</p>
<h3 id="juniper-ex3300">Juniper EX3300</h3>
<p><img src="/img/ex3300.jpg" alt="ex3300-24t" /></p>
<p>My EX3300 would likely make more sense as a switch in this environment, as I would just need the single switch as it has the four 10 gig connections (perfect for me with my four nodes), and it’s wire speed, but ultimately I just liked that the Mikrotiks are quieter and lower power, and, so far, I haven’t run into any performance problems (that I’m aware of).</p>
<p>I’ve had both the EX3300 and the Mikrotiks in place in different versions of the lab. If performance was a key, then I would definitely use the EX3300, and accept the additional volume and power use. Honestly, the EX3300 is the perfect lab switch, but I’m not using it right now.</p>
<p>Next time I rebuild the lab, I might use the EX3300. :)</p>
<h2 id="firewall">Firewall</h2>
<p>I run a small fanless OpenBSD based firewalling device that has six interfaces that I used to segregate my various home networks. I’m an OpenBSD fan, so I’m always looking for a spot to put some OpenBSD.</p>
<blockquote>
<p>NOTE: This device runs really hot. I’ve read that some people change the thermal paste on these kinds of systems, though I have not done that. I’m expecting this device to fail at some point just due to being so high temperature all the time. Perhaps it was not a wise investment. That remains to be seen.</p>
</blockquote>
<p>Six interfaces sounds like a lot, but if you’re physically separating networks out, it’s just the right amount.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code># uname -a
OpenBSD firewall 6.9 GENERIC.MP#473 amd64
# ifconfig | grep em
em0: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> mtu 1500
em1: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> mtu 1500
em2: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> mtu 1500
em3: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> mtu 1500
em4: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> mtu 1500
em5: flags=8802<BROADCAST,SIMPLEX,MULTICAST> mtu 1500
</code></pre></div></div>
<p>Only certain networks are allowed to talk to other networks: basic segregation.</p>
<h2 id="battery-backup">Battery Backup</h2>
<p>Power goes off in Toronto fairly regularly, one every three or four months, but usually it’s only a blip…maybe a minute or two of power failure. For a while I just kept restarting everything, but finally I experienced a corruption issue and had to rebuild, so it was time for a battery backup. Better to spend a couple hundred dollars than the time rebuilding and restarting. With this in place my nodes have not gone down once, though it would only last for maybe 10, 15 minutes, so if it’s an extended power loss, then everything will go down.</p>
<h2 id="dns-ntp---laptop">DNS, NTP - Laptop</h2>
<p>I use an old IBM laptop for DNS and NTP. Because, as a laptop, it has a battery in it, this laptop has been up for a long, long time…years in fact:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ uptime
21:26:05 up 952 days, 23:24, 2 users, load average: 0.00, 0.00, 0.00
</code></pre></div></div>
<p>That’s right, 952 days. Insecure, yes, but wow, this is some serious uptime. The screen has stopped working, but I can still ssh in. I don’t know how this thing is still working, but at this point I have to leave it just to see how long it will continue to stay up!</p>
<h2 id="environment">Environment</h2>
<p>All these servers and switches are installed into a medium sized enclosed rack that I bought off of Kijiji. I don’t run any air conditioning at all, and these servers live in my cold room, which isn’t that cold, and can easily be 30C or higher in the summer, but the whole system just keeps chugging along. It’s also dusty in the basement, and again, things–surprisingly–just keep working. Maybe once a year I shut most things down and clean everything off.</p>
<h2 id="what-is-this-lab-running">What is this lab running?</h2>
<p><img src="/img/vsphere-homelab.jpg" alt="vsphere GUI" /></p>
<ul>
<li>vSphere 7</li>
<li>vSphere with Tanzu, using NSX Advanced Loadbalancer (AVI)</li>
<li>Tanzu Kubernetes Grid - internet restricted and non-restricted deployments</li>
<li>Many Kubernetes clusters (thanks to TKG and vSphere with Tanzu)</li>
<li><a href="https://serverascode.com/2020/07/20/vsphere-7-with-kubernetes-nsxt-3.html">Used to run NSX</a>, but it’s currently not deployed in this version of the lab</li>
</ul>
<h2 id="conclusion">Conclusion</h2>
<p>This all uses 6 or 7 AMPs of power and has been running for well over three years. The Supermicro’s just keep running, no matter how dusty or hot. One major issue is that if I continue to run a vSphere lab, it’s unlikely the CPUs in these nodes will be supported. So to continue with vSphere 8 would be a major investment.</p>
Creating CUSTOM Secure Software Supply Chains with Tanzu2022-05-11T00:00:00+00:00http://serverascode.com/2022/05/11/creating-custom-secure-software-supply-chains<h1 id="creating-custom-secure-software-supply-chains-with-tanzu">Creating CUSTOM Secure Software Supply Chains with Tanzu</h1>
<p>In the <a href="/2022/05/10/creating-secure-software-supply-chains-with-tanzu.html">last post</a> I looked at creating secure software supply chains with the Tanzu Application Platform (TAP). In that post I used a default supply chain. But what if we wanted to create our own, custom supply chain instead of using the “out of the box” examples provided with the platform?</p>
<h2 id="quicklywhat-is-the-tanzu-application-platform">Quickly…What is the Tanzu Application Platform?</h2>
<p>TAP is:</p>
<blockquote>
<p>VMware Tanzu Application Platform is a modular, application-aware platform that provides a rich set of developer tooling and a prepaved path to production to build and deploy software quickly and securely on any compliant public cloud or on-premises Kubernetes cluster. - <a href="https://tanzu.vmware.com/application-platform">VMware Tanzu</a></p>
</blockquote>
<p>Here’s a key point:</p>
<ul>
<li>It can run in <strong>any compliant</strong> Kubernetes cluster</li>
</ul>
<p>But enough about TAP, let’s build a custom supply chain.</p>
<h2 id="creating-a-custom-supply-chain">Creating a Custom Supply Chain</h2>
<p>Ok, so we have two supply chains by default in the TAP install.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ k get clustersupplychains.carto.run
NAME READY REASON AGE
basic-image-to-url True Ready 5d2h
source-to-url True Ready 5d2h
</code></pre></div></div>
<p>The reason we have these two is that when TAP was installed the TAP values file was configured with the below option.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>supply_chain: basic
</code></pre></div></div>
<p>There are other options to provide “out of the box templates”. That said, we expect that most organizations will build their own supply chains using our platform and its various building blocks.</p>
<p>For the purposes of this blog post I start with the two basic chains and I’d like to add another <em>custom</em> chain, an extension of source-to-url.</p>
<h2 id="creating-a-custom-supply-chain-1">Creating a Custom Supply Chain</h2>
<p>Let’s say my goal is:</p>
<ul>
<li>Take the “source-to-url” chain, create a new chain, and add “image scanning” to it, so that the image that is created is also scanned to see if there are any CVEs</li>
</ul>
<p>I’m going to grab the “source-to-url” chain and edit it.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ k neat get -- clustersupplychains.carto.run source-to-url
apiVersion: carto.run/v1alpha1
kind: ClusterSupplyChain
metadata:
annotations:
kapp.k14s.io/identity: v1;/carto.run/ClusterSupplyChain/source-to-url;carto.run/v1alpha1
name: source-to-url
spec:
params:
- default: main
name: gitops_branch
- default: supplychain
name: gitops_user_name
- default: supplychain
name: gitops_user_email
- default: supplychain@cluster.local
name: gitops_commit_message
- default: ""
name: gitops_ssh_secret
resources:
- name: source-provider
params:
- name: serviceAccount
value: default
- name: gitImplementation
value: go-git
templateRef:
kind: ClusterSourceTemplate
name: source-template
- name: deliverable
params:
- name: registry
value:
repository: tap-inner-loop-1-1-full/supply-chain
server: somerepo.example.com
templateRef:
kind: ClusterTemplate
name: deliverable-template
- name: image-builder
params:
- name: serviceAccount
value: default
- name: clusterBuilder
value: default
- name: registry
value:
repository: tap-inner-loop-1-1-full/supply-chain
server: somerepo.example.com
sources:
- name: source
resource: source-provider
templateRef:
kind: ClusterImageTemplate
name: kpack-template
- images:
- name: image
resource: image-builder
name: config-provider
params:
- name: serviceAccount
value: default
templateRef:
kind: ClusterConfigTemplate
name: convention-template
- configs:
- name: config
resource: config-provider
name: app-config
templateRef:
kind: ClusterConfigTemplate
name: config-template
- configs:
- name: config
resource: app-config
name: config-writer
params:
- name: serviceAccount
value: default
- name: registry
value:
repository: tap-inner-loop-1-1-full/supply-chain
server: somerepo.example.com
templateRef:
kind: ClusterTemplate
name: config-writer-template
selector:
apps.tanzu.vmware.com/workload-type: web
</code></pre></div></div>
<p>Next, let’s change it so that it looks like the below.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>apiVersion: carto.run/v1alpha1
kind: ClusterSupplyChain
metadata:
name: source-to-url-with-image-scan
spec:
params:
- default: main
name: gitops_branch
- default: supplychain
name: gitops_user_name
- default: supplychain
name: gitops_user_email
- default: supplychain@cluster.local
name: gitops_commit_message
- default: ""
name: gitops_ssh_secret
resources:
- name: source-provider
params:
- name: serviceAccount
value: default
- name: gitImplementation
value: go-git
templateRef:
kind: ClusterSourceTemplate
name: source-template
- name: deliverable
params:
- name: registry
value:
repository: tap-inner-loop-1-1-full/supply-chain
server: somerepo.example.com
templateRef:
kind: ClusterTemplate
name: deliverable-template
- name: image-builder
params:
- name: serviceAccount
value: default
- name: clusterBuilder
value: default
- name: registry
value:
repository: tap-inner-loop-1-1-full/supply-chain
server: somerepo.example.com
sources:
- name: source
resource: source-provider
templateRef:
kind: ClusterImageTemplate
name: kpack-template
#scan-image
- name: scan-image
images:
- name: image
resource: image-builder
templateRef:
kind: ClusterImageTemplate
name: image-scanner-template
- images:
- name: image
resource: scan-image
name: config-provider
params:
- name: serviceAccount
value: default
templateRef:
kind: ClusterConfigTemplate
name: convention-template
- configs:
- name: config
resource: config-provider
name: app-config
templateRef:
kind: ClusterConfigTemplate
name: config-template
- configs:
- name: config
resource: app-config
name: config-writer
params:
- name: serviceAccount
value: default
- name: registry
value:
repository: tap-inner-loop-1-1-full/supply-chain
server: somerepo.example.com
templateRef:
kind: ClusterTemplate
name: config-writer-template
selector:
apps.tanzu.vmware.com/workload-type: web-image-scan
</code></pre></div></div>
<blockquote>
<p>NOTE: The selector is now “web-image-scan”.</p>
</blockquote>
<p>At this point we have a diff something like this. All that’s happened is the insertion of the “scan-image” block into the chain, and changed the name to make it unique.</p>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="nv">$ </span>git diff source-to-url-original.yml curtis-source-to-url-with-image-scan.yml
diff <span class="nt">--git</span> a/source-to-url-original.yml b/curtis-source-to-url-with-image-scan.yml
index 06e8dff..3c22bac 100644
<span class="nt">---</span> a/source-to-url-original.yml
+++ b/curtis-source-to-url-with-image-scan.yml
@@ <span class="nt">-1</span>,12 +1,7 @@
apiVersion: carto.run/v1alpha1
kind: ClusterSupplyChain
metadata:
- annotations:
- kapp.k14s.io/identity: v1<span class="p">;</span>/carto.run/ClusterSupplyChain/source-to-url<span class="p">;</span>carto.run/v1alpha1
- labels:
- kapp.k14s.io/app: <span class="s2">"1651760734110088811"</span>
- kapp.k14s.io/association: v1.4e1a1027543b1d663294132ebfdd4f33
- name: source-to-url
+ name: source-to-url-with-image-scan
spec:
params:
- default: main
@@ <span class="nt">-54</span>,9 +49,17 @@ spec:
templateRef:
kind: ClusterImageTemplate
name: kpack-template
- - images:
+ <span class="c">#scan-image</span>
+ - name: scan-image
+ images:
- name: image
resource: image-builder
+ templateRef:
+ kind: ClusterImageTemplate
+ name: image-scanner-template
+ - images:
+ - name: image
+ resource: scan-image
name: config-provider
params:
- name: serviceAccount
@@ <span class="nt">-86</span>,4 +89,4 @@ spec:
kind: ClusterTemplate
name: config-writer-template
selector:
- apps.tanzu.vmware.com/workload-type: web
<span class="se">\ </span>No newline at end of file
+ apps.tanzu.vmware.com/workload-type: web-image-scan
<span class="se">\ </span>No newline at end of file
</code></pre></div></div>
<p>The new chain looks like this in Cartographer’s live editor. As you can see, there is now “scan-image” in the chain.</p>
<p><img src="/img/carto3.jpg" alt="image scan pipeline" /></p>
<p>Which, of course, is different from the non-image scan version. Note how there is no “scan image” box.</p>
<p><img src="/img/carto2.jpg" alt="cartographer diagram 2" /></p>
<p>Checkout the image scanner template.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ k neat get -- clusterimagetemplates.carto.run image-scanner-template -oyaml
apiVersion: carto.run/v1alpha1
kind: ClusterImageTemplate
metadata:
annotations:
kapp.k14s.io/identity: v1;/carto.run/ClusterImageTemplate/image-scanner-template;carto.run/v1alpha1
kapp.k14s.io/original-diff-md5: c6e94dc94aed3401b5d0f26ed6c0bff3
labels:
kapp.k14s.io/app: "1651760721125747499"
kapp.k14s.io/association: v1.7d6419553fe4d29522bcc6dc11d61feb
name: image-scanner-template
spec:
imagePath: .status.compliantArtifact.registry.image
ytt: |
#@ load("@ytt:data", "data")
#@ def merge_labels(fixed_values):
#@ labels = {}
#@ if hasattr(data.values.workload.metadata, "labels"):
#@ labels.update(data.values.workload.metadata.labels)
#@ end
#@ labels.update(fixed_values)
#@ return labels
#@ end
apiVersion: scanning.apps.tanzu.vmware.com/v1beta1
kind: ImageScan
metadata:
name: #@ data.values.workload.metadata.name
labels: #@ merge_labels({ "app.kubernetes.io/component": "image-scan" })
spec:
registry:
image: #@ data.values.image
scanTemplate: private-image-scan-template
scanPolicy: scan-policy
</code></pre></div></div>
<p>If we look at the above definition, we see that it’s using “private-image-scan-template” of “kind: ImageScan”.</p>
<p>Let’s look at those.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ k get scantemplates.scanning.apps.tanzu.vmware.com
NAME AGE
blob-source-scan-template 5d2h
private-image-scan-template 5d2h
public-image-scan-template 5d2h
public-source-scan-template 5d2h
</code></pre></div></div>
<p>Now the private scan template…</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ k neat get -- scantemplates.scanning.apps.tanzu.vmware.com private-image-scan-template -oyaml
apiVersion: scanning.apps.tanzu.vmware.com/v1beta1
kind: ScanTemplate
metadata:
name: private-image-scan-template
namespace: default
spec:
template:
containers:
- args:
- -c
- ./image/copy-docker-config.sh /secret-data && ./image/scan-image.sh /workspace
scan.xml true
command:
- /bin/bash
image: registry.tanzu.vmware.com/tanzu-application-platform/tap-packages@sha256:d3a8f3cae0db15e416e805dc598223f93059c3a295cbf33f1409bc6cb9a9709c
imagePullPolicy: IfNotPresent
name: scanner
resources:
limits:
cpu: 1000m
requests:
cpu: 250m
memory: 128Mi
volumeMounts:
- mountPath: /.docker
name: docker
readOnly: false
- mountPath: /workspace
name: workspace
readOnly: false
- mountPath: /secret-data
name: registry-cred
readOnly: true
imagePullSecrets:
- name: scanner-secret-ref
restartPolicy: Never
securityContext:
runAsNonRoot: true
volumes:
- name: docker
- name: workspace
- name: registry-cred
secret:
secretName: registry-credentials
</code></pre></div></div>
<p>Ok, great. To do image scanning we’ll need a scan policy.</p>
<h2 id="scan-policy">Scan Policy</h2>
<p>Next we need a scan policy.</p>
<blockquote>
<p>NOTE: We are only looking for “Critical” vulnerabilities. Those will fail, everything else will pass the scan test.</p>
</blockquote>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>apiVersion: scanning.apps.tanzu.vmware.com/v1beta1
kind: ScanPolicy
metadata:
name: scan-policy
spec:
regoFile: |
package policies
default isCompliant = false
# Accepted Values: "Critical", "High", "Medium", "Low", "Negligible", "UnknownSeverity"
violatingSeverities := ["Critical"]
ignoreCVEs := []
contains(array, elem) = true {
array[_] = elem
} else = false { true }
isSafe(match) {
fails := contains(violatingSeverities, match.Ratings.Rating[_].Severity)
not fails
}
isSafe(match) {
ignore := contains(ignoreCVEs, match.Id)
ignore
}
isCompliant = isSafe(input.currentVulnerability)
</code></pre></div></div>
<p>That needs to be installed.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ k create -f image-scan-policy.yml
</code></pre></div></div>
<p>Now it’s available to use.</p>
<h2 id="install-and-use">Install and Use</h2>
<p>Let’s load that new, custom supply chain into TAP/k8s.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ k create -f curtis-source-to-url-with-image-scan.yml
clustersupplychain.carto.run/source-to-url-with-image-scan created
</code></pre></div></div>
<p>Voila:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ k get clustersupplychains.carto.run
NAME READY REASON AGE
basic-image-to-url True Ready 5d2h
source-to-url True Ready 5d2h
source-to-url-with-image-scan True Ready 19s
</code></pre></div></div>
<p>Now to deploy the app.</p>
<blockquote>
<p>NOTE: I’m flipping between an Ubuntu WSL terminal and a Powershell terminal. Here I’m using Powershell to run the tanzu CLI. Note the type is “web-image-scan”.</p>
</blockquote>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$Env:TAP_DEV_NAMESPACE = "default"
tanzu apps workload create tanzu-java-web-app-with-image-scan `
--git-repo https://github.com/sample-accelerators/tanzu-java-web-app `
--git-branch main `
--type web-image-scan `
--label app.kubernetes.io/part-of=tanzu-java-web-app-with-image-scan `
--label tanzu.app.live.view=true `
--label tanzu.app.live.view.application.name=tanzu-java-web-app-with-image-scan `
--annotation autoscaling.knative.dev/minScale=1 `
--namespace $env:TAP_DEV_NAMESPACE `
--yes
</code></pre></div></div>
<p>I can check the results of the scan.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ k logs scan-tanzu-java-web-app-with-image-scan-qr9q4--1-9b4w9 | grep severity | sort | uniq -c
27 <v:severity>Low</v:severity>
8 <v:severity>Medium</v:severity>
</code></pre></div></div>
<p>Many low, a few medium.</p>
<p>Now we have imagescans:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ k get imagescans.scanning.apps.tanzu.vmware.com
NAME PHASE SCANNEDIMAGE
AGE CRITICAL HIGH MEDIUM LOW UNKNOWN CVETOTAL
tanzu-java-web-app-with-image-scan Completed somerepo.example.com/tap-inner-loop-1-1-full/supply-chain/tanzu-java-web-app-with-image-scan-default@sha256:bb0da26d42537abaa7a7f02afac8eb77387c42524fbd413a265d716934ec2f4c 20m 0 0 3 12 0 15
</code></pre></div></div>
<p>The app is up and running.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>PS C:\Users\curtis> curl.exe http://tanzu-java-web-app-with-image-scan-default.apps.example.com
Greetings from Spring Boot + Tanzu!
</code></pre></div></div>
<h2 id="conclusion">Conclusion</h2>
<p>At this point we’ve created a custom supply chain by adding image scanning to the default source-to-url chain.</p>
<p>This is a simple example, but you can see how powerful, and modular, TAP is.</p>
<h2 id="additional-links-and-resources">Additional Links and Resources</h2>
<ul>
<li><a href="https://dodd-pfeffer.medium.com/tanzu-application-platforms-ootb-supply-chain-with-testing-and-scanning-events-cfc0d50506f7">Tanzu Application Platform’s OOTB Supply Chain with Testing and Scanning Events</a></li>
<li><a href="https://dodd-pfeffer.medium.com/deep-dive-on-tanzu-application-platforms-ootb-supply-chain-ac8a929d2e43">Deep-dive on Tanzu Application Platform’s OOTB Supply Chain</a></li>
<li><a href="https://tanzu.vmware.com/developer/learningpaths/secure-software-supply-chain/">SSSC learning path</a> provided by VMware Tanzu.</li>
</ul>
Secure Software Supply Chains and the Tanzu Application Platform2022-05-10T00:00:00+00:00http://serverascode.com/2022/05/10/creating-secure-software-supply-chains-with-tanzu<h1 id="secure-software-supply-chains-and-the-tanzu-application-platform">Secure Software Supply Chains and the Tanzu Application Platform</h1>
<p>If you are a company that makes software, then you have a software supply chain, whether you want one or not. Building software is challenging, even without thinking about where all the underlying dependencies and other software comes from, and what’s in it, never mind cataloguing and checksumming it all, and being able to replace it within a few hours.</p>
<p>This is all hard work, work that many companies spend thousands and thousands of engineering hours on trying to build themselves, often unsuccessfully. Other companies simply don’t have the people power–the time, the resources–to even try to implement secure pipelines.</p>
<h2 id="whats-a-secure-software-supply-chain">What’s a secure software supply chain?</h2>
<p>A “secure software supply chain” (SSSC) is…</p>
<blockquote>
<p>…a fancy way of saying “we know all the components that went into building and deploying this software and trust those components.” It also includes the actual CI/CD pipeline that you trust and that’s resistant to third parties including malicious code, as we’ve seen happen in recent years. - <a href="https://tanzu.vmware.com/content/blog/devops-vs-devsecops">Tanzu Blog</a></p>
</blockquote>
<p>Here are some outcomes organizations are looking for with regards to SSSC:</p>
<ul>
<li>“We need to be able to deploy code to our staging and production environments reliably every time”</li>
<li>“When there is a CVE for one of our applications or dependencies, we need to be able to remediate the problem within 24 hours”</li>
<li>“We must ensure our software is validated during the build process and that it is built upon known secure images”</li>
</ul>
<p>If you want to find out more about secure software supply chains, take a look at this <a href="https://tanzu.vmware.com/developer/learningpaths/secure-software-supply-chain/">learning path</a> provided by VMware Tanzu.</p>
<h2 id="the-tanzu-application-platform">The Tanzu Application Platform</h2>
<p>I’ve talked about the Tanzu Application Platform (TAP) on this blog before. Suffice it to say that Kubernetes can do more than just containers, we can teach to do anything, and TAP is a way to show Kubernetes how to manage and secure applications; to turn it into more than just a “container orchestration engine”.</p>
<p>With TAP we use Kubernetes as a base platform that we add on to, and then turn into a full blown application platform…a <em>modular</em> system that understands how to deploy, manage and secure applications on its own, without having to be told what to do (unless we want to).</p>
<h2 id="tap-supply-chains">TAP Supply Chains</h2>
<p>I’ve got the Tanzu Application Platform deployed into a single cluster (in this case Minikube running on my <a href="/2022/04/26/tanzu-application-platform-on-windows-workstation.html">Windows workstation</a>). It’s has a couple of software supply chains installed by default.</p>
<p>As you can see, I’m asking the Kubernetes API what it knows about “clustersupplychains”, i.e. TAP and its components are NATIVE to Kubernetes–we’ve taught Kubernetes how to do supply chains (and more).</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ k get clustersupplychains.carto.run
NAME READY REASON AGE
basic-image-to-url True Ready 4d23h
source-to-url True Ready 4d23h
</code></pre></div></div>
<p>With TAP 1.1 you get a few default supply chains, e.g. basic-image-to-url and source-to-url.</p>
<p>source-to-url is the easiest one to understand. This supply chain does the following:</p>
<ol>
<li>Watch a git repository</li>
<li>When there are changes, build a new image using that code (no Dockerfile anywhere)</li>
<li>Deploy the new image</li>
</ol>
<p>This all happens from within Kubernetes, and can be across multiple clusters, each with specific duties. (In this case I just have a single cluster though.)</p>
<h2 id="clustersupplychains">ClusterSupplyChains</h2>
<p>Let’s look at the YAML that defines the ClusterSupplyChain.</p>
<blockquote>
<p>NOTE: I’m trying out the “neat” plugin for kubectl here. It removes some of the extra things you see when pulling the YAML from k8s. A few other things I removed by hand.</p>
</blockquote>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ k neat get -- clustersupplychain source-to-url
apiVersion: carto.run/v1alpha1
kind: ClusterSupplyChain
metadata:
name: source-to-url
spec:
params:
- default: main
name: gitops_branch
- default: supplychain
name: gitops_user_name
- default: supplychain
name: gitops_user_email
- default: supplychain@cluster.local
name: gitops_commit_message
- default: ""
name: gitops_ssh_secret
resources:
- name: source-provider
params:
- name: serviceAccount
value: default
- name: gitImplementation
value: go-git
templateRef:
kind: ClusterSourceTemplate
name: source-template
- name: deliverable
params:
- name: registry
value:
repository: tap-inner-loop-1-1-full/supply-chain
server: somerepo.example.com
templateRef:
kind: ClusterTemplate
name: deliverable-template
- name: image-builder
params:
- name: serviceAccount
value: default
- name: clusterBuilder
value: default
- name: registry
value:
repository: tap-inner-loop-1-1-full/supply-chain
server: somerepo.example.com
sources:
- name: source
resource: source-provider
templateRef:
kind: ClusterImageTemplate
name: kpack-template
- images:
- name: image
resource: image-builder
name: config-provider
params:
- name: serviceAccount
value: default
templateRef:
kind: ClusterConfigTemplate
name: convention-template
- configs:
- name: config
resource: config-provider
name: app-config
templateRef:
kind: ClusterConfigTemplate
name: config-template
- configs:
- name: config
resource: app-config
name: config-writer
params:
- name: serviceAccount
value: default
- name: registry
value:
repository: tap-inner-loop-1-1-full/supply-chain
server: somerepo.example.com
templateRef:
kind: ClusterTemplate
name: config-writer-template
selector:
apps.tanzu.vmware.com/workload-type: web
</code></pre></div></div>
<p>Now we can take that output and plug it into the <a href="https://cartographer.sh/live-edito">Cartographer live editor</a>, and it will show us a nice diagram which depicts the supply chain flow.</p>
<blockquote>
<p>NOTE: Cartographer is the open source project that underlies some of TAP…it’s the k8s native component that ties all the disparate, separate functions together into a pipeline.</p>
</blockquote>
<p><img src="/img/carto.jpg" alt="cartographer diagram" /></p>
<p>Here’s a larger version. The arrows mean “depends on”, as opposed to the directional flow.</p>
<p><img src="/img/carto2.jpg" alt="cartographer diagram 2" /></p>
<p>If you look into the YAML, we can see the first section under resources is <code class="language-plaintext highlighter-rouge">source-provider</code>.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>SNIP!
resources:
- name: source-provider
params:
- name: serviceAccount
value: default
- name: gitImplementation
value: go-git
templateRef:
kind: ClusterSourceTemplate
name: source-template
SNIP!
</code></pre></div></div>
<p>The kind “ClusterSourceTemplate” exists in the cluster.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ k get clustersourcetemplates.carto.run
NAME AGE
delivery-source-template 4d23h
source-scanner-template 4d23h
source-template 4d23h
testing-pipeline 4d23h
</code></pre></div></div>
<p>Above we can see there is one called “source-template”.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ k neat get -- clustersourcetemplates.carto.run source-template -oyaml
apiVersion: carto.run/v1alpha1
kind: ClusterSourceTemplate
metadata:
name: source-template
spec:
params:
- default: default
name: serviceAccount
- default: go-git
name: gitImplementation
revisionPath: .status.artifact.revision
urlPath: .status.artifact.url
ytt: |
#@ load("@ytt:data", "data")
#@ def merge_labels(fixed_values):
#@ labels = {}
#@ if hasattr(data.values.workload.metadata, "labels"):
#@ labels.update(data.values.workload.metadata.labels)
#@ end
#@ labels.update(fixed_values)
#@ return labels
#@ end
#@ def param(key):
#@ if not key in data.values.params:
#@ return None
#@ end
#@ return data.values.params[key]
#@ end
---
#@ if hasattr(data.values.workload.spec.source, "git"):
apiVersion: source.toolkit.fluxcd.io/v1beta1
kind: GitRepository
metadata:
name: #@ data.values.workload.metadata.name
labels: #@ merge_labels({ "app.kubernetes.io/component": "source" })
spec:
interval: 1m0s
url: #@ data.values.workload.spec.source.git.url
ref: #@ data.values.workload.spec.source.git.ref
gitImplementation: #@ data.values.params.gitImplementation
ignore: |
!.git
#@ if/end param("gitops_ssh_secret"):
secretRef:
name: #@ param("gitops_ssh_secret")
#@ end
#@ if hasattr(data.values.workload.spec.source, "image"):
apiVersion: source.apps.tanzu.vmware.com/v1alpha1
kind: ImageRepository
metadata:
name: #@ data.values.workload.metadata.name
labels: #@ merge_labels({ "app.kubernetes.io/component": "source" })
spec:
serviceAccount: #@ data.values.params.serviceAccount
interval: 1m0s
image: #@ data.values.workload.spec.source.image
#@ end
</code></pre></div></div>
<p>A lot of the above YAML is a “template” built with Carvel’s YAML templating tool, ytt, which may look a little unusual to those who haven’t seen ytt before.</p>
<p>From this section of the YAML, it’s somewhat obvious that this is a “if/then” template, and IF the source comes from GIT, then use “kind: GitRepository”. (And if it’s an IMAGE then use ImageRepository.)</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>SNIP!
#@ if hasattr(data.values.workload.spec.source, "git"):
apiVersion: source.toolkit.fluxcd.io/v1beta1
kind: GitRepository
SNIP!
</code></pre></div></div>
<p>The demo app, tanzu-java-web-app, is using a git repository, as defined in its YAML manifest / k8s object. Note the “source.git” section.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ k neat get -- workloads.carto.run tanzu-java-web-app -oyaml
apiVersion: carto.run/v1alpha1
kind: Workload
SNIP!
source:
git:
ref:
branch: main
url: https://github.com/sample-accelerators/tanzu-java-web-app
</code></pre></div></div>
<p>So there must be a manifest for that…yep.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ k get gitrepositories.source.toolkit.fluxcd.io
NAME URL READY STATUS
AGE
tanzu-java-web-app https://github.com/sample-accelerators/tanzu-java-web-app True Fetched revision: main/f5cf96ef23f3fddba94616112dfad882882aabe4 4d23h
</code></pre></div></div>
<p>Note the above is “…fluxcd.io”. TAP is using parts of the open source flux project, in this case specifically the flux capability to get code from a git repository.</p>
<p>We can continue this k8s sleuthing to follow the entire software supply chain. So far we’ve just looked at how source code is retrieved.</p>
<p>An important point is that this is all programmable, so much so that we can simply use the Cartographer live editor and paste in the YAML definition and it can easily produce an image.</p>
<p>This is also what is visualized in the TAP web interface.</p>
<p><img src="/img/tap-on-lap-gui3.jpg" alt="TAP GUI supply chain" /></p>
<h2 id="conclusion">Conclusion</h2>
<p>Here we’ve sleuthed through one stage of one of the supply chains, and looked at how we can visualize the chains with Cartographer’s live editor and the TAP GUI. In the next post we’ll create a custom supply chain.</p>
Deploy Tanzu Kubernetes Grid in an Offline/Airgapped Environment2022-05-03T00:00:00+00:00http://serverascode.com/2022/05/03/offline-airgapped-tanzu-kubernetes-grid<h1 id="deploy-tanzu-kubernetes-grid-in-an-offlineairgapped-environment">Deploy Tanzu Kubernetes Grid in an Offline/Airgapped Environment</h1>
<p><a href="https://tanzu.vmware.com/kubernetes-grid/">Tanzu Kubernetes Grid (TKG)</a> is VMware’s distribution of Kubernetes that can be deployed into vSphere and public clouds like Azure and AWS. Sometimes customers prefer that the deployment and management of TKG is done “offline” without needing to obtain any artifacts of the deployment from Internet hosted resources, that the deployment is self-contained.</p>
<p>This is a fairly common requirement, especially in organizations that consider segmentation of resources important, and it’s usually done at the network level, i.e. “network segmentation”, which has become even more popular as of late, around terms like microsegmentation and zero-trust networking.</p>
<h2 id="documentation-and-links">Documentation and Links</h2>
<ul>
<li><a href="https://docs.vmware.com/en/VMware-Tanzu-Kubernetes-Grid/1.5/vmware-tanzu-kubernetes-grid-15/GUID-mgmt-clusters-airgapped-environments.html">VMware Tanzu TKG - Internet Restricted Environments</a></li>
<li><a href="https://customerconnect.vmware.com/en/downloads/details?downloadGroup=TKG-153&productId=988&rPId=88185">Downloading TKG 1.5.3 CLIs</a></li>
</ul>
<h2 id="offline-environment">Offline Environment</h2>
<p>Firewall rules:</p>
<ul>
<li>tkg-offline-* networks: no internet access, all packets dropped at the edge firewall</li>
<li>Office network can connect to anything, i.e. the host that copies the container images from VMware to the internal Harbor instance</li>
<li>Anything on lab switch is available to tkg-offline-*, e.g. vCenter, DNS, Harbor, no firewalling, i.e. the TKG management clusters can talk to vCenter, etc</li>
</ul>
<p>Hardware, software:</p>
<ul>
<li>TKG >= 1.5.3</li>
<li>3 ESXI hosts</li>
<li>Running vSphere 7U2</li>
<li>Enough resources for TKG</li>
<li>A Linux + Docker instance to download the container images used in deployment, and to run the tanzu CLI from, as well as certain <a href="https://carvel.dev">Carvel</a> CLIs</li>
</ul>
<h2 id="a-word-on-container-images">A Word on Container Images</h2>
<p>When we think of container images we think of running an application, like, oh I don’t know, nginx. But container images aren’t only used for software, they can also be used to store configuration information. That is something that TKG does a lot of. As the industry gets more and more mature around the use of container images, we will do more with them, and that will cause us to simply have more of them. Smaller images, but more of them. My point here is that the number of container images that TKG could use can seem considerable, around 500 or so, but most of them are quite small, on the order of a few megabytes or even kilobytes, and often contain configuration information like BOMs.</p>
<p>In an online environment, one that is connected to the Internet, we probably wouldn’t even notice how many images are used by TKG when it’s being deployed. However, in an offline environment, one in which we need to copy these images, these artifacts, we have an opportunity to see first hand exactly how many images there are, and it can be surprising to some. I’d say there are about 500 total container images needed for ALL of TKG, and this is to support not only TKG itself, but also EVERY Kuberentes version that we support, which is many.</p>
<h2 id="a-word-on-tls-certificates">A Word on TLS Certificates</h2>
<p>In offline environments organizations almost always also use self-signed certificates, or certificates that are not part of the typical bundle found in operating systems, mostly for browsers. When deploying TKG many container images are pulled from the internal container image registry, in this case Harbor, and that Harbor instance will have a custom TLS certificate.</p>
<p>This means we need to ensure that TLS certificate, or certificate authority, is deployed into the TKG nodes, the virtual machines that underlie the Kubernetes clusters. Along with the various image artifacts, this is a big part of managing the offline deployment.</p>
<h2 id="relocating-container-images">Relocating Container Images</h2>
<p>One of the things we have to do is relocate the necessary container images from VMware’s Internet available registry to the organizations offline registry. This requires some sort of intermediary system, a jumpbox/bastion host or similar.</p>
<p>Currently our official docs provide a couple of scripts to do perform the actual relocation.</p>
<p>First we generate a list of images to relocate. To run this script we need to set some variables.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>export TKG_CUSTOM_IMAGE_REPOSITORY="<harbor>/<project>"
export TKG_IMAGE_REPO="projects.registry.vmware.com/tkg"
export TKG_CUSTOM_IMAGE_REPOSITORY_CA_CERTIFICATE=<base64 certificate>
</code></pre></div></div>
<p>I created a project in my Harbor called “tkg-1-5-3”.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>export TKG_CUSTOM_IMAGE_REPOSITORY="<harbor>/tkg-1-5-3"
</code></pre></div></div>
<p>I use mkcert to manage my certificates internally, so for the CA certificate I used that. You might take a different approach, but it’s the same idea.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>base64 -w 0 < /home/curtis/.local/share/mkcert/rootCA.pem
</code></pre></div></div>
<p>The result of that command I put into TKG_CUSTOM_IMAGE_REPOSITORY_CA_CERTIFICATE environment variable.</p>
<p>Now I can run the script to generate the list of images to copy to the internal Harbor.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ ./gen-publish-images.sh > image-copy-list
</code></pre></div></div>
<p>That will create this list of images. Most of the lines will be imgpkg commands. imgpkg is a CLI from the Carvel set of tools.</p>
<p>imgpkg is used to:</p>
<blockquote>
<p>Package, distribute, and relocate your Kubernetes configuration and dependent OCI images as one OCI artifact: a bundle. Consume bundles with confidence that their contents are unchanged after relocation.</p>
</blockquote>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ wc -l image-copy-list
4275 image-copy-list
</code></pre></div></div>
<p>While that seems like a lot of lines, some of the image copy commands are duplicates. So if we sort and uniq them, there are many fewer lines.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ grep imgpkg image-copy-list | sort | uniq | wc -l
568
</code></pre></div></div>
<p>The download image script does filter out the duplicate lines, so don’t worry about doing that yourself. I’m just illustrating what it does.</p>
<p>Then we use that list of images via another script to download each image and copy it to the Harbor instance.</p>
<blockquote>
<p>NOTE: I’m using Harbor, but it could be any OCI compliant registry.</p>
</blockquote>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ ./download-images.sh image-copy-list
</code></pre></div></div>
<p>Depending on the speed of your internet connection and your environment, this can take a few minutes or a couple hours.</p>
<p>Here’s what it looks like in Harbor.</p>
<p><img src="/img/tkg-offline-1.jpg" alt="harbor" /></p>
<h2 id="deploying-tkg">Deploying TKG</h2>
<p>Now that all the images are copied to the internal container image registry, we can deploy TKG.</p>
<p>First we need to set some configuration variables. These are the same as we set before for the image copy scripts, but now we’re going to set them up for TKG.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>tanzu config set env.TKG_CUSTOM_IMAGE_REPOSITORY <harbor>/<project>
tanzu config set env.TKG_CUSTOM_IMAGE_REPOSITORY_SKIP_TLS_VERIFY false
tanzu config set env.TKG_CUSTOM_IMAGE_REPOSITORY_CA_CERTIFICATE <base64 certificate>
</code></pre></div></div>
<p>Now validate those are set.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ tanzu config get | grep TKG
</code></pre></div></div>
<p>At this point we can now go through the standard deployment.</p>
<p>Usually I use the install GUI to setup the initial configuration file for the management cluster.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ tanzu mc create --ui --bind 0.0.0.0:8080 --browser none
Validating the pre-requisites...
Serving kickstart UI at http://[::]:8080
</code></pre></div></div>
<p>I connect to this host on port 8080 and fill out the install GUI, and that will generate a randomly named file in “~/.config/tanzu/tkg/clusterconfigs/” and the GUI will give you a command to run from the CLI (or you can launch it from the GUI, but I always stop the GUI process run it from the CLI)</p>
<h2 id="conclusion">Conclusion</h2>
<p>There are quite a few images to copy, but after that work has been done, and the CA certificate has been properly setup for use, the deployment is straightforward. So, for an offline deployment, it’s really two big steps:</p>
<ol>
<li>Relocate all the images locally, and,</li>
<li>Determine what certificate is used in the Harbor instance and make sure that TKG knows about it.</li>
</ol>
<p>I’m skipping quite a few other steps here, but those steps will be the same in any TKG deployment, offline or not, such as uploading the OVA file, or deploying/obtaining a container image registry like Harbor.</p>
Tanzu Application Platform on a Windows Workstation2022-04-26T00:00:00+00:00http://serverascode.com/2022/04/26/tanzu-application-platform-on-windows-workstation<h1 id="tanzu-application-platform-on-a-windows-workstation">Tanzu Application Platform on a Windows Workstation</h1>
<p>My current favorite VMware document is this:</p>
<ul>
<li><a href="https://tanzu.vmware.com/developer/guides/tanzu-application-platform-local-devloper-install/">Running Tanzu Application Platform Locally on Your Laptop</a></li>
</ul>
<p>If you run through the above how-to document, which is affectionately called TAPonLAP, at the end you will have a functioning <a href="https://tanzu.vmware.com/application-platform">Tanzu Application Platform</a> (TAP) profile-defined environment to use, and it’s all running locally on your personal workstation.</p>
<h2 id="what-is-tap">What is TAP?</h2>
<p>TAP is:</p>
<blockquote>
<p>…a modular, application-aware platform that provides a rich set of developer tooling and a prepaved path to production to build and deploy software quickly and securely on any compliant public cloud or on-premises Kubernetes cluster. - <a href="https://tanzu.vmware.com/application-platform">VMware Tanzu</a></p>
</blockquote>
<p>Using TAP we get all kinds of interesting and useful modular, Kubernetes native components which can work together, in concert with other tools and systems, to abstract way the complexity, and technical debt, of things like Dockerfiles and Kubernetes manifests, while also providing the ability to secure and understand workloads, even across multiple Kubernetes clusters.</p>
<p>It’s important to understand that TAP isn’t a single binary–it’s not a monolithic thing–instead it’s a collection of tools that can work together, even across multiple Kubernetes clusters. Some TAP components will be deployed in production clusters that run the apps, other pieces will only be deployed into clusters that build images and compile code, and still more parts only need to be deployed locally for a developers inner loop (if desired). We use the concept of profiles to determine what tools get deployed where. Honestly–it’s a new paradigm for Kubernetes based application platforms.</p>
<p>Another thing to keep in mind is that VMware Tanzu is extremely focused on Developer Experience (DX). Because of that focus we care very much about the developers “inner loop”…the things developers do with code before they commit it. With that in mind, the TAPonLAP document is focussed on building a local environment, specifically to meet the needs of that inner loop. I take it a little farther here and deploy most of the TAP components, but this won’t be commonplace, unless someone is learning about all of the components.</p>
<h2 id="my-taponlap-environment">My TAPonLAP Environment</h2>
<p>My main operating system is Linux (how do you know someone runs Linux on their desktop…just wait and they’ll tell you) but I use a Windows workstation for talking to customers with (Zoom, Teams, etc). Because I use Windows when I demonstrate software…well, that software has to run there too. So I’ve spent a fair amount time running through the TAPonLAP document, using the powershell commands, etc, overall making sure I’ve got the best local Windows development environment I can.</p>
<p>What I have:</p>
<ul>
<li>Windows 10</li>
<li>Hyper-V enabled</li>
<li>Minikube</li>
<li>32GB main memory, but using 12GB for the minikube instance</li>
<li>Enough disk (I use a Minikube instance with 80GB or more)</li>
<li>AMD Ryzen 5 3600 6-Core Processor</li>
</ul>
<h2 id="taponlap">TAPonLAP</h2>
<p>Please note: I’m not going to go through the <a href="https://tanzu.vmware.com/developer/guides/tanzu-application-platform-local-devloper-install/">entire document</a> and copy and paste the same commands here. However, I will detail some changes I made for my particular situation. So don’t expect to be able to follow this blog post and get TAP deployed–instead read the TAPonLAP doc, and this post, and then make your own decisions about how best to deploy TAP locally. Keep in mind it’s easy to delete or update TAP and redo the minikube install if needed. This combination of minikube and TAP is a great way to experiment.</p>
<h2 id="minikube-start">Minikube Start</h2>
<p>I use the below. Note that I am adding more disk, I think the default is ~20GB, which should be fine in most situations, but if you run the “full” TAP profile you’ll need more resources.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>minikube start `
--kubernetes-version='1.22.8' `
--cpus='8' --memory='12g' `
--driver='hyperv' `
--disk-size='80g'
</code></pre></div></div>
<h2 id="a-note-about-profiles">A Note About Profiles</h2>
<p>TAP is modular. It has many components, and not all of them need to be deployed in every situation. The TAPonLAP document shows the “iterate” profile, but in this blog post I use the “full” profile.</p>
<p>Most people using TAP locally, as part of their inner loop, would not run the full profile. Instead they are iterating on their own code before committing it, and want to make sure it mostly works before the commit, and when the CI system takes over. That is why the “iterate” profile exists.</p>
<h2 id="tap-full-profile">TAP Full Profile</h2>
<p>The TAPonLAP document shows using the iterative profile. Here’s an example full profile.</p>
<blockquote>
<p>NOTE: This, of course, this will consume more resources that the “iterative” profile.</p>
</blockquote>
<blockquote>
<p>NOTE: I’m using “example.com” as the domain, which you may or may not want to do.</p>
</blockquote>
<blockquote>
<p>NOTE: You’ll have to fill in all the image registry information, users, passwords, etc.</p>
</blockquote>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>profile: full
ceip_policy_disclosed: true # Installation fails if this is set to 'false'
buildservice:
kp_default_repository: "<some repository>/tap-inner-loop-1-1-full/build-service"
kp_default_repository_username: ""
kp_default_repository_password: ""
tanzunet_username: ""
tanzunet_password: ""
enable_automatic_dependency_updates: true
cnrs:
domain_name: apps.example.com
domain_template: "{{.Name}}-{{.Namespace}}.{{.Domain}}"
provider: local
supply_chain: basic
ootb_supply_chain_basic:
registry:
server: "<some repository>"
repository: "tap-inner-loop-1-1-full/supply-chain"
gitops:
ssh_secret: ""
learningcenter:
ingressDomain: "lc.example.com"
tap_gui:
service_type: ClusterIP
ingressEnabled: "true"
ingressDomain: "example.com"
app_config:
app:
baseUrl: http://tap-gui.example.com
catalog:
locations:
- type: url
target: https://github.com/sample-accelerators/tanzu-java-web-app/blob/main/catalog/catalog-info.yaml
- type: url
target: https://github.com/benwilcock/tap-gui-blank-catalog/blob/main/catalog-info.yaml
backend:
baseUrl: http://tap-gui.example.com
cors:
origin: http://tap-gui.example.com
metadata_store:
app_service_type: LoadBalancer
grype:
namespace: "default"
targetImagePullSecret: "registry-credentials"
# e.g. App Accelerator specific values go under its name
accelerator:
server:
service_type: ClusterIP
contour:
envoy:
service:
type: LoadBalancer
</code></pre></div></div>
<h2 id="once-tap-deploys">Once TAP deploys</h2>
<p>We should see the below.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>PS C:\Windows\system32> tanzu package installed get tap -n tap-install
NAME: tap
PACKAGE-NAME: tap.tanzu.vmware.com
PACKAGE-VERSION: 1.1.0
STATUS: Reconcile succeeded
CONDITIONS: [{ReconcileSucceeded True }]
USEFUL-ERROR-MESSAGE:
</code></pre></div></div>
<h2 id="hostnames">Hostnames</h2>
<p>Depending on the profile in use, there may be many hostnames needed to be added to the Windows hosts file. Here’s a list of hostnames I use.</p>
<blockquote>
<p>NOTE: I’m a big fan of our <a href="https://docs.vmware.com/en/Tanzu-Application-Platform/1.1/tap/GUID-learning-center-about.html">Learning Center</a> tool, more about that in future posts I’m sure, so many of these hostnames are related to that project, which is part of TAP. If you don’t deploy it, then you won’t need these hostnames. It is part of the “full” profile though. That said, you can exclude packages from deployment.</p>
</blockquote>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>192.168.0.10 tap-gui.example.com tanzu-java-web-app.default.apps.example.com learning-center-guided.lc.example.com learning-center-guided-w01-s001.lc.example.com tanzu-java-web-app-default.apps.example.com learning-center-guided-w01-s001-editor.lc.example.com learning-center-guided-w01-s001-console.lc.example.com learning-center-guided-w01-s001-nginx.lc.example.com learning-center-guided-w01-s001-nginx-via-proxy.lc.example.com learning-center-guided-w01-s001-registry.lc.example.com
</code></pre></div></div>
<h2 id="deploying-an-application-aka-workload">Deploying an Application (AKA WOrkload)</h2>
<p>Using the Tanzu CLI, which itself is using Kubernetes under the hood (you could simply use the YAML that it shows as well) we can deploy a Java application.</p>
<blockquote>
<p>NOTE: We are not building or managing the container image. A TAP component called the Tanzu Build Service is doing that for us. So no Dockerfiles to manage.</p>
</blockquote>
<blockquote>
<p>NOTE: Ensure you prepare the dev namespace as per the TAPonLAP document.</p>
</blockquote>
<p>E.g. command. Note that I’m just using the default namespace.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$Env:TAP_DEV_NAMESPACE = "default"
tanzu apps workload create tanzu-java-web-app `
--git-repo https://github.com/sample-accelerators/tanzu-java-web-app `
--git-branch main `
--type web `
--label app.kubernetes.io/part-of=tanzu-java-web-app `
--label tanzu.app.live.view=true `
--label tanzu.app.live.view.application.name=tanzu-java-web-app `
--annotation autoscaling.knative.dev/minScale=1 `
--namespace $env:TAP_DEV_NAMESPACE `
--dry-run
</code></pre></div></div>
<p>E.g. output of that command:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>PS C:\Windows\system32> tanzu apps workload create tanzu-java-web-app `
>> --git-repo https://github.com/sample-accelerators/tanzu-java-web-app `
>> --git-branch main `
>> --type web `
>> --label app.kubernetes.io/part-of=tanzu-java-web-app `
>> --label tanzu.app.live.view=true `
>> --label tanzu.app.live.view.application.name=tanzu-java-web-app `
>> --annotation autoscaling.knative.dev/minScale=1 `
>> --namespace $env:TAP_DEV_NAMESPACE `
>> --yes
Create workload:
←[32m 1 + |---
←[0m←[32m 2 + |apiVersion: carto.run/v1alpha1
←[0m←[32m 3 + |kind: Workload
←[0m←[32m 4 + |metadata:
←[0m←[32m 5 + | labels:
←[0m←[32m 6 + | app.kubernetes.io/part-of: tanzu-java-web-app
←[0m←[32m 7 + | apps.tanzu.vmware.com/workload-type: web
←[0m←[32m 8 + | tanzu.app.live.view: "true"
←[0m←[32m 9 + | tanzu.app.live.view.application.name: tanzu-java-web-app
←[0m←[32m 10 + | name: tanzu-java-web-app
←[0m←[32m 11 + | namespace: default
←[0m←[32m 12 + |spec:
←[0m←[32m 13 + | params:
←[0m←[32m 14 + | - name: annotations
←[0m←[32m 15 + | value:
←[0m←[32m 16 + | autoscaling.knative.dev/minScale: "1"
←[0m←[32m 17 + | source:
←[0m←[32m 18 + | git:
←[0m←[32m 19 + | ref:
←[0m←[32m 20 + | branch: main
←[0m←[32m 21 + | url: https://github.com/sample-accelerators/tanzu-java-web-app
←[0m
←[32;1mCreated workload "tanzu-java-web-app"
←[0m
</code></pre></div></div>
<p>Above you can see that the command displays the YAML that is actually deployed into Kubernetes. Note the kind.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>kind: Workload
</code></pre></div></div>
<p>With this command or a few lines of YAML, you can completely manage an application in Kubernetes, from source to running application.</p>
<h2 id="the-application-is-deployed">The Application is Deployed!</h2>
<p>The example Java application has now been deployed.</p>
<blockquote>
<p>NOTE: By default the application is running in <a href="https://knative.dev/docs/">knative</a>, which can scale to zero. But, in the above command we told knative that the minimum scale is 1, ie. not to scale to zero, so there will always be at least one pod running.</p>
</blockquote>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>PS C:\Windows\system32> kubectl get pods
NAME READY STATUS RESTARTS AGE
tanzu-java-web-app-00001-deployment-7fffdb9fcb-2s47s 2/2 Running 0 17m
tanzu-java-web-app-build-1-build-pod 0/1 Completed 0 19m
tanzu-java-web-app-config-writer-69xhb-pod 0/1 Completed 0 18m
</code></pre></div></div>
<p>If we get the routes we can see the URL to connect to.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>PS C:\Windows\system32> kubectl get routes
NAME URL READY REASON
tanzu-java-web-app http://tanzu-java-web-app-default.apps.example.com True
</code></pre></div></div>
<p>Curl it:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>PS C:\Windows\system32> curl.exe http://tanzu-java-web-app-default.apps.example.com
Greetings from Spring Boot + Tanzu!
</code></pre></div></div>
<p>Done (for now)!</p>
<h2 id="observe-in-the-tap-gui">Observe in the TAP GUI</h2>
<p>TAP comes with a web GUI, which can be found at http://tap-gui.example.com if using the above “full” profile.</p>
<p><img src="/img/tap-on-lap-gui.jpg" alt="TAP GUI" /></p>
<p>We can start to “drill down” into the running application as well.</p>
<p><img src="/img/tap-on-lap-gui2.jpg" alt="TAP GUI 2" /></p>
<p>We can also visualize our secure software flow, the secure supply chains that were created by default.</p>
<p><img src="/img/tap-on-lap-gui3.jpg" alt="TAP GUI 3" /></p>
<p>Above we are using the default “source-to-url” supply chain.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>PS C:\Windows\system32> kubectl get clustersupplychains
NAME READY REASON AGE
basic-image-to-url True Ready 29m
source-to-url True Ready 29m
</code></pre></div></div>
<h2 id="conclusion">Conclusion</h2>
<p>TAP, and its modular components, are meant to run in many places in many ways, from large clusters, to minikube instances. If TAP is running locally, then the developer can use it to “iterate” on code: to write code, try deploying it, test it out, understand a bit about TAP, and then commit their code at which point TAP can again take over and build the image and run it in production, but of course, not locally, instead on a production Kubernetes cluster (or, more likely, cluster<strong>s</strong>).</p>
<p>This post just brings us through a bit of TAP, gives a few hints, and provides a starting point to understand more about the TAP paradigm.</p>
<h2 id="extra-notes">Extra Notes</h2>
<h3 id="dont-forget-to-run-the-minikube-tunnel">Don’t Forget to Run the Minikube Tunnel</h3>
<p>If you forget the below…</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>minikube tunnel
</code></pre></div></div>
<p>or didn’t leave it running while installing TAP, then the Ingress load balancer will stay pending and TAP won’t deploy completely.</p>
<h3 id="kubeconfig-into-wsl">Kubeconfig into WSL</h3>
<p>This might not be the right motion, but I prefer to use Linux to work with Kubernetes as opposed to a powershell…er shell. So here I send the kubeconfig for minikube into my WSL users kube config.</p>
<blockquote>
<p>NOTE: This would, of course, destroy anything existing in your kubeconfig.</p>
</blockquote>
<blockquote>
<p>NOTE: This assumes your WSL instance is named “Ubuntu” and that your user’s name is “curtis” which is unlikely. :)</p>
</blockquote>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>PS C:\Windows\system32> kubectl config view --flatten > \\wsl$\Ubuntu\home\curtis\.kube\config
</code></pre></div></div>
<h3 id="minikube-ip">Minikube IP</h3>
<p>One thing I’ve noticed is that the minikube IP will changed, say on a Windows OS reboot. So if that happens you’ll need to change the IP in the hosts file.</p>
<h3 id="minikube-purge">Minikube Purge</h3>
<p>I’ve had to purge the minikube instance once or twice. For some reason, I had one instance of minikube that was acting very slow. I didn’t take the time to try to figure out why it was acting slow. I don’t believe it was because of TAP, more likely because of some storage/disk issue.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>PS C:\Windows\system32> minikube delete --purge
</code></pre></div></div>
<h3 id="memory-usage">Memory Usage</h3>
<p>So far it seems reasonable to run this on my desktop, though again, most of the time one would run a lighter TAP profile than the “full” profile.</p>
<p><img src="/img/tap-on-lap-4.jpg" alt="Performance" /></p>
Tanzu Application Platform, knative, and a NodeJS App2022-01-12T00:00:00+00:00http://serverascode.com/2022/01/12/tap-knative-nodejs<h1 id="tanzu-application-platform-knative-and-a-nodejs-app">Tanzu Application Platform, knative, and a NodeJS App</h1>
<h2 id="previously">Previously…</h2>
<p>In an <a href="https://serverascode.com/2022/01/11/tap-knative.html">earlier post</a> I deployed a simple demo container image into Kubernetes via knative, and knative itself was installed as part of VMware Tanzu’s Cloud Native Runtimes, which is also Part of the Tanzu Application Platform. If that sounds like a lot, that’s OK, it is a lot.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>Tanzu Application Platform (provides ->) Cloud Native Runtimes (provides ->) knative
</code></pre></div></div>
<p>All of this is using the Tanzu Application Platform and in this example is running on a GKE cluster.</p>
<h2 id="deploy-a-nodejs-application">Deploy a NodeJS application</h2>
<p>In this post I’ll deploy a NodeJS application into knative.</p>
<p>Again, the same as the previous post, I have a GKE cluster with TAP installed.</p>
<p>I’ve got no pods running.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ k get pods
No resources found in cnr-demo namespace.
</code></pre></div></div>
<p>Though I still have the knative service I deployed in the last post running.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ /usr/local/bin/kn service list
NAME URL LATEST AGE CONDITIONS READY REASON
hello-yeti http://hello-yeti.cnr-demo.example.com hello-yeti-00001 17h 3 OK / 3 True
</code></pre></div></div>
<p>Now I want to add a new knative service, but this time in an image that I build, and the app is running NodeJS.</p>
<p>Here’s an <a href="https://github.com/knative/docs/tree/main/code-samples/serving/hello-world/helloworld-nodejs">example knative NodeJS app</a>.</p>
<p>First grab the code.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ git clone https://github.com/knative/docs.git knative-docs
$ cd knative-docs/code-samples/serving/hello-world/helloworld-nodejs
</code></pre></div></div>
<p>There’s an index.js file. There’s really nothing to it.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ cat index.js
const express = require('express');
const app = express();
app.get('/', (req, res) => {
console.log('Hello world received a request.');
const target = process.env.TARGET || 'World';
res.send(`Hello ${target}!\n`);
});
const port = process.env.PORT || 8080;
app.listen(port, () => {
console.log('Hello world listening on port', port);
});
</code></pre></div></div>
<p>Add npm packages.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ npm install
</code></pre></div></div>
<p>I’m using this version of node.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ node --version
v16.13.0
</code></pre></div></div>
<p>I’m going to update the Dockerfile to use 16-slim.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ git diff Dockerfile
diff --git a/code-samples/serving/hello-world/helloworld-nodejs/Dockerfile b/code-samples/serving/hello-world/helloworld-nodejs/Dockerfile
index 14fc5a7f..5593df68 100644
--- a/code-samples/serving/hello-world/helloworld-nodejs/Dockerfile
+++ b/code-samples/serving/hello-world/helloworld-nodejs/Dockerfile
@@ -1,6 +1,6 @@
# Use the official lightweight Node.js 12 image.
# https://hub.docker.com/_/node
-FROM node:12-slim
+FROM node:16-slim
# Create and change to the app directory.
WORKDIR /usr/src/app
</code></pre></div></div>
<p>Build the image.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ docker build -t knative-hello-world-nodejs .
Sending build context to Docker daemon 37.38kB
SNIP!
found 0 vulnerabilities
npm notice
npm notice New minor version of npm available! 8.1.2 -> 8.3.0
npm notice Changelog: <https://github.com/npm/cli/releases/tag/v8.3.0>
npm notice Run `npm install -g npm@8.3.0` to update!
npm notice
Removing intermediate container 05788fe68bda
---> 0d87e2185381
Step 5/6 : COPY . ./
---> e799b6c92ec9
Step 6/6 : CMD [ "npm", "start" ]
---> Running in 28f3c37d21e2
Removing intermediate container 28f3c37d21e2
---> 4fc708b92f84
Successfully built 4fc708b92f84
Successfully tagged knative-hello-world-nodejs:latest
</code></pre></div></div>
<p>Tag and push the image to the registry.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ docker tag knative-hello-world-nodejs <registry>/random-builds/knative-hello-world-nodejs
$ docker push <registry>/random-builds/knative-hello-world-nodejs
Using default tag: latest
The push refers to repository [<registry>/random-builds/knative-hello-world-nodejs]
bd83fded2ed1: Pushed
888c1936e335: Pushed
602368557b6e: Pushed
a58aa2b5afe6: Pushed
2c1769b8f2cd: Pushed
b5e79c5c6912: Pushed
18be021c4ec0: Pushed
4a67e24013ff: Pushed
ad6b69b54919: Pushed
latest: digest: sha256:ffe4ba5bed5e9e692d8ca8f441a9209f2d20ab7adef927f0128c027364d1a3e9 size: 2201
</code></pre></div></div>
<p>Aply some knative Kubernetes YAML. (Could use the knative CLI as well, but hey, this time let’s write some YAML.)</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>cat << EOF | kubectl create -f -
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: knative-helloworld-nodejs
namespace: cnr-demo
spec:
template:
spec:
containers:
- image: <registry>/random-builds/knative-hello-world-nodejs
env:
- name: TARGET
value: "Node.js Sample v1"
EOF
</code></pre></div></div>
<p>Now I’ve got both my knative services running, one of which is the NodeJS hello world app.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ /usr/local/bin/kn service list
NAME URL LATEST AGE CONDITIONS READY REASON
hello-yeti http://hello-yeti-cnr-demo.cnrs.gke.<redacted> hello-yeti-00001 3d12h 3 OK / 3 True
knative-helloworld-nodejs http://knative-helloworld-nodejs-cnr-demo.cnrs.gke.<redacted> knative-helloworld-nodejs-00001 2d19h 3 OK / 3 True
</code></pre></div></div>
<p>Once that’s up and running we can curl the app.</p>
<blockquote>
<p>NOTE: The LB variable is my load balancer fronting the Kubernetes ingress service provided by the Tanzu Application Platform.</p>
</blockquote>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ http http://knative-helloworld-nodejs-cnr-demo.cnrs.gke.<redacted>
HTTP/1.1 200 OK
content-length: 25
content-type: text/html; charset=utf-8
date: Sat, 15 Jan 2022 10:54:45 GMT
etag: W/"19-9t2w57sw0IX9vcOiByda5bvW2a4"
server: envoy
x-envoy-upstream-service-time: 2195
x-powered-by: Express
Hello Node.js Sample v1!
</code></pre></div></div>
<p>Hello NodeJS World indeed.</p>
<h2 id="building-container-imagesknative-used-to-do-this">Building container Images…knative used to do this</h2>
<p>As you can see from this post and the previous one, the container image used to run the knative service has to come from somewhere.</p>
<p>When the knative project originated, building images was part of its mandate.</p>
<blockquote>
<p>First version of Knative came with three parts: Serving, Eventing, and Build. These may sound like they are three orthogonal concerns, because they really were. Knative Build was the first part to get separated (and became the Tekton project). - <a href="https://ahmet.im/blog/knative-positioning/">Did we market Knative wrong?</a></p>
</blockquote>
<p>But, as can be read in the above paragraph, people felt that having build be part of knative was confusing, so a proposal to move build out into Tekton was made:</p>
<blockquote>
<p>This removes Serving optional dependency on Knative Build, making Knative Build fully decoupled from the rest of the Knative components and only responsible to build images that will be using in services later on. This responsibility is shared with any projects capable of building images in Kubernetes. - <a href="https://github.com/knative/build/issues/614">
Proposal: Knative Build deprecation in favor of Tekton Pipelines</a></p>
</blockquote>
<p>And “knative build” moved out into Tekton.</p>
<blockquote>
<p>Tekton Pipelines is the technological successor to Knative Build. Tekton entities are based on Knative Build’s entities but provide additional flexibility and reusability. This page explains how to convert your Knative Build entities to Tekton entities of equivalent functionality. - <a href="https://tekton.dev/docs/pipelines/migrating-from-knative-build/">Migrating from Knative Build</a></p>
</blockquote>
<p>Obviously having a container image is key to using knative, so we’ve got to build one somehow. From a knative project perspective, they moved the build from out of knative and into Tekton. But, is Tekton the best way to build images?</p>
<p>What I can say for sure is that from the perspective of the Tanzu Application Platform, the way we (optionally, but by default) build container images is via the Tanzu Build Service (TBS), which is based on the open source projects <a href="https://github.com/pivotal/kpack">kpack</a> and <a href="https://paketo.io/">Paketo</a>.</p>
<p>That said, Tekton Pipelines are also installed and used in the Tanzu Application Service (more on that in some other future post) but they are not used to directly <em>build</em> images, that’s done by TBS, at least by default. To run a container you have to have a container image, and thus to help in simplifying and securing Kubernetes TAP provides that capability. It’s a must have feature.</p>
<h2 id="conclusion">Conclusion</h2>
<p>So there’s not much more to this post than the previous one, the one difference being that in this post I build the container image (using docker build) and pushed it to a registry myself, as opposed to using an image that someone, or something, else has built. To build my image I needed to <em>write/maintain/borrow/steal</em> a Dockerfile, which is not a small amount of additional work. Maybe instead of using a Dockerfile I could somehow use Tekton, or, I can absolutely use the Tanzu Build Service through TAP and have zero Dockerfiles (like none).</p>
<p>While I’m using knative to help simplify using Kubernetes, which is great, I still have a lot of work to do as a developer to participate in a container deployment workflow…again, for example, having to build and maintain (forever) a container image.</p>
<p>Another developer concern: how do I test all this? What if I change the code? Now I need to manually build the container image? Well, of course, no one would want to do that every time so there are several different ways to solve that problem, but it’s still work.</p>
<p>Plus we have all the other fun stuff like how do we observe our app while it’s running in production, how do we debug, etc, etc. More to think about!</p>
<h2 id="a-note-on-tap">A Note on TAP</h2>
<p>I want to be clear here, the full Tanzu Application Platform takes on all these challenges and more. In these two posts I’ve simply been exploring the knative component of TAP, which is only a subset of TAP’s capabilities, and in fact, when all of TAP is utilized the power is more than the sum of its parts.</p>
<p>What I’m doing with these posts is building up piece by piece the modular components of TAP to explore why they are important and what value they add.</p>
Tanzu Application Platform and knative2022-01-11T00:00:00+00:00http://serverascode.com/2022/01/11/tap-knative<h1 id="tanzu-application-platform-and-knative">Tanzu Application Platform and knative</h1>
<h2 id="tldr">tl;dr</h2>
<p>The point of this post is to show that knative is part of The <a href="https://tanzu.vmware.com/application-platform">Tanzu Application Platform</a>, AKA TAP, and one can use knative outside of TAP, directly with the kn CLI, if desired. (Though, in the real world you would probably use the rest of TAP as well, but it’s modular so you don’t <em>have</em> to.)</p>
<p>In this post TAP has been deployed into a GKE cluster (yep, a GKE cluster). TAP includes knative, so in this post I’ll deploy a simple demo app into the GKE cluster and that deployment will be done via the knative CLI. Serverless here we come!</p>
<h2 id="gke-cluster">GKE Cluster</h2>
<p>First, as I mentioned, I’ve got a Google Kubernetes Cluster.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ k get nodes
NAME STATUS ROLES AGE VERSION
gke-gke-tap-1-default-pool-4e593ad2-9dk4 Ready <none> 4d2h v1.22.3-gke.700
gke-gke-tap-1-default-pool-4e593ad2-m8qs Ready <none> 4d2h v1.22.3-gke.700
gke-gke-tap-1-default-pool-8dc7b056-8g1l Ready <none> 4d2h v1.22.3-gke.700
gke-gke-tap-1-default-pool-8dc7b056-drtd Ready <none> 4d2h v1.22.3-gke.700
gke-gke-tap-1-default-pool-bb825ba8-3pgz Ready <none> 4d2h v1.22.3-gke.700
gke-gke-tap-1-default-pool-bb825ba8-6v55 Ready <none> 4d2h v1.22.3-gke.700
</code></pre></div></div>
<p>It has a bunch of nodes and is running the “full” TAP profile.</p>
<h2 id="what-is-the-tanzu-application-platform">What is the Tanzu Application Platform?</h2>
<blockquote>
<p>VMware Tanzu Application Platform is a modular, application-aware platform that provides a rich set of developer tooling and a prepaved path to production to build and deploy software quickly and securely on any compliant public cloud or on-premises Kubernetes cluster.</p>
</blockquote>
<p>TAP is a set of modular components which extend Kubernetes, making it easier and more secure to use. It’s important to understand that underlying TAP is still Kubernetes–all the pieces of TAP are “native” Kubernetes which means they become part of the Kubernetes API. The way we interact with TAP is through the Kubernetes API, though that will often be hidden away by pipelines and developer inner loop tooling. (No one should have to use kubectl, but you can of course.)</p>
<p>For an example of extending Kubernetes, once you’ve deployed TAP you have an image resource, which, in plain old vanilla Kubernetes, doesn’t exist. (NOTE: I believe the power of Kubernetes is not so much in orchestrating containers, instead the fact that it is a platform to <em>build other platforms on top of</em>, which is precisely what TAP is…it’s even in the name!).</p>
<p>Below I have a couple of container images represented in Kubernetes for a demo application for Spring called Pet Clinic, which can be deployed via knative through TAP. knative is part of what VMware Tanzu calls <a href="https://docs.vmware.com/en/Cloud-Native-Runtimes-for-VMware-Tanzu/1.0/tanzu-cloud-native-runtimes-1-0/GUID-cnr-overview.html">Cloud Native Runtimes</a></p>
<p>Here I ask what Kubernetes knows about container images.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ k get images
NAME IMAGE
pet-clinic-00001-cache-workload <registry>/tap-beta-4/supply-chain/pet-clinic-default@sha256:3b4ef38a43d464750d63ca0226c67ae59fdf990efe01c37ae88e8e10d2f574e8
pet-clinic-00002-cache-workload <registry>/tap-beta-4/supply-chain/pet-clinic-default@sha256:edfeabd87ee782f06510a0f1bc984a6134ae923121a6437cd5f401c59ff815de
</code></pre></div></div>
<blockquote>
<p>NOTE: The images resource is provided by the Tanzu Build Service (also part of TAP), which itself is built on the open source projects <a href="https://github.com/pivotal/kpack">kpack</a> and <a href="https://paketo.io/">Paketo</a> and years of history and experience with Cloud Foundry and Buildpacks.</p>
</blockquote>
<p>But that’s just an example of how we build a platform on Kubernetes, in this post I’ll try to stay focussed on knative.</p>
<h2 id="cloud-native-runtimes-and-knative">Cloud Native Runtimes and knative</h2>
<p><a href="https://docs.vmware.com/en/Cloud-Native-Runtimes-for-VMware-Tanzu/1.0/tanzu-cloud-native-runtimes-1-0/GUID-cnr-overview.html">Cloud Native Runtimes</a> is VMware’s product to provide various ways of running applications in Kubernetes. Currently there is only the single runtime, knative, but more will be added over time.</p>
<p>So what’s knative? It’s an open source project that makes developers more productive by abstracting away some of the complexity of Kubernetes.</p>
<blockquote>
<p>Knative components build on top of Kubernetes…by codifying the best practices shared by successful real-world implementations, Knative solves the “boring but difficult” parts of deploying and managing cloud native services so you don’t have to. - <a href="https://knative.dev/docs/">knative website</a></p>
</blockquote>
<p>knative provides:</p>
<ol>
<li>Serverless - “Run serverless containers on Kubernetes with ease, Knative takes care of the details of networking, autoscaling (even to zero), and revision tracking. You just have to focus on your core logic.”</li>
<li>Eventing - “Universal subscription, delivery, and management of events. Build modern apps by attaching compute to a data stream with declarative event connectivity and developer-friendly object model.”</li>
</ol>
<p>I’d like to look specifically at just running a serverless app in knative, which in this case is easily provided/installed into Kubernetes by TAP. (That said, eventing is clearly important to modern applications, so it’s important to keep in mind that knative satisfies that need as well.)</p>
<h2 id="deploying-an-app-into-knative">Deploying an App into knative</h2>
<p>In our GKE cluster we have many packages from TAP installed, including knative, aka Cloud Native Runtimes. That means we can run serverless workloads!</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ tanzu package installed list --namespace tap-install
\ Retrieving installed packages...
NAME PACKAGE-NAME PACKAGE-VERSION STATUS
accelerator accelerator.apps.tanzu.vmware.com 1.0.0 Reconcile succeeded
api-portal api-portal.tanzu.vmware.com 1.0.8 Reconcile succeeded
appliveview run.appliveview.tanzu.vmware.com 1.0.1 Reconcile succeeded
appliveview-conventions build.appliveview.tanzu.vmware.com 1.0.1 Reconcile succeeded
buildservice buildservice.tanzu.vmware.com 1.4.2 Reconcile succeeded
cartographer cartographer.tanzu.vmware.com 0.1.0 Reconcile succeeded
cert-manager cert-manager.tanzu.vmware.com 1.5.3+tap.1 Reconcile succeeded
cnrs cnrs.tanzu.vmware.com 1.1.0 Reconcile succeeded
contour contour.tanzu.vmware.com 1.18.2+tap.1 Reconcile succeeded
conventions-controller controller.conventions.apps.tanzu.vmware.com 0.5.0 Reconcile succeeded
developer-conventions developer-conventions.tanzu.vmware.com 0.5.0-build.1 Reconcile succeeded
fluxcd-source-controller fluxcd.source.controller.tanzu.vmware.com 0.16.0 Reconcile succeeded
grype grype.scanning.apps.tanzu.vmware.com 1.0.0 Reconcile succeeded
image-policy-webhook image-policy-webhook.signing.apps.tanzu.vmware.com 1.0.0 Reconcile succeeded
learningcenter learningcenter.tanzu.vmware.com 0.1.0 Reconcile succeeded
learningcenter-workshops workshops.learningcenter.tanzu.vmware.com 0.1.0 Reconcile succeeded
metadata-store metadata-store.apps.tanzu.vmware.com 1.0.1 Reconcile succeeded
ootb-delivery-basic ootb-delivery-basic.tanzu.vmware.com 0.5.1 Reconcile succeeded
ootb-supply-chain-basic ootb-supply-chain-basic.tanzu.vmware.com 0.5.1 Reconcile succeeded
ootb-templates ootb-templates.tanzu.vmware.com 0.5.1 Reconcile succeeded
scanning scanning.apps.tanzu.vmware.com 1.0.0 Reconcile succeeded
service-bindings service-bindings.labs.vmware.com 0.6.0 Reconcile succeeded
services-toolkit services-toolkit.tanzu.vmware.com 0.5.0 Reconcile succeeded
source-controller controller.source.apps.tanzu.vmware.com 0.2.0 Reconcile succeeded
spring-boot-conventions spring-boot-conventions.tanzu.vmware.com 0.3.0 Reconcile succeeded
tap tap.tanzu.vmware.com 1.0.0 Reconcile succeeded
tap-gui tap-gui.tanzu.vmware.com 1.0.1 Reconcile succeeded
tap-telemetry tap-telemetry.tanzu.vmware.com 0.1.2 Reconcile succeeded
tekton-pipelines tekton.tanzu.vmware.com 0.30.0 Reconcile succeeded
</code></pre></div></div>
<p>That’s a lot of stuff. Those pieces are currently part of the Tanzu Application Platform. But lets just use a single piece: knative.</p>
<p>First I’ve got the <code class="language-plaintext highlighter-rouge">kn</code> CLI.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ which kn
/usr/local/bin/kn
</code></pre></div></div>
<p>Next I’ll create a namespace (and switch to it).</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ kubectl create namespace cnr-demo
</code></pre></div></div>
<p>Then I’ll setup a reg secret because my registry requires authentication.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ kubectl create secret docker-registry registry-credentials \
--docker-server=<redacted> \
--docker-email=<redacted> \
--docker-username=<redacted> \
--docker-password=<redacted>
</code></pre></div></div>
<p>Allow the namespace’s default SA to use it…</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ kubectl patch serviceaccount default -p "{\"imagePullSecrets\": [{\"name\": \"registry-credentials\"}]}"
</code></pre></div></div>
<p>Now deploy a workload, pointing to an image that resides in the registry I previously setup secret credentials for.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ kn service create hello-yeti -n cnr-demo \
--image <registry>/hello-yeti --env TARGET='hello-yeti'
</code></pre></div></div>
<p>Output:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ kn service create hello-yeti -n cnr-demo --image <registry>/hello-yeti --env TARGET='hello-yeti'
Creating service 'hello-yeti' in namespace 'cnr-demo':
0.043s The Route is still working to reflect the latest desired specification.
0.091s ...
0.148s Configuration "hello-yeti" is waiting for a Revision to become ready.
5.639s ...
5.712s Ingress has not yet been reconciled.
5.756s Waiting for Envoys to receive Endpoints data.
6.108s Waiting for load balancer to be ready
6.329s Ready to serve.
Service 'hello-yeti' created to latest revision 'hello-yeti-00001' is available at URL:
http://hello-yeti.cnr-demo.example.com
</code></pre></div></div>
<p>Once that deploys there will be a pod running.</p>
<blockquote>
<p>NOTE: The deployment will scale to zero if it’s not being used, something to remember.</p>
</blockquote>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ k get pods
NAME READY STATUS RESTARTS AGE
hello-yeti-00001-deployment-6f49f84f5-z6lgq 2/2 Running 0 13s
</code></pre></div></div>
<p>List the knative deployments/services.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ kn service list
NAME URL LATEST AGE CONDITIONS READY REASON
hello-yeti http://hello-yeti.cnr-demo.example.com hello-yeti-00001 3m48s 3 OK / 3 True
</code></pre></div></div>
<p>Curl the app.</p>
<blockquote>
<p>NOTE: TAP also deploys an ingress controller for you. To connect to the knative service we’ll need the IP of the Kubernetes loadbalancer for the ingress service.</p>
</blockquote>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ export LB=`kubectl get services -n tanzu-system-ingress envoy -o jsonpath="{.status.loadBalancer.ingress[0].ip}"`
$ curl -H "Host: hello-yeti.cnr-demo.example.com" $LB
</code></pre></div></div>
<p>Output:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ curl -H "Host: hello-yeti.cnr-demo.example.com" $LB
______________
/ \
| hello from |
| cloud native |
| runtimes | .xMWxw.
\______________\ | wY Ym.
\| C , , O
\ ww /.
..x x..
.x wwwww x.
.x x.
x \ / x
Y Y Y Y
wwv x vww
\ /\ /
:www: :www:
</code></pre></div></div>
<p>If the application isn’t accessed for a while it’ll scale to zero.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ k get pods
No resources found in cnr-demo namespace.
</code></pre></div></div>
<p>If we try to hit the URL again, the pods will be restarted automatically by knative.</p>
<p>So, that was pretty easy. Of course it’s a simple demo application which lives in an existing container image, but the point of this post was to illustrate that by deploying TAP we have access to knative, and we can even use knative outside of the TAP workflow if we want, or deploy it outside of TAP as well. knative is a major part of VMware Tanzu.</p>
<h2 id="conclusion">Conclusion</h2>
<p>The Tanzu Application Platform gives you cutting edge tools like serverless via knative. Now, the point of TAP isn’t necessarily to just directly use knative like this, but I wanted to show that knative is indeed part, an integral part, of TAP, that you can use if you want to (by default most TAP demos will use knative) but you don’t have to use it.</p>
<p>Another thing to keep in mind in the context of this post, is exactly where did that hello-yeti container image come from? What if we want to deploy our own code? Not surprisingly, I’ll look into that in the next post in this series.</p>
<p>Thanks for reading!</p>
Azure Functions, Managed Identity, NodeJS, and Key Vault2021-12-21T00:00:00+00:00http://serverascode.com/2021/12/21/azure-functions-keyvault<h1 id="azure-functions-managed-identity-nodejs-and-key-vault">Azure Functions, Managed Identity, NodeJS, and Key Vault</h1>
<p>Azure has functions. Azure as a way to manage secrets called Key Vault. How do these work together? If you create a function and you want to access a Key Vault secret, clearly it has to authenticate to the Key Vault service…but how?</p>
<p>Managed identity is the answer. But what is “managed identity”?</p>
<blockquote>
<p>A managed identity from Azure Active Directory (Azure AD) allows your app to easily access other Azure AD-protected resources such as Azure Key Vault. The identity is managed by the Azure platform and does not require you to provision or rotate any secrets. - <a href="https://docs.microsoft.com/en-us/azure/app-service/overview-managed-identity?tabs=dotnet">Azure Docs</a></p>
</blockquote>
<p>Basically your function can authenticate without having to login in the way that we typically think of “logging in”, ie. with a username and password. If we did have to use a username and password then the function would have to get that information from somewhere, and if that information became public in some way we’d have to rotate (ie. change) those secrets, which is a huge pain. But with managed identity we don’t have to do that, instead we configure Azure to allow our function to access Key Vault. Thus, the platform takes care of everything in the background, which is what platforms are supposed to do. :)</p>
<p>Also, and this is interesting, in my NodeJS code I’m using the below to setup the credential so that I can access Key Vault secrets.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>const credential = new DefaultAzureCredential();
</code></pre></div></div>
<p>The above assumes there are AZURE_TENANT_ID, AZURE_CLIENT_ID and AZURE_CLIENT_SECRET variables configured, ie. when developing locally, having logged in with <code class="language-plaintext highlighter-rouge">az login</code> or setup those variables. However, once the function has been pushed to Azure, if those variables are not available, the code will try to use a managed identity. So I don’t have to use one method locally and another in production.</p>
<p>In my case, initially managed identity access wasn’t configured for the functionapp, so I received this error when running in Azure:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>2021-12-21T11:59:26.309 [Error] Executed 'Functions.etc-hosts' (Failed, Id=56fdb72b-eb86-41b9-a215-d7e7b3f22425, Duration=98ms)Result: FailureException: Error: Azure CLI could not be found. Please visit https://aka.ms/azure-cli for installation instructions and then, once installed, authenticate to your Azure account using 'az login'.Stack: Error: Azure CLI could not be found. Please visit https://aka.ms/azure-cli for installation instructions and then, once installed, authenticate to your Azure account using 'az login'.at AzureCliCredential.getToken
</code></pre></div></div>
<p>I needed to setup managed identity and allow it to access a Key Vault.</p>
<h2 id="configure-managed-identity-access-for-function">Configure Managed Identity Access for Function</h2>
<p>First, I setup some vars representing my function deployment. Of course these are filled out when I run it in my environment. They’re empty here.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>export RG=
export REGION=
export APPNAME=
export STORAGE=
export KV=
</code></pre></div></div>
<p>Next, assign and identity.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>az functionapp identity assign --resource-group ${RG} --name ${APPNAME}
</code></pre></div></div>
<p>Eg. output:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ az functionapp identity assign --resource-group ${RG} --name ${APPNAME}
{
"principalId": "<redacted",
"tenantId": "<redacted>",
"type": "SystemAssigned",
"userAssignedIdentities": null
}
</code></pre></div></div>
<p>Now we can just grab the principalId (or copy it from the above output).</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>export PRINCIPAL_ID=$(az functionapp identity show -n ${APPNAME} --query principalId --resource-group ${RG} -o tsv)
</code></pre></div></div>
<p>Finally setup a policy for key vault to allow this principal to access the secrets.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>az keyvault set-policy -n ${KV} \
--object-id ${PRINCIPAL_ID} \
--resource-group ${RG} \
--secret-permissions get list
</code></pre></div></div>
<p>At this point, even when using <code class="language-plaintext highlighter-rouge">DefaultAzureCredential()</code>, when pushed into Azure the system is smart enough to use the managed identity.</p>
Dev Experience: My First Look at Azure Functions2021-12-13T00:00:00+00:00http://serverascode.com/2021/12/13/dev-experience-azure-functions<h1 id="dev-experience-my-first-look-at-azure-functions">Dev Experience: My First Look at Azure Functions</h1>
<h2 id="what-do-i-want-to-do">What Do I Want to Do?</h2>
<p>I’ve not used Azure Functions before, so I’m going to run through a quick start to deploy an example nodejs function.</p>
<p>What I have/want to do:</p>
<ul>
<li>Already have <code class="language-plaintext highlighter-rouge">az</code> installed and an Azure account to work with</li>
<li>Running from a Linux workstation</li>
<li>Don’t want to use VSCode integration currently, prefer to use CLI for now</li>
<li>Deploy a NodeJS 16 “hello world” function manually</li>
</ul>
<h2 id="installing">Installing</h2>
<ul>
<li><a href="https://docs.microsoft.com/en-us/azure/azure-functions/functions-run-local?tabs=v4%2Clinux%2Ccsharp%2Cportal%2Cbash%2Ckeda#v2">Docs</a></li>
</ul>
<p>Get the core tools, which presumably includes the func CLI.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ sudo apt-get install azure-functions-core-tools-4
Reading package lists... Done
SNIP!
Preparing to unpack .../azure-functions-core-tools-4_4.0.3971-1_amd64.deb ...
Unpacking azure-functions-core-tools-4 (4.0.3971-1) ...
Setting up azure-functions-core-tools-4 (4.0.3971-1) ...
Telemetry
---------
The Azure Functions Core tools collect usage data in order to help us improve your experience.
The data is anonymous and doesn't include any user specific or personal information. The data is collected by Microsoft.
You can opt-out of telemetry by setting the FUNCTIONS_CORE_TOOLS_TELEMETRY_OPTOUT environment variable to '1' or 'true' using your favorite shell.
</code></pre></div></div>
<p>Now I have the <code class="language-plaintext highlighter-rouge">func</code> command.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ which func
/usr/bin/func
</code></pre></div></div>
<p>Init a new project. I’m going to use nodejs.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ func init .
Select a number for worker runtime:
1. dotnet
2. dotnet (isolated process)
3. node
4. python
5. powershell
6. custom
Choose option: 3
node
Select a number for language:
1. javascript
2. typescript
Choose option: 1
javascript
Writing package.json
Writing .gitignore
Writing host.json
Writing local.settings.json
Writing /home/curtis/working/sparrow-dns-azure-function/.vscode/extensions.json
g /home/curtis/working/sparrow-dns-azure-function/MyFunctionProj/.vscode/extensions.json
</code></pre></div></div>
<p>That creates a few files.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ tree
.
├── host.json
├── local.settings.json
└── package.json
0 directories, 3 files
</code></pre></div></div>
<p>Next, let’s create a function.</p>
<h2 id="creating-a-function">Creating a Function</h2>
<ul>
<li><a href="https://docs.microsoft.com/en-us/azure/azure-functions/create-first-function-cli-node?tabs=azure-cli%2Cbrowser">Docs</a></li>
</ul>
<p>Create a function from a template “HTTP Trigger”.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ func new --name HttpExample --template "HTTP trigger" --authlevel "anonymous"
Select a number for template:HTTP trigger
Function name: [HttpTrigger] Writing /home/curtis/working/sparrow-dns-azure-function/HttpExample/index.js
Writing /home/curtis/working/sparrow-dns-azure-function/HttpExample/function.json
The function "HttpExample" was created successfully from the "HTTP trigger" template.
</code></pre></div></div>
<p>Interesting that there is a template option.</p>
<h3 id="test-locally">Test Locally</h3>
<p>Now in one terminal:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ func start
</code></pre></div></div>
<p>Example output:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ func start
Azure Functions Core Tools
Core Tools Version: 4.0.3971 Commit hash: d0775d487c93ebd49e9c1166d5c3c01f3c76eaaf (64-bit)
Function Runtime Version: 4.0.1.16815
Functions:
HttpExample: [GET,POST] http://localhost:7071/api/HttpExample
For detailed output, run func with --verbose flag.
info: Microsoft.AspNetCore.Hosting.Diagnostics[1]
Request starting HTTP/2 POST http://127.0.0.1:40553/AzureFunctionsRpcMessages.FunctionRpc/EventStream application/grpc -
info: Microsoft.AspNetCore.Routing.EndpointMiddleware[0]
Executing endpoint 'gRPC - /AzureFunctionsRpcMessages.FunctionRpc/EventStream'
[2021-12-13T11:29:47.400Z] Worker process started and initialized.
[2021-12-13T11:29:52.128Z] Host lock lease acquired by instance ID '000000000000000000000000AC5DB4CC'.
</code></pre></div></div>
<p>And in another terminal, curl..</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ curl http://localhost:7071/api/HttpExample
This HTTP triggered function executed successfully. Pass a name in the query string or in the request body for a personalized response
</code></pre></div></div>
<p>OK, great, but now how to publish to “the cloud”…</p>
<h3 id="configure-azure-to-be-able-to-deploy-the-function-to-azure">Configure Azure to be able to Deploy the function to azure…</h3>
<p>First we need to configure a resource group, etc.</p>
<p>Login.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ az login
</code></pre></div></div>
<p>Create a resource group.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>export RG=sparrow-dns-functions-rg
export REGION=canadacentral
export APPNAME=<project name>
export STORAGE=sparrowdnsfuncstorage
az group create --name $RG --location $REGION
</code></pre></div></div>
<p>Storage account.</p>
<blockquote>
<p>NOTE: What’s the deal with the storage names, yeesh. Lower case letters or numbers only. Don’t like it.</p>
</blockquote>
<blockquote>
<p>Question: What does a function need a storage account for?</p>
</blockquote>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>az storage account create --name $STORAGE --location $REGION --resource-group $RG --sku Standard_LRS
</code></pre></div></div>
<p>Create the function app.</p>
<blockquote>
<p>NOTE: Using node 16, not 14.</p>
</blockquote>
<blockquote>
<p>“…replace <STORAGE_NAME> with the name of the account you used in the previous step, and replace <APP_NAME> with a globally unique name appropriate to you. The <APP_NAME> is also the default DNS domain for the function app."</APP_NAME></APP_NAME></STORAGE_NAME></p>
</blockquote>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>az functionapp create --resource-group $RG \
--consumption-plan-location $REGION \
--runtime node --runtime-version 16 --functions-version 4 \
--name $APPNAME \
--storage-account $STORAGE
</code></pre></div></div>
<p>oh no error.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ az functionapp create --resource-group $RG \
> --consumption-plan-location $REGION \
> --runtime node --runtime-version 16 --functions-version 4 \
> --name $APPNAME \
> --storage-account $STORAGE
az functionapp create: '4' is not a valid value for '--functions-version'. Allowed values: 2, 3.
TRY THIS:
az functionapp create --resource-group MyResourceGroup --plan MyPlan --name MyUniqueAppName --storage-account MyStorageAccount
Create a basic function app.
https://docs.microsoft.com/en-US/cli/azure/functionapp#az_functionapp_create
Read more about the command in reference docs
</code></pre></div></div>
<p>Must need newer az CLI?</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ sudo apt-get --only-upgrade install azure-cli
$ az version
{
"azure-cli": "2.31.0",
"azure-cli-core": "2.31.0",
"azure-cli-telemetry": "1.0.6",
"extensions": {}
}
</code></pre></div></div>
<p>Now run again…</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ az functionapp create --resource-group $RG\
--consumption-plan-location $REGION \
--runtime node --runtime-version 16 --functions-version 4 \
--name $APPNAME \
--storage-account $STORAGE
Resource provider 'Microsoft.Web' used by this operation is not registered. We are registering for you.
Registration succeeded.
SNIP!
</code></pre></div></div>
<p>That gives you a link to this page to see “Application Insights” which it seems will be deprecated.</p>
<p><img src="/img/azure-func-app-insight.jpg" alt="application insights" /></p>
<p>Onward!</p>
<h2 id="deploy-the-function">Deploy the Function</h2>
<p>Now we actually push the function to the function app.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>export APPNAME=<project name>
func azure functionapp publish $APPNAME
</code></pre></div></div>
<p>Now can access.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ func azure functionapp publish $APPNAME
Getting site publishing info...
Creating archive for current directory...
Uploading 1.3 KB [#####################################################################]
Upload completed successfully.
Deployment completed successfully.
Syncing triggers...
Functions in sparrow-dns:
HttpExample - [httpTrigger]
Invoke url: https://<project name>.azurewebsites.net/api/httpexample
</code></pre></div></div>
<p>Connect with httpie.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ http https://<project name>.azurewebsites.net/api/httpexample
HTTP/1.1 200 OK
Content-Encoding: gzip
Content-Type: text/plain; charset=utf-8
Date: Mon, 13 Dec 2021 12:13:02 GMT
Request-Context: appId=cid-v1:dd33b7ce-86e0-4822-a59b-9dd8b4116385
Transfer-Encoding: chunked
Vary: Accept-Encoding
This HTTP triggered function executed successfully. Pass a name in the query string or in the request body for a personalized response.
</code></pre></div></div>
<p>Provide a name.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ http post https://<project name>.azurewebsites.net/api/httpexample name=curtis
HTTP/1.1 200 OK
Content-Encoding: gzip
Content-Type: text/plain; charset=utf-8
Date: Mon, 13 Dec 2021 12:14:01 GMT
Request-Context: appId=cid-v1:dd33b7ce-86e0-4822-a59b-9dd8b4116385
Transfer-Encoding: chunked
Vary: Accept-Encoding
Hello, curtis. This HTTP triggered function executed successfully.
</code></pre></div></div>
<p>That’s it.</p>
<h2 id="conclusion">Conclusion</h2>
<p>Hereare some basic thoughts:</p>
<ul>
<li>I find Azure naming unusual</li>
<li>I like that there is a “template” option for functions, should explore what that means (Can I create my own templates? Probably not. That’s something that the <a href="https://docs.vmware.com/en/Application-Accelerator-for-VMware-Tanzu/index.html">Tanzu Application Acclerator</a> can do, template any application including Azure Functions)</li>
<li>Keep multiple functions in the same repo</li>
<li>Not sure why the <code class="language-plaintext highlighter-rouge">az</code> and <code class="language-plaintext highlighter-rouge">func</code> CLIs exist, can’t deploy a function with <code class="language-plaintext highlighter-rouge">az</code>?</li>
<li>I like the domain: your-project.azurewebsites.net/api/somefunction</li>
<li>Having links point me to services that are being deprecated is a bit concering, but Azure is a massive ecosystem so not unexpected, definitely good that there are application metrics/monitoring integrated of course</li>
<li>The localhost name of the function is “HttpExample” and the deployed version is “httpexample”</li>
<li>As is common with functions, I’m not sure what version of nodejs is being used everywhere….presumably 16 is being used in the cloud, as that is what I specified, but not sure locally what <code class="language-plaintext highlighter-rouge">func</code> does…</li>
</ul>
<p>Obviously this is my first time using Azure Functions, but so far, other than setting up the resource group and such, I quite like it. Didn’t take long to get a function deployed. Several languages are supported, including Java which I should experiment with.</p>
<p>I’ll take Azure Functions a bit deeper in future posts. So far looks really great.</p>
<h2 id="links">Links</h2>
<ul>
<li><a href="https://docs.microsoft.com/en-us/azure/azure-functions/functions-reference-node?tabs=v2">Azure Functions Developer Guide</a></li>
</ul>
Dev Experience: Managing Secrets with Doppler2021-12-01T00:00:00+00:00http://serverascode.com/2021/12/01/dev-experience-doppler-secrets<h1 id="dev-experience-managing-secrets-with-doppler">Dev Experience: Managing Secrets with Doppler</h1>
<p>Secrets. I need to manage them. As part of my exploration of developer experience I plan on having many micro-services running on different platforms. However, I don’t want to have to manage the secrets across all of them individually…that would be a nightmare, never mind thinking about various environments (dev, test, prod…). For example, I’m using Basic Authentication as a simple API key and API secret key, and I need to manage those secrets across all services, my CLI, and of course, various environments (which should have different secrets).</p>
<p>So I need something to help me do that.</p>
<p>One option is <a href="https://www.doppler.com/">Doppler</a>. Doppler bills itself as a “universal secrets manager” and I think, after a bit of use, that’s a pretty accurate description.</p>
<h2 id="about-doppler">About Doppler</h2>
<p>What’s Doppler?</p>
<blockquote>
<p>Doppler [has] launched the industry’s first Universal Secrets Manager, a modern secrets manager offering built to win the hearts and minds of developers. It works across every language, stack and infrastructure, increasing developer productivity while strengthening a company’s overall security. Early adopters, including Stripe, Point Banking, Snackpass, Kopa and Convictional, use Doppler to securely store secrets such as API keys, credentials, ENV variables and database URLs. - <a href="https://blog.doppler.com/press-release">Press Release</a></p>
</blockquote>
<p>Secrets and credentials are a major problem. Organizations have more environments in use than they are often willing to admit (or even track).</p>
<blockquote>
<p>Secrets and credentials management is widely considered to be the most overlooked aspect of software development. Many teams struggle daily to organize and sync secrets between environments, with manually maintained .env files being one of the most common sources of frustration for developers and DevSecOps. - <a href="https://blog.doppler.com/what-is-a-secrets-manager">Doppler</a></p>
</blockquote>
<p>Focus on developer experience.</p>
<blockquote>
<p>Security tools are often process heavy and come with horrible experiences which leads to low usage. At Doppler we strongly believe in building tools that developers will love. The more you love it, the more you will want to use it. - <a href="https://www.doppler.com/about">Doppler</a></p>
</blockquote>
<p>What a great attitude.</p>
<h2 id="tldr">tl;dr</h2>
<p>I really like Doppler. I like pretty much everything about it. I like how it’s setup, I like how it guides you through using it. I like that it has a CLI that I can integrate with everything. I like that it had examples for Firebase. Looks like there are integrations for Netlify and Vercel (two services I plan on checking out). I also like that it will copy secrets to each environment, and let you know when environments have secrets that don’t exist in other environments.</p>
<p>It’s just a really well thought out secrets as a service, and I’ve only–just barely–scratched the surface of using it.</p>
<h2 id="installing-doppler-cli">Installing doppler cli</h2>
<p>I’m running Linux as my main OS for writing software.</p>
<p>To install <code class="language-plaintext highlighter-rouge">doppler</code>, get the package.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code># Install pre-reqs
sudo apt-get update && sudo apt-get install -y apt-transport-https ca-certificates curl gnupg
# Add Doppler's GPG key
curl -sLf --retry 3 --tlsv1.2 --proto "=https" 'https://packages.doppler.com/public/cli/gpg.DE2A7741A397C129.key' | sudo apt-key add -
# Add Doppler's apt repo
echo "deb https://packages.doppler.com/public/cli/deb/debian any-version main" | sudo tee /etc/apt/sources.list.d/doppler-cli.list
# Fetch and install latest doppler cli
sudo apt-get update && sudo apt-get install doppler
</code></pre></div></div>
<p>Now we’ve got <code class="language-plaintext highlighter-rouge">doppler</code>.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ which doppler
/usr/bin/doppler
</code></pre></div></div>
<p>Login.</p>
<h2 id="initial-configuration">Initial Configuration</h2>
<p>Login.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ doppler login
? Open the authorization page in your browser? No
Complete authorization at https://dashboard.doppler.com/workplace/auth/cli
Your auth code is:
<SNIP!>
Waiting...
Welcome, Curtis
</code></pre></div></div>
<p>I’ve already setup a project called sparrow-dns.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ doppler setup
? Select a project: sparrow-dns
? Select a config: dev
┌─────────┬─────────────┬──────────────────────────────────┐
│ NAME │ VALUE │ SCOPE │
├─────────┼─────────────┼──────────────────────────────────┤
│ config │ dev │ /home/curtis/working/sparrow-dns │
│ project │ sparrow-dns │ /home/curtis/working/sparrow-dns │
└─────────┴─────────────┴──────────────────────────────────┘
</code></pre></div></div>
<p>By default there are three environments configured, of course you could have more or fewer.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ doppler environments
┌─────┬─────────────┬───────────────┬──────────────────────────┬─────────────┐
│ ID │ NAME │ INITIAL FETCH │ CREATED AT │ PROJECT │
├─────┼─────────────┼───────────────┼──────────────────────────┼─────────────┤
│ dev │ Development │ │ 2021-12-04T12:45:27.568Z │ sparrow-dns │
│ stg │ Staging │ │ 2021-12-04T12:45:27.568Z │ sparrow-dns │
│ prd │ Production │ │ 2021-12-04T12:45:27.568Z │ sparrow-dns │
└─────┴─────────────┴───────────────┴──────────────────────────┴─────────────┘
</code></pre></div></div>
<h2 id="using-doppler">Using Doppler</h2>
<p>To use it with Firebase I’ve added the following to the scripts section of my package.json.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code> "serve": "doppler run -- firebase emulators:start",
"shell": "doppler run -- firebase functions:shell",
"update_config": "firebase functions:config:unset env && firebase functions:config:set env=\"$(doppler secrets download --config prd --no-file --silent)\"",
"deploy": "firebase functions:config:unset env && firebase functions:config:set env=\"$(doppler secrets download --config prd --no-file --silent)\" && firebase deploy --only functions",
</code></pre></div></div>
<p>I’ve also got a CLI for using the DNS arecords demo API (I’m currently calling it Sparrow DNS) and I can easily integrate with it, and set the endpoint URL to the local URL that is setup when I use the Firebase emulator. This helps a lot with local testing.</p>
<p>For example, if I want to use the CLI with the dev secrets…</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>doppler run -- ./scripts/sparrow-cli arecord list
</code></pre></div></div>
<p>But if I want to use the production environment…</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>doppler run --config prd -- ./scripts/sparrow-cli arecord list
</code></pre></div></div>
<p>I’ll need to think about how to integrated the <code class="language-plaintext highlighter-rouge">doppler</code> CLI into the Sparrow CLI.</p>
<h2 id="conclusion">Conclusion</h2>
<p>Again, so far I’m a big fan of Doppler, 1) because it works and 2) because it’s obvious that they are not only talking about creating a great developer experience, they are actually doing it!</p>
<p>I would imagine I’ll write another post once I’ve worked more with Doppler and various “serverless” platforms, as well as tooling like <a href="https://cloud.spring.io/spring-cloud-config/reference/html/">Spring Cloud Config</a>.</p>
Dev Experience: Writing a NodeJS REST API with Firebase2021-11-29T00:00:00+00:00http://serverascode.com/2021/11/29/dev-experience-firebase<h1 id="dev-experience-writing-a-nodejs-rest-api-with-firebase">Dev Experience: Writing a NodeJS REST API with Firebase</h1>
<h2 id="developer-experience">Developer Experience</h2>
<p>Working at <a href="https://tanzu.vmware.com/">VMware in the Tanzu group</a> I’m always focussed on developer experience (DX). Often people think of VMware as an infrastructure only company, but we’re not. Tanzu is heavily focussed on developers. I’d say 10-20% of what we do is infrastructure related (Kubernetes, Cloud Foundry) and the other 80-90% is related to devops, security, developers, and software architects to name a few. What’s the point of platforms if there’s no apps running on them.</p>
<p>Overall Tanzu is working extremely hard on improving DX. For example we recently released beta versions of the <a href="https://tanzu.vmware.com/content/blog/announcing-vmware-tanzu-application-platform">Tanzu Application Platform</a>, a way to de-expose kubernetes to developers…by that I mean abstract it away into a 15 lines of YAML instead of 2000.</p>
<p>But let me get to the point of this post–<strong>developers should not be futzing around with Kubernetes</strong>. They should be able to write code and put apps in production as easily as possible.</p>
<p>With that in mind, I like to keep my eye on any products or tools or platforms that can improve DX. I decided to take a look at Google’s Firebase to see what it’s like, and how it helps DX. While Firebase has been around for a long time, I’ve never taken a look at it to understand what it does. Time to change that. :)</p>
<h2 id="itch-to-scratch---simple-hostnamearecords-rest-api">Itch to Scratch - Simple hostname/arecords REST API</h2>
<p>Historically I’m not a developer (surprise!). I don’t write code every day, and I don’t normally have a reason to. But I have had an “itch to scratch” so to speak for a while, in that I want a way to easily manage my home DNS server. I have a homelab and it requires many host, ie. arecord, entries. My internal DNS server is dnsmasq and it can run off of the entries in <code class="language-plaintext highlighter-rouge">/etc/hosts</code>. So when I add internal DNS entries, I just add them to the <code class="language-plaintext highlighter-rouge">/etc/hosts</code> file on the dnsmasq server and that’s it.</p>
<p>I wanted an API and CLI that I can use to easily do that, and then (eventually) a templated API response that will generate <code class="language-plaintext highlighter-rouge">/etc/hosts</code> (and other config files) for me based on those entries. The idea is that if I build the main API, then I can add microservices that can template out configuration files for any DNS server (not just dnsmasq). But that’s down the road….</p>
<p>The thing I need to build first is a simple REST API for managing DNS arecords.</p>
<h2 id="what-do-i-want">What do I want?</h2>
<p>Base requirements:</p>
<ul>
<li>Runs in “the cloud”; no infra required</li>
<li>Document database</li>
<li>Functions (no exposed k8s)</li>
<li>NodeJS support</li>
<li>Easy push to prod</li>
<li>Low cost entry (hopefully free for small projects)</li>
<li>Easy local development</li>
</ul>
<p>I know SQL is making a comeback in terms of the marketplace (not that it left) but for this use case I’m interested in a document database.</p>
<h2 id="firebase">Firebase</h2>
<h3 id="history">History</h3>
<blockquote>
<p>Firebase is a platform developed by Google for creating mobile and web applications. It was originally an independent company founded in 2011. In 2014, Google acquired the platform[1] and it is now their flagship offering for app development.</p>
</blockquote>
<p>Firebase has been around for 10 years. Much like App Engine, it doesn’t get much press, and I’m not even sure how I came across it, but after reading a bit, it seemed like an interesting platform to look at in terms of DX.</p>
<p>This post, <a href="https://medium.com/firebase-developers/what-is-firebase-the-complete-story-abridged-bcc730c5f2c0">What is Firebase, The complete story, abridged</a>, which I didn’t read until I started writing this post, gives some good perspective on what Firebase is, and isn’t.</p>
<h3 id="my-experience-with-firebase">My Experience with Firebase</h3>
<p>Here are my base base requirements.</p>
<table>
<thead>
<tr>
<th>Item</th>
<th>Supported</th>
<th>Comment</th>
</tr>
</thead>
<tbody>
<tr>
<td>nodejs</td>
<td>yes</td>
<td>first class, but hard to tell what version?</td>
</tr>
<tr>
<td>document database</td>
<td>yes</td>
<td>firestore</td>
</tr>
<tr>
<td>functions</td>
<td>yes</td>
<td>cloud run with deep integration, but need “blaze” plan level</td>
</tr>
<tr>
<td>low cost</td>
<td>yes</td>
<td>great for small projects like mine</td>
</tr>
</tbody>
</table>
<p>But what else might one need for a good development platform? Here’s a few I thought about in this context.</p>
<blockquote>
<p>NOTE: Please understand that I don’t write code every day. More experienced developers will have different opinions of what is important and what isn’t.</p>
</blockquote>
<table>
<thead>
<tr>
<th>Item</th>
<th>Supported</th>
<th>Comment</th>
</tr>
</thead>
<tbody>
<tr>
<td>local development</td>
<td>yes</td>
<td>firestore emulator is amazing</td>
</tr>
<tr>
<td>getting to prod</td>
<td>yes</td>
<td>easy as firebase deploy</td>
</tr>
<tr>
<td>authentication</td>
<td>yes</td>
<td>hard for me to grasp difference between admin sdk and other users</td>
</tr>
<tr>
<td>data schema</td>
<td>yes, for users</td>
<td>filebase.rules is great, but doesn’t apply to admin sdk</td>
</tr>
<tr>
<td>data indexes</td>
<td>yes</td>
<td>need to manually apply them with cli or gui</td>
</tr>
<tr>
<td>logging</td>
<td>yes</td>
<td>didn’t explore</td>
</tr>
<tr>
<td>metrics</td>
<td>yes</td>
<td>didn’t explore</td>
</tr>
<tr>
<td>testing</td>
<td>yes</td>
<td>didn’t explore</td>
</tr>
<tr>
<td>ci/cd integration</td>
<td> </td>
<td>didn’t explore</td>
</tr>
</tbody>
</table>
<p>Certainly developers need a lot more than this, but I didn’t want to write out 100 needs.</p>
<h2 id="some-things-i-ran-into-using-firebase">Some Things I Ran Into Using Firebase</h2>
<ul>
<li>Functions are not available in the “free tier” you have to go up to the Blaze level, which still has a free tier that is fairly substantial for a small app like mine, one which might see a few requests per day at most</li>
<li>Firebase rules (ie. data schemas) don’t apply to the admin sdk…lost some time on this</li>
<li>I had trouble figuring out what nodejs version is supported</li>
</ul>
<h2 id="some-results">Some Results</h2>
<p>Here’s using a simple httpie based script to talk to the API and perform CRUD operations. Right now I’m calling this project “Sparrow” for some reason.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ ./scripts/sparrow-cli arecord add www.example.com 192.168.88.10
{
"arecord": {
"_id": "JWgEXUlfVdK5FUQeLeBr",
"ip": "192.168.88.10",
"name": "www.example.com"
}
}
info: added arecord
$ ./scripts/sparrow-cli arecord list
[
{
"_id": "JWgEXUlfVdK5FUQeLeBr",
"ip": "192.168.88.10",
"name": "www.example.com"
},
{
"_id": "K3fwiWQOSS3wc6srpv9h",
"ip": "10.10.10.10",
"name": "new2.domain.com"
},
{
"_id": "O8OIERUTclPpg75cIAlq",
"ip": "10.10.10.10",
"name": "new.domain.com"
},
{
"_id": "ytgACQTVZZyXJi0pYPJ5",
"ip": "10.0.10.10",
"name": "some.domain.com"
}
]
</code></pre></div></div>
<p>The script uses these environment variables to connect. The API keys have nothing to do with Firebase…they’re part of the app.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ env | grep SPAR
SPARROW_API_ENDPOINT=https://us-central1-<my firebase project>.cloudfunctions.net/api
SPARROW_API_KEY=<key>
SPARROW_API_SECRET_KEY=<secret>
</code></pre></div></div>
<p>Pretty straightforward, simplistic stuff…and yet, it’s a perfectly usable REST API.</p>
<h2 id="conclusion">Conclusion</h2>
<p>Overall I used Firebase to provide a place to run nodejs functions that talk to a document store, where the functions and document store are provided by the platform. As well I made heavy use of the firebase CLI and emulator to test locally.</p>
<p>With just over 100 lines of NodeJS I was able to write a functional REST API for my arecords app requirement.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ cloc --exclude-list-file=.clocignore .
8045 text files.
7117 unique files.
8051 files ignored.
github.com/AlDanial/cloc v 1.82 T=0.93 s (6.5 files/s, 293.3 lines/s)
--------------------------------------------------------------------------------
Language files blank comment code
--------------------------------------------------------------------------------
JavaScript 4 30 34 156
Bourne Again Shell 1 7 1 37
JSON 1 0 0 7
--------------------------------------------------------------------------------
SUM: 6 37 35 200
--------------------------------------------------------------------------------
</code></pre></div></div>
<p>That’s pretty cool.</p>
<p>The CLI <code class="language-plaintext highlighter-rouge">firebase</code> lets you setup a project, run the emulators, and push to prod.</p>
<p>Maybe writing nodejs REST APIs isn’t the what most Firebase users do, but it certainly works for me.</p>
<p>My use of Firebase gives me a great data point in my path to understanding great developer experience–what’s good, what’s bad, where innovation is required. That said, the main focus of Firebase is not building REST APIs, AFAIK, it’s more of a “backend as a service” where you don’t even have to write the API (but obviously I didn’t use that part of Firebase).</p>
<p>Now to explore other platforms… :)</p>
Deploy Tanzu Build Service into a vSphere with Tanzu Workload Cluster2021-09-10T00:00:00+00:00http://serverascode.com/2021/09/10/deploy-tanzu-build-service-on-vsphere-with-tanzu<h1 id="deploy-tanzu-build-service-into-a-vsphere-with-tanzu-workload-cluster">Deploy Tanzu Build Service into a vSphere with Tanzu Workload Cluster</h1>
<p>In this post we’ll deploy the <a href="https://tanzu.vmware.com/build-service">Tanzu Build Service</a> (TBS) onto a <a href="https://www.vmware.com/ca/products/vsphere/vsphere-with-tanzu.html">vSphere with Tanzu</a> Kubernetes workload cluster.</p>
<h2 id="requirements">Requirements</h2>
<ol>
<li>vSphere with Tanzu deployed and enough resources for the TBS workload cluster</li>
<li>A container image repository, such as Harbor, or Azure CR, etc, any compliant registry should do</li>
<li>A place to run commands (a linux host is best IMHO)</li>
</ol>
<h2 id="about-the-tanzu-build-service">About the Tanzu Build Service</h2>
<p>There are several ways to build container images (not just Dockerfiles).</p>
<p>The Tanzu Build Service makes building container images easier, ie. no Dockerfiles, and provides an image control plane, which I believe Kubernetes sorely misses.</p>
<blockquote>
<p>You have plenty of options for building containers from source code. Yet many require significant effort and ongoing maintenance to use them properly. And it can be hard to enforce security and operational rigor at scale. Tanzu Build Service offers the convenience of these workflows with more automation and the governance capabilities enterprises need. - <a href="https://tanzu.vmware.com/build-service">Tanzu Build Service</a></p>
</blockquote>
<h2 id="about-vsphere-with-tanzu">About vSphere with Tanzu</h2>
<p>vSphere with Tanzu, what you may remember as being called “Project Pacific”, is Kubernetes lifecycle management built directly into vSphere.</p>
<p>VMware believes that you will have many Kubernetes clusters. Not just one or two or three. So, the main feature of vSphere with Tanzu is to manage the lifecycle of <strong>many</strong> Kubernetes clusters. The way we do this is by extending Kubernetes with something called Cluster API.</p>
<p>This means, and this can be confusing, that when we want to create a Kubernetes cluster, we actually ask a specialized Kubernetes cluster–the Supervisor Cluster–to do this for us. So we use Kubernetes to deploy Kubernetes. Make sense?</p>
<p>Once the Supervisor Cluster has created our “workload” cluster (and there will be many of these), we can then talk directly to that new workload cluster via its own, completely separate, Kubernetes API.</p>
<p>So, to create a workload cluster we ask the supervisor cluster. Once the workload cluster is created, we talk to it to deploy applications into it. Simple enough once you get the hang of it.</p>
<h2 id="deploy-a-vsphere-with-tanzu-workload-cluster-for-tbs">Deploy a vSphere with Tanzu Workload Cluster for TBS</h2>
<p>We need a cluster to install TBS into. That cluster needs a couple of things:</p>
<ol>
<li>Enough room on the nodes to build images - the default 16Gi disk size is not enough, we need a cluster with at least 50Gi on each node for the image builds that TBS does</li>
<li>The right RBAC configuration and permissions</li>
</ol>
<p>First, let’s deploy the cluster with larger disks.</p>
<h3 id="login-to-the-supervisor-cluster">Login to the Supervisor Cluster</h3>
<p>Ensure you are logged into your vSphere with Tanzu supervisor Kubernetes cluster.</p>
<blockquote>
<p>NOTE: I alias <code class="language-plaintext highlighter-rouge">kubectl</code> to <code class="language-plaintext highlighter-rouge">k</code>.</p>
</blockquote>
<blockquote>
<p>NOTE: I’m logging into my vSphere with Tanzu supervisor cluster found at 10.0.14.128…yours will of course be different. I’m also using the admin account.</p>
</blockquote>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ k vsphere login --server 10.0.14.128 --insecure-skip-tls-verify -u administrator@vsphere.local
Password:
Logged in successfully.
You have access to the following contexts:
10.0.14.128
dev-team-purple
dev-team-tundra
test-ns
If the context you wish to use is not in this list, you may need to try
logging in again later, or contact your cluster administrator.
To change context, use `kubectl config use-context <workload name>`
</code></pre></div></div>
<p>Now that I’m logged in, I have access to the supervisor cluster as well as the supervisor namespaces. So there will be several kube contexts set up.</p>
<blockquote>
<p>NOTE: I’m using kubectx aliased to kc instead of <code class="language-plaintext highlighter-rouge">kubectl config use-context</code> just because it’s what I always use and I find it easier, IMHO.</p>
</blockquote>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ kc
10.0.14.128
dev-team-purple
dev-team-tundra
test-ns
</code></pre></div></div>
<p><br /></p>
<h3 id="switch-the-desired-supervisor-namespace">Switch the Desired Supervisor Namespace</h3>
<p>I’m going to deploy the TBS workload cluster into the <code class="language-plaintext highlighter-rouge">dev-team-tundra</code> supervisor namespace. So I’ll switch to that config.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ kc dev-team-tundra
✔ Switched to context "dev-team-tundra".
</code></pre></div></div>
<p><br /></p>
<h3 id="deploy-a-workload-cluster">Deploy a Workload Cluster</h3>
<p>Set up a few variables that will be dependent on how you have set up the supervisor cluster, storage, etc.</p>
<blockquote>
<p>NOTE: Change these to fit your environment.</p>
</blockquote>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>export NS=dev-team-tundra # the supervisor namespaces to use
export SC=k8s-storage-policy # the storage policy configured when enabling workload management
export CLUSTER_NAME="tanzu-build-service-cluster2" # the name of the workload cluster
export K8S_VERSION=v1.20.7 # version of k8s to deploy
</code></pre></div></div>
<p>Now I’ll deploy a cluster to that supervisor namespace.</p>
<blockquote>
<p>NOTE: This will deploy the cluster! Note the pipe at the top of the command to <code class="language-plaintext highlighter-rouge">kubectl</code>.</p>
</blockquote>
<blockquote>
<p>NOTE: Notice that in the YAML here we define a separate disk for /var/lib/containerd that is 50Gi in size. We need this for TBS.</p>
</blockquote>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>cat << EOF | kubectl create -f-
apiVersion: run.tanzu.vmware.com/v1alpha1
kind: TanzuKubernetesCluster
metadata:
name: $CLUSTER_NAME
namespace: $NS
spec:
distribution:
version: $K8S_VERSION
topology:
controlPlane:
count: 1
class: best-effort-medium
storageClass: $SC
volumes:
- name: etcd
mountPath: /var/lib/etcd
capacity:
storage: 4Gi
workers:
count: 3
class: best-effort-medium
storageClass: $SC
volumes:
- name: containerd
mountPath: /var/lib/containerd
capacity:
storage: 50Gi
settings:
network:
services:
cidrBlocks: ["10.96.0.0/16"]
pods:
cidrBlocks: ["172.20.0.0/16"]
storage:
classes: ["$SC"]
defaultClass: $SC
EOF
</code></pre></div></div>
<p>After a few minutes the cluster will be deployed. (How long depends on the speed of your infrastructure, but say 15-20 minutes.)</p>
<h3 id="login-to-the-workload-cluster">Login to the Workload Cluster</h3>
<p>Once the new, completely separate k8s cluster is created, we use the <code class="language-plaintext highlighter-rouge">kubectl vsphere</code> plugin to login to the workload cluster, switch to that kube context, and from this point on we’ll talk to that cluster’s Kubernetes API, not the supervisor cluster.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>k vsphere login --server 10.0.14.128 --insecure-skip-tls-verify -u administrator@vsphere.local\
--tanzu-kubernetes-cluster-name $CLUSTER_NAME \
--tanzu-kubernetes-cluster-namespace $NS
</code></pre></div></div>
<p>Once that command completes you’ll have a new context for the workload cluster.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ kc
10.0.14.128
dev-team-purple
dev-team-tundra
tanzu-build-service-cluster2
test-ns
</code></pre></div></div>
<p>Use that context to deploy TBS into that cluster.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ kc tanzu-build-service-cluster2
✔ Switched to context "tanzu-build-service-cluster2".
</code></pre></div></div>
<p>Once switched to taht config, we can talk to that cluster’s API, and for example, get the nodes that make up the cluster. There should be one control plane and three worker nodes, unless you adjusted the cluster YAML.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ k get nodes
NAME STATUS ROLES AGE VERSION
tanzu-build-service-cluster2-control-plane-86zx9 Ready control-plane,master 39m v1.20.7+vmware.1
tanzu-build-service-cluster2-workers-268cf-9686cf46d-4ccdh Ready <none> 33m v1.20.7+vmware.1
tanzu-build-service-cluster2-workers-268cf-9686cf46d-6sznb Ready <none> 33m v1.20.7+vmware.1
tanzu-build-service-cluster2-workers-268cf-9686cf46d-d7nld Ready <none> 33m v1.20.7+vmware.1
</code></pre></div></div>
<p><br /></p>
<h3 id="configure-pod-security-policy">Configure Pod Security Policy</h3>
<p>The supervisor cluster configures some default security which we will need to further configure to allow TBS to deploy into this cluster.</p>
<blockquote>
<p>NOTE: Ensure your kubeconfig is set to the workload cluster, not the supervisor cluster!</p>
</blockquote>
<blockquote>
<p>NOTE: This RBAC is good for a PoC, it’s likely that we would want to customize this for production.</p>
</blockquote>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>cat << EOF | kubectl create -f-
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: psp:privileged
rules:
- apiGroups: ['policy']
resources: ['podsecuritypolicies']
verbs: ['use']
resourceNames:
- vmware-system-privileged
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: all:psp:privileged
roleRef:
kind: ClusterRole
name: psp:privileged
apiGroup: rbac.authorization.k8s.io
subjects:
- kind: Group
name: system:serviceaccounts
apiGroup: rbac.authorization.k8s.io
EOF
</code></pre></div></div>
<p>Now we can deploy TBS!</p>
<h2 id="install-tbs">Install TBS</h2>
<blockquote>
<p>NOTE: Best to read through the <a href="https://docs.pivotal.io/build-service/1-2/installing.html">official docs</a> before proceeding.</p>
</blockquote>
<p>I’m going to skip through the requirements section and assume that you have read through it and downloaded all the correct pieces which are laid out in the above docs. There are quite a few pieces so please do read carefully. There are some activities you have to do, like downloading CLIs and accepting EULAs and the like.</p>
<p>At this point we can start the deployment.</p>
<h3 id="copy-tbs-images-to-your-container-image-repository">Copy TBS Images to Your Container Image Repository</h3>
<p>We use <code class="language-plaintext highlighter-rouge">imgpkg</code> to copy the TBS images to your repo.</p>
<p>First set up a variable.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>export IMAGE_REPO="<your.repo/some-repo>"
</code></pre></div></div>
<p>In my example I’m using the Azure container registry. (Usually I would use Harbor, but I thought I’d try something different today.)</p>
<blockquote>
<p>NOTE: This will take a few minutes to complete as we are copying several images from one repo to another.</p>
</blockquote>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>imgpkg copy -b "registry.pivotal.io/build-service/bundle:1.2.2" --to-repo $IMAGE_REPO
</code></pre></div></div>
<p>Now pull this image locally and unpack in /tmp.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>imgpkg pull -b $IMAGE_REPO:1.2.2 -o /tmp/bundle
</code></pre></div></div>
<p>There should be files in <code class="language-plaintext highlighter-rouge">/tmp/bundle</code>.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ find /tmp/bundle/ | head
/tmp/bundle/
/tmp/bundle/values.yaml
/tmp/bundle/.imgpkg
/tmp/bundle/.imgpkg/images.yml
/tmp/bundle/config
/tmp/bundle/config/values.star
/tmp/bundle/config/ca-cert.yaml
/tmp/bundle/config/pod-webhook
/tmp/bundle/config/pod-webhook/rbac.yaml
/tmp/bundle/config/pod-webhook/deployment.yaml
</code></pre></div></div>
<p><br /></p>
<h2 id="deploy-tbs">Deploy TBS</h2>
<p>And we can now deploy.</p>
<p>First configure some variables.</p>
<blockquote>
<p>NOTE: Please configure all of these variables. They should not be empty.</p>
</blockquote>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>export IMAGE_REPO="" # where we we copied the TBS images to
export REGISTRY_USER=""
export REGISTRY_PASS=""
export TANZUNET_USER=""
export TANZUNET_PASS=""
</code></pre></div></div>
<p>Next, perform the deployment.</p>
<blockquote>
<p>NOTE: We’re using various Carvel tools to perform the deployment. <code class="language-plaintext highlighter-rouge">ytt</code>, <code class="language-plaintext highlighter-rouge">kbld</code>, and <code class="language-plaintext highlighter-rouge">kapp</code> to name a few.</p>
</blockquote>
<blockquote>
<p>NOTE: If you supply the tanzunet user/password TBS will be configured to automatically talk to tanzunet and download the latest buildpacks so that you will always be automatically up to date. If they aren’t supplied, that’s fine, you’ll just be in charge of updating the underlying buildpacks. When supplying this information the last step in the deployment can take a while because it’s downloading and uploading images into your registry.</p>
</blockquote>
<blockquote>
<p>NOTE: Of course this assumes that you’ve followed the TBS docs and downloaded all the Carvel CLIs.</p>
</blockquote>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>ytt -f /tmp/bundle/values.yaml \
-f /tmp/bundle/config/ \
-v docker_repository="$IMAGE_REPO" \
-v docker_username="$REGISTRY_USER" \
-v docker_password="$REGISTRY_PASS" \
-v tanzunet_username="$TANZUNET_USER" \
-v tanzunet_password="$TANZUNET_PASS" \
| kbld -f /tmp/bundle/.imgpkg/images.yml -f- \
| kapp deploy -a tanzu-build-service -f- -y
</code></pre></div></div>
<p>This will take a few minutes to deploy.</p>
<p>Once it completes we can run <code class="language-plaintext highlighter-rouge">kapp list</code>.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ kapp list
Target cluster 'https://10.0.14.140:6443' (nodes: tanzu-build-service-cluster2-control-plane-86zx9, 3+)
Apps in namespace 'default'
Name Namespaces Lcs Lca
tanzu-build-service (cluster),build-service,kpack, true 2m
stacks-operator-system
Lcs: Last Change Successful
Lca: Last Change Age
1 apps
Succeeded
</code></pre></div></div>
<p>And would want to see <code class="language-plaintext highlighter-rouge">succeeded</code>.</p>
<h2 id="build-an-image">Build an Image</h2>
<p>With TBS installed we have extended the Kubernetes API so that it knows how to build container images. So to build images we’ll talk to the Kubernetes API using YAML, just like any other Kubernetes object such as pods.</p>
<h3 id="configure-container-image-repository-secret">Configure Container Image Repository Secret</h3>
<p>Decide what namespace you want to have the images in. I’ll use the default namespace.</p>
<blockquote>
<p>NOTE: I use <a href="https://github.com/ahmetb/kubectx">kubectx</a> to manage my clusters and namespaces.</p>
</blockquote>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ kn default
✔ Active namespace is "default"
</code></pre></div></div>
<p>Create a repository secret. TBS needs to have write access to the container image repo to push the resulting image to.</p>
<p>Use <code class="language-plaintext highlighter-rouge">kp</code> to do that.</p>
<blockquote>
<p>NOTE: <code class="language-plaintext highlighter-rouge">kp</code> is the kpack CLI. It’s a way to use TBS and kpack. But it’s important to understand that kp just talks to Kubernetes, we can get the same information out of Kubernetes using kubectl as we can with <code class="language-plaintext highlighter-rouge">kp</code>.</p>
</blockquote>
<p>Set up some vars.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>export SECRET_NAME=""
export REGISTRY=""
export REGISTRY_USER=""
export REGISTRY_PASS=""
</code></pre></div></div>
<p>Now create the secret.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>kp secret create $SECRET_NAME --registry $REGISTRY --registry-user $REGISTRY_USER --namespace default
</code></pre></div></div>
<p>You will have to enter the registry password on the command line.</p>
<p>Now that we have TBS installed and a repo secret configured we can build an image.</p>
<h3 id="build-spring-petclinic">Build Spring Petclinic</h3>
<p>We need to ensure we’re going to upload the newly built image to the right container image repository. This repository is where you want the resulting image to end up!</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>export REPOSITORY="your.container.image.repo/some-repo"
</code></pre></div></div>
<p>Now ask TBS to build the image by using the <code class="language-plaintext highlighter-rouge">kp</code> CLI.</p>
<blockquote>
<p>NOTE: This will take a while on the first build as all the maven dependencies will get downloaded…Spring Petclinic is written in Java.</p>
</blockquote>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>[ -z "$REGISTRY" ] && echo "ERROR: Please set REGISTRY variable" || \
kp image create spring-petclinic-image \
--tag $REGISTRY/spring-petclinic-image \
--git https://github.com/ccollicutt-tanzu/spring-petclinic \
--git-revision main
</code></pre></div></div>
<p>We can watch logs of the build with:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>kp build logs spring-petclinic-image
</code></pre></div></div>
<p>Once the build is completed, the image will be pushed to the <code class="language-plaintext highlighter-rouge">$REPOSITORY</code>.</p>
<blockquote>
<p>NOTE: I’ve pushed to Azure’s container image registry, yours would be different. <a href="https://goharbor.io/">Harbor</a> is a great choice as well. I just wanted to try out Azure’s registry.</p>
</blockquote>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ az acr repository list --name $MY_REPO --output table | grep spring-petclinic-image
build-service/spring-petclinic-image
</code></pre></div></div>
<p>From here on we can magically build almost any application just from the artifacts or source, without having to write and manage a dockerfile. Amazing!</p>
<h2 id="conclusion">Conclusion</h2>
<p>Ultimately this post was about setting up a vSphere with Tanzu cluster that can accept a TBS deployment to it. We didn’t spend much time on <strong>why</strong> you’d want to use TBS. For that I’d suggest watching a <a href="https://www.youtube.com/watch?v=IMmUjUjBzes">video</a>.</p>
<h2 id="hat-tip">Hat Tip</h2>
<ul>
<li>This <a href="https://github.com/papivot/deploy-TBS-on-vSphere7">repo</a></li>
</ul>
Using kubectl run to create privileged container2021-08-24T00:00:00+00:00http://serverascode.com/2021/08/24/run-privileged-pod-kubectl-run<h1 id="using-kubectl-run-to-create-privileged-container">Using kubectl run to create privileged container</h1>
<p>This is the whole post. (Is there an easier way to do this?)</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code> kubectl run --rm -i --tty busybox --image=busybox --restart=Never --overrides='{"spec": {"template": {"spec": {"containers": [{"securityContext": {"privileged": true} }]}}}}' -- whoami
</code></pre></div></div>
<p><br />
Boom! Now make sure you can’t do that in your cluster.</p>
Software Supply Chain Security Part 1 - Container Images2021-07-30T00:00:00+00:00http://serverascode.com/2021/07/30/supply-chain-security-part-1<h1 id="software-supply-chain-security-part-1---container-images">Software Supply Chain Security Part 1 - Container Images</h1>
<p><strong>Problem : I need to package software</strong></p>
<p><strong>Solution: Dockerfiles</strong></p>
<p><strong>New Problem: I need to manage Dockerfiles</strong></p>
<p><strong>New solution: ???</strong></p>
<h2 id="overview">Overview</h2>
<p>There are many pieces to a modern, secure software supply chain. I say modern because this series of posts will focus on what it takes to build a secure software supply chain when the target for runnign these applications is Kubernetes. Kubernetes means containers…and containers mean, you guessed it, container images. So let’s start there.</p>
<h2 id="tldr">tl;dr</h2>
<p>There are many tools to build container images, not just Dockerfiles. In fact, in large organizations, Dockerfiles are IMHO an anti-pattern. You need a tool that can 1) build images without Dockerfiles and 2) separates the OS from the app. <a href="https://buildpacks.io">Buildpacks</a> and more specifically <a href="https://paketo.io">Paketo</a> solve these, and other, problems.</p>
<h2 id="container-images">Container Images</h2>
<p>I talk to many organizations about container images. The reality is that almost everyone equates container images with Dockerfiles, meaning most people believe the only way to create a container image, which they might call a “Docker image” is by using a Dockerfile.</p>
<p>If you get any one thing from this post, it’s important to understand what a container image really is. What it <em>really</em> is…is an open source specification that defines the “file bundle” that makes up what we call a “container image.” (Ultimately, at this time, a container image is a glorified tar file.)</p>
<blockquote>
<p>This specification defines how to create an OCI Image, which will generally be done by a build system, and output an image manifest, a filesystem (layer) serialization, and an image configuration. - <a href="https://opencontainers.org/about/overview/">OCI</a></p>
</blockquote>
<p>The reality is that anyone can build a tool that can create an image which meets this specification. Anyone. It <em>does not</em> have to be based on Dockerfiles. In fact I would suggest that while Dockerfiles are great they are not necessarily the best tool to use as part of building a secure software supply chain. There are other solutions, not many, but there are definitely choices that can be made (and I present one of them in this post).</p>
<h2 id="examples-of-oci-compliant-container-image-build-tools">Examples of OCI Compliant Container Image Build Tools</h2>
<p>First, what other tools are out there for building OCI compliant images?</p>
<blockquote>
<p>NOTE: Not all of these tools are maintained, and not all would be usable in production. This is just a list to show that there are several tools one can use to build an OCI compliant image, not all of which use Dockerfiles. (However, that said, I don’t think there are quite enough tools to show the vibrant OCI image building ecosystem that one would expect given the popularity of containers.)</p>
</blockquote>
<p>Here’s an incomplete list:</p>
<ul>
<li><a href="https://buildpacks.io/">Buildpacks</a></li>
<li><a href="https://github.com/genuinetools/img">img</a></li>
<li>Buildah</li>
<li>Kaniko</li>
<li>Jib</li>
<li><a href="https://github.com/openshift/source-to-image">s2i</a></li>
<li><a href="https://github.com/moby/buildkit">Buildkit</a></li>
<li><a href="https://github.com/google/ko">ko</a></li>
</ul>
<p>As can be seen from the above there are several tools which could be used, as opposed to “docker build…”. Each of these tools makes different architectural and usability choices. In fact some target only specific runtimes, eg. ko targets golang apps.</p>
<h2 id="what-makes-a-good-secure-oci-image-build-tool">What Makes a Good Secure OCI Image Build Tool?</h2>
<h3 id="no-dockerfiles">No Dockerfiles</h3>
<p>My opinion is that a secure supply chain requires that there is, effectively, preferably, no Dockerfile. In my opinion, there’s too much power in Dockerfiles, too many ways to make mistakes and create security issues to allow people to have access to them, or for them to even be available. Developers should not be spending time crafting Dockerfiles.</p>
<p>To me Dockerfiles are an anti-pattern, especially in large organizations with many applications. However, please don’t get me wrong: Dockerfiles have been and will continue to be an amazing tool for developers to build container images, bringing that capability to the masses. That said, using them as part of a secure supply chain is challenging…I believe too challenging for most organizations. It’s preferable for the image build tool to not use Dockerfiles or at least abstract (hide) them away from the developers and application ops teams. However, when hiding things in technology we know that issues can and will still <a href="https://www.joelonsoftware.com/2002/11/11/the-law-of-leaky-abstractions/">leak out</a>, so perhaps best to just not have Dockerfiles at all.</p>
<h3 id="separation-of-concerns">Separation of Concerns</h3>
<p><img src="/img/hashed.jpg" alt="hashed layers" /></p>
<p>I want a OCI build tool that separates, at the very least, the operating system from the application. I want to be able to swap out the OS without breaking, or even affecting, the application. This is because if there is one thing that we can depend on in IT, it’s that the OS will have security issues, ie. CVEs, and we’ll need to fix those CVEs to remain secure. However, if the application, and its dependencies, and its runtime, and the OS are all hashed together into a container image, and we can’t swap any one of those without affecting the other layers, then that is a major security issue, as development and/or application operation teams will be (very) hesitant to update the image because they don’t know what will happen to the application.</p>
<p>An easy way to test if this capability is available in an OCI image tool is if we can use it to build an image “out of band” from the build pipeline. Can we update the OS of an image, most likely to fix any CVEs or bugs, and roll that image out to all applications that use it, without having to go through the entire application build pipeline? In most situations that would not be possible because the build pipeline and the images are so tightly intertwined that it is not feasible. But it <em>should be</em>.</p>
<h3 id="other-needs">Other Needs</h3>
<p>There are other things that a great OCI image build tool should have. I’ll list a few here, but I don’t want this post to go on for too long. (I may tackle these in a future blog post.)</p>
<ul>
<li>Reproducable builds</li>
<li>Built-in intelligence</li>
<li>Just enough customization capability</li>
<li>Bill of materials (BoM)</li>
<li>Minimal attack surface</li>
<li>Support many runtimes</li>
<li>Caching</li>
<li>Build images in unprivileged containers</li>
</ul>
<h2 id="recommended-solution-buildpacks-and-paketo">Recommended Solution: Buildpacks and Paketo</h2>
<p>I think that <a href="https://buildpacks.io/features/">Buildpacks</a>–and more specifically <a href="https://paketo.io">Paketo</a>–present a solution to many of the problems organizations will encounter when trying to build a secure software supply chain using container images.</p>
<p>With regards to my two main points:</p>
<ul>
<li><strong>No Dockerfiles</strong> - Buildpacks do not use Dockerfiles at all. They are not hidden away through abstraction, they just don’t exist. Can’t edit what doesn’t exist. (Though if you want to create custom buildpacks, you can use Dockerfiles)</li>
<li><strong>Separation of Concerns</strong> - The application, dependencies, and OS are separated out and in fact the resulting images can be “rebased” in which one layer is changed without affecting the others</li>
</ul>
<h3 id="using-pack-and-paketo-buildpacks-but-not-dockerfiles">Using Pack and Paketo Buildpacks (but not Dockerfiles)</h3>
<h4 id="paketo">Paketo</h4>
<p>First, what’s Paketo?</p>
<p>I would say that Paketo is a project that uses Buildpacks to provide container images that can run anywhere, including Kubernetes. As well they support many language runtimes. I would almost consider Paketo a distribution of modern, well-considered, usable, community generated buildpacks that have taken what buildpacks have done and built upon it, by making them even more composable and modular.</p>
<p>For the purposes of this post, I’ll use Paketo Buildpacks to build apps which target Kubernetes.</p>
<h4 id="pack">Pack</h4>
<p>Pack is the tool that actually generates the Buildpack images so let’s use pack to build a container image.</p>
<p>First, install pack which can be used to create buildpack based images. I’m doing so on Linux.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>sudo add-apt-repository ppa:cncf-buildpacks/pack-cli
sudo apt-get update
sudo apt-get install pack-cli
</code></pre></div></div>
<p>Now I’ve got the pack cli.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ which pack
/usr/bin/pack
$ pack version
0.19.0
</code></pre></div></div>
<p>Next, build an <a href="https://buildpacks.io/docs/app-journey/">app</a>. First checkout the sample.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>git clone https://github.com/paketo-buildpacks/samples
cd samples/java/maven/
</code></pre></div></div>
<p>Now build the app.</p>
<blockquote>
<p>NOTE: Here I’m calling the image “applications/maven”.</p>
</blockquote>
<blockquote>
<p>NOTE: I’m using the Paketo buildpack found at “paketobuildpacks/builder:base”.</p>
</blockquote>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>pack build applications/maven --builder paketobuildpacks/builder:base
</code></pre></div></div>
<p>Eg. output:</p>
<blockquote>
<p>NOTE: This is pulling Java dependencies, and, well, there are many of those to pull on the first build.</p>
</blockquote>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ pack build applications/maven --builder paketobuildpacks/builder:base
base: Pulling from paketobuildpacks/builder
Digest: sha256:4fae5e2abab118ca9a37bf94ab42aa17fef7c306296b0364f5a0e176702ab5cb
Status: Downloaded newer image for paketobuildpacks/builder:base
base-cnb: Pulling from paketobuildpacks/run
Digest: sha256:a285e73bc3697bc58c228b22938bc81e9b11700e087fd9d44da5f42f14861812
Status: Downloaded newer image for paketobuildpacks/run:base-cnb
===> DETECTING
7 of 18 buildpacks participating
paketo-buildpacks/ca-certificates 2.3.2
paketo-buildpacks/bellsoft-liberica 8.2.0
paketo-buildpacks/maven 5.3.2
paketo-buildpacks/executable-jar 5.1.2
paketo-buildpacks/apache-tomcat 5.6.1
paketo-buildpacks/dist-zip 4.1.2
paketo-buildpacks/spring-boot 4.4.2
===> ANALYZING
Previous image with name "applications/maven" not found
===> RESTORING
===> BUILDING
Paketo CA Certificates Buildpack 2.3.2
https://github.com/paketo-buildpacks/ca-certificates
Launch Helper: Contributing to layer
Creating /layers/paketo-buildpacks_ca-certificates/helper/exec.d/ca-certificates-helper
Paketo BellSoft Liberica Buildpack 8.2.0
SNIP!
Paketo Spring Boot Buildpack 4.4.2
https://github.com/paketo-buildpacks/spring-boot
Creating slices from layers index
dependencies
spring-boot-loader
snapshot-dependencies
application
Launch Helper: Contributing to layer
Creating /layers/paketo-buildpacks_spring-boot/helper/exec.d/spring-cloud-bindings
Spring Cloud Bindings 1.7.1: Contributing to layer
Downloading from https://repo.spring.io/release/org/springframework/cloud/spring-cloud-bindings/1.7.1/spring-cloud-bindings-1.7.1.jar
Verifying checksum
Copying to /layers/paketo-buildpacks_spring-boot/spring-cloud-bindings
Web Application Type: Contributing to layer
Reactive web application detected
Writing env.launch/BPL_JVM_THREAD_COUNT.default
4 application slices
Image labels:
org.opencontainers.image.title
org.opencontainers.image.version
org.springframework.boot.version
===> EXPORTING
Adding layer 'paketo-buildpacks/ca-certificates:helper'
Adding layer 'paketo-buildpacks/bellsoft-liberica:helper'
Adding layer 'paketo-buildpacks/bellsoft-liberica:java-security-properties'
Adding layer 'paketo-buildpacks/bellsoft-liberica:jre'
Adding layer 'paketo-buildpacks/bellsoft-liberica:jvmkill'
Adding layer 'paketo-buildpacks/executable-jar:classpath'
Adding layer 'paketo-buildpacks/spring-boot:helper'
Adding layer 'paketo-buildpacks/spring-boot:spring-cloud-bindings'
Adding layer 'paketo-buildpacks/spring-boot:web-application-type'
Adding 5/5 app layer(s)
Adding layer 'launcher'
Adding layer 'config'
Adding layer 'process-types'
Adding label 'io.buildpacks.lifecycle.metadata'
Adding label 'io.buildpacks.build.metadata'
Adding label 'io.buildpacks.project.metadata'
Adding label 'org.opencontainers.image.title'
Adding label 'org.opencontainers.image.version'
Adding label 'org.springframework.boot.version'
Setting default process type 'web'
Saving applications/maven...
*** Images (d7dcc3fd9295):
applications/maven
Adding cache layer 'paketo-buildpacks/bellsoft-liberica:jdk'
Adding cache layer 'paketo-buildpacks/maven:application'
Adding cache layer 'paketo-buildpacks/maven:cache'
Successfully built image applications/maven
</code></pre></div></div>
<p>That’s created this “applications/maven” image in my local Docker.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ docker images | grep application
applications/maven latest d7dcc3fd9295 41 years ago 269MB
</code></pre></div></div>
<blockquote>
<p>NOTE: It says 41 years ago because it is a reproducable build. More on that maybe in other blog posts.</p>
</blockquote>
<p>But where is the Dockerfile?</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ tree
.
├── bindings
│ └── maven
│ ├── settings.xml
│ └── type
├── mvnw
├── mvnw.cmd
├── pom.xml
├── README.md
└── src
├── main
│ ├── java
│ │ └── io
│ │ └── paketo
│ │ └── demo
│ │ └── DemoApplication.java
│ └── resources
│ └── application.properties
└── test
└── java
└── io
└── paketo
└── demo
└── DemoApplicationTests.java
14 directories, 9 files
</code></pre></div></div>
<p>There is none! pack uses buildpacks and does NOT use a Dockerfile. Nice!</p>
<h3 id="buildpack-rebasing---out-of-band-image-updates">Buildpack Rebasing - Out of Band Image Updates</h3>
<p>Most customers I talk to have to push an image through the entire build pipeline to build it…where “it” is the OS, dependencies, and application artifacts. This means that any time there is a CVE, the entire build must be run. What this also suggests is that the ability for the application to properly run is also tied to the entirety of the image. This makes updating images when there isn’t an application change challenging, as no one is really sure if it’s going to work or not…</p>
<p>But with buildpacks, the application, OS, and runtimes, and dependencies (and more) are separated out into individual pieces that can be swapped out without harming the application. With buildpacks this is called <a href="https://buildpacks.io/docs/concepts/operations/rebase/">rebasing</a>.</p>
<blockquote>
<p>Rebase allows app developers or operators to rapidly update an app image when its stack’s run image has changed. By using image layer rebasing, this command avoids the need to fully rebuild the app.</p>
</blockquote>
<p>The term rebase mostly comes from the world of git:</p>
<blockquote>
<p>Rebasing is the process of moving or combining a sequence of commits to a new base commit. – <a href="https://www.atlassian.com/git/tutorials/rewriting-history/git-rebase">git rebase</a></p>
</blockquote>
<p>So let’s rebase the image.</p>
<p>Inspect the current version.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ pack inspect applications/maven
Inspecting image: applications/maven
REMOTE:
(not present)
LOCAL:
Stack: io.buildpacks.stacks.bionic
Base Image:
Reference: 5eaa2a599cd59e0e1d67132de78d590ef0f34512ede6acefd09416548f52a994
Top Layer: sha256:10dd4d5e8186feb5b6ab2a877c80e1616e426ed383b7f19358b7703686fa4f9a
Run Images:
index.docker.io/paketobuildpacks/run:base-cnb
gcr.io/paketo-buildpacks/run:base-cnb
Buildpacks:
ID VERSION HOMEPAGE
paketo-buildpacks/ca-certificates 2.3.2 https://github.com/paketo-buildpacks/ca-certificates
paketo-buildpacks/bellsoft-liberica 8.2.0 https://github.com/paketo-buildpacks/bellsoft-liberica
paketo-buildpacks/maven 5.3.2 https://github.com/paketo-buildpacks/maven
paketo-buildpacks/executable-jar 5.1.2 https://github.com/paketo-buildpacks/executable-jar
paketo-buildpacks/apache-tomcat 5.6.1 https://github.com/paketo-buildpacks/apache-tomcat
paketo-buildpacks/dist-zip 4.1.2 https://github.com/paketo-buildpacks/dist-zip
paketo-buildpacks/spring-boot 4.4.2 https://github.com/paketo-buildpacks/spring-boot
Processes:
TYPE SHELL COMMAND ARGS
web (default) java org.springframework.boot.loader.JarLauncher
executable-jar java org.springframework.boot.loader.JarLauncher
task java org.springframework.boot.loader.JarLauncher
</code></pre></div></div>
<p>Rebasing using a much older image. Of course, this would be done in reverse in the real world, where we would rebase with a newer image (that presumably has the security issues fixed). But for simplicity, given I’ve already created an image using the most recent run image, I’ll go backwards here just for fun. Same idea no matter which way we go.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ pack rebase applications/maven --run-image paketobuildpacks/builder:0.1.135-base
0.1.135-base: Pulling from paketobuildpacks/builder
71c12072e01c: Already exists
8ac523e239f0: Pulling fs layer
SNIP!
72ad9888618d: Pull complete
4f4fb700ef54: Pull complete
Digest: sha256:06fc9acb3b8098f7b717420d35f9cd8485ea1f92ce540769a2924ad7a161dad7
Status: Downloaded newer image for paketobuildpacks/builder:0.1.135-base
Rebasing applications/maven on run image paketobuildpacks/builder:0.1.135-base
Saving applications/maven...
*** Images (b72546026b22):
applications/maven
Rebased Image: b72546026b22fff4797625e36b8f4a6c0e4a5386fcd5460c12d173cb1000718e
Successfully rebased image applications/maven
</code></pre></div></div>
<p>Inspect that version:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ pack inspect applications/maven
Inspecting image: applications/maven
REMOTE:
(not present)
LOCAL:
Stack: io.buildpacks.stacks.bionic
Base Image:
Reference: a8b66bfbe49565ffa1c74374ed0a38fb91adb43fa4a7a7c740b3f099b93a9c78
Top Layer: sha256:5f70bf18a086007016e948b04aed3b82103a36bea41755b6cddfaf10ace3c6ef
Run Images:
index.docker.io/paketobuildpacks/run:base-cnb
gcr.io/paketo-buildpacks/run:base-cnb
Buildpacks:
ID VERSION HOMEPAGE
paketo-buildpacks/ca-certificates 2.3.2 https://github.com/paketo-buildpacks/ca-certificates
paketo-buildpacks/bellsoft-liberica 8.2.0 https://github.com/paketo-buildpacks/bellsoft-liberica
paketo-buildpacks/maven 5.3.2 https://github.com/paketo-buildpacks/maven
paketo-buildpacks/executable-jar 5.1.2 https://github.com/paketo-buildpacks/executable-jar
paketo-buildpacks/apache-tomcat 5.6.1 https://github.com/paketo-buildpacks/apache-tomcat
paketo-buildpacks/dist-zip 4.1.2 https://github.com/paketo-buildpacks/dist-zip
paketo-buildpacks/spring-boot 4.4.2 https://github.com/paketo-buildpacks/spring-boot
Processes:
TYPE SHELL COMMAND ARGS
web (default) java org.springframework.boot.loader.JarLauncher
executable-jar java org.springframework.boot.loader.JarLauncher
task java org.springframework.boot.loader.JarLauncher
</code></pre></div></div>
<p>If I run that app, which was rebased onto a much older run image…</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ docker run --rm -p 8080:8080 applications/maven
Setting Active Processor Count to 12
Calculating JVM memory based on 38994352K available memory
Calculated JVM Memory Configuration: -XX:MaxDirectMemorySize=10M -Xmx38598153K -XX:MaxMetaspaceSize=88998K -XX:ReservedCodeCacheSize=240M -Xss1M (Total Memory: 38994352K, Thread Count: 50, Loaded Class Count: 13299, Headroom: 0%)
Adding 129 container CA certificates to JVM truststore
Spring Cloud Bindings Enabled
Picked up JAVA_TOOL_OPTIONS: -Djava.security.properties=/layers/paketo-buildpacks_bellsoft-liberica/java-security-properties/java-security.properties -agentpath:/layers/paketo-buildpacks_bellsoft-liberica/jvmkill/jvmkill-1.16.0-RELEASE.so=printHeapHistogram=1 -XX:ActiveProcessorCount=12 -XX:MaxDirectMemorySize=10M -Xmx38598153K -XX:MaxMetaspaceSize=88998K -XX:ReservedCodeCacheSize=240M -Xss1M -Dorg.springframework.cloud.bindings.boot.enable=true
. ____ _ __ _ _
/\\ / ___'_ __ _ _(_)_ __ __ _ \ \ \ \
( ( )\___ | '_ | '_| | '_ \/ _` | \ \ \ \
\\/ ___)| |_)| | | | | || (_| | ) ) ) )
' |____| .__|_| |_|_| |_\__, | / / / /
=========|_|==============|___/=/_/_/_/
:: Spring Boot :: (v2.5.3)
2021-07-30 13:44:52.093 INFO 1 --- [ main] io.paketo.demo.DemoApplication : Starting DemoApplication v0.0.1-SNAPSHOT using Java 11.0.12 on 331541f6d651 with PID 1 (/workspace/BOOT-INF/classes started by cnb in /workspace)
2021-07-30 13:44:52.096 INFO 1 --- [ main] io.paketo.demo.DemoApplication : No active profile set, falling back to default profiles: default
2021-07-30 13:44:52.906 INFO 1 --- [ main] o.s.b.a.e.web.EndpointLinksResolver : Exposing 1 endpoint(s) beneath base path '/actuator'
2021-07-30 13:44:53.184 INFO 1 --- [ main] o.s.b.web.embedded.netty.NettyWebServer : Netty started on port 8080
2021-07-30 13:44:53.196 INFO 1 --- [ main] io.paketo.demo.DemoApplication : Started DemoApplication in 1.376 seconds (JVM running for 1.646)
</code></pre></div></div>
<p>So as you can see it’s simple and fast to “rebase” an image, ie. swap out the version of the OS but NOT the application, without having to go through an entire build.</p>
<h2 id="conclusion">Conclusion</h2>
<p>Dockerfiles are great, but, IMHO, not for building a secure software supply chain (not without considerable extra work at least). There are other ways to build container images that lend themselves more easily to building a secure software supply chain.</p>
<p>I should mention that buildpacks and pack are just part of a full solution for managing images. Please check out <a href="https://github.com/pivotal/kpack">kpack</a> and the <a href="https://tanzu.vmware.com/build-service">Tanzu Build service</a> for more thoughts on what else is needed in the Kubernetes ecosystem. More on that in future posts.</p>
<h2 id="thanks">Thanks</h2>
<p>Please note that the container flipping image in the title image is borrowed from the <a href="https://github.com/google/ko">ko project</a>. I’m using it because I think it’s hilarious, not because I necessarily am suggesting ko is a great build tool–I haven’t used it.</p>
Thoughts on the Certified Kubernetes Security Specialist Certification Exam2021-07-27T00:00:00+00:00http://serverascode.com/2021/07/27/thoughts-on-the-cks-exam<h1 id="thoughts-on-the-certified-kubernetes-security-specialist-certification-exam">Thoughts on the Certified Kubernetes Security Specialist Certification Exam</h1>
<p>First, let me say that Kubernetes is an extremely challenging piece of software to use, and, of course, to secure. I work at <a href="https://tanzu.vmware.com/">VMware in the Tanzu group</a> and Kubernetes is a massive part of our portfolio–in fact it’s the base of almost everything we do. But it’s just the base. You have to add so much on top of Kubernetes to make it useful, and even more to secure it. But enough about that, let’s talk about the Certified Kubernetes Security Specialist Certification (CKS).</p>
<h2 id="tldr">tl;dr</h2>
<ul>
<li>It took me two tries to pass the test, but I didn’t do much extra in terms of studying for the second try. I think the first try just made me realize how fast I have to be to complete the test…get fast!</li>
<li>I used the <a href="https://kodekloud.com/courses/certified-kubernetes-security-specialist-cks/">Kodecloud</a> and the <a href="https://www.udemy.com/share/103O5A2@Pm5gfWJgc1MLcUdHC3ZNfj1tYFc=/">Kim Wüstkamp Udemy course</a></li>
<li>At this time, when you register for the test you get access to two practice test sessions on <a href="https://killer.sh/">killer.sh</a>. When I initially registered, I did not have access to these from the CNCF, instead they came with the Udemy course. But right now, when you register for the test, you get two sessions on killer.sh “for free”. These are extremely helpful, as are any practical lab or questions available.</li>
<li>I find practical labs and tests to be far the most valuable…videos and other training is not as useful</li>
<li>If I went through this again I would use the Kodecloud class which has great automated labs, and the two killer.sh practice test sessions</li>
</ul>
<h2 id="some-areas-to-focus-on">Some Areas to Focus On</h2>
<p>Ultimately, in my opinion, the CKS test is–not surprisingly–a test taking exercise. Two hours is not a lot of time to answer all the questions, and it’s really about speed and confidence.</p>
<ul>
<li>Ensure you are following all the exam requirements, eg. make sure your desk is clear so you aren’t spending time worrying about that just before writing the exam. Note that these requirements can and will change over time, so double check prior to your own exam!</li>
<li>Use the copy buttons on the test to copy text instead of typing it out (in case you make a typo)</li>
<li>Be great with the command line, know how to edit with vi–the better you are at vi the faster you will finish questions</li>
<li>Know how to setup kubectl completion and use it</li>
<li>Copy initial configs to something like .orig in case you break the deployment</li>
<li>Go through all the questions and use the notepad to note the number, points, and area of the question</li>
<li>Do the highest value easiest questions first, moving onto lower value, etc etc</li>
<li>Get all of the questions you easily can answer first, then move onto the harder questions, but don’t leave any high points questions unanswered (if you do, you aren’t fast enough yet)</li>
<li>Double check that you have answered all of the question components before moving on (and if you have time at the end, come back and check)</li>
<li>Don’t worry if you don’t pass the first time, you have a second try, and will do much better in the second exam</li>
</ul>
<h2 id="from-a-technical-perspective">From a Technical Perspective</h2>
<p><strong>Kubernetes Services</strong></p>
<p>Know how to:</p>
<ul>
<li>configure the Kubernetes manifests of the major k8s services, such as kube-apiserver</li>
<li>find the docs for the settings that are available for each service</li>
<li>configure the services manifests and how they restart</li>
<li>find the logs for the containers</li>
<li>use admission controllers, especially ImagePolicyWebhook</li>
</ul>
<p><strong>Kuberentes Config</strong></p>
<p>Know how to:</p>
<ul>
<li>create network policies</li>
<li>copy an running pod/deploy config and edit it</li>
</ul>
<p><strong>3rd Party Tools</strong></p>
<p>Know how to:</p>
<ul>
<li>deploy an apparmor profile</li>
<li>configure a pod to use an app armor profile</li>
<li>add rules quickly to Falco and start falco</li>
<li>implement security best practices on Dockerfiles</li>
<li>use the docs for these services, but ONLY the ones that have been listed as OK to use during the CKS exam</li>
</ul>
<h2 id="conclusion">Conclusion</h2>
<p>Note that I have only listed a <em>few</em> major things on this blog post. To pass the test you’d need to know a lot more, and all of that is covered in the documentation for the test, at least in terms of what is on the test.</p>
<p>I personally believe that practical..er…practice is most important in terms of studying for the test. Watch fewer videos and instead practice <em>actually implementing</em> practical technical things as quickly as possible via the command line and the vi editor. Make up your own questions if you have to. This is why Killer.sh and the Kodecloud labs and practice tests are so useful. I would spend at least 75% of my time, if not more, on practical hands on (timed if possible) labs and questions as opposed to standard video training. But…this is just my opinion.</p>
<p>Best of luck on your exam!</p>
<h2 id="ps">PS.</h2>
<p>I put up my <a href="https://github.com/ccollicutt/cks-bookmarks">CKS Chrome bookmarks</a> in github, but again, the allowed sites may change over time so please double check.</p>
How to Fix a Blinking Cursor on Ubuntu Boot2021-07-03T00:00:00+00:00http://serverascode.com/2021/07/03/blinking-cursor-linux<h1 id="how-to-fix-a-blinking-cursor-on-ubuntu-boot">How to Fix a Blinking Cursor on Ubuntu Boot</h1>
<p>Today I figured I’d update my Linux workstation. Honestly I don’t like to do it because stuff breaks all the time. But I don’t want an out of date system either, so I just ran it (<em>eep</em>), and of course the update crashed midway through, and when I went to hard reboot I had a blinking cursor, which, from an existential perspective is awful and yet perfect at the same time. Thanks Linux! Haha.</p>
<p>Fortunately the fix is pretty easy, certainly easier than fixing urban ennui and lockdown depression.</p>
<p>First, don’t panic.</p>
<p>Second, use “CTRL + ALT + F3” to switch to a console, then login from there. (See, Linux is up and running, it’s just the GUI login that’s borked.)</p>
<p>Third, fix gdm3 and the failed update.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>sudo dpkg --configure -a
sudo dpkg-reconfigure gdm3
sudo service gdm3 restart
</code></pre></div></div>
<p>And that should fix it. Or at least it did in my case. Best of luck!</p>
OpenBSD 6.9 on Protecli 6 Port Firewall2021-05-31T00:00:00+00:00http://serverascode.com/2021/05/31/openbsd-protecli<h1 id="openbsd-69-on-protecli-6-port-firewall">OpenBSD 6.9 on Protecli 6 Port Firewall</h1>
<p>I’ve had a homelab for a while. And an old printer. And a wifi network. And a office network. Up until now it’s been a bit of a free for all, everything was connected to everything else with no limitations or isolation. That’s probably not great security-wise. Also…all this ransomware talk…it’s concerning. Looks like it’s time to implement some network isolation. So I bought a six port fanless firewall and put OpenBSD on it.</p>
<h2 id="protecli-6-port">Protecli 6 Port</h2>
<p><img src="/img/protecli-box.jpg" alt="protecli box" /></p>
<p>The device was about $500, which is pricey. But I wanted 6 ports.</p>
<p>What I bought:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>Protectli Vault 6 Port, Firewall Micro Appliance/Mini PC - Intel Dual Core, AES-NI, 4GB RAM, 32GB mSATA SSD
</code></pre></div></div>
<p>What it has:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>THE VAULT: Secure your network with a compact, fanless & silent firewall. Comes with US-based Support & 30-day money back guarantee!
CPU: Intel Dual Core Celeron 3865U, 64 bit, 1.8GHz, 2MB Smart Cache, Intel AES-NI hardware support
PORTS: 6x Intel Gigabit Ethernet NIC ports, 4x USB 3.0, 1x RJ-45 COM, 1x HDMI
COMPONENTS: 4GB DDR4 RAM, 32GB mSATA SSD
COMPATIBILITY: Firewalls tested with pfSense, untangle, OPNsense and other popular open-source software solutions.
</code></pre></div></div>
<p>The CPU isn’t great, there are definitely better options, but it started to get to expensive. I think this CPU will be fine for my purposes.</p>
<h2 id="install-openbsd">Install OpenBSD</h2>
<p>I installed via the com port. I used a USB to serial adapter connected to my Linux workstation.</p>
<p>To connect:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>sudo screen /dev/ttyUSB0 115200
</code></pre></div></div>
<p>I downloaded the OpenBSD 6.9 img file and <code class="language-plaintext highlighter-rouge">dd</code>ed it to a USB device.</p>
<p>Then plugged that device into the Protecli.</p>
<p>Next I set the BIOS in the Protecli to be “legacy only”, othewise OpenBSD will give this error:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>probing: pc0 com0 mem[352K 280K 2153M 83M 1M 1776M]
disk: hd0 hd1*
>> OpenBSD/amd64 BOOTX64 3.57
boot>
cannot open hd0a:/etc/random.seed: No such file or directory
booting hd0a:/6.9/amd64/bsd.rd: 3818189+1590272+3878376+0+704512 [109+288+28]=0x989530
entry point at 0x1001000
</code></pre></div></div>
<p>So get into the BIOS by pressing the <code class="language-plaintext highlighter-rouge">DEL</code> key when the box is booting up. Then change to “legacy only” and OpenBSD should boot.</p>
<p>Once OpenBSD boots up, enter the following to setup the com port.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>stty com0 115200
set tty com0
</code></pre></div></div>
<p>From there you should be good to install. I just use all the defaults for now.</p>
<p>Here you can see all six ports:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code># ifconfig | grep em
em0: flags=8802<BROADCAST,SIMPLEX,MULTICAST> mtu 1500
em1: flags=8802<BROADCAST,SIMPLEX,MULTICAST> mtu 1500
em2: flags=8802<BROADCAST,SIMPLEX,MULTICAST> mtu 1500
em3: flags=8802<BROADCAST,SIMPLEX,MULTICAST> mtu 1500
em4: flags=8802<BROADCAST,SIMPLEX,MULTICAST> mtu 1500
em5: flags=8802<BROADCAST,SIMPLEX,MULTICAST> mtu 1500
</code></pre></div></div>
<h2 id="conclusion">Conclusion</h2>
<p>I haven’t put this into use yet, but I should soon. I’m assuming it’s going to work fine, but I’ll update this post after I’ve used it for a while.</p>
Using xfreerdp from Linux to Windows (with i3)2021-02-10T00:00:00+00:00http://serverascode.com/2021/02/10/xfreerdp-from-linux-to-windows<h1 id="using-xfreerdp-from-linux-to-windows-with-i3">Using xfreerdp from Linux to Windows (with i3)</h1>
<p>I use Ubuntu 20.04. I have a Windows VM, mostly for doing things like Power Point. I like to connect to that VM with xfreerdp so that I can easily flit around and still use i3 on my desktop. I put the xfreerdp session on one of my virtual desktops.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>xfreerdp /u:USER /p:SOMEPASS /v:SOMEIP /f +fonts /floatbar /smart-sizing -grab-keyboard /sound /microphone /multimon
</code></pre></div></div>
<p>I run the above command, whcih I usually alias. One of the key commands is the <code class="language-plaintext highlighter-rouge">-grab-keyboard</code> otherwise i3’s MOD key might not work.</p>
<p>Then the xfreerdp window pops up. Then I:</p>
<ul>
<li>Hit “MOD + SHIFT + Spacebar” to make the window floating</li>
<li>Hit “MOD” and drag the window to position it properly over the two monitors</li>
</ul>
<p>That’s it. That’s the post. I really find this a useful way of working.</p>
<p>Sound works, but I can’t get the micrphone to work.</p>
<p>Let me know if you have any ideas to make this better!</p>
Linux Budget Workstation2020-12-15T00:00:00+00:00http://serverascode.com/2020/12/15/linux-budget-workstation<h1 id="linux-budget-workstation">Linux Budget Workstation</h1>
<p>There’s not a lot of pieces to a desktop computer. Here’s what I have, bought just after the pandemic started and it became clear I was going to be working from home for a substantial amount of time</p>
<p>I had a few goals and requirements for this build:</p>
<ol>
<li>Low cost</li>
<li>Lots of CPU</li>
<li>Not annoyingly loud</li>
<li>Minimum 64GB of memory</li>
<li>No need for gaming</li>
</ol>
<p>I knew that I would run several VMs on the workstation, mostly to split out different things I need to do, for example access work related systems via a VPN in a Windows based virtual machine, have a VM for doing demos, ect ect, so I would need at least 64gb of memory.</p>
<h2 id="the-build">The Build</h2>
<p>The cost of this build was, pre-tax, $1300 CDN! With Ontario tax and the $50 build fee it came out to just over $1500. (I should note that this build was done about 7 months prior to this post, so it’s been a while, a quick glance suggests the pricing is still about the same.)</p>
<p>I bought the parts at <a href="https://www.memoryexpress.com/">Memory Express</a> and had them build the system for an extra $50. They were great to work with.</p>
<table>
<thead>
<tr>
<th>Component</th>
<th>Item</th>
<th>Cost</th>
</tr>
</thead>
<tbody>
<tr>
<td>CPU</td>
<td>AMD Ryzen 5 3600 Processor</td>
<td>$259.99</td>
</tr>
<tr>
<td>Case</td>
<td>Corsair Carbide Series 100R Mid-Tower Case, Silent Edition, Black</td>
<td>$89.99</td>
</tr>
<tr>
<td>Memory</td>
<td>Corsair Vengeance LPX 64GB DDR4 2666MHz CL16 Dual Channel Kit (4x 16GB), Black</td>
<td>$389.99</td>
</tr>
<tr>
<td>Storage</td>
<td>Western Digital Blue SN550 M.2 PCI-E NVMe SSD, 1TB</td>
<td>$169.99</td>
</tr>
<tr>
<td>Power Source</td>
<td>Corsair RMx Series RM550x 80+ Gold Fully Modular ATX Power Supply, 550W</td>
<td>$144.99</td>
</tr>
<tr>
<td>Motherboard</td>
<td>Asus TUF B450-PRO GAMING w/ DDR4-2666</td>
<td>$169.99</td>
</tr>
<tr>
<td>Video Card</td>
<td>Gigabyte GeForce GT 710 2GB GDDR5 Low-Profile PCI-E w/ HDMI, DVI</td>
<td>$79.99</td>
</tr>
</tbody>
</table>
<blockquote>
<p>NOTE: This video card is pretty limited, but works great to power a HDMI monitor.</p>
</blockquote>
<h2 id="conclusion">Conclusion</h2>
<p>In the end, I couldn’t be more happy with this build. It’s stable, quiet, and, as far as I’m concerned, high performance. But, that said, I don’t play video games, or do any GPU related activities. I just need to output to a monitor. It’s the perfect workstation for me, both from a cost and an experience perspective.</p>
Install Tanzu Kubernetes Grid in Azure2020-11-25T00:00:00+00:00http://serverascode.com/2020/11/25/deploy-tkg-to-azure<h1 id="install-tanzu-kubernetes-grid-in-azure">Install Tanzu Kubernetes Grid in Azure</h1>
<p>Tanzu Kubernetes Grid 1.2 (TKG) was recently released, and with it comes the ability to deploy TKG to Azure. Prior to 1.2 you could deploy to vSphere and AWS, but now, with 1.2, Azure is also supported. So you can now run the same Kubernetes with the same life cycle manager across vSphere, AWS, and Azure. That’s pretty powerful from a multicloud perspective.</p>
<p>For this post, let’s focus on Azure.</p>
<blockquote>
<p>NOTE: Read the official docs <a href="https://docs.vmware.com/en/VMware-Tanzu-Kubernetes-Grid/1.2/vmware-tanzu-kubernetes-grid-12/GUID-mgmt-clusters-azure.html">here</a>.</p>
</blockquote>
<h2 id="requirements">Requirements</h2>
<h3 id="tkg-cli">TKG CLI</h3>
<p>Use this <a href="https://www.vmware.com/go/get-tkg">link</a> to access my.vmware.com and download the TKG CLI. You’ll have to login to actually download.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ tkg version
Client:
Version: v1.2.0
Git commit: 05b233e75d6e40659247a67750b3e998c2d990a5
</code></pre></div></div>
<p>The above is the version of TKG that we’ll be using for this post.</p>
<h3 id="azure-cli">Azure CLI</h3>
<p>Here are the <a href="https://github.com/kubernetes-sigs/cluster-api-provider-azure/blob/master/docs/getting-started.md#prerequisites">docs for the prerequisites</a> for Azure’s Cluster API implementation. But don’t worry about reading that doc unless you want to. Not required.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>az account show
</code></pre></div></div>
<p>This post assumes that the <code class="language-plaintext highlighter-rouge">az</code> CLI has been setup and configured enough so that you can run something like the above.</p>
<h3 id="docker">Docker</h3>
<p>TKG uses a local Docker install to setup a small, ephemeral, temporary <a href="https://kind.sigs.k8s.io/">kind</a> based Kubernetes cluster to build the TKG management cluster in Azure. (More about that later.) Thus we need Docker locally to run the kind cluster.</p>
<p>I’m just using an Ubuntu 18.04 instance with the default docker.io package.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ cat /etc/lsb-release
DISTRIB_ID=Ubuntu
DISTRIB_RELEASE=18.04
DISTRIB_CODENAME=bionic
DISTRIB_DESCRIPTION="Ubuntu 18.04.5 LTS"
$ dpkg --list docker.io
Desired=Unknown/Install/Remove/Purge/Hold
| Status=Not/Inst/Conf-files/Unpacked/halF-conf/Half-inst/trig-aWait/Trig-pend
|/ Err?=(none)/Reinst-required (Status,Err: uppercase=bad)
||/ Name Version Architecture Description
+++-======================-================-================-==================================================
ii docker.io 19.03.6-0ubuntu1 amd64 Linux container runtime
</code></pre></div></div>
<p>The Linux user doing the TKG deploy must be able to access Docker, ie. run something like the below.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>docker ps
</code></pre></div></div>
<p>Easy peasy.</p>
<h3 id="ssh-key">SSH Key</h3>
<p>We’ll also need an ssh key in ssh format. If there isn’t an ssh key setup, then the below command will create one.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>ssh-keygen
</code></pre></div></div>
<p>In this post I assume the key is in <code class="language-plaintext highlighter-rouge">~/.ssh/id_rsa.pub</code>.</p>
<h2 id="setup-azure-and-tkg-variables">Setup Azure and TKG Variables</h2>
<p>First, decide on an Azure application name, such as “tkg-azure” and export that as a variable. This name is up to you.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>export AZURE_APP_NAME="tkg-azure"
</code></pre></div></div>
<p>Next get your Azure subscription ID.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>export AZURE_SUBSCRIPTION_ID=$(az account show --query id --output tsv)
</code></pre></div></div>
<p>Now we can setup an Azure application with a service principle.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>export RETURNED_SP_APP_JSON=$(az ad sp create-for-rbac --name $AZURE_APP_NAME)
</code></pre></div></div>
<p>And use the information returned by that command to configure the other variables we need.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>export AZURE_CLIENT_ID=$(echo "$RETURNED_SP_APP_JSON" | jq -r '.appId')
export AZURE_CLIENT_SECRET=$(echo "$RETURNED_SP_APP_JSON" | jq -r '.password')
export AZURE_TENANT_ID=$(echo "$RETURNED_SP_APP_JSON" | jq -r '.tenant')
</code></pre></div></div>
<p>Need a couple of standard Azure variables.</p>
<blockquote>
<p>NOTE: <code class="language-plaintext highlighter-rouge">AZURE_ENVIRONMENT</code> will always be “AzurePublicCLoud” but the <code class="language-plaintext highlighter-rouge">AZURE_LOCATION</code> can be any region you’d lke.</p>
</blockquote>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>export AZURE_LOCATION="canadacentral"
export AZURE_ENVIRONMENT="AzurePublicCloud"
</code></pre></div></div>
<p>Also, decide on a management cluster name, such as “tkg-mgmt”.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>export MANAGEMENT_CLUSTER_NAME="tkg-mgmt"
</code></pre></div></div>
<p>Setup a base64 encoded string of your ssh public key. Assuming your key is in <code class="language-plaintext highlighter-rouge">~/.ssh/id_rsa.pub</code>.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>export AZURE_SSH_PUBLIC_KEY_B64=$(base64 < ~/.ssh/id_rsa.pub | tr -d '\r\n')
</code></pre></div></div>
<p>At this point we should have this many variables setup:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ env | grep "AZURE\|MANAGEMENT_CLUSTER" | wc -l
9
</code></pre></div></div>
<p>If so, you are good to go to the next step.</p>
<h2 id="accept-image-license">Accept Image License</h2>
<p>Accept the license agreement for the images published to Azure. (This only has to be done once.)</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>az vm image terms accept --publisher vmware-inc --offer tkg-capi --plan k8s-1dot19dot1-ubuntu-1804
</code></pre></div></div>
<h2 id="deploy-management-cluster">Deploy Management Cluster</h2>
<p>At this point, with only a few Azure az commands, we’re setup to build the TKG management cluster.</p>
<blockquote>
<p>NOTE: TKG uses <a href="https://cluster-api.sigs.k8s.io/">Cluster API</a> to manage the life cycle of Kubernetes clusters. TKG will first deploy a management cluster to Azure, which will contain Cluster API. To do that it uses a local Docker-based Kind cluster to bootstrap the management cluster. Once the management cluster has been bootstrapped into Azure the local Kind cluster is deleted, and going forward TKG will use the Azure based management cluster to build workload clusters. There are a few artifacts that should be kept, eg. <code class="language-plaintext highlighter-rouge">~/.kube</code> and <code class="language-plaintext highlighter-rouge">~/.tkg</code> on the bootstrap node prior to its removal, but once those files are stored and secured the Linux virtual machine could be deleted.</p>
</blockquote>
<p>Now we can deploy the management cluster.</p>
<p>Run <code class="language-plaintext highlighter-rouge">tkg get mc</code> to setup the <code class="language-plaintext highlighter-rouge">~/.tkg</code> directory.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>tkg get mc
</code></pre></div></div>
<p>Now build the management cluster.</p>
<blockquote>
<p>NOTE: We are using the <code class="language-plaintext highlighter-rouge">dev</code> plan.</p>
</blockquote>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>tkg init --infrastructure=azure --name="$MANAGEMENT_CLUSTER_NAME" --plan=dev -v 6
</code></pre></div></div>
<p>With the management cluster deployed, we can now build many workload clusters.</p>
<blockquote>
<p>NOTE: Like many others, I believe that organizations will require many Kubernetes clusters as opposed to a couple large ones. So TKG controls the life cycle of many, many clusters.</p>
</blockquote>
<p>Once that command has completed you’ll see something like:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>SNIP!
Deleting Cluster="tkg-mgmt" Namespace="tkg-system"
Deleting ClusterResourceSet="tkg-mgmt-cni-antrea" Namespace="tkg-system"
Resuming the target cluster
Set Cluster.Spec.Paused Paused=false Cluster="tkg-mgmt" Namespace="tkg-system"
Context set for management cluster tkg-mgmt as 'tkg-mgmt-admin@tkg-mgmt'.
Deleting kind cluster: tkg-kind-buv4teb68jjgrg38f0kg
Management cluster created!
You can now create your first workload cluster by running the following:
tkg create cluster [name] --kubernetes-version=[version] --plan=[plan]
</code></pre></div></div>
<p>At this point we can create workload clusters.</p>
<h2 id="create-workload-clusters">Create Workload Clusters</h2>
<p>Let’s create a workload cluster.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>tkg create cluster workload-01 --plan=dev
</code></pre></div></div>
<p>eg. output looks like:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ tkg create cluster workload-01 --plan=dev
Logs of the command execution can also be found at: /tmp/tkg-20201125T132139302956804.log
Validating configuration...
Creating workload cluster 'workload-01'...
Waiting for cluster to be initialized...
Waiting for cluster nodes to be available...
Waiting for addons installation...
Workload cluster 'workload-01' created
</code></pre></div></div>
<p>Boom! Workload cluster done. That workload cluster can then be used for any Kubernetes applications.</p>
<blockquote>
<p>NOTE: Use <code class="language-plaintext highlighter-rouge">tkg get credentials workload-01</code> to obtain Kubernetes credentials for the workload cluster.</p>
</blockquote>
<h2 id="conclusion">Conclusion</h2>
<p>At this point we have two clusters, one management, and one workload, and this was all done with a few commands. While the IaaS object configuration will look slightly different in each IaaS, the use of TKG will be the same though all.</p>
<blockquote>
<p>Notice how we have Kubernets 1.19!</p>
</blockquote>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ tkg get clusters --include-management-cluster
NAME NAMESPACE STATUS CONTROLPLANE WORKERS KUBERNETES ROLES
workload-01 default running 1/1 1/1 v1.19.1+vmware.2 <none>
tkg-mgmt tkg-system running 1/1 1/1 v1.19.1+vmware.2 management
</code></pre></div></div>
<p>At first glance, the bootstrapping process can seem a bit complex, but it’s only because we are using Kubernetes to bootstrap Kubernetes via Cluster API. When you view it through the lens of using Kubernetes constructs where ever possible with the product, it makes sense. Instead of building a separate bootstrapping installer, we use Cluster API, an open source Kubernetes project, the same that is used to build workload clusters. Why re-invent the wheel.</p>
<p>Using TKG gets you the ability to manage the same kubernetes in the same way across many infrastructure as as service products. If multicloud capability is a goal for your organization, then TKG can definitely get you there in terms of Kubernetes. So TKG lets you bootstrap Cluster API onto several common IaaS solutions, thus abstracting away the underlying IaaS. And, of course, it provides life cycle management of Kubernetes clusters.</p>
Merge Kubernetes Config Files2020-11-06T00:00:00+00:00http://serverascode.com/2020/11/06/merge-kubeconfigs<h1 id="merge-kubernetes-config-files">Merge Kubernetes Config Files</h1>
<p>Weirdly there aren’t a lot of examples of merging Kubeconfigs, I always end up on stackoverflow.</p>
<p>Basically we use a env var to have multiple kubeconfigs set, the new standalone kube config and ~/.kube/config and merge them with –flatten.</p>
<p>Here are the few CLI steps.</p>
<p>First, make a copy of your kube config.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ cp ~/.kube/config ./kubeconfig-backup
</code></pre></div></div>
<p>Next, setup a variable, <code class="language-plaintext highlighter-rouge">KUBECONFIG</code>, to point to both the config files and run <code class="language-plaintext highlighter-rouge">kubectl config view --flatten</code>, piping the output to a new file. Here I’m use the file name <code class="language-plaintext highlighter-rouge">new-standalone.kubeconfig</code> but your file name will be different, so change that.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ KUBECONFIG=./kubeconfig-backup:./new-standalone.kubeconfig kubectl config view --flatten > new-kube-config
</code></pre></div></div>
<p>Copy the new config file created to <code class="language-plaintext highlighter-rouge">~/.kube/config</code>. Note that this over writes your existing config file, but for now you still have the backup copy that we created above.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ cp new-kube-config ~/.kube/config
</code></pre></div></div>
<p>Validate that your config is working.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ kubectl config get-contexts
</code></pre></div></div>
<p>Finally, if you are sure that your new config is good, remove the copy.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ rm ./kubeconfig-backup
</code></pre></div></div>
<p>That’s it!</p>
Upgrade Tanzu Kubernetes Grid Multicloud 1.1.3 to 1.22020-11-04T00:00:00+00:00http://serverascode.com/2020/11/04/upgrade-tkg-multicloud<h1 id="upgrade-tanzu-kubernetes-grid-multicloud-113-to-12">Upgrade Tanzu Kubernetes Grid Multicloud 1.1.3 to 1.2</h1>
<p>This is just a quick example of upgrading <a href="https://docs.vmware.com/en/VMware-Tanzu-Kubernetes-Grid/index.html">Tanzu Kubernetes Grid (multicloud)</a> 1.1.3 to 1.2. In this example, TKGm is running on vSphere.</p>
<p>For those not familiar, TKG:</p>
<blockquote>
<p>provides a consistent, upstream-compatible implementation of Kubernetes, that is tested, signed, and supported by VMware. Tanzu Kubernetes Grid is central to many of the offerings in the VMware Tanzu portfolio.</p>
</blockquote>
<p>TKGm, as I call it, can be deployed into various public clouds, more all the time, and provides the same Kubernetes no matter where it is deployed. 1.2 supports vSphere, Azure, and AWS as host infrastructure, and more will be added over time.</p>
<h2 id="whats-new-in-12">What’s new in 1.2?</h2>
<ul>
<li>Moving from a separate loadbalancer to kube-vip</li>
<li>New default CNI: Antrea</li>
<li>Addition of Harbor as a shared service</li>
<li>Backup and restore management clusters with Velero</li>
</ul>
<p>And more!</p>
<h2 id="upgrade-from-113-to-12-on-vsphere">Upgrade from 1.1.3 to 1.2 (on vSphere)</h2>
<p>The <a href="https://docs.vmware.com/en/VMware-Tanzu-Kubernetes-Grid/1.2/vmware-tanzu-kubernetes-grid-12/GUID-upgrade-tkg-management-cluster.html">documentation</a> for this process is great, and I’m mostly just repeating what it shows. Best to follow those docs, but sometimes having an example is nice.</p>
<p>Initially I have the tkg 1.1.3 CLI.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ tkg version
Client:
Version: v1.1.3
Git commit: 0e8e58f3363a1d4b4063b9641f44a3172f6ff406
</code></pre></div></div>
<p>I’m just running one management and one workload cluster.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ tkg get cluster --include-management-cluster
NAME NAMESPACE STATUS CONTROLPLANE WORKERS KUBERNETES ROLES
my-cluster default running 1/1 2/2 v1.18.6+vmware.1 <none>
tkg-mgmt tkg-system running 1/1 1/1 v1.18.6+vmware.1 <none>
</code></pre></div></div>
<p>So the first step is to download the new 1.2 CLI as well as three OVAs. These artifacts are all downloaded from <a href="https://my.vmware.com">VMware</a>.</p>
<ul>
<li>
<p>Install the new CLI first.</p>
</li>
<li>
<p>Next, upload the three OVAs into vSphere and mark them as templates.</p>
</li>
</ul>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>Kubernetes v1.19.1: Photon v3 Kubernetes v1.19.1 OVA
Kubernetes v1.18.8: Photon v3 Kubernetes v1.18.8 OVA
Kubernetes v1.17.11: Photon v3 Kubernetes v1.17.11 OVA
</code></pre></div></div>
<p>First we upgrade the management cluster.</p>
<ul>
<li>I’m conservative so I copied the old config files first.</li>
</ul>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ cp -rp ~/.tkg/ ~/.tkg-pre-1.2-upgrade
</code></pre></div></div>
<ul>
<li>List the management cluster.</li>
</ul>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ tkg get management-cluster
It seems that the TKG settings on this system are out-of-date. Proceeding on this command will cause them to be backed up and overwritten by the latest settings.
Do you want to continue? [y/N]: y
the old providers folder /home/ubuntu/.tkg/providers is backed up to /home/ubuntu/.tkg/providers-20201102220133-xryjaxet
The old bom folder /home/ubuntu/.tkg/bom is backed up to /home/ubuntu/.tkg/bom-20201102220133-sk8je1f4
MANAGEMENT-CLUSTER-NAME CONTEXT-NAME STATUS
tkg-mgmt * tkg-mgmt-admin@tkg-mgmt Success
</code></pre></div></div>
<ul>
<li>Make sure to be using the mgmt cluster context.</li>
</ul>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ kubectl config use-context tkg-mgmt-admin@tkg-mgmt
Switched to context "tkg-mgmt-admin@tkg-mgmt".
</code></pre></div></div>
<ul>
<li>Add labels (new in 1.2):</li>
</ul>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ kubectl label -n tkg-system cluster.cluster.x-k8s.io/tkg-mgmt cluster-role.tkg.tanzu.vmware.com/management="" --overwrite=true
cluster.cluster.x-k8s.io/tkg-mgmt labeled
</code></pre></div></div>
<ul>
<li>Run the upgrade of the mgmt cluster.</li>
</ul>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ tkg upgrade management-cluster tkg-mgmt
SNIP!
Patching MachineDeployment with the kubernetes version v1.19.1+vmware.2...
Waiting for kubernetes version to be updated for worker nodes...
Management cluster 'tkg-mgmt' successfully upgraded to TKG version 'v1.2.0' with kubernetes version 'v1.19.1+vmware.2'
</code></pre></div></div>
<ul>
<li>Now the mgmt cluster has been upgraded.</li>
</ul>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ tkg get cluster --include-management-cluster
NAME NAMESPACE STATUS CONTROLPLANE WORKERS KUBERNETES ROLES
my-cluster default running 1/1 2/2 v1.18.6+vmware.1 <none>
tkg-mgmt tkg-system running 1/1 1/1 v1.19.1+vmware.2 management
</code></pre></div></div>
<ul>
<li>Can list the k8s versions. Note 1.19! Nice.</li>
</ul>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ tkg get kubernetesversions
VERSIONS
v1.17.11+vmware.1
v1.17.3+vmware.2
v1.17.6+vmware.1
v1.17.9+vmware.1
v1.18.2+vmware.1
v1.18.3+vmware.1
v1.18.6+vmware.1
v1.18.8+vmware.1
v1.19.1+vmware.2
</code></pre></div></div>
<ul>
<li>Finally, upgrade the workload cluster.</li>
</ul>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ tkg upgrade cluster my-cluster
Logs of the command execution can also be found at: /tmp/tkg-20201102T223108680260342.log
Upgrading workload cluster 'my-cluster' to kubernetes version 'v1.19.1+vmware.2'. Are you sure? [y/N]: y
Validating configuration...
Verifying kubernetes version...
Retrieving configuration for upgrade cluster...
Create InfrastructureTemplate for upgrade...
Upgrading control plane nodes...
Patching KubeadmControlPlane with the kubernetes version v1.19.1+vmware.2...
Waiting for kubernetes version to be updated for control plane nodes
Upgrading worker nodes...
Patching MachineDeployment with the kubernetes version v1.19.1+vmware.2...
Waiting for kubernetes version to be updated for worker nodes...
Cluster 'my-cluster' successfully upgraded to kubernetes version 'v1.19.1+vmware.2'
</code></pre></div></div>
<p>Well, that was pretty easy.</p>
<h2 id="optional-create-a-new-cluster">OPTIONAL: Create a New Cluster</h2>
<p>Here I create a new cluster. Note the use of the <code class="language-plaintext highlighter-rouge">--vsphere-controlplane-endpoint-ip</code> which is available in 1.2 so you can set the k8s API IP address and presumably pre-set the DNS entry for your end users.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>tkg create cluster --plan dev 1-2-cluster --vsphere-controlplane-endpoint-ip 10.0.6.10
Logs of the command execution can also be found at: /tmp/tkg-20201103T173324591159647.log
Validating configuration...
Creating workload cluster '1-2-cluster'...
Waiting for cluster to be initialized...
Waiting for cluster nodes to be available...
Waiting for addons installation...
Workload cluster '1-2-cluster' created
</code></pre></div></div>
<p>That’s it!</p>
<h2 id="vsphere_template-issue">VSPHERE_TEMPLATE Issue</h2>
<p>Due to the way I had originally deployed TKGm, I had set the <code class="language-plaintext highlighter-rouge">VSPHERE_TEMPLATE</code> in the TKG config file and to deploy a new 1.2 cluster I needed to comment that out. Most users won’t have this set AFAIK, and it’s a simple config file change.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ tkg create cluster --plan dev 1-2-cluster --vsphere-controlplane-endpoint-ip 10.0.6.10
Logs of the command execution can also be found at: /tmp/tkg-20201103T172950440339415.log
Validating configuration...
Error: : workload cluster configuration validation failed: vSphere config validation failed: vSphere template kubernetes version validation failed: unable to get or validate VSPHERE_TEMPLATE for given k8s version: incorrect VSPHERE_TEMPLATE (/Datacenter/vm/photon-3-kube-v1.18.6_vmware.1) specified for Kubernetes version (v1.19.1+vmware.2). TKG CLI will autodetect the correct VM template to use, so VSPHERE_TEMPLATE should be removed unless required to disambiguate among multiple matching templates
Detailed log about the failure can be found at: /tmp/tkg-20201103T172950440339415.log
</code></pre></div></div>
<p>Commented out the option:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ grep -i template ~/.tkg/config.yaml
VSPHERE_HAPROXY_TEMPLATE: /Datacenter/vm/photon-3-haproxy-v1.2.4-vmware.1
# VSPHERE_TEMPLATE will be autodetected based on the kubernetes version. Please use VSPHERE_TEMPLATE only to override this behavior
#VSPHERE_TEMPLATE: /Datacenter/vm/photon-3-kube-v1.18.6_vmware.1
</code></pre></div></div>
Deploy Harbor with Helm2020-10-03T00:00:00+00:00http://serverascode.com/2020/10/03/deploy-harbor-with-helm<h1 id="deploy-harbor-with-helm">Deploy Harbor with Helm</h1>
<p>I’ve put together a demo/workshop/lab/what-have-you for deploying Harbor to Kubernetes with Helm. There’s also a video below that goes through all the steps, showing deploying a Tanzu Kubernetes Grid workload cluster via vSphere with Tanzu, and using the Tanzu Application Catalog to consume a Harbor Helm Chart.</p>
<p>The idea with this demo is to provide a starting place to build up a production deployment of Harbor via Helm.</p>
<p>That said, any Kubernetes cluster should be fine, as long as it has load balancer and persistent volume capability.</p>
<ul>
<li>Git repo with documentation <a href="https://github.com/ccollicutt/harbor-demos">deploying Harbor with Helm</a></li>
</ul>
<p>Here’s a couple links to vSphere with Tanzu and the Tanzu Application Catalog which were used as the Kubernetes and Helm chart provider respectively.</p>
<ul>
<li><a href="https://tanzu.vmware.com/kubernetes-grid">vSphere with Tanzu</a></li>
<li><a href="https://tanzu.vmware.com/application-catalog">Tanzu Application Catalog</a></li>
</ul>
Use a Github Personal Access Token with the Concourse CI/CD System2020-08-17T00:00:00+00:00http://serverascode.com/2020/08/17/personal-access-token-concourse<h1 id="use-a-github-personal-access-token-with-the-concourse-cicd-system">Use a Github Personal Access Token with the Concourse CI/CD System</h1>
<p>It’s actually pretty easy, but I don’t see many examples of setting it up online.</p>
<p>First, you need a Gitub Personal Access Token configured.</p>
<p>Next, here’s the github resource. I’m using a forked <a href="https://github.com/spring-projects/spring-petclinic">Spring Petclinic</a> as an example repository, which comes from a variable, as well as the access token. Note the use of <code class="language-plaintext highlighter-rouge">password: x-oauth-basic</code>.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>resources:
- name: spring-petclinic
type: git
source:
uri: ((spring-petclinic-repo-uri))
icon: github
branch: main
username: ((github-apptoken))
password: x-oauth-basic
</code></pre></div></div>
<p>This is the credentials file:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>spring-petclinic-repo-uri: https://github.com/ccollicutt/spring-petclinic.git
github-apptoken: YOUR_GITHUB_TOKEN
</code></pre></div></div>
<p>That’s it!</p>
Remove Recent Commits from a Git Repo2020-08-12T00:00:00+00:00http://serverascode.com/2020/08/12/remove-the-last-few-git-commits<h1 id="remove-recent-commits-from-a-git-repo">Remove Recent Commits from a Git Repo</h1>
<p>I’ve been building a workshop that uses the <a href="https://github.com/spring-projects/spring-petclinic">Spring Petclinic</a> example application.</p>
<p>I’ve made two commits updating the welcome message, and I’ve pushed those commits to a repo in github, but now I want to remove them.</p>
<p>Here are the commits:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ git log
commit 9fec5226ec3dbc900bf3939c10f7f5e2b3c5ee94 (HEAD -> main, origin/main, origin/HEAD)
Author: curtis <curtis@serverascode.com>
Date: Tue Aug 11 21:30:01 2020 -0400
update welcome
commit 405d7567681871bd04439c2f49e13f96a0816d27
Author: curtis <curtis@serverascode.com>
Date: Tue Aug 11 21:20:01 2020 -0400
change welcome message
commit c42f95980a943634106e7584575c053265906978
Author: Martin Lippert <mlippert@gmail.com>
Date: Wed Jul 29 16:43:31 2020 +0200
remove push-to-pws button from guide, since pws free trials end
commit 02cc84223b296e7b401cdba74905b2e18a87e51e
Author: Stephane Nicoll <snicoll@pivotal.io>
Date: Sat Jul 11 08:57:33 2020 +0200
Polish
SNIP!
</code></pre></div></div>
<p>As you can see above there are two commits, 9fec5226ec3dbc900bf3939c10f7f5e2b3c5ee94 and 405d7567681871bd04439c2f49e13f96a0816d27 and I want to remove them from the remote repo.</p>
<p>It’s actually quite easy! I’m going to reset to the commit prior to my two commits, c42f95980a943634106e7584575c053265906978.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ git reset --hard c42f95980a943634106e7584575c053265906978
HEAD is now at c42f959 remove push-to-pws button from guide, since pws free trials end
</code></pre></div></div>
<p>Now git log shows…</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ git log
commit c42f95980a943634106e7584575c053265906978 (HEAD -> main)
Author: Martin Lippert <mlippert@gmail.com>
Date: Wed Jul 29 16:43:31 2020 +0200
remove push-to-pws button from guide, since pws free trials end
commit 02cc84223b296e7b401cdba74905b2e18a87e51e
Author: Stephane Nicoll <snicoll@pivotal.io>
Date: Sat Jul 11 08:57:33 2020 +0200
Polish
commit 5ad6bc3ccde1c61379d751f0751a1731114761af
Author: Stephane Nicoll <snicoll@pivotal.io>
Date: Sat Jul 11 08:56:32 2020 +0200
Upgrade to spring javaformat 0.0.22
SNIP!
</code></pre></div></div>
<p>And force push:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ git push --force
Total 0 (delta 0), reused 0 (delta 0)
To github.com:ccollicutt/spring-petclinic.git
+ 9fec522...c42f959 main -> main (forced update)
</code></pre></div></div>
<p>Done!</p>
Quick Look at the Tanzu Build Service2020-08-06T00:00:00+00:00http://serverascode.com/2020/08/06/tanzu-build-service<h1 id="quick-look-at-the-tanzu-build-service">Quick Look at the Tanzu Build Service</h1>
<p>Building container images isn’t easy. Dockerfiles make it look easy, but it’s not. Not in the real world anyways. Container image security is hard. Managing dependencies is hard. Building pipelines (good ones)…is hard. Building pipelines on your own to do the same thing that everyone deploying apps on Kubernetes has to do–i.e. build images–likely doesn’t make (business) sense. Why build it on your own with bash and CI/CD systems when you can use something like kpack or the Tanzu Build Service…and make it declarative ala Kubernetes (you know, the thing you are actually deploying the app to).</p>
<p><em>Aside: I use the term pipelines all the time, but often CI/CD pipelines are just poorly tested bash spaghetti code that ties together a few actions in a row. See my homelab automation haha. That sounds harsh, but it’s fair to say that the quality level of pipeline code is a wide, wide spectrum. And, of course, is usually not declarative.</em></p>
<h2 id="tanzu-build-service">Tanzu Build Service</h2>
<p>Tanzu Build Service (TBS) helps with automating image creation, as well as using buildpacks as the base image. To quote our <a href="https://tanzu.vmware.com/build-service">Tanzu Build Service</a> site:</p>
<blockquote>
<p>Tanzu Build Service uses the magic of Cloud Native Buildpacks to rebase app images when specialized contractual base images are updated in a registry. This means you can resolve certain common vulnerabilities and exposures (CVE) without a rebuild.</p>
</blockquote>
<p>TBS uses Kubernetes CRDs.</p>
<blockquote>
<p>Tanzu Build Service follows a Kubernetes-native declarative model and executes builds automatically against user-defined configuration. It includes kpack, a set of open-source resource controllers for Kubernetes maintained by VMware Tanzu.</p>
</blockquote>
<p>It’s based on the upstream, open source tool <a href="https://github.com/pivotal/kpack">kpack</a>.</p>
<p>If you want to review the features, checkout this <a href="https://buildpacks.io/features/">page</a>.</p>
<h2 id="how-to-get-the-tanzu-build-service">How to Get the Tanzu Build Service</h2>
<p>As of today, TBS is not GA (generally available) but if you sign up for the <a href="https://network.pivotal.io/">Tanzu Network</a> you can download the 0.2 non-GA release.</p>
<h2 id="install">Install</h2>
<p>I’m not going to go over the install as it currently uses Duffle. There’s a great <a href="https://tanzu.vmware.com/content/practitioners/getting-started-with-vmware-tanzu-build-service-0-2-0-beta">blog post</a> that covers the Duffle-based install, configuring git repos, credentials, ect. This is exactly what I followed for this blog post.</p>
<p>In my case, I’m using Docker Hub as the image repository, but I have a local Gitlab install that I’m pulling code from. That said TBS can use most any image registry or git server.</p>
<h2 id="build-an-image">Build an Image</h2>
<p>I’ve gone ahead and installed TBS. Now that it’s installed, we have several CRDs available.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ k get crd | grep pivotal
builders.build.pivotal.io 2020-08-04T19:50:47Z
builds.build.pivotal.io 2020-08-04T19:50:47Z
clusterbuilders.build.pivotal.io 2020-08-04T19:50:47Z
custombuilders.experimental.kpack.pivotal.io 2020-08-04T19:50:47Z
customclusterbuilders.experimental.kpack.pivotal.io 2020-08-04T19:50:47Z
images.build.pivotal.io 2020-08-04T19:50:47Z
sourceresolvers.build.pivotal.io 2020-08-04T19:50:47Z
stacks.experimental.kpack.pivotal.io 2020-08-04T19:50:47Z
stores.experimental.kpack.pivotal.io 2020-08-04T19:50:47Z
</code></pre></div></div>
<p>I’ve already built an image based on the Spring Petclinic code.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ k get img
NAME LATESTIMAGE READY
spring-petclinic index.docker.io/ccollicutttanzu/spring-petclinic@sha256:994c9fb87f591c734a86c2a8d18ca4f0beb339ee9cbe1e6ae19c989b541fd773 True
</code></pre></div></div>
<p>TBS comes with a CLI called kp.</p>
<p>To create an image:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>kp image create spring-petclinic ccollicutttanzu/spring-petclinic --git git@gitlab.example.com:root/test-project.git
</code></pre></div></div>
<p>I’ve built it a few times already.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ kp build list spring-petclinic
BUILD STATUS IMAGE STARTED FINISHED REASON
SNIP!
6 SUCCESS index.docker.io/ccollicutttanzu/spring-petclinic@sha256:eaed806fb9027a1b12d507464faab637afe92e76e3f995cb318a55275b3f9fa4 2020-08-06 10:00:51 2020-08-06 10:21:28 TRIGGER
7 SUCCESS index.docker.io/ccollicutttanzu/spring-petclinic@sha256:994c9fb87f591c734a86c2a8d18ca4f0beb339ee9cbe1e6ae19c989b541fd773 2020-08-06 10:59:25 2020-08-06 11:03:47 COMMIT
</code></pre></div></div>
<p>For build 6 I triggered it manually with the kp CLI.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>kp image trigger spring-petclinic
</code></pre></div></div>
<p>For build 7 I simply committed a change to the Spring Petclinic git repo (my git repo) and TBS noticed the commit and built the new image. So on every commit you’ll get a new image. Of course that sounds like a lot, but most organizations would have some kind of production branch, maybe it’s main, and code only makes it to that branch once it’s tested.</p>
<p>Now that you have an image, you could use some kind of gitops workflow to deploy based on that new image, and you could use something like the <a href="https://github.com/k14s/kapp-controller">kapp-controller</a> to automate that.</p>
<p>Here’s a snippet from the build logs.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ kp build logs spring-petclinic -b 7 -n build-service | tail -20
Reusing layer 'launcher'
Reusing layer 'paketo-buildpacks/bellsoft-liberica:class-counter'
Reusing layer 'paketo-buildpacks/bellsoft-liberica:java-security-properties'
Reusing layer 'paketo-buildpacks/bellsoft-liberica:jre'
Reusing layer 'paketo-buildpacks/bellsoft-liberica:jvmkill'
Reusing layer 'paketo-buildpacks/bellsoft-liberica:link-local-dns'
Reusing layer 'paketo-buildpacks/bellsoft-liberica:memory-calculator'
Reusing layer 'paketo-buildpacks/bellsoft-liberica:openssl-security-provider'
Reusing layer 'paketo-buildpacks/bellsoft-liberica:security-providers-configurer'
Reusing layer 'paketo-buildpacks/executable-jar:class-path'
Adding 1/1 app layer(s)
Adding layer 'config'
*** Images (sha256:994c9fb87f591c734a86c2a8d18ca4f0beb339ee9cbe1e6ae19c989b541fd773):
ccollicutttanzu/spring-petclinic
index.docker.io/ccollicutttanzu/spring-petclinic:b7.20200806.145925
Reusing cache layer 'paketo-buildpacks/bellsoft-liberica:jdk'
Adding cache layer 'paketo-buildpacks/maven:application'
Reusing cache layer 'paketo-buildpacks/maven:cache'
===> COMPLETION
Build successful
</code></pre></div></div>
<p>Above you can see <a href="https://buildpacks.io/">buildpacks</a> in use by TBS to create the container image.</p>
<h2 id="conclusion">Conclusion</h2>
<p>This is just a quick example of TBS. While this looks very simple, and sometimes simple things look like they have no value, I can assure you there are a lot of things happening in the background, and without something like TBS organizations are typically left on their own to build it, and often fail, or only partially succeed.</p>
vSphere 7 with Kubernetes and NSXT 3.02020-07-20T00:00:00+00:00http://serverascode.com/2020/07/20/vsphere-7-with-kubernetes-nsxt-3<h1 id="vsphere-7-with-kubernetes-and-nsxt-30">vSphere 7 with Kubernetes and NSXT 3.0</h1>
<p>Kuberenetes is a commodity. There I said it. Sure, I work in the <a href="https://tanzu.vmware.com/">Tanzu business unit of VMware</a>, and we heavily value Kubernetes, as does VMware overall. VMware is a massive contributor to upstream Kubernetes–see <a href="https://github.com/kubernetes-sigs/cluster-api">Cluster API</a> for example, and, well, there’s the whole Kubernetes-built-into-vsphere thing. But we are also very interested in what happens AFTER you have Kubernetes.</p>
<p>At VMware we make it easy to get Kubernetes dial tone so that you can get to the good stuff, the important stuff: deploying applications. Dial tone is the easy part, writing new apps quickly and getting them running in production…that’s hard. With that said, the majority of Tanzu’s focus is on what you do <em>after</em> you have Kubernetes, and of course getting apps in production.</p>
<p>But, let’s talk about the dial tone here, and especially NSXT 3.0.</p>
<h2 id="getting-kubernetes-up-and-running-in-vsphere-7">Getting Kubernetes up and running in vSphere 7</h2>
<p>There are many great blog posts on the matter:</p>
<ul>
<li><a href="https://blog.acepod.com/tanzu-vsphere-7-with-kubernetes-on-nsx-t-3-0-vds-install-part-1-overview/">Tanzu vSphere 7 with Kubernetes on NSX-T 3.0 VDS Install Part 1: Overview</a></li>
<li><a href="https://www.viktorious.nl/2020/06/30/deploy-a-tanzu-kubernetes-cluster-on-vsphere-7/">Deploy a Tanzu Kubernetes cluster on vSphere 7</a></li>
<li><a href="https://www.viktorious.nl/2020/06/30/deploy-a-tanzu-kubernetes-cluster-on-vsphere-7/">Automated vSphere 7 and vSphere with Kubernetes Lab Deployment Script</a></li>
<li><a href="http://www.boche.net/blog/2020/05/17/vsphere-with-kubernetes/">vSphere with Kubernetes</a></li>
</ul>
<p>Any one of those will get you up and running. This post is my version of the above. That said, likely there is not quite enough here to get you completley up and running, but it will certainly provide you some direction.</p>
<ul>
<li>This is also a great post on <a href="https://beyondelastic.com/2020/07/17/verify-and-troubleshoot-vsphere-7-with-kubernetes/">troubleshooting</a></li>
</ul>
<h2 id="networking">Networking</h2>
<p>To enable “Workload Management” in vSphere 7 (aka Kubernetes) NSXT is required. Designing networks is not easy, and there are many paths that can be taken, but I’ll describe my overly simplified lab/PoC style path and you can diverge from it where ever you feel necessary.</p>
<p>I still have two nics in these ESXi hosts, I’ve left the various management interfaces, vmotion, storage, ect, on one nic and everything else, i.e. NSXT, on the other, though it’s not strictly necessary, and the advantages of NSXT would probably be better displayed with a single interface…but I’m too lazy to change it! Suffice it to say you can use a single nic now, which is great for PoC and lab work.</p>
<h3 id="virtual-switches">Virtual Switches</h3>
<p>One of the biggest changes to networking with NSXT 3.0 and vSphere 7 is that VDS can be used by NSXT, instead of having to hand over a physical nic completely to NSX. This makes deployment a lot simpler!</p>
<blockquote>
<p>With the release of vSphere 7 comes the vSphere Distributed Switch 7.0. This latest version comes with support for NSX-T Distributed Port Groups. Now, for the first time ever it is possible to use a single vSphere Distributed Switch for both NSX-T 3.0 and vSphere 7 networking! - <a href="https://rutgerblom.com/2020/04/08/nsx-t-3-0-meets-vsphere-7-vds-7-0/">Rutger Blom</a></p>
</blockquote>
<p>In a <a href="https://serverascode.com/2020/07/03/nsxt-design-1.html">previous post</a> I diagrammed a simple NSXT VDS and NVDS layout, shown below. This design has separate VDS and NVDS switches as well as a full nic provided to NSXT. (Right click and view image if you want to see it larger.)</p>
<p><img src="/img/nsx-design-1.jpg" alt="dual nvds layout with vds" /></p>
<p>For vSphere 7 and NSXT 3.0, it looks like the below. Note that in this setup we’ve got separate VLANs for the “Edge TEP” and the “Host TEP” but they have to be able to connect to one another at layer 3. So, now we need to have a MTU >=1600 on the VLANs, but also the router needs to be able to route packets >=1600 (but only between the Edge and Hosts TEP). Very important.</p>
<p><img src="/img/v7wk8s-subnets-and-routing.jpg" alt="nsx 3 subnet and routing" /></p>
<p>Wondering why we have two TEP networks? Here’s why:</p>
<blockquote>
<p>You probably thinking why is there a need for a 2nd network specifically for Edge VMs. The reason is because we are using only 1 Physical NIC and therefore in order to “force” the Geneve TEP traffic egressing from the Edge VM to pass through the Physical NIC as the traffic would require routing when communicating with the ESXi hosts Geneve TEP interfaces. - <a href="https://blog.acepod.com/tanzu-vsphere-7-with-kubernetes-on-nsx-t-3-0-vds-install-part-1-overview/">Acepod blog</a></p>
</blockquote>
<p>Here’s a list of NSX switches, er, well, “switch”.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>[root@nested-esxi7-2:~] nsxdp-cli vswitch instance list
DvsPortset-1 (DNSX) 50 0e 6d 8d 5b b6 35 9c-b5 af c9 18 f5 76 b4 a9
Total Ports:4096 Available:4080
Client PortID DVPortID MAC Uplink
Management 100663301 00:00:00:00:00:00 n/a
vmnic0 2248146952 8 00:00:00:00:00:00
Shadow of vmnic0 100663305 00:50:56:52:bd:fe n/a
vmk10 100663307 739a47e2-3c93-483f-ac4d-df039cfd559d 00:50:56:6a:06:11 vmnic0
vmk50 100663308 40335d75-be5f-41f8-a5d5-5e4be4f9e996 00:50:56:66:71:7d void
vdr-vdrPort 100663309 vdrPort 02:50:56:56:44:52 vmnic0
nsx-edge-1.eth2 100663310 19 00:50:56:8e:b5:2a vmnic0
nsx-edge-1.eth1 100663311 36 00:50:56:8e:9a:7d vmnic0
SupervisorControlPlaneVM 100663314 69576165-6ade-491f-a429-999655c87028 00:50:56:8e:b9:69 vmnic0
(2).eth0
SupervisorControlPlaneVM 100663315 f6fba7ac-e04b-4d7e-9f71-0aa07886c83f 04:50:56:00:c8:01 vmnic0
(2).eth1
</code></pre></div></div>
<p>Note just the one VDS, which I’ve called “DNSX” in my deployment.</p>
<h2 id="subnetting-and-layer-3-routing">Subnetting and Layer 3 Routing</h2>
<p>I am not the worlds greatest authority on networking. But one thing I think that I do that helps me to understand networking is separate broadcast domains from subnetting. A VLAN or a “segment” or a “logical switch”…these things are all about broadcast domains. What IPs are put onto those broadcast domains are completely separate items. Often people get quite confused and conflate the two.</p>
<blockquote>
<p>A broadcast domain is a logical division of a computer network, in which all nodes can reach each other by broadcast at the data link layer. - <a href="https://www.cbtnuggets.com/blog/technology/networking/networking-basics-what-are-broadcast-domains">CBTNuggets</a></p>
</blockquote>
<p>So, as far as I’m concerned, in the NVDS/VDS layout diagram we’re really assigning network interfaces and applying broadcast domains to them. After we do that THEN we can decide what subnets will be assigned where, and, as well, think about layer 3 routing for t0, though that is relatively easy when using a simple static route to forward the networks handled by NSXT (in my lab, I give it a huge /16, haha).</p>
<p>Here’s the nice topology visualization NSXT provides, and this topology occurs AFTER the Workload Control Plane (WCP) is deployed, as well as a Tanzu Kubernetes Grid cluster.</p>
<p><img src="/img/v7wk8s-nsx-topology.png" alt="nsx topology" /></p>
<p>Here’s the subnets configured for WCP, which are entered initially during the “WCP Enable” wizard. The routable ingress and egress networks will be created by the enablement process, and, if using static routing, should be forwarded from the central network to the t0 router.</p>
<p><img src="/img/v7wk8s-wcp-networking.png" alt="wcp configuration of subnets" /></p>
<p>Not routable:</p>
<ul>
<li>Pod CIDRs = 10.244.0.0/21</li>
<li>Services CIDR = 10.96.0.0/24</li>
</ul>
<p>Routable:</p>
<ul>
<li>Ingress CIDRs (load balancing) = 10.4.3.0/24</li>
<li>Egress CIDRs (NAT) = 10.4.4.0/24</li>
</ul>
<h2 id="nsxt-configuration">NSXT Configuration</h2>
<p>Ultimately, NSXT configuration is about setting up some profiles and applying them to edge VMs and ESXI hosts.</p>
<h3 id="host-transport-node-profile">Host Transport Node Profile</h3>
<p>Note how the switch in use is VDS, not NVDS.</p>
<p><img src="/img/v7wk8s-tn-profile.png" alt="img" /></p>
<h3 id="uplink-profiles">Uplink Profiles</h3>
<p>Host uplink:</p>
<p><img src="/img/v7wk8s-tn-profile-2.png" alt="img" /></p>
<p>Edge uplink:</p>
<p><img src="/img/v7wk8s-edge-profile.png" alt="img" /></p>
<h2 id="conclusion">Conclusion</h2>
<p>I’ve left out quite a bit about the actual clicking to install NSXT and vSphere 7 with Kubernetes. But at the end, what I’m most interested in is how the networking is laid out. The rest o the work to enable Kubernetes in vSphere 7 is quite straight forward, such as setting up the Kubernetes content library, creating a storage policy, etc. Once the network is up and running, it’s very, very easy to get WCP enabled and get access to the ability to deploy your own Tanzu Kubernetes Grid clusters.</p>
Simple NSX-T Design - Dual N-VDS and Edge VM on VDS2020-07-03T00:00:00+00:00http://serverascode.com/2020/07/03/nsxt-design-1<h1 id="simple-nsx-t-design---dual-n-vds-and-edge-vm-on-vds">Simple NSX-T Design - Dual N-VDS and Edge VM on VDS</h1>
<p>There are a few different ways to “design” an NSX-T deployment. Mostly I think about what VLANs, virtual switches, and physical NICs are available and what gets assigned where.</p>
<p>Please note the inspiration for the diagram and design come from this <a href="https://www.ovnetworks.com/2019/12/nsx-t-edge-vm-design-single-n-vds-edge.html">great site</a>. I loved the layout of the diagram, so it is a huge influence for the image above (though I completely recreated and adapted it as a Power Point slide of all things).</p>
<h2 id="design-dual-n-vds-edge-vm-on-vds-four-physical-nics-default-nsx-t-profiles-and-tep-on-access-ports">Design: Dual N-vDS, Edge VM on VDS, Four Physical Nics, Default NSX-T Profiles, and TEP on Access Ports</h2>
<p>That’s quite a mouthful, but it is what it is. This particular design consists of the following:</p>
<ul>
<li>Dual N-vDS: one for the overlay and one for the uplink</li>
<li>Four physical network interfaces: two for VDS and two for NSX-T</li>
<li>The NSX-T Edge VM is on vSphere VDS provided interfaces (thus VLAN 0)</li>
<li>Using the default NSX-T profiles (both using VLAN 0)</li>
<li>The Transport End Point (TEP) VLAN is on access ports for the physical NICs that make up the NSX-T managed interfaces</li>
</ul>
<p>I believe in NSX-T 2.5 you can get this down to having a single N-vDS, but then would need to put the Edge VM TEP on a separate VLAN and have traffic routable between the two, i.e. the Edge VM’s TEP interface would not be on a VDS port group, as well as some additional advantages. But I’ll try to explore that in another post. For now, I like this design because it is quite simple, and is a pretty good design for a PoC of <a href="https://tanzu.vmware.com/kubernetes-grid">Tanzu Kubernetes Grid Integrated Edition</a> (TKGI, formerly known as PKS).</p>
<p>Ultimately it’s pretty easy to create a new NSX-T profile for the ESXi hosts, a few clicks, a few seconds, and that is what most people do as the ESXi host’s TEP VLAN is often a trunk port. But in this design I’m just using an access port, so the default profile with VLAN 0 works.</p>
<h1 id="conclusion">Conclusion</h1>
<p>I haven’t created this design for production use. This is what I think is the simplest design for a proof of concept (where NSX-T isn’t the PoC focus). I would imagine a production design would look much different. Also this design works great in a nested lab.</p>
<p>Don’t forget to set your TEP VLAN MTU >=1600. Most people set it to 9k and are done with it. :)</p>
Kubernetes Tips and Tricks2020-06-02T00:00:00+00:00http://serverascode.com/2020/06/02/kubernetes-tips-and-tricks<h1 id="kubernetes-tips-and-tricks">Kubernetes Tips and Tricks</h1>
<p>A few tips and tricks I’ve come across. Starting off small!</p>
<h2 id="export-cluster-config-from-kubeconfig">Export Cluster Config from Kubeconfig</h2>
<p>Say you have a whole bunch of clusters set in your kubeconfig file and you want to extract one. Just one.</p>
<p>Set your config to that cluster (maybe use kubectx) and do:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>kubectl config view --minify --raw > cluster.kubeconfig
</code></pre></div></div>
<p>Boom!</p>
<h2 id="merge-kube-configs">Merge Kube Configs</h2>
<p>Copy your backup, set an env var pointing to the backup config and the new standalone file, and use config view with the flatten option to produce a new, merged, config file, and finally copy that file back to ~/.kube/config.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ cp ~/.kube/config ./config-backup
$ KUBECONFIG=./config-backup:./new-standalone.kubeconfig kubectl config view --flatten > new-kube-config
$ cp new-kube-config ~/.kube/config
</code></pre></div></div>
<h2 id="writing-an-operator-in-shell">Writing an Operator in Shell!</h2>
<p>See the <a href="https://github.com/flant/shell-operator">shell operator</a>. Good times!</p>
<h2 id="troubleshoot-dns">Troubleshoot DNS</h2>
<p>See this <a href="https://kubernetes.io/docs/tasks/administer-cluster/dns-debugging-resolution/">k8s doc</a></p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>kubectl apply -f https://k8s.io/examples/admin/dns/dnsutils.yaml
</code></pre></div></div>
<p>Make sure you are in the default namespace.</p>
<p>Run a dig command from the pod.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ kubectl exec -i -t dnsutils -- dig +short google.com
172.217.165.14
</code></pre></div></div>
TUF, Notary, and Harbor Registry2020-05-28T00:00:00+00:00http://serverascode.com/2020/05/28/notary-with-harbor<h1 id="tuf-notary-and-harbor-registry">TUF, Notary, and Harbor Registry</h1>
<p>If you watch this <a href="https://www.youtube.com/watch?v=Hnzc6va4l6k">video</a> by Justin Cormack, he starts it off by talking about an attack vector that is used successfully by “evil doers” time and time again…<strong>software updates</strong>. Securing software updates is complicated and can’t be solved with simple solutions, and what’s worse, when using simple solutions can make software updates ineffective. Without some kind of process/framework for managing updates, securing systems is impossible. Sure, securing software updates will require signing things digitally, most technical people get that, but that’s just one part of the solution and it’s not enough on its own.</p>
<p>That’s where <a href="https://theupdateframework.io/">TUF</a>, “The Update Framework,” comes in.</p>
<blockquote>
<p>The Update Framework (TUF) helps developers maintain the security of software update systems, providing protection even against attackers that compromise the repository or signing keys. TUF provides a flexible framework and specification that developers can adopt into any software update system.</p>
</blockquote>
<p>The <a href="https://github.com/theupdateframework/tuf/blob/develop/docs/OVERVIEW.rst">overview</a> for TUF is quite good. I don’t want to try (and fail) to reproduce that work here. So just go read it. :)</p>
<h2 id="harbor">Harbor</h2>
<p>The easiest way to describe Harbor is that it’s an image registry. But, with the <a href="https://goharbor.io/blog/harbor-2.0/">recent release of Harbor 2.0</a>, it is much more than just a simple image registry…it’s an OCI compliant registry!</p>
<blockquote>
<p>This release makes Harbor the first OCI ( Open Container Initiative)-compliant open source registry capable of storing a multitude of cloud-native artifacts like container images, Helm charts, OPAs, Singularity, and much more.</p>
</blockquote>
<p>When Harbor is deployed it can have Notary enabled.</p>
<h2 id="notary">Notary</h2>
<p>Notary is an implementation of TUF, and, like TUF, it’s a <a href="https://www.linuxfoundation.org/cloud-containers-virtualization/2017/10/cncf-host-two-security-projects-notary-tuf-specification/">CNCF project</a>.</p>
<blockquote>
<p>Notary is one of the industry’s most mature implementations of the TUF specification and its Go implementation is used today to provide robust security for container image updates, even in the face of a registry compromise. Notary takes care of the operations necessary to create, manage, and distribute the metadata needed to ensure the integrity and freshness of user content. Notary/TUF provides both a client, and a pair of server applications to host signed metadata and perform limited online signing functions.</p>
</blockquote>
<h2 id="quick-look-at-notary-and-harbor">Quick Look at Notary and Harbor</h2>
<p>I’ve got a Harbor installation setup to use. I’ve also installed the notary CLI.</p>
<p>First, I tell Docker to use content trust and point it to the Notary instance that comes with Harbor. In this case Harbor was deployed via the Helm chart, and Notary is exposed on its own hostname via ingress.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>export DOCKER_CONTENT_TRUST=1
export DOCKER_CONTENT_TRUST_SERVER=https://notary.example.com
</code></pre></div></div>
<p>Next I try to push an image. By doing this, I’ll be initializing the keys for use with Notary. I’m glossing over what is happening here, as generating these keys should have a lot of thought put around it, and they should be properly stored and themselves secured. More on this in a future post, I hope.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ docker pull alpine
$ docker tag alpine harbor.example.com/secure/alpine-signed:1.0
$ docker push harbor.example.com/secure/alpine-signed:1.0
The push refers to repository [harbor.example.com/secure/alpine-signed]
3e207b409db3: Pushed
1.0: digest: sha256:39eda93d15866957feaee28f8fc5adb545276a64147445c64992ef69804dbf01 size: 528
Signing and pushing trust metadata
You are about to create a new root signing key passphrase. This passphrase
will be used to protect the most sensitive key in your signing system. Please
choose a long, complex passphrase and be careful to keep the password and the
key file itself secure and backed up. It is highly recommended that you use a
password manager to generate the passphrase and keep it safe. There will be no
way to recover this key. You can find the key in your config directory.
Enter passphrase for new root key with ID 6b438eb:
Repeat passphrase for new root key with ID 6b438eb:
Enter passphrase for new repository key with ID aafd072:
Repeat passphrase for new repository key with ID aafd072:
Finished initializing "harbor.example.com/secure/alpine-signed"
Successfully signed harbor.example.com/secure/alpine-signed:1.0
</code></pre></div></div>
<p>This first signed image push initializes TUF. Files are created in ~/.docker/trust.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ find ~/.docker/trust/ | head
/home/ubuntu/.docker/trust/
/home/ubuntu/.docker/trust/tuf
/home/ubuntu/.docker/trust/tuf/harbor.example.com
/home/ubuntu/.docker/trust/tuf/harbor.example.com/secure
/home/ubuntu/.docker/trust/tuf/harbor.example.com/secure/alpine-signed
/home/ubuntu/.docker/trust/tuf/harbor.example.com/secure/alpine-signed/changelist
/home/ubuntu/.docker/trust/tuf/harbor.example.com/secure/alpine-signed/metadata
/home/ubuntu/.docker/trust/tuf/harbor.example.com/secure/alpine-signed/metadata/targets.json
/home/ubuntu/.docker/trust/tuf/harbor.example.com/secure/alpine-signed/metadata/root.json
/home/ubuntu/.docker/trust/tuf/docker.io
</code></pre></div></div>
<p>Using the Notary CLI we can see that image is registered.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ alias notary="notary -s https://notary.example.com -d ~/.docker/trust"
$ notary list harbor.example.com/secure/alpine-signed
Enter username: admin
Enter password:
NAME DIGEST SIZE (BYTES) ROLE
---- ------ ------------ ----
1.0 39eda93d15866957feaee28f8fc5adb545276a64147445c64992ef69804dbf01 528 targets
</code></pre></div></div>
<p>In the Harbor GUI the image is show as being signed.</p>
<p><img src="/img/harbor-tuf2.png" alt="signed image in harbor" /></p>
<p>The Harbor project we are pushing the image to has content trust enabled.</p>
<p><em>NOTE: What enabling this means is that Harbor won’t allow any images to be pulled from this repo unless they are signed.</em></p>
<p><img src="/img/harbor-tuf1.png" alt="harbor project content trust enabled" /></p>
<p>As an example, here I’m trying to pull an <strong>UNSIGNED</strong> image into a k8s cluster, which, when “content trust” is enabled in the project, Harbor will not allow.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ k describe pod alpine-unsigned-1.0 | tail
node.kubernetes.io/unreachable:NoExecute for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 48s default-scheduler Successfully assigned default/alpine-unsigned-1.0 to central-tools-md-0-5bfcdd98d9-2w5kx
Normal BackOff 21s (x3 over 47s) kubelet, central-tools-md-0-5bfcdd98d9-2w5kx Back-off pulling image "harbor.example.com/secure/alpine-unsigned:1.0"
Warning Failed 21s (x3 over 47s) kubelet, central-tools-md-0-5bfcdd98d9-2w5kx Error: ImagePullBackOff
Normal Pulling 9s (x3 over 47s) kubelet, central-tools-md-0-5bfcdd98d9-2w5kx Pulling image "harbor.example.com/secure/alpine-unsigned:1.0"
Warning Failed 9s (x3 over 47s) kubelet, central-tools-md-0-5bfcdd98d9-2w5kx Failed to pull image "harbor.example.com/secure/alpine-unsigned:1.0": rpc error: code = Unknown desc = failed to pull and unpack image "harbor.example.com/secure/alpine-unsigned:1.0": failed to copy: httpReaderSeeker: failed open: unexpected status code https://harbor.example.com/v2/secure/alpine-unsigned/manifests/sha256:39eda93d15866957feaee28f8fc5adb545276a64147445c64992ef69804dbf01: 412 Precondition Failed - Server message: unknown: The image is not signed in Notary.
Warning Failed 9s (x3 over 47s) kubelet, central-tools-md-0-5bfcdd98d9-2w5kx Error: ErrImagePull
</code></pre></div></div>
<p>Note the error message Harbor responds with:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code> 412 Precondition Failed - Server message: unknown: The image is not signed in Notary.
</code></pre></div></div>
<p>Pulling a signed image is fine, of course.</p>
<h2 id="conclusion">Conclusion</h2>
<p>Here’s a very basic example of using Notary and content trust in Harbor. To put this process into production would take a fair amount of consideration and should not be taken lightly. But if you want to quickly try out signing an image in combination with using content trust with Harbor, then it’s quite simple to do. Deploying Harbor with Helm is also <a href="http://localhost:4000/2020/04/28/local-harbor-install.html">straight forward</a> if you have a k8s cluster to use. :)</p>
Deploy Harbor with Helm and Custom CA Certs2020-05-21T00:00:00+00:00http://serverascode.com/2020/05/21/install-harbor-with-helm<h1 id="deploy-harbor-with-helm-and-custom-ca-certs">Deploy Harbor with Helm and Custom CA Certs</h1>
<p>This is just a quick post on how to use a custom CA with Helm and Harbor. I won’t show installing helm or anything like that.</p>
<p>Below are the versions deployed. Note that Harbor 2.0 has recently been released, but here we are using Harbor 1.10.2 as the helm chart hasn’t been updated.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ helm ls
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
harbor-central harbor 1 2020-05-21 07:20:04.248551864 -0700 PDT deployed harbor-1.3.2 1.10.2
</code></pre></div></div>
<p>I’m using mkcert, and I’ve generated the cert files. Note that I’m creating a cert for both the harbor and notary service.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>mkcert harbor.example.com notary.example.com
</code></pre></div></div>
<p>Now we need to create a tls secret. NOTE: “<em>tls</em>” secret not a generic secret.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>kubectl create secret tls harbor-certs \
--cert=harbor.example.com+1.pem \
--key=harbor.example.com+1-key.pem
</code></pre></div></div>
<p>Export the values file.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>helm show values harbor/harbor > harbor-values.yaml
</code></pre></div></div>
<p>And edit that file so that it knows about “harbor-certs”. E.g.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ grep -A 2 -B 2 harbor-certs harbor-values.yaml
# link on portal to download the certificate of CA
# These files will be generated automatically if the "secretName" is not set
secretName: "harbor-certs"
# By default, the Notary service will use the same cert and key as
# described above. Fill the name of secret if you want to use a
</code></pre></div></div>
<p>And deploy!</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>helm install harbor-central harbor/harbor -f harbor-values.yaml
</code></pre></div></div>
<p>There are probably several other ways to do this, but this is certainly one! Of course this CA is going to have to be distributed as well.</p>
A Week with Ubuntu 20.042020-05-18T00:00:00+00:00http://serverascode.com/2020/05/18/a-week-with-ubuntu-20-04<h1 id="a-week-with-ubuntu-2004">A Week with Ubuntu 20.04</h1>
<p>I know a lot of people like to make fun of running Linux on the desktop, and maybe it deserves the criticism that has built up year over year, like a thousand paper cuts (which never seem to heal, but I digress). I’ll be honest and say that I love running Linux as my main OS, and am much more proficient with it than any other operating system. Some people like Linux on the desktop and some don’t. That’s fine with me!</p>
<p>Because I feel like I’m going to be doing a lot more work from home, I decided it was time to get a new linux workstation/desktop. So I did. Given that Ubuntu 20.04 recently came out, I thought that sounded like a good distribution of Linux to run, and I especially liked the idea of using ZFS as the boot file system.</p>
<ul>
<li>Hardware</li>
</ul>
<p>The hardware I’m using is really entry level, but boy, does it feel faster than my mac laptop and, of course, my old circa 2012 desktop. (Amazing to have 1TB NVMe drive for $170 CDN.)</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>AMD Ryzen™ 5 3600 Processor, 3.6GHz w/ 35MB Cache
Corsair Vengeance LPX 64GB DDR4 2666MHz CL16 Dual Channel Kit (4x 16GB), Black
Western Digital Blue SN550 M.2 PCI-E NVMe SSD, 1TB
Asus TUF B450-PRO GAMING w/ DDR4-2666, 7.1 Audio, Gigabit LAN, CrossFire
</code></pre></div></div>
<p>At least with 64G of main memory I can keep some tabs open.</p>
<p>I have not seen any errors, issues, etc, with the hardware so far.</p>
<ul>
<li>ZFS</li>
</ul>
<p>When I installed 20.04 I decided vto install via the <a href="https://linuxconfig.org/install-ubuntu-20-04-with-zfs">experimental</a> use of ZFS as the boot file system. The interesting thing about ZFS here is that you can get <a href="https://www.phoronix.com/scan.php?page=news_item&px=Trying-Ubuntu-20.04-ZFS-Snaps">snapshots</a> of your OS. When a new package is added via apt a zfs snapshot will be taken. It’s possible to revert by booting from the snapshot. For example, here I install wireguard. Note the “INFO” lines regarding creating a snapshot and updating grub.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ sudo apt install wireguard
[sudo] password for curtis:
Reading package lists... Done
Building dependency tree
Reading state information... Done
The following additional packages will be installed:
wireguard-tools
The following NEW packages will be installed:
wireguard wireguard-tools
0 upgraded, 2 newly installed, 0 to remove and 0 not upgraded.
Need to get 85.3 kB of archives.
After this operation, 341 kB of additional disk space will be used.
Do you want to continue? [Y/n] y
Get:1 http://ca.archive.ubuntu.com/ubuntu focal/universe amd64 wireguard-tools amd64 1.0.20200319-1ubuntu1 [82.4 kB]
Get:2 http://ca.archive.ubuntu.com/ubuntu focal/universe amd64 wireguard all 1.0.20200319-1ubuntu1 [2,912 B]
Fetched 85.3 kB in 0s (544 kB/s)
INFO Requesting to save current system state
Successfully saved as "autozsys_hku7gp"
Selecting previously unselected package wireguard-tools.
(Reading database ... 177462 files and directories currently installed.)
Preparing to unpack .../wireguard-tools_1.0.20200319-1ubuntu1_amd64.deb ...
Unpacking wireguard-tools (1.0.20200319-1ubuntu1) ...
Selecting previously unselected package wireguard.
Preparing to unpack .../wireguard_1.0.20200319-1ubuntu1_all.deb ...
Unpacking wireguard (1.0.20200319-1ubuntu1) ...
Setting up wireguard-tools (1.0.20200319-1ubuntu1) ...
Setting up wireguard (1.0.20200319-1ubuntu1) ...
Processing triggers for man-db (2.9.1-1) ...
INFO Updating GRUB menu
</code></pre></div></div>
<p>There is a boot pool and a root pool.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ zpool list
NAME SIZE ALLOC FREE CKPOINT EXPANDSZ FRAG CAP DEDUP HEALTH ALTROOT
bpool 1.88G 260M 1.62G - - 0% 13% 1.00x ONLINE -
rpool 920G 110G 810G - - 5% 11% 1.00x ONLINE -
</code></pre></div></div>
<ul>
<li>Kubernetes in Docker</li>
</ul>
<p>I do a lot of work with k8s, and would prefer to use Kind locally, but it doesn’t work with ZFS. Minikube is fine because it runs in its own VM, which is perhaps better security-wise anyways.</p>
<ul>
<li>kvm, virt-manager</li>
</ul>
<p>I run several VMs to keep some separation. I have work Windows, work Linux demo vm, etc. With 64G of ram I have enough room for several vms and many tabs. 12 cpus helps too. So far no problems with KVM.</p>
<ul>
<li>Crashes</li>
</ul>
<p>I have had a couple of crashes. One when I installed Docker. Not sure what happened there. That concerns me. That said, every desktop I’ve used in the last year crashes. Windows crashes. OSX crashes. Linux vms crash on OSX. Linux workstation crashes. Crash crash crash crash crash crash. No OS stays up 100% of the time. Brutal out there.</p>
<ul>
<li>GUI</li>
</ul>
<p>A lot of the features mentioned for Fossa are related to the Gnome GUI. I use i3, which pretty much abstracts away the underlying GUI so I don’t see it. It’s to the point where my workflow is just 100% i3 based.</p>
<ul>
<li>Snaps</li>
</ul>
<p>I haven’t used snaps much. I use vscode and you can install it from snaps but I just did the package based install. That said I don’t have a problem with Snaps either. There does seem to be some controversy around it, but packaging is hard, and I’m all for options being available.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ snap list
Name Version Rev Tracking Publisher Notes
core18 20200427 1754 latest/stable canonical✓ base
gnome-3-34-1804 0+git.3009fc7 33 latest/stable/… canonical✓ -
gtk-common-themes 0.1-36-gc75f853 1506 latest/stable/… canonical✓ -
snap-store 3.36.0-74-ga164ec9 433 latest/stable/… canonical✓ -
snapd 2.44.3 7264 latest/stable canonical✓ snapd
</code></pre></div></div>
<ul>
<li>Wireguard</li>
</ul>
<p>I do use Wireguard, so having it back ported to the Fossa kernel is useful,no compiling for kernel module necessary.</p>
<ul>
<li>Encryption</li>
</ul>
<p>I usually encrypt the OS device. But I haven’t in this workstation, I guess because of ZFS I just didn’t think of it at the time. Something to consider in the future.</p>
<ul>
<li>xfreerdp and i3</li>
</ul>
<p>I run a couple of vms for demos and work, and this xfreerdp command works great and still allows me to flit around virtual desktops with $MOD+NUM without having to escape the virtual session. That said I haven’t tested the mic yet, but the “speaker” works great for audio in the vm. What I mean is that I can use i3 on the desktop and windows in the vm, and jump back to linux with $MOD+NUM.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>xfreerdp /u:curtis /p:$PASS /v:$IP /f +fonts /floatbar /smart-sizing -grab-keyboard /sound /microphone
</code></pre></div></div>
<p>That is working really well and I’m super happy with it.</p>
<h2 id="updates">Updates</h2>
<p>zfs and docker issue…I could not remove a container, and had to use the below script to temporarily recreate the pool and then rm the container.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>#!/bin/bash
stuck=$(docker ps -a | grep Removal | cut -f1 -d' ')
echo $stuck
for container in $stuck; do
zfs_path=$(docker inspect $container | jq -c '.[] | select(.State | .Status == "dead")|.GraphDriver.Data.Dataset')
zfs_path=$(echo $zfs_path|tr -d '"')
sudo zfs destroy -R $zfs_path
sudo zfs destroy -R $zfs_path-init
sudo zfs create $zfs_path
sudo zfs create $zfs_path-init
docker rm $container
done
</code></pre></div></div>
<h2 id="conclusion">Conclusion</h2>
<p>So far, so good. Other than ZFS as the boot file system, I don’t actually see that much different with Focal Fossa. Everything works fine like usual, yes, even sound!</p>
Virtual NSX-t and TKGI Lab2020-05-13T00:00:00+00:00http://serverascode.com/2020/05/13/simplest-nsx-t-tkgi-virtual-lab<h1 id="virtual-nsx-t-and-tkgi-lab">Virtual NSX-t and TKGI Lab</h1>
<p>I used to do a lot of work in the telecom field, especially around Network Function Virtualization (NFV) and I’ve deployed several Software Defined Networks (SDN) into production. I’ve even seen a few <a href="https://midonet.org/">good ones</a> come into existence, and then sometimes disappear.</p>
<p>Now that I work at VMware in the <a href="https://tanzu.vmware.com/">Tanzu group</a>, I work with VMware’s SDN system <a href="https://docs.vmware.com/en/VMware-NSX-T-Data-Center/index.html">NSX-t</a> and, of course, Kubernetes. One way that VMware can provide customers with k8s is via <a href="https://cloud.vmware.com/vmware-enterprise-pks">Tanzu Kubernetes Grid Integrated Edition</a> (TKGI) which was previously called the Pivotal Container Service, or PKS. IMHO, TKGI works best with NSX-t. Networking is key to running k8s effectively.</p>
<p>NSX-t, TKGI, k8s…these are all complicated technologies. There is just no way around it. The best way to learn how it all works is to deploy it. Currently I have what I consider to be a simpler virtual lab setup of NSX-t and TKGI deployed as virtual infrastructure, meaning that the ESXI hosts are virtual machines.</p>
<h2 id="tldr">tl;dr</h2>
<p>This isn’t really a prescriptive document, it’s more like a bunch of notes on some things I did to build this lab. On one hand it seems complex due to the use of a virtual vcenter and esxi nodes, but ultimately this is the simplest deployment of NSX-t and TKGI on vSphere that is possible. It’s really not that challenging and I actually ran into ZERO issues. I didn’t have one single problem getting this working (unless I’ve just missed something, lol). That said, I’ve been running NSX-t and TKGI in my lab for quite a while. For this deployment I was looking at NSX-t 2.5 and EPMC, neither of which I’ve deployed previously.</p>
<p>PS. <a href="https://blogs.vmware.com/networkvirtualization/2020/04/nsx-t-3-0.html/">NSX-t 3.0 is out!</a></p>
<h2 id="lab-design">Lab Design</h2>
<p>The point of this particular lab is to create similar environment as to what would be deployed in a TKGI + NSX-t + vSphere proof of concept. This means that:</p>
<ul>
<li>Only <a href="https://docs.vmware.com/en/VMware-NSX-T-Data-Center/2.4/installation/GUID-3770AA1C-DA79-4E95-960A-96DAC376242F.html">2 nics</a> are used on the ESXI hosts</li>
<li>There is no high availability at all, especially with regards to network traffic</li>
<li>Trying to deploy the least amount of resources</li>
<li>The <a href="https://docs.pivotal.io/pks/1-7/console/console-index.html">EPMC</a> system is used to abstract away the deployment of ops manager and bosh, and the initial setup of TKGI -> NSX-t connectivity</li>
</ul>
<p><img src="/img/tkgi-nsx/nics.png" alt="nics" /></p>
<h2 id="virtual-esxi">Virtual ESXI</h2>
<p>Thank goodness for the fact that you can run ESXI hosts as virtual machines. This makes it a lot easier to build up lab infrastructure for learning how it all works and deploying it in many different ways. William Lam’s virtual ESXI <a href="https://www.virtuallyghetto.com/2018/04/nested-esxi-6-7-virtual-appliance-updates.html">content library</a> is a godsend and allows me to build all kinds of fun infrastructure. having only recently been introduced to vSphere it’s taken me a while to get to the point where I’m building virtual clusters.</p>
<p>I’ve got three virtual, nested, esxi nodes in a vSphere cluster.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ govc find . -type h
/Datacenter/host/Cluster/10.0.1.237
/Datacenter/host/Cluster/10.0.1.238
/Datacenter/host/Cluster/10.0.1.239
</code></pre></div></div>
<p>These are the resources they have:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ govc host.info /Datacenter/host/Cluster/10.0.1.237
Name: 10.0.1.237
Path: /Datacenter/host/Cluster/10.0.1.237
Manufacturer: VMware, Inc.
Logical CPUs: 16 CPUs @ 2000MHz
Processor type: Intel(R) Xeon(R) CPU E5-2650 0 @ 2.00GHz
CPU usage: 7694 MHz (24.0%)
Memory: 65534MB
Memory usage: 39759 MB (60.7%)
Boot time: 2020-05-10 01:32:26.217102 +0000 UTC
State: connected
</code></pre></div></div>
<p>And these are all the vms that have been created for a full TKGI deployment, with one cluster deployed.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ govc find . -type m
/Datacenter/vm/pks_vms/vm-6dbd0bf0-9b12-40fd-bd06-05898d3f6a18
/Datacenter/vm/pks_vms/vm-05632c06-2abd-4997-a7db-d5366f798281
/Datacenter/vm/pks_templates/sc-a0414145-7c72-4991-9c87-1539fe36efe6
/Datacenter/vm/pks_vms/vm-d341f649-fe5b-4487-9702-18ea60c265c9
/Datacenter/vm/pks_vms/vm-422cbe25-f60d-4ae4-a2bb-2254f9dcf1eb
/Datacenter/vm/pks_vms/vm-1456f8d2-24c3-4790-a622-9e9c6ef579e0
/Datacenter/vm/opsman-WnmxrhR3zg
/Datacenter/vm/pks-management-console-1.7.0-rev.1-978372
/Datacenter/vm/pks_vms/vm-3b5fbbc7-bc27-43b7-a40b-4c2984419b3b
/Datacenter/vm/pks_templates/sc-6f5a71cb-5949-4697-9245-418ece3d0182
/Datacenter/vm/nsx-unified-appliance-2.5.1.0.0.15314292
/Datacenter/vm/pks_vms/vm-7fd9e63c-3276-439e-a358-e074d0f4d453
/Datacenter/vm/pks_vms/vm-fbc5e464-56cf-4eca-aad6-0e46f1bb3144
/Datacenter/vm/pks_templates/sc-8caf221d-a04c-4f48-8747-f7cead82e788
/Datacenter/vm/nsx-edge1
</code></pre></div></div>
<p>As you can see, there is an ops manager instance, a nsx manager, and an nsx edge instance. As well, there is a bosh director as well, and finally a TGKI management console (here called “pks-management-console”).</p>
<p>There is a lot of abstraction going on here, e.g. EPMC deploys Ops Manager, which deploys the Bosh Director, which deploys the TKGI API, which deploys the TGKI clusters.</p>
<p><img src="/img/tkgi-nsx/drawing-epmc1.jpg" alt="overview" /></p>
<p>One of the most important features of TKGI is that it is a k8s cluster life cycle manager, it can deploy and manage N k8s clusters.</p>
<h2 id="enabling-nested-networking">Enabling Nested Networking</h2>
<p>There are a lot of ways to approach this setup. I took this approach</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>for h in $(govc find . -type h | grep -v nested); do \
govc host.portgroup.add -vswitch vSwitch0 -vlan 4095 -host=$h NestedVLANTrunk; \
done
</code></pre></div></div>
<p>to add a VLAN trunk that the nested esxi hosts would have access to to get trunk VLAN traffic, i.e. see more than one VLAN on a virtual nic.</p>
<p>In the image below the nested esxi vm has two nics, one on the NestedVLANTrunk and one on “nested-pks-poc-nsx-tep” which is a physical VLAN in the underlying physical network, but one specifically setup for the nsx tep traffic. So this design only has 2 nics, which is nice, and what would typically be done in a physical proof of concept.</p>
<p><img src="/img/tkgi-nsx/nested-esxi-nics1.jpg" alt="nested esxi nics" /></p>
<p>Then in the nested vcenter there are more networks defined, which are VLANS available on the NestedVLANTrunk interface. The initial VSS based networks were migrated onto VDS. So there is the “VM Network” (also VLAN101), and a network for “vmotion” as well. And, of course, the “nsx-uplink” and “nsx-tep” networks. Again, these are all physical VLANs in this lab, and are presented to the virtual vsphere system, in this case via the VLAN trunk and the distributed port group.</p>
<p><img src="/img/tkgi-nsx/nested-vcenter-networks1.jpg" alt="nested vcsa networks" /></p>
<p>I suppose it’s a bit confusing that I’m using VSS in the physical hosts and VDS in the virtual ones, but that’s what I did.</p>
<p>Also, and this is important, promiscuous networking must be enabled in the er…physical virtual switch in the physical esxi nodes. As well note that the MTU is set to 1600.</p>
<p><img src="/img/tkgi-nsx/physical-vss-security1.jpg" alt="physical vss security" /></p>
<p>Also the DVS in the nested VCSA has a 1600 MTU.</p>
<p><img src="/img/tkgi-nsx/virtual-dswitch-mtu1.jpg" alt="nested vcsa dvs mtu" /></p>
<h2 id="nsx-t-configuration">NSX-t Configuration</h2>
<p>The configuration for this lab is bog standard, 2 NIC setup. The <a href="https://docs.pivotal.io/pks/1-7/nsxt-topologies.html">topology</a> is the standard, most commonly used NAT model.</p>
<p>Everything is NATed. The T0 router has several DNAT and SNAT configurations.</p>
<p><img src="/img/tkgi-nsx/nsx-nat.jpg" alt="nat configs" /></p>
<p>With TKGI 1.7, each k8s cluster gets its own T1 router. Right now there are 2 k8s clusters.</p>
<p><img src="/img/tkgi-nsx/nsx-routers.jpg" alt="nsx routers" /></p>
<p>I created 3 VLANs in the physical network for this lab. There is also the “VM Network” which is 10.1.0.0/24 and has most management interfaces. Note that I just use /24s because it’s my lab.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>name vlan range
nested-pks-poc-vmotion 119 10.0.19.0/24
nested-pks-nsx-tep 120 10.0.20.0/24
nested-pks-nsx-uplink 121 10.0.21.0/24
</code></pre></div></div>
<p>My habit, though it is a ridiculously sized network, is to set a static route for my NSX T0 routers and give them a /16. Within that /16 I’ve designated a couple /24s for use by NSX, most importantly the 10.2.1.0/24 range which is floating IPs for load balancers, etc. Because I’m using a simple static route there’s no need for BGP setup.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>10.2.0.0/16 static route pointed to T0 router at 10.0.21.100
10.2.0.0/24 deployment range
10.2.1.0/24 floating ips
</code></pre></div></div>
<p>10.2.0.0/24 is the deployment range, and that is where things like ops manager and bosh director end up.</p>
<h2 id="epmc">EPMC</h2>
<p>EPMC is a great tool that helps to abstract away the complexity of the underlying TKGI deployment, especially around ops manager, bosh, and NSX-t networking configuration. And what’s more, it allows operators to download the configuration as a set of files. EPMC has a familiar, wizard like interface to take operators through configuration all the TKGI components. Though note that NSX-t has to be in place already, but not configured for TKGI.</p>
<p>Below is a screenshot of the network configuration as set up in EPMC.</p>
<p><img src="/img/tkgi-nsx/epmc-network-config.png" alt="epmc network config" /></p>
<p>As mentioned, you can download the configuration file which is powerful, as you can reuse it.</p>
<p><img src="/img/tkgi-nsx/epmc-download-config.png" alt="epmc download config" /></p>
<h2 id="nsx-edges">NSX Edges</h2>
<p>When NSX-t is deployed it needs at least one edge node.</p>
<p>One of the more challenging things to understand about deploying NSX is that the ESXI nodes are (usually) physical, and the edge nodes virtual, but, in this design, they all need to be able to access TEP interface IPs…they need that reachability. Layer 2 is not required for this reachability, but in the case of this particular design, the edge nodes have an interface on the TEP VLAN and vnic1 on the ESXI nodes is also connected to that same VLAN as an access port, i.e. it looks like VLAN 0 to them. Please note that NSX-t is extremely flexible, and this design is the most basic.</p>
<p>This <a href="https://blogs.vmware.com/networkvirtualization/2018/10/flexible-deployment-options-for-nsx-t-edge-vm.html/">blog post</a> describes a couple of different ways to deploy nsx edges. Typically 4 nics are expected. This particular deployment is the one they have a not so subtle warning about:</p>
<blockquote>
<p>In a Collapsed Compute and Edge Cluster topology, compute host is prepared for NSX-T which implies that this host has N-VDS installed and is also configured with a Tunnel End point. <strong>This deployment option is NOT recommended on a host with two pNICs. The simple reason being, this host has two virtual switches now, a VSS/VDS and a N-VDS, each consuming one pNIC. So, there is no redundancy for either of the virtual switches.</strong> A host with 4 pNICs or more is recommended in this deployment option. NSX-T Edge VM deployment or configuration doesn’t change from option 1 as the Edge VM still leverages the VSS/VDS portgroups.</p>
</blockquote>
<p>But that’s fine for this lab because it’s not meant for production.</p>
<p>So the nsx edge, a virtual machine, has 3 nics in use:</p>
<ol>
<li>Access to the TEP network</li>
<li>Access to the uplink network</li>
<li>A management interface</li>
</ol>
<p><img src="/img/tkgi-nsx/nsx-edge-nics1.jpg" alt="nsx edge nics" /></p>
<h2 id="pings">Pings</h2>
<p>Can’t network without pings. :)</p>
<p><img src="/img/tkgi-nsx/pings.jpg" alt="pings" /></p>
<h2 id="conclusion">Conclusion</h2>
<p>So there you have it, a somewhat haphazard tour of a virtual, 2 nic TKGI + NSX-t deployment. You could do this on a single ESXI host.</p>
Spring Cloud Gateway - Animal Rescue2020-05-06T00:00:00+00:00http://serverascode.com/2020/05/06/spring-clould-gateway-animal-rescue<h1 id="spring-cloud-gateway---animal-rescue">Spring Cloud Gateway - Animal Rescue</h1>
<p><a href="https://github.com/spring-cloud-services-samples/animal-rescue">Animal Rescue</a> is a sample application used to demonstrate Spring Cloud Gateway, and Single Sign On, in the <a href="https://tanzu.vmware.com/application-service">Tanzu Application Service</a> (TAS), which is based on Cloud Foundry. This particular demo has an an automated script that will deploy the microservice based Animal Rescue into TAS, and in doing so will setup a Spring Cloud Gateway (SCG) instance via a service in TAS. By using marketplace services in TAS developers get easy-to-use self-service access to single sign on and a API gateway.</p>
<h2 id="whats-an-api-gateway">What’s an API gateway?</h2>
<blockquote>
<p>An API gateway takes all API calls from clients, then routes them to the appropriate microservice with request routing, composition, and protocol translation. Typically it handles a request by invoking multiple microservices and aggregating the results, to determine the best path. It can translate between web protocols and web‑unfriendly protocols that are used internally. - <a href="https://www.nginx.com/learn/api-gateway/s">Nginx</a></p>
</blockquote>
<p>An API gateway organizes client requests to various microservices. It can manipulate those requests, aggregate multiple microservices together, translate protocols, etc, etc. They can consolidate authorization and other cross cutting concerns. Gateways can also help reduce the number of calls clients need to make, i.e. they don’t need to understand every backend service, just enough to talk to the gateway. Another useful thing about gateways is that they can add in security. They can kind of do anything, and frankly that is what often makes them confusing, especially to people like myself who don’t write code 100% of the time.</p>
<h2 id="spring-cloud-gateway">Spring Cloud Gateway</h2>
<p>If you write apps in Java there is a very high likelihood that you also are using the Spring Framework and Spring has it’s own gateway, thoughtfully called <a href="https://tanzu.vmware.com/content/blog/microservices-essentials-getting-started-with-spring-cloud-gateway">Spring Cloud Gateway</a>.</p>
<p>Spring Cloud (API?) Gateway:</p>
<blockquote>
<p>This project provides a library for building an API Gateway on top of Spring MVC. Spring Cloud Gateway aims to provide a simple, yet effective way to route to APIs and provide cross cutting concerns to them such as: security, monitoring/metrics, and resiliency. - <a href="https://spring.io/projects/spring-cloud-gateway">Spring Cloud docs</a></p>
</blockquote>
<p>A few key features of SCG:</p>
<ul>
<li>Built on Spring Framework 5, Project Reactor and Spring Boot 2.0</li>
<li>Able to match routes on any request attribute</li>
<li>Predicates and filters are specific to routes</li>
<li>Hystrix Circuit Breaker integration</li>
<li>Spring Cloud DiscoveryClient integration</li>
<li>Easy to write Predicates and Filters</li>
<li>Request Rate Limiting</li>
<li>Path Rewriting</li>
</ul>
<h2 id="install-spring-gateway-tile-into-tanzu-application-service">Install Spring Gateway Tile into Tanzu Application Service</h2>
<p>In order to deploy Animal Rescue with Spring Cloud Gateway, we need the Spring Cloud Gateway Tile deployed in Tanzu Application Service (TAS). This is not the only way to use Spring Cloud Gateway, but it’s how Animal Rescue is expecting to access it, at least in terms of the bash script that comes with the repo that can initialize and deploy the app. So in this example, SCG will be a service managed by the platform (TAS) that can be bound to an application.</p>
<p>The Single Sign On Tile is also required and in my case I enabled it for all orgs.</p>
<p><img src="/img/animal-rescue4.jpg" alt="img" /></p>
<p>There are a few tiles installed in this TAS instance, but the important ones for Animal Rescue are the SSO and SCG tiles.</p>
<h2 id="deploy-animal-rescue-to-tanzu-application-service">Deploy Animal Rescue to Tanzu Application Service</h2>
<p>Clone the repo:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>git clone https://github.com/spring-cloud-services-samples/animal-rescue
cd animal-rescue
</code></pre></div></div>
<p>Login to TAS:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>cf login -a api.sys.yourdomain.com
</code></pre></div></div>
<p>I needed make, g++, jq installed, there may be other requirements my Linux box already had installed.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>sudo apt install make g++ jq -y
</code></pre></div></div>
<p>Run the init script.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ ./scripts/cf_deploy.sh init
npm WARN prepare removing existing node_modules/ before installation
> core-js@2.6.11 postinstall /home/curtis/working/animal-rescue/frontend/node_modules/babel-runtime/node_modules/core-js
> node -e "try{require('./postinstall')}catch(e){}"
Thank you for using core-js ( https://github.com/zloirock/core-js ) for polyfilling JavaScript standard library!
The project needs your help! Please consider supporting of core-js on Open Collective or Patreon:
> https://opencollective.com/core-js
> https://www.patreon.com/zloirock
SNIP!
BUILD SUCCESSFUL in 3s
4 actionable tasks: 4 executed
</code></pre></div></div>
<p>Then deploy to TAS:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ ./scripts/cf_deploy.sh deploy
Service instance gateway-demo not found
Gateway service does not exist, creating...
Creating service instance gateway-demo in org java / space spring-cloud-gateway as admin...
OK
Create in progress. Use 'cf services' or 'cf service gateway-demo' to check operation status.
Waiting for service instance to be ready...
SNIP!
< X-Content-Type-Options: nosniff
< X-Frame-Options: DENY
< X-Vcap-Request-Id: 8c89f955-543f-4b3a-7e51-a9b42b1fbe31
< X-Xss-Protection: 1 ; mode=block
< Date: Thu, 07 May 2020 15:37:11 GMT
<
* Connection #0 to host gateway-demo.apps.sf.vsphere.local left intact
=====
Bound app animal-rescue-backend route configuration update response status: 204
</code></pre></div></div>
<p>Now I’ve got the frontend and backend apps running on internal urls.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ cf apps
Getting apps in org java / space spring-cloud-gateway as admin...
OK
name requested state instances memory disk urls
animal-rescue-backend started 1/1 1G 1G animal-rescue-backend.apps.internal
animal-rescue-frontend started 1/1 1G 1G animal-rescue-frontend.apps.internal
</code></pre></div></div>
<p>I can access that via the browser, login, and adopt animals.</p>
<p>If I use the gateway org I can see the instance of the gateway service:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ cf apps
Getting apps in org p-spring-cloud-gateway-service / space fb081bbf-fa60-4a40-bbb0-4f4c47ab2c0a as admin...
OK
name requested state instances memory disk urls
gateway started 1/1 1G 1G gateway-demo.apps.sf.vsphere.local, gateway-fb081bbf-fa60-4a40-bbb0-4f4c47ab2c0a.apps.internal
</code></pre></div></div>
<p>And then that can be accessed in the browser. The login is via SSO.</p>
<p>Look at all those cute animals up for microservice adoption.</p>
<p><img src="/img/animal-rescue.jpg" alt="img" /></p>
<h2 id="spring-cloud-gateway-configuration-and-service">Spring Cloud Gateway Configuration and Service</h2>
<p>In the apps GUI, we can see the SCG instance.</p>
<p><img src="/img/animal-rescue2.jpg" alt="scg" /></p>
<p>And the corresponding routes.</p>
<p><img src="/img/animal-rescue3.jpg" alt="routes" /></p>
<p>Note that the route is internal.</p>
<p>It’s worthwhile to have a look at the <a href="https://docs.pivotal.io/spring-cloud-gateway/1-0/configuring-routes.html">routes</a> that are configured in the gateway, frontend, and backend gateway-config.json files.</p>
<h2 id="conclusion">Conclusion</h2>
<p>API gateways can be really helpful with microservices. There are several solutions out there, but one of the most flexible is Spring Cloud Gateway. It’s absolutely worth looking at and is a serious competitor and will be improving, and innovating, rapidly. In this particular example, SCG was deployed and managed as a service in TAS, which makes it extremely easy for developers to use, but it can also be managed in other manners.</p>
<p>This post only barely scratches the surface of what Spring Cloud Gateway can do, and in combination with TAS. There’s tons of <a href="https://spring.io/guides/gs/gateway/">docs</a> out there on getting started with SCG.</p>
GraalVM Native Images2020-05-05T00:00:00+00:00http://serverascode.com/2020/05/05/graalvm-native-image<h1 id="graalvm-native-images">GraalVM Native Images</h1>
<p>People are often concerned about the startup speed of Java applications. I don’t think it matters for most use cases, but there are, of course, some situations where a very fast startup time and less memory usage would be useful…say small microservices. <a href="https://www.graalvm.org/docs/reference-manual/native-image/">GraalVM Native Images</a> can, in certain situations, help with this.</p>
<blockquote>
<p>GraalVM Native Image allows you to ahead-of-time compile Java code to a standalone executable, called a native image. This executable includes the application classes, classes from its dependencies, runtime library classes from JDK and statically linked native code from JDK. It does not run on the Java VM, but includes necessary components like memory management and thread scheduling from a different virtual machine, called “Substrate VM”. Substrate VM is the name for the runtime components (like the deoptimizer, garbage collector, thread scheduling etc.). The resulting program has faster startup time and lower runtime memory overhead compared to a Java VM. - <a href="https://www.graalvm.org/docs/reference-manual/native-image/">GraalVM Docs</a></p>
</blockquote>
<p>Dave Syer, a key, long time member of the Spring open source project, recently wrote a <a href="https://spring.io/blog/2020/05/04/spring-cloud-function-native-images">post</a> discussing the performance of GraalVM Native Images and the JIT when using Spring Cloud Function with AWS Lambda.</p>
<blockquote>
<p>Using Spring Cloud Function is a very convenient way to develop functions that run on AWS and other platforms. If you also use the experimental Spring Graal Native Feature project to compile the result to a native binary executable they can run faster than the same application on a regular JVM.</p>
</blockquote>
<p>A couple reasons why you might use native images:</p>
<blockquote>
<p>Once compiled to a platform specific native-image applications should have very fast startup and a more reliable memory profile (no JIT causing memory spikes at the beginning). - <a href="https://spring.io/blog/2020/04/09/spring-graal-native-0-6-0-released">Spring Blog</a></p>
</blockquote>
<h2 id="compile-using-graalvm-native-image">Compile using GraalVM Native Image</h2>
<p>Let’s build a native image with GraalVM.</p>
<p>I’ll use sdkman to install the Java and GraalVM requirements.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>sdk install java 20.0.0.r8-grl
</code></pre></div></div>
<p>Also we need gcc and zlib1g-dev, at least on Ubuntu 18.04 anyways.</p>
<blockquote>
<p>For compilation native-image depends on the local toolchain, so please make sure: glibc-devel, zlib-devel (header files for the C library and zlib) and gcc are available on your system. - <a href="https://www.graalvm.org/docs/reference-manual/native-image/">GraalVM docs</a></p>
</blockquote>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>sudo apt install gcc zlib1g-dev -y
</code></pre></div></div>
<p>Clone the repo.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>git clone https://github.com/spring-projects-experimental/spring-graal-native
cd spring-graal-native/spring-graal-native-samples/function-netty
</code></pre></div></div>
<p>Now I’ve got Java 8.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ java -version
openjdk version "1.8.0_242"
OpenJDK Runtime Environment (build 1.8.0_242-b06)
OpenJDK 64-Bit Server VM GraalVM CE 20.0.0 (build 25.242-b06-jvmci-20.0-b02, mixed mode)
</code></pre></div></div>
<p>And then use gu to install native-image.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ gu install native-image
Downloading: Component catalog from www.graalvm.org
Processing Component: Native Image
Downloading: Component native-image: Native Image from github.com
Installing new component: Native Image (org.graalvm.native-image, version 20.0.0)
</code></pre></div></div>
<p>At the root of the project, run <code class="language-plaintext highlighter-rouge">build.sh</code>.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ pwd
/home/curtis/working/spring-graal-native
$ ./build.sh
</code></pre></div></div>
<p>Then build the function-netty sample.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ cd spring-graal-native-samples/function-netty
$ ./build.sh
</code></pre></div></div>
<p>I was initially building this on a VM with 8GB of memory and no swap, and it crashed out. I bumped the memory to 12GB and it built. I see a note in the native image docs about memory for builds, but couldn’t quite grok it.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>SNIP!
Error: Image build request failed with exit status 137
com.oracle.svm.driver.NativeImage$NativeImageError: Image build request failed with exit status 137
at com.oracle.svm.driver.NativeImage.showError(NativeImage.java:1527)
at com.oracle.svm.driver.NativeImage.build(NativeImage.java:1289)
at com.oracle.svm.driver.NativeImage.performBuild(NativeImage.java:1250)
at com.oracle.svm.driver.NativeImage.main(NativeImage.java:1209)
real 3m44.437s
user 11m4.659s
sys 0m17.460s
FAILURE: an error occurred when compiling the native-image.
</code></pre></div></div>
<p>With enough memory now, the build takes a few minutes:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ ./build.sh
=== Building function-netty sample ===
Packaging function-netty with Maven
Unpacking function-netty-0.0.1-SNAPSHOT.jar
Compiling function-netty with GraalVM Version 20.0.0 CE
SUCCESS
Testing executable 'function-netty'
SUCCESS
Build memory: 7.07GB
Image build time: 432.0s
RSS memory: 87.4M
Image size: 79.2M
Startup time: 0.178 (JVM running for 0.182)
</code></pre></div></div>
<p>Start up the function.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ ./target/function-netty
. ____ _ __ _ _
/\\ / ___'_ __ _ _(_)_ __ __ _ \ \ \ \
( ( )\___ | '_ | '_| | '_ \/ _` | \ \ \ \
\\/ ___)| |_)| | | | | || (_| | ) ) ) )
' |____| .__|_| |_|_| |_\__, | / / / /
=========|_|==============|___/=/_/_/_/
:: Spring Boot ::
2020-05-05 14:12:00.458 INFO 9705 --- [ main] com.example.demo.DemoApplication : Starting DemoApplication on tanzu-ubuntu-2 with PID 9705 (/home/curtis/working/spring-graal-native/spring-graal-native-samples/function-netty/target/function-netty started by curtis in /home/curtis/working/spring-graal-native/spring-graal-native-samples/function-netty)
2020-05-05 14:12:00.458 INFO 9705 --- [ main] com.example.demo.DemoApplication : No active profile set, falling back to default profiles: default
2020-05-05 14:12:00.515 INFO 9705 --- [ main] o.s.c.f.web.flux.FunctionHandlerMapping : FunctionCatalog: org.springframework.cloud.function.context.catalog.BeanFactoryAwareFunctionRegistry@7f0b166628d8
2020-05-05 14:12:00.527 WARN 9705 --- [ main] io.netty.channel.DefaultChannelId : Failed to find the current process ID from ''; using a random value: 398582704
2020-05-05 14:12:00.528 INFO 9705 --- [ main] o.s.b.web.embedded.netty.NettyWebServer : Netty started on port(s): 8080
2020-05-05 14:12:00.528 INFO 9705 --- [ main] com.example.demo.DemoApplication : Started DemoApplication in 0.081 seconds (JVM running for 0.083)
</code></pre></div></div>
<p><code class="language-plaintext highlighter-rouge">0.081</code> seconds, that’s pretty quick.</p>
<p>Curl it:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ curl -s localhost:8080/ -d world -H "Content-Type: text/plain"; echo
hi world!
</code></pre></div></div>
<p>What is <code class="language-plaintext highlighter-rouge">target/function-netty</code>?</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ file target/function-netty
target/function-netty: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/l, for GNU/Linux 3.2.0, BuildID[sha1]=680512d5d6ab33e499ecdb9a45d4b199841de0fb, with debug_info, not stripped
</code></pre></div></div>
<p>Size:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ du -hsc target/function-netty
80M target/function-netty
80M total
</code></pre></div></div>
<p>Now I’ll push it to Cloud Foundry (also now known as <a href="https://tanzu.vmware.com/application-service">Tanzu Application Service</a> downstream-wise):</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code> $ cf push -b binary_buildpack -c target/function-netty cc-ni
Pushing app cc-ni to org Canada / space ccollicutt as ccollicutt@pivotal.io...
Getting app info...
Creating app with these attributes...
+ name: cc-ni
path: /home/curtis/working/spring-graal-native/spring-graal-native-samples/function-netty
buildpacks:
+ binary_buildpack
+ command: target/function-netty
routes:
+ cc-ni.cfapps.io
Creating app cc-ni...
Mapping routes...
Comparing local files to remote cache...
Packaging files to upload...
Uploading files...
41.83 MiB / 41.83 MiB [===============================================================================================================================================================================] 100.00% 9s
Waiting for API to complete processing files...
Staging app and tracing logs...
Downloading binary_buildpack...
Downloaded binary_buildpack
Cell 850bb788-0cb8-4092-b839-32661cb636dc creating container for instance c3c3ad17-10a8-4885-a762-4b3ae5811cc4
Cell 850bb788-0cb8-4092-b839-32661cb636dc successfully created container for instance c3c3ad17-10a8-4885-a762-4b3ae5811cc4
Downloading app package...
Downloaded app package (56.9M)
-----> Binary Buildpack version 1.0.36
Exit status 0
Uploading droplet, build artifacts cache...
Uploading droplet...
Uploading build artifacts cache...
Uploaded build artifacts cache (214B)
Uploaded droplet (56.4M)
Uploading complete
Cell 850bb788-0cb8-4092-b839-32661cb636dc stopping instance c3c3ad17-10a8-4885-a762-4b3ae5811cc4
Cell 850bb788-0cb8-4092-b839-32661cb636dc destroying container for instance c3c3ad17-10a8-4885-a762-4b3ae5811cc4
Cell 850bb788-0cb8-4092-b839-32661cb636dc successfully destroyed container for instance c3c3ad17-10a8-4885-a762-4b3ae5811cc4
Waiting for app to start...
name: cc-ni
requested state: started
routes: cc-ni.cfapps.io
last uploaded: Tue 05 May 15:15:33 EDT 2020
stack: cflinuxfs3
buildpacks: binary
type: web
instances: 1/1
memory usage: 1024M
start command: target/function-netty
state since cpu memory disk details
#0 running 2020-05-05T19:15:47Z 0.0% 0 of 1G 0 of 1G
</code></pre></div></div>
<p>And curl that:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ curl -s cc-ni.cfapps.io -d "online curtis" -H "Content-Type: text/plain"; echo
hi online curtis!
</code></pre></div></div>
<p>Nice!</p>
<p>It’s only using 40mb of memory.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ cf app cc-ni
Showing health and status for app cc-ni in org Canada / space ccollicutt as ccollicutt@pivotal.io...
name: cc-ni
requested state: started
routes: cc-ni.cfapps.io
last uploaded: Tue 05 May 15:15:33 EDT 2020
stack: cflinuxfs3
buildpacks: binary
type: web
instances: 1/1
memory usage: 1024M
state since cpu memory disk details
#0 running 2020-05-05T19:15:48Z 0.5% 40.4M of 1G 114.7M of 1G
</code></pre></div></div>
<h2 id="push-the-jar-file">Push the Jar File</h2>
<p>I can also just push the jar file instead of the native image binary.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ cf push -p target/function-netty-0.0.1-SNAPSHOT.jar cf-ni-jar
</code></pre></div></div>
<p>Slightly more memory in use, about 110M more than the native image.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ cf app cf-ni-jar
Showing health and status for app cf-ni-jar in org Canada / space ccollicutt as ccollicutt@pivotal.io...
name: cf-ni-jar
requested state: started
routes: cf-ni-jar.cfapps.io
last uploaded: Tue 05 May 15:30:15 EDT 2020
stack: cflinuxfs3
buildpacks: client-certificate-mapper=1.11.0_RELEASE container-security-provider=1.18.0_RELEASE
java-buildpack=v4.30-offline-https://github.com/cloudfoundry/java-buildpack.git#6986fd5
java-main java-opts java-security jvmkill-agent=1.16.0_RELEASE open-jdk...
type: web
instances: 1/1
memory usage: 1024M
state since cpu memory disk details
#0 running 2020-05-05T19:30:33Z 0.6% 158.3M of 1G 127.2M of 1G
</code></pre></div></div>
<p>Also can curl it…</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code> $ curl -s cf-ni-jar.cfapps.io -d "online curtis" -H "Content-Type: text/plain"; echo
hi online curtis!
</code></pre></div></div>
<h2 id="conclusion">Conclusion</h2>
<p>So this is really interesting…the ability to create a single binary file for a Java and Spring app. I’d like to understand this better, especially what it is doing for 5 or 6 minutes while compiling, which also takes a considerable amount of RAM. I’m sure there is a lot of ongoing work, and that this will mostly be applicable in certain sitations, specifically cloud functions, but progress is definitely being made. Overall, faster startup time and lower memory usage will be extremely valuable.</p>
<p>There’s a good article <a href="https://dzone.com/articles/profiling-native-images-in-java">here</a> that discusses some of the pros and cons of native image.</p>
<p>It also appears that Java will take on building in some of this functionality itself in a project <a href="https://mail.openjdk.java.net/pipermail/discuss/2020-April/005429.html">called Leyden</a>.</p>
<blockquote>
<p>Leyden will address these pain points by introducing a concept of <em>static
images</em> to the Java Platform, and to the JDK.</p>
<ul>
<li>A static image is a standalone program, derived from an application,
which runs that application – and no other.</li>
<li>A static image is a closed world: It cannot load classes from outside
the image, nor can it spin new bytecodes at run time.</li>
</ul>
</blockquote>
Tanzu Kubernetes Grid and Antrea2020-05-02T00:00:00+00:00http://serverascode.com/2020/05/02/tanzu-kubernetes-grid-antrea<h1 id="tanzu-kubernetes-grid-and-antrea">Tanzu Kubernetes Grid and Antrea</h1>
<p>In this post I’ll briefly discuss Tanzu Kubernetes Grid, and then get a bit into the Antrea Container Network Interface (CNI) for Kubernetes.</p>
<h2 id="tanzu-kubernetes-grid">Tanzu Kubernetes Grid</h2>
<p><a href="https://tanzu.vmware.com/kubernetes-grid">Tanzu Kubernetes Grid</a>, otherwise known as TKG, is the underlying Kuberenetes distribution for all of VMware’s Kuberenete based products. It’s part of vSphere with Kubernetes. It’s part of TKGI (what was once PKS). But it’s not just a distribution…it’s also a standalone lifecycle manager that heavily utilizes <a href="https://github.com/kubernetes-sigs/cluster-api">Cluster API</a> to manage virtual machines on which Kubernetes runs.</p>
<p>I’m not going to get into how TKG works, other than to say one of the first things you do with TKG is to deploy a management cluster. That cluster is then used to manage the life cycle of many other k8s “workload” clusters.</p>
<p>Here’s all the CRDs that are part of the management cluster.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ k get crds | grep "machine/|vsphere\|cluster"
clusterinformations.crd.projectcalico.org 2020-04-21T19:03:46Z
clusterissuers.cert-manager.io 2020-04-21T19:03:48Z
clusters.cluster.x-k8s.io 2020-04-21T19:05:35Z
haproxyloadbalancers.infrastructure.cluster.x-k8s.io 2020-04-21T19:05:46Z
kubeadmconfigs.bootstrap.cluster.x-k8s.io 2020-04-21T19:05:39Z
kubeadmconfigtemplates.bootstrap.cluster.x-k8s.io 2020-04-21T19:05:39Z
kubeadmcontrolplanes.controlplane.cluster.x-k8s.io 2020-04-21T19:05:43Z
machinedeployments.cluster.x-k8s.io 2020-04-21T19:05:35Z
machinehealthchecks.cluster.x-k8s.io 2020-04-21T19:05:35Z
machinepools.exp.cluster.x-k8s.io 2020-04-21T19:05:36Z
machines.cluster.x-k8s.io 2020-04-21T19:05:36Z
machinesets.cluster.x-k8s.io 2020-04-21T19:05:36Z
providers.clusterctl.cluster.x-k8s.io 2020-04-21T19:03:46Z
vsphereclusters.infrastructure.cluster.x-k8s.io 2020-04-21T19:05:46Z
vspheremachines.infrastructure.cluster.x-k8s.io 2020-04-21T19:05:46Z
vspheremachinetemplates.infrastructure.cluster.x-k8s.io 2020-04-21T19:05:47Z
vspherevms.infrastructure.cluster.x-k8s.io 2020-04-21T19:05:47Zs
</code></pre></div></div>
<p>You can see some fun ones like machines and machinesets, as well as CRDs related to using vSphere.</p>
<p>Using TKG I have deployed three workload clusters.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ tkg get clusters
+--------------+-------------+
| NAME | STATUS |
+--------------+-------------+
| dc-cluster | Provisioned |
| edge-cluster | Provisioned |
| tkg-antrea | Provisioned |
+--------------+-------------+
</code></pre></div></div>
<p>One of them is using Antrea as the container networking interface (tkg-antrea). The other two clusters are using the current TKG default CNI, Calico.</p>
<h2 id="antrea">Antrea</h2>
<p>There are quite a few networking options with k8s. One of the best is <a href="https://docs.vmware.com/en/VMware-NSX-T-Data-Center/index.html">VMware’s NSX-t</a>. But another interesting networking option that VMware supports is the open source project <a href="https://github.com/vmware-tanzu/antrea/">Antrea</a>.</p>
<blockquote>
<p>Antrea is a Kubernetes networking solution intended to be Kubernetes native. It operates at Layer3/4 to provide networking and security services for a Kubernetes cluster, leveraging Open vSwitch as the networking data plane.</p>
</blockquote>
<p>Basically it orchestrates Open vSwitch. Version 0.6 was <a href="https://github.com/vmware-tanzu/antrea/releases/tag/v0.6.0">released </a>only a few days ago.</p>
<p>William Lam has a <a href="https://www.virtuallyghetto.com/2020/04/how-to-deploy-tanzu-kubernetes-grid-tkg-cluster-with-antrea-cni.html">blog post</a> on how to deploy a TKG workload cluster with Antrea instead of Calico. It’s pretty straight forward. TKG uses the concept of “plans” to configure k8s clusters. These plans are basically YAML templates, and by default Calico is set up in the template, but Antrea can be swapped in.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ diff cluster-template-dev-antrea.yaml cluster-template-dev.yaml | head
247,952c247,1036
< ---
< apiVersion: apiextensions.k8s.io/v1beta1
< kind: CustomResourceDefinition
< metadata:
< labels:
< app: antrea
< name: antreaagentinfos.clusterinformation.antrea.tanzu.vmware.com
< spec:
< group: clusterinformation.antrea.tanzu.vmware.com
</code></pre></div></div>
<p>Follow Mr. Lam’s blog post if you want to try this out. A few quick commands and you’ll be all set.</p>
<h2 id="antrea-1">Antrea</h2>
<p>I configured the tkg-antrea workload cluster to have three worker nodes. Then I applied the below busybox deployment.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ cat deployment.yml
apiVersion: apps/v1
kind: Deployment
metadata:
name: busybox-deployment
labels:
app: busybox
spec:
replicas: 6
strategy:
type: RollingUpdate
selector:
matchLabels:
app: busybox
template:
metadata:
labels:
app: busybox
spec:
containers:
- name: busybox
image: busybox
imagePullPolicy: IfNotPresent
command: ['sh', '-c', 'echo Container 1 is Running ; sleep 3600']
</code></pre></div></div>
<p>Here are the pods.</p>
<p><em>NOTE: I always alias kubectl to k.</em></p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ k get pods
NAME READY STATUS RESTARTS AGE
busybox-deployment-66458f7d4b-4s6vh 1/1 Running 11 11h
busybox-deployment-66458f7d4b-5kv5l 1/1 Running 11 11h
busybox-deployment-66458f7d4b-fgjzx 1/1 Running 11 11h
busybox-deployment-66458f7d4b-gqs8g 1/1 Running 11 11h
busybox-deployment-66458f7d4b-h25sf 1/1 Running 11 11h
busybox-deployment-66458f7d4b-r977v 1/1 Running 11 11h
</code></pre></div></div>
<p>We can also checkout their IP addresses. (Hat tip to this <a href="https://alexbrand.dev/post/first-look-at-antrea-a-cni-plugin-based-on-open-vswitch/">blog</a>.)</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ k get pods -o custom-columns='name:.metadata.name,pod ip:.status.podIPs[0].ip,node:.spec.nodeName' --sort-by='.spec.nodeName'
name pod ip node
busybox-deployment-66458f7d4b-4s6vh 100.96.1.3 tkg-antrea-md-0-548d498b47-2xjf8
busybox-deployment-66458f7d4b-h25sf 100.96.1.4 tkg-antrea-md-0-548d498b47-2xjf8
busybox-deployment-66458f7d4b-fgjzx 100.96.2.3 tkg-antrea-md-0-548d498b47-ckwvd
busybox-deployment-66458f7d4b-r977v 100.96.2.4 tkg-antrea-md-0-548d498b47-ckwvd
busybox-deployment-66458f7d4b-5kv5l 100.96.3.4 tkg-antrea-md-0-548d498b47-f4rmz
busybox-deployment-66458f7d4b-gqs8g 100.96.3.3 tkg-antrea-md-0-548d498b47-f4rmz
</code></pre></div></div>
<p>We have two pods per node. With Antrea, each k8s node gets a /24. In this case node tkg-antrea-md-0-548d498b47-2xjf8 has 100.96.1.0/24m the next node is 100.96.2.0/24, and so on.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ k get nodes -o custom-columns=Name:.metadata.name,PodCIDR:.spec.podCIDR
Name PodCIDR
tkg-antrea-control-plane-fzb44 100.96.0.0/24
tkg-antrea-md-0-548d498b47-2xjf8 100.96.1.0/24
tkg-antrea-md-0-548d498b47-ckwvd 100.96.2.0/24
tkg-antrea-md-0-548d498b47-f4rmz 100.96.3.0/24
</code></pre></div></div>
<p>antctl is quite useful.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ k -n kube-system exec -it antrea-agent-2d8xp antrea-agent -- antctl get ovsflows -h
Defaulting container name to antrea-agent.
Use 'kubectl describe pod/antrea-agent-2d8xp -n kube-system' to see all of the containers in this pod.
Dump all the OVS flows or the flows installed for the specified entity.
Usage:
antctl get ovsflows [flags]
Aliases:
ovsflows, of
Examples:
Dump all OVS flows
$ antctl get ovsflows
Dump OVS flows of a local Pod
$ antctl get ovsflows -p pod1 -n ns1
Dump OVS flows of a NetworkPolicy
$ antctl get ovsflows --networkpolicy np1 -n ns1
Dump OVS flows of a flow Table
$ antctl get ovsflows -t IngressRule
Antrea OVS Flow Tables:
0 Classification
10 SpoofGuard
20 ARPResponder
30 ConntrackZone
31 ContrackState
40 DNAT
50 EgressRule
60 EgressDefaultRule
70 L3Forwarding
80 L2Forwarding
90 IngressRule
100 IngressDefaultRule
105 ConntrackCommit
110 Output
SNIP!
</code></pre></div></div>
<p>We can dump the flows using antctl based on the above flow table names. There are no network polices in place right now, so the returned flows are few.</p>
<p><em>NOTE: Use an antrea agent that is on a worker node.</em></p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ k -n kube-system exec -it antrea-agent-hs5kp antrea-agent -- antctl get ovsflows -T IngressRule
Defaulting container name to antrea-agent.
Use 'kubectl describe pod/antrea-agent-hs5kp -n kube-system' to see all of the containers in this pod.
FLOW
table=90, n_packets=155728, n_bytes=14819958, priority=210,ct_state=-new+est,ip actions=resubmit(,105)
table=90, n_packets=17156, n_bytes=1269544, priority=210,ip,nw_src=100.96.1.1 actions=resubmit(,105)
table=90, n_packets=15, n_bytes=1110, priority=0 actions=resubmit(,100)
</code></pre></div></div>
<p>Above we can see the default flows when there are no network polices.</p>
<h2 id="network-policies">Network Policies</h2>
<p>k8s started out with the idea that every pod could talk to every other pod over the network. Obviously it couldn’t stay like this…we need to be able to limit and control connectivity. So Antrea supports <a href="https://kubernetes.io/docs/concepts/services-networking/network-policies/">Kubernetes Network Policies</a>.</p>
<blockquote>
<p>By default, pods are non-isolated; they accept traffic from any source. Pods become isolated by having a NetworkPolicy that selects them. Once there is any NetworkPolicy in a namespace selecting a particular pod, that pod will reject any connections that are not allowed by any NetworkPolicy. (Other pods in the namespace that are not selected by any NetworkPolicy will continue to accept all traffic.) - <a href="https://kubernetes.io/docs/concepts/services-networking/network-policies/">k8s docs</a></p>
</blockquote>
<p>Deploy nginx:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ cat nginx-deployment-service.yaml
---
apiVersion: apps/v1 # for versions before 1.9.0 use apps/v1beta2
kind: Deployment
metadata:
name: nginx
spec:
strategy:
type: Recreate
selector:
matchLabels:
app: nginx
replicas: 3 # tells deployment to run 1 pods matching the template
template: # create pods using pod definition in this template
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: nginx
namespace: default
labels:
app: nginx
annotations:
service.beta.kubernetes.io/aws-load-balancer-type: "nlb"
spec:
externalTrafficPolicy: Local
ports:
- name: http
port: 80
protocol: TCP
targetPort: 80
selector:
app: nginx
type: NodePort
</code></pre></div></div>
<p>ClusterIP:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ k get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 100.64.0.1 <none> 443/TCP 23h
nginx NodePort 100.70.238.176 <none> 80:31710/TCP 30m
</code></pre></div></div>
<p>With nginx deployed, I can exec into one of the busybox instances I already created and do this:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>/ # wget -q -O - 100.70.238.176 | grep title
<title>Welcome to nginx!</title>
</code></pre></div></div>
<p>But now lets apply a network policy.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ cat network-policy.yml
kind: NetworkPolicy
apiVersion: networking.k8s.io/v1
metadata:
name: nginx-allow
spec:
podSelector:
matchLabels:
app: nginx
ingress:
- from:
- podSelector:
matchLabels:
app: nginx
$ k apply -f network-policy.yml
networkpolicy.networking.k8s.io/nginx-allow created
$ k get networkpolicy
NAME POD-SELECTOR AGE
nginx-allow app=nginx 3s
</code></pre></div></div>
<p>A busybox pod can no longer connect to the nginx deployment (only pods with 32app=nginx).</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ k -n default exec -it busybox-deployment-66458f7d4b-4s6vh -- /bin/sh
/ # wget -q -O - 100.70.238.176 | grep title
wget: can't connect to remote host (100.70.238.176): Connection timed out
</code></pre></div></div>
<p>Let’s check the flows now.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ k -n kube-system exec -it antrea-agent-hs5kp antrea-agent -- antctl get ovsflows -T IngressRule
Defaulting container name to antrea-agent.
Use 'kubectl describe pod/antrea-agent-hs5kp -n kube-system' to see all of the containers in this pod.
FLOW
table=90, n_packets=155929, n_bytes=14839032, priority=210,ct_state=-new+est,ip actions=resubmit(,105)
table=90, n_packets=17178, n_bytes=1271172, priority=210,ip,nw_src=100.96.1.1 actions=resubmit(,105)
table=90, n_packets=0, n_bytes=0, priority=200,ip,nw_src=100.96.3.5 actions=conjunction(1,1/2)
table=90, n_packets=0, n_bytes=0, priority=200,ip,nw_src=100.96.2.5 actions=conjunction(1,1/2)
table=90, n_packets=0, n_bytes=0, priority=200,ip,nw_src=100.96.1.5 actions=conjunction(1,1/2)
table=90, n_packets=0, n_bytes=0, priority=200,ip,reg1=0x6 actions=conjunction(1,2/2)
table=90, n_packets=0, n_bytes=0, priority=190,conj_id=1,ip actions=resubmit(,105)
table=90, n_packets=15, n_bytes=1110, priority=0 actions=resubmit(,100)
</code></pre></div></div>
<p>More flows!</p>
<p>Those IPs are of the nginx pods.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ k get pods -o custom-columns='name:.metadata.name,pod ip:.status.podIPs[0].ip,node:.spec.nodeName' --sort-by='.spec.nodeName' --selector app=nginx
name pod ip node
nginx-85ff79dd56-2ndjq 100.96.1.5 tkg-antrea-md-0-548d498b47-2xjf8
nginx-85ff79dd56-fdrsp 100.96.2.5 tkg-antrea-md-0-548d498b47-ckwvd
nginx-85ff79dd56-cxjvw 100.96.3.5 tkg-antrea-md-0-548d498b47-f4rmz
</code></pre></div></div>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ k -n kube-system exec -it antrea-agent-hs5kp antrea-agent -- antctl get networkpolicies
Defaulting container name to antrea-agent.
Use 'kubectl describe pod/antrea-agent-hs5kp -n kube-system' to see all of the containers in this pod.
NAMESPACE NAME APPLIED-TO RULES
default nginx-allow 766a9e51-f132-5c2f-b862-9ac68e75d77d 1
</code></pre></div></div>
<p>Above we can ask Antrea about network polices as well.</p>
<h2 id="conclusion">Conclusion</h2>
<p>Open vSwitch is the swiss army knife of networking. It’s open. It’s widely used. It can run on Linux and Windows. It serves as a great basis for a software defined networking system for Kubernetes.</p>
<p>Checkout Antrea’s <a href="https://github.com/vmware-tanzu/antrea/blob/master/ROADMAP.md">roadmap</a> to see where they are going. Many great features on the horizon!</p>
<p><strong>PS.</strong> Please note that TKG does not officially support Antrea at the time I wrote this, but they are definitely looking at it.</p>
Install the Harbor Container Image Registry Locally2020-04-28T00:00:00+00:00http://serverascode.com/2020/04/28/local-harbor-install<h1 id="install-the-harbor-container-image-registry-locally">Install the Harbor Container Image Registry Locally</h1>
<p>In this post I’ll deploy a Harbor image registry on a local OSX workstation/laptop.</p>
<p>Requirements:</p>
<ul>
<li>OSX</li>
<li>Brew</li>
<li>Docker for Desktop</li>
</ul>
<h2 id="kind">Kind</h2>
<p><a href="https://kind.sigs.k8s.io/">Kind</a> stands for “Kubernetes in Docker” and is an easy way to get a local Kubernetes cluster running.</p>
<p><em>Note: Docker for Desktop also provides Kubernetes functionality, but in this example we are using Kind to provide k8s.</em></p>
<p>Install kind with brew.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>brew install kind
</code></pre></div></div>
<p>Create a kind based cluster.</p>
<p><em>Note the use of “extraPortMappings”.</em></p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>cat <<EOF | kind create cluster --config=-
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
nodes:
- role: control-plane
kubeadmConfigPatches:
- |
kind: InitConfiguration
nodeRegistration:
kubeletExtraArgs:
node-labels: "ingress-ready=true"
authorization-mode: "AlwaysAllow"
extraPortMappings:
- containerPort: 80
hostPort: 80
protocol: TCP
- containerPort: 443
hostPort: 443
protocol: TCP
EOF
</code></pre></div></div>
<p>Once that kind cluster is created we can see k8s nodes.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
kind-control-plane Ready master 2m31s v1.17.0
</code></pre></div></div>
<p>Nice!</p>
<h2 id="contour-ingress">Contour Ingress</h2>
<p><a href="https://projectcontour.io/">Contour</a> is an advanced open source ingress system supported in part by VMware.</p>
<blockquote>
<p>Contour is an open source Kubernetes ingress controller providing the control plane for the Envoy edge and service proxy. Contour supports dynamic configuration updates and multi-team ingress delegation out of the box while maintaining a lightweight profile.</p>
</blockquote>
<p>Deploy Contour.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>kubectl apply -f https://projectcontour.io/quickstart/contour.yaml
</code></pre></div></div>
<p>Patch it:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>kubectl patch daemonsets -n projectcontour envoy -p '{"spec":{"template":{"spec":{"nodeSelector":{"ingress-ready":"true"},"tolerations":[{"key":"node-role.kubernetes.io/master","operator":"Equal","effect":"NoSchedule"}]}}}}'
</code></pre></div></div>
<p>Contour should now be running.</p>
<p><em>Note: kubectl is provided by Docker for Desktop.</em></p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ kubectl get pods -n projectcontour
NAME READY STATUS RESTARTS AGE
contour-54df6b8854-dlsnr 1/1 Running 0 83s
contour-54df6b8854-m2w8k 1/1 Running 0 83s
contour-certgen-n78dz 0/1 Completed 0 83s
envoy-kwr8x 2/2 Running 0 10s
</code></pre></div></div>
<p>Contour will provide an easy way to get ingress. Of course, Contour offers a lot more than just ingress, but it’s all we need for now.</p>
<h2 id="install-helm">Install Helm</h2>
<p>Getting helm is quite easy with brew.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>brew install helm
</code></pre></div></div>
<p>Also we get helm 3!</p>
<h2 id="install-harbor">Install Harbor</h2>
<p>Now that we have Kubernetes and Helm, installing Harbor is straight forward, though there are many options available in the Helm chart. We will not be making any changes and use the defaults provided.</p>
<p>Add the Harbor Helm repository.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>helm repo add harbor https://helm.goharbor.io
</code></pre></div></div>
<p>And install Harbor:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>helm install local-harbor harbor/harbor
</code></pre></div></div>
<p>After a few minutes, there should be several Harbor k8s objects, such as pods.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ k get pods
NAME READY STATUS RESTARTS AGE
local-harbor-harbor-chartmuseum-bd9c45cbc-gwkbj 1/1 Running 0 58s
local-harbor-harbor-clair-865c9bc5db-cvbk8 1/2 Running 2 58s
local-harbor-harbor-core-64479f8d85-rkqm2 1/1 Running 0 58s
local-harbor-harbor-database-0 1/1 Running 0 58s
local-harbor-harbor-jobservice-8448b58df7-pgknp 1/1 Running 0 58s
local-harbor-harbor-notary-server-5bd9f5d966-56kk6 1/1 Running 0 58s
local-harbor-harbor-notary-signer-5fbfb48945-l2x54 1/1 Running 0 58s
local-harbor-harbor-portal-756d5d7d9d-xlv2g 1/1 Running 0 58s
local-harbor-harbor-redis-0 1/1 Running 0 58s
local-harbor-harbor-registry-57989b6446-w8vd8 2/2 Running 0 58s
</code></pre></div></div>
<p><em>NOTE: There are a lot of services running with Harbor. Future work for this post will include trying to make it a bit easier on resources on a workstation.</em></p>
<h2 id="access-harbor">Access Harbor</h2>
<p>Add a hostname to your <code class="language-plaintext highlighter-rouge">/etc/hosts</code> file.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>127.0.0.1 core.harbor.domain
</code></pre></div></div>
<p>Now open a browser session to http://core.harbor.domain/harbor</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>login: admin
password: Harbor12345
</code></pre></div></div>
<p>At this point Harbor is available for local use.</p>
<h2 id="delete-harbor-and-kind">Delete Harbor and Kind</h2>
<p>To remove everything added:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>helm uninstall local-harbor
kind delete cluster
</code></pre></div></div>
<p>Then shutdown Docker for Desktop.</p>
<h2 id="conclusion">Conclusion</h2>
<p>There are still a few things to be ironed out here. My Mac laptop starts sounding like a 747 pretty quickly. In a future post or update I’ll see how small we can make harbor, for now whatever helm deploys by default is what we are getting. The Harbor helm chart has many options that can be applied, but all defaults are being used here.</p>
Use .local Domain in Ubuntu 18.042020-03-28T00:00:00+00:00http://serverascode.com/2020/03/28/use-dot-local-domain-ubuntu<h1 id="use-local-domain-in-ubuntu-1804">Use .local Domain in Ubuntu 18.04</h1>
<p>I have a homelab and part of that homelab is a vSphere deployment. For whatever reason I used vsphere.local as the domain for some functionality. But Ubuntu doesn’t like the .local domain, I believe because it’s usually used with multicast DNS. TBH I’m not going to look to deep into why or why not one should use .local, the fact is that I am and I’m not changing it right now. :)</p>
<p>To use .local in Ubuntu I did this:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ grep Domain /etc/systemd/resolved.conf
Domains=vsphere.local
</code></pre></div></div>
<p>And moved the “dns” option in /etc/nsswitch.conf to be before mdns…</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>#hosts: files mdns4_minimal [NOTFOUND=return] dns myhostname
hosts: files dns mdns4_minimal [NOTFOUND=return]
</code></pre></div></div>
<p>After that I could resolve .local domains.</p>
<p>Happy .local domaining!</p>
Change or Rewrite cluster.local in Kubernetes2020-03-25T00:00:00+00:00http://serverascode.com/2020/03/25/rewrite-change-cluster-local-kubernetes<h1 id="change-or-rewrite-clusterlocal-in-kubernetes">Change or Rewrite cluster.local in Kubernetes</h1>
<p>Some organizations may want to use a domain other than cluster.local as the service domain in Kubernetes.</p>
<p>One way to do that is to add a rewrite substring rule in CoreDNS. (Of course this assumes the use of CoreDNS.)</p>
<p>I have a VMware Enterprise PKS cluster to test with.</p>
<p>The CoreDNS configmap starts out looking like this:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code> $ kubectl get -n kube-system cm/coredns -o yaml
apiVersion: v1
data:
Corefile: |
.:53 {
errors
health
kubernetes cluster.local in-addr.arpa ip6.arpa {
pods insecure
upstream
fallthrough in-addr.arpa ip6.arpa
}
prometheus :9153
proxy . /etc/resolv.conf {
policy sequential # needed for workloads to be able to use BOSH-DNS
}
cache 30
loop
reload
loadbalance
}
kind: ConfigMap
metadata:
annotations:
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"v1","data":{"Corefile":".:53 {\n errors\n health\n kubernetes cluster.local in-addr.arpa ip6.arpa {\n pods insecure\n upstream\n fallthrough in-addr.arpa ip6.arpa\n }\n prometheus :9153\n proxy . /etc/resolv.conf {\n policy sequential # needed for workloads to be able to use BOSH-DNS\n }\n cache 30\n loop\n reload\n loadbalance\n}\n"},"kind":"ConfigMap","metadata":{"annotations":{},"name":"coredns","namespace":"kube-system"}}
creationTimestamp: "2020-03-25T14:21:39Z"
name: coredns
namespace: kube-system
resourceVersion: "1341"
selfLink: /api/v1/namespaces/kube-system/configmaps/coredns
uid: 0dd853af-a4d7-498d-9745-752cbf8fbffb
</code></pre></div></div>
<p>All I want to do is add this line:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>rewrite name substring svc.example.com svc.cluster.local
</code></pre></div></div>
<p>So the full file looks like:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>apiVersion: v1
data:
Corefile: |
.:53 {
errors
health
rewrite name substring svc.example.com svc.cluster.local
kubernetes cluster.local in-addr.arpa ip6.arpa {
pods insecure
upstream
fallthrough in-addr.arpa ip6.arpa
}
prometheus :9153
proxy . /etc/resolv.conf {
policy sequential # needed for workloads to be able to use BOSH-DNS
}
cache 30
loop
reload
loadbalance
}
kind: ConfigMap
metadata:
name: coredns
namespace: kube-system
</code></pre></div></div>
<p>Let’s replace the existing configmap with the new one.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ k replace -f coredns-configmap-rewrite.yml
configmap/coredns replaced
</code></pre></div></div>
<p>After a few seconds, CoreDNS will restart.</p>
<p>I’ve deployed two nginx based servcies.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ k get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.100.200.1 <none> 443/TCP 3h30m
nginx-1 LoadBalancer 10.100.200.226 10.1.4.18 80:31668/TCP 138m
nginx-2 LoadBalancer 10.100.200.160 10.1.4.19 80:31692/TCP 116m
</code></pre></div></div>
<p>I’ll exec into one and run dig.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>root@nginx-1-56958fdfdd-d26tj:/# dig +short nginx-1.default.svc.cluster.local
10.100.200.226
root@nginx-1-56958fdfdd-d26tj:/# dig +short nginx-2.default.svc.cluster.local
10.100.200.160
root@nginx-1-56958fdfdd-d26tj:/# dig +short nginx-2.default.svc.example.com
10.100.200.160
root@nginx-1-56958fdfdd-d26tj:/# dig +short nginx-1.default.svc.example.com
10.100.200.226
</code></pre></div></div>
<p>Note how both domains work. Nice!</p>
<p>That’s it.</p>
PKS and Persistent Volumes2020-03-21T00:00:00+00:00http://serverascode.com/2020/03/21/pks-max-persistent-disks-statefulsets<h1 id="pks-and-persistent-volumes">PKS and Persistent Volumes</h1>
<p>I work at <a href="https://tanzu.vmware.com/">VMware in the Tanzu group</a> as a Solutions Engineer. Occasionally customers ask me numbers questions, by that I mean they ask about so called “speeds and feeds” like “How many of this can you do?” and “How fast is that?”. The answers to these change all the time, and overall exact numbers aren’t typically important to the business outcomes. That said, sometimes it’s good to explore what the limitation are, and perhaps more importantly <em>where</em> the limitations exist.</p>
<p>Actually, as I write this, I don’t think <em>limitations</em> is the right word, as it’s really about how systems and products work together to create constraints. Yes, I like that better. Constraints.</p>
<h2 id="statefulset">StatefulSet</h2>
<p>In this lab I have:</p>
<ul>
<li>vSphere 6.7u3 - Single physical host</li>
<li>NSX-t 2.5</li>
<li>Harbor 1.10</li>
<li>PKS 1.6 and 1.7</li>
</ul>
<p>PKS has kindly created a small cluster, called small-pks. Actually this cluster is 1.7, but that doesn’t have any bearing on this quick test.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ pks cluster small-pks
PKS Version: 1.7.0-build.19
Name: small-pks
K8s Version: 1.16.7
Plan Name: small
UUID: f5879fcf-46ec-4a7e-b2cb-7a74004aed87
Last Action: UPGRADE
Last Action State: succeeded
Last Action Description: Instance update completed
Kubernetes Master Host: small.example.com
Kubernetes Master Port: 8443
Worker Nodes: 3
Kubernetes Master IP(s): 10.197.123.128
Network Profile Name:
</code></pre></div></div>
<p>The cluster has 3 worker nodes, so we should be able to get a max of stateful sets that is 3x…something. But what is that something? I’m making a guess the limitation is not more than 64, so let’s try 200. (This example is <a href="https://github.com/kubernetes/examples/blob/master/staging/volumes/vsphere/simple-statefulset.yaml">from here</a>.)</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ cat simple-statefulset.yaml
---
apiVersion: v1
kind: Service
metadata:
name: nginx
labels:
app: nginx
spec:
ports:
- port: 80
name: web
clusterIP: None
selector:
app: nginx
---
apiVersion: apps/v1 # for k8s versions before 1.9.0 use apps/v1beta2 and before 1.8.0 use extensions/v1beta1
kind: StatefulSet
metadata:
name: web
labels:
app: nginx
spec:
serviceName: "nginx"
selector:
matchLabels:
app: nginx
replicas: 200
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: k8s.gcr.io/nginx-slim:0.8
ports:
- containerPort: 80
name: web
volumeMounts:
- name: www
mountPath: /usr/share/nginx/html
volumeClaimTemplates:
- metadata:
name: www
spec:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 1Gi
storageClassName: ci-storage
</code></pre></div></div>
<p>After that runs for a while, I end up stuck with 132 replicas.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ k get statefulsets
NAME READY AGE
web 132/200 5h12m
</code></pre></div></div>
<p>Why is that?</p>
<p>Well, it turns out, and <a href="https://orchestration.io/2018/06/13/storage-classes-in-pivotal-container-service-pks/">this post</a> does a better job of discussing it, that vSphere allows for 4 SCSI adapters per virtual machine, and PKS will use 3 of them. Each of those 3 adapters can have 15 disks. Thus we end up with a constraint of 45 disks per vm for use with persistent volumes.</p>
<p>In the image below you can see the vm has 48 disks. 3 disks are for the OS and managing the vm itself via bosh, and are attached to the first SCSI adapter, the other 45 are persistent volumes attached to the remaining 3 adapters. (<a href="https://configmax.vmware.com/guest?vmwareproduct=vSphere&release=vSphere%206.7&categories=1-0.">Here are the maximums for vSphere 6.7</a>.)</p>
<p><img src="/img/vm-disks.jpg" alt="vm disks" /></p>
<p>In the end the constraint is around the number of SCSI adapters possible, how PKS uses them, and how many virtual drives can be attached. With those all in play, we get a constraint of 45 persistent volumes per virtual machine in PKS. Is 45 a lot, a little, or just right? Hard to say. Sounds about right.</p>
<hr />
<p><em>PS. Note that numbers like this change all the time. By the time you read this, maybe it will be higher than 45 PVs per node.</em></p>
Wireguard, Dante, and Firefox2020-03-01T00:00:00+00:00http://serverascode.com/2020/03/01/wireguard-danted-firefox<h1 id="wireguard-dante-and-firefox">Wireguard, Dante, and Firefox</h1>
<p>I usually proxy my Firefox through to a remote server running in a public cloud. Typically I just do that with ssh.</p>
<p>e.g. I run the below in a separate terminal and just leave it open. (I could have used autossh, but never quite got around to it.)</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>ssh -D 8888 remote-vpn
</code></pre></div></div>
<p>Then Firefox is configured to use the local proxy. Note that I set it to proxy DNS as well.</p>
<p><img src="/img/ff-proxy.jpg" alt="firefox proxy settings" /></p>
<p>It’s a bit of a weird setup, but it’s simple and I’m used to it.</p>
<h2 id="wireguard-instead-of-ssh">Wireguard Instead of ssh</h2>
<p>I’ve been using Wireguard in another situation, and decided it’s time to move from a manually setup ssh command to letting wireguard take care of it.</p>
<p>On local laptop:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code># pwd
/etc/wireguard
# cat wg0.conf
[Interface]
Address = 192.168.100.3/32
PrivateKey = <redacted>
ListenPort = 21842
[Peer]
PublicKey = <redacted>
Endpoint =<redacted>:<redacted>
AllowedIPs = 192.168.100.1/32
PersistentKeepalive = 25
</code></pre></div></div>
<p>On the remote server. Note that I’m enabling/disabling nat for the wg0 interface IP based on whether the wg0 interface is up or down.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code># cat wg0.conf
[Interface]
Address = 192.168.100.1/24
PrivateKey = <redacted>
ListenPort = <redacted>
PostUp = iptables -t nat -A POSTROUTING -s 192.168.100.1/32 -o eth0 -j MASQUERADE
PostDown = iptables -t nat -D POSTROUTING -s 192.168.100.1/32 -o eth0 -j MASQUERADE
[Peer]
PublicKey = <redacted>
AllowedIPs = 192.168.100.3/32
</code></pre></div></div>
<p>iptables config. OF course packets must be forwarded too.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code># sysctl net.ipv4.ip_forward
net.ipv4.ip_forward = 1
# iptables -L -n -t nat
Chain PREROUTING (policy ACCEPT)
target prot opt source destination
Chain INPUT (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
Chain POSTROUTING (policy ACCEPT)
target prot opt source destination
MASQUERADE all -- 192.168.100.1 0.0.0.0/0
</code></pre></div></div>
<p>On the laptop, enable and start wg0.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>sudo systemctl enable wg-quick@wg0
sudo systemctl start wg-quick@wg0
</code></pre></div></div>
<p>And I’m now connected:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code> $ sudo wg show
interface: wg0
public key: <redacted>
private key: (hidden)
listening port: <redacted>
peer: <redacted>
endpoint: <redacted>
allowed ips: 192.168.100.1/32
latest handshake: 1 minute, 44 seconds ago
transfer: 149.80 MiB received, 10.38 MiB sent
persistent keepalive: every 25 seconds
</code></pre></div></div>
<p>ssh is convenient because it can do proxying without any extra work. But that is not so with wireguard. I need a second proxy system. In this case, the easiest thing to use seemed to be dante.</p>
<p>I’ve configured danted in /etc/danted.conf. (This configuration could probably use some improvement.)</p>
<p>NOTE: Only listening on wg0. Don’t put it on the external interface.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code># cat /etc/danted.conf
logoutput: /var/log/socks.log
internal: wg0 port = 1080
external: wg0
clientmethod: none
socksmethod: none
user.privileged: root
user.notprivileged: nobody
client pass {
from: 0.0.0.0/0 to: 0.0.0.0/0
log: error connect disconnect
}
client block {
from: 0.0.0.0/0 to: 0.0.0.0/0
log: connect error
}
socks pass {
from: 0.0.0.0/0 to: 0.0.0.0/0
log: error connect disconnect
}
socks block {
from: 0.0.0.0/0 to: 0.0.0.0/0
log: connect error
}
</code></pre></div></div>
<p>Configure firefox.</p>
<p>NOTE: Firefox I guess doesn’t support user/password for proxies? Very weird.</p>
<p><img src="/img/ff-proxy2.jpg" alt="firefox proxy danted" /></p>
<p>Sessions through dante. Note the “nobody” user.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code># lsof -Pni :1080 | head
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
danted 683 nobody 26u IPv4 609554 0t0 TCP 192.168.100.1:1080->192.168.100.3:56096 (ESTABLISHED)
danted 685 nobody 20u IPv4 609980 0t0 TCP 192.168.100.1:1080->192.168.100.3:56166 (ESTABLISHED)
danted 685 nobody 22u IPv4 609961 0t0 TCP 192.168.100.1:1080->192.168.100.3:56160 (ESTABLISHED)
danted 685 nobody 58u IPv4 622465 0t0 TCP 192.168.100.1:1080->192.168.100.3:57406 (ESTABLISHED)
danted 30447 nobody 9u IPv4 575223 0t0 TCP 192.168.100.1:1080 (LISTEN)
danted 32313 nobody 12u IPv4 619529 0t0 TCP 192.168.100.1:1080->192.168.100.3:57080 (ESTABLISHED)
danted 32313 nobody 16u IPv4 612166 0t0 TCP 192.168.100.1:1080->192.168.100.3:56324 (ESTABLISHED)
danted 32313 nobody 22u IPv4 610614 0t0 TCP 192.168.100.1:1080->192.168.100.3:56212 (ESTABLISHED)
danted 32313 nobody 62u IPv4 618755 0t0 TCP 192.168.100.1:1080->192.168.100.3:57010 (ESTABLISHED)
</code></pre></div></div>
<h2 id="conclusion">Conclusion</h2>
<p>Using ssh was definitely simpler, but I wanted to try something else, specifically wireguard. But this means 1) setting up wireguard (FYI: is an out of tree kernel module), 2) adding a proxy and 3) configuring nat. At least one valuable option in using wireguard is that I can send all traffic through wireguard if I want to. I’m not right now, but I could.</p>
<p>That said, I need to do some more work related to the proxy configuration, and whether dante is really the best option here. I’ll experiment with this setup for a while and determine if there are better options. Do I recommend this setup? I think wireguard is an important technology, but I don’t have a great understanding of it yet. So, of course, your mileage may vary.</p>
<p>PS. I also need to check on ipv6 support for this setup, but I don’t think my home internet provider supports it (lol).</p>
Overriding Docker Entrypoint when Running from CLI2020-02-22T00:00:00+00:00http://serverascode.com/2020/02/22/ovrride-docker-entrypoint<h1 id="overriding-docker-entrypoint-when-running-from-cli">Overriding Docker Entrypoint when Running from CLI</h1>
<p>I have a very simple Dockerfile that I’m using as an example of layers.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ cat Dockerfile
FROM ubuntu
RUN echo "layer 1" >> /layers
RUN echo "layer 2" >> /layers
RUN echo "layer 3" >> /layers
RUN echo "layer 4" >> /layers
ENTRYPOINT cat /layers
</code></pre></div></div>
<p>I’ve built it. Now if I run it…</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ docker run --rm layer-example
layer 1
layer 2
layer 3
layer 4
</code></pre></div></div>
<p>But what if I don’t want to use that entrypoint? I can override the entyrpoint and then provide another command.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>docker run --entrypoint "/usr/bin/env" --name layer-example layer-example /bin/bash -c 'while true; do echo sleeping; sleep 2; done'
</code></pre></div></div>
<p>Note that I’m using <code class="language-plaintext highlighter-rouge">env</code> as the entrypoint, and then the actual command I want ot run is <code class="language-plaintext highlighter-rouge">/bin/bash -c 'while true; do echo sleeping; sleep 2; done'</code>.</p>
<p>Interestingly <code class="language-plaintext highlighter-rouge">env</code> just forwards the command on and runs it.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ /usr/bin/env echo hi
hi
</code></pre></div></div>
<p>If I run it:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ docker run --entrypoint "/usr/bin/env" --name layer-example layer-example /bin/bash -c 'while true; do echo sleeping; sleep 2; done'
sleeping
sleeping
sleeping
sleeping
sleeping
...
</code></pre></div></div>
<p>In another terminal I stop and remove the container via:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>docker rm -f layer-example
</code></pre></div></div>
20 Tools to Manage Kubernetes Manifests2020-02-16T00:00:00+00:00http://serverascode.com/2020/02/16/20-tools-to-manage-kubernetes-maniftest<h1 id="20-tools-to-manage-kubernetes-manifests">20 Tools to Manage Kubernetes Manifests</h1>
<blockquote>
<p>Of all the problems we have confronted, the ones over which the most brainpower, ink, and code have been spilled are related to managing <em>configurations.</em> - <a href="https://queue.acm.org/detail.cfm?id=2898444">Brendan Burns, Brian Grant, David Oppenheimer, Eric Brewer, and John Wilkes, Google Inc</a>.</p>
</blockquote>
<p>I spent some time tracking down tools that seem like they manage K8S manifests. I found…many. This list of ~20 only touches the surface of a bubbling ecosystem.</p>
<p>Some of these tools are large and some are small. Some are simple templating systems, others can manage the entire life cycle of applications across many kinds of infrastructure. Some are libraries for programming languages, others complete languages themselves. A few are mature projects, some brand new, and others side projects of a single developer. The breadth and variance is quite amazing!</p>
<p>Please note that these are in no specific order, and neither does that order represent any kind of preference. Further, some of these tools, eg. Ksonnet, are no longer maintained. <em>This is not an exhaustive list!</em></p>
<p>But let’s get to it.</p>
<h3 id="20-tools-and-2-bonus-tools"><em><strong>20 Tools (and 2 Bonus Tools)</strong></em></h3>
<ol>
<li>
<p><a href="https://jsonnet.org/"><strong>Jsonnet</strong></a> - A data templating language. Used by many tools in this list behind the scenes. Powerful, but sometimes with great power comes with great, uh, cognitive load?</p>
</li>
<li>
<p><a href="https://jkcfg.github.io/#/"><strong>jk</strong></a> - <em>“jk generates all your JSON, YAML and arbitrary text configuration files. With a little luck, you will not have to touch a YAML file again. Ever.”</em> Bold claim!</p>
</li>
<li>
<p><a href="https://cuelang.org/"><strong>Cue</strong></a> - Apparently created by the person (or persons) behind the Borg Configuration Language (BCL) used at Google. <em>“CUE is an open source language, with a rich set APIs and tooling, for defining, generating, and validating all kinds of data: configuration, APIs, database schemas, code, … you name it.”</em></p>
</li>
<li>
<p><a href="https://github.com/cruise-automation/isopod"><strong>Isopod</strong></a> - <em>“Isopod is an expressive DSL framework for Kubernetes configuration. Without intermediate YAML artifacts, Isopod renders Kubernetes objects as <a href="https://github.com/protocolbuffers/protobuf"></a></em> <a href="https://github.com/protocolbuffers/protobuf"><em>Protocol Buffers</em></a><em>, so they are strongly typed and consumed directly by the Kubernetes API.”</em> Interesting that they skip the YAML. Based on <a href="https://github.com/stripe/skycfg"></a> <a href="https://github.com/stripe/skycfg">Skycfg</a>. A good intro <a href="https://medium.com/cruise/isopod-5ad7c565d350"></a> <a href="https://medium.com/cruise/isopod-5ad7c565d350">here</a>.</p>
</li>
<li>
<p><a href="https://github.com/brendandburns/configula"><strong>Configula</strong></a> - “<em>Configula is inspired by the <a href="https://reactjs.org/docs/introducing-jsx.html"></a></em> <a href="https://reactjs.org/docs/introducing-jsx.html"><em>JSX language</em></a> <em>in <a href="https://reactjs.org/"></a></em> <a href="https://reactjs.org/"><em>React</em></a> <em>that combines Javascript and HTML tags. Configula defines a similar pattern for Python and YAML (for now).”</em> Joe Beda went over it in <a href="https://www.youtube.com/watch?v=efUAuOxR-ro"></a> <a href="https://www.youtube.com/watch?v=efUAuOxR-ro">TKIG</a>. It’s a Go utility that calls out to Python!</p>
</li>
<li>
<p><a href="https://github.com/google/ko"><strong>Ko</strong></a> - Point your K8S container image to a Go repo. It will build a container image using the binary generated from the repo. Does not use Docker to actually build the image. Wraps kubectl in some places.</p>
</li>
<li>
<p><a href="https://kustomize.io/"><strong>Kustomize</strong></a> - <em>“kustomize targets kubernetes; it understands and can patch kubernetes style API objects. It’s like make, in that what it does is declared in a file, and it’s like sed, in that it emits edited text.”</em> I’ve seen Kustomize used a few times; seems popular. Also it is conveniently part of Kubectl.</p>
</li>
<li>
<p><a href="https://helm.sh/"><strong>Helm</strong></a> <strong>-</strong> Helm is likely the most commonly used tool on this list. Recently Helm 3 was released removing its main criticism regarding the use of the tiller server.</p>
</li>
<li>
<p><a href="https://github.com/bitnami/kubecfg"><strong>Kubecfg</strong></a> - <em>“Kubecfg relies heavily on <a href="http://jsonnet.org/"></a></em> <a href="http://jsonnet.org/"><em>jsonnet</em></a> <em>to describe Kubernetes resources, and is really just a thin Kubernetes-specific wrapper around jsonnet evaluation.”</em> ‘nuff said!</p>
</li>
<li>
<p><a href="https://ksonnet.io/"><strong>Ksonnet</strong></a> - Ksonnet is no longer worked on, but I think it’s a good thing to have in this list as a reminder ensure that not every tool will stick around. Experimentation will continue in this space.</p>
</li>
<li>
<p><a href="https://k14s.io/"><strong>k14s</strong></a> - <em>“We believe that working with <a href="https://content.pivotal.io/blog/introducing-k14s-kubernetes-tools-simple-and-composable-tools-for-application-deployment"></a></em> <em><a href="https://content.pivotal.io/blog/introducing-k14s-kubernetes-tools-simple-and-composable-tools-for-application-deployment">simple, single-purpose tools</a></em> <em>that easily interoperate with one another results in a better, workflow compared to the all-in-one approach chosen by Helm. We have found this approach to be easier to understand and debug.”</em> k14s is developed by people at Pivotal (where I work, now part of VMware). There’s a <a href="https://www.youtube.com/watch?v=CSglwNTQiYg"></a> <a href="https://www.youtube.com/watch?v=CSglwNTQiYg">TGIK</a> episode on it. The Unix philosophy has done us all well over time, perhaps this is the right approach to managing K8S manifests.</p>
</li>
<li>
<p><a href="https://www.pulumi.com/"><strong>Pulumi</strong></a> - Allows you to use “real” programming languages to manipulate cloud environments, including K8S. Interestingly supports multiple programming languages. <em>“Define infrastructure in JavaScript, TypeScript, Python, Go, or any .NET language, including C#, F#, and VB.”</em></p>
</li>
<li>
<p><a href="https://ballerina.io/"><strong>Ballerina</strong></a> - _ “Ballerina is an open source programming language and platform for cloud-era application programmers to easily write software that just works.”_ Write code in the ballerina language that can build K8S objects for you.</p>
</li>
<li>
<p><a href="https://github.com/deepmind/kapitan"><strong>Kapitan</strong></a> - <em>“…a tool to manage complex deployments using jsonnet, kadet (alpha) and jinja2. Use Kapitan to manage your Kubernetes manifests, your documentation, your Terraform configuration or even simplify your scripts.”</em> Another tool wrapping jsonnet.</p>
</li>
<li>
<p><a href="https://docs.ansible.com/ansible/latest/modules/k8s_module.html"><strong>Ansible</strong></a> - Ansible can manage K8S objects and is also fairly good a templating, allowing you to easily write custom inventories and pull in metadata about your systems. Simple and powerful.</p>
</li>
<li>
<p><a href="https://www.terraform.io/docs/providers/kubernetes/index.html"><strong>Terraform</strong></a> - Terraform can manage K8S objects. Read about why one would use Terraform and K8S <a href="https://www.hashicorp.com/blog/managing-kubernetes-applications-with-hashicorp-terraform/"></a> <a href="https://www.hashicorp.com/blog/managing-kubernetes-applications-with-hashicorp-terraform/">here</a>. The fact that Terraform is declarative would likely be a good match for K8S.</p>
</li>
<li>
<p><a href="https://www.habitat.sh/"><strong>Habitat</strong></a> - <em>“Chef Habitat is open source software that creates platform-independent build artifacts and provides built-in deployment and management capabilities.”</em> I can’t do Habitat any justice here, other than to say my impression is that it is a can manage applications on several different types of platforms, of which K8S is one.</p>
</li>
<li>
<p><a href="https://github.com/GoogleContainerTools/skaffold"><strong>Skaffold</strong></a> - <em>“Skaffold is a command line tool that facilitates continuous development for Kubernetes applications. You can iterate on your application source code locally then deploy to local or remote Kubernetes clusters.”</em> Aimed at the inner dev loop, but can deploy to K8S as well.</p>
</li>
<li>
<p><a href="https://github.com/smartive/kuby/"><strong>Kuby</strong></a> - <em>“</em><a href="https://blog.smartive.ch/how-we-simplified-our-kubernetes-deployments-with-an-alternative-to-helm-aafedcfd4cce"><em>Kuby</em></a> <em>wraps kubectl and provides commands like kuby prepare to replace variables in YAML or kuby deploy to prepare and apply deployments to Kubernetes.”</em></p>
</li>
<li>
<p><a href="https://github.com/dekorateio/dekorate"><strong>Dekorate</strong></a> - <em>“The are tons of tools out there for scaffolding / generating kubernetes manifests. Sooner or later these manifests will require customization…Using external tools, is often too generic. Using build tool extensions and adding configuration via xml, groovy etc is a step forward, but still not optimal.”</em> I think that introduction is apropos given this list. Keep manifest generation as part of your development/language environment, makes sense to me especially if your org is focussed on one language, i.e. Java.</p>
</li>
<li>
<p><strong>BONUS: <a href="https://github.com/pivotal/kpack"></a></strong> <a href="https://github.com/pivotal/kpack"><strong>Kpack</strong></a> - A system for using Cloud Native <a href="https://buildpacks.io/"></a> <a href="https://buildpacks.io/">buildpacks.</a> Buildpacks are a more structured, opinionated way to build container images. Joe Beda ran a <a href="https://www.youtube.com/watch?v=4zkRX9PSJ5k&feature=youtu.be"></a> <a href="https://www.youtube.com/watch?v=4zkRX9PSJ5k&feature=youtu.be">TKIG</a> on it. The pack command line can be used to build local images, or kpack can be deployed into K8S and will automatically rebuild images when code is changed in repositories. Kpack is focussed in image builds, not so much on generating manifests. (NOTE: Built by Pivotal, now VMware.)</p>
</li>
<li>
<p><strong>BONUS: Any programming language</strong> - I wanted to make sure that I put this on the list, as ultimately any language that can print to standard out could be used to generate K8S manifests. Of course, we would likely not want to do something that simplistic, but I don’t think it’s far fetched or unreasonable to use templates and a generic programming language to build manifests.</p>
</li>
</ol>
<h3 id="conclusion"><strong>Conclusion</strong></h3>
<p>As I mentioned at the start this list is random–the order it comes in was the order I discovered them on the Internet. (Certainly there are some cool tools I have missed, let me know in the comments.)</p>
<p>Ultimately, these tools provide some kind of templating, wrapper, abstraction, or other convenience around K8S, though, of course, they all do it in different ways and chose different approaches. The differences and value of these individual tools is typically under the surface layer and thus require some investigation to truly understand when, or when not, to use them.</p>
<p>With so many options it does seem like the market (made up of us technical people–the people who want and use K8S) hasn’t decided how exactly to use Kubernetes. A “silver bullet” approach probably won’t work. Will one of these tools win out? A handful? Will we get something new? Or does Platform as a Service still make the most sense? Time will tell. Until then, we all have to perform some due diligence and keep innovating.</p>
<hr />
<p>PS. Once I found ~20 I stopped. A few minutes later I found <a href="https://docs.google.com/spreadsheets/d/1FCgqz1Ci7_VCz_wdh8vBitZ3giBtac_H8SBw4uxnrsE/edit#gid=0">this spreadsheet</a> with 120 similar tools!</p>
Kubernetes and Mimesis - The YAML is not the (M)App2020-02-15T00:00:00+00:00http://serverascode.com/2020/02/15/the-yaml-is-not-the-app-or-map<h1 id="kubernetes-and-mimesis---the-yaml-is-not-the-mapp">Kubernetes and Mimesis - The YAML is not the (M)App</h1>
<p>100% of organizations I have worked with and talk to either want to automate or already doing so. Everyone “automates.” Everyone “DevOps.”</p>
<blockquote>
<p>“Yes, yes, we have DevOps, we have automation. Been doing that forever. But it’s not enough.” - Customer</p>
</blockquote>
<p>Most want to do more than what automation can provide on its own. In my opinion, doing more demands abstraction.</p>
<h2 id="fear-of-abstraction">Fear of Abstraction</h2>
<p>Technology leaders often equate abstraction with “lock-in,” be it technical lock-in, contractual lock-in, or other. Abstraction is, to them, a concerning concept and something to be avoided.</p>
<p>To engineers the mention of abstraction conjures a fear of the inscrutable. To engineers, abstraction is a black box. Key, even sacred, information is hidden within the confines of the dreaded cube. Of course, some information hiding is precisely the goal of abstraction. However, as an engineer might ask you, if information is hidden, then how can one truly understand every component of their vast and complex platform? Full stack or full stop.</p>
<p>Thus we end up, as an industry, in a situation where abstraction is alarming to both technical leadership and engineers. So it is typically avoided, especially in terms of infrastructure.</p>
<p>Instead of innovating and building powerful business outcomes on abstraction, we recreate–we imitate–the existing terrain by drawing an extremely detailed but novel map (just like the old one). With a new and detailed map in hand engineers feel safe and energized. With a new and detailed map, technology leaders have an artefact that can be displayed under glass with a label of progress. But I’m getting ahead of myself.</p>
<p><img src="/img/not-the-map-2.jpg" alt="" /></p>
<h2 id="release-the-shackles">Release the Shackles!</h2>
<p>Prior to, oh say around about 1910, give or take, artists painted real things and those paintings looked like real things (as much as a two dimensional image can, anyway). In fact, if you didn’t paint real things that looked like real things, say something “abstract,” it was cause for serious concern. Take, for example, the harsh criticism of James Whistler’s “Nocturne in Black and Gold – The Falling Rocket” via which he eventually entered bankruptcy.</p>
<p>When Malevich created his most well known work, “Black Square,” it was arguably “the first time someone made a painting that wasn’t of something.” Malevich’s work was designed, in part, to free the art world from its current limitations related to the explicit desire to continually imitate something real.</p>
<p>Most importantly, I believe, in Malevich’s work “the white backgrounds against which they were set mapped the boundless space of the ideal.” When we avoid abstraction in technology, we also miss out on the benefits of the open playing field it creates. Without abstraction we don’t have room to run.</p>
<p><img src="/img/not-the-map-3.jpg" alt="" /></p>
<h2 id="kubernetes-and-mimesis">Kubernetes and Mimesis</h2>
<p>First off, no, mimesis is not some new Kubernetes related project or product (at least…I don’t think it is). The typical definition of mimesis revolves around the idea of imitating or reproducing reality. To reiterate the quote I have from Richard Spalding above, “Malevich’s intent [was] to liberate painting from the shackles of mimesis.” I believe mimesis is an easy trap to fall into with k8s.</p>
<p>Make no mistake, I am a big fan of Kubernetes. I even spent three hours wrangling YAML for the Certified Kubernetes Administrator exam. That said, I do feel like we, as an industry, have to be careful not to end up creating yet another detailed map of the territory. We should endeavour not to simply imitate existing constructs. We have to be willing to not only accept the wide open playing field the box/square/abstraction provides but to have an appetite for it. And, most importantly, use k8s to create it.</p>
<p>This point has been well made by some of the originators of Kubernetes, people such as Joe Beda and Craig McLuckie of Heptio, and now VMWare, fame. Others too.</p>
<p><img src="/img/not-the-map-4.png" alt="" /></p>
<p>Kubernetes role is not to mimic the existing platforms and systems, ie. a map where the scale is a mile to a mile. Rather its mission is to provide the advanced machinery necessary to develop new abstractions on which we can then create novel, and financially beneficial, work. Abstraction doesn’t create black boxes, it provides the freedom to invent.</p>
<p>In conclusion, suffice it to say, the YAML is not the (m)app.</p>
Investigating Curl Bash Installs with Docker2020-02-02T00:00:00+00:00http://serverascode.com/2020/02/02/curl-bash-investigation-docker-diff<h1 id="investigating-curl-bash-installs-with-docker">Investigating Curl Bash Installs with Docker</h1>
<p>Many sytems install with some version of <code class="language-plaintext highlighter-rouge">curl https://install.example.com | bash</code>. Using this model for installation is typically DIScouraged. But what if you don’t have much of an option for installation? How can you investigate what this bash script does?</p>
<p>One simple way is to use docker diff.</p>
<h2 id="sdkman-install-inspection">sdkman Install Inspection</h2>
<p>Recently I have started working with Java. Pretty new to it all. I’m used to basic Python development and often use virtual environments. What provides a similar pattern in the Java ecosystem? One example may be sdkman. I’m not sure, haven’t used it. However, to install it requires the curl bash (anti?) pattern. I’d like to investigate what that curl bash does.</p>
<p>First, an image with the base requirements for sdkman. It uses which to check for zip, ect.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>localhost$ cat Dockerfile
FROM fedora
RUN dnf install -y unzip zip curl which
</code></pre></div></div>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>localhost$ docker build . -t sdkman-test
</code></pre></div></div>
<p>Run it.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>docker run -it --name sdkman-test-run sdkman-test /bin/bash
</code></pre></div></div>
<p>Manually install sdkman into that container through the curl bash.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>container$ curl -s "https://get.sdkman.io" | bash
</code></pre></div></div>
<p>Inspect the differences in the filesystem in the RUNNING container.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>localhost$ docker diff sdkman-test-run
C /root
C /root/.bashrc
A /root/.sdkman
A /root/.sdkman/ext
A /root/.sdkman/src
A /root/.sdkman/src/sdkman-offline.sh
A /root/.sdkman/src/sdkman-selfupdate.sh
A /root/.sdkman/src/sdkman-uninstall.sh
A /root/.sdkman/src/sdkman-use.sh
A /root/.sdkman/src/sdkman-availability.sh
A /root/.sdkman/src/sdkman-env-helpers.sh
A /root/.sdkman/src/sdkman-install.sh
A /root/.sdkman/src/sdkman-list.sh
A /root/.sdkman/src/sdkman-update.sh
A /root/.sdkman/src/sdkman-version.sh
A /root/.sdkman/src/sdkman-current.sh
A /root/.sdkman/src/sdkman-default.sh
A /root/.sdkman/src/sdkman-help.sh
A /root/.sdkman/src/sdkman-main.sh
A /root/.sdkman/src/sdkman-broadcast.sh
A /root/.sdkman/src/sdkman-flush.sh
A /root/.sdkman/src/sdkman-upgrade.sh
A /root/.sdkman/src/sdkman-cache.sh
A /root/.sdkman/src/sdkman-path-helpers.sh
A /root/.sdkman/src/sdkman-utils.sh
A /root/.sdkman/tmp
A /root/.sdkman/tmp/sdkman-5.7.4+362.zip
A /root/.sdkman/tmp/stage
A /root/.sdkman/var
A /root/.sdkman/var/candidates
A /root/.sdkman/var/version
A /root/.sdkman/archives
A /root/.sdkman/bin
A /root/.sdkman/bin/sdkman-init.sh
A /root/.sdkman/candidates
A /root/.sdkman/etc
A /root/.sdkman/etc/config
A /root/.zshrc
</code></pre></div></div>
<p>Seems like /root/.bashrc has changed. Unfortunately docker diff can’t diff individual files. So I’ll need to build a new image and diff the base Fedora file.</p>
<p>Let’s add the curl bash to the image so we can diff it.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>localhost$ cat Dockerfile
FROM fedora
RUN dnf install -y unzip zip curl which
RUN curl -s "https://get.sdkman.io" | bash
</code></pre></div></div>
<p>Build again.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>localhost$ docker build . -t sdkman-test
</code></pre></div></div>
<p>Now grab the two bashrc file, one from the base fedora image and one from the image just built.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>docker run --rm -v `pwd`:/out sdkman-test /bin/cp /root/.bashrc /out/bashrc-sdkman
docker run --rm -v `pwd`:/out fedora /bin/cp /root/.bashrc /out/bashrc-base
</code></pre></div></div>
<p>Diff.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>localhost$ diff bashrc-base bashrc-sdkman
12a13,16
>
> #THIS MUST BE AT THE END OF THE FILE FOR SDKMAN TO WORK!!!
> export SDKMAN_DIR="/root/.sdkman"
> [[ -s "/root/.sdkman/bin/sdkman-init.sh" ]] && source "/root/.sdkman/bin/sdkman-init.sh"
</code></pre></div></div>
<p>Not surprisingly the install has added sourcing an sdkman init script to <code class="language-plaintext highlighter-rouge">~/.bashrc</code>.</p>
<h2 id="conclusion">Conclusion</h2>
<p>Obviously there is no limit to the amount of inspection one could do on foreign code, nor the amount of changes an imported bash file could do to an OS. In this case all I’ve done is find out what files sdkman adds or changes, and review the diffs on one file. But at least it gives me an idea of what is going on with the install.</p>
<p>Using docker to evaluate tools makes a lot of sense to me, mostly because I don’t want to mess up my physical OS (which is actually running in a virtual machine, but I digress). Some people take this <a href="https://github.com/jessfraz/dockerfiles">much farther</a> and use containers to run things like sdkman.</p>
<p>Even though I’ve worked a lot with Docker, I’ve never tried to inspect the diffs of image layers. Likely that would be a better option that what I’ve done above. Something to look into…</p>
Cloud Native Buildpacks2019-12-16T00:00:00+00:00http://serverascode.com/2019/12/16/buidpack-pack<h1 id="cloud-native-buildpacks">Cloud Native Buildpacks</h1>
<p>How does code turn into an application running on Kubernetes? Good question. Many things have to happen: Dockerfiles written and rewritten, base images picked, builds pushed to repositories, and, of course, much k8s YAML wrangled. These simple phrases, e.g. “Dockerfile written,” represent considerable complexity.</p>
<p>How can we make getting code into production simpler for everyone?</p>
<p>One way is to use <a href="https://buildpacks.io">buildpacks</a>, which help to make the generation of <a href="https://www.opencontainers.org/">OCI images</a> easier. What if I told you that with buildpacks you don’t even <em>NEED</em> a Dockerfile?</p>
<h2 id="building-container-images-is-hard---use-buildpacks">Building Container Images is Hard - Use Buildpacks</h2>
<p>For quite a while Docker was the only easy way to build container images. It’s still responsible for building the vast majority container images. However, with the creation of the <a href="https://github.com/opencontainers/image-spec">OCI image spec</a> other tools have been developed.</p>
<p>It can’t be denied that giving development teams the ability to create their own runtime images improved the developer experience. They could run the same image locally as what would, in theory, go into production. They knew the apps dependencies and could add them to the Dockerfile.</p>
<p>However, in the socio-technical realm of enterprise organizations, operations typically does not allow arbitrary container images in production, for various reasons, some valid, some not. Further to that, many ops organizations will try to manage container images exactly like they manage virtual machine templates (<em>if</em> they manage them at all) which is an anti-pattern.</p>
<p>Ultimately Dockerfiles make building operationally resilient images <strong>look</strong> easy, but it’s not.</p>
<p>Here are a few considerations one has to make when building container images:</p>
<ul>
<li>Keeping image sizes small</li>
<li>Dealing with dependencies</li>
<li>Picking the right base image</li>
<li>Ensuring appropriate application memory settings</li>
<li>Day 2 ops - e.g. How to update the JDK without breaking the image cache or rebasing on a new base image</li>
<li>Defining who is responsible for the images - Ops, Dev, or DevOps?</li>
<li>Dealing with CVEs</li>
</ul>
<p>Issues with typical container images:</p>
<ul>
<li>Lack of app awareness</li>
<li>Not composable - How do we combine images? (Only have multistage builds in Dockerfiles)</li>
<li>Leaky abstraction - e.g. Container images mix operational concerns with application development concerns</li>
<li>Non-reproducible/untestable builds</li>
<li>Security - e.g. many Dockerfiles assume running as root</li>
<li>Treating containers images as VMs</li>
</ul>
<h2 id="enter-buildpacksio">Enter Buildpacks.io</h2>
<blockquote>
<p>Buildpacks are pluggable, modular tools that translate source code into OCI images.</p>
</blockquote>
<p>Buildpacks are currently a CNCF Sandbox project supported by companies like Pivotal and Heroku.</p>
<blockquote>
<p><a href="https://medium.com/buildpacks/cloud-native-buildpacks-hit-beta-4d9f2c85dd22s">Buildpacks</a> have always been about the developer experience. We want buildpacks to make your job easier by eliminating operational and platform concerns that you might otherwise need to consider when using containers.</p>
</blockquote>
<p>Buildpacks are a higher level abstraction than Dockerfiles and are really meant for developers.</p>
<p>What do you <a href="https://buildpacks.io/#learn-more">get</a>?</p>
<blockquote>
<ul>
<li>Provide a balance of control that reduces the operational burden on developers and supports enterprise operators who manage apps at scale</li>
<li>Ensure that apps meet security and compliance requirements without developer intervention</li>
<li>Provide automated delivery of both OS-level and application-level dependency upgrades, efficiently handling day-2 app operations that are often difficult to manage with Dockerfiles</li>
<li>Rely on compatibility guarantees to safely apply patches without rebuilding artifacts and without unintentionally changing application behavior</li>
</ul>
</blockquote>
<h2 id="using-buildpacks">Using Buildpacks</h2>
<p>I run on Linux so I just <a href="https://github.com/buildpacks/pack/releases">downloaded the binary</a> into my home bin directory and made it executable.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ which pack
~/bin/pack
</code></pre></div></div>
<p>Let’s clone a repo, <em>spring-music</em>, and build an image.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ git clone https://github.com/cloudfoundry-samples/spring-music
</code></pre></div></div>
<p>Now cd into spring-music. Note no Dockerfiles exist. Just plain code and build files.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ cd spring-music
$ ls
build.gradle gradle gradle.properties gradlew gradlew.bat LICENSE manifest.yml README.md src
</code></pre></div></div>
<p>Now, with one simple command, let’s build a hardened container image that has been run millions of times on the Pivotal Platform and Heroku.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ pack build spring-music
</code></pre></div></div>
<p>Here’s the resulting image…264MB:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ docker images spring-music
REPOSITORY TAG IMAGE ID CREATED SIZE
spring-music latest 0ea601302547 15 minutes ago 264MB
</code></pre></div></div>
<p>Run it.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ docker run --rm -d -p 8080:8080 spring-music
</code></pre></div></div>
<p>Curl localhost:8080 to test.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code> $ curl -s localhost:8080 | grep title
<meta name="title" content="Spring Music">
<title>Spring Music</title>
</code></pre></div></div>
<p>Well, that was pretty easy…and no Dockerfiles!</p>
<h2 id="a-bit-more">A Bit More</h2>
<p>While there is a lot to…er…“unpack,” here, I’d like to point out a couple of things that I think are interesting and important about buildpacks.</p>
<ul>
<li>Disconnection of Operating System from Application</li>
</ul>
<p>With standard Docker images when a security issue is discovered in a operating system package many, if not all, of the image layers have to be rebuilt. This makes redeploying applications slow. It also handcuffs the OS requirements to the app requirements. With buildpacks these concerns are separated.</p>
<ul>
<li>Java BuildPack Memory Calculator</li>
</ul>
<p>I find that it’s quite easy to ignore or forget JVM memory settings…especially in a container centric world. Buildpacks use the <a href="https://github.com/cloudfoundry/java-buildpack-memory-calculator">Java BuildPack Memory Calculator</a> to dynamically set requirements for memory. I have yet to see a Dockerfile that implements this or anything like it. *</p>
<h2 id="conclusion">Conclusion</h2>
<p>Building hardened, operationally reliable container images is difficult. Using Buildpacks not only makes Dockerfiles unnecessary, but provides access to images that have been in constant, heavy production use for years.</p>
<p>Using pack and buildpacks you don’t need to:</p>
<ul>
<li>Write your own Dockerfiles</li>
<li>Add individual files before app code to improve caching</li>
<li>Dance around for user permissions and root access</li>
<li>Force docker to rebuild all layers for a security patch</li>
<li>Understand the base operating system</li>
<li>Couple applications to the build pipeline</li>
<li>Burn in images over time to feel that they are trustworthy</li>
</ul>
<p>Running applications in production isn’t easy. Using buildpacks can help to reduce the operational burden, for everyone.</p>
<p>I recommend watching a <a href="https://www.youtube.com/watch?v=spW9ZlJpobM&t=407s">couple</a> of <a href="https://www.youtube.com/watch?v=KiDK5C0kzJs">videos</a> for more in-depth information on buildpacks.</p>
<hr />
<p>* Hat tip to my colleague Adib Saikali for information on the Java memory calculator. Watch his Toronto Java meetup talk on <a href="https://www.youtube.com/watch?v=meE888uPLyc">Spring and Kubernetes</a>.</p>
Speedy Software Distribution2019-11-27T00:00:00+00:00http://serverascode.com/2019/11/27/speedy-software-distribution<h1 id="speedy-software-distribution">Speedy Software Distribution</h1>
<p>I would wager most, if not all, developers have edited a file on a remote server to update an application. Those were the days. Now the spectrum of software distribution ranges from manually copying files, to container images, to bit-torrent and more.</p>
<h2 id="the-current-standard-container-images">The Current Standard: Container Images</h2>
<p><a href="https://www.opencontainers.org/">Container images</a> have vastly affected how we distribute software. Given the desire for many organizations to use <a href="https://pivotal.io/platform/pivotal-container-service">Kubernetes</a>, which relies on containers, which in turn rely on container images, the model of distributing singular binaries of an OS file system has become the default modern day standard.</p>
<p>While in the past we may have used simple things like copying and rsync-ing files, operating system packages, even bit-torrent, we now strive to distribute OCI images.*</p>
<h2 id="were-all-distributed-programmers-now">We’re All Distributed Programmers Now</h2>
<p>Cornelia Davis, CTO Pivotal, has <a href="https://devclass.com/2019/08/16/pivotal-cto-kubernetes-means-were-all-distributed-systems-programmers-now/">this to say</a> about modern day software development:</p>
<blockquote>
<p>“…we’re all distributed systems programmers now. When I started my degree 30 years ago, that was niche. Now, in the cloud, everything is distributed…”</p>
</blockquote>
<p>The prevalence of distributed systems means that we need to get software running on >1 application instance. Maybe thousands. How can we quickly, efficiently, and accurately distribute software to thousands of servers running around the globe?</p>
<h2 id="the-need-for-speed">The Need for Speed</h2>
<p>I believe speed is key to the future of software distribution. How container images, or some other package, get from host is as important as how those packages are defined. I would like to have my software running globally in hundreds of milliseconds.</p>
<p>One doesn’t have to look much further than <a href="https://eng.uber.com/introducing-kraken/">Uber’s Kraaken</a> project to see what might be involved in speeding up software distribution.</p>
<p>Kraaken is a peer to peer Docker registry:</p>
<blockquote>
<p>Docker containers are a foundational building block of Uber’s infrastructure…but as the number and size of our compute clusters grew, a simple Docker registry setup with sharding and caches couldn’t keep up with the throughput required to distribute Docker images efficiently.</p>
</blockquote>
<p>Another interesting and speedy software distribution component is <a href="https://blog.chromium.org/2009/07/smaller-is-faster-and-safer-too.html">Chrome’s Courgette</a> (from 2009 no less). Courgette can be 10x more efficient than something like <a href="http://www.daemonology.net/bsdiff/">bsdiff</a> (which itself is extremely bit thrifty). Courgette does not directly help container images, but it represents an efficient way to create a binary delta. Smaller deltas mean faster distribution. Faster distribution can mean more frequent updates.</p>
<blockquote>
<p>If the update is a tenth of the size, we can push ten times as many per unit of bandwidth.</p>
</blockquote>
<p>In that post they show the improvement in data transfer using Courgette.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>Full update: 10,385,920 bytes
bsdiff update: 704,512 bytes
Courgette update: 78,848 bytes
</code></pre></div></div>
<p>700k to 78k…that’s a an impressive improvement resulting in many bits that don’t have to traverse the network (and again, <a href="https://pdfs.semanticscholar.org/4697/3fb8c3b038648e1fe848a72275a75ff49fd2.pdf?_ga=2.252430473.1684130984.1567251025-566867337.1566753693">bsdiff</a> is extremely efficient). For those of you that would like more information on the Courgette model, there is considerable research in the area, going back at least to <a href="https://robert.muth.org/Papers/1999-exediff.pdf">exediff</a>.</p>
<h2 id="whats-next">What’s Next</h2>
<p>At this time I believe there are at least three major things to think about when thinking about distributing code:</p>
<ul>
<li>Peer to peer deployment (eg. Kraaken)</li>
<li>Advanced delta encoding (ala Courgette and exediff)</li>
<li>Improvements in code injection / application restarts</li>
</ul>
<p>This post has only, just barely, grazed the surface of software distribution. As we continue down the distributed programming path and focus on getting obstacles out of the way of developers, we will find that distributing applications at insanely fast speeds will be a key enabler.</p>
<hr />
<p>* <em>Of course these binary images are made up of things like OS packages, but lets not think about that too much right now. Also, what we are really distributing is the layers of these images.</em></p>
Mikrotik CRS326-24G-2S+RM2019-09-29T00:00:00+00:00http://serverascode.com/2019/09/29/mikrotik-CRS326-24G-2S-RM<h1 id="mikrotik-crs326-24g-2srm">Mikrotik CRS326-24G-2S+RM</h1>
<p>I have a bunch of loud noisy switches…<em>cough</em> Juniper EX4200s <em>cough</em>. I recently moved and haven’t had the time yet to setup proper sound proofing for all my homelab gear and thus I need to be quieter where I can be. Lower power consumption would help too.</p>
<p>So I bought a <a href="https://mikrotik.com/product/CRS326-24G-2SplusRM">Mikrotik CRS326-24G-2S+RM</a> to be my main 1GB switch. I purchased the switch from <a href="https://solimedia.net/">Solimedia</a> and it was about $250 CDN.</p>
<h2 id="power-consumption-and-volume">Power Consumption and Volume</h2>
<p>Right now the switch has about 20 ports populated and is doing a fair amount of work. It’s pulling only 17 watts. My EX4200 pull about 135 watts; that’s a substantial difference. Based on my calculations, running an EX4200 24/7 would cost about $8.70/month in Ontario and the CRS326 about $1.50.</p>
<p>The switch also has no fans, so it’s virtually silent.</p>
<h2 id="configuration">Configuration</h2>
<p>The challenging part of this switch is that Mikrotik has many different products, and they use many different CPUs and ASICs.</p>
<p>In their C3XX line you configure VLANs differently than their other switches, as they do hardware VLANS. They have some <a href="https://wiki.mikrotik.com/wiki/Manual:Interface/Bridge#VLAN_Example_.231_.28Trunk_and_Access_Ports.29">docs</a> on configuration. These short docs are not detailed, but they are accurate in my experience.</p>
<p>Example 3 is probably the one most people would use…“VLAN Example #3 (InterVLAN Routing by Bridge)”:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>/interface bridge
add name=bridge1 vlan-filtering=yes
/interface bridge port
add bridge=bridge1 interface=ether6 pvid=200
add bridge=bridge1 interface=ether7 pvid=300
add bridge=bridge1 interface=ether8 pvid=400
/interface bridge vlan
add bridge=bridge1 tagged=bridge1 untagged=ether6 vlan-ids=200
add bridge=bridge1 tagged=bridge1 untagged=ether7 vlan-ids=300
add bridge=bridge1 tagged=bridge1 untagged=ether8 vlan-ids=400
/interface vlan
add interface=bridge1 name=VLAN200 vlan-id=200
add interface=bridge1 name=VLAN300 vlan-id=300
add interface=bridge1 name=VLAN400 vlan-id=400
/ip address
add address=20.0.0.1/24 interface=VLAN200
add address=30.0.0.1/24 interface=VLAN300
add address=40.0.0.1/24 interface=VLAN400
</code></pre></div></div>
<p>A few notes:</p>
<ul>
<li>The bridge concept is an abstraction you don’t see in a lot of other network gear, so it will take a few minutes to get used to it</li>
<li>Make sure you are reading configuration examples for the C3XX line of products as other products are configured differently</li>
<li>For access ports set the PVID (as shown and documented), otherwise they will get dynamically added to PVID 1, for trunk ports leaving off the PVID seems the proper config</li>
<li>Notice how the bridge “bridge1” is being added as a tagged port; don’t forget that if you want to route inter-VLAN</li>
<li>Set each VLAN ID separately so you can edit them easier later</li>
<li><code class="language-plaintext highlighter-rouge">/interface bridge port</code> and <code class="language-plaintext highlighter-rouge">/interface bridge vlan</code> will be your friend</li>
<li>RouterOS reports “current tagged” and “current untagged” which can be confusing, use “print detail” to see what is actually tagged and untagged</li>
<li>Note “vlan-filtering=yes” during bridge creation. Many of the docs show starting with “vlan-filtering=no” while building the configuration because they don’t want you to lock yourself out of the switch (if you are connected over the network) before you are done. So their examples are create the bridge, configure the switch, then finally turn vlan filtering on once you are done. But it would be easy to forget to turn it on. I changed the example above to set it to yes at the start.</li>
</ul>
<p>Also note that if you don’t have an “H” beside a port then it’s not being managed in hardware and will be slow.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>[admin@MikroTik] > /interface bridge port print
Flags: X - disabled, I - inactive, D - dynamic, H - hw-offload
# INTERFACE BRIDGE HW PVID PRIORITY PATH-COST INTERNAL-PATH-COST HORIZON
0 H ether1 bridge1 yes 102 0x80 10 10 none
1 H ether2 bridge1 yes 103 0x80 10 10 none
2 H ether3 bridge1 yes 104 0x80 10 10 none
3 H ether4 bridge1 yes 1 0x80 10 10 none
4 H ether5 bridge1 yes 106 0x80 10 10 none
SNIP!
</code></pre></div></div>
<h2 id="conclusion">Conclusion</h2>
<p>For some reason I like Mikrotik gear. I have quite a bit of it, including some wireless (don’t get me started on the whole capsman thing). What I don’t like about Mikrotik is that the documentation is somewhat lacking. Configuring a Juniper switch can be done easily with some surface level googling as pretty much every Juniper question has been answered succinctly and search engine indexed. Not so with Mikrotik. Their large and changing product line, part of their value proposition, makes this even more difficult.</p>
<p>One thing I do like about Mikrotik is that the OS comes with many features, even MPLS. This system is not just a dumb switch, it is a full featured router.</p>
<p>Finally, the switch is only 24 ports. Technically I’d have to have two of them to match the 48 ports of the EX4200. When you have many boxes ports will run out quickly.</p>
<p>You can certainly find cheaper, older used switches, but they will likely be loud and power hungry.</p>
Mikrotik RB2011 Won't Reset to Default Configuration2019-07-01T00:00:00+00:00http://serverascode.com/2019/07/01/mikrotik-rb2011-default-config<h1 id="mikrotik-rb2011-wont-reset-to-default-configuration">Mikrotik RB2011 Won’t Reset to Default Configuration</h1>
<h2 id="tldr">tl;dr</h2>
<p>If you can’t get your RB32011 router to go back to default configuration, ie. it just comes up with a blank configuration, you’ll likely need to netinstall it, which wipes everything.</p>
<h2 id="mikrotik">Mikrotik</h2>
<p>I have an old <a href="https://mikrotik.com/product/RB2011UiAS-2HnD-IN">Mikrotik RB2011</a> and it’s been sitting unused in a box for several years. But I’m back on my Mikrotik thing as I’m wiring up my house with more than one WIFI device. I don’t know if this will actually improve my home WIFI, but I’m doing it anyways.</p>
<p>I like Mikrotik because they support MPLS and I like to pretend I know what I’m doing. Not that I’ll use MPLS for a wireless network, but I like the possibility of using it…even if I don’t.</p>
<p>Mikrotik was in the <a href="https://www.zdnet.com/article/thousands-of-mikrotik-routers-are-snooping-on-user-traffic/">news</a> last year for some security issues, which I have not paid enough attention to.</p>
<h2 id="default-configuration">Default Configuration</h2>
<p>As I try to figure out how to configure CAPsMAN, Mikrotik’s multi AP management system, I needed to put my RB2011 back into factory default configuration more than once (as I make mistakes and lose access to the router). But, after an upgrade to the OS and a reset, it wouldn’t come back up with the default settings, rather it boots with a completely blank configuration, which makes it challenging to work with as you can’t access it easily over the network (of course, the serial console works). I only found one <a href="https://forum.mikrotik.com/viewtopic.php?t=78638">post</a> about it and it didn’t help.</p>
<p>At any rate, my assumption is the old default script stored in the device wasn’t compatible with the new OS version. Unfortunately I didn’t keep a copy of the old default-config script, which you can view with:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>/system default-configuration print
</code></pre></div></div>
<p>Believe me that the most recent default config file, the one that exists after a netinstall, is much different than the original one I had on my RB2011 with the older OS.</p>
<p>To ge the new script installed I had to reinstall via NetInstall, which actually worked. I had to use my Windows computer, but I was able to reinstall in less than 10 minutes, which is nice.</p>
<p>So, after netinstalling, I could again run the reset command.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>/system reset-configuration
</code></pre></div></div>
<p>Once the node came back up, it has this default config.</p>
<h2 id="ps-serial-access">PS. Serial Access</h2>
<p>Also, serial access works just fine using a USB serial console device and cable to the back of the RB2011.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>sudo screen /dev/ttyUSB0 115200
</code></pre></div></div>
The Hard Thing About Hard Things2019-07-01T00:00:00+00:00http://serverascode.com/2019/07/01/hard-things-book-review<h1 id="the-hard-thing-about-hard-things">The Hard Thing About Hard Things</h1>
<p>For some reason I was expecting this book to be about how to do hard things. In my mind a “hard thing” was a single project that was technically difficult. I’m not sure where that idea came from, but that isn’t what this book is about. <em>The Hard Thing about Hard Things</em> is about being a CEO and how challenging that job is.</p>
<p>I enjoyed the book and it’s something one could come back to again and again over the span of a career.</p>
<h2 id="loudcloudopsware">Loudcloud/Opsware</h2>
<p>I remember hearing about Opsware waaaaay back in the day. At the time it wasn’t something I would keep track of; I wasn’t paying attention to the whole Silicon Valley thing at the time. I was just getting out of school and into a job that was almost as far away from Silicon Valley as you could get (Northern Alberta). I should do some more reading on Loudcloud and Opsware, as it sounds like they were far ahead of the game for a while, and this was prior to even virtualization. (In fact in the book Horowitz mentions that the invention of virtualization was a part of why he decided to sell Opsware to HP, in that they would have had to spend a lot of time and money supporting virtualization in their product.)</p>
<h2 id="a-few-notes-from-my-reading">A few notes from my reading</h2>
<ul>
<li>The right kind of ambition</li>
</ul>
<blockquote>
<p>At a macro level, a company will be most successful if the senior managers optimize for the company’s success (think of this as global optimization) as opposed to their own personal success (local optimization)</p>
</blockquote>
<blockquote>
<p>When I spoke to Mark Cranney…it was difficult to get him to discuss his personal accomplishments. He really only wanted to discuss how his old company won.</p>
</blockquote>
<ul>
<li>
<p>Much discussion of wartime vs peacetime CEOs…what wartime CEOs do is much different than peacetime, and most of the time one person is not great at both styles. So if you are “at war” you need a different CEO.</p>
</li>
<li>
<p>“The struggle” of the CEO</p>
</li>
</ul>
<blockquote>
<p>…if there is one skill that stands out, it’s the ability to focus and make the best move when there are no good moves. It’s the moments where you feel most like hiding or dying that you can make the biggest difference as CEO…I offer some lessons on how to make it through the struggle without quitting or throwing up too much.</p>
</blockquote>
<ul>
<li>Training</li>
</ul>
<p>This book is very pro-training. I love it. Horowitz quotes Andy Grove:</p>
<blockquote>
<p>Training is, quite simply, one of the highest-leverage activities a manager can perform.</p>
</blockquote>
<ul>
<li>
<p>Andy Grove, Bill Campbell - Horowitz mentions these people many times throughout the book. A <a href="https://www.trilliondollarcoach.com/">new book</a> about Bill Campbell is out. Definitely going to read it.</p>
</li>
<li>
<p>Being honest</p>
</li>
</ul>
<blockquote>
<p>If you run a company, you will experience overwhelming psychological pressure to be overly positive. Stand up to the pressure, face your fear, and tell it like it is.</p>
</blockquote>
<p>I’m assuming Horiwitz determined when to be honest very carefully.</p>
<ul>
<li>$1.6 billion sale to HP</li>
</ul>
<p>Everything in the book is working towards this sale. That number is the success of the company. Nothing else matters. Any other choices Horowitz could have made over the lifetime of the company might have watered down this number. He fought hard to get a specific share price and was willing to have the deal fall through if he didn’t get it.</p>
<ul>
<li>Mark Cranney</li>
</ul>
<p>I found any discussion around Mark Cranney fascinating. I have a pet theory, which I think is more than a theory, that most high ranking managers and sales people are…just tall. Note that I am exactly average height so maybe that has something to do with it. :)</p>
<blockquote>
<p>I interviewed Mark Cranney. He wasn’t what I expected: he didn’t fit the stereotype of a hard-charging sales executive. For starters, Mark was average height, whereas most sales executives tend to be rather tall. Next, he was as wide as he was tall. not fat, just square. His square body seemed to fit rather uncomfortably into what must have been a custom-tailored suit–there is no way an off-the-rack business suite would fit a square guy like Mark.</p>
</blockquote>
<p>Later in the book Horowitz says that if Cranney had better met the physical stereotype of an executive he would have been CEO of IBM, ie. that Opsware got Cranney at a discount.</p>
<ul>
<li>Hire for strength</li>
</ul>
<p>He discusses reasons why CEOs fail executives and then have to fire them. One of the reasons is not hiring for strengths.</p>
<blockquote>
<p>You hired for lack of weakness rather than for strengths. This is especially common when you run a consensus-based hiring process. The group will often find the candidate’s weaknesses, but they won’t place a high enough value on the areas where you need the executive to be a world-class performer. As a result you hire an executive…who is mediocre where you need her to be great.</p>
</blockquote>
<p>There’s much more to get out of this book. Like most of Silicon Valley, I heavily suggest just picking up a copy.</p>
WIFI - Error Connection activation failed, Secrets were required, but not provided.2019-05-31T00:00:00+00:00http://serverascode.com/2019/05/31/secrets-were-required<h1 id="wifi---error-connection-activation-failed-secrets-were-required-but-not-provided">WIFI - Error Connection activation failed, Secrets were required, but not provided.</h1>
<p>Prior to a presentation, I was trying to connect to a Cisco Meraki based wireless network with a Lenovo Gen3 X1 Fedora 30 laptop, and kept getting this error:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ nmcli dev wifi connect <SSID> password <password>
Error: Connection activation failed: (7) Secrets were required, but not provided.
</code></pre></div></div>
<p>Obviously I provided the password. I was totally stumped. Then I saw <a href="https://unix.stackexchange.com/questions/420640/unable-to-connect-to-any-wifi-with-networkmanager-due-to-error-secrets-were-req/444433">this</a> Stackexchange post and decided to give it a try.</p>
<p>This is my wireless device:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ lspci -vv -s 04:00.0
04:00.0 Network controller: Intel Corporation Wireless 7265 (rev 59)
Subsystem: Intel Corporation Dual Band Wireless-AC 7265
Control: I/O- Mem+ BusMaster+ SpecCycle- MemWINV- VGASnoop- ParErr- Stepping- SERR- FastB2B- DisINTx+
Status: Cap+ 66MHz- UDF- FastB2B- ParErr- DEVSEL=fast >TAbort- <TAbort- <MAbort- >SERR- <PERR- INTx-
Latency: 0, Cache Line Size: 64 bytes
Interrupt: pin A routed to IRQ 49
Region 0: Memory at f1000000 (64-bit, non-prefetchable) [size=8K]
Capabilities: <access denied>
Kernel driver in use: iwlwifi
Kernel modules: iwlwifi
</code></pre></div></div>
<p>I should note that I’ve connected to several WIFI networks since installing Fedora 30 and have had no issues. Just this one Meraki based network so far.</p>
<p>I added the below:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ tail -2 /etc/NetworkManager/NetworkManager.conf
[device]
wifi.scan-rand-mac-address=no
</code></pre></div></div>
<p>And restarted NetworkManager, and lo behold was able to connect to the WIFI. I am not sure why this works. The MAC address randomization is a good thing to have security/privacy-wise. I’d prefer that it was enabled. But I really do need to connect to WIFI as easily as possible. This caused me major issues as this cropped up prior to a presentation (ugh). Previously I was on Fedora 26 for a (too) long time. Presumably this feature is new. Or it is some other related bug.</p>
<p>However, that said, I don’t know why this would cause the problem.</p>
<ul>
<li>Related <a href="https://bugs.launchpad.net/ubuntu/+source/network-manager/+bug/1681513">bug report</a></li>
<li>Related <a href="https://askubuntu.com/questions/902992/ubuntu-gnome-17-04-wi-fi-not-working-mac-address-keeps-changing">post</a></li>
<li>Article on <a href="https://arstechnica.com/gadgets/2014/06/ios8-to-stymie-trackers-and-marketers-with-mac-address-randomization/">WIFI MAC randomization</a></li>
</ul>
<p>The bug report seems to be related to USB WIFI devices but there are a few onboard as well.</p>
<p>The reality is turning off the randomization allowed me to connect. <em>sigh</em></p>
What is StarlingX?2019-05-20T00:00:00+00:00http://serverascode.com/2019/05/20/what-is-starlingx<h1 id="what-is-starlingx">What is StarlingX?</h1>
<p>I recently joined the Technical Steering Committee (TSC) of the open source <a href="https://www.starlingx.io/">StarlingX</a> project. As one of the members of the TSC, I work to enable the governance model of the project, which is part of the OpenStack Foundation. Good open source governance is important, but it’s not the most interesting part. :)</p>
<h2 id="what-is-starlingx-1">What is StarlingX?</h2>
<p>StarlingX, which I usually abbreviate to STX, is an open source project that provides a customized Linux distribution which delivers a fully managed Kubernetes and OpenStack deployment on one, two, or more physical servers. It’s designed to run mission critical workloads on the edge.</p>
<p>If you are working in the world of Network Function Virtualization (NFV), “Industry 4.0”, Internet of Things (IoT), and other similar areas, STX would likely be interesting as it presents a way to provide de-facto standard infrastructure APIs in edge locations–locations where it may only be feasible to have one or two physical servers. STX can manage hundreds of compute nodes if needed, but for the edge single and dual modes are the most compelling.</p>
<h2 id="openstack-foundation---more-than-openstack">OpenStack Foundation - More than OpenStack</h2>
<p>StarlingX is open source project that is supported by the OpenStack Foundation. The seed code came from Wind River’s Titanium product. Going forward, Wind River Titanium will be the downstream commercial based on the upstream open source code. Of course, as open source software, anyone is free to take the code and artifacts generated and deploy it or build it into their own product.</p>
<p>For those of you that don’t know, the OpenStack Foundation provides structure for more open source projects than OpenStack. At this time there are four other major projects within the OpenStack Foundation:</p>
<ul>
<li><a href="https://starlingx.io">StarlingX</a> - Edge OpenStack and Kubernetes</li>
<li><a href="https://zuul-ci.org/">Zuul</a> - CI/CD and project gating</li>
<li><a href="https://katacontainers.io/">Kata Containers</a> - Virtual machines instead of containers</li>
<li><a href="https://www.airshipit.org/">Airship</a> - Declarative OpenStack and Kubernetes automation</li>
</ul>
<h2 id="features-of-stx---designed-for-the-edge">Features of STX - Designed for the Edge</h2>
<p>STX does a lot of things, but I think the most important features that help to differentiate it are:</p>
<ul>
<li>It can run on a single physical server and still provide Kubernetes and OpenStack APIs. This is called “simplex” mode.</li>
<li>It can run on two physical servers, providing a highly available version of Kubernetes and OpenStack. This is called “duplex” mode.</li>
<li>It runs OpenStack on top of a fully managed Kubernetes deployment–OpenStack is just an app in k8s.</li>
<li>StarlingX has made design choices and created specialized software services and features designed specifically to run mission critical workloads. High availability. Integrity. Safety. These are words the project’s values.</li>
</ul>
<p>(Note that STX has many other features and integrated systems that I haven’t mentioned here in an attempt to keep this post short.)</p>
<h2 id="open-source-software---help-wanted">Open Source Software - Help Wanted!</h2>
<p>Much of the work going on in the project now is to upstream the seed code into various open source projects, from the Linux kernel to OpenStack Neutron. However, StarlingX is also advancing and adding new features and functionality. A good example is the Kubernetes integration work occurring right now.</p>
<p>If OpenStack, Kubernetes, and new technology paradigms such as the edge, NFV, IoT, and others are of interest to you, I heavily suggest getting involved in the project. Have a look at the community page on the website and get in touch if you’d like to participate. Or, if your organization would like to run a proof of concept or has questions about the project, reach out and let us know.</p>
<p><img src="/img/starlingx-logo-1.png" alt="Starlingx Logo" /></p>
Install and Use Podman (Instead of Docker)2019-05-19T00:00:00+00:00http://serverascode.com/2019/05/19/docker-podman-fedora-30<h1 id="install-and-use-podman-instead-of-docker">Install and Use Podman (Instead of Docker)</h1>
<h2 id="tldr">tl;dr</h2>
<p>I reinstalled my laptop with Fedora 30. I tried to install a stable Docker, but the Docker repo for Fedora 30 stable doesn’t exist. I realized podman is available and is a command for command replacement for Docker. So far I’m quite happy with it and am actually kind of glad I was forced into it.</p>
<h2 id="what-distro-to-run">What Distro to Run?</h2>
<p>Recently I reinstall my laptop with Fedora 30. I won’t mention what version of Fedora I “upgraded” from, but suffice it to say I was using my old install for quite a while. I wouldn’t have minded using Fedora Silverblue, Fedora CoreOS, or CentOS 8. However, two of those don’t have anything to install yet, and Silverblue…it seems a bit too early for me. So I stuck with good old Fedora.</p>
<p>I don’t actually need much from Linux. I use the i3 window manager, Firefox browser, smartcd, VSCode (from Microsoft) and a few other tools. As long as I can apt/yum/dnf install common tools the Linux distribution I use doesn’t really matter. I don’t actually even use Docker locally that much, but I do use it to manage this blog, and it’s nice to have a container runtime available.</p>
<h2 id="docker-on-fedora-30-or-lack-thereof">Docker on Fedora 30 (or lack thereof)</h2>
<p>After reinstalling my laptop, I went to <a href="https://docs.docker.com/install/linux/docker-ce/fedora/">install docker</a>. In retrospect I should have read the docs better:</p>
<blockquote>
<p>To install Docker, you need the 64-bit version of one of these Fedora versions:
28
29</p>
</blockquote>
<p>30 is not 28 or 29. :) Regardless, I kept going.</p>
<p>I installed the official repo.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ sudo dnf config-manager \
> --add-repo \
> https://download.docker.com/linux/fedora/docker-ce.repo
Adding repo from: https://download.docker.com/linux/fedora/docker-ce.repo
$ head /etc/yum.repos.d/docker-ce.repo
[docker-ce-stable]
name=Docker CE Stable - $basearch
baseurl=https://download.docker.com/linux/fedora/$releasever/$basearch/stable
enabled=1
gpgcheck=1
gpgkey=https://download.docker.com/linux/fedora/gpg
[docker-ce-stable-debuginfo]
name=Docker CE Stable - Debuginfo $basearch
baseurl=https://download.docker.com/linux/fedora/$releasever/debug-$basearch/stable
</code></pre></div></div>
<p>Then I tried to install docker.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ sudo dnf install docker-ce docker-ce-cli containerd.io
Docker CE Stable - x86_64 1.7 kB/s | 577 B 00:00
Failed to synchronize cache for repo 'docker-ce-stable'
Fedora Modular 30 - x86_64 46 kB/s | 17 kB 00:00
Fedora Modular 30 - x86_64 - Updates 69 kB/s | 16 kB 00:00
Fedora 30 - x86_64 - Updates 55 kB/s | 17 kB 00:00
Fedora 30 - x86_64 - Updates 645 kB/s | 625 kB 00:00
Fedora 30 - x86_64 52 kB/s | 17 kB 00:00
RPM Fusion for Fedora 30 - Free - Updates 592 B/s | 3.0 kB 00:05
RPM Fusion for Fedora 30 - Free 9.8 kB/s | 3.2 kB 00:00
RPM Fusion for Fedora 30 - Nonfree - Updates 4.7 kB/s | 3.0 kB 00:00
RPM Fusion for Fedora 30 - Nonfree 4.4 kB/s | 3.2 kB 00:00
Ignoring repositories: docker-ce-stable
No match for argument: docker-ce
No match for argument: docker-ce-cli
No match for argument: containerd.io
Error: Unable to find a match
</code></pre></div></div>
<p>Doh. Seems like no “docker-ce-stable” repo. I don’t want to run nightly or test. What to do? Get docker from somewhere else? Or is there an alternative…I remember something about podman…</p>
<p>I removed the Docker repo.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code> sudo rm docker-ce.repo
</code></pre></div></div>
<p>Onto podman.</p>
<h2 id="install-podman">Install podman</h2>
<p>podman, short for “pod manager” I believe, is:</p>
<blockquote>
<p>…a daemonless container engine for developing, managing, and running OCI Containers on your Linux System. Containers can either be run as root or in rootless mode. Simply put: <code class="language-plaintext highlighter-rouge">alias docker=podman</code>.</p>
</blockquote>
<p>Install.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>sudo dnf install podman
</code></pre></div></div>
<p>This is the version I have:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ rpm -q podman
podman-1.2.0-2.git3bd528e.fc30.x86_64
</code></pre></div></div>
<p>Now, the question is can I use it just like I use docker?</p>
<h2 id="the-first-test-jekyll">The first test: Jekyll</h2>
<p>As I mentioned I used to use Docker to create a preview of this blog using Jekyll.</p>
<p>Below is the command I previously used to build a preview site. I’ve been using this same command for at least a couple years.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>export JEKYLL_VERSION=3.5
docker run --rm \
--volume="$PWD:/srv/jekyll" \
-p 127.0.0.1:4000:4000 \
-it jekyll/jekyll:pages \
jekyll serve
</code></pre></div></div>
<p>That would server up my Jekyll based blog on port 4000, and use the local directory as a volume. Would this command simply work if I replaced Docker with podman?</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ podman run --rm \
> --volume="$PWD:/srv/jekyll" \
> -p 127.0.0.1:4000:4000 \
> -it jekyll/jekyll:pages \
> jekyll serve
ruby 2.6.3p62 (2019-04-16 revision 67580) [x86_64-linux-musl]
Configuration file: /srv/jekyll/_config.yml
Source: /srv/jekyll
Destination: /srv/jekyll/_site
Incremental build: disabled. Enable with --incremental
Generating...
Build Warning: Layout 'nil' requested in atom.xml does not exist.
done in 4.247 seconds.
Auto-regeneration: enabled for '/srv/jekyll'
Server address: http://0.0.0.0:4000
Server running... press ctrl-c to stop.
</code></pre></div></div>
<p>I was surprised when this worked without a problem.</p>
<p>Same command to exec in.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ podman exec -it 895a3ca0845c /bin/bash
bash-4.4# ps ax
PID TTY STAT TIME COMMAND
1 pts/0 Ss+ 0:00 /bin/sh /usr/jekyll/bin/jekyll serve
15 pts/0 Sl+ 0:20 ruby -r github-pages /usr/gem/bin/jekyll serve -H 0.0.0.0
52 pts/1 Ss 0:00 /bin/bash
58 pts/1 R+ 0:00 ps ax
bash-4.4#
</code></pre></div></div>
<p>How about good old hello-world?</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ podman run hello-world
Trying to pull docker.io/library/hello-world...Getting image source signatures
Copying blob 1b930d010525 done
Copying config fce289e99e done
Writing manifest to image destination
Storing signatures
Hello from Docker!
This message shows that your installation appears to be working correctly.
To generate this message, Docker took the following steps:
1. The Docker client contacted the Docker daemon.
2. The Docker daemon pulled the "hello-world" image from the Docker Hub.
(amd64)
3. The Docker daemon created a new container from that image which runs the
executable that produces the output you are currently reading.
4. The Docker daemon streamed that output to the Docker client, which sent it
to your terminal.
To try something more ambitious, you can run an Ubuntu container with:
$ docker run -it ubuntu bash
Share images, automate workflows, and more with a free Docker ID:
https://hub.docker.com/
For more examples and ideas, visit:
https://docs.docker.com/get-started/
</code></pre></div></div>
<p>It “just works.”</p>
<h2 id="a-few-notes">A few notes</h2>
<p>Even though podman is command for command the same as docker, there are some major differences, especially in philosophy.</p>
<ul>
<li><a href="https://developers.redhat.com/blog/2019/02/21/podman-and-buildah-for-docker-users/">podman uses runc</a></li>
</ul>
<blockquote>
<p>The Podman approach is simply to directly interact with the image registry, with the container and image storage, and with the Linux kernel through the runC container runtime process (not a daemon).</p>
</blockquote>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ runc -h | head -6
NAME:
runc - Open Container Initiative runtime
runc is a command line client for running applications packaged according to
the Open Container Initiative (OCI) format and is a compliant implementation of the
Open Container Initiative specification.
</code></pre></div></div>
<ul>
<li>You do not need to be root to run podman</li>
<li>As mentioned, <a href="https://developers.redhat.com/blog/2019/02/21/podman-and-buildah-for-docker-users/">same commands</a></li>
</ul>
<blockquote>
<p>When building Podman, the goal was to make sure that Docker users could easily adapt. So all the commands you are familiar with also exist with Podman. In fact, the claim is made that if you have existing scripts that run Docker you can create a docker alias for podman and all your scripts should work (alias docker=podman).</p>
</blockquote>
<ul>
<li>“<a href="https://developers.redhat.com/blog/2019/02/21/podman-and-buildah-for-docker-users/">Podman’s local repository is in /var/lib/containers instead of /var/lib/docker</a>”</li>
<li>“<a href="https://opensource.com/article/18/10/podman-more-secure-way-run-containers">Podman uses a traditional fork/exec model (vs. a client/server model) for running containers.</a>”</li>
<li>You won’t be able to use docker-compose with podman, that could be an issue for some. There seems to be some <a href="https://developers.redhat.com/blog/2019/01/29/podman-kubernetes-yaml/">work in making transitioning to podman</a> easier</li>
<li><a href="https://developers.redhat.com/blog/2019/01/15/podman-managing-containers-pods/">Surprise! podman can manage pods</a>:</li>
</ul>
<blockquote>
<p>The ability for Podman to handle pod deployment is a clear differentiator to other container runtimes. As a libpod maintainer, I am still realizing the advantages of having pods even in a localized runtime. There will most certainly be more development in Podman around pods as we learn how users exploit the use of them.</p>
</blockquote>
<ul>
<li>There is a introductory <a href="https://www.katacoda.com/courses/containers-without-docker/running-containers-with-podman">course</a> on Katacoda, so you can try it out without even installing</li>
</ul>
<h2 id="conclusion">Conclusion</h2>
<p>I like that podman is a command for command replacement for Docker. I also like the focus on security, and the fact that there is no docker server running. Not having docker compose could be problem for developers who have to install things like databases to get a development environment. I like that the community and RedHat have written quite a few blog posts about podman.</p>
<p>Overall, podman, while it could maybe use a better name, is interesting because it moves the container ecosystem forward and provides some diversity. I have no problems with Docker, it’s a simple fact that I just wasn’t able to install a stable version on Fedora 30 (yet) and thus ended up exploring podman.</p>
<p>I barely touched the tip of the iceberg with the podman ecosystem, in future posts I’ll take a more in-depth look. I’m sure there are some edge cases. :)</p>
DevOps - You Need a Factory2019-05-18T00:00:00+00:00http://serverascode.com/2019/05/18/devops-needs-a-factory<h1 id="devops---you-need-a-factory">DevOps - You Need a Factory</h1>
<p>A few months ago I listened Kelsey Hightower speak at a function in Toronto. During that talk he said something that has stuck with me, and that is that you need a factory.</p>
<h2 id="devops-produces-artifacts">DevOps Produces Artifacts</h2>
<p>The definition and application of DevOps is oft-debated. However, the fact is that in as technologists we produce things–perhaps they are applications, ie. code, or systems that manage these applications (with automation now also code). Maybe the product is an IoS application or maybe it’s complex infrastructure–OpenStack, Kubernetes, large networks, what have you. Regardless, we create a product. Increasingly that product is generated or operated via the DevOps paradigm.</p>
<p>DevOps has, at this point, a relatively long history and is well documented in terms of its influences: W. Edward Deming, Agile, Toyota Kata, and Lean Manufacturing to name a few. Many of these theories and processes are designed for factories; for the creation of physical products. If we are doing “the DevOps”, and we are automating in the spirit of its influences, such as lean manufacturing, then…where is the factory?</p>
<h2 id="cicd---the-too-easy-answer">CI/CD - The (Too) Easy Answer</h2>
<p>The easy answer to the factory question is the use of continuous integration and delivery: CI/CD. Many organizations participating in DevOps know that CI/CD is important, but I’m not sure they know why. Often CI/CD is simply “cargo culted” into an organization. (You can usually tell because of the paralysis around selecting a CI/CD system.)</p>
<p>In my opinion, to truly participate in a DevOps model you need a factory, and your CI/CD pipeline is the floor of that factory. The CI/CD system takes input, resources, materials, and work from real live people and produces artifacts which can be evaluated in terms of quality. Like a factory, it can create overstock and has bottlenecks. Most importantly, it is the main system that can be improved over time as part of an ongoing, continuous process.</p>
<h2 id="build-a-virtual-factory">Build a (Virtual) Factory</h2>
<p>I have talked to many organizations that say they are following the DevOps paradigm. They use small teams, have removed walls between groups, and <em>cough</em> use Slack. They might even do some CI/CD…but do they really have a factory? If not, that is something that should be striven for. Without a factory full of people there’s nowhere to continuously improve.</p>
Install and Boot an Older Kernel in Ubuntu2019-05-17T00:00:00+00:00http://serverascode.com/2019/05/17/install-and-boot-older-kernel-ubuntu<h1 id="install-and-boot-an-older-kernel-in-ubuntu">Install and Boot an Older Kernel in Ubuntu</h1>
<p>Stangely it was hard to find good instructions on installing an older kernel and setting it to boot on Ubuntu 16.04. Here are some quick instructions.</p>
<p>The instance is Ubuntu 16.04 (in Digital Ocean) with the following kernel:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>root@old-kernely:~# uname -a
Linux old-kernely 4.4.0-148-generic #174-Ubuntu SMP Tue May 7 12:20:14 UTC 2019 x86_64 x86_64 x86_64 GNU/Linux
root@old-kernely:~#
</code></pre></div></div>
<p>Install an older kernel, 4.4.0-22-generic.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>root@old-kernely:~# apt install linux-image-4.4.0-22-generic
Reading package lists... Done
Building dependency tree
Reading state information... Done
The following package was automatically installed and is no longer required:
grub-pc-bin
Use 'apt autoremove' to remove it.
Suggested packages:
fdutils linux-doc-4.4.0 | linux-source-4.4.0 linux-tools linux-headers-4.4.0-22-generic
The following NEW packages will be installed:
linux-image-4.4.0-22-generic
0 upgraded, 1 newly installed, 0 to remove and 0 not upgraded.
Need to get 18.7 MB of archives.
After this operation, 55.4 MB of additional disk space will be used.
Get:1 http://mirrors.digitalocean.com/ubuntu xenial-updates/main amd64 linux-image-4.4.0-22-generic amd64 4.4.0-22.40 [18.7 MB]
Fetched 18.7 MB in 0s (69.0 MB/s)
Selecting previously unselected package linux-image-4.4.0-22-generic.
(Reading database ... 54537 files and directories currently installed.)
Preparing to unpack .../linux-image-4.4.0-22-generic_4.4.0-22.40_amd64.deb ...
Done.
Unpacking linux-image-4.4.0-22-generic (4.4.0-22.40) ...
Setting up linux-image-4.4.0-22-generic (4.4.0-22.40) ...
Running depmod.
update-initramfs: deferring update (hook will be called later)
Examining /etc/kernel/postinst.d.
run-parts: executing /etc/kernel/postinst.d/apt-auto-removal 4.4.0-22-generic /boot/vmlinuz-4.4.0-22-generic
run-parts: executing /etc/kernel/postinst.d/initramfs-tools 4.4.0-22-generic /boot/vmlinuz-4.4.0-22-generic
update-initramfs: Generating /boot/initrd.img-4.4.0-22-generic
W: mdadm: /etc/mdadm/mdadm.conf defines no arrays.
run-parts: executing /etc/kernel/postinst.d/unattended-upgrades 4.4.0-22-generic /boot/vmlinuz-4.4.0-22-generic
run-parts: executing /etc/kernel/postinst.d/update-notifier 4.4.0-22-generic /boot/vmlinuz-4.4.0-22-generic
run-parts: executing /etc/kernel/postinst.d/x-grub-legacy-ec2 4.4.0-22-generic /boot/vmlinuz-4.4.0-22-generic
Searching for GRUB installation directory ... found: /boot/grub
Searching for default file ... found: /boot/grub/default
Testing for an existing GRUB menu.lst file ... found: /boot/grub/menu.lst
Searching for splash image ... none found, skipping ...
Found kernel: /boot/vmlinuz-4.4.0-148-generic
Found kernel: /boot/vmlinuz-4.4.0-148-generic
Found kernel: /boot/vmlinuz-4.4.0-22-generic
Updating /boot/grub/menu.lst ... done
run-parts: executing /etc/kernel/postinst.d/zz-update-grub 4.4.0-22-generic /boot/vmlinuz-4.4.0-22-generic
Generating grub configuration file ...
Found linux image: /boot/vmlinuz-4.4.0-148-generic
Found initrd image: /boot/initrd.img-4.4.0-148-generic
Found linux image: /boot/vmlinuz-4.4.0-22-generic
Found initrd image: /boot/initrd.img-4.4.0-22-generic
done
root@old-kernely:~#
</code></pre></div></div>
<p>OK, now that the new kernel is installed, how can it be made the default? One way would be to reboot and chose that kernel at the grub menu but that is not that easy in a cloud environment, and wouldn’t be a permanent change.</p>
<p>Figuring out what to put in /etc/default/grub isn’t that easy. Let’s look at the submenus and menuentries (<a href="https://unix.stackexchange.com/questions/198003/set-default-kernel-in-grub">hat tip</a>).</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>root@old-kernely:~# awk '/menuentry/ && /class/ {count++; print count-1"****"$0 }' /boot/grub/grub.cfg
0****menuentry 'Ubuntu' --class ubuntu --class gnu-linux --class gnu --class os $menuentry_id_option 'gnulinux-simple-3bfdf15c-91ab-470e-a04a-6d95c9a1fbac' {
1**** menuentry 'Ubuntu, with Linux 4.4.0-148-generic' --class ubuntu --class gnu-linux --class gnu --class os $menuentry_id_option 'gnulinux-4.4.0-148-generic-advanced-3bfdf15c-91ab-470e-a04a-6d95c9a1fbac' {
2**** menuentry 'Ubuntu, with Linux 4.4.0-148-generic (recovery mode)' --class ubuntu --class gnu-linux --class gnu --class os $menuentry_id_option 'gnulinux-4.4.0-148-generic-recovery-3bfdf15c-91ab-470e-a04a-6d95c9a1fbac' {
3**** menuentry 'Ubuntu, with Linux 4.4.0-22-generic' --class ubuntu --class gnu-linux --class gnu --class os $menuentry_id_option 'gnulinux-4.4.0-22-generic-advanced-3bfdf15c-91ab-470e-a04a-6d95c9a1fbac' {
4**** menuentry 'Ubuntu, with Linux 4.4.0-22-generic (recovery mode)' --class ubuntu --class gnu-linux --class gnu --class os $menuentry_id_option 'gnulinux-4.4.0-22-generic-recovery-3bfdf15c-91ab-470e-a04a-6d95c9a1fbac' {
</code></pre></div></div>
<p>Under the submenu at entry 3 is the older kernel. However, numbering restarts with the submenu. So to boot the 4.4.0-22 kernel the required entry is submenu 1 and menuentry 2.</p>
<p>We add this to /etc/default/grub. Currently it’s set to 0.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>root@old-kernely:~# grep GRUB_DEFAULT /etc/default/grub
GRUB_DEFAULT=0
</code></pre></div></div>
<p>Set it to “1>2”.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>root@old-kernely:~# grep GRUB_DEFAULT /etc/default/grub
GRUB_DEFAULT="1>2"
</code></pre></div></div>
<p>Update grub.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>root@old-kernely:~# update-grub
Generating grub configuration file ...
Found linux image: /boot/vmlinuz-4.4.0-148-generic
Found initrd image: /boot/initrd.img-4.4.0-148-generic
Found linux image: /boot/vmlinuz-4.4.0-22-generic
Found initrd image: /boot/initrd.img-4.4.0-22-generic
done
</code></pre></div></div>
<p>Reboot.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>root@old-kernely:~# reboot
</code></pre></div></div>
<p>When the node reboots it’s using the older kernel specified.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>root@old-kernely:~# uname -a
Linux old-kernely 4.4.0-22-generic #40-Ubuntu SMP Thu May 12 22:03:46 UTC 2016 x86_64 x86_64 x86_64 GNU/Linux
</code></pre></div></div>
<p>Presumably there is a better way to do this. Let me know in the comments!</p>
Install a Linux Rootkit to Test Security Systems With2019-05-17T00:00:00+00:00http://serverascode.com/2019/05/17/install-a-rootkit-for-testing<h1 id="install-a-linux-rootkit-to-test-security-systems-with">Install a Linux Rootkit to Test Security Systems With</h1>
<p>Let’s say you wnat to install a rootkit to test with. There could be various reasons, maybe you are testing some kind of specialized security system. Regardless of the reason, you need a rootkit to test out.</p>
<p>The first place I ended up at is <a href="https://github.com/milabs/awesome-linux-rootkits">Awesome Rootkits</a>, a big list of rootkits.</p>
<p>The one that I picked from that list, somewhat randomly, was <a href="https://github.com/En14c/LilyOfTheValley">LilyOfTheValley</a>. I have no good reason as to why I picked this particular one, other than it seemed to suggest it would work on several kernel versions, and was a small amount of code.</p>
<h2 id="warning">WARNING</h2>
<p>Obviously this is a rootkit. Don’t install it on your local machine. Get a temporary, disposable virtual machine. Also, please review the code in the rootkit files. You’ve been warned!</p>
<h2 id="install">Install</h2>
<p>The kernel version in this example is 4.4.0-22 on Ubuntu 16.04.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code># uname -a
Linux old-kernely 4.4.0-22-generic #40-Ubuntu SMP Thu May 12 22:03:46 UTC 2016 x86_64 x86_64 x86_64 GNU/Linux
</code></pre></div></div>
<p>Clone the rootkit repo.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code># git clone https://github.com/En14c/LilyOfTheValley
# cd LilyOfTheValley
</code></pre></div></div>
<p>Install build-essential.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code># apt install build-essential -y
</code></pre></div></div>
<p>Get headers too.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code># apt install linux-headers-4.4.0-22-generic
</code></pre></div></div>
<p>Make.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code># make
make -C /lib/modules/4.4.0-22-generic/build M=/root/LilyOfTheValley modules
make[1]: Entering directory '/usr/src/linux-headers-4.4.0-22-generic'
CC [M] /root/LilyOfTheValley/lilyofthevalley.o
Building modules, stage 2.
MODPOST 1 modules
CC /root/LilyOfTheValley/lilyofthevalley.mod.o
LD [M] /root/LilyOfTheValley/lilyofthevalley.ko
make[1]: Leaving directory '/usr/src/linux-headers-4.4.0-22-generic'
</code></pre></div></div>
<p>Now there is a kernel module, lilyofthevalley.ko.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code># ls -1
client.c
lilyofthevalley.c
lilyofthevalley.ko
lilyofthevalley.mod.c
lilyofthevalley.mod.o
lilyofthevalley.o
Makefile
modules.order
Module.symvers
README.md
</code></pre></div></div>
<p>Install that module.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code># insmod lilyofthevalley.ko
</code></pre></div></div>
<p>Once it’s loaded /proc can be used to find commands that can be sent to the module.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code># cat /proc/lilyofthevalleyr00tkit
###########################
LilyOfTheValley Commands
###########################
* [givemerootprivileges] -->> to gain root access
* [hidepidPID] -->> to hide a given pid. replace (PID) with target pid
* [unhidepidPID] -->> to unhide a given pid. replace (PID) with target pid
* [hidingfiles] -->> just prepend lilyofthevalley to the file or dir name that u want to hide
</code></pre></div></div>
<p>Also, note how any files in the directory that started with the string “lilyofthevalley” now no longer appear in ls.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code># ls -1
client.c
Makefile
modules.order
Module.symvers
README.md
</code></pre></div></div>
<p>This is because the rootkit makes those files “invisble.”</p>
<p>See line 409 of lilyofthevalley.c.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code> /*
hide any file in the root filesystem,
if first chars of it's name == r00tkit_name
*/
if (strncmp(name,R00TKIT_NAME,R00TKIT_NAMELEN) == 0)
return 0;
</code></pre></div></div>
<p>Create a file that starts with that particular string. Note how it’s not visible in ls.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code># touch lilyofthevalley.txt
# ls
client.c Makefile modules.order Module.symvers README.md
</code></pre></div></div>
<p>After rebooting the node the kernel module is no longer loaded and the missing files are again visible..</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code># ls -1
client.c
lilyofthevalley.c
lilyofthevalley.ko
lilyofthevalley.mod.c
lilyofthevalley.mod.o
lilyofthevalley.o
lilyofthevalley.txt
Makefile
modules.order
Module.symvers
README.md
</code></pre></div></div>
<p>With the module in place security systems can be tested to see if they can find it.</p>
First Look - Kubeaudit2019-04-10T00:00:00+00:00http://serverascode.com/2019/04/10/kubeaudit<h1 id="first-look---kubeaudit">First Look - Kubeaudit</h1>
<p>I wanted to call this article “Gleaming the Kube” but <a href="http://dougbtv.com/nfvpe/2017/05/12/kubernetes-from-source/">someone</a> already did that.</p>
<p>Kubernetes is a relatively complex system, and I typically deal with OpenStack so that is saying something. With any new and complex (and valuable) system it’s easy to use that system to build, shall we say, services with less than desirable security settings. And thus we have people building tools that help to ensure systems and definitions are as secure as is reasonably possible. Enter kubeaudit.</p>
<h2 id="kubeaudit">Kubeaudit</h2>
<p><a href="https://github.com/Shopify/kubeaudit">Kubeaudit</a> is a helpful tool from the folks at Shopify. A Canadian company by the way!</p>
<blockquote>
<p>kubeaudit is a command line tool to audit Kubernetes clusters for various different security concerns: run the container as a non-root user, use a read only root filesystem, drop scary capabilities, don’t add new ones, don’t run privileged, … You get the gist of it and more on that later. Just know: <strong>kubeaudit makes sure you deploy secure containers!</strong></p>
</blockquote>
<p>Because go compiles into a nice clean binary, it’s easy to install kubeaudit.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>wget -P /tmp https://github.com/Shopify/kubeaudit/releases/download/v0.5.3/kubeaudit_0.5.3_linux_amd64.tar.gz
mkdir ~/bin # if you don't have one
export PATH=$PATH:~/bin
# only untar kubeaudit, there is a licence and readme file in there as well which we don't need
tar zxvf /tmp/kubeaudit_0.5.3_linux_amd64.tar.gz -C ~/bin kubeaudit
</code></pre></div></div>
<p>Check version.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ kubeaudit version
INFO[0000] Kubeaudit version BuildDate="2019-03-29T15:36:37Z" Commit=b19f6509d92abc22a8cf2789a98a740af20831e6 Version=0.5.3
INFO[0000] Not running inside cluster, using local config
INFO[0000] Kubernetes server version Major=1 Minor=13 Platform=linux/amd64
</code></pre></div></div>
<p>Note that this will check the Kubernetes version as well through reading the <code class="language-plaintext highlighter-rouge">.kube/config</code>.</p>
<h2 id="audit">Audit</h2>
<p>Let’s deploy an nginx container.</p>
<p><em>NOTE: I alias kubectl to k</em></p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ k run nginx --image=nginxinc/nginx-unprivileged --port=8080
</code></pre></div></div>
<p>It’s up and running.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ k get all
NAME READY STATUS RESTARTS AGE
pod/nginx-6c6d45d55d-ckhzw 1/1 Running 0 51s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/nginx 1/1 1 1 51s
NAME DESIRED CURRENT READY AGE
replicaset.apps/nginx-6c6d45d55d 1 1 1 51s
</code></pre></div></div>
<p>Now audit it with <code class="language-plaintext highlighter-rouge">kubeaudit</code>, but we’ll only check for nonroot.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ kubeaudit nonroot -n nginx-unpriv
INFO[0000] Not running inside cluster, using local config
ERRO[0000] RunAsNonRoot is not set in ContainerSecurityContext, which results in root user being allowed! Container=nginx KubeType=deployment Name=nginx Namespace=nginx-unpriv
ERRO[0000] RunAsNonRoot is not set in ContainerSecurityContext, which results in root user being allowed! Container=nginx KubeType=pod Name=nginx-6c6d45d55d-ckhzw Namespace=nginx-unpriv
</code></pre></div></div>
<p>Ok let’s fix that by patching the deployment.</p>
<p>Here is the patch:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ cat nginx-unpriv-runasnonroot.yml
spec:
template:
spec:
containers:
- image: nginxinc/nginx-unprivileged
name: nginx
securityContext:
runAsNonRoot: true
securityContext:
runAsNonRoot: true
</code></pre></div></div>
<p>Apply the patch.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ k patch deployment nginx --patch "$(cat nginx-unpriv-runasnonroot.yml)"
deployment.extensions/nginx patched
</code></pre></div></div>
<p>A new pod should be created.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>~$ k get all
NAME READY STATUS RESTARTS AGE
pod/nginx-686cc9b75c-jfc8t 1/1 Running 0 24s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/nginx 1/1 1 1 3m50s
NAME DESIRED CURRENT READY AGE
replicaset.apps/nginx-686cc9b75c 1 1 1 24s
replicaset.apps/nginx-6c6d45d55d 0 0 0 3m50s
</code></pre></div></div>
<p>And now to run audit again:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ kubeaudit nonroot -n nginx-unpriv
INFO[0000] Not running inside cluster, using local config
</code></pre></div></div>
<p>No errors.</p>
<p>That’s it. A simple example of using <code class="language-plaintext highlighter-rouge">kubeaudit</code>.</p>
Check Host Keys in Ansible Tower/AWX2019-02-01T00:00:00+00:00http://serverascode.com/2019/02/01/check-host-keys-tower-awx<h1 id="check-host-keys-in-ansible-towerawx">Check Host Keys in Ansible Tower/AWX</h1>
<p>By default AWX doesn’t validate host keys.</p>
<p>Users of plain old Ansible will know this is an option that you can enable or disable–by default in Ansible it’s enabled. However, by default in AWX it is <strong>disabled</strong>, which means that AWX does not validate host keys. However, you can enable it. The way that is done is a bit clunky, but it can be done.</p>
<p>In the AWX web interface, go to “Settings -> Jobs”. There you will see a section called “EXTRA ENVIRONMENT VAIRABLES.” Add <code class="language-plaintext highlighter-rouge">"ANSIBLE_HOST_KEY_CHECKING": "true"</code> as one of the variables. In my deployment the full configuration looked like this (yours might be different):</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>{
"HOME": "/var/lib/awx",
"ANSIBLE_HOST_KEY_CHECKING": "true"
}
</code></pre></div></div>
<p>Then ensure you save your new settings. At this point AWX should now start validating SSH host keys.</p>
<p><em>NOTE: I’m not aware of a way to do this outside of using the GUI, but maybe there is? If so, please let me know!</em></p>
<h2 id="example-failed-job-run">Example Failed Job Run</h2>
<p>I have an inventory that has already imported some hosts and a job has run against them, and thus the initial host key has already been set in AWX.</p>
<p>In one of the hosts in the inventory I’ll force a new host key.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>ubuntu@c03-01:/etc/ssh$ sudo rm /etc/ssh/ssh_host_*
ubuntu@c03-01:/etc/ssh$ sudo dpkg-reconfigure openssh-server
Creating SSH2 RSA key; this may take some time ...
2048 SHA256:4dFI8aTPISOOZssvPKG+jUnASrft0xTQdWOJhqQLnPo root@c03-01 (RSA)
Creating SSH2 DSA key; this may take some time ...
1024 SHA256:t3bYKZW2FFIUnDxD5uvqpPJbh3h2jjT80GLxttzRU6U root@c03-01 (DSA)
Creating SSH2 ECDSA key; this may take some time ...
256 SHA256:GaONanT4kLLUMJuTH4rghjXfrrahAY0aa98jEL8pXEA root@c03-01 (ECDSA)
Creating SSH2 ED25519 key; this may take some time ...
256 SHA256:qvw390bj+BEOd15NjcHLYtdbk9qzaN5rCE4Xaoi6teQ root@c03-01 (ED25519)
ubuntu@c03-01:/etc/ssh$
</code></pre></div></div>
<p>Now that that is done, let’s copy the key from <code class="language-plaintext highlighter-rouge">/etc/ssh/ssh_host_ecdsa_key.pub</code>.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>ubuntu@c03-01:/etc/ssh$ cat ssh_host_ecdsa_key.pub
ecdsa-sha2-nistp256 AAAAE2VjZHNhLXNoYTItbmlzdHAyNTYAAAAIbmlzdHAyNTYAAABBBK/6oDS05/WR6Cn8camUDFW3OuyRS3ThiTg+8AzS4s68fkP4EUS86IPVjvNb7w180JxGCBA2Dkmi5QdSCPZsLdg= root@c03-01
</code></pre></div></div>
<p>Later we will add that to the AWX task container in <code class="language-plaintext highlighter-rouge">/root/.ssh/known_hosts</code>.</p>
<p>I have a job that constantly runs. It just ensures all new hosts have python 2.7, for $reasons…</p>
<p>Because I’ve changed the host key and set AWX to check host keys, that job now fails for that host.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>(tower-cli) ubuntu@awx-client:~$ tc job stdout 22314
Identity added: /tmp/awx_22314_cU7Zqd/credential_2 (/tmp/awx_22314_cU7Zqd/credential_2)
PLAY [all] *********************************************************************
TASK [ensure python 2.7 is installed] ******************************************
ok: [c02-03]
ok: [c02-01]
ok: [c02-04]
ok: [c03-02]
ok: [c02-02]
fatal: [c03-01]: UNREACHABLE! => {"changed": false, "msg": "Failed to connect to the host via ssh: @@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@\\r\\n@ WARNING: REMOTE HOST IDENTIFICATION HAS CHANGED! @\\r\\n@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@\\r\\nIT IS POSSIBLE THAT SOMEONE IS DOING SOMETHING NASTY!\\r\\nSomeone could be eavesdropping on you right now (man-in-the-middle attack)!\\r\\nIt is also possible that a host key has just been changed.\\r\\nThe fingerprint for the ECDSA key sent by the remote host is\\nSHA256:GaONanT4kLLUMJuTH4rghjXfrrahAY0aa98jEL8pXEA.\\r\\nPlease contact your system administrator.\\r\\nAdd correct host key in /root/.ssh/known_hosts to get rid of this message.\\r\\nOffending ECDSA key in /root/.ssh/known_hosts:13\\r\\nECDSA host key for 172.20.50.16 has changed and you have requested strict checking.\\r\\nHost key verification failed.\\r\\n", "unreachable": true}
ok: [c01-01]
ok: [c01-02]
ok: [c01-03]
TASK [ping] ********************************************************************
ok: [c02-04]
ok: [c02-03]
ok: [c02-02]
ok: [c02-01]
ok: [c03-02]
ok: [c01-03]
ok: [c01-01]
ok: [c01-02]
PLAY RECAP *********************************************************************
c03-01 : ok=0 changed=0 unreachable=1 failed=0
c03-02 : ok=2 changed=0 unreachable=0 failed=0
c02-01 : ok=2 changed=0 unreachable=0 failed=0
c02-02 : ok=2 changed=0 unreachable=0 failed=0
c02-03 : ok=2 changed=0 unreachable=0 failed=0
c02-04 : ok=2 changed=0 unreachable=0 failed=0
c01-01 : ok=2 changed=0 unreachable=0 failed=0
c01-02 : ok=2 changed=0 unreachable=0 failed=0
c01-03 : ok=2 changed=0 unreachable=0 failed=0
OK. (changed: false)
</code></pre></div></div>
<p>Note the big “IT IS POSSIBLE THAT SOMEONE IS DOING SOMETHING NASTY!” warning.</p>
<h2 id="add-new-key-to-awx-and-rerun-job">Add New Key to AWX and Rerun Job</h2>
<p>To set the new host key, I’ll login to the AWX host. In my deployment AWX is “containerized” which means AWX is actually made up of several different Docker based containers.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>root@awx:~# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
1169cf7d8918 ssl-haproxy "/bin/bash" 4 weeks ago Up 4 weeks 0.0.0.0:443->443/tcp haproxy
c4bfceeba785 ubuntu:xenial "/bin/bash" 4 weeks ago Up 4 weeks tower-cli
75ac023a773b ansible/awx_task:2.1.2 "/tini -- /bin/sh -c…" 4 weeks ago Up 4 weeks 8052/tcp awx_task_1
0773f80c42cc ansible/awx_web:2.1.2 "/tini -- /bin/sh -c…" 4 weeks ago Up 4 weeks 0.0.0.0:80->8052/tcp awx_web_1
54d91fe6c00f memcached:alpine "docker-entrypoint.s…" 4 weeks ago Up 4 weeks 11211/tcp awx_memcached_1
1540a632c139 ansible/awx_rabbitmq:3.7.4 "docker-entrypoint.s…" 4 weeks ago Up 4 weeks 4369/tcp, 5671-5672/tcp, 15671-15672/tcp, 25672/tcp awx_rabbitmq_1
6b8e0dfd7aab postgres:9.6 "docker-entrypoint.s…" 4 weeks ago Up 4 weeks 5432/tcp awx_postgres_1
root@awx:~#
</code></pre></div></div>
<p>I’ll login to the awx_task host and edit the line for this particular host, adding the ecdsa key.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>root@awx:~# docker exec -it 75ac023a773b /bin/bash
[root@awx awx]# vi ~/.ssh/known_hosts
# Add the key to the correct entry
</code></pre></div></div>
<p>The next time the job runs the host key will not cause an error.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>(tower-cli) ubuntu@awx-client:~$ tc job stdout 22329
Identity added: /tmp/awx_22329_zl5Pd7/credential_2 (/tmp/awx_22329_zl5Pd7/credential_2)
PLAY [all] *********************************************************************
TASK [ensure python 2.7 is installed] ******************************************
ok: [c01-01]
ok: [c02-04]
ok: [c01-02]
ok: [c01-03]
ok: [c03-02]
ok: [c02-01]
ok: [c02-02]
ok: [c03-01]
ok: [c02-03]
TASK [ping] ********************************************************************
ok: [c02-04]
ok: [c01-01]
ok: [c01-03]
ok: [c01-02]
ok: [c03-02]
ok: [c02-01]
ok: [c02-03]
ok: [c02-02]
ok: [c03-01]
PLAY RECAP *********************************************************************
c03-01 : ok=2 changed=0 unreachable=0 failed=0
c03-02 : ok=2 changed=0 unreachable=0 failed=0
c02-01 : ok=2 changed=0 unreachable=0 failed=0
c02-02 : ok=2 changed=0 unreachable=0 failed=0
c02-03 : ok=2 changed=0 unreachable=0 failed=0
c02-04 : ok=2 changed=0 unreachable=0 failed=0
c01-01 : ok=2 changed=0 unreachable=0 failed=0
c01-02 : ok=2 changed=0 unreachable=0 failed=0
c01-03 : ok=2 changed=0 unreachable=0 failed=0
OK. (changed: false)
</code></pre></div></div>
<p>All good again. :)</p>
<h2 id="conclusion">Conclusion</h2>
<p>All that I did in this post was enable host key checking in AWX and then do a simple verification that it was indeed checking host keys, and failing with unknown host keys.</p>
Ten Million Packets per Second with Moongen2018-12-31T00:00:00+00:00http://serverascode.com/2018/12/31/ten-million-packets-per-second<h1 id="ten-million-packets-per-second-with-moongen">Ten Million Packets per Second with Moongen</h1>
<h2 id="network-performance-testing">Network Performance Testing</h2>
<p>Over the last few years I have been doing a lot of work in the Network Function Virtualization (NFV) world, specifically Virtual Network Function (VNF) on-boarding. When on-boarding any application, it’s important to test it, and one part of testing is performance testing. But how do we effectively performance test network applications?</p>
<p>We need to push performance to the breaking point. Many of these applications are designed to be extremely fast, thus it’s difficult to even push them to their limits without some kind of specialized traffic generator. Further, traffic generators themselves are just applications, and have the same issues getting high performance as the systems that are under test. Commercial traffic generators available but are typically esoteric, expensive, and inflexible.</p>
<h2 id="how-much-of-our-network-do-we-really-use">How Much of Our Network Do We Really Use?</h2>
<p>I’m going to make a statement that is perhaps controversial: we don’t really use much of our networks…they’re rarely pushed to their limits. In fact, I think we build many of our systems assuming that the network will hardly be used. Frankly I think it would be fair to apply this to much of what we do: compute, network, and storage. This is in part why virtualization is so successful. But, as usual, I digress…</p>
<p>We should push our networks, and more specifically our network interfaces and the applications that create and manage packets, to the limit. Throughput is relatively easy, packets per second, however, is a bit harder–a good 10GB interface should be able to send about 10 million 64 byte packets per second (PPS). That’s what hardware can do, but what about software?</p>
<h2 id="the-linux-kernel-and-dpdk">The Linux Kernel and DPDK</h2>
<p>The Linux Kernel, and presumably all other OS kernels, just can’t deal with that many packets. Here’s what <a href="https://blog.cloudflare.com/kernel-bypass/">CloudFlare</a> has to say:</p>
<blockquote>
<p>Unfortunately the speed of vanilla Linux kernel networking is not sufficient for more specialized workloads. For example, here at CloudFlare, we are constantly dealing with large packet floods. Vanilla Linux can do only about 1M pps. This is not enough in our environment, especially since the network cards are capable of handling a much higher throughput. Modern 10Gbps NIC’s can usually process at least 10M pps.</p>
</blockquote>
<p>This performance issue is well known and usually doesn’t come into play in most networks and applications. However, when we need a high level of performance we can get around the kernel with something like DPDK, where we pull most the networking into userland. While the Data Plane Development Kit (DPDK) is available to allow vastly increased performance, it still requires some complex programming…unless you use Moongen!</p>
<h2 id="moongen">Moongen</h2>
<p><a href="https://github.com/emmericp/MoonGen">Moongen</a> is truly an amazing–and more importantly accessible–piece of software for generating extreme amounts of traffic.</p>
<blockquote>
<p>MoonGen is a fully scriptable high-speed packet generator built on DPDK and LuaJIT. It can saturate a 10 Gbit/s connection with 64 byte packets on a single CPU core while executing user-provided Lua scripts for each packet. Multi-core support allows for even higher rates. It also features precise and accurate timestamping and rate control.</p>
</blockquote>
<p>Using Moongen one can access DPDK though simply Lua scripts. I was able to easily create a custom DNS UDP packet generator in less than a hundred lines of Lua. Using that code I could push about 6.5GB of DNS queries towards a DNS server to test its performance capability, all using an older x86 server with a common, and inexpensive 10GB Intel 82599ES network card.</p>
<p>A quick example of running that code:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code># ./build/MoonGen ./examples/dns-query.lua -r 10000
[INFO] Initializing DPDK. This will take a few seconds...
EAL: Detected 16 lcore(s)
EAL: No free hugepages reported in hugepages-1048576kB
EAL: Probing VFIO support...
EAL: PCI device 0000:03:00.0 on NUMA socket 0
EAL: probe driver: 8086:1521 net_e1000_igb
EAL: PCI device 0000:03:00.1 on NUMA socket 0
EAL: probe driver: 8086:1521 net_e1000_igb
EAL: PCI device 0000:81:00.0 on NUMA socket 1
EAL: probe driver: 8086:10fb net_ixgbe
EAL: PCI device 0000:81:00.1 on NUMA socket 1
EAL: probe driver: 8086:10fb net_ixgbe
[INFO] Found 3 usable devices:
Device 0: 0C:C4:7A:92:63:7D (Intel Corporation I350 Gigabit Network Connection)
Device 1: 0C:C4:7A:BB:70:82 (Intel Corporation 82599ES 10-Gigabit SFI/SFP+ Network Connection)
Device 2: 0C:C4:7A:BB:70:83 (Intel Corporation 82599ES 10-Gigabit SFI/SFP+ Network Connection)
[WARN] device.config() without named arguments is deprecated and will be removed. See documentation for libmoons device.config().
PMD: ixgbe_dev_link_status_print(): Port 1: Link Up - speed 0 Mbps - half-duplex
[INFO] Waiting for devices to come up...
[INFO] Device 1 (0C:C4:7A:BB:70:82) is up: 10000 MBit/s
[INFO] 1 device is up.
starting arp
starting send
starting counter
in send
in counter
[INFO] starting in moongen loop
[nil] TX: 5.48 Mpps, 4562 Mbit/s (5439 Mbit/s with framing)
[nil] TX: 6.56 Mpps, 5455 Mbit/s (6504 Mbit/s with framing)
[nil] TX: 6.73 Mpps, 5601 Mbit/s (6679 Mbit/s with framing)
[nil] TX: 6.74 Mpps, 5606 Mbit/s (6684 Mbit/s with framing)
[nil] TX: 6.77 Mpps, 5636 Mbit/s (6719 Mbit/s with framing)
[nil] TX: 6.77 Mpps, 5631 Mbit/s (6714 Mbit/s with framing)
[nil] TX: 6.79 Mpps, 5645 Mbit/s (6731 Mbit/s with framing)
[nil] TX: 6.77 Mpps, 5633 Mbit/s (6717 Mbit/s with framing)
[nil] TX: 6.76 Mpps, 5624 Mbit/s (6706 Mbit/s with framing)
[nil] TX: 6.79 Mpps, 5647 Mbit/s (6733 Mbit/s with framing)
[nil] TX: 6.81 Mpps, 5664 Mbit/s (6753 Mbit/s with framing)
SNIP!
</code></pre></div></div>
<p><br /></p>
<p>Pretty incredible how easy it is to write a little bit of Lua and generate (or process) such a huge number of packets! One server. One NIC. One CPU. 6Mpps of traffic.</p>
<h2 id="use-all-your-network-with-much-less-cpu">Use All Your Network (With Much Less CPU)</h2>
<p>What I found was that very few network applications, including the Linux kernel, can deal with that much traffic. In my simplistic testing it was easy to get the Linux kernel and network applications to drop packets by the millions, or get applications to just plain fall over and either crash or stop processing packets (looking at you named). Ultimately, dealing with this many packets is difficult, and a well known problem, but using things like DPDK and Moongen makes it much more accessible to solve.</p>
<p>In situations that call for high performance using considerably fewer CPU resources, DPDK, possibly with Moongen, becomes an easy choice, and that goes double for performance testing with a relatively limited budget.</p>
<h2 id="thanks-moongen-and-cloudflare-too">Thanks Moongen (and CloudFlare too)</h2>
<p>Moongen is truly an amazing piece of software. Thanks to the relatively few people who put this project together, especially Mr. Paul Emmerich.</p>
<p>I also want to give a shout out to the CloudFlare folks. I don’t know if they know how important their network performance blog posts are. I also used some of their example code. Thanks greatly!</p>
Book Review - Leading the Unleadable2018-11-24T00:00:00+00:00http://serverascode.com/2018/11/24/book-review-leading-the-unleadable<h1 id="book-review---leading-the-unleadable">Book Review - Leading the Unleadable</h1>
<h2 id="tldr">tldr;</h2>
<p><a href="https://alanwillett.com/leading-the-unleadable/">Leading the Unleadable</a> is really more about generic leadership principles than it is about dealing with difficult employees or other challenging interpersonal issues at work. But that does not diminish the value of the book overall, and I would suggest that the relatively short time it takes to read this book is well worth it.</p>
<h2 id="technology-is-easy-people-are-hard">Technology is Easy; People are Hard</h2>
<p>We know some technology is hard (distributed systems I’m looking at you) but generally speaking as an industry I think we actually are pretty good at getting technology in place and working…eventually. Sure, usually it takes awhile and is more expensive than we’d like, but ultimately it gets done.</p>
<p>However, if the DevOps paradigm has showed us anything, it’s that of the triumvirate of people, process, and tools, people are the most difficult. Then comes process (because it’s so related to people) and finally, technology.</p>
<h2 id="leading-the-unleadable">Leading the Unleadable</h2>
<p><a href="https://alanwillett.com/leading-the-unleadable/">Leading the Unleadable</a> (LtU), by Alan Willett, is a management and leadership book about dealing with difficult people. Interestingly the preface of this book, ie. the very first page, contains the following sentence:</p>
<blockquote>
<p>Sometimes leaders terminate difficult people too quickly, which harms the group by giving it no chance to change the difficult people and reclaim them.</p>
</blockquote>
<p>There is a lot to unpack in that sentence. Perhaps the most interesting part is the idea that leadership is often about helping a team integrate and deal with difficult people, as opposed to having a “leader” deal with them. Later on in the book (pg. 35) we get a supporting quote:</p>
<blockquote>
<p>Exceptional leaders know that when encountering some behaviour or action that appears unacceptable their first thought should be to wonder what they don’t understand about the person and the communication process.</p>
</blockquote>
<p>The book suggests that more often than not difficult people can be understood and reclaimed or integrated by understanding their personal story; that overall people are good and should be approached as such. It is certainly a positive view on difficult people.
Troublesome Individuals</p>
<h2 id="the-book-lays-out-a-few-archetypes-of-challenging-people">The book lays out a few archetypes of challenging people:</h2>
<ul>
<li>The Cynic</li>
<li>The Slacker</li>
<li>The Diva</li>
<li>The Pebble in the Shoe</li>
<li>The Maverick</li>
</ul>
<p>A couple of examples are given in terms of dealing with the above archetypes, specifically Divas and Mavericks. However, while the examples are good, I don’t feel that they in depth enough, nor do the archetypes cover enough possibilities, especially for a book that is supposed to deal with a specific subject: dealing with difficult people. Actually, not just “difficult” but “unleadable.”</p>
<p>However, LtU does give an interesting model for determining whether or not to “remove or improve” an employee or team member (chpt 7). Leaders could adopt that model to help determine what to do with challenging employees.
Leadership Advice</p>
<p>The book does provide great leadership advice. For people who want to be leaders, it puts the following points in order of importance:</p>
<ol>
<li>Provide a great return on investment to your employer</li>
<li>Improve yourself</li>
<li>Reduce your labour while dramatically improving the value you provide</li>
</ol>
<p>LtU also constantly reinforces the need for leadership to set the bar high in terms of what the organization can accomplish. Willett also discusses how exceptional leaders accept reality but don’t let it define them. He is definitely a proponent of “the need for mountains” and setting audacious goals. It would seem that Willett believes that many issues in the workplace are caused when people, teams, and even the organization itself, aren’t challenged.</p>
<h2 id="conclusion">Conclusion</h2>
<p>I do recommend the book. It is a quick read and there is valuable information that can be gleaned from it, especially about general leadership.</p>
<p>There are a couple of useful chapters on processes for dealing with difficult people, especially chapters 5 and 6. If the difficult people are really misunderstood people, then these ideas, tools, and processes should help.</p>
<p>If there is any specific message that I took from the book, it’s that setting the bar high is important. Often people, teams, and organizations don’t give themselves enough credit in terms of what they can accomplish.</p>
Configure Bind to Respond with a Single IP to Any Query2018-11-18T00:00:00+00:00http://serverascode.com/2018/11/18/configure-bind-authoritative-return-same-ip<h1 id="configure-bind-to-respond-with-a-single-ip-to-any-query">Configure Bind to Respond with a Single IP to Any Query</h1>
<p>In this post I’ll lay out how to setup bind to be authoritative for a single domain, and to respond with a single IP address for any request for that domain.</p>
<h2 id="why">Why?</h2>
<p>I’m doing a bunch of DNS performance testing. I want to see how fast bind can respond to authoritative domains, but the requests could be for any hostname. Eg. If I request the IP for somerandomhost.example.com I want it to report the same IP as for someotherrandomhost.example.com.</p>
<h2 id="configure-bind">Configure Bind</h2>
<p>Running on Ubuntu 16.04, I first install bind9.</p>
<p>Note that I’m using example.com. It might be better to use a internal domain in your case. At any rate, try to make sure that your testing doesn’t egress outside the boundaries of your lab.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>sudo apt update
sudo apt install bind9
</code></pre></div></div>
<p>Next, configure an example.com zone file in /etc/bind.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$TTL 86400
@ IN SOA ns.yourdomain.com. hostmaster.yourdomain.com. (
2008032701 ; Serial
8H ; Refresh
2H ; Retry
1W ; Expire
1D) ; Minimum
NS ns
* A 127.0.0.1
</code></pre></div></div>
<p>Note the “*” line that means respond to any request with 127.0.0.1.</p>
<p>Add the below to named.conf.local to get bind to pickup the example.com domain.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>zone "example.com" in {
type master;
file "/etc/bind/example.com";
};
</code></pre></div></div>
<p>Add these options to named.conf.options. This will disable recursive queries. I’m only going to be testing authoritative requests and don’t want external requests at all.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>recursion no;
additional-from-auth no;
additional-from-cache no;
</code></pre></div></div>
<p>Start/restart bind9.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>systemctl restart bind9
systemctl status bind9
</code></pre></div></div>
<p>Run a quick test to ensure recursion is not allowed.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ dig @localhost news.google.com
; <<>> DiG 9.10.3-P4-Ubuntu <<>> @localhost news.google.com
; (1 server found)
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: REFUSED, id: 47477
;; flags: qr rd; QUERY: 1, ANSWER: 0, AUTHORITY: 0, ADDITIONAL: 1
;; WARNING: recursion requested but not available
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 4096
;; QUESTION SECTION:
;news.google.com. IN A
;; Query time: 0 msec
;; SERVER: 127.0.0.1#53(127.0.0.1)
;; WHEN: Sun Nov 18 11:09:29 UTC 2018
;; MSG SIZE rcvd: 44
</code></pre></div></div>
<p>Note in the above “WARNING: recursion requested but not available”. That is what we want to see: no recursion.</p>
<p>Once that has all been setup and bind9 restarted, we can do something like this:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ dig @localhost `cat /proc/sys/kernel/random/uuid`.example.com
; <<>> DiG 9.10.3-P4-Ubuntu <<>> @localhost 69a65fd2-2223-485b-a6aa-156152db4318.example.com
; (1 server found)
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 3370
;; flags: qr aa rd; QUERY: 1, ANSWER: 1, AUTHORITY: 1, ADDITIONAL: 2
;; WARNING: recursion requested but not available
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 4096
;; QUESTION SECTION:
;69a65fd2-2223-485b-a6aa-156152db4318.example.com. IN A
;; ANSWER SECTION:
69a65fd2-2223-485b-a6aa-156152db4318.example.com. 86400 IN A 127.0.0.1
;; AUTHORITY SECTION:
example.com. 86400 IN NS ns.example.com.
;; ADDITIONAL SECTION:
ns.example.com. 86400 IN A 127.0.0.1
;; Query time: 0 msec
;; SERVER: 127.0.0.1#53(127.0.0.1)
;; WHEN: Sun Nov 18 11:27:45 UTC 2018
;; MSG SIZE rcvd: 126
</code></pre></div></div>
<p>bind responds that the IP for the host is at 127.0.0.1.</p>
<p>Let’s run it once more, with +short.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ dig +short @localhost `cat /proc/sys/kernel/random/uuid`.example.com
127.0.0.1
</code></pre></div></div>
<p>Note how I’m using /proc/sys/kernel/random/uuid to generate a new…er random uuid. Neat huh.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ cat /proc/sys/kernel/random/uuid
f6759215-323d-438b-b4da-535a8aabc63f
</code></pre></div></div>
<p>If you ever need a uuid, that is an easy way to get one without having to install any other software.</p>
<h2 id="conclusion">Conclusion</h2>
<p>If, for some reason, you want to configure bind to be</p>
<ul>
<li>authoritative only (not resolve)</li>
<li>respond to any request for a single domain to be a single IP</li>
</ul>
<p>then at this point you should be happy!</p>
OpenStack Zun and Kata Containers2018-11-14T00:00:00+00:00http://serverascode.com/2018/11/14/openstack-zun-and-kata-containers<p><em>(diagram of kata containers)</em></p>
<h1 id="openstack-zun-and-kata-containers">OpenStack Zun and Kata Containers</h1>
<p>In this post I’ll explore using DevStack to deploy OpenStack Zun. After that, I’ll setup Zun to use Kata Containers as the container runtime.</p>
<h2 id="openstack-zun">OpenStack Zun</h2>
<p>So what is OpenStack Zun? The <a href="https://wiki.openstack.org/wiki/Zun">wiki page</a> for Zun actually does a pretty good job of explaining it:</p>
<blockquote>
<p>Zun is for users who want to create and manage containers as OpenStack-managed resource. Containers managed by Zun are supposed to be integrated well with other OpenStack resources, such as Neutron network and Cinder volume. Users are provided a simplified APIs to manage containers without the need to explore the complexities of different container technologies. Magnum is for users who want a self-service solution to provision and manage a Kubernetes (or other COEs) cluster.</p>
</blockquote>
<p>To unpack that paragraph, Zun provides an API that lets you manage containers. It is not Kubernetes, or Docker, or LXD, or any other Container Orchestration Engine (COE). The Zun API is its own API. It uses many pieces from OpenStack and other container related systems, but it’s its own API.</p>
<p>I should say here that if one <em>does</em> want a COE, then the <a href="https://docs.openstack.org/magnum/latest/">OpenStack Magnum</a> project can provide that. What Zun and Magnum do are quite different.</p>
<h2 id="kata-containers">Kata Containers</h2>
<blockquote>
<p>Kata Containers is an open source project and community working to build a standard implementation of lightweight Virtual Machines (VMs) that feel and perform like containers, but provide the workload isolation and security advantages of VMs. – <a href="https://katacontainers.io/">Kata Containers</a>:</p>
</blockquote>
<p>Basically, Kata containers are virtual machines which act as much like containers as possible.</p>
<p>(I don’t want to discuss what containers are in this blog post, as it would take up too much room, but it’s worth doing some reading about cgroups, namespaces, etc, and what exactly makes up containers.)</p>
<h2 id="devstack--zun--kata-containers">DevStack + Zun + Kata Containers</h2>
<p>The best way to quickly try out Zun and Kata Containers is to use DevStack to deploy a small OpenStack deployment with the Zun plugin. I’m mostly following <a href="https://github.com/kata-containers/documentation/blob/master/zun/zun_kata.md">this document</a> with a few small changes (overall the linked document does work).</p>
<p>First, we need a DevStack with Zun.</p>
<p>DevStack + Zun will be deployed onto Ubuntu 16.04. Note that the stable/rocky release of both DevStack and Zun is used, more recent versions should work as well.</p>
<p><em>NOTE: I am disabling Horizon because I kept running into a permissions bug that stops DevStack from completing. By the time you read this perhaps that bug is fixed in DevStack.</em></p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>apt update
apt install git screen -y
screen -R install
sudo useradd -s /bin/bash -d /opt/stack -m stack
echo "stack ALL=(ALL) NOPASSWD: ALL" | sudo tee /etc/sudoers.d/stack
su - stack
sudo mkdir -p /opt/stack
sudo chown $USER /opt/stack
git clone https://github.com/openstack-dev/devstack /opt/stack/devstack
cd /opt/stack/devstack
git checkout stable/rocky
HOST_IP="$(ip addr | grep 'state UP' -A2 | tail -n1 | awk '{print $2}' | cut -f1 -d'/')"
git clone https://github.com/openstack/zun /opt/stack/zun
cd /opt/stack/zun
git checkout stable/rocky
cd /opt/stack/devstack
cat /opt/stack/zun/devstack/local.conf.sample \
| sed "s/HOST_IP=.*/HOST_IP=$HOST_IP/" \
> /opt/stack/devstack/local.conf
sed -i "s/KURYR_CAPABILITY_SCOPE=.*/KURYR_CAPABILITY_SCOPE=local/" /opt/stack/devstack/local.conf
echo "ENABLE_CLEAR_CONTAINER=true" >> /opt/stack/devstack/local.conf
# bug in horizon deployment...
echo "disable_service horizon" >> /opt/stack/devstack/local.conf
</code></pre></div></div>
<p>Finally, run the stack.sh script to install DevStack.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>./stack.sh
</code></pre></div></div>
<p><em>NOTE: stack.sh can take an hour to complete, depending on network connectivity.</em></p>
<p>Once stack.sh completes, we should be able to access OpenStack and Zun.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>source /opt/stack/devstack/openrc admin admin
# Make a couple of aliases for less typing
alias os=openstack
alias ac="openstack appcontainer"
os token issue
ac list
</code></pre></div></div>
<p>Hopefully <code class="language-plaintext highlighter-rouge">os token issue</code> returns a token, and <code class="language-plaintext highlighter-rouge">ac list</code> runs and shows no containers built yet. If not, then DevStack did not deploy properly.</p>
<h2 id="setting-up-zun-and-kata-containers-post-devstack-deploy">Setting up Zun and Kata Containers Post DevStack Deploy</h2>
<p>DevStack has deployed OpenStack and Zun, but we still need to setup Zun to use Kata Containers.</p>
<p>To install Kata Containers:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>sudo sh -c "echo 'deb http://download.opensuse.org/repositories/home:/katacontainers:/release/xUbuntu_$(lsb_release -rs)/ /' >> /etc/apt/sources.list.d/kata-containers.list"
curl -sL https://download.opensuse.org/repositories/home:/katacontainers:/release/xUbuntu_$(lsb_release -rs)/Release.key | sudo apt-key add -
sudo -E apt-get update
sudo -E apt-get -y install kata-runtime kata-proxy kata-shim
</code></pre></div></div>
<p>Next, we configure Docker to use the kata-runtime.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>sudo sed -i 's/"cor"/"kata-runtime"/' /etc/docker/daemon.json
sudo sed -i 's/"\/usr\/bin\/cc-oci-runtime"/"\/usr\/bin\/kata-runtime"/' /etc/docker/daemon.json
sudo systemctl daemon-reload
sudo systemctl restart docker
</code></pre></div></div>
<p>At this point Zun should be able to use the kata-runtime.</p>
<p><em>NOTE: We could also setup Zun to use kata-runtime as the default. If you’d like to do that, you can add the below line into the default section of <code class="language-plaintext highlighter-rouge">/etc/zun/zun.conf</code>.</em></p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>container_runtime = kata-runtime
</code></pre></div></div>
<p>Then restart Zun.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>for i in `systemctl list-unit-files | grep devstack@zun | cut -f 1 -d " "`; do sudo systemctl restart $i; done
</code></pre></div></div>
<p>If that line is not added, then the default container runtime is runc, but you can request the kata-runtime with an option, <code class="language-plaintext highlighter-rouge">--runtime kata-runtime</code>.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>openstack appcontainer run --name kata --runtime kata-runtime nginx:latest
</code></pre></div></div>
<p>With the above command the container will use the kata-runtime. If the default run time is kata-container, then that option is not needed.</p>
<h2 id="using-zun-and-kata-containers">Using Zun and Kata Containers</h2>
<p>Now that OpenStack with Zun has been deployed, and Kata Containers installed and Zun/Docker configured to use the kata-runtime, we can finally boot a Kata Container.</p>
<p>First, lets create a Kata based container.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>openstack appcontainer run --name kata nginx:latest
</code></pre></div></div>
<p>After that command completes, a container should boot up.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code># openstack appcontainer list
+--------------------------------------+------+--------------+---------+------------+--------------------------+-------+
| uuid | name | image | status | task_state | addresses | ports |
+--------------------------------------+------+--------------+---------+------------+--------------------------+-------+
| c9f8e734-d616-404d-b3e1-425a0882e45b | kata | nginx:latest | Running | None | 172.24.4.10, 2001:db8::7 | [80] |
+--------------------------------------+------+--------------+---------+------------+--------------------------+-------+
</code></pre></div></div>
<p>Let’s introspect the container and see what runtime it is using.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code># openstack appcontainer show kata | grep runtime
| runtime | kata-runtime
</code></pre></div></div>
<p>As can be seen above, it’s using the kata-runtime.</p>
<p>Now lets create a runc based container.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code># openstack appcontainer run --name runc --runtime runc nginx:latest
</code></pre></div></div>
<p>What runtime is it using?</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code># openstack appcontainer show runc | grep runtime
| runtime | runc
</code></pre></div></div>
<p>So it’s using runc.</p>
<p>Now let’s introspect each containers kernel.</p>
<p>Here’s the physical hosts kernel version.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code># uname -a
Linux kata6 4.4.0-134-generic #160-Ubuntu SMP Wed Aug 15 14:58:00 UTC 2018 x86_64 x86_64 x86_64 GNU/Linux
</code></pre></div></div>
<p>Now here’s the kernel version of the runc container.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code># openstack appcontainer exec runc uname -a
Linux 8697605d373b 4.4.0-134-generic #160-Ubuntu SMP Wed Aug 15 14:58:00 UTC 2018 x86_64 GNU/Linux
</code></pre></div></div>
<p>Note that the host kernel and the runc container kernel are the same.</p>
<p>Let’s see what kernel is in the kata-runtime based container.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code># openstack appcontainer exec kata uname -a
Linux a41bb53476f6 4.14.67-139.container #1 SMP Mon Oct 22 22:43:15 UTC 2018 x86_64 GNU/Linux
</code></pre></div></div>
<p>Aha!, that is <code class="language-plaintext highlighter-rouge">4.14.67-139.container</code> not <code class="language-plaintext highlighter-rouge">4.4.0-134-generic</code>. So that container is actually a virtual machine with its own kernel.</p>
<p>We can also use the kata-runtime command to list the containers it is supporting.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code># kata-runtime list
ID PID STATUS BUNDLE CREATED OWNER
a41bb53476f64576bcfd2db999f8245c794ea9fce0784594a2239af1c972aaf3 10543 running /run/containerd/io.containerd.runtime.v1.linux/moby/a41bb53476f64576bcfd2db999f8245c794ea9fce0784594a2239af1c972aaf3 2018-11-14T14:06:12.414823873Z #0
</code></pre></div></div>
<p>Also, if we do a <code class="language-plaintext highlighter-rouge">ps ax | grep qemu</code> we can see the container is actually running via a custom qemu process.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code># ps ax | grep qemu
10526 ? Sl 0:02 /usr/bin/qemu-lite-system-x86_64 -name sandbox-a41bb53476f64576bcfd2db999f8245c794ea9fce0784594a2239af1c972aaf3 SNIP!
</code></pre></div></div>
<p>Note that it is <code class="language-plaintext highlighter-rouge">qemu-lite-system-x86_64</code>.</p>
<h2 id="conclusion">Conclusion</h2>
<p>If you like virtual machines, for whatever reason, perhaps security (all though that is tough to quantify), but you want to use them like containers, then Kata Containers is perfect for you. Also, if you are not interested in using COEs like Docker or Kubernetes, then Zun presents another possibility for obtaining a container.</p>
<p>Ultimately deploying OpenStack and Zun and configuring Zun to use Kata Containers will not be the most common way to use containers (Kubernetes has certainly won that battle). However, it is an <em>option</em>, and an option that some might choose to utilize. Diversity is good. :)</p>
Inverting, Reversing, or Mirroring a Binary Tree2018-10-10T00:00:00+00:00http://serverascode.com/2018/10/10/reversing-mirroring-inverting-binary-tree<h1 id="inverting-reversing-or-mirroring-a-binary-tree">Inverting, Reversing, or Mirroring a Binary Tree</h1>
<p>Interviews based on algorithms and data structures will continue to be the norm. Here I take a look at inverting a binary tree.</p>
<h2 id="tldr">tldr</h2>
<p>Reversing/mirroring/inverting, whatever you call it, has a nice recursive answer.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>def recurseInvertTree(root):
if root is not None:
root.left, root.right = invertTree(root.right), \
invertTree(root.left)
return root
</code></pre></div></div>
<p><br /></p>
<p>That’s it. :)</p>
<h2 id="history">History</h2>
<p>The way organizations hire developers is varied. However, <strong>for better or worse</strong>, I feel that whiteboarding interviews that involve solving complex algorithm based problems is the default model, and will continue to be the default model. Some people like it, some don’t, but regardless it’s the defacto standard, and it’s unavoidable.</p>
<p>One of the more famous kurfuffles around algorithmic whiteboarding interviews came out of this tweet:</p>
<blockquote class="twitter-tweet" data-lang="en"><p lang="en" dir="ltr">Google: 90% of our engineers use the software you wrote (Homebrew), but you can’t invert a binary tree on a whiteboard so fuck off.</p>— Max Howell (@mxcl) <a href="https://twitter.com/mxcl/status/608682016205344768?ref_src=twsrc%5Etfw">June 10, 2015</a></blockquote>
<script async="" src="https://platform.twitter.com/widgets.js" charset="utf-8"></script>
<p>The developer of a popular and useful open source project, Homebrew, did not pass a whiteboarding interview in which he was apparently asked to invert a binary tree on a whiteboard.</p>
<p>Despite the drama around this particular tweet, being able to perform well in a whiteboarding interview could mean the difference between getting an Okay job versus getting a great job, so it’s a skill worth having. Over a career it could mean hundreds of thousands of dollars in salary.</p>
<p>So how can we invert/reverse/mirror a binary tree?</p>
<h2 id="naming-things">Naming Things</h2>
<p>The first problem I ran into when researching this was what to call it. Inverting seems like the most common name, but reversing or mirroring would work too.</p>
<p>For the purposes of this blog post, I’ll use inverting. I think an example is easiest to explain.</p>
<p>Original tree. (Sorry about printing it like this, I actually prefer it as you don’t run out of horizontal space as easily.)</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code> 14
6
13
2
12
5
11
0
10
4
9
1
8
3
7
</code></pre></div></div>
<p>Inverted tree.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code> 7
3
8
1
9
4
10
0
11
5
12
2
13
6
14
</code></pre></div></div>
<p>It’s the same tree but the leafs have been flipped/reversed what have you.</p>
<p><em>Aside: it’s kind of amazing how many names there could be for this. Inverted. Reversed. Flipped. Mirrored. Transposed. Part of answering an interview question like this would be getting some terms defined.</em></p>
<h2 id="recursion">Recursion</h2>
<p>I believe the reason that this question was originally asked is because it has such a nice recursive answer. I can imagine interviewers asking the question, then watching a developer muddle through it for X minutes, getting an answer, and then being shown that there is a ~4 line solution using recursion.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>def recurseInvertTree(root):
if root is not None:
root.left, root.right = invertTree(root.right), \
invertTree(root.left)
return root
</code></pre></div></div>
<p>I mean, ultimately, that is a pretty easy algorithm to whiteboard.</p>
<p>But there are other ways to solve this as well.</p>
<h2 id="depth-first-search-stack-solution">Depth First Search Stack solution</h2>
<p>This doesn’t seem too bad either.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>def stackInvertTree(root):
if root is not None:
nodes = []
nodes.append(root)
while nodes:
node = nodes.pop()
node.left, node.right = node.right, node.left
if node.left is not None:
nodes.append(node.left)
if node.right is not None:
nodes.append(node.right)
return root
</code></pre></div></div>
<p>I’m guessing that is what a lot of people would come up with if the recursive version wasn’t obvious to them.</p>
<h2 id="breadth-first-search-with-queue">Breadth First Search with Queue</h2>
<p>We can use a queue as well.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>def queueInvertTree(root):
queue = collections.deque([(root)])
while queue:
node = queue.popleft()
if node:
node.left, node.right = node.right, node.left
queue.append(node.left)
queue.append(node.right)
return root
</code></pre></div></div>
<p>That’s nice too.</p>
<h2 id="conclusion">Conclusion</h2>
<p>These are the most common solutions I can find. There is a lot of computer science in this question, and I’m only touching the layperson’s surface here. Much more to discover.</p>
<p>If you see any issues with what I’ve put up here, likely around naming, do let me know.</p>
How to Study for the Certified Kubernetes Administrator (CKA) Exam2018-10-06T00:00:00+00:00http://serverascode.com/2018/10/06/how-to-study-for-the-certified-kubernetes-administrator<h1 id="how-to-study-for-the-certified-kubernetes-administrator-cka-exam">How to Study for the Certified Kubernetes Administrator (CKA) Exam</h1>
<p>Last week I successfully passed the CKA exam, and I wanted to give some pointers on how to best study for it.</p>
<p>Obviously I can’t discuss any of the exam content. You’ll need to know a lot more than what I’ve listed here in terms of deploying and managing Kubernetes. I’ve only covered some basics–though I think the information on kubectl generators will really help. Kubernetes the hard way is also useful.</p>
<h2 id="the-cka-exam">The CKA Exam</h2>
<p>Here are a few basic skills you will need to pass the exam. Well, even to take the exam.</p>
<ol>
<li>Exam time management</li>
<li>Linux command line</li>
<li>Command line text editor</li>
<li>Generating valid YAML with kubectl</li>
<li>Using and searching the kubernetes.io/docs pages</li>
<li>Editing YAML live</li>
</ol>
<p>Again, there is quite a bit more you will need to know, especially about deploying and managing Kubernetes, but these are the basics. Checkout the <a href="https://github.com/cncf/curriculum">curriculum</a> for more ideas on what to study.</p>
<p><strong>Exam Time Management</strong></p>
<p>It’s a three hour exam and I expect that most people will use the entire time. Questions have differing levels of difficulty and value. You are allowed to open a note pad in the exam browser application, so it’s a good idea to take notes on what questions have what value and which one’s you have completed. Definitely figure out a strategy for picking which questions to answer first, and last.</p>
<p><strong>Linux Command Line</strong></p>
<p>You need to be comfortable with the Linux command line. The basics would be Ok. If you can change directories, open files with vim, and run kubectl you will probably be fine.</p>
<p><strong>Command Line Text Editor</strong></p>
<p>This is a big one. If you are not capable of opening and closing vim (or nano), typing into it, and search and replace, the exam will likely not be possible to pass. I would suggest being very comfortable with vim. Search and replace is a good skill to have: <code class="language-plaintext highlighter-rouge">:s/new/old/g</code>. <code class="language-plaintext highlighter-rouge">:x</code> is the same as <code class="language-plaintext highlighter-rouge">:wq</code>. :)</p>
<p><strong>Generating YAML with kubectl</strong></p>
<p>It’s easy to create a deployment from the command line and then export the YAML. Actually there are several <a href="https://kubernetes.io/docs/reference/kubectl/conventions/#generators">generators</a>. Using <code class="language-plaintext highlighter-rouge">kubectl run</code> with different options can create: pods, deployments, replication controllers, jobs, and cron jobs.</p>
<p>First create a deployment with the run command. Without any options a deployment is created.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>master $ kubectl run --image nginx nginx
deployment.apps/nginx created
</code></pre></div></div>
<p>Now we can export the YAML that kubectl generated behind the scenes.</p>
<p>Note the <code class="language-plaintext highlighter-rouge">--export</code> option.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>master $ kubectl get deploy nginx -o yaml --export
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
annotations:
deployment.kubernetes.io/revision: "1"
creationTimestamp: null
generation: 1
labels:
run: nginx
name: nginx
selfLink: /apis/extensions/v1beta1/namespaces/default/deployments/nginx
spec:
progressDeadlineSeconds: 600
replicas: 1
revisionHistoryLimit: 2
selector:
matchLabels:
run: nginx
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
creationTimestamp: null
labels:
run: nginx
spec:
containers:
- image: nginx
imagePullPolicy: Always
name: nginx
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
dnsPolicy: ClusterFirst
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
terminationGracePeriodSeconds: 30
status: {}
</code></pre></div></div>
<p>The best thing to do is to export that to a file.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>kubectl get deploy nginx -o yaml --export > nginx-deploy.yml
</code></pre></div></div>
<p>Then delete that deploy if you don’t need it.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>kubectl delete deploy nginx
</code></pre></div></div>
<p>Now we have an example deployment that can be used to create other deployments…a base file effectively.</p>
<p>To generate a YAML for a <strong>pod</strong>, use <code class="language-plaintext highlighter-rouge">--restart=Never</code></p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>master $ kubectl run nginx --image=nginx --port=80 --restart=Never
pod/nginx created
master $ kubectl get pod nginx -o yaml --export
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: nginx
SNIP!
</code></pre></div></div>
<p>Remember that other options can create jobs, cron jobs, recplication controllers, etc.</p>
<p>To practice generating YAML you don’t need much more than a <a href="https://www.katacoda.com/courses/kubernetes/playground">Katacoda playground</a>.</p>
<p><strong>kubernetes.io/docs</strong></p>
<p>This is a very useful page. Get used to being able to search it and find the documents for key resources.</p>
<p><strong>Editing YAML Live</strong></p>
<p>In some cases it might be easiest to edit the YAML live.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>kubectl edit deploy nginx
</code></pre></div></div>
<p>This will open up the YAML for the nginx deploy in $EDITOR, ie. vim. When you close it, the new YAML will be applied (or if the YAML has errors then it will error and reopen in vim, like visudo if you’ve ever used it).</p>
<h2 id="conclusion">Conclusion</h2>
<p>The CKA exam is a tough one, but mostly due to time limitations and the fact that you need to generate a lot of YAML quickly, without cutting and pasting. I think the CKA is a good certification to get at this point in time, and I’m glad that I only had to write it once.</p>
Add a User to Kubernetes2018-09-27T00:00:00+00:00http://serverascode.com/2018/09/27/add-user-kubernetes<h1 id="add-a-user-to-kubernetes">Add a User to Kubernetes</h1>
<p>Ok, so the title is a bit misleading. k8s doesn’t manage users, and instead expects them to be managed externally.</p>
<blockquote>
<p>Normal users are assumed to be managed by an outside, independent service. An admin distributing private keys, a user store like Keystone or Google Accounts, even a file with a list of usernames and passwords. In this regard, Kubernetes does not have objects which represent normal user accounts. Normal users cannot be added to a cluster through an API call.</p>
</blockquote>
<p>Basically if a user can authenticate, it’s a user. That’s how I look at it anyways. Note that service accounts are a different story.</p>
<p>So, in this example, I’m assuming you’ve deployed using kubeadm and aren’t managing users externally. kubeadm has a nice command to generate a kubeconfig for a “new user.” It has to read files /etc/kubernetes/pki.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>sudo kubeadm alpha phase kubeconfig user --client-name="curtis" > ~/curtis.kubeconfig
</code></pre></div></div>
<p>Now that I’ve created a kubeconfig for the user “curtis” I can use it to access the k8s API.</p>
<p>Or, well I could if RBAC was setup for the user. But at least I’m authenticating, I’m just not going to be authorized (if RBAC is enabled).</p>
<p>You can also create the certs using openssl and <a href="https://docs.bitnami.com/kubernetes/how-to/configure-rbac-in-your-kubernetes-cluster/">bitnami</a> has some good docs on doing that, so I won’t copy them here.</p>
Local Persistent Volumes with Kubernetes2018-09-19T00:00:00+00:00http://serverascode.com/2018/09/19/persistent-local-volumes-kubernetes<h1 id="local-persistent-volumes-with-kubernetes">Local Persistent Volumes with Kubernetes</h1>
<p>Let’s quickly discuss using persistent local volumes with Kubernetes.</p>
<p>First, get yourself a k8s. I have one here running on a packet.net instance. It’s only a single node. Deployed with kubeadm and is running calico as the network plugin.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code># k get nodes
NAME STATUS ROLES AGE VERSION
cka Ready master 6h v1.11.1
</code></pre></div></div>
<p>Let’s look at everything that’s running.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code># k get all
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes ClusterIP 172.17.0.1 <none> 443/TCP 6h
# k get all -n kube-system
NAME READY STATUS RESTARTS AGE
pod/calico-etcd-2hcdc 1/1 Running 0 6h
pod/calico-kube-controllers-74b888b647-qr86d 1/1 Running 0 6h
pod/calico-node-5jmrc 2/2 Running 17 6h
pod/coredns-78fcdf6894-4ngmq 1/1 Running 0 6h
pod/coredns-78fcdf6894-gzqcw 1/1 Running 0 6h
pod/etcd-cka 1/1 Running 0 6h
pod/kube-apiserver-cka 1/1 Running 0 6h
pod/kube-controller-manager-cka 1/1 Running 0 6h
pod/kube-proxy-62hp2 1/1 Running 0 6h
pod/kube-scheduler-cka 1/1 Running 0 6h
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/calico-etcd ClusterIP 172.17.0.136 <none> 6666/TCP 5h
service/kube-dns ClusterIP 172.17.0.10 <none> 53/UDP,53/TCP 6h
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
daemonset.apps/calico-etcd 1 1 1 1 1 node-role.kubernetes.io/master= 6h
daemonset.apps/calico-node 1 1 1 1 1 <none> 6h
daemonset.apps/kube-proxy 1 1 1 1 1 beta.kubernetes.io/arch=amd64 6h
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
deployment.apps/calico-kube-controllers 1 1 1 1 6h
deployment.apps/calico-policy-controller 0 0 0 0 6h
deployment.apps/coredns 2 2 2 2 6h
NAME DESIRED CURRENT READY AGE
replicaset.apps/calico-kube-controllers-74b888b647 1 1 1 6h
replicaset.apps/calico-policy-controller-55b469c8fd 0 0 0 6h
</code></pre></div></div>
<p>The c2.medium.x86 (AMD EPYC!) has two extra SSDs.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>mkfs.ext4 /dev/sdc
mkfs.ext4 /dev/sdd
mkdir -p /mnt/disks/sdc
mkdir -p /mnt/disks/sdd
mount /dev/sdc /mnt/disks/sdc
mount /dev/sdd /mnt/disks/sdd
</code></pre></div></div>
<p>Now both are formated and mounted.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code># lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 111.8G 0 disk
sdb 8:16 0 111.8G 0 disk
├─sdb1 8:17 0 512M 0 part /boot/efi
├─sdb2 8:18 0 1.9G 0 part
└─sdb3 8:19 0 109.4G 0 part /
sdc 8:32 0 447.1G 0 disk /mnt/disks/sdc
sdd 8:48 0 447.1G 0 disk /mnt/disks/sdd
</code></pre></div></div>
<p>I usually abbreviate kubectl to k.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>alias k=kubectl
</code></pre></div></div>
<p>Setup a storage class.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>cat > storage-class.yml <<EOF
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: local-storage
provisioner: kubernetes.io/no-provisioner
volumeBindingMode: WaitForFirstConsumer
EOF
kubectl create -f storage-class.yml
</code></pre></div></div>
<p>List the available storage classes.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code># k get sc
NAME PROVISIONER AGE
local-storage kubernetes.io/no-provisioner 4s
</code></pre></div></div>
<p>Create a persistent volume.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>cat > pv-sdc.yml <<EOF
apiVersion: v1
kind: PersistentVolume
metadata:
name: local-pv-sdc
spec:
capacity:
storage: 440Gi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Retain
storageClassName: local-storage
local:
path: /mnt/disks/sdc
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- cka
EOF
kubectl create -f pv-sdc.yml
</code></pre></div></div>
<p>Same for sdd.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>cat > pv-sdd.yml <<EOF
apiVersion: v1
kind: PersistentVolume
metadata:
name: local-pv-sdd
spec:
capacity:
storage: 440Gi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Retain
storageClassName: local-storage
local:
path: /mnt/disks/sdd
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- cka
EOF
kubectl create -f pv-sdd.yml
</code></pre></div></div>
<p>Now I have two PVs.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code># k get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
local-pv-sdc 440Gi RWO Retain Available local-storage 53s
local-pv-sdd 440Gi RWO Retain Available local-storage 4s
</code></pre></div></div>
<p>Create a persistent volume claim.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>cat > pvc1.yml <<EOF
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: pvc1
spec:
accessModes:
- ReadWriteOnce
storageClassName: local-storage
resources:
requests:
storage: 100Gi
EOF
kubectl create -f pvc1.yml
</code></pre></div></div>
<p>PVC will be pending until we create a node that uses it.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code># k get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
pvc1 Pending local-storage 3s
</code></pre></div></div>
<p>Now a deployment that uses the pvc.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>cat > deploy-nginx.yml <<EOF
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
volumeMounts:
- mountPath: "/usr/share/nginx/html"
name: storage
volumes:
- name: storage
persistentVolumeClaim:
claimName: pvc1
EOF
kubectl create -f deploy-nginx.yml
</code></pre></div></div>
<p>pvc is now bound.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code># k get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
pvc1 Bound local-pv-sdc 440Gi RWO local-storage 21m
</code></pre></div></div>
<p>Expose nginx.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code># kubectl expose deployment nginx-deployment --type=NodePort
service/nginx-deployment exposed
# kubectl get svc nginx-deployment
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
nginx-deployment NodePort 172.17.0.157 <none> 80:31813/TCP 7m
</code></pre></div></div>
<p>Now create an index.html page. I’ll use a uuid just to show it’s not already setup.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code># uuid=`uuidgen`
# echo $uuid
b5d3c8cd-a56f-4252-a026-7107790fcd44
# echo $uuid > /mnt/disks/sdc/index.html
# curl 172.17.0.157
b5d3c8cd-a56f-4252-a026-7107790fcd44
</code></pre></div></div>
<p>Let’s delete the pod.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code># k delete pod nginx-deployment-7d869874bc-dlz4s
pod "nginx-deployment-7d869874bc-dlz4s" deleted
</code></pre></div></div>
<p>A new pod will automatically be created by Kubernetes.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code># k get pods
NAME READY STATUS RESTARTS AGE
nginx-deployment-7d869874bc-fkt4m 1/1 Running 0 28s
</code></pre></div></div>
<p>Run the same curl.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code># curl 172.17.0.157
b5d3c8cd-a56f-4252-a026-7107790fcd44
</code></pre></div></div>
<p>Same UUID.</p>
<p>Lets check from the pod.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code># k exec -it nginx-deployment-7d869874bc-fkt4m -- cat /usr/share/nginx/html/index.html
b5d3c8cd-a56f-4252-a026-7107790fcd44
</code></pre></div></div>
<p>As expected.</p>
<h2 id="conclusion">Conclusion</h2>
<p>Kubernetes.io has a <a href="https://kubernetes.io/blog/2018/04/13/local-persistent-volumes-beta/">blog post</a> announcing local persistent volumes. It’s worth a read. Anything I say here of value would just be copying from that. :) There are several reasons not to use this model for storage. Seems like it would be best for data heavy applications…data gravity. There is also a <a href="https://github.com/kubernetes-incubator/external-storage/tree/master/local-volume">simple volume manager</a> available as well, but I didn’t explore that in this blog post.</p>
Vent - Kubernetes the Hard Way with Ansible and Packet.net2018-09-03T00:00:00+00:00http://serverascode.com/2018/09/03/vent-kubernetes-the-hard-way<h1 id="vent---kubernetes-the-hard-way-with-ansible-and-packetnet">Vent - Kubernetes the Hard Way with Ansible and Packet.net</h1>
<p>In preparation to write the Certificate Kubernetes Administrator exam I’m going through the ever popular Kubernetes the Hard way (kthw), as developed by Mr. Kelsey Hightower. I actually did <a href="https://github.com/ccollicutt/kubernetes-the-hard-way-with-aws-and-ansible">the same thing a couple of years ago</a>, in which I translated kthw from a step by step command line depoyment into some Ansible that deployed kthw to Amazon Web Services.</p>
<p>In this blog post I discuss a repo I created that does something similar–it still converts the shell commands into Ansible, but instead of AWS it deploys Kubernetes to bare metal nodes on Packet.net.</p>
<h2 id="packetnet">Packet.net</h2>
<p>I’m a big fan of packet.net. I like four major things about packet.net:</p>
<ol>
<li>Bare Metal resources</li>
<li>Layer 3 networking</li>
<li>Simplicity</li>
<li>Spot pricing</li>
</ol>
<h3 id="baremetal">Baremetal</h3>
<p>Obviously the main point of packet.net is that instead of getting virtual machines, you get bare metal nodes. I really like getting bare metal nodes. You don’t have to worry about sharing resources with other tenants. You get the full speed of bare metal. They can be pricey over time, but if I was an organization seeking speed, for example in CI/CD, it would be well worth it to utilize packet to push things as fast as they can go.</p>
<p>Specifically for Vent I focussed on the AMD EPYC nodes which are under plan c2.medium.x86. With 64GB of RAM, 20GB of networking, 24 cores, and about 1TB of SSD, it’s perfect for Kubernetes.</p>
<p>Other cloud providers also have bare metal nodes, but I haven’t used them. I think AWS provides bare metal, and they have the Nitro hypervisor, which is effectively bare metal. But that is a discussion for another day. :)</p>
<h3 id="networking">Networking</h3>
<p>I like how Packet.net has done their networking–it’s all layer 3 based. As a public cloud, this is the right way to go. People often think networking means a shared layer 2 with a /24 netmask, like what you get with most clouds virtual private networking.</p>
<p>Packet.net’s layer 3 model means that each node gets three IPs: a public IPv4, an Ipv6, and an internal, private RFC 1918 address (all on the same bond0 interface). The private address is in the 10.0.0.0/8 range, but it’s usually a /31, which means it just has a couple usable addresses–the hosts IP and the gateway. A route is setup to send all 10.0.0.0/8 addresses through that gateway, and packet must be doing filtering to allow “private networking” in the sense that other nodes in the same project are put into a filtering group (ie. network ACL), so that they can only talk to each other on the private network. So if you have three nodes, they each have their own /31 private IP space, but are part of an ACL group (presumably).</p>
<p>This is a very scalable model for packet.net, and with an underlying layer 3 private network as a tenant you can set up an overlay network if you like, vxlan, what have you, and in the example of Kubernetes you could do something simple like use flannel, which is an overlay.</p>
<p>When deploying things like Kubernetes and OpenStack I pay a lot of attention to networking models–it takes some thought about how to fit k8s into an environment. Overlays almost always work because they just ride on top of the underlying physical network and just need L3 connectivity between the virtual switches or whatever is taking care of the overlay. However, overlays are not alway the. Good architecture decisions must be made.</p>
<p>One issue I have with this model is that I don’t necessarily want nodes listening on public IPv{4,6} address if they don’t need to be, but would still like them to have egress access to the Internet. It would be worthwhile for packet.net to have a nat gateway setup like AWS can do. They would have to perform some network magic in the background, but I think it’d be doable. More likely they will create a VPC-like model with a hidden overlay, perhaps using EVPN. Who knows. :)</p>
<p>(Aside: I did do a lot of work and setup dnsmasq, squid, and apt-cacher-ng in packet.net. I removed the public IPv{4,6} addresses from the interface and setup nodes to go through a cache. This worked for 99% of what I was doing–but in some cases applications <em>cough</em> docker images <em>cough</em> are really annoying and require access to the Internet without a proxy. Again, another story for another day.)</p>
<p>I had to do some tricks with macvlan to get flannel working with packet.net’s model, but it’s flannel’s issue. See the <a href="https://github.com/ccollicutt/vent">vent repo</a> for more information on that. At least I finally learned about macvlan to work around the issue.</p>
<p><em>NOTE: Packet also support setting up your own standard VLANs in some capacity, but I haven’t explored that yet.</em></p>
<h3 id="spot-pricing">Spot pricing</h3>
<p>Spot pricing is essentially a way to bid on computing time. You put in your bid, and if it’s high enough you get the compute resources you asked for. Later on, if someone puts in a higher bid your resources get diverted to them. What this really means is that your bare metal server will be deleted.</p>
<p>I’m a big fan of spot pricing, as I think that economics is really important in computing, or it should be at least. With spot markets you can really test out some economic theories. Or, at least, get less expensive short term resources, such as CI/CD or for testing out deployments, which I do a lot of. While working on Vent I usually was able to get the AMD EPYC nodes for about $.30 in spot pricing versus $1 they normally are per hour. That’s quite a discount.</p>
<h2 id="simplicity">Simplicity</h2>
<p>There is a core set of features that a public cloud requires, IMHO. Public clouds like AWS have hundreds of custom services. It can be very confusing to understand what is available and how they work, let alone their billing mode. I’m not saying one way is better than another, but it’s often refreshing to have a simpler view of public cloud resources. Digital Ocean is similar in their desire to keep things clean. Time will tell if this is a good product design, but I appreciate it. A good networking model, access to compute resources, and persistent volumes, elastic IPs…the basic requirements, it’s all I need. I’m not even a big fan of “security groups” which packet does not have. Load balancers are probably a good idea though.</p>
<h2 id="kthw">kthw</h2>
<p>Mr. Hightower has changed kthw considerably over the years. As I write this I’m sure he’s creating a new version that will come out soon. WHen I last worked with Kubernetes and kthw it was version 1.3.0. Now we are on 1.10.7 for Vent, 1.10.2 for kthw, and 1.11 for Kubernetes proper.</p>
<p>kthw is not at this time using docker in a way that you think it would. Docker is not actually installed, instead it’s using <a href="https://containerd.io/">containerd</a>. It also uses <a href="https://github.com/google/gvisor">gvisor</a>, another Google project.</p>
<blockquote>
<p>Gvisor [is] a new kind of sandbox that helps provide secure isolation for containers, while being more lightweight than a virtual machine (VM). gVisor integrates with Docker and Kubernetes, making it simple and easy to run sandboxed containers in production environments.</p>
</blockquote>
<p>I really appreciate the work that Mr. Hightower has put into kthw as I have used it quite a bit to learn about Kubernetes.</p>
<h2 id="vent">Vent</h2>
<p>Finally, lets chat about Vent a bit. First, I have an <a href="https://github.com/ccollicutt/vent/blob/master/OVERVIEW.md">overview document</a> in the vent repo that discusses the choices I made and issues I ran into if you’d like something more in depth.</p>
<p>With Vent I took kthw and turned it into a set of Ansible playbooks. Specifically I didn’t use roles, each step in kthw is a separate playbook. For convenience, they are all brought together in a monolithic file, all.yml. I chose this model to make it look like kthw, with a step by step process. In the future I may change this to be role based.</p>
<p>Provisioning packet.net instances is not done with Ansible, and instead I’m using the packet.net golang based CLI. it has support for spot instances. You can provision Packet.net instances with Ansible or Terraform, and probably other systems, but Ansible and Terraform don’t seem to support spot instance pricing (at least at this time). I should probably contribute that to the Ansible module, but haven’t had time.</p>
<p>One thing I don’t like about how I’m deploying k8s is that I’m relying pretty heavily on the flannel k8s deployment yaml to manage the networking. I’d like to have Ansible set that up instead of using the magic deployment from CoreOS. Also, I’d like to not use flannel at all and move to an Open vSwitch based networking model, but that will take some time to research. For now it’s magic flannel. :)</p>
<p>Like kthw, I’m not putting the k8s control plane into containers or self-hosted in k8s itself. Self-hosting is what kubeadm and some other deployment tools do. Something to look into in the future.</p>
<p>Going forward I hope to write a “vent” CLI that does a lot of the setup, including provisioning, setting up a few basic variables, etc.</p>
<h2 id="conclusion">Conclusion</h2>
<p>Thanks to packet.net for a great service. Thanks to Mr. Hightower for kthw. And wish me luck on the CKA exam!</p>
Infinite Regress - Dependencies All the Way Down2018-07-18T00:00:00+00:00http://serverascode.com/2018/07/18/its-all-about-dependencies<h1 id="infinite-regress---dependencies-all-the-way-down">Infinite Regress - Dependencies All the Way Down</h1>
<p>I have a pet theory that it’s all about dependencies.</p>
<p>I used to work in an area, Network Function Virtualization, NFV for short, that is made up of many complex systems. The most obvious example is OpenStack, which is notoriously considered complicated. To be fair, there are many more high level systems like it that are also part of the ecosystem. Also see Kubernetes or almost any Software Defined Network.</p>
<h2 id="complexity-reigns">Complexity Reigns</h2>
<p>It’s <a href="https://en.wikipedia.org/wiki/Turtles_all_the_way_down">“turtle’s all the way down”</a> as OpenStack is built on the Linux ecosystem, which is itself extremely complex, never mind the underlying hardware Linux typically runs on: CPUs, proprietary firmware and drivers, etc. Code is everywhere. And code has dependencies.</p>
<blockquote>
<p>“Turtles all the way down” is an expression of the problem of <a href="https://en.wikipedia.org/wiki/Infinite_regress">infinite regress</a>.</p>
</blockquote>
<p>I’ve spent some of my 20 years in IT as a Linux systems administrator which has given me a particularly strong view of operating system dependencies. Having worked so much with OS packages (RPMs, deb files) and similar mechanisms (Pip, CPAN) I’m keenly aware of how important dependencies are, and how challenging they can be to manage.</p>
<h2 id="hidden-dependencies">Hidden Dependencies</h2>
<p>Unless you write code or manage systems that have packages you might not be as aware just how many dependencies there are. Often organizations pay companies to abstract away dependency issues.</p>
<p>As far as I’m concerned, a large part of what you are buying when you purchase commercial software, especially distributions of complex systems like OpenStack, is the ability to mitigate the risk of dependencies.</p>
<p>However, ignoring dependencies through abstraction is a double edged sword. The thesis of this article is that “it’s all about dependencies.” In my opinion, if an organization is going to be good at managing complex technology they also must be (very) good at managing dependencies. If dependencies exist throughout the technology stack (“turtles all the way down”), there comes a point when every organization must deal with them.
Breaking Changes</p>
<p>I recently read this fascinating paper, <a href="https://arxiv.org/pdf/1801.05198.pdf">“Why and How Java Developers Break APIs”</a>, which studied a set of Java libraries for breaking changes.</p>
<blockquote>
<p>…we monitored 400 real world Java libraries and frameworks hosted on GitHub during 116 days. During this period, we detected 282 possible breaking changes</p>
</blockquote>
<p>As part of the study, the authors attempted to contact the developers of the libraries to ascertain if the detected changes were actual breaking changes or not. Of those 282 potential breaking changes, 59 (39%) were confirmed by the library developers. (The rest remain unconfirmed and are still potential breaking changes.)</p>
<p>Thus, over a relatively short period of about 4 months, 59 confirmed breaking changes occurred in only 400 libraries. That is a considerable number.</p>
<h2 id="you-own-your-uptime">You Own Your Uptime</h2>
<p>If I can conclude with anything it’s that in order to manage complex systems (and apparently they are all complex) I believe organizations must be great at understanding and managing dependencies. To deal with complexity requires expertise in dependencies. Certainly we can try to push the risk onto vendors, but at some point we must take responsibility. You own your uptime.</p>
Using OpenShift's Docker Remote Registry2018-07-02T00:00:00+00:00http://serverascode.com/2018/07/02/openshift-remote-registry-docker<h1 id="using-openshifts-docker-remote-registry">Using OpenShift’s Docker Remote Registry</h1>
<p>In this post I will cover using an OpenShift Origin deployment that has a registry as a remote registry for Docker images. Note that I’m not covering installing OpenShift–it’s already deployed. I’m just going to use its registry.</p>
<h2 id="official-documentation">Official Documentation</h2>
<p>This <a href="https://docs.openshift.com/container-platform/3.9/install_config/registry/accessing_registry.html">doc</a> is pretty good; won’t get you all the way, but it’s close.</p>
<h2 id="about-the-deployment">About the Deployment</h2>
<p>This OpenShift installation is running in AWS (not that it really matters where it’s running) and the registry is backed by S3. As far as I’m concerned object storage is the best backend for Docker images. Well, at least it’s effectively infinite.</p>
<p>The version of OpenShift Origin being used is 3.9.</p>
<h2 id="s3-permissions">S3 Permissions</h2>
<p>OpenShift was deployed using openshift-ansible, and the hosts file was configured to use an AWS user that has been configured with specific permissions.</p>
<p>A bucket, <code class="language-plaintext highlighter-rouge">openshift-1-registry</code>, was created by an administrative user. The OpenShift AWS user was provided the below permissions to be able to use that bucket.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "s3:*",
"Resource": [
"arn:aws:s3:::openshift-1-registry",
"arn:aws:s3:::openshift-1-registry/*"
]
}
]
}
</code></pre></div></div>
<p>I’m sure that could be firmed up, wildcards are frowned upon, but at least the OpenShift user only has access to his particular bucket. The user can’t list all buckets, but can access <code class="language-plaintext highlighter-rouge">openshift-1-registry</code>.</p>
<p>Below I’m using the AWS CLI as an example of access permissions.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ aws s3 ls
An error occurred (AccessDenied) when calling the ListBuckets operation: Access Denied
$ aws s3 ls s3://openshift-1-registry
PRE registry/
</code></pre></div></div>
<p><br /></p>
<h2 id="registry-information">Registry Information</h2>
<p>As root on the controller instance I can find out the route for the docker registry. Of course this assumes that OpenShift has been setup with a wildcard apps domain.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>openshift-controller# oc get routes
NAME HOST/PORT PATH SERVICES PORT TERMINATION WILDCARD
docker-registry docker-registry-default.apps.example.com docker-registry <all> passthrough None
registry-console registry-console-default.apps.example.com registry-console <all> passthrough None
</code></pre></div></div>
<p>*.apps.example.com is available through an ELB on AWS.</p>
<p><em>NOTE: I’ve replaced the real URL with example.com.</em></p>
<h2 id="local-docker">Local Docker</h2>
<p>This post assumes you have a local docker instance. In this example, docker 1.13.1 is running in a CentOS 7 host.</p>
<p>We need to add an insecure registry to the local docker (that is, of course, unless you have properly setup all the SSL certificates, which would be a good thing to do for production).</p>
<p>Edit Docker’s daemon.json file to add the insecure registry.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>local-docker$ sudo cat /etc/docker/daemon.json
{
"insecure-registries" : ["docker-registry-default.apps.example.com:443"]
}
</code></pre></div></div>
<p>The restart it.</p>
<h2 id="login">Login</h2>
<p>On the local docker, which also has the <code class="language-plaintext highlighter-rouge">oc</code> command line and access to OpenShift…</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>local-docker$ oc login
local-docker$ docker login -u $(oc whoami) -p $(oc whoami -t) docker-registry-default.apps.example.com:443
</code></pre></div></div>
<p><br /></p>
<h2 id="pull-and-push-and-image">Pull and Push and Image</h2>
<p>Check what OC project you are in. Note that I’ve created a “example-project” project.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>local-docker$ oc project
Using project "example-project" on server "https://openshift.example.com:443".
</code></pre></div></div>
<p>Pull, tag, and push an image.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>local-docker$ docker pull docker.io/busybox
local-docker$ docker tag docker.io/busybox docker-registry-default.apps.example.com:443/example-project/busybox
local-docker$ docker push docker-registry-default.apps.example.com:443/example-project/busybox
</code></pre></div></div>
<p><br /></p>
<h2 id="conclusion">Conclusion</h2>
<p>Now you’re using a remote registry that is managed by OpenShift. The part I found most confusing was the project name and how it relates to the image tag.</p>
Using Cloud Images With KVM2018-06-26T00:00:00+00:00http://serverascode.com/2018/06/26/using-cloud-images<h1 id="using-cloud-images-with-kvm">Using Cloud Images With KVM</h1>
<p>Most Linux distributions offer some kind of binary image that is typically used in “cloudy” situations–such as public cloud or with OpenStack. These images have been pre-built, use cloud-init, and are expecting to be configured based on metadata provided through a combination of the user and the infrastructure as a service (IaaS) system, either via network metadata or a “config drive” (a specially created ISO image that is attached to the vm).</p>
<p>However, one doesn’t always have an IaaS system available, and sometimes we just want to use KVM and not have to attach a custom cloud init ISO image, so here are some quick instructions on using a cloud image with plain KVM, and manually configuring the image.</p>
<h2 id="step-1-download-the-image">Step 1: Download the image</h2>
<p>Download from Ubuntu’s cloud image cache.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>wget https://cloud-images.ubuntu.com/bionic/current/bionic-server-cloudimg-amd64.img
</code></pre></div></div>
<p>Other bigger distros should offer a “cloud image” in some fashion.</p>
<h2 id="enlarge-virtual-disk">Enlarge Virtual Disk</h2>
<p>By default it’s only 2.2G. That’s not very many Gs. :)</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ qemu-img info bionic-server-cloudimg-amd64.img
image: bionic-server-cloudimg-amd64.img
file format: qcow2
virtual size: 2.2G (2361393152 bytes)
disk size: 322M
cluster_size: 65536
Format specific information:
compat: 0.10
refcount bits: 16
</code></pre></div></div>
<p>Resize it to 20G.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ qemu-img resize bionic-server-cloudimg-amd64.img 20G
Image resized.
$ qemu-img info bionic-server-cloudimg-amd64.img
image: bionic-server-cloudimg-amd64.img
file format: qcow2
virtual size: 20G (21474836480 bytes)
disk size: 322M
cluster_size: 65536
Format specific information:
compat: 0.10
refcount bits: 16
</code></pre></div></div>
<p>Once we boot it we’ll resize inside the OS.</p>
<h2 id="set-root-password">Set Root Password</h2>
<p>virt-customize is an easy way to “edit” images.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ virt-customize -a bionic-server-cloudimg-amd64.img --root-password password:coolpass
[ 0.0] Examining the guest ...
[ 22.3] Setting a random seed
virt-customize: warning: random seed could not be set for this type of
guest
[ 22.3] Setting the machine ID in /etc/machine-id
[ 22.4] Setting passwords
[ 24.4] Finishing off
</code></pre></div></div>
<p><br /></p>
<h2 id="remove-cloud-init">Remove Cloud Init</h2>
<p>Let’s uninstall cloud-init as well.</p>
<p>(NOTE: These two virt-customize steps could be put into one command.)</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ virt-customize -a bionic-server-cloudimg-amd64.img --uninstall cloud-init
[ 0.0] Examining the guest ...
[ 12.1] Setting a random seed
virt-customize: warning: random seed could not be set for this type of
guest
[ 12.1] Uninstalling packages: cloud-init
[ 17.1] Finishing off
</code></pre></div></div>
<p><br /></p>
<h2 id="boot-the-vm">Boot the VM</h2>
<p>Create a vm definition file for virsh. Replace the various variables indicated by double braces with your choices of resources and file locations.</p>
<p>Note that you could use virt-manager and load the backing image and do this graphically if you like that sort of thing.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code><domain type='kvm'>
<name>{{ vm_name }}</name>
<memory unit='KiB'>{{ vm_required_memory }}</memory>
<currentMemory unit='KiB'>{{ vm_required_memory }}</currentMemory>
<vcpu>{{ vm_required_vcpu }}</vcpu>
<os>
<type arch='x86_64'>hvm</type>
<boot dev='hd'/>
</os>
<clock offset='utc'/>
<on_poweroff>destroy</on_poweroff>
<on_reboot>restart</on_reboot>
<on_crash>destroy</on_crash>
<devices>
<emulator>/usr/bin/qemu-kvm</emulator>
<disk type='file' device='disk'>
<driver name='qemu' type='qcow2'/>
<source file='{{ location_of_backing_image }}'/>
<target dev='vda' bus='virtio'/>
</disk>
<interface type='bridge'>
<source bridge='virbr0'/>
<model type='virtio'/>
</interface>
<serial type='pty'>
<target port='0'/>
</serial>
<console type='pty'>
<target type='serial' port='0'/>
</console>
</devices>
</domain>
</code></pre></div></div>
<p><br /></p>
<h2 id="define-and-start-the-vm">Define and Start the VM</h2>
<p>Define and start.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>virsh define vm.xml
virsh start vm_name
</code></pre></div></div>
<p><br /></p>
<h2 id="access-console">Access Console</h2>
<p>Handy dandy virsh console.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>virsh console vm_name
</code></pre></div></div>
<p>Login with username: root password: coolpass (or whatever you set it to).</p>
<h2 id="setup-dhcp-ubuntu-bionic-only-example">Setup DHCP (Ubuntu Bionic only example)</h2>
<p>Networking will likely not be configured at all (b/c we removed cloud-init).</p>
<p>Create the below. Note the interface name. Could probably add this with virt-customize.</p>
<p><em>NOTE: This is Ubuntu Bionic/18.04 and it has new networking configuration.</em></p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>root@ubuntu:/etc/netplan# cat 01-netcfg.yaml
network:
version: 2
renderer: networkd
ethernets:
enp0s2:
dhcp4: true
</code></pre></div></div>
<p>Apply it.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>root@ubuntu:/etc/netplan# sudo netplan --debug apply
** (generate:930): DEBUG: 19:24:16.431: Processing input file //etc/netplan/01-netcfg.yaml..
** (generate:930): DEBUG: 19:24:16.433: starting new processing pass
** (generate:930): DEBUG: 19:24:16.434: enp0s2: setting default backend to 1
** (generate:930): DEBUG: 19:24:16.435: Generating output files..
** (generate:930): DEBUG: 19:24:16.436: NetworkManager: definition enp0s2 is not for us (backend 1)
DEBUG:netplan generated networkd configuration exists, restarting networkd
DEBUG:no netplan generated NM configuration exists
DEBUG:device lo operstate is unknown, not replugging
DEBUG:netplan triggering .link rules for lo
DEBUG:replug enp0s2: unbinding virtio0 from /sys/bus/virtio/drivers/virtio_net
DEBUG:replug enp0s2: rebinding virtio0 to /sys/bus/virtio/drivers/virtio_net
</code></pre></div></div>
<p>Now interface should have an IP. (Assuming the hypervisor was setup with a default network that does DHCP.)</p>
<h2 id="disk-size">Disk size</h2>
<p>Note that cloud-init usually does this. But b/c we don’t have it, we’ll perform the same basic steps manually.</p>
<p>Growpart.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>root@ubuntu:/etc/netplan# growpart /dev/vda 1
CHANGED: partition=1 start=227328 old: size=4384735 end=4612063 new: size=41715679,end=41943007
</code></pre></div></div>
<p>Resize.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>root@ubuntu:/etc/netplan# resize2fs /dev/vda1
resize2fs 1.44.1 (24-Mar-2018)
Filesystem at /dev/vda1 is mounted on /; on-line resizing required
old_desc_blocks = 1, new_desc_blocks = 3
The filesystem on /dev/vda1 is now 5214459 (4k) blocks long.
root@ubuntu:/etc/netplan# df -h
Filesystem Size Used Avail Use% Mounted on
udev 985M 0 985M 0% /dev
tmpfs 200M 460K 199M 1% /run
/dev/vda1 20G 959M 19G 5% /
tmpfs 997M 0 997M 0% /dev/shm
tmpfs 5.0M 0 5.0M 0% /run/lock
tmpfs 997M 0 997M 0% /sys/fs/cgroup
/dev/vda15 105M 3.4M 102M 4% /boot/efi
tmpfs 200M 0 200M 0% /run/user/0
</code></pre></div></div>
<p>Should have a 20G / now.</p>
<h2 id="conclusion">Conclusion</h2>
<p>One should really use cloud-init properly, but if you are stuck or just plain don’t feel like it, then this is one way to go about getting a vm setup in KVM using a cloud image.</p>
An Introduction to 5G Network Slicing2018-06-14T00:00:00+00:00http://serverascode.com/2018/06/14/5g-network-slicing<h1 id="an-introduction-to-5g-network-slicing">An Introduction to 5G Network Slicing</h1>
<p>A colleague and I gave a presentation entitled “<a href="https://www.youtube.com/watch?v=x_b4-w4Mrcg">5G Network Slicing and OpenStack</a>” at the 2018 Vancouver OpenStack summit. We did a lot of research, reading 70 to 100 papers (whitepapers, standards body papers, academic papers, you name it–so many we <a href="https://github.com/idx-labs/openstack-network-slicing/blob/master/BIBLIOGRAPHY.md_">published a bibliography</a>) to try to determine what network slicing is and how OpenStack can participate.</p>
<h2 id="what-is-network-slicing">What is Network Slicing?</h2>
<p>After reading all of those documents, I ended up with a set of quotes that I particularly liked. Here are a couple of them.</p>
<blockquote>
<p>“We define network slices as end-to-end(E2E) logical networks running on a common underlying (physical or virtual) network, mutually isolated, with independent control and management, and which can be created on demand.”- Network Slicing for 5G with SDN/NFV</p>
</blockquote>
<blockquote>
<p>“Network slicing is a key feature for the next generation network. It is about transforming the network/system from a static “one size fits all” paradigm, to a new paradigm where logical networks/partitions are created, with appropriate isolation, resources and optimized topology to serve a particular purpose or service category…” - 3GPP 28.801</p>
</blockquote>
<blockquote>
<p>“Slicing allows to concurrently support a large variety of use cases with diverging requirements on a common infrastructure platform…Examples of resources to be partitioned or shared, understanding they can be physical or virtual, would be: bandwidth on a network link, forwarding tables in a network element (switch, router), processing capacity of servers, processing capacity of network elements.” - Applying SDN Architecture to 5G Slicing</p>
</blockquote>
<p>Whether or not network slicing truly comes into existence, it’s fascinating to see how much change people think <em>could happen</em>. NS is nothing more than a total transformation of the network.</p>
<h2 id="what-is-network-slicing-1">What is Network Slicing?</h2>
<p>The main reason Network Slicing (NS) is required is to meet the need to support diverse 5G use cases. Typically the following use cases are provided as examples:</p>
<ul>
<li>Enhanced mobile broadband</li>
<li>Massive machine type communications</li>
<li>Ultra reliable and low latency connections</li>
</ul>
<p>The requirements of these networks are quite different. Some focusing on (much higher) bandwidth, and others latency. There is also a need to provide network access to 3rd parties and support MVNOs-like (Mobile Virtual Network Operator) business models. Safe, secure, and reliable critical communications also plays an important role. Slices could even exist across multiple operators.</p>
<p>Simply stated, Network Slicing is the ability to provide APIs that, through the use of virtualization and quality of service, partition a network into diversified sections (AKA slices) across a set of heterogeneous domains. Effectively, the same concepts used in Infrastructure as a Service are applied to the network. By creating network slices we can make physical networks capable of carrying diverse traffic in a secure, multi-tenant fashion.</p>
<h2 id="requirements">Requirements</h2>
<p><img src="/img/ns.jpg" alt="network slicing" /></p>
<p><em>(One of my favorite diagrams, care of <a href="https://www.netmanias.com/en/post/blog/8325/5g-iot-network-slicing-sdn-nfv/e2e-network-slicing-key-5g-technology-what-is-it-why-do-we-need-it-how-do-we-implement-it">Netmanias</a>)</em></p>
<p>Once all of these papers have been read, a set of common requirements starts to develop.</p>
<ul>
<li>End to End - RAN, CN, Transport, edge clouds, core clouds–all of it :)</li>
<li>Orchestration - Manage heterogeneous network resources</li>
<li>On Demand - CRUD actions at any time</li>
<li>Elastic - Grow/shrink network services resources based on need</li>
<li>Extensible - Expand network slice with additional functionality and characteristics</li>
<li>Safety - Failures in one slice not causing failures in others</li>
<li>Protection - Events in one slice do not have a negative impact on other slices</li>
<li>Recursion - Ability to build a new network slice out of other slices</li>
<li>Isolation - Guaranteed isolation and non-interference between network slices in data and control plane</li>
<li>Flexible - Simultaneously accommodate diverse use cases</li>
<li>Exposure - Provide secure access to 3rd parties</li>
<li>Network Functions - Not just switches and routers</li>
</ul>
<h2 id="ns-with-sdn-and-nfv">NS with SDN and NFV</h2>
<p><img src="/img/slice2.jpg" alt="slice" /></p>
<p><em>(image care of <a href="https://www.metaswitch.com/blog/5g-network-slicing-separating-the-internet-of-things-from-the-internet-of-talk">metaswitch</a>)</em></p>
<p>SDN and NFV aren’t strictly required to perform NS, but it would be surprising if they were not involved.</p>
<p>An important part of the definition of a slice is that it can include network functions. A slice isn’t just a partition, but also a series or chain of network functions. Sometimes these functions are part of multiple slices.</p>
<p>SDN is also key because it provides the ability to program the network, and with functionality like Service Function Chaining (SFC) packets don’t necessarily have to follow a standard layer 3 path. (Note that I don’t define SDN as a centralized OpenFlow controller–it’s much more than that.)</p>
<h2 id="how-does-openstack-fit-in">How does OpenStack fit in?</h2>
<p>Simply: it’s just a domain. By end-to-end I mean multiple domains are crossed, such as the Radio Access Network (RAN), edge clouds, MPLS core, data center networks (and intra-DC), WAN, etc. That said, as a domain OpenStack will have to support the required features to enable network slicing. The good news is that by supporting virtualized networks and having an API OpenStack already meets a large portion of the aforementioned requirements. However, some work, a discussion of which would not fit into this post, still needs to be done.</p>
<h2 id="conclusion">Conclusion</h2>
<p>Network Slicing is a fascinating topic. Like any new, complex, paradigm shifting technology it’s easy to push back on (see NFV), but from my perspective the same value in IaaS would be gained from NS, and IaaS has shown to have considerable return on investment, especially in the area of automation. To what extent NS requirements are met remains to be seen, but overall NS in some fashion makes so much sense its likely unavoidable.</p>
The Four Major Components of NFV2018-06-10T00:00:00+00:00http://serverascode.com/2018/06/10/four-components-of-nfv<h1 id="the-four-major-components-of-nfv">The Four Major Components of NFV</h1>
<p>Network Function Virtualization (NFV) is a broad and complex topic. However, I think there are four major components to NFV and they are as follows:</p>
<ol>
<li>NFV Infrastructure</li>
<li>Softwarization of the network and SDN</li>
<li>Management and Orchestration</li>
<li>Deploying Network Services</li>
</ol>
<p>Certainly the above is a simplification, but I think that these four pieces are the underlying structure of NFV.</p>
<h2 id="nfv-infrastructure">NFV Infrastructure</h2>
<p>This is probably the best defined at this time, because, generally speaking, OpenStack is the defacto NFVi and Virtualization Infrastructure Manager (VIM). It’s not the only option, but it’s the most common.</p>
<p>Regardless of whether it’s OpenStack or something else, there has to be a system that can act as Infrastructure as a Service (IaaS) with APIs and schedulers and the like–something to manage compute, network, and storage, as well as other more advanced NFV resources (GPUs, Numa, etc).</p>
<p>ETSI is doing an admirable job of working to standardize the NFVi and VIM (as well as other areas, of course).</p>
<h2 id="softwareization-of-the-network-and-sdn">Softwareization of the Network and SDN</h2>
<p>While some people believe that SDN has failed, I’m not one of them. If we only consider SDN as a centralized controller that uses OpenFlow, then perhaps failed is correct (though I usually suggest that OpenFlow was an academic effort). But that is not the only way to define SDN.</p>
<p>Regardless of the definition of SDN, to be successful with NFV we need the ability to automate the network, and the only way to do that is to have access to APIs that talk to schedulers and resource managers to control network components. When we talk about the NFVi, or IaaS, we often say that it will control compute, storage, <em>and networking</em>. And it does. However, we need to step outside the boundaries of the NFVi into the rest of the network–including the core network. We need to manage as much of the network as we can as though it is software…APIs, libraries, dependencies (ugh) , and code.</p>
<p>Thus we end up with the somewhat clumsy phrase “softwareization of the network.” Clumsy but appropriate and workable. To be successful with NFV many traditionally separate network domains need to be combined together into a global interface.</p>
<p>Certainly implementation of this concept will be challenging. Traditional, legacy networks will push back on any kind of softwareization, but, in my opinion, it has to happen to some degree in order to be able to deploy network services successfully.</p>
<p>Unfortunately it does not seem like this is an area that can be standardized, at least not at this time. While networks tend to do the same thing, they all seem to have been designed differently, and may be unique.</p>
<h2 id="management-and-orchestration">Management and Orchestration</h2>
<p>This is another area that ETSI is working to <a href="http://www.etsi.org/deliver/etsi_gs/NFV-MAN/001_099/001/01.01.01_60/gs_NFV-MAN001v010101p.pdf">standardize</a>. What we need is some kind of higher level system that can talk to all the other APIs that we have made available (VIM and the “softwareized network”) to actually be able to deploy network services that customers can use (and pay for).</p>
<p>Currently it is exemplified by the rather complex system called <a href="https://www.onap.org/">ONAP</a>–the Open Network Automation Platform. There are other similar systems, such as ETSI’s own <a href="https://osm.etsi.org/">OSM</a> and many commercial products as well.</p>
<p>By using a management and orchestration (MANO) system, we can abstract away the underlying complexity of the NFVi and network and move towards the real work of actually (for real) deploying network services.</p>
<h2 id="deploying-network-services">Deploying Network Services</h2>
<p>Once we have the NFVi/VIM, a softwareized network, and a management and orchestration system (or systems), we can finally get to the work of onboarding VNFs, building network services, and selling them to customers.</p>
<p>However, it’s important to note that this is not a layer that one can simply purchase. The other three layers are infrastructure. They are systems to be deployed, and theoretically could be completely outsourced. This final layer is where all the actual work should occur–all the investment in the other layers is to service this one.</p>
<p>This layer is effectively a form of application development. I don’t want to go into too much detail in this particular post, but typically onboarding a VNF or Network Service requires writing some code (eg. TOSCA). Even if the code is provided by vendors or from open source, each Service Provider (SP) will have to do some customization of this code, as well as do their own testing and validation of the VNFs and Network Services it defines. Further, SPs will need to develop workflows for deployment of services that match their historical corporate organizational structure. While overall every SP is the same, the way they approach that sameness is different and often (unfortunately) unique, much like their network and security policies.</p>
<h2 id="conclusion">Conclusion</h2>
<p>The first three layers are infrastructure. They need to be commoditized and automated as much as possible in order to abstract away their complexity. Once those layers are available and trusted, the hard work to deploy customer facing network services can begin.</p>
OpenStack Vancouver Summit 20182018-05-28T00:00:00+00:00http://serverascode.com/2018/05/28/openstack-vancouver-2018-summit<h1 id="openstack-vancouver-summit-2018">OpenStack Vancouver Summit 2018</h1>
<p>Last week I was at the OpenStack Summit in Vancouver. This is the second time I’ve been to a OpenStack summit in this amazing location. It is probably the best place in the world to hold a conference, as the conference center is beautiful and the view is absolutely unbeatable. I am sure that this will not be the last OpenStack conference held in BC.</p>
<h2 id="openstack-slows-down-and-matures">OpenStack Slows Down and Matures</h2>
<p>Having been at the previous Vancouver summit, I believe in 2015, I know that it was much larger. I’m sure that the attendance at the 2015 version was six or seven thousand. This summit I believe was about 2500 people. There is a good reason for the reduction in attendance in that there are not as many developers that go as they now, instead, attend another event called the “PTG” (Project Team Gathering) which usually happens in a less expensive city (such as Denver…but strangely also Dublin). So that drops attendance by about half.</p>
<p>The other factor is that OpenStack is maturing. It’s coming through they hype cycle and settling down. Certainly there is a lot of work that needs to be done to keep OpenStack going, especially with regards to NFV, but overall it’s a bit less “exciting” at this point. For example Telecoms are putting it into production. Think about that. The most conservative organizations in the world and deploying thousands of OpenStack instances.</p>
<p>For another perspective, Redmonk has a <a href="http://redmonk.com/sogrady/2018/05/25/openstack-at-a-crossroads/">balanced blog post</a>.</p>
<blockquote>
<p>Many event organizers, OpenStack included, set themselves up for this criticism by using attendance themselves as a sign of health and progress, but that doesn’t change the fact that moving towards smaller events can be a boon for communities as it makes the events more navigable and weeds out less committed third parties. Attendance, in other words, is not a particularly useful metric if you’re trying to assess the OpenStack project’s health, and not just because it forked its developer and user events.</p>
</blockquote>
<p>Should there be a Linux Foundation, an OpenStack (or Open Infra) foundation, and a CNCF foundation? I think so. OpenStack’s community is really built on collaboration. I give them a hard time occasionally, but compared to other open source projects they really try to keep things civil. I think the triumvirate of these three foundations is a powerful substrate for open source software development. Two might not be enough, and four too many.</p>
<h2 id="open-infrastructure">Open Infrastructure</h2>
<p>As OpenStack focuses on other open source projects under their umbrella (Zuul and Kata Containers) it’s becoming fairly obvious that OpenStack will rebrand in some fashion around “Open Infrastructure.” They are putting out signals that this might happen, and I think it makes sense. I help to run the Toronto OpenStack meetup, and as well I recently started an Open Source Networking meetup. Just from my own view it would make sense to rebrand our meetups as Open Infrastructure and start focusing on a broader topic base.</p>
<p>Vendors like to try to pin OpenStack to just being a set of APIs into which any backend can be plugged into. However I don’t really view it like that as OpenStack is a Linux ecosystem integration platform. It really is open infrastructure. I prefer to consider what gets tested by the OpenStack CI system as being what “OpenStack” is, and add in some key components like Ceph and open networking, as well as automation systems such as ONAP.</p>
<h2 id="network-slicing">Network Slicing</h2>
<p>We presented a couple of talks at the summit. The one that probably resonated most with attendees was our presentation on <a href="https://www.youtube.com/watch?v=x_b4-w4Mrcg">5G Network Slcing and OpenStack</a>. Like a lot of technologies, it’s not that easy to define what Network Slicing is, but I personally find it fascinating, if at the very least academically. Certainly Network Slicing will occur in some fashion, but it is possible we won’t call it that…could just be some form of end to end virtualization. Or we could go all the way and build tools and APIs that meet all requirements for network slicing and create amazingly diverse networks and applications running on top of them, all the while providing secure, safe access for emergency communications.</p>
<h2 id="code-drops---airship-starlingx-akraino">Code Drops - Airship, StarlingX, Akraino…</h2>
<p>There were several code drops from larger companies:</p>
<ul>
<li><a href="https://www.akraino.org/">Akraino</a></li>
<li><a href="http://www.starlingx.io/">StarlingX</a></li>
<li><a href="http://www.airshipit.org/">Airship</a></li>
</ul>
<h3 id="akraino">Akraino</h3>
<p>AFAIK Akraino is essentially an integration project to create an edge stack. I’m not sure how much code actually exists at this time, , but I think it’s a good idea to do work in this area whether it’s successful or not. Certainly there is a good opportunity to get involved in the project right now as it’s still quite fluid.</p>
<p>I personally still think that innovation occurs in open source, so this kind of project is needed.</p>
<h3 id="starlingx">StarlingX</h3>
<p>Wind River has an OpenStack distribution (Titanium) which is aimed at Network Function Virtualizion (NFV) infrastructure and thus telecoms (and to be fair, industrial use cases as well). They had many proprietary changes to OpenStack in order to improve it and for various reasons have decided to try to upstream that code.</p>
<p>Wind River is a pretty interesting company. I’ve got to give props to any company that writes code that has to work or otherwise lives are in danger.</p>
<blockquote>
<p>For over 20 years, Wind River® has provided NASA with the most proven software platform to bring dozens of unmanned systems to space, resulting in some of the most significant space missions in history. - <a href="https://www.windriver.com/inspace/">Wind River: 20 Years in Space</a></p>
</blockquote>
<h3 id="airship">Airship</h3>
<p>It’s unfortunate that it seems like we need another way to deploy OpenStack, but apparently we do. From my limited introduction to Airship I like the overall tone of the project in terms of how it’s abstracting the layers, and I believe it is also taking care of Kubernetes deployments as well. But don’t quote me on that as I haven’t looked at it closely enough. It also relies heavily on <a href="https://docs.openstack.org/openstack-helm/latest/readme.html">OpenStack-Helm</a>.</p>
<h2 id="conclusion">Conclusion</h2>
<p>Overall, it was a nice summit. Times are a changin’. I fully expect the OpenStack Foundation to rebrand in some fashion, that is assuming once doesn’t already consider them as having rebranded with “Open Infra” and emphasis on Zuul and Kata Containers as new, separate projects. I also expect a push back on complexity in NFV, but we need infrastructure that has APIs and schedulers, so the complexity is unavoidable, we just have to get good at it.</p>
<p>The foundation has changed the PTG so that now operators, such as myself, are invited. We used to have a separate operators meetup, but now that will be co-located with the five day PTG. So the next time I go to an OpenStack event will be the upcoming PTG event in Denver.</p>
Service Providers and Telecoms Must Accept Complexity2018-05-13T00:00:00+00:00http://serverascode.com/2018/05/13/service-providers-accept-complexity-of-nfv<h1 id="service-providers-and-telecoms-must-accept-complexity">Service Providers and Telecoms Must Accept Complexity</h1>
<h2 id="tldr">tl;dr</h2>
<p>NFV is complex. But in order to automate we need APIs. Something has to schedule compute, network, and storage. Something has to provide the APIs to orchestrate it all. That something is NFV. Telecoms can’t give up so easily on NFV, because to do so would be at worst a rejection of automation and at best a renaming of NFV.</p>
<h2 id="accepting-nfv-complexity">Accepting NFV Complexity</h2>
<p>I’ve been working with OpenStack and SDN for a long time. As well, for the last 2+ years, I have also been working in the area of Network Function Virutalization (NFV). At this point NFV is a bit of a catch all term for all the new things that have been happening in and around the service provider or telecom industry. Automation. SDN. 5G. All of these things are complex and perhaps complicated.</p>
<p>OpenStack has found a place in telecoms. I think it’s fair to say that every telecom in the world is thinking about OpenStack in some capacity. We are at the point now, I believe, where many telecoms are past the proof of concept phase and are really starting to try to put OpenStack, and more specifically NFV infrastucture (NFVi), into production. However, this is the point where we will also start to see telecoms give up on NFV (and SDN) because it’s too complex.</p>
<p>Telecoms are good at deploying physical boxes and manually deploying required applications on top of them because they heavily rely on the vendors to do it. If a telecom buys a piece of software from a vendor, they then put the vendor through the wringer to get them to deploy it and ensure it works. Unfortunately, this is “set and forget.”</p>
<p>In the case of NFV, however, it’s not just a single vendor that is involved, and what’s more, telecom staff are being asked to understand how NFV works and to be able to deploy network functions into NFV infrastructure via automation (eg. ETSI MANO). Instead of relying on vendor professional services internal telecom staff are being asked to deploy network functions. But doing that is not as easy as beating up on a vendor. It’s at this point we will start to see a rejection of NFV as operationalizing NFVi, SDN, and automation is challenging. Not impossible, just challenging. (Aside: the real issue often in telecoms is the complexity of the organization, not the technology.)</p>
<h2 id="rejection-of-nfv">Rejection of NFV?</h2>
<p>I read Tom Nolle’s CIMI Corp blog quite a bit. I enjoy his take on telecoms and NFV. He has a recent post entitled <a href="http://blog.cimicorp.com/?p=3375">Have Operators Uncovered a New Transformation Path?</a> from which I take the following quote.</p>
<blockquote>
<p>The leading technologies in transformation, according to popular wisdom, are SDN and NFV. Operators have been griping about both in both conversations with me and surveys I’ve done. SDN, they say, is too transformational in terms of the network technical model. Central control of forwarding, the classic ONF OpenFlow SDN model, may or may not scale far enough and may or may not handle large-scale faults. NFV, they say, is simply too complicated to be able to control operations costs, and its capital savings are problematic even without opex complications.</p>
</blockquote>
<p>I have some issues with the above statement. (Again, I like Tom’s work, I just have an issue with this particular post.)</p>
<p>First, I don’t think anyone really wants a “OpenFlow” model of SDN. I prefer to think of OpenFlow as an academic project that furthered our thinking about SDN, not as something we would actually want to put into production. We need SDN, absolutely, but SDN != OpenFlow.</p>
<p>The second statement I disagree with is that “NFV is too complicated.” We need automation to drive down costs. In order to automate we need APIs. And what APIs? OpenStack has the defacto NFVi API. In order to automatically deploy network functions we need something to schedule compute, storage, and network resources. That something is NFV. The vast majority of NFVi will probably be based on OpenStack.</p>
<p>If we were to reject NFV all that would happen is that the abstraction of compute, storage, and networking would be hidden by another API (example Mesosphere perhaps?) but that does not avoid the complexity, it just gives it another name or is another product. We can create as many abstractions as are necessary to provide the appearance of reduced complexity, but somewhere there is an NFVi, and somewhere there is SDN, and these things must be well understood and operationally perfect, and that is challenging. But not so challenging that we have to give up on NFV, because giving up on NFV means giving up on automation and staying with the status quo of <em>manually</em> deploying applications onto physical boxes and <em>manually</em> wiring them up.</p>
<p>My suggestions to telecoms would be to understand that some complexity is unavoidable and to allow their staff to get up to speed on operationalizing management of NFVi and deployment of NFs with the understanding that it is definitely harder to do than a one-time, static, unrepeatable deployment handled by a vendor. If you want to see complexity try altering one of those deployments a year down the road. ;)</p>
Open Networking Summit North America 20182018-03-31T00:00:00+00:00http://serverascode.com/2018/03/31/ons-na-2018<h1 id="open-networking-summit-north-america-2018">Open Networking Summit North America 2018</h1>
<p>Last week I was lucky enough to attend the 2018 North American Open Networking Summit put on by the Linux Foundation.</p>
<p>Overall, the ONS summit was great. I learned a lot, had some good conversations, and was reminded of how much cool stuff is going on in the realm of networking.</p>
<h2 id="themes">Themes</h2>
<p>There were a few themes I identified:</p>
<ul>
<li>The amount of NFV related work being done is amazing. I was a bit overwhelmed the first day as I reminded of all the work that is happening, most, if not all, in the NFV area. It’s not a stretch to say that Linux networking = NFV, IMHO.</li>
<li>Optical networking was also often mentioned as a place for automation, which surprised me.</li>
<li>ONAP - The Open Networking Automation Platform is nearing the top of the hype cycle. I believe ONAP is extremely important. However, it’s quite complicated and has a long way to go in terms of stability. Some telecoms are using pieces of it in production right now. It’s a large project and not everyone will use every single sub project.</li>
<li>Canada has a many companies working in networking and telecom, especially in Ottawa and Montreal. Ottawa has Wind River, Ciena, and Amdocs to name a few.</li>
<li>Speaking of complexity - I complained several times to people about the level of complexity we are entering. People used to think OpenStack is complex. Well now you have to add SDN, ONAP and containers onto that. OpenStack is probably the easy part now (relatively speaking). Sure, Kubernetes is easy to deploy, but how many people who deploy it truly understand how it works.</li>
<li>Dependencies - Still on the complexity front, I see tons of issues with dependencies and managing them. All of these systems, OpenStack, SDN, ONAP, etc, will have to not only be deployed, but talk to one another. We are heading into some serious dependency issues. I took some ONAP training on the last day, and we had several dependency issues just in terms of deployment, and the trainers had deployed this particular set of ONAP modules hundreds of times.</li>
<li>Central Office - There are so many COs spread across NA…tens of thousands of them. This is a real key area, perhaps the most key, for NFV in the next few years. ONF is doing a ton of work in this area around the idea of “Central Office Rearchitected as Data Center” or CORD for short.</li>
</ul>
<h2 id="additional-notes">Additional Notes</h2>
<p>A few other small points:</p>
<ul>
<li>OpenContrail has been renamed “Tungsten Fabric.” Bit of an awkward name, but I don’t mind it. Especially if you drop it down to just TF. Juniper really needs the community around TF to grow, as it’s really a single vendor project which is no good to anyone in terms of open source.</li>
<li>dNOS has been renamed DANOS. There are a few Network Operating Systems (NOS): DANOS, Sonic (from Microsoft), and the recently announced Stratum (thought I am not completely sure Stratum would consider itself a NOS). AT&T plans to deploy 60k whitebox switches with DANOS. I am very excited to see more work being done in the NOS area. All we really need are some good drivers for switch hardware and some more work around common networking protocols (as well as the new advanced technologies) and we should be able to have a thriving Linux NOS.</li>
<li>The P4 programming language was mentioned quite a bit. Will be very interested to see where that goes.</li>
<li>AT&T sees 200PB of mobile traffic per day, up 50% from a year ago.</li>
<li>Wind River is open sourcing some (all?) of their platform.</li>
<li>OpenStack is still trying to figure out what it is going to look like on the edge. Will it be remote hypervisor, multi-region, cell based, or light weight. No one knows. Probably all of them I guess.</li>
<li>Network slicing was often mentioned, but no one seemed to know what it was actually going to look like in terms of implementation. I heard it in several presentations, but no real details.</li>
<li>Fd.io/vpp was mentioned quite often. I need to better understand that technology.</li>
</ul>
<p>Again, overall, the amount of work being done in the networking area is astounding and it will be hard for people to keep up with the pace. It’s a great area to be working in. I’m going to try to attend the European ONS summit upcoming this year.</p>
Jinja2 Namespaces and Variable Scope2018-03-15T00:00:00+00:00http://serverascode.com/2018/03/15/jinja2-namespaces<h1 id="jinja2-namespaces-and-variable-scope">Jinja2 Namespaces and Variable Scope</h1>
<p>I have been doing some Network automation lately, specifically using the Juniper vSRX and generating config templates via Ansible.</p>
<p>I quickly found out about variable scope in Jinja.</p>
<blockquote>
<p>Please keep in mind that it is not possible to set variables inside a block and have them show up outside of it. This also applies to loops. The only exception to that rule are if statements which do not introduce a scope. - <a href="http://jinja.pocoo.org/docs/2.10/templates/">Jinja Docs</a></p>
</blockquote>
<p>Putting a lot of logic into templates is probably not a good idea, but I’m doing it anyway in this case. :)</p>
<p>Example. I have two friends. One has a car, one doesn’t. Does the group of friends have a car?</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>
#!/usr/bin/env python
from jinja2 import Template
friends = []
friend1 = {
"name": "Frank",
"car": False
}
friend2 = {
"name": "Anna",
"car": True
}
friends.append(friend1)
friends.append(friend2)
t_example = """
{% set ns = namespace(hasCar=false) %}
{% for f in friends %}
Friend {{ f.name }}
{% if f.car == true %}
{% set ns.hasCar = true %}
{% endif %}
{% endfor %} {# for n in friends #}
{% if ns.hasCar == true %}
SOMEONE HAS A CAR: TRUE
{% else %}
SOMEONE HAS A CAR: FALSE
{% endif %}
"""
template = Template(t_example, trim_blocks=True)
render = template.render(friends=friends)
print render
</code></pre></div></div>
<p>If I run this in ipython I get:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>
In [1]: run jinja-ns.py
Friend Frank
Friend Anna
SOMEONE HAS A CAR: TRUE
In [2]:
</code></pre></div></div>
<p><br /></p>
<p>That’s it. Namespaces in jinja.</p>
Juniper vSRX MPLS Lab2018-02-19T00:00:00+00:00http://serverascode.com/2018/02/19/juniper-vsrx-mpls-network<p><em>(network diagram of the lab)</em></p>
<h1 id="juniper-vsrx-mpls-lab">Juniper vSRX MPLS Lab</h1>
<p>I’ve wrote up a <a href="https://github.com/ccollicutt/mpls-networking/blob/master/JUNIPER-MPLS.md">lab</a> (available on github) on deploying a MPLS core network using Juniper vSRX routers. It’s completely based on <a href="https://juniperlabs.wordpress.com/2014/01/16/simple-juniper-mpls-core-with-l3vpn/">this</a> blog post, entitled “Simple Juniper MPLS Core.”</p>
<p>My goal with replicating the simple MPLS network was to try to get a better understanding of how MPLS will work in NFV and 5G where there is a desire to do “network slicing.”</p>
<p>I’m not sure who wrote the initial blog post, but I am thankful they did because I was able to completely replicate it. I’m indebted to them because I feel like I now have a better understanding of Juniper and MPLS networks, which was my goal. This lab provides a base that I can build off of.</p>
<p>I don’t want to say much more in this blog post because I put a lot of work into the lab, so please take a look at the <a href="https://github.com/ccollicutt/mpls-networking">github repo</a> where it resides.</p>
<p>Here’s a listing of all the virtual routers running an a baremetal KVM node.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ virsh list
Id Name State
----------------------------------------------------
86 ce-ny running
120 pe-lo4 running
122 p2-njh running
123 p1-ny8 running
124 pe-nj2 running
125 ce-uk running
</code></pre></div></div>
<p>Here’s a session of ce-ny pinging/tracerouting ce-uk.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ ssh root@ce-ny
Password:
--- JUNOS 17.3R1.10 built 2017-08-23 06:47:03 UTC
root@ce-ny%
root@ce-ny% cli
root@ce-ny> ping 6.6.6.6
PING 6.6.6.6 (6.6.6.6): 56 data bytes
64 bytes from 6.6.6.6: icmp_seq=0 ttl=61 time=6.536 ms
64 bytes from 6.6.6.6: icmp_seq=1 ttl=61 time=3.840 ms
^C
--- 6.6.6.6 ping statistics ---
2 packets transmitted, 2 packets received, 0% packet loss
round-trip min/avg/max/stddev = 3.840/5.188/6.536/1.348 ms
root@ce-ny> traceroute 6.6.6.6
traceroute to 6.6.6.6 (6.6.6.6), 30 hops max, 40 byte packets
1 10.3.5.0 (10.3.5.0) 4.759 ms 4.345 ms 4.514 ms
2 10.2.3.0 (10.2.3.0) 6.033 ms 6.077 ms 5.291 ms
MPLS Label=299776 CoS=0 TTL=1 S=0
MPLS Label=299776 CoS=0 TTL=1 S=1
3 10.2.4.1 (10.2.4.1) 6.693 ms 6.012 ms 8.049 ms
MPLS Label=299776 CoS=0 TTL=1 S=1
4 6.6.6.6 (6.6.6.6) 4.826 ms 5.409 ms 5.222 ms
root@ce-ny>
</code></pre></div></div>
<p>It works! :)</p>
<p><em>NOTE: On the diagram each router has a .17x IP address (full address is the management network, 192.168.122.17x). The x for each is also their router ID and loopback address. So ce-uk, .176, is 6.6.6.6.</em></p>
<h2 id="conclusion">Conclusion</h2>
<p>I’m really happy with how this worked out, and as mentioned, I now have a base to do more exploration around MPLS, BGP, OSPF and other protocols, hopefully ending with me having a good understanding of what network slicing could or should look like in a service provider.</p>
<p>One of the major things I learned is that building a virtual lab like this is really about understanding nodes and edges, just like what one would do with <code class="language-plaintext highlighter-rouge">graphviz</code> dot diagrams. This is why I’ve listed the “links” (aka edges) and interfaces on the diagram, to help me automate and validate. Building a network diagram like the above should be completely automatable, based on well understood graphing. But that is another story… :)</p>
Connecting to Juniper with Ansible2018-01-24T00:00:00+00:00http://serverascode.com/2018/01/24/juniper-ansible<h1 id="connecting-to-juniper-with-ansible">Connecting to Juniper with Ansible</h1>
<p>Recently I wanted to test out using Ansible to connect to Juniper vSRX routers. Unfortunately this was not as easy as I had thought/hoped it would be.</p>
<h2 id="juniper-vsrx">Juniper vSRX</h2>
<p>Juniper provides a virtual machine image for the virtual SRX firewall.</p>
<p>The version I’m using here is:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>media-vsrx-vmdisk-17.3R1.10.qcow2
</code></pre></div></div>
<p>I’m running it in kvm on Ubuntu 16.04…but that’s another story.</p>
<h2 id="configure-vsrx">Configure vSRX</h2>
<p>This is the easy part.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>set system services netconf ssh
set system services ssh hostkey-algorithm no-ssh-ecdsa
set system services ssh hostkey-algorithm ssh-rsa
</code></pre></div></div>
<p><em>NOTE: In the future the ssh hostkey-algorithm settings might not be needed. More on this later in the post.</em></p>
<p>Also, the <code class="language-plaintext highlighter-rouge">known_hosts</code> file for where ever Ansible is running would need to be setup. HINT: ssh-keyscan.</p>
<h2 id="setup-playbook">Setup Playbook</h2>
<p>Here’s an example playbook. Note the <code class="language-plaintext highlighter-rouge">provider</code> section. This took a little while to get right. The <code class="language-plaintext highlighter-rouge">junos_facts</code> module requires some connection information, and it uses a dictionary called <code class="language-plaintext highlighter-rouge">provider</code> that can be setup in the task. Obviously these variables could be pulled from somewhere else, like an Ansible Vault file, but I’m leaving it bare as an example here.</p>
<p>Ansible’s default facts gathering doesn’t understand how to gather facts from Juniper, so the <code class="language-plaintext highlighter-rouge">juniper_facts</code> module is required to get facts. Note I’m also gathing a subset of information in the example.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>- name: test
hosts:
- routers
roles:
- Juniper.junos
connection: local
gather_facts: no
tasks:
- name: check is netconf port is listening
wait_for:
host: "{{ ansible_host }}"
timeout: 5
port: 830
- name: collect default set of facts and configuration
junos_facts:
gather_subset: "config"
provider:
username: "root"
password: "coolpass"
transport: "netconf"
timeout: 5
host: "{{ ansible_host }}"
</code></pre></div></div>
<p><br /></p>
<h2 id="issues-with-ecdsa-keys">Issues with ECDSA keys</h2>
<p>It seems that the ncclient code can’t handle, at this time, ECDSA keys. It just fails with an “unknown key” message.</p>
<p>I had to disable ECDSA keys in the Juniper routers.</p>
<p>I tried this super simple test code, prior to forcing ECDSA on the Junipers, and it errored out with hostkey_verify=True, and succeeded with it set to False.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ cat test-netconf.py
from ncclient import manager
with manager.connect(host="<hostname>", port=830, username="root", password="coolpass", hostkey_verify=True) as m:
c = m.get_config(source='running').data_xml
print c
</code></pre></div></div>
<p>As far as I know at this time this is the latest ncclient code.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ pip freeze | grep ncclient
ncclient==0.5.3
</code></pre></div></div>
<p>Maybe there is another issue hidden away somewhere. Worth some more digging when I have time.</p>
<h2 id="conclusion">Conclusion</h2>
<p>Overall, I’m not happy with how this looks. I like Ansible, but sometimes the whole module thing, which exists with almost all configuration management tools, just seems hacky. Here I have to turn of fact gathering, and then turn on a task based Juniper fact gathering. Further, getting this to work with a recent vSRX node took like an hour due to the ECDSA issue. One simple little thing like that breaks connectivity via Ansible. Dependencies and versioning…these are hard and don’t seem to be getting any easier, this is too brittle.</p>
<p>I know the Ansible and networking (vendors) have done a lot of work to get many devices supported, it just doesn’t seem quite right to me. That said, Ansible is probably one of the best options for managing many individual network devices.</p>
Setting Up Google Cloud DNS with gcloud2018-01-14T00:00:00+00:00http://serverascode.com/2018/01/14/gcloud-dns-setup<h1 id="setting-up-google-cloud-dns-with-gcloud">Setting Up Google Cloud DNS with gcloud</h1>
<p>Of all the things to outsource, mail and DNS should be first. :)</p>
<p>I’m going to migrate my serverascode.com domain DNS from an old hosting company to Google Cloud DNS. Finally.</p>
<p>I also have some DNS hosting done with AWS Route 53, but I am trying to learn more about gcloud. Also, I think hosting DNS at Google is slightly cheaper, in that each “zone” is $0.20/month vs $0.50/month at AWS. Each charges $0.40 for some huge number of DNS requests.</p>
<p>One thing I find that is a problem with gcloud is that there is very little documentation outside of gclouds official docs. I am not really a fan of any of the official docs, be it for AWS or gcloud…they always read like autogenerated API docs. Also I find gclouds look, feel, and organization to be difficult to grasp.</p>
<p>I’m only going to use the gcloud command line.</p>
<h2 id="setting-up-the-dns-project">Setting Up the DNS Project</h2>
<p>First, setup a new project. I’m not sure if the best way to use gcloud is to setup multiple projects, but I’m going to setup a DNS hosting project.</p>
<p><em>NOTE:</em> Replace “some-uuid” with some kind of random string. Projects need to have a unique name.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ gcloud projects create dns-hosting-<some-uuid> --name "DNS Hosting"
</code></pre></div></div>
<p>List your billing accounts. This assumes you have setup at least one account for billing.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ gcloud alpha billing accounts list
ID NAME OPEN
<billing account ID> My Billing Account
</code></pre></div></div>
<p>Switch to the DNS project.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ gcloud config set project dns-hosting-<some-uuid>
Updated property [core/project].
</code></pre></div></div>
<p>Assign a billing account to the DNS project.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ gcloud alpha billing accounts projects link dns-hosting-<some-uuid> --account-id=<billing account ID>
</code></pre></div></div>
<p>Now the project can be billed.</p>
<p>Enable the DNS API <em>on this project</em>.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ gcloud services enable dns.googleapis.com
</code></pre></div></div>
<p>DNS should be in the list of available services for this project.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ gcloud services list
NAME TITLE
bigquery-json.googleapis.com BigQuery API
cloudtrace.googleapis.com Stackdriver Trace API
servicemanagement.googleapis.com Google Service Management API
monitoring.googleapis.com Stackdriver Monitoring API
storage-api.googleapis.com Google Cloud Storage JSON API
dns.googleapis.com Google Cloud DNS API
logging.googleapis.com Stackdriver Logging API
clouddebugger.googleapis.com Stackdriver Debugger API
datastore.googleapis.com Google Cloud Datastore API
sql-component.googleapis.com Google Cloud SQL
cloudapis.googleapis.com Google Cloud APIs
storage-component.googleapis.com Google Cloud Storage
</code></pre></div></div>
<p>Now for the actual DNS setup.</p>
<h2 id="setting-up-dns-zone">Setting Up DNS Zone</h2>
<p>Now that the project is created and has a billing account we can setup the DNS zone.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ gcloud dns managed-zones create --dns-name="serverascode.com." --description="serverascode"
</code></pre></div></div>
<p>List zones.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ gcloud dns managed-zones list
NAME DNS_NAME DESCRIPTION
serverascode serverascode.com. serverascode
</code></pre></div></div>
<p>The process is:</p>
<ol>
<li>Start the transaction</li>
<li>Make changes, add DNS records, etc</li>
<li>Execute the transaction</li>
</ol>
<p>Start a DNS zone editing transaction.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ gcloud dns record-sets transaction start --zone=serverascode
</code></pre></div></div>
<p>A <code class="language-plaintext highlighter-rouge">transaction.yaml</code> file will be created where ever you run this command. Further commands will edit this file, and then finally we will execute this file to push the changes up to gcloud.</p>
<p>Add an A record. In this example I am pointing <code class="language-plaintext highlighter-rouge">serverascode.com</code> to Github’s page servers.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ gcloud dns record-sets transaction add --zone=serverascode --name="serverascode.com" --ttl 3600 --type A 192.30.252.153 192.30.252.154
</code></pre></div></div>
<p>Add a CNAME for www.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ gcloud dns record-sets transaction add -z=serverascode --type=CNAME --name="www.serverascode.com" --ttl 3600 "serverascode.com."
</code></pre></div></div>
<p>If you host your mail somewhere for this domain, add MX records. Here I enter two mail hosts.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>gcloud dns record-sets transaction add --zone=serverascode --name="serverascode.com" --ttl 3600 --type MX "10 mail1.somemailhost.com." "20 mail2.somemailhost.com."
</code></pre></div></div>
<p>Finally execute those changes.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ gcloud dns record-sets transaction execute --zone serverascode
</code></pre></div></div>
<p>And once they have been pushed we can list them.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ gcloud dns record-sets list --zone=serverascode
NAME TYPE TTL DATA
serverascode.com. A 3600 192.30.252.153,192.30.252.154
serverascode.com. MX 3600 10 mail1.somemailhost.com.,20 mail2.somemailhost.com.
serverascode.com. NS 21600 ns-cloud-d1.googledomains.com.,ns-cloud-d2.googledomains.com.,ns-cloud-d3.googledomains.com.,ns-cloud-d4.googledomains.com.
serverascode.com. SOA 21600 ns-cloud-d1.googledomains.com. cloud-dns-hostmaster.google.com. 6 21600 3600 259200 300
www.serverascode.com. CNAME 3600 serverascode.com.
</code></pre></div></div>
<p>If that looks good then go to your registar and change the nameservers to Google’s, which is what I did.</p>
<p>If you are reading this post then it must have worked!</p>
My Thoughts on Meltdown and Spectre2018-01-06T00:00:00+00:00http://serverascode.com/2018/01/06/my-thoughts-on-meltdown-spectre<h1 id="my-thoughts-on-meltdown-and-spectre">My Thoughts on Meltdown and Spectre</h1>
<p>First off, I don’t really expect anyone to care what I think about all this. That’s the beauty of the Internet, I can just write what I’d like on my blog and it’s easy to ignore this backwater HTML. :)</p>
<p>But I do have some fairly strong thoughts on Meltdown and Spectre, which I consider to be a rather large mess and frankly fairly concerning for the future of humanity. (Certainly computing is only one of our problems though.)</p>
<h2 id="computing-power">Computing power</h2>
<p>I’m not an academic or a philosopher, but I’ve always had this strong feeling that humanity would continue to push computing to the farthest it can go, that we would build <a href="https://en.wikipedia.org/wiki/Matrioshka_brain">Matrioshka</a> brains or other similarly massive computers, and maybe have to move them to cold parts of the universe to run them.</p>
<p>But the Meltdown and Spectre issues have set me back a bit on that thinking. I’m sure it’s just a bump in the road, but it is a bit depressing. Computer security is so difficult. Here we are moving everything into the public cloud which is based on CPUs that were never meant to be multi-tenant. If we can’t understand the CPUs that we are building now, imagine the issues we will have in the future when we have to deal with even more complexity. Perhaps Meltdown/Spectre will bring about change.</p>
<h2 id="computer-security">Computer security</h2>
<p>With the recent WIFI hacks, SSL being in a poor state, and now massive CPU issues, things are not looking well (and in fact may never have never been)–I may have to do online banking on a <a href="https://www.raspberrypi.org/blog/why-raspberry-pi-isnt-vulnerable-to-spectre-or-meltdown/">Raspberry Pi</a>.</p>
<p>This <a href="https://www.nytimes.com/2018/01/06/opinion/looming-digital-meltdown.html">NYT</a> article makes a good point:</p>
<blockquote>
<p>As things stand, we suffer through hack after hack, security failure after security failure. If commercial airplanes fell out of the sky regularly, we wouldn’t just shrug. We would invest in understanding flight dynamics, hold companies accountable that did not use established safety procedures, and dissect and learn from new incidents that caught us by surprise.</p>
</blockquote>
<h2 id="who-was-part-of-the-embargo">Who was part of the embargo?</h2>
<p>One thing that I hope comes out in the near future is a time line of who and what companies knew of the issue. I applaud Google for figuring this out, and letting people know. I think there was a lot of unfairness regarding how this all came about.</p>
<h2 id="kernel-devs-working-the-holidays">Kernel devs working the Holidays</h2>
<p><a href="http://kroah.com/log/blog/2018/01/06/meltdown-status/">Greg Kroah-Hartman</a> has a pretty good post on the status of kernel devs.</p>
<blockquote>
<p>Right now, there are a lot of very overworked, grumpy, sleepless, and just generally pissed off kernel developers working as hard as they can to resolve these issues that they themselves did not cause at all. Please be considerate of their situation right now. They need all the love and support and free supply of their favorite beverage that we can provide them to ensure that we all end up with fixed systems as soon as possible.</p>
</blockquote>
<h2 id="canonical-is-a-small-company">Canonical is a small company</h2>
<p>I’ve seen a bit of complaining about Ubuntu not having a patch yet (as of me writing this they do not) but one thing people don’t know is that Canonical is a very small company, the best stats I could find suggest ~550 staff. RedHat has ~10,000. That’s a big difference. I have a lot of empathy right now for their kernel team.</p>
<h2 id="google-p0-team">Google P0 Team</h2>
<p>I’ve got to give Google props for having the Project Zero (P0) team. Google does provide some pretty useful things for the global community, and P0 is one of the more important. What other large companies or public clouds do the same? Not many.</p>
<h2 id="spectre-is-not-fixed">Spectre is not fixed…</h2>
<p>Something I think is getting a little lost is that Spectre is not fixed. It seems Meltdown is mitigated, with some workloads having considerable performance impact, but Spectre is not solved. Again I go back to Kroah-Hartman’s blog. Note the part about “claim.”</p>
<blockquote>
<p>Again, if you are running a distro kernel, you might be covered as some of the distros have merged various patches into them that they claim mitigate most of the problems here. I suggest updating and testing for yourself to see if you are worried about this attack vector</p>
<p>For upstream, well, the status is there is no fixes merged into any upstream tree for these types of issues yet. There are numerous patches floating around on the different mailing lists that are proposing solutions for how to resolve them, but they are under heavy development, some of the patch series do not even build or apply to any known trees, the series conflict with each other, and it’s a general mess.</p>
</blockquote>
<p>Google <a href="https://blog.google/topics/google-cloud/answering-your-questions-about-meltdown-and-spectre/">argues</a> that public clouds are better equipped to deal with these issues. Perhaps it’s true. Though live migration is available in other IaaS systems, and, of course, if your app is “cloud native” you don’t have to live migrate anything, just drain (perhaps using Kubernetes).</p>
<blockquote>
<p>In many respects, public cloud users are better-protected from security vulnerabilities than are users of traditional datacenter-hosted applications. Security best practices rely on discovering vulnerabilities early, and patching them promptly and completely. Each of these activities is aided by the scale and automation that top public cloud providers can offer — for example, few companies maintain a several-hundred-person security research team to find vulnerabilities and patch them before they’re discovered by others or disclosed. Having the ability to update millions of servers in days, without causing user disruption or requiring maintenance windows, is difficult technology to develop but it allows patches and updates to be deployed quickly after they become available, and without user disruption that can damage productivity.</p>
</blockquote>
<h2 id="abstractions-get-all-the-hype-and-yet-we-still-need-baremetal-knowledge">Abstractions get all the hype, and yet we still need baremetal knowledge</h2>
<p>Many technical people don’t know have much knowledge CPUs work. Or can’t compile a Linux kernel. We now have all these high level abstractions (lambda) but still have to have knowledge of low level things. People who I admire on twitter aren’t working on figuring out how to deploy to AWS better, and instead are figuring out <a href="https://jvns.ca/blog/2018/01/04/how-does-gdb-call-functions/">gdb</a> and writing baremetal code in Rust or Go. This is a curious state to be in.</p>
<h2 id="diversity-in-technology">Diversity in Technology</h2>
<p>I believe that diversity in technology is a good thing, and by this I mean different kinds of CPUs and other hardware, as well as operating systems and network protocols, etc. Thus Intel’s effective monopoly is not positive. I don’t know if trading Intel for AWS is better. I think we need something more.</p>
<p>I know that many organizations are seeking to reduce cost by using commodity hardware, which usually just means virtualization on x86. I think that may be an overly simplistic way to look at the problem of reducing cost.</p>
<p>Perhaps investing in other <a href="http://www.tomshardware.com/news/risc-v-not-vulnerable-meltdown-spectre-cpu-bugs,36231.html">CPUs</a> is a good idea if only to achieve some diversity and avoid systemic risk. (Frankly it would be pretty cool to have a non-x86 CPU laptop, we should just do that anyways.)</p>
<h2 id="conclusion">Conclusion</h2>
<p>This is a pretty rambling post, but I think it makes sense given the what’s happening this week in technology.</p>
<h2 id="bonus-fun-tweets">Bonus: fun tweets</h2>
<blockquote class="twitter-tweet" data-lang="en"><p lang="en" dir="ltr">This is interesting. This vulnerability illustrates an interesting economic upside for multi-tenant cloud providers: REVENUE. The vulnerability which they patched quickly drives CPU utilization up and they get to charge more based on CPU use! Rename Meltdown to “Cache-ing” $$$ <a href="https://t.co/fzBrpFWY4q">https://t.co/fzBrpFWY4q</a></p>— Hoff (@Beaker) <a href="https://twitter.com/Beaker/status/950024936130834432?ref_src=twsrc%5Etfw">January 7, 2018</a></blockquote>
<script async="" src="https://platform.twitter.com/widgets.js" charset="utf-8"></script>
<blockquote class="twitter-tweet" data-lang="en"><p lang="en" dir="ltr">It's impossible to reason about computer security in a meaningful manner anymore. The gap between "architectural behavior" and "micro-architectural implementation" is so great, so dark, and is basically, "Here be Dragons." We cannot build solid structures on faulty foundations.</p>— Bitweasil (@Bitweasil) <a href="https://twitter.com/Bitweasil/status/949405590631022592?ref_src=twsrc%5Etfw">January 5, 2018</a></blockquote>
<script async="" src="https://platform.twitter.com/widgets.js" charset="utf-8"></script>
<blockquote class="twitter-tweet" data-lang="en"><p lang="en" dir="ltr">This means the 6 month embargo of <a href="https://twitter.com/hashtag/meltdown?src=hash&ref_src=twsrc%5Etfw">#meltdown</a> and <a href="https://twitter.com/hashtag/Spectre?src=hash&ref_src=twsrc%5Etfw">#Spectre</a> cost those that weren't in on the club one full year of time responding to it. <a href="https://twitter.com/intel?ref_src=twsrc%5Etfw">@intel</a> and <a href="https://twitter.com/Google?ref_src=twsrc%5Etfw">@Google</a> decided who would get that advantage and who wouldn't.</p>— John-Mark Gurney (@encthenet) <a href="https://twitter.com/encthenet/status/949344637398863872?ref_src=twsrc%5Etfw">January 5, 2018</a></blockquote>
<script async="" src="https://platform.twitter.com/widgets.js" charset="utf-8"></script>
<blockquote class="twitter-tweet" data-lang="en"><p lang="und" dir="ltr"><a href="https://t.co/KRKypYAEiw">pic.twitter.com/KRKypYAEiw</a></p>— 防毒面を着ているサイバーテロ狼 (@wolfniya) <a href="https://twitter.com/wolfniya/status/948863886131941377?ref_src=twsrc%5Etfw">January 4, 2018</a></blockquote>
<script async="" src="https://platform.twitter.com/widgets.js" charset="utf-8"></script>
<blockquote class="twitter-tweet" data-lang="en"><p lang="en" dir="ltr">5 lines of JavaScript broke every single Intel processor made in the past 15 years. <a href="https://t.co/fyQcHk6haJ">pic.twitter.com/fyQcHk6haJ</a></p>— Mike Pan (@themikepan) <a href="https://twitter.com/themikepan/status/949059784908484608?ref_src=twsrc%5Etfw">January 4, 2018</a></blockquote>
<script async="" src="https://platform.twitter.com/widgets.js" charset="utf-8"></script>
<blockquote class="twitter-tweet" data-lang="en"><p lang="en" dir="ltr">“A CPU predicts you will walk into a bar, you do not. Your wallet has been stolen”<br />— The Internet</p>— Mike Skalnik (@skalnik) <a href="https://twitter.com/skalnik/status/948998374384025600?ref_src=twsrc%5Etfw">January 4, 2018</a></blockquote>
<script async="" src="https://platform.twitter.com/widgets.js" charset="utf-8"></script>
<blockquote class="twitter-tweet" data-lang="en"><p lang="en" dir="ltr">Don't panic y'all!<br /><br />Step 1) Don't use Intel processors.<br />Step 2) Don't use AMD or anything ARM based.<br />Step 3) You know what? Just give up technology altogether.<br />Step 4) Retreat to the woods and build a cabin out of derelict silicon.<br />Step 5) You're now Ted Kaczynski, you psycho.</p>— Josh Cincinnati (@acityinohio) <a href="https://twitter.com/acityinohio/status/948741317789564928?ref_src=twsrc%5Etfw">January 4, 2018</a></blockquote>
<script async="" src="https://platform.twitter.com/widgets.js" charset="utf-8"></script>
<blockquote class="twitter-tweet" data-lang="en"><p lang="en" dir="ltr">CERT brings the harsh truth. <a href="https://twitter.com/hashtag/Meltdown?src=hash&ref_src=twsrc%5Etfw">#Meltdown</a> <a href="https://twitter.com/hashtag/Spectre?src=hash&ref_src=twsrc%5Etfw">#Spectre</a> <a href="https://t.co/UFPiYA39hd">pic.twitter.com/UFPiYA39hd</a></p>— Sciuridae Hero (@attritionorg) <a href="https://twitter.com/attritionorg/status/948759303153856512?ref_src=twsrc%5Etfw">January 4, 2018</a></blockquote>
<script async="" src="https://platform.twitter.com/widgets.js" charset="utf-8"></script>
<blockquote class="twitter-tweet" data-lang="en"><p lang="en" dir="ltr">Update #7 - Due to the incomplete information provided by hardware manufacturers, we joined forces with other impacted cloud providers including <a href="https://twitter.com/linode?ref_src=twsrc%5Etfw">@linode</a>, <a href="https://twitter.com/packethost?ref_src=twsrc%5Etfw">@packethost</a> and <a href="https://twitter.com/OVH?ref_src=twsrc%5Etfw">@ovh</a> to share information and work all together. <a href="https://t.co/iVHi72nmFJ">https://t.co/iVHi72nmFJ</a></p>— scaleway (@scaleway) <a href="https://twitter.com/scaleway/status/949014513487171585?ref_src=twsrc%5Etfw">January 4, 2018</a></blockquote>
<script async="" src="https://platform.twitter.com/widgets.js" charset="utf-8"></script>
<blockquote class="twitter-tweet" data-lang="en"><p lang="en" dir="ltr">8/ <a href="https://twitter.com/Canonical?ref_src=twsrc%5Etfw">@Canonical</a> engineers have been working on this since we were made aware under the embargoed disclosure (Nov 2017) and have worked through the holidays, testing and integrating an incredibly complex patch set into a broad set of <a href="https://twitter.com/ubuntu?ref_src=twsrc%5Etfw">@ubuntu</a> kernels and CPU architectures.</p>— Dustin Kirkland (@dustinkirkland) <a href="https://twitter.com/dustinkirkland/status/949011894395985920?ref_src=twsrc%5Etfw">January 4, 2018</a></blockquote>
<script async="" src="https://platform.twitter.com/widgets.js" charset="utf-8"></script>
Three Things About 20172017-12-30T00:00:00+00:00http://serverascode.com/2017/12/30/three-things-in-2017<h1 id="three-things-about-2017">Three Things About 2017</h1>
<p>Well, the year 2017 is almost over. I wanted to take a few minutes to think about what happened this year and write at least three of them down.</p>
<h2 id="1-moving-to-toronto">1) Moving to Toronto</h2>
<p>By far the biggest thing that happened to me this year was the decision to move to Toronto. My wife is from Toronto, and she had spent many years with me in Edmonton. I was born in Edmonton, and, other than a short stint in Athabasca, have lived there all my life. Edmonton is a great place, better than most people think, but it was just time for me to move on and experience some other place in Canada. We almost moved to Ottawa, but for personal reasons ended up in Toronto.</p>
<p>Unfortunately the housing market in Toronto is insane. I don’t think anyone understands just how bad it is. We initially decided to rent for a while and figure things out, but the small house near Yonge and Eglinton we had rented turned out to be filled with black mold (as we unfortunately discovered, our landlord was one of the scuzzy ones you always hear about). We opted not to move in and ended up living with family in a house in suburban Woodbridge while we continue to sort things out.</p>
<p>If we had moved to Toronto 3 or 4 years ago, houses would be almost half of their cost now. In terms of moving to Toronto, it is bad timing, but we will do our best. Researching real estate has made me realize how the low interest rates have affected housing and the stock market. The 2017 stock market did not have a negative month which is the first time that has ever happened. I, like many others, personally believe we are due for a correction, ala 2008, but I’m not sure what will cause it, and it could take years before it occurs…or it could be tomorrow. Also, I think over time we will discover just how many homes are owned by foreign entities. I don’t have an issue with foreign investment, but homes are not supposed to be investments, they are places for Canadians to live. The same goes for speculators, no matter where they reside.</p>
<p>Toronto and Ontario are also much more expensive than Alberta (as most know). However, what many don’t know is that while Toronto <em>and</em> Ontario have land transfer tax, Alberta does not. This tax adds up to tens of thousands of dollars which the buyer pays upon purchase of property. It is very, very expensive to live here compared to Edmonton. I’m surprised that there is not considerable migration from Toronto to Calgary (I say Calgary because Edmonton just doesn’t have the reputation Calgary does, nor is it as close to the Rocky Mountains) but I suppose the Alberta economy is scaring people off.</p>
<p>Of course Toronto has many advantages, especially around food and entertainment, which is why we came here in the first place. It’s amazing to see companies like Google and Mozilla with offices here. In fact <a href="https://www.blogto.com/tech/2017/10/google-alphabet-neighbourhood-future-toronto/">Google is investing heavily in Toronto</a>. I look forward to seeing a lot of live music in 2018. In 2017 we only made it to a LCD Soundsystem concert, but already have a couple great events lined up for 2018, such as <a href="https://en.wikipedia.org/wiki/Destroyer_(band)">Destroyer</a>. I am also a basketball fan and hope to make it out to some Raptors games, though they are quite expensive to attend. And, of course, how can we forget TIFF. Despite its obvious issues (housing, scuzzy landlords, car culture–I’ve never seen so many Maseratis), Toronto really is a world class city with much to offer.</p>
<h2 id="technology">Technology</h2>
<h3 id="2-meetups">2) Meetups</h3>
<p>During the first few weeks I went to several technology meetups. I plan to continue that in 2018. I’m also helping organize the <a href="https://www.meetup.com/OpenStackTO/">Toronto OpenStack Meetup</a>. Further to that I’ve taken over the <a href="https://www.meetup.com/Toronto-Software-Defined-Networking-Meetup/">Toronto SDN Meetup</a> and am starting the <a href="https://www.meetup.com/Open-Source-Networking-Toronto/">Toronto Open Source Networking Meetup</a> which I may combine with the SDN meetup.</p>
<p>I also have other grandiose plans (as usual) around some kind of group or event regarding <em>The Future of Networking</em> but have not ironed out all the details as of yet. Hopefully being in Toronto will help the organization of such a group or event.</p>
<h3 id="3-network-function-virtualization">3) Network Function Virtualization</h3>
<p>Over the last couple of years I have been doing a lot of work in this area. Despite not having a classical networking background (which I think is almost an advantage in some situations) I am fascinated by networking and all the recent advancements…things like automation, Software Defined Networking, and Intent Based Networking. I also believe that network simulation is an important area that has not been given sufficient attention. Virtual Network Function (VNF) on-boarding will also continue to be a focus as it combines networking and automation.</p>
<p>I have also been working with a colleague on <a href="https://github.com/OpenStackSanDiego/SecurityServiceChains">Service Function Chaining workshops</a>. I am really enjoying the workshop model. We have been putting SFC into practice and are finding that there are many problems that still need to be figured out. I like SFC because it removes the standard route based model of packet movement, and in fact makes it somewhat arbitrary. Once you start doing SFC you realize why large organizations, usually telcos, are using things like MPLS to manage their core networks. Segment routing in some form is very important going forward. I believe (and hope) networking will look much different in the future, and in fact if 5G is really to come to fruition (which is debatable) it has to.</p>
<p>In a previous post I put automation, SDN, and intent based networking as major themes in networking. To that I would now add network simulation and SFC/segment routing as well.</p>
<h2 id="bonus-4-movies">Bonus: 4) Movies</h2>
<p>I didn’t watch as many films this year as I have in the past, but I can give two films as recommendations:</p>
<ul>
<li>Good Time</li>
<li>The Killing of a Sacred Deer</li>
</ul>
<h2 id="conclusion">Conclusion</h2>
<p>2017 was an interesting and challenging year. I expect more of the same in 2018, especially if there is some kind of black swan event that causes a market correction.</p>
Fedora 27 Automatic Updates2017-11-22T00:00:00+00:00http://serverascode.com/2017/11/22/fedora-27-automatic-updates<h1 id="fedora-27-automatic-updates">Fedora 27 Automatic Updates</h1>
<p>I thought I’d write a quick short port on setting up automatic updates on Fedora 27.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ dnf install dnf-automatic
</code></pre></div></div>
<p>I am only going to do security updates and have them applied. What you do is up to you. :)</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code># diff /etc/dnf/automatic.conf /etc/dnf/automatic.conf.orig
5c5
< upgrade_type = security
---
> upgrade_type = default
18c18
< apply_updates = yes
---
> apply_updates = no
</code></pre></div></div>
<p>What timers do we have right now? (Ah, systemd, let’s replace cron. Sigh.)</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ systemctl list-timers *dnf-*
NEXT LEFT LAST PASSED UNIT ACTIVATES
Wed 2017-11-22 08:36:26 EST 58min left Wed 2017-11-22 07:36:24 EST 1min 47s ago dnf-makecache.timer dnf-makecache.service
1 timers listed.
Pass --all to see loaded but inactive timers, too.
</code></pre></div></div>
<p>Hmm there are several dnf timers.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>root# ls -1 /usr/lib/systemd/system/dnf*.timer
/usr/lib/systemd/system/dnf-automatic-download.timer
/usr/lib/systemd/system/dnf-automatic-install.timer
/usr/lib/systemd/system/dnf-automatic-notifyonly.timer
/usr/lib/systemd/system/dnf-automatic.timer
/usr/lib/systemd/system/dnf-makecache.timer
</code></pre></div></div>
<p>What does automatic.timer do? Runs the dnf-automatic service.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>root# cat /usr/lib/systemd/system/dnf-automatic.service
[Unit]
Description=dnf automatic
# See comment in dnf-makecache.service
ConditionPathExists=!/run/ostree-booted
[Service]
Type=oneshot
Nice=19
IOSchedulingClass=2
IOSchedulingPriority=7
Environment="ABRT_IGNORE_PYTHON=1"
ExecStart=/usr/bin/dnf-automatic /etc/dnf/automatic.conf --timer
</code></pre></div></div>
<p>Ok, let’s start the timer.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>root# systemctl enable dnf-automatic.timer && systemctl start dnf-automatic.timer
Created symlink /etc/systemd/system/basic.target.wants/dnf-automatic.timer → /usr/lib/systemd/system/dnf-automatic.timer.
</code></pre></div></div>
<p>Status:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>root# systemctl status dnf-automatic.timer
● dnf-automatic.timer - dnf-automatic timer
Loaded: loaded (/usr/lib/systemd/system/dnf-automatic.timer; enabled; vendor preset: disabled)
Active: active (waiting) since Wed 2017-11-22 07:41:30 EST; 6min ago
Trigger: Thu 2017-11-23 07:43:53 EST; 23h left
Nov 22 07:41:30 comput0r systemd[1]: Started dnf-automatic timer.
</code></pre></div></div>
<p>Let’s try running.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>root# dnf-automatic
Last metadata expiration check: 0:13:23 ago on Wed 22 Nov 2017 07:36:25 AM EST.
Running transaction check
Transaction check succeeded.
Running transaction test
Transaction test succeeded.
Running transaction
The following updates have been applied on 'comput0r':
============================================================================================================================================================================
Package Arch Version Repository Size
============================================================================================================================================================================
Upgrading:
git x86_64 2.14.3-2.fc27 updates 1.1 M
git-core x86_64 2.14.3-2.fc27 updates 4.1 M
git-core-doc x86_64 2.14.3-2.fc27 updates 2.3 M
openssl x86_64 1:1.1.0g-1.fc27 updates 564 k
openssl-libs x86_64 1:1.1.0g-1.fc27 updates 1.3 M
perl-Git noarch 2.14.3-2.fc27 updates 68 k
xen-libs x86_64 4.9.0-14.fc27 updates 674 k
xen-licenses x86_64 4.9.0-14.fc27 updates 117 k
Transaction Summary
============================================================================================================================================================================
Upgrade 8 Packages
</code></pre></div></div>
<p>Logs of installed packages are kept.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>root# tail /var/log/dnf.rpm.log
2017-11-22T12:49:56Z INFO Upgraded: xen-libs-4.9.0-14.fc27.x86_64
2017-11-22T12:49:56Z INFO Upgraded: openssl-1:1.1.0g-1.fc27.x86_64
2017-11-22T12:49:56Z INFO Cleanup: openssl-1:1.1.0f-9.fc27.x86_64
2017-11-22T12:49:56Z INFO Cleanup: git-2.14.3-1.fc27.x86_64
2017-11-22T12:49:56Z INFO Cleanup: git-core-doc-2.14.3-1.fc27.x86_64
2017-11-22T12:49:56Z INFO Cleanup: git-core-2.14.3-1.fc27.x86_64
2017-11-22T12:49:56Z INFO Cleanup: xen-libs-4.9.0-13.fc27.x86_64
2017-11-22T12:49:56Z INFO Cleanup: xen-licenses-4.9.0-13.fc27.x86_64
2017-11-22T12:49:57Z INFO Cleanup: perl-Git-2.14.3-1.fc27.noarch
2017-11-22T12:49:57Z INFO Cleanup: openssl-libs-1:1.1.0f-9.fc27.x86_64
</code></pre></div></div>
<p>So, there you go. Will this computer be more secure now? I hope so. :)</p>
Three Toronto Tech Meetups2017-11-09T00:00:00+00:00http://serverascode.com/2017/11/09/three-toronto-tech-meetups<h1 id="three-toronto-tech-meetups">Three Toronto Tech Meetups</h1>
<p>Recently I moved from Edmonton to Toronto. There were a lot of reasons to make the move, and I won’t get into them here. Suffice it to say I’m sure I’ll be living in Toronto for the next five to ten years, then maybe, if I’m really lucky, retire to Drumheller, AB or Nelson, BC, a nice small town somewhere, something like that. It’s good to have goals. (Yes the housing market is insane in Toronto, and Ontario is much more expensive overall compared to Alberta…financially speaking moving here was probably a mistake. But so is having dogs.)</p>
<p>One of the things I felt would be valuable about living in Toronto is the large information technology community. I was part of a lot of meetups and the like in Edmonton, such as the Python meetup and the Golang meetup. There were several good meetups that I didn’t attend, so it’s not like there was a lack of technology, it just didn’t have the breadth of Toronto. Often it was hard to get enough people to come out to the events…there’s a certain number that is a critical mass of attendees and we often couldn’t hit that number. We had a good location to have those meetups in Startup Edmonton, but attendance could be challenging. Not so in Toronto. (Though getting space here might be next to impossible.)</p>
<h2 id="meetup-1---toronto-artificial-intelligence-and-deep-learning-meetup">Meetup #1 - Toronto Artificial Intelligence and Deep Learning Meetup</h2>
<p>The title of this talk was “How Machine Learning Saved $25 million!”</p>
<p>I enjoyed the presentation, as it was more of a practical overview of how to do machine learning from a process standpoint, based on the example of an e-commerce site trying to predict the shipping weight of items, errors in which was costing millions of dollars per year. A real life issue to be sure.</p>
<p>Ultimately, I believe the point of the presentation was not a technical one, rather that Machine Learning is really 75% data science, 10% deployment, and 15% actual ML. The ratios aren’t from the presentation, nor accurate, but my point is it’s mostly data science, and then you still have to deploy the ML code somehow (maybe as a H2O.io plain old java object?).</p>
<p>I’d say about 120 people attended, and the audience was very diverse in terms of demographics, which was nice to see. It took place at the WeWork space in downtown Toronto, and was organized and sponsored by H2O.io which is some kind of ML and AI toolkit. They were very nice about being sponsors and tried not to tout their product too much. I’m sure it cost $1000 or more to rent the WeWork space, so thanks H2O.io.</p>
<h2 id="meetup-2---toronto-pivotal-user-meetup">Meetup #2 - Toronto Pivotal User Meetup</h2>
<p>I don’t really know anything about the Pivotal product, other than it’s some kind of PaaS based on Cloud Foundry, and they have some kind of configuration management tool, BOSH, that is apparently magic, and that they are a very successful business unit of DELL/EMC or whatever that conglomerate is called. That sentence sounds a little flip, but I really do like that Pivotal exists and I’m happy that they are doing so well in the Global Fortune 500ish space. It says a lot about automation, containers, and just delivering applications. I would imagine that OpenShift is a competitor of sorts, and OpenShift is also doing very well in the enterprise.</p>
<p>The talk was by <a href="http://snappydata.io">SnappyData</a>. First off, please take what I say here with a grain of salt because I don’t have any experience with Apache Spark. My impression of what Snappy does is allow data to be stored in Spark so that you don’t have to go out to an external cluster, say a Cassandra system, to get data, which reduces complexity and latency. I might be wrong about that but that is certainly my impression from the talk.</p>
<p>Snappy is actually based on an existing product called <a href="https://pivotal.io/pivotal-gemfire">GemFire</a> which apparently has been around for more than a decade and is in production in 1400 customers. I get the impression that this is one of those pieces of software that is quite valuable to those who know they need it. It’s always amazing to me how valuable software can be. There are all these small, hidden companies making tens of millions of dollars of a bunch of C code that a small, long term team has been writing and refactoring for years. But that’s just me speculating based on previous experience.</p>
<p>Anyways, a lot of features Snappy has come from Gemfire. But, one of the more interesting things that Snappy can do is statistically sample large data sets and query that instead of the whole data set. This makes the queries much faster. Less accurate, but faster. But often there are situations where we don’t need great accuracy to make decisions or do things, such as visualization. It’s called their “synopsis engine” and seems very promising for quick decision making.</p>
<p>Also, I learned about <a href="https://zeppelin.apache.org/">Apache Zeppelin</a>.</p>
<h2 id="meetup-3---toronto-enterprise-devops">Meetup #3 - Toronto Enterprise DevOps</h2>
<p>Next, I went to the Toronto Enterprise DevOps meeting held at ObjectSharp, who also bought the pizza. (So far every single one has served pizza. This particular pizza was not great lol. But three days of pizza is two days too many.)</p>
<p>I really wanted to go to this meetup because it was called “Hashistacking the Enterprise” and I thought this meant that there were enterprises in Toronto that were really into the Hashicorp stack, ie. Vault, Nomad, etc. But the talk, although well done, was really an introduction to Hashicorp projects.</p>
<p>The presenter had recently worked at Chef and was a big fan of Inspec so that was also discussed. I like Inspec too but it is difficult to use across a large fleet because you have to replicate the inventory somehow, though that wouldn’t be too hard if you have a centralized CMDB of some kind. But still a pain.</p>
<p>I have worked a little bit with Nomad, mostly using it as a distributed cron system which is not really what it is meant for. I have also used Vault a bit, but am having some issues understanding the security model around it handing out certificates. I used to be a big user of Vagrant, but I don’t run VMs on my local workstation any more.</p>
<p>One thing I did learn is that Terraform does everything in order, much like Ansible, and opposed to say Puppet which has a compilation step. I should say I have not used Terraform yet. Another interesting point is that it can be used for multiple clouds, as opposed to Cloud Formation or Azure ARM. That point/feature is quite important and I think Terraform is a successful product simply based on that.</p>
<p>Their recently released Sentinel product was discussed as well, and I think it is absolutely fascinating as a policy engine, but it is closed source so I doubt I will ever have a chance to use it. Maybe it will spur an open source project that provides similar functionality. If only I was a 10x coder… ;)</p>
<h2 id="openstack-toronto">OpenStack Toronto</h2>
<p>I am also helping out with the OpenStack Toronto meetup. Space is a challenge.</p>
<h2 id="conclusion">Conclusion</h2>
<p>Toronto has a diverse tech community, but I’m just basing that on three meetups. There are all kinds of people doing all kinds of technology, some advanced, some not, some with new technology, some not. This is great to see.</p>
<p>Obviously space is a big issue for having meetups in TO. I am trying to help the Toronto OpenStack meetup, but there are challenges for getting a low cost space that meets all requirements. The meetup space market, just like the housing market, is very difficult to get into.</p>
Three Pillars of Modern Networking2017-11-05T00:00:00+00:00http://serverascode.com/2017/11/05/three-pillars-of-modern-networking<h1 id="three-pillars-of-modern-networking">Three Pillars of Modern Networking</h1>
<p>Computer networking is at an interesting state. We have many new interesting technologies and methodologies for building and managing networks, but ultimately those new technologies have not made much of a dent in how the vast majority of computer networking is architectured and operated.</p>
<p>I don’t have a classical networking background, no CCIE or anything like that, but I am very interested in new networking technologies and I believe in some cases my lack of traditional training (dare I say “baggage”) allows me a bit more room to operate in terms of adopting new technologies.</p>
<p>Ultimately we still do networks with things like ARP, STP, VLANs, LACP and BGP. We connect relatively large broadcast domains together with layer 3 routes managed by BGP. That’s really about it. It does work, but we aren’t really moving ahead, even something like Ipv6 is just not seeing adoption. (There may be valid reasons for that, but I mention it anyways.)</p>
<p>In this post I want to talk about three major technologies that can help to improve modern networking:</p>
<ul>
<li>Network Automation</li>
<li>Software Defined Networking</li>
<li>Intent Based Networking</li>
</ul>
<h2 id="network-automation">Network Automation</h2>
<p>At its base, Network Automation is the application of the same configuration management tooling and methodologies as have been applied to server infrastructure, but instead of servers we simply apply them to network switches and routers. That’s about it. Useful? Yes. Revolutionary? No.</p>
<p>Ansible, the configuration management tool I usually reach for (which has as many shortcomings as it does valuable features) has probably taken the lead in having the most easily accessible network automation tooling as well as scope of devices it is able to manage. Ansible’s module based approach makes it pretty simple for even novice developers (like myself) to create new modules and thus there are many core modules related to networking in Ansible.</p>
<p>Python is a go to language for many people who need to write code but being a developer isn’t necessarily in their job title, people such as network engineers. Python also has a substantial network library called Napalm that can help to abstract many network devices into code.</p>
<p>Ultimately, configuration management is probably a stop-gap measure between current methodologies and something better, something that has not necessarily arrived in networking yet. In the area of “server administration” overall configuration management is still valuable, but containers have moved the cutting edge to immutable style deployments based on one-time images as opposed to continuous usually agent based configuration management.</p>
<p>Will this happen to networking…unknown. Technically many switches and routers are already configured to utilize an image model of updates and monolithic configuration files, but convergence time could be an issue in devices that are expected never to slow a packet let alone stop accepting a flow, nevermind the absolute fear in the minds of network admins around changes. Some switches, like Arista, can run containers and I expect to see more of that. Further, many large organizations are realizing the millions and millions of lines of unused code on switches and routers are a liability and are requesting modularity from vendors or rolling their own simpler networking operating systems (though companies doing that are the likes of LinkedIn and Google). But I digress.</p>
<h2 id="software-defined-networking">Software Defined Networking</h2>
<p>Software Defined Networking (SDN), like many new technologies, was, for a while, considered a potential panacea. Unsurprisingly that did not turn out the way many expected or hoped. However, what is surprising is how little overall traction SDN was able to achieve, and how few SDN startups, if any, succeeded. The joke that SDN means “still don’t know” managed to become reality. Sure we have some successful deployments, but their functionality is limited in terms of the massive scope that SDN originally had.</p>
<p>I have been working with SDN for quite some time at about the time when everyone was just starting to realize OpenFlow was not going to win out. Well over 3 years ago now, I designed and deployed one of the first production SDN deployments in Canada when I built a public cloud based on OpenStack which used Midokura’s Midonet product. Midonet is a good example of where the SDN ecosystem has gone as they never quite achieved the success they were looking for and have pivoted into another business model and, I’m afraid, ultimately might not exist.</p>
<p>What I like about SDN is that is presented the possibility to create networks that can do anything. Unfortunately, what we ended up with SDN is a bunch of overly complex control planes that are essentially wrappers around VXLAN, BGP, and some kind of distributed state stored in a system like ZooKeeper et al (see OpenContrail, Nuage, Midonet, etc, etc). Because they rely on an underlying physical network (the “underlay”) and universally speak BGP at the edge, all the legacy networking deployments we are used to are still required and instead we just pile on SDN as another layer. (“So now you have two problems/networks.”) I do think overlays are valuable, but the complexity required to get them in this exact context are considerable.</p>
<p>Further, AFAIK, most SDNs are deployed in concert with either OpenStack or VMWare, though VMWare is essentially (practically speaking) enforcing only using their SDN product NSX. I am quite biased in terms of my experience mostly being related to OpenStack, but I have not met anyone doing SDN outside of the context of a virtualization system and usually SDNs are “boxed inside” of the virtualization platform, though they may interact with larger networks at the BGP level for North/South traffic.</p>
<p>Frankly I think that we didn’t push hard enough on really rethinking networking as a whole. As well the traditional, dare I say “heritage”, networking is too embedded and difficult to remove, and thus we ended up just piling more layers on top of if. On one hand if it ain’t broke don’t fix it, but on the other we can’t stagnate at the network level, because the network really is a major component of “the computer.” Are we losing value as a species with our inability to move past IPv4?</p>
<p>I look at technologies like Service Function Chaining, which, while still based on the reliability of standard networks, make packets appear on ports as though transported through a wormhole, as a direction that SDN should have gone in. Networks don’t have to look like they do.</p>
<p>I still have hope for SDN. :)</p>
<h2 id="intent-based-networking">Intent Based Networking</h2>
<p>Intent Based Networking (IBN) is where SDN was three to five years ago. IBN is a lot of things, but I believe that first and foremost the idea is that some kind of consumer asks for something, such as transport from A to B, and IBN determines how that is done. This is pretty well described in the paper <a href="https://www.opennetworking.org/images/stories/downloads/sdn-resources/technical-reports/TR-523_Intent_Definition_Principles.pdf">Intent NBI – Definition and Principles</a> presented by the Open Networking Foundation.</p>
<p>Practically speaking it’s an admission that organizations are unwilling to alter or replace their existing legacy infrastructure, or legacy vendor relationships, with SDN. IBN is a higher layer of abstraction working above network automation and seeks to utilize a methodology where the intent of the network (say, to run applications) is described in some kind of language or configuration, and the actual deployment and operations of the network is created from that “intent” but that the actual underlying physical and virtual devices are not relevant.</p>
<p>In some situations this simply looks like a piece of software that can abstract the configuration of multiple brownfield systems (all your Juniper and Cisco and Arista routers and switches, different versions and variations thereof) and then (re-?)configure them in such a way as that the network will fulfil the obligations “suggested” by the intent or consumer requests. (See Apstra Networks.) Instead of human beings interpreting business and technical requirements and writing, often by hand, over long periods of time, thousands of configuration files for network devices, and what’s more/worse keeping the connections in their head, the IBN system automates that, in effect forcing us to forget about the how and just focus on the what and why. At least in theory anyways.</p>
<p>Machine learning may also be applicable to IBN, so expect to see considerable fanfare around that. Maybe IBNs can the “hallucinate” the network design (ala <a href="http://letsenhance.io">letsenhance.io</a> product that upscales any JPG to 4K by hallucinating detalis). Or maybe we can have AI invent new network protocols like AlphaGo created new Go moves.</p>
<h2 id="conclusion">Conclusion</h2>
<p>So there you have it. Three technologies that I believe are the current pillars of modern networking. They all have issues, but promise as well. Maybe IBN and Machine Learning will take us to some kind of network nirvana, or maybe it will stagnate like SDN seems to have. Only time will tell.</p>
Forms of Service Functioning Chaining and a BigSwitch Example2017-09-25T00:00:00+00:00http://serverascode.com/2017/09/25/service-function-chaining-and-bigswitch<h1 id="forms-of-service-functioning-chaining-and-a-bigswitch-example">Forms of Service Functioning Chaining and a BigSwitch Example</h1>
<p>Service Function Chaining is an important concept in Network Function Virtualization (NFV). But it is also a powerful tool in more generic Software Defined Networking (SDN) as well.</p>
<p>I quite like the definition the <a href="https://wiki.openstack.org/wiki/Neutron/ServiceInsertionAndChaining">OpenStack Networking SFC</a> project has/had:</p>
<blockquote>
<p>Service Function Chaining is a mechanism for overriding the basic destination based forwarding that is typical of IP networks. It is conceptually related to Policy Based Routing in physical networks but it is typically thought of as a Software Defined Networking technology. It is often used in conjunction with security functions although it may be used for a broader range of features. Fundamentally SFC is the ability to cause network packet flows to route through a network via a path other than the one that would be chosen by routing table lookups on the packet’s destination IP address. It is most commonly used in conjunction with Network Function Virtualization when recreating in a virtual environment a series of network functions that would have traditionally been implemented as a collection of physical network devices connected in series by cables.</p>
</blockquote>
<p>Essentially, at a high level, what we want to do is replicate several physical network devices connected together in a chain, except do it virtually. A simple example would be a network gateway, firewall, and intrusion detection system, all physical and all connected to one another through direct connections, potentially without even a switch involved, except, and this is important, it’s not done at layer 3, it’s done at layer 1 as a port to port setup.</p>
<p>I have been working with SFC for a while and have found that there are three major types:</p>
<ol>
<li>Layer 3 SFC - Which isn’t what I would actually consider SFC, but often it is done this way, because it is easier</li>
<li>Single Switch Layer 1 SFC - This is what this blog post will discuss in terms of BigSwitch</li>
<li>Multi-switch Layer 1 SFC - This is the Holy Grail of SFC, so to speak</li>
</ol>
<h2 id="bigswitch">BigSwitch</h2>
<p>BigSwitch is an SDN vendor with an interesting set of features. They provide an operating system that runs on baremetal whitebox switches (Switch Light OS) and a centralized controller. Their focus seems to be around security. I won’t get into the details here, but they have a couple of different product options and what we are using is <a href="http://www.bigswitch.com/sdn-products/sdn-products/big-monitoring-fabric/overview">Big Monitoring Fabric</a>.</p>
<p>SDN is an interesting area to work in mostly because there are so many different ways one can implement networking when it is done (almost) completely in software. Certainly most of SDN systems rely on the now nearly standard ASICs in a physical switch, but the network logic is all in software. As I like to say, if we want to do SDN that is Apple Talk over USB we probably could. ;)</p>
<p>BigSwitch has an interesting layer 1 style SFC mode, which they call “big chains” or “inline security” or something to that effect. Using their technology one can dynamically insert devices into a chain of physical ports on a physical switch. This is not all that useful from an NFV perspective, as it is limited to a single physical switch and its physical ports, but in terms of a security chain, say one based on the connection of an insecure network (eg. Internet) to a secure one (a DMZ or other internal network), it is useful, certainly more useful than physically plugging and unplugging network cables. At least using BigSwitch we can do these things dynamically through a REST API.</p>
<p>Below we can see a “big chain” service chain. To start with there is no service inserted into the chain.</p>
<p><img src="/img/chain1.jpg" alt="initial chain" /></p>
<p>After inserting the service, we can see that some kind of device, in this case a firewall, has been dynamically inserted into the layer 1 port to port service chain.</p>
<p><img src="/img/chain2.jpg" alt="after insertion chain" /></p>
<p>It’s important to note that this can be done manually from the web interface, or it can be done via the BigSwitch API. The ability to insert services directly into a layer 1 chain via a REST API is extremely powerful…it’s hard to indicate with text and some pictures exactly how powerful that is. So take my word for it!</p>
<h2 id="switchy">Switchy</h2>
<p>To accomplish the service insertion, I wrote a quick command line based tool that can access some of the BigSwitch features via the BigSwitch controller’s REST API.</p>
<p>It’s written in Python and uses the fun <a href="http://click.pocoo.org/5/">Click</a> library to accomplish most of the structure for the actual commands. BigSwitch has some <a href="https://github.com/bigswitch/sample-scripts">Python examples</a> which I used to create a little library for some of their Big Chain features. Click is also useful because it is smart enough to be able to use environment variables, so things like usernames and passwords don’t have to be set on each run of the command, but can still be made required by the CLI.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ switchy
Usage: switchy [OPTIONS] COMMAND [ARGS]...
bigswitch command line interface
Options:
--version Show the version and exit.
--controller TEXT Controller IP or URL [required]
--switch TEXT Switch ID [required]
--username TEXT Controller username [required]
--password TEXT Controller password [required]
--help Show this message and exit.
Commands:
insert-service insert a service into a chain
list-chains list all bigswitch chains
list-instances list all bigswitch instances
list-services list all bigswitch services
remove-service remove a service from a chain
show-chain show a chain and services
</code></pre></div></div>
<p>For example we can list current chains, which show the chain name and which physical ports make up the ingress/egress points:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ switchy list-chains
TEST-CHAIN-03, ethernet1, ethernet2
TEST-CHAIN-02, ethernet11, ethernet12
TEST-CHAIN-01, ethernet5, ethernet6
</code></pre></div></div>
<p>And list services:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ switchy list-services
TEST-SERVICE-02
TEST-SERVICE-01
</code></pre></div></div>
<p>Or insert a service into a chain:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ switchy insert-service --chain TEST-CHAIN-01 --service TEST-SERVICE-01 --instance 1
Inserted service into chain
</code></pre></div></div>
<p>Obviously anything one can do with the REST API can be done with Switchy, and of course we could add any logic that we would like into the command line application (which is the fun part of programming).</p>
<h2 id="conclusion">Conclusion</h2>
<p>Layer 1 port to port SFC is extremely powerful. It’s important to note, however, that the BigSwtich example given here is not really one meant for NFV, as in NFV we have some kind of underlying infrastructure (termed the NFVi by ETSI), such as OpenStack, which manages many, many hypervisors, each with their own virtual switch. SFC that works in a multi-hypervisor/multi-switch environment looks much different than what is shown here, but this <strong>IS</strong> a stepping stone towards full blown SFC.</p>
<h2 id="ps">PS.</h2>
<p>In this post I’ve taken a very narrow view of what BigSwitch can do. The point of this post was not to review BigSwitch but rather to use it as an example of various ways people implement different kinds of SFC. BigSwitch is a great product and if it sounds interesting to you I highly suggest <a href="http://labs.bigswitch.com/users/login">trying it out</a>. Further to that I have not completely explored everything BigSwitch does nor how it does it.</p>
Clean Keystone Catalog URLs2017-08-28T00:00:00+00:00http://serverascode.com/2017/08/28/clean-keystone-urls<h1 id="clean-keystone-catalog-urls">Clean Keystone Catalog URLs</h1>
<p>I think the way OpenStack Keystone is deployed demands more consideration than people tend to give it. There are several different architectural models for Keystone and it would be well worth an organizations investment to take some time and think about the possibilities.</p>
<p>I find that OpenStack distros (not that there are that many) limit the possibilities of Keystone models. I am not a huge fan of distros, but I can understand why organizations use them. All I mean is that distros tend to limit architectural possibilities. OpenStack is so flexible that it seems a shame to limit it. But enough ranting…</p>
<h2 id="split-keystone">Split Keystone</h2>
<p>I tend to use a split keystone, one internal and one external. I’ve <a href="http://serverascode.com/2016/06/24/split-keystone-catalog.html">written about it before</a>. I think this model can lead to a soft-center security issue, but its flexibility in terms of what catalog is presented to the end user makes up for it, IMHO.</p>
<h2 id="clean-urls">Clean URLs</h2>
<p>Because I have an external Keystone I can provide a different catalog to external end users.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ os catalog list
+--------------------+-----------+------------------------------------------------------------------------------------------+
| Name | Type | Endpoints |
+--------------------+-----------+------------------------------------------------------------------------------------------+
| Image Service | image | someregion |
| | | admin: https://api.somecloud.com/image/ |
| | | someregion |
| | | public: https://api.somecloud.com/image/ |
| | | someregion |
| | | internal: https://api.somecloud.com/image/ |
| | | |
| Compute Service | compute | someregion |
| | | admin: https://api.somecloud.com/compute/v2.1/7b61f0aece1b4aa896020f51fd724b1f |
| | | someregion |
| | | public: https://api.somecloud.com/compute/v2.1/7b61f0aece1b4aa896020f51fd724b1f |
| | | someregion |
| | | internal: https://api.somecloud.com/compute/v2.1/7b61f0aece1b4aa896020f51fd724b1f |
| | | |
| Network Service | network | someregion |
| | | admin: https://api.somecloud.com/network/ |
| | | someregion |
| | | public: https://api.somecloud.com/network/ |
| | | someregion |
| | | internal: https://api.somecloud.com/network/ |
| | | |
| Identity Service | identity | someregion |
| | | admin: https://api.somecloud.com/identity/v3 |
| | | someregion |
| | | public: https://api.somecloud.com/identity/v3 |
| | | someregion |
| | | internal: https://api.somecloud.com/identity/v3 |
| | | |
| Compute Service V3 | computev3 | someregion |
| | | admin: https://api.somecloud.com/computev3/v3 |
| | | someregion |
| | | public: https://api.somecloud.com/computev3/v3 |
| | | someregion |
| | | internal: https://api.somecloud.com/computev3/v3 |
| | | |
+--------------------+-----------+------------------------------------------------------------------------------------------+
</code></pre></div></div>
<p>As can be seen above, there are no ports other than 443/https being used, nor any api-someserver.somecloud.com hostnames either. Everything is on the same hostname and then each service is identified using the <code class="language-plaintext highlighter-rouge">/servicetype/</code> model. I think it makes for cleaner URLs.</p>
<h2 id="how-is-this-accomplished">How Is This Accomplished?</h2>
<p>There are a few things that have to be altered to accomplish this:</p>
<ol>
<li>Use an external Keystone that reports a different catalog</li>
<li>Setup keystone.conf to set the <code class="language-plaintext highlighter-rouge">admin_endpoint</code> and <code class="language-plaintext highlighter-rouge">public_endpoint</code> to the external identiy endpoint, but only on the external Keystone nodes</li>
<li>Disable <strong>catalog</strong> caching (not all caching just catalog) if both external and internal Keystones are using the same memcache</li>
<li>Configure your loadbalancer to recognize <code class="language-plaintext highlighter-rouge">/servicetype/</code> and forward to a proper backend</li>
<li>Configure your loadbalancer to strip the <code class="language-plaintext highlighter-rouge">/servicetype/</code> when forwarding to the backend service</li>
</ol>
<h2 id="haproxy-example">Haproxy Example</h2>
<p>Forwarding is based on <code class="language-plaintext highlighter-rouge">path_beg</code>. Below Glance is used as an example.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>acl frontend-external-glance path_beg /image/
use_backend backend-external-glance if frontend-external-glance
</code></pre></div></div>
<p>Here’s an example of haproxy config to strip the <code class="language-plaintext highlighter-rouge">/servicetype/</code> in the backend definition:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>reqrep ^([^\ ]*\ /)image[/]?(.*) \1\2
</code></pre></div></div>
<p>The above would have to be setup for each service in the external catalog.</p>
<h2 id="conclusion">Conclusion</h2>
<p>I’ve been testing this for a while and can’t find any issues (yet). There may be better ways to do this that I’m not aware of, and if so please let me know.</p>
<p>I’m very happy with these clean URLs and I feel like it makes OpenStack look a bit less complicated to those who might be writing code using these APIs.</p>
Create an OpenStack Load Balancer2017-08-15T00:00:00+00:00http://serverascode.com/2017/08/15/use-openstack-loadbalancer<h1 id="create-an-openstack-load-balancer">Create an OpenStack Load Balancer</h1>
<p>In a recent post I discussed the <a href="http://serverascode.com/2017/08/11/install-openstack-octavia-loadbalancer.html">OpenStack Octavia</a> project which provides a backend to Neutron’s LBaaS system.</p>
<p>In this post I’ll just go over a quick example of creating and using a load balancer and using it in OpenStack.</p>
<p>The <a href="https://docs.openstack.org/mitaka/networking-guide/config-lbaas.html">official docs</a> are pretty good on this, but it’s worthwhile to cover them in a real environment.</p>
<h2 id="create-two-webservers">Create Two Webservers</h2>
<p>I’ve already created two web servers, web-1 and web-2.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ os server list | grep web-
| 05f0bb14-2895-4c7b-a493-ef2a1b57c721 | web-2 | ACTIVE | vxlan1=10.50.0.15 | xenial |
| 3ff621cd-46cb-4fcf-8d9d-2193718a11f5 | web-1 | ACTIVE | vxlan1=10.50.0.35 | xenial |
</code></pre></div></div>
<p><br /></p>
<p>I’ve also changed each of the /var/www/html/index.html pages to have only the hostname in it, so that if you connect to port 80 on either of them they respond with their hostname.</p>
<h2 id="create-a-load-balancer">Create a Load Balancer</h2>
<p>First, we create a load balancer and put it onto a specific network.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ neutron lbaas-loadbalancer-create --name web-lb vxlan1-subnet
Created a new loadbalancer:
+---------------------+--------------------------------------+
| Field | Value |
+---------------------+--------------------------------------+
| admin_state_up | True |
| description | |
| id | 6b9c75c1-4af2-424d-8b20-681926de4e0d |
| listeners | |
| name | web-lb |
| operating_status | OFFLINE |
| pools | |
| provider | octavia |
| provisioning_status | PENDING_CREATE |
| tenant_id | 3b29434130cd487186f1da0b5831232f |
| vip_address | 10.50.0.11 |
| vip_port_id | b88dd055-e963-4227-86e1-558df52dc946 |
| vip_subnet_id | 5ce133ce-cce6-4142-89d4-a71da87bbde6 |
+---------------------+--------------------------------------+
</code></pre></div></div>
<p><br /></p>
<p>Show the newly created loadbalancer. Note the “octavia” provider, and the IP the load balancer received.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ neutron lbaas-loadbalancer-show web-lb
+---------------------+--------------------------------------+
| Field | Value |
+---------------------+--------------------------------------+
| admin_state_up | True |
| description | |
| id | 6b9c75c1-4af2-424d-8b20-681926de4e0d |
| listeners | |
| name | web-lb |
| operating_status | ONLINE |
| pools | |
| provider | octavia |
| provisioning_status | ACTIVE |
| tenant_id | 3b29434130cd487186f1da0b5831232f |
| vip_address | 10.50.0.11 |
| vip_port_id | b88dd055-e963-4227-86e1-558df52dc946 |
| vip_subnet_id | 5ce133ce-cce6-4142-89d4-a71da87bbde6 |
+---------------------+--------------------------------------+
</code></pre></div></div>
<p><br /></p>
<p>There is also an existing security group called web that allows port 80.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ os security group list | grep web
| db3f7e2d-2453-416d-8651-ba8544502d0f | web | web | 3b29434130cd487186f1da0b5831232f |
</code></pre></div></div>
<p><br /></p>
<p>The security group must be added to the LB VIP port which was shown above in the LB show.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ neutron port-update --security-group web b88dd055-e963-4227-86e1-558df52dc946
Updated port: b88dd055-e963-4227-86e1-558df52dc946
</code></pre></div></div>
<p><br /></p>
<p>Now to create a listener.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ neutron lbaas-listener-create --name web-lb-http --loadbalancer web-lb --protocol HTTP --protocol-port 80
Created a new listener:
+---------------------------+------------------------------------------------+
| Field | Value |
+---------------------------+------------------------------------------------+
| admin_state_up | True |
| connection_limit | -1 |
| default_pool_id | |
| default_tls_container_ref | |
| description | |
| id | 364c08e7-29a6-4c02-b6e6-7b0d18f3e10e |
| loadbalancers | {"id": "6b9c75c1-4af2-424d-8b20-681926de4e0d"} |
| name | web-lb-http |
| protocol | HTTP |
| protocol_port | 80 |
| sni_container_refs | |
| tenant_id | 3b29434130cd487186f1da0b5831232f |
+---------------------------+------------------------------------------------+
</code></pre></div></div>
<p><br /></p>
<p>Create a pool.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ neutron lbaas-pool-create \
> --name web-lb-pool-http \
> --lb-algorithm ROUND_ROBIN \
> --listener web-lb-http \
> --protocol HTTP
Created a new pool:
+---------------------+------------------------------------------------+
| Field | Value |
+---------------------+------------------------------------------------+
| admin_state_up | True |
| description | |
| healthmonitor_id | |
| id | 19e86ff3-aa58-4582-8399-4ad3c9eaeb9d |
| lb_algorithm | ROUND_ROBIN |
| listeners | {"id": "364c08e7-29a6-4c02-b6e6-7b0d18f3e10e"} |
| loadbalancers | {"id": "6b9c75c1-4af2-424d-8b20-681926de4e0d"} |
| members | |
| name | web-lb-pool-http |
| protocol | HTTP |
| session_persistence | |
| tenant_id | 3b29434130cd487186f1da0b5831232f |
+---------------------+------------------------------------------------+
</code></pre></div></div>
<p><br /></p>
<p>Add the first member.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ neutron lbaas-member-create \
> --subnet vxlan1-subnet \
> --address 10.50.0.35 \
> --protocol-port 80 \
> web-lb-pool-http
Created a new member:
+----------------+--------------------------------------+
| Field | Value |
+----------------+--------------------------------------+
| address | 10.50.0.35 |
| admin_state_up | True |
| id | 38fb7a37-24f4-4fc5-a50b-4e21502d239e |
| name | |
| protocol_port | 80 |
| subnet_id | 5ce133ce-cce6-4142-89d4-a71da87bbde6 |
| tenant_id | 3b29434130cd487186f1da0b5831232f |
| weight | 1 |
+----------------+--------------------------------------+
</code></pre></div></div>
<p><br /></p>
<p>Add the second member.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ neutron lbaas-member-create \
> --subnet vxlan1-subnet \
> --address 10.50.0.15 \
> --protocol-port 80 \
> web-lb-pool-http
Created a new member:
+----------------+--------------------------------------+
| Field | Value |
+----------------+--------------------------------------+
| address | 10.50.0.15 |
| admin_state_up | True |
| id | 02074bde-90b2-4c0d-bfb1-2bb2e215d7fb |
| name | |
| protocol_port | 80 |
| subnet_id | 5ce133ce-cce6-4142-89d4-a71da87bbde6 |
| tenant_id | 3b29434130cd487186f1da0b5831232f |
| weight | 1 |
+----------------+--------------------------------------+
</code></pre></div></div>
<p><br /></p>
<h2 id="assign-a-floating-ip-to-the-load-balancer">Assign a Floating IP to the Load Balancer</h2>
<p>A floating IP has already been created.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ neutron floatingip-list
+--------------------------------------+------------------+---------------------+---------+
| id | fixed_ip_address | floating_ip_address | port_id |
+--------------------------------------+------------------+---------------------+---------+
| 9e048a99-8533-4dc6-9e6f-1347c09d28e9 | | <floating ip> | |
+--------------------------------------+------------------+---------------------+---------+
</code></pre></div></div>
<p><br /></p>
<p>Actually associate the floating IP. In this case we are associating a floating IP with a port instead of a “server.”</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>neutron floatingip-associate 9e048a99-8533-4dc6-9e6f-1347c09d28e9 b88dd055-e963-4227-86e1-558df52dc946
Associated floating IP 9e048a99-8533-4dc6-9e6f-1347c09d28e9
</code></pre></div></div>
<p><br /></p>
<h2 id="testing-a-load-balancer">Testing a Load balancer</h2>
<p>Now that the floating IP is up and attached to a working load balancer, and behind it is a couple of working web servers…</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ while true; do curl <floating ip>; sleep 1; done
web-2
web-1
web-2
web-1
web-2
web-1
web-2
web-1
^
</code></pre></div></div>
<p><br /></p>
Install the Ocatvia Loadbalancing System into an OpenStack Cloud2017-08-11T00:00:00+00:00http://serverascode.com/2017/08/11/install-openstack-octavia-loadbalancer<h1 id="install-the-ocatvia-loadbalancing-system-into-an-openstack-cloud">Install the Ocatvia Loadbalancing System into an OpenStack Cloud</h1>
<p>This post discusses OpenStack as Infrastructure as a Service (IaaS) and–although not completely–how to deploy the Octavia load balancing system into an OpenStack cloud. To be forthcoming, I don’t think you could get Octavia running just by reading this post, and it wasn’t necessarily the reason for it, but there might be some helpful notes and links somewhere in this text.</p>
<h2 id="the-usefulness-of-load-balancers-in-iaas">The Usefulness of Load Balancers in IaaS</h2>
<p>Most public clouds have a load balancing service. In Amazon Web Services (AWS) it’s the Elastic Load Balancer service. In Google’s Cloud, it’s the Google Cloud Load Balancer. Azure also has a load balancer. Fortunatley so does OpenStack.</p>
<p>Technically a load balancer service is not necessary to run an OpenStack cloud, but for all intents and purposes in order to deploy applications on top of OpenStack in a “cloud native” fashion, load balancers are a practical requirement.</p>
<h2 id="openstack-and-load-balancer-as-a-service">OpenStack and Load Balancer as a Service</h2>
<p>People who run OpenStack clouds have some choices they can make in terms of how the LBaaS operates within their cloud. One of the newer methods for providing LBaaS in an OpenStack cloud is the <a href="https://docs.openstack.org/octavia/latest/reference/introduction.html">Octavia</a> project.</p>
<blockquote>
<p>Octavia accomplishes its delivery of load balancing services by managing a fleet of virtual machines, containers, or bare metal servers—collectively known as amphorae—which it spins up on demand. This on-demand, horizontal scaling feature differentiates Octavia from other load balancing solutions, thereby making Octavia truly suited “for the cloud.”</p>
</blockquote>
<p><strong>Service Tenant / Service VM Model</strong></p>
<p>One of the things that I like most about Octavia is the concept of the “service tenant” or “service virtual machine.” It’s important that the systems underpinning an OpenStack cloud be scalable. The way that Octavia approaches this is to create a specific virtual machine (or machines) for each load balancer that is created, and this VM is only used by a specific tenant. Essentially, hidden behind the scenes is a service tenant that is used to create virtual machines for end-user services.</p>
<p>For example, if LBaaS + Octavia has already been deployed and we create a load balancer, we can see the virtual machine running in the Octavia service tenant. (This VM is not visible or accessible by the actual end user, other than as a load balancer endpoint.)</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code># NOTE: As the octavia service tenant user...
$ openstack server list
+--------------------------------------+----------------------------------------------+--------+--------------------------------------------------+------------+
| ID | Name | Status | Networks | Image Name |
+--------------------------------------+----------------------------------------------+--------+--------------------------------------------------+------------+
| 9135a037-d67d-450e-b809-5a28a26b8b74 | amphora-3521b6fa-1824-448d-85d0-5f0cf1e87f67 | ACTIVE | test-vxlan=10.50.0.30; octavia-mgmt=172.16.31.20 | |
+--------------------------------------+----------------------------------------------+--------+--------------------------------------------------+------------+
</code></pre></div></div>
<p><br /></p>
<h2 id="environment">Environment</h2>
<p>The environment I’m working in is an OpenStack deployment based on Ubuntu Xenial/16.04 and the Ubuntu cloud archive packages (all though Octavia is not yet packaged and Octavia is installed from pip), and the version of OpenStack deployed is Ocata.</p>
<h2 id="octavia-and-lbaas--documentation">Octavia and LBaaS Documentation</h2>
<p>At the time I’m writing this blog post, the documentation for Octavia is not that detailed. In order to deploy Neutron LBaaS one would probably have to read the code for some deployment tools such as the devstack plugin for Octavia or the OpenStack Ansible projects role for Octavia. I would suggest that the Ansible role provides the most detailed information, especially their configuration file template.</p>
<ul>
<li><a href="https://docs.openstack.org/ocata/networking-guide/config-LBaaS.html">Neutron documentation</a></li>
<li><a href="https://docs.openstack.org/octavia/latest/">Octavia Documentation</a></li>
<li><a href="https://github.com/openstack/octavia/blob/master/devstack/plugin.sh">Devstack Octavia Plugin Script</a></li>
<li><a href="https://docs.openstack.org/openstack-ansible-os_octavia/latest/configure-octavia.html">OpenStack Ansible Octavia Role</a></li>
</ul>
<h2 id="pre-deployment-steps">Pre-deployment Steps</h2>
<p>To use Octavia and Neutron a few things have to exist. Of course these could (and should) be provisioned through your automation system.</p>
<p>The following needs to be done:</p>
<ol>
<li>Create Octavia Neutron management network</li>
<li>Create Octavia service user</li>
<li>Create an Amphora image</li>
<li>Upload the Amphora image into Glance</li>
<li>Create Octavia security group</li>
<li>Create certificates</li>
<li>(Optional) Create SSH keys for admin level troubleshooting Amphora images</li>
</ol>
<p>Once these tasks have been completed, Octavia and Neutron LBaaS can be deployed.</p>
<h2 id="neutron-configuration">Neutron Configuration</h2>
<p>Basically the process is to configure Neutron to provide the load balancing API, and then setup Octavia to be the back end for that API.</p>
<p>There are three files that I have altered from a standard deployment. I believe some of them could be converged, but I kind of like the separation.</p>
<ul>
<li>neutron.conf</li>
<li>neutron_lbaas.conf</li>
<li>services_lbaas.conf</li>
</ul>
<p>I’ve also altered <code class="language-plaintext highlighter-rouge">/etc/default/neutron-server</code> to start <code class="language-plaintext highlighter-rouge">neutron-server</code> with the additional config files.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>neutron-api:/etc/neutron# cat /etc/default/neutron-server
# defaults for neutron-server
# path to config file corresponding to the core_plugin specified in
# neutron.conf
NEUTRON_PLUGIN_CONFIG="/etc/neutron/plugins/ml2/ml2_conf.ini"
DAEMON_ARGS="$DAEMON_ARGS --config-file=/etc/neutron/neutron_lbaas.conf --config-file=/etc/neutron/services_lbaas.conf"
neutron-api:/etc/neutron# ps ax | grep neutron-server | head -1
538 ? Ss 1:16 /usr/bin/python /usr/bin/neutron-server --config-file=/etc/neutron/neutron.conf --config-file=/etc/neutron/plugins/ml2/ml2_conf.ini --config-file=/etc/neutron/neutron_lbaas.conf --config-file=/etc/neutron/services_lbaas.conf --log-file=/var/log/neutron/neutron-server.log
</code></pre></div></div>
<p><br /></p>
<p><strong>neutron.conf</strong></p>
<p>The first is to add the LBaaS service plugin to <code class="language-plaintext highlighter-rouge">neutron.conf</code>.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>service_plugins = router,neutron_lbaas.services.loadbalancer.plugin.LoadBalancerPluginv2
</code></pre></div></div>
<p><br /></p>
<p><strong>neutron_lbaas.conf</strong></p>
<p>Also there is the addition of the <code class="language-plaintext highlighter-rouge">neutron_lbaas.conf</code> configuration file.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>[service_providers]
service_provider = service_provider = LOADBALANCERV2:Octavia:neutron_lbaas.drivers.octavia.driver.OctaviaDriver:default
[service_auth]
auth_url = http://<internal keystone endpoint>:5000/v3
admin_user = octavia
admin_tenant_name = service
admin_password = <octavia password>
admin_user_domain = default
admin_project_domain = default
region = tor1
auth_version = 3
endpoint_type = internalURL
# NOTE(curtis): not sure of service name???
#service_name = LBaaS
# Disable server certificate verification (boolean value)
#insecure = false
</code></pre></div></div>
<p><br /></p>
<p><strong>services_lbaas.conf</strong></p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>neutron-api:/etc/neutron# grep -v "^#\|^$" services_lbaas.conf
[DEFAULT]
[haproxy]
[octavia]
base_url = http://<Octavia API or internal VIP>:9876
[radwarev2]
[radwarev2_debug]
</code></pre></div></div>
<p><br /></p>
<p><strong>Update the Neutron Database</strong></p>
<p>Once Neutron has been configured to provide the LBaaS API, the database needs some “migrations.”</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>neutron-db-manage --config-file /etc/neutron/neutron.conf --config-file /etc/neutron/plugins/ml2/ml2_conf.ini upgrade head
</code></pre></div></div>
<p><br /></p>
<p><strong>Ensure neutron-lbaasv2-agent is Stopped and Disabled</strong></p>
<p>It’s not used with Octavia and must not be running.</p>
<h2 id="setup-octavia">Setup Octavia</h2>
<p>Besides Neutron changes, Octavia also needs to be installed and configured.</p>
<p>Ubuntu does not have packages for Octavia yet, so Octavia code will be installed via Pip. I’m using 0.10.0. (One can find all the release versions for OpenStack projects <a href="https://releases.openstack.org/teams/octavia.html">here</a>.)</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code># pip install ocatavia==0.10.0
</code></pre></div></div>
<p>Pip installs Octavia services in <code class="language-plaintext highlighter-rouge">/usr/local/bin/</code>:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code># ls -1 /usr/local/bin/octavia-*
/usr/local/bin/octavia-api
/usr/local/bin/octavia-db-manage
/usr/local/bin/octavia-health-manager
/usr/local/bin/octavia-housekeeping
/usr/local/bin/octavia-worker
</code></pre></div></div>
<p>Running those services would require some sort of init mechanism, such as systemd but that’s beyond the scope of this blog post. Suffice it to say, octavia-api, octavia-health-manager, octavia-housekeeping, and octavia-worker need to be running somewhere.</p>
<p><strong>Configure octavia.conf</strong></p>
<p>The octavia conifguration file is fairly complex. One of the best examples is the <a href="https://git.openstack.org/cgit/openstack/openstack-ansible-os_octavia/tree/templates/octavia.conf.j2">OpenStack Ansible Octavia Role’s octavia.conf template</a>. Unfortunately it’s beyond the scope of this blog post to completely detail the Octavia config file, and it will take some consideration to get correct for your particular environment.</p>
<p>As another example, I deployed a devstack instance based on the Pike release and put up the resulting octavia.conf in a <a href="https://gist.github.com/ccollicutt/3f9f5d2cf0d34b55034aef2241106071">Github gist</a>.</p>
<p><strong>Create Certificates</strong></p>
<p>In the <a href="git clone https://github.com/openstack/octavia.git">Octavia git repository</a> there is a <code class="language-plaintext highlighter-rouge">create_certificates.sh</code> script which can be used to generate (example, non-prod) certificates. Production deployments would probably require some consideration in terms of certificate management.</p>
<h2 id="conclusion">Conclusion</h2>
<p>Hopefully this blog post has provided some useful information, and can get you on your way towards implementing Octavia and OpenStack LBaaS.</p>
<p>Please feel free to email me (curtis at serverascode.com ) or perhaps add a comment to the post if you have any questions, notice any mistakes, or have improvements that could be made.</p>
<p>Thanks for reading.</p>
Install easy-rsa on Ubuntu2017-07-28T00:00:00+00:00http://serverascode.com/2017/07/28/easy-rsa<h1 id="install-easy-rsa-on-ubuntu">Install easy-rsa on Ubuntu</h1>
<p>At some point, usually multiple points, a sysadmin/operator/devops/whatever needs a certificate authority (CA). At first this seems easy, then it seems hard, then you think you know what you are doing but you don’t, and I’m not sure you ever do. But you still need that CA. Even if you are using some sort of fancy certificate managment system (such as <a href="https://www.vaultproject.io/">Hashicorp Vault</a>) you still probably need to manage your top level CA.</p>
<p>Perhaps <a href="https://github.com/OpenVPN/easy-rsa">easy-rsa</a> is the answer? Certainly it is “an answer.” :)</p>
<h2 id="install">Install</h2>
<p>As usual I am using Ubuntu 16.04/Xenial and there does seem to be a package for <code class="language-plaintext highlighter-rouge">easy-rsa</code></p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>easyrsa$ sudo apt install easy-rsa
easyrsa$ dpkg --list easy-rsa
Desired=Unknown/Install/Remove/Purge/Hold
| Status=Not/Inst/Conf-files/Unpacked/halF-conf/Half-inst/trig-aWait/Trig-pend
|/ Err?=(none)/Reinst-required (Status,Err: uppercase=bad)
||/ Name Version Architecture Description
+++-=====================================-=======================-=======================-===============================================================================
ii easy-rsa 2.2.2-2 all Simple shell based CA utility
</code></pre></div></div>
<p>So we have version 2.2.2-2.</p>
<p>Presumably we have an <code class="language-plaintext highlighter-rouge">easyrsa</code> command?</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>easyrsa:~/vurt$ which easy-rsa
easyrsa:~/vurt$ which easyrsa
</code></pre></div></div>
<p>oops no.</p>
<p>Maybe there are some docs somewhere.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>easyrsa:~/vurt$ locate easy-rsa | grep README
/usr/share/doc/easy-rsa/README-2.0.gz
/usr/share/doc/easy-rsa/README.Debian
</code></pre></div></div>
<p>Aha!</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>easyrsa:~/vurt$ cat /usr/share/doc/easy-rsa/README.Debian
easy-rsa for Debian
-------------------
easy-rsa is a set of scripts to easy the administration of a Certificate
Authority. For example to manage openvpn scripts.
The effortless way to use it is calling "make-cadir DIRECTORY", which will
create a new directory with symlinks to the scripts and a copy of the
configuration files so you can edit them to suit your needs.
i.e.
~$ make-cadir my_ca
~$ cd my_ca
~/my_ca$ vi vars
-- Alberto Gonzalez Iniesta <agi@inittab.org> Mon, 12 Nov 2012 18:18:57 +0100
Improving security of created certificates
------------------------------------------
easy-rsa defaults use 2048 bits for keylength and 10 years (3650 days) as
certificate lifetime.
bettercrypto.org suggests increasing the keylength to 4096 bits and decreasing
the certificate lifetime. You can change those values in the 'vars' file of your
CA directory.
-- Alberto Gonzalez Iniesta <agi@inittab.org> Tue, 07 Jan 2014 12:36:35 +0100
</code></pre></div></div>
<h2 id="make-cadir">make-cadir</h2>
<p>Seems like <code class="language-plaintext highlighter-rouge">make-cadir</code> is the way to go.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>easyrsa:~$ make-cadir my_ca
easyrsa:~$ cd my_ca/
easyrsa:~/my_ca$ ls
build-ca build-inter build-key-pass build-key-server build-req-pass inherit-inter openssl-0.9.6.cnf openssl-1.0.0.cnf revoke-full vars
build-dh build-key build-key-pkcs12 build-req
</code></pre></div></div>
<p>What’s in vars?</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>ubuntu@vc-tor1-2-easyrsa:~/my_ca$ grep -v "^#\|^$" vars
export EASY_RSA="`pwd`"
export OPENSSL="openssl"
export PKCS11TOOL="pkcs11-tool"
export GREP="grep"
export KEY_CONFIG=`$EASY_RSA/whichopensslcnf $EASY_RSA`
export KEY_DIR="$EASY_RSA/keys"
echo NOTE: If you run ./clean-all, I will be doing a rm -rf on $KEY_DIR
export PKCS11_MODULE_PATH="dummy"
export PKCS11_PIN="dummy"
export KEY_SIZE=2048
export CA_EXPIRE=3650
export KEY_EXPIRE=3650
export KEY_COUNTRY="US"
export KEY_PROVINCE="CA"
export KEY_CITY="SanFrancisco"
export KEY_ORG="Fort-Funston"
export KEY_EMAIL="me@myhost.mydomain"
export KEY_OU="MyOrganizationalUnit"
export KEY_NAME="EasyRSA"
</code></pre></div></div>
<p>Let’s change those.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>ubuntu@vc-tor1-2-easyrsa:~/my_ca$ diff vars vars.orig
64,69c64,69
< export KEY_COUNTRY="CA"
< export KEY_PROVINCE="AB"
< export KEY_CITY="Edmonton"
< export KEY_ORG="Serverascode"
< export KEY_EMAIL="curtis@serverascode.com"
< export KEY_OU="OpenStack"
---
> export KEY_COUNTRY="US"
> export KEY_PROVINCE="CA"
> export KEY_CITY="SanFrancisco"
> export KEY_ORG="Fort-Funston"
> export KEY_EMAIL="me@myhost.mydomain"
> export KEY_OU="MyOrganizationalUnit"
</code></pre></div></div>
<p>After a bit of googling <a href="https://openvpn.net/index.php/open-source/documentation/miscellaneous/77-rsa-key-management.html">this</a> seems to be a good set of docs for using this version of <code class="language-plaintext highlighter-rouge">easy-rsa</code>.</p>
<p>Source vars and clean all.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>ubuntu@vc-tor1-2-easyrsa:~/my_ca$ . vars
NOTE: If you run ./clean-all, I will be doing a rm -rf on /home/ubuntu/my_ca/keys
ubuntu@vc-tor1-2-easyrsa:~/my_ca$ ./clean-all
</code></pre></div></div>
<p>Build the CA.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>ubuntu@vc-tor1-2-easyrsa:~/my_ca$ ./build-ca
Generating a 2048 bit RSA private key
........................................+++
............+++
writing new private key to 'ca.key'
-----
You are about to be asked to enter information that will be incorporated
into your certificate request.
What you are about to enter is what is called a Distinguished Name or a DN.
There are quite a few fields but you can leave some blank
For some fields there will be a default value,
If you enter '.', the field will be left blank.
-----
Country Name (2 letter code) [CA]:
State or Province Name (full name) [AB]:
Locality Name (eg, city) [Edmonton]:
Organization Name (eg, company) [Serverascode]:
Organizational Unit Name (eg, section) [OpenStack]:Certifcate Authority
Common Name (eg, your name or your server's hostname) [Serverascode CA]:
Name [EasyRSA]:
Email Address [curtis@serverascode.com]:
</code></pre></div></div>
<p>That creates this directory and the files in it:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>ubuntu@vc-tor1-2-easyrsa:~/my_ca$ ls keys/
ca.crt ca.key index.txt serial
</code></pre></div></div>
<p>Build an intermediate key.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>ubuntu@vc-tor1-2-easyrsa:~/my_ca$ ./build-inter inter
Generating a 2048 bit RSA private key
.............................................+++
........+++
writing new private key to 'inter.key'
-----
You are about to be asked to enter information that will be incorporated
into your certificate request.
What you are about to enter is what is called a Distinguished Name or a DN.
There are quite a few fields but you can leave some blank
For some fields there will be a default value,
If you enter '.', the field will be left blank.
-----
Country Name (2 letter code) [CA]:
State or Province Name (full name) [AB]:
Locality Name (eg, city) [Edmonton]:
Organization Name (eg, company) [Serverascode]:
Organizational Unit Name (eg, section) [OpenStack]:Intermediate CA
Common Name (eg, your name or your server's hostname) [inter]:
Name [EasyRSA]:
Email Address [curtis@serverascode.com]:
Please enter the following 'extra' attributes
to be sent with your certificate request
A challenge password []:
An optional company name []:
Using configuration from /home/ubuntu/my_ca/openssl-1.0.0.cnf
Check that the request matches the signature
Signature ok
The Subject's Distinguished Name is as follows
countryName :PRINTABLE:'CA'
stateOrProvinceName :PRINTABLE:'AB'
localityName :PRINTABLE:'Edmonton'
organizationName :PRINTABLE:'Serverascode'
organizationalUnitName:PRINTABLE:'Intermediate CA'
commonName :PRINTABLE:'inter'
name :PRINTABLE:'EasyRSA'
emailAddress :IA5STRING:'curtis@serverascode.com'
Certificate is to be certified until Jul 26 18:32:25 2027 GMT (3650 days)
Sign the certificate? [y/n]:y
1 out of 1 certificate requests certified, commit? [y/n]y
Write out database with 1 new entries
Data Base Updated
</code></pre></div></div>
<p>Build a certificate request and sign it.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>ubuntu@vc-tor1-2-easyrsa:~/my_ca$ ./build-key mycert
Generating a 2048 bit RSA private key
..+++
.............................................+++
writing new private key to 'mycert.key'
-----
You are about to be asked to enter information that will be incorporated
into your certificate request.
What you are about to enter is what is called a Distinguished Name or a DN.
There are quite a few fields but you can leave some blank
For some fields there will be a default value,
If you enter '.', the field will be left blank.
-----
Country Name (2 letter code) [CA]:
State or Province Name (full name) [AB]:
Locality Name (eg, city) [Edmonton]:
Organization Name (eg, company) [Serverascode]:
Organizational Unit Name (eg, section) [OpenStack]:
Common Name (eg, your name or your server's hostname) [mycert]:
Name [EasyRSA]:
Email Address [curtis@serverascode.com]:
Please enter the following 'extra' attributes
to be sent with your certificate request
A challenge password []:
An optional company name []:
Using configuration from /home/ubuntu/my_ca/openssl-1.0.0.cnf
Check that the request matches the signature
Signature ok
The Subject's Distinguished Name is as follows
countryName :PRINTABLE:'CA'
stateOrProvinceName :PRINTABLE:'AB'
localityName :PRINTABLE:'Edmonton'
organizationName :PRINTABLE:'Serverascode'
organizationalUnitName:PRINTABLE:'OpenStack'
commonName :PRINTABLE:'mycert'
name :PRINTABLE:'EasyRSA'
emailAddress :IA5STRING:'curtis@serverascode.com'
Certificate is to be certified until Jul 26 16:34:19 2027 GMT (3650 days)
Sign the certificate? [y/n]:y
1 out of 1 certificate requests certified, commit? [y/n]y
Write out database with 1 new entries
Data Base Updated
</code></pre></div></div>
<h2 id="conclusion">Conclusion</h2>
<p>This was just a quick exploration of easy-rsa. I should note that the version available by default on Ubuntu 16.04 is a bit older. In another post I’ll explore a more recent version of <code class="language-plaintext highlighter-rouge">easy-rsa</code>.</p>
Setting up a Sensu Slack Handler2017-06-10T00:00:00+00:00http://serverascode.com/2017/06/10/slack-handler-sensu<h1 id="setting-up-a-sensu-slack-handler">Setting up a Sensu Slack Handler</h1>
<p>I’ve been working on a Sensu install recently. I had some trouble getting the Slack handler working. The docs were a little off in terms of how to do this. But I can now say that it’s working. :)</p>
<p>First, you will need the sensu-plugins-slack plugin.</p>
<p>I have Sensu embedded, so I use that gem to install it. It’s already been installed below; I’m just showing the command.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code># /opt/sensu/embedded/bin/gem install sensu-plugins-slack
You can use the embedded Ruby by setting EMBEDDED_RUBY=true in /etc/default/sensu
Successfully installed sensu-plugins-slack-1.0.0
Parsing documentation for sensu-plugins-slack-1.0.0
Installing ri documentation for sensu-plugins-slack-1.0.0
Done installing documentation for sensu-plugins-slack after 0 seconds
1 gem installed
</code></pre></div></div>
<p>Next, login to your slack account and create a webhook.</p>
<p>Now to configure it to be used.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code># cat /etc/sensu/conf.d/slack_handler.json
{
"handlers": {
"slack": {
"type": "pipe",
"command": "handler-slack.rb",
"severites": ["critical", "unknown"]
}
},
"slack": {
"webhook_url": "<your slack webhook url>",
"template" : "",
"channel": "#general"
}
}
</code></pre></div></div>
<p>I have also setup Slack to be a default handler.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code># cat /etc/sensu/conf.d/default_handlers.json
{
"handlers": {
"default": {
"type": "set",
"handlers": [
"slack"
]
}
}
}
</code></pre></div></div>
<p>Once that is setup and Sensu restarted, you should be able to get alerts into a Slack channel.</p>
<p>Happy Sensu Slacking!</p>
Setting the Default MTU in Neutron VXLAN Networks to be 15002017-06-06T00:00:00+00:00http://serverascode.com/2017/06/06/neutron-vxlan-tenant-mtu-1500<h1 id="setting-the-default-mtu-in-neutron-vxlan-networks-to-be-1500">Setting the Default MTU in Neutron VXLAN Networks to be 1500</h1>
<p>Dealing with MTU issues is no fun. They are hard to diagnose. One of the issues I have commonly had is when I create a Docker node in a tenant VXLAN based Neutron network in an OpenStack cloud, and the interface in the virtual machine gets a MTU of 1450 (default 1500 - 50 for VXLAN) but Docker sets up an interface with an MTU of 1500. This will fail in all kinds of ugly ways that aren’t obvious, unless you know what MTU issues look like.</p>
<p>Below I show the docker0 interface on a docker node that is running in a default Neutron VXLAN. Note 1500 on the docker0 interface and 1450 on ens3.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ ip ad sh docker0
3: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:90:79:85:26 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.1/16 scope global docker0
valid_lft forever preferred_lft forever
inet6 fe80::42:90ff:fe79:8526/64 scope link
valid_lft forever preferred_lft forever
$ ip ad sh ens3
2: ens3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc pfifo_fast state UP group default qlen 1000
link/ether fa:16:3e:39:e5:c7 brd ff:ff:ff:ff:ff:ff
inet 10.50.0.18/24 brd 10.50.0.255 scope global ens3
valid_lft forever preferred_lft forever
inet6 fe80::f816:3eff:fe39:e5c7/64 scope link
valid_lft forever preferred_lft forever
</code></pre></div></div>
<p>So how do we change this?</p>
<ol>
<li>Ensure the physical network has an MTU > 1550.</li>
<li>Make a few configuration changes to Neutron.</li>
</ol>
<h2 id="physical-network">Physical network</h2>
<p>Whichever interface (usually a bond) that holds the “underlay” tunnel IP address, ie. the one that Open vSwitch listens on, needs to have an MTU > 1550. Usually people set it to “jumbo frames”, ie. 9000 or higher.</p>
<p>Say you have some Juniper switches, the MTU of the bond interface can be set to have an MTU of 9200. We’d want to do that for all the interfaces that are part of the tunnel/underlay setup.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>switch# set interfaces ae0 mtu 9200
# commit etc
switch> show interfaces ae0 | match MTU
Link-level type: Ethernet, MTU: 9200, Speed: 2Gbps, BPDU Error: None, MAC-REWRITE Error: None, Loopback: Disabled, Source filtering: Disabled, Flow control: Disabled,
</code></pre></div></div>
<p>Now that the physical infrastructure will do > 1550 we can configure Neutron.</p>
<h2 id="configure-neutron-to-set-the-mtu-of-vxlans-to-1500">Configure Neutron to Set the MTU of VXLANs to 1500</h2>
<p>First, I should note this is an Otaka based cloud I’m working on.</p>
<p>I want a couple things:</p>
<ul>
<li>VXLAN interfaces in instances to have an MTU of 1500</li>
<li>Provider networks to also have a MTU of 1500 so that they can communicate with the Internet</li>
</ul>
<p>To do this I set three variables in Neutron configuration files:</p>
<ol>
<li>neutron.conf: [DEFAULT] - global_physnet_mtu = 1550</li>
<li>ml2_conf.ini: [DEFAULT] - path_mtu = 1550</li>
<li>ml2_conf.ini: [DEFAULT] - physical_network_mtus = provider:1500</li>
</ol>
<p>Where the “provider” in “provider:1500” is the name of your bridge mapping.</p>
<p>Once this change is made and Neutron services restarted VXLAN networks should show an MTU of 1500.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ os network show test-vxlan | grep mtu
| mtu | 1500
</code></pre></div></div>
<p>New instances will get an MTU of 1500. Old instances should get it if their dhcp client is restarted or they are rebooted.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code># After a reboot
$ ip ad sh ens3
2: ens3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether fa:16:3e:39:e5:c7 brd ff:ff:ff:ff:ff:ff
inet 10.50.0.18/24 brd 10.50.0.255 scope global ens3
valid_lft forever preferred_lft forever
inet6 fe80::f816:3eff:fe39:e5c7/64 scope link
valid_lft forever preferred_lft forever
</code></pre></div></div>
<h2 id="conclusion">Conclusion</h2>
<p>Overall, it would just be easier on everyone if the default MTU ended up being 1500 in Neutron VXLAN networks, so I think everyone should make a change like this to their OpenStack cloud. Otherwise inevitably things will fail in weird ways, if for no other reason then everything seems to expect an MTU of 1500.</p>
Build a Docker Private Registry with Self-Signed SSL2017-06-05T00:00:00+00:00http://serverascode.com/2017/06/05/docker-private-registry-with-ssl<h1 id="build-a-docker-private-registry-with-self-signed-ssl">Build a Docker Private Registry with Self-Signed SSL</h1>
<p>Recently I’ve been getting back into Kubernetes, which, for the time being, uses Docker as the underlying container CRUD system. At some point when using k8s one will likely need a private Docker registry.</p>
<p>Frankly the hardest part of this is getting the SSL certificates to work.</p>
<h2 id="assumptions">Assumptions</h2>
<ul>
<li>Ubuntu 16.04</li>
<li>Docker is installed, in this post it’s <code class="language-plaintext highlighter-rouge">17.03.1~ce-0~ubuntu-xenial</code></li>
</ul>
<h2 id="create-ssl-certificates">Create SSL Certificates</h2>
<p>I’m not 100% sure of the model I’m using to create the SSL certificates, but it is working with Docker. I don’t know if you’d want to use it in production. :)</p>
<p>First, I create a OpenSSL configuration file called <code class="language-plaintext highlighter-rouge">ca.conf</code>. You might want to edit the distinguished name variables as well as the CN and alt_names.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>[req]
distinguished_name = req_distinguished_name
req_extensions = v3_req
x509_extensions = v3_ca
prompt = no
[req_distinguished_name]
C = CA
ST = Alberta
L = Edmonton
O = Example.com
OU = CA
CN = ca.example.com
[v3_req]
keyUsage = keyEncipherment, dataEncipherment, keyCertSign
extendedKeyUsage = serverAuth
subjectAltName = @alt_names
[ v3_ca ]
subjectKeyIdentifier=hash
authorityKeyIdentifier=keyid:always,issuer
basicConstraints = CA:true
[alt_names]
DNS.1 = ca.example.com
</code></pre></div></div>
<p>Next I also created a <code class="language-plaintext highlighter-rouge">server.conf</code> OpenSSL config file. You will want to change the CN and IP.1 or DNS.1. I am using an IP.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>[req]
distinguished_name = req_distinguished_name
x509_extensions = v3_req
prompt = no
[req_distinguished_name]
C = CA
ST = Alberta
L = Edmonton
O = Example.com
OU = Docker
CN = registry.example.com
[v3_req]
keyUsage = keyEncipherment, dataEncipherment
extendedKeyUsage = serverAuth
subjectAltName = @alt_names
basicConstraints = CA:FALSE
[alt_names]
#DNS.1 = registry.example.com
IP.1 = <ip of registry server>
</code></pre></div></div>
<p>Now that we have those configured, we can run this script. Note that this will update the local CA repository and restart Docker.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>#!/bin/bash
set -e
openssl genrsa -out ca-privkey.pem 2048
openssl req -config ./ca.conf -new -x509 -key ca-privkey.pem \
-out cacert.pem -days 365
openssl req -config ./server.conf -newkey rsa:2048 -days 365 \
-nodes -keyout server-key.pem -out server-req.pem
openssl rsa -in server-key.pem -out server-key.pem
openssl x509 -req -in server-req.pem -days 365 \
-CA cacert.pem -CAkey ca-privkey.pem \
-set_serial 01 -out server-cert.pem \
-extensions v3_req \
-extfile server.conf
echo "INFO: print cacert.pem..."
openssl x509 -text -in cacert.pem -noout
echo "INFO: print server-req.pem..."
openssl req -text -in server-req.pem -noout
echo "INFO: print server-cert.pem..."
openssl x509 -text -in server-cert.pem -noout
openssl verify -verbose -CAfile ./cacert.pem server-cert.pem
echo "INFO: updating local CA..."
# Have to use .crt file name for update command to work
sudo cp cacert.pem /usr/local/share/ca-certificates/cacert.crt
sudo update-ca-certificates
echo "INFO: restarting docker"
sudo service docker restart
</code></pre></div></div>
<p>The cacert.pem file would need to be distributed to all hosts that would use the private repository.</p>
<h2 id="create-a-docker-registry">Create a Docker registry</h2>
<p>The <a href="https://docs.docker.com/registry/deploying/">Docker documentation</a> has an example of doing this.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>docker run -d -p 5000:5000 --restart=always --name registry \
-v `pwd`/certs:/certs \
-e REGISTRY_HTTP_TLS_CERTIFICATE=/certs/server-cert.pem \
-e REGISTRY_HTTP_TLS_KEY=/certs/server-key.pem \
registry:2
</code></pre></div></div>
<p>The above assumes the certs that were created with the <code class="language-plaintext highlighter-rouge">ssl.sh</code> script are in a <code class="language-plaintext highlighter-rouge">certs</code> directory.</p>
<h2 id="push-an-image">Push an Image</h2>
<p>Now that a docker registry is running, I can push an image to it, and have done so. I find the Docker tagging and pushing system very awkward.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
10.70.0.28:5000/static-site latest fcaa5e0ee8f2 9 hours ago 109 MB
static-site latest fcaa5e0ee8f2 9 hours ago 109 MB
10.70.0.28:5000/static-site <none> 60ceae523ef0 14 hours ago 109 MB
registry 2 9d0c4eabab4d 3 weeks ago 33.2 MB
</code></pre></div></div>
<p>Without the right SSL setup I wouldn’t be able to push images.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ docker -D push 10.70.0.28:5000/static-site
The push refers to a repository [10.70.0.28:5000/static-site]
6ce8e637d806: Layer already exists
a552ca691e49: Layer already exists
7487bf0353a7: Layer already exists
8781ec54ba04: Layer already exists
latest: digest: sha256:eb52222d9a7e00426ad94eacaf442dd07e52243ecec7f328537515f0b4c035da size: 1155
</code></pre></div></div>
<p>Now I have an internal, private repository that is using SSL so that I don’t have to reconfigure all the Docker nodes to use an insecure repository, though one would still have to ensure the cacert is installed on all the Docker nodes.</p>
<h2 id="conclusion">Conclusion</h2>
<p>The hardest part of this is SSL, which I’m sure I’ve done wrong but is working. Please let me know of any ways to do this better. :)</p>
Installing Kubernetes with Kubeadm2017-06-02T00:00:00+00:00http://serverascode.com/2017/06/02/kubeadm-openstack<h1 id="installing-kubernetes-with-kubeadm">Installing Kubernetes with Kubeadm</h1>
<p>I have done a good amount of work with Kubernetes in the last year or so. I created a fairly substantial set of Ansible playbooks and workflows, called <a href="https://github.com/sk8ts">Sk8ts</a>, which would deploy Kubernetes to AWS. It would create networks, gateways, instances, setup clusters, etc. But to be honest I only went about 85% as far as I should have and ran out of time to spend on it. Further, perhaps creating my own distribution is not a great idea, though I certainly learned a lot about Ansible, AWS, and k8s.</p>
<p>I mention my work in Sk8ts because it was essentially a 3rd party installer or distribution. I also need to add to the context of this post the fact that I have spent years working on OpenStack, which does not have a specific, project led installer, and some people consider this to be a problem. Whether or not large, complicated infrastructure systems like OpenStack and Kubernetes have official installers is a bit of a conundrum.</p>
<p>While OpenStack does not have an official installer, Kubernetes does: <a href="https://kubernetes.io/docs/admin/kubeadm/">Kubedadm</a>. So in this post I will look at deploying Kubernetes 1.6 with Kubeadm. Please note that Kubeadm is not production ready yet. But someday…</p>
<h2 id="create-hosts">Create hosts</h2>
<p>K8s needs somewhere to run. I have an OpenStack cloud that I can create networks and instances in.</p>
<p>I’ve created four nodes to deploy k8s to. I’ve done this a few times so I kept the command around. For reference it’s below. I’ll use the first node as the master and the other three as the workers. The <code class="language-plaintext highlighter-rouge">m1.medium</code> flavor just has 4GB of memory, so they are not that large resource-wise.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>#!/bin/bash
NET=cee24724-e062-4370-ba9f-57bed80f32cd
openstack server create \
--image xenial \
--key-name curtis \
--flavor m1.medium \
--min 4 \
--max 4 \
--nic net-id=$NET \
k8s
</code></pre></div></div>
<p>Just note that that will boot four instances. :)</p>
<h2 id="setup-docker">Setup Docker</h2>
<p>Once the instances have been created, we can install the k8s and docker packages.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ os server list
+--------------------------------------+-------+--------+---------------------------------------------------+------------+
| ID | Name | Status | Networks | Image Name |
+--------------------------------------+-------+--------+---------------------------------------------------+------------+
| 5da0a8b9-9635-47ba-b381-f3f10b569523 | k8s-4 | ACTIVE | k8s-vxlan=10.50.0.16 | xenial |
| b033b2f6-b7b1-4f62-81c6-cc486320880a | k8s-3 | ACTIVE | k8s-vxlan=10.50.0.13 | xenial |
| 9a4f75d9-20ba-4be0-8daf-7b9a5b6ae289 | k8s-2 | ACTIVE | k8s-vxlan=10.50.0.17 | xenial |
| edfccc19-98da-463a-b0d4-a779ff19e12a | k8s-1 | ACTIVE | k8s-vxlan=10.50.0.11 | xenial |
+--------------------------------------+-------+--------+---------------------------------------------------+------------+
</code></pre></div></div>
<p>Above are the four k8s-x instances. Now I’ll ssh into k8s-1 and install the k8s and docker packages. To do the install I’ll just a script.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>ubuntu@k8s-1:~$ cat kube-install.sh
#!/bin/bash
apt-get update
apt-get install \
apt-transport-https \
ca-certificates \
curl \
software-properties-common
apt-add-repository \
"deb http://apt.kubernetes.io/ kubernetes-xenial main"
add-apt-repository \
"deb [arch=amd64] https://download.docker.com/linux/ubuntu \
$(lsb_release -cs) \
stable"
apt-get update
apt-get install docker-ce -y --allow-unauthenticated
apt-get install -y kubelet kubeadm kubectl kubernetes-cni --allow-unauthenticated
</code></pre></div></div>
<p>That will <em>insecurely</em> install various packages. I’m not getting any GPG keys, etc.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>ubuntu@k8s-1:~$ sudo bash kube-install.sh
sudo: unable to resolve host k8s-1
Get:1 http://security.ubuntu.com/ubuntu xenial-security InRelease [102 kB]
SNIP!
Setting up docker-ce (17.03.1~ce-0~ubuntu-xenial) ...
Processing triggers for libc-bin (2.23-0ubuntu7) ...
Processing triggers for systemd (229-4ubuntu17) ...
Processing triggers for ureadahead (0.100.0-19) ...
Reading package lists... Done
Building dependency tree
Reading state information... Done
The following additional packages will be installed:
ebtables socat
The following NEW packages will be installed:
ebtables kubeadm kubectl kubelet kubernetes-cni socat
0 upgraded, 6 newly installed, 0 to remove and 10 not upgraded.
Need to get 43.2 MB of archives.
After this operation, 323 MB of additional disk space will be used.
WARNING: The following packages cannot be authenticated!
kubernetes-cni kubelet kubectl kubeadm
Authentication warning overridden.
Get:5 http://nova.clouds.archive.ubuntu.com/ubuntu xenial/main amd64 ebtables amd64 2.0.10.4-3.4ubuntu1 [79.6 kB]
Get:6 http://nova.clouds.archive.ubuntu.com/ubuntu xenial/universe amd64 socat amd64 1.7.3.1-1 [321 kB]
Get:1 https://packages.cloud.google.com/apt kubernetes-xenial/main amd64 kubernetes-cni amd64 0.5.1-00 [5,560 kB]
Get:2 https://packages.cloud.google.com/apt kubernetes-xenial/main amd64 kubelet amd64 1.6.4-00 [18.3 MB]
Get:3 https://packages.cloud.google.com/apt kubernetes-xenial/main amd64 kubectl amd64 1.6.4-00 [9,659 kB]
Get:4 https://packages.cloud.google.com/apt kubernetes-xenial/main amd64 kubeadm amd64 1.6.4-00 [9,234 kB]
Fetched 43.2 MB in 4s (10.4 MB/s)
Selecting previously unselected package ebtables.
(Reading database ... 54160 files and directories currently installed.)
Preparing to unpack .../ebtables_2.0.10.4-3.4ubuntu1_amd64.deb ...
Unpacking ebtables (2.0.10.4-3.4ubuntu1) ...
Selecting previously unselected package kubernetes-cni.
Preparing to unpack .../kubernetes-cni_0.5.1-00_amd64.deb ...
Unpacking kubernetes-cni (0.5.1-00) ...
Selecting previously unselected package socat.
Preparing to unpack .../socat_1.7.3.1-1_amd64.deb ...
Unpacking socat (1.7.3.1-1) ...
Selecting previously unselected package kubelet.
Preparing to unpack .../kubelet_1.6.4-00_amd64.deb ...
Unpacking kubelet (1.6.4-00) ...
Selecting previously unselected package kubectl.
Preparing to unpack .../kubectl_1.6.4-00_amd64.deb ...
Unpacking kubectl (1.6.4-00) ...
Selecting previously unselected package kubeadm.
Preparing to unpack .../kubeadm_1.6.4-00_amd64.deb ...
Unpacking kubeadm (1.6.4-00) ...
Processing triggers for systemd (229-4ubuntu17) ...
Processing triggers for ureadahead (0.100.0-19) ...
Processing triggers for man-db (2.7.5-1) ...
Setting up ebtables (2.0.10.4-3.4ubuntu1) ...
update-rc.d: warning: start and stop actions are no longer supported; falling back to defaults
Setting up kubernetes-cni (0.5.1-00) ...
Setting up socat (1.7.3.1-1) ...
Setting up kubelet (1.6.4-00) ...
Setting up kubectl (1.6.4-00) ...
Setting up kubeadm (1.6.4-00) ...
Processing triggers for systemd (229-4ubuntu17) ...
Processing triggers for ureadahead (0.100.0-19) ...
</code></pre></div></div>
<p>Nice. Now we have all the k8s packages and Docker installed. I should note that the Docker version we are getting is perhaps not supported by k8s. I believe k8s is only validated on Docker 1.11 or 1.12. Frankly I’m not sure how to get that version any more, as Docker has split out into a community and enterprise versions. The k8s install does seem to work with this version though.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>ubuntu@k8s-1:~$ dpkg --list docker-ce
Desired=Unknown/Install/Remove/Purge/Hold
| Status=Not/Inst/Conf-files/Unpacked/halF-conf/Half-inst/trig-aWait/Trig-pend
|/ Err?=(none)/Reinst-required (Status,Err: uppercase=bad)
||/ Name Version Architecture Description
+++-=====================================-=======================-=======================-===============================================================================
ii docker-ce 17.03.1~ce-0~ubuntu-xen amd64 Docker: the open-source application container engine
</code></pre></div></div>
<p>So I’m getting 17.02-1-ce…??? Honestly, I don’t know what that version means.</p>
<h2 id="installing-the-k8s-master">Installing the k8s master</h2>
<p>Now I can use kubeadm.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>ubuntu@k8s-1:~$ sudo kubeadm init
sudo: unable to resolve host k8s-1
[kubeadm] WARNING: kubeadm is in beta, please do not use it for production clusters.
[init] Using Kubernetes version: v1.6.4
[init] Using Authorization mode: RBAC
[preflight] Running pre-flight checks
[preflight] WARNING: docker version is greater than the most recently validated version. Docker version: 17.03.1-ce. Max validated version: 1.12
[preflight] WARNING: hostname "k8s-1" could not be reached
[preflight] WARNING: hostname "k8s-1" lookup k8s-1 on 10.50.0.1:53: no such host
[certificates] Generated CA certificate and key.
[certificates] Generated API server certificate and key.
[certificates] API Server serving cert is signed for DNS names [k8s-1 kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local] and IPs [10.96.0.1 10.50.0.11]
[certificates] Generated API server kubelet client certificate and key.
[certificates] Generated service account token signing key and public key.
[certificates] Generated front-proxy CA certificate and key.
[certificates] Generated front-proxy client certificate and key.
[certificates] Valid certificates and keys now exist in "/etc/kubernetes/pki"
[kubeconfig] Wrote KubeConfig file to disk: "/etc/kubernetes/admin.conf"
[kubeconfig] Wrote KubeConfig file to disk: "/etc/kubernetes/kubelet.conf"
[kubeconfig] Wrote KubeConfig file to disk: "/etc/kubernetes/controller-manager.conf"
[kubeconfig] Wrote KubeConfig file to disk: "/etc/kubernetes/scheduler.conf"
[apiclient] Created API client, waiting for the control plane to become ready
[apiclient] All control plane components are healthy after 23.025086 seconds
[apiclient] Waiting for at least one node to register
[apiclient] First node has registered after 4.505916 seconds
[token] Using token: bdc910.dac015f93ad5a064
[apiconfig] Created RBAC rules
[addons] Created essential addon: kube-proxy
[addons] Created essential addon: kube-dns
Your Kubernetes master has initialized successfully!
To start using your cluster, you need to run (as a regular user):
sudo cp /etc/kubernetes/admin.conf $HOME/
sudo chown $(id -u):$(id -g) $HOME/admin.conf
export KUBECONFIG=$HOME/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
http://kubernetes.io/docs/admin/addons/
You can now join any number of machines by running the following on each node
as root:
kubeadm join --token bdc910.dac015f93ad5a064 10.50.0.11:6443
</code></pre></div></div>
<p>There are a bunch of containers running.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>ubuntu@k8s-1:~$ sudo docker ps
sudo: unable to resolve host k8s-1
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
bf36a19d1d61 gcr.io/google_containers/kube-proxy-amd64@sha256:44cc08e7e8a2089eb8dfad6b692e9ece5994d6e6cff07fc9e9b1273cab0f6c6a "/usr/local/bin/ku..." 2 minutes ago Up 2 minutes k8s_kube-proxy_kube-proxy-jvdkl_kube-system_fbc037b7-4864-11e7-acb2-fa163ef42293_0
9bda7bb1a3f2 gcr.io/google_containers/pause-amd64:3.0 "/pause" 2 minutes ago Up 2 minutes k8s_POD_kube-proxy-jvdkl_kube-system_fbc037b7-4864-11e7-acb2-fa163ef42293_0
d5a926f598ef gcr.io/google_containers/kube-scheduler-amd64@sha256:57661c79890b01ef2ff183ed4b467ca470efc4fb8d0517cd29abe49e72f6d904 "kube-scheduler --..." 2 minutes ago Up 2 minutes k8s_kube-scheduler_kube-scheduler-k8s-1_kube-system_3145edd89dab0492bdacc0dd589d0e90_0
95faeb5d116b gcr.io/google_containers/kube-controller-manager-amd64@sha256:a93d4c26d71de94861f78cf5ea62600e4952685d580e2774c630ea206b7c18ee "kube-controller-m..." 2 minutes ago Up 2 minutes k8s_kube-controller-manager_kube-controller-manager-k8s-1_kube-system_8d185204c4cf91dd9e76230d0642391b_0
fc4c977e5061 gcr.io/google_containers/etcd-amd64@sha256:d83d3545e06fb035db8512e33bd44afb55dea007a3abd7b17742d3ac6d235940 "etcd --listen-cli..." 2 minutes ago Up 2 minutes k8s_etcd_etcd-k8s-1_kube-system_7075157cfd4524dbe0951e00a8e3129e_0
c3d248897b53 gcr.io/google_containers/kube-apiserver-amd64@sha256:6d5aa429c2b0806e4b6d1d179054d6deee46eec0aabe7bd7bd6abff97be36ae7 "kube-apiserver --..." 2 minutes ago Up 2 minutes k8s_kube-apiserver_kube-apiserver-k8s-1_kube-system_76f5cdc7dab34e6c8b32d96a42cc51e8_0
8482b6284833 gcr.io/google_containers/pause-amd64:3.0 "/pause" 2 minutes ago Up 2 minutes k8s_POD_kube-scheduler-k8s-1_kube-system_3145edd89dab0492bdacc0dd589d0e90_0
4016d11d968d gcr.io/google_containers/pause-amd64:3.0 "/pause" 2 minutes ago Up 2 minutes k8s_POD_kube-controller-manager-k8s-1_kube-system_8d185204c4cf91dd9e76230d0642391b_0
ebc0ef82e638 gcr.io/google_containers/pause-amd64:3.0 "/pause" 2 minutes ago Up 2 minutes k8s_POD_kube-apiserver-k8s-1_kube-system_76f5cdc7dab34e6c8b32d96a42cc51e8_0
045d7c8d75ba gcr.io/google_containers/pause-amd64:3.0 "/pause" 2 minutes ago Up 2 minutes k8s_POD_etcd-k8s-1_kube-system_7075157cfd4524dbe0951e00a8e3129e_0
</code></pre></div></div>
<h2 id="install-networking-plugin">Install Networking Plugin</h2>
<p>Now we need a networking plugin. By default kubeadm is ready to use weave. This is amazingly simple.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>root@k8s-1:/etc/kubernetes# kubectl --kubeconfig ./admin.conf apply -f https://git.io/weave-kube-1.6
clusterrole "weave-net" created
serviceaccount "weave-net" created
clusterrolebinding "weave-net" created
daemonset "weave-net" created
</code></pre></div></div>
<p>This will modify the networking on the host.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>root@k8s-1:/etc/kubernetes# ip ad sh
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc pfifo_fast state UP group default qlen 1000
link/ether fa:16:3e:f4:22:93 brd ff:ff:ff:ff:ff:ff
inet 10.50.0.11/24 brd 10.50.0.255 scope global ens3
valid_lft forever preferred_lft forever
inet6 fe80::f816:3eff:fef4:2293/64 scope link
valid_lft forever preferred_lft forever
3: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default
link/ether 02:42:59:52:32:1d brd ff:ff:ff:ff:ff:ff
inet 172.17.0.1/16 scope global docker0
valid_lft forever preferred_lft forever
4: datapath: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1376 qdisc noqueue state UNKNOWN group default qlen 1
link/ether a2:29:39:a0:df:49 brd ff:ff:ff:ff:ff:ff
inet6 fe80::a029:39ff:fea0:df49/64 scope link
valid_lft forever preferred_lft forever
6: weave: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1376 qdisc noqueue state UP group default qlen 1000
link/ether 9a:80:36:0d:7c:64 brd ff:ff:ff:ff:ff:ff
inet 10.32.0.1/12 scope global weave
valid_lft forever preferred_lft forever
inet6 fe80::9880:36ff:fe0d:7c64/64 scope link
valid_lft forever preferred_lft forever
7: dummy0: <BROADCAST,NOARP> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether ee:ec:e0:cc:a1:9e brd ff:ff:ff:ff:ff:ff
9: vethwe-datapath@vethwe-bridge: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1376 qdisc noqueue master datapath state UP group default qlen 1000
link/ether 2e:9b:d3:2f:66:21 brd ff:ff:ff:ff:ff:ff
inet6 fe80::2c9b:d3ff:fe2f:6621/64 scope link
valid_lft forever preferred_lft forever
10: vethwe-bridge@vethwe-datapath: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1376 qdisc noqueue master weave state UP group default qlen 1000
link/ether 9e:1d:61:4f:c1:71 brd ff:ff:ff:ff:ff:ff
inet6 fe80::9c1d:61ff:fe4f:c171/64 scope link
valid_lft forever preferred_lft forever
11: vxlan-6784: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 65485 qdisc noqueue master datapath state UNKNOWN group default qlen 1000
link/ether 8e:12:6f:d6:0c:1d brd ff:ff:ff:ff:ff:ff
inet6 fe80::8c12:6fff:fed6:c1d/64 scope link
valid_lft forever preferred_lft forever
13: vethweplc205ec0@if12: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1376 qdisc noqueue master weave state UP group default
link/ether 62:6f:d0:66:4a:2b brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet6 fe80::606f:d0ff:fe66:4a2b/64 scope link
valid_lft forever preferred_lft forever
</code></pre></div></div>
<p>Note the weave components.</p>
<p>There are also weave containers created.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>root@k8s-1:/etc/kubernetes# docker ps | grep weave
fa0eaddf9b6e weaveworks/weave-npc@sha256:d4b37edd345b42fdc4cd4fdc9398233db035916c7ad04f2a99fb8230b1d2f6e9 "/usr/bin/weave-npc" About a minute ago Up About a minute k8s_weave-npc_weave-net-8n654_kube-system_889073fd-4865-11e7-acb2-fa163ef42293_0
f3e22468fc86 weaveworks/weave-kube@sha256:0445da5b752a50133133e2d4d6383e622f4a06a3c744268740238c23ae05c594 "/home/weave/launc..." About a minute ago Up About a minute k8s_weave_weave-net-8n654_kube-system_889073fd-4865-11e7-acb2-fa163ef42293_0
3953f0b070dd gcr.io/google_containers/pause-amd64:3.0 "/pause" About a minute ago Up About a minute k8s_POD_weave-net-8n654_kube-system_889073fd-4865-11e7-acb2-fa163ef42293_0
</code></pre></div></div>
<h2 id="add-k8s-workers">Add K8s workers</h2>
<p>I’ll ssh into the other nodes and install the k8s and docker packages.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>ubuntu@k8s-2:~$ sudo bash kube-install.sh
SNIP!
</code></pre></div></div>
<p>Now they can join via kubeadm.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>ubuntu@k8s-2:~$ sudo kubeadm join --token bdc910.dac015f93ad5a064 10.50.0.11:6443
sudo: unable to resolve host k8s-2
[kubeadm] WARNING: kubeadm is in beta, please do not use it for production clusters.
[preflight] Running pre-flight checks
[preflight] WARNING: docker version is greater than the most recently validated version. Docker version: 17.03.1-ce. Max validated version: 1.12
[preflight] WARNING: hostname "k8s-2" could not be reached
[preflight] WARNING: hostname "k8s-2" lookup k8s-2 on 10.50.0.1:53: no such host
[discovery] Trying to connect to API Server "10.50.0.11:6443"
[discovery] Created cluster-info discovery client, requesting info from "https://10.50.0.11:6443"
[discovery] Cluster info signature and contents are valid, will use API Server "https://10.50.0.11:6443"
[discovery] Successfully established connection with API Server "10.50.0.11:6443"
[bootstrap] Detected server version: v1.6.4
[bootstrap] The server supports the Certificates API (certificates.k8s.io/v1beta1)
[csr] Created API client to obtain unique certificate for this node, generating keys and certificate signing request
[csr] Received signed certificate from the API server, generating KubeConfig...
[kubeconfig] Wrote KubeConfig file to disk: "/etc/kubernetes/kubelet.conf"
Node join complete:
* Certificate signing request sent to master and response
received.
* Kubelet informed of new secure connection details.
Run 'kubectl get nodes' on the master to see this machine join.
</code></pre></div></div>
<p>We can see there are two nodes now.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>root@k8s-1:/etc/kubernetes# kubectl --kubeconfig ./admin.conf get nodes
NAME STATUS AGE VERSION
k8s-1 Ready 16m v1.6.4
k8s-2 Ready 5m v1.6.4
</code></pre></div></div>
<p>Now I’ll add the other nodes.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>root@k8s-1:/etc/kubernetes# kubectl --kubeconfig ./admin.conf get nodes
NAME STATUS AGE VERSION
k8s-1 Ready 21m v1.6.4
k8s-2 Ready 10m v1.6.4
k8s-3 Ready 1m v1.6.4
k8s-4 NotReady 7s v1.6.4
</code></pre></div></div>
<p>Great, now we have a k8s cluster of four nodes that was deployed by kubeadm.</p>
<h2 id="deploy-sock-shop">Deploy sock-shop</h2>
<p>So how do we know this is even working? Lets deploy the socks shop app.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>root@k8s-1:/etc/kubernetes# kubectl --kubeconfig ./admin.conf create namespace sock-shop
namespace "sock-shop" created
root@k8s-1:/etc/kubernetes# kubectl --kubeconfig ./admin.conf apply -n sock-shop -f "https://github.com/microservices-demo/microservices-demo/blob/master/deploy/kubernetes/complete-demo.yaml?raw=true"
Warning: kubectl apply should be used on resource created by either kubectl create --save-config or kubectl apply
namespace "sock-shop" configured
namespace "zipkin" created
deployment "carts-db" created
service "carts-db" created
deployment "carts" created
service "carts" created
deployment "catalogue-db" created
service "catalogue-db" created
deployment "catalogue" created
service "catalogue" created
deployment "front-end" created
service "front-end" created
deployment "orders-db" created
service "orders-db" created
deployment "orders" created
service "orders" created
deployment "payment" created
service "payment" created
deployment "queue-master" created
service "queue-master" created
deployment "rabbitmq" created
service "rabbitmq" created
deployment "shipping" created
service "shipping" created
deployment "user-db" created
service "user-db" created
deployment "user" created
service "user" created
the namespace from the provided object "zipkin" does not match the namespace "sock-shop". You must pass '--namespace=zipkin' to perform this operation.
the namespace from the provided object "zipkin" does not match the namespace "sock-shop". You must pass '--namespace=zipkin' to perform this operation.
the namespace from the provided object "zipkin" does not match the namespace "sock-shop". You must pass '--namespace=zipkin' to perform this operation.
the namespace from the provided object "zipkin" does not match the namespace "sock-shop". You must pass '--namespace=zipkin' to perform this operation.
the namespace from the provided object "zipkin" does not match the namespace "sock-shop". You must pass '--namespace=zipkin' to perform this operation.
</code></pre></div></div>
<p>This might take a while to complete in terms of downloading docker images and such.</p>
<p>We can ask for the port information.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>root@k8s-1:/etc/kubernetes# kubectl --kubeconfig ./admin.conf -n sock-shop get svc front-end
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
front-end 10.96.97.28 <nodes> 80:30001/TCP 55s
</code></pre></div></div>
<p>We can access the socks shop page…</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>root@k8s-1:/etc/kubernetes# curl localhost:30001 | head
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<meta name="robots" content="all,follow">
<meta name="googlebot" content="index,follow,snippet,archive">
<meta name="viewport" content="width=device-width, initial-scale=1">
<meta name="description" content="WeaveSocks Demo App">
100 8688 100 8688 0 0 314k 0 --:--:-- --:--:-- --:--:-- 326k
curl: (23) Failed writing body (248 != 744)
</code></pre></div></div>
<h2 id="issues">Issues</h2>
<ul>
<li>Initially I tried installing using kubeadm from behind an http proxy, but that brought all kinds of issues, so I gave up.</li>
<li>As mentioned, perhaps should be installing docker 1.12.</li>
<li>Not clear on the zipkin issue with socks-shop</li>
<li>I am confused with regards to how to setup access to deployed applications. With AWS it was straightfoward, configured K8s to create AWS loadbalancers. But in this situation, I’m not sure…yet. :)</li>
</ul>
<h2 id="conclusion">Conclusion</h2>
<p>k8s has changed a lot since I was using it in version 1.4. I’m quite behind. :)</p>
<p>I’m curious to see if kubeadm will catch on and actually be the best way to deploy and manage k8s. There are many other (competing?) projects.</p>
<p>I was inspired to try kubeadm by <a href="https://blog.heptio.com/why-heptio-is-a-kubernetes-company-not-a-kubernetes-distribution-df35bb0a559f">this heptio blog post</a> in which they discuss how they don’t want to be k8s distribution.</p>
<blockquote>
<p>…we need to be careful: distributions can be a dangerous path for a community. Each distributor has strong incentives to deliver differentiated experiences, and differentiated capabilities. As they develop a customer following their customers clamor for features. The community cannot move as fast as they could and so they deliver a patch. And somewhere a fairy dies. The community gets fragmented one really great customer request at a time. You end up with semantic divergence, and a community ‘dark ages’ period happens until a conquering empire emerges to pull it all together.</p>
</blockquote>
<p>I don’t know if kubeadm can deploy k8s in a way that every single organization will be happy with. But we shall see.</p>
<p>At the very least, it’s an easy way to get a test/dev k8s install.</p>
Installing Weave Scope into Kubernetes2017-06-02T00:00:00+00:00http://serverascode.com/2017/06/02/install-weave-scope<h1 id="installing-weave-scope-into-kubernetes">Installing Weave Scope into Kubernetes</h1>
<p>In a <a href="/2017/06/02/kubeadm-openstack.html">previous post</a> I installed a k8s cluster using kubeadm.</p>
<p>Now I would like to add the <a href="https://www.weave.works/oss/scope/">Weave Scope</a> application to the cluster so that I can visualize what is going on. I should note that I first saw Scope used in a presentation regarding <a href="https://www.youtube.com/watch?v=9-EgvlJ0dvY">OpenStack Helm</a>. (Yeah, that’s right, using k8s to manage the OpenStack control plane.)</p>
<p>Weave Scope allows you to:</p>
<blockquote>
<p>See your Docker hosts, containers and services in real time. Easily identify and correct issues to ensure the stability and performance of your containerized applications.</p>
</blockquote>
<h2 id="installation">Installation</h2>
<p>Basically it’s just a matter of getting the command correct. There are <a href="https://www.weave.works/docs/scope/latest/installing/#k8s">official docs</a> on how to install Weave Scope.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ kubectl --kubeconfig ./admin.conf apply --namespace kube-system -f "https://cloud.weave.works/k8s/scope.yaml?k8s-service-type=NodePort&k8s-version=$(kubectl --kubeconfig ./admin.conf version | base64 | tr -d '\n')"
</code></pre></div></div>
<p>Note that I added the <code class="language-plaintext highlighter-rouge">k8s-service-type=NodePort</code>.</p>
<p>After a few seconds we can validate the deployment:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>root@k8s-1:/etc/kubernetes# kubectl --kubeconfig ./admin.conf -n kube-system get svc
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kube-dns 10.96.0.10 <none> 53/UDP,53/TCP 2h
weave-scope-app 10.111.34.232 <nodes> 80:31863/TCP 1h
</code></pre></div></div>
<p>Above we can see what port it’s on, in this case <code class="language-plaintext highlighter-rouge">31863</code>. Note that I’m not exporting this service in any fashion right now, to use Scope I’m connecting my browser directly to node:31863.</p>
<h2 id="sock-shop">sock-shop</h2>
<p>In the previous post I deployed <code class="language-plaintext highlighter-rouge">sock-shop</code>.</p>
<p>Here’s a view from Weave Scope of the <code class="language-plaintext highlighter-rouge">sock-shop</code> namespace.</p>
<p><img src="/img/weave-scope-2.jpg" alt="sock shop weave" /></p>
<h2 id="more-images">More Images</h2>
<p>There are all kinds of handy tools.</p>
<p><img src="/img/weave-scope-3.jpg" alt="sock shop weave" /></p>
<p>The Internet.</p>
<p><img src="/img/weave-scope-4.jpg" alt="sock shop weave" /></p>
<p>Processes.</p>
<p><img src="/img/weave-scope-5.jpg" alt="sock shop weave" /></p>
<p>I’m leaving a lot out.</p>
<h2 id="conclusion">Conclusion</h2>
<p>I usually don’t reach for visualization tools, but with k8s it was helpful to get a picture of what’s going on. Plus, it’s so simple to install. I really like how services like this are installed into the kube-system namespace, a form of self-hosting. It’s a great model.</p>
OpenStack Boston Summit 20172017-05-13T00:00:00+00:00http://serverascode.com/2017/05/13/boston-openstack-summit-2017<p><em>(A picture I took at the Boston Museum of Fine Arts)</em></p>
<h1 id="openstack-boston-summit-2017">OpenStack Boston Summit 2017</h1>
<p>I’m not sure how many OpenStack summits I’ve been to, the first one I attended was the San Diego summit. I felt like this was one of the better summits I’ve been to, mostly because I had some colleagues to hang out with. Unfortunately, while other people from my current employer were supposed to attend, due to business reasons they had to cancel. But I was able to have some good discussions with some fellow Canadians (we have <a href="https://openstack-canada-slack-invite.herokuapp.com/">slack channel</a> now) as well as my co-presenters for the multi-cloud/mult-site/what-have-you session.</p>
<h2 id="nfv">NFV</h2>
<p>I mostly work in the area surrounding “Network Function Virualization” (NFV). If you haven’t been to a summit in a while, I think I can sum up telecommunications companies participation in OpenStack by saying Verizon sent 100 people to the summit. As another example, AT&T is leading the <a href="https://git.openstack.org/cgit/openstack/openstack-helm/">OpenStack Helm</a> project. Yes, AT&T, and according to their presentation on the helm project, they will be replacing all of their current OpenStack control planes with it (presumably moving away from Mirantis Fuel, which itself has been replaced by Mirantis MCP, but I digress).</p>
<h2 id="openstack-helm---deploying-the-openstack-control-plane-on-kubernetes">OpenStack Helm - Deploying the OpenStack Control Plane on Kubernetes</h2>
<p>Previously I wasn’t sure if the OpenStack control plane really needed a full <em>Container Orchestration Engine</em> (COE) like Kubernetes, because it’s hard enough to run OpenStack let alone an underlying (and complex) COE. Personally I usually use LXC based containers. But after seeing some of the work AT&T on the helm project, I think my mind has changed. That said, I am not sure how they are provisioning the actual underlying Kubernetes infrastructure, which I presume is outside of the scope of the Helm project (ie. probably something like kubadm.</p>
<p>I wanted to attend the hands on session, but it was at the same time as the telecom/NFV working group session. From this <a href="https://www.projectcalico.org/3-takeaways-on-the-future-of-openstack-networking-from-the-boston-summit/">Calico blog post</a> it sounds like they were using Calico in the workshop. I wonder if that is what they are using in production…that would be surprising:</p>
<blockquote>
<p>Even more impressively, the AT&T Integrated Cloud team hosted a hands-on workshop with over 100 participants in a packed room also performing the same task of deploying, and upgrading OpenStack on Kubernetes leveraging Helm, and Calico for networking, and completing this lab in mere minutes.</p>
</blockquote>
<p>Can/should Telecoms act like Facebook? Not everything hyperscalers like Facebook is doing is applicable, but if you are using containers then I don’t think everything should be dealt with on layer 2. We should be using IPv6 with containers. But Calico with IPv4 and treating everything as layer 3 is a good start.</p>
<p>Treating infrastructure as software is difficult. It’s not the same as running a web application. There is a lot of hidden state in the underlying infrastructure. However, we cannot continue to treat infrastructure, such as private cloud, as hand-rolled bespoke, manually installed one-off systems. We have to find the right balance between running highly available infrastructure, and treating it like software, with continuous integration, and multiple deployments per day, as well as reconciling the fact that infrastructure will fail and applications have to be “cloud native.” Too far one way, and infrastructure is unstable, too far the other and we end up with set-and-forget.</p>
<blockquote class="twitter-tweet" data-lang="en"><p lang="en" dir="ltr">@ Most pop workshop <a href="https://twitter.com/OpenStack">@OpenStack</a> Summit on OpenStack-helm with <a href="https://twitter.com/v1k0d3n">@v1k0d3n</a> <a href="https://twitter.com/portdirect">@portdirect</a>. thanks to <a href="https://twitter.com/kubernetesio">@kubernetesio</a> to move OpenStack to next level! <a href="https://t.co/cRhoQFZYNO">pic.twitter.com/cRhoQFZYNO</a></p>— Archy (@archyufa) <a href="https://twitter.com/archyufa/status/862802663779577857">May 11, 2017</a></blockquote>
<script async="" src="//platform.twitter.com/widgets.js" charset="utf-8"></script>
<h3 id="att-zones-and-regions">AT&T: Zones and Regions</h3>
<p>First, this is something I need to do more research into, because I only heard a tiny snippet of a conversation around this, but, it sounded to me like AT&T was deploying clouds with a region and zone concept, where every region had two (availability?) zones. This would be very similar to what AWS, and any intelligent cloud provider, would do. Presumably the concept is that if one zone fails (which is probably an entire cloud) then the other (geographically close) zone is still running, and whatever application you deploy would exist over both zones.</p>
<p>My point is not that this is a new concept, but the fact that a large telecom grasps, and has implemented, zones is impressive because it shows some “cloud building” (sorry) maturity.</p>
<h2 id="nfv-nirvana-stack">NFV: Nirvana Stack</h2>
<p>Naming is hard. I don’t know if I like the name of this project, but I can understand where they are coming from. :)</p>
<p>Telecoms and groups like OPNFV are coming together to establish some kind of reference stack with OpenStack and other open source systems, mostly around “Sofware Defined Networking” (SDN) plus OpenStack. I could not watch all the presentations, as they had an entire day dedicated to this in the OpenDayLight track, but my impression is that while using OpenStack has become fairly standard to do NFV, implementing an SDN solution is not part of the OpenStack project itself, and typically telecoms want the extra features and capabilities that an SDN solution can provide, but they are often difficult to integrate. So they want to perform some integration work on OpenStack + “Open Source SDN”, like Open Daylight, and this work is under the umbrella of the <em>Nirvana Stack</em>.</p>
<p>It makes sense to me as while I have done a fair amount of work with ODL, installing it with OpenStack is not that straight forward. Also, part of the integration would be to identify and help to fix any issues upstream.</p>
<blockquote class="twitter-tweet" data-lang="en"><p lang="en" dir="ltr">ATT Lisa Fung gave introduction to Nirvana stack and objectives <a href="https://twitter.com/OpenDaylightSDN">@OpenDaylightSDN</a> day <a href="https://twitter.com/hashtag/OpenStackSummit?src=hash">#OpenStackSummit</a> <a href="https://t.co/dW6AmumjzU">pic.twitter.com/dW6AmumjzU</a></p>— George Zhao (@georgeyzhao) <a href="https://twitter.com/georgeyzhao/status/862658180681265153">May 11, 2017</a></blockquote>
<script async="" src="//platform.twitter.com/widgets.js" charset="utf-8"></script>
<h2 id="nfv-onap">NFV: ONAP</h2>
<p>If you work in the NFV area, you have probably heard about AT&Ts <a href="http://about.att.com/content/dam/snrdocs/ecomp.pdf">ECOMP</a> project. Basically it’s a massive layer of software (MANO+) that sits above OpenStack performing all kinds of automation. However, ECOMP has now transitioned into being a project named ONAP, and it’s in the process of <a href="https://www.sdxcentral.com/articles/news/logical-happens-open-o-merges-ecomp/2017/02/">merging</a> another open source MANO system, Open-O. This transition is ongoing and will take some time, but at this point there is <a href="https://git.onap.org/">actual working ONAP code</a>!</p>
<p>AT&T demoed ONAP (ECOMP) at the summit, and also provide Heat templates which will deploy the ONAP application itself into an OpenStack cloud. (However, I believe at this time the templates are only tested with Rackspace, though any OpenStack cloud (with Heat) would presumably work, perhaps with a little tweaking.)</p>
<p>I’m really impressed with AT&Ts willingness to release this code. Combined with their work on projects like OpenStack Helm, they are doing some really great things. Very impressive for such a huge telecom.</p>
<blockquote class="twitter-tweet" data-lang="en"><p lang="en" dir="ltr">Telco grade Orchestration ONAP for Openstack Orchestration <a href="https://t.co/sBLsB7TeU7">pic.twitter.com/sBLsB7TeU7</a></p>— Sudeep Batra (@sudeepbatra) <a href="https://twitter.com/sudeepbatra/status/862324663510335488">May 10, 2017</a></blockquote>
<script async="" src="//platform.twitter.com/widgets.js" charset="utf-8"></script>
<h2 id="open-contrail">Open Contrail</h2>
<p>Contrail is a SDN system from Juniper. They have an open source version called <a href="http://www.opencontrail.org/">Open Contrail</a>. On Wednesday night they had a Contrail user group meeting at Fenway park.</p>
<p><a href="https://twitter.com/randybias">Randy Bias</a> recently joined Juniper to spearhead the Contrail product. For those of you not familiar with Randy, he is usually considered the progenitor of the “Pets vs Cattle” meme (which I don’t like, but sometimes it’s the easiest way to get the point across). So, you know, he like gets cloud and stuff and has for quite some time.</p>
<p>He started off the Open Contrail night by saying they (Juniper) were going to totally reboot the community. Everything he said sounded great, and are things that need to happen with Open Contrail, with one exception…he mentioned the term “open core.” I personally don’t think open core really works…but then again I am not much of a business person. That said, I’m not actually clear on what he meant by open core, so we will just have to wait and see. Overall, the changes he mentioned during the talk were all things that need to happen. I’m not sure Juniper corp. will like it much, but he was certainly saying the right things.</p>
<p>One of the major items Bias mentioned was that he wants to grow the number of Contrail deployments by an order of magnitude or two. I think that this is something that needs to happen if Contrail is going to be successful. They just don’t have enough deployments right now to get good community contributions and feedback…it’s a single vendor open source project and those rarely work out. It’s not so much that they need to make more money (ie. get more commercial deployments), which of course they do, it’s that they aren’t getting enough feedback and external contributions to improve the product, not enough critical mass.</p>
<blockquote class="twitter-tweet" data-lang="en"><p lang="en" dir="ltr">Another great <a href="https://twitter.com/hashtag/opencontrail?src=hash">#opencontrail</a> meetup at the <a href="https://twitter.com/hashtag/OpenStackSummit?src=hash">#OpenStackSummit</a> by <a href="https://twitter.com/emaganap">@emaganap</a> good lineup of speakers and their stories at <a href="https://twitter.com/hashtag/fenwaypark?src=hash">#fenwaypark</a> <a href="https://t.co/2xg8yowWUe">pic.twitter.com/2xg8yowWUe</a></p>— Amit Tank (@amitTank) <a href="https://twitter.com/amitTank/status/862769221398351872">May 11, 2017</a></blockquote>
<script async="" src="//platform.twitter.com/widgets.js" charset="utf-8"></script>
<h2 id="massively-distributed-clouds">Massively Distributed Clouds</h2>
<p>Part of the presentation I worked on for the summit regarded “massively distributed clouds” (MD). As usual there are many issues around this in terms of naming and use-cases definition. I was in several sessions during the week regarding the phrase “massively distributed” and most of the sessions became quickly confusing to all in attendance. Often telecoms (somehow) know they need massively distributed clouds but they don’t actually know what it means, what is possible with OpenStack now, what isn’t, and what would require new architecture and designs…and most importantly new code.</p>
<p>I heard three or four things in these meetings over and over again which are not related to what I would consider <em>massively distributed clouds</em>:</p>
<ol>
<li>Some people just want massive single data center systems. This is possible now and is not massively distributed. It’s just a large cloud; a buncha compute nodes. If you have 5000 servers in a single data center I don’t think it matters if you have to dedicate 0.5% of them to the control plane. It’s massive, but not massively distributed.</li>
<li>Some organizations want a massive number of distinct, <em>separate clouds</em>. This is possible now. There are not many good options for managing a large number of clouds, and would likely involve some kind of Management and Orchestration (MANO) system and other software to manage and sync them, but I don’t really consider it a massively distributed use case. Large number yes, distributed no.</li>
<li>Another desire is for “zero touch provisioning” in which you have many small clouds or devices and you want a “zero touch” method install and update them. To me this is an important requirement, but it can be solved many ways outside of OpenStack, and would probably be a project of its own (or maybe using Ironic…I don’t know). Hopefully something is happening around this in the IoT area or we are in big trouble security-wise. The point is that we can provide this functionality outside of OpenStack if required.</li>
<li>I also encountered some people, more than one person, OK, two, that was quite sure that if you use Kubernetes or containerize the OpenStack control plane then it somehow gets smaller. I suppose it’s possible, but in general that is not the case. No matter if you run all the of the required control plane services in containers or not they are still taking up resources, need to be managed, etc.</li>
</ol>
<p>Finally we have what some people call “the retail use-case” in which an organization, say, for example, Walmart, has 10,000 stores with a few hypervisors in each. They don’t want to put a full, highly available OpenStack control plane in each and every store, ie. the cloud is made up of remote (or distributed) hypervisors. I believe that if we solve this use case we would solve most related problems, ie. reducing the size of the OpenStack control plane, dealing with latency, etc. To accomplish this OpenStack would have to change considerably. In my mind, this is what <em>massively distributed</em> really means. Sure, you have some other problems to solve (like “zero touch”) but overall if we could solve this problem then many other issues and use-cases fall into place.</p>
<p>There’s an <a href="https://etherpad.openstack.org/p/BOS-Fog-Edge-MassivelyDistributed-BoF">etherpad</a> page (essentially online collaborative notes) from one of the sessions, the Birds of a Feather meeting, if you are interested in perusing some of the thoughts around MD.</p>
<p>I should also mention that several people from the OpenStack foundation were in the room, including Sparky Collier, Jonathan Bryce, and Lauren Sell. It’s pretty clear to me that the foundation believes MD (or edge, fog, what have you) is important to the future of OpenStack.</p>
<h2 id="the-forum">The Forum</h2>
<p>A major change to this summit was the creation of <em>The Forum</em>. Previously summits were also well attended by developers and there was an entire section of the summit dedicated to getting developers together discussing their projects. However that work has now been moved to a separate meeting, called the “Project Team Gathering” (PTG), which is not held at the same time and location as the summit. The first one was held in Atlanta in February, and I believe the next one is in Denver. What this means is that there are fewer developers at this summit. Three people mentioned to me that the summit felt more business like, and they didn’t know about the forum component how it had changed the makeup of the attendees.</p>
<p>I attended many forum sessions, and they mostly turned out well. Certainly all positive discussions.</p>
<h2 id="openstack-operators-telecomnfv-working-group-session">OpenStack Operators Telecom/NFV Working Group Session</h2>
<p>I have been involved with, and currently chair, and OpenStack working group called the <strong>OpenStack Operators Telecom/NFV Working Group</strong>. I won’t go into too much detail on what this group is about–it’s for people who build and operate NFV related clouds on a day to day basis, and the OpenStack foundation was kind enough to provide us some time and space to meet face to face.</p>
<p>There is an <a href="https://etherpad.openstack.org/p/BOS-ops-telecom-nfv">etherpad</a> page that was created for this session and it has some notes about what we discussed during the session. Have a look. :)</p>
<p>Overall, I made a request to everyone in the room to go back to their respective organizations and seek out people who might fit well into this group and to let them know about it. Hopfully at the next <a href="http://eavesdrop.openstack.org/#OpenStack_Operators_Telco_and_NFV_Working_Group">meeting</a> we have some new members!</p>
<p>I should also mention another working group in the OpenStack community that has ties to Telecom and NFV: the <a href="https://wiki.openstack.org/wiki/LCOO">Large Contributing OpenStack Operators</a> group (otherwise known as the LCOO). I think they missed an opportunity to name themselves the <em>Contributing OpenStack Operators who are Large</em>, ie. COOL, but no one asked me. :)</p>
<p>I’ve been working pretty closely with this group for a while, and they have been welcoming and accommodating, as they try to work with various large, usually telecom, companies who want to participate in the OpenStack community but maybe don’t quite know how…yet.</p>
<h2 id="conclusion">Conclusion</h2>
<p>For me, the summit was good. I missed hearing about what the developers are doing and working on by being able to sit in on their sessions, but I can understand why the OpenStack Foundation moved to creating the PTG concept. Only time will tell if it can improve the development of OpenStack, but I have a feeling it will. The worst part was that there wasn’t as many free drinks and candy around…only devs get that perk. ;) Devs, devs, devs.</p>
<p>Because I work in the NFV area, I was extremely attuned to what is happening around it at the summit, and there is a lot. AT&T, and soon Verizon (among others?) are really trying to participate in the open source community and putting resources into writing open source code. In contrast, other, usually smaller, telecoms are in over their head and will continue to rely on beating up vendors as their main technical strategy. My recommendation to all telecoms would be to invest in people and everything needed to make them successful.</p>
<p>It’s going to take telecoms time to figure it all out, but if they do, then they will make a considerable impact on OpenStack over the next few years, and in fact it would not surprise me if NFV became the dominant use case for OpenStack…as telecoms around the world will be deploying thousands of clouds, which honestly I believe is thousands more than what has been deployed in the enterprise.</p>
<p>Now I’m looking forward to the OpenStack Operators meetup in August in Mexico City, and the next summit which is in Sydney Australia. It’s a long way to go, but it should be fun.</p>
OpenStack Multi-site, Multi-clouds, and Distributed Clouds2017-05-09T00:00:00+00:00http://serverascode.com/2017/05/09/openstack-multisite-multicloud<h1 id="openstack-multi-site-multi-clouds-and-distributed-clouds">OpenStack Multi-site, Multi-clouds, and Distributed Clouds</h1>
<p>One OpenStack cloud is rarely enough. Most organizations that deploy one OpenStack cloud will, at some point, at least think about deploying a second. Some organizations will not only want to depoy a couple clouds, but maybe 10, or 20, or 50…or even more. In some industries, such as telecommunications, organizations may want to deploy hundreds of OpenStack instances. And, as unbelievable as it sounds, some use cases require thousands. But what are the options available when deploying more than one OpenStack cloud? How would we deploy 2, 10, or 100+ clouds?</p>
<p>In this post I will go over some options and their pros and cons, as well as consider some of the features and architectural changes OpenStack may need to implement in order to meet the requirements of use cases such as massively distributed clouds.</p>
<p>I should also mention that this post is based on a talk I did at the 2017 Boston OpenStack summit with two colleagues, Adrien Lebre and Chaoyi Huang. Adrien is the chair of the “Fog, Edge, and Massively Distributed Working Group” and Chaoyi works on the Tricircle and Kingbird projects and is active in many areas of Network Function Virtualization (NFV). I learned a lot from the two of them while putting together the presentation. I won’t link to the video here, because I’m not a huge fan of being recorded, but a simple Youtube search will find it. :)</p>
<h2 id="definitions">Definitions</h2>
<p>Terminology for multiple OpenStack clouds is difficult. Some people use different terms for the same thing, and use the same terms for different things. I’ll make a couple of definitions, but be aware that other people might not use them the same way I do, or might disagree with my choices.</p>
<p><strong>Regions/Multi-region</strong>: When I talk about multi-region, I essentially mean that the OpenStack Keystone database is shared in some fashion.</p>
<p><strong>Mult-site</strong>: I define multi-site as having multiple OpenStack clouds, but no shared Keystone.</p>
<p><strong>Fog/Edge/Massively Distributed</strong>: I will use these interchangeably. Essentially it means that we have many small “data centers” (which may not be datacenters at all) and there will be only a few hypervisors located there–the OpenStack control plane will be remote, ie. in a different datacenter. This is for use cases like retail and such where an organization has thousands of locations, and many one or two hypervisors in each location.</p>
<p><img src="/img/shared-keystone.jpg" alt="shared keystone" /></p>
<h2 id="openstack-regions---the-historical-method">OpenStack Regions - The Historical Method</h2>
<p>I used to work at a public cloud in Canada which was based on OpenStack. We planned on having two OpenStack regions in Canada, one in Vancouver and one in Toronto. OpenStack regions are a good way to manage authentication and authorization for two or three OpenStack clouds (or more, depending on your risk profile). The fact that I mention authorization (authz) and authentication (authn) is important, because in general this is all regions provide–shared identity. Only Keystone (and potentially Glance and Horizon) are suited for being shared across regions. Most of the other services, such as Nova and Neutron, will have completely separate installations in each region, and are not shared.</p>
<p>We’ve established that with regions we share Keystone in some fashion. In the image above, we can see a simplistic diagram of a Keystone that is shared across datacenters of a secure, private link. Each datacenter has MySQL Galera nodes that are part of a Galera cluster that exists across multiple datacenters.</p>
<p>To share the Keystone across mutliple datacenters you have three main options:</p>
<p><strong>Centralized Keystone DB</strong>: In this model there is only one centralized Keystone database, and the other regions access the database directly via the WAN link; they have no local Keystone DB.</p>
<p><strong>Asyncronous Keystone DB</strong>: Here you would have database instances in each region/DC, but only one would be the “master” version (ie. read/write) and the other regions would have their DBs asynchronously updated by the master, ie. they would be <a href="https://dev.mysql.com/doc/refman/5.7/en/group-replication-primary-secondary-replication.html">secondary databases</a>.</p>
<p><strong>Syncronous (Clustered) Keystone DB</strong>: Using MySQL/MaraiDB Galera clustering, the Keystone database would be synchronously shared across all regions. This is the model that is usually given as an example of regions.</p>
<p>All of these options have pros and cons. Asynchronous is probably the most scalable model, but overall my opinion is that none of these are all that useful. Essentially regions, as I define them, are no longer a good option.</p>
<p>The reality is that all a shared Keystone model buys you is shared authz/authn. We still have all kinds of other issues to deal with, from keys to images to determining how to share Neutron tenant networks across clouds. There are things that every OpenStack multi-cloud deployer wants, and regions don’t help with any of that. Further to this, using a shared Keystone has some additional cons, such as operational complexity, and the fact that the Keystone version would probably have to be the same across all clouds, making upgrades slightly more difficult.</p>
<p><img src="/img/cells-v2.jpg" alt="Cells V2" /></p>
<h2 id="nova-cells-v2">Nova Cells V2</h2>
<p>Nova has had a cell model (V1) for quite some time. Essentially it allows the creation of reduced (Nova) failure domains and allows for better scalability. In V2 this is accomplished by adding a <code class="language-plaintext highlighter-rouge">nova_api</code> DB to the control plan, and a <code class="language-plaintext highlighter-rouge">nova</code> DB in the cell. Also each Cell has its own messaging queue (aka RabbitMQ). However, V1 is not widely used, and in fact I was recently at a OpenStack summit where Nova developers mentioned that they are surprised V1 even works.</p>
<p>However, V2 is is now default in OpenStack Ocata+. If you deploy Ocata you will have one cell. However, Cells V2 is not yet done, and in fact you can’t add additional cells. Right now you can have as many cells as you want as long as it’s one. This is expected to change in Pike or Queens. The point is that V2 will now be widely used, and at some point will be usable, and will enable Nova to be highly scalable.</p>
<p>Unfortunately, this is just for Nova. I would love to see a similar model applied to all major OpenStack projects. But even if they all decided they wanted to do that, it would probably take a couple years for the changes to make their way into the releases.</p>
<p>I’d also like to mention that, at least when Cells V2 is production ready, using it in combination with something like <a href="https://docs.openstack.org/newton/networking-guide/config-routed-networks.html">routed provider networks</a> would be extremely powerful. I would consider routed provider networks complimentary to cells. Imagine doing Nova Cells V2 on a per rack basis, and also routed provider networks.</p>
<h2 id="shared-ldap">Shared LDAP</h2>
<p>I should note that Keystone can authenticate to a LDAP backend, and that backend could be shared/synced across many clouds. Often this is done with Active Directory (which I know nothing about). But, of course, this just provides shared authn.</p>
<h2 id="shared-nothing-multi-cloud">Shared-Nothing Multi-cloud</h2>
<p>Mirantis has a good <a href="https://www.mirantis.com/blog/scaling-openstack-shared-nothing-architecture/">blog post</a> on shared-nothing OpenStack multi-cloud. On first blush, it seems overly simplistic. We just deploy a bunch of completely separate clouds.</p>
<p>The reality is that you can’t just stop there. In a multi-cloud deployment with shared-nothing we are going to have to rely on some kind of 3rd party abstraction layer that sits above the clouds and manages users, groups, keys, images, etc. There is a lot of work required to implement that kind of model, as at least the 3rd party “cloud broker” must be implemented or developed. But, as Mirantis mentions, there are a lot of pros to using this model.</p>
<p>Realistically, if you are deploying 10s or 100s of clouds, this is probably the only model that will work (at least at this time).</p>
<h3 id="etsi-mano">ETSI MANO</h3>
<p>Over the last year or so I have been doing a lot of work within the realm of “Network Function Virtualization” (NFV). The European Telecommunications Standards Institution (ETSI) has defined some NFV components. One of those complements is the “Management and Orchestration” (MANO) system. I’m sure there is a proper, specific definition for MANO, but I tend to see it as an amorphous blob that can take any shape and perform any function (ie. the ultimate lock-in).</p>
<p>There are several MANO vendors and <a href="http://about.att.com/innovationblog/onap">open source projects</a>. Suffice it to say that overall it seems like the MANO layer would not mind taking complete control of all OpenStack clouds. I’m not so sure that is a good idea, and may not be in OpenStack’s best interest. However, that doesn’t mean it’s not the best solution for telecommunications companies, such as AT&T. That said, MANO systems won’t be able to do absolutely everything without some help from additional projects, especially around networking.</p>
<p><img src="/img/federation.jpg" alt="Federation" /></p>
<h2 id="openstack-federation">OpenStack Federation</h2>
<p><a href="https://docs.openstack.org/developer/keystone/federation/federated_identity.html">Federation</a> is a powerful technology that essentially allows one cloud to trust the users of another. The canonical use case for federation is when non-profit or academic institutions would like to enable their cloud users to utilize resources in another organizations cloud (and potentially vice-versa). Further to this, it could also be used as a form of centralized identity.</p>
<p>For this blog post I just want to go over some potential solutions, and don’t want to go in depth into any of the solutions in particular. In future blog posts I hope to go into federation more deeply.</p>
<h2 id="tricircle-and-kingbird">Tricircle and Kingbird</h2>
<p>There are a couple of projects I would like to mention that could be used to help deploy multiple clouds. As mentioned, it’s often desirable to have networking in OpenStack understand multi-cloud. <a href="https://wiki.openstack.org/wiki/Tricircle">Tricircle</a> helps with this. Further, as mentioned, even if we used regions, we would still have to manage keys, images, and such. This is where <a href="https://wiki.openstack.org/wiki/Kingbird">Kingbird</a> enters the picture.</p>
<p>I can’t comment much more on either of those projects as I have not used them. But, suffice it to say that they are in active development and are very important for organizations such as telecommunications companies who would like to deploy tens or hundreds of clouds.</p>
<h2 id="fog-edge-and-massively-distributed">Fog, Edge, and Massively distributed</h2>
<p>As previously mentioned, there are use cases, such as retail stores with a couple hypervisors in each store, which we would consider as requiring some kind of massively distributed deployment model. This model does not currently exist, but there is a <a href="https://wiki.openstack.org/wiki/Fog_Edge_Massively_Distributed_Clouds">working group</a> within the OpenStack community that is defining the surrounding use-cases, and over time will begin to define a recommended implementation.</p>
<p>It’s also fairly apparent to me that the OpenStack Foundation would like to see this use case supported. It is going to take a considerable amount of work to enable this use case, but over the next few releases I would expect to see it being earnestly discussed and worked on at some level. I’m excited to see increasing interest in the edge model, as to enable it we’ll have to make substantial changes to OpenStack.</p>
<h2 id="conclusion">Conclusion</h2>
<p>OpenStack has some fairly rich authn/authz models. Unfortunately, my go to multi-cloud model of yesteryear, regions, doesn’t work (IMHO) when you have more than a handful of clouds, and doesn’t provide all that many features anyways. NFV deployments, and deployments requiring massively distributed hypervisors, won’t be able to use regions (not that they would help anyways), so we have to look at other models, some of which don’t yet exist.</p>
<p>Likely we will require a combination of tools such as software defined networking, perhaps Tricircle, Kingbird and massively distributed in order to deploy and operate large numbers of clouds. Generally speaking the telecommunications industry is going to drive these requirements as they are the ones that need thousands of tiny clouds or hundreds of small/medium ones.</p>
<p>It’s an exciting time in OpenStack, partially because I’m not sure what is going to happen. Will OpenStack pivot to support large NFV deployments? I think they will have to in order to continue to grow, assuming that is a goal. If not, then it is hard to say. Perhaps I’m just in denial that OpenStack just has to be able to provide shared-nothing clouds and some magical MANO or other higher layer abstraction along with SDN solutions and a couple cell-like models will be enough. What’s more, there does seem to be a lot of interest in creating an Open Source MANO solution, for example <a href="https://www.onap.org/">ONAP</a>.</p>
SDN on All Interfaces2017-01-24T00:00:00+00:00http://serverascode.com/2017/01/24/sdn-all-host-interfaces<h1 id="sdn-on-all-interfaces">SDN on All Interfaces</h1>
<p>Recently I have been involved in some discussions surrounding network segmentation, specifically around the concept of PVLAN…private VLAN. Note that this is different from the idea of a private network, or a tenant network in a virtualization system, and is instead a form of network isolation, and I believe is described in <a href="https://tools.ietf.org/html/rfc5517">RFC 5517</a>.</p>
<blockquote>
<p>Private VLAN, also known as port isolation, is a technique in computer networking where a VLAN contains switch ports that are restricted such that they can only communicate with a given “uplink”. The restricted ports are called “private ports”. Each private VLAN typically contains many private ports, and a single uplink. The uplink will typically be a port (or link aggregation group) connected to a router, firewall, server, provider network, or similar central resource. - <a href="https://en.wikipedia.org/wiki/Private_VLAN"> Wikipedia</a></p>
</blockquote>
<p>PVLAN is based on physical switch ports, and only works on access ports, not trunk ports. This is a problem in environments where we have bonds on hosts that are accessing multiple VLANs and, of course, virtual switches in a virtualization environment. (That said, some distributed virtual switches support PVLANs, but not OVS which is common in most open source virtualization systems, such as OpenStack.)</p>
<h2 id="micro-segmentation">Micro-segmentation</h2>
<p>What we are really talking about, as far as I’m concerned, is micro-segmentation. This concept has become popular recently, mostly due to a desire for <em>zero-trust networks</em> and the proliferation of containers.</p>
<p>One way to deploy containers is to give them all an IP, be it IPv4 or IPv6, and to not be concerned as to what IP they get, and where this IP is actually located in the datacenter. This suggests that we need powerful network policies to control what these containers need to connect to, and thus we get micro-segmentation. Frankly I’m not sure how <a href="http://blog.ipspace.net/2014/06/why-is-ipv6-layer-2-security-so-complex.html">layer 2 networks</a> make sense in a situation where we have zero-trust, but if it does, then the virtualization hosts will have to have their interfaces, especially virtual switches, controlled by SDN, or perhaps some kind of centralized firewall management (where firewall means managing flows, not blocking ports).</p>
<p>See <a href="https://www.nanog.org/sites/default/files/20161018_Lapukhov_Internet-Scale_Virtual_Networking_v1.pdf">this fascinating Facebook presentation</a> on <em>Internet-scale Virtual Networking Using Identifier-Locator Addressing</em> for some mindblowing ideas. <em>cough</em> IPv6 <em>cough</em>. There is a <a href="https://www.youtube.com/watch?v=xy3DPkwcbvA">video</a> as well.</p>
<h2 id="zero-trust-networks">Zero-trust Networks</h2>
<p>East/west traffic has grown considerably.</p>
<blockquote>
<p>The threat from inside is bigger than ever before and is further exacerbated by the fact that around 80 percent of traffic in data centers is now of east-west nature - <a href="https://www.sdxcentral.com/articles/contributed/data-center-security-shiv-agarwal/2016/02/">SDX Central</a></p>
</blockquote>
<p>Organizations of all kinds are getting cracked left and right, or…er…east and west. Clearly security is broken, most often because we build networks that are secure on the perimeter but wide open internally (also humans make mistakes and write software).</p>
<blockquote>
<p>The Zero Trust Model is simple: cybersecurity professionals must stop trusting packets as if they were people. Instead, they must eliminate the idea of a trusted network (usually the internal network) and an untrusted network (external networks). In Zero Trust, all network traffic is untrusted. - <a href="http://csrc.nist.gov/cyberframework/rfi_comments/040813_forrester_research.pdf">Forrester</a></p>
</blockquote>
<p>I believe Ronald Reagan popularized the phrase “trust but verify” which unfortunately has become a common refrain, and one I have never liked. Clearly we cannot automatically trust any network activity, and frankly I don’t know how much network verification has ever occurred.</p>
<p>Some organizations use PVLAN to try to deter lateral movement of bad actors, but in a modern, virtualized, or even worse, containerized, datacenter PVLAN is of no use. So we need another technology to achieve zero trust.</p>
<h2 id="separation-of-duties">Separation of Duties</h2>
<p>Clearly one area PVLAN may have an edge is that it is performed by physical network hardware. If micro-segmentation is managed by the local vswitch on a physical host, or (ugh) firewall rules in a VM, then there is not as much separation of duty. Further these systems are typically managed out of band of the network (though things like routing protocols would not be).</p>
<p>That said, virtualization is so important that it likely cancels out any security issues; it’s just too useful. Even <a href="https://www.openbsd.org/papers/asiabsdcon2016-vmm-slides.pdf">OpenBSD is getting a hypervisor</a>. If we are going to do large scale virtualization, ie. IaaS, then we have no choice but to trust the hypervisors, and thus the vswitches. If you work in a place that believes hypervisor breakouts are too risky, then I would imagine your infrastructure is quite different than most, and you have unique requirements.</p>
<p>Further, it could be that the fact that <em>all</em> hypervisors are secured via micro-segmentation is helpful should some of them become compromised. Unless the centralized “micro-segmentation” provider is also compromised, then all of the other micro-segmentation rules would still be in place, making it hard to hop from one compromised node to the other because the security polices are highly distributed and exist in some fashion on all nodes at all times.</p>
<h2 id="routing-on-the-host">Routing on the Host</h2>
<p>I want to mention “routing on the host” because it is a model that is becoming more popular, though still not that common. The idea is to allow hosts to announce what IPs they own, ie. typically become BGP speakers. This certainly comes with its own set of issues and benefits, which I won’t get into here. Certainly this model would have an effect on implementing micro-segmentation.</p>
<p>Some network companies, such as Cumulus Linux, are making routing on the host easier. I should note that I am a big fan of Cumulus, though no one I’ve ever worked with seems to like them. Cumulus, at least started out, trying to make <a href="https://cumulusnetworks.com/routing-on-the-host/">routing on the host</a> more commonplace. But I am not sure how well they have succeeded. They have gone so far as to create a custom <a href="https://github.com/CumulusNetworks/quagga">Quagga</a> package to enable routing on the host.</p>
<p><a href="https://www.projectcalico.org/">Project Calico</a> is similar:</p>
<blockquote>
<p>Based on the same scalable IP network principles as the Internet, Calico leverages the existing Linux kernel forwarding engine without the need for virtual switches or overlays. Each host propagates workload reachability information (routes) to the rest of the data center – either directly in small scale deployments or via infrastructure route reflectors to reach Internet level scales in large deployments.</p>
</blockquote>
<p>Calico seems to be picking up steam regarding Kubernetes (k8s), where k8s has made the major architectural decision to give each container its own IP.</p>
<p><img src="/img/cosmic.jpg" alt="https://flic.kr/p/aiLeiD" /></p>
<h2 id="virtual-switches-are-part-of-your-network-infrastructure">Virtual Switches are Part of Your Network Infrastructure</h2>
<p>I think if there is a valuable idea in this post it is to consider virtual switches as part of your <strong>network</strong> infrastructure. For example in a small OpenStack deployment you might have four physical switches, but then you will have one virtual switch for every OpenStack Neutron DHCP/L3 server and of course all the compute nodes. That adds up to a lot of switches. If you have 100 hypervisors then you have 100+ switches.</p>
<p>These vswitches can break–they can get hit by cosmic rays, be attacked by viral switches (I made that up) and run into all kinds of other issues.</p>
<h2 id="interfaces-and-bonds-are-part-of-your-network-infrastructure">Interfaces (and Bonds) are Part of Your Network Infrastructure</h2>
<p>Hosts often have bonds that are configured to accept multiple VLANs. We have Link Layer Discovery Protocol (LLDP) to help with this, and to show that the interfaces and bonds are really part of the network infrastructure. Perhaps OVS sits on top of the bonds. Perhaps the bonds are only used for underlying IaaS infrastructure. Perhaps the bonds are Linux bonds or they are OVS bonds or both types exist.
I have not tried as of yet, but apparently OVS supports <a href="http://www.dorm.org/blog/finally-a-workaround-for-lldp-with-open-vswitch/">LLDP</a>.</p>
<p>Presumably, in a post-VLAN micro-segmentation enabled world, we would need something like OVS to control all interfaces in a physical host, even ones that aren’t supporting virtual machines. Linux bridge isn’t going to cut it. Don’t get me started on <a href="http://blog.ipspace.net/2017/01/never-take-two-chronometers-to-sea.html">MLAG</a>… :)</p>
<h2 id="open-vswitch-is-pretty-important">Open vSwitch is Pretty Important</h2>
<p>Does Open vSwitch support PVLANS? Not right now. Perhaps if OVS did then this whole thing would not even be a question. But to me, even if it did, how would it do it? It would be done with flows. Which you can do now. Further, as discussed in this blog post, in my opinion PVLAN is a heavy handed way to try to enable micro-segmentation, meaning that if we are to do micro-segmentation with OVS then it would likely be considerably more sophisticated than simply emulating PVLAN.</p>
<p>In the case of IaaS, virtual switches are in effect distributed and are controlled by a centralized system (for example OpenStack Neutron) or with an SDN controller (perhaps in conjunction with Neutron). If you have hundreds of OVS instances, then they need to be centrally managed. It’s not enough to push a one-time configuration into each vswitch as obviously workloads are being constantly created and destroyed or (yuck) moved.</p>
<h2 id="potential-micro-segmentation-solutions">Potential Micro-segmentation Solutions</h2>
<h3 id="security-groups-for-tenant-workloads">Security Groups for Tenant Workloads</h3>
<p>One potential solution to micro-segmentation is firewall rules on the host. Or, if some form of segmentation is required in tenant workloads in an IaaS system, then usually they support security groups.</p>
<p>Generally speaking, security groups in IaaS are used to specifically allow communication on a layer 2 network, just like any normal network would do, and are typically used to stop external layer 3 ingress connections. Usually the default is to allow all traffic on the local network, which makes sense in most cases. Depending on their implementation they may be able to implement a form of micro-segmentation but occasionally security group functionality is somewhat limited.</p>
<h3 id="host-based-firewalls">Host-based Firewalls</h3>
<p>For physical hosts, we could setup Iptables rules as a way to achieve micro-segmentation. Perhaps some 3rd party system would manage and deploy Iptables rules. It could be as simple as configuration management tooling, such as Ansible, but the question is what happens on changes, and what is the “single source of truth” for the config tooling to access? For example if a container is created, and it can come up with any IP on any hypervisor, then how will this 3rd party Iptables configurator know what to do and when to do it, unless that system is what is managing the life cycle of containers.</p>
<p>However, even without containers, things start to get rapidly ugly, even in a non-hypervisor environment, basically around heterogeneous systems, where there is a lot of variation in things like operating systems. Managing firewall rules on multiple platforms will not be easy.</p>
<p>Also, Iptables is global and you will take a performance hit.</p>
<blockquote>
<p>There is no concept of per-interface rules in iptables, iptables rules are global. This means that for every packet, incoming interface needs to be checked and execution of rules branched to the set of rules appropriate for the particular interface. This means linear search using interface name matches which is costly, especially with a high number of VMs. - <a href="http://redhatstackblog.redhat.com/2016/07/22/how-connection-tracking-in-open-vswitch-helps-openstack-performance/">RedHat</a></p>
</blockquote>
<h3 id="firewall-vendors-service-function-chaining">Firewall Vendors, Service Function Chaining</h3>
<p>Firewalls will probably never go away. I wish they would…all these middleboxes getting in the way, slowing things down, costing money, etc. Typically firewalls just have two sides: inside and outside. With zero-trust and micro-segregation we are trying to get rid of that false dichotomy.</p>
<p>Firewall vendors love the idea of micro-segmentation though. Palo Alto is a popular firewall provider; they have managed to step into the role that Checkpoint used to fill. They have a neat <a href="https://www.youtube.com/watch?v=68zhDttmnIc&t=1341s">demo</a> using service function chaining and OpenStack to dynamically insert a firewall into a service chain. Very interesting and quite powerful, but also resource intensive. We can’t insert an entire firewall into every flow on the network or drop one in front of every container…maybe one on every host? If the firewall is on every host, then it might as well be the vswitch. Perhaps companies like Palo Alto could either write their own OVS compatible vswitch or there is some kind of a plugin system.</p>
<p>We likely need something less resource intensive. While SFC is an important concept for providing tenant security and functionality, it is, however, not as useful for securing the underlying infrastructure, ie. it is an NFV technology as opposed to a datacenter security technology. That said in situations where attacks are detected inserting a powerful firewall or IDS may be valuable even in the DC.</p>
<h3 id="firewalls-in-the-nics">Firewalls in the NICs</h3>
<p>We are likely to see a surge in specialized hardware, partially due to the slowdown in Moore’s law. This could include having “smart NICs.” VXLAN offloading is common, so why not flows as well.</p>
<p><a href="https://www.netronome.com/products/agilio-cx/">Netronome</a> has some interesting products, though I have not used them. And of course now we’d be relying on firmware which is notoriously painful. However, this could be beneficial in that it is potentially separate(ish) hardware. But that said, I’m not sure how they are programmed or what their control plane looks like…perhaps from the host. :0</p>
<blockquote>
<p>Compounding the problem is heightened security, which is moving from a firewall on the perimeter of the network to policy-based security with network rules governing access to virtual machines and now software containers. Das says that it is common to require 1,000 security policy rules per VM in clouds these days, which works out to 48,000 rules for a two-socket server with a total of 48 VMs, and moreover that at some infrastructure running inside of the datacenters in China, a single server might have to juggle as many as 1 million – yes, more than a factor of 20X more – security policy rules. Shifting from VMs to containers, where a single server might have thousands of containers and yet a large number of security policy rules, will make the situation even worse. - <a href="https://www.nextplatform.com/2016/01/27/offloading-the-network-like-a-hyperscaler/">The Next Platform</a></p>
</blockquote>
<p>1000 rules per VM sounds crazy. But maybe.</p>
<p>If we could get higher performance with specialized NICs, regain CPU cores, and still have the ability to easily update and install software on them, then this might be a good way to go about obtaining micro-segmentation.</p>
<h3 id="software-defined-networking">Software Defined Networking</h3>
<p>My thesis is that if we want micro-segmentation, then they way to do this is in the network using some form of SDN which manages the local virtual switch as well as the underlying physical infrastructure, and hopefully it would utilize IPv6. (Surprisingly IPv6 is probably the hardest part, because few seem to support it.)</p>
<p>The prior solutions, mostly utilizing firewall rules in some fashion, were really just ideas/brainstorming if a true SDN solution is not possible for whatever reason.</p>
<p>I don’t want to get into what SDN systems might be able to meet these requirements in this post, so for now I will just leave it as a statement to come back to in future writing, especially once I have done some work in the lab.</p>
<h2 id="various-paradoxes-twiddling-with-vlans-and-lets-do-as-we-say-too">Various Paradoxes, Twiddling with VLANs, and Let’s Do as We Say Too</h2>
<p>Typically the underlying IaaS infrastructure will be deployed just like we have deployed “enterprise” systems for the last 20 years (minus virtualization). VLANS. Bonds. MLAG. Middleboxes. Manual configuration. Servers or server pairs that can never be down. Hand crafted and bug ridden. Expensive. Instance high availability. Time consuming. Waterfall. Complicated. Tribal knowledge. Security choke points. Hard-candy coating with soft milk chocolate inside. On and on.</p>
<p>We put IaaS on top of this old-school enterprise architecture and deployment and force the tenants to do “cloud native.” It just doesn’t seem good or fair to me. If anything this is why private clouds fail. Why do IaaS if it is just going to look like VMWare deployments of the last decade or two? Most of the time the answers are circular: we deploy it this way because nobody else is doing it the other way, so we deploy it this way. See IPv6.</p>
<p>PVLAN is a great example of VLAN twiddling. In an era where security is failing, we really need to inhibit malware and lateral movement in DCs where east/west traffic is growing. Thus, we need to push SDN–not Iptables rules–all the way to host interfaces in order to enable micro-segmentation…somehow…</p>
<p>I’m not sure if anyone will actually read this post. I’m sorry it’s kind of long (I left some things out, honestly, like Intent Based Networking for example) but I find this area is fascinating and there are many options. It’s not a solved space. We really need to do something about at least two things 1) enabling zero-trust networks and 2) not continuing to deploy underlying IaaS infrastructure the way we have for the last 20 years: we need to deploy the systems that support the IaaS using cloud native designs as well.</p>
<p>Certainly I mention containers a lot in this post, and that makes it easy to dismiss much of what I’m saying because how many organizations are really going to run containers and be successful at it. Not many. Most organizations will still have a majority of workloads that will not fit into the container paradigm. However, they will certainly be using virtualization (really are they that different), and in some cases perhaps be looking at a technology like OpenStack, and in that situation it would be completely possible to work on enabling zero-trust networks and micro-segmentation, likely through and SDN solution. My thesis is that that SDN should not just live only in OpenStack, but should also be part of the underlying IaaS infrastructure. I think that is completely possible. Further to that, it is likely, if not inevitable, and if not already, that the OpenStack control plane will be containerized, meaning that if you run OpenStack you will be running containers, whether you want to or not.</p>
OpenDaylight Boron, OpenStack, and Networking-ODL2017-01-09T00:00:00+00:00http://serverascode.com/2017/01/09/opendaylight-boron-openstack-networking-odl<h1 id="opendaylight-boron-openstack-and-networking-odl">OpenDaylight Boron, OpenStack, and Networking-ODL</h1>
<p>Software Defined Networking (SDN), like many other technical terms (<em>cough</em> devops <em>cough</em>) is often considered a panacea, but is also fraught with peril, etc, etc…you can see where I’m going, feel free to complete this thought on your own.</p>
<p>Anyways, the point of this post is that I have recently been able to spend some time getting the OpenDaylight Boron release to work as the SDN controller for an OpenStack cloud, and I thought I would relay some of the issues I encountered as well as some of the required software and steps to complete the integration.</p>
<h2 id="tldr---official-documentation">tl;dr - Official Documentation</h2>
<p>As I write this there is a <a href="http://docs.opendaylight.org/en/latest/opendaylight-with-openstack/openstack-with-netvirt.html">page</a> that details how to integrate ODL Boron with OpenStack.</p>
<p>I only encountered two issues with this documentation, the first is that the DLUX web GUI feature/plugin mentioned is incorrect and you would want the DLUX-core plugin. But that wouldn’t affect actually using ODL, just access to a simple GUI.</p>
<p>Next, due to a bug in OpenStack which was fixed in master and <a href="https://review.openstack.org/#/c/403672/">back-ported</a> to Newton, I needed to deploy Newton Neutron from the stable branch. I would imagine that that back-port will now be in most OS packaging though, so you probably won’t have to worry about it, unless you are deploying a pre-Newton OpenStack. Not sure if it was back ported to release before Newton.</p>
<p>Otherwise, besides showing first deploying OpenStack and then deleting all the neutron state (not sure why all the examples do that), the documentation is pretty good and I’m sure will improve.</p>
<h2 id="this-is-boron">This is Boron</h2>
<p>Most of the blog posts and documentation you will find on the Internet are related to previous releases of OpenDaylight, and most of these instructions will only be about 75% correct.</p>
<p>Boron has a new ODL feature, <a href="https://wiki.opendaylight.org/view/NetVirt">Netvirt</a> which has taken over some of the functionality for supporting an OpenStack cloud. Essentially, instead of using the <em>odl-ovsdb-openstack</em> feature/plugin, you will use the <em>odl-netvirt-openstack</em> plugin.</p>
<p>Other than Netvirt and requiring Java 8, Boron seems to be quite similar from a systems administration perspective.</p>
<h2 id="networking-odl">Networking-ODL</h2>
<p><a href="http://docs.openstack.org/developer/networking-odl/readme.html">Networking-ODL</a> is required code, perhaps driver is the right term, to allow the Neutron API to work with and OpenDaylight controller.</p>
<blockquote>
<p>OpenStack networking-odl is a library of drivers and plugins that integrates OpenStack Neutron API with OpenDaylight Backend. For example it has ML2 driver and L3 plugin to enable communication of OpenStack Neutron L2 and L3 resources API to OpenDayLight Backend.</p>
</blockquote>
<p>It does not come with Neutron packaging at this time, and needs to be installed separately, either via Pip as most examples show or via source. Typically I will install from source using <em>stable/<openstack version></em> just to get the latest code.</p>
<h2 id="configuration-management-of-open-vswitch">Configuration Management of Open vSwitch</h2>
<p>There are a couple of settings that need to be made to each Open vSwitch before it can be used by ODL. Typically this will be done with your configuration management tooling, ie. what ever is managing OpenStack’s configuration.</p>
<p>The first is the “manager”. Most documentation will show how to set that.</p>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="nv">$ </span><span class="nb">sudo </span>ovs-vsctl show | <span class="nb">head
</span>7f7084b9-f0d8-449a-97fa-06476303d3cf
Manager <span class="s2">"tcp:10.15.0.190:6640"</span>
is_connected: <span class="nb">true
</span>Bridge br-int
Controller <span class="s2">"tcp:10.15.0.190:6653"</span>
is_connected: <span class="nb">true
</span>fail_mode: secure
Port <span class="s2">"tap35617dae-c8"</span>
Interface <span class="s2">"tap35617dae-c8"</span>
Port <span class="s2">"tun18897aa9c4e"</span>
</code></pre></div></div>
<p>Above the manager is connected to the ODL controller.</p>
<p>Next is the <em>local_ip</em>.</p>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="nv">$ </span><span class="nb">sudo </span>ovs-vsctl list Open_vSwitch | <span class="nb">grep </span>other_config
other_config : <span class="o">{</span><span class="nv">local_ip</span><span class="o">=</span><span class="s2">"10.15.0.11"</span>, <span class="nv">provider_mappings</span><span class="o">=</span><span class="s2">"provider:bond1"</span><span class="o">}</span>
</code></pre></div></div>
<p>That IP will become the endpoint for VXLAN tunnels.</p>
<p>Finally, as can be seen above as well, there is a <em>provider_mappings</em> key/value pair. This will list out the various Neutron networks and the physical interfaces they are supposed to use. This will be what floating IP or provider networks (ie. “external networks”) will use. ODL will use the value to setup OVS on each node.</p>
<p>All three of these settings would be put in place by your config mgmt tool, eg. Ansible. :)</p>
<p><img src="/img/odl_netvirt_pipeline.jpg" alt="ODL Netvirt Pipeline" /></p>
<p>(Example of <a href="https://docs.google.com/presentation/d/15h4ZjPxblI5Pz9VWIYnzfyRcQrXYxA1uUoqJsgA53KM/edit#slide=id.p">ODL Netvirt Pipeline</a>)</p>
<h2 id="issues">Issues</h2>
<ul>
<li>The NATP component, currently at least, does not support ICMP. So if you have an instance on VXLAN and there is a router with an external gateway on on external network, ping, for example, won’t work, but UDP and TCP will. I recieved the errors below on the ODL controller when pinging from an instance. Apparently it is because OpenFlow doesn’t support ICMP on flows. This can be confusing while testing…it certainly confused me for a while.</li>
</ul>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code>2017-01-10 19:13:03,772 | ERROR | pool-21-thread-1 |
NaptPacketInHandler | 345 -
org.opendaylight.netvirt.natservice-impl - 0.3.2.Boron-SR2 | Incoming
Packet is neither TCP or UDP packet
2017-01-10 19:13:03,772 | ERROR | pool-21-thread-1 |
NaptPacketInHandler | 345 -
org.opendaylight.netvirt.natservice-impl - 0.3.2.Boron-SR2 | Incoming
Packet is neither TCP or UDP packet
</code></pre></div></div>
<ul>
<li>I wonder about having a tunnel from each host to every other host. Not sure how well that will scale. Something to look into.</li>
<li>Like many other SDN systems, sometimes the initial setup of an unknown flow can be slow, but once it is in place on the OVS switch obviously it’s faster. I’ve experienced this with Midokura’s Midonet as well.</li>
</ul>
<p>Otherwise everything seemed to work fine.</p>
<h2 id="why-opendaylight">Why OpenDaylight?</h2>
<p>What does one get from deploying ODL?</p>
<p>My opinion is that it provides the potential to perform fairly advanced network configurations that without an SDN controller would be difficult or impossible. Frankly at this state ODL + OpenStack is still being worked on. Most of the basic features are there, but where it really starts to get interesting is once we are past that stage, and want to do things like connecting tenants across multiple clouds, connecting to hardware VTEPs, things like that. It is going to take a while for all of this to become ready for production use.</p>
<p>There were a fair number of features delivered in ODL Boron (3):</p>
<ul>
<li>Merge of NetVirt and VPNService projects</li>
<li>L2, L3</li>
<li>Auto-bridge creation</li>
<li>Auto-tunnel creation</li>
<li>Floating IP’s</li>
<li>VLAN and Flat provider network support for multiple internal and external networks</li>
<li>Security Groups: Stateful using conntrack, Stateless, Learn (for OVS-DPDK)</li>
<li>NAPT, SNAT</li>
<li>IPv6</li>
<li>Layer 2 Gateway</li>
</ul>
<p>My thoughts on the above, as well as additional capability not mentioned:</p>
<ul>
<li>No more br-int/iptables. Ok, br-int still exists, but security groups are NOT done by iptables. This was something that always bugged me, and a lot of people, but it was a good solution. However, now, with ODL, iptables is taken out of the stack and security groups are done with OVS rules. This is very powerful and important, as it will “remove the many layers of bridges/ports required in iptable implementation.” (1)</li>
<li>ODL takes care of layer 3 with a “distributed virtual router” that is on par with Neutron DVR (2), though no ICMP with NATP.</li>
<li>Ability to do Service Function Chaining (SFC). This functionality may come to “vanilla” Neutron, but most existing software that supports deploying SF chains will support ODL.</li>
</ul>
<h2 id="whats-next">What’s next?</h2>
<ul>
<li>Troubleshooting ODL - This is not easy, as the paths through tables are somewhat convoluted, but the flow map above certainly helps.</li>
<li>High Availability - ODL can be clustered, but I have not ventured into that area as of yet. Distributed systems are tough.</li>
<li><a href="https://wiki.openstack.org/wiki/Neutron/L2-GW">L2 Gateway</a> - Wanting to get your VXLAN based workloads out into a physical network is an oft requested feature. It seems ODL Boron has the ability to use L2 Gateway. This needs to be explored.</li>
<li>Service Function Chaining - This might not be as useful for organizations who are not interested in Network Function Virtualization (NFV), but that said, this is still quite powerful and useful in many “cloudy” situations. :)</li>
<li>OVS-DPDK</li>
</ul>
<h2 id="footnotes">Footnotes</h2>
<ol>
<li><a href="http://docs.opendaylight.org/en/stable-boron/user-guide/ovsdb-netvirt.html">OVSDB Netvirt</a></li>
<li><a href="https://media.readthedocs.org/pdf/opendaylight/1.0.0/opendaylight.pdf">OpenDaylight PDF</a></li>
<li><a href="https://docs.google.com/presentation/d/1VLzRIOEptSOY1b0w4PezRIQ0gF5vx7GyLKECWXRV5mE/edit#slide=id.g13650d2e5d_0_15">NetVirt Basic Tutorial</a></li>
</ol>
What OpenStack Distros?2016-12-21T00:00:00+00:00http://serverascode.com/2016/12/21/what-openstack-distros<p><em>Oops that’s Destro not Distro. Note the OpenStack logo though :)</em></p>
<h1 id="what-openstack-distros">What OpenStack Distros?</h1>
<p>On the surface it seems like there are many ways to install an OpenStack cloud; many <a href="https://www.openstack.org/marketplace/distros/">OpenStack distributions</a>.</p>
<p>OpenStack requires services and infrastructure and the only way to get those all co-oridinated is to use some kind of automated tooling, which is typically what these “distros” provide.</p>
<p>However, my definition of “distro” may not line up with most. Essentially I would consider a “distro” a OpenStack installer, and, more importantly something that helps manage OpenStack <em>after</em> the initial installation. Often the installation process is called “Day 1” and managing OpenStack after the installation “Day 2.” It’s not enough just to install OpenStack, distros need to provide Day 2 help as well.</p>
<h2 id="tldr">tl;dr</h2>
<p>There are way fewer OpenStack distros than one would think. Also, even if you have an OpenStack distro you will <em>still</em> need internal staff and/or professional services from the distro vendor. I’m aware that is not that helpful a conclusion. :)</p>
<p>To quote <a href="https://www.mirantis.com/blog/infrastructure-software-is-dead/">Boris Renski of Mirantis</a>:</p>
<blockquote>
<p>Everybody’s OpenStack software is equally bad</p>
</blockquote>
<p>But let’s go through this process anyways… :)</p>
<h2 id="official-distro-list">Official Distro List</h2>
<p>OpenStack provides a <a href="https://www.openstack.org/marketplace/distros/">list of most of the distros</a>. Here’s what is listed on there as of today:</p>
<ul>
<li>Stratosphere</li>
<li>Appformix</li>
<li>Dell EMC RedHat Solution</li>
<li>StackBuffet</li>
<li>Cisco Metacloud</li>
<li>HPE Helion OpenStack</li>
<li>T2 Cloud OS</li>
<li>Hyper-C</li>
<li>Enovance Service Provider Cloud</li>
<li>Suse OpenStack Cloud</li>
<li>H3 Cloud OS</li>
<li>Dell EMC VXRack with Neutrino</li>
<li>Aqorn Thunder</li>
<li>Redhat OpenStack Platform</li>
<li>Platform9</li>
<li>Ubuntu OpenStack</li>
<li>Bright Computing</li>
<li>Mirantis OpenStack</li>
<li>Oracle OpenStack</li>
<li>TransCirrus Cloud Appliance</li>
<li>Mirantis</li>
<li>IBM Spectrum Scale for Object Storage</li>
<li>AWCloud OpenStack Distribution</li>
<li>Oracle OpenStack for Oracle Linux</li>
<li>RackSpace Private Cloud</li>
<li>Vmware VIO</li>
<li>EasyStack ESCloud</li>
<li>Animbus CloudOS</li>
<li>Huawei Fusionsphere OpenStack</li>
<li>Ultimum Cloud Platform</li>
<li>IBM Cloud Manager with OpenStack</li>
<li>ZTE TECS OpenStack</li>
<li>Debian</li>
<li>SwiftStack</li>
<li>Breqwatr Cloud Appliance</li>
</ul>
<p>That seems like a long list with 35 entries; let’s go through it, examine the entries and see what can, and should, be removed.</p>
<p><strong>Not Distros</strong></p>
<p>A few are not OpenStack distros: Appformix (which was just bought by Juniper and is really a metrics system), IBM Spectrum (just object storage), SwiftStack (also just object storage), as well as Debian (which provides invaluable packaging, but not actually an installation and/or management system). I’m a big fan of Swift and thus SwiftStack, but it is not a full fledged OpenStack distro (ie. does not provide compute, networking).</p>
<p><strong>Defunct</strong></p>
<p>Then there are a few that are essentially defunct: eNovance was bought by RedHat some time ago, and Suse just bought HPE Helion. Oracle just cancelled Solaris. I think IBM Cloud Manager is dead too.</p>
<p><strong>Biased Removals</strong></p>
<p>A few I am going to remove just because I don’t see them as real entries, such as Oracle and VMware VIO, also the VXRack entry. Add them back in if you prefer, best of luck. :)</p>
<p><strong>APAC</strong></p>
<p>Some of these companies I just can’t find much information about, mostly because I am not familiar with APAC companies or languages. I wish I knew more. T2 Cloud. H3Cloud OS. AWCloud. Animbus Cloud. EasyStack. If your company is an APAC or works with APAC customers, then perhaps one of these entries would be a great choice. I would certainly be interested to know how these companies OpenStack distro works.</p>
<p><strong>Small Companies</strong></p>
<p>Next up are small companies. I think it would be very difficult to recommend a small company for an OpenStack distro as who knows if they will be around in a couple years. I suppose the same can be said for larger companies, given HPEs sad retreat. Bright Computing (Amsterdam). Aqorn (US). Ultimum (Prague).</p>
<p>Further, many companies, large and small, actually use someone elses distro, eg. RedHat or Mirantis.</p>
<p><strong>Appliances</strong></p>
<p>Personally, I would toss any appliance vendor. What is an appliance in 2016? It’s an x86 box with Linux on it. Which is what you would deploy the OpenStack control plane on anyways. So out go Breqwatr and Transcirrus (both of which I’m guessing are quite small companies). Mirantis Unlocked Appliances isn’t even a distro, it’s just certified hardware for the Mirantis plaform, not sure why it’s on the list at all.</p>
<p><strong>Solutions</strong></p>
<p>Some options are “solutions” as opposed to distros. Example Dell + EMC + RedHat. Presumably I could put my own solution up, say Mirantis + SolidFire + OpenDaylight or any combination of OpenStack, Storage, and SDN. Not a distro.</p>
<p><strong>Unclear</strong></p>
<p>I’m not sure what Aptira StackBuffet is, but based on a quick look it seems to be a system to generate OpenStack packages for the operating system layer. I would not consider that a distro. I’m sure Aptira provides OpenStack clouds, but I’m not sure how.</p>
<p><strong>Overspecialized</strong></p>
<p>I’d put Hyper-C into this category as it seems to be directed at Windows only shops. Presumably you can run any workload on their distro, but it does seem to have a specific marketing orientation. I would put Stratoscale here as well as they are a hyperconverged entry, apparently with their own hypervisor.</p>
<h2 id="so-what-are-we-left-with">So what are we left with?</h2>
<ul>
<li>SUSE/HPE Helion</li>
<li>Cisco Metacloud</li>
<li>RedHat OpenStack Platform</li>
<li>Platform9</li>
<li>Ubuntu OpenStack (does this mean BootStack?)</li>
<li>Mirantis</li>
<li>RackSpace Private Cloud</li>
<li>Huawei FusionSphere</li>
<li>ZTE TECS OpenStack</li>
</ul>
<p>Before going further with that list, lets checkout some open source “distros.”</p>
<h2 id="opensource-distros">OpenSource Distros</h2>
<p>The OpenStack project hosts several distros, or libraries:</p>
<ul>
<li><a href="http://docs.openstack.org/developer/puppet-openstack-guide/">Puppet OpenStack</a></li>
<li><a href="http://docs.openstack.org/developer/openstack-ansible/">OpenStack Ansible</a></li>
<li><a href="http://docs.openstack.org/developer/kolla/">OpenStack Kolla</a></li>
<li><a href="http://docs.openstack.org/developer/tripleo-docs/">Tripleo</a></li>
</ul>
<p>Puppet OpenStack is probably the most commonly used of the three I mention above, but it is more like a libary of Puppet manifests that can be used to deploy OpenStack. However, you need to create your own “composition layer” that will actually utilize those manifests. Thus I would not consider it a distro, though again, it is commonly used and well tested, it just requires some additional work.</p>
<p>OpenStack Ansible and Kolla are distros though. OpenStack Ansible is quite mature and stable, and is also, I believe, the basis for the RackSpace Private Cloud. Koll, on the other hand, is relatively new. It is getting a lot of press, so to speak, because it uses Docker images as a deployment mechanism, and, of course, it is also embroiled in the k8s hype.</p>
<p>I am quite familiar with Tripleo. It is the basis for RedHat’s Director installer. I am not it’s biggest fan, but it does work. It uses the aforementioned OpenStack Puppet as well as Ironic and Heat to deploy OpenStack. I personally have a concern with Day 2 and Tripleo, however.</p>
<p>Also, and this might be lesser known, the Open Platform for Network Function Virutalization (OPNFV) project has a <a href="https://wiki.opnfv.org/display/bgs/Installers">few installers</a>. Some are based on existing systems like Tripleo. I don’t know if you could use any of these in production, as they are mostly meant to be part of OPNFV’s continuous integration system, but they do exist.</p>
<h2 id="conclusion">Conclusion</h2>
<p>Whether you agree or disagree with my inclusions and removals, I think it’s safe to say that there is not a massive number of OpenStack distributions, and the ones that do exist are quite different in what they support and how they work after Day 1.</p>
<p>But…what distros do we have left?</p>
<ul>
<li>SUSE/HPE Helion</li>
<li>Cisco Metacloud</li>
<li>RedHat OpenStack Platform</li>
<li>Platform9</li>
<li>Ubuntu OpenStack (does this mean <a href="https://www.ubuntu.com/cloud/openstack/managed-cloud">BootStack</a>?)</li>
<li>Mirantis</li>
<li>RackSpace Private Cloud</li>
<li>Huawei FusionSphere</li>
<li>ZTE TECS OpenStack</li>
<li>OpenStack Ansible</li>
<li>OpenStack Kolla</li>
<li>OpenStack Tripleo</li>
</ul>
<p>I don’t know anything about Huawei Fusionsphere or ZTE TECS OpenStack. They may very well be based on an existing distro. Can’t comment.</p>
<p>Platform9 is a unique entry due to its SaaS design, which may not be suitable for all deployments, but I do think it is quite innovative.</p>
<p>RackSpace Private Cloud is based on OpenStack Ansible.</p>
<p>RedHat OpenStack Platform is based on Tripleo.</p>
<p>Mirantis is/was a “pure-play” distro which is now <a href="https://www.mirantis.com/company/press-center/company-news/openstack-kubernetes-mirantis-collaborates-intel-google/">moving quickly</a> to use Kubernetes to manage the OpenStack control plane. (1)</p>
<p>As far as Cisco Metacloud, I don’t know much about it, so can’t really comment, though it does seem t o be a valid option, assuming you like dealing with mega-sales-companies.</p>
<p>Next up, the Ubuntu/Canonical entry. I have not used it, but it seems to be a valid choice. I am hesitant regarding the Juju configuration management tool, but I have not used it so that is unfair. The visualization of components is interesting.</p>
<p>The sale of the HPE Helion intellectual property to SUSE is weird. There would have to be some period of instability here. I can’t see it being a viable option right now. Basically HPE has completely removed its involvment in OpenStack.</p>
<p>So, in my extremely biased opinion, what are we left with? Not much.</p>
<h2 id="whats-left-recommendations">What’s left? Recommendations…</h2>
<p>The Ubuntu/Juju distro seems like it would be Ok, but I have not used it.</p>
<p>RedHat OpenStack and Tripleo are good too. I have concerns about Tripleo on Day 2.</p>
<p>Rackspace Private Could is probably a great option given it is based on OpenStack-Ansible. Or OpenStack-Ansible by itself is great, if you want to use the open source version and support it yourself with help from the community.</p>
<p>Mirantis is still viable, but their k8s direction is concerning. Also, they are themselves questioning the value of a distro:</p>
<blockquote>
<p>…very few companies can manage a complex, distributed and fast moving piece of software such as OpenStack…Therefore, most customers end up utilizing extensive professional services from the distribution vendor. - <a href="https://www.mirantis.com/blog/how-does-the-world-consume-private-clouds/">Mirantis Blog</a></p>
</blockquote>
<p>So even <em>with a distro</em> you are still using professional services. That said, their recent focus on Day 2 is powerful, though to be honest I have not used Fuel.</p>
<p>If you are a company that wants to use OpenStack and is hoping to make it simpler by using a distro, then I think you are in for a surprise. OpenStack is not cheap as it usually requires a team of fairly sophisticated infrastructure engineers to deploy and maintain, whether you are using a distro or not. Now, those engineers may be employees of your company, or they may be employees of a professional services firm. Either way, OpenStack requires people to manage it. Frankly distros may get in the way.</p>
<h2 id="footnotes">Footnotes</h2>
<ol>
<li>Kubernetes (k8s) has really thrown a wrench into distros because everyone is scrambling to keep up with the hype. Kubernetes is great, but I think using k8s simply to manage the OpenStack control plane is overkill, and the additional complexity is not needed.</li>
</ol>
Tracing or Logging RabbitMQ2016-12-17T00:00:00+00:00http://serverascode.com/2016/12/17/tracing-logging-rabbitmq<h1 id="tracing-or-logging-rabbitmq">Tracing or Logging RabbitMQ</h1>
<p>Messaging queues like <a href="https://www.rabbitmq.com/">RabbitMQ</a> are widely used. For example it is a key component in an OpenStack deployment.</p>
<p>Sometimes you need to peek into the queue and see what is happening and I thought I would write a quick post on one way to do that.</p>
<h2 id="turn-on-the-firehose">Turn on the firehose</h2>
<p>Rabbit has an option to turn on “tracing” so that you can see every message that is coming through the queue.</p>
<blockquote>
<p>RabbitMQ has a “firehose” feature, where the administrator can enable (on a per-node, per-vhost basis) an exchange to which publish- and delivery-notifications should be CCed. - <a href="http://www.rabbitmq.com/firehose.html">RabbitMQ</a></p>
</blockquote>
<p>If you have a default install and just want the “/” vhost, you can simply turn on tracing.</p>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code>root@rabbit:~# rabbitmqctl trace_on
Starting tracing <span class="k">for </span>vhost <span class="s2">"/"</span> ...
</code></pre></div></div>
<p>Now you need to read that queue.</p>
<h2 id="reading-messages-on-the-firehose-queue">Reading messages on the firehose queue</h2>
<p>You will need a script to read the queue.</p>
<p>I just grabbed one off of github, but it would be straight forward to write your own.</p>
<script src="https://gist.github.com/khomenko/2562165.js"></script>
<p>This particular python script uses the pika library.</p>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code>ubuntu@rabbit:~<span class="nv">$ </span>virtualenv venv
ubuntu@rabbit:~<span class="nv">$ </span><span class="nb">.</span> venv/bin/activate
ubuntu@rabbit:~<span class="nv">$ </span>pip <span class="nb">install </span>pika
</code></pre></div></div>
<p>Now you can turn on the firehose. I’m going to redirect to a file because there are a lot of messages.</p>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="o">(</span>venv<span class="o">)</span> ubuntu@rabbit:~<span class="nv">$ </span><span class="nb">time</span> ./trace.py <span class="o">></span> trace.out
^CTraceback <span class="o">(</span>most recent call last<span class="o">)</span>:
File <span class="s2">"./trace.py"</span>, line 37, <span class="k">in</span> <module>
channel.start_consuming<span class="o">()</span>
File <span class="s2">"/home/ubuntu/venv/local/lib/python2.7/site-packages/pika/adapters/blocking_connection.py"</span>, line 1681, <span class="k">in </span>start_consuming
self.connection.process_data_events<span class="o">(</span><span class="nv">time_limit</span><span class="o">=</span>None<span class="o">)</span>
File <span class="s2">"/home/ubuntu/venv/local/lib/python2.7/site-packages/pika/adapters/blocking_connection.py"</span>, line 647, <span class="k">in </span>process_data_events
self._flush_output<span class="o">(</span>common_terminator<span class="o">)</span>
File <span class="s2">"/home/ubuntu/venv/local/lib/python2.7/site-packages/pika/adapters/blocking_connection.py"</span>, line 410, <span class="k">in </span>_flush_output
self._impl.ioloop.poll<span class="o">()</span>
File <span class="s2">"/home/ubuntu/venv/local/lib/python2.7/site-packages/pika/adapters/select_connection.py"</span>, line 590, <span class="k">in </span>poll
events <span class="o">=</span> self._poll.poll<span class="o">(</span>self.get_next_deadline<span class="o">())</span>
KeyboardInterrupt
real 0m2.421s
user 0m0.096s
sys 0m0.024s
<span class="o">(</span>venv<span class="o">)</span> ubuntu@rabbit:~<span class="nv">$ </span><span class="nb">wc</span> <span class="nt">-l</span> trace.out
99 trace.out
<span class="o">(</span>venv<span class="o">)</span> ubuntu@rabbit:~<span class="nv">$ </span><span class="nb">head </span>trace.out
<span class="o">[</span><span class="k">*</span><span class="o">]</span> Waiting <span class="k">for </span>logs. To <span class="nb">exit </span>press CTRL+C
<span class="o">[</span>x] <span class="s1">'publish.nova'</span>:u<span class="s1">'rabbit@rabbit'</span>:[u<span class="s1">'conductor'</span><span class="o">]</span>:<span class="s1">'{"oslo.message": "{\\"_context_domain\\": null, \\"_msg_id\\": \\"91deacb97e0948069f234db946d661ae\\", \\"_context_quota_class\\": null, \\"_context_read_only\\": false, \\"_context_request_id\\": \\"req-e282aa6c-ccd0-4a23-aa1c-e818a339c56a\\", \\"_context_service_catalog\\": [], \\"args\\": {\\"objmethod\\": \\"save\\", \\"args\\": [], \\"objinst\\": {\\"nova_object.version\\": \\"1.20\\", \\"nova_object.changes\\": [\\"report_count\\"], \\"nova_object.name\\": \\"Service\\", \\"nova_object.data\\": {\\"binary\\": \\"nova-compute\\", \\"deleted\\": false, \\"created_at\\": \\"2016-12-13T21:53:45Z\\", \\"updated_at\\": \\"2016-12-17T15:31:28Z\\", \\"report_count\\": 32164, \\"topic\\": \\"compute\\", \\"host\\": \\"server03\\", \\"version\\": 15, \\"disabled\\": false, \\"forced_down\\": false, \\"last_seen_up\\": \\"2016-12-17T15:31:28Z\\", \\"deleted_at\\": null, \\"disabled_reason\\": null, \\"id\\": 7}, \\"nova_object.namespace\\": \\"nova\\"}, \\"kwargs\\": {}}, \\"_unique_id\\": \\"3d3aaa47d8b94fc8bf025a797e788d87\\", \\"_context_resource_uuid\\": null, \\"_context_instance_lock_checked\\": false, \\"_context_is_admin_project\\": true, \\"_context_user\\": null, \\"_context_user_id\\": null, \\"_context_project_name\\": null, \\"_context_read_deleted\\": \\"no\\", \\"_context_user_identity\\": \\"- - - - -\\", \\"_reply_q\\": \\"reply_0949e6a10e0345c4ba494eb121edc1f1\\", \\"_context_auth_token\\": null, \\"_context_show_deleted\\": false, \\"_context_tenant\\": null, \\"_context_roles\\": [], \\"_context_is_admin\\": true, \\"version\\": \\"3.0\\", \\"_context_project_id\\": null, \\"_context_project_domain\\": null, \\"_context_timestamp\\": \\"2016-12-16T16:05:25.637936\\", \\"_context_user_domain\\": null, \\"_context_user_name\\": null, \\"method\\": \\"object_action\\", \\"_context_remote_address\\": null}", "oslo.version": "2.0"}'</span>
<span class="o">[</span>x] <span class="s1">'deliver.conductor'</span>:u<span class="s1">'rabbit@rabbit'</span>:[u<span class="s1">'conductor'</span><span class="o">]</span>:<span class="s1">'{"oslo.message": "{\\"_context_domain\\": null, \\"_msg_id\\": \\"91deacb97e0948069f234db946d661ae\\", \\"_context_quota_class\\": null, \\"_context_read_only\\": false, \\"_context_request_id\\": \\"req-e282aa6c-ccd0-4a23-aa1c-e818a339c56a\\", \\"_context_service_catalog\\": [], \\"args\\": {\\"objmethod\\": \\"save\\", \\"args\\": [], \\"objinst\\": {\\"nova_object.version\\": \\"1.20\\", \\"nova_object.changes\\": [\\"report_count\\"], \\"nova_object.name\\": \\"Service\\", \\"nova_object.data\\": {\\"binary\\": \\"nova-compute\\", \\"deleted\\": false, \\"created_at\\": \\"2016-12-13T21:53:45Z\\", \\"updated_at\\": \\"2016-12-17T15:31:28Z\\", \\"report_count\\": 32164, \\"topic\\": \\"compute\\", \\"host\\": \\"server03\\", \\"version\\": 15, \\"disabled\\": false, \\"forced_down\\": false, \\"last_seen_up\\": \\"2016-12-17T15:31:28Z\\", \\"deleted_at\\": null, \\"disabled_reason\\": null, \\"id\\": 7}, \\"nova_object.namespace\\": \\"nova\\"}, \\"kwargs\\": {}}, \\"_unique_id\\": \\"3d3aaa47d8b94fc8bf025a797e788d87\\", \\"_context_resource_uuid\\": null, \\"_context_instance_lock_checked\\": false, \\"_context_is_admin_project\\": true, \\"_context_user\\": null, \\"_context_user_id\\": null, \\"_context_project_name\\": null, \\"_context_read_deleted\\": \\"no\\", \\"_context_user_identity\\": \\"- - - - -\\", \\"_reply_q\\": \\"reply_0949e6a10e0345c4ba494eb121edc1f1\\", \\"_context_auth_token\\": null, \\"_context_show_deleted\\": false, \\"_context_tenant\\": null, \\"_context_roles\\": [], \\"_context_is_admin\\": true, \\"version\\": \\"3.0\\", \\"_context_project_id\\": null, \\"_context_project_domain\\": null, \\"_context_timestamp\\": \\"2016-12-16T16:05:25.637936\\", \\"_context_user_domain\\": null, \\"_context_user_name\\": null, \\"method\\": \\"object_action\\", \\"_context_remote_address\\": null}", "oslo.version": "2.0"}'</span>
<span class="o">[</span>x] <span class="s1">'publish.reply_0949e6a10e0345c4ba494eb121edc1f1'</span>:u<span class="s1">'rabbit@rabbit'</span>:[u<span class="s1">'reply_0949e6a10e0345c4ba494eb121edc1f1'</span><span class="o">]</span>:<span class="s1">'{"oslo.message": "{\\"_msg_id\\": \\"91deacb97e0948069f234db946d661ae\\", \\"failure\\": null, \\"_unique_id\\": \\"fbb674f006f54c939dd3df7b8e234748\\", \\"result\\": [{\\"last_seen_up\\": \\"2016-12-17T15:31:38Z\\", \\"updated_at\\": \\"2016-12-17T15:31:38Z\\", \\"obj_what_changed\\": []}, null], \\"ending\\": true}", "oslo.version": "2.0"}'</span>
<span class="o">[</span>x] <span class="s1">'deliver.reply_0949e6a10e0345c4ba494eb121edc1f1'</span>:u<span class="s1">'rabbit@rabbit'</span>:[u<span class="s1">'reply_0949e6a10e0345c4ba494eb121edc1f1'</span><span class="o">]</span>:<span class="s1">'{"oslo.message": "{\\"_msg_id\\": \\"91deacb97e0948069f234db946d661ae\\", \\"failure\\": null, \\"_unique_id\\": \\"fbb674f006f54c939dd3df7b8e234748\\", \\"result\\": [{\\"last_seen_up\\": \\"2016-12-17T15:31:38Z\\", \\"updated_at\\": \\"2016-12-17T15:31:38Z\\", \\"obj_what_changed\\": []}, null], \\"ending\\": true}", "oslo.version": "2.0"}'</span>
<span class="o">[</span>x] <span class="s1">'publish.nova'</span>:u<span class="s1">'rabbit@rabbit'</span>:[u<span class="s1">'conductor'</span><span class="o">]</span>:<span class="s1">'{"oslo.message": "{\\"_context_domain\\": null, \\"_msg_id\\": \\"1db1384294174e8d83ba30ffae7912e2\\", \\"_context_quota_class\\": null, \\"_context_read_only\\": false, \\"_context_request_id\\": \\"req-e8d0d0c9-35b1-4d47-9ab9-b0d6f08283eb\\", \\"_context_service_catalog\\": [], \\"args\\": {\\"objmethod\\": \\"save\\", \\"args\\": [], \\"objinst\\": {\\"nova_object.version\\": \\"1.20\\", \\"nova_object.changes\\": [\\"report_count\\"], \\"nova_object.name\\": \\"Service\\", \\"nova_object.data\\": {\\"binary\\": \\"nova-compute\\", \\"deleted\\": false, \\"created_at\\": \\"2016-12-13T21:50:18Z\\", \\"updated_at\\": \\"2016-12-17T15:31:29Z\\", \\"report_count\\": 32176, \\"topic\\": \\"compute\\", \\"host\\": \\"server02\\", \\"version\\": 15, \\"disabled\\": false, \\"forced_down\\": false, \\"last_seen_up\\": \\"2016-12-17T15:31:29Z\\", \\"deleted_at\\": null, \\"disabled_reason\\": null, \\"id\\": 6}, \\"nova_object.namespace\\": \\"nova\\"}, \\"kwargs\\": {}}, \\"_unique_id\\": \\"d484f67b6dc34bc88b26c7a011015c36\\", \\"_context_resource_uuid\\": null, \\"_context_instance_lock_checked\\": false, \\"_context_is_admin_project\\": true, \\"_context_user\\": null, \\"_context_user_id\\": null, \\"_context_project_name\\": null, \\"_context_read_deleted\\": \\"no\\", \\"_context_user_identity\\": \\"- - - - -\\", \\"_reply_q\\": \\"reply_eab5dc5ef70a480881932f27d8d2157b\\", \\"_context_auth_token\\": null, \\"_context_show_deleted\\": false, \\"_context_tenant\\": null, \\"_context_roles\\": [], \\"_context_is_admin\\": true, \\"version\\": \\"3.0\\", \\"_context_project_id\\": null, \\"_context_project_domain\\": null, \\"_context_timestamp\\": \\"2016-12-16T16:05:22.325724\\", \\"_context_user_domain\\": null, \\"_context_user_name\\": null, \\"method\\": \\"object_action\\", \\"_context_remote_address\\": null}", "oslo.version": "2.0"}'</span>
<span class="o">[</span>x] <span class="s1">'deliver.conductor'</span>:u<span class="s1">'rabbit@rabbit'</span>:[u<span class="s1">'conductor'</span><span class="o">]</span>:<span class="s1">'{"oslo.message": "{\\"_context_domain\\": null, \\"_msg_id\\": \\"1db1384294174e8d83ba30ffae7912e2\\", \\"_context_quota_class\\": null, \\"_context_read_only\\": false, \\"_context_request_id\\": \\"req-e8d0d0c9-35b1-4d47-9ab9-b0d6f08283eb\\", \\"_context_service_catalog\\": [], \\"args\\": {\\"objmethod\\": \\"save\\", \\"args\\": [], \\"objinst\\": {\\"nova_object.version\\": \\"1.20\\", \\"nova_object.changes\\": [\\"report_count\\"], \\"nova_object.name\\": \\"Service\\", \\"nova_object.data\\": {\\"binary\\": \\"nova-compute\\", \\"deleted\\": false, \\"created_at\\": \\"2016-12-13T21:50:18Z\\", \\"updated_at\\": \\"2016-12-17T15:31:29Z\\", \\"report_count\\": 32176, \\"topic\\": \\"compute\\", \\"host\\": \\"server02\\", \\"version\\": 15, \\"disabled\\": false, \\"forced_down\\": false, \\"last_seen_up\\": \\"2016-12-17T15:31:29Z\\", \\"deleted_at\\": null, \\"disabled_reason\\": null, \\"id\\": 6}, \\"nova_object.namespace\\": \\"nova\\"}, \\"kwargs\\": {}}, \\"_unique_id\\": \\"d484f67b6dc34bc88b26c7a011015c36\\", \\"_context_resource_uuid\\": null, \\"_context_instance_lock_checked\\": false, \\"_context_is_admin_project\\": true, \\"_context_user\\": null, \\"_context_user_id\\": null, \\"_context_project_name\\": null, \\"_context_read_deleted\\": \\"no\\", \\"_context_user_identity\\": \\"- - - - -\\", \\"_reply_q\\": \\"reply_eab5dc5ef70a480881932f27d8d2157b\\", \\"_context_auth_token\\": null, \\"_context_show_deleted\\": false, \\"_context_tenant\\": null, \\"_context_roles\\": [], \\"_context_is_admin\\": true, \\"version\\": \\"3.0\\", \\"_context_project_id\\": null, \\"_context_project_domain\\": null, \\"_context_timestamp\\": \\"2016-12-16T16:05:22.325724\\", \\"_context_user_domain\\": null, \\"_context_user_name\\": null, \\"method\\": \\"object_action\\", \\"_context_remote_address\\": null}", "oslo.version": "2.0"}'</span>
<span class="o">[</span>x] <span class="s1">'publish.reply_eab5dc5ef70a480881932f27d8d2157b'</span>:u<span class="s1">'rabbit@rabbit'</span>:[u<span class="s1">'reply_eab5dc5ef70a480881932f27d8d2157b'</span><span class="o">]</span>:<span class="s1">'{"oslo.message": "{\\"_msg_id\\": \\"1db1384294174e8d83ba30ffae7912e2\\", \\"failure\\": null, \\"_unique_id\\": \\"366886d2234e49649665576f43ae3f72\\", \\"result\\": [{\\"last_seen_up\\": \\"2016-12-17T15:31:39Z\\", \\"updated_at\\": \\"2016-12-17T15:31:39Z\\", \\"obj_what_changed\\": []}, null], \\"ending\\": true}", "oslo.version": "2.0"}'</span>
<span class="o">[</span>x] <span class="s1">'deliver.reply_eab5dc5ef70a480881932f27d8d2157b'</span>:u<span class="s1">'rabbit@rabbit'</span>:[u<span class="s1">'reply_eab5dc5ef70a480881932f27d8d2157b'</span><span class="o">]</span>:<span class="s1">'{"oslo.message": "{\\"_msg_id\\": \\"1db1384294174e8d83ba30ffae7912e2\\", \\"failure\\": null, \\"_unique_id\\": \\"366886d2234e49649665576f43ae3f72\\", \\"result\\": [{\\"last_seen_up\\": \\"2016-12-17T15:31:39Z\\", \\"updated_at\\": \\"2016-12-17T15:31:39Z\\", \\"obj_what_changed\\": []}, null], \\"ending\\": true}", "oslo.version": "2.0"}'</span>
<span class="o">[</span>x] <span class="s1">'publish.nova'</span>:u<span class="s1">'rabbit@rabbit'</span>:[u<span class="s1">'conductor'</span><span class="o">]</span>:<span class="s1">'{"oslo.message": "{\\"_context_domain\\": null, \\"_msg_id\\": \\"06d003ee9aa0445e8947c27a92275f0c\\", \\"_context_quota_class\\": null, \\"_context_read_only\\": false, \\"_context_request_id\\": \\"req-dc8f9ccf-151e-4f9b-9fd9-52350c39fd6f\\", \\"_context_service_catalog\\": [], \\"args\\": {\\"object_versions\\": {\\"PciDevicePoolList\\": \\"1.1\\", \\"ServiceList\\": \\"1.19\\", \\"PciDevicePool\\": \\"1.1\\", \\"Service\\": \\"1.20\\", \\"TagList\\": \\"1.1\\", \\"InstancePCIRequests\\": \\"1.1\\", \\"VirtCPUModel\\": \\"1.0\\", \\"MigrationContext\\": \\"1.1\\", \\"SecurityGroup\\": \\"1.1\\", \\"DeviceBus\\": \\"1.0\\", \\"Instance\\": \\"2.3\\", \\"KeyPair\\": \\"1.4\\", \\"KeyPairList\\": \\"1.3\\", \\"DeviceMetadata\\": \\"1.0\\", \\"InstancePCIRequest\\": \\"1.1\\", \\"EC2Ids\\": \\"1.0\\", \\"InstanceInfoCache\\": \\"1.5\\", \\"VirtCPUFeature\\": \\"1.0\\", \\"Flavor\\": \\"1.1\\", \\"SecurityGroupList\\": \\"1.0\\", \\"PciDevice\\": \\"1.5\\", \\"VirtCPUTopology\\": \\"1.0\\", \\"InstanceNUMACell\\": \\"1.3\\", \\"InstanceList\\": \\"2.1\\", \\"ComputeNode\\": \\"1.16\\", \\"InstanceFault\\": \\"1.2\\", \\"Tag\\": \\"1.1\\", \\"HVSpec\\": \\"1.2\\", \\"InstanceDeviceMetadata\\": \\"1.0\\", \\"InstanceNUMATopology\\": \\"1.2\\", \\"PciDeviceList\\": \\"1.3\\"}, \\"objmethod\\": \\"get_by_host\\", \\"args\\": [\\"server03\\"], \\"objname\\": \\"InstanceList\\", \\"kwargs\\": {\\"use_slave\\": true, \\"expected_attrs\\": []}}, \\"_unique_id\\": \\"42f089b774994641a15621df44b4493e\\", \\"_context_resource_uuid\\": null, \\"_context_instance_lock_checked\\": false, \\"_context_is_admin_project\\": true, \\"_context_user\\": null, \\"_context_user_id\\": null, \\"_context_project_name\\": null, \\"_context_read_deleted\\": \\"no\\", \\"_context_user_identity\\": \\"- - - - -\\", \\"_reply_q\\": \\"reply_0949e6a10e0345c4ba494eb121edc1f1\\", \\"_context_auth_token\\": null, \\"_context_show_deleted\\": false, \\"_context_tenant\\": null, \\"_context_roles\\": [\\"admin\\"], \\"_context_is_admin\\": true, \\"version\\": \\"3.0\\", \\"_context_project_id\\": null, \\"_context_project_domain\\": null, \\"_context_timestamp\\": \\"2016-12-17T15:31:43.661237\\", \\"_context_user_domain\\": null, \\"_context_user_name\\": null, \\"method\\": \\"object_class_action_versions\\", \\"_context_remote_address\\": null}", "oslo.version": "2.0"}'</span>
</code></pre></div></div>
<p>Once you’ve got the messages you want, turn off tracing.</p>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code>root@rabbit:~# rabbitmqctl trace_off
Stopping tracing <span class="k">for </span>vhost <span class="s2">"/"</span> ...
</code></pre></div></div>
<p>You might need to empty out the firehost queue.</p>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code>root@rabbit:~# rabbitmqctl list_queues | <span class="nb">grep </span>firehose
firehose 450
root@rabbit:~# rabbitmqctl purge_queue firehose
Purging queue <span class="s1">'firehose'</span> <span class="k">in </span>vhost <span class="s1">'/'</span> ...
root@rabbit:~# rabbitmqctl list_queues | <span class="nb">grep </span>firehose
firehose 0
</code></pre></div></div>
OpenStack Bifrost2016-12-11T00:00:00+00:00http://serverascode.com/2016/12/11/openstack-ironic-bifrost<h1 id="openstack-bifrost">OpenStack Bifrost</h1>
<p>No matter how you deploy OpenStack, you need some kind of software that manages the operating system that runs directly on the baremetal. Sure, maybe you have all kinds of exotic container management systems, but one of the problems with running your own private cloud is that you still need to manage the physical hosts and their base operating system. Those containers have to run somewhere!</p>
<p>So most OpenStack deployment systems come with some kind of baremetal installer. For example Mirantis uses Cobber and Tripleo uses Ironic (within the concept of an undercloud).</p>
<p>There are other baremetal installers too, such as Ubuntu MaaS, I think Foreman also, and if you feel like it you can even roll your own based on PXE booting with dnsmasq or similar. The point is you want to automatically deploy the baremetal OS (BOS).</p>
<h2 id="bifrost">Bifrost</h2>
<p>I already mentioned OpenStack Ironic as a way to manage the BOS. <a href="http://docs.openstack.org/developer/bifrost/">Bifrost</a> also uses Ironic:</p>
<blockquote>
<p>Bifrost (pronounced bye-frost) is a set of Ansible playbooks that automates the task of deploying a base image onto a set of known hardware using ironic. It provides modular utility for one-off operating system deployment with as few operational requirements as reasonably possible.</p>
</blockquote>
<p>Basically it installs a standalone Ironic system, and then also uses Ansible playbooks to generate OS images and deploys them to baremetal nodes. It is a combination of Ironic and Disk Image Builder with Ansible to install and orchestrate them.</p>
<h2 id="installation">Installation</h2>
<p><a href="http://docs.openstack.org/developer/bifrost/readme.html#installation">Installation</a> is straight forward. I would repeat the docs here, but they are quite good in terms of installation. The only thing to really remember is to set the <em>network_interface</em> variable to the correct interface on the bifrost node. You will need at least one server to run this from. I’m using a virtual machine. One of the interfaces on the bifrost node must be on the same network as the DHCP interfaces of the physical nodes you want to manage with bifrost. Like most BOS installers, Ironic installs via PXE booting.</p>
<p>Once the install completes you should be able to run Ironic commands.</p>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code>ubuntu@p3-bifrost-01:~<span class="nv">$ </span>ironic node-list
+--------------------------------------+----------+---------------+-------------+--------------------+-------------+
| UUID | Name | Instance UUID | Power State | Provisioning State | Maintenance |
+--------------------------------------+----------+---------------+-------------+--------------------+-------------+
+--------------------------------------+----------+---------------+-------------+--------------------+-------------+
</code></pre></div></div>
<p>But of course you won’t have any Ironic nodes because you have not enrolled servers into Ironic.</p>
<h2 id="disk-image">Disk Image</h2>
<p>The installation process also creates a disk image that will be deployed to the physical node.</p>
<p>This image is in <em>/httpboot</em>.</p>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code>ubuntu@p3-bifrost-01:~<span class="nv">$ </span><span class="nb">ls</span> /httpboot/<span class="k">*</span>.qcow2
/httpboot/deployment_image.qcow2
</code></pre></div></div>
<p>By default the image is named <em>deployment_image.qcow2</em>.</p>
<p>If you don’t change any defaults it will be Debian Jessie.</p>
<p>You can change what OS is build using a couple of options. For example if you wanted Ubuntu Trusty:</p>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code>dib_os_release: <span class="s2">"trusty"</span>
dib_os_element: <span class="s2">"ubuntu"</span>
</code></pre></div></div>
<p>Note that I had some issues with Ubuntu Xenial and Bifrost which I will discuss later in the post.</p>
<p>But just be aware that part of the installation process also creates this image, and the image is obviously very important as it is what gets deployed to the physical node. Likely you will want to customize that image.</p>
<h2 id="environment">Environment</h2>
<p>I’ve added sourcing a couple of bifrost files to the .profile of the local user:</p>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="c"># Bifrost</span>
<span class="nb">.</span> ~/bifrost/env-vars
<span class="nb">.</span> /opt/stack/ansible/hacking/env-setup
</code></pre></div></div>
<p>Just makes it a bit easier to use Bifrost.</p>
<h2 id="hardware-enrollment">Hardware Enrollment</h2>
<p>Again, the docs are good on this.</p>
<p>Basically you need to setup a file that details your inventory of physical servers. The inventory can be defined in the old CSV manner, or in a newer method with either JSON or YAML.</p>
<p>Here’s an example of a single server in YAML. Obviously your real inventory should include tens or hundreds of physical servers.</p>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="nt">---</span>
node01:
uuid: <span class="s2">"00000000-0000-0000-0000-000000000001"</span>
driver_info:
power:
ipmi_username: <span class="s2">"PXE_USER"</span>
ipmi_address: <span class="s2">"10.10.0.10"</span>
ipmi_password: <span class="s2">"PXE_PASSWORD"</span>
nics:
-
mac: <span class="s2">"48-8C-83-E7-A5-D5"</span>
driver: <span class="s2">"agent_ipmitool"</span>
properties:
cpu_arch: <span class="s2">"x86_64"</span>
ram: <span class="s2">"128375"</span>
disk_size: <span class="s2">"400"</span>
cpus: <span class="s2">"48"</span>
name: <span class="s2">"node01"</span>
</code></pre></div></div>
<p>When you start a deployment, the dnsmasq server running on the node will wait to see DHCP requests from the above mac address, and when it receives them proceed to install a specific OS image to that physical node.</p>
<h2 id="deployment">Deployment</h2>
<p>Deployment of nodes is a single Ansible command. Again the docs are good on this.</p>
<p>Here’s an example deployment of a single node. I’ve put it into a deploy script just to make it a bit easier to use. :)</p>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code>ubuntu@p3-bifrost-01:~<span class="nv">$ </span><span class="nb">cat </span>deploy.sh
<span class="c">#!/bin/bash</span>
<span class="nb">export </span><span class="nv">BIFROST_INVENTORY_SOURCE</span><span class="o">=</span>~/node01.yml
<span class="nb">pushd</span> ~/bifrost/playbooks
ansible-playbook <span class="nt">-vvvv</span> <span class="nt">-i</span> inventory/bifrost_inventory.py deploy-dynamic.yaml
<span class="nb">popd</span>
</code></pre></div></div>
<p>Once the deployment completes, you should have some nodes listed as active in Ironic.</p>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code>ubuntu@p3-bifrost-01:~<span class="nv">$ </span>ironic node-list
+--------------------------------------+----------+---------------+-------------+--------------------+-------------+
| UUID | Name | Instance UUID | Power State | Provisioning State | Maintenance |
+--------------------------------------+----------+---------------+-------------+--------------------+-------------+
| 00000000-0000-0000-0000-000000000001 | node01 | None | power on | active | False |
+--------------------------------------+----------+---------------+-------------+--------------------+-------------+
</code></pre></div></div>
<p>Hopefully in your deployment you will have more than one node. :)</p>
<h2 id="what-ip-address-did-the-node-get">What IP address did the node get?</h2>
<p>You can specify what IP address the node will get on the DHCP/PXE network as a static entry in the nodes inventory information, but I have not done that. Thus it will get a random IP from the DHCP pool.</p>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code>ubuntu@p3-bifrost-01:~<span class="nv">$ </span><span class="nb">cat</span> /var/lib/misc/dnsmasq.leases
1481507199 48-8C-83-E7-A5-D5 10.100.0.31 node01 01:48-8C-83-E7-A5-D5
</code></pre></div></div>
<p>I can ssh into that node:</p>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code>ubuntu@p3-bifrost-01:~<span class="nv">$ </span>ssh 10.100.0.31
Welcome to Ubuntu 16.04.1 LTS <span class="o">(</span>GNU/Linux 4.4.0-53-generic x86_64<span class="o">)</span>
<span class="k">*</span> Documentation: https://help.ubuntu.com
<span class="k">*</span> Management: https://landscape.canonical.com
<span class="k">*</span> Support: https://ubuntu.com/advantage
Get cloud support with Ubuntu Advantage Cloud Guest:
http://www.ubuntu.com/business/services/cloud
0 packages can be updated.
0 updates are security updates.
Last login: Sun Dec 11 13:54:29 2016 from 10.100.0.3
ubuntu@node01:~<span class="nv">$ </span>
</code></pre></div></div>
<p>Bwoop!</p>
<h2 id="ubuntu-xenial-and-building-your-own-images">Ubuntu Xenial and building your own images</h2>
<p>Bifrost will try to help out and generate a working image for you. This is nice. However, it did not work with Ubuntu Xenial. I ran into some kind of Python related error which I will investigate further. I believe it’s related to the default use of simple-init instead of cloud-init, but I’m not completely sure at this time.</p>
<p>But, you an also generate your own image using <a href="http://docs.openstack.org/developer/diskimage-builder/">Disk Image Builder</a> (dib).</p>
<p>Dib is very easy to install. Using it takes a bit more work as there are many options.</p>
<p>I am building a working Xenial image like so:</p>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code>ubuntu@p3-bifrost-01:~/dib<span class="nv">$ </span><span class="nb">cat </span>build.sh
<span class="c">#!/bin/bash</span>
<span class="nb">cd</span> /home/ubuntu/dib
<span class="nb">export </span><span class="nv">PATH</span><span class="o">=</span><span class="nv">$PATH</span>:/home/ubuntu/dib/diskimage-builder/bin:/home/ubuntu/dib/dib-utils/bin
<span class="nb">export </span><span class="nv">DIB_RELEASE</span><span class="o">=</span>xenial
<span class="nb">export </span><span class="nv">DIB_DEV_USER_PASSWORD</span><span class="o">=</span><span class="s2">"SOME_USER"</span>
<span class="nb">export </span><span class="nv">DIB_DEV_USER_USERNAME</span><span class="o">=</span><span class="s2">"SOME_PASS"</span>
<span class="nb">export </span><span class="nv">DIB_DEV_USER_PWDLESS_SUDO</span><span class="o">=</span><span class="s2">"Yes"</span>
<span class="nb">export </span><span class="nv">DIB_DEV_USER_PASSWORD</span><span class="o">=</span><span class="s2">"/bin/bash"</span>
<span class="nb">export </span><span class="nv">DIB_CLOUD_INIT_DATASOURCES</span><span class="o">=</span><span class="s2">"ConfigDrive"</span>
<span class="c"># dib elements to use in creating the image</span>
<span class="nv">EL</span><span class="o">=</span><span class="s2">"ubuntu vm cloud-init devuser serial-console cloud-init-datasources"</span>
disk-image-create <span class="nt">-a</span> amd64 <span class="nt">-t</span> qcow2 <span class="nt">-o</span> xenial.qcow2 <span class="se">\</span>
<span class="nt">-p</span> python2.7,python-simplejson <span class="se">\</span>
<span class="nv">$EL</span>
</code></pre></div></div>
<p>This creates a Xenial image that has cloud-init installed but set to only use ConfigDrive as a data source. The bifrost installation does not have a metadata service that the instance can call back to, and instead uses ConfigDrive to add things to the instance dynamically, such as ssh keys and the like.</p>
<p>Then I just copy the resulting image to <em>/httpboot/deployment_image.qcow2</em> and that is what will be deployed to the physical node.</p>
<p>I should note that:</p>
<ul>
<li>serial-console does not seem to work in Xenial</li>
<li>Adding a devuser in production is probably not a great idea</li>
</ul>
<p>I also add python2.7 and python-simplejson for use with Ansible.</p>
<h2 id="configdrive">ConfigDrive</h2>
<p>The drive is attached to the physical node and has a json file that defines some dynamic changes to the host. Below it is just hostname and an ssh key for the ubuntu user’s authorized_keys file.</p>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code>ubuntu@node01:~<span class="nv">$ </span><span class="nb">sudo </span>mount /dev/sda2 /mnt
mount: /dev/sda2 is write-protected, mounting read-only
ubuntu@node01:~<span class="nv">$ </span>find /mnt
/mnt
/mnt/openstack
/mnt/openstack/2012-08-10
/mnt/openstack/2012-08-10/meta_data.json
/mnt/openstack/content
/mnt/openstack/latest
/mnt/openstack/latest/meta_data.json
ubuntu@node01:~<span class="nv">$ </span><span class="nb">cat</span> /mnt/openstack/latest/meta_data.json
<span class="o">{</span>
<span class="s2">"availability_zone"</span>: <span class="s2">""</span>,
<span class="s2">"files"</span>: <span class="o">[]</span>,
<span class="s2">"hostname"</span>: <span class="s2">"node01"</span>,
<span class="s2">"name"</span>: <span class="s2">"node01"</span>,
<span class="s2">"meta"</span>: <span class="o">{}</span>,
<span class="s2">"public_keys"</span>: <span class="o">{</span>
<span class="s2">"mykey"</span>: <span class="s2">"ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQC0tdpS1S83ZQPMzFVwJ603CiKyapIOSfjmofqlYExYm+UCcFuC1eUF+xYA/dwFucKbd6shdLxC/cSLtHilQjolyg32jKw8G0LwittPH7Npi1BSCmLg5xnwUML6Hh/g/r3Xjj0NfuqIMBiiwQR/XkCyWHt5tE8ztGCm14Mz4SSL8qFhPdZXF0r5O9iBsWCJ6OsabuPK3lZQUqeMnKynARocnqXa4KHUr1yEOM/VHMNnUuJbRPEJoFHPrqS+vHOwKPWBvfv8Eia6GxsCXt3Z+ioWYA4Ejed/Csv1kRAWLDA4xuExD4VjgHdpHPoPt1M3nv3BdhwJpDzhSrXumGdFZz79 ubuntu@p3-bifrost-01"</span>
<span class="o">}</span>,
<span class="s2">"uuid"</span>: <span class="s2">"00000000-0000-0000-0000-000000000001"</span>
<span class="o">}</span>
</code></pre></div></div>
<p>If you have not used OpenStack or any IaaS that uses metadata it can be a bit confusing. Suffice it to say that in image based deployment systems there is often some dynamic configuration you need to make, at least inject ssh keys, and this is done with a combination of information from some datasource, and cloud-init in the image.</p>
<p>I should note that Bifrost generates this ConfigDrive automatically.</p>
<h2 id="conclusion">Conclusion</h2>
<p>This is a basic overview of using Bifrost. I have quite a bit more work to do in terms of understanding and customizing Bifrost, but in a few hours I had a basic system going that works well. If you are using Ubuntu Trusty you will probably have a bit of an easier time as opposed to Xenial, but I expect that will either improve or I will discover that I was doing something silly. :)</p>
<p>The ability to automatically deploy a custom image to many baremetal servers is a basic requirement for a successful deployment of OpenStack or any other large, complicated system.</p>
Moore's Law and the Datacenter2016-12-03T00:00:00+00:00http://serverascode.com/2016/12/03/moores-law-and-the-datacenter<h1 id="moores-law-and-the-datacenter">Moore’s Law and the Datacenter</h1>
<p>I’m a big fan of <a href="http://packetpushers.net">Packet Pushers</a> and their various podcasts. Recently I listened to a <a href="http://packetpushers.net/podcast/podcasts/show-315-future-networking-pradeep-sindhu/">podcast</a> with Pradeep Sindhu who is the CTO and co-founder of Juniper Networks. I quite enjoyed the podcast, and while I think perhaps the hosts found Pradeep’s desire to explain and define a baseline for everything a bit long winded, I enjoyed his obviously science-driven attitude towards discussing technology. We should all strive to be more precise.</p>
<p>Many people are aware that Moore’s Law, which Pradeep redefined as an observation, not a law, is ending. For decades we haven’t had to do much to get continual, massive (exponential) increases in computing power. But this is no longer. Instead, currently, we get access to more cores instead of faster CPUs. Clock speeds have maxed out. Now in order to achieve increases in computing power we have to look to parallelism, specialized hardware, and ways to deal with latency.</p>
<h2 id="networking">Networking</h2>
<p>What I thought was interesting in this particular podcast is that this also applies to networking technology. A good example that was given is the fact that a 100 GB network connection is actually 4 25GB connections which are tied together (1). So even in networking we have hit the end of Moore’s Law and have to deal with parallelism, which is more complex. As Pradeep mentions in the podcast, most, if not all, applications will have to be (re)written to use parallelism, and those that do not will be left behind.</p>
<p>That said there does seem to be some debate if Moore’s Law applies to networking at all, given it’s really bounded by the speed of light, and that managing latency is going to be what is important.</p>
<blockquote>
<p>…the future of telecoms in general is firmly centred on managing latency due to contention between flows created by competing applications and users. This means scheduling resources appropriately to match supply and demand. - <a href="http://www.martingeddes.com/think-tank/five-reasons-moores-law-networks/">Five reasons why there is no Moore’s Law for networks</a></p>
</blockquote>
<p>But then again, if we are going to use software to manage networks, then indeed that software will hit Moore’s law.</p>
<p>I suppose the point is that in order to keep moving forward and gaining performance, networks will have to become smarter, and, likely, less predictable.</p>
<blockquote>
<p>The path forward requires that the bandwidth our networks provide becomes smarter. The networks themselves need to become programmable platforms. The infrastructure needs to be as real-time, flexible and dynamic as our smartphones have become. The answer to the problem of increased demand on the network is to flip that phrase around and evolve to what can be called network-on-demand. Network topology, connectivity, service class and quality of service all need to be on-demand services that can be customized to suit the needs of the end user. - <a href="http://techonomy.com/2016/01/when-moore-is-not-enough-why-our-growing-networks-require-more-software/">When Moore Is Not Enough – Why Our Growing Networks Require More Software</a></p>
</blockquote>
<p>This reminds me of the requirement of 5G to have very low latency. In fact I believe the target is 1ms (though I don’t see how that is possible, frankly).</p>
<blockquote>
<p>Physics stands a bit in the way of this. The speed of light and electricity is limited and in 1 ms, light can only travel around 200 km through an optical fibre. So even if network equipment does not add any latency whatsoever, the maximum round trip distance is 100 km. - <a href="https://www.linkedin.com/pulse/5g-latency-1ms-possible-akshay-mahajan">5G Latency - 1ms - Is it Possible?</a></p>
</blockquote>
<p>Some of Pradeep’s suggestions are discussed in a Network World article:</p>
<blockquote>
<p>The next step will be to use the network to interconnect multiple data centers with low latency connections. In this case, think of the cloud as a collection of pooled resources, like processing and storage, over geographic distance and being inter-connected with a high-performance network. In this scenario, its unlikely that network managers can continuously update the network fast and efficient enough to meet the needs of an environment that must scale over distance. This brings up step two of Pradeep’s Principle: network automation. This doesn’t mean simple automation like the provisioning of QoS or VLANs. Sindhu made it clear he was talking about a network that was almost autonomic and self learning in nature and could quickly adapt to any kind of environmental changes. - <a href="http://www.networkworld.com/article/3130229/software-defined-networking/pradeeps-principle-give-up-on-moores-law-and-embrace-automation.html">Pradeep’s Principle: Give up on Moore’s Law and embrace automation</a></p>
</blockquote>
<p>Many network engineers are unsure if software defined networking (SDN) is really all that useful. Pradeep suggests that in order to increase performance we are not going to have much choice but to look to SDN, network automation and even machine learning. Things are going to get a lot more complex in the network.</p>
<h2 id="hardware-is-more-important-than-ever">Hardware is more important than ever</h2>
<p>Another interesting point made in the podcast is that hardware is more important than ever. Because we are nearing the end of Moore’s law, and thus general computing is no longer receiving the easy gains of the last few decades, we will likely see more specialized, single-purpose hardware being developed. This specialized hardware can realize the large performance gains we require to move ahead in computing as a species. Thus, while in many ways we have moved to commodity hardware in the datacenter, it’s quite likely we will also see a movement towards specialized hardware, especially in the realm of artificial intelligence, machine learning, and networking, among others. Certainly we see that already in terms of TCP offloading in network interface cards and chips like <a href="https://www.wired.com/2016/06/barefoot-networks-new-chips-will-transform-tech-industry/">Barefoot Networks</a> P4 processor.</p>
<p>Further, given the recent advances in machine learning, there will likely be specialized hardware developed to increase performance in this area:</p>
<blockquote>
<p>Strong demand for silicon tuned for algebra that’s crucial to a powerful machine-learning technique called deep learning seems inevitable, for example. Graphics chip company Nvidia and several startups are already moving in that direction… - <a href="https://www.technologyreview.com/s/601441/moores-law-is-dead-now-what/">Moore’s Law is Dead: Now What</a></p>
</blockquote>
<h2 id="co-processors">Co-processors</h2>
<p>As a simple systems administrator, I can see the value in “co-processors” and the easiest example I have is of a network card that is doing TCP off-loading or other intelligent network processing. One company working in this area is <a href="https://www.netronome.com/products/intelligent-server-adapters/overview/">Netronome</a>.</p>
<p>These co-processors concern me a bit because that will mean a lot of the functionality will be embedded into the firmware of the network card, and there is not much worse for a systems administrator than firmware and it’s related issues, but there is probably no way around that if we are to continue improving intelligence and speed in the network. To enable performance we give up the ability to easily change software. That will be more costly, however.</p>
<p><img src="/img/altera.jpg" alt="By Altera Corporation - Altera Corporation, CC BY 3.0, https://commons.wikimedia.org/w/index.php?curid=6642224" /></p>
<h2 id="fpga">FPGA</h2>
<p>This is not an area I understand well yet. However, recently AWS released a developer preview where users can rent large FPGAs. It does seem that they are currently difficult to program.</p>
<blockquote>
<p>Amazon’s AWS cloud computing service today announced that it is launching a new instance type (F1) with field-programmable gate arrays (FPGAs). The promise of FPGAs is that they are essentially chips that you can reprogram on the fly and tune them for your specific applications, making them faster than traditional CPU/GPU combinations. - <a href="https://techcrunch.com/2016/11/30/aws-announces-fpga-instances-for-its-ec2-cloud-computing-service/">TechCrunch</a></p>
</blockquote>
<h2 id="paradoxes">Paradoxes</h2>
<p>These thoughts lead me to a couple of paradoxes:</p>
<p><strong>1) Hardware is more important than ever</strong></p>
<p>Most startups are based on software. Software is awesome. It’s (relatively) easy and cost effective. But as discussed so far in this post, given Moore’s law and our lost of easy performance gains with general computing, we will need specialized hardware.</p>
<p>Futher, there has been a rapid movement to commodity hardware which essentially means many x86 servers. Thanks to virtualization, most workloads are heading to x86. I don’t expect to see AWS offer Power CPU based virtual machines, though Google always threatens with Power processors, most likely to be able to have some kind of bargaining…er chip…with Intel.</p>
<p>That said, perhaps we just need some new inventions to get us past the limits of silicon CPUs. Certainly novel CPU technology is inevitable, but will it be enough, who will do it, and when?</p>
<p>Also, co-processors have/will become much more important.</p>
<p><strong>2) Lower latency means datacenters and/or caching closer to end-users</strong></p>
<p>It seems to me that telecoms are <a href="http://fortune.com/2016/11/04/centurylink-data-center/">selling off datacenters</a>. Further, the public cloud is concentrating computing in fewer, much larger datacenters. If we are really going to be limited by latency, this seems to be a paradox. Perhaps there will simply be a point where we either can’t get faster networking, or we don’t need it. Then again people are still moving into cities, perhaps we’ll just have an AWS region per large city and they will be large data caches. Isn’t caching one of those hard computer science problems? :) That said, I believe Akamai is doing well.</p>
<h2 id="conclusion">Conclusion</h2>
<p>There is a lot happening in the IT world, and some of it is paradoxical. On one hand we have a serious movement towards the concentration of computing power in large, regional data centers (ie. AWS), but on the other the speed of light is a serious boundary and will require (some? most?) data and computing to be closer to end users. Further, software development gets most of the attention, but we are going to need considerable material and engineering breakthroughs in hardware to continue to increase computing performance. What’s more, despite the movement towards commodity hardware (ie. x86 + virtualization), we will need specialized physical systems in networking and machine learning.</p>
<h2 id="links">Links</h2>
<p>Here are a few random links that I’ve read while writing this blog post.</p>
<ul>
<li><a href="http://www.economist.com/technology-quarterly/2016-03-12/after-moores-law">After Moore’s Law</a></li>
<li><a href="https://www.wired.com/2016/06/barefoot-networks-new-chips-will-transform-tech-industry/">Barefoot Network’s Chips Will Transform the Tech Industry</a></li>
<li><a href="https://en.wikipedia.org/wiki/100_Gigabit_Ethernet">Wikipedia - 100 Gigabit Ethernet</a></li>
<li><a href="http://www.pcworld.com/article/3072256/google-io/googles-tensor-processing-unit-said-to-advance-moores-law-seven-years-into-the-future.html">Google’s Tensor Processing Unit could advance Moore’s Law 7 years into the future</a></li>
<li><a href="https://cloudplatform.googleblog.com/2016/05/Google-supercharges-machine-learning-tasks-with-custom-chip.html">Google supercharges machine learning tasks with TPU custom chip</a></li>
<li><a href="http://fortune.com/2016/11/04/centurylink-data-center/">CenturyLink Reaches $2 Billion Deal to Sell Data Centers</a></li>
<li><a href="http://boingboing.net/2016/07/01/even-if-moores-law-is-runn.html">Even if Moore’s Law is “running out,” there’s still plenty of room at the bottom</a></li>
<li><a href="http://www.martingeddes.com/think-tank/five-reasons-moores-law-networks/">Five reasons why there is no Moore’s Law for networks</a></li>
<li><a href="http://spectrum.ieee.org/semiconductors/design/the-death-of-moores-law-will-spur-innovation">The Death of Moore’s Law Will Spur Innovation</a></li>
<li><a href="https://aws.amazon.com/blogs/aws/developer-preview-ec2-instances-f1-with-programmable-hardware/">AWS Developer Preview of FPGA</a></li>
</ul>
<h2 id="footnotes">Footnotes</h2>
<p>1) <a href="https://en.wikipedia.org/wiki/100_Gigabit_Ethernet">4 25 gigabaud lanes</a></p>
The First OpenStack Days Canada2016-11-23T00:00:00+00:00http://serverascode.com/2016/11/23/openstack-canada-day<h1 id="the-first-openstack-days-canada">The First OpenStack Days Canada</h1>
<p>On November 22nd, 2016 the first <a href="http://openstackca.org/">OpenStack Days Canada</a> (OSDCA) was held in Montreal. <a href="https://www.openstack.org/community/events/openstackdays">OpenStack Days</a> are regional events that bring together people using and operating OpenStack clouds. They are slightly bigger in size and geographic pull than your typical meetup, but not nearly as big as the OpenStack Summits. I believe the attendance at the first OpenStack Days Canada was around 190, which is very good. You can find a few tweets about the event with the <a href="https://twitter.com/search?q=osdca&src=typd">#OSDCA hashtag</a>.</p>
<p>Basically they are a small, one or two day conference. There are speakers, panels, and some of them do workshops and such, and perhaps some kind of social evening event.</p>
<h2 id="montreal-a-hotbed-of-openstack">Montreal a Hotbed of OpenStack</h2>
<p>There is a ton of OpenStack related activity in Montreal. Actually, <a href="http://www.cbc.ca/news/canada/montreal/montreal-institute-learning-algorithms-1.3859460">technology in general</a>. Montreal is an extremely wired city. There are many data centers, service providers, and service providers for service providers. There are great schools here, relatively low cost of living, and many interesting companies. It’s probably the only place a boring anglophone like myself could live in Quebec, as English is pretty common, though I still feel like an doofus even ordering a coffee.</p>
<p>Some of the companies that were at OpenStack days and which are based in the Montreal area:</p>
<ul>
<li>Vexxhost</li>
<li>Inocybe</li>
<li>Internap</li>
<li>Ormuco</li>
<li>CloudOps</li>
<li>and more I’m sure</li>
</ul>
<h2 id="the-talks">The Talks</h2>
<p>There were two tracks of talks at OSDCA, a “user” track and a “fan” track. I jumped around a lot between the two tracks.</p>
<p>Below are the talks I attended. I can’t remember what company everyone was from, but I remember a few.</p>
<p><strong>1 - Running Production Ready Kubernetes Cluster on Openstack</strong> by Ayrat Khayretdinov</p>
<p>It’s impossible to attend any kind of OpenStack technical event without hearing about Kubernetes from either the standpoint of 1) running the OpenStack control plane in k8s, or 2) running k8s in OpenStack on instances as part of a project. This talk was regarding option #2 (and I assure you the two models are completely different and almost not related at all).</p>
<p>One of his main points is that currently k8s does not do multi-tenancy well, so one way to do that would be to deploy multiple k8s in different OpenStack projects.</p>
<p>He also reminded me of the <a href="https://wiki.openstack.org/wiki/Murano">Murano</a> application catalog system which I should look into again, as it does manage TOSCA templates (I believe), which is related to the work I do in Network Function Virtualization (NFV).</p>
<p><strong>2 - Ceph OSD hardware – a pragmatic guide</strong> by Piotr Wachowicz of <a href="http://www.brightcomputing.com/">Bright Computing</a></p>
<p>This talk gave real examples of what kind of hardware and configuration is best for a Ceph cluster. There are real considerations to make in terms of the sizing of the Ceph nodes, especially in regards to the number and size of disks, the amount of SSD caching, and finally the size and utilization of the networking components. NUMA is also a concern, and frankly it seemed that one socket systems match up very well for Ceph storage nodes. It also sounded like PCIe SSDs would make a lot of sense in Ceph nodes as they can cache for a larger number of spinning disks.</p>
<p><strong>3 - Tales From OpenStack’s Gate: How Debugging the Gate Helps Your Enterprise</strong> by Matthew Treinish</p>
<p>This was part of a talk that was done at the <a href="https://www.openstack.org/summit/vancouver-2015/summit-videos/presentation/tales-from-the-gate-how-debugging-the-gate-helps-your-enterprise">Vancouver summit</a>. I was quite interested in their use of Elastic Search, specifically their elastic-recheck setup. Hunting for bugs using Elastic Search is a pretty interesting subject.</p>
<p><strong>4 - InfraCloud, a Community Cloud Managed by the Project Infrastructure Team</strong> - by Paul Belanger</p>
<p>The OpenStack foundation is now running its own OpenStack cloud, called <a href="http://docs.openstack.org/infra/system-config/infra-cloud.html">infracloud</a>. The OpenStack CI system uses many, mostly public, OpenStack-based clouds to run millions of tests. Now they can also rely on their own internal cloud as one of those regions. Infracloud does not need to be highly available because if it is down they can just use one of their other clouds. But they are learning what it is like to actually run an OpenStack cloud, other than DevStack, which I think is very valuable to operators such as myself, as they will likely find bugs that other testing may not.</p>
<p>Paul also reminded me of <a href="https://github.com/openstack/bifrost">bifrost</a> which is a way to deploy a stand alone Ironic system to manage baremetal servers. Basically you could use this instead of something like Cobbler.</p>
<p>Finally, Paul went through their configuration management tooling which is a combination of Puppet and Ansible. They no longer use a true “puppet master” system, and instead run Puppet via Ansible, which is surprisingly quite common.</p>
<p><strong>5 - OpenStack and Opendaylight integration</strong> by Rashmi Pujar and Mohamed Elserngawy from <a href="http://www.inocybe.com/">Inocybe</a></p>
<p>I’m a big fan of OpenDaylight. I’m hoping to add OpenDaylight to my OpenStack lab environment, which is currently running “vanilla” OpenStack networking, and only using provider networks.</p>
<p>The talk was quite dense, and they had a demo as well, and frankly they just ran out of time. It’s great to see a Canadian company, Inocybe, trying to lead the way in an important open source technology like OpenDaylight.</p>
<p>Many of the advanced networking features being worked in the OpenStack ecosystem are first developed using OpenDaylight, so if you want to be on the cutting edge of things like “service function chaining” then running OpenDaylight can be important.</p>
<p><strong>6 -Store All the Things: Storage options for your OpenStack Cloud</strong> by Sean McGinnis</p>
<p>Sean is the Primary Technical Lead (PTL) of Cinder. He discussed Cinder (block storage), Manila (shared file systems) and Swift (object storage). I often forget about Manila, and it would be an important and useful system for applications that need shared storage.</p>
<p>His talk would be useful to people who aren’t sure how to use storage in an OpenStack cloud.</p>
<p><strong>7 - OpenStack adoption stories: Linux Foundation & Opta Insurance Services</strong> a panel with with Konstantin Ryabitsev (Linux Foundation) and Jin Lee (Opta Insurance, a division of SCM insurance) moderated by Mohammed Nasser (<a href="https://vexxhost.com/">Vexx Host</a>).</p>
<p>This was probably the most interesting discussion for me as Jin Lee from Opta is a mathematician with the company and they do machine learning. He was very positive about their use of OpenStack and how easy it was for him to start writing basic code to spin up hundreds of instances to run their machine learning algorithms. The OpenStack foundation would have been very happy to hear his comments. If I remember correctly they use a combination of in-house OpenStack and Vexxhost to obtain computing resources.</p>
<p>He also mentioned speed as being important, in terms of their ability to run algorithms, discover information, and then create microservices that can provide that information. If they can provide services to their customers faster than their competitors, that is an advantage.</p>
<h2 id="toronto-is-next">Toronto is Next</h2>
<p>The 2017 OpenStack Days Canada will be in Toronto. I look forward to attending and perhaps next year I will submit a talk.</p>
<h2 id="thanks-to-the-organizers">Thanks to the organizers</h2>
<p>I’m sure a lot of work went into this event. Thanks to the sponsors and organizers of the event, and I look forward to the 2017 OpenStack Days Canada.</p>
Demystifying Kubernetes and OpenStack2016-11-23T00:00:00+00:00http://serverascode.com/2016/11/23/demystifying-kubernetes-and-openstack<p><em>OpenStack on k8s and/or k8s on OpenStack</em></p>
<h1 id="demystifying-kubernetes-and-openstack">Demystifying Kubernetes and OpenStack</h1>
<p>There seems to be some confusion around using Kubernetes (k8s) and OpenStack together. As an OpenStack Operator, it bugs me a little bit that two very different models of using OpenStack and Kubernetes together are often conflated, occasionally for marketing purposes. In this post I want to identify the two major ways they work together and which is which.</p>
<p>##tl;dr</p>
<p>The two main ways of using OpenStack and k8s together are:</p>
<p><strong>1) Use k8s to manage the OpenStack Control Plane</strong></p>
<p>You can use k8s to manage the OpenStack control plane. Many people don’t realize (especially VMWare administrators), that OpenStack has a fairly complex and resource intensive control plane. For example, if you are buying hardware for an OpenStack deployment, you need to buy hardware for the compute nodes AND the control plane. Typically OpenStack Operators use (n/2)+1 nodes for the control plane due to the use of distributed systems for messaging and state.</p>
<p>This would be a methodology used by OpenStack Operators.</p>
<p><strong>2) Install k8s into an OpenStack Project</strong></p>
<p>Once you have deployed an OpenStack cloud, you can then deploy k8s into a project within that cloud, ie. you, as an OpenStack end-user, provision virtual machines within OpenStack and deploy k8s onto those virtual machines.</p>
<p>This would be a methodology used by OpenStack end-users.</p>
<h2 id="k8s-and-the-openstack-control-plane">k8s and the OpenStack Control Plane</h2>
<p>OpenStack is a complex system. It requires many API servers and other services in order to work. APIs and other OpenStacks services are typically Python based servers. Supporting infrastructure such as MySQL/MariaDB and RabbitMQ, among others, are also required. These systems all have to run somewhere, and this somewhere makes up the OpenStack control plane.</p>
<p>For example, Nova, which provides compute in OpenStack, is made up of several servers, a few of which I list below:</p>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code>/usr/bin/nova-api
/usr/bin/nova-cert
/usr/bin/nova-conductor
/usr/bin/nova-consoleauth
/usr/bin/nova-novncproxy
/usr/bin/nova-scheduler
</code></pre></div></div>
<p>Each of those services could be run on a monolithic “controller” server, ie. a single physical server, or they could each be split out into their own container (or virtual machine).</p>
<p>Using containers can make an OpenStack Operators life easier, especially when it comes to upgrading, or when you would like to run different versions of particular services which can often have dependency issues.</p>
<p>If you decide to use containers to deploy OpenStack services, then you will either have to manually schedule them, or you will need some kind of Container Orchestration Engine (COE) such as k8s, Docker Swarm, or something else. (I should note that in talking with other OpenStack Operators, it is not actually that common to use a COE to manage containers. Quite often containers are “manually” scheduled using some kind of configuration management tool such as Puppet or Ansible, both of which can provision containers.)</p>
<p>If you would like to use a COE, or have additional feature requirements, then using k8s may be of value to you. You could use k8s to manage each OpenStack service. Not only can k8s schedule containers, it also has some additional features that helps to keep those containers running. But it also brings additional complexity. k8s still requires care and feeding like any complex system. If an OpenStack Operator is running 60 containers on 3 physical servers, it may not be worth the additional complexity to run k8s.</p>
<p>In this example, k8s would only run the services required to provide the OpenStack control plane.</p>
<p>Certain OpenStack distributions, such as Mirantis’, are working to alter their deployment system to use k8s as the underlying COE for the OpenStack control plane.</p>
<h2 id="running-k8s-in-openstack">Running k8s in OpenStack</h2>
<p>This is likely the more common use of k8s and OpenStack together. OpenStack would be used like any other Infrastructure as a Service system (IaaS), be it public or private cloud. You would somehow provision virtual machines within and OpenStack project/tenant and then deploy k8s to those virtual machines. k8s would then be running <em>in OpenStack</em>.</p>
<p>There are many ways to install k8s into OpenStack, from using kubeup.sh (which I believe supports OpenStack) to using the <a href="https://wiki.openstack.org/wiki/Magnum">OpenStack Magnum</a> project, and many others. I don’t want to list them all here, but suffice it to say that there are many ways to get k8s installed <em>into</em> an OpenStack cloud. Likely one would use some kind of automated k8s-onto-OpenStack deployment system.</p>
<h2 id="conclusion">Conclusion</h2>
<p>Hopefully I’ve demonstrated that there are two major ways that k8s and OpenStack can work together, and that they are quite different. By far the most common way of using k8s and OpenStack together will be to deploy a k8s cluster <em>into</em> an OpenStack tenant/project. That said, managing the OpenStack control plane with k8s could also be beneficial, but it does bring additional complexity.</p>
<p>Finally, to make things confusing, one could run the OpenStack control plane on k8s, and then also install another k8s cluster, or multiple k8s clusters, into the OpenStack cloud. Fun!</p>
Rsyslog to Elasticsearch2016-11-11T00:00:00+00:00http://serverascode.com/2016/11/11/ryslog-to-elasticsearch<h1 id="rsyslog-to-elasticsearch">Rsyslog to Elasticsearch</h1>
<p>For decades systems administrations have known that it’s important to centralize logs, be it for troubleshooting or security reasons. In my case, not only do I want to centralize logs, but I also want them to be searchable. (Not that grep on a centralized log file isn’t powerful, but that’s not the solution I’m looking for at this time.)</p>
<h2 id="elasticsearch">Elasticsearch</h2>
<p>Elasticsearch has also been around for a while.</p>
<p>Elasticsearch:</p>
<blockquote>
<p>… is a distributed, RESTful search and analytics engine capable of solving a growing number of use cases. As the heart of the Elastic Stack, it centrally stores your data so you can discover the expected and uncover the unexpected.</p>
</blockquote>
<p>Bascially it allows storing, indexing, and searching data. Typically it’s part of a stack, the “ELK” stack, made up of Elasticsearch, Logstash, and Kibana.</p>
<p>As a systems administrator, I think it’s also important to note that Elasticsearch is, when used as a cluster, a distributed system, which means Aphyr has <a href="https://aphyr.com/posts/323-jepsen-elasticsearch-1-5-0">tested it</a>. One shouldn’t take the addition of yet another distributed system lightly. As an example, I have MySQL Galera, RabbitMQ, Nomad, and now Elasticsearch for distributed systems in production right now.</p>
<h2 id="rsyslog-directly-to-elasticsearch">Rsyslog directly to Elasticsearch</h2>
<p>The point of this post is to show how to use rsyslog to send logs directly into an Elasticsearch cluster. Currently I am not using the L part of the stack, meaning I have no Logstash. I’m just using rsyslog to send log messages directly into Elasticsearch, and I use Kibana as a graphical interface to search logs. I would imagine that in the future I will use Logstash, but for now I am not.</p>
<p>I’ve put up a very simple <a href="https://github.com/ccollicutt/ansible-role-elasticsearch-rsyslog">Ansible role</a> to configure rsyslog to send logs to Elasticsearch. I run Haproxy in front of the Elasticsearch cluster so I send all the logs to the Haproxy virtual IP, which loadbalances across the Elasticsearch cluster. But other than that, this is what I use, and it has been taking in millions of logs, probably 30/second, for a few weeks.</p>
<h2 id="omelasticsearch">omelasticsearch</h2>
<p>omelasticsearch does all the work. You just need a rsyslog version recent enough to have that module. Then add in a configuration file which points to your Elasticsearch cluster, and you’re done. Quite simple actually.</p>
<p>Here is the package:</p>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="nv">$ </span>dpkg <span class="nt">--list</span> rsyslog-elasticsearch
<span class="nv">Desired</span><span class="o">=</span>Unknown/Install/Remove/Purge/Hold
| <span class="nv">Status</span><span class="o">=</span>Not/Inst/Conf-files/Unpacked/halF-conf/Half-inst/trig-aWait/Trig-pend
|/ Err?<span class="o">=(</span>none<span class="o">)</span>/Reinst-required <span class="o">(</span>Status,Err: <span class="nv">uppercase</span><span class="o">=</span>bad<span class="o">)</span>
<span class="o">||</span>/ Name Version Architecture Description
+++-<span class="o">=====================================</span>-<span class="o">=======================</span>-<span class="o">=======================</span>-<span class="o">===============================================================================</span>
ii rsyslog-elasticsearch 8.16.0-1ubuntu3 amd64 Elasticsearch output plugin <span class="k">for </span>rsyslog
</code></pre></div></div>
<p>And here is the configuration file:</p>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="nv">$ </span><span class="nb">cat </span>templates/etc/rsyslog.d/elasticsearch.conf
module<span class="o">(</span><span class="nv">load</span><span class="o">=</span><span class="s2">"omelasticsearch"</span><span class="o">)</span> <span class="c"># Elasticsearch output module</span>
<span class="c"># this is for index names to be like: logstash-YYYY.MM.DD</span>
template<span class="o">(</span><span class="nv">name</span><span class="o">=</span><span class="s2">"logstash-index"</span>
<span class="nb">type</span><span class="o">=</span><span class="s2">"list"</span><span class="o">)</span> <span class="o">{</span>
constant<span class="o">(</span><span class="nv">value</span><span class="o">=</span><span class="s2">"logstash-"</span><span class="o">)</span>
property<span class="o">(</span><span class="nv">name</span><span class="o">=</span><span class="s2">"timereported"</span> <span class="nv">dateFormat</span><span class="o">=</span><span class="s2">"rfc3339"</span> position.from<span class="o">=</span><span class="s2">"1"</span> position.to<span class="o">=</span><span class="s2">"4"</span><span class="o">)</span>
constant<span class="o">(</span><span class="nv">value</span><span class="o">=</span><span class="s2">"."</span><span class="o">)</span>
property<span class="o">(</span><span class="nv">name</span><span class="o">=</span><span class="s2">"timereported"</span> <span class="nv">dateFormat</span><span class="o">=</span><span class="s2">"rfc3339"</span> position.from<span class="o">=</span><span class="s2">"6"</span> position.to<span class="o">=</span><span class="s2">"7"</span><span class="o">)</span>
constant<span class="o">(</span><span class="nv">value</span><span class="o">=</span><span class="s2">"."</span><span class="o">)</span>
property<span class="o">(</span><span class="nv">name</span><span class="o">=</span><span class="s2">"timereported"</span> <span class="nv">dateFormat</span><span class="o">=</span><span class="s2">"rfc3339"</span> position.from<span class="o">=</span><span class="s2">"9"</span> position.to<span class="o">=</span><span class="s2">"10"</span><span class="o">)</span>
<span class="o">}</span>
<span class="c"># template to generate JSON documents for Elasticsearch in Logstash format</span>
template<span class="o">(</span><span class="nv">name</span><span class="o">=</span><span class="s2">"plain-syslog"</span>
<span class="nb">type</span><span class="o">=</span><span class="s2">"list"</span><span class="o">)</span> <span class="o">{</span>
constant<span class="o">(</span><span class="nv">value</span><span class="o">=</span><span class="s2">"{"</span><span class="o">)</span>
constant<span class="o">(</span><span class="nv">value</span><span class="o">=</span><span class="s2">"</span><span class="se">\"</span><span class="s2">@timestamp</span><span class="se">\"</span><span class="s2">:</span><span class="se">\"</span><span class="s2">"</span><span class="o">)</span> property<span class="o">(</span><span class="nv">name</span><span class="o">=</span><span class="s2">"timereported"</span> <span class="nv">dateFormat</span><span class="o">=</span><span class="s2">"rfc3339"</span><span class="o">)</span>
constant<span class="o">(</span><span class="nv">value</span><span class="o">=</span><span class="s2">"</span><span class="se">\"</span><span class="s2">,</span><span class="se">\"</span><span class="s2">host</span><span class="se">\"</span><span class="s2">:</span><span class="se">\"</span><span class="s2">"</span><span class="o">)</span> property<span class="o">(</span><span class="nv">name</span><span class="o">=</span><span class="s2">"hostname"</span><span class="o">)</span>
constant<span class="o">(</span><span class="nv">value</span><span class="o">=</span><span class="s2">"</span><span class="se">\"</span><span class="s2">,</span><span class="se">\"</span><span class="s2">severity-num</span><span class="se">\"</span><span class="s2">:"</span><span class="o">)</span> property<span class="o">(</span><span class="nv">name</span><span class="o">=</span><span class="s2">"syslogseverity"</span><span class="o">)</span>
constant<span class="o">(</span><span class="nv">value</span><span class="o">=</span><span class="s2">",</span><span class="se">\"</span><span class="s2">facility-num</span><span class="se">\"</span><span class="s2">:"</span><span class="o">)</span> property<span class="o">(</span><span class="nv">name</span><span class="o">=</span><span class="s2">"syslogfacility"</span><span class="o">)</span>
constant<span class="o">(</span><span class="nv">value</span><span class="o">=</span><span class="s2">",</span><span class="se">\"</span><span class="s2">severity</span><span class="se">\"</span><span class="s2">:</span><span class="se">\"</span><span class="s2">"</span><span class="o">)</span> property<span class="o">(</span><span class="nv">name</span><span class="o">=</span><span class="s2">"syslogseverity-text"</span><span class="o">)</span>
constant<span class="o">(</span><span class="nv">value</span><span class="o">=</span><span class="s2">"</span><span class="se">\"</span><span class="s2">,</span><span class="se">\"</span><span class="s2">facility</span><span class="se">\"</span><span class="s2">:</span><span class="se">\"</span><span class="s2">"</span><span class="o">)</span> property<span class="o">(</span><span class="nv">name</span><span class="o">=</span><span class="s2">"syslogfacility-text"</span><span class="o">)</span>
constant<span class="o">(</span><span class="nv">value</span><span class="o">=</span><span class="s2">"</span><span class="se">\"</span><span class="s2">,</span><span class="se">\"</span><span class="s2">syslogtag</span><span class="se">\"</span><span class="s2">:</span><span class="se">\"</span><span class="s2">"</span><span class="o">)</span> property<span class="o">(</span><span class="nv">name</span><span class="o">=</span><span class="s2">"syslogtag"</span> <span class="nv">format</span><span class="o">=</span><span class="s2">"json"</span><span class="o">)</span>
constant<span class="o">(</span><span class="nv">value</span><span class="o">=</span><span class="s2">"</span><span class="se">\"</span><span class="s2">,</span><span class="se">\"</span><span class="s2">message</span><span class="se">\"</span><span class="s2">:</span><span class="se">\"</span><span class="s2">"</span><span class="o">)</span> property<span class="o">(</span><span class="nv">name</span><span class="o">=</span><span class="s2">"msg"</span> <span class="nv">format</span><span class="o">=</span><span class="s2">"json"</span><span class="o">)</span>
constant<span class="o">(</span><span class="nv">value</span><span class="o">=</span><span class="s2">"</span><span class="se">\"</span><span class="s2">}"</span><span class="o">)</span>
<span class="o">}</span>
action<span class="o">(</span><span class="nb">type</span><span class="o">=</span><span class="s2">"omelasticsearch"</span>
<span class="nv">server</span><span class="o">=</span><span class="s2">"{{ elastic_search_ip }}"</span>
<span class="nv">serverport</span><span class="o">=</span><span class="s2">"9200"</span>
<span class="nv">template</span><span class="o">=</span><span class="s2">"plain-syslog"</span> <span class="c"># use the template defined earlier</span>
<span class="nv">searchIndex</span><span class="o">=</span><span class="s2">"logstash-index"</span>
<span class="nv">dynSearchIndex</span><span class="o">=</span><span class="s2">"on"</span>
<span class="nv">searchType</span><span class="o">=</span><span class="s2">"events"</span>
<span class="nv">bulkmode</span><span class="o">=</span><span class="s2">"on"</span> <span class="c"># use the Bulk API</span>
queue.dequeuebatchsize<span class="o">=</span><span class="s2">"5000"</span> <span class="c"># ES bulk size</span>
queue.size<span class="o">=</span><span class="s2">"100000"</span> <span class="c"># capacity of the action queue</span>
queue.workerthreads<span class="o">=</span><span class="s2">"5"</span> <span class="c"># 5 workers for the action</span>
action.resumeretrycount<span class="o">=</span><span class="s2">"-1"</span> <span class="c"># retry indefinitely if ES is unreachable</span>
<span class="nv">errorfile</span><span class="o">=</span><span class="s2">"/var/log/omelasticsearch.log"</span>
<span class="o">)</span>
</code></pre></div></div>
<p><br /></p>
<h2 id="curator">Curator</h2>
<p>You will probably want to prune the logs that are entered into your ES cluster, that is unless you have a lot of storage space. I am using <a href="https://github.com/elastic/curator">Curator</a> to do that. The omelastic module configuration show above adds indices with names like “logstash-YYY-MM-DD” and you can use that pattern with a curator action file to delete indices older than a certain number of days. I have a daily job that is run out of a Nomad cluster to prune indices over 30 days old.</p>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="nv">$ </span>curl <span class="s1">'elasticsearch-vip:9200/_cat/indices?v'</span>
health status index pri rep docs.count docs.deleted store.size pri.store.size
SNIP!
green open logstash-2016.11.04 5 1 158184 0 55.4mb 27.7mb
green open .kibana 1 1 7 1 72.1kb 36kb
green open logstash-2016.11.05 5 1 538415 0 181mb 90.5mb
green open logstash-2016.11.06 5 1 538909 0 181.1mb 90.5mb
green open logstash-2016.11.07 5 1 591699 0 219.6mb 109.9mb
green open logstash-2016.11.08 5 1 574186 0 207mb 103.5mb
green open logstash-2016.11.09 5 1 626842 0 231.8mb 115.9mb
green open logstash-2016.11.10 5 1 570544 0 203.8mb 101.9mb
green open logstash-2016.11.11 5 1 350968 0 145mb 69.9mb
</code></pre></div></div>
<p><br /></p>
<h2 id="performance">Performance</h2>
<p>I should also note that this configuration may not be as performant as you would like. There are certainly considerations to make in terms of the number of indices, and shards, and their size, and how that relates to performance of the ES cluster over time. I would doubt that this example will be useful in large systems and would require a fair amount of tuning. Please keep that in mind. :)</p>
<h2 id="conclusion">Conclusion</h2>
<p>This is a pretty simplistic example of Elasticsearch use. But I think it’s helpful because it can get you up and running, logging to Elasticsearch, quickly, and from this point you can work on improving things as you learn about ES. That’s my plan anyways. :)</p>
OpenStack and ETSI MANO2016-11-02T00:00:00+00:00http://serverascode.com/2016/11/02/openstack-etsi-mano<h1 id="openstack-and-etsi-mano">OpenStack and ETSI MANO</h1>
<p>The summit for the Newton release of OpenStack was held in Barcelona. I attended and found it to be a very interesting summit, one that, as usual, marks change for OpenStack.</p>
<p>OpenStack has always had more existential crisis than other open source projects. Previous crisis have regarded things like CloudStack (remember that?), the “public cloud” (which is still partially ongoing), the “big tent,” the continued–but improving–separation of developers and users, whether or not it is simply a vendor dumping ground, etc, etc.</p>
<p>The current crisis would be around its growing adoption by telecommunications companies. As we enter a phase of OpenStack’s lifecycle in which it sees serious adoption by extremely large, conservative, (<em>cough</em> inefficient) enterprises I would imagine that we could very well see OpenStack slowly change into something that might be unrecognizable to early adopters.</p>
<h2 id="telecommunications">Telecommunications</h2>
<p>One of the biggest changes that has occurred in the past year for OpenStack is that telecommunication companies have (finally) begun adoption. And they are going all in, so to speak.</p>
<p>Telecommunications is potentially a 1 trillion dollar industry. Even a small percentage of that is a huge sum of money, and given the relatively minimal size of the OpenStack market share, is considerable in terms of how it could sway OpenStack’s development and progress. (1)</p>
<p>Jay Pipes, someone who has been around the community for some time, has thoughts, or at least a tweet, on where he thinks OpenStack is going:</p>
<blockquote class="twitter-tweet" data-lang="en"><p lang="en" dir="ltr">Prediction: in less than 2 years, Telcos will have fully taken over <a href="https://twitter.com/hashtag/OpenStack?src=hash">#OpenStack</a> and converted it into a purpose-built NFVi+MANO solution</p>— Jay Pipes (@jaypipes) <a href="https://twitter.com/jaypipes/status/790943000931233792">October 25, 2016</a></blockquote>
<script async="" src="//platform.twitter.com/widgets.js" charset="utf-8"></script>
<h2 id="mano---management-and-orchestration">MANO - Management and Orchestration</h2>
<p>For those of you unfamiliar with the acronym MANO, it stands for “Management and Orchestration.” The standards group ETSI has defined a large part of the way that telecommunications companies are going to perform Network Function Virtualization (NFV).</p>
<p>At this point OpenStack mostly makes up the NFV infrastructure (NFVi) and Virtualization Infrastructure Manager (VIM) components, and, in my opinion, currently stops there. The ETSI MANO layer, however, sits on top of all of this infrastructure, which would likely include many OpenStack clouds in many datacenters as well as other components such as Software Defined Networking (SDN) controllers, and magically manages and orchestrates it. (4)</p>
<p>To suggest that OpenStack will also own the MANO component is surprising. So far, other than relatively unused multi-region support, OpenStack has not had many projects dealing with managing multiple clouds, or external systems outside of its own particular realm. Adding a MANO system would be a big change for the OpenStack project, one I’m not sure will happen. There are several open source MANO projects (2) and I have difficulty seeing them being moved within the OpenStack namespace. But, it could happen.</p>
<p>An example of an OpenStack project within reach of the MANO layer is the Tacker (3) project. Tacker is a generic Virtual Network Function Manager (VNFM) and a Network Function Orchestrator (NFO) but (I guess) not a full fledged MANO. But in effect it can act as one, as one of Tacker’s features is the “[a]bility to orchestrate VNFs across Multiple VIMs and Multiple Sites (POPs).” So in some respects there is already evidence of OpenStack working (somewhat?) at the MANO level. Once could see a MANO project coming into existence (if it’s not there already) and use Tacker as the VNFM component, and the rest of OpenStack as the NFVi and VIM blocks.</p>
<p>However, these MANO layers are going to be extremely important to the success of telecoms as they migrate/evolve to NFV. Further, these MANO layers are going to be extremely complicated and feature rich. My impression is that they will attempt to be all-encompassing.(5,6) They will have to talk to all kinds of complex systems. The MANO layer might simply be too big to be part of the OpenStack project and may more likely end up beneath the Linux Foundation (which is where Jay Pipes says OpenStack will end up eventually anyways).</p>
<p>Common sense suggests that OpenStack remain a set of primitives that higher level abstractions can use. So this MANO layer can use Neutron, Nova, Heat, Telemetry, etc, etc, to perform its job across multiple, complex systems, and not just OpenStack clouds. But, perhaps instead of common sense this is really just opinion, and other people and organizations will have a differing one.</p>
<h2 id="footnotes">Footnotes</h2>
<ol>
<li>“Revenue from OpenStack, the open source software platform for cloud computing, will likely top $5 billion by 2020 and grow at a 35 percent compounded annual growth rate, according to 451 Research. While that growth rate is strong, the platform’s overall revenue is still fairly small compared to that of market leaders like VMware and Amazon Web Services (AWS), the firm said.” - via <a href="https://www.sdxcentral.com/articles/news/openstack-revenue-will-top-5b-by-2020-says-451-research/2016/10/">SDXCentral</a> and <a href="https://451research.com/images/Marketing/press_releases/10.24.16_OpenStack_Pulse_PR_Final.pdf">451 Research</a></li>
<li>Eg. <a href="https://osm.etsi.org/">OSM</a> and <a href="https://www.open-o.org/">Open-O</a></li>
<li><a href="https://wiki.openstack.org/wiki/Tacker">Tacker</a></li>
<li>Should have called it ETSI MAGI. ;)</li>
<li>Video: <a href="https://www.youtube.com/watch?v=pxrDmqCMBLQ">OpenStack and the Orchestration Options for Telecom NFV</a></li>
<li>I would expect all-encompassing MANO systems, ones that try to take over everything (<em>hint</em> vendor lock-in <em>hint</em>) to fail.</li>
</ol>
Distributed Cron With Nomad2016-10-18T00:00:00+00:00http://serverascode.com/2016/10/18/distributed-cron-with-nomad<h1 id="distributed-cron-with-nomad">Distributed Cron With Nomad</h1>
<p>Everybody loves <a href="https://www.hashicorp.com/">Hashicorp!</a> Most technologists have probably used <a href="https://www.vagrantup.com/">Vagrant</a> at some point. Besides Vagrant, Hashicorp has other great technologies, however, in this post I’d like to talk about <a href="https://www.nomadproject.io/">Nomad</a>.</p>
<h2 id="nomad">Nomad</h2>
<p>Nomad is:</p>
<blockquote>
<p>A Distributed, Highly Available, Datacenter-Aware Scheduler</p>
</blockquote>
<p>Nomad has many use cases. For example it has a Docker driver which means it can handle running Docker containers. I prefer to think of it as a job scheduler. You want something done, you create a job in Nomad and Nomad handles it for you. In this blog post, I describe a specific example: using Nomad to handle cron jobs, such as backing up a MySQL database.</p>
<h2 id="caveats">Caveats</h2>
<ul>
<li>I should note that the example discussed is in a lab setting. But it is backing up an OpenStack MySQL Galera cluster in a permanent lab deployment, so it’s important data.</li>
<li>Instead of running Nomad as root, I run it as the nomad user. This might get in the way if you are planning on using it to run docker workloads. I don’t know because I haven’t done that.</li>
<li>Because I’m not running Nomad as root, I’m allowing the use of raw_exec.</li>
<li>I’m not using a Consul cluster. Instead I’m using Nomad’s built in clustering capability. I would imagine in a large production environment you would have a Consul cluster running.</li>
</ul>
<h2 id="setting-up-a-nomad-cluster">Setting Up a Nomad Cluster</h2>
<p>One thing I like about Nomad, and various Go-based systems, is that they are distributed in a single binary. Add a user, and a systemd startup file, and you are done. Well, installing anyways.</p>
<p>I have some Ansible that takes care of this, but in way of illustration, below is the configuration on a server member.</p>
<p>First, the base.hcl file.</p>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code>ubuntu@NODE-1-nomad-server:/etc/nomad<span class="nv">$ </span><span class="nb">cat </span>base.hcl
<span class="c"># Increase log verbosity</span>
log_level <span class="o">=</span> <span class="s2">"DEBUG"</span>
<span class="c"># Setup data dir</span>
data_dir <span class="o">=</span> <span class="s2">"/var/lib/nomad"</span>
bind_addr <span class="o">=</span> <span class="s2">"172.17.5.129"</span>
<span class="c"># Enable debug endpoints.</span>
enable_debug <span class="o">=</span> <span class="nb">true</span>
</code></pre></div></div>
<p>Now the server.hcl file. The retry join IP is the IP of the first Nomad cluster member.</p>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code>ubuntu@NODE-1-nomad-server:/etc/nomad<span class="nv">$ </span><span class="nb">cat </span>server.hcl
server <span class="o">{</span>
enabled <span class="o">=</span> <span class="nb">true
</span>bootstrap_expect <span class="o">=</span> 3
retry_join <span class="o">=</span> <span class="o">[</span><span class="s2">"172.17.5.129"</span><span class="o">]</span>
<span class="o">}</span>
</code></pre></div></div>
<p>The nice thing about Nomad configuration is that it can be additive, so to speak, in that we can have a base file and then a server configuration and a client configuration. The server configuration would only be deployed to servers, and the client with the clients, but the base configuration to all nodes. It’s good for configuration management.</p>
<p>Once the server members come up you can check their status:</p>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code>ubuntu@NODE-3-nomad-server:~<span class="nv">$ </span>nomad server-members <span class="nt">-address</span> http://172.17.5.126:4646
Name Address Port Status Leader Protocol Build Datacenter Region
NODE-1-nomad-server.global 172.17.5.129 4648 alive <span class="nb">true </span>2 0.4.1 dc1 global
NODE-2-nomad-server.global 172.17.5.127 4648 alive <span class="nb">false </span>2 0.4.1 dc1 global
NODE-3-nomad-server.global 172.17.5.126 4648 alive <span class="nb">false </span>2 0.4.1 dc1 global
</code></pre></div></div>
<p>And we are done with the cluster.</p>
<h2 id="setting-up-a-nomad-client">Setting Up a Nomad Client</h2>
<p>Same binary, same startup, same user, same base.hcl, remove server.hcl and add in client.hcl.</p>
<p>The server IPs are those of the three Nomad cluster servers.</p>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code>ubuntu@NODE-1-mysql-backup:/etc/nomad<span class="nv">$ </span><span class="nb">cat </span>client.hcl
client <span class="o">{</span>
enabled <span class="o">=</span> <span class="nb">true
</span>servers <span class="o">=</span> <span class="o">[</span> <span class="s2">"172.17.5.129"</span>,<span class="s2">"172.17.5.127"</span>,<span class="s2">"172.17.5.126"</span> <span class="o">]</span>
<span class="c"># Enable raw_exec. We are not running nomad as root.</span>
options <span class="o">=</span> <span class="o">{</span>
<span class="s2">"driver.raw_exec.enable"</span> <span class="o">=</span> <span class="s2">"1"</span>
<span class="o">}</span>
<span class="o">}</span>
</code></pre></div></div>
<p>Once the clients startup you can check their status:</p>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code>ubuntu@NODE-3-nomad-server:~<span class="nv">$ </span>nomad node-status <span class="nt">-address</span> http://172.17.5.126:4646
ID DC Name Class Drain Status
306dcf6b dc1 NODE-3-mysql-backup <none> <span class="nb">false </span>ready
6a3109d5 dc1 NODE-1-mysql-backup <none> <span class="nb">false </span>ready
8e3abc4a dc1 NODE-2-mysql-backup <none> <span class="nb">false </span>ready
</code></pre></div></div>
<h2 id="periodic-job">Periodic Job</h2>
<p>Nomad supports <a href="https://www.nomadproject.io/docs/jobspec/">periodic jobs</a>. To my simplistic layperson mind that means cron jobs…but <em>distributed</em> cron jobs!</p>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code>job <span class="s2">"mysql-backup"</span> <span class="o">{</span>
datacenters <span class="o">=</span> <span class="o">[</span><span class="s2">"dc1"</span><span class="o">]</span>
<span class="nb">type</span> <span class="o">=</span> <span class="s2">"batch"</span>
constraint <span class="o">{</span>
attribute <span class="o">=</span> <span class="s2">"</span><span class="k">${</span><span class="nv">attr</span><span class="p">.unique.hostname</span><span class="k">}</span><span class="s2">"</span>
regexp <span class="o">=</span> <span class="s2">".*mysql-backup"</span>
<span class="o">}</span>
periodic <span class="o">{</span>
// Launch every hour
cron <span class="o">=</span> <span class="s2">"0 * * * * *"</span>
// Do not allow overlapping runs.
prohibit_overlap <span class="o">=</span> <span class="nb">true</span>
<span class="o">}</span>
task <span class="s2">"run-mysql-backup"</span> <span class="o">{</span>
driver <span class="o">=</span> <span class="s2">"raw_exec"</span>
config <span class="o">{</span>
<span class="c"># When running a binary that exists on the host, the path must be absolute</span>
<span class="nb">command</span> <span class="o">=</span> <span class="s2">"/usr/local/bin/mysql-backup.sh"</span>
<span class="o">}</span>
resources <span class="o">{</span>
<span class="c"># defaults</span>
<span class="o">}</span>
<span class="o">}</span>
<span class="o">}</span>
</code></pre></div></div>
<p>Certainly the job shown above is overly simplistic. I haven’t put in many jobs or read through the jobs documentation properly. But the above job seems to be working and it is using at least one constraint in that the hostname of the nomad client must end in “mysql-backup.” I have three mysql-backup nodes running, thus on an hourly basis the job will run on one, and only one, of the three nodes. Each of the three mysql-backup nodes are LXC containers running on a different physical hosts, so the idea is that if one of the containers, or the host, becomes unavailable, the job will still continue to run on the surviving nodes.</p>
<p>Also I should read up more on resources. I don’t think the default resources provide much in the way of CPU and memory.</p>
<p>Once the job is added to the cluster, it looks like this:</p>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code>ubuntu@NODE-3-nomad-server:~<span class="nv">$ </span>nomad status <span class="nt">-address</span> http://172.17.5.126:4646 mysql-backup
ID <span class="o">=</span> mysql-backup
Name <span class="o">=</span> mysql-backup
Type <span class="o">=</span> batch
Priority <span class="o">=</span> 50
Datacenters <span class="o">=</span> dc1
Status <span class="o">=</span> running
Periodic <span class="o">=</span> <span class="nb">true
</span>Next Periodic Launch <span class="o">=</span> 10/18/16 23:00:00 UTC <span class="o">(</span>37m51s from now<span class="o">)</span>
Previously launched <span class="nb">jobs</span>:
ID Status
mysql-backup/periodic-1476824400 dead
mysql-backup/periodic-1476828000 dead
</code></pre></div></div>
<p>In this example there have only been two runs of the job created, and strangely they are listed as having a status of “dead”, but I believe that is actually the correct status as the jobs have completed. Slightly confusing terminology.</p>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code>ubuntu@NODE-3-nomad-server:~<span class="nv">$ </span>nomad status <span class="nt">-address</span> http://172.17.5.126:4646 mysql-backup/periodic-1476824400
ID <span class="o">=</span> mysql-backup/periodic-1476824400
Name <span class="o">=</span> mysql-backup/periodic-1476824400
Type <span class="o">=</span> batch
Priority <span class="o">=</span> 50
Datacenters <span class="o">=</span> dc1
Status <span class="o">=</span> dead
Periodic <span class="o">=</span> <span class="nb">false
</span>Summary
Task Group Queued Starting Running Failed Complete Lost
run-mysql-backup 0 0 0 0 1 0
Allocations
ID Eval ID Node ID Task Group Desired Status Created At
5e661d1e 373600be 306dcf6b run-mysql-backup run <span class="nb">complete </span>10/18/16 21:00:00 UTC
</code></pre></div></div>
<h2 id="conclusion">Conclusion</h2>
<p>High performance computing experts are probably used to being able to run batch jobs like this, certainly the idea has been around for a long time, but I am not an HPC specialist. I just want a simple distributed (lol) system that can run a backup script on any available node. Plus I like trying out “new stuff” even if it partially implements older ideas.</p>
<p>More to come in future posts!</p>
Getting an AWS Instance's Region with Boto2016-10-01T00:00:00+00:00http://serverascode.com/2016/10/01/boto-get-region<h1 id="getting-an-aws-instances-region-with-boto">Getting an AWS Instance’s Region with Boto</h1>
<p>This is a quick post on how to get the region an AWS instance is in using Boto.</p>
<h2 id="tldr">tl;dr</h2>
<p>I’m using a virtualenv with boto installed in an instance in AWS. To use <em>boto.ec2.connect_to_region()</em> I need to provide the region. But how do I know that without having to hard code it or get it from a config file? I can use the instances AWS metadata.</p>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="o">(</span>venv<span class="o">)</span> ubuntu@ip-172-31-14-171:~<span class="nv">$ </span><span class="nb">cat </span>region.py
<span class="c">#!/opt/venv/bin/python2.7</span>
import boto.utils
data <span class="o">=</span> boto.utils.get_instance_identity<span class="o">()</span>
region_name <span class="o">=</span> data[<span class="s1">'document'</span><span class="o">][</span><span class="s1">'region'</span><span class="o">]</span>
print region_name
<span class="o">(</span>venv<span class="o">)</span> ubuntu@ip-172-31-14-171:~<span class="nv">$ </span>./region.py
us-west-1
</code></pre></div></div>
<p>Now I know what region the instance is in programmatically.</p>
<h2 id="a-bit-more">A bit more</h2>
<p>AWS instances can have an IAM role that allows them to do many things in AWS, such as creating instances or uploading files to S3 or creating “virtual private clouds” (VPCs, ie. networking). They don’t have to have API IDs or keys, they can just be given roles on creation. Obviously, once they are deleted they no longer have that access.</p>
<p>Further, the Boto library is smart enough to know when it is running in an AWS instance.</p>
<p>This way we can list all ec2 instances from within a particular instance without having to provide it specific credentials. However, in order to connect to ec2 using Boto we need to provide the region. As mentioned, thankfully Boto provides a way to do that prior to connecting using the instances metadata.</p>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="o">(</span>venv<span class="o">)</span> ubuntu@ip-172-31-14-171:~<span class="nv">$ </span><span class="nb">cat </span>connect.py
<span class="c">#!/opt/venv/bin/python2.7</span>
import boto.utils
import boto.ec2
data <span class="o">=</span> boto.utils.get_instance_identity<span class="o">()</span>
region_name <span class="o">=</span> data[<span class="s1">'document'</span><span class="o">][</span><span class="s1">'region'</span><span class="o">]</span>
conn <span class="o">=</span> boto.ec2.connect_to_region<span class="o">(</span>region_name<span class="o">)</span>
<span class="k">for </span>i <span class="k">in </span>conn.get_only_instances<span class="o">()</span>:
print i
<span class="o">(</span>venv<span class="o">)</span> ubuntu@ip-172-31-14-171:~<span class="nv">$ </span>./connect.py
Instance:i-5ed52dea
</code></pre></div></div>
<p>That’s it! Now depending on the roles and permissions the instance has in terms of AWS, it can use those APIs to manage all kinds of instructure and tools.</p>
<p>Hat tip to this <a href="http://stackoverflow.com/questions/21365408/boto-python-library-still-thinks-it-is-in-original-ec2-datacentre-after-migratio_">Stackoverflow</a> post.</p>
Kubernetes the Hard Way in AWS with Ansible2016-09-05T00:00:00+00:00http://serverascode.com/2016/09/05/kubernetes-the-hard-way-in-aws-with-ansible<h1 id="kubernetes-the-hard-way-in-aws-with-ansible">Kubernetes the Hard Way in AWS with Ansible</h1>
<p>Even though I mostly work with OpenStack, I also quite like Amazon Web Services (AWS). Further I am doing a lot of work with containers, and have been doing so for a while–I was messing around with <a href="https://github.com/ccollicutt/ansible-mesos-playbook">Mesos</a> two years ago.</p>
<p>Kubernetes has a lot of attention right now. Docker has slightly cooled off, but is moving rapidly forwards <a href="https://blog.docker.com/2016/06/docker-1-12-built-in-orchestration/">technology-wise</a>. Kubernetes has recently reached some kind of front-runner status in terms of container management systems, though I should note that Docker is being used as the container runtime in all the examples discussed in this blog post. Kubernetes does not provide containers directly, and instead uses an underlying system such as Docker, or more recently, <a href="https://coreos.com/rkt/">rkt</a> for that layer. Kubernetes focuses on managing the deployment of containerized applications.</p>
<h2 id="tldr">tl;dr</h2>
<p>I’ve released some <a href="https://github.com/ccollicutt/kubernetes-the-hard-way-with-aws-and-ansible">Ansible playbooks</a> and documents that will deploy Kubernetes into AWS, and configure Kubernetes to manage some AWS features like route tables and elastic load balancers.</p>
<h2 id="kubernetes-the-hard-way">Kubernetes the Hard Way</h2>
<p>A couple months ago <a href="https://twitter.com/kelseyhightower">Kelsey Hightower</a> released a set of documents entitled <a href="https://github.com/kelseyhightower/kubernetes-the-hard-way">Kubernetes the Hard Way</a> (KtHW) which details how to manually deploy k8s. k8s comes with a <em>kube-up.sh</em> script that will deploy it to several IaaS providers, but it hides much of the deployment complexity, which is considerable. I don’t see how you could run k8s in production with just the <em>kube-up.sh</em> script.</p>
<p>I took the example that Mr. Hightower had provided and altered it to use AWS (instead of Google Compute Engine) and also use Ansible instead of running individual commands. But I still kept the “one step at a time” mentality, which combines perfectly with Ansible when using multiple playbooks for each infrastructure layer.</p>
<p>If you’d like to try out <em>Kubernetes the Hard Way in AWS with Ansible</em> (KtHWAA) then you can take a look at <a href="https://github.com/ccollicutt/kubernetes-the-hard-way-with-aws-and-ansible">this Github repository</a>. If you run into any errors, please don’t hesitate to submit an issue via Github and I will work on getting it fixed right away.</p>
<h2 id="k8s-in-aws">k8s in AWS</h2>
<p>k8s integrates well with AWS. For example, using the networking methodology that is shown in KtHW, route tables need to be setup in the VPC to point the node networks to particular nodes. k8s can do this automatically.</p>
<p>Further, when you create a service in k8s, it can automatically configure an AWS EC2 load balancer to expose the service externally. This includes creating appropriate security groups.</p>
<p>There are a few other integrations that I have yet to configure in my KtHWAA repository, but the two important ones, 1) pod routes and 2) ELB are completed and work great.</p>
<p>The ability of k8s to configure the IaaS around it is quite amazing. I’m sure seasoned AWS users understand that IAM roles and policies are powerful, but to me it means something special because the infrastructure I create in AWS, such as k8s, can also configure AWS features. It seems obvious, but that is extremely dynamic. This capability is something that is lacking in OpenStack–the ability to create roles and policies and provide components, such as a virtual machine, the ability to alter the tenant infrastructure around it.</p>
<p>I’m also impressed that the k8s project has put so much work in AWS integration. Given k8s is a Google led project, I’m happy to see them supporting other IaaS providers. So kudos to Google and the other members of the k8s project team.</p>
<h2 id="using-aws-with-ansible">Using AWS with Ansible</h2>
<p>I ran into a few funny issues with Ansible modules and AWS, but overall I’m happy with how things turned out. I could do everything I needed to with Ansible, though certainly there are some improvements to be made. Even though Ansible has been around for a while the modules are constantly improving and as AWS continues to grow at an unprecedented pace I’m sure the Ansible will get better and better in terms of managing AWS, as will my ability to properly use both.</p>
<p>One example is that, at this time, is not an ec2_group_facts module, so you can only get information about a security group if you create it with the ec2_group module. But that will be easily fixed.</p>
<h2 id="forward-looking-statement">Forward Looking Statement</h2>
<p>I plan on doing a lot more work with k8s in AWS. There are at least of couple of areas, 1) volumes and 2) auto scaling, that I would like to investigate. k8s is powerful but complicated, and the real goal isn’t to be someone running k8s infrastructure, but rather to use k8s to run <em>actual</em> applications.</p>
<p>AWS is extremely powerful and granular. Through creating KtHWAA I learned a lot about AWS Virtual Private Cloud (ie. networking) as well as the load balancer service. I’ve always been a big fan of AWS spot instances, so I use those as well (though I wouldn’t use them as much in a production instance). As mentioned, IAM roles and policies are a huge feature and differentiator, though I haven’t used other IaaS systems as extensively.</p>
<p>Regarding networking in k8s, I don’t completely understand the <a href="https://github.com/containernetworking/cni">Container Networking Interface</a> (CNI) setup, so there is some reading and experimentation to do in that area as well.</p>
<h2 id="thanks">Thanks!</h2>
<p>Thanks to <a href="https://twitter.com/kelseyhightower">Kelsey Hightower</a> for releasing KtHW, as well as the team that put together <a href="https://github.com/ivx/kubernetes-the-hard-way-aws">KtHW with AWs</a>, which replaces GCE commands with similar AWS ones.</p>
Installing ZFS in an AWS EC2 Instance Using User-Data2016-09-05T00:00:00+00:00http://serverascode.com/2016/09/05/aws-zfs-user-data<h1 id="installing-zfs-in-an-aws-ec2-instance-using-user-data">Installing ZFS in an AWS EC2 Instance Using User-Data</h1>
<p>Quick post on installing ZFS into an AWS instance using user-data and cloud-init.</p>
<p>I’m doing some work with Kubernetes, which uses Docker, and Docker can use ZFS as a backing store. I want ZFS configured before I do anything else, and the best way to do that is to either create a specific Amazon machine image (AMI) or to use user-data. I chose the former.</p>
<p>Note that this is an instance-store AMI and has two block devices, xvdb and xvdc.</p>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="c">#cloud-config</span>
packages:
- zfsutils-linux
runcmd:
- umount <span class="nt">-f</span> /mnt
- zpool create <span class="nt">-f</span> zpool-docker /dev/xvdb /dev/xvdc
- zfs create <span class="nt">-o</span> <span class="nv">mountpoint</span><span class="o">=</span>/var/lib/docker zpool-docker/docker
</code></pre></div></div>
<p>That’s it.</p>
<p>Once the instance is booted up, you can login and see that there is a /var/lib/docker file system mounted from the zpool-docker zpool.</p>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code>root@docker0:/home/ubuntu# zfs list /var/lib/docker
NAME USED AVAIL REFER MOUNTPOINT
zpool-docker/docker 265M 29.0G 1.59M /var/lib/docker
</code></pre></div></div>
Ansible and Ubuntu 16.04 Xenial - Get Python 2.72016-08-16T00:00:00+00:00http://serverascode.com/2016/08/16/ansible-python2-xenial<h1 id="ansible-and-ubuntu-1604-xenial---get-python-27">Ansible and Ubuntu 16.04 Xenial - Get Python 2.7</h1>
<p>Quick post on getting Ansible working with an Ubuntu 16.04/Xenial server.</p>
<p>I have a bunch of nodes running in Amazon Web Services (AWS) and I need to put them under configuration management. This is a default Xenial image which does not have Python 2.7 apparently. No problem!</p>
<p>I can use the raw module to get Python 2.7.</p>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code>ansible_host<span class="nv">$ </span>ansible <span class="nt">--sudo</span> <span class="nt">-m</span> raw <span class="nt">-a</span> <span class="s2">"apt-get install -y python2.7 python-simplejson"</span> some_group
SNIP!
Setting up python2.7 <span class="o">(</span>2.7.12-1~16.04<span class="o">)</span> ...
Setting up libpython-stdlib:amd64 <span class="o">(</span>2.7.11-1<span class="o">)</span> ...
Setting up python <span class="o">(</span>2.7.11-1<span class="o">)</span> ...
Setting up javascript-common <span class="o">(</span>11<span class="o">)</span> ...
Setting up libjs-jquery <span class="o">(</span>1.11.3+dfsg-4<span class="o">)</span> ...
Setting up python-simplejson <span class="o">(</span>3.8.1-1ubuntu2<span class="o">)</span> ...
</code></pre></div></div>
<p>Now I can run ansible ping.</p>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="nv">$ </span>ansible <span class="nt">-m</span> ping some_group
10.20.1.30 | success <span class="o">>></span> <span class="o">{</span>
<span class="s2">"changed"</span>: <span class="nb">false</span>,
<span class="s2">"ping"</span>: <span class="s2">"pong"</span>
<span class="o">}</span>
10.20.1.25 | success <span class="o">>></span> <span class="o">{</span>
<span class="s2">"changed"</span>: <span class="nb">false</span>,
<span class="s2">"ping"</span>: <span class="s2">"pong"</span>
<span class="o">}</span>
10.20.1.113 | success <span class="o">>></span> <span class="o">{</span>
<span class="s2">"changed"</span>: <span class="nb">false</span>,
<span class="s2">"ping"</span>: <span class="s2">"pong"</span>
<span class="o">}</span>
</code></pre></div></div>
<p>Done!</p>
<p>Of course it would probably be a better idea to create an AWS image that has Python 2.7 already installed.</p>
<p>Futher, if you want to do it from a playbook, just make sure to set gather_facts to false.</p>
<div class="language-yaml highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="nn">---</span>
<span class="pi">-</span> <span class="na">hosts</span><span class="pi">:</span> <span class="s">all</span>
<span class="na">gather_facts</span><span class="pi">:</span> <span class="s">False</span>
<span class="na">tasks</span><span class="pi">:</span>
<span class="pi">-</span> <span class="na">name</span><span class="pi">:</span> <span class="s">ensure python 2.7 is installed</span>
<span class="na">raw</span><span class="pi">:</span> <span class="s">apt-get install -y python2.7 python-simplejson</span>
<span class="c1"># try pinging now</span>
<span class="pi">-</span> <span class="na">ping</span><span class="pi">:</span>
</code></pre></div></div>
RedHat OpenStack Director - Part 1 - Overview2016-07-23T00:00:00+00:00http://serverascode.com/2016/07/23/redhat-openstack-director-part-1<h1 id="redhat-openstack-director---part-1---overview">RedHat OpenStack Director - Part 1 - Overview</h1>
<p>Due to the complexity, number of services, clustered systems, and other components that comprise an OpenStack cloud, some kind of tooling is required to manage its deployment (and hopefully life-cycle over time). There are several systems available to manage an OpenStack cloud, such as Mirantis’ Fuel, <a href="http://docs.openstack.org/developer/openstack-ansible/install-guide/">OpenStack Ansible</a>, upstream <a href="http://docs.openstack.org/developer/tripleo-docs/">Tripleo</a>, to name only a few.</p>
<p>RedHat also offers such a product: <a href="https://access.redhat.com/documentation/en/red-hat-openstack-platform/8/director-installation-and-usage/director-installation-and-usage">Director</a>. At least I think it’s called Director, and I believe is part of the RedHat OpenStack Platform.</p>
<p>In this blog post I’ll do a quick overview of RedHat Director 8 with regards to using it to install an OpenStack cloud. I should note that I am still working to understand some functionality of Director, especially around custom modification and post-deployment changes–though things are not looking well on those two points at this time. However, more investigation and experimentation is required. So there will be a second post on Director in the near future.</p>
<p>I should also note that I usually prefer to deploy OpenStack myself, most commonly using Cobbler and Ansible, though at some point I’d prefer to try to use Ironic over Cobbler. I find that I can deploy a complex OpenStack cloud in a couple thousand lines of Ansible. Whether or not to use an OpenStack deployment tool is a difficult discussion, though I can understand why deployment tools such as Director are chosen. It’s similar to discussions on web frameworks. Some people like them, some people don’t. Occasionally it’s not possible to use a framework, but most of the time it’s a good decision–as long as they are flexible.</p>
<h2 id="features-of-openstack-deployment-tools">Features of OpenStack Deployment Tools</h2>
<p>Most OpenStack deployment systems do at least the following in some manner:</p>
<ul>
<li>Baremetal operating system deployment</li>
<li>Network design/deployment</li>
<li>Configuration management</li>
<li>Orchestration of services</li>
<li>Vetted OpenStack configuration options</li>
<li>OpenStack version upgrades</li>
<li>Monolithic or container based deployment</li>
<li>Plugin based architecture</li>
<li>Engineering decisions made for you</li>
<li>Reduction of complexity through abstraction layer</li>
<li>Occasionally Day 2 operational tooling</li>
<li>HA deployment using clustered/distributed systems</li>
</ul>
<p>Each of these systems will make different, though similar decisions. For example RedHat Director uses Ironic to manage baremetal operating systems, whereas Mirantis Fuel uses Cobbler. While Director’s configuration management component is mostly based on upstream OpenStack Puppet modules, OpenStack Ansible uses…you guessed it…Ansible. Regarding OpenStack control services, Director currently takes a monolithic approach and deploys all control services onto a single operating system instance (though can have multiple controllers), OpenStack Ansible deploys tens of LXC based containers with each major service running in its own container.</p>
<p>##What I like about Director</p>
<p>There are a few things that I like about RedHat’s Director:</p>
<ol>
<li>It’s command line and template based and overall quite sparse</li>
<li>It uses Ironic for baremetal OS management</li>
<li>It works in terms of a repeatable installation</li>
<li>That it’s based on midstream and upstream opensource projects</li>
<li>Undercloud/overcloud model</li>
</ol>
<p><strong>Sparse</strong></p>
<p>Director is quite sparse. There is no fancy web interface, or at least not one that I’m aware of. I don’t mind because I prefer to use the command line, and more specifically, if there is no web GUI, and the deployment is based on templates and the <em>openstack overcloud</em> command, then the deployment definition can be stored in a source code repository. This makes it much easier to have repeatable installations.</p>
<p><strong>Ironic</strong></p>
<p><a href="http://docs.openstack.org/developer/ironic/index.html">OpenStack Ironic</a> is an interesting project used to manage baremetal (ie. physical servers) instead of virtual machines.</p>
<blockquote>
<p>Ironic is an OpenStack project which provisions bare metal (as opposed to virtual) machines by leveraging common technologies such as PXE boot and IPMI to cover a wide range of hardware, while supporting pluggable drivers to allow vendor-specific functionality to be added.</p>
</blockquote>
<p>As mentioned, I typically use Cobbler for this part of an OpenStack deployment, but I’m enjoying using Ironic with Director. That said, Ironic is much more complicated than Cobbler, and things that are easy with Cobbler are not so easy with Ironic. However, they are much different systems and even though they effectively do the same thing, I’m not sure it’s possible to compare them. Given my preference for an undercloud, it would make sense to incorporate Ironic there.</p>
<p><strong>Repeatable</strong></p>
<p>Repeatable deployments are important but perhaps not for the reason you would expect. All of these deployment tools need to be developed using modern continuous integration tools. And in fact all of the examples I provided, Director, Fuel, and OpenStack Ansible, do just that. This improves their quality because every change to their code is checked via CI. Though, I’m not sure how many of them test an HA deployment, as they typically only have the resources for some kind of all-in-one virtual deployment.</p>
<p>During my own investigation I have probably deployed the Overcloud 40 times. Each time make slight changes to the Director templates, gradually improving my deployment. It’s important that a deployment be based in code, not in clicking buttons in a graphical interface.</p>
<p>For example, a new deployment requires these steps:</p>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code>director<span class="nv">$ </span>heat stack-delete overcloud <span class="nt">-y</span> <span class="c">#delete the current cloud</span>
director<span class="nv">$ </span><span class="c">#edit templates if required</span>
director<span class="nv">$ </span>./bin/overcloud-deploy.sh <span class="c">#this contains the rather long deployment command referencing several templates</span>
director<span class="nv">$ </span><span class="c">#wait for it to complete</span>
director<span class="nv">$ </span>heat stack-list
+--------------------------------------+------------+-----------------+---------------------+--------------+
| <span class="nb">id</span> | stack_name | stack_status | creation_time | updated_time |
+--------------------------------------+------------+-----------------+---------------------+--------------+
| e24a92a9-dc9f-462b-af16-c8329714f238 | overcloud | CREATE_COMPLETE | 2016-07-22T19:18:11 | None |
+--------------------------------------+------------+-----------------+---------------------+--------------+
director<span class="nv">$ </span><span class="c">#run validation tests, if everything looks good, check in the changes</span>
</code></pre></div></div>
<p>Repeatable deployments are extremely important, and that is one area Director (and Tripleo) shines.</p>
<p>I should note that the Director node itself is quite “pet-like” and unless you do some work to automate its deployment, it is a system of record (<a href="https://www.youtube.com/watch?v=Wbv3gJ76NT8">in the parlance of our times</a>…lol).</p>
<p><strong>Based on Opensource Code</strong></p>
<p>Director is mostly Tripleo. In fact I’m not completely sure where it differs from the upstream code. Specifically, Director consumes the output of the <a href="https://www.rdoproject.org/">RDO</a> project. In turn, RDO consumes upstream Tripleo–thus it’s “midstream”, in between RedHat and Tripleo.</p>
<p>One issue is that the upstream code is considerably farther ahead than Directors. There are features in Tripleo trunk right now that I would love to have, and in fact seem completely necessary, but are not in Director because it’s a few releases behind upstream. If I had my choice I would probably use the RDO output instead of Director, or perhaps even upstream.</p>
<p><strong>Undercloud/Overcloud</strong></p>
<p><a href="http://docs.openstack.org/developer/tripleo-docs/">Tripleo</a> stands for “OpenStack on OpenStack.”</p>
<blockquote>
<p>TripleO is a project aimed at installing, upgrading and operating OpenStack clouds using OpenStack’s own cloud facilities as the foundation - building on Nova, Ironic, Neutron and Heat to automate cloud management at datacenter scale.</p>
</blockquote>
<p>When you use Tripleo you have two clouds:</p>
<ol>
<li>Undercloud, ie. Director</li>
<li>Overcloud</li>
</ol>
<p>The Undercloud is an OpenStack instance where Ironic and Heat (as well as all the other required services) run so that you can deploy the Overcloud.</p>
<p>Most people don’t grasp, at the beginning anyways, that an OpenStack cloud requires considerable infrastructure to run. You will probably need three or four potentially highly available or clustered virtual machines to run services such as Jenkins and other operational components, perhaps software defined network controllers (SDN), virtual machine management nodes for other traditional systems (SolidFire I’m looking at you), and more.</p>
<p>You will need an Undercloud whether you give it that name or not. In fact in my lab I have at least three clouds: first, a cloud to run Director(s) in, then Director, then finally the Overcloud. It’s fairly involved, and over and above the hardware you need for the HA plane of the overcloud. This is why container based deployments make a lot of sense, and unfortunately that is not something Tripleo supports at this time.</p>
<p>##Things I don’t like</p>
<ol>
<li>The Undercloud instance is a pet</li>
<li>Tripleo does not have much in the way of “life-cycle” management</li>
<li>Seemingly inflexible</li>
<li>Limited documentation</li>
<li>Hundreds of thousands of lines of Puppet</li>
<li>Orchestration?</li>
<li>Scaling controller services</li>
<li>Lack of containerization</li>
</ol>
<p><strong>Undercloud: System of Record</strong></p>
<p>My impression of the Director system itself is that it is not “cloud native” for lack of a better phrase and would take some work to make it highly available in a fashion that would be typical of an application in an OpenStack cloud. Whether you call it a “pet” or a “system of record” or “not cloud native” it is an awkward system to operate.</p>
<p><strong>Lack of Life-cycle</strong></p>
<p>This is the biggest issue I have with Director. At this time I can find little having to do with operating a cloud over time, what some people call Day 2 (where Day 1 is the installation). Certainly there is some mention of upgrades and the like, but I have been working with Director for a few weeks and still really have no idea what it does in this area, despite looking through all the documentation. I have also heard that other organizations, HPe specifically, started out with Tripleo but dropped it because they realized the need to provide a life cycle for OpenStack deployments. Setting and forgetting an OpenStack installation is the easiest way to fail.</p>
<p>Currently I would be concerned at having to run a long-term cloud using Director, and I’m not even sure if you could. That said I have more to learn, and also Director is a young product. But so far it doesn’t look good for Day 2 operations, let alone day 300.</p>
<p><strong>Lots of Puppet</strong></p>
<p>There is a ton of puppet.</p>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="o">[</span>stack@director-01 ~]<span class="nv">$ </span><span class="nb">sudo </span>find / <span class="nt">-name</span> <span class="s2">"*.pp"</span> | xargs <span class="nb">wc</span> <span class="nt">-l</span>
SNIP!
1952 /home/stack/openstack-tripleo-heat-templates-0.8.14-14/puppet/manifests/overcloud_controller_pacemaker.pp
57 /home/stack/openstack-tripleo-heat-templates-0.8.14-14/puppet/manifests/overcloud_object.pp
61 /home/stack/openstack-tripleo-heat-templates-0.8.14-14/puppet/manifests/overcloud_volume.pp
96 /home/stack/openstack-tripleo-heat-templates-0.8.14-14/puppet/manifests/ringbuilder.pp
0 /opt/stack/selinux-policy/ipxe.pp
115712 total
</code></pre></div></div>
<p>Eep. Certainly not all that Puppet is getting executed with every deploy, but even if it’s 50%, that is still a lot of Puppet to understand. I can deploy a production OpenStack cloud with 3-5K lines of Ansible. If you don’t understand it, then it’s an abstraction.</p>
<p><strong>Seemingly Inflexible</strong></p>
<p>I have tried to update an overcloud twice post-deploy. Both have failed and in fact broke the overcloud. This is pretty concerning.</p>
<p>Further, on one deploy I attemped to disable Swift. The default deployment of swift configures a storage device on each of the controllers.</p>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="o">[</span>heat-admin@overcloud-controller-2 swift]<span class="nv">$ </span>swift-ring-builder object.builder
object.builder, build version 3
1024 partitions, 3.000000 replicas, 1 regions, 1 zones, 3 devices, 0.00 balance, 0.00 dispersion
The minimum number of hours before a partition can be reassigned is 1
The overload <span class="nb">factor </span>is 0.00% <span class="o">(</span>0.000000<span class="o">)</span>
Devices: <span class="nb">id </span>region zone ip address port replication ip replication port name weight partitions balance meta
0 1 1 172.17.19.12 6000 172.17.19.12 6000 d1 100.00 1024 0.00
1 1 1 172.17.19.13 6000 172.17.19.13 6000 d1 100.00 1024 0.00
2 1 1 172.17.19.11 6000 172.17.19.11 6000 d1 100.00 1024 0.00
</code></pre></div></div>
<p>In hopes of reducing the complexity of the deployment somewhat, and not relying on a somewhat unusual Swift deployment, I attempted to turn it off by setting <em>ControllerEnableSwiftStorage</em> to false.</p>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code>director<span class="nv">$ </span><span class="nb">grep</span> <span class="nt">-A</span> 2 <span class="s2">" ControllerEnableSwift"</span> overcloud.yaml
ControllerEnableSwiftStorage:
default: <span class="nb">true
</span>description: Whether to <span class="nb">enable </span>Swift Storage on the Controller
</code></pre></div></div>
<p>Disabling that still had Swift deployed, it just didn’t work because the storage component was not configured. lol. It seems that in Tripleo trunk there is the ability to <a href="https://github.com/openstack/tripleo-heat-templates/blob/master/overcloud.yaml#L367">select services</a> which I could really use…like right now.</p>
<p>Further, I can’t find a way to disable Ceilometer. By default Ceilometer is deployed with a MongoDB backend, all on the controllers. In a busy OpenStack cloud that will surely fail.</p>
<p><strong>Limited Documentation</strong></p>
<p>The RedHat provided documentation is limited. Further, it seems that the suggestions made in the documentation are not really what is used in production. Also, by default the Director templates implement things like bonding using Open vSwitch, but then in the documentation it suggests not using OVS bonding. The upstream documentation is much better, and you could then ask questions on the RDO or Tripleo mailing lists or IRC channels…not so much for RedHat.</p>
<p>In fact, in order to really understand how Tripleo works, I think you’d have to run upstream in the lab and learn from that. Then perhaps you could drop down to Director.</p>
<p><strong>Orchestration</strong></p>
<p>Orchestration is an overloaded term. In this context I mean the ability to perform complex actions on a cloud once it’s already deployed. For example upgrades. Or a simpler example, restart a clustered service. I am not clear on how to performan these kinds of actions using Director. Fuel performs these kind of actions using MCollective, and OpenStack Ansible can just use Ansible. But for Director? I’m not exactly sure. My guess is that it is done via the various custom os-* commands the project has created. More investigation is required.</p>
<p><strong>Scaling Controller Services</strong></p>
<p>How do I add a controller? Or provide more nova-conductor services? According to the <a href="https://access.redhat.com/documentation/en/red-hat-openstack-platform/8/director-installation-and-usage/chapter-9-scaling-the-overcloud">RedHat docs</a> you cannot scale up, or down, the controller nodes.</p>
<p><strong>Lack of Containerization</strong></p>
<p>Monolithic OpenStack controllers have largely been left behind. Most people are using containers to split out OpenStack services. I would not, if I had the choice, deploy monolithic controllers. I’ve made that mistake before. At the very least LXC should be used. I believe Director/Tripleo is starting to support Docker, but RedHat lists it as a tech preview.</p>
<p>It seems counter-intuitive, but using something like <a href="http://kubernetes.io/">Kubernetes</a> makes a lot of sense for the OpenStack control plane. Or, as mentioned, at least LXC, which I am using in my own undercloud. LXC 2.0 recently came out and while I have issues with it, overall I’m happy.</p>
<p>##Conclusion</p>
<p>I’ve deployed large, production, high SLA OpenStack clouds before, and run them over time. Deploying is easy, operating is bloody difficult. I know what is required…what works and what doesn’t. Today my impression of Director is that it is fairly behind in terms of what successful, modern OpenStack operators are doing to manage their clouds. I have a lot more to learn about Director and Tripleo, but three or four weeks in I feel I have a good idea of what they offer.</p>
<p>Hopefully in the next post I’ll know more about Day 2 capabilities, and perhaps I’ll be more comfortable with it. Certainly there is no denying that behind the scenes Director, based on Tripleo, is quite complicated and has many components to learn and understand. Perhaps those components allow for operational proficiency. Or perhaps not.</p>
Glance with Multiple Backend Stores2016-07-08T00:00:00+00:00http://serverascode.com/2016/07/08/glance-multiple-backend-stores<h1 id="glance-with-multiple-backend-stores">Glance with Multiple Backend Stores</h1>
<p>Every OpenStack cloud needs a Glance deployment. Thus, I’ve deployed it many times–but every time I’ve only put one backend into use: either simple file based storage or object storage using Swift.</p>
<p>Recently I was surprised to learn that you can have multiple backends, or stores as Glance calls it, and can upload images into whichever store you prefer using an option on the Glance command line.</p>
<h2 id="devstack">Devstack</h2>
<p>If you want to test it out it’s very easy–just deploy a <a href="http://docs.openstack.org/developer/devstack/">DevStack</a> instance. All you need is vm with a few gigs of ram.</p>
<p>Here is the local.conf I used. It enables Swift.</p>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code>ubuntu@devstack:~/devstack<span class="nv">$ </span><span class="nb">cat </span>local.conf
<span class="o">[[</span><span class="nb">local</span>|localrc]]
<span class="c"># Credentials</span>
<span class="nv">ADMIN_PASSWORD</span><span class="o">=</span>password
<span class="nv">DATABASE_PASSWORD</span><span class="o">=</span>password
<span class="nv">RABBIT_PASSWORD</span><span class="o">=</span>password
<span class="nv">SERVICE_PASSWORD</span><span class="o">=</span>password
<span class="nv">SERVICE_TOKEN</span><span class="o">=</span>password
<span class="nv">SWIFT_HASH</span><span class="o">=</span>password
<span class="nv">SWIFT_TEMPURL_KEY</span><span class="o">=</span>password
<span class="c"># Enable Neutron</span>
disable_service n-net
disable_service n-novnc
enable_service q-svc
enable_service q-agt
enable_service q-dhcp
enable_service q-l3
enable_service q-meta
enable_service neutron
<span class="c"># Enable Swift</span>
enable_service s-proxy
enable_service s-object
enable_service s-container
enable_service s-account
<span class="c"># Disable Horizon</span>
disable_service horizon
<span class="c"># Disable Heat</span>
disable_service heat h-api h-api-cfn h-api-cw h-eng
<span class="c"># Disable Cinder</span>
disable_service cinder c-sch c-api c-vol
<span class="c"># Swift temp URL's are required for agent_* drivers.</span>
<span class="nv">SWIFT_ENABLE_TEMPURLS</span><span class="o">=</span>True
<span class="c"># By default, DevStack creates a 10.0.0.0/24 network for instances.</span>
<span class="c"># If this overlaps with the hosts network, you may adjust with the</span>
<span class="c"># following.</span>
<span class="nv">NETWORK_GATEWAY</span><span class="o">=</span>10.1.0.1
<span class="nv">FIXED_RANGE</span><span class="o">=</span>10.1.0.0/24
<span class="nv">FIXED_NETWORK_SIZE</span><span class="o">=</span>256
<span class="c"># Log all output to files</span>
<span class="nv">LOGFILE</span><span class="o">=</span><span class="nv">$HOME</span>/devstack.log
<span class="nv">LOGDIR</span><span class="o">=</span><span class="nv">$HOME</span>/logs
</code></pre></div></div>
<p>Ah, good old DevStack.</p>
<h2 id="glance-config">Glance config</h2>
<p>Once DevStack is done, the <em>/etc/glance/glance-api.conf</em> file will contain this section:</p>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="o">[</span>glance_store]
stores <span class="o">=</span> file, http, swift
default_swift_reference <span class="o">=</span> ref1
swift_store_config_file <span class="o">=</span> /etc/glance/glance-swift-store.conf
swift_store_create_container_on_put <span class="o">=</span> True
default_store <span class="o">=</span> swift
filesystem_store_datadir <span class="o">=</span> /opt/stack/data/glance/images/
</code></pre></div></div>
<p>Note the “stores” option, and that “file, http, swift” are configured.</p>
<h2 id="glance-api-v1">Glance API V1</h2>
<p>One caveat at this time is that the Glance V2 API does not seem to allow for setting an option when uploading an image as to which backend to use. Thus, with Glance V2 you will always be using the default_store, which in this example is Swift.</p>
<p>But, if you use V1, you can set the “–store” option and choose a backend.</p>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code>ubuntu@uc-osclient-01:~<span class="nv">$ </span>glance <span class="nt">--os-image-api</span> 2 <span class="nb">help </span>image-create | <span class="nb">grep</span> <span class="s2">"</span><span class="se">\-\-</span><span class="s2">store"</span>
<span class="c"># No option</span>
ubuntu@uc-osclient-01:~<span class="nv">$ </span>glance <span class="nt">--os-image-api</span> 1 <span class="nb">help </span>image-create | <span class="nb">grep</span> <span class="s2">"</span><span class="se">\-\-</span><span class="s2">store"</span>
usage: glance image-create <span class="o">[</span><span class="nt">--id</span> <IMAGE_ID>] <span class="o">[</span><span class="nt">--name</span> <NAME>] <span class="o">[</span><span class="nt">--store</span> <STORE>]
<span class="nt">--store</span> <STORE> Store to upload image to.
</code></pre></div></div>
<p>Perhaps in the future V2 will also have a backend store option.</p>
<h2 id="uploading-images-to-multiple-backend-stores">Uploading images to multiple backend stores</h2>
<p>Ok, lets use the Glance CLI to upload images to the file and Swift backends.</p>
<p>First, I downloaded the Cirros image.</p>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code>ubuntu@devstack:~<span class="nv">$ </span>wget http://download.cirros-cloud.net/0.3.4/cirros-0.3.4-x86_64-disk.img
<span class="nt">--2016-07-09</span> 03:04:11-- http://download.cirros-cloud.net/0.3.4/cirros-0.3.4-x86_64-disk.img
Resolving download.cirros-cloud.net <span class="o">(</span>download.cirros-cloud.net<span class="o">)</span>... 64.90.42.85
Connecting to download.cirros-cloud.net <span class="o">(</span>download.cirros-cloud.net<span class="o">)</span>|64.90.42.85|:80... connected.
HTTP request sent, awaiting response... 200 OK
Length: 13287936 <span class="o">(</span>13M<span class="o">)</span> <span class="o">[</span>text/plain]
Saving to: ‘cirros-0.3.4-x86_64-disk.img’
100%[<span class="o">==================================================================================================================================>]</span> 13,287,936 3.61MB/s <span class="k">in </span>4.2s
2016-07-09 03:04:15 <span class="o">(</span>3.04 MB/s<span class="o">)</span> - ‘cirros-0.3.4-x86_64-disk.img’ saved <span class="o">[</span>13287936/13287936]
</code></pre></div></div>
<p>Cubswin:).</p>
<p>As a note, I’m using the Glance CLI version 2.1.0.</p>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code>ubuntu@devstack:~<span class="nv">$ </span>glance <span class="nt">--version</span>
2.1.0
</code></pre></div></div>
<p>Next, upload an image to the Swift backend.</p>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code>ubuntu@devstack:~<span class="nv">$ </span>glance <span class="nt">--os-image-api-version</span> 1 image-create <span class="nt">--store</span> swift <span class="nt">--name</span> swift-cirros <span class="nt">--disk-format</span> qcow2 <span class="nt">--container-format</span> bare <span class="nt">--is-public</span> True <span class="nt">--file</span> cirros-0.3.4-x86_64-disk.img
+------------------+--------------------------------------+
| Property | Value |
+------------------+--------------------------------------+
| checksum | ee1eca47dc88f4879d8a229cc70a07c6 |
| container_format | bare |
| created_at | 2016-07-09T03:07:09.000000 |
| deleted | False |
| deleted_at | None |
| disk_format | qcow2 |
| <span class="nb">id</span> | a8dc5259-9579-4cff-be0a-f175278f60f3 |
| is_public | True |
| min_disk | 0 |
| min_ram | 0 |
| name | swift-cirros |
| owner | fc42df31d6c84c04b55cf116e06c2b38 |
| protected | False |
| size | 13287936 |
| status | active |
| updated_at | 2016-07-09T03:07:11.000000 |
| virtual_size | None |
+------------------+--------------------------------------+
</code></pre></div></div>
<p>Now upload another image, this time using the file backend.</p>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code>ubuntu@devstack:~<span class="nv">$ </span>glance <span class="nt">--os-image-api-version</span> 1 image-create <span class="nt">--store</span> file <span class="nt">--name</span> file-cirros <span class="nt">--disk-format</span> qcow2 <span class="nt">--container-format</span> bare <span class="nt">--is-public</span> True <span class="nt">--file</span> cirros-0.3.4-x86_64-disk.img
+------------------+--------------------------------------+
| Property | Value |
+------------------+--------------------------------------+
| checksum | ee1eca47dc88f4879d8a229cc70a07c6 |
| container_format | bare |
| created_at | 2016-07-09T03:07:55.000000 |
| deleted | False |
| deleted_at | None |
| disk_format | qcow2 |
| <span class="nb">id</span> | e361ad97-6336-45d9-9c6a-e461ed91126d |
| is_public | True |
| min_disk | 0 |
| min_ram | 0 |
| name | file-cirros |
| owner | fc42df31d6c84c04b55cf116e06c2b38 |
| protected | False |
| size | 13287936 |
| status | active |
| updated_at | 2016-07-09T03:07:55.000000 |
| virtual_size | None |
+------------------+--------------------------------------+
</code></pre></div></div>
<p>We can peek into the Glance database to see where the image_location is.</p>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code>mysql> <span class="k">select </span>value from image_locations where image_id <span class="o">=</span> <span class="s2">"e361ad97-6336-45d9-9c6a-e461ed91126d"</span><span class="p">;</span>
+---------------------------------------------------------------------------+
| value |
+---------------------------------------------------------------------------+
| file:///opt/stack/data/glance/images/e361ad97-6336-45d9-9c6a-e461ed91126d |
+---------------------------------------------------------------------------+
1 row <span class="k">in </span><span class="nb">set</span> <span class="o">(</span>0.00 sec<span class="o">)</span>
mysql> <span class="k">select </span>value from image_locations where image_id <span class="o">=</span> <span class="s2">"a8dc5259-9579-4cff-be0a-f175278f60f3"</span><span class="p">;</span>
+-----------------------------------------------------------------+
| value |
+-----------------------------------------------------------------+
| swift+config://ref1/glance/a8dc5259-9579-4cff-be0a-f175278f60f3 |
+-----------------------------------------------------------------+
1 row <span class="k">in </span><span class="nb">set</span> <span class="o">(</span>0.01 sec<span class="o">)</span>
</code></pre></div></div>
<p>As can be seen above, the swift-cirros image is stored in the Swift backend, and the file-cirros image is stored in the file based backend. I was quite surprised to learn this was possible, and even more surprised to see that the option does not seem to be in the Glance V2 API…and even more surprised that the Glance CLI has different options based on the API used.</p>
<p>There’s always something to learn about OpenStack. :)</p>
Split OpenStack Keystone Catalog2016-06-24T00:00:00+00:00http://serverascode.com/2016/06/24/split-keystone-catalog<h1 id="split-openstack-keystone-catalog">Split OpenStack Keystone Catalog</h1>
<p>OpenStack Keystone is aptly named–it’s a service almost everyone who deploys OpenStack need to run. From a high level it provides authentication.</p>
<blockquote>
<p>Keystone is an OpenStack project that provides Identity, Token, Catalog and Policy services for use specifically by projects in the OpenStack family. It implements OpenStack’s Identity API. – <a href="http://docs.openstack.org/developer/keystone/">Keystone documentation</a></p>
</blockquote>
<p>However, as the above quote mentions it also provides a catalog of OpenStack service endpoints, where endpoints essentially means where you make REST API calls to.</p>
<h2 id="listing-the-catalog">Listing the catalog</h2>
<p>When Keystone is deployed, you can use the OpenStack command line client to list the endpoints.</p>
<p>Below I just show the endpoints for the compute service. Note that the endpoint starts with https, and thus these endpoints are TLS enabled. (Note that I alias <em>openstack</em> to <em>os</em>.)</p>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code>ubuntu@uc-external-osclient-01:~<span class="nv">$ </span>os catalog show compute
+-----------+-----------------------------------------------------------------------+
| Field | Value |
+-----------+-----------------------------------------------------------------------+
| endpoints | yeg-uc-1 |
| | admin: https://uc- |
| | api.lab.example.com:8774/v2/9a6a0815d6e74146bb76f19fd580bc31 |
| | yeg-uc-1 |
| | public: https://uc- |
| | api.lab.example.com:8774/v2/9a6a0815d6e74146bb76f19fd580bc31 |
| | yeg-uc-1 |
| | internal: https://uc- |
| | api.lab.example.com:8774/v2/9a6a0815d6e74146bb76f19fd580bc31 |
| | |
| name | Compute Service |
| <span class="nb">type</span> | compute |
+-----------+-----------------------------------------------------------------------+
</code></pre></div></div>
<p>But if I run the same command from an internal client we see slightly different endpoints.</p>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code>ubuntu@uc-internal-osclient-01:~<span class="nv">$ </span>os catalog show compute
+-----------+-----------------------------------------------------------------------------------------+
| Field | Value |
+-----------+-----------------------------------------------------------------------------------------+
| endpoints | yeg-uc-1 |
| | admin: http://uc-api.lab.example.com:8774/v2/9a6a0815d6e74146bb76f19fd580bc31 |
| | yeg-uc-1 |
| | public: http://uc-api.lab.example.com:8774/v2/9a6a0815d6e74146bb76f19fd580bc31 |
| | yeg-uc-1 |
| | internal: http://uc-api.lab.example.com:8774/v2/9a6a0815d6e74146bb76f19fd580bc31 |
| | |
| name | Compute Service |
| <span class="nb">type</span> | compute |
+-----------+-----------------------------------------------------------------------------------------+
</code></pre></div></div>
<p>Note that it is <em>http</em> not <em>https</em>.</p>
<h2 id="split-catalog">Split Catalog</h2>
<p>In this example there are actually two Keystone servers running, and they are identical except for their default_catalog.template file. In fact that file is identical except that the internal Keystone server will use <em>http</em> as the protocol, and the external Keystone server provides a catalog of endpoints with TLS enabled.</p>
<p>Why would we do this?</p>
<p>Well, in some cases we want internal OpenStack services to simply use http/plaintext, perhaps for performance reasons, but obviously external access, even if it’s only accessible from a companies internal network, should be TLS enabled. Separating the Keystone catalog using two Keystone servers and perhaps a load balancer makes this split Keystone setup possible.</p>
<p>In short, external is encrypted and internal is not.</p>
<h2 id="default_catalogtemplate">default_catalog.template</h2>
<p>There are two major ways to define the Keystone catalog: 1) via the database and 2) default_catalog.template.</p>
<p>The template file is just that–a configuration file. Using this configuration file, different Keystone servers can return different catalogs. This is, in my opinion, the easiest way to manage the catalog, and what’s more, is much easier to maintain using configuration management tools. (To all developers: don’t put configuration information into the database if you can avoid it. LXC 2.0 I’m looking at you.)</p>
<h2 id="split-dns">Split DNS</h2>
<p>In this particular example internal and external access uses the same Keystone endpoint host name: <em>uc-api.lab.example.com</em> but the internal systems have a different IP address associated with that hostname than the external servers do.</p>
<p>The load balancer in front of the Keystone servers directs traffic to the correct Keystone backend based on the IP address that is being accessed by the client. So external systems access the external Keystone server and vice-versa for internal.</p>
<h2 id="configuration-management">Configuration management</h2>
<p>Typically I use Ansible to manage configurations. The Keystone servers are separated into two groups: internal and external.</p>
<p>The external servers have their protocol set to https.</p>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="o">[</span>ansible-openstack]<span class="nv">$ </span><span class="nb">cat </span>group_vars/external-keystone-api
<span class="nt">---</span>
keystone_endpoint_protocol: <span class="s2">"https"</span>
</code></pre></div></div>
<p>By default the protocol in the default_catalog.template file is http.</p>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="o">[</span>ansible-openstack]<span class="nv">$ </span><span class="nb">head </span>roles/keystone/templates/default_catalog.templates
<span class="c"># keystone</span>
catalog.<span class="o">{{</span> region <span class="o">}}</span>.identity.publicURL <span class="o">=</span> <span class="o">{{</span> keystone_endpoint_protocol | default<span class="o">(</span><span class="s1">'http'</span><span class="o">)</span> <span class="o">}}</span>://<span class="o">{{</span> api_fqdn <span class="o">}}</span>:<span class="si">$(</span>public_port<span class="si">)</span>s/v2.0
catalog.<span class="o">{{</span> region <span class="o">}}</span>.identity.adminURL <span class="o">=</span> <span class="o">{{</span> keystone_endpoint_protocol | default<span class="o">(</span><span class="s1">'http'</span><span class="o">)</span> <span class="o">}}</span>://<span class="o">{{</span> api_fqdn <span class="o">}}</span>:<span class="si">$(</span>admin_port<span class="si">)</span>s/v2.0
catalog.<span class="o">{{</span> region <span class="o">}}</span>.identity.internalURL <span class="o">=</span> <span class="o">{{</span> keystone_endpoint_protocol | default<span class="o">(</span><span class="s1">'http'</span><span class="o">)</span> <span class="o">}}</span>://<span class="o">{{</span> api_fqdn <span class="o">}}</span>:<span class="si">$(</span>public_port<span class="si">)</span>s/v2.0
catalog.<span class="o">{{</span> region <span class="o">}}</span>.identity.name <span class="o">=</span> Identity Service
<span class="c"># nova</span>
catalog.<span class="o">{{</span> region <span class="o">}}</span>.compute.publicURL <span class="o">=</span> <span class="o">{{</span> keystone_endpoint_protocol | default<span class="o">(</span><span class="s1">'http'</span><span class="o">)</span> <span class="o">}}</span>://<span class="o">{{</span> api_fqdn <span class="o">}}</span>:8774/v2/<span class="si">$(</span>tenant_id<span class="si">)</span>s
catalog.<span class="o">{{</span> region <span class="o">}}</span>.compute.adminURL <span class="o">=</span> <span class="o">{{</span> keystone_endpoint_protocol | default<span class="o">(</span><span class="s1">'http'</span><span class="o">)</span> <span class="o">}}</span>://<span class="o">{{</span> api_fqdn <span class="o">}}</span>:8774/v2/<span class="si">$(</span>tenant_id<span class="si">)</span>s
catalog.<span class="o">{{</span> region <span class="o">}}</span>.compute.internalURL <span class="o">=</span> <span class="o">{{</span> keystone_endpoint_protocol | default<span class="o">(</span><span class="s1">'http'</span><span class="o">)</span> <span class="o">}}</span>://<span class="o">{{</span> api_fqdn <span class="o">}}</span>:8774/v2/<span class="si">$(</span>tenant_id<span class="si">)</span>s
</code></pre></div></div>
<p>Certainly there are many other things that the configuration management tool will have to do, but the basics are shown above. There has to be some way to set the external Keystone template to use https and http for internal. This is just one way to accomplish that.</p>
<h2 id="issues-with-this-model">Issues with this model</h2>
<p>Using this model we are classifying traffic into internal and external. Further, we are suggesting that internal traffic for the OpenStack services does not require encryption. This is a big decision. Certainly it’s a common model, but it creates a “chewy center” so to speak, meaning that external access is a hard shell, but that once you get through that hard shell, everything within is easier to crack. Sometimes people thing that “defense in depth” means that it’s okay for each ring to be less secure, but that is not necesarily the goal.</p>
<p>Another way to secure the API endpoints is to assume that all traffic, regardless of origin, may be malicious. With that assumption splitting Keystone would not be desirable, and instead it would be worthwhile to secure Keystone as much as possible regardless of the origin of the traffic, and in fact there would only be one API endpoint used by external end users and internal OpenStack services. Something to consider.</p>
<p>That said, it’s sometimes difficult to get internal OpenStack services to use https, or at least it has been previously.</p>
OPNFV Summit 20162016-06-24T00:00:00+00:00http://serverascode.com/2016/06/24/opnvf-summit-2016<h1 id="opnfv-summit-2016">OPNFV Summit 2016</h1>
<p>I was fortunate to be able to attend the Open Platform for Network Function Virtualization (OPNFV) 2016 summit in Berlin.</p>
<h2 id="first-opnfv-event">First OPNFV event</h2>
<p>This was my first OPNFV related event. To be honest prior to attending I wasn’t quite sure what OPNFV really was. I mean, I <em>knew</em> it was related to NFV in general, but what were the actual goals of the organization? After attending I feel like I have a better idea of what OPNFV’s purpose is, and also the realization that it is still early times with regards to this entire area of cultural, business and technological change related to NFV.</p>
<h2 id="design-summit">Design Summit</h2>
<p>The first two days of the summit were the design summit. Like OpenStack, OPNFV uses its summit to also provide a place for the contributers involved in OPNFV to get together face-to-face and discuss the technical aspects of various projects.</p>
<h2 id="openstack-operators-telecomnfv-working-group">OpenStack Operators Telecom/NFV Working Group</h2>
<p>Recently I have been trying to start up a new working group within OpenStack specifically dealing with OpenStack Operators and how they are designing, deploying, maintaining and operating OpenStack NFV clouds. For those that don’t know, there is an <a href="http://lists.openstack.org/cgi-bin/mailman/listinfo/openstack-operators">OpenStack Operators mailing list</a>, and this group has meetups between OpenStack summits, and as well a portion of the OpenStack design summit time is dedicated to it.</p>
<p>During the OPNFV design summit we were privileged to be given a time slot to have a “birds of a feather” meetup for OpenStack operators. Unfortunately the BoF was lightly attended. Like I mentioned previously, this is a new group and it’s going to take some time to get going. I feel like over the next year or so we will see an explosion of NFV systems installed which are based on OpenStack and thus there will be a considerable number of OpenStack operators managing these clouds, and they are going to want a place to discuss issues with their peers. (I hope.)</p>
<p>My hope is that like other OpenStack working groups we will be able to shepherd positive changes back up through the OpenStack community, be it through working with OpenStack projects to meet NFV related requirements, or via documenting common deployment designs, and similar items.</p>
<p>If you, or anyone you know, would like to participate in this working group we have <a href="http://eavesdrop.openstack.org/#OpenStack_Operators_Telco_and_NFV_Working_Group">bi-weekly IRC meetings</a>.</p>
<h2 id="tacker-and-service-function-chaining">Tacker and Service Function Chaining</h2>
<p><a href="https://wiki.openstack.org/wiki/Tacker">OpenStack Tacker</a> is an interesting project that initially started under the OPNFV umbrella, but has now migrated to be beneath OpenStack. Tacker is a “generic virtual network functions (VNF) manager.”</p>
<p>I had the chance to interact with the project technical lead (PTL) for Tacker a couple of times and it was fascinating to hear their story of how the project is maturing and navigating the various open source communities it interacts with. Time and time again I hear how development is largely a social interaction, not just writing code in your basement or cubicle. It takes a lot of work to understand various communities guidelines and cultures. In fact a large component of OPNFV is around understanding how best to work with upstream projects like OpenStack.</p>
<p>One of the major requirements Tacker has from OpenStack is the need for service function chaining (SFC). There is a project within OpenStack now, called <a href="http://git.openstack.org/cgit/openstack/networking-sfc/">networking-sfc</a> which will enable SFC in Neutron, and thus it will be usable by Tacker. With SFC being enabled in Neutron the ability to move workloads from one cloud to another irrespective of the underlying networking technology will be possible. Interoperability is important.</p>
<blockquote>
<p>Fundamentally SFC is the ability to cause network packet flows to route through a network via a path other than the one that would be chosen by routing table lookups on the packet’s destination IP address. It is most commonly used in conjunction with Network Function Virtualization when recreating in a virtual environment a series of network functions that would have traditionally been implemented as a collection of physical network devices connected in series by cables. – <a href="http://docs.openstack.org/developer/networking-sfc/">networking-sfc</a></p>
</blockquote>
<p>Tacker, as well as SFC, provide important NFV-related functionality and it will be great to see how they are used by the community.</p>
<h2 id="open-vswitch-opendaylight-and-openstack-performance">Open vSwitch, OpenDaylight, and OpenStack Performance</h2>
<p>There was a good presentation by HPE regarding Open vSwitch (OVS) performance when using OpenDaylight (ODL) in OpenStack.</p>
<p>The two main points in terms of performance were:</p>
<ol>
<li>Use Open vSwitch DPDK</li>
<li>Using ODL allows for 110x improvement in layer 3 routing versus standard OpenStack layer 3 (ie. <a href="http://docs.openstack.org/liberty/networking-guide/scenario-dvr-ovs.html">DVR</a>)</li>
</ol>
<p>The 110x improvement is pretty amazing. From my impression of the presentation, it wouldn’t be possible to use DVR if performance is a requirement for your particular use-case. Note that this was layer 3 only, not layer 2. That said there was an improvement in layer 2 performance, just not as drastic.</p>
<p>In the presentation some reasons for this lack of performance in “vanilla Neutron” were listed as:</p>
<blockquote>
<ol>
<li>Linux qRouter performance issues <br /></li>
<li>Low performance of additional bridges and iptables <br /></li>
<li>Connection from OVS to the qrouter is not accelerated by DPDK.</li>
</ol>
</blockquote>
<p>More to look into here.</p>
<h2 id="main-summit">Main Summit</h2>
<p>After the first two days of the design collaboration, the summit moved on to a more standard presentation and panel model.</p>
<h2 id="openstack-community-panel">OpenStack Community Panel</h2>
<p>I was lucky to be on the OpenStack community panel session and we talked a bit about where NFV is going in terms of OpenStack and what we see happening, or would like to happen, in the future.</p>
<p>I spoke a bit about the OpenStack Operators Telecom/NFV working group, and I’m hoping that participating in the panel helps to get the word out, so to speak, about the group. The Neutron and Tacker PTLs were the other members of the panel.</p>
<h2 id="cengn">CENGN</h2>
<p>I would be remiss if I didn’t mention the Canadian non-profit <a href="http://www.cengn.ca/">CENGN</a> which has been involved with OPNFV from early on. They were the first associate member of the OPNFV. For some reason Canada is usually well behind the technology curve, especially around networking, perhaps due to the void left by the utter (and sad) collapse of Nortel. With CENGN it seems there may be some recovery on the horizon in Canada, or at least an example of an organization designed to push the bleeding edge into Canadian business.</p>
<h2 id="mikko-hypponen---complexity-is-the-enemy-of-security">Mikko Hypponen - Complexity is the Enemy of Security</h2>
<blockquote>
<p>How many of the Fortune 500 are hacked? 500. – Mikko Hypponen</p>
</blockquote>
<p>While the talk was titled with regards to complexity, he didn’t really get into the complexity around NFV, other than calling this summit “the acronym conference”which is both funny and accurate. He did mention how Heartbleed and Shellshock have led to the creation of the <a href="https://www.coreinfrastructure.org/">Core Infrastructure Initiative</a> which irregardless of the silly names given large vulnerabilities is an extremely positive change.</p>
<h2 id="the-hitchhikerhackers-guide-to-nfv-benchmarking">The Hitchhiker/Hacker’s Guide to NFV Benchmarking</h2>
<p>There was a short and information packed presentation on <a href="http://www.slideshare.net/OPNFV/summit-16-the-hitchhikerhackers-guide-to-nfv-benchmarking">benchmarking</a>. There is just a ton of information in the slides and I heavily suggest going through them if you need to benchmark your NFV deployments.</p>
<h2 id="netready-gluon-service-function-chaining-sfc">NetReady, Gluon, Service Function Chaining (SFC)</h2>
<p>NetReady is a OPNFV project to identify gaps in networking requirements (at this point mainly dealing with OpenStack Neutron) and write prototype code to fill those gaps.</p>
<p>Gluon is a project that allows those prototypes to be easily created, but it does so outside of Neutron by manipulating Nova port binding and, as far as I can tell, avoiding Neutron entirely, which is not great, but I can understand the need to be able to prototype and fail fast.</p>
<p>SFC was all over the OpenStack summit in Austin, and it’s no surprise to see it highlighted at the OPNFV summit as well. I watched a good presentation/demo on it, and there were a lot of questions about competing implementations, from Huawei doing something in ONOS, Redhat doing something with ODL, networking-sfc, etc, etc.</p>
<h2 id="machine-learning">Machine learning</h2>
<p><img src="/img/opnfv-machine-learning.jpg" alt="Machine learing" /></p>
<p>There was a great, but short, <a href="http://www.slideshare.net/OPNFV/summit-16-applying-machine-learning-to-intentbased-networking-and-nfv-scaling-strategies">presentation</a> on applying machine learning to network scaling strategies.</p>
<p>One thing I realized from this presentation, because they specifically stated it, is that reactive scaling is not enough–you need predictive <em>and</em> reactive in order to scale properly, and one way to get predictive is to use machine learning.</p>
<p>Another important point made was the lack of production data available for use in research and development of predictive scaling. They are hoping the OPNFV can help with that somehow.</p>
<h2 id="berlin">Berlin</h2>
<p>Berlin is an amazing place. Fortunately it’s still one of the less expensive cities in Europe which means artists can afford to live here and do interesting things. The weather was great. I went around and, of course, visited many tourist attractions, but my favourite thing was a fascinating bicycle race called the <a href="http://www.rad-race.com/postevent-19062016-fxd42">Fixie 42</a> which is a 42km race on fixie bikes. The average speed for the fixie race was 49 km/h; they were practically flying. Also while in Berlin I was fortunate enough to see Beck live!</p>
<h2 id="conclusion">Conclusion</h2>
<p>Overall, I feel attending the OPNFV summit was extremely valuable. OPNFV is only in year two–it’s early times. Most telecoms are only now getting started with NFV. The learning curve, both cultural and technological, is considerable. Recently I heard a quote along the lines of “telecommunications is too important to leave to Telecoms” and in some respects this is what OPNFV is doing.</p>
<p>Further, I’d like to get involved in OPNFV more. Unfortunately I missed the two security presentations, but there is an OPNFV Security group and that might be something I look into helping out with. OPNFV is still a small organization, and while I expect it to grow over time, much like OpenStack has, now seems like a good time to be involved.</p>
Getting a Data Simcard while Travelling in Germany2016-06-22T00:00:00+00:00http://serverascode.com/2016/06/22/buying-simcard-in-germany<h1 id="getting-a-data-simcard-while-travelling-in-germany">Getting a Data Simcard while Travelling in Germany</h1>
<p>Recently I travelled to Berlin for a technology conference. Strangely I don’t have a data plan for my “smart phone” at home in Canada, but when travelling there is nothing that makes getting around a new city easier than having a smart phone with a data plan. I don’t know how I did it before smart phones. I guess I just got lost a lot.</p>
<p>I did some research on how to get a data plan while in Germany, but nothing really came up that was all that recent. So I thought I’d detail how I found an inexpensive data plan.</p>
<h2 id="tldr">tl;dr</h2>
<p>Have an unlocked phone. Buy a BlauWorld SIM card at the Alexanderplatz Saturn store. Go back to your hotel and use your hotel wifi to register the SIM card using your hotel’s address in the Blau online activation form. Once the form is completed, wait about 30 minutes, then put the SIM into your phone, enter the SIM card’s pin number from the letter in your BlauWorld package into the phone when requested. Done! Now you can access the internet via your phone.</p>
<h2 id="blauworld">BlauWorld</h2>
<p>After doing a <a href="http://prepaid-data-SIM-card.wikia.com/wiki/Germany">bit of research</a> I decided (rightly I believe) that a Blau card would be easiest, mostly because they have an English version of their website. Specifically I was looking for a <em>BlauWorld</em> card, which is apparently a card often used by foreign workers in Germany. Further, it doesn’t seem to have much in the way of restrictions–just a simple online signup. Also, in theory they are widely available, though I have only seen them at Saturn stores.</p>
<p>Saturn is a technology store–they sell TVs, computers, cell phones, and, of course, BlauWorld SIM cards. The first Saturn I tried did not have a BlauWorld SIM card package, but they suggested I to go to another location–the Saturn at Alexanderplatz. So I did, and they had a BlauWorld card for about 10 euros, which is quite low-cost. It comes with a SIM card and a 10 euro credit. With the credit the BlauWorld SIM card is essentially free.</p>
<p>The BlauWorld SIM card can be resized to nano, micro, and regular SIM card sizes so it should fit in all phones.</p>
<h2 id="activationregistration">Activation/Registration</h2>
<p>There is an <a href="http://www.blauworld.de/index-locale=en.php">English version</a> of the Blau website which is quite helpful if, like myself, you can’t read German. Click on the <em>Activate</em> tab and follow the instructions. You’ll need the phone number from the letter in the BlauWorld package to start the activation. Enter your name and a German address. I used my hotel’s address. It might take a couple tries to get the right information into the right fields.</p>
<p>During the activation I was able to select a 1GB data plan with the 10 euro credit that came with the SIM card. Actually the 1GB option was the only option during the initial activation. There are other options you can pick once you’ve registered the card completely if you want SMS and/or voice, but it would cost extra. The SMS and voice plans were fairly expensive, but not unreasonable. I didn’t need voice or SMS. Data was just fine.</p>
<p>Once the registration is finished, wait 30 minutes or so then put the SIM card into your phone and start it up. Enter the pin number from the letter.</p>
<p>At this point you have 1GB of data, which is perfect for a weeks stay, and it only cost 10 euros total, for both the SIM card and the 1GB plan.</p>
<p>Now, knowing you can use your phones map application, you can venture out and explore Germany.</p>
OpenStack Provider Networks2016-06-11T00:00:00+00:00http://serverascode.com/2016/06/11/openstack-provider-networks<h1 id="openstack-provider-networks">OpenStack Provider Networks</h1>
<p>There are many ways to deploy networking in OpenStack. I’ve deployed it old-school with nova-network, new-school with Neutron and Midokura’s Midonet, and just recently I put up a lab deployment of Neutron + <a href="http://docs.openstack.org/mitaka/networking-guide/scenario-provider-ovs.html">provider networks</a>.</p>
<p>To me, provider networks are kind of like nova-network in terms of their simplicity of deployment, where simplcity means your network team probably doesn’t have to do anything new, and can rely on their (potentially) tried and true network designs. I mean, let’s face it–many network architects are going to dislike SDN and/or overlays, etc. Using provider networks will at least allow OpenStack to be deployed in somewhat hostile network environments.</p>
<p>From the <a href="http://docs.openstack.org/mitaka/networking-guide/scenario-provider-ovs.html">OpenStack Networking Guide</a>:</p>
<blockquote>
<p>Provider networks generally offer simplicity, performance, and reliability at the cost of flexibility. Unlike other scenarios, only administrators can manage provider networks because they require configuration of physical network infrastructure…In many cases, operators who are already familiar with network architectures that rely on the physical network infrastructure can easily deploy OpenStack Networking on it.</p>
</blockquote>
<p>The goal of this post is to go over the deployment and include some snippets of configuration to give a cursory example of how this deployment is working and what it looks like while running. Please note this is a lab deployment and is not necessarily meant for production use. Oh, and I’m not a “network architect” by any stretch, but I have deployed some fairly complicated networks in relation to OpenStack.</p>
<h2 id="the-stack">The Stack</h2>
<ol>
<li>Ubuntu 14.04</li>
<li>Edgecore 5712</li>
<li>Cumulus Linux 2.5.7</li>
<li>Open vSwitch 2.5.0 from Ubuntu’s Cloud Archive</li>
<li>OpenStack Mitaka from Ubuntu’s Cloud Archive</li>
<li>A single controller running LXC 2.0 and a bunch of containers</li>
<li>A couple of baremetal compute nodes</li>
<li>100% managed by Ansible</li>
</ol>
<h2 id="cumulus-linux">Cumulus Linux</h2>
<p>In my case I control the physical network and it consists of an Edgecore 5712 with Cumulus Linux loaded on it.</p>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code>cumulus@oc-sw-02<span class="nv">$ </span><span class="nb">cat</span> /etc/lsb-release
<span class="nv">DISTRIB_ID</span><span class="o">=</span><span class="s2">"Cumulus Linux"</span>
<span class="nv">DISTRIB_RELEASE</span><span class="o">=</span>2.5.7
<span class="nv">DISTRIB_DESCRIPTION</span><span class="o">=</span>2.5.7-753304d-201603071654-build
</code></pre></div></div>
<p>Recently Cumulus released 3.0 so I should load that on soon, but for now I’m back on 2.5.7.</p>
<p>Cumulus has an interesting feature called <a href="https://docs.cumulusnetworks.com/display/DOCS/VLAN-aware+Bridge+Mode+for+Large-scale+Layer+2+Environments">VLAN aware bridge mode</a> and that is what I’m using.</p>
<p>Here’s a snippet of my interfaces file, which is managed by Ansible. VLANs 12 and 13 are meant to be the provider networks.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code># VLANS
auto bridge0
iface bridge0
bridge-ports controller-01-bond0 compute-01-bond0 compute-02-bond0
bridge-vlan-aware yes
bridge-vids 10 12 13 11
bridge-pvid 1
bridge-stp on
auto bridge0.10
iface bridge0.10
address 172.17.3.1/24
auto bridge0.12
iface bridge0.12
address 172.16.5.33/27
auto bridge0.13
iface bridge0.13
address 172.16.5.65/27
auto bridge0.11
iface bridge0.11
address 172.16.5.1/28
</code></pre></div></div>
<p>I quite like working with Cumulus linux. The Edgecore 5712 + Cumulus is a compelling offer.</p>
<h1 id="neutron">Neutron</h1>
<p>I deployed Neutron exactly like the Open vSwitch and provider networks is shown in the networking guide. One difference from the guide is that neutron-server by default doesn’t use the ml2_conf.ini file, only the openvswitch_agent.ini file.</p>
<p>My deployment has the physical network providing layer 2 and layer 3, but Neutron is handling DHCP. So on the neutron-api node it sets up some namespaces where the DHCP server listens.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>root@uc-neutron-api-01:/etc/neutron/plugins/ml2# cat openvswitch_agent.ini
[ml2]
type_drivers = flat,vlan
# empty because we don't support project/private networks
tenant_network_types =
mechanism_drivers = openvswitch
extension_drivers = port_security
[ml2_type_flat]
flat_networks = provider
[ml2_type_vlan]
network_vlan_ranges = provider
[securitygroup]
firewall_driver = iptables_hybrid
enable_security_group = True
[ovs]
bridge_mappings = provider:br-provider
</code></pre></div></div>
<p>There are a couple of networks setup in neutron.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>ubuntu@uc-osclient-01:~$ neutron net-list
+--------------------------------------+------------+-----------------------------------------------------+
| id | name | subnets |
+--------------------------------------+------------+-----------------------------------------------------+
| 5e73a2f5-a52b-4833-9978-531fc98cd783 | vlan_13 | 725c3dbe-65f2-4dc5-b9ec-596309bc2229 172.16.5.64/27 |
| eb175122-2500-4234-becb-030da538893a | vlan_12 | 7b799b92-ba55-454c-8db7-558476559b4e 172.16.5.32/27 |
+--------------------------------------+------------+-----------------------------------------------------+
ubuntu@uc-osclient-01:~$ neutron subnet-list
+--------------------------------------+-------------------+----------------+------------------------------------------------+
| id | name | cidr | allocation_pools |
+--------------------------------------+-------------------+----------------+------------------------------------------------+
| 725c3dbe-65f2-4dc5-b9ec-596309bc2229 | vlan_13-subnet | 172.16.5.64/27 | {"start": "172.16.5.66", "end": "172.16.5.94"} |
| 7b799b92-ba55-454c-8db7-558476559b4e | vlan_12-subnet | 172.16.5.32/27 | {"start": "172.16.5.34", "end": "172.16.5.62"} |
+--------------------------------------+-------------------+----------------+------------------------------------------------+
</code></pre></div></div>
<p>We can see their network namespaces.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>root@uc-neutron-api-01:~# ip netns list
qdhcp-5e73a2f5-a52b-4833-9978-531fc98cd783
qdhcp-eb175122-2500-4234-becb-030da538893a
</code></pre></div></div>
<p>And with a couple of virtual machines deployed we can see what interfaces OVS has created.</p>
<p>I should note that the neutron-api server is an lxc container. eth2 in the container is bridged to a bonded interface in the baremetal OS.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>root@uc-neutron-api-01:~# ovs-vsctl show
58669c80-e22a-4ea8-9b2d-2d21d1c95163
Bridge br-provider
Port phy-br-provider
Interface phy-br-provider
type: patch
options: {peer=int-br-provider}
Port "eth2"
Interface "eth2"
Port br-provider
Interface br-provider
type: internal
Bridge br-int
fail_mode: secure
Port br-int
Interface br-int
type: internal
Port int-br-provider
Interface int-br-provider
type: patch
options: {peer=phy-br-provider}
Port "tapd404a48d-df"
tag: 3
Interface "tapd404a48d-df"
type: internal
Port "tapa02b5817-23"
tag: 2
Interface "tapa02b5817-23"
type: internal
ovs_version: "2.5.0"
</code></pre></div></div>
<p>On the compute node OVS looks like this. br-provider sits on bond0 and adds VLAN tags.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>root@compute-01:/home/ubuntu# ovs-vsctl show
543d058b-8452-4902-bc4c-77bd62ae3e07
Bridge br-int
fail_mode: secure
Port int-br-provider
Interface int-br-provider
type: patch
options: {peer=phy-br-provider}
Port br-int
Interface br-int
type: internal
Port "qvo60f707e9-0d"
tag: 3
Interface "qvo60f707e9-0d"
Port "qvoe77743d9-e1"
tag: 2
Interface "qvoe77743d9-e1"
Port "qvoaad386ab-2f"
tag: 2
Interface "qvoaad386ab-2f"
Bridge br-provider
Port "bond0"
Interface "bond0"
Port phy-br-provider
Interface phy-br-provider
type: patch
options: {peer=int-br-provider}
Port br-provider
Interface br-provider
type: internal
ovs_version: "2.5.0"
</code></pre></div></div>
<p>If I tcpdump bond0 on the compute node and ping an instance on that provider network…</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>root@compute-01:/home/ubuntu# tcpdump -n -e -ttt -i bond0 | grep "vlan 12"
tcpdump: WARNING: bond0: no IPv4 address assigned
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on bond0, link-type EN10MB (Ethernet), capture size 65535 bytes
00:00:00.000848 fa:16:3e:c3:6f:17 > cc:37:ab:2c:9c:92, ethertype 802.1Q (0x8100), length 102: vlan 12, p 0, ethertype IPv4, 172.16.5.35 > 172.16.4.4: ICMP echo reply, id 19867, seq 1, length 64
00:00:00.136563 cc:37:ab:2c:9c:92 > fa:16:3e:c3:6f:17, ethertype 802.1Q (0x8100), length 102: vlan 12, p 0, ethertype IPv4, 172.16.4.4 > 172.16.5.35: ICMP echo request, id 19867, seq 2, length 64
00:00:00.000225 fa:16:3e:c3:6f:17 > cc:37:ab:2c:9c:92, ethertype 802.1Q (0x8100), length 102: vlan 12, p 0, ethertype IPv4, 172.16.5.35 > 172.16.4.4: ICMP echo reply, id 19867, seq 2, length 64
00:00:00.999631 cc:37:ab:2c:9c:92 > fa:16:3e:c3:6f:17, ethertype 802.1Q (0x8100), length 102: vlan 12, p 0, ethertype IPv4, 172.16.4.4 > 172.16.5.35: ICMP echo request, id 19867, seq 3, length 64
</code></pre></div></div>
<p>Looks good to me. :)</p>
<h2 id="ansible-openstack-network-modules">Ansible OpenStack network modules</h2>
<p>Ansible 2.1 has modules for OpenStack networks and subnets that work quite well. The modules have been around for a while, but 2.1 added a couple required features for adding a provider network.</p>
<p>Here’s a snippet of creating a provider network. The networks dict is a yaml dict that I’m working on to define the entire network stack.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code> - name: ensure provider networks exist
os_network:
name: "{{ item.key }}"
provider_network_type: "vlan"
provider_physical_network: "provider"
provider_segmentation_id: "{{ item.value.vlan_id }}"
shared: True
delegate_to: uc-osclient-01
when: item.value.type == "provider"
with_dict: networks
- name: ensure provider subnets exist
os_subnet:
network_name: "{{ item.key }}"
name: "{{ item.key }}-subnet"
cidr: "{{ item.value.network }}{{ item.value.cidr }}"
gateway_ip: "{{ item.value.address }}"
delegate_to: uc-osclient-01
when: item.value.type == "provider"
with_dict: networks
</code></pre></div></div>
<p>It’s so nice to be able to automate the creation of the entire network stack, from Cumulus and bonds all the way up to neutron subnets.</p>
<h2 id="interfaces-down">Interfaces down?</h2>
<p>One thing that really confused me when working on this deployment was that the interfaces are marked down.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>root@compute-01:/home/ubuntu# ip ad sh | grep DOWN | grep "ovs\|br-"
15: ovs-system: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default
16: br-int: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default
17: br-provider: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default
</code></pre></div></div>
<p>I’m not clear on why these are down, but everything is working fine. This is something I would like to understand.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>root@compute-01:/home/ubuntu# ovs-ofctl show br-provider
OFPT_FEATURES_REPLY (xid=0x2): dpid:000090e2babace6c
n_tables:254, n_buffers:256
capabilities: FLOW_STATS TABLE_STATS PORT_STATS QUEUE_STATS ARP_MATCH_IP
actions: output enqueue set_vlan_vid set_vlan_pcp strip_vlan mod_dl_src mod_dl_dst mod_nw_src mod_nw_dst mod_nw_tos mod_tp_src mod_tp_dst
1(bond0): addr:90:e2:ba:ba:ce:6c
config: 0
state: 0
speed: 0 Mbps now, 0 Mbps max
2(phy-br-provider): addr:ea:dc:cb:d8:23:25
config: 0
state: 0
speed: 0 Mbps now, 0 Mbps max
LOCAL(br-provider): addr:90:e2:ba:ba:ce:6c
config: PORT_DOWN
state: LINK_DOWN
speed: 0 Mbps now, 0 Mbps max
</code></pre></div></div>
<p>Again, not sure why the LOCAL(br-povider) is down, but it is, and everything works fine.</p>
<h2 id="instances">Instances</h2>
<p>Here’s the routing table of a virtual machine running in the OpenStack cloud using a provider network.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>ubuntu@t4:~$ netstat -rn
Kernel IP routing table
Destination Gateway Genmask Flags MSS Window irtt Iface
0.0.0.0 172.16.5.33 0.0.0.0 UG 0 0 0 eth0
169.254.169.254 172.16.5.34 255.255.255.255 UGH 0 0 0 eth0
172.16.5.32 0.0.0.0 255.255.255.224 U 0 0 0 eth0
</code></pre></div></div>
<p>Note the metadata server route at 169.254.169.254.</p>
<h2 id="conclusion">Conclusion</h2>
<p>If you are deploying a private cloud into an environment where software defined networking and/or overlays are not welcome, then provider networks might be your only option. If you are old-school OpenStack and liked nova-network, then provider networks will seem similar. I do like their simplicity.</p>
<p>Not every OpenStack deployment is going to require hundreds or thousands of private tenant networks. If you have an OpenStack-hostile network environment, which is quite common I assure you, then this might help. Hopefully they’ll at least allow you to have neutron manage DHCP on the provider networks.</p>
<p>Next up I need to look into IPv6 and Open vSwitch DPDK as well as performance testing and a host of other items.</p>
Austin 2016 OpenStack Summit2016-05-01T00:00:00+00:00http://serverascode.com/2016/05/01/openstack-summit-2016-austin<p><em>Random shopping cart in Austin</em></p>
<h1 id="austin-2016-openstack-summit">Austin 2016 OpenStack Summit</h1>
<p>##Or, You Know What’s Cool? A Trillion Dollars</p>
<p>The OpenStack summit is a large, multi-faceted event. It brings vendors, operators, developers and users (among others) all together in one massive conference. At this summit there were ~7500 people in attendance [1]. The scale wasn’t just based on the number of people though–the number of conference tracks and talks was almost overwhelming.</p>
<p>##Niche Clouds</p>
<p>First I have to say that I felt that, even before leaving for the event, I would be more interested in what was going on at this conference than the Tokyo summit. During that summit I worked on operating a small public cloud in Canada. There are not that many, in my opinion, OpenStack-based public clouds. Thus it was hard to find some kind of operations solidarity in that particular niche. While I believe that there are in total somewhere around 18 public OpenStack-based public clouds [0], some much larger than others, their influence, especially the smaller ones, pales in comparison to the number of private OpenStack cloud deployments.</p>
<p>At any rate, my point is that I no longer work in this particular OpenStack niche, and have moved into a new niche, one that is getting a considerable amount of attention.</p>
<p>##Network Function Virtualization (NFV)</p>
<p>I knew coming into this summit that NFV would be pretty high on the hype cycle. The sleeping telco giants have all been startled awake and their millions of employees and billions of dollars are yawning and stretching. Despite the hype of NFV and influence of telco (TELCO SMASH!) it is an exciting time in technology, especially around networking, automation, containers, and I would argue, operations. Change is good, but it’s hard.</p>
<p>In one of the sessions it was suggested that telecommunications is a trillion dollar market. That is a massive number, and most of these organizations are only getting started with OpenStack. However, I have no doubt in saying <strong>all</strong> of them are looking to deploy OpenStack clouds. (Certainly, some will be implementing OpenStack clouds in hopes they fail, and they probably will, but others will be putting in an honest effort to succeed.) This is a sea change in IT if there ever was one.</p>
<p>Almost every networking related design session I went to dealt with, in some capacity, the need to improve support for telecommunications requirements–especially around technologies and workflows like service function chaining (SFC) and monitoring/fault management. I went to several network component design sessions and SFC was discussed in nearly all of them. Networks are about to get a lot more complex, but also easier to automate and program.</p>
<p>##Ops Telco/NFV Working Group</p>
<p>I moderated a session in the Ops summit on Telco/NFV. Quite a few people showed up and we had a good discussion on Telco/NFV. [2] I think there is so much interest in NFV that people are looking anywhere for help and information. That’s why we ended up with so much interest in the working group. However, it’s an ops group, so if there is an operators need for the Telco/NFV group then we need to make sure we’re meeting that need, and not overlapping with other working groups and entities. So it will take a bit of time to figure out what we can do.</p>
<p>One thing I can say is that I quite like the approach the Ops large deployment team has taken, which is to select one or two changes they would like to see in OpenStack and really shepherd those changes through the…uh stack over a long period of time to make sure they get into the project. More on this later.</p>
<p>##Open Platform for NFV - OPNFV</p>
<p>OPNFV is a really interesting project. I realized at this summit that OPNFV is essentially a group of OpenStack operators. They are doing the same work a large operators group would do, specifically around getting OpenStack and NFV up and running and nearly ready for production. They are modelling and improving, as best they can, OpenStack + NFV in production-like environments. I watched a couple great presentations by people working within OPNFV, and I’m hoping to go to their summit in June in Berlin.</p>
<p>##Ops Informal Meetup</p>
<p>At the Tokyo summit there was an informal ops meetup on the Friday, basically hanging out in the dev summit lunch area. I didn’t attend that meetup because there wasn’t quite room at the time for me even to sit down. I didn’t mind because I just went out into Tokyo for the day. But it apparently was a great meetup because the foundation scheduled a large room for the entire Friday for operators to meetup and have an informal discussion about being OpenStack operators. The result was a wide-ranging discussion on almost all facets of OpenStack. We ended up with a 700 line etherpad. [3]</p>
<p>Some items I took out of the informal meetup:</p>
<ul>
<li>Maybe there is a need in Horizon to have some sort of “simplistic” interface option, where simple means less options. After having worked in a public cloud I have no problem saying that most customers are using it to create long-lived virtual machines, and are not using much of the other functionality, at least not yet. Having some kind of operator option to…er reduce options would be a good idea. See Digital Ocean.</li>
<li>Redfish - I’m still not sure what this is, but if it’s about making IPMI/ILOM/BMC/out-of-band management easier then I’m all in. [4]</li>
<li>ZFS is in Ubuntu Xenial, but there is no OpenStack Cinder driver that I’m aware of. That’d be cool. Someone should do that. I would if I was good enough to do it quickly, but I’m not.</li>
<li>OCP hardware - There were a couple of people deploying OCP hardware. OpenStack Ops discussions never seem to talk much about hardware, perhaps because it’s so vendor centric. One would think OCP would be a different story. That said, it’s not always easy to buy small amounts of OCP hardware.</li>
</ul>
<p>Those are just a few things that I took from the informal session. I had hoped to split out the Telco/NFS working group in the afternoon, but I had the feeling most of the Telco/NFVers left after the morning session and the facilities just weren’t quite setup for splitting off. Perhaps the next ops meetup or summit will be better suited.</p>
<p>##OpenStack Mission Statement</p>
<p>I went to one BoF session on the mission statement. It seemed like the goal of the session was to try to ascertain how well OpenStack was doing in particular areas mentioned in the relatively new mission statement:</p>
<blockquote>
<p>To produce a ubiquitous Open Source Cloud Computing platform that is
easy to use, simple to implement, interoperable between deployments,
works well at all scales, and meets the needs of users and operators of
both public and private clouds.</p>
</blockquote>
<p>They broke out pieces of the statement:</p>
<ul>
<li>Ubiquitous</li>
<li>Open Source Cloud Computing Platform</li>
<li>Easy to use</li>
<li>Simple to implement</li>
<li>Interoperable</li>
<li>Scales</li>
<li>(Can’t remember how they broke out the rest)</li>
</ul>
<p>and we talked about how well we were meeting these objectives.</p>
<p>We got stuck on easy to use and simple to implement for a while. I personally don’t think those are actually OpenStack goals, especially around “simple to implement” because OpenStack is not a singular product, rather it’s a framework to build “Open Source Cloud Computing Platforms.” OpenStack doesn’t really have any artifacts of its build process–it’s just a collection of code and some documentation, and of course, a community around that code. (Actually I think they publish tgzs somewhere…)</p>
<p>The tone in the room felt unusual, in that the people writing and thinking about the mission statement are pretty far away from actually using it or operating it. I understand that these phrases are long term goals for OpenStack, but at least one is not possible to meet.</p>
<p>I would probably write something more like:</p>
<blockquote>
<p>To produce an ubiquitous Open Source <strong>framework</strong> for cloud computing that is easy to use, interoperable between deployments, works well at all scales, and meets the needs of users and operators of both public and private clouds.</p>
</blockquote>
<p>and just get rid of the whole “simple to implement” component.</p>
<p>##Austin</p>
<p>I’ve been to Austin twice now. Austin is a great city, very eccentric. My home town of Edmonton always wants to be Austin. I took the bus from the Alamo Drafthouse downtown to Book People, and it was the happiest bus ride I’ve ever been on. An entire bus load of strangers was just laughing and having a great time. I thought I had stepped onto some kind of roaming festival, but nope, just a normal Austin bus ride. Oh, and I had a quick discussion with an Austinite who had recently watched Strange Brew. If it wasn’t so damn humid in Austin I could probably live there. Humidity is only 40% in Edmonton today.</p>
<p>Also–Cheer Up Charlies was a great bar. People were bringing their dogs in! Crazy. Also, Argo’s foodtruck at Cheer Up Charlies had the best vegetarian bacon burger I’ve ever had. It was perfect. I think my biggest personal expense for the trip was eating there.</p>
<p>##Conclusion</p>
<p>OpenStack, public clouds like AWS, automation, containers, software defined networking–I was wondering where we’d go after innovation in these areas. At this point it seems like Telecos are now entering these relatively new spaces and bringing their considerable clout to bear. Perhaps we flounder around here a bit and then move on to whatever comes next. There is some danger of the massive resources of telcos putting pressure in the wrong places for OpenStack, and that things might break (though I didn’t see any obvious signals at the summit).</p>
<p>I would imagine the OpenStack foundation is working hard to determine how to best direct those resources and ensure that the OpenStack project stays healthy, but it will be a difficult job. Telcos are strange beasts, but I think it’s important to remember that they, as organizations, have more change to implement to use OpenStack than vice-versa, mostly around their culture. Relatively speaking it’s much easier to deploy OpenStack than it is to adapt your culture to use it. OpenStack does offer a tremendous opportunity for telcos, and I suppose I should really be worried if telcos can handle the change, not the other way around.</p>
<hr />
<p>[0] <a href="https://twitter.com/e_monty/status/725482310879997953">https://twitter.com/e_monty/status/725482310879997953</a></p>
<p>[1] Note that the summit will be changing over the next year or so. I believe the design portion of the summit is going to be split out into its own event.</p>
<p>[2] <a href="https://etherpad.openstack.org/p/AUS-ops-NFV-Telco">https://etherpad.openstack.org/p/AUS-ops-NFV-Telco </a></p>
<p>[3] <a href="https://etherpad.openstack.org/p/AUS-ops-informal-meetup">https://etherpad.openstack.org/p/AUS-ops-informal-meetup </a></p>
<p>[4] <a href="http://redfish.dmtf.org/redfish/v1">http://redfish.dmtf.org/redfish/v1</a></p>
Analysis of OpenStack Austin 2016 NFV/Telco Track2016-04-14T00:00:00+00:00http://serverascode.com/2016/04/14/openstack-austin-2016-summit-nfv-telco-track<h1 id="analysis-of-openstack-austin-2016-nfvtelco-track">Analysis of OpenStack Austin 2016 NFV/Telco Track</h1>
<p>I went through all the presentations in the <a href="https://www.openstack.org/summit/austin-2016/summit-schedule/global-search?t=Telecom+/+NFV">Telco/NFV</a> track at the summit to find out what companies were presenting, and how many presenters each had.</p>
<p>Please note this is not a scientific look at the numbers by any stretch of the imagination:</p>
<ul>
<li>This analysis is occurring before the summit.</li>
<li>I’m not sure about a couple of companies in terms of their size.</li>
<li>I’m not counting unique presenters, just the occurrences. So if the same person did three presentations I’d count them as three different presenters.</li>
<li>I wrote this up on 2016-04-14 and things may have changed by then.</li>
<li>A presentation can have multiple people presenting, or it could be a panel which also has multiple people presenting.</li>
<li>I took the number of employees each company has from a simple Google search, so not accurate, but ball park. A recent article in the New York Times suggested AT&T has 280000 employees.</li>
<li>Some companies are owned by larger companies, for example Nuage is owned by Alcatel-Lucent which I think is now owned by Nokia. Or something.</li>
<li>I did not submit a talk to the Austin 2016 summit.</li>
</ul>
<h2 id="information-about-telconfv-track-presentations-and-presenters">Information about Telco/NFV track presentations and presenters</h2>
<p>Some basic numbers on the presentations.</p>
<table>
<thead>
<tr>
<th>Item</th>
<th>#</th>
</tr>
</thead>
<tbody>
<tr>
<td>Presentations</td>
<td>26</td>
</tr>
<tr>
<td>Companies presenting</td>
<td>22</td>
</tr>
<tr>
<td>Total Presenters</td>
<td>75</td>
</tr>
<tr>
<td>Presenters with no affiliations</td>
<td>2</td>
</tr>
<tr>
<td>Presenters with unknown affiliations</td>
<td>2</td>
</tr>
<tr>
<td>Presenters from companies with > 1000 employees</td>
<td>62</td>
</tr>
<tr>
<td>Presenters from companies with > 100,000 employees</td>
<td>40</td>
</tr>
<tr>
<td>Presenters from non-profit foundations</td>
<td>5</td>
</tr>
<tr>
<td>Presenters from startups</td>
<td>4</td>
</tr>
</tbody>
</table>
<p><br /></p>
<p><img src="/img/chart.jpg" alt="# of presenters" /></p>
<h2 id="topics">Topics</h2>
<p>The topics are fairly varied. I was hoping to be able to categorize them, but it does seem diverse, at least within the NFV realm.</p>
<p>Below are some keywords I pulled out of the blurb for each talk.</p>
<table>
<thead>
<tr>
<th>Keyword</th>
<th> </th>
<th> </th>
<th> </th>
<th> </th>
</tr>
</thead>
<tbody>
<tr>
<td>VNF</td>
<td>Distributed NFV</td>
<td>Service Chaining</td>
<td>Open Source</td>
<td>vCPE</td>
</tr>
<tr>
<td>Panel</td>
<td>VM Placement</td>
<td>Uptime</td>
<td>Orchestration</td>
<td>OPNFV</td>
</tr>
<tr>
<td>Deployment</td>
<td>Service Chaining</td>
<td>IPv6</td>
<td>OpenStack Congress</td>
<td>Multi-site Distributed</td>
</tr>
<tr>
<td>OpenStack Tacker</td>
<td>Performance</td>
<td>SR-IOV</td>
<td>Monitoring/Telemetry</td>
<td>Latency</td>
</tr>
<tr>
<td>Platform Aware Scheduling</td>
<td>OPNFV Doctor</td>
<td>CPU Pinning</td>
<td>Huge Pages</td>
<td>NUMA</td>
</tr>
</tbody>
</table>
<p><br /></p>
<p>Some of them were mentioned more than once, such as OPNFV, service chaining, and technologies like SR-IOV/CPU Pinning/NUMA/Huge Pages. Multi-site or distributed was mentioned a couple of times. Both OpenStack and OPNFV have ongoing Telecom/NFV related projects such as Congress and Tacker as well as Doctor that should be well represented.</p>
<h2 id="number-of-employees">Number of employees</h2>
<p>Below is a table of the larger companies and how many people each employs. It’s a considerable sum of over <em>two million employees!</em> That’s a lot of people.</p>
<table>
<thead>
<tr>
<th> </th>
<th>Company</th>
<th># of Employees</th>
</tr>
</thead>
<tbody>
<tr>
<td>1</td>
<td>Juniper</td>
<td>9500</td>
</tr>
<tr>
<td>2</td>
<td>AT&T</td>
<td>240000</td>
</tr>
<tr>
<td>3</td>
<td>HP(e?)</td>
<td>240000</td>
</tr>
<tr>
<td>4</td>
<td>BT</td>
<td>99000</td>
</tr>
<tr>
<td>5</td>
<td>Intel</td>
<td>107000</td>
</tr>
<tr>
<td>6</td>
<td>Redhat</td>
<td>8000</td>
</tr>
<tr>
<td>7</td>
<td>Ericsson</td>
<td>118000</td>
</tr>
<tr>
<td>8</td>
<td>Cisco</td>
<td>72000</td>
</tr>
<tr>
<td>9</td>
<td>Canonical</td>
<td>700</td>
</tr>
<tr>
<td>10</td>
<td>PlumGrid</td>
<td>250*</td>
</tr>
<tr>
<td>11</td>
<td>451 Research</td>
<td>250*</td>
</tr>
<tr>
<td>12</td>
<td>Midokura</td>
<td>100*</td>
</tr>
<tr>
<td>13</td>
<td>Nuage/Nokia</td>
<td>62000</td>
</tr>
<tr>
<td>14</td>
<td>Verizon</td>
<td>178000</td>
</tr>
<tr>
<td>15</td>
<td>Big Switch</td>
<td>100*</td>
</tr>
<tr>
<td>16</td>
<td>China Mobile</td>
<td>246000</td>
</tr>
<tr>
<td>17</td>
<td>NTT</td>
<td>242000</td>
</tr>
<tr>
<td>18</td>
<td>Orange</td>
<td>157000</td>
</tr>
<tr>
<td>19</td>
<td>Brocade</td>
<td>4000</td>
</tr>
<tr>
<td>20</td>
<td>Huawei</td>
<td>170000</td>
</tr>
<tr>
<td>21</td>
<td>NEC</td>
<td>102000</td>
</tr>
<tr>
<td>22</td>
<td>99Cloud</td>
<td>Unknown</td>
</tr>
</tbody>
</table>
<p><br /></p>
<p>Again, more than <a href="https://www.youtube.com/watch?v=r0mO6UY6uTg">two million</a> employees represented from all over the world. Amazing stuff.</p>
<p>Please note for the “*“-ed companies I’m pretty much just guessing.</p>
<h2 id="conclusions">Conclusions</h2>
<p>The vast majority of presenters in the Telco/NFV track are from extremely large companies. In fact most have more than 100,000 employees. 40 of the 75 presenters are from companies with more than 100,000 employees.</p>
<p>I’m amazed at how large these companies are. As someone who is employed at a small company that works on NFV projects, I’m not sure what to make of this. Either small companies don’t submit presentations, or they are not accepted. Is NFV only important to large Telecoms? Are the only telecoms interested in OpenStack very large companies? Do small telecom companies even exist? Will they in the future? Who are the people working on NFV in these companies…are they large teams or small, R&D type groups? Do smaller companies help telecoms to deploy OpenStack-based NFV solutions?</p>
<p>On one hand, the results are somewhat obvious: the majority of the companies doing presentations at the OpenStack summit on NFV related topics are very large because telecoms are very large. But on the other I’m surprised there aren’t more startups and the like in this mix. There is so much work to be done–so much software to be created–that there is, I believe, considerable opportunity. Perhaps this says something about the ability of a small company to able to participate in the OpenStack ecosystem.</p>
Edgecore 5712 Switch2016-03-25T00:00:00+00:00http://serverascode.com/2016/03/25/edgecore-5712<p><em>Slightly blurry picture of our 5712s in our lab</em></p>
<h1 id="edgecore-5712-switch">Edgecore 5712 Switch</h1>
<p>By now most people in IT, especially if involved in networking, have heard the term “whitebox,” mostly in relation to switches. Whitebox switches are essentially commodity network devices that come without an operating system. For various reasons it’s now possible to purchase a fast, relatively low-cost switch based on merchant silicon <a id="merchan">[1]</a> and run any of several (usually Linux based) network operating systems on it. This is quite powerful in terms of commoditization as well as providing access to a large open source ecosystem (again, Linux).</p>
<h2 id="my-use-case">My use case</h2>
<p>Currently my use case if fairly small or simplistic at this point. Basically our two 5712s will be used to provide the underlying physical network for an OpenStack lab. While I hope to get into larger network designs, our basic case will be to run Cumulus Linux on the switches and use their <a href="https://docs.cumulusnetworks.com/display/CL25/Multi-Chassis+Link+Aggregation+-+CLAG+-+MLAG">CLAG</a> feature,ie. multi-chassis link aggregation, to provide network high availability to our hosts. Nothing too fancy, and in fact keeping it simple is one of the “features” I like about whitebox switching. Sometimes less is more. Further, because Cumulus Linux is Linux, it lends itself well to automation. I’ll be able to manage all our OpenStack lab network infrastructure using Ansible, which is the same tool I use to manage OpenStack itself.</p>
<h2 id="specs">Specs</h2>
<p><img src="/img/edgecore2.jpg" alt="Edgecore 5712" /></p>
<p><em>The unboxening</em></p>
<p>The <a href="http://www.edge-core.com/ProdDtl.asp?sno=457&AS5712-54X">Edgecore 5712</a> is a 10GB switch with 6 40GB uplink ports.</p>
<ul>
<li>48 x SFP+ switch ports, supporting 10GbE (DAC, 10GBASE-SR/LR) or 1GbE (1000BASE-T/SX/LX).</li>
<li>Switch Silicon: Broadcom BCM56854 Trident II 720 Gbps.</li>
<li>CPU: Intel Rangeley C2538.</li>
<li>Network design approved by Open Compute Project (OCP)</li>
</ul>
<p>The Intel Rangeley CPU is an <a href="http://ark.intel.com/products/77988/Intel-Atom-Processor-C2758-4M-Cache-2_40-GHz">Atom chip</a>. The switch also comes with 8GB of memory.</p>
<h2 id="trident-ii">Trident II</h2>
<p>From my layperson perspective the important part is the <a href="https://www.broadcom.com/products/Switching/Data-Center/BCM56850-Series">Trident II</a> chip. This would be the “merchant silicon” that is the engine of this device, and it is a very powerful engine. A large number of switches will use this silicon so you will see the features that it provides in many whitebox switches.</p>
<p>From the Broadcom site;</p>
<ul>
<li>First switch to support VMWare VXLAN and Microsoft NVGRE tunneling protocols supported by SmartNV technology</li>
<li>Enables spanning-tree-free and CLOS-style network topologies through TRILL, SPB and ECMP with SmartHash technology</li>
<li>SmartTable and SmartBuffer technologies enable large-scale data centers with 10,000+ end user nodes</li>
<li>Up to 128x 10G integrated SerDes with Energy Efficient Ethernet for maximum port density per RU</li>
<li>Standards-compliant 10GbE/40GbE switch with support for up to 32 ports of 40GbE or up to 100+ ports 1GbE/10GbE</li>
</ul>
<p>The same chip is used in Edgecore’s 32 port 40GB switch, which I would have preferred to purchase because you can split out each 40GB port into four 10GB ports, and thus have 128 10GB ports from one switch! Most organizations could get away with only two switches in their data center. You could run a lot of virtual machines with 128x2 10GB ports. But I digress…</p>
<p>The VXLAN feature will also be useful, as I have deployed software defined networking systems such as Midokura’s Midonet that rely heavily on VXLAN overlays.</p>
<h2 id="available-network-operating-systems">Available Network Operating systems</h2>
<p>Fortunately the 5712 is one of the best supported whitebox switches. That said there are only a handful of network operating systems available right now. These are the ones that I know of:</p>
<ul>
<li>Cumulus Linux</li>
<li>Pico8</li>
<li>OpenSwitch (not the same as Open-V-Switch)</li>
</ul>
<p>Right now I have only installed OpenSwitch and Cumulus Linux. <a href="http://www.openswitch.net/">OpenSwitch</a> is open source and is mostly backed by HP (I believe). However it’s not quite ready for production, as far as I know. I’ve yet to try out Pica8’s PicOS so I can’t really comment on it. Both Cumulus and OpenSwitch installed perfectly on the 5712. <a id="install">[2]</a> I believe, as of right now, the only switch that OpenSwitch supports is the 5712, whereas Cumulus supports several makes and models.</p>
<h2 id="purchasing">Purchasing</h2>
<p>We fluked out and one of the resellers we deal with had two in stock. They didn’t even know what they were. It was weird. But were like “hey, can we get these two switches off you” and after a while they sold them to us. We also ordered a 1GB Edgecore switch that was not in stock, and it still hasn’t come in yet (this was several weeks ago). Being in Canada doesn’t help, as everything has to get imported from the US.</p>
<p>This is part of why IaaS like AWS/Google/Azure is going to win a majority share: because it’s hard to even order physical equipment. Don’t even get me started on the process of buying licenses for Cumulus. The money wasn’t a problem, as we are getting good value, rather it’s the process…but that’s another blog post. A big part of open source software use is convenience–it’s only a download away. Certainly this convenience comes with its own set of issues, but location, location, location. I am on month three of waiting for hardware for my OpenStack/OPNFV lab, and still have another month or two to go.</p>
<p>While I try not to focus on how much hardware costs in terms of commoditization, as I feel that companies tend to focus on that too much, I can say that these switches are very cost effective, even including a Cumulus Linux license. The 40GB versions are even better value.</p>
<h2 id="conclusion">Conclusion</h2>
<p>In my opinion, merchant silicon has paved the way for disaggregation of the switch hardware from the operating system which has thus enabled commoditization. Whitebox switches plus an OS like Cumulus makes for a powerful network platform. The trickle down of technology from the “hyperscalers” has allowed people like myself and the organizations we work for access to advanced network systems. This shift is very similar to what happened, or is happening, with x86 commodity servers and Linux/*BSD. That said we are still in the early days but I expect it to unfold much like commodity x86. <a id="human">[3]</a></p>
<p>Further, I believe that the somewhat limited feature set of the network operating systems is actually a feature in itself…when buying network gear from larger vendors you often pay for features you don’t need, so it allows some choice. That said, if you know exactly what you need and this whitebox model doesn’t provide it, then you’re still free to purchase from whatever vendor you would like. There will be many situations where that is the case, however, maybe I don’t need a huge network infrastructure, maybe all I need is two 32 port 40GB switches with MLAG to support 6000 virtual machines, or maybe I want to implement a relatively large-but-simple ECMP-based CLOS design. Choice is good.</p>
<hr />
<p><a name="merchant">1</a>: Merchant silicon is a fancy phrase for “off the shelf chips”, ie. the vendor doesn’t have to spend money on developing and making their own network device chips. Cisco, for example, spends a considerable amount of money developing their own switching silicon.
<br />
<a name="install">2</a>: Actually I did have one problem. I had OpenSwitch installed on one of the two switches, then I installed Cumulus over top. Something happened during the install that broke Cumulus, but it still completed the install and booted up. For some reason my ability to boot back into ONIE from the Cumulus operating system was broken. I had to use the console to boot into ONIE so I could continue testing my install automation setup. It was fairly unusual…as though the install had crashed part way through, just enough to boot the OS but break some functionality. I could not replicate the issue.
<br />
<a name="human">3</a>: A recent <a href="http://us2.campaign-archive1.com/?u=5e5640dc2e2a939f35bf54df2&id=b100cbe0d5#mctoc8">Human Infrastructure Magazine entry</a> briefly discussed merchant silicon, ECMP designs, etc.</p>
Packaged OpenVSwitch with DPDK on Ubuntu Trusty2016-03-24T00:00:00+00:00http://serverascode.com/2016/03/24/trusty-openvswitch-dpdk<p><em>Murano by Mathieu St-Pierre</em></p>
<h1 id="packaged-openvswitch-with-dpdk-on-ubuntu-trusty">Packaged OpenVSwitch with DPDK on Ubuntu Trusty</h1>
<p>This is just a quick post on getting OpenVSwitch with DPDK installed on Ubuntu 14.04/Trusty using a package instead of compiling it on your own.</p>
<h2 id="tldr">tl;dr</h2>
<p>Install the Ubuntu Liberty Cloud Archive. Then you can install openvswitch-switch-dpdk. However I have not completed the configuration component because there are some bugs, as well I’m lacking a baremetal server at the moment as I was working in AWS. So really this post is just to say that there is a DPDK OpenVSwitch for Ubuntu Trusty. I’ll follow up with more information in a later post.</p>
<h2 id="installation">Installation</h2>
<p>First ensure python3-software-properties is installed.</p>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="nv">$ </span>apt-get <span class="nb">install </span>python3-software-properties
</code></pre></div></div>
<p>Then install the cloud archive.</p>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="nv">$ </span>add-apt-repository cloud-archive:liberty
</code></pre></div></div>
<p>Now apt-get update and check the policy/version of the openvswitch-switch-dpdk package.</p>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="nv">$ </span>apt-cache policy openvswitch-switch-dpdk
openvswitch-switch-dpdk:
Installed: 2.4.0-0ubuntu1~cloud0
Candidate: 2.4.0-0ubuntu1~cloud0
Version table:
<span class="k">***</span> 2.4.0-0ubuntu1~cloud0 0
500 http://ubuntu-cloud.archive.canonical.com/ubuntu/ trusty-updates/liberty/main amd64 Packages
100 /var/lib/dpkg/status
</code></pre></div></div>
<p>Now it can be installed.</p>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="nv">$ </span>apt-get update
<span class="nv">$ </span>apt-get <span class="nb">install </span>openvswitch-switch-dpdk
</code></pre></div></div>
<p><br /></p>
<h2 id="configuring-to-use-dpdk">Configuring to use DPDK</h2>
<p>Set alternatives.</p>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="nv">$ </span>update-alternatives <span class="nt">--set</span> ovs-vswitchd /usr/lib/openvswitch-switch-dpdk/ovs-vswitchd-dpdk
update-alternatives: using /usr/lib/openvswitch-switch-dpdk/ovs-vswitchd-dpdk to provide /usr/sbin/ovs-vswitchd <span class="o">(</span>ovs-vswitchd<span class="o">)</span> <span class="k">in </span>manual mode
</code></pre></div></div>
<p>At this point you could follow the rest of the <a href="http://openvswitch.org/support/dist-docs/INSTALL.DPDK.md.txt">instructions for using OVS</a> however I will warn you that it’s not that straightforward at this time, though I’m sure that will improve in the future. This <a href="https://bugs.launchpad.net/ubuntu/+source/openvswitch-dpdk/+bug/1547463">bug report</a> has some hints. I expect this will be much easier soon. At any rate, at least OVS with DPDK is installed and you can start messing around with getting it working.</p>
Infrastructure Zero2016-03-11T00:00:00+00:00http://serverascode.com/2016/03/11/infrastructure-zero<p><em><a href="http://pixelnoizz.wordpress.com">Image by David Szauder</a></em></p>
<h1 id="infrastructure-zero">Infrastructure Zero</h1>
<h2 id="tldr">tl;dr</h2>
<p>In terms of Infrastructure as a service (IaaS) the point of open source software and hardware IMHO the point is to:</p>
<ol>
<li>innovate faster than closed source, and,</li>
<li>drive down the cost of IaaS to near zero to focus on deploying applications.</li>
</ol>
<p>Perhaps #2 is merely a by-product, but I think there is a considerable distinction between what enterprise organizations think they are supposed to do with Open Source Software (OSS), ie. not pay for it and fire staff (lol), and what they are really doing: using highly collaborative, world-wide software and hardware projects to implement <em>and manage</em> new technology and reduce the costs of particular layers (such as, right now, the infrastructure layer) so that we can spend money on higher level systems, if not higher level abstractions, and thus do more with the same resources.</p>
<p>There’s a difference between getting something for free, and using that something to commoditize systems and move up the value chain.</p>
<h2 id="props-to-randy-bias">Props to Randy Bias</h2>
<p>In this <a href="http://www.cloudscaling.com/blog/openstack/five-things-openstack-needs-to-do-now/">blog post</a> Randy Bias, now of EMC, formerly of Cloudscaling (which was purchased by EMC) mentions that infrastructure has no value.</p>
<blockquote>
<p>All value is from applications that consume [infrastructure].</p>
</blockquote>
<p>In <a href="https://youtu.be/rI13aja9zm0?t=12m32s">this video</a> he talks a bit more about <em>infrastructure zero</em>, likening infrastructure to utilities like power and water, and how it is not a differentiating part of your business in that we all need CPU, storage, and networking–that what <em>is</em> differentiating is the applications, and custom code, that utilizes those primitives.</p>
<p>I’ve always liked what Randy says about OpenStack and infrastructure, because I feel that he’s usually right, but the market tends to disagree with him and go on to screw everything up. Cloudscaling had some good ideas regarding infrastructure choices for OpenStack, but even though the company “exited,” ultimately it failed, and as far as I know the Cloudscaling product no longer exists.</p>
<p>In an <a href="http://blog.appformix.com/openstack-2016-what-you-need-to-know">Appformix blog post</a>, Mr. Dunnigan rephrases Randy’s theory:</p>
<blockquote>
<p>…the sole purpose of infrastructure is to serve the applications they run. Infrastructure running zero workloads has zero value.</p>
</blockquote>
<h2 id="infrastructure-zero-1">Infrastructure Zero</h2>
<p><img src="/img/glitch-5.png" alt="glitch" /></p>
<p><em>Image: The facade 2010, Robert Overweg</em></p>
<p>Currently IaaS is going through a period in which we are attempting to use OSS and hardware, as well as automation, to drive down the cost of operating IaaS as close to zero as possible. The reality is that IaaS has little value unless it’s not working, in which case it has negative value.</p>
<p>But in general its value is zero or close to zero, and the real goal is to get the <strong>cost</strong> of operating IaaS as close to zero as possible. But there is a long way to go, and doing so requires resources and talent given that important components of IaaS, such as OpenStack, are not as operationally mature as we would require to fully commoditize. Further, while we have whitebox network switches the operating systems available for them are relatively new.</p>
<p>This is not to say that OpenStack is not “production ready” (it is) rather that it doesn’t necessarily cost less to operate than other traditional virtualization solutions because of the human resources required to, for example, upgrade it. That said it does come with what is now considered a standard API which most other IaaS-like systems do not. So if you consider the costs a wash then just having an API will improve things. But I digress…</p>
<h2 id="public-cloud">Public Cloud</h2>
<p>I don’t want to get into private cloud vs public cloud debate in this post. That said I feel comfortable saying a large majority of IT organizations will be using public clouds like Amazon, Azure, and Google. But it’s unlikely to be 100%, and will take many years, if not decades. There will still be tens of billions of dollars available for private clouds, just not hundreds of billions.</p>
<p>Further, <a href="http://superuser.openstack.org/articles/why-openstack-is-the-kernel-of-the-data-center?awesm=awe.sm_eOjxU">some people</a> believe that the bigger Amazon Web Services gets, the bigger OpenStack (ie. private clouds) will be. However, based on who is saying that there may be bias in that thinking.</p>
<p>Suffice it to say that I am a believer in public clouds, but also a realist in terms of the fact that businesses have to sell what people want, and many organizations–at least right now–want private clouds.</p>
<p>It’s from this standpoint that I make most of my generalizations on <em>infrastructure zero</em>, in that work that public clouds, and other large IaaS users (eg. Facebook) are are doing is trickling down into private clouds (see Open Compute or the Xeon-D processor), and in conjunction with software like OpenStack we hope to drive the cost to zero so that we can work on deploying applications and systems that provide differentiation and ultimately <em>make money</em>.</p>
<h2 id="nobody-wants-iaas-but-everyone-needs-it">Nobody wants IaaS, but everyone needs it</h2>
<p><img src="/img/glitch-city.jpg" alt="glitch city" /></p>
<p>I have been working with OpenStack for several years, including deploying a public cloud in Canada based on OpenStack. I can say without reservation that no one wants <em>just OpenStack</em>.</p>
<p>Deploying an OpenStack cloud and handing over credentials is a surefire way to fail, because, most often, end users will have no idea what to do with it. Users want to deploy applications. Simply having access to OpenStack APIs is (usually) not enough. There needs to be another layer of abstraction in between IaaS and most users–another layer of utility.</p>
<p>Recently Werner Vogels, of AWS fame, posted an <a href="http://www.allthingsdistributed.com/2016/03/10-lessons-from-10-years-of-aws.html">entry</a> on his blog that detailed ten things he has learned building a public cloud (perhaps <em>the</em> public cloud). One of his points regards “primitives”:</p>
<blockquote>
<p>One of the most important mechanisms we provided was to offer customers a collection of primitives and tools, where they could pick and choose their preferred way to engage with the AWS cloud…</p>
</blockquote>
<p>What I take that to mean is that building a cloud requires ensuring certain primitives exist so that layers of abstraction and workflows can be defined and overlaid on those blocks. The primitives are obvious (compute, network, storage, etc) and have to exist, but they do no directly provide value as we still need abstraction and automation above them.</p>
<p>In many ways I am surprised that AWS has grown so quickly given that it is a complex system of primitives sans frameworks. In this post I am suggesting that primitives are not enough, and yet AWS is thriving, and is, I believe, one of the fasted technology companies to a 10 billion run rate.</p>
<p>However, as AWS matures, and the (<a href="http://www.nytimes.com/2015/08/16/technology/inside-amazon-wrestling-big-ideas-in-a-bruising-workplace.html">somewhat creepy?</a>) socio-techo organization behinds it learns what frameworks and workflows its customers want, I expect it to begin identifying layers of abstraction that will continue to drive growth and enable simpler, faster, more powerful deployments of technologies, making it easier to develop, deploy, scale, and operate new applications. (Such as <a href="https://aws.amazon.com/lumberyard/">games</a>.) They’ll develop frameworks that will quickly become standards.</p>
<p>Another point of note: I recently listened to a podcast interview with someone from Pivotal (a platform as a service product based on Cloud Foundry). Unfortunately I can’t find it so this is anecdotal. Occasionally when Pivotal talks to prospective customers, these customers have technical staff who ask what operating system their code is running on, and Pivotal pushes back on that question, because why do they need to know? Is the application running properly? If yes, then it’s irrelevant what the underlying virtual machine operating system is, just like it’s irrelevant as to what the IaaS is. The abstraction layer will (hopefully) deal with it. The user doesn’t need to know. The PaaS can ask the IaaS for CPU, storage, and network. Push your code up, it’s running properly…that’s all that matters.</p>
<h2 id="controllercontroller">controller.controller</h2>
<p><img src="/img/controller.jpg" alt="controller.controller" /></p>
<p>By “controller.controller” I mean a “controller of controllers” or “manager of managers.” In the Vogel post I mentioned about he also uses the term “framework” which is probably similar. Right now this area is rather messy. Everyone is working on building these systems and it is a difficult thing to do. It reminds me of how many Javascript frameworks there are. I don’t know if we want as many IaaS abstraction frameworks as there are Javascript frameworks. Then again most attempts at a “single pane of glass” fail. So somewhere between two and several.</p>
<p>From my perspective a controller of controllers could be as simple as using OpenStack Heat or Hashicorp’s <a href="https://www.terraform.io/">Terraform</a>, or as complex as the <a href="http://www.etsi.org/deliver/etsi_gs/NFV/001_099/002/01.01.01_60/gs_NFV002v010101p.pdf">ETSI defined MANO layer</a>. The point is that when an OpenStack system cloud is deployed, so to should systems that enable higher level abstractions, and likely more than one.</p>
<p>These systems will be incredibly important in terms of not only managing infrastructure but also in terms of driving business profitability, on both sides of the equation.</p>
<h2 id="the-infrastructuresoftware-paradox">The Infrastructure|Software Paradox</h2>
<p><img src="/img/price-of-software.jpg" alt="price of software" /></p>
<p><em>(Image from <a href="http://www.bloomberg.com/news/articles/2015-02-05/six-things-technology-has-made-insanely-cheap">Bloomberg</a>)</em></p>
<p>I recently ordered the book <a href="http://thesoftwareparadox.com/">The Software Paradox</a> but it hasn’t arrived yet so I haven’t read it. But I can’t wait to dig in. The premise:</p>
<blockquote>
<p>The Software Paradox explores the counterintuitive idea that software’s realizable commercial value is headed in the opposite direction of its market importance.</p>
</blockquote>
<p>Essentially <a href="http://genius.com/3115790">“software is eating the world”</a> but it’s getting harder to make money off of it. How can that be?</p>
<p>In many ways this post regards “The Infrastructure Paradox” in which infrastructure is more important than ever but it’s become less profitable. Or is it simply that it has become commoditized and has lower margins which requires a different business model? To be honest I don’t know, but the reality is that the change is unstoppable.</p>
<h2 id="what-do-we-do-now">What do we do now?</h2>
<p>From my standpoint as a long-time systems administrator, I feel like my best path is to work to aggressively reduce the cost of IaaS (ie. automation, monitoring, ect), make deploying applications as easy and automatable as possible, and understand the dynamics of the public and private cloud marketplace. Further–as a systems administrator of all things–understanding the business model of a product that is simultaneously incredibly important but has limited positive financial value seems paramount.</p>
<hr />
<p><a name="band">1</a>: controller.controller was a <a href="https://en.wikipedia.org/wiki/Controller.controller">Toronto indie rock band</a>. I don’t know if I’ve ever even heard one of their songs, but I remember their name because it always seemed like a tech company rather than a band.
<br/ >
<a name="utility">2</a>: Not sure where to put this but perhaps this is all just a rehash of “utility computing” that I believe originated in 1961!</p>
OpenStack Operators Midcycle, OpenStack Ansible Midcycle, and Ansible Fest2016-02-23T00:00:00+00:00http://serverascode.com/2016/02/23/osops-ansible-meetups<h1 id="openstack-operators-midcycle-openstack-ansible-midcycle-and-ansible-fest">OpenStack Operators Midcycle, OpenStack Ansible Midcycle, and Ansible Fest</h1>
<p>This is a brief post on my recent trip to the UK to attend:</p>
<ul>
<li>The OpenStack Operators Midcycle meetup in Manchester</li>
<li>The OpenStack Ansible project’s midcycle meetup at Rackspace’s UK HQ in London Hayes</li>
<li>Ansible Fest London</li>
</ul>
<h2 id="openstack-operators-midcycle-meetup-manchester-uk">OpenStack Operators Midcycle Meetup (Manchester, UK)</h2>
<p>For the first leg of the trip I spent two days in Manchester’s Media City attending the OpenStack Operators midcycle meetup. Originally this meetup was for European operators. At the time I registered for the meetup, a few months ago, I was working at a Canadian OpenStack-based regional public cloud. Europe has several similar clouds and I was interested in meeting up with the operators of those clouds to exchange ideas. So that was my original intention in terms of attending the meetup. After registering, the meetup turned into the official midcycle operators event, and I also moved on to a new job that didn’t involve running a public cloud. So both the event and my purposes for attending the event changed, but in such a way that it made sense for me to participate.</p>
<p>The most important thing I learned from the midcyle event is that OpenStack is the perfect cloud system for Europeans. The European Union recently put out a RFP (I have been looking but cannot find the actual document) requesting vendors to propose how they would run a series of cloud systems (IaaS, PaaS, etc) for the EU. In some parts of that document OpenStack was called out as a standard.</p>
<p>OpenStack fits much better into the mentality of the EU than it does with North America. In my opinion, the EU wants OpenStack because OpenStack is an open project, because it’s open source, it’s an open community…all the values that the project stands for and stands on. In fact OpenStack is based on <a href="https://wiki.openstack.org/wiki/Open">“the four opens.”</a> This is opposed to what I typically see in North America which is reducing costs and trying to avoid the dreaded “vendor lock-in.” (Neither of which are likely to be achieved when adopting OpenStack.) Further, European operators are interested in federation, and the private clouds of NA are not.</p>
<p>Other notes from the midcycle:</p>
<ul>
<li>I met a couple of people who are using whitebox switches and network OSes like Cumulus Linux. This is good because when I returned to my desk in Edmonton there were a couple of Edgecore 5712s on my desk that are due to go into our lab.</li>
<li>Ceph continues to be a popular storage system to go along with OpenStack installations. I’m finally setting up a ceph cluster, for the first time, in the near future as we have a small cluster of ceph nodes on order as well, more lab fodder. There are large companies heavily relying on ceph storage for production systems.</li>
<li>People are finding that Chef and Puppet are not completely working out. It’s becoming common to utilize Ansible in combination, especially around orchestration (depending on how you define the word).</li>
<li>OpenStack Ansible was used to deploy a large cluster (500+ compute nodes). Anecdotally people have said that once you hit a couple hundred compute nodes that it’s time to start looking at cells. That does not seem to be the case with more recent versions of OpenStack. 500+ compute nodes is a lot of virtual machines.</li>
<li>Speaking of cells…in Mitaka everyone will use cells V2, but to start you can only have one cell.</li>
<li>Apparently a lot of “ceph enablement” has been done in Mitaka</li>
</ul>
<p>Manchester’s Media City reminded me a lot of the business area of Santa Clara. It’s a vast business desert. Very few places to eat, no drug store, not much to do. In short not a great place to visit. I’m sure Manchester itself has a lot to offer, but if I was staying longer to enjoy the city I’d definitely be moving to different hotel downtown. I don’t usually like to have breakfast in the hotel, but I had little choice in Media City. I find it amazing that hotels can charge $25-30 for a buffet lunch made up of oily eggs and weird tasting hashbrowns. At least the coffee had caffeine in it.</p>
<h2 id="openstack-ansible-midcyle">OpenStack Ansible Midcyle</h2>
<p>The midcyle ocurred at Rackspace’s UK HQ, and there were about 12 people there, with a few more coming in and out online via video conferencing. Notably four members of the HPE Helion lifecycle management team were also in attendance.</p>
<p>I have been following the OpenStack-Ansible project since it started. At my previous job I was able to make use of some of the components of the project, such as the roles to deploy and manage MySQL Galera and RabbitMQ, but that was over a year ago. Much has changed. I would imagine the code has completely rolled over as the project has seen impressive growth. At my current position I’m hoping to make use of the OpenStack-Ansible project to deploy our OpenStack lab, and in doing so be able to commit some code back to the project. For the purposes of our lab I’ll need OpenVSwitch (OVS) support, which does not quite exist in the project yet, but is on the way. Fortunately OpenStack-Ansible already supports using a ceph cluster (though does not deploy one, rather <a href="https://github.com/ceph/ceph-ansible">ceph-ansible does that</a>).</p>
<p>Topics for discussion ranged from patterns and workflows that should be in use in OpenStack-Ansible to how to manage the life cycle of an OpenStack cloud. HPE (now with an E) recently released a snapshot of their <a href="https://github.com/hpe-helion-os">Ansible-based</a> deployment and management system for their Helion project. Several HPE employees were in attendance as it seemed like there was the possibility of some collaboration, or at least shared learning (misery?) in terms of what each group has done with OpenStack and Ansible. The HP team had moved from Chef to TripleO and are now using Ansible, specifically because they found the previous two difficult to use in terms of managing (mangling?) an OpenStack system over time. Certainly Ansible is not the perfect tool, but, at least in HPE’s experience, it is a more appropriate configuration management system for their purposes. Unfortunately the reality is that it is hard to maintain a life cycle for any system, especially complex ones like OpenStack. As I am often saying, even today in fact: it’s easy to deploy OpenStack, but managing it over time (eg. upgrades) is much, much more difficult.</p>
<p>One thing I learned from the midcycle is that code talks. In many cases it’s easier to discuss the results of a proof of a concept, based on code, than it is to discuss that concept without any code. It’s easy to lapse into a two hour discussion about what <em>could</em> happen if a pattern or workflow was followed, as opposed to a five minute discussion when you have actual code to look at. Code can talk much faster.</p>
<p>It was certainly nice to meet a good portion of the core OpenStack-Ansible team and to put IRC nicks to faces. I hope to be able to contribute back to the project in the near future as the OpenStack lab I’m working on is deployed. I’m appreciative of the OpenStack-Ansible team for allowing me to attend the midcycle, especially given my limited ability to contribute to the conversation.</p>
<h2 id="ansible-fest">Ansible Fest</h2>
<p><img src="/img/ansiblefest.jpg" alt="ansiblefest" /></p>
<p><em>(Ansible Fest from the middle row, before the talks started)</em></p>
<p>First off it’s important to note that I was at a previous Ansible Fest, the 2014 event in NYC (I think that’s when it was). It was a small event and one that I felt was technical. It’s possible that I’m remembering incorrectly. However, I felt it was technical, and that the Ansible Fest London 2016 event was not. London was much larger, which is to be expected given Ansible’s popularity and growth. According to the event staff there were about 530 people in attendance. Growth is good. RedHat buying Ansible is probably good. Certainly more developers have been added to the project and if that is the only thing that RedHat adds then that is positive just by itself.</p>
<p>However, I don’t think I would go to AnsibleFest again, mostly because the event seemed to be focused on telling people to do automation, devops, immutable infrastructure and the like, as opposed to really showing what Ansible can do, ie. telling vs showing. Certainly there were some attempts to provide examples of powerful uses of Ansible, especially around networking and winops (a term I first heard at this event, which I like), as well as a presentation by jimi-c on how (and why) to write Ansible modules, but it just wasn’t quite enough. If I went to an Ansible event again it would have to be more workshop-like or perhaps have multiple tracks with less showy presentations. In the end I think they did their best and catered to the crowd they knew they would have.</p>
<p>Another nit: for a day long conference it was quite expensive. Certainly cost is a relative thing, but compared to other events I’ve been to AnsibleFest was costly</p>
<p>A few things I learned from the conference:</p>
<ul>
<li>I was speaking with a company that works in the gambling industry, and they are using AWS as their main site host, but also have a secondary physical site (“luke warm” was the term used) in a co-location center so the government can have something physical to seize in case of some sort of legal or regulatory issue.</li>
<li>Ansible is often used in continuous integration or deployment (CI/CD) pipelines. These pipelines are important to organizations because if the pipeline stops working, perhaps due to Ansible, then they can’t deploy their code, can’t get fixes or features out, and that costs money. So they want support from Ansible so they can get their pipelines back up and running as soon as possible. Basically everything in that pipeline requires support of some kind.</li>
<li>Speaking of support, most of the questions in the question/answer periods were about support. Many organizations want Ansible support.</li>
<li>Through a “raise your hand if” question from a presenter, it was noted that the large majority of people in the audience work at companies with more than 1000 employees.</li>
<li>Ansible Galaxy runs on donated resources from Microsoft Azure.</li>
<li>One of the main announcements from the conference is that Ansible is dedicated to supporting network automation, and released several modules for various networking companies such as Cisco and Cumulus Linux. I’ve been using the Cumulus modules for a couple weeks, so in effect they just moved the modules from one github repository into another, but it’s great to see a focus on networking for Ansible. It’s dearly needed.</li>
<li>Ansible is in some ways a better fit for network automation because it’s agentless. You can run Ansible over SSH, or you can write Ansible modules that use APIs that the networking system provides.</li>
<li>CLOS networks are becoming the norm.</li>
<li>Some organizations have to manage millions of lines of network configuration that are cut and pasted into network devices. I can’t see how that works.</li>
</ul>
<p>All of the presentation videos are <a href="https://www.ansible.com/videos-ansiblefest-london-2016">available online</a>.</p>
<h2 id="europe-in-general">Europe in general</h2>
<p><img src="/img/globe.jpg" alt="Shakespeare's Globe Theatre" /></p>
<p><em>(Shakespeare’s Globe Theatre, under construction for a new show)</em></p>
<p>Other than getting the flu, which seems to happen on every trip, I had a great time traveling from Edmonton to Amsterdam to Manchester to London and home again. Edmonton has a direct flight to Amsterdam via KLM, so that makes travel to Europe easier for me. Unfortunately it’s currently the only direct flight to Europe. We used to have a direct flight to NYC as well, but this isn’t a “Edmonton Direct Flight Blog.” :)</p>
<p>I was in five hotel rooms in nine days but everything worked out 0K, and I made it home in almost one piece. However, I did get lucky in a couple instances. At one point I was quite lost after getting off the train from Manchester (forgot about a transfer) and had to take an expensive cab from the train station to my hotel. However, the cab driver could not find the hotel and we drove around for an extra 30,40 minutes with the meter off as he tried to locate it. I did eventually get to my hotel and he was apologetic. In general I found Londoners to be a pleasant group of people no matter how many of them we crammed onto the underground. Once I was looking at a map of Canary Wharf and a policeman actually gave me directions. This has never happened to me anywhere else, not even in Edmonton.</p>
<p>Probably the biggest thing that I learned is that Europe (OK, just Amsterdam and London) is cold and rainy at this time of year. Edmonton is quite a dry place, and that makes it feel warmer than it is. Zero degrees in Amsterdam felt like -10 in Edmonton, and one of the first things I had to do was buy a scarf. I was freezing. Also it rains a lot in Amsterdam and London. It rarely rains in Edmonton, and my home town is one of the sunniest places in the world. We get over 2300 hours of sunshine per year versus 1662 for Amsterdam and 1481 for London [1]. Even notoriously rain-soaked-everyone-has-an-umbrella Vancouver has more sunshine than London. Poor London. (Apparently Yuma, Arizona is the sunniest place in the world with 4000 hours of sunshine a year…11 hours a day.)</p>
<p>My next trip should be to Austin for the OpenStack summit. I love Austin, but am a bit concerned about the recent Texas open carry laws. However, Austin is such an amazing place that it might be worth the risk.</p>
<hr />
<p>1: <a href="https://www.currentresults.com/Weather/United-Kingdom/annual-sunshine.php">Sunshine Hours</a></p>
GRE point to point and AWS VPC2016-01-25T00:00:00+00:00http://serverascode.com/2016/01/25/aws-gre<h1 id="gre-point-to-point-and-aws-vpc">GRE point to point and AWS VPC</h1>
<p>This is a quick, and simple, post on setting up a GRE tunnel between two instances in an Amazon VPC. Not all that useful in the real world, but it is part of exploring creating overlay and other network models within an EC2 VPC. I can’t find the original link I was working off of, but there are several blog posts out there that discuss setting up a simple GRE point to point tunnel on Linux, such as <a href="http://ask.xmodulo.com/create-gre-tunnel-linux.html">this one</a>.</p>
<h2 id="first-aws-spot-instances">First: AWS spot instances</h2>
<p>I like spot instances, so that’s what I used in this example. You put in a bid and you can get EC2 instances for a fraction of the “regular” price. These instances can go away at any time depending on market forces, but I have found that they are perfect for testing and so far have not had one disappear out from under me–I’ve always terminated them myself after a few hours. Usually I start up a couple instances in the morning and shut them down at the end of the day. Costs about $0.02 for 2 or 3 m3.medium instances, if not less. Great for labs or training. Also I like the fact that it forces me to get used to destroying and rebuilding instances, and automating as much as possible to make the new instances ready as quickly as possible.</p>
<p>So create two AWS instances in the same VPC. In the example that follows they have the IPs of 172.22.1.{76,238}.</p>
<h2 id="configure-interfaces">Configure interfaces</h2>
<p>First we’ll manually create network interface files. The OS here is Ubuntu 14.04.</p>
<pre>
<code>root@ip-172-22-1-238:/etc/network/interfaces.d# cat gre1.cfg
auto gre1
iface gre1 inet tunnel
mode gre
netmask 255.255.255.255
address 10.0.0.2
dstaddr 10.0.0.1
endpoint 172.22.1.76
local 172.22.1.238
ttl 255
</code>
</pre>
<p>And on the other node:</p>
<pre>
<code>root@ip-172-22-1-76:/etc/network/interfaces.d# cat gre1.cfg
auto gre1
iface gre1 inet tunnel
mode gre
netmask 255.255.255.255
address 10.0.0.1
dstaddr 10.0.0.2
endpoint 172.22.1.238
local 172.22.1.76
ttl 255
</code>
</pre>
<p>Then start the interfaces.</p>
<pre>
<code>$ # both instances
$ ifup gre1
</code>
</pre>
<p>And now you should see something like…</p>
<pre>
<code>root@ip-172-22-1-76:/etc/network/interfaces.d# netstat -rn
Kernel IP routing table
Destination Gateway Genmask Flags MSS Window irtt Iface
0.0.0.0 172.22.1.1 0.0.0.0 UG 0 0 0 eth0
10.0.0.2 0.0.0.0 255.255.255.255 UH 0 0 0 gre1
172.22.1.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0
root@ip-172-22-1-76:/etc/network/interfaces.d# ip ro sh
default via 172.22.1.1 dev eth0
10.0.0.2 dev gre1 proto kernel scope link src 10.0.0.1
172.22.1.0/24 dev eth0 proto kernel scope link src 172.22.1.76
</code>
</pre>
<h2 id="iperf">Iperf</h2>
<p>Without GRE overlay:</p>
<pre>
<code># iperf -c 172.22.1.238
------------------------------------------------------------
Client connecting to 172.22.1.238, TCP port 5001
TCP window size: 325 KByte (default)
------------------------------------------------------------
[ 3] local 172.22.1.76 port 52187 connected with 172.22.1.238 port 5001
[ ID] Interval Transfer Bandwidth
[ 3] 0.0-10.0 sec 464 MBytes 388 Mbits/sec
</code>
</pre>
<p>With GRE:</p>
<pre>
<code># iperf -c 10.0.0.2
------------------------------------------------------------
Client connecting to 10.0.0.2, TCP port 5001
TCP window size: 325 KByte (default)
------------------------------------------------------------
[ 3] local 10.0.0.1 port 47969 connected with 10.0.0.2 port 5001
[ ID] Interval Transfer Bandwidth
[ 3] 0.0-10.0 sec 462 MBytes 387 Mbits/sec
</code>
</pre>
<p>Surprisingly close. Perhaps too surprisingly.</p>
<h2 id="tcpdump">tcpdump</h2>
<p>If I ping one node from the other, and then tcpdump GRE on eth0…</p>
<pre>
<code>root@ip-172-22-1-76:/etc/network/interfaces.d# sudo tcpdump -n -e -ttt -i eth0 proto gre
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 65535 bytes
00:00:00.000000 02:28:2a:9e:bb:03 > 02:f4:ec:79:c6:7b, ethertype IPv4 (0x0800), length 122: 172.22.1.238 > 172.22.1.76: GREv0, proto IPv4 (0x0800), length 88: 10.0.0.2 > 10.0.0.1: ICMP echo request, id 2533, seq 1, length 64
00:00:00.000043 02:f4:ec:79:c6:7b > 02:28:2a:9e:bb:03, ethertype IPv4 (0x0800), length 122: 172.22.1.76 > 172.22.1.238: GREv0, proto IPv4 (0x0800), length 88: 10.0.0.1 > 10.0.0.2: ICMP echo reply, id 2533, seq 1, length 64
00:00:01.000261 02:28:2a:9e:bb:03 > 02:f4:ec:79:c6:7b, ethertype IPv4 (0x0800), length 122: 172.22.1.238 > 172.22.1.76: GREv0, proto IPv4 (0x0800), length 88: 10.0.0.2 > 10.0.0.1: ICMP echo request, id 2533, seq 2, length 64
00:00:00.000038 02:f4:ec:79:c6:7b > 02:28:2a:9e:bb:03, ethertype IPv4 (0x0800), length 122: 172.22.1.76 > 172.22.1.238: GREv0, proto IPv4 (0x0800), length 88: 10.0.0.1 > 10.0.0.2: ICMP echo reply, id 2533, seq 2, length 64
^C
4 packets captured
4 packets received by filter
0 packets dropped by kernel
</code>
</pre>
<p>Listening on gre1 for icmp:</p>
<pre>
<code>root@ip-172-22-1-76:/etc/network/interfaces.d# sudo tcpdump -n -e -ttt -i gre1 icmp
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on gre1, link-type LINUX_SLL (Linux cooked), capture size 65535 bytes
00:00:00.000000 In ethertype IPv4 (0x0800), length 100: 10.0.0.2 > 10.0.0.1: ICMP echo request, id 2534, seq 1, length 64
00:00:00.000024 Out ethertype IPv4 (0x0800), length 100: 10.0.0.1 > 10.0.0.2: ICMP echo reply, id 2534, seq 1, length 64
00:00:00.998982 In ethertype IPv4 (0x0800), length 100: 10.0.0.2 > 10.0.0.1: ICMP echo request, id 2534, seq 2, length 64
00:00:00.000023 Out ethertype IPv4 (0x0800), length 100: 10.0.0.1 > 10.0.0.2: ICMP echo reply, id 2534, seq 2, length 64
^C
4 packets captured
4 packets received by filter
0 packets dropped by kernel
</code>
</pre>
<h2 id="gre-overhead">GRE overhead</h2>
<p>GRE adds 24 bytes of overhead. So the GRE tunnel MTU is 8977, 24 less than eth0’s 9001 MTU. (Some EC2 instances support jumbo frames, and in this case my spot instances came up with an MTU of 9001, but this is not always the case, and is <a href="http://docs.aws.amazon.com/AWSEC2/latest/UserGuide/network_mtu.html">not always desirable</a>.)</p>
<pre>
<code>ubuntu@ip-172-22-1-76:~$ ip ad sh eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 9001 qdisc pfifo_fast state UP group default qlen 1000
link/ether 02:f4:ec:79:c6:7b brd ff:ff:ff:ff:ff:ff
inet 172.22.1.76/24 brd 172.22.1.255 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::f4:ecff:fe79:c67b/64 scope link
valid_lft forever preferred_lft forever
</code>
</pre>
<pre>
<code>ubuntu@ip-172-22-1-76:~$ ip ad sh gre1
5: gre1@NONE: <POINTOPOINT,NOARP,UP,LOWER_UP> mtu 8977 qdisc noqueue state UNKNOWN group default
link/gre 172.22.1.76 peer 172.22.1.238
inet 10.0.0.1 peer 10.0.0.2/32 scope global gre1
valid_lft forever preferred_lft forever
inet6 fe80::5efe:ac16:14c/64 scope link
valid_lft forever preferred_lft forever
</code>
</pre>
<h2 id="conclusion">Conclusion</h2>
<p>This was just a simple exercise for me to get used to networking within AWS VPC, and to gradually work towards more complicated overlay (or other) models and software defined solutions.</p>
A Year with Midokura's Midonet and OpenStack2015-12-31T00:00:00+00:00http://serverascode.com/2015/12/31/a-year-with-midokura-midonet-and-openstack<h1 id="a-year-with-midokuras-midonet-and-openstack">A Year with Midokura’s Midonet and OpenStack</h1>
<p>One of the first things to do when deciding to deploy OpenStack is figure out what the Neutron network is going to look like. For that, one needs the project requirements, what your network administrators are willing to deploy (allow), and what the operators are comfortable using. Maybe those are all the same person, I don’t know. :) There are all the general Neutron deployment options, as well as plugins like <a href="http://www.projectcalico.org/">Project Calico</a>, <a href="http://www.plumgrid.com/">Plumgrid</a>, and <a href="https://wiki.OpenStack.org/wiki/Neutron_Plugins_and_Drivers">many others</a> to choose from. One might say you have a <a href="http://www.imdb.com/title/tt0092086/quotes?item=qt0400510">plethora of choices</a>.</p>
<p>Before I get too far, I should note that I don’t have a lot of experience with non-Midonet deployments of Neutron, so I have “strong opinions, lightly held” in terms of how to deploy Neutron.</p>
<p>My feeling when deciding to use Midonet was that the more generic Neutron deployment model, something like <a href="http://docs.openstack.org/networking-guide/scenario_dvr_ovs.html">HA with DVR</a>, sounded complicated and in some cases limited. Tales of debugging sounded awful. OpenStack operators love to anecdotally complain about standard Neutron deployment models, so I thought I’d just skip all that and implement Midonet. I needed a highly available system that also supported a <a href="https://aws.amazon.com/vpc/">VPC</a> style of tenant networking. Also I like software defined networking (whatever that actually means). Midonet seemed like a perfect fit, and after a year in production, I feel it was a good choice. Now if I complain about networking in OpenStack I’d be really be complaining about Midonet as opposed to Neutron (which is essentially just the front-end API).</p>
<p>However, other networking models should be considered. I think it’s safe to say I have experience operating Enterprise Midonet 1.8, but after that things get fuzzy. So complete whatever due-diligence seems necessary for your project.</p>
<h2 id="what-is-midonet">What is Midonet?</h2>
<p>From my perspective as an OpenStack operator, Midonet is a Neutron plugin and software defined networking system. It falls into the category of “overlay” models. It creates a logical network topology over top of the physical one, essentially using VXLAN (or GRE) encapsulation. The network state is distributed and stored mostly in Zookeeper. The Midolman agent runs on API, gateway, and compute nodes. Midonet has good documentation, so I suggest taking at look at that to get a better understanding of how it all works.</p>
<p>Here’s the standard Midonet diagram. It shows how Midonet “overlays” on top of the physical network.</p>
<p><img src="/img/midonet_topology.png" alt="" /></p>
<h2 id="things-i-like-about-midonet">Things I like about Midonet</h2>
<p>There are many things to like about Midonet.</p>
<ul>
<li><em>It is open source, though I’m not sure how many non-Midokura developers contribute</em></li>
</ul>
<p>Note: I have not deployed the open source version, only the commercial 1.8 series</p>
<ul>
<li><em>BGP-based HA on the gateway nodes for north/south</em></li>
</ul>
<p>This means you can drop a gw node and only lose about 10 packets before the IP fails over. I really like this feature. Requires your network admin to do some work setting up BGP sessions. Midonet takes care of them on its side when BGP ports are configured. Also requires stateful port groups to be configured, but that is not hard. I’m not sure why anyone would deploy Midonet gateways without doing that.</p>
<ul>
<li><em>Good support from Midokura</em></li>
</ul>
<p>I don’t recommend many commercial systems, but I do recommend Enterprise Midonet. The support team has been fantastic.</p>
<ul>
<li><em>Midokura is a modern, fast moving company with new ideas</em></li>
</ul>
<p>There are lots of interesting things that could/can be done with a system that enables SDN. Think about anycast with floating IPs across WAN-connected regions, cool stuff like that. An overlay is certainly not less complicated, but the features and capabilities it adds are worth it in my opinion.</p>
<ul>
<li><em>Because it is software features can be added without requiring new hardware</em></li>
<li><em>Has an API</em></li>
<li><em>Gets rid of standard Neutron network nodes, though north/south goes through the gw nodes</em></li>
</ul>
<p>Some Neutron deployments require dedicated network nodes.</p>
<ul>
<li><em>Your network admins can probably ignore it and just provide L3 connectivity</em></li>
<li><em>Security groups are not iptables based</em></li>
<li><em>Potential for service chaining, NFV, all that hyped up stuff</em></li>
<li><em>Does have a web interface, but I have never used it</em></li>
<li>_Midokura is working hard on important OpenStack projects like <a href="http://superuser.openStack.org/articles/project-kuryr-brings-container-networking-to-openStack-neutron_">Kuryr</a></li>
<li><em>Layer-3 forwarding in the hypervisor</em></li>
<li><em>LBaaS driver does work, though has some caveats</em></li>
</ul>
<h2 id="things-that-arent-as-much-fun">Things that aren’t as much fun</h2>
<ul>
<li><em>Configuring ports, BGP sessions, and stateful port groups</em></li>
</ul>
<p>This is a bit painful for me, only because I didn’t have time to write an Ansible module for it. This process would be easily automated, but if it isn’t, then it is fairly complicated. In the end I wrote a terrible bash script to do it for me, which made me feel bad.</p>
<ul>
<li><em>Does have the extra requirements of Zookeeper and Cassandra</em></li>
</ul>
<p>Many people dislike Zookeeper. I’m not sure why. I’m not a big fan of Java-based systems, but I can tell you that Zookeeper has been running fine for over a year with absolutely no issues. That said it’s recommended to run the network service database (NSDB) nodes, ie. Zookeeper and Cassandra, on baremetal servers that are separate from the rest of the infrastructure. Nodes with 32GB or more is fine. Certainly these clusters require some care and feeding.</p>
<p>Then again, the network state has to go somewhere. Other solutions have to store it as well. Physical routers store network state too, just in config files or other local databases. Every SDN system has to store state, and usually that will be some kind of distributed database (perhaps they rolled their own).</p>
<ul>
<li><em>Knowing that Midokura’s exit plan likely involves being bought out</em></li>
</ul>
<p>I would imagine they will eventually be bought by a large conglomerate like Cisco. One of my other favorite tools, Ansible, was recently purchased by RedHat. Sometimes the exit turns out well, sometimes not.</p>
<h2 id="issues-i-encountered">Issues I encountered</h2>
<ul>
<li><em>Memory resource sizing for midolman</em></li>
</ul>
<p>The Midolman agent can use a fair amount of memory. The package comes with some example sizing configurations. It is definitely a good idea to use the correct configuration file for the particular service and size of server that is being deployed, then make sure Nova knows to hold back that memory on compute nodes. This is for the deployer to do.</p>
<ul>
<li><em>Clean up Cassandra</em></li>
</ul>
<p>Eventually the Cassandra database can become large and needs to be cleaned up.</p>
<ul>
<li><em>Not being able to keep up with releases</em></li>
</ul>
<p>I believe Enterprise Midonet is in a 1.9 release now. It’s not easy to keep up, and doing so would be something to take into consideration. Like OpenStack itself, you will want to upgrade as frequently as you can, which in the end…is never enough. Again, this is a deployer issue not a Midonet issue. New code is a good thing and we need to get it deployed.</p>
<h2 id="related-things-i-have-not-yet-worked-with">Related things I have not (yet) worked with</h2>
<ul>
<li>VXLAN off-loading</li>
<li>VTEP integration</li>
<li>vhost-net driver (should increase performance)</li>
</ul>
<h2 id="conclusion">Conclusion</h2>
<p>I chose to deploy Midonet based on several assumptions and project requirements. In the end, Midonet works as advertised, and, I feel, makes my life as an OpenStack operator easier. I definitely recommend Midonet for OpenStack deployments, or anyone who is interested in software defined networking.</p>
Easy VPN or Proxy for Firefox with SSH2015-12-23T00:00:00+00:00http://serverascode.com/2015/12/23/ssh-vpn-firefox<h1 id="easy-vpn-or-proxy-for-firefox-with-ssh">Easy VPN or Proxy for Firefox with SSH</h1>
<p>I thought I would write a quick post on using OpenSSH as a simple vpn for use with Firefox. There are quite a few blog posts on how to do this already, but I think it’s so simple and easy that it’s worth repeating. It’s really easy to setup, and if you use Firefox profiles you can have a profile that is pre-configured to use with any ssh socks connection. I will often use Firefox over an SSH connection to a remote host when using wifi at airports, on planes, in coffee shops, etc.</p>
<p>Also–I use it to gain access to internal web services remotely, as opposed to using some awful vpn system, one where the vpn server hasn’t been updated in X number of years. Who wants to maintain a complex vpn system when all one needs is a safe and secure ssh server? Not me. :)</p>
<p>When using Firefox over an ssh vpn as discussed in this post, all your web and dns traffic from Firefox will be tunneled through the ssh socks proxy, and come out through the remote server. What’s more, the tunnel is encrypted with ssh.</p>
<p>Of course, in order to use this you need a remote ssh server. But those are easy to come by, and you could easily startup a server in a public cloud, such as Digital Ocean. The instance could be quite small…512MB should be fine. $5 a month, start it up only when you know when you are going to need it, very inexpensive.</p>
<h2 id="setup-ssh-session">Setup SSH Session</h2>
<p>It can be this easy:</p>
<pre>
<code>your-laptop$ ssh -D 127.0.0.1:8080 you@some.remote.host
some.remote.host$ # now logged in to remote host, ssh proxy is setup
</code>
</pre>
<p>You can see that ssh is listening on localhost 8080.</p>
<pre>
<code>your-laptop$ lsof -n -P -i :8080 -sTCP:LISTEN
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
ssh 27005 curtis 4u IPv4 1769809 0t0 TCP 127.0.0.1:8080 (LISTEN)
</code>
</pre>
<p>You could also use the -N and -T switches to not execute a remote command and disable getting a tty.</p>
<p>As long as that ssh session is up the proxy will be working.</p>
<h2 id="configuring-firefox">Configuring Firefox</h2>
<p>It’s straightforward to configure Firefox. To access the network settings in Firefox, go to Preferences -> Advanced -> Network.</p>
<ol>
<li>Manual proxy</li>
<li>Socks host: 127.0.0.1</li>
<li>Port 8080 (or any you want, just has to be the same as you set in the ssh command)</li>
<li>Select “Socks V5”</li>
<li>Use remote DNS (which I prefer, but you don’t have to)</li>
</ol>
<p><img src="/img/ssh-vpn.jpg" alt="" /></p>
<h2 id="firefox-profiles">Firefox profiles</h2>
<p>Firefox can have profiles. I have a specific profile setup to use with an ssh-based vpn on port 8080. So when I want to use Firefox over the ssh vpn I just open up Firefox using that profile. Unless you use Firefox with the ssh vpn all the time I prefer to use a profile so I don’t have to go into the settings every time and make changes. I believe there might be some plugins that make it easier to have proxies setup, turned off and on and such, but I haven’t used one so can’t make a recommendation.</p>
<h2 id="conclusion">Conclusion</h2>
<p>We all need to use wifi, especially when travelling. However, wifi networks can have security issues. I definitely recommend using a vpn when working remotely over unknown wifi, and one of the easiest ways to do that is with ssh.</p>
Docker Machine, OpenStack, and Neutron LBaaS2015-12-22T00:00:00+00:00http://serverascode.com/2015/12/22/docker-machine-openstack-neutron-lbaas<h1 id="docker-machine-openstack-and-neutron-lbaas">Docker Machine, OpenStack, and Neutron LBaaS</h1>
<p>In this post I’ll setup a docker swarm using OpenStack as the IaaS provider and then boot some containers that are loadbalanced by a Neutron-based LBaaS.</p>
<p>I was re-introduced to docker via this interesting <a href="http://container-solutions.com/using-binpack-with-docker-swarm/">post</a> that discusses docker-machine and the binpack strategy, which I must look into more, as I’m intersting in the area of binpacking. However this post just deals with setting up a small docker-machine cluster and loadbalancing it.</p>
<h2 id="tldr">tl;dr</h2>
<p>Using an OpenStack cloud that has a loadbalancer-as-a-service (LBaaS) feature, I created a swarm of docker machines using…er docker-machine. I also created a private docker image repository server that the swarm machines use. Next up I added an index.php file to the php:5-apache image, ie. a new dockerfile with FROM php:5-apache, and pushed that image to the local private repository. Then I created three instances of that image and added the appropriate ports and IPs to the LBaaS pool. Finally I could curl the LBaaS public virtual IP (VIP), and would be “round-robinned” to the docker instances.</p>
<pre>
<code>curtis-laptop$ while true; do curl http://<public vip="">/; sleep 1; done
version 2 51166cb9c64c
version 2 adc5bdca0cba
version 2 3ee186d80986
^C
</code>
</pre>
As you can see in the above output, the index.php on the webservers outputs the docker instance's hostname, which is part of its ID. With three containers as members of the lb, we see three unique hostnames, which means the traffic to the VIP is getting loadbalanced across the three containers.
## Mistakes I made
As a note, this blog post came from a couple hours of me messing around with docker-machine for the first time. It's been a while since I've used docker, and I'm behind on the new systems and features that are available. This means take anything I do here with a grain of salt, because I don't necessarily know what I'm doing. Especially around the management of images.
While working on this blog post I made several silly mistakes and false starts, such as:
- Using --swarm-master for every swarm node I created (not just the first one)
- Could not find a good webserver/php docker image, first one I tried was [broken](https://hub.docker.com/r/eboraas/apache-php/). Finally realized I could use the php:5-apache image as a base.
- Spent quite a while figuring out how to run an insecure private repository.
- If I restarted the swarm nodes the swarm-agent container on each node did not startup automatically. Due to this I received TLS errors, but in reality it's failing to connect to port 3376 for docker machine, and that port will not be up if the swarm-master container isn't running.
- Have to specify port for insecure-registry option.
- Made some mistakes with local and remote (?) repositories with Docker...still working on this.
The rest of this post will detail the steps I followed to setup this particular infrastructure.
## OpenStack rc file
I prefer to have an openstackrc file to source to use with docker-machine instead of setting up the command line switches.
<pre>
<code>#!/bin/bash
export OS_USERNAME=<user>
export OS_PASSWORD=<password>
export OS_TENANT_NAME=<tenant>
export OS_AUTH_URL=<auth url="">
export OS_REGION_NAME=<region>
# basic trusty image from ubuntu cloud image
export OS_IMAGE_ID=<trusty>
export OS_FLAVOR_ID=<flavor>
# if you have VPC style openstack neutron to access
export OS_NETWORK_ID=<network>
# the user for docker-machine to ssh in with
export OS_SSH_USER=ubuntu
</code>
</pre>
Source that file in order to provide the environment variables to docker-machine.
<pre>
<code>docker-machine$ source openstackrc
</code>
</pre>
## OpenStack instances
I created a "docker-machine" instance where I installed docker-machine and also setup a private repository on that node.
Then using docker-machine and a proper OpenStack env file I created several swarm instances (more later on that). Don't create those instances yet, you just need a place to run docker-machine from and it's probably easiest to do that from an instance with the OpenStack tenant network.
<pre>
<code>docker-machine$ os server list
+--------------------------------------+-----------------------------+--------+---------------------------------+
| ID | Name | Status | Networks |
+--------------------------------------+-----------------------------+--------+---------------------------------+
| 164cac1c-1762-417a-8f0c-397e1965db51 | swarm-3 | ACTIVE | test-network=10.0.33.30 |
| 62e0f05f-4818-427e-8be7-ae998304d1ec | swarm-2 | ACTIVE | test-network=10.0.33.28 |
| 65aa5c10-590a-4a0b-a2a3-debb8b53d1ca | swarm-1 | ACTIVE | test-network=10.0.33.27 |
| 0c60c7fe-2e19-4e39-bee2-2b09a79d9d17 | docker-machine | ACTIVE | test-network=10.0.33.7, <public ip="">|
+--------------------------------------+-----------------------------+--------+---------------------------------+
</code>
</pre>
## Install docker machine
Install the docker-machine CLI on the docker-machine instance. Doesn't seem to be a package for docker-machine.
<pre>
<code>docker-machine$ curl -L https://github.com/docker/machine/releases/download/v0.5.3/docker-machine_linux-amd64 >/usr/local/bin/docker-machine && \
> chmod +x /usr/local/bin/docker-machine
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 599 0 599 0 0 3760 0 --:--:-- --:--:-- --:--:-- 3791
100 14.1M 100 14.1M 0 0 18.5M 0 --:--:-- --:--:-- --:--:-- 35.8M
docker-machine$ which docker-machine
/usr/local/bin/docker-machine
docker-machine$ docker-machine --version
docker-machine version 0.5.3, build 4d39a66
</code>
</pre>
## Bash completion
I also setup the bash completion scripts for docker-machine.
First I cloned the docker-machine repository.
<pre>
<code>docker-machine$ git clone https://github.com/docker/machine
Cloning into 'machine'...
remote: Counting objects: 14693, done.
remote: Compressing objects: 100% (10/10), done.
remote: Total 14693 (delta 3), reused 0 (delta 0), pack-reused 14683
Receiving objects: 100% (14693/14693), 10.94 MiB | 11.63 MiB/s, done.
Resolving deltas: 100% (7937/7937), done.
Checking connectivity... done.
</code>
</pre>
Then I sourced the bash completion scripts in my bashrc file.
<pre>
<code>source ~/machine/contrib/completion/bash/docker-machine.bash
source ~/machine/contrib/completion/bash/docker-machine-prompt.bash
source ~/machine/contrib/completion/bash/docker-machine-wrapper.bash
PS1='[\u@\h \W$(__docker_machine_ps1 " [%s]")]\$ '
</code>
</pre>
## Install docker on docker-machine instance
Just to be confusing I also installed docker on the docker-machine virtual machine. I added my user to the docker group and then re-logged in so that I could run docker commands without having to sudo to root.
<pre>
<code>docker-machine$ docker -v
Docker version 1.9.1, build a34a1d5
</code>
</pre>
I run the private docker image registry on the docker-machine host, not in the swarm. More on that later.
<pre>
<code>docker-machine$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
49a78c2588f7 registry:2 "/bin/registry /etc/d" 2 hours ago Up About an hour 0.0.0.0:5000->5000/tcp registry
</code>
</pre>
## Create a private docker image repository
It seems that if I want custom images on my docker swarm then they have to come from somewhere. I decided to setup a local registry so that each docker node in the swarm can obtain custom images from it.
The [documentation](https://docs.docker.com/registry/) for creating your own internal, private repository is quite good and it's easy to do. Well, easy to create an "insecure" repository, ie. one that isn't properly protected by TLS and other measures. But, as usual, for the purposes of exploration, I created an insecure image repo.
In this case the repo ends up on the IP of my docker-machine instance (not part of the swarm). Below is an example of an image in the 10.0.33.7:5000 repo.
<pre>
<code>docker-machine$ docker images | grep 10.0.33
10.0.33.7:5000/apache-php-5 latest ef50e992d38e 2 hours ago 480.5 MB
</code>
</pre>
## Create a php:5-apache image that will echo hostname
For the example, I want each host to print its hostname in the php page that apache gives out, so that I can see that each container is actually being used. That means putting a custom index.php file into the php:5-apache image, building it, and uploading it into the private repository.
<pre>
<code>docker-machine$ cat Dockerfile
FROM php:5-apache
COPY index.php /var/www/html/index.php
docker-machine$ cat index.php
<?php
echo "version 2 ";
echo gethostname();
?>
</code>
</pre>
The process is (afaik):
1. Build image
2. Tag image
3. Push to private repository
Example:
<pre>
<code>docker-machine$ docker build -t apache-php-5 .
Sending build context to Docker daemon 4.096 kB
Step 1 : FROM php:5-apache
---> cb016a201e95
Step 2 : COPY index.php /var/www/html/index.php
---> 916c65313b03
Removing intermediate container 609b66516729
docker-machine$ docker tag -f apache-php-5 10.0.33.7:5000/apache-php-5
docker-machine$ docker push 10.0.33.7:5000/apache-php-5
The push refers to a repository [10.0.33.7:5000/apache-php-5] (len: 1)
916c65313b03: Pushed
cb016a201e95: Image already exists
bf61c2e22863: Image already exists
1e2f9e5b3fb5: Image already exists
e70a54e5b8fe: Image already exists
869ca7daafc8: Image already exists
d5b98059a0c3: Image already exists
98990d4b1772: Image already exists
f90b4bdd0fe0: Image already exists
8cdb621c15a4: Image already exists
08d3d3dae3d4: Image already exists
619689ca2bd1: Image already exists
44f9dadf58c0: Image already exists
a53e1776c44e: Image already exists
9ee13ca3b908: Image already exists
latest: digest: sha256:c5044670f7a8e325791bd818826d1f1b7f3fbc6f62ab839232fdb0dffd289efc size: 49053
</code>
</pre>
## Create the swarm
Now using docker-machine we can create the swarm.
<pre>
<code>docker-machine$ docker run swarm create
Unable to find image 'swarm:latest' locally
latest: Pulling from library/swarm
d681c900c6e3: Pull complete
188de6f24f3f: Pull complete
90b2ffb8d338: Pull complete
237af4efea94: Pull complete
3b3fc6f62107: Pull complete
7e6c9135b308: Pull complete
986340ab62f0: Pull complete
a9975e2cc0a3: Pull complete
Digest: sha256:c21fd414b0488637b1f05f13a59b032a3f9da5d818d31da1a4ca98a84c0c781b
Status: Downloaded newer image for swarm:latest
e922e4c46e469b4eb29d96f7d1723f08
</code>
</pre>
Now that the swarm token is created we can boot some swarm instances. Start with the *swarm-master*. Note the "--engine-insecure-registry 10.0.33.7:5000" option. Also note that I'm using the token that the "docker run swarm create" command returned.
<pre>
<code>docker-machine$ docker-machine create -d openstack --swarm --swarm-master --swarm-discovery token://$TOKEN --engine-insecure-registry 10.0.33.7:5000 swarm-1
# this will take a few minutes...
</code>
</pre>
Now create two more swarm members.
Second swarm member.
<pre>
<code>docker-machine$ docker-machine create -d openstack --swarm --swarm-discovery token://$TOKEN --engine-insecure-registry 10.0.33.7:5000 swarm-2
</code>
</pre>
3rd swarm member.
<pre>
<code>docker-machine$ docker-machine create -d openstack --swarm --swarm-discovery token://$TOKEN --engine-insecure-registry 10.0.33.7:5000 swarm-3
</code>
</pre>
Eval the environment for the swarm, so that when we use the docker command we are connecting to the swarm not the local docker host.
<pre>
<code>docker-machine$ eval $(docker-machine env --swarm swarm-1)
docker-machine ~ [swarm-1]$
</code>
</pre>
Now we can connect to the swarm. :)
<pre>
<code>docker-machine$ docker info
Containers: 7
Images: 11
Role: primary
Strategy: spread
Filters: health, port, dependency, affinity, constraint
Nodes: 3
swarm-1: 10.0.33.27:2376
└ Status: Healthy
└ Containers: 3
└ Reserved CPUs: 0 / 1
└ Reserved Memory: 0 B / 2.053 GiB
└ Labels: executiondriver=native-0.2, kernelversion=3.13.0-74-generic, operatingsystem=Ubuntu 14.04.3 LTS, provider=openstack, storagedriver=aufs
swarm-2: 10.0.33.28:2376
└ Status: Healthy
└ Containers: 2
└ Reserved CPUs: 0 / 1
└ Reserved Memory: 0 B / 2.053 GiB
└ Labels: executiondriver=native-0.2, kernelversion=3.13.0-74-generic, operatingsystem=Ubuntu 14.04.3 LTS, provider=openstack, storagedriver=aufs
swarm-3: 10.0.33.30:2376
└ Status: Healthy
└ Containers: 2
└ Reserved CPUs: 0 / 1
└ Reserved Memory: 0 B / 2.053 GiB
└ Labels: executiondriver=native-0.2, kernelversion=3.13.0-74-generic, operatingsystem=Ubuntu 14.04.3 LTS, provider=openstack, storagedriver=aufs
CPUs: 3
Total Memory: 6.158 GiB
Name: swarm-1
</code>
</pre>
## Start some containers
With the swarm setup and the apache-php-5 container image ready, containers can be started up.
<pre>
<code>docker-machine ~ [swarm-1]$ docker run -p 80:80 -p 443:443 -d 10.0.33.7:5000/apache-php-5
fd30a72b4c112374c70b1609f5ffe773ce7121f69da2005f066fb151a89f100b
docker-machine ~ [swarm-1]$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
51166cb9c64c 10.0.33.7:5000/apache-php-5 "apache2-foreground" 12 hours ago Up 11 hours 10.0.33.27:80->80/tcp swarm-1/stupefied_wright
adc5bdca0cba 10.0.33.7:5000/apache-php-5 "apache2-foreground" 12 hours ago Up 12 hours 10.0.33.30:80->80/tcp swarm-3/loving_jepsen
3ee186d80986 10.0.33.7:5000/apache-php-5 "apache2-foreground" 12 hours ago Up 12 hours 10.0.33.28:80->80/tcp swarm-2/serene_booth
</code>
</pre>
So we have three containers with port 80 on the swarm node forwarding to port 80 in the container(s).
## Create OpenStack loadbalancer
The cloud I'm using has a loadbalancer feature. It's somewhat limited, in that it can only do TCP and round robin, but that's still useful, especially given the public VIP is handled at the OpenStack IaaS layer, and is not something I have to manage. Nor do I have to create any complicated methods to move a floating IP in case of the failure of a node.
First the pool is created.
<pre>
<code>docker-machine$ neutron lb-pool-create --lb-method ROUND_ROBIN --protocol TCP --name docker-lb --subnet-id 832fc99e-42ab-4234-8a5f-acacde56713f
Created a new pool:
+------------------------+--------------------------------------+
| Field | Value |
+------------------------+--------------------------------------+
| admin_state_up | True |
| description | |
| health_monitors | |
| health_monitors_status | |
| id | e2e38662-a994-4e86-bc68-05bbe95b95ce |
| lb_method | ROUND_ROBIN |
| members | |
| name | docker-lb |
| protocol | TCP |
| provider | |
| router_id | 16ce36bd-94a2-4203-8e30-871134c47272 |
| status | ACTIVE |
| status_description | |
| subnet_id | 832fc99e-42ab-4234-8a5f-acacde56713f |
| tenant_id | 0b33fce4b64d4c288098344b3b443370 |
| vip_id | |
+------------------------+--------------------------------------+
</code>
</pre>
Next members are added to the pool.
<pre>
<code>docker-machine$ neutron lb-member-create --address 10.0.33.27 --protocol-port 80 docker-lb
Created a new member:
+--------------------+--------------------------------------+
| Field | Value |
+--------------------+--------------------------------------+
| address | 10.0.33.27 |
| admin_state_up | True |
| id | 6a187959-49ea-4570-bbab-27c9427fd030 |
| pool_id | e2e38662-a994-4e86-bc68-05bbe95b95ce |
| protocol_port | 80 |
| status | ACTIVE |
| status_description | |
| tenant_id | 0b33fce4b64d4c288098344b3b443370 |
| weight | 1 |
+--------------------+--------------------------------------+
docker-machine$ neutron lb-member-create --address 10.0.33.28 --protocol-port 80 docker-lb
Created a new member:
+--------------------+--------------------------------------+
| Field | Value |
+--------------------+--------------------------------------+
| address | 10.0.33.28 |
| admin_state_up | True |
| id | 3ae848e0-8d96-4b9a-afd2-b07ead463f78 |
| pool_id | e2e38662-a994-4e86-bc68-05bbe95b95ce |
| protocol_port | 80 |
| status | ACTIVE |
| status_description | |
| tenant_id | 0b33fce4b64d4c288098344b3b443370 |
| weight | 1 |
+--------------------+--------------------------------------+
docker-machine$ neutron lb-member-create --address 10.0.33.30 --protocol-port 80 docker-lb
Created a new member:
+--------------------+--------------------------------------+
| Field | Value |
+--------------------+--------------------------------------+
| address | 10.0.33.30 |
| admin_state_up | True |
| id | a2c6a6c7-d300-4e76-9110-0ca22d4e5b76 |
| pool_id | e2e38662-a994-4e86-bc68-05bbe95b95ce |
| protocol_port | 80 |
| status | ACTIVE |
| status_description | |
| tenant_id | 0b33fce4b64d4c288098344b3b443370 |
| weight | 1 |
+--------------------+--------------------------------------+
</code>
</pre>
Now a virtual IP for the loadbalancer. The subnet ID in this case is a public external network, not a VPC-style tenant network.
<pre>
<code>docker-machine$ neutron lb-vip-create --name docker-lbvip --protocol-port 80 --protocol TCP --subnet-id 832fc99e-42ab-4234-8a5f-acacde56713f docker-lb
Created a new vip:
+---------------------+--------------------------------------+
| Field | Value |
+---------------------+--------------------------------------+
| address | 10.0.33.19 |
| admin_state_up | True |
| connection_limit | -1 |
| description | |
| id | 61f5c2b1-1af9-4c0a-8e26-c7130ede58a8 |
| name | docker-lbvip |
| pool_id | e2e38662-a994-4e86-bc68-05bbe95b95ce |
| port_id | ca71900c-10a1-4e22-8f48-0b2ce0d04ee2 |
| protocol | TCP |
| protocol_port | 80 |
| session_persistence | |
| status | ACTIVE |
| status_description | |
| subnet_id | 832fc99e-42ab-4234-8a5f-acacde56713f |
| tenant_id | 0b33fce4b64d4c288098344b3b443370 |
+---------------------+--------------------------------------+
</code>
</pre>
Create a monitor.
<pre>
<code>docker-machine$ neutron lb-healthmonitor-create --delay 6 --type TCP --max-retries 3 --timeout 2
Created a new health_monitor:
+----------------+--------------------------------------+
| Field | Value |
+----------------+--------------------------------------+
| admin_state_up | True |
| delay | 6 |
| id | c6b2ebbf-fa31-48f1-9861-96400ec2dcba |
| max_retries | 3 |
| pools | |
| tenant_id | 0b33fce4b64d4c288098344b3b443370 |
| timeout | 2 |
| type | TCP |
+----------------+--------------------------------------+
</code>
</pre>
Associate that monitor to the loadblancer pool.
<pre>
<code>docker-machine$ neutron lb-healthmonitor-associate c6b2ebbf-fa31-48f1-9861-96400ec2dcba docker-lb
Associated health monitor c6b2ebbf-fa31-48f1-9861-96400ec2dcba
</code>
</pre>
## Curl away!
Now we can curl the docker-lb VIP and hit each container...
<pre>
<code>curtis@laptop ~ $ while true; do curl http://<public vip="">/; sleep 1; done
version 2 51166cb9c64c
version 2 adc5bdca0cba
version 2 3ee186d80986
^C
</code>
</pre>
Phewph. That was a lot of typing.
## docker-machine
I quite like docker-machine. It seems like a rather simple way to get multiple docker hosts up and running and working together. I could see this being very useful for organizations that want to keep things simple. That said, I haven't looked "under the hood" so to speak, with regards as to how it's working. I would imaging running it in production would be considerably more difficult. I haven't even touched on use of volumes, etc.
## Future work
One thing to note is that I'm just running one container per host and using the host's external IP and port 80 as the endpoint for the loadbalancer. But what we'd really want to do is be able to have a container running on any port and have the lb round robin to that port, regardless of whether or not it's port 80 or some random port. That's a common thing to do. I did test it out quickly but using another port such as 8080 wasn't working with the lb. At some point a normal docker user would want to run many, many containers and have the lb use them. Something to figure out in the near future.
Having said that, a strategy I might pursue regardless of how the lb works is to use the Neutron LBaaS as a layer 4 lb (which is what it is in this specific case) that brings the traffic onto layer 7 haproxy servers running in containers in the swarm which would further distribute traffic. That way the public VIP is highly available, and I can use the more powerful haproxy to do sophisticated loadbalancing at the application layer.
Also--I'm reminded of how working with images with Docker is difficult. If I ever decide to use Docker in production I'd have to really work on getting the right image workflow. It also makes me wonder if anyone is working on a private Docker repository system as a service in OpenStack. That'd be interesting.
</public></code></pre></public></code></pre></network></flavor></trusty></region></auth></tenant></password></user></code></pre></public></code></pre>
DevOps is a Useful Label2015-12-05T00:00:00+00:00http://serverascode.com/2015/12/05/devops-is-a-useful-label<h1 id="devops-is-a-useful-label">DevOps is a Useful Label</h1>
<h2 id="tldr">tl;dr</h2>
<p>Define DevOps on your own. It’s mostly about teamwork, not just automation. Ignore the haters–it’s a useful label.</p>
<h2 id="devops-and-iaas-make-their-way-up-north">DevOps and IaaS make their way up north</h2>
<p>I live in Edmonton, Alberta, Canada. Because I’ve lived here so long I sometimes forget how isolated we can be. However, I don’t mean isolated in terms of where Edmonton physically is. Surprising to many, we have a great university, a large international airport (I can fly direct to Amsterdam, and used to be able to fly direct to New York City), lots of good restaurants, a great theatre festival, and all kinds of wonderful things–especially in the summer when we celebrate being warm. :)</p>
<p>Instead what I mean is that it takes a long time for new technologies and related concepts to make their way up north. I’m talking about things like DevOps and using infrastructure as a service–be it AWS, other public clouds, and/or OpenStack. I might be in a bit of a filter bubble because based on my daily readings the technologies I just mentioned are so commonplace as to be standards. But not in Edmonton (yet). However, that is changing, and it seems to be changing right now.</p>
<p>In the last few weeks I’ve been talking to many people and organizations in Edmonton that are interested in modernizing, so to speak. Even though few companies in Edmonton are using public/private clouds or implementing concepts like DevOps, there are more every day.</p>
<h2 id="devops---what-is-it">DevOps - What is it?</h2>
<p>Many people I talk to don’t like the term. They think it’s a dumb fad. In fact I had to unfollow some people on twitter to get away from the constant negativity. I definitely think it’s a real, and useful, thing.</p>
<p>When people talk to me about DevOps I usually try to qualify what I think it is with the following statements:</p>
<p>1) It’s a useful label
2) It has no real official definition, and in fact my be defined by the fact that it tries not to be defined
3) In my opinion, it’s about creating high performing teams (which means empathy and communication, ie. teamwork)</p>
<p>I should note that my perspective is one of deploying infrastructure, because that’s what I do for a living. Most organizations use DevOps to deploy their applications(s) to a public cloud like AWS. A SaaS company is a canonical example: no servers of their own, many daily deploys, devs and ops working together, etc.</p>
<p>In my day to day work the application being deployed is OpenStack, and the code is Ansible playbooks. The infrastructure I maintain is defined in code or yaml as much as possible, and also goes through a continuous integration workflow. But I still have to deal with IPMI. :)</p>
<p>If you want to see a good presentation on the most recent thinking on DevOps, checkout <a href="https://jaxenter.com/tools-culture-and-aesthetics-the-art-of-devops-122535.html">this talk</a> by J. Paul Reed. I wasn’t sure that I was going to like the talk at the start, but in the end I agreed with much of what Reed said. It made me start to think about artifacts and aesthetics.</p>
<h2 id="its-not-just-automation">It’s not just automation</h2>
<p>Most IT organizations want to increase their performance, but don’t know how. To management, automation sounds great because then they might be able to reduce staff (which is, of course, not true). In fact I find that automation requires more staff, not less. Many companies try to get by with the minimal people required to complete a project and they hope to bring more on once the project is profitable. Unfortunately that is backwards. Automation projects should have a large front-end investment in people. But I can understand how finances can get in the way of doing that.</p>
<p>Automation projects also have high expectations. However, automation, like DevOps, is not a panacea. There’s a great set of slides titled _<a href="http://www.slideshare.net/ice799/infrastructure-as-code-might-be-literally-impossible_">Infrastructure as Code Might Literally be Impossible</a> that has many good points about how difficult things like programming (even bash) and operating system packages are. Basically a form of “how do computers even?” Once you abandon some abstractions it becomes clear that it is hard to determine what a complex system is doing. Repeatedly operating on that complex system in a predictable way is difficult.</p>
<p>At the very least automation systems like Puppet, Chef, and Ansible manage configuration files, services, and packages. If, at a low level, we can’t trust how packages and package managers work, then how can we trust automation? Perhaps this is where abstraction fails us in computer systems engineering. I have been doing automation for quite some time and still find that it’s easy to do an OK job, but difficult to do a <em>great</em> job. Perhaps I’m not at the level I need to be yet, or I’m not choosing the right tools and workflows, or looking at it scientifically enough…I’m not sure. Regardless, writing a bunch of Puppet manifests isn’t going to create magic.</p>
<h2 id="the-switch-to-devops---change-is-hard">The switch to DevOps - change is hard</h2>
<p>Not being able to define something important drives people crazy. Agile is nice because they have a convenient manifesto made up of a set of statements, or rules (which are often ignored). I’m sure that wasn’t the entire point of Agile, but regardless the document exists and people link to it.</p>
<p>With DevOps organizations need to define it on their own. I have seen more organizations fail at implementing DevOps related practices than succeed. The transition is extremely difficult because it requires a different mindset, and in the end relies on teamwork, which most organizations don’t do at all, let alone well.</p>
<h2 id="a-convenient-label">A convenient label</h2>
<p>DevOps is an extremely useful label. Just because it’s difficult to define doesn’t mean an organization can’t work on defining it internally (in fact that is what I think they <em>should</em> do). Just because it seems like a fad doesn’t mean it can’t help people to solve difficult problems and to create amazing teams that develop and operate complex systems and applications that are extremely profitable.</p>
<p>On one hand, there is no such thing as a “DevOps” but on the other hand, there are many people and organizations who do implement multiple facets of the DevOps paradigm, enough to be considered as “doing DevOps,” certainly on their own terms. What’s more, I often find that people who are already doing DevOps-like things are the most irritated by the label, perhaps because it’s often misused and co-opted. I’m not clear on why people want to adopt DevOps strategies but reject the term.</p>
<p>Finally, if trying to work with the tools, processes and people involved in DevOps makes my life easier, and putting it on a resume helps me to find a great job, then I’m going to do that. People are both literally and figuratively searching for DevOps. Whether or not some people dislike the term, it’s a useful label, and, I believe, a process for creating high performing teams.</p>
OpenStack Tokyo Summit2015-11-07T00:00:00+00:00http://serverascode.com/2015/11/07/openstack-tokyo-summit<h1 id="openstack-tokyo-summit">OpenStack Tokyo Summit</h1>
<p>I was lucky enough to be able to attend the OpenStack Tokyo Summit, which of course, is in Tokyo. Weirdly enough it is quite easy to get to Tokyo from Edmonton–all I had to do was the short flight from Edmonton to Vancouver, up and over the Rockies, and then from there take All Nippon Air (ANA) to Tokyo. I flew on on a nice, new 787 complete with USB connections. (Aside: ANA is the best airline I’ve flown on.)</p>
<p>I think it was cheaper, just flight and hotel, to send me to Tokyo for a week than it was for the Palo Alto operators meetup for three days. Tokyo is not that expensive for a major city, and Palo Alto bloody well is (for a minor one).</p>
<h2 id="the-summit">The Summit</h2>
<p>The summit took place at the Grand Prince International Convention center. This was a collection of buildings, more like a campus, that the summit spread out over. I’ve never looked at the same map so many times. I missed the start of a couple of sessions because I got a bit lost. The Vancouver convention center was much easier to navigate, but it’s also much newer, so not a fair comparison.</p>
<p>For the last few summits I’ve been to I spend most, if not all of my time in the design summit going to operator sessions. Which makes sense because I am a OpenStack operator. Surprisingly I am a real person, not some mythical beast. :) I have to wrangle this massive OpenStack conglomerate into a working, highly available system. It’s not easy, but it’s not impossible either.</p>
<p>Here are some of the sessions and talks I went to:</p>
<ul>
<li>Ops - Quotas and Billing (which I moderated as best I could)</li>
<li>Ops - How to work with the community on a small budget</li>
<li>Cross project workshop - Performance</li>
<li>Talk - Kuryr: Docker networking in an OpenStack World</li>
<li>Ops - Upgrades</li>
<li>Ops working session - Large Deployments Team</li>
<li>Talk - How to reboot the cloud (in the face of a Xen vulnerability)</li>
<li>Magnum - Networking past, present, and future (related to Kuryr)</li>
<li>Ansible collaboration day - Most sessions</li>
<li>Talk - Real world devops experience securing a cloud (this was not a great presentation unfortunately)</li>
<li>Security - How should security serve the community? (very few in attendance, mostly for security team members, which I am not)</li>
<li>Talk - CloudKitty</li>
</ul>
<p>All of the sessions were great, if short and either really busy or not busy at all. There were some sessions where it was so busy I couldn’t even get into the room and had to go watch something else. Basically I learned my lesson on getting there early. A couple of the Ansible collaboration day sessions and the informal operators meetup on the Friday were both so busy I couldn’t get in or get a seat because I showed up a bit late.</p>
<p>Primarily it seemed that at this summit I was interested in billing and networking. I am not a networking expert, but I certainly have to know a lot about it, especially with Neutron. I almost want to run a few clouds to try out different networking models, like Midokura, DragonFlow, and Calico. One thing I noticed is how there are fewer security sessions now. OpenStack security has moved to primarily supplying tools like Bandit and security notes, and not much more than that.</p>
<p>I can definitely say that Ansible’s popularity has expanded considerably compared to the last summit, which was only six months ago. Here’s hoping the Redhat purchase goes well. OpenStack infra uses Ansible as well and the new <a href="http://docs.openstack.org/infra/shade/">Shade</a> library is an important piece of the puzzle. The OpenStack Ansible project (OSAD) also continues to move along, almost too fast for me to keep up. Well, not almost–I can’t keep up with the improvements just due to lack of time. If you want to learn about how to use Ansible that is the best project to look at in terms of actually writing playbooks and modules and callbacks.</p>
<p>Billing is also interesting because it’s heavily tied into metrics, ie. Ceilometer. CloudKitty is fascinating and I’m sure I will be implementing it soon. Perhaps that is something we can contribute back to.</p>
<h2 id="regional-clouds">Regional Clouds</h2>
<p>Probably the best session I had was at the LDT meeting where we talked a bit about public clouds, specifically what I call “regional” public clouds, which are typically clouds meant for use in a particular country or geographical area, eg. Canada or New Zealand or Europe. Many people don’t know this, but, for example, in Canada there are many companies that want to use IaaS but don’t want their data in the US. It’s like some kind of data-protectionism and it happens in many countries, which leads to regional clouds.</p>
<p>These clouds are usually smaller than other clouds, but have to be more featureful–or “complete” was another word that was used. I think it’s harder to run a smaller cloud with more features, as opposed to a larger cloud that has less features, especially around the networking component.</p>
<p>Weirdly it’s somewhat lonely working in a regional cloud. Typically we (as in regional clouds) don’t have a large staff, nor a large budget to send people to meetups and summits. Further we don’t have the resources to contribute back much because we’re so busy (like all operators generally speaking), and, what’s more, because of the smaller scale we don’t typically run into common larger issues like running cells or applying custom patches to run a simpler network setup. Instead we run a lot of features such as LBaaS and have to do real billing. Customers want features like backups and DNS and containers and VPNaaS, etc, etc. Larger OpenStack public clouds typically don’t provide those services, but we have to. Oh, and AWS compatibility, that’s a big one too. Big clouds do less but have more vms running, regional clouds do more but have less vms.</p>
<p>I’m hoping that various regional clouds can start working together in some fashion, even if it only means sharing operational aspects, or perhaps even doing a exchange. I’m not sure if the OpenStack foundation is interested in helping regional clouds, but we’ll do our best anyways.</p>
<h2 id="japantokyo">Japan/Tokyo</h2>
<p>I stayed a few days longer in Tokyo. I didn’t leave the city except for a short trip out to Hakone (which kind of felt like Japan’s Jasper). I visited most of the museums, including the incredible 500 Arhats exhibit at the Mori. I also visited all the areas such as Akihabara and “Kitchen Town.” Mostly I rode the subway a lot and then caught an awful cold. The public transport system is massive, but by the end I had it kinda figured out. I think I visited every vegetarian restaurant in Tokyo. For a city of 13 million plus, there is not much for vegetarian options. Edmonton probably has twice the vegetarian restaurants that Tokyo does. Strange.</p>
<p>My trip was a bit up and down–at first I was like “Wow! Look at all these people!” then after a while it became overwhelming. I spent a lot of mental energy just walking around trying not to bump into people and remembering to walk on the left side. But then after a couple more days I came back around to enjoying it. I had one poor experience, which I won’t mention other than to say I had one poor experience.</p>
<p>My favorite morning activity was to grab a coffee at the Starbucks in the train station (yeah, Starbucks, but the location was perfect for people watching) and sit and watch all the commuters on their way to work. The number of men wearing a black suit and a white shirt with no tie was staggering. I tried counting for a while but after ten or twenty seconds I couldn’t keep up. Literally thousands would pass in an hour. Sometimes the cadence of their footsteps would all fall in line and echo throughout the station. Very surreal.</p>
<p>Finally it was time to come home. In the end I packed four bottles of (what I hope is) premium sake–which the nice Canadian border guard let me in without having to pay duty on! She sure asked me a lot of questions but then didn’t care about the sake.</p>
<p>Overall I had a great first trip to Japan, and now that I’ve been there once I think I have a good idea of what I’d like to do the next time I go. I found the flight to Tokyo to be fairly easy, but the jet lag was a killer. I’m still not sleeping 100% correctly. But only having one stop in Vancouver is convenient.</p>
<p>I’m looking forward to the next operators meetup which should be relatively soon, and also, I’m guessing, may not be in North America.</p>
Thoughts on Redhat buying Ansible2015-10-18T00:00:00+00:00http://serverascode.com/2015/10/18/redhat-buys-ansible<h1 id="thoughts-on-redhat-buying-ansible">Thoughts on Redhat buying Ansible</h1>
<p>Recently Redhat bought Ansible. Most people went “yay!”, but I, as the curmundgeonly sysadmin, said “that sucks…for me.”</p>
<h2 id="the-exit">The “exit”</h2>
<p>People seem happy that Redhat bought Ansible–there were many congratulatory tweets. It appeared that, at least on the surface, most thought it was a good exit for Ansible. $150 million. Pay back those VCs, and slip back into the comforting arms of old softy Redhat.</p>
<p>However, I don’t think it’s good for me, and I think that’s an Ok position to take–as a long time user I think I should get some kind of pass. The company I work for also purchased Ansible Tower so we weren’t just using it for free either. Also I think it’s the only open source project that I can actually say I contributed some code to (even if that code was only used by myself).</p>
<p>There are different views on how companies exit. I think most people would consider me contrarian. To that point, I don’t know if companies should exit. What does that even mean? In startup terms, I think exit usually means either go IPO, or get bought out–both so that you can repay the venture capitalists. However, those are not the only options for a company. In fact, despite not being an economist by any stretch of the imagination, I feel like there is a lot of value in our economies that is made up of small or medium sized businesses–companies that aren’t part of some conglomerate “ecosystem,” ie. sales machine.</p>
<p>Puppet and Chef are still individual organizations. However, it seems like at some point they too will be bought up by a larger conglomerate like, I guess, EMC/Dell, uh, IBM?, Cisco–companies that many people think are <a href="http://www.wired.com/2015/10/meet-walking-dead-hp-cisco-dell-emc-ibm-oracle/">doomed</a>. Or I suppose their real goal is to IPO. Ugh.</p>
<blockquote>
<p>HP. CISCO. DELL. EMC. IBM. Oracle. Think of them as the walking dead. Oh, sure, they’ll shuffle along for some time. They’ll sell some stuff. They’ll make some money. They’ll command some headlines. They may even do some new things. But as tech giants, they’re dead. (<a href="http://www.wired.com/2015/10/meet-walking-dead-hp-cisco-dell-emc-ibm-oracle/">wired</a>)</p>
</blockquote>
<p>Does Redhat fit into that list as well? If not, why not? Is Redhat a niche company or is it the open-source EMC? Or is it something completely different? (Unlikely.)</p>
<p>As of this moment, Redhat has a market cap of about 14 billion. Their PE is about 74. I think they are over-valued, otherwise I’d actually own their stock. This <a href="http://techcrunch.com/2014/02/13/please-dont-tell-me-you-want-to-be-the-next-red-hat/">article</a> talks a bit about the problems with open source companies. Redhat is a one-off situation. I don’t know if we’ll see something like Redhat again for some time. For whatever reason, the business/finance world is much different than the innovation world. So we end up with companies like EMC and Redhat kind of fuddling along, extracting boring cash for newish systems from enterprise companies, who for the most part are moving to AWS, or other public clouds. (Great, now I’ve confused myself.)</p>
<h2 id="redhat-acquisitions">Redhat acquisitions</h2>
<p>There’s a nice list of acquisitions made by Redhat <a href="https://en.wikipedia.org/wiki/Red_Hat#Mergers_and_acquisitions">here</a>. Their model seems to be to pick up small companies that produce valuable open source systems, and to do so for about 100 million. In that respect I don’t see them picking up anything else I use, other than perhaps haproxy. MariaDB would probably be too expensive for them. OpenStack is run by a foundation so you can’t really buy it, though you can buy expertise, just like Redhat did with eNovance. Codership, who I believe makes the galera component of MySQL/MariaDB (I may be wrong) might be something good to look into.</p>
<p>Examples:</p>
<ul>
<li>JBoss - Which they bought for $420 million in 2006 (I’ve never used it)</li>
<li>KVM</li>
<li>Gluster</li>
<li>Ceph/Inktank</li>
<li>eNovance (OpenStack consultants)</li>
<li>Ansible</li>
</ul>
<p>KVM is probably the most important piece of software they’ve “picked up” and I have to admit it seems to be doing fine. It’s what I use with Ubuntu. Gluster and Ceph also seem to be doing fine too. eNovance I only added because it is OpenStack related. So just based on that list perhaps I shouldn’t be too concerned.</p>
<h2 id="configuration-management-tools">Configuration management tools</h2>
<p>I’ve used Chef and Puppet enough to know that I don’t enjoy using them. I have preferred Ansible and run a large OpenStack system exclusively with it. However, it certainly has limitations, as does every other configuration management (or automation? or orchestration?) system. I’m not super happy with any of them, though I definitely feel like Day 1 (ie. the installation) is easy, but what about day 40? Or day 200? Ansible seems a better fit for actually operating a system over time. For example, I’m not clear on how one would migrate a bunch of databases from one cluster to another using Puppet, but then again I haven’t looked too hard. Puppet seems like the Java of configuration management. But I digress…</p>
<h2 id="inability-to-compete">Inability to compete</h2>
<p>As a company, Ansible is quite small. I believe about 50 people. I’m sure Puppet has more than 300. (Aside: I was in the Puppet office once. It’s the nicest office I have ever been in. Full kitchen. Beer. Presentation space. It was way too nice. It was spooky.) Presumably Chef is similar in size and funding to Puppet. They are bigger than Ansible and better funded (to what end, I don’t know). They have sales teams with white boards and quotas; perhaps dreams of an IPO.</p>
<p>Funding (pulled from <a href="http://crunchbase.com">Crunchbase</a>:)</p>
<ul>
<li>Chef - $137 million in 6 rounds</li>
<li>Puppet - $85 million in 5 rounds</li>
<li>Ansible - $6 million in 1 round, then bought for about $150 million</li>
<li>SaltStack - $685K in a seed round (probably a good deal–someone buy them)</li>
</ul>
<p>So Puppet and Chef are big. Puppet is probably working on another round of funding. They are both putting out features like nobody’s business, with Puppet releasing some kind of orchestration engine and Chef with a continuous delivery system.</p>
<p>Basically, I’m sure Ansible felt much too small and underfunded to “take on” Puppet and Chef. Or perhaps they didn’t feel like they had the staff to keep up with all the changes coming into Ansible from the public, ie. they couldn’t merge all the pull requests in a timely fashion. Either way, too small. Not enough cash to burn on hiring for the short term as Ansible matures as a CM. Which is too bad, because I think they should have found a way to stay small, but that may not be possible with an open source license.</p>
<h2 id="the-future-of-cm">The future of CM</h2>
<p>My feeling is that CM products aren’t doing a great job. That we need something different, and that it might be at the OS layer. But we’re so entrenched with the OS that it will take a long, long time before anything changes there. Perhaps AWS’ Lambda is closest to something really new, something really different. Even though I’ve been managing servers for over a decade, I don’t think all these servers is a good thing–it seems like a waste of resources, not only to run them but also to manage them with a CM. Sure, we have all these new container scheduler systems, but I don’t think that’s the endgame. Containers are great but virtual machines are only 2% overhead anyways, so where’s the gain? Boot up time? Who knows.</p>
<h2 id="in-the-end">In the end</h2>
<p>I do think Redhat managed to obtain a great company for a reasonable amount of money (considerably less than what VCs will be trying to extract from Puppet/Chef). So it will be good for Redhat. However, I don’t think it will be good for me, as a long time Ansible user. I’m sure Redhat will put more resources (especially sales, lol) towards Ansible, but I imagine a lot of those resources will be going towards integrating Ansible into the Redhat stable of products, and not necessarily towards making Ansible better for people like myself, who, right now anyways, don’t use any Redhat products.</p>
<p>Further more, if Redhat is such an unusual company, and with AWS absorbing enterprise IT like a black hole, and huge sales organizations like EMC failing, soon Redhat itself will crumble. Which is scary.</p>
<p>Finally, one has to wonder how open source makes money. I need to do some research into smaller, private companies that provide open source software. I have a feeling there are quite a few software-as-a-service companies that are doing Ok, but otherwise…it’s complicated. Just based on my current investigation, I don’t think I would start a company that completely open sources its product, nor would I aim for exiting to pay back venture capitalists. Frankly I don’t see the issue with small, non-public companies, and perhaps I’m projecting that onto Ansible. Hashicorp will be one to watch, though they may be an aberration.</p>
<p>Anyways, looking forward to Cloudforms (whatever that is) integrating with Ansible, and also looking forward to exploring other methods of system automation.</p>
Mariadb Galera 5.5.42 Crash2015-10-17T00:00:00+00:00http://serverascode.com/2015/10/17/galera-crash<h1 id="mariadb-galera-5542-crash">Mariadb Galera 5.5.42 Crash</h1>
<p>Recently I have been working on setting up a “global” MariaDB 5.5.42 Galera cluster, which means a cluster that has to sync up across a wide area network (WAN), one that is several thousand kilometers long. Normally I’d try to avoid doing this kind of thing, but in this particular situation, running a multi-region OpenStack deployment, I don’t have much choice.</p>
<p>Unfortunately during my initial test, yes the very first test, the cluster crashed. It didn’t partition due to a network issue or anything obvious like that, it just simply hard crashed.</p>
<p>In this situation I had 3 regions:</p>
<p>Region 1) 3 initial nodes in a cluster
Region 2) 1 galera arbitrator
Region 3) 1 new node</p>
<p>I added the new node and after a couple of hours, the entire cluster had crashed. The arbitrator and the new node were still running, but the databases were inaccessible. The 3 nodes in region #1 had all crashed with the below message. I had planned on adding the other 2 nodes in region #3 later, but didn’t have the chance before it crashed.</p>
<pre>
<code>ubuntu@node2:/var/log/mysql$ tail -100 galera_server_error.log
eb91a487,1
} joined {
} left {
} partitioned {
})
151014 22:50:09 [Note] WSREP: save pc into disk
151014 22:50:09 [Note] WSREP: New COMPONENT: primary = yes, bootstrap = no, my_idx = 2, memb_num = 5
151014 22:50:09 [Note] WSREP: STATE EXCHANGE: Waiting for state UUID.
151014 22:50:09 [Note] WSREP: STATE EXCHANGE: sent state msg: 1afbdabb-728b-11e5-a0f7-7b10174ed580
151014 22:50:09 [Note] WSREP: STATE EXCHANGE: got state msg: 1afbdabb-728b-11e5-a0f7-7b10174ed580 from 0 (garb)
151014 22:50:09 [Note] WSREP: STATE EXCHANGE: got state msg: 1afbdabb-728b-11e5-a0f7-7b10174ed580 from 1 (node3)
151014 22:50:09 [Note] WSREP: STATE EXCHANGE: got state msg: 1afbdabb-728b-11e5-a0f7-7b10174ed580 from 2 (node2)
151014 22:50:09 [Note] WSREP: STATE EXCHANGE: got state msg: 1afbdabb-728b-11e5-a0f7-7b10174ed580 from 3 (node5)
151014 22:50:10 [Note] WSREP: STATE EXCHANGE: got state msg: 1afbdabb-728b-11e5-a0f7-7b10174ed580 from 4 (node1-zone-1)
151014 22:50:10 [Note] WSREP: Quorum results:
version = 3,
component = PRIMARY,
conf_id = 20,
members = 4/5 (joined/total),
act_id = 134798064,
last_appl. = 134797950,
protocols = 0/7/3 (gcs/repl/appl),
group UUID = 16e6742c-d7b9-11e4-8f72-af6e67877366
151014 22:50:10 [Note] WSREP: Flow-control interval: [36, 36]
151014 22:50:10 [Note] WSREP: New cluster view: global state: 16e6742c-d7b9-11e4-8f72-af6e67877366:134798064, view# 21: Primary, number of nodes: 5, my index: 2, protocol version 3
151014 22:50:10 [Note] WSREP: wsrep_notify_cmd is not defined, skipping notification.
151014 22:50:10 [Note] WSREP: REPL Protocols: 7 (3, 2)
151014 22:50:10 [Note] WSREP: Service thread queue flushed.
151014 22:50:10 [Note] WSREP: Assign initial position for certification: 134798064, protocol version: 3
151014 22:50:10 [Note] WSREP: Service thread queue flushed.
151014 22:50:10 [Note] WSREP: Member 4.1 (node1-zone-1) requested state transfer from '*any*'. Selected 3.0 (node5)(SYNCED) as donor.
151014 22:50:12 [Note] WSREP: (acc7d568, 'tcp://0.0.0.0:4567') turning message relay requesting off
151014 22:50:15 [Note] WSREP: 3.0 (node5): State transfer to 4.1 (node1-zone-1) complete.
151014 22:50:15 [Note] WSREP: Member 3.0 (node5) synced with group.
151014 22:50:29 [Note] WSREP: 4.1 (node1-zone-1): State transfer from 3.0 (node5) complete.
151014 22:50:29 [Note] WSREP: Member 4.1 (node1-zone-1) synced with group.
pure virtual method called
terminate called without an active exception
151015 0:48:27 [ERROR] mysqld got signal 6 ;
This could be because you hit a bug. It is also possible that this binary
or one of the libraries it was linked against is corrupt, improperly built,
or misconfigured. This error can also be caused by malfunctioning hardware.
To report this bug, see http://kb.askmonty.org/en/reporting-bugs
We will try our best to scrape up some info that will hopefully help
diagnose the problem, but since we have already crashed,
something is definitely wrong and this may fail.
Server version: 5.5.42-MariaDB-1~trusty-wsrep-log
key_buffer_size=134217728
read_buffer_size=131072
max_used_connections=551
max_threads=2002
thread_count=15
It is possible that mysqld could use up to
key_buffer_size + (read_buffer_size + sort_buffer_size)*max_threads = 4523910 K bytes of memory
Hope that's ok; if not, decrease some variables in the equation.
Thread pointer: 0x0x7f1406812000
Attempting backtrace. You can use the following information to find out
where mysqld died. If you see no messages after this, something went
terribly wrong...
stack_bottom = 0x7f144f95ea00 thread_stack 0x48000
/usr/sbin/mysqld(my_print_stacktrace+0x2e)[0x7f14502bfa0e]
/usr/sbin/mysqld(handle_fatal_signal+0x457)[0x7f144fea6f57]
/lib/x86_64-linux-gnu/libpthread.so.0(+0x10340)[0x7f144e8fa340]
/lib/x86_64-linux-gnu/libc.so.6(gsignal+0x39)[0x7f144df51cc9]
/lib/x86_64-linux-gnu/libc.so.6(abort+0x148)[0x7f144df550d8]
/usr/lib/x86_64-linux-gnu/libstdc++.so.6(_ZN9__gnu_cxx27__verbose_terminate_handlerEv+0x155)[0x7f144e6466b5]
/usr/lib/x86_64-linux-gnu/libstdc++.so.6(+0x5e836)[0x7f144e644836]
/usr/lib/x86_64-linux-gnu/libstdc++.so.6(+0x5e863)[0x7f144e644863]
/usr/lib/x86_64-linux-gnu/libstdc++.so.6(+0x5f33f)[0x7f144e64533f]
/usr/sbin/mysqld(_Z14wsrep_apply_cbPvPKvmjPK14wsrep_trx_meta+0x7c7)[0x7f144fe57c37]
/usr/lib/galera/libgalera_smm.so(_ZNK6galera9TrxHandle5applyEPvPF15wsrep_cb_statusS1_PKvmjPK14wsrep_trx_metaERS6_+0xd8)[0x7f144bb188f8]
/usr/lib/galera/libgalera_smm.so(+0x1df27d)[0x7f144bb4f27d]
/usr/lib/galera/libgalera_smm.so(_ZN6galera13ReplicatorSMM9apply_trxEPvPNS_9TrxHandleE+0xd2)[0x7f144bb51b32]
/usr/lib/galera/libgalera_smm.so(_ZN6galera13ReplicatorSMM11process_trxEPvPNS_9TrxHandleE+0x10e)[0x7f144bb5498e]
/usr/lib/galera/libgalera_smm.so(_ZN6galera15GcsActionSource8dispatchEPvRK10gcs_actionRb+0x1b8)[0x7f144bb33668]
/usr/lib/galera/libgalera_smm.so(_ZN6galera15GcsActionSource7processEPvRb+0x58)[0x7f144bb33ef8]
/usr/lib/galera/libgalera_smm.so(_ZN6galera13ReplicatorSMM10async_recvEPv+0x73)[0x7f144bb54ef3]
/usr/lib/galera/libgalera_smm.so(galera_recv+0x18)[0x7f144bb634e8]
/usr/sbin/mysqld(+0x49c5a1)[0x7f144fe585a1]
/usr/sbin/mysqld(start_wsrep_THD+0x514)[0x7f144fcb3cc4]
/lib/x86_64-linux-gnu/libpthread.so.0(+0x8182)[0x7f144e8f2182]
/lib/x86_64-linux-gnu/libc.so.6(clone+0x6d)[0x7f144e01547d]
Trying to get some variables.
Some pointers may be invalid and cause the dump to abort.
Query (0x0): is an invalid pointer
Connection ID (thread ID): 2
Status: NOT_KILLED
Optimizer switch: index_merge=on,index_merge_union=on,index_merge_sort_union=on,index_merge_intersection=on,index_merge_sort_intersection=off,engine_condition_pushdown=off,index_condition_pushdown=on,derived_merge=on,derived_with_keys=on,firstmatch=on,loosescan=on,materialization=on,in_to_exists=on,semijoin=on,partial_match_rowid_merge=on,partial_match_table_scan=on,subquery_cache=on,mrr=off,mrr_cost_based=off,mrr_sort_keys=off,outer_join_with_cache=on,semijoin_with_cache=on,join_cache_incremental=on,join_cache_hashed=on,join_cache_bka=on,optimize_join_buffer_size=off,table_elimination=on,extended_keys=off
The manual page at http://dev.mysql.com/doc/mysql/en/crashing.html contains
information that should help you find out what is causing the crash.
151015 00:48:27 mysqld_safe Number of processes running now: 0
151015 00:48:27 mysqld_safe WSREP: not restarting wsrep node automatically
151015 00:48:27 mysqld_safe mysqld from pid file /var/lib/mysql/node2.pid ended
</code>
</pre>
<h2 id="similar-errors">Similar errors</h2>
<p>I found this <a href="https://bugs.launchpad.net/galera/+bug/1330622">error</a> in the Galera bug tracker. The submitter notes:</p>
<blockquote>
<p>One node in my 5-node cluster suddenly failed today with the following backtrace. I haven’t seen a node go down abruptly like this before, and don’t know how to reproduce.</p>
</blockquote>
<p>Interesting that they also experienced the bug with a 5 node cluster. That bug leads to this Codership github <a href="https://github.com/codership/galera/issues/66">issue</a>.</p>
<h2 id="minor-versions">Minor versions</h2>
<p>One thing I noticed is that I had 5.5.45 in the new node, not 5.5.42 like all the other nodes. Presumably that is not a good thing to do. So I setup my automation to ensure I’m pulling from the right archive because the standard MariaDB mirrors only include the latest version.</p>
<p>You can find archived versions of MariaDB software <a href="http://archive.mariadb.org/">here</a>.</p>
<p>While I can’t be sure the version difference was the actual issue, as I haven’t had time to try to replicate this bug, I’m sure it didn’t help.</p>
<p>Even small version increments can be problematic. It’s not good enough to install mariadb-galera-server-5.5, I have to ensure the minor version number is the same as well. This has me looking at all the other major software packages I’m running and I know I’ll have to setup my automation to include minor versions.</p>
<h2 id="current-status">Current status</h2>
<p>Now that all the nodes have the same version of MariaDB Galera Server and I have expanded the nodes from 5 to the full 7 (including the arbitrator) things seem to be running ok.</p>
<pre>
<code>MariaDB [(none)]> show status like 'wsrep_cluster%';
+--------------------------+--------------------------------------+
| Variable_name | Value |
+--------------------------+--------------------------------------+
| wsrep_cluster_conf_id | 17 |
| wsrep_cluster_size | 7 |
| wsrep_cluster_state_uuid | 16e6742c-d7b9-11e4-8f72-af6e67877366 |
| wsrep_cluster_status | Primary |
+--------------------------+--------------------------------------+
4 rows in set (0.01 sec)
</pre>
</code>
## 5.5.46 is out
I would like to eventually get to a newer version of MariaDB. I know that 10.0 is out, it'd be great to get there soon. I am considering going to 5.5.46 if I have any other issues with the cluster in testing.
</pre>
First look at ZeroTier2015-10-03T00:00:00+00:00http://serverascode.com/2015/10/03/zerotier<h1 id="first-look-at-zerotier">First look at ZeroTier</h1>
<p>ZeroTier is:</p>
<blockquote>
<p>…an imaginary Ethernet switch or a WiFi network with unlimited range. Actual traffic is carried by your local LAN or the Internet, but the network virtualization engine takes care of encrypting, authenticating, and routing it.</p>
</blockquote>
<p>It’s (I think anyways) an ad-hoc virtual private network, and apparently it uses its own VXLAN-like encapsulation and includes encryption. The two use cases they espouse on their website are 1) hybrid cloud connections and 2) peer to peer VPNs.</p>
<p>I decided to take a look into what this is, or at least try it out, because I have recently been doing some work with OpenVPN and other VPN solutions, of which there are few, and none of them make me very happy. This zerotier essentially sounds like a simple to use VPN with a “joiner” concept.</p>
<h2 id="install">Install</h2>
<p>I tested this out on two Ubuntu Trusty boxes. I downloaded the deb from zerotier, installed it and started the service.</p>
<pre>
<code>zclient1:~$ wget https://download.zerotier.com/dist/zerotier-one_1.0.5_amd64.deb
--2015-10-03 14:47:15-- https://download.zerotier.com/dist/zerotier-one_1.0.5_amd64.deb
Resolving download.zerotier.com (download.zerotier.com)... 104.207.155.202, 2001:19f0:6000:91c7:5400:ff:fe10:2421
Connecting to download.zerotier.com (download.zerotier.com)|104.207.155.202|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 326330 (319K) [application/octet-stream]
Saving to: ‘zerotier-one_1.0.5_amd64.deb’
100%[=====================================================================================================================>] 326,330 1.96MB/s in 0.2s
2015-10-03 14:47:15 (1.96 MB/s) - ‘zerotier-one_1.0.5_amd64.deb’ saved [326330/326330]
zclient1:~$ sudo dpkg -i zerotier-one_1.0.5_amd64.deb
sudo: unable to resolve host openvpn1
Selecting previously unselected package zerotier-one.
(Reading database ... 51354 files and directories currently installed.)
Preparing to unpack zerotier-one_1.0.5_amd64.deb ...
Unpacking zerotier-one (1.0.5) ...
Setting up zerotier-one (1.0.5) ...
*** ZeroTier One install/update ***
Getting version of existing install... NONE
Extracting files...
tmp/
tmp/systemd_zerotier-one.service
tmp/init.d_zerotier-one
var/
var/lib/
var/lib/zerotier-one/
var/lib/zerotier-one/zerotier-one
var/lib/zerotier-one/ui/
var/lib/zerotier-one/ui/main.js
var/lib/zerotier-one/ui/ZeroTierNetwork.jsx
var/lib/zerotier-one/ui/ztui.min.js
var/lib/zerotier-one/ui/index.html
var/lib/zerotier-one/ui/ZeroTierNode.jsx
var/lib/zerotier-one/ui/react.min.js
var/lib/zerotier-one/ui/simpleajax.min.js
var/lib/zerotier-one/ui/zerotier.css
var/lib/zerotier-one/uninstall.sh
Getting version of new install... 1.0.5
Creating symlinks...
Installing zerotier-one service...
Done! Installed and service configured to start at system boot.
To start now or restart the service if it's already running:
sudo service zerotier-one restart
</code>
</pre>
<p>Now to start it up…</p>
<pre>
zclient1# service zerotier-one start
Starting ZeroTier One...
</code>
</pre>
<p>Nice, that was super easy.</p>
<p>Then I joined the “earth” network, a test network provided by zerotier.</p>
<pre>
<code>zclient2# zerotier-cli join e5cd7a9e1ce71cff
200 join OK
zclient2# ip ad sh
SNIP!
6: zt0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 2800 qdisc pfifo_fast state UNKNOWN group default qlen 500
link/ether 02:63:6c:ab:02:48 brd ff:ff:ff:ff:ff:ff
inet 28.183.225.45/7 brd 29.255.255.255 scope global zt0
valid_lft forever preferred_lft forever
inet6 fd80:56c2:e21c:0:199:9363:6cb7:e08a/88 scope global
valid_lft forever preferred_lft forever
inet6 fe80::63:6cff:feab:248/64 scope link
valid_lft forever preferred_lft forever
SNIP!
</code>
</pre>
<p>After doing so I have a zt0 network interface with an IP from the 28.0.0.0/7 network.</p>
<pre>
<code>zclient2# zerotier-cli listnetworks
200 listnetworks <nwid> <name> <mac> <status> <type> <dev> <ZT assigned="" ips="">
200 listnetworks 8056c2e21c000001 earth.zerotier.net 02:63:6c:ab:02:48 OK PUBLIC zt0 28.183.225.45/7,fd80:56c2:e21c:0000:0199:9363:6cb7:e08a/88
</code>
</pre>
## Creating your own private network
Unfortunately it seems that you have to create an account, login to the zerotier web interface (ie. it's a saas service), and create private networks from there. There are a few options, and the interface is a litle unpolished but it's straight forward enough. Once you've created a private network (which is default, and can only have a max of 10 devices or you are required to pay $4 a month which is fine) you can have systems/devices join that private network. One of the choices you'll have to make is what network IP space to give it, or to manage it yourself. By default zerotier will manage who gets what IP.
<pre>
<code>zclient1# zerotier-cli join <private net="">
200 join OK
</code>
</pre>
And then in the interface set the device to be allowed and it'll get an IP.
<pre>
<code>zclient1# zerotier-cli listnetworks
200 listnetworks <nwid> <name> <mac> <status> <type> <dev> <ZT assigned="" ips="">
200 listnetworks <redacted> testnet fe:42:1f:5d:f2:7d OK PRIVATE zt0 10.147.17.23/24
</code>
</pre>
## Quick performance test
I ran a quick iperf test against the two nodes. So first I should note that I'm running these tests on virtual machines inside an OpenStack system and the network between them is also "virtualized", ie. is based on a VXLAN overlay, which is then running on VLANS underneath. So there is a lot of encapsulation going on here. :)
Performance over the zerotier VPN:
<pre>
<code>zclient2# iperf -c 10.147.17.23
------------------------------------------------------------
Client connecting to 10.147.17.23, TCP port 5001
TCP window size: 85.0 KByte (default)
------------------------------------------------------------
[ 3] local 10.147.17.61 port 59802 connected with 10.147.17.23 port 5001
[ ID] Interval Transfer Bandwidth
[ 3] 0.0-10.0 sec 509 MBytes 426 Mbits/sec
</code>
</pre>
Performance over the regular network:
<pre>
<code>zclient2# iperf -c 192.168.44.35
------------------------------------------------------------
Client connecting to 192.168.44.35, TCP port 5001
TCP window size: 45.0 KByte (default)
------------------------------------------------------------
[ 3] local 192.168.44.2 port 39575 connected with 192.168.44.35 port 5001
[ ID] Interval Transfer Bandwidth
[ 3] 0.0-10.0 sec 1.06 GBytes 911 Mbits/sec
</code>
</pre>
So you can see we get almost wirespeed without zerotier and then about half that with zerotier. So there is a performance hit. And, as I mentioned, the "normal network" is based on VXLAN, so it's already encapsulated. Perhaps the performance hit comes from the encryption. That is most likely. I haven't looked into the encryption provided by zerotier at all yet.
## Conclusion
I'm a big fan of software defined networking, whatever it actually means. I am not a big fan of the current state of virtual private networking. It seems OpenVPN is the best we have right now, and it's quite complicated and unwieldy. I think it's fairly obvious that one of the best things about SDN is going to be easier creation of secure virtual private networks, and I think they will either look something like zerotier, or even easier.
While I like how easy zerotier is, I'm not sure I like that it is essentially software as a service (saas), which means centralized. They say their system hasn't gone down, but it will. Then again they mention that existing devices will be able to communicate if their central system is down, but new devices can't be added and new networks can't be created. However, I'm a proponent of the public cloud (at least IaaS) so it'd be hypocritical of me to say that a centralized "cloud" network controller is not a good idea when I think using compute and storage in a public cloud is. That said, I'm not sure what performance issues there might be in having a cloud based controller. I would imagine that zerotier will eventually provide a controller that can be installed on premise. That'd be interesting, and if they made encryption optional then maybe performance would come up. Then again, it would be interesting to encrypt all network communication on premise too.
I quite like the idea of servers joining networks. Recently I have been installing a lot of Linux boxes, sure, using an automated process based on Cobbler, but I find the networking component to be extremely time consuming and frustrating, even just in terms of setting up templates. I'd really like to have the networks on servers setup by pulling from some kind of data center level source of truth (CMDB?) and just automatically being allowed to join specific networks based on their function. Can I hack that kind of process up, yes, but I don't want to do that work myself all the time. I want to just "happen" based on some tags pulled from the SST.
</redacted></ZT></dev></type></status></mac></name></nwid></code></pre></private></code></pre></ZT></dev></type></status></mac></name></nwid></code></pre>
MariaDB MaxScale Read and Write Splitting2015-09-29T00:00:00+00:00http://serverascode.com/2015/09/29/mariadb-maxscale<p><em>(the image is supposed to be like that ;P )</em></p>
<h1 id="mariadb-maxscale-read-and-write-splitting">MariaDB MaxScale Read and Write Splitting</h1>
<p>Maxscale is a new open source product from MariaDB. It’s a MySQL/MariaDB proxy and loadbalancer, and, what’s most interesting to me, is that it can send write queries to one particular node of a cluster and reads to other nodes, thereby avoiding some nastiness in terms of writing to multiple nodes. There are some caveats to writing to multiple masters and not every application can.</p>
<blockquote>
<p>MariaDB MaxScale is an open-source, database-centric proxy that works with MariaDB Enterprise, MariaDB Enterprise Cluster, MariaDB 5.5, MariaDB 10 and Oracle MySQL®. It’s pluggable architecture is designed to increase flexibility and aid customization.</p>
</blockquote>
<h2 id="read-write-split">Read Write Split</h2>
<p>It’s fairly common to want to try to split reads and writes up using some kind of proxy system. I’m not up to date on the history of the requirement, but it has been around for a long time. There are, I believe, a few systems that try to do the RW split, but I’m not sure anything has really succeeded.</p>
<p>As an OpenStack operator I’m keenly aware that I need a highly available MySQL/MariaDB Galera cluster, but also that I can only, as far as I know at this time, write to one of the cluster nodes at a time. If I write to all the nodes using a master/master strategy I’ll run into issues. This is better laid out by <a href="https://www.percona.com/blog/2014/09/11/openstack-users-shed-light-on-percona-xtradb-cluster-deadlock-issues">this</a> Percona post. Some parts of OpenStack use a “SELECT … FOR UPDATE”:</p>
<blockquote>
<p>The SELECT … FOR UPDATE construct reads the given records in InnoDB, and locks the rows that are read from the index the query used, not only the rows that it returns. Given how write set replication works, the row locks of SELECT … FOR UPDATE are not replicated. – From the above Percona post</p>
</blockquote>
<p>But, using some kind of load balancing system, eg. haproxy, so that I only write to one cluster node also means that I only read from one cluster node as well. That’s where MaxScale’s ability to split read and writes comes into play.</p>
<p>I should note there is a <a href="http://www.severalnines.com/blog/deploy-and-configure-maxscale-sql-load-balancing">good post</a> on SeveralNine’s site that has some good information in it on MaxScale.</p>
<h2 id="install-maxscale">Install MaxScale</h2>
<p>I created an account on MariaDB’s site. MaxScale is, I believe, <a href="https://github.com/mariadb-corporation/MaxScale/blob/master/LICENSE">GPL2</a>. But in order to grab the deb file from MariaDB you need to login and get your own unique repository. Once I did that I configured the repository and now MaxScale is available to install via apt. You could always download the source and compile on your own if you would like.</p>
<pre>
<code>ubuntu@maxscale-1:~$ apt-cache policy maxscale
maxscale:
Installed: 1.2.0
Candidate: 1.2.0
Version table:
*** 1.2.0 0
1000 http://downloads.mariadb.com/enterprise/<unique>/mariadb-maxscale/latest/ubuntu/ trusty/main amd64 Packages
100 /var/lib/dpkg/status
</code>
</pre>
## Configuration
Surprisingly MaxScale is pretty straight forward to configure for read/write splitting.
This is what my config file looks like (just in my testing phase, so this is not in production at all):
<pre>
<code>[maxscale]
threads=4
[Splitter Service]
type=service
router=readwritesplit
servers=dbserv1,dbserv2,dbserv3
user=maxscale
passwd=7313125C85ABDFB93A4CE397FC2B198D
max_slave_connections=100%
router_options=slave_selection_criteria=LEAST_CURRENT_OPERATIONS
[Splitter Listener]
type=listener
service=Splitter Service
protocol=MySQLClient
port=3306
socket=/tmp/ClusterMaster
[dbserv1]
type=server
address=192.168.44.32
port=3306
protocol=MySQLBackend
[dbserv2]
type=server
address=192.168.44.33
port=3306
protocol=MySQLBackend
[dbserv3]
type=server
address=192.168.44.34
port=3306
protocol=MySQLBackend
[Galera Monitor]
type=monitor
module=galeramon
diable_master_failback=1
servers=dbserv1, dbserv2, dbserv3
user=maxscale
passwd=7313125C85ABDFB93A4CE397FC2B198D
[CLI]
type=service
router=cli
[CLI Listener]
type=listener
service=CLI
protocol=maxscaled
address=localhost
port=6603
</code>
</pre>
As you can see each of the three nodes in my cluster is listed in the configuration file: dbserv1, dbserv2, and dbserv3.
I like the config file. While I hand-rolled this one, the format certainly lends itself to automation.
Now maxscale can be started.
## maxpasswd and maxkeys
I should mention that the "password" in the configuration file above was creating using a combination of maxpasswd and maxkeys. I believe you can just enter the plaintext password into the config file if you want to avoid that extra step.
## Start maxscale
If you used the deb to install, then it comes with the init scripts. Just use "service maxscale start" and it should start up.
<pre>
<code>ubuntu@maxscale-1:/etc$ sudo service maxscale status
* Checking MaxScale
* maxscale is running
</code>
</pre>
## maxadmin
MaxScale has a command line interface to MaxScale.
<pre>
<code>ubuntu@maxscale-1:/etc$ maxadmin -pmariadb list servers
Servers.
-------------------+-----------------+-------+-------------+--------------------
Server | Address | Port | Connections | Status
-------------------+-----------------+-------+-------------+--------------------
dbserv1 | 192.168.44.32 | 3306 | 5 | Slave, Synced, Running
dbserv2 | 192.168.44.33 | 3306 | 83 | Master, Synced, Running
dbserv3 | 192.168.44.34 | 3306 | 89 | Slave, Synced, Running
-------------------+-----------------+-------+-------------+--------------------
</code>
</pre>
As we can see above, MaxScale has made dbserv2 "the master" which is a MaxScale only construction (ie. has nothing really to do with the cluster itself, rather it'll send writes to that node and reads to the other, assuming it's setup in a RW split configuration).
We can list the services configured.
<pre>
<code>ubuntu@maxscale-1:/etc$ maxadmin -pmariadb list services
Services.
--------------------------+----------------------+--------+---------------
Service Name | Router Module | #Users | Total Sessions
--------------------------+----------------------+--------+---------------
Splitter Service | readwritesplit | 2 | 54357
CLI | cli | 2 | 68
--------------------------+----------------------+--------+---------------
</code>
</pre>
We can also check stats on the splitter service.
<pre>
<code>ubuntu@maxscale-1:/etc$ maxadmin -pmariadb show service "Splitter Service"
Service 0x35bc5e0
Service: Splitter Service
Router: readwritesplit (0x7f0ad8ace4a0)
State: Started
Number of router sessions: 54339
Current no. of router sessions: 0
Number of queries forwarded: 4052477
Number of queries forwarded to master: 2704498
Number of queries forwarded to slave: 1347979
Number of queries forwarded to all: 55274
Started: Sun Sep 27 21:54:32 2015
Root user access: Disabled
Backend databases
192.168.44.34:3306 Protocol: MySQLBackend
192.168.44.33:3306 Protocol: MySQLBackend
192.168.44.32:3306 Protocol: MySQLBackend
Users data: 0x35168d0
Total connections: 54357
Currently connected: 2
SSL: Disabled
</code>
</pre>
While running a test we can check sessions too.
<pre>
<code>ubuntu@maxscale-1:/etc$ maxadmin -pmariadb list sessions
Sessions.
-----------------+-----------------+----------------+--------------------------
Session | Client | Service | State
-----------------+-----------------+----------------+--------------------------
0x38819f0 | 127.0.0.1 | CLI | Session ready for routing
0x7f0ab4044620 | 192.168.44.35 | Splitter Service | Session ready for routing
0x7f0ab4063280 | 192.168.44.35 | Splitter Service | Session ready for routing
0x7f0ab4001800 | 192.168.44.35 | Splitter Service | Session ready for routing
0x7f0ab403a630 | 192.168.44.35 | Splitter Service | Session ready for routing
0x7f0ab4029110 | 192.168.44.35 | Splitter Service | Session ready for routing
0x7f0ab00c60d0 | 192.168.44.35 | Splitter Service | Session ready for routing
0x7f0ab00c73a0 | 192.168.44.35 | Splitter Service | Session ready for routing
0x7f0ab4017710 | 192.168.44.35 | Splitter Service | Session ready for routing
0x7f0ab4090310 | 192.168.44.35 | Splitter Service | Session ready for routing
0x7f0aa80113e0 | 192.168.44.35 | Splitter Service | Session ready for routing
0x7f0aa8034430 | 192.168.44.35 | Splitter Service | Session ready for routing
0x7f0aa8032e30 | 192.168.44.35 | Splitter Service | Session ready for routing
0x7f0aa8032180 | 192.168.44.35 | Splitter Service | Session ready for routing
0x7f0ab405e270 | 192.168.44.35 | Splitter Service | Session ready for routing
0x7f0aa8022f20 | 192.168.44.35 | Splitter Service | Session ready for routing
0x35dfa90 | 192.168.44.35 | Splitter Service | Session ready for routing
0x7f0aa8022790 | 192.168.44.35 | Splitter Service | Session ready for routing
0x35c9070 | 192.168.44.35 | Splitter Service | Session ready for routing
0x7f0ab4000de0 | 192.168.44.35 | Splitter Service | Session ready for routing
0x35c95b0 | 192.168.44.35 | Splitter Service | Session ready for routing
0x35b8b90 | 192.168.44.35 | Splitter Service | Session ready for routing
0x35c7b30 | | CLI | Listener Session
0x35b8960 | | Splitter Service | Listener Session
0x35b98f0 | | Splitter Service | Listener Session
-----------------+-----------------+----------------+--------------------------
</code>
</pre>
## Stop a cluster node
If I stop MariaDB on one of the cluster nodes, MaxScale knows:
<pre>
<code>ubuntu@maxscale-1:/etc$ maxadmin -pmariadb list servers
Servers.
-------------------+-----------------+-------+-------------+--------------------
Server | Address | Port | Connections | Status
-------------------+-----------------+-------+-------------+--------------------
dbserv1 | 192.168.44.32 | 3306 | 5 | Slave, Synced, Running
dbserv2 | 192.168.44.33 | 3306 | 83 | Master, Synced, Running
dbserv3 | 192.168.44.34 | 3306 | 108 | Down
-------------------+-----------------+-------+-------------+--------------------
</code>
</pre>
MaxScale will only bring the node back into rotation once it's synced up.
## Test it out
First, I tried using sysbench. However I found that sysbench seems to work in such a way that it will only, even though maxscale, connect to one node of the cluster at time. I'll have to look into this. I was even using the "--oltp-skip-trx=on" option.
In the end I just used a mysqlslap test that is running a simple select from the fake employees database I installed. The 192.168.77.6 IP address is that of the MaxScale node.
<pre>
<code>ubuntu@mysql-client-1:~$ cat mysqlslap.sh
#!/bin/bash
mysqlslap \
--user=sysbench \
--password=syb3nch \
--host=192.168.77.6 \
--concurrency=20 \
--number-of-queries=1000 \
--create-schema=employees \
--query="/home/ubuntu/select.sql" \
--delimiter=";" \
--verbose \
--iterations=2 \
--debug-info
ubuntu@mysql-client-1:~$ cat select.sql
SELECT * FROM employees;
</code>
</pre>
Here's innotop output on one of the nodes:
<pre>
<code>root@dbsrv1:/home/ubuntu# innotop --count 1 --nonint
cmd mysql_thread_id state user hostname db time info
Query 132 Sending data sysbench 192.168.77.6 employees 00:03 SELECT * FROM employees
Query 135 Sending data sysbench 192.168.77.6 employees 00:03 SELECT * FROM employees
Query 139 Sending data sysbench 192.168.77.6 employees 00:03 SELECT * FROM employees
Query 141 Sending data sysbench 192.168.77.6 employees 00:03 SELECT * FROM employees
Query 130 Writing to net sysbench 192.168.77.6 employees 00:02 SELECT * FROM employees
Query 136 Sending data sysbench 192.168.77.6 employees 00:02 SELECT * FROM employees
Query 129 Sending data sysbench 192.168.77.6 employees 00:01 SELECT * FROM employees
Query 131 Sending data sysbench 192.168.77.6 employees 00:01 SELECT * FROM employees
Query 133 Sending data sysbench 192.168.77.6 employees 00:01 SELECT * FROM employees
Query 137 Sending data sysbench 192.168.77.6 employees 00:01 SELECT * FROM employees
Query 138 Sending data sysbench 192.168.77.6 employees 00:01 SELECT * FROM employees
Query 134 Sending data sysbench 192.168.77.6 employees 00:00 SELECT * FROM employees
Query 140 Sending data sysbench 192.168.77.6 employees 00:00 SELECT * FROM employees
</code>
</pre>
And on the "master" node, which shouldn't be getting any reads:
<pre>
<code>root@dbsrv2:/home/ubuntu# innotop --nonint --count 1
cmd mysql_thread_id state user hostname db time info
</code>
</pre>
These are the results of my overly simplistic test using the MaxScale proxy:
<pre>
<code>ubuntu@mysql-client-1:~$ ./mysqlslap.sh
Benchmark
Average number of seconds to run all queries: 112.675 seconds
Minimum number of seconds to run all queries: 111.592 seconds
Maximum number of seconds to run all queries: 113.759 seconds
Number of clients running queries: 20
Average number of queries per client: 50
User time 137.57, System time 69.91
Maximum resident set size 717064, Integral resident set size 0
Non-physical pagefaults 2160414, Physical pagefaults 0, Swaps 0
Blocks in 0 out 0, Messages in 0 out 0, Signals 0
Voluntary context switches 610086, Involuntary context switches 277132
</code>
</pre>
And then without it...going directly to a single node:
<pre>
<code>ubuntu@mysql-client-1:~$ ./mysqlslap.sh
Benchmark
Average number of seconds to run all queries: 194.296 seconds
Minimum number of seconds to run all queries: 193.582 seconds
Maximum number of seconds to run all queries: 195.011 seconds
Number of clients running queries: 20
Average number of queries per client: 50
User time 144.00, System time 71.97
Maximum resident set size 746008, Integral resident set size 0
Non-physical pagefaults 1948959, Physical pagefaults 0, Swaps 0
Blocks in 0 out 0, Messages in 0 out 0, Signals 0
Voluntary context switches 1781510, Involuntary context switches 163916
</code>
</pre>
## Basic introduction
So that was my initial exploration of MaxScale. Seems promising. The biggest problem is that I don't know a whole heck of a lot about databases. Despite being a sysadmin for quite a while, I've not had to do much with databases, be it performance or otherwise, so the limitations here seem to be on my end.
The other issue is that MaxScale is relatively new. I'd be willing to try it out in a staging environment for sure. Using it might require a support contract for me to feel entirely comfortable, but then again if I had issues with it I could just pull it from use and go straight to on node. I don't say that lightly either because I don't have much in the way of support contracts right now. ;)
Hopefully in the future I can do more testing with MaxScale as it seems extremely useful, especially in terms of being able to stop servers and split read/write.
I also have some more work to do with sysbench. It seems like it's the best tool, that I know of, to test database performance with, but it is not working well with MaxScale.
</unique></code></pre>
Notes on MySQL, MariaDB, and Galera2015-09-25T00:00:00+00:00http://serverascode.com/2015/09/25/notes-on-mysql-galera-mariadb<h1 id="notes-on-mysql-mariadb-and-galera">Notes on MySQL, MariaDB, and Galera</h1>
<p>This is just a set of random notes on MySQL, MariaDB, Galera, other database related thoughts, and googling results for test databases and performance testing MySQL/MariaDB as I work towards getting a better understanding of my MariaDB galera cluster.</p>
<h2 id="mariadb-cluster">MariaDB Cluster</h2>
<p>I’ve got a MariaDB cluster made up (well, as of right this moment) 3 nodes on one network and a garbd on another. This is not the right way to do this, but again, this is just a set of notes. Eventually I’ll have 3 networks (in test) that are meant to represent 3 data centers. Two networks will have 3 nodes on each (for a total of 6) and another network a single garbd server. What I’m aiming for is for any of the DCs to go down and to still have a working cluster in the remaining DC. The nodes are all virtual machines.</p>
<p>I’m a bit behind on my MariaDB version, so I’m still back on 5.5, but that is what is in production right now so that is what I need to test with.</p>
<pre>
<code>root@mariadb-1:/home/ubuntu# dpkg --list | grep mariadb
ii libmariadbclient18 5.5.45+maria-1~trusty amd64 MariaDB database client library
ii mariadb-client 5.5.45+maria-1~trusty all MariaDB database client (metapackage depending on the latest version)
ii mariadb-client-5.5 5.5.45+maria-1~trusty amd64 MariaDB database client binaries
ii mariadb-client-core-5.5 5.5.45+maria-1~trusty amd64 MariaDB database core client binaries
ii mariadb-common 5.5.45+maria-1~trusty all MariaDB database common files (e.g. /etc/mysql/conf.d/mariadb.cnf)
ii mariadb-galera-server-5.5 5.5.45+maria-1~trusty amd64 MariaDB database server with Galera cluster binaries
</code>
</pre>
<h2 id="openstack-ansible-galera-playbooks">OpenStack Ansible Galera playbooks</h2>
<p>I (internally) forked the OpenStack Ansible Galera playbooks some time ago. They are a good way to get a MariaDB Galera cluster up and running quickly. The roles can easily be found on the <a href="https://github.com/openstack/openstack-ansible/tree/master/playbooks/roles">github site</a>.</p>
<h2 id="galera-arbitrator-arbiter">Galera-arbitrator (arbiter?)</h2>
<p>Galera-arbitrator (garb or garbd) is a useful service that can help a Galera cluster with maintaining quorum, but doesn’t take up as many resources to run it as it would a full-fledged database server. Usually people who only have two good database servers use garbd on a lower-end server to help with quorum because you shouldn’t have a cluster of two nodes or you’ll end up in split-brain, and split-brain is as bad as it sounds. So if you have MariaDB + Galera on two good servers and garbd on a third (less good) server, then you should be able to avoid split-brain.</p>
<p>In my case I have two datacenters with multiple galera nodes in a large cluster, and I want a garbd running in a third datacenter so that if I lose an entire DC, or the interconnect between them, I don’t end up in split-brain at the datacenter level.</p>
<pre>
<code>ubuntu@garb-1:~$ dpkg --list | grep galera
ii galera-arbitrator-3 25.3.9-trusty amd64 Galera arbitrator daemon
</code>
</pre>
<p>This is what my /etc/default/garb looks like. Again there are four nodes, which isn’t quite correct, but I’m in testing mode. :)</p>
<pre>
<code>ubuntu@garb-1:/etc/default$ cat garb
# Copyright (C) 2012 Codership Oy
# This config file is to be sourced by garb service script.
# A space-separated list of node addresses (address[:port]) in the cluster
GALERA_NODES="192.168.77.6:4567 192.168.44.34:4567 192.168.44.33:4567 192.168.44.32:4567"
# Galera cluster name, should be the same as on the rest of the nodes.
GALERA_GROUP="rpc_galera_cluster"
# Optional Galera internal options string (e.g. SSL settings)
# see http://www.codership.com/wiki/doku.php?id=galera_parameters
# GALERA_OPTIONS=""
# Log file for garbd. Optional, by default logs to syslog
# LOG_FILE=""
</code>
</pre>
<p>This is what the wsrep_incoming_addresses looks like on one of the mariadb nodes.</p>
<pre>
<code>MariaDB [(none)]> show status like 'wsrep_incoming_addresses';
+--------------------------+-----------------------------------------------------------+
| Variable_name | Value |
+--------------------------+-----------------------------------------------------------+
| wsrep_incoming_addresses | 192.168.44.33:3306,,192.168.44.34:3306,192.168.44.32:3306 |
+--------------------------+-----------------------------------------------------------+
1 row in set (0.00 sec)
</code>
</pre>
<p>Lots of interesting information. :)</p>
<h2 id="test-fake-databases">Test (fake) databases</h2>
<p>One that I found is the <a href="https://launchpad.net/test-db/employees-db-1/1.0.6/+download/employees_db-full-1.0.6.tar.bz2">employees</a> database. I believe I stumbled upon the existence of the employees test database through <a href="https://www.digitalocean.com/community/tutorials/how-to-measure-mysql-query-performance-with-mysqlslap">this post</a>.</p>
<p>Once you download that and unbzip it, you’ll have these files.</p>
<pre>
<code>ubuntu@mariadb-1:~/employees_db$ ls
Changelog employees_partitioned.sql load_dept_emp.dump load_salaries.dump README
employees_partitioned2.sql employees.sql load_dept_manager.dump load_titles.dump test_employees_md5.sql
employees_partitioned3.sql load_departments.dump load_employees.dump objects.sql test_employees_sha.sql
</code>
</pre>
<p>Then you can simply import the database using:</p>
<pre>
<code>$ mysql < employees.sql
</code>
</pre>
<p>For example, the salaries table has quite a few entries.</p>
<pre>
<code>MariaDB [employees]> select count(*) from salaries;
+----------+
| count(*) |
+----------+
| 2844047 |
+----------+
1 row in set (0.70 sec)
</code>
</pre>
<h2 id="mysql-procedures">MySQL Procedures</h2>
<p>While I was looking for test databases, I stumbled on <a href="https://stackoverflow.com/questions/3766282/fill-database-tables-with-a-large-amount-of-test-data">this stackoverflow post</a> that had an example prepared statement in it. I figured why not give it a try, I’d never used a prepared statement in MySQL before. Another technology to look into…</p>
<pre>
<code>root@mariadb-1:/home/ubuntu# cat fake_data.sql
CREATE TABLE your_table (id int NOT NULL PRIMARY KEY AUTO_INCREMENT, val int);
DELIMITER $$
CREATE PROCEDURE prepare_data()
BEGIN
DECLARE i INT DEFAULT 100;
WHILE i < 100000 DO
INSERT INTO your_table (val) VALUES (i);
SET i = i + 1;
END WHILE;
END$$
DELIMITER ;
-- CALL prepare_data()
</code>
</pre>
<p>All it’s going to do is create a table called “your_table” and load ~100000 entries into it.</p>
<p>I ran it a few times to try it out.</p>
<pre>
<code>MariaDB [fake_data]> select count(*) from your_table;
+----------+
| count(*) |
+----------+
| 299700 |
+----------+
1 row in set (0.16 sec)
</code>
</pre>
<p>Here’s how to list the procedures.</p>
<pre>
<code>MariaDB [fake_data]> SHOW PROCEDURE STATUS;
+-----------+--------------+-----------+---------+---------------------+---------------------+---------------+---------+----------------------+----------------------+--------------------+
| Db | Name | Type | Definer | Modified | Created | Security_type | Comment | character_set_client | collation_connection | Database Collation |
+-----------+--------------+-----------+---------+---------------------+---------------------+---------------+---------+----------------------+----------------------+--------------------+
| fake_data | prepare_data | PROCEDURE | root@% | 2015-09-25 22:27:16 | 2015-09-25 22:27:16 | DEFINER | | utf8 | utf8_general_ci | utf8_unicode_ci |
+-----------+--------------+-----------+---------+---------------------+---------------------+---------------+---------+----------------------+----------------------+--------------------+
1 row in set (0.02 sec)
</code>
</pre>
<h2 id="size-of-databases">Size of databases</h2>
<p>Here’s one way to get the size of the databases in your MySQL/MariaDB cluster. This was borrowed from <a href="https://stackoverflow.com/questions/1733507/how-to-get-size-of-mysql-database">this stackoverflow post</a>. (I guess I use stackoverflow questions/answers more than I thought.)</p>
<pre>
<code>MariaDB [(none)]> SELECT table_schema "table name", sum( data_length + index_length ) / 1024 / 1024 "Data Base Size in MB"
-> FROM information_schema.TABLES GROUP BY table_schema ;
+--------------------+----------------------+
| table name | Data Base Size in MB |
+--------------------+----------------------+
| employees | 197.43750000 |
| fake_data | 8.51562500 |
| information_schema | 0.15625000 |
| mysql | 0.62678719 |
| performance_schema | 0.00000000 |
| sysbench | 4752.00000000 |
+--------------------+----------------------+
6 rows in set (0.14 sec)
</code>
</pre>
<h2 id="sysbench">sysbench</h2>
<p>I put up a quick Ansible playbook that installs the lastest sysbench <a href="https://gist.github.com/ccollicutt/2a96ca4f03a7f18b9da9">here</a>. Currently that is version 0.5. Apparently 0.5 adds the ability to use lua scripts, and in fact comes with some example scripts which I use below.</p>
<p>Following <a href="http://blog.secaserver.com/2014/07/sysbench-0-5-ubuntu-14-04-trusty-percona-server-xtradb-cluster/">this post</a> I setup and ran tests using the below commands (where all the right databases and users and permissions and such were put into place).</p>
<pre>
<code>ubuntu@mysql-client-1:/usr/local/bin$ cat sysbench-prepare-test.sh
#!/bin/bash
sysbench \
--db-driver=mysql \
--mysql-table-engine=innodb \
--oltp-table-size=20000000 \
--mysql-host=192.168.44.34 \
--mysql-db=sysbench \
--mysql-port=3306 \
--mysql-user=sysbench \
--mysql-password=syb3nch \
--test=/usr/local/src/sysbench/sysbench/tests/db/oltp.lua \
prepare
</code>
</pre>
<p>20000000 records is probably way to many for the size of servers I’m using now (which is about 4 gigs of memory per MariaDB node).</p>
<p>This is the test run script:</p>
<pre>
<code>ubuntu@mysql-client-1:/usr/local/bin$ cat sysbench-run-test.sh
#!/bin/bash
sysbench \
--db-driver=mysql \
--num-threads=8 \
--max-requests=50000 \
--oltp-table-size=20000000 \
--oltp-test-mode=complex \
--test=/usr/local/src/sysbench/sysbench/tests/db/oltp.lua \
--mysql-host=192.168.44.34 \
--mysql-db=sysbench \
--mysql-port=3306 \
--mysql-user=sysbench \
--mysql-password=syb3nch \
run
</code>
</pre>
<p>And the results of running that test:</p>
<pre>
<code>ubuntu@mysql-client-1:/usr/local/bin$ ./sysbench-run-test.sh
sysbench 0.5: multi-threaded system evaluation benchmark
Running the test with following options:
Number of threads: 8
Random number generator seed is 0 and will be ignored
Threads started!
OLTP test statistics:
queries performed:
read: 700000
write: 200000
other: 100000
total: 1000000
transactions: 50000 (309.68 per sec.)
read/write requests: 900000 (5574.19 per sec.)
other operations: 100000 (619.35 per sec.)
ignored errors: 0 (0.00 per sec.)
reconnects: 0 (0.00 per sec.)
General statistics:
total time: 161.4584s
total number of events: 50000
total time taken by event execution: 1291.3610s
response time:
min: 7.33ms
avg: 25.83ms
max: 172.26ms
approx. 95 percentile: 43.51ms
Threads fairness:
events (avg/stddev): 6250.0000/118.29
execution time (avg/stddev): 161.4201/0.01
</code>
</pre>
<p>When I dropped the number of entries to 50000, these are my results.</p>
<pre>
<code>ubuntu@mysql-client-1:/usr/local/bin$ ./sysbench-run-test.sh
sysbench 0.5: multi-threaded system evaluation benchmark
Running the test with following options:
Number of threads: 8
Random number generator seed is 0 and will be ignored
Threads started!
^[9OLTP test statistics:
queries performed:
read: 700000
write: 200000
other: 100000
total: 1000000
transactions: 50000 (270.09 per sec.)
read/write requests: 900000 (4861.63 per sec.)
other operations: 100000 (540.18 per sec.)
ignored errors: 0 (0.00 per sec.)
reconnects: 0 (0.00 per sec.)
General statistics:
total time: 185.1233s
total number of events: 50000
total time taken by event execution: 1480.6339s
response time:
min: 7.53ms
avg: 29.61ms
max: 269.02ms
approx. 95 percentile: 50.34ms
Threads fairness:
events (avg/stddev): 6250.0000/158.26
execution time (avg/stddev): 185.0792/0.01
</code>
</pre>
<p>For some kind of comparison, good or bad, here’s the same test run on a single instance of the default mysql server you get when you install it on Ubuntu trusty. Same instance type as the above tests were run on.</p>
<pre>
<code>ubuntu@mysql-client-1:/usr/local/bin$ ./sysbench-run-test.sh
sysbench 0.5: multi-threaded system evaluation benchmark
Running the test with following options:
Number of threads: 8
Random number generator seed is 0 and will be ignored
Threads started!
OLTP test statistics:
queries performed:
read: 700000
write: 200000
other: 100000
total: 1000000
transactions: 50000 (511.80 per sec.)
read/write requests: 900000 (9212.48 per sec.)
other operations: 100000 (1023.61 per sec.)
ignored errors: 0 (0.00 per sec.)
reconnects: 0 (0.00 per sec.)
General statistics:
total time: 97.6936s
total number of events: 50000
total time taken by event execution: 781.2354s
response time:
min: 5.55ms
avg: 15.62ms
max: 234.14ms
approx. 95 percentile: 24.31ms
Threads fairness:
events (avg/stddev): 6250.0000/163.33
execution time (avg/stddev): 97.6544/0.01
</code>
</pre>
<h2 id="more-work-to-do">More work to do</h2>
<p>So, like I said, these are just a bunch of notes I took when messing around with a virtual Galera cluster and doing some basic research into performance testing. I’ll update this post as I continue on. Now that I have a virtualized test cluster that I can destroy and rebuild at will I can really get into understanding how it works and what the failure domains are, as well as how it performs. Eventually I would like to get <a href="https://mariadb.com/products/mariadb-maxscale">MariaDB MaxScale</a> into the loop as well, and send writes to one host and reads to all.</p>
Why I like SDN2015-08-25T00:00:00+00:00http://serverascode.com/2015/08/25/why-i-like-sdn<h1 id="why-i-like-sdn">Why I like SDN</h1>
<p>Recently, I helped give a presentation on SDN to the <a href="https://edmontongo.org/">Edmonton Go</a> meetup. Basically my part of the presentation was to talk about what SDN is and how it relates to containers and Go. That is actually easy because SDN, containers, and Go are the parts of a “so hot right now” trifecta. There’s a lot of money in those three things, perhaps more when together. I did joke that I hoped we’d come out of the presentation with a fully funded startup. Alas that did not happpen, as we are in Edmonton, not Palo Alto.</p>
<p>The only startup I’m aware of that did all three, Socketplane, was bought by Docker before they even put out a real product. I’m surprised there aren’t more Go-based SDN startups. Maybe there are and I’m just not aware of them. Maybe they all get bought before they get a twitter account. [1]</p>
<h2 id="i-use-sdn-every-day">I use SDN every day</h2>
<p>As a systems administrator, I tend to concern myself with applying technologies in production, which is to say that theory is not enough. I use Midokura’s Midonet (which is open source[2]) to provide multi-tenant virtual private networks for openstack users. It’s in production and has been for months. Midonet acts as a plugin to Neutron and centralizes state in a Zookeeper cluster. Everything’s been working great. My point is that I am using a software defined network every day to meet customers needs, and I think it would be difficult to do it without some kind of SDN system.</p>
<p>There are quite a few “plugins” (or perhaps “network models” would be a better term) for OpenStack that could be considered SDN. If you don’t like overlay or encapsulation models and prefer a large layer 3 design, perhaps <a href="http://www.projectcalico.org/">Project Calico</a> would be of interest. Also the neutron team and some large OpenStack deployers are working on a large layer 3 design.</p>
<h2 id="some-thoughts-on-sdn">Some thoughts on SDN</h2>
<p>First off, SDN is “an abstract concept which can mean many things.” The term of overloaded.</p>
<p>For a while OpenFlow defined SDN, but that’s no longer the case as it seems the market has outrun OpenFlow. I would think that at the very least an SDN system would have to provide an API. After that it gets harder to define.</p>
<h3 id="whats-great-about-sdn">What’s great about SDN?</h3>
<ul>
<li>Making the network programmable</li>
<li>Reducing capex and opex</li>
<li>Enabling multi-tenancy and massive networks</li>
<li>Avoid some limitations (eg. > 4096 VLANs, which, honestly, is still a lot of VLANs)</li>
<li>Providing a bit of a shakeup to networking (yes, the Internet works amazingly well in terms of layer 3 routing, but is it the ultimate networking model?[3])</li>
</ul>
<h3 id="whats-great-about-containers-and-sdn">What’s great about containers and SDN?</h3>
<p>Docker has been around for a couple years now, but the container “space” is still on fire. Every day there are new announcements. Even if you don’t like containers, you have to admit there is a lot of work being done, a lot of innovation happening and that innovation is “trickling down” to other areas, such as networking. Maybe all the “new” ideas existed before. At any rate I think Linux namespaces and cgroups have been a catalyst for change, perhaps under the guise of Docker (and now the <a href="https://www.opencontainers.org/">Open Container Initiative</a>). These systems need network information, and screen-scraping or grepping dhcp.leases isn’t going to do it.</p>
<p>The canonical example of containers and SDN is how easy it is to setup one Docker host, and how much tricker it is to setup two docker hosts with networking between containers.</p>
<p>Another example I like is if you have many container hosts with a large proxy layer on top, and you are recreating containers like crazy, how does that proxy layer know the network address of all the containers and what they do? Through an API provided by SDN.</p>
<p>I believe the model used by most container schedulers is one IP per container. Given that containers don’t contain, multi-tenant container systems aren’t used in production (yet) which means a flat layer 3 model works well. But at some point I think multi-tenant containers will be commonplace and then it will make more sense to apply other networking models, just like we do with vms.</p>
<h3 id="network-ops-pushback">Network ops pushback</h3>
<p>I get a lot of pushback on SDN. Other than being interested in SDN, enough knowledge to get servers up and running, and messing around with BGP and OSPF for high availability, I’m not a networking expert. No one has ever let me login to a switch at work (they defend those things with their lives). And yet here I am, managing a rather large (virtual, software defined) network inside an OpenStack cloud. I’m looking at change in a few areas, 1) SDN on the WAN 2) Using whitebox switches and Cumulus Linux and 3) getting rid of virtual IPs by using BPG and OSPF. The first two are tough battles, only #3 seems doable in my current environment.</p>
<h3 id="centralized-control-plane">Centralized control plane?</h3>
<blockquote>
<p>We’ve had centralized architectures for decades, from SNA to various WAN technologies (SDH/SONET, Frame Relay and ATM). They all share a common problem: when the network partitions, the nodes cut off from the central intelligence stop functioning (in SNA case) or remain in a frozen state (WAN technologies). [4]</p>
</blockquote>
<p>I’m still slightly confused on the centralized control plane. The above quote makes it fairly clear that a centralized control plane is counter-productive when thinking about scale-out systems.</p>
<h2 id="conclusion">Conclusion</h2>
<p>So, while there are many popular new technologies (some would say “over-hyped,” though I would not) I think over time SDN will prove invaluable, and the ability to program a network will slowly seep into almost every vendors system, and will dominate open source networking solutions. Eventually SDN will just be the way networks are done. Certainly that could take years, even decades (as IPv6 hasn’t even been accepted yet, and we really need it), but I would feel safe making a long-term bet on SDN and related technologies.</p>
<hr />
<p>1: It’s not like it really matters whether it’s Java, C, Go, or some other language. I just happen to like Go.</p>
<p>2: Midokura has open sourced their application. But it is definitely more like open core. There aren’t a lot of non-Midokura contributors. But again, networking gear isn’t free either.</p>
<p>3: I’m really asking. Is it?</p>
<p>4: <a href="http://blog.ipspace.net/2014/05/does-centralized-control-plane-make.html">Does Centralized Control Plane Make Sense?</a></p>
Bin Packing with Python2015-08-23T00:00:00+00:00http://serverascode.com/2015/08/23/bin-packing-python<h1 id="bin-packing-with-python">Bin Packing with Python</h1>
<p>I’ve been working with OpenStack for a while now, since back at the Essex release, and every once and a while I hear the phrase “bin packing” with regards to scheduling vms on physical hosts. I didn’t study computer science in university, and am not particularly interested in that kind of thing, but at work we have also been discussing how to deploy racks of servers, or what size of physical hosts to buy (ie. how much memory, disk, cpu to put in them).</p>
<p>As far as server racks go, we are constrained on power, space, and possibly network ports. Given those constraints, how can we best deploy servers and network gear? Then, with regards to vms, if we have several types of openstack flavors, how does that work into what we can support and what the distribution on the physical hosts will look like?</p>
<p>For the most part I believe people just do whatever in terms of hypervisor host sizing. If deploying openstack they just buy the same hosts as they have always bought for virtualization. But I wanted to 1) take planning a step further and at least be able to calculate requirements in some fashion and 2) finally figure out what bin packing is.</p>
<h2 id="what-is-bin-packing">What is bin-packing?</h2>
<blockquote>
<p>In the bin packing problem, objects of different volumes must be packed into a finite number of bins or containers each of volume V in a way that minimizes the number of bins used. In computational complexity theory, it is a combinatorial NP-hard problem. [1]</p>
</blockquote>
<p>Basically, if you have a bunch of different sized objects and bins to put them in, how do they best fit? I would imagine most compsci grads saw this problem and related problem in early courses.</p>
<p>The other interesting thing is that it is NP-hard. This is another term that I’ve heard quite often but haven’t researched what it is. Until now. :)</p>
<blockquote>
<p>What does it mean to be NP-hard? It means that if you can solve an NP-hard problem in polynomial time, then you can solve all the NP problems in polynomial time. [2]</p>
</blockquote>
<p>From my layman point of view, it means that bin packing is a difficult problem to solve in that it can take a long time to get an answer, and what’s more, that if we could solve it quickly then we could solve a lot of other things quickly too. Because it can take a long time to find the answer, often bin packing algorithms take shortcuts to provide an answer quickly.</p>
<h2 id="bin-packing-with-python-1">Bin packing with python</h2>
<p>I did a lot of googling to find examples of bin packing with python. The first good one I came across was <a href="https://github.com/hudora/pyShipping">pyShipping</a> which has a couple of examples of bin packing and 3d bin packing. But after looking through that a bit I realized that I was looking for bin packing with multiple constraints.</p>
<p>Finally I ended up on one of the oldest looking websites I’ve seen in a long time, <a href="http://openopt.org">OpenOpt</a>. Yes, that “coming soon” gif is blinking.</p>
<p><img src="/img/openopt.jpg" alt="" /></p>
<p>Anyways, OpenOpt has a couple nice examples and there is a short page on the site for <a href="http://openopt.org/BPP">bin packing</a>. I based my work on is the <a href="http://trac.openopt.org/openopt/browser/PythonPackages/OpenOpt/openopt/examples/bpp_2.py">advanced, multiple constaints example</a>.</p>
<h2 id="laymans-bin-packing">Laymans bin packing</h2>
<p>I’ve just been doing a bit of testing with the OpenOpt example. Below my example has three flavors (vm sizes): small, medium, and large, each with different cpu, memory, and disk requirements.</p>
<p>Then I have server “bins”, ie. hypervisor hosts, with 2TB of disk, ~240GB of memory, and 48 cpus with a 4x overcommit (so 192 virtual cpus). When I run the bpp algo which uses the glpk solver, it distributes the vms over the hypervisors in what we hope is the best use of the resources, with the lowest number of hypervisors being used.</p>
<p>The code:</p>
<pre>
<code>#!/usr/bin/python
from openopt import *
N = 60
items = []
for i in range(N):
small_vm = {
'name': 'small%d' % i,
'cpu': 2,
'mem': 2048,
'disk': 20,
'n': 1
}
med_vm = {
'name': 'medium%d' % i,
'cpu': 4,
'mem': 4096,
'disk': 40,
'n': 1
}
large_vm = {
'name': 'large%d' % i,
'cpu': 8,
'mem': 8192,
'disk': 80,
'n': 1
}
items.append(small_vm)
items.append(med_vm)
items.append(large_vm)
bins = {
'cpu': 48*4, # 4.0 overcommit with cpu
'mem': 240000,
'disk': 2000,
}
p = BPP(items, bins, goal = 'min')
r = p.solve('glpk', iprint = 0) # requires cvxopt and glpk installed, see http://openopt.org/BPP for other solvers
print(r.xf)
print(r.values) # per each bin
print "total vms is " + str(len(items))
print "servers used is " + str(len(r.xf))
for i,s in enumerate(r.xf):
print "server " + str(i) + " has " + str(len(s)) + " vms"
</code>
</pre>
<p>The results:</p>
<pre>
<code>$ time python vms.py
Initialization: Time = 6.7 CPUTime = 6.7
------------------------- OpenOpt 0.5625 -------------------------
problem: unnamed type: MILP goal: min
solver: glpk
iter objFunVal log10(maxResidual)
0 0.000e+00 0.00
GLPK Integer Optimizer, v4.54
33480 rows, 32580 columns, 162900 non-zeros
32580 integer variables, none of which are binary
Preprocessing...
720 rows, 32580 columns, 130140 non-zeros
32580 integer variables, all of which are binary
Scaling...
A: min|aij| = 1.000e+00 max|aij| = 2.400e+05 ratio = 2.400e+05
GM: min|aij| = 9.204e-01 max|aij| = 1.087e+00 ratio = 1.181e+00
EQ: min|aij| = 8.812e-01 max|aij| = 1.000e+00 ratio = 1.135e+00
2N: min|aij| = 5.000e-01 max|aij| = 1.000e+00 ratio = 2.000e+00
Constructing initial basis...
Size of triangular part is 720
Solving LP relaxation...
GLPK Simplex Optimizer, v4.54
720 rows, 32580 columns, 130140 non-zeros
0: obj = 0.000000000e+00 infeas = 1.706e+02 (0)
500: obj = 3.010416667e+00 infeas = 4.995e+01 (0)
- 628: obj = 4.375000000e+00 infeas = 1.599e-14 (0)
OPTIMAL LP SOLUTION FOUND
Integer optimization begins...
+ 628: mip = not found yet >= -inf (1; 0)
+ 6048: >>>>> 5.000000000e+00 >= 5.000000000e+00 0.0% (46; 0)
+ 6048: mip = 5.000000000e+00 >= tree is empty 0.0% (0; 91)
INTEGER OPTIMAL SOLUTION FOUND
1 0.000e+00 -100.00
istop: 1000 (optimal)
Solver: Time Elapsed = 6.86 CPU Time Elapsed = 6.85
objFuncValue: 5 (feasible, MaxResidual = 0)
[{'medium12': 1, 'medium13': 1, 'medium10': 1, 'medium11': 1, 'small9': 1, 'medium18': 1, 'medium57': 1, 'medium55': 1, 'large8': 1, 'small11': 1, 'small10': 1, 'small12': 1, 'large1': 1, 'large3': 1, 'large2': 1, 'large6': 1, 'large33': 1, 'medium9': 1, 'small55': 1, 'medium0': 1, 'large14': 1, 'medium2': 1, 'large16': 1, 'large11': 1, 'large10': 1, 'large12': 1, 'medium26': 1, 'medium22': 1, 'large57': 1, 'large54': 1, 'small58': 1, 'medium1': 1, 'large56': 1, 'large22': 1, 'large26': 1}, {'medium39': 1, 'medium35': 1, 'medium36': 1, 'medium54': 1, 'medium52': 1, 'medium50': 1, 'medium51': 1, 'medium59': 1, 'small13': 1, 'small51': 1, 'small50': 1, 'small52': 1, 'large37': 1, 'large36': 1, 'large35': 1, 'large34': 1, 'large15': 1, 'large17': 1, 'small35': 1, 'large18': 1, 'medium49': 1, 'medium48': 1, 'large51': 1, 'large50': 1, 'large52': 1, 'medium47': 1, 'medium46': 1, 'large49': 1, 'large46': 1, 'large47': 1, 'large23': 1, 'large48': 1, 'small48': 1, 'small49': 1, 'small47': 1, 'medium7': 1, 'small40': 1, 'small41': 1}, {'medium38': 1, 'medium34': 1, 'small8': 1, 'medium37': 1, 'medium32': 1, 'medium33': 1, 'medium53': 1, 'large9': 1, 'small53': 1, 'large32': 1, 'small39': 1, 'small38': 1, 'small54': 1, 'small33': 1, 'large39': 1, 'large38': 1, 'small37': 1, 'small36': 1, 'medium6': 1, 'small34': 1, 'medium42': 1, 'medium41': 1, 'medium40': 1, 'large53': 1, 'large41': 1, 'medium45': 1, 'medium44': 1, 'medium20': 1, 'medium3': 1, 'small28': 1, 'large21': 1, 'large44': 1, 'large45': 1, 'large42': 1, 'large43': 1, 'large40': 1, 'large27': 1, 'small46': 1, 'small44': 1, 'small45': 1, 'small42': 1, 'small43': 1, 'small27': 1}, {'small1': 1, 'small0': 1, 'small3': 1, 'small2': 1, 'small5': 1, 'small4': 1, 'small7': 1, 'small6': 1, 'large0': 1, 'large5': 1, 'large4': 1, 'large7': 1, 'medium8': 1, 'medium56': 1, 'small59': 1, 'large58': 1, 'medium4': 1, 'medium5': 1}, {'medium16': 1, 'medium17': 1, 'medium14': 1, 'medium15': 1, 'medium19': 1, 'medium30': 1, 'medium31': 1, 'medium58': 1, 'small15': 1, 'small14': 1, 'small17': 1, 'small16': 1, 'small19': 1, 'small18': 1, 'large31': 1, 'large30': 1, 'large19': 1, 'small57': 1, 'small56': 1, 'small32': 1, 'small31': 1, 'small30': 1, 'medium43': 1, 'large13': 1, 'large59': 1, 'medium29': 1, 'medium28': 1, 'medium27': 1, 'large55': 1, 'medium25': 1, 'medium24': 1, 'medium23': 1, 'medium21': 1, 'large28': 1, 'large29': 1, 'large20': 1, 'small29': 1, 'large24': 1, 'large25': 1, 'small20': 1, 'small21': 1, 'small22': 1, 'small23': 1, 'small24': 1, 'small25': 1, 'small26': 1}]
{'mem': (196608.0, 196608.0, 196608.0, 75776.0, 194560.0), 'disk': (1920.0, 1920.0, 1920.0, 740.0, 1900.0), 'cpu': (192.0, 192.0, 192.0, 74.0, 190.0)}
total vms is 180
servers used is 5
server 0 has 35 vms
server 1 has 38 vms
server 2 has 43 vms
server 3 has 18 vms
server 4 has 46 vms
real 0m24.788s
user 0m23.894s
sys 0m0.944s
</code>
</pre>
<p>So from the above, we know we would need five hypervisor hosts to run this set of 180 vms, 60 small, 60 medium, and 60 large.</p>
<p>From the output it also seems like we max out on cpus and are actually getting pretty close on disk too.</p>
<pre>
<code>{
'mem': (196608.0, 196608.0, 196608.0, 75776.0, 194560.0),
'disk': (1920.0, 1920.0, 1920.0, 740.0, 1900.0),
'cpu': (192.0, 192.0, 192.0, 74.0, 190.0)
}
</code>
</pre>
<p>Now we can play around with numbers and see if we can reduce the number of hypervisors. In the next attempt I changed the cpu overcommit to 5 and the disk on the host to 3TB.</p>
<pre>
<code>{
'mem': (184320.0, 198656.0, 239616.0, 237568.0),
'disk': (1800.0, 1940.0, 2340.0, 2320.0),
'cpu': (180.0, 194.0, 234.0, 232.0)
}
total vms is 180
servers used is 4
server 0 has 37 vms
server 1 has 39 vms
server 2 has 55 vms
server 3 has 49 vms
</code>
</pre>
<p>Now we are down to only four hypervisors fitting the 180 vms.</p>
<p>Certainly this is the most simplistic example. But I feel like it’s still pretty powerful, and it will make much more sense when I can input real-world data for flavor usage in a cloud. If I can input real usage data in terms of flavors, instead of just 60 of each, then I can really start to understand what the minimum hardware investment is, or at least what the servers could look like for memory, disk, and cpu.</p>
<h2 id="live-migration">Live migration</h2>
<p>I’ve never been a big fan of live migration. Usually it means a distributed file system, or a shared file system, and those are both hard to run and scale. Also, there is the whole pets vs cattle thing. Using that metaphor, there’s no reason to live migrate cattle.</p>
<p>However, I did read through a paper, “Adaptive Resource Provisioning for the Cloud
Using Online Bin Packing”:http://www.cs.princeton.edu/~haipengl/papers/binpacking.pdf, that discussed using bin-packing to move vms around in a cloud so that some hypervisors could be turned off and thus save power. To me that sounds like a good use of live migration.</p>
<p>We have talked about making booting from volumes a default as potential methodology in an OpenStack cloud, which would enable live migration without a large shared file system or a distributed file system. So that could be a direction to go in. I’ve always thought of cinder with plain old lvm hosts to be pretty powerful and having a small failure domain. In theory we could let OpenStack schedule however it wants, and then run a bin packing algorithm every once and a while and live migrate instances to make better use of hypervisors. Easier said than done of course, but would be interesting.</p>
<h2 id="conclusion">Conclusion</h2>
<p>In the end, despite being a compsci layman, I think I’ve got what I wanted: a calculator that can help me to look at our rack resources and our hypervisor servers and do some sizing. As I continue down this path I’m sure I’ll learn more about bin packing. It’s a start. :)</p>
<p>The next area I need to understand is how OpenStack schedules vms…</p>
<hr />
<p>1: <a href="https://en.wikipedia.org/wiki/Bin_packing_problem">Bin Packing Problem</a></p>
<p>2: <a href="https://www.quora.com/What-is-an-explanation-of-P-versus-NP-problems-and-other-related-terms-in-laymans-terms">Explanation of P versus NP</a></p>
Palo Alto OpenStack Operators Meetup2015-08-19T00:00:00+00:00http://serverascode.com/2015/08/19/pao-openstack-operators-meetup<h1 id="palo-alto-openstack-operators-meetup">Palo Alto OpenStack Operators Meetup</h1>
<p>I am really early for my flight home to Edmonton from the San Franciso airport. Maybe I didn’t need to be as concerned about traffic as I was. I bought <a href="https://en.wikipedia.org/wiki/The_Martian_%28Weir_novel%29">The Martian</a> book so I should be reading it, but I’m not, instead I’m writing this blog post about the Palo Alto OpenStack Operators mid-cycle meetup that I attended.</p>
<p>If you want to see the full, official notes from each session, you can find links to them from <a href="https://etherpad.openstack.org/p/PAO-ops-meetup">this etherpad page</a>.</p>
<h2 id="my-notes-from-the-meetup">My notes from the meetup</h2>
<p>Here are some general notes I made from the sessions. Sorry the below is rambling, but that’s how I think. Also these are my interpretations of what was said, and I’ve been wrong before. If you notice something incorrect, just let me know in the comments and I’ll change it.</p>
<ul>
<li>The vast, vast majority of operators have moved off of nova-network and are on Neutron now. Only one person had their hand up for running nova-network, though I’m sure there are more, they just didn’t respond to the informal poll. I think it’s good that Neutron is now the standard. Neutron is more complicated than nova-network and doesn’t necessarily meet everyones needs, but I think having a common base will help get things moving forward. The large deployments team is working on helping the Neutron team create a model that works for them, and I think once that happens everyone will be happy. For the record my neutron “model” is to use Midonet with VXLAN. I really like Midonet and the overlay model fits our customer base well. Several large deployments prefer straight up L3 based networks, and I’m sure Neutron will provide that model soon. That said, it will be hard for Neutron to meet the requirements of every single network model.</li>
<li>RabbitMQ isn’t as much of a burning issue as it used to be. Seems like people still have no idea whether to run it behind a load balancer or not, or to list all the rabbit’s in the config, or what. Still quite confusing. However, a definite consensus is that Kilo is much better with rabbit. I’d like to backport some of the things that make it better as we are still on Juno, but I’m not sure we’ll have time for that. Soon we will upgrade from Juno to Kilo anyways. Another point made was that you probably have issues whether you use a loadbalancer or not, so either way…</li>
<li>Also–someone from RabbitMQ was at the meeting and gave an update. They are working on making RabbitMQ easier to operate. They are also keenly aware of how much it is used in OpenStack, and may provide OpenStack-specific documentation on using RabbitMQ. That would be great.</li>
<li>CMDB was a big topic at this meetup. Lots of people want a good CMDB so that they can start to do capacity planning. Obviously this means there are many large OpenStack installations out there.</li>
<li>HP talked about their billing solution. It’s fairly complex…as far as I can remember it pulls information off of various sources, such as rabbit, sticks them into Hadoop, there are jobs that crunch that data and store it into an SQL database which is fronted by an API that internal systems can query for billing. They intend to opensource this system in some fashion, or maybe just parts of it. Not sure.</li>
<li>Burning issues: The etherpad can be found <a href="https://etherpad.openstack.org/p/PAO-ops-burning-issues">here</a>.</li>
<li>Many, many hands were put up for Neutron as a “burning issue,” but when the time came around to actually complain about it, no one really said anything, or perhaps I just missed it. My impression is that Neutron is working pretty well for most.</li>
<li>Ceilometer is still an issue, but people are also still using it, and many are investing heavily in getting it working. I think Ceilometer is an important project and I feel like eventually it’ll be production worthy. I keep forgetting Heat can use it for autoscaling. We stopped using it due to performance issues on the backend (like many others) but we also didn’t put that much effort into it. Many other metrics gathering systems are resource intensive, and also use backends like Mongo. If you throw too much data at a backend it stops working, no matter what technology you’re using. One provider mentioned using Influxdb and ceilometer, I believe with statsd as an intermediary.</li>
<li>Keystone was also listed fairly high in terms of burning issues. Many clouds would like to flexible roles, as basically there are only three right now: admin, member, and no role. As usual the policy json files were mentioned as being complex and somewhat undocumented. I’m personally not sure how much effort to put into the policy files if there are only three roles. Something to look into. The important thing to know is that the Keystone project is well aware of these requirements and they are working on them. Also, many clouds have added an extra layer on top of Keystone to allow some tenants to do admin-like functions, such as add users to their project and things like that. But that functionality is “hacked” in, so to speak by the providers.</li>
<li>I didn’t get to ask my question about putting Keystone tokens in memcached. I read a bug a while ago where it was mentioned that the memcached driver being used is not that great, and that using memcached isn’t recommended, even though it’s part of the official install docs (or was the last time I looked). Darned if I can find that bug listing again. Several providers have moved to Fernet tokens which don’t need to be stored, though are slower. I would imagine that once we get to Kilo that we will use Fernet tokens as well and just avoid the whole caching/storage issue.</li>
<li>Containers: There was some discussion about containers. It seemed forced. Some people use containers in their OpenStack infrastructure…LXC, Docker. I will probably use so-called “fat” containers, ie. LXC, for some infrastructure. Yeah, containers are still hot. Docker is cool. Multi-tenancy is hard, etc, etc.</li>
<li>Install guide: There was at least one mention of how a particular technology was used in someones OpenStack cloud because it was a step in the install guide. I think the install guide is a lot more important than people know in terms of how people deploy OpenStack. If memcached is listed as an install step then people will use it. If OVS is mentioned in the install guide then people will use it (as opposed to Linux bridge, which large operators seem to prefer, at least at this time).</li>
<li>Many operators use MySQL/MariaDB and Galera. Most using this combination, if not all, only write to one node. Usually a virtual IP points to one node and clients read and write to it. I think one operator had managed to get read-only APIs up and running and those work against the read nodes of a Galera cluster. That would be something I would like to do, at least send all reads out to any node, but writes to one node. It was noted that CERN does this for Ceilometer to make sure it doesn’t overload the write APIs. I’ve been looking at some MySQL proxies that can do this, but maybe it’s just extra complexity that I don’t need.</li>
<li>Everyone loves haproxy. I quite like haproxy myself. Some ops prefer it over the $$$ commercial solution they are also using. It’s very powerful and is working well for me, and I, like others, terminate SSL with it.</li>
<li>Most operators have to do some database cleanup. I’m not clear on all the things that need to be cleaned up. There is at least one project, <a href="https://github.com/stackforge/ospurge">ospurge</a>, that might help get some of the way towards all the cleanup jobs that need to happen. 80% of the time it’ll get you 60% of the way.</li>
<li>Every summit and operator meetup has a call for a place to share tools. Every summit and meetup <a href="https://github.com/osops">osops</a> is mentioned and that is where the conversation ends. osops has been around for quite some time but there aren’t many contributions to it. One of the great things about openstack is how you can run it in almost any way you want, but that also means that every openstack install is different, and it makes it somewhat hard to share tools…which is why I think this repo doesn’t get much love.</li>
<li>There was talk about sharing Grafana configs. Then there was the mention that the new Kibana (not Grafana, Kibana) makes it difficult to import/export configs. I’m doing some testing with Grafana and Influxdb for metrics, so that would be great to at least see what others are graphing, if not actually use those graphs.</li>
<li><a href="https://github.com/openstack/dragonflow">Dragonflow</a> was mentioned as a very new project. I don’t know anything about it other than what is says on at the github repo: “Dragonflow - SDN based Distributed Virtual Router for OpenStack Neutron.” Even though I’m not an expert at networking, I am fascinated by SDN.</li>
</ul>
<h2 id="public-cloud">Public cloud</h2>
<p>There were also some concrete steps towards getting a public cloud group going in/around OpenStack. I think this is great and hope to participate as much as possible. There may not be many public clouds based on OpenStack, and some are much larger than others, but I think this is an important sub-group of operators, and is not necessarily the same as the large deployments team. Public clouds definitely have some specific requirements.</p>
<h2 id="short-trip">Short trip</h2>
<p>For me it was a short trip. We were in late Monday night and had to leave about 3PM on the Wednesday, so we missed some of the tail end of the meetup, mostly around Tokyo planning, which was unfortunate but unavoidable due to California traffic and flight times.</p>
<p>Thanks to HP and Godaddy as sponsors and for all the work put into the meetup by the foundation and volunteers. While I’m not a big fan of the Palo Alto [1] location, the meetup certainly met its goal of enabling the exchange of ideas and practical OpenStack experiences.</p>
<p>If you’re wondering, my flight back was great because there was an extra seat beside me, and it’s only a 2.5 hour trip back to sunny Edmonton from overcast SF0. :) Also I read almost all of “The Martian.” If you like NASA then you will read this book in one sitting, it’s a fascinating and thrilling read with tons of science.</p>
<hr />
<p>1: Palo Alto hotels are expensive and you pretty much have to rent a car. It’s great that companies are willing to sponsor the meetup with a location and food and such, but it seemed to me like the costs were just transfered to hotels and rental cars. Then again, a large number of attendees were from California, so maybe it all evens out.</p>
The Layers of OpenStack2015-07-25T00:00:00+00:00http://serverascode.com/2015/07/25/openstack-layers<h1 id="the-layers-of-openstack">The Layers of OpenStack</h1>
<p>I think anyone who has looked into OpenStack has read that it is complicated and difficult to install let alone operate over time. However, that’s not the point of this post–rather the point of this short post is just to discuss what pieces are involved in OpenStack and how I tend to approach deploying it, an approach that I feel simplifies the system somewhat.</p>
<p>Computering is complicated. Sometimes it helps to simplify it from a high level, and I use “layers” to do that. What’s more this model can help people who don’t have to understand every single component of the entire system to get in idea of what it looks like. An OpenStack production system can be very large, especially when considering all the ancilliary infrastructure required.</p>
<p>I do want to note that once it’s deployed the order of the layers is not all that relevant, but I think putting the layers in order prior to deployment can help people understand the components of OpenStack.</p>
<h2 id="prior-to-installation">Prior to installation</h2>
<p>Before installing all kinds of decisions have to be made, things like what server vendor will be used, same for network, datacenter requirements, what OpenStack will look like (eg. are you using Ceph for block and object, booting from volumes, nova network or neutron, neutron with a plugin, etc, etc) but I’m not going to cover any of that, rather I will just simply list what I usually install and in what order.</p>
<p>Before starting these layers I have applied the base OS to every server, and there is basic network connectivity on the managment network that Ansible operates over.</p>
<h2 id="the-layers">The Layers</h2>
<p>I use Ansible to deploy OpenStack. Perhaps that’s why I’ve settled on the layer strategy. Ansible pretty much works in a serial fashion, one task after another, one playbook after another. Ansible is applied “top to bottom” versus something like Puppet where modules are compiled and then applied. So with Puppet order isn’t defined unless it’s specifically defined.</p>
<p>The basic layers are below. Some of the layers are more complicated than others, ie. have more tasks to complete.</p>
<ol>
<li>ssh-keys - Setup operator ssh keys</li>
<li>node-network - Setup more comlicated /etc/network/interfaces</li>
<li>sshd - Setup sshd securely, eg. only listen on specific interfaces, no password logins, etc</li>
<li>baremetal - Some basic common requirements and security settings</li>
<li>rsyslog - Setup rsyslog server and clients</li>
<li>etc-hosts - Configure /etc/hosts</li>
<li>lxc-hosts - Configure servers that will be lxc hosts</li>
<li>lxc-containers - Start various lxc-containers</li>
<li>mariadb-galera - MySQL Galera cluster</li>
<li>haproxy - haproxy does all the API load balancing</li>
<li>rabbitmq-cluster - Rabbit cluster</li>
<li>memcached - Setup memcached servers</li>
<li>openstack-repo - If installing OpenStack from packages, setup the repo (eg. Juno, Kilo, etc)</li>
<li>keystone - Keystone authentication service</li>
<li>swift-common - Next up, Swift because it’s backing Glance</li>
<li>swift-object - Setup Swift storage nodes</li>
<li>swift-ring - Create Swift ring</li>
<li>swift-fetch-ring-files - Obtain the created Swift ring files</li>
<li>swift-distribute-ring-files - Distribute the ring files across all Swift nodes</li>
<li>swift-proxy - Configure Swift-proxy servers</li>
<li>glance - Setup Glance</li>
<li>nova-common - Next up, Nova for compute</li>
<li>nova-controller</li>
<li>nova-compute</li>
<li>neutron-common - Networking!</li>
<li>neutron-controller</li>
<li>neutron-network</li>
<li>neutron-compute</li>
<li>cinder-common - Block storage!</li>
<li>cinder-controller</li>
<li>cinder-storage</li>
<li>heat - And Heat (heat is nice and easy to install)</li>
<li>horizon - Finally the GUI</li>
</ol>
<p>Obviously there are more pieces (metrics, monitoring, cron jobs, backups, alerting, more logging, DNS, etc) but I won’t cover those in this post. And of course there are many other OpenStack projects that could be used (and more every day).</p>
<h2 id="openstack-deployed">OpenStack deployed!</h2>
<p>Now with all those layers laid down, you have an OpenStack system. At this point the layers don’t really exist in a defined order and you are going to be operating this system over a long period of time. And that, my Internet friend, is a whole other story. :)</p>
Dealing with Zombie Cinder Volumes2015-07-15T00:00:00+00:00http://serverascode.com/2015/07/15/cinder-zombie-volumes<h1 id="dealing-with-zombie-cinder-volumes">Dealing with Zombie Cinder Volumes</h1>
<p>For some reason I ended up with a few volumes that were attached to non-existent virtual machines–ie. the vm had been deleted, but cinder thinks it is still attached to the vm. But the vm doesn’t exist so you can’t unattach or delete the volume. Maybe it’s a chicken-egg volume not a zombie volume.</p>
<p>Here’s a query to find these “zombie” volumes. I’m building somewhat on this <a href="http://blog.carlos-spitzer.com/openstack-delete-cinder-orphan-volumes/">blog post</a>. (Don’t tell anyone but this was my first ever join SQL command–I haven’t had to work much with databases.) This join was kind of fun because I had to pull information from both the nova and cinder databases, so note that it is using both the cinder and nova databases and expecting that their names will be “cinder” and “nova” respectively.</p>
<pre>
<code>MariaDB [cinder]> SELECT tn.display_name as 'VM Name', tn.uuid as 'VM UUID', tn.vm_state as 'VM State', tc.status as 'Vol Status', tc.attach_status as 'Vol Attach Status', tc.id as "Vol UUID" FROM cinder.volumes tc JOIN nova.instances tn ON tc.instance_uuid = tn.uuid WHERE tn.vm_state = 'deleted' AND tc.attach_status = 'attached';
+-----------------------------------------+--------------------------------------+----------+------------+-------------------+--------------------------------------+
| VM Name | VM UUID | VM State | Vol Status | Vol Attach Status | Vol UUID |
+-----------------------------------------+--------------------------------------+----------+------------+-------------------+--------------------------------------+
| coolvm1 | 2cf50467-044e-4f6c-8aad-283fb1c18f49 | deleted | in-use | attached | 59a92e86-df60-4046-9cbe-221f9501cc5d |
| coolvm2 | 80f837ec-a076-4116-8443-34c17ff8b363 | deleted | in-use | attached | 92926e7e-8015-449e-893e-e84b4a7a9fdc |
| coolvm3 | 7b6a15b2-b9ad-439b-a05f-acf6af4e7a86 | deleted | in-use | attached | ffc905ad-6655-4e8b-8e21-6322e93773c4 |
+-----------------------------------------+--------------------------------------+----------+------------+-------------------+--------------------------------------+
3 rows in set (0.00 sec)
</code>
</pre>
<p>Once I found all the volumes I considered “zombie” I updated their status manually in the cinder database. This was not much fun from an operator perspective. I think there is a “force_detach” command coming in future cinders.</p>
<pre>
<code>MariaDB [cinder]> update volumes set attach_status='detached',status='available',instance_uuid=NULL where id='6fbd830c-3976-4427-be4b-c4daa11f9f49';
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
</code>
</pre>
<p>I haven’t been able to replicate this issue, so not sure why it happened in the first place.</p>
Rabbitmq Server with SSL/TLS2015-06-23T00:00:00+00:00http://serverascode.com/2015/06/23/rabbitmq-server-ssl<h1 id="rabbitmq-server-with-ssltls">Rabbitmq Server with SSL/TLS</h1>
<p>For some reason I am a glutton for punishment as I try to “TLS enable all the things” which doesn’t always work out. Note that the <a href="https://www.rabbitmq.com/ssl.html">rabbitmq documentation</a> for SSL/TLS is pretty good; I’m not showing here much more than you can get from that, but I thought I’d post it anyway. :)</p>
<p>Anyways, one of the more interesting things I’ve enabled TLS on lately is Rabbitmq. What’s more this is in production right now and is working fine. There is some debate as to whether or not it’s a good idea to do TLS with Rabbitmq, especially if it’s an internal only queue, but I think it’s always best to encrypt when we can. I suppose there is the possibility of performance issues, but I don’t mind throwing hardware at it. I should also note that I’m just doing “over the wire” encryption. The certificates aren’t being used for authentication. (Future work.)</p>
<p>This is an example configuration for a three node Rabbitmq cluster:</p>
<pre>
<code>[
{ssl, [{versions, ['tlsv1.2', 'tlsv1.1']}]},
{rabbit, [
{cluster_nodes, ['rabbit`node2','rabbit`node5']},
{tcp_listeners, []},
{ssl_listeners, [{"192.168.0.12",5671}]},
{ssl_options, [{cacertfile,"/etc/ssl/certs/example.com-intermediate.crt"},
{certfile, "/etc/ssl/private/example.com.crt"},
{keyfile, "/etc/ssl/private/example.com.key"},
{versions, ['tlsv1.2', 'tlsv1.1']}
]}
]}
].
</code>
</pre>
<p>This is the contents of the rabbitmq-env.conf file, not that it should be necessary in most cases. Sometimes I name the node something different than the hostname, or perhaps internal communication only happens on a specific VLAN so it has to listen on a specific interface.</p>
<pre>
<code>export RABBITMQ_NODENAME=rabbit@node2
export RABBITMQ_NODE_IP_ADDRESS=192.168.0.12
</code>
</pre>
<p>Then rabbitmq will be listening on port 5671.</p>
<pre>
<code>ubuntu@node2:/etc/rabbitmq$ sudo lsof -i -nP | grep LISTEN | grep ":5671"
beam.smp 18935 rabbitmq 20u IPv4 165304426 0t0 TCP 192.169.0.12:5671 (LISTEN)
</code>
</pre>
<p>Now any of your applications that are using the rabbitmq queue can connect via TLS on port 5671.</p>
<p>There’s a lot more work to be done here, but it’s a start!</p>
Monitorama 20152015-06-21T00:00:00+00:00http://serverascode.com/2015/06/21/monitorama-2015<h1 id="monitorama-2015">Monitorama 2015</h1>
<p>Last week I was privileged to attend the 2015 Monitorama conference. It’s a great small conference that deals with the area of monitoring, from logging to metrics to stream processing, alerting, people…everything. It’s actually a giant topic.</p>
<p>It’s amazing how many different kinds of conferences there are. Recently I was at the OpenStack Vancouver summit which has about 6000 people and takes over a huge conference center. Compared to Monitorama the summit is a massive, “enterprisey-feeling” event where they have to feed 6000 people lunch. Conversely, at Monitorama in “The Pearl” section of Portland you can just walk out the door and there are tons of restaurants and food trucks.</p>
<h2 id="the-presentations">The Presentations</h2>
<p>Here I’ll just go through some of the presentations I recall. I missed a few presentations because of work, so this isn’t necessarily a list of “the best” presentations or anything like that, just ones that were memorable for me.</p>
<ul>
<li>
<p><a href="https://github.com/Randommood/ZerotoCapacityPlanning">Zero to Capacity Planning</a> (<a href="https://vimeo.com/131377938">video</a>) - If I recall correctly this was the journey the presenter Inés Sombra went on to find out about capacity planning and do something about it. The <a href="https://speakerdeck.com/randommood/zero-to-capacity-planning">slides</a> are online. In order to plan to grow you need to monitor your infrastructure and then decide when to add more capacity. But what does that actually mean? How does it happen?</p>
</li>
<li>
<p>Stephen Boak - <em>I’m a designer and I’m here to help</em> (<a href="https://vimeo.com/131385892">video</a>) - I think there was a lot to learn from this. The first thing anyone does when adding a monitoring solution is make sure there are a bunch of graphs to show people. Who knows what those graphs actually mean or if they are of any use is another matter. (Can’t find the slides online.)</p>
</li>
<li>
<p><em>Observability, Interactivity and Mental Models in Web Operations</em> (<a href="https://vimeo.com/131390945">video</a>) - Benjamin Anderson gave a very interesting talk. Unfortunately I can’t find the slides online. Will update when I can find them. Let’s just say “anthropomorphizing systems.” Update: Video is up now for this talk.</p>
</li>
<li>
<p>Laura Thomson - <a href="https://speakerdeck.com/lauraxt/engineering-happiness">Engineering Happiness</a> (<a href="https://vimeo.com/131484322">video</a>) - Process, software…and people. This presentation went over some ideas around what metrics one could monitor to determine how people are feeling, but not from a creepy perspective, rather looking at things like hours worked or technical debt to try to determine employee happiness (ie. working too much makes people unhappy). We certainly all want to be happy at work and this presentation gave some ideas on how to make that happen.</p>
</li>
<li>
<p>Loris Degioanni - <a href="http://sssslide.com/www.slideshare.net/LorisDegioanni/monitorama-slides">The Dark Art of Container Monitoring</a> (<a href="https://vimeo.com/131495389">video</a>-) Basically, sysdig is amazing and the sysdig monitoring cloud can map your infrastructure and make it zoomable, which drew some gasps from the audience.</p>
</li>
<li>
<p><a href="https://speakerdeck.com/chrissiebrodigan/measuring-hard-to-measure-things">Measuring Hard to Measure Things</a> (<a href="https://vimeo.com/131495388">video</a>-) Chrissie Brodigan gave a great talk on the user research work she does at Github. The talk was really about dealing with people at a macro level to make things better for individuals. She was really focussed on making things better, and in one particular case, making Github Enterprise easier to administrate. One thing I realized is that often oganizations only have surveys to determine how people feel about products and they need demographic information in those surveys to do the math right.</p>
</li>
<li>
<p><a href="http://www.slideshare.net/Librato2015/stream-processing-at-librato">Stream Processing Inside Librato</a> (<a href="https://vimeo.com/131502992">video</a>) - Dave Josephsen gave one of the first talks at Monitorama 2015 on stream processing, essentially comparing stream processing with signal processing using the sound mixer as an example.</p>
</li>
<li>
<p>Dave Josephsen - Lightning talk (<a href="https://vimeo.com/131502995">video</a>) - Dave gave an emotional talk on imposter syndrome, through relating stories of his difficult time in the Marines. It was an amazing presentation full of honesty and vulnerability–two very difficult things to do in the modern world.</p>
</li>
</ul>
<h2 id="technologies">Technologies</h2>
<p>Here are some technologies I wrote down in my notes as the conference went on:</p>
<ul>
<li><a href="http://www.standu.ps">StandUps</a></li>
<li>sysdig</li>
<li>zktraffic</li>
<li>Tinypulse</li>
<li>Bosun</li>
<li>Heka</li>
</ul>
<h2 id="conclusion">Conclusion</h2>
<p>I’m constantly amazed at how organizers can pull off conferences like this; how good they are at dealing with people and trying to make things better in the IT industry. I was also impressed at how honest some of the presenters were in terms of being open about their fears and themselves in general. At the end I kept thinking of what <a href="https://www.youtube.com/watch?v=-U4Pvodwm0U">Big Chris says</a> in <em>Lock Stock and Two Smoking Barrels</em>: “It’s been emotional.”</p>
ucarp Virtual IP Addresses2015-04-05T00:00:00+00:00http://serverascode.com/2015/04/05/ucarp<h1 id="ucarp-virtual-ip-addresses">ucarp Virtual IP Addresses</h1>
<p>I haven’t written a blog post for a while; like everyone else I’m working on other things and haven’t been able to dedicate any time towards blogging. However, on a slow Sunday morning I thought I’d take a quick look at <a href="http://manpages.ubuntu.com/manpages/utopic/man8/ucarp.8.html">ucarp</a> which is a way to provide virtual IPs, ie. IP addresses that can failover to another server, should the one it’s running on stop working.</p>
<h2 id="highly-available-ip-addresses">Highly available IP addresses</h2>
<p>Frankly I don’t have a lot of experience providing highly available IP addresses (from now on I’ll call the virtual IPs or vips, though that’s probably not the right term). There are quite a few ways to achieve vips, such as using technologies like VRRP, Pacemaker, Corosync, Keepalived, ECMP/BGP, etc. All have their pros and cons, some are simpler than others…make your own well-informed decision. :)</p>
<p>For my particular purposes, at this time at least, I chose CARP.</p>
<h2 id="carp">CARP</h2>
<p>There was a big kerfuffle back in the late 90’s about Cisco creating, and patenting, VRRP. OpenBSD was not happy with the situation, and created CARP. I’ve used CARP a lot over the years, especially with OpenBSD firewalls. So when it came time to do highly available virtual IPs with Linux, CARP seemed a good choice. I didn’t want to over-engineer too early, so using something simple like CARP seemed a good strategy.</p>
<p>PS. Use more OpenBSD!</p>
<h2 id="ucarp">ucarp</h2>
<blockquote>
UCARP allows a couple of hosts to share common virtual IP addresses in order
to provide automatic failover. It is a portable userland implementation of the
secure and patent-free Common Address Redundancy Protocol (CARP, OpenBSD’s
alternative to the patents-bloated VRRP).
</blockquote>
<p>In Ubuntu the <a href="http://www.pureftpd.org/project/ucarp">ucarp</a> system/package provides CARP virtual IP capability.</p>
<pre>
<code>$ dpkg --list ucarp
Desired=Unknown/Install/Remove/Purge/Hold
| Status=Not/Inst/Conf-files/Unpacked/halF-conf/Half-inst/trig-aWait/Trig-pend
|/ Err?=(none)/Reinst-required (Status,Err: uppercase=bad)
||/ Name Version Architecture Description
+++-===============================================-============================-============================-===================================================================================================
ii ucarp 1.5.2-1+nmu1ubuntu1 amd64 user-space replacement to VRRP -- automatic IP fail-over
</code>
</pre>
<h2 id="configuration">Configuration</h2>
<p>Once the ucarp package is installed, the /etc/network/interfaces file can be configured to use ucarp.</p>
<p>Below are a couple example sections from a ucarp configured network interface file. Please note that I am using bonding and VLANs as well as ucarp. Bonding and vlans are not required to use ucarp, but it’s fun so why not.</p>
<p>The primary node (node1):</p>
<pre>
<code># internal network
auto bond0.777
iface bond0.777 inet static
vlan-raw-device bond0
address 192.168.1.12
netmask 255.255.252.0
ucarp-vid 1
ucarp-vip 192.168.1.9
ucarp-password SHAREDSECRET
ucarp-advskew 10
ucarp-advbase 1
ucarp-master yes
</code>
</pre>
<p>And here is a secondary (node2):</p>
<pre>
<code># internal network
auto bond0.777
iface bond0.777 inet static
vlan-raw-device bond0
address 192.168.1.13
netmask 255.255.252.0
ucarp-vid 1
ucarp-vip 192.168.1.9
ucarp-password SHAREDSECRET
ucarp-advskew 20
ucarp-advbase 1
ucarp-master no
</code>
</pre>
<p>Once I configured the interfaces, I rebooted all the nodes.</p>
<h2 id="who-has-the-vip">Who has the vip?</h2>
<p>Here’s the output from running ansible across all the nodes looking for the ucarp vip.</p>
<pre>
<code>$ ansible -m shell -a "ip ad sh | grep bond0.777:ucarp" ucarp-node
node1 | success | rc=0 >>
inet 192.168.1.9/32 brd 192.168.1.9 scope global bond0.777:ucarp
node2 | FAILED | rc=1 >>
node3 | FAILED | rc=1 >>
</code>
</pre>
<p>As can be seen above, only one of the nodes has the ucarp vip. If I were to power off node2 one of the other nodes would obtain the vip. If you see more than one node with the same IP then likely ucarp is configured but the ucarp package is not installed.</p>
<h2 id="thoughts-and-future-work">Thoughts and future work</h2>
<p>Right now, to me ucarp’s only limitation is that it’s active/passive. However, ucarp is quite easy to setup and works well. Simplicity helps uptime too.</p>
<p>There are a few things I still have to investigate</p>
<ul>
<li>Dialing in the failover time</li>
<li>Determining if the master should take back the vip when it’s restored</li>
<li>Configuring more than on vip per interface is not straight forward</li>
</ul>
<p>While we are investigating other more complicated active/active HA processes for IP addresses, thanks to its simplicity I’m quite sure parts of my infrastructure will continue to use ucarp.</p>
Trying OSPF with Quagga and OpenBGP2015-02-02T00:00:00+00:00http://serverascode.com/2015/02/02/quagga-openospfd<h1 id="trying-ospf-with-quagga-and-openbgp">Trying OSPF with Quagga and OpenBGP</h1>
<p>I’ve recently being doing some research into Equal Cost Multipath Routing (ECMP) as well as Open Shortest Path First (OSPF).</p>
<p>The first thing that I should note is that I have no idea really what I’m doing…I’m just messing around with OSPF really.</p>
<p>I put together a quick <a href="https://github.com/ccollicutt/ansible-ospf-test">Vagrant + Ansible</a> test setup that uses a single OpenBSD router, two Ubuntu Trusty servers and a Trusty client instance. That means the Vagrantfile I created will setup four virtual machines. I used OpenBSD’s ospfd (part of <a href="http://www.openbgpd.org/">OpenBGP</a>) and <a href="http://www.nongnu.org/quagga/">Quagga</a> on the Ubuntu hosts.</p>
<h2 id="get-started">Get started</h2>
<pre>
<code>you@workstation$ git clone https://github.com/ccollicutt/ansible-ospf-test
you@workstation$ cd ansible-ospf-test
you@workstation$ vagrant up
SNIP!
you@workstation$ $ ansible -m ping all
router | success >> {
"changed": false,
"ping": "pong"
}
client | success >> {
"changed": false,
"ping": "pong"
}
zone0 | success >> {
"changed": false,
"ping": "pong"
}
zone1 | success >> {
"changed": false,
"ping": "pong"
}
you@workstation$ ansible-playbook site.yml
SNIP!
PLAY RECAP ********************************************************************
client : ok=3 changed=1 unreachable=0 failed=0
router : ok=11 changed=8 unreachable=0 failed=0
zone0 : ok=9 changed=7 unreachable=0 failed=0
zone1 : ok=9 changed=7 unreachable=0 failed=0
</code>
</pre>
<h2 id="routes">Routes</h2>
<p>Once that is done we should be able to login to the client and see the default route has changed to 10.0.10.2.</p>
<pre>
<code>curtis# vagrant ssh client
SNIP!
vagrant@client:~$ ip ro sh
default via 10.0.10.2 dev eth1
10.0.2.0/24 dev eth0 proto kernel scope link src 10.0.2.15
10.0.10.0/24 dev eth1 proto kernel scope link src 10.0.10.10
</code>
</pre>
<p>We should be able to ping 172.0.3.10 from the client, and it’ll go through the OpenBSD router, which is at 10.0.10.2.</p>
<pre>
<code>vagrant@client:~$ ping -c 1 -w 1 172.0.3.10
PING 172.0.3.10 (172.0.3.10) 56(84) bytes of data.
64 bytes from 172.0.3.10: icmp_seq=1 ttl=63 time=0.696 ms
--- 172.0.3.10 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 0.696/0.696/0.696/0.000 ms
</code>
</pre>
<p>The zone servers should have their default gateway set to the internal IP of the OpenBSD router.</p>
<pre>
<code>vagrant@zone0:~$ ip ro sh
default via 172.0.1.2 dev eth1
10.0.2.0/24 dev eth0 proto kernel scope link src 10.0.2.15
172.0.1.0/24 dev eth1 proto kernel scope link src 172.0.1.10
</code>
</pre>
<p>The router’s table ends up looking like this:</p>
<pre>
<code>$ route -nv show -inet
Routing tables
Internet:
Destination Gateway Flags Refs Use Mtu Prio Iface Label
default 10.0.2.2 UGS 0 6499 - 8 em0 DHCLIENT 16899
10.0.2/24 link#1 UC 1 0 - 4 em0
10.0.2.2 52:54:00:12:35:02 UHLc 2 1060 - 4 em0
10.0.2.15 08:00:27:53:fe:30 UHLl 0 0 - 1 lo0
10.0.10/24 link#2 UC 0 0 - 4 em1
10.0.10.2 08:00:27:b5:8a:87 UHLl 0 0 - 1 lo0
127/8 127.0.0.1 UGRS 0 4 32768 8 lo0
127.0.0.1 127.0.0.1 UH 1 0 32768 4 lo0
172.0.1/24 link#3 UC 2 0 - 4 em2
172.0.1/24 172.0.1.2 UG 0 0 - 32 em2
172.0.1.2 08:00:27:99:55:cd UHLl 1 0 - 1 lo0
172.0.1.10 08:00:27:e0:98:1b UHLc 1 12 - 4 em2
172.0.1.11 08:00:27:b6:ef:74 UHLc 1 9 - 4 em2
172.0.3.10/32 172.0.1.10 UGP 0 27 - 32 em2
172.0.3.10/32 172.0.1.11 UGP 0 0 - 32 em2
224/4 127.0.0.1 URS 0 0 32768 8 lo0
</code>
</pre>
<h2 id="configuration">Configuration</h2>
<p>Once Ansible has finished, the quagga ospfd.conf file looks like this on both zone servers:</p>
<pre>
<code>$ vagrant ssh zone1
SNIP!
vagrant@zone1:~$ sudo cat /etc/quagga/ospfd.conf
! -*- ospf v10 -*-
![]()
hostname zone1
password zebra
enable password zebra
![]()
interface eth1
![]()
router ospf
router-id 172.0.1.11
network 172.0.1.11/24 area 0.0.0.0
network 172.0.3.0/24 area 0.0.0.0
log file /var/log/quagga/ospfd.log
</code>
</pre>
<p>The ospfd.conf file on the OpenBSD box looks like this:</p>
<pre>
<code>$ sudo cat /etc/ospfd.conf
router-id 5.5.5.5
area 0.0.0.0 {
interface em2 {
}
}
</code>
</pre>
<h2 id="ospf-neighbors">ospf neighbors</h2>
<pre>
<code>$ sudo ospfctl show neighbor
ID Pri State DeadTime Address Iface Uptime
172.0.1.11 1 FULL/BCKUP 00:00:33 172.0.1.11 em2 02:19:25
172.0.1.10 1 FULL/OTHER 00:00:33 172.0.1.10 em2 02:19:25
</code>
</pre>
<h2 id="the-fun-part">The fun part</h2>
<p>Now with all that setup I can start pinging 172.0.3.11, an IP that is on both of the zone servers, then delete it from one and pings will switchover to the other zone server.</p>
<pre>
<code>vagrant@client:~$ cat ping.sh
#!/bin/bash
COUNTER=0
while true; do
if ping -c 1 -w 1 172.0.3.10 > /dev/null; then
echo "$COUNTER - 172.0.3.10 is alive"
else
echo "$COUNTER - 172.0.3.10 is dead"
fi
let COUNTER=COUNTER+1
sleep 1
done
vagrant@client:~$ ./ping.sh
0 - 172.0.3.10 is alive
1 - 172.0.3.10 is alive
2 - 172.0.3.10 is alive
3 - 172.0.3.10 is alive
4 - 172.0.3.10 is alive
5 - 172.0.3.10 is alive
6 - 172.0.3.10 is alive
7 - 172.0.3.10 is alive
8 - 172.0.3.10 is dead
9 - 172.0.3.10 is alive
10 - 172.0.3.10 is alive
11 - 172.0.3.10 is alive
12 - 172.0.3.10 is alive
13 - 172.0.3.10 is alive
^C
</code>
</pre>
<p>The part where we cat 172.0.3.10 being dead is when I drop it on the zone server currently being used by the OpenBSD router table.</p>
<pre>
<code>vagrant@zone1:~$ sudo ip add del 172.0.3.10/32 dev eth1
</code>
</pre>
<p>Routing table looks like this now:</p>
<pre>
<code># route -nv show -inet | grep "172.0.3.10"
172.0.3.10/32 172.0.1.10 UGP 0 9 - 32 em2
</code>
</pre>
<h2 id="tcpdump-and-ospf">tcpdump and ospf</h2>
<p>Dumping OSPF is pretty easy…</p>
<pre>
<code># tcpdump -n -e -ttt -i em2 proto ospf
tcpdump: listening on em2, link-type EN10MB
tcpdump: WARNING: compensating for unaligned libpcap packets
Feb 02 23:22:47.527622 08:00:27:b6:ef:74 01:00:5e:00:00:05 0800 78: 172.0.1.11 > 224.0.0.5: OSPFv2-hello 44: rtrid 172.0.1.11 backbone [tos 0xc0] [ttl 1]
Feb 02 23:22:47.527988 08:00:27:99:55:cd 01:00:5e:00:00:05 0800 86: 172.0.1.2 > 224.0.0.5: OSPFv2-hello 52: rtrid 5.5.5.5 backbone dr 172.0.1.2 bdr 172.0.1.10 [tos 0xc0] [ttl 1]
Feb 02 23:22:47.528136 08:00:27:99:55:cd 01:00:5e:00:00:05 0800 94: 172.0.1.2 > 224.0.0.5: OSPFv2-ls_upd 60: rtrid 5.5.5.5 backbone [tos 0xc0] [ttl 1]
SNIP!
</code>
</pre>
<h2 id="issues">Issues</h2>
<ul>
<li>I could not get md5/crypt authentication working between the OpenBSD server running ospfd (part of <a href="http://www.openbgpd.org/">OpenBGP</a>) and <a href="http://www.nongnu.org/quagga/">Quagga</a>. Not sure what the problem was, there are no examples I could find of getting this working. Ran out of time to test, so for now there is no authentication.</li>
</ul>
<h2 id="ping-fun">Ping fun</h2>
<p>So that was a lot of work to do a simple ping. Kinda fun though. I haven’t done a lot with networking, but as I work more with systems such as OpenStack and containers and such I realize how important it is and how much I’m missing out by not knowing more. This was a nice, quick little foray into OSPF.</p>
<p>I don’t know how much anyone will get from reading this post, but I did learn a few things myself, and perhaps at least it’ll show that getting a quick OSPF environment up for playing around with isn’t that difficult. (Though perhaps interacting between Linux and Quagga and OpenBSD and OpenBGP isn’t that easy, maybe I should have just gone 100% Ubuntu for this example.)</p>
<p>I had hoped to learn a bit about ECMP as well, but that didn’t quite materialize. OpenBSD does support ECMP, but I’m not sure how it would work in this example. Certainly with OpenBSD it’s possible to route over multiple equal interfaces; most of the examples are for when you have multiple uplinks, eg. more than one Internet provider.</p>
<p>Hopefully I don’t lead anyone down the wrong path with this blog post, but I like to write up little projects like this to help me determine what I learned and what I did not. Sometimes you get into something to find out how much you don’t know. :)</p>
Tinc VPN (and Ansible)2015-01-29T00:00:00+00:00http://serverascode.com/2015/01/29/tinc-vpn-ansible<h1 id="tinc-vpn-and-ansible">Tinc VPN (and Ansible)</h1>
<p>VPNs are a pain. The more I work with technology the more I see how some things like VPNs are just poor constructs and are, in a way, workarounds. Maybe that’s all IT is…workarounds. I don’t know. This is philosophical. At any rate, VPNs are difficult to setup, secure, and use, so sometimes it’s fun to play with technologies that try to make things easier, and I think tinc fits into that category. Would I use it in production? Probably not, but it’s still good to take a look at other implementations and see what can be done.</p>
<h2 id="tinc">Tinc</h2>
<p>I think the most interesting thing about <a href="http://www.tinc-vpn.org/">tinc</a> is that it sets up a mesh.</p>
<blockquote>
<p>Regardless of how you set up the tinc daemons to connect to each other, VPN traffic is always (if possible) sent directly to the destination, without going through intermediate hops.</p>
</blockquote>
<p>Also, it’s easy to extend.</p>
<blockquote>
<p>When you want to add nodes to your VPN, all you have to do is add an extra configuration file, there is no need to start new daemons or create and configure new devices or network interfaces</p>
</blockquote>
<p>So those are a couple of good reasons to try out tinc.</p>
<h2 id="tinc-with-ansible">Tinc with Ansible</h2>
<p>I was playing around with tinc a few days ago and came up with an <a href="https://github.com/ccollicutt/ansible-tinc">Ansible playbook</a> to setup a tinc VPN between several Ubuntu Trusty servers.</p>
<p>Right now I have four virtual machines running in the same OpenStack infrastructure, which is a FlatDHCP system, so the tenants don’t share a private network…unless we set one up for them with Tinc. (This is not something you’d normally want for production systems…I don’t think, I’m just messin’ around.)</p>
<pre>
<code>curtis@parker:~/tinc-testing$ cat hosts
trusty1 ansible_ssh_host=x.y.z.21
trusty2 ansible_ssh_host=x.y.z.22
trusty3 ansible_ssh_host=x.y.z.23
trusty4 ansible_ssh_host=x.y.z.24
</code>
</pre>
<p>I can ping all those with Ansible.</p>
<pre>
<code>curtis@parker:~/tinc-testing$ ansible -m ping all
trusty3 | success >> {
"changed": false,
"ping": "pong"
}
trusty4 | success >> {
"changed": false,
"ping": "pong"
}
trusty1 | success >> {
"changed": false,
"ping": "pong"
}
trusty2 | success >> {
"changed": false,
"ping": "pong"
}
</code>
</pre>
<p>And I can run the Ansible playbook that sets up one VPN, called “vpnone.”</p>
<pre>
<code>curtis@parker:~/tinc-testing$ ansible-playbook site.yml
SNIP!
PLAY RECAP ********************************************************************
trusty1 : ok=17 changed=1 unreachable=0 failed=0
trusty2 : ok=17 changed=1 unreachable=0 failed=0
trusty3 : ok=17 changed=1 unreachable=0 failed=0
trusty4 : ok=17 changed=1 unreachable=0 failed=0
</code>
</pre>
<p>Now Tinc has setup a tun0 on each node.</p>
<pre>
<code>curtis@parker:~/tinc-testing$ ansible -a "ip ad sh tun0" all
trusty3 | success | rc=0 >>
4: tun0: <POINTOPOINT,MULTICAST,NOARP,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UNKNOWN group default qlen 500
link/none
inet 10.0.0.23/24 scope global tun0
valid_lft forever preferred_lft forever
trusty2 | success | rc=0 >>
4: tun0: <POINTOPOINT,MULTICAST,NOARP,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UNKNOWN group default qlen 500
link/none
inet 10.0.0.22/24 scope global tun0
valid_lft forever preferred_lft forever
trusty1 | success | rc=0 >>
4: tun0: <POINTOPOINT,MULTICAST,NOARP,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UNKNOWN group default qlen 500
link/none
inet 10.0.0.21/24 scope global tun0
valid_lft forever preferred_lft forever
trusty4 | success | rc=0 >>
4: tun0: <POINTOPOINT,MULTICAST,NOARP,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UNKNOWN group default qlen 500
link/none
inet 10.0.0.24/24 scope global tun0
valid_lft forever preferred_lft forever
</code>
</pre>
<p>And I can ping nodes from one another. In this example I just ping 10.0.0.24 from all four nodes.</p>
<pre>
<code>curtis@parker:~/tinc-testing$ ansible -m shell -a "ping -c 1 -w 1 10.0.0.24" all
trusty2 | success | rc=0 >>
PING 10.0.0.24 (10.0.0.24) 56(84) bytes of data.
64 bytes from 10.0.0.24: icmp_seq=1 ttl=64 time=0.685 ms
--- 10.0.0.24 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 0.685/0.685/0.685/0.000 ms
trusty4 | success | rc=0 >>
PING 10.0.0.24 (10.0.0.24) 56(84) bytes of data.
64 bytes from 10.0.0.24: icmp_seq=1 ttl=64 time=0.029 ms
--- 10.0.0.24 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 0.029/0.029/0.029/0.000 ms
trusty3 | success | rc=0 >>
PING 10.0.0.24 (10.0.0.24) 56(84) bytes of data.
64 bytes from 10.0.0.24: icmp_seq=1 ttl=64 time=0.501 ms
--- 10.0.0.24 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 0.501/0.501/0.501/0.000 ms
trusty1 | success | rc=0 >>
PING 10.0.0.24 (10.0.0.24) 56(84) bytes of data.
64 bytes from 10.0.0.24: icmp_seq=1 ttl=64 time=0.702 ms
--- 10.0.0.24 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 0.702/0.702/0.702/0.000 ms
</code>
</pre>
<p>By default the playbook sets up “vpnone” but the name is configurable. But it only does one VPN right now, though tinc can support many.</p>
<pre>
<code>ubuntu@trusty1:~$ ls /etc/tinc/vpnone/
hosts rsa_key.priv tinc.conf tinc-down tinc-up
ubuntu@trusty1:~$ ls /etc/tinc/vpnone/hosts
trusty1 trusty2 trusty3 trusty4
ubuntu@trusty1:~$ ls /etc/tinc/
nets.boot vpnone
</code>
</pre>
<h2 id="firewall-rules">Firewall rules</h2>
<p>I should note that tcp/udp on port 655 needs to be open between the nodes.</p>
<h2 id="so-there-you-go">So there you go</h2>
<p>If you want a VPN setup between several hosts, then tinc is a good way to do that, and if you want to use my <a href="https://github.com/ccollicutt/ansible-tinc">playbook</a> to automatically setup a single vpn between several hosts, then that’d be great. The playbook is not perfect, so if you see something you’d like changed, just let me know or send a pull request. :)</p>
<p>Happy tincing!</p>
Ansible Custom Facts2015-01-27T00:00:00+00:00http://serverascode.com/2015/01/27/ansible-custom-facts<p><em>(<a href="http://apod.nasa.gov/apod/ap150127.html">nasa image</a></em>)</p>
<h1 id="ansible-custom-facts">Ansible Custom Facts</h1>
<p>I like Ansible. It’s not perfect but nothing is. Recently I was playing around with the <a href="https://github.com/ccollicutt/ansible-tinc">tinc vpn</a> system and wanted a way to set a custom fact per virtual machine based on the vms public ip address. I figured the best way to do that would be to setup a custom fact. It turns out there isn’t that much documentation on just how to do that, or I simply can’t find it. So I’m going to describe what I did in order to setup and use a custom fact.</p>
<h2 id="a-bash-script">A bash script</h2>
<p>I just wanted a simple script to parse the ip address of the server and return a private ip based on the last octet of the address.</p>
<p>This is the script I ended up using.</p>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="c">#!/bin/bash</span>
<span class="nv">IP_INDEX</span><span class="o">=</span><span class="sb">`</span><span class="nb">hostname</span> <span class="nt">-i</span> | <span class="nb">cut</span> <span class="nt">-f</span> 4 <span class="nt">-d</span> <span class="s2">"."</span><span class="sb">`</span>
<span class="nb">cat</span> <span class="o"><<</span><span class="no">EOF</span><span class="sh">
{
"vpn_ip" : "10.0.0.</span><span class="nv">$IP_INDEX</span><span class="sh">"
}
</span><span class="no">EOF
</span></code></pre></div></div>
<p>Using ansible I put that file into the /etc/ansible/facts.d directory. Note it has to be executable, return json, and end with the .fact extension.</p>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code>ubuntu@trusty2:~<span class="nv">$ </span><span class="nb">cd</span> /etc/ansible/facts.d/
ubuntu@trusty2:/etc/ansible/facts.d<span class="nv">$ </span>./tinc_facts.fact
<span class="o">{</span>
<span class="s2">"vpn_ip"</span> : <span class="s2">"10.0.0.22"</span>
<span class="o">}</span>
</code></pre></div></div>
<p>Pretty simple so far.</p>
<h2 id="loading-the-custom-fact">Loading the custom fact</h2>
<p>So, the <em>first time</em> that file is loaded onto the server Ansible setup won’t have it yet (unless it was loaded up in a previous role) so if you do load the facts file in the same role you’ll have to use setup in the task list to load the custom fact.</p>
<p>Here’s a snippet of my playbook. It’s creating the facts.d directory, copying over the script, and finally re-running setup with the ansible_local filter.</p>
<p>I should be registering a variable and only reload the ansible_local if the facts.d scripts have changed on this particular run.</p>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code>- name: ensure custom facts directory exists
file: <span class="o">></span>
<span class="nv">path</span><span class="o">=</span>/etc/ansible/facts.d
<span class="nv">recurse</span><span class="o">=</span><span class="nb">yes
</span><span class="nv">state</span><span class="o">=</span>directory
- name: <span class="nb">install </span>custom fact module <span class="k">for </span>IP address
template: <span class="o">></span>
<span class="nv">src</span><span class="o">=</span>tinc_facts.sh.j2
<span class="nv">dest</span><span class="o">=</span>/etc/ansible/facts.d/tinc_facts.fact
<span class="nv">mode</span><span class="o">=</span>0755
- name: reload ansible_local
setup: <span class="nv">filter</span><span class="o">=</span>ansible_local
</code></pre></div></div>
<p>Otherwise, on the next Ansible run it’ll be available.</p>
<h2 id="using-the-fact">Using the fact</h2>
<p>It seems as though the fact gets loaded into the ansible_local namespace under the name of the name of the fact script.</p>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="nv">$ </span>ansible <span class="nt">-m</span> setup trusty2 | <span class="nb">grep</span> <span class="nt">-A</span> 4 ansible_local
<span class="s2">"ansible_local"</span>: <span class="o">{</span>
<span class="s2">"tinc_facts"</span>: <span class="o">{</span>
<span class="s2">"vpn_ip"</span>: <span class="s2">"10.0.0.22"</span>
<span class="o">}</span>
<span class="o">}</span>,
</code></pre></div></div>
<p>I use the fact like this in my playbook.</p>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code>- name: ensure subnet ip address is properly <span class="nb">set </span><span class="k">in </span>tinc host file
lineinfile: <span class="o">></span>
<span class="nv">dest</span><span class="o">=</span>/etc/tinc/<span class="o">{{</span> vpn_name <span class="o">}}</span>/hosts/<span class="o">{{</span> ansible_hostname <span class="o">}}</span>
<span class="nv">line</span><span class="o">=</span><span class="s2">"Subnet = {{ ansible_local.tinc_facts.vpn_ip }}/32"</span>
<span class="nv">create</span><span class="o">=</span><span class="nb">yes
</span>notify:
- restart tinc
</code></pre></div></div>
<p>And there we go, relatively simple custom facts for Ansible. Now we can do all sorts of silly things like make new ips based on old ips. haha.</p>
Non-Cartesian OpenStack2015-01-25T00:00:00+00:00http://serverascode.com/2015/01/25/non-cartesian-openstack<p><em>(<a href="https://en.wikipedia.org/wiki/Gaston_Bachelard">Gaston Bachelard</a></em>)</p>
<h1 id="non-cartesian-openstack">Non-Cartesian OpenStack</h1>
<p>Recently I gave the same talk twice, once at the Calgary OpenStack meetup and the other at a lunch and learn at a Vancouver based IT company.</p>
<p>In the talk I discuss quite a few things, from trying to answer the question as to what OpenStack is, to my <a href="https://github.com/ccollicutt/simplestack">SimpleStack</a> automated deployment, to armchair philosophy. These topics are related to a central theme of simplicty, complication, and complexity, especially around the idea that OpenStack is difficult to define and deploy.</p>
<p>Some examples of thoughts on complexity:</p>
<ul>
<li>At the recent Edmonton Ruby meetup I was talking to someone about what I do for a living (which is essentially work with OpenStack) and they said, “oh yeah, isn’t that that thing that’s really complicated to install?”</li>
<li>As I write this there is a <a href="http://www.gossamer-threads.com/lists/OpenStack/operators/43442">small conversation</a> on the OpenStack-operators list about what a small OpenStack installed (three to five compute nodes) would look like. (Nobody seems to really know.)</li>
<li>People who I follow on twitter who often say things like “computers are hard” or “how is this [computer] even working?” These are sentiments I can certainly relate to.</li>
</ul>
<h2 id="openstack-structure-reform">OpenStack Structure Reform</h2>
<p>OpenStack has recently decided, or at least I think the technical committee has decided, that their current model of defining components of OpenStack as either <a href="http://docs-draft.OpenStack.org/04/138504/5/check//gate-governance-docs/db0e837//doc/build/html/resolutions/20141202-project-structure-reform-spec.html">integrated or incubating is not working</a>.</p>
<blockquote>
<p>First, the integrated release as it stands today is not a useful product for our users…Skilled operators aren’t deploying “the integrated release”: they are picking and choosing between components they feel are useful. New users, however, are presented with a complex and scary “integrated release” as the thing they have to deploy and manage: this inhibits adoption, and this inhibits the adoption of a slice of OpenStack that could serve their need.</p>
</blockquote>
<h2 id="non-cartesian">Non-Cartesian</h2>
<p>While staying in Vancouver I went into a local used book store. I needed something to read. I’ve always wanted to know more about philosophy and who some great thinkers are and their main thesis. While wandering around the store and I found the book <a href="http://www.abebooks.com/book-search/isbn/0415074088/">Fifty Key Contemporary Thinkers</a> and decided that would be a good place to start.</p>
<p>The first person discussed in that book is Bachelard. On page five, author Lechte provides this passage:</p>
<blockquote>
<p>Whereas Descartes had argued that to progress, thought had to start from the point of clear and simple ideas, Bachelard charges that there are no simple ideas, only complexities.</p>
</blockquote>
<p>Lechte further describes this as Bachelard’s anti-Cartesian stance, and goes on to say that Bachelard suggests:</p>
<blockquote>
<p>…that reality is never simple, and that in the history of science attempts to achieve simplicity…have invariable turned out to be over-simplification.</p>
</blockquote>
<p><img src="/img/continuum.jpg" alt="" /></p>
<h2 id="rejection-of-over-simplification">Rejection of over-simplification</h2>
<p>I think what has happened in OpenStack recently is the realization that trying to simplify the definition of what it is (ie. all of the “integrated components”) isn’t working and doesn’t work. And, I think, despite not knowing much about philosophy and epistemology, that they are moving in the same general philosophical direction as some of Bachelard’s work.</p>
<p>While I’m not even worthy of the title of armchair philosopher, I do think it’s interesting to think of how we could consider technology in the same way that epistemologists think about science, and further, that trying to distill a (over?) complicated system like OpenStack down to a simple definition will likely fail.</p>
<p>I end this blog post with a picture of the coordinates of an OpenStack system, so that you can easily find it. :)</p>
<p><img src="/img/coordinates.jpg" alt="" /></p>
OpenStack - Bridge not replying to ARP Requests2015-01-21T00:00:00+00:00http://serverascode.com/2015/01/21/bridge-not-replying-arp<p><em>(a super simple diagram to give you an idea of the network layout)</em></p>
<h1 id="openstack---bridge-not-replying-to-arp-requests">OpenStack - Bridge not replying to ARP Requests</h1>
<p>I’ve been working on my <a href="https://github.com/ccollicutt/simplestack">SimpleStack</a> OpenStack install lately. This design currently uses a FlatDHCP nova-network.</p>
<p>I have a couple of hardware servers that I’m deploying it on at work, and I was having a ton of trouble with the public and flat interface being able to receive arp requests, but not sending them back.</p>
<p>It turns out the answer was simple: <strong>the vlan coming down the port to the interface was tagged.</strong></p>
<p>This is part of the nova.conf file:</p>
<pre>
<code>flat_network_bridge = br100
flat_interface = em2
public_interface = em2
</code>
</pre>
<p>Here’s some ARP traffic off the em2 interface.</p>
<pre>
<code>curtis@compute1:~$ sudo tcpdump -n -e -ttt -i br100 arp
00:00:00.888602 5c:5e:ab:d9:e0:f0 > ff:ff:ff:ff:ff:ff, ethertype 802.1Q (0x8100), length 60: vlan 601, p 0, ethertype ARP, Request who-has x.y.z.22 tell x.y.z.18, length 42
00:00:00.900232 5c:5e:ab:d9:e0:f0 > ff:ff:ff:ff:ff:ff, ethertype 802.1Q (0x8100), length 60: vlan 601, p 0, ethertype ARP, Request who-has x.y.z.22 tell x.y.z.18, length 42
00:00:00.600620 5c:5e:ab:d9:e0:f0 > ff:ff:ff:ff:ff:ff, ethertype 802.1Q (0x8100), length 60: vlan 601, p 0, ethertype ARP, Request who-has x.y.z.22 tell x.y.z.18, length 42
00:00:00.703113 5c:5e:ab:d9:e0:f0 > ff:ff:ff:ff:ff:ff, ethertype 802.1Q (0x8100), length 60: vlan 601, p 0, ethertype ARP, Request who-has x.y.z.22 tell x.y.z.18, length 42
</code>
</pre>
<p>As you can see, we have “ethertype 802.1Q” and vlan 601. It took me quite a while to notice that, but once I did everything made sense.</p>
<p>The arp requests were getting to em2, but because they were tagged with vlan 601 the server wouldn’t reply because it wasn’t setup to use that vlan.</p>
<p>As soon as I added the 601 vlan and configured nova to use it, everything started working.</p>
<pre>
<code>curtis@compute1:~$ sudo modprobe 8021q
curtis@compute1:~$ sudo vconfig add em2 601
Added VLAN with VID == 601 to IF -:em2:-
curtis@compute1:~$ sudo ifconfig em2.601 up
</code>
</pre>
<p>The I changed the nova.conf file to look like this:</p>
<pre>
<code>flat_network_bridge = br100
flat_interface = em2.601
public_interface = em2.601
</code>
</pre>
<p>Then I restarted nova-network.</p>
<p>Finally I ended up with this bridge config:</p>
<pre>
<code>curtis@compute1:/etc/nova# sudo brctl show
bridge name bridge id STP enabled interfaces
br100 8000.782bcb617008 no em2.601
vnet0
virbr0 8000.000000000000 yes
</code>
</pre>
<p>And I was able to have my flat network, which is all public IPs, working.</p>
<h2 id="tagged-and-untagged-getting-lost-in-details">Tagged and untagged, getting lost in details</h2>
<p>Now, there’s no reason (in this situation) for this port to have the vlan tagged on it, we just need that one network on the physical interface, but it was tagged and in this case it was just easier to go with that then to try to have any changes made on the network operator side.</p>
<p>For a while we were chasing red herrings on this problem, and finally I just took a hard look at the arp packets and realized it was a tagged vlan. Obvious now, but it took a while to figure out just how obvious.</p>
<p>It was a good feeling to realize the problem, fix it, and to get SimpleStack up and running on physical computers with public IPv4 addresses so that I can continue to experiment with small OpenStack installations. I’ve already realized this network design probably wouldn’t work for anyone who doesn’t have a lot of IPv4 addresses or can’t support IPv6. IPv6 would be so great for this. When will we really start using it…ISPs I’m looking at you…</p>
Providing gems as debs using fpm and Package Cloud2014-12-13T00:00:00+00:00http://serverascode.com/2014/12/13/building-debs-from-gems<h1 id="providing-gems-as-debs-using-fpm-and-package-cloud">Providing gems as debs using fpm and Package Cloud</h1>
<p>There are a lot of package managers.</p>
<p>Some of them provide binary packages, which are pre-compiled. But others don’t, especially ones around programming language packages such as pip (python) and rubygems (ruby). Basically if you want to install a pip or gem package you have to have a build environment (ie. compilers, make, etc) installed on each instance or container in order to install the packages. That increases the size of images, and magnifies the attack surface of the instance/container, among other things.</p>
<h2 id="before-i-get-too-far">Before I get too far…</h2>
<p>Many of the pip and gem packages are available already as OS packages. Usually pip packages start with “python-“ and ruby gems with “ruby-“. But not all of them are packaged. Most of the common packages can be installed with apt/yum, but not all. I did a brief search and <a href="http://askubuntu.com/questions/431780/apt-get-install-vs-pip-install">this page</a> listed a few good differences between getting python libraries via pip and apt-get.</p>
<h2 id="sensu">Sensu</h2>
<p>Recently I went to install sensu. Sensu provides a repository that provides the base sensu install. (It gets installed in /opt, as an “omnibus” package.)</p>
<p>However, if you want to use plugins, many of them use the “sensu-plugins” gem, so that needs to be installed. The instructions say that you don’t need to install the sensu-plugins gem if you’re using the omnibus package.</p>
<blockquote>
<p>If you have installed Sensu from the omnibus packages you can continue to installing the check-procs.rb plugin. Otherwise we need to install the sensu-plugin gem which has various helper classes used by many of the community plugins.</p>
</blockquote>
<p>Unfortunately, I believe that would mean ensuring plugins are called using the “embedded” ruby.</p>
<p>Example:</p>
<pre>
<code>ubuntu@curtis-sensu:/etc/sensu/plugins$ /opt/sensu/embedded/bin/ruby check-procs.rb
CheckProcs OK: Found 83 matching processes
</code>
</pre>
<p>But without the sensu-plugin gem…</p>
<pre>
<code>ubuntu@curtis-build:/etc/sensu/plugins$ ./check-procs.rb
/usr/lib/ruby/1.9.1/rubygems/custom_require.rb:36:in `require': cannot load such file -- sensu-plugin/check/cli (LoadError)
from /usr/lib/ruby/1.9.1/rubygems/custom_require.rb:36:in `require'
from ./check-procs.rb:29:in `<main>'
</code>
</pre>
Most plugins will use the ruby pointed to by env.
<pre>
<code>ubuntu@curtis-sensu:/etc/sensu/plugins$ head -1 check-procs.rb
#!/usr/bin/env ruby
</code>
</pre>
I guess one question would be as to what environment plugin developers are writing plugins for--a base OS ruby or the embedded ruby in Sensu's omnibus. Probably the OS ruby would be specified, but that would depend on your developers and organization. The plugin files could be altered to use the embedded ruby.
Thus, I decided to package up that gem.
## Packaging gems with fpm
[fpm](https://github.com/jordansissel/fpm) to the rescue!
One of the first things I do at any job is setup a packaging server. Typically I'm the only one that uses it, but I still do it. :)
For my build/packaging server I installed:
* ruby-dev
* gcc
* make
from the OS packages, and:
* fpm
* package_cloud
from rubygems.
I've been using [packagecloud](http://packagecloud.io) for a while now, nd it's a very handy and easy way to setup your own custom repository. Once you build a pacakge you can just use the package cloud CLI to push that package up to your own "cloudy" repo. But I'm getting ahead of myself...
[fpm](https://github.com/jordansissel/fpm) is a great tool to easily build packages. You can tell the developer of fpm takes this very seriously by his all caps usage. :)
> It helps you build packages quickly and easily (Packages like RPM and DEB formats). FUNDAMENTAL PRINCIPLE: IF FPM IS NOT HELPING YOU MAKE PACKAGES EASILY, THEN THERE IS A BUG IN FPM.
Using fpm we can build debian packages from gems.
First, install the gems.
<pre>
<code>ubuntu@curtis-build:~$ gem install --no-ri --no-rdoc --install-dir /tmp/gems sensu-plugin
</code>
</pre>
Next, build the debs using fpm.
<pre>
<code>ubuntu@curtis-build:~$ mkdir debs; cd debs
ubuntu@curtis-build:~/debs$ find /tmp/gems/cache -name '*.gem' | xargs -rn1 fpm -d ruby -s gem -t deb
</code>
</pre>
That will build all the dependencies of sensu-plugin as well.
<pre>
<code>ubuntu@curtis-build:~/debs$ ls
rubygem-json_1.8.1_amd64.deb rubygem-sensu-plugin_1.1.0_all.deb
rubygem-mixlib-cli_1.5.0_all.deb
</code>
</pre>
## Package cloud
Next we can push those debs to package cloud.
<pre>
<code>ubuntu@curtis-build:~/debs$ package_cloud push serverascode/custom/ubuntu/trusty rubygem-mixlib-cli_1.5.0_all.deb
</code>
</pre>
I do that will all the gems in that dir. Now they show up in my [package cloud repo](https://packagecloud.io/serverascode/custom).
Package cloud has some examples as to how configure your custom repos on your server, but for me it basically looks like this:
<pre>
<code>ubuntu@curtis-sensu:/etc/apt/sources.list.d$ cat packagecloud_io_serverascode_custom_ubuntu.list
deb https://packagecloud.io/serverascode/custom/ubuntu/ trusty main
</code>
</pre>
(Don't forget the package cloud GPG key too.)
I usually use Ansible to setup my servers, including configuring this repository. Below is a snippet from a playbook.
<pre>
<code>- name: install the serverascode custom repository
apt_repository: >
repo='deb https://packagecloud.io/serverascode/custom/ubuntu/ trusty main'
state=present
- name: ensure the packagecloud reposity gpg key is installed
apt_key: >
url=https://packagecloud.io/gpg.key
state=present
</code>
</pre>
Now that the repo is setup, I can install my custom built packages.
<pre>
<code>ubuntu@curtis-build:~/debs$ apt-cache policy rubygem-sensu-plugin
rubygem-sensu-plugin:
Installed: 1.1.0
Candidate: 1.1.0
Version table:
*** 1.1.0 0
500 https://packagecloud.io/serverascode/custom/ubuntu/ trusty/main amd64 Packages
100 /var/lib/dpkg/status
</code>
</pre>
And, the ultimate goal, run the sensu plugin.
<pre>
<code>ubuntu@curtis-build:/etc/sensu/plugins$ ./check-procs.rb
CheckProcs OK: Found 68 matching processes
</code>
</pre>
## Conclusion
So, certainly there are still some issues here. I haven't used this process a lot yet, but I plan on doing a lot more with it because I don't want to be installing compilers and other build tools in every virtual machine or (especially) containers. Containers, as an example, should be as small as is reasonably possible, which I think is going to preclude any build tools. Also there are some security concerns with having build tools in the OS, and a few other infosec issues that I should refamiliarize myself with.
At any rate, at some point most systems administrators will need to package their own debs or rpms, and using fpm and [Package Cloud](http://packagecloud.io) to package and provide repositories is quick and painless.
</main></code></pre>
Inaugural Vancouver OpenStack and Ansible Meetups2014-12-06T00:00:00+00:00http://serverascode.com/2014/12/06/vancouver-openstack-ansible-meetups<p><small><em>(openstack meetup at the plenty of fish “aquarium”)</em></small></p>
<h1 id="inaugural-vancouver-openstack-and-ansible-meetups">Inaugural Vancouver OpenStack and Ansible Meetups</h1>
<p>Last week I was lucky enough to be in Vancouver for the inaugural <a href="http://www.meetup.com/Vancouver-OpenStack-Meetup/">Vancouver OpenStack meetup</a>, sponsored by <a href="http://auro.io">Auro</a> and Plenty of Fish, as well as a pre-planning session for the <a href="http://www.meetup.com/Vancouver-Ansible-Meetup/">Vancouver Ansible meetup</a>.</p>
<h2 id="vancouver-openstack-meetup">Vancouver OpenStack Meetup</h2>
<p>The first Vancouver OpenStack meetup was fun and had a good turnout.</p>
<p>Being from Edmonton, where the tech community is a bit smaller, I would have been happy with a few people. In fact that last AWS meetup I went to in Edmonton had about four people, and I don’t really use AWS at all. I think there was about 30 people in attendance at the Vancouver meetup, so that is a great start.</p>
<p>Unfortunately one of the speakers had to cancel on account of illness, but we still managed to fill up the time with a <a href="http://www.slideshare.net/seanmwinn/vancouver-open-stack-meetup-presentation">presentation</a> from Sean Winn of EMC/Cloudscaling as well as from Auro’s Matt Mckinney.</p>
<p>Sean gave an introduction to OpenStack, discussed how to contribute code, and also how to find a career related to OpenStack. (I’m hoping contributing has become easier because about 18 months ago someone spent six hours helping me through the process of getting setup in the workflow and we still didn’t complete it.)</p>
<p>Matt discussed the results of the recent <a href="http://superuser.openstack.org/articles/openstack-user-survey-insights-november-2014">OpenStack User survey</a> and what the results might mean for OpenStack users. His slides are <a href="http://www.slideshare.net/mattm948/auro-cloud-computing">here</a>. What I got from the survey results is that OpenStack is being used in production more and there are still several pain points in doing that, especially around networking.</p>
<p>Given the next OpenStack summit is in Vancouver, it’s good timing to get the OpenStack meetups going.</p>
<h2 id="vancouver-ansible-meetup-pre-planning">Vancouver Ansible Meetup Pre-planning</h2>
<p>Again, being from Edmonton, I’m not sure we could even support an Ansible meetup right now. But there were seven or eight people just at the Vancouver pre-planning session, so that was great.</p>
<p>Part of the planning was deciding where to host the event, and luckly Vancouver has several companies and organizations that have good social spaces for this kind of meetup. In fact it’s almost becoming common for some of the larger startups to create a social space for events like this, eg. Hootsuite, OpenDNS, Plenty of Fish, etc.</p>
<p>Once the planning session was over some of us hung out for a bit and just talked about technology, which is something I don’t actually do very much. We talked about all kinds of things, such as how FreeBSD might be due for a renaissance, about how SmartOS is actually pretty cool and probably doesn’t get used enough (Joyent <a href="https://www.joyent.com/blog/sdc-and-manta-are-now-open-source">open sourced</a> their data center management tool as well), and a several other technologies. Also, pretty much every operator is in awe of <a href="http://www.brendangregg.com/">Brendan Gregg</a>.</p>
<p>I also tried to get the group to call the meetup the “Vansible meetup” but I don’t think that was generally accepted. :)</p>
<h2 id="conclusion">Conclusion</h2>
<p>While I will be in Edmonton most of the time I hope to make it out to a few of the Vancouver OpenStack and Ansible meetups over the next while.</p>
<h2 id="ps-calgary-openstack-meetup">PS. Calgary OpenStack Meetup</h2>
<p>I think Calgary will be having an OpenStack meetup sometime in January, and I will likely make the three hour trek down to attend that too.</p>
SimpleStack2014-11-14T00:00:00+00:00http://serverascode.com/2014/11/14/simple-openstack-simplestack<p><small><em>(simple diagram of…simplestack network setup)</em></small></p>
<h1 id="simplestack">SimpleStack</h1>
<p>For some reason I’m fascinated by the thought of simplifying an OpenStack installation. As a Linux/Unix systems administrator, I actually think OpenStack is great–it’s like this huge ball of every Linuxy system and service packed together to provide useful infrastructure via an API. It’s got everything: storage backends, database, queues, web servers, hypervisors, firewalls, image files, file systems, load balancers, plus all the networking components . You name it you can probably use it in OpenStack. Thus, as a systems administrator, you have to be able to use pretty much everything, and then automate it and operate it. From PXE boot to haproxy. It’s a challenge that’s for sure.</p>
<p>Because OpenStack can be so varied and pluggable it means a large number of choices. However, generally speaking, people don’t want choices.</p>
<h2 id="choices">Choices</h2>
<p>I read about this paper once a few years ago: <a href="http://www.wjh.harvard.edu/~dtg/Gilber%20t&%20Ebert%20%28DECISIONS%20&%20REVISIONS%29.pdf">Decisions and Revisions: The Affective Forecasting of Changeable Outcomes</a>. In the study, students were asked to pick a photograph. One group had to pick it right away, and the other group could wait for up to four days to decide which print they wanted.</p>
<blockquote>
...students believed that having the opportunity to change their minds about which prints to keep would not influence their liking of the prints. However, those who had the opportunity to change their minds liked their prints less than those who did not.
</blockquote>
<p>I’m not a scientist of any sort, but that paper has always stuck in my mind as being an example of how having too many choices makes things hard for people, and in fact can lead to regret. This is part of why IT workers are always searching for the mythical “best practice,” as in:</p>
<blockquote>
How do I reduce the possibility of regretting what I did by narrowing my choices, and reducing the time it takes to make those choices?
</blockquote>
<h2 id="linux-distributions">Linux distributions</h2>
<p>I’m typing this post on Ubuntu 14.10. I didn’t build my own Linux Kernel or the entire system using <a href="http://www.linuxfromscratch.org/">Linux From Scratch</a> (though maybe everyone should try that at least once). Most systems administrators and developers I’ve worked with haven’t even heard of the <a href="http://en.wikipedia.org/wiki/Filesystem_Hierarchy_Standard">Linux File System Hierarchy</a>.</p>
<p>Linux distos are a way of reducing complexity; of making things simple. Linux distributions make all kinds of choices for us, especially with regards to packaging. When we use the OpenStack packages from Ubuntu 14.04 Canonical has made many decisions regarding OpenStack already. For most of us that is a good thing. (Though certainly many OpenStack operators build their own packages of OpenStack.) Choices are reduced, and for most, that’s good.</p>
<h2 id="too-many-features">Too many features?</h2>
<p>As I write this Amazon re:invent is going on. The size of AWS is difficult to grasp. It’s so huge. It has hundreds of features and services. Even billing is extremely complex. Some people and organizations need these features. Some are intimidated by them.</p>
<p>With AWS complexity in mind, I can see how an infrastructure as a service (IaaS) provider such as <a href="http://digitalocean.com">Digital Ocean</a> can be successful in a niche. They provide a vastly simplified system with few extra features:</p>
<ul>
<li>Simple virtual machine sizes and pricing</li>
<li>Multiple regions across the world</li>
<li>One shared internal network per region</li>
<li>Snapshotting, copying snapshots to all regions</li>
<li>DNS</li>
<li>No volumes</li>
</ul>
<p>That’s it. I think over time they will add additional features in order to try to grow, but I hope they don’t. I hope they stay in their niche and keep it as simple as possible. Nothing wrong with a successful company that doesn’t grow by 20% year after year (except in the stock market).</p>
<h2 id="simplestack-1">SimpleStack</h2>
<p>I put together <a href="https://github.com/ccollicutt/simplestack">SimpleStack</a> to use as an example of a “simple” OpenStack installation. I’ve got more work to do on it, so it’s just an example, but a fun place to start, if you’re into that kind of thing. :)</p>
<p>SimpleStack will setup and install one controller and two compute nodes using <a href="http://vagrantup.com">Vagrant</a> and <a href="http://ansible.com">Ansible</a>.</p>
<p>I did recently use it to provide a company with a test installation of OpenStack on two hardware servers, a sort of Proof-of-Concept, so I know it can work in a Virtualbox/Vagrant as well as a hardware environment, though the playbooks would need a couple of changes to work in a non-vagrant environment (something I’ll fix soon).</p>
<p>Notable features, or lack thereof:</p>
<ul>
<li>Automated, idempotent install using Ansible</li>
<li>One controller, multiple compute nodes</li>
<li>Front facing APIs using self-signed SSL</li>
<li>Multihost FlatDHCP networking</li>
<li>No private network (or private networks)</li>
<li>No Horizon (so no web gui)</li>
<li>No Cinder (so no volumes)</li>
<li>Not using Neutron, instead nova-network</li>
</ul>
<p>And that’s it.</p>
<h2 id="try-it-out">Try it out</h2>
<p>If you want to give it a test drive, just checkout the latest README file in the <a href="https://github.com/ccollicutt/simplestack">Github repo</a>. As I mentioned, there is more work to do so it’s not perfect.</p>
<p>I like that I can see exactly how many actions it takes to setup a simple OpenStack system, 55 for the controller and 18 for the compute nodes. Though I’m using templates so that reduces a lot of the tasks.</p>
<pre>
<code>curtis$ ansible-playbook site.yml
SNIP!
PLAY RECAP ********************************************************************
compute01 : ok=18 changed=0 unreachable=0 failed=0
compute02 : ok=18 changed=0 unreachable=0 failed=0
controller01 : ok=55 changed=0 unreachable=0 failed=0
</code>
</pre>
<h2 id="conclusion">Conclusion</h2>
<p>This is a fun little experiment to see how much OpenStack can be simplified, and, in effect try to make it look something like Digital Ocean, though even SimpleStack is missing some features comparitively.</p>
<p>A few things I want to try out in the next “version”:</p>
<ul>
<li>Separate the networks in the Vagrant config (all vms are on all networks at this point)</li>
<li>Add a shared private network ala DO, <a href="http://www.sebastien-han.fr/blog/2012/08/03/openstack-auto-assign-floating-ip/">automatic floating IPs</a> on the public interface for all instances</li>
<li>Find a way to figure out the interface’s purpose without using names like em2, eth0, ect, so that SimpleStack can work in any environment, not just Vagrant (that is, without changing the playbooks–there are a couple spots where “ansible_eth2” and the like is used, this is an Ansible variable issue I need to figure out)</li>
<li>IPv6?</li>
<li>A second region? Share glance images?</li>
<li>A simplified API with a command line tool?</li>
<li>Firewalling and routing with OpenBSD?</li>
</ul>
<p>Let me know if you have any ideas or see a mistake. :)</p>
8 Months with So You Start (OVH) - A review2014-11-04T00:00:00+00:00http://serverascode.com/2014/11/04/review-of-soyoustart-ovh<h1 id="8-months-with-so-you-start-ovh---a-review">8 Months with So You Start (OVH) - A review</h1>
<p>For the last eight months I’ve had a server at <a href="http://www.soyoustart.com/ca/en/">So You Start</a> (SYS) which is a division of <a href="http://ovh.com">OVH</a>, and is meant to be an entry level service. This harware server (not virtual, hardware) costs me about $60 a month, has a eight cores (hyperthreading), 32GB of ECC ram, a 250MB Internet connection, and 2x2TB disks. Also it’s in Canada, which, as a Canadian, suits me great.</p>
<h2 id="but-had-to-give-it-up">But had to give it up</h2>
<p>I have recently given up this server, but only because I wasn’t using it, not because it didn’t work for me. In fact quite the opposite–it was working great. It was a great deal, real hardware (albeit a bit old), and it was up pretty much the whole darn time. I wish I could have kept it because it was a good deal, especially considering it’s probably 2/3 of the price most people (at least in Canada) pay for their cell phone.</p>
<h2 id="lack-of-complaints">Lack of complaints</h2>
<p>I really don’t have any complaints. Most of the below notes are minor issues or positives.</p>
<ul>
<li>
<p>Always seem to be sold out of all the different models of hardware they have (I think this is because they are very popular). You’d almost have to write a script to check the site. This is the opposite of the OVH “business” site on which most of the servers are available within 120 seconds.</p>
</li>
<li>
<p>There is no KVM attached. This is pretty hair-raising if when updating the server. It seems they have a KVM service, which is $30 for 24 hours, and they say they will attach it within two hours. This would make it pretty hard to run a “real” production service off So You Start, but I don’t think that’s the point.</p>
</li>
<li>
<p>If you need any help from So You Start, you probably won’t get it in any timely fashion. But, I’m just guessing based on forum posts and reputation–I never asked for help from them so can’t say from experience.</p>
</li>
<li>
<p>This is my own fault, but I should have got an SSD based server. Spinning disks are so slow.</p>
</li>
<li>
<p>Billing: They could not do recurring credit card payments. You could pay for one or several months in a row, but not recurring. I always felt like if I forgot to pay, just once, my server would be deleted and given to someone else. I’d have preferred to have recurring CC payments, but you could do multi-months.</p>
</li>
<li>
<p>FTP backup: They do provide 100GB of FTP backup which I used. I gpg-zipped my backup files and uploaded them to the FTP server. If I was running a production service I’d find a way to go off-site with those backups, but it’s great that So You Start provides 100Gb of backup.</p>
</li>
<li>
<p>No 2-factor authentication to the admin panel, so if your login was compromised then your server is owned. I’m not even sure if the higher end OVH service provides this, not that they should differentiate on that feature. Every service should 2-factor their logins.</p>
</li>
<li>
<p>ECC memory: my server was ECC, but many of the So You Start models are not. On the range page they do incidate which servers are ECC and the rest are not. This is something to pay attention to if you want to avoid memory errors cropping up. As of this writing it seems like none of the models with SSDs are ECC.</p>
</li>
</ul>
<pre>
<code>root# dmidecode --type 16
# dmidecode 2.12
SMBIOS 2.7 present.
Handle 0x0028, DMI type 16, 23 bytes
Physical Memory Array
Location: System Board Or Motherboard
Use: System Memory
Error Correction Type: Single-bit ECC
Maximum Capacity: 32 GB
Error Information Handle: Not Provided
Number Of Devices: 4
</code>
</pre>
<pre>
<code>root# dmidecode --type 17
# dmidecode 2.12
SMBIOS 2.7 present.
Handle 0x002B, DMI type 17, 34 bytes
Memory Device
Array Handle: 0x0028
Error Information Handle: Not Provided
Total Width: 72 bits
Data Width: 64 bits
Size: 8192 MB
Form Factor: DIMM
Set: None
Locator: DIMM_A2
Bank Locator: BANK 0
Type: DDR3
Type Detail: Synchronous
Speed: 1600 MHz
Manufacturer: Samsung
Serial Number: 378CA173
Asset Tag: 9876543210
Part Number: M391B1G73QH0-YK0
Rank: 2
Configured Clock Speed: 1600 MHz
SNIP!
</code>
</pre>
<h2 id="uptime">Uptime</h2>
<p>I had this server for 8 months. It had ~18 minutes of downtime, about 15 of which were my own fault. Otherwise, I had pingdom monitoring it for the last four months, and it had 7 small outages, most less than a few seconds, and none that I recieved an email notice from Pingdom about.</p>
<h2 id="hardware-infomation">Hardware infomation</h2>
<p>I believe this system is the <a href="http://www.soyoustart.com/ca/en/offers/e3-sat-3.xml">E3-SAT-3</a> model, though it wasn’t called that when I first purchased the service. Also I believe mine is actually ECC memory, though the E3-SAT-3 model isn’t supposed to be.</p>
<p>For CPUs it has eight cores: four physical, four hyperthreading. I’m just showing one core below.</p>
<pre>
<code>processor : 7
vendor_id : GenuineIntel
cpu family : 6
model : 58
model name : Intel(R) Xeon(R) CPU E3-1245 V2 @ 3.40GHz
stepping : 9
microcode : 0x15
cpu MHz : 3401.000
cache size : 8192 KB
physical id : 0
siblings : 8
core id : 3
cpu cores : 4
apicid : 7
initial apicid : 7
fpu : yes
fpu_exception : yes
cpuid level : 13
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx rdtscp lm constant_tsc arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc aperfmperf eagerfpu pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 cx16 xtpr pdcm pcid sse4_1 sse4_2 x2apic popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm ida arat epb xsaveopt pln pts dtherm tpr_shadow vnmi flexpriority ept vpid fsgsbase smep erms
bogomips : 6784.57
clflush size : 64
cache_alignment : 64
address sizes : 36 bits physical, 48 bits virtual
power management:
</code>
</pre>
<p>For memory:</p>
<pre>
<code>MemTotal: 32902800 kB
MemFree: 474852 kB
Buffers: 179312 kB
Cached: 29534464 kB
SwapCached: 37392 kB
Active: 18247988 kB
Inactive: 12369164 kB
Active(anon): 551720 kB
Inactive(anon): 499556 kB
Active(file): 17696268 kB
Inactive(file): 11869608 kB
Unevictable: 65104 kB
Mlocked: 65104 kB
SwapTotal: 5118972 kB
SwapFree: 4963700 kB
Dirty: 200 kB
Writeback: 0 kB
AnonPages: 931436 kB
Mapped: 125728 kB
Shmem: 141504 kB
Slab: 1149056 kB
SReclaimable: 985140 kB
SUnreclaim: 163916 kB
KernelStack: 4608 kB
PageTables: 32776 kB
NFS_Unstable: 0 kB
Bounce: 0 kB
WritebackTmp: 0 kB
CommitLimit: 21570372 kB
Committed_AS: 7632684 kB
VmallocTotal: 34359738367 kB
VmallocUsed: 522704 kB
VmallocChunk: 34358922952 kB
HardwareCorrupted: 0 kB
AnonHugePages: 397312 kB
HugePages_Total: 0
HugePages_Free: 0
HugePages_Rsvd: 0
HugePages_Surp: 0
Hugepagesize: 2048 kB
DirectMap4k: 166884 kB
DirectMap2M: 33341440 kB
</pre>
</code>
## Disk IO
Pretty much looks like a 2x2TB SATA mirror. Bleh. But again, expected. I usually take disk IO testing pretty seriously, but I just chucked this test together in a couple minutes, so take it as you will.
<pre>
<code>
# cat *.fio
[random-read]
rw=randread
size=128m
directory=/tmp/fio-testing/data
[random-write1mb]
rw=randwrite
size=128m
directory=/tmp/fio-testing/data
direct=1
bs=1m
[random-write]
rw=randwrite
size=128m
directory=/tmp/fio-testing/data
direct=1
<pre>
Random read:
<pre>
<code># fio randread.fio
random-read: (g=0): rw=randread, bs=4K-4K/4K-4K/4K-4K, ioengine=sync, iodepth=1
fio-2.1.3
Starting 1 process
random-read: Laying out IO file(s) (1 file(s) / 128MB)
SNIP!
random-read: (groupid=0, jobs=1): err= 0: pid=10023: Mon Nov 3 21:22:14 2014
read : io=131072KB, bw=1009.3KB/s, iops=252, runt=129874msec
clat (usec): min=52, max=236152, avg=3955.39, stdev=4034.99
lat (usec): min=52, max=236152, avg=3955.79, stdev=4035.00
clat percentiles (usec):
| 1.00th=[ 55], 5.00th=[ 77], 10.00th=[ 114], 20.00th=[ 119],
| 30.00th=[ 126], 40.00th=[ 2416], 50.00th=[ 3696], 60.00th=[ 4960],
| 70.00th=[ 6240], 80.00th=[ 7520], 90.00th=[ 8768], 95.00th=[ 9408],
| 99.00th=[10176], 99.50th=[10304], 99.90th=[18560], 99.95th=[31616],
| 99.99th=[96768]
bw (KB /s): min= 506, max= 4221, per=98.48%, avg=993.71, stdev=325.57
lat (usec) : 100=6.09%, 250=27.71%, 500=0.05%, 750=0.04%, 1000=0.11%
lat (msec) : 2=2.93%, 4=15.37%, 10=45.83%, 20=1.77%, 50=0.06%
lat (msec) : 100=0.02%, 250=0.01%
cpu : usr=0.28%, sys=0.98%, ctx=33070, majf=0, minf=28
IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued : total=r=32768/w=0/d=0, short=r=0/w=0/d=0
Run status group 0 (all jobs):
READ: io=131072KB, aggrb=1009KB/s, minb=1009KB/s, maxb=1009KB/s, mint=129874msec, maxt=129874msec
Disk stats (read/write):
sda: ios=32491/327, merge=0/601, ticks=128180/16464, in_queue=144612, util=98.77%
</code>
</pre>
Random writes 4k blocksize.
<pre>
<code># fio randwrite.fio
random-write: (g=0): rw=randwrite, bs=4K-4K/4K-4K/4K-4K, ioengine=sync, iodepth=1
fio-2.1.3
Starting 1 process
random-write: Laying out IO file(s) (1 file(s) / 128MB)
Jobs: 1 (f=1): [w] [100.0% done] [0KB/472KB/0KB /s] [0/118/0 iops] [eta 00m:00s]
random-write: (groupid=0, jobs=1): err= 0: pid=11028: Mon Nov 3 21:45:39 2014
write: io=131072KB, bw=484491B/s, iops=118, runt=277028msec
clat (msec): min=1, max=227, avg= 8.45, stdev= 6.98
lat (msec): min=1, max=227, avg= 8.45, stdev= 6.98
clat percentiles (msec):
| 1.00th=[ 3], 5.00th=[ 4], 10.00th=[ 5], 20.00th=[ 6],
| 30.00th=[ 7], 40.00th=[ 8], 50.00th=[ 8], 60.00th=[ 9],
| 70.00th=[ 9], 80.00th=[ 10], 90.00th=[ 10], 95.00th=[ 11],
| 99.00th=[ 40], 99.50th=[ 43], 99.90th=[ 74], 99.95th=[ 95],
| 99.99th=[ 147]
bw (KB /s): min= 184, max= 591, per=100.00%, avg=473.57, stdev=48.38
lat (msec) : 2=0.28%, 4=7.89%, 10=85.24%, 20=2.71%, 50=3.70%
lat (msec) : 100=0.15%, 250=0.03%
cpu : usr=0.15%, sys=0.73%, ctx=33273, majf=0, minf=27
IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued : total=r=0/w=32768/d=0, short=r=0/w=0/d=0
Run status group 0 (all jobs):
WRITE: io=131072KB, aggrb=473KB/s, minb=473KB/s, maxb=473KB/s, mint=277028msec, maxt=277028msec
Disk stats (read/write):
sda: ios=0/33913, merge=0/5241, ticks=0/329844, in_queue=329792, util=99.17%
</code>
</pre>
Rand writes 1mb blocksize:
<pre>
<code># fio randwrite1mb.fio
random-write1mb: (g=0): rw=randwrite, bs=1M-1M/1M-1M/1M-1M, ioengine=sync, iodepth=1
fio-2.1.3
Starting 1 process
random-write1mb: Laying out IO file(s) (1 file(s) / 128MB)
Jobs: 1 (f=1)
random-write1mb: (groupid=0, jobs=1): err= 0: pid=11513: Mon Nov 3 21:50:09 2014
write: io=131072KB, bw=75199KB/s, iops=73, runt= 1743msec
clat (msec): min=8, max=26, avg=13.56, stdev= 2.34
lat (msec): min=8, max=26, avg=13.61, stdev= 2.33
clat percentiles (usec):
| 1.00th=[ 8256], 5.00th=[ 9792], 10.00th=[10688], 20.00th=[11712],
| 30.00th=[12352], 40.00th=[13120], 50.00th=[13760], 60.00th=[14400],
| 70.00th=[14784], 80.00th=[15040], 90.00th=[15808], 95.00th=[16192],
| 99.00th=[19840], 99.50th=[26240], 99.90th=[26240], 99.95th=[26240],
| 99.99th=[26240]
bw (KB /s): min=73142, max=76749, per=99.63%, avg=74922.67, stdev=1803.93
lat (msec) : 10=6.25%, 20=92.97%, 50=0.78%
cpu : usr=0.40%, sys=0.69%, ctx=135, majf=0, minf=27
IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued : total=r=0/w=128/d=0, short=r=0/w=0/d=0
Run status group 0 (all jobs):
WRITE: io=131072KB, aggrb=75199KB/s, minb=75199KB/s, maxb=75199KB/s, mint=1743msec, maxt=1743msec
Disk stats (read/write):
sda: ios=0/241, merge=0/0, ticks=0/2876, in_queue=2900, util=92.62%
</code>
</pre>
## Bandwidth
Using the speedtest-cli, which is very handy. Only found out about it today.
Closest speedtest server:
<pre>
<code># speedtest
Retrieving speedtest.net configuration...
Retrieving speedtest.net server list...
Testing from OVH Hosting (<redacted>)...
Selecting best server based on latency...
Hosted by 3Men@Work (Montreal, QC) [2.38 km]: 39.06 ms
Testing download speed........................................
Download: 358.12 Mbits/s
Testing upload speed..................................................
Upload: 58.36 Mbits/s
</code>
</pre>
New York City!
<pre>
<code># speedtest --server 5029
Retrieving speedtest.net configuration...
Retrieving speedtest.net server list...
Testing from OVH Hosting (<redacted>)...
Hosted by AT&T (New York City, NY) [533.43 km]: 45.257 ms
Testing download speed........................................
Download: 384.99 Mbits/s
Testing upload speed..................................................
Upload: 18.05 Mbits/s
</code>
</pre>
My hometown ISP, Shaw. Good old monopolies.
<pre>
<code># speedtest --list | grep -i "edmonton"
4242) Shaw Communications (Edmonton, AB, Canada) [2972.64 km]
3050) Telus (Edmonton, AB, Canada) [2972.64 km]
1051) Tera-byte Dot Com Inc (Edmonton, AB, Canada) [2972.64 km]
root@vurt01:~# speedtest --server 4242
Retrieving speedtest.net configuration...
Retrieving speedtest.net server list...
Testing from OVH Hosting (<redacted>)...
Hosted by Shaw Communications (Edmonton, AB) [2972.64 km]: 126.014 ms
Testing download speed........................................
Download: 118.54 Mbits/s
Testing upload speed..................................................
Upload: 38.73 Mbits/s
</code>
</pre>
Toronto:
<pre>
<code># speedtest --server 3575
Retrieving speedtest.net configuration...
Retrieving speedtest.net server list...
Testing from OVH Hosting (<redacted>)...
Hosted by TELUS (Toronto, ON) [504.80 km]: 65.678 ms
Testing download speed........................................
Download: 126.21 Mbits/s
Testing upload speed..................................................
Upload: 45.24 Mbits/s
</code>
</pre>
## Conclusion
This server worked great for me. I had no problems. However, if I was thinking of hosting a production server, I would probably go with the OVH "business" servers which are more money, but have additional features like full-time KVM and a virtual network that can be setup between servers. Also I would like SSDs and ECC memory, a combination So You Start doesn't seem to provide. But, given my positive experience at So You Start, I would certainly give it a try at OVH, especially because they are in Quebec!
</redacted></code></pre></redacted></code></pre></redacted></code></pre></redacted></code></pre></pre></code></pre></pre>
Also Blogging at flatlinesecurity.com2014-10-15T00:00:00+00:00http://serverascode.com/2014/10/15/flatline-security<h1 id="also-blogging-at-flatlinesecuritycom">Also Blogging at flatlinesecurity.com</h1>
<p>I’ve decided to get back into information security. I used to do a lot more infosec related work, including being the security administrator for a large university. To that effect, I’m doing some security blogging over at <a href="https://flatlinesecurity.com">Flatline Security</a> and I’ll write posts about the things I learn about infosec as I refresh my knowledge. There are a couple of certifications I’m going to work on as well, such as the <em>Certified Ethical Hacker</em> qualification.</p>
<p>I don’t know whether it’s a good idea to have two different but slightly related blogs, but I’m going to give it a try. serverascode.com will be for sysadmin related posts, and Flatline Security for information security associated writing. I think Flatline might have less technical posts occasionally, and more philosophical or high level concepts.</p>
<p>I have a few ideas for blog posts here, and will soon have more time to write articles. If you have any ideas for what you’d like to see, let me know in the comments.</p>
Why OpenStack Swift is Great for Platform as a Service2014-08-23T00:00:00+00:00http://serverascode.com/2014/08/23/swift-paas<h1 id="why-openstack-swift-is-great-for-platform-as-a-service">Why OpenStack Swift is Great for Platform as a Service</h1>
<p>I’m a big fan of object storage. What is object storage? To me:</p>
<blockquote>
<p>Object storage is a system that allows storing and retrieving files via a HTTP restful interface.</p>
</blockquote>
<p>Object storage is not a file system and doesn’t look anything like one.</p>
<p>In terms of this blog post, I think object storage system should also be highly available, scalable, redundant, and durable. (Maybe some of those terms mean the same thing.)</p>
<p>So we have these minimal requirements:</p>
<ul>
<li>Store and retrieve files via restful HTTP interface</li>
<li>Highly available / Redundant</li>
<li>Scalable</li>
<li>Durable</li>
</ul>
<p>Guess what open source solution meets those requirements? <a href="http://docs.openstack.org/developer/swift/">OpenStack Swift</a>.</p>
<h2 id="paas-platform-as-a-service">PaaS: Platform as a service</h2>
<p>I really like the concept of platform as a service (PaaS). However, like almost every difficult to define term in information technology, it’s become overloaded. PaaS could mean anything from <a href="http://heroku.com">Heroku</a> to a git hook.</p>
<p>Recently Ander Shafer wrote a <a href="http://blog.pivotal.io/cloud-foundry-pivotal/p-o-v/the-silent-aas">blog post</a> for Pivotal that suggests the “as a service” should be silent.</p>
<blockquote>
<p>[Is a] platform is just how one deploys code?</p>
</blockquote>
<p>I would tend to agree with that sentiment, in that PaaS is really just a platform to which code is deployed and turned into a managed application (of some kind). Why make it more complicated than that? There are a lot of different PaaS implementations and I doubt there will ever be a canonical definition. What is PaaS for me could just be <a href="http://mesos.apache.org/">Mesos</a> and <a href="https://github.com/mesosphere/marathon">Marathon</a>, and what is PaaS for you could be an exact Heroku clone, or Cloud Foundry, or OpenShift, or a bash script kicked off by a git hook.</p>
<p>Typically, however, there are certain things that people want out of a PaaS system:</p>
<ul>
<li>Don’t want to run <em>the servers</em></li>
<li>Want it to be <em>scalable</em> in some fashion</li>
<li>Highly available</li>
<li>Just push code (binary, git, zip, war…whatever)</li>
<li><em>Some</em> state: database, file, nosql…thus backups!</li>
</ul>
<p>I don’t want to go much farther into what PaaS is…or isn’t (partly because I don’t know). I think it suffices enough to say that most users want the PaaS system they use to at least be scalable and highly available, and that is where OpenStack Swift can help.</p>
<h2 id="1-replace-shared-and-distributed-file-systems-with-swift">1. Replace shared and distributed file systems with Swift</h2>
<p>Many applications require the ability to upload or generally create files and then be able to access them later. However, if you run multiple application servers each application server probably needs to access those files. Now you need some kind of shared or distributed file system, eg. NFS or Gluster (among others) respectfully. While those systems can scale up or out fairly far, at some point they might not be enough for a large system, or to be a data store for a PaaS.</p>
<p>Enter Swift. If your application can be (re?)written to support object storage such as OpenStack Swift, and the PaaS being used supports it as a backend, then you don’t need a complicated distributed or shared filesystem–you can just store and retrieve files from object storage.</p>
<h2 id="2-store-docker-images-in-swift">2. Store Docker images in Swift</h2>
<p>Many PaaS systems use, or will use, Docker as an important component for isolation. Docker is heavily dependendant on its registry server to manage images. Thus, any HA PaaS will also needs its Docker registry to be up as much as possible. Certainly Docker images could be cached on the servers that run Docker, but at some point a new image might need to be downloaded, and that has to come from a Docker registry.</p>
<p>Not surprisingly, the <a href="https://github.com/docker/docker-registry">Docker Registry server</a> already supports using OpenStack Swift as a backend.</p>
<h2 id="3-store-code-in-swift">3. Store code in Swift</h2>
<p>The code to be deployed has to come from somewhere. One example I have is with Apache Mesos and the Marathon framework. When you create an application in Marathon you can specify a uniform resource identifier (URI) where the application/code can be downloaded from. When a new instance of that application is created, for example when an application is scaled up, Marathon downloads the code from the URI(s).</p>
<p><img src="/img/marathon-uri.png" alt="" />
<em>(screenshot from creating an application in the marathon webgui)</em></p>
<p>Thus, in order to scale an application, at least in this example, the URI, typically a web server URL, needs to be up and running so that the code can be downloaded.</p>
<p>If the application files are stored in an HA OpenStack Swift system, then that code should be availble to each application node to install. Certainly there are a lot of other ways this could be done, but I like the idea of using OpenStack Swift for this. Many of the examples given for deploying an application with Marathon show using Amazon’s S3 object storage system.</p>
<p>I even see at least <a href="http://techs.enovance.com/6642/openstack-swift-as-backend-for-git-part-1">one try</a> to back git with Swift.</p>
<h2 id="4-store-backups-in-swift">4. Store backups in Swift</h2>
<p>Depending on your definition, perhaps magic backups are part of your PaaS requirements. I say magic only slightly facetiously. I do believe that if a PaaS supplies data stores that they are backed up properly.</p>
<p>If you’re building your own PaaS, having backups automatically replicated <em>and</em> replicated off-site would be a nice thing to have. Thus, if you have an OpenStack Swift cluster that spans multiple data centers, then all you have to do is stick whatever backup files you have into Swift and they will be replicated across zones. Swift even has the ability to create a <a href="http://docs.openstack.org/developer/swift/replication_network.html">replication only network</a> that can run over your data center interconnect so you can do quality of service (QoS) if desired. Because of Swift’s eventual consistency model it doesn’t even break the <a href="http://en.wikipedia.org/wiki/CAP_theorem">CAP theorem</a>. Upload a file once and have it replicated across timezones? Yes please!</p>
<h2 id="conclusion">Conclusion</h2>
<p>I am just learning about PaaS, but already I can see how valuable object storage can be to platform as a service, and not just in terms of replacing file systems. OpenStack Swift is a mature and well thought out system that can have storage servers and proxy servers down for maintenance–unplanned or otherwise–and objects will still be available. Further, it’s possible to upgrade Swift in-place without downtime. Also, as mentioned, it can scale across data centers.</p>
<p>If you are deploying a PaaS system then I heavily suggest taking some time to consider deploying OpenStack Swift along side it as a datastore.</p>
<p>I’m sure there are more good uses of object storage in a PaaS system, so if you think of anything let me know and I’ll add it.</p>
<h2 id="notes">Notes</h2>
<ul>
<li>
<p>Like OpenStack in general, Swift can be a bit difficult to deploy. It depends on your skillset (ie. Linux). Start with <a href="http://docs.openstack.org/developer/swift/development_saio.html">Swift All-in-one</a> to get an idea of the complexity. I don’t think deploying Swift, or OpenStack completely, is that bad, but maybe some do. Also I have a project called <a href="https://github.com/ccollicutt/swiftacular">Swiftacular</a> that can setup a multi-host test OpenStack Swift system using Vagrant and Ansible.</p>
</li>
<li>
<p>PaaS is not a silver bullet, but I do think it helps to consider a platform as just a platform, with all its parts, good, bad, and missing. This is a great <a href="http://blog.lusis.org/blog/2014/06/22/feedback-on-paas-realism/">blog post</a> (and the previous one, <a href="http://blog.lusis.org/blog/2014/06/14/paas-for-realists/"><em>Paas for Realists</em></a>) which discuss what may or may not be missing from popular PaaS systems, and what people building PaaS systems should consider as requirements.</p>
</li>
<li>
<p>There are many people who believe that scaling applications is not as easy as some PaaS sytems make it out to be. Certainly it would be fairly straight forward to scale a stateless app up and down, but almost all apps have state of some kind, be it files or database or nosql entries, and at some point those data stores might fall over if there are too many application servers making requests. Also, same for the network.</p>
</li>
</ul>
Provision and Configure OpenStack Instances in One Ansible Run2014-08-19T00:00:00+00:00http://serverascode.com/2014/08/19/provision-openstack-instances-with-ansible<h1 id="provision-and-configure-openstack-instances-in-one-ansible-run">Provision and Configure OpenStack Instances in One Ansible Run</h1>
<p>In order to configure servers with tools like Ansible, they need to be up and running. These servers could be hardware systems in your data center, or, more likely, virtual machines running in any number of infrastructure-as-a-service (IaaS) providers, including a private OpenStack cloud (which is what I will be using here).</p>
<p>The goal in this blog post is not just to provision the instances, but to provision <em>and</em> configure them in <em>one Ansible playbook run</em>. This process is somewhat complicated by the fact that you don’t know the ip address of the instance until it’s created, which typically means provisioning and configuration happens in at least two runs, perhaps even with different tools.</p>
<h2 id="ansible-modules">Ansible modules</h2>
<p>Two Ansible modules make what I’m doing possible: <a href="http://docs.ansible.com/nova_compute_module.html">nova_compute</a> and <a href="http://docs.ansible.com/add_host_module.html">add_host</a>.</p>
<p><em>nova_compute</em> can create instances in most OpenStack clouds, and <em>add_host</em> can update information about hosts, such as the instances <em>ansible_ssh_host</em> ip address, and do so while the playbook is running.</p>
<p>In combination with a custom inventory script these two modules can be used to provision and configure/converge instances in one playbook run.</p>
<h2 id="the-playbook">The playbook</h2>
<p>In order to use <em>nova_compute</em>, at least in the way that I am using it, we need a minimum of five files, which are shown below. I’m using the Ansible roles model to configure the playbook.</p>
<p>1) site.yml
2) hosts
3) group_vars/openstack_instances
4) roles/openstack_instances/tasks/main.yml
5) nova.py - a custom inventory script (ugly as it may be)</p>
<p>Note that there is a <a href="https://github.com/ccollicutt/ansible-provision-openstack">github repository</a> that has all the files used in this example.</p>
<p>For simplicities sake, all this playbook is going to do is create all of the virtual machines in OpenStack, and then ping them via a role called common.</p>
<h3 id="novapy-and-the-hosts-file">nova.py and the hosts file</h3>
<p>Because of the <a href="https://github.com/ccollicutt/ansible-provision-openstack/blob/master/nova.py">custom inventory script</a> I’m using, called nova.py (but not the same as what comes with Ansible by default), I have a somewhat unusual ansible hosts file, though it does follow the typical Ansible hosts file format.</p>
<p>Below we can see there is a group called <em>openstack_instances</em> and there are four instances listed there, each with a flavor_id and group variable associated.</p>
<pre>
<code>curtis$ cat hosts
[openstack_instances]
lb flavor_id=1 group=load_balancers
app flavor_id=2 group=application_servers
db flavor_id=2 group=database_servers
app2 flavor_id=2 group=application_servers
</pre>
</code>
The _nova.py_ script reads each line of the hosts file and sets up the flavor_id and group for each instance. If I run _nova.py_ I get json output that looks like this:
<pre>
<code>curtis$ ./nova.py
{
"_meta": {
"hostvars": {
"app": {
"flavor_id": "2"
},
"app2": {
"flavor_id": "2"
},
"db": {
"flavor_id": "2"
},
"lb": {
"flavor_id": "1"
}
}
},
"application_servers": {
"hosts": [
"app",
"app2"
]
},
"database_servers": {
"hosts": [
"db"
]
},
"load_balancers": {
"hosts": [
"lb"
]
},
"openstack_instances": {
"hosts": [
"lb",
"app",
"db",
"app2"
]
},
"undefined": {
"hosts": [
"lb",
"app",
"db",
"app2"
]
}
}
</code>
</pre>
As can be seen above, each inventory entry has it's _flavor_id_ meta variable set, as well as being put into a specific group.
## The openstack_instances file
I've included an example openstack_instances file. Copy that to _group_vars/openstack_instances_ and fill it out with your OpenStack credentials.
<pre>
<code>curtis$ ls group_vars/openstack_instances.example
group_vars/openstack_instances.example
curtis$ cp group_vars/openstack_instances.example
group_vars/openstack_instances
curtis$ vi group_vars/openstack_instances # and enter your credentials
</code>
</pre>
Just as an example, this is what the _nova_compute_ task looks like.
<pre>
<code>curtis$ cat roles/openstack_instances/tasks/main.yml
---
- name: ensure instance exists in openstack
nova_compute:
state: present
login_username: "{{ os_username }}"
login_password: "{{ os_password }}"
login_tenant_name: "{{ os_tenant_name }}"
auth_url: "{{ os_auth_url }}"
region_name: "{{ os_region_name }}"
name: "{{ inventory_hostname }}"
image_id: "{{ os_image_id }}"
key_name: "{{ os_key_name }}"
flavor_id: "{{ flavor_id }}"
security_groups: default
</code>
</pre>
## ssh_config
I should also mention that I have a gateway server setup in my OpenStack tenant and that is configured to be used with the private OpenStack network for that tenant. So while my OpenStack instances have a private ip address, they can still be accessed remotely via the ssh gateway server. Another option would be to run Ansible from inside the tenant.
<pre>
<code>host openstack-gw
Hostname some.floating.ip.address
User ubuntu
host 10.2.*.*
ProxyCommand ssh -q openstack-gw netcat %h 22
User ubuntu
</code>
</pre>
## Run the playbook
Finally, with all those files created and OpenStack credentials entered, we can run the playbook and create the instances if necessary.
<pre>
<code>curtis$ ansible-playbook -i nova.py site.yml
PLAY [openstack_instances] ****************************************************
GATHERING FACTS ***************************************************************
ok: [db]
ok: [lb]
ok: [app]
ok: [app2]
SNIP!
TASK: [common | debug msg=""] ****************************
ok: [app] => {
"msg": "app"
}
ok: [app2] => {
"msg": "app2"
}
ok: [db] => {
"msg": "db"
}
ok: [lb] => {
"msg": "lb"
}
PLAY RECAP ********************************************************************
app : ok=12 changed=2 unreachable=0 failed=0
app2 : ok=12 changed=2 unreachable=0 failed=0
db : ok=12 changed=2 unreachable=0 failed=0
lb : ok=12 changed=2 unreachable=0 failed=0
</pre>
</code>
If we run it again, it won't recreate the instances, because they already exist.
<pre>
<code>curtis$ ansible-playbook -i nova.py site.yml
PLAY [openstack_instances] ****************************************************
GATHERING FACTS ***************************************************************
ok: [app]
ok: [app2]
ok: [db]
ok: [lb]
SNIP!
PLAY RECAP ********************************************************************
app : ok=11 changed=1 unreachable=0 failed=0
app2 : ok=11 changed=1 unreachable=0 failed=0
db : ok=11 changed=1 unreachable=0 failed=0
lb : ok=11 changed=1 unreachable=0 failed=0
</code>
</pre>
If I run nova list I can see the instances. (Note that in the private cloud I am using IPv6 addresses are also provided.)
<pre>
<code>curtis$ nova list | grep "app\|db\|lb"
| 11b0fcae-b296-44fd-9105-ea0edc8e796b | app | ACTIVE | - | Running | private=10.2.0.160, 2605:fd00:4:1001:f816:3eff:fec3:b1b1 |
| 79fa841a-6cc9-4542-b523-e7f55e13663d | app2 | ACTIVE | - | Running | private=10.2.0.127, 2605:fd00:4:1001:f816:3eff:fe9d:3287 |
| 89085c7b-eee6-4cb2-b2ee-c2bf0cf7931a | db | ACTIVE | - | Running | private=10.2.0.159, 2605:fd00:4:1001:f816:3eff:feda:41f |
| 6330e609-463a-47e7-93c3-864d04e5a840 | lb | ACTIVE | - | Running | private=10.2.1.18, 2605:fd00:4:1001:f816:3eff:fe67:aa12 |
</code>
</pre>
## Conclusion
At this point we have an ansible playook that can provision OpenStack instances, find out their ip address, and then configure them, all in one playbook run. Of course to do this we have to use a custom inventory script, but I don't mind that. Python is a great language to do things like this in, and since Ansible is written in Python it's much easier.
## Issues
- My custom nova.py script isn't very smart.
- Depending on your OpenStack provider you may need to change the name of the network in the _set_fact_ task, which below is set to the name "private." Sometimes different clouds have different default network names.
<pre>
<code>- set_fact: ansible_ssh_host={{ nova.info.addresses.private[0].addr }}
</code>
</pre>
- Also, sometimes a particular instance won't come up. Just run the playbook again and as long as your OpenStack provider is working, everything should complete at some point. I found that sometimes it would take about a minute for some instances sshd to become available; that Ansible would have connection problems on the first run. Right now there is a 30 second pause in the playbook to try to account for that in a non-intelligent way.
- Another problem could be that OpenStack can have many instances with the same name, so there could be 10 "app2" servers. _nova_compute_ is using the name rather than the OpenStack uuid to see if instances are instantiated. Something to look into because that could go sideways quickly.
- Maybe there is a better way to do this? If so, let me know. :)
</pre></pre>
Basic Configuration of a Cisco 1000V CSR2014-07-17T00:00:00+00:00http://serverascode.com/2014/07/17/basic-configuration-cisco-1000v-csr<p><img src="/img/virtnet.png" alt="" /></p>
<h1 id="basic-configuration-of-a-cisco-1000v-csr">Basic Configuration of a Cisco 1000V CSR</h1>
<p>In a “previous post”:/2014/07/14/cisco-1000v-csr-libvirt-kvm.html I looked at installing the Cisco 1000V Cloud Services Router into a KVM environment. Now let’s do some basic configuration. Again I have to note that I’m not a professional Cisco network administrator by any stretch, and in fact it would be great if readers noticed mistakes or better ways of doing things and let me know in the comments. :)</p>
<h2 id="colorredissue">%{color:red}Issue%</h2>
<p>At this time TCP seems busted with CSR + KVM. I’m not sure why at this time. ICMP seems to work but not TCP.</p>
<p>Troubleshooting steps so far:</p>
<ol>
<li>Insert a simple Linux router: This worked fine, ~20 gbps with iperf</li>
<li>Try out this process in virtual box on a Windows computer: Also worked as expected</li>
<li>Try out on a Ubuntu 12.04.4 system–still no dice. I would have expected this to work as it is a supported environment for the CSR. Perhaps some configuration issue with KVM…</li>
<li>Also tried the qcow2 image instead of installing from the ISO, no joy</li>
</ol>
<p>So I’m not sure at this time what the issue is. Something to do with the CSR in this particular environment, be it misconfiguration on my part, or something else. I’ll update when I figure out what is going on. If you do try it and get the expected performance (such as 50000 kbps when the premium license is enabled) please let me know.</p>
<p>Even though the KVM environments aren’t yet working, all the configuration information below should be Ok (I think). I did run this exact same process in Windows with Virtualbox and that worked fine. Also, like I said above, a simple Linux router works as well. However, when using the CSR and KVM, everything runs Ok, it’s just that TCP isn’t working. Very weird.</p>
<p>My plan is to pass this post around a bit and see if anyone has any ideas.</p>
<h2 id="the-environment">The environment</h2>
<p>I’m working in an Ubuntu Trusty 14.04 KVM single host environment. I’m also using he default Openvswitch that comes with Trusty, and of course I’m using libvirt.</p>
<p>For now I’ll connect the CSR to three virtual networks within the KVM host, two of which are managed by openvswitch and one by libvirt.</p>
<pre>
<code># ovs-vsctl list-br
corebr0
distbr0
# brctl show |grep virbr0
virbr0 8000.fe540021831d yes vnet0
</code>
</pre>
<p>So the router will have three interfaces:</p>
<ol>
<li>“virbr0” - Default libvirt network, Linux bridge</li>
<li>“corebr0” - Openvswitch</li>
<li>“distbr0” - Openvswitch</li>
</ol>
<p>I altered the libvirt default network to start providing DHCP addresses at 192.168.122.3 instead of the default 192.168.122.2 so that the router can have 192.168.122.2 as it’s IP on the default virbr0 bridge.</p>
<h2 id="basic-configuration">Basic configuration</h2>
<p>First, turn off domain lookups, otherwise the route will think mistyped commands are potential domains and spend time looking them up.</p>
<pre>
<code>Router>enable
Router#conf t
Enter configuration commands, one per line. End with CNTL/Z.
Router(config)#no ip domain-lookup
</code>
</pre>
<p>Here we can see all the interfaces and their mapping. (Note that the MAC addresses might be different from other examples in this post–that’s Ok, I’ve done this same process several times.)</p>
<pre>
<code>Router#show platform software vnic-if interface-mapping
-------------------------------------------------------------
Interface Name Driver Name Mac Addr
-------------------------------------------------------------
GigabitEthernet3 virtio 5254.0064.67e2
GigabitEthernet2 virtio 5254.0039.2c47
GigabitEthernet1 virtio 5254.0006.685d
-------------------------------------------------------------
</code>
</pre>
<p>Configure the first interface.</p>
<pre>
<code>Router(config)#int gigabit 1
Router(config-if)#ip address 192.168.122.2 255.255.255.0
Router(config-if)#no shutdown
Router(config-if)#exit
</code>
</pre>
<p>Try pinging 192.168.122.2.</p>
<pre>
<code>Router#ping 192.168.122.2
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 192.168.122.2, timeout is 2 seconds:

Success rate is 100 percent (5/5), round-trip min/avg/max = 1/1/3 ms
</code>
</pre>
<p>Configure the second interface.</p>
<pre>
<code>Router(config)#int gigabit 2
Router(config-if)#ip address 10.100.0.1 255.255.255.0
Router(config-if)#no shutdown
Router(config-if)#exit
</code>
</pre>
<p>Configure the third interface.</p>
<pre>
<code>Router(config)#int gigabit 3
Router(config-if)#ip address 10.100.1.1 255.255.255.0
Router(config-if)#no shutdown
Router(config-if)#exit
</code>
</pre>
<p>Show the routes.</p>
<pre>
<code>Router#sh ip route
Codes: L - local, C - connected, S - static, R - RIP, M - mobile, B - BGP
D - EIGRP, EX - EIGRP external, O - OSPF, IA - OSPF inter area
N1 - OSPF NSSA external type 1, N2 - OSPF NSSA external type 2
E1 - OSPF external type 1, E2 - OSPF external type 2
i - IS-IS, su - IS-IS summary, L1 - IS-IS level-1, L2 - IS-IS level-2
ia - IS-IS inter area, * - candidate default, U - per-user static route
o - ODR, P - periodic downloaded static route, H - NHRP, l - LISP
a - application route
+ - replicated route, % - next hop override
Gateway of last resort is not set
10.0.0.0/8 is variably subnetted, 4 subnets, 2 masks
C 10.100.0.0/24 is directly connected, GigabitEthernet2
L 10.100.0.1/32 is directly connected, GigabitEthernet2
C 10.100.1.0/24 is directly connected, GigabitEthernet3
L 10.100.1.1/32 is directly connected, GigabitEthernet3
192.168.122.0/24 is variably subnetted, 2 subnets, 2 masks
C 192.168.122.0/24 is directly connected, GigabitEthernet1
L 192.168.122.2/32 is directly connected, GigabitEthernet1
</code>
</pre>
<h2 id="configure-dhcp-servers">Configure DHCP servers</h2>
<p>I’m going to put DHCP servers on gigabit 2 and gigabit 3, core and dist networks respectfully.</p>
<pre>
<code>Router(config)#ip dhcp pool core
Router(dhcp-config)#network 10.100.0.0 /24
Router(dhcp-config)#default-router 10.100.0.1
Router(dhcp-config)#exit
Router(config)#ip dhcp excluded-address 10.100.0.1 10.100.0.100
</code>
</pre>
<p>Check the pool.</p>
<pre>
<code>Router#sh ip dhcp pool
Pool core :
Utilization mark (high/low) : 100 / 0
Subnet size (first/next) : 0 / 0
Total addresses : 254
Leased addresses : 0
Excluded addresses : 100
Pending event : none
1 subnet is currently in the pool :
Current index IP address range Leased/Excluded/Total
10.100.0.1 10.100.0.1 - 10.100.0.254 0 / 100 / 254
</code>
</pre>
<p>Do the same on gigabit 3 with network 10.100.1.0/24.</p>
<h2 id="add-virtual-machines-to-the-networks">Add virtual machines to the networks</h2>
<p>I want to add a server onto the core network, expecting that the CSR will hand it a DHCP address.</p>
<pre>
<code># virsh list |grep core
4 core-srv1 running
</code>
</pre>
<p>Now that that’s up, let’s see if it gets an IP from the router.</p>
<pre>
<code>Router#sh ip dhcp pool
Pool core :
Utilization mark (high/low) : 100 / 0
Subnet size (first/next) : 0 / 0
Total addresses : 254
Leased addresses : 1
Excluded addresses : 100
Pending event : none
1 subnet is currently in the pool :
Current index IP address range Leased/Excluded/Total
10.100.0.102 10.100.0.1 - 10.100.0.254 1 / 100 / 254
Router#sh arp
Protocol Address Age (min) Hardware Addr Type Interface
Internet 10.100.0.1 - 5254.0013.bd53 ARPA GigabitEthernet2
Internet 10.100.0.2 1 b60d.1368.3044 ARPA GigabitEthernet2
Internet 10.100.0.101 1 5254.00db.4454 ARPA GigabitEthernet2
Internet 10.100.1.1 - 5254.001e.fceb ARPA GigabitEthernet3
Internet 192.168.122.2 - 5254.0021.831d ARPA GigabitEthernet1
</code>
</pre>
<p>As can be seen the KVM virtual machine received IP 10.100.0.101, and we can ping that from the router.</p>
<pre>
<code>Router#ping 10.100.0.101
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 10.100.0.101, timeout is 2 seconds:

Success rate is 100 percent (5/5), round-trip min/avg/max = 1/1/2 ms
</code>
</pre>
<p>I can access the console of the vm using “virsh console”.</p>
<pre>
<code># virsh console core-srv1
</code>
</pre>
<p>I’ve also started a second virtual machine on the dist network.</p>
<pre>
<code># virsh list | grep dist
13 dist-srv1 running
</code>
</pre>
<p>From core-srv1 I can ping dist-srv1, and we are using the router to manage the traffic. Notice I am using -I due to the TCP issue I mention at the start of the post.</p>
<pre>
<code>ubuntu@core-srv1:~$ traceroute -I 10.100.1.101
traceroute to 10.100.1.101 (10.100.1.101), 64 hops max
1 10.100.0.1 0.736ms 0.601ms 0.494ms
2 10.100.1.101 0.896ms 0.663ms 0.646ms
ubuntu@core-srv1:~$ ip route show
default via 10.100.0.1 dev eth0
10.100.0.0/24 dev eth0 proto kernel scope link src 10.100.0.101
</code>
</pre>
<p>We can see the mac addresses of the virtual machines in the routers arp table, including dist-srv1 and core-srv1.</p>
<pre>
<code>Router#sh arp
Protocol Address Age (min) Hardware Addr Type Interface
Internet 10.100.0.1 - 5254.0013.bd53 ARPA GigabitEthernet2
Internet 10.100.0.101 172 5254.00db.4454 ARPA GigabitEthernet2
Internet 10.100.1.1 - 5254.001e.fceb ARPA GigabitEthernet3
Internet 10.100.1.2 52 7e65.7502.9f41 ARPA GigabitEthernet3
Internet 10.100.1.101 4 5254.00ec.b81e ARPA GigabitEthernet3
Internet 192.168.122.1 91 5254.0073.6d2e ARPA GigabitEthernet1
Internet 192.168.122.2 - 5254.0021.831d ARPA GigabitEthernet1
</code>
</pre>
<h2 id="license">License</h2>
<p>By default the unlicensed CSR is pretty limited bandwidth-wise.</p>
<pre>
<code>Router#show platform hardware throughput level
The current throughput level is 2500 kb/s
</code>
</pre>
<p>Use the standard level evaluation license. (I think.)</p>
<pre>
<code>Router#conf t
Enter configuration commands, one per line. End with CNTL/Z.
Router(config)#license boot level standard
Feature Name:prem_eval
SNIP!
ACCEPT? (yes/[no]): yes
*Jul 18 19:08:12.085: %LICENSE-6-EULA_ACCEPTED: EULA for feature prem_eval 1.0 has been accepted. UDI=CSR1000V:9L7UG7XECKE; StoreIndex=0:Built-In License Storage% use 'write' command to make license boot config take effect on next boot
</code>
</pre>
<p>Reload.</p>
<pre>
<code>Router#reload
</code>
</pre>
<p>As can be seen, the license level has been changed, throughput is now 50000 kbps.</p>
<pre>
<code>SNIP!
*Jul 18 19:10:51.476: %SMART_LIC-6-AGENT_READY: Smart Agent for Licensing is initialized
*Jul 18 19:10:51.481: %VUDI-6-EVENT: [serial number: 9L7UG7XECKE], [vUDI: ], vUDI is successfully retrieved from license file
*Jul 18 19:10:51.684: %IOS_LICENSE_IMAGE_APPLICATION-6-LICENSE_LEVEL: Module name = csr1000v Next reboot level = standard and License = prem_eval
*Jul 18 19:10:52.557: %VXE_THROUGHPUT-6-LEVEL: Throughput level has been set to 50000 kbps
SNIP!
Router#sh platform hardware throughput level
The current throughput level is 50000 kb/s
</code>
</pre>
<h2 id="shutdown">Shutdown</h2>
<p>I just wanted to know that “virsh shutdown” will halt this router just fine, and this message will appear on the router console.</p>
<pre>
<code>*Jul 19 16:36:44.836: %IOSXE-5-PLATFORM: F0: shutdown: shutting down for system halt
</code>
</pre>
<h2 id="iperf">Iperf</h2>
<p>I would like to run iperf between the hosts, but given the weird issue I’m seeing on KVM hosts, I can’t.</p>
<h2 id="conclusion">Conclusion</h2>
<p>So here we have a super basic virtual network setup that is routed by a Cisco 1000V CSR router. What I’ve done here could easily be accomplished with a simple firewall or other basic router, but I think it’s a good step towards getting a test environment setup with a Cisco router.</p>
<p>Again, it must be noted that this is not working yet in a KVM environment (Ubuntu 12.04 or 14.04) but does work with Windows + Virtualbox.</p>
Using the Cisco 1000v CSR with Libvirt and KVM2014-07-14T00:00:00+00:00http://serverascode.com/2014/07/14/cisco-1000v-csr-libvirt-kvm<h1 id="using-the-cisco-1000v-csr-with-libvirt-and-kvm">Using the Cisco 1000v CSR with Libvirt and KVM</h1>
<p>This blog post is going to cover installing and booting the <a href="http://www.cisco.com/c/en/us/products/routers/cloud-services-router-1000v-series/index.html">Cisco 1000v Cloud Services Router</a> with KVM on Ubuntu Trusty 14.04.</p>
<p>It’s important to note that I haven’t touched a Cisco device in over a decade. At least until the blog post that is. I’ve been an open source based systems administrator for all of my career, and now I would like to learn a bit more about networking, which is considerably more closed source than I am used to. Thankfully, however, Cisco offers a free download of their cloud router.</p>
<h2 id="getting-the-cisco-1000v-csr-images-and-isos">Getting the Cisco 1000v CSR images and ISOs</h2>
<p>First, if you don’t have an account with <a href="http://cisco.com">Cisco</a>, then create one and login.</p>
<p>To find the download page, this <a href="http://software.cisco.com/download/release.html?mdfid=284364978&softwareid=282046477&release=3.12.0S&flowid=39582">link</a> might work. If if doesn’t work:</p>
<ol>
<li><a href="http://www.cisco.com/c/en/us/products/routers/cloud-services-router-1000v-series/index.html">CSR Index page</a></li>
<li>Right menu, “Download Software for this Product”</li>
<li>Right panel, “Cisco Cloud Services outer 1000V”</li>
<li>Select “IOS XE Software”</li>
<li>Pick your download, ISO, OVA, qcow2, etc.</li>
</ol>
<p>In this post I’m going to work from the ISO.</p>
<h2 id="install-from-iso-into-qcow2-image">Install from ISO into qcow2 image</h2>
<p>Using the ISO process, we boot the ISO using KVM, which will automatically install the router software onto the disk image specified. Once that’s done you can boot the qcow2 image like any regular virtual machine.</p>
<p>I’ve downloaded the ISO file.</p>
<pre>
<code># ls *.iso
csr1000v-universalk9.03.12.00.S.154-2.S-std.iso
</code>
</pre>
<p>Next, create a backing image to install the software onto. It has to be at least 8 gigs.</p>
<pre>
<code># qemu-img create -f qcow2 csr.img 8G
Formatting 'csr.img', fmt=qcow2 size=8589934592 encryption=off cluster_size=65536 lazy_refcounts=off
</code>
</pre>
<p>Now we can boot the ISO with KVM and set the backing image on which the ISO will install the 1000v router. Note that you need to hit a key pretty quickly to get to the GRUB boot menu.</p>
<pre>
<code># kvm -boot d csr.img -enable-kvm -m 4096M -cpu Nehalem -smp 4,sockets=4,cores=1,threads=1 -cdrom csr1000v-universalk9.03.12.00.S.154-2.S-std.iso -nographic
</code>
</pre>
<p>After hitting the “any” key, you should see the below. Select “Serial Console” and hit enter.</p>
<pre>
<code> GNU GRUB version 0.97 (639K lower / 3144696K upper memory)
+-------------------------------------------------------------------------+
| CSR 1000V Virtual Console -- Wed-26-Mar-14-15:35 |
| CSR 1000V Serial Console -- Wed-26-Mar-14-15:35 |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
+-------------------------------------------------------------------------+
Use the ^ and v keys to select which entry is highlighted.
Press enter to boot the selected OS, or 'c' for a command-line.
</code>
</pre>
<p>At this point the ISO should install the 1000v CSR router into the csr.img qcow2 file, and some text should fly by, such as the below. It should only take a minute or two to install the CSR onto the hd image.</p>
<pre>
<code>Booting 'CSR 1000V Serial Console -- Wed-26-Mar-14-15:35'
root (cd)
Filesystem type is iso9660, using whole disk
kernel /boot/csr1000v-universalk9.03.12.00.S.154-2.S-std.SPA.bin rw root=/dev/r
am quiet console= max_loop=64 HARDWARE=virtual SR_BOOT=cdrom:csr1000v-universal
k9.03.12.00.S.154-2.S-std.iso
package header rev 1 structure detected
Calculating SHA-1 hash...done
SHA-1 hash:
calculated f51efee9:bfc569d7:9a732dee:4af42ccc:7003719d
expected f51efee9:bfc569d7:9a732dee:4af42ccc:7003719d
Package type:0x7530, flags:0x0
[Linux-bzImage, setup=0x2e00, size=0x11706720]
[isord @ 0x6fe6c000, 0x10183000 bytes]
SNIP!
%IOSXEBOOT-4-BOOT_CDROM: (rp/0): Installing GRUB
%IOSXEBOOT-4-BOOT_CDROM: (rp/0): Copying super package csr1000v-universalk9.03.12.00.S.154-2.S-std.SPA.bin
%IOSXEBOOT-4-BOOT_CDROM: (rp/0): Expanding super package on /bootflash
%IOSXEBOOT-4-BOOT_CDROM: (rp/0): Creating /boot/grub/menu.lst
%IOSXEBOOT-4-BOOT_CDROM: (rp/0): CD-ROM Installation finished
%IOSXEBOOT-4-BOOT_CDROM: (rp/0): Ejecting CD-ROM tray
%IOSXEBOOT-4-BOOT_CDROM: (rp/0): Rebooting from HD
SNIP!
Press any key to continue.
Press any key to continue.
Press any key to continue.
</code>
</pre>
<p>Again you have to be quick on hitting a key when the “Press any key to continue” message comes up. (Must be a better way to do this.) The vm is now booting off of the hd image instead of the ISO image.</p>
<p>Select virtual console once more and the router should boot up and ask if we want to configure from a dialog.</p>
<pre>
<code>SNIP!
cisco CSR1000V (VXE) processor with 2170596K/6147K bytes of memory.
Processor board ID 9W17YZL34P2
1 Gigabit Ethernet interface
32768K bytes of non-volatile configuration memory.
4194304K bytes of physical memory.
7774207K bytes of virtual hard disk at bootflash:.
--- System Configuration Dialog ---
Would you like to enter the initial configuration dialog? [yes/no]:
</code>
</pre>
<p>I enter no, though you may want to enter yes. The router continues booting, eventually stops and we can just hit enter to get the “Router>” prompt.</p>
<pre>
<code>SNIP!
*Jul 15 01:40:39.304: %VMAN-5-PACKAGE_SIGNING_LEVEL_ON_INSTALL: F0: vman: Package 'csrmgmt.1_3_1.20140213_121708.ova
Building configuration...
' for service container 'csr_mgmt' is 'Cisco signed', signing level cached on original install is 'Cisco signed'
*Jul 15 01:40:39.745: Not MO, application name is csr_mgmt
*Jul 15 01:40:39.745: %VIRT_SERVICE-5-INSTALL_STATE: Successfully installed virtual service csr_mgmt
*Jul 15 01:40:39.748: IOS-FIREWALL-POLICY-SHIM-REGISTER[OK]
*Jul 15 01:40:42.273: %CONFIG_CSRLXC-5-CONFIG_DONE: Configuration was applied and saved to NVRAM. See bootflash:/csrlxc-cfg.log for more details.
# hit enter!
Router> #here we are at the router prompt!
</code>
</pre>
<p>Now we have a full fledged Cisco router!</p>
<p>At this point I usually kill the KVM process from another terminal, and the installation is complete. (Killing from another terminal is a little awkward, so let me know if you find a better way, which probably involves not using “-serial stdio”, but I like that it just streams in the terminal. Lots of ways to do this.)</p>
<h2 id="using-the-image-file">Using the image file</h2>
<p>Now that the ISO has finished installing the software, we have an image file to work with.</p>
<pre>
<code># du -hs csr.img
1.6G csr.img
# file csr.img
csr.img: QEMU QCOW Image (unknown version)
</code>
</pre>
<p>Copy that image to /var/lib/libvirt/images.</p>
<pre>
<code># cp csr.img /var/lib/libvirt/images/
</code>
</pre>
<p>In /var/lib/libvirt/images, create a qcow2 snapshot.</p>
<pre>
<code># qemu-img create -f qcow2 -b csr.img csr-01.img
Formatting 'csr-01.img', fmt=qcow2 size=8589934592 backing_file='csr.img' encryption=off cluster_size=65536 lazy_refcounts=off
</code>
</pre>
<p>Now we can use that image with libvirt.</p>
<h2 id="libvirt-xml-file">Libvirt XML file</h2>
<p>Create an XML file like the below, ensuring to replace the image file location if necessary. I believe the CSR requires 4GB of memory and 4 VCPUS.</p>
<p>Note that if you want the CSR to have more than one interface, you’ll have to add it to the XML file, and perhaps add networks to libvirt.</p>
<pre>
<code># cat csr-01.xml
<domain type="kvm">
<name>csr-01/name>
<memory unit="KiB">4194304</memory>
<currentMemory unit="KiB">4194304</currentMemory>
<vcpu placement="static">4</vcpu>
<os>
<type arch="x86_64" machine="pc-0.14">hvm</type>
<boot dev="hd" />
</os>
<cpu>
<model>Nehalem</model>
</cpu>
<features>
<acpi />
<apic />
<pae />
</features>
<clock offset="utc" />
<on_poweroff>destroy</on_poweroff>
<on_reboot>restart</on_reboot>
<on_crash>restart</on_crash>
<devices>
<emulator>/usr/bin/kvm</emulator>
<disk type="file" device="disk">
<driver name="qemu" type="qcow2" />
<source file="/var/lib/libvirt/images/csr-01.img" />
<target dev="vda" bus="virtio" />
</disk>
<controller type="usb" index="0">
</controller>
<interface type="network">
<source network="default" />
<model type="virtio" />
</interface>
<serial type="pty">
<target port="0" />
</serial>
<console type="pty">
<target type="serial" port="0" />
</console>
<input type="tablet" bus="usb" />
<input type="mouse" bus="ps2" />
<graphics type="vnc" port="-1" autoport="yes" />
<sound model="ich6">
</sound>
<video>
<model type="cirrus" vram="9216" heads="1" />
</video>
<memballoon model="virtio">
</memballoon>
</devices>
</domain>
</code>
</pre>
Define the vm and start it.
<pre>
<code># virsh define csr-01.xml
Domain csr-01 defined from csr-01.xml
# virsh start csr-01
Domain csr-01 started
</code>
</pre>
You can use "virsh console csr-01" to access the console. To exit (at least when using OSX's terminal) hit "CTRL-5."
<pre>
<code># virsh console csr-01
Booting 'CSR1000v - packages.conf'
root (hd0,0)
Filesystem type is ext2fs, partition type 0x83
kernel /packages.conf rw quiet root=/dev/ram console= max_loop=64 HARDWARE=virt
ual SR_BOOT=bootflash:packages.conf
Calculating SHA-1 hash...done
SHA-1 hash:
calculated 514e2831:94ee1441:2404193c:f37dac1e:4c196e19
expected 514e2831:94ee1441:2404193c:f37dac1e:4c196e19
package header rev 1 structure detected
Calculating SHA-1 hash...done
SHA-1 hash:
calculated 134e1e2e:319d85c6:34a4d2b3:965dcb75:dc20afef
expected 134e1e2e:319d85c6:34a4d2b3:965dcb75:dc20afef
Package type:0x7531, flags:0x0
[Linux-bzImage, setup=0x2e00, size=0xd1c0720]
[isord @ 0x743b2000, 0xbc3d000 bytes]
SNIP!
</code>
</pre>
Check the interfaces and show version.
<pre>
<code>SNIP!
*Jul 15 02:46:04.712: %CONFIG_CSRLXC-5-CONFIG_DONE: Configuration was applied and saved to NVRAM. See bootflash:/csrlxc-cfg.log for more details.
Router>enable
Router#show int desc
Interface Status Protocol Description
Gi1 admin down down
Gi2 admin down down
Gi3 admin down down
Router#show version
Cisco IOS XE Software, Version 03.12.00.S - Standard Support Release
Cisco IOS Software, CSR1000V Software (X86_64_LINUX_IOSD-UNIVERSALK9-M), Version 15.4(2)S, RELEASE SOFTWARE (fc2)
Technical Support: http://www.cisco.com/techsupport
Copyright (c) 1986-2014 by Cisco Systems, Inc.
Compiled Wed 26-Mar-14 21:09 by mcpre
SNIP!
</code>
</pre>
Again, you can hit "CTRL-5" to exit "virsh console."
## Conclusion
Now that we have a base image and a working libvirt XML file, we can create all kinds of interesting network configurations and learn how to use a Cisco router without actually having any Cisco hardware. Nothing is stopping you from booting several CSR virtual machines and configuring them to work together.
</name></domain></code></pre>
Nested Virtualization and KVM2014-07-09T00:00:00+00:00http://serverascode.com/2014/07/09/nested-virtualization-kvm<h1 id="nested-virtualization-and-kvm">Nested Virtualization and KVM</h1>
<p>Recently I was working on getting virtual machines to boot inside a virtual machine running on Ubuntu Trusty 14.04 (insert <a href="http://www.imdb.com/title/tt1375666/">inception</a> joke here). However I was getting an error:</p>
<pre>
<code>libvirtError: internal error no supported architecture for os type 'hvm'
</code>
</pre>
<p>In my case that mean that nested virtualization was not turned on in the operating system that is running on the baremetal. (I should note there’s another good <a href="http://kashyapc.com/2012/01/14/nested-virtualization-with-kvm-intel/">blog post here</a> that describes turning on nested virtualization in KVM as well.)</p>
<p>To enable it, I removed the kvm_intel module and re-added it with nested=1.</p>
<pre>
<code># modprobe -r kvm_intel
# modprobe kvm_intel nested=1
</code>
</pre>
<p>Now I should see a “Y” after the below command. (Why it reports a “Y” I don’t understand.)</p>
<pre>
<code># cat /sys/module/kvm_intel/parameters/nested
Y
</code>
</pre>
<p>And we are good to go with nested virtualization.</p>
<p>I also setup this file:</p>
<pre>
<code># cat /etc/modprobe.d/kvm_intel.conf
options kvm_intel nested=1
</code>
</pre>
<p>So that it will be added on a reboot.</p>
<p>Happy nesting!</p>
Fake OpenStack with Dwarf2014-07-07T00:00:00+00:00http://serverascode.com/2014/07/07/dwarf-openstack<h1 id="fake-openstack-with-dwarf">Fake OpenStack with Dwarf</h1>
<p><a href="https://github.com/juergh/dwarf">Dwarf</a> is this really cool little project by <a href="https://github.com/juergh">Juerg Haefliger</a> that provides a subset of the OpenStack APIs to use libvirt on a single host. For some context, here’s the <a href="http://www.gossamer-threads.com/lists/openstack/dev/36420?search_string=dwarf;#36420">original email</a> that was sent to the OpenStack list. What it does is allow you to use manage a single libvirt host as though it were OpenStack, ie. use nova, glance, and keystone commands to manage libvirt virtual machines.</p>
<h2 id="why">Why?</h2>
<p>For some reason I find faking APIs really interesting. I guess a better word than faking would be “compatability” but really what is going on is APIs are being faked. For example, OpenStack has always, as far as I know, provided some Amazon Web Services (AWS) compatibility. OpenStack Swift also can provide Amazon S3 API compatibility. Another example is <a href="http://www.cloudscaling.com/blog/openstack/gce-api-available-now-on-openstack-stackforge/">Cloudscaling providing a GCE compatabile API for OpenStack</a>.</p>
<p>I think fake APIs also suggests that a certain application or service is becoming popular, and so having a little fake OpenStack subset API using Dwarf is a compliment to OpenStack. Also it can help in terms of understanding how OpenStack works. Do you wonder what the keystone catalog does? Well, now you can mess around with it in Dwarf and find out.</p>
<h2 id="caveats">Caveats</h2>
<p>As Haefliger says in the README for Dwarf:</p>
<ul>
<li>No authentication!</li>
<li>Just for one host</li>
<li>A subset of OpenStack commands</li>
<li>Serialized and blocking</li>
</ul>
<h2 id="install-dwarf">Install Dwarf</h2>
<p>First install the Dwarf PPA. I’m running this on Ubuntu Precise 12.04, which is itself a virtual machine, and thus we’ll be doing nested virtualization, which may need to be turned on in some hosts.</p>
<pre>
<code>ubuntu@dwarf:~$ sudo apt-add-repository ppa:juergh/dwarf
</code>
</pre>
<p>Then install Dwarf.</p>
<pre>
<code>ubuntu@dwarf:~$ sudo apt-get install dwarf
</code>
</pre>
<p>Now we have a dwarf command.</p>
<pre>
<code>ubuntu@dwarf:~$ which dwarf
/usr/bin/dwarf
</code>
</pre>
<p>We can start dwarf with service.</p>
<pre>
<code>root@dwarf:~# service dwarf start
</code>
</pre>
<p>That starts a few processes listening, openstack identity, openstack compute, and openstack images, ie. keystone, nova, and glance respectively.</p>
<pre>
<code>root@dwarf:/etc# netstat -ant
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN
tcp 0 0 127.0.0.1:35357 0.0.0.0:* LISTEN
tcp 0 0 127.0.0.1:8774 0.0.0.0:* LISTEN
tcp 0 0 127.0.0.1:9292 0.0.0.0:* LISTEN
tcp 0 0 192.168.122.77:22 192.168.122.1:38835 ESTABLISHED
tcp6 0 0 :::22 :::* LISTEN
</code>
</pre>
<p>Need python-novaclient, python-keystoneclient too. I’m going to use pip to get more recent versions of these commands. I guess glance comes from glance-client? Weird.</p>
<pre>
<code>root@dwarf:~# apt-get install python-pip
root@dwarf:~# pip install python-novaclient
root@dwarf:~# nova --version
2.17.0
root@dwarf:~# glance --version
0.12.0
root@dwarf:~# keystone --version
0.9.0
</code>
</pre>
<h2 id="use-dwarf">Use Dwarf</h2>
<p>Create a default openstack rc file and source it. Again note there is no real authentication.</p>
<pre>
<code>root@dwarf:~# cat dwarfrc
export OS_AUTH_URL=http://127.0.0.1:35357/v2.0/
export OS_COMPUTE_API_VERSION=1.1
export OS_REGION_NAME=dwarf-region
export OS_TENANT_NAME=dwarf-tenant
export OS_USERNAME=dwarf-user
export OS_PASSWORD=dwarf-password
root@dwarf:~# . dwarfrc
</code>
</pre>
<p>And finally we can run some nova commands.</p>
<pre>
<code>root@dwarf:~# nova list
+----+------+--------+----------+
| ID | Name | Status | Networks |
+----+------+--------+----------+
+----+------+--------+----------+
root@dwarf:~# nova flavor-list
+-----+-----------------+-----------+------+-----------+------+-------+-------------+
| ID | Name | Memory_MB | Disk | Ephemeral | Swap | VCPUs | RXTX_Factor |
+-----+-----------------+-----------+------+-----------+------+-------+-------------+
| 100 | standard.xsmall | 512 | 10 | N/A | | 1 | |
| 101 | standard.small | 768 | 30 | N/A | | 1 | |
| 102 | standard.medium | 1024 | 30 | N/A | | 1 | |
+-----+-----------------+-----------+------+-----------+------+-------+-------------+
root@dwarf:~# keystone catalog
WARNING:keystoneclient.httpclient:Failed to retrieve management_url from token
Service: image
+-------------+----------------------------+
| Property | Value |
+-------------+----------------------------+
| publicURL | http://127.0.0.1:9292/v1.0 |
| region | dwarf-region |
| tenantId | 1000 |
| versionId | 1.0 |
| versionInfo | http://127.0.0.1:9292/v1.0 |
| versionList | http://127.0.0.1:9292 |
+-------------+----------------------------+
Service: compute
+-------------+---------------------------------+
| Property | Value |
+-------------+---------------------------------+
| publicURL | http://127.0.0.1:8774/v1.1/1000 |
| region | dwarf-region |
| tenantId | 1000 |
| versionId | 1.1 |
| versionInfo | http://127.0.0.1:8774/v1.1 |
| versionList | http://127.0.0.1:8774 |
+-------------+---------------------------------+
</code>
</pre>
<p>For some reason the latest python-glanceclient was broken in my install. Not sure if it’s something I did wrong or what, but I ended up using 0.12.0. Note the glance that comes with 12.04 does not have the image-create command.</p>
<pre>
<code>root@dwarf:/tmp# pip install python-glanceclient==0.12.0
root@dwarf:/tmp# which glance
/usr/local/bin/glance
root@dwarf:/tmp# glance --version
0.12.0
</code>
</pre>
<pre>
<code>root@dwarf:~# glance index
No handlers could be found for logger "keystoneclient.httpclient"
ID Name Disk Format Container Format Size
------------------------------------ ------------------------------ -------------------- -------------------- --------------
96b8b4cc-bf45-4dc2-add0-c6d0fc96aec4
d0a3d8f7-d336-40d1-b548-fbb5e5e01d8f
ced791fc-bd11-4d91-9eb6-3fe892dd2a6d
40bee026-03a4-4020-88bc-bc0acf9465a6
0a29e5fc-fb0b-487d-b957-f4fd296d71b1
f51efef5-fe73-4957-94c0-bf94038a2685
</code>
</pre>
<p>Interestingly running glance image-create with no options with dwarf creates empty images. I deleted all those and also added a cirros image.</p>
<p>Download the Cirros image. I’m using Cirros because I’m running Dwarf inside a virtual machine, so have limited resources.</p>
<pre>
<code>root@dwarf:~# wget http://download.cirros-cloud.net/0.3.2/cirros-0.3.2-x86_64-disk.img
</code>
</pre>
<p>Add that image to Dwarf using glance.</p>
<pre>
<code>root@dwarf:~# glance image-create --name "Cirros" --file cirros-0.3.2-x86_64-disk.img
</code>
</pre>
<p>Now it’s in glance.</p>
<pre>
<code>root@dwarf:~# glance image-list
No handlers could be found for logger "keystoneclient.httpclient"
+--------------------------------------+--------+-------------+------------------+----------+--------+
| ID | Name | Disk Format | Container Format | Size | Status |
+--------------------------------------+--------+-------------+------------------+----------+--------+
| 56105cdc-00d8-4e69-beae-fbe20abcbe36 | Cirros | | | 13167616 | ACTIVE |
+--------------------------------------+--------+-------------+------------------+----------+--------+
</code>
</pre>
<p>Add a keypair. (Though cirros won’t use it.)</p>
<pre>
<code>
root@dwarf:~# nova keypair-add --pub-key ~/.ssh/id_rsa.pub root
root@dwarf:~# nova keypair-list
+------+-------------------------------------------------+
| Name | Fingerprint |
+------+-------------------------------------------------+
| root | 7f:21:e1:9b:ee:3d:84:89:a5:bc:c1:3e:79:20:e5:c0 |
+------+-------------------------------------------------+
</code>
</pre>
<p>If you are nesting, ie. a vm inside a vm, before going further edit the default libvirt network. Change 192.168.122.0/24 to some other network, such as 10.0.0.0/24. 192.168.122.0/24 will likely already be in use and the default network won’t start, and neither will libvirt based vms.</p>
<pre>
<code>root@dwarf:~# virsh net-edit default
# Edit to look like this:
<code><network>
<name>default</name>
<uuid>7fd26ceb-ed87-7887-198e-d9cbc4759b70</uuid>
<forward mode="nat" />
<bridge name="virbr0" stp="on" delay="0" />
<ip address="10.0.0.1" netmask="255.255.255.0">
<dhcp>
<range start="10.0.0.2" end="10.0.0.254" />
</dhcp>
</ip>
</network>
</code>
</pre>
Start that network.
<pre>
<code>root@dwarf:~# virsh net-start default
setlocale: No such file or directory
Network default started
root@dwarf:~# brctl show
bridge name bridge id STP enabled interfaces
virbr0 8000.525400a6a92a yes virbr0-nic
</code>
</pre>
Looks good.
Next: boot a vm.
<pre>
<code>root@dwarf:~# nova boot --flavor 100 --image 56105cdc-00d8-4e69-beae-fbe20abcbe36 --key_name root test1
ERROR: 'NoneType' object has no attribute 'get'
</code>
</pre>
I see there is an error reported, but the vm does indeed get started up. Something to look into, might have to do with the version of nova client being used. I certainly had some trouble with the glance client.
That vm is now running:
<pre>
<code>root@dwarf:~# virsh list
setlocale: No such file or directory
Id Name State
----------------------------------
2 dwarf-00000003 running
root@dwarf:~# nova list
+--------------------------------------+-------+--------+------------+-------------+-------------------+
| ID | Name | Status | Task State | Power State | Networks |
+--------------------------------------+-------+--------+------------+-------------+-------------------+
| 0e8a17bf-4c99-455d-87d6-4eb8d35af1d7 | test1 | ACTIVE | N/A | N/A | private=10.0.0.28 |
+--------------------------------------+-------+--------+------------+-------------+-------------------+
root@dwarf:~# cat /var/lib/libvirt/dnsmasq/default.leases
1404773235 52:54:00:2c:94:14 10.0.0.28 * 01:52:54:00:2c:94:14
root@dwarf:~# ping -c 1 -w 1 10.0.0.28
PING 10.0.0.28 (10.0.0.28) 56(84) bytes of data.
64 bytes from 10.0.0.28: icmp_req=1 ttl=64 time=0.694 ms
--- 10.0.0.28 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 0.694/0.694/0.694/0.000 ms
</code>
</pre>
ssh into the vm...login "cirros", password "cubswin:)"
<pre>
<code>root@dwarf:~# ssh cirros@10.0.0.28
The authenticity of host '10.0.0.28 (10.0.0.28)' can't be established.
RSA key fingerprint is 44:8a:7a:ce:25:d6:f6:aa:2f:98:bb:c3:ec:a2:e8:2a.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added '10.0.0.28' (RSA) to the list of known hosts.
cirros@10.0.0.28's password:
$ ifconfig eth0
eth0 Link encap:Ethernet HWaddr 52:54:00:2C:94:14
inet addr:10.0.0.28 Bcast:10.0.0.255 Mask:255.255.255.0
inet6 addr: fe80::5054:ff:fe2c:9414/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:92 errors:0 dropped:0 overruns:0 frame:0
TX packets:70 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:9758 (9.5 KiB) TX bytes:7502 (7.3 KiB)
$ cat /proc/meminfo | head -1
MemTotal: 503476 kB
</code>
</pre>
In fact Dwarf does at least one nice thing for us in that it'll determine the virtual machines IP address automatically, which libvirt doesn't do.
## Conclusion
Using Dwarf we can boot instances using libvirt and qemu. The [code is out there on github](https://github.com/juergh/dwarf) ready to be hacked on and improved or forked for your own purposes. Once you get your host configured properly and the right nova and glance clients installed it seems to work well.
Thanks [Juerg Haefliger](https://github.com/juergh) for Dwarf. :)
</code></pre>
Add SSD as cache to ZFS on Linux2014-07-03T00:00:00+00:00http://serverascode.com/2014/07/03/add-ssd-cache-zfs<h1 id="add-ssd-as-cache-to-zfs-on-linux">Add SSD as cache to ZFS on Linux</h1>
<p>I just physically added a SSD into my <a href="http://localhost:4000/2014/07/01/ZFS-ubuntu-trusty.html">home backup server</a> and I would like to configure it as a ZFS l2arc cache device. Doing so will mean new files will be written to the SSD first, then the spinning disk later, and that recently used files will be accessed via the SSD drive instead of the slower spinning disks. Depending on your workload, this should make most disk operations faster.</p>
<p>In my case, the SSD is /dev/sdc.</p>
<pre>
<code>root@storage:/home/curtis# lsblk /dev/sdc
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sdc 8:32 0 232.9G 0 disk
├─sdc1 8:33 0 232.9G 0 part
└─sdc9 8:41 0 8M 0 part
</code>
</pre>
<p>It’s a 240GB Samsung 840.</p>
<pre>
<code>root@storage:/home/curtis# smartctl -a /dev/sdc
smartctl 6.2 2013-07-26 r3841 [x86_64-linux-3.13.0-24-generic] (local build)
Copyright (C) 2002-13, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Model Family: Samsung based SSDs
Device Model: Samsung SSD 840 Series
Serial Number: S14GNEACC11801K
LU WWN Device Id: 5 002538 5500d4588
Firmware Version: DXT06B0Q
User Capacity: 250,059,350,016 bytes [250 GB]
Sector Size: 512 bytes logical/physical
Rotation Rate: Solid State Device
Device is: In smartctl database [for details use: -P show]
ATA Version is: ACS-2, ATA8-ACS T13/1699-D revision 4c
SATA Version is: SATA 3.1, 6.0 Gb/s (current: 3.0 Gb/s)
Local Time is: Wed Jul 2 18:57:51 2014 MDT
SMART support is: Available - device has SMART capability.
SMART support is: Disabled
SMART Disabled. Use option -s with argument 'on' to enable it.
(override with '-T permissive' option)
</code>
</pre>
<p>Now let’s simply add it to the tank zpool. Note that “-f” means force, as this SSD was previously used with other file systems.</p>
<pre>
<code>root@storage:/home/curtis# zpool add -f tank cache sdc
</code>
</pre>
<p>Hasn’t even been used!</p>
<pre>
<code>root@storage:/home/curtis# zpool iostat -v tank
capacity operations bandwidth
pool alloc free read write read write
---------- ----- ----- ----- ----- ----- -----
tank 757G 635G 0 0 262 1.25K
mirror 757G 635G 0 0 262 1.25K
sdb - - 0 0 1.35K 1.77K
sdd - - 0 0 1.82K 1.77K
cache - - - - - -
sdc 400K 233G 0 0 595 1.76K
---------- ----- ----- ----- -----
</code>
</pre>
<p>Fio is my favorite disk performance tool, so lets use that to test the new cache device. Note that this is just a basic, example fio test. Interestingly ZFS doesn’t support “direct=1”.</p>
<pre>
<code>root@storage:/home/curtis# cat random-rw.fio
[random_rw]
rw=randrw
size=1024m
directory=/tank/bup
root@storage:/home/curtis# fio random-rw.fio
random_rw: (g=0): rw=randrw, bs=4K-4K/4K-4K/4K-4K, ioengine=sync, iodepth=1
fio-2.1.3
Starting 1 process
random_rw: Laying out IO file(s) (1 file(s) / 1024MB)
Jobs: 1 (f=1): [m] [99.1% done] [10468KB/10444KB/0KB /s] [2617/2611/0 iops] [eta 00m:01s]
random_rw: (groupid=0, jobs=1): err= 0: pid=1932: Wed Jul 2 18:43:00 2014
read : io=524704KB, bw=5017.9KB/s, iops=1254, runt=104567msec
clat (usec): min=3, max=3444, avg=16.18, stdev=34.60
lat (usec): min=3, max=3444, avg=16.42, stdev=34.61
clat percentiles (usec):
| 1.00th=[ 5], 5.00th=[ 7], 10.00th=[ 8], 20.00th=[ 9],
| 30.00th=[ 10], 40.00th=[ 11], 50.00th=[ 12], 60.00th=[ 13],
| 70.00th=[ 14], 80.00th=[ 15], 90.00th=[ 36], 95.00th=[ 41],
| 99.00th=[ 53], 99.50th=[ 63], 99.90th=[ 189], 99.95th=[ 462],
| 99.99th=[ 1848]
bw (KB /s): min= 3200, max=17824, per=99.26%, avg=4979.99, stdev=1839.92
write: io=523872KB, bw=5009.1KB/s, iops=1252, runt=104567msec
clat (usec): min=9, max=5490, avg=772.32, stdev=244.37
lat (usec): min=9, max=5490, avg=772.62, stdev=244.38
clat percentiles (usec):
| 1.00th=[ 213], 5.00th=[ 318], 10.00th=[ 414], 20.00th=[ 620],
| 30.00th=[ 692], 40.00th=[ 748], 50.00th=[ 804], 60.00th=[ 852],
| 70.00th=[ 916], 80.00th=[ 972], 90.00th=[ 1020], 95.00th=[ 1048],
| 99.00th=[ 1112], 99.50th=[ 1144], 99.90th=[ 2928], 99.95th=[ 3152],
| 99.99th=[ 3440]
bw (KB /s): min= 3408, max=17048, per=99.27%, avg=4972.41, stdev=1761.31
lat (usec) : 4=0.01%, 10=13.65%, 20=29.22%, 50=6.90%, 100=0.48%
lat (usec) : 250=0.93%, 500=5.35%, 750=14.01%, 1000=22.28%
lat (msec) : 2=7.04%, 4=0.12%, 10=0.01%
cpu : usr=1.59%, sys=8.40%, ctx=132043, majf=0, minf=27
IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued : total=r=131176/w=130968/d=0, short=r=0/w=0/d=0
Run status group 0 (all jobs):
READ: io=524704KB, aggrb=5017KB/s, minb=5017KB/s, maxb=5017KB/s, mint=104567msec, maxt=104567msec
WRITE: io=523872KB, aggrb=5009KB/s, minb=5009KB/s, maxb=5009KB/s, mint=104567msec, maxt=104567msec
</code>
</pre>
<p>Now the stats show some usage. The stats below are after a few test runs.</p>
<pre>
<code>root@storage:/home/curtis# zpool iostat -v tank
capacity operations bandwidth
pool alloc free read write read write
---------- ----- ----- ----- ----- ----- -----
tank 757G 635G 0 57 1.15K 6.68M
mirror 757G 635G 0 57 1.15K 6.68M
sdb - - 0 55 1.24K 6.68M
sdd - - 0 55 1.14K 6.68M
cache - - - - - -
sdc 11.7G 221G 0 54 79 6.81M
---------- ----- ----- ----- ----- ----- -----
</code>
</pre>
<p>That’s all it takes! Please let me know if you see anything incorrect.</p>
<p>Happy caching!</p>
Install ZFS on Ubuntu Trusty 14.042014-07-01T00:00:00+00:00http://serverascode.com/2014/07/01/zfs-ubuntu-trusty<h1 id="install-zfs-on-ubuntu-trusty-1404">Install ZFS on Ubuntu Trusty 14.04</h1>
<p>In this blog post I’ll install <a href="http://zfsonlinux.org/">ZFS-on-Linux</a> (ZoL) on trusty old Ubuntu Trusty 14.04.</p>
<p>ZFS is an amazing file system that is now also usable on Linux. One of ZFS’ best features is that it can “self heal” as it is a checksumming file system. Also it can use SSDs in a couple of different ways, such as the ZIL drive and the L2ARC cache.</p>
<p>There are other interesting file systems and ways to cache with solid state drives. <a href="https://btrfs.wiki.kernel.org/index.php/Main_Page">btrfs</a> is continually getting better (I use it with <a href="http://serverascode.com/2014/06/09/docker-btrfs.html">Docker</a>) and recently the Linux kernel gained a few ways to do SSD caching: dmcache, flashcache, and bcache.</p>
<p>In my situation I have various media files from short films I’ve made that I need to backup and protect from bitrot. To do that I’ve decided to use ZFS on Linux. I worked with ZFS + FreeBSD a bit, but I also want the ability to mount many different types of file systems, and surprisingly FreeBSD doesn’t support that many of them. I’m also a big fan of XFS, which I believe FreeBSD only supports in read-only mode. So Linux it is.</p>
<h2 id="zol-ppa">ZoL PPA</h2>
<p>The easiest way to get ZoL is to use the ZFS-native PPA. The software-properties-common package is required for the add-apt-repository command.</p>
<pre>
<code>curtis@storage:~$ sudo apt-get install software-properties-common
curtis@storage:~$ sudo add-apt-repository ppa:zfs-native/stable
</code>
</pre>
<p>Now we can install ZoL. Installing will also compile a kernel module.</p>
<p><em>NOTE: I’m removing a lot of the output below for brevity; I usually mark that with SNIP!.</em></p>
<pre>
<code>curtis@storage:~$ sudo apt-get update
curtis@storage:~$ sudo apt-get install -y ubuntu-zfs
SNIP!
zfs.ko:
Running module version sanity check.
- Original module
- No original module exists within this kernel
- Installation
- Installing to /lib/modules/3.13.0-24-generic/updates/dkms/
depmod....
SNIP!
Setting up ubuntu-zfs (8~trusty) ...
Processing triggers for libc-bin (2.19-0ubuntu6) ...
</code>
</pre>
<p>Now load the module.</p>
<pre>
<code>curtis@storage:~$ modprobe zfs
curtis@storage:~$ lsmod | grep zfs
zfs 1185541 0
zunicode 331251 1 zfs
zavl 15010 1 zfs
zcommon 51321 1 zfs
znvpair 89166 2 zfs,zcommon
spl 175436 5 zfs,zavl,zunicode,zcommon,znvpair
</code>
</pre>
<h2 id="configure-zpool">Configure zpool</h2>
<p>I have an older computer that I am using as the zfs backup server. In this example it has two 1.5TB drives that I want to use in a zfs mirror (ie. RAID1). I’ll add more storage later but for this example just the two 1.5TB drives, sdb and sdd. They were previously used elsewhere and need to be reformatted for zfs.</p>
<pre>
<code>curtis@storage:~$ lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 119.2G 0 disk
├─sda1 8:1 0 113.3G 0 part /
├─sda2 8:2 0 1K 0 part
└─sda5 8:5 0 6G 0 part [SWAP]
sdb 8:16 0 1.4T 0 disk
├─sdb1 8:17 0 200M 0 part
├─sdb2 8:18 0 1.4T 0 part
└─sdb3 8:19 0 128M 0 part
sdc 8:32 0 465.8G 0 disk
├─sdc1 8:33 0 64K 0 part
├─sdc2 8:34 0 462G 0 part
└─sdc3 8:35 0 3.8G 0 part
sdd 8:48 0 1.4T 0 disk
├─sdd1 8:49 0 200M 0 part
├─sdd2 8:50 0 1.4T 0 part
└─sdd3 8:51 0 128M 0 part
sr0 11:0 1 1024M 0 rom
</code>
</pre>
<p>We’ll create a zpool mirror callled tank.</p>
<pre>
<code>curtis@storage:~$ sudo zpool create tank mirror sdb sdd
curtis@storage:~$ zfs list
NAME USED AVAIL REFER MOUNTPOINT
tank 91.5K 1.34T 30K /tank
</code>
</pre>
<p>Interestingly zfs didn’t warn me about reformatting.</p>
<p>There is now a /tank directory of about ~1.4TB.</p>
<pre>
<code>curtis@storage:~$ df -h | grep tank
tank 1.4T 0 1.4T 0% /tank
</code>
</pre>
<p>Now create another file system on tank. Note the casesensitivity=mixed for use with Windows.</p>
<pre>
<code>curtis@storage:/tank$ zfs create -o casesensitivity=mixed tank/bup
</code>
</pre>
<h2 id="samba-and-zfs">Samba and ZFS</h2>
<p>As stated previously, I want to use this as a backup server. I do a lot of work with video and audio files and that is all, unfortunately, done from a windows workstation. So I want to be able to backup from Windows to the ZoL backup server. I’ll use samba (SMB) to do that.</p>
<p>Please note that I haven’t used samba in years, so I’m not quite sure this is the right way to go about it. But it is working for me. :)</p>
<p>First, install samba.</p>
<pre>
<code>curtis@storage:~$ sudo apt-get install samba
</code>
</pre>
<p>Now we can create a file system in /tank and share that via SMB.</p>
<pre>
<code>curtis@storage:~$ sudo zfs set sharesmb=on tank/bup
curtis@storage:~$ sudo chown curtis:curtis /tank/bup
</code>
</pre>
<p>Check what zfs thinks about the share status with regards to samba and nfs.</p>
<pre>
<code>root@storage:/var/log/samba# sudo zfs get sharesmb,sharenfs
NAME PROPERTY VALUE SOURCE
tank sharesmb on local
tank sharenfs off default
tank/bup sharesmb on local
tank/bup sharenfs off default
</code>
</pre>
<p>Based on <a href="http://unix.stackexchange.com/questions/97812/fedora-19-zfsonlinux-how-to-configure-cifs-share">this blog post</a> I added the below to /etc/samba/smb.conf and restarted smbd and nmbd. These settings may or may not be appropriate for your use case.</p>
<pre>
<code>usershare path = /var/lib/samba/usershares
usershare max shares = 100
usershare allow guests = yes
usershare owner only = n
</code>
</pre>
<p>Next, add a samba user.</p>
<pre>
<code>root@storage:/var/log/samba# sudo smbpasswd -a curtis
New SMB password:
Retype new SMB password:
Added user curtis.
</code>
</pre>
<p>Finally I can connect to that server with \storage\tank_bup or the server and share should be browsable from the Windows workstation, assuming they are on the same network, and in this case they are.</p>
<h2 id="conclusion">Conclusion</h2>
<p>In this post I’ve done a couple things:</p>
<ul>
<li>Install ZFS on Linux</li>
<li>Create a pool with mirrored drives</li>
<li>Configure a samba share to access from Windows</li>
</ul>
<p>So far the performance has been fine. I get about 111MB/s write which is basically as fast as a 1GB network can go.</p>
<p>Soon I’ll add an SSD caching device which will get me more IOPS but I’ve hit the limit on the network.</p>
<h2 id="updates">Updates</h2>
<ul>
<li>Commenter Ofer B says <em>apt-get update</em> is necessary, so I added that.</li>
</ul>
Deploy OpenStack Swift OnlyOne to Digital Ocean2014-06-26T00:00:00+00:00http://serverascode.com/2014/06/26/openstack-swift-onlyone-digitalocean<h1 id="deploy-openstack-swift-onlyone-to-digital-ocean">Deploy OpenStack Swift OnlyOne to Digital Ocean</h1>
<p>In this blog post I want to show how to get your very own internet available object storage system using <a href="http://docs.openstack.org/developer/swift/">OpenStack Swift</a> and <a href="https://docker.com">Docker</a>. Also it will be terminated by SSL (though with a self-signed certificate).</p>
<p>It’s important to note that this is a special case OpenStack Swift setup–it only has one storage device and will only make one replica, which I call OpenStack Swift OnlyOne. Normally Swift installations are huge! But his one is small, which I think is cool. Or fun. But not fun and cool. That’s too much.</p>
<p>This is what we are going to do:</p>
<ul>
<li>Boot a virtual machine on Digital Ocean</li>
<li>Configure it to be able to use xattr</li>
<li>Pull a few docker images</li>
<li>Start three docker containers</li>
<li>Create swift containers and upload files into them</li>
<li>Set a container to serve an index.html page</li>
</ul>
<h2 id="get-a-docker-virtual-machine">Get a docker virtual machine</h2>
<p>Handily Digital Ocean has an image that comes with Docker 1.0 already. I’m going to use the tugboat CLI.</p>
<pre>
<code>curtis$ tugboat images --global | grep Docker
Docker 1.0 on Ubuntu 14.04 (id: 4296335, distro: Ubuntu)
Dokku v0.2.3 on Ubuntu 14.04 (w/ Docker 1.0) (id: 4381169, distro: Ubuntu)
</code>
</pre>
<p>Let’s boot it. 66 is the 512MB image.</p>
<p><em>NOTE: If you really plan on using this for work instead of just testing Swift, a larger droplet size will likely be necessary. I did get some out of memory errors with the 512MB size.</em></p>
<pre>
<code>curtis$ tugboat create swifty-onlyone -i 4296335 -s 66 -k 118429
Queueing creation of droplet 'swifty-onlyone'...done
curtis$ tugboat droplets
swifty-onlyone (ip: <droplet IP="">, status: new, region: 4, id: 1945827)
</code>
</pre>
Wait until it's active, then ssh in.
<pre>
<code>curtis$ tugboat droplets
swifty-onlyone (ip: <droplet IP="">, status: active, region: 4, id: 1945827)
curtis$ ssh root@<droplet IP="">
SNIP!
root@swifty-onlyone:~#
</code>
</pre>
Add xattr attribute to fstab for root and remount.
_NOTE: Swift requires the file system support xattr. I'm not sure if it's enabled by default or not._
<pre>
<code>root@swift-onlyone:~# # vi /etc/fstab and add user_xattr
root@swift-onlyone:~# grep xattr /etc/fstab
UUID=050e1e34-39e6-4072-a03e-ae0bf90ba13a / ext4 errors=remount-ro,user_xattr 0 1
root@swift-onlyone:~# mount -o remount /
</code>
</pre>
## Get docker images
Pull some docker images:
- busybox
- serverascode/swift-onlyone
- serverascode/pound
<pre>
<code>root@swift-onlyone:~# docker pull busybox; docker pull serverascode/swift-onlyone; docker pull serverascode/pound
</code>
</pre>
Now we have all those images locally.
<pre>
<code>root@swifty-onlyone:~# docker images
REPOSITORY TAG IMAGE ID CREATED VIRTUAL SIZE
serverascode/swift-onlyone latest 1b562d4e3975 3 hours ago 349.2 MB
serverascode/pound latest 2bfef1fdc39d 3 hours ago 285.2 MB
busybox buildroot-2013.08.1 d200959a3e91 3 weeks ago 2.489 MB
busybox ubuntu-14.04 37fca75d01ff 3 weeks ago 5.609 MB
busybox ubuntu-12.04 fd5373b3d938 3 weeks ago 5.455 MB
busybox buildroot-2014.02 a9eb17255234 3 weeks ago 2.433 MB
busybox latest a9eb17255234 3 weeks ago 2.433 MB
</code>
</pre>
## Create the containers
We're going to create three containers:
1. SWIFT_DATA: A volume only container
2. SWIFT: Has OnlyOne installed, volume from SWIFT_DATA
3. A pound ssl termination container, linked to SWIFT
First, create a volume only container.
<pre>
<code>root@swift-onlyone:~# docker run -v /srv --name SWIFT_DATA busybox
root@swift-onlyone:~# docker ps -a | grep DATA
838c68ce031b busybox:buildroot-2014.02 /bin/sh 15 seconds ago Exited (0) 14 seconds ago SWIFT_DATA
</code>
</pre>
Should see a volume in /var/lib/docker/volumes now.
<pre>
<code>root@swift-onlyone:~# ls /var/lib/docker/volumes/
1b6e87f07e2e5c0e49362bfa51f22fb8a32bca691a12d5c5872db0b90baf5241 _tmp
</code>
</pre>
Now create the OnlyOne container using a volume from SWIFT_DATA. Make sure to call it SWIFT.
Please note a couple of environment variables being set:
- *SWIFT_STORAGE_URL_SCHEME=https* Tells Swift Proxy to use https for the storage url
- *SWIFT_SET_PASSWORDS=yes* The startmain.sh script for Swift OnlyOne will change the default password for each use to one password.
<pre>
<code>root@swift-onlyone:~# docker run -d -e SWIFT_SET_PASSWORDS=yes -e SWIFT_STORAGE_URL_SCHEME=https --volumes-from SWIFT_DATA --name SWIFT -t serverascode/swift-onlyone
</code>
</pre>
If SWIFT_SET_PASSWORDS=yes was set, then the password will be echoed to the container log.
As an example, below it's been set to: laibiibooghu.
<pre>
<code>root@swift-onlyone:~# docker logs 6807caaaaf3b | head
Ring files already exist in /srv, copying them to /etc/swift...
Setting default_storage_scheme to https in proxy-server.conf...
storage_url_scheme = https
Setting passwords in /etc/swift/proxy-server.conf
user_test_tester = laibiibooghu .admin
user_test2_tester2 = laibiibooghu .admin
user_test_tester3 = laibiibooghu
Starting supervisord...
Starting to tail /var/log/syslog...(hit ctrl-c if you are starting the container in a bash shell)
Jun 27 16:46:24 6807caaaaf3b object-replicator: Starting object replicator in daemon mode.
</code>
</pre>
Finally create a pound container. This will be the ssl termination point and will be available from the Internet.
This container will be linked to the SWIFT container.
<pre>
<code>root@swift-onlyone:~# docker run -d --link SWIFT:SWIFT -p 443:443 -t serverascode/pound
</code>
</pre>
Now we have three containers, two of them running, and the other being the volume only container.
<pre>
<code>root@swift-onlyone:~# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
2f6dcdae1db2 serverascode/pound:latest /bin/sh -c /usr/loca 15 seconds ago Up 14 seconds 0.0.0.0:443->443/tcp naughty_turing
76d27dafa403 serverascode/swift-onlyone:latest /bin/sh -c /usr/loca About a minute ago Up About a minute 8080/tcp SWIFT,naughty_turing/SWIFT
838c68ce031b busybox:buildroot-2014.02 /bin/sh About an hour ago Exited (0) About an hour ago SWIFT_DATA
</code>
</pre>
Now from my laptop I can run the swift command line.
<pre>
<code>curtis$ alias sw='swift --insecure -A https://<droplet IP="">/auth/v1.0 -U test:tester -K <password>'
curtis$ sw stat
Account: AUTH_test
Containers: 0
Objects: 0
Bytes: 0
Content-Type: text/plain; charset=utf-8
X-Timestamp: 1403882745.61961
X-Trans-Id: tx28102150d50b484a92f3a-0053ad8cf9
X-Put-Timestamp: 1403882745.61961
</code>
</pre>
And upload a directory with a file in it.
<pre>
<code>curtis$ echo "hi" > index.html
curtis$ sw upload www index.html
index.html
</code>
</pre>
Set permissions so that anyone can read the files in the www container, ie. they are public.
<pre>
<code>curtis$ sw post --read-acl='.r:*,.rlistings' www
curtis$ sw stat www
Account: AUTH_test
Container: www
Objects: 1
Bytes: 3
Read ACL: .r:*,.rlistings
Write ACL:
Sync To:
Sync Key:
Accept-Ranges: bytes
X-Timestamp: 1403883848.54012
X-Trans-Id: txd858295e7d294d39bdf3e-0053ad921d
Content-Type: text/plain; charset=utf-8
</code>
</pre>
Make index.html the default web index.
<pre>
<code>curtis$ sw post -m 'web-index:index.html' www
</code>
</pre>
Now we can access that page in a web browser, and get the index.html.
<pre>
<code>curtis$ wget --no-check-certificate https://<droplet IP="">/v1/AUTH_test/www/
--2014-06-27 11:48:20-- https://<droplet IP="">/v1/AUTH_test/www/
Connecting to <droplet IP="">:443... connected.
WARNING: cannot verify <droplet IP="">'s certificate, issued by '/C=US/ST=Oregon/L=Portland/O=IT/CN=172.17.0.13':
Self-signed certificate encountered.
WARNING: certificate common name '172.17.0.13' doesn't match requested host name '<droplet IP="">'.
HTTP request sent, awaiting response... 200 OK
Length: 3 [text/html]
Saving to: 'index.html'
100%[====================================================================================================================================================>] 3 --.-K/s in 0s
2014-06-27 11:48:20 (109 KB/s) - 'index.html' saved [3/3]
curtis$ cat index.html
hi</code>
</pre>
Note that I just wanted to use that as a demonstration, not the actual use case for Swift. Swift stores unstructured data, which we, as a planet, have a lot of. It doesn't have to serve web pages.
## Conclusion
Now for $5 a month you have a little swift install. The storage on that instance is pretty limited, at 20GB, but at any rate you can put all kinds of [DevOps reactions](http://devopsreactions.tumblr.com/) gifs there if you want. Or, perhaps use it to create interesting, proof-of-concept scalable web systems.
I should note as well that you could deploy OnlyOne in the same fashion on any Docker host, which is one of Docker's most interesting features.
</droplet></droplet></droplet></droplet></droplet></code></pre></password></droplet></code></pre></droplet></droplet></code></pre></droplet></code></pre>
Automated deployment of the Wordpress database2014-06-22T00:00:00+00:00http://serverascode.com/2014/06/22/automated-wordpress-database-deployment<h1 id="automated-deployment-of-the-wordpress-database">Automated deployment of the Wordpress database</h1>
<p>I’ve been working on a proof-of-concept (PoC) <a href="http://serverascode.com/2014/06/16/build-your-own-paas-docker.html">Wordpress-as-a-service</a> (WPaas?) that uses docker (among other technologies). However, one thing I can’t seem to find is anyone showing how to easily install the Wordpress database after the application files have been installed and the Wordpress configuration file…er…configured.</p>
<p>Most automated installs seem to stop after creating the database, which means you access the site via http and then continue the install manually. But obviously I don’t want to stop at that point, I want the site name, admin password, admin user, etc, all entered and the database installed so the user can simply access the the site they asked for, you know, as though the install was fully automated.</p>
<h2 id="first-try-http-post">First try: http post</h2>
<p>My first try was just doing a post with the right variables. Here’s a simplified (no error checking) snippet of the python code I was using to do this.</p>
<pre>
<code>payload = {'weblog_title': sitename, 'user_name': 'adminName', 'admin_password': dbPass, 'admin_password2': dbPass, 'admin_email': adminEmail }
r = requests.post("http://" + fullSiteName + "/wp-admin/install.php?step=2", data=payload)
</code>
</pre>
<p>You could also use a post request with something like curl:</p>
<pre>
<code>$ curl -d "weblog_title=<weblog_title>&user_name=<admin_user>&admin_password=<password>&admin_password2=<password>2&admin_email=<email>" \
http://<your_wp_URL>/wp-admin/install.php?step=2
</code>
</pre>
This worked and seemed like an Ok option, but the only thing I didn't like was that I would have to wait until the container was up to send the http request. Not only was it annoying to have to wait (it's containers after all) but it's not very secure to have the site up but not completely installed, ie. anyone who happened onto it could set the admin user name and password. Even if I didn't add the site to the web router to be available externally, it still doesn't feel right. So while this was Ok for some basic testing, it's not good enough.
## Second try: wp_install() function
After a bit more sleuthing I found that wordpress has a handy install function. There's a good example of using it on [this blog](http://www.openlogic.com/wazi/bid/324425/How-to-install-WordPress-from-the-command-line). However, I found that I need the WP_SITEURL set as well.
Below is a snippet of a bash script that calls out to php to use wp_install().
<pre>
<code>#!/bin/bash
# ...
# Variable settings not shown
/usr/bin/php -r "
define('WP_SITEURL', '"${WP_SITEURL}"');
include '/app/wp-admin/install.php';
wp_install('"${WP_SITE}"', 'admin', '"${WP_EMAIL}"', 1, '', '"${DB_PASSWORD}"');
"
</code>
</pre>
This works better. Note the above is the bare minimum, and there should be some error checking as well, in case the wp_install call fails. It should really be a separate php script that can take arguments and return errors to the bash code calling it.
Running this from the container still concerns me a little.
## Database snapshots?
As I mentioned previously, this is a PoC. What would likely happen in a production environment is that certain versions of Wordpress would be supported, and the SQL for that would be configured automatically, ie. generate an SQL file for each site, and simply install that into the database instead of using wp_install. Or perhaps do something more advanced with database or file system snapshots. Once the db was snapshotted/cloned you could just change variables like siteurl, the admin user, and their password. Would likely be faster too. I'm sure there are a lot of interesting ways to perform database snapshots or clones.
Obviously newer versions of Wordpress could come with different database schemas, which would mean I'd have to "certify" various versions and properly create snapshots for those versions, should their be any schema differences. Totally doable though. Something to look into in the future, but a bit much for my little PoC.
## WP-CLI
[WP-CLI](http://wp-cli.org/), or "wordpress command line", is a pretty interesting project. I'm not sure how valuable it is in my particular use case, but it seems like a good piece of software, especially if you admin a multisite wordpress installation. Worth taking a look at.
</your_wp_URL></email></password></password></admin_user></weblog_title></code></pre>
Build your own platform as a service with Docker2014-06-16T00:00:00+00:00http://serverascode.com/2014/06/16/build-your-own-paas-docker<h1 id="build-your-own-platform-as-a-service-with-docker">Build your own platform as a service with Docker</h1>
<p>First off, let me be clear–<a href="http://www.docker.com/">Docker</a> is not a “platform as a service” (PaaS) by itself. However, I do think it’s an important component, one that makes deploying a PaaS much simpler.</p>
<p>Second, for the most part I’m discussing the concept of building “your own PaaS” from my personal perspective, which is that I have a few blogs and Wordpress sites that I run for friends (ie. not a business venture or anything) and I have a single hardware server out there on the Internet that I use to do this. I thought it would be fun to use that server to think about how I one could provide a Wordpress PaaS that could potentially scale out to multiple hosts, even though I could never afford to or need to do that.</p>
<p>In a way, what I’m doing is creating a proof of concept (PoC) wordpress as a service, mostly for a single host which once in place could provide almost any application, and could potentially scale out to multiple container hosts.</p>
<h2 id="why-not-just-use-dokku">Why not just use Dokku?</h2>
<p><a href="https://github.com/progrium/dokku">Dokku</a> is a piece of software created by <a href="https://twitter.com/progrium">Jeff Lindsay</a> that essentially creates a single-host PaaS.</p>
<blockquote>
<p>Docker powered mini-Heroku. The smallest PaaS implementation you’ve ever seen.</p>
</blockquote>
<p>But I’m not going to use Dokku, even though that is probably the best way to go about this. Instead I’m going to mostly layout the minimum systems and components needed to create a low-fi PaaS. Also <a href="http://deis.io/">Deis</a>, Flynn and <a href="http://stackoverflow.com/questions/18285212/how-to-scale-docker-containers-in-production">other</a> container management systems, in various states with differing features, exist.</p>
<h2 id="components">Components</h2>
<p>These are the minimum components I think you would need to create your own PaaS.</p>
<ol>
<li>Wildcard DNS entry</li>
<li>“Web router” (such as <a href="https://github.com/dotcloud/hipache">Hipache</a>)</li>
<li>Docker - Application server/container provisioning and image creation</li>
<li>Application source code</li>
<li>Environment variables</li>
<li>Datastores, such as MySQL, NoSQL, object storage, etc</li>
<li>Something to tie them all together</li>
</ol>
<h2 id="wildcard-dns-entry">Wildcard DNS entry</h2>
<p>The first thing you need is a wildcard DNS entry for a domain name. This <a href="https://gist.github.com/ngoldman/7287753">gist</a> describes how to configure one using Namecheap, which happens to also be my registrar of choice (like a few other registrars, but not all, they support two factor authentication). So I bought a domain name like “somedomainapp.com” to run my “apps” and then configured a wildcard entry using Namecheap’s DNS service.</p>
<p>Obviously in a larger production environment you’d either manage your own nameservers or perhaps use something like <a href="https://gist.github.com/ngoldman/7287753">Google’s DNS as a service</a>, which I would love to try out, and some loadbalancers or similar.</p>
<p>At this point, at minimum, you have a wildcard DNS entry pointing to an IP on your server which apps will be able to use, such as *.yourdomainapp.com.</p>
<h2 id="web-router">Web router</h2>
<p><img src="https://raw.githubusercontent.com/ccollicutt/ccollicutt.github.com/master/img/somedomain.png" alt="" />
(<em>Above: hipache non-existent domain page</em>)</p>
<p>I’m not sure what to call this layer. Heroku calls this <a href="https://devcenter.heroku.com/articles/http-routing">HTTP routing</a>. Web routing works for me.</p>
<p>Essentially what his does is route incoming requests for apps to the right webserver, which in our case will be a docker container, or several docker containers. A request for someapp.somedomainapp.com would go to 127.0.0.1:49899 or 172.17.0.3:80 and such, which are docker containers.</p>
<p>In my situation I am using <a href="https://github.com/dotcloud/hipache">hipache</a> which is backed by redis. This means you can add routes to hipache by entering them into redis, and hipache isn’t required to restart because it will query redis for domain configuration. By default hipache allows the use of wildcard domains, so it’ll route any configured entry, or send a default page if it doesn’t exist.</p>
<p>My PoC python script, which is called “wpd” (more on that later), can dump the keys setup in redis for hipache. The below output means hipache will randomly balance requests for someapp.yourdomainapp.com to the two containers listed in redis.</p>
<pre>
<code>$ wpd listkeys
someapp.yourdomainapp.com
===> http://127.0.0.1:49156
===> http://127.0.0.1:49157
$ redis-cli lrange someapp.yourdomainapp.com 0 -1
1) "someapp.yourdomainapp.com"
2) "http://127.0.0.1:49156"
3) "http://127.0.0.1:49157"
</code>
</pre>
<p>There are many other ways to do “web routing.” Dokku uses nginx. There is also <a href="https://github.com/mailgun/vulcand">vulcand</a> which is backed by <a href="https://github.com/coreos/etcd">etcd</a> and though it’s new it sounds exciting. Hipache does support SSL, but as of a few weeks ago Vulcand did not, though I think it’s on the roadmap (but I am a golang fanboy, so am biased).</p>
<h2 id="docker">Docker!</h2>
<p>Again comparing Heroku to what we are doing here, I think that Docker would fill the roles of <a href="https://devcenter.heroku.com/articles/buildpacks">buildpack</a> and <a href="https://devcenter.heroku.com/articles/dynos">dyno</a> though perhaps in terms of the buildpack part not containing a “slug” of the application code, rather only the environment the application would run in. Perhaps it’s better to consider a Dockerfile a type of buildpack.</p>
<p>Using my wordpress example, the Dockerfile would create the image which docker then runs to create a wordpress application container, for example using apache2 + php.</p>
<p>Docker manages the container and provides networking and network address translation to expose the apache2’s port to the web router.</p>
<p>So Docker is doing quite a bit of the work for us. Without Docker, we would probably need a way to create virtual machines images programmatically, and a way to start up and instance and get it networked, which could be as simple as something like <a href="http://www.packer.io/">packer</a> and libvirtd (perhaps with kvm or lxc) or other combinations such as packer and openstack. Certainly that would require a few more resources. (Interestingly packer can build docker images as well.)</p>
<h2 id="application-source-code">Application source code</h2>
<p>In Dokku code is pushed to a git repository which kicks off other processes. This is also how Heroku works. Those processes somehow get the code into the application container.</p>
<p>However, in my wordpress example, the wordpress code is downloaded in the startup script. Once the container is started from the wordpress image, the startup script runs something like:</p>
<pre>
<code>if [ ! -e /app/wp-settings.php ]; then
cd /app
curl -O http://wordpress.org/latest.tar.gz
tar zxvf latest.tar.gz
mv wordpress/* /app
rm -f /app/wordpress
chown -R www-data:www-data /app
rm -f latest.tar.gz
fi
</code>
</pre>
<p>to grab the code. The url used to download could be taken from an environment variable instead of just being static as in the example.</p>
<p>The git push/recieve style probably makes more sense in a PaaS, but I haven’t looked into what it takes to do that. Again Jeff Lindsay has <a href="https://github.com/progrium/gitreceive">gitrecieve</a> and Flynn (a Jeff Lindsay project) has <a href="https://github.com/flynn/gitreceived">gitrecieved</a>. Also he has <a href="https://github.com/progrium/execd">execd</a> and more. Busy guy!</p>
<p>Obviously there are a lot of ways to get code into the container to run it. If there is any one important thing a PaaS does, it’s run your code.</p>
<h2 id="environment-variables">Environment variables</h2>
<p>I think Docker images should be fairly generic. Also you don’t want to commit configuration information to the image, such as passwords, so they should come from environment variables, and those variables need to get injected into the containers environment somehow.</p>
<p>For my wordpress example, I set environment variables with Docker. The Docker run command has the “-e” option which allows setting environment variables which will be exposed in the container. Below is an example.</p>
<pre>
<code>$ docker run -e FOO=bar -e BAR=foo busybox env
HOME=/
PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
HOSTNAME=6cf2d6e8acb3
FOO=bar
BAR=foo
</code>
</pre>
<p>My wordpress startup script checks for a few environment variables</p>
<pre>
<code>DB_NAME=${DB_NAME:-"wordpress"}
DB_USER=${DB_USER:-"wordpress"}
DB_PASSWORD=${DB_PASSWORD:-"wordpress"}
DB_HOST=${DB_HOST:-$1}
</code>
</pre>
<p>and uses them to create the wordpress configuration file with the right database settings.</p>
<p>Later on I’ll talk about “tying the whole room together” which I do with a python script, and in it I set the environment variables for the container.</p>
<p>Below is a snippet of python code used to start a container with environment variables.</p>
<pre>
<code>env = {
'DB_HOST': MYSQL_HOST,
'DB_NAME': dbname,
'DB_USER': dbname,
'DB_PASSWORD': dbpass,
}
container = dockerConn.create_container(image, detach=True, environment=env)
</code>
</pre>
<p>Docker and python go well together using <a href="https://github.com/dotcloud/docker-py">docker-py</a>.</p>
<p>Another method is using a shared configuration system. Previously I mentioned etcd.</p>
<blockquote>
<p>[etcd is] a highly-available key value store for shared configuration and service discovery.</p>
</blockquote>
<p>etcd can store configuration information and <a href="https://github.com/kelseyhightower/confd">confd</a> is a configuration management agent which can query etcd for information and generate configuration files that applications can use, and also restart the services that use those configuration files.</p>
<p>Given that I’m suggesting environment/configuration variables are a key part to PaaS, things like etcd, confd, and <a href="https://github.com/hashicorp/consul">consul</a> are going to be important projects. But again, with my limited wordpress PaaS I’m just working on a very simplified PoC, where environment variables come at container runtime. However, I would imagine most larger PaaS or PaaS-like systems will use something like consul or etcd.</p>
<h2 id="datastores">Datastores</h2>
<p>If your application needs to persist data, then it’s got to put that data somewhere and the application container itself is not a good place. In general, I think there are two approaches:</p>
<ol>
<li>Another container</li>
<li>A separate service</li>
</ol>
<p>In terms of “a separate service” I’m talking about something like <a href="http://aws.amazon.com/rds/">Amazon RDS</a> or <a href="https://wiki.openstack.org/wiki/Trove">OpenStack Trove</a> (both of those being Database as a service) or object storage like <a href="http://docs.openstack.org/developer/swift/">OpenStack Swift</a>. In short I mean a service that is managed by someone else, perhaps the same provider that either runs Docker or the server that Docker is running on.</p>
<p>The other option is another container. Again using the wordpress example, instead of running one application container, perhaps I would run a second container that has a MySQL server running (or both services could even be in a single container). Maybe that MySQL service is a container, maybe it’s a hardware server configured with Ansible. Who knows. Docker also recommends the <a href="https://docs.docker.com/userguide/dockervolumes/">volumes from</a> approach, which works great when the data doesn’t have to be distributed across multiple containers, which would be the case in a MySQL or <a href="http://serverascode.com/2014/06/12/run-swift-in-docker.html">OpenStack Swift</a> container.</p>
<p>My feeling is that either is Ok, but I prefer to run a separate service. So in my wordpress example there is a single MySQL server that all wordpress apps will connect to, each having their own database. Perhaps that separate service is using Docker too.</p>
<h2 id="something-to-tie-them-all-together">Something to tie them all together</h2>
<p>I’m working on a python script called “wpd” that ties all of this together, and what it does is:</p>
<ol>
<li>Creates a site entry in the wpd MySQL database</li>
<li>Creates a database datastore that the site can use for wordpress</li>
<li>Creates couple of wordpress containers</li>
<li>Provides those containers with environment variables regarding how to connect to a worpress database</li>
<li>Adds that site to redis so that hipache can route/loadbalance requests to those containers</li>
</ol>
<pre>
<code>$ wpd -h
usage: wpd [-h] {listkeys,addsite,listsites,addimage,deploysite,dumpsite} ...
positional arguments:
{listkeys,addsite,listsites,addimage,deploysite,dumpsite}
listkeys list all the keys in redis
addsite add a site to the database
listsites list all the sites in the database
addimage add a docker image to the database
deploysite startup a sites containers
dumpsite show all information about a site
optional arguments:
-h, --help show this help message and exit
</code>
</pre>
<p>As you can see it has a few options, such as “addsite” and “deploysite”. It’s not complete yet. Adding a site just enters it into the wpd database, and deploying it means starting up containers and adding the information to redis so that hipache can route http requests to them.</p>
<p>What this would look like in a larger system…I’m not sure. It seems like a user management system more than anything else–users have sites, sites have names, containers, images and datastores.</p>
<h2 id="issues">Issues</h2>
<p>There are a few issues that I’d like to mention (though I’m probably not covering them all).</p>
<p><em>Logging</em> - Getting logs out of docker is still a bit of an problem. At this point likely you’ll need to configure syslog in the container to ship logs to a centralized system. I expect that eventually docker will have more advanced ways of dealing with logs, if they don’t already.</p>
<p><em>File systems</em> - Wordpress is a good example of a web application that is difficult to scale because it relies a lot on the file system for data persistence, such as media uploaded by users. In order to scale out a file system across multiple docker hosts you’ll need a distributed file system, which is a huge pain and can also increase the size of your failure domain dramatically. I suggest not using file systems to store files and instead use object storage such as OpenStack Swift, which isn’t as hard to deploy as some might think. What’s more Swift doesn’t think it can do <a href="http://en.wikipedia.org/wiki/CAP_theorem">consistency and availability</a> at the same time.</p>
<p><em>Datastore credentials</em> - I’m not sure what the best way to securely store these is. Credentials and other important configuration information will need to be injected into the container somehow, and thus will need to be stored in a database or etcd or similar. Something to look into.</p>
<h2 id="conclusion">Conclusion</h2>
<p>In the end, I think that docker is a great system to use as a component in PaaS and that, to me, it simplifies rolling your own small platform as a service host. All you need is a web router, a Dockerfile and a docker host, a way to get the app into the container, and <em>pow</em> now you’re cookin’ with PaaS. Just remember to make your containers fairly generic, pipe in environment variables for configuration (or get them from somewhere else), and avoid file systems if possible.</p>
<h2 id="the-future">The Future!</h2>
<p>Obviously I’m leaving a lot out. There’s a huge difference between toying around with a PoC like this and running a production PaaS. I haven’t even mentioned the terms “service discovery” or “container scheduling”, which theoretically things like etcd and <a href="https://github.com/docker/libswarm">libswarm</a> could take care of respectively, though I’m not sure libswarm will turn into a container scheduler. Recently Google released <a href="https://news.ycombinator.com/item?id=7873897">Kubernetes</a> which is as docker cluster manager of some kind, though it currently only runs on GCE. Mesosphere is also working on its <a href="https://github.com/mesosphere/deimos">Deimos</a> project. Further, CoreOS has <a href="https://github.com/coreos/fleet">fleet</a> and Spotify <a href="https://github.com/spotify/helios">helios</a>. <a href="http://serverascode.com/2014/05/25/docker-shipyard-multihost.html">Shipyard</a> can also control multiple docker hosts. Also there is <a href="https://github.com/ehazlett/havok">Havok</a> which is a way to monitor docker containers and add them to vulcand via etcd. Neither have I discussed limiting resources, such as container memory and CPU and a about a billion other things, but I look forward to learning more.</p>
<h2 id="updates">Updates</h2>
<ul>
<li>Changed Apache Mesos to Mesosphere with regards to Deimos</li>
<li>Added Shipyard and Havok</li>
</ul>
Swift OnlyOne - Run OpenStack Swift in Docker2014-06-12T00:00:00+00:00http://serverascode.com/2014/06/12/run-swift-in-docker<h1 id="swift-onlyone---run-openstack-swift-in-docker">Swift OnlyOne - Run OpenStack Swift in Docker</h1>
<p>First, let met say that this is not about how to run a cluster of OpenStack Swift servers in Docker, rather it’s about running a single container that has a version of <a href="http://docs.openstack.org/developer/swift/development_saio.html">OpenStack Swift all-in-one</a> deployed, and specifically that version only has one storage device (a docker volume) and is configured to store one replica on that device.</p>
<h2 id="why-swift-onlyone">Why Swift OnlyOne?</h2>
<p>I’m calling it Swift OnlyOne because it just has one server, one device, and is configured to do one replica. Swift All-in-one, on the other hand, sets up four servers and devices, though within one virtual machine.</p>
<p>Most people will use Swift in a much larger context as typically Swift is used to store huge amounts (petabytes!) of files. But in this case I just want a small deployment that can provide object storage to several other containers, or perhaps to do development against.</p>
<p>As an example–I think that OpenStack Swift is a perfect partner for Docker, and I don’t just mean deploying Swift with Docker, I mean having Docker containers use Swift as a datastore.</p>
<p>If you have multiple containers on multiple hosts, and some of the containers run an application which needs access to the same files, then you need a way to share those files. Usually this is done with a distributed file system (DFS), but that has all kinds of complexity associated, and, I think, makes Docker hard to use in an idiomatic way. What if, instead of using a DFS you used OpenStack Swift, and thus, instead of relying on a file system your application used object storage? I think you would be better off in the long run.</p>
<h2 id="use-swift-onlyone">Use Swift OnlyOne</h2>
<p>First, because <em>Swift requires the filesystem have xattr</em>, Docker must be setup with either btrfs or XFS (or some other xattr supporting file system). I have only used it with btrfs. So /var/lib/docker is a btrfs volume and the docker daemon is run with “-s btrfs”.</p>
<p><em>NOTE: I have Vagrant file and Ansible playbook on <a href="https://github.com/ccollicutt/vagrant-docker-btrfs">github</a> that will setup a Vagrant-based virtual machine with docker and btrfs configured. So all you would have to do is clone that repo and run “vagrant up” to get docker + btrfs.</em></p>
<pre>
<code>vagrant@host1:~$ sudo btrfs fi show /var/lib/docker
Label: none uuid: 732ee044-4b3a-4391-8b53-fd7da224c008
Total devices 1 FS bytes used 1.99GiB
devid 1 size 20.00GiB used 4.04GiB path /dev/sdb
Btrfs v3.12
vagrant@host1:~$ ps ax | grep [d]ocker
997 ? Sl 6:40 /usr/bin/docker.io -d -s btrfs
</code>
</pre>
<p>There is a <a href="https://github.com/ccollicutt/docker-swift-onlyone">github repository</a> that has the Dockefile and Swift configuration files used for this example, or you can pull it from the <em>Docker repository</em>.</p>
<pre>
<code>vagrant@host1:~$ docker pull serverascode/swift-onlyone
Pulling repository serverascode/swift-onlyone
7e8283467cba: Download complete
SNIP!
d7279e38d8cd: Download complete
</code>
</pre>
<p>Now we can run an interactive Swift OnlyOne container.</p>
<pre>
<code>vagrant@host1:/vagrant/dockerfiles/swift-onlyone$ docker run -i -t serverascode/swift-onlyone /bin/bash
root@f2f8ccb82c0e:/# /usr/local/bin/startmain.sh
Device d0r1z1-127.0.0.1:6010R127.0.0.1:6010/sdb1_"" with 1.0 weight got id 0
Reassigned 128 (100.00%) partitions. Balance is now 0.00.
Device d0r1z1-127.0.0.1:6011R127.0.0.1:6011/sdb1_"" with 1.0 weight got id 0
Reassigned 128 (100.00%) partitions. Balance is now 0.00.
Device d0r1z1-127.0.0.1:6012R127.0.0.1:6012/sdb1_"" with 1.0 weight got id 0
Reassigned 128 (100.00%) partitions. Balance is now 0.00.
Starting to tail /var/log/syslog...(hit ctrl-c if you are starting the container in a bash shell)
^C
</code>
</pre>
<p>Note that I hit “ctrl-c” when it says “Starting to tail…” because when running this container in non-interactive mode, I tail /var/log/syslog to be able to do “docker logs $ID” and get the Swift logs.</p>
<p>We can see what processes are running, and there are quite a few, including rsyslog and memcached. Usually Docker models processes, but in this case I am taking a role-based approach to using Docker.</p>
<pre>
<code>root@f2f8ccb82c0e:/# ps ax
PID TTY STAT TIME COMMAND
1 ? Ss 0:00 /bin/bash
43 ? Ss 0:00 /usr/bin/python /usr/bin/supervisord -c /etc/supervisor/conf.d/supervisord.conf
45 ? S 0:00 /usr/bin/python /usr/bin/swift-container-server /etc/swift/container-server.conf
46 ? S 0:00 /usr/bin/python /usr/bin/swift-account-reaper /etc/swift/account-server.conf
47 ? S 0:00 /usr/bin/python /usr/bin/swift-object-replicator /etc/swift/object-server.conf
48 ? S 0:00 /usr/bin/python /usr/bin/swift-account-auditor /etc/swift/account-server.conf
49 ? S 0:00 /usr/bin/python /usr/bin/swift-object-server /etc/swift/object-server.conf
50 ? S 0:00 /usr/bin/python /usr/bin/swift-container-sync /etc/swift/container-server.conf
51 ? S 0:00 /usr/bin/python /usr/bin/swift-account-replicator /etc/swift/account-server.conf
52 ? S 0:00 /usr/bin/python /usr/bin/swift-account-server /etc/swift/account-server.conf
53 ? S 0:00 /bin/bash -c source /etc/default/rsyslog && /usr/sbin/rsyslogd -n -c3
54 ? S 0:00 /usr/bin/python /usr/bin/swift-proxy-server /etc/swift/proxy-server.conf
55 ? S 0:00 /usr/bin/python /usr/bin/swift-object-updater /etc/swift/object-server.conf
56 ? Sl 0:00 /usr/bin/memcached -u memcache
57 ? Sl 0:00 /usr/sbin/rsyslogd -n -c3
86 ? S 0:00 /usr/bin/python /usr/bin/swift-object-server /etc/swift/object-server.conf
87 ? S 0:00 /usr/bin/python /usr/bin/swift-container-server /etc/swift/container-server.conf
88 ? S 0:00 /usr/bin/python /usr/bin/swift-account-server /etc/swift/account-server.conf
89 ? S 0:00 /usr/bin/python /usr/bin/swift-proxy-server /etc/swift/proxy-server.conf
91 ? R+ 0:00 ps ax
</code>
</pre>
<p>Now we can use Swift.</p>
<pre>
<code>root@f2f8ccb82c0e:/# swift -A http://127.0.0.1:8080/auth/v1.0 -U test:tester -K testing stat
Account: AUTH_test
Containers: 0
Objects: 0
Bytes: 0
Content-Type: text/plain; charset=utf-8
X-Timestamp: 1402590362.23352
X-Trans-Id: tx1c32b455aa7c4178a4add-005399d49a
X-Put-Timestamp: 1402590362.23352
root@f2f8ccb82c0e:/# swift -A http://127.0.0.1:8080/auth/v1.0 -U test:tester -K testing upload etc_swift /etc/swift
etc/swift/dispersion.conf
etc/swift/account-server.conf
etc/swift/backups/1402588704.container.ring.gz
etc/swift/backups/1402588704.object.ring.gz
etc/swift/backups/1402588704.container.builder
etc/swift/proxy-server.conf
etc/swift/object-server.conf
etc/swift/swift.conf
etc/swift/backups/1402588704.object.builder
etc/swift/container-server.conf
etc/swift/backups/1402588704.account.builder
etc/swift/backups/1402588705.account.ring.gz
etc/swift/object.builder
etc/swift/backups/1402588705.account.builder
etc/swift/object.ring.gz
etc/swift/container.builder
etc/swift/account.ring.gz
etc/swift/supervisord.log
etc/swift/container.ring.gz
etc/swift/account.builder
etc/swift/supervisord.pid
root@f2f8ccb82c0e:/#
</code>
</pre>
<p>We can also start the container in non-interactive mode, and add a port mapping.</p>
<pre>
<code>vagrant@host1:~$ ID=$(docker run -d -p 8080 -t serverascode/swift-onlyone)
</code>
</pre>
<p>Now that container should be running with a port mapped to 8080.</p>
<pre>
<code>vagrant@host1:~$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
0c57f60e1de6 serverascode/swift-onlyone:latest /bin/sh -c /usr/loca 3 seconds ago Up 3 seconds 0.0.0.0:49162->8080/tcp loving_hawking
</code>
</pre>
<p>Above we can see that port 49162 on the container host is mapped to 8080 on the container.</p>
<p>We can also check the logs.</p>
<pre>
<code> vagrant@host1:~$ docker logs $ID
Device d0r1z1-127.0.0.1:6010R127.0.0.1:6010/sdb1_"" with 1.0 weight got id 0
Reassigned 128 (100.00%) partitions. Balance is now 0.00.
Device d0r1z1-127.0.0.1:6011R127.0.0.1:6011/sdb1_"" with 1.0 weight got id 0
Reassigned 128 (100.00%) partitions. Balance is now 0.00.
Device d0r1z1-127.0.0.1:6012R127.0.0.1:6012/sdb1_"" with 1.0 weight got id 0
Reassigned 128 (100.00%) partitions. Balance is now 0.00.
Starting to tail /var/log/syslog...(hit ctrl-c if you are starting the container in a bash shell)
</code>
</pre>
<p>Let’s run stat again, but this time from the container host, not the container.</p>
<p>Note that it’s not port 8080 any more for the auth url, it’s 49162.</p>
<pre>
<code>vagrant@host1:~$ swift -A http://127.0.0.1:49162/auth/v1.0 -U test:tester -K testing stat
Account: AUTH_test
Containers: 0
Objects: 0
Bytes: 0
Content-Type: text/plain; charset=utf-8
X-Timestamp: 1402590701.15270
X-Trans-Id: txfebf58919cbf4c61ac73c-005399d5ed
X-Put-Timestamp: 1402590701.15270
vagrant@host1:~$ swift -A http://127.0.0.1:49162/auth/v1.0 -U test:tester -K testing upload test swift.txt
swift.txt
vagrant@host1:~$ swift -A http://127.0.0.1:49162/auth/v1.0 -U test:tester -K testing list test
swift.txt
</code>
</pre>
<p>Check the logs again:</p>
<pre>
<code>vagrant@host1:~$ docker logs $ID | tail
Jun 12 16:33:16 0c57f60e1de6 account-replicator: Replication run OVER
Jun 12 16:33:16 0c57f60e1de6 account-replicator: Attempted to replicate 1 dbs in 0.00341 seconds (292.99204/s)
Jun 12 16:33:16 0c57f60e1de6 account-replicator: Removed 0 dbs
Jun 12 16:33:16 0c57f60e1de6 account-replicator: 0 successes, 0 failures
Jun 12 16:33:16 0c57f60e1de6 account-replicator: no_change:0 ts_repl:0 diff:0 rsync:0 diff_capped:0 hashmatch:0 empty:0
Jun 12 16:33:16 0c57f60e1de6 object-replicator: Starting object replication pass.
Jun 12 16:33:16 0c57f60e1de6 object-replicator: 1/1 (100.00%) partitions replicated in 0.00s (767.48/sec, 0s remaining)
Jun 12 16:33:16 0c57f60e1de6 object-replicator: 1 suffixes checked - 0.00% hashed, 0.00% synced
Jun 12 16:33:16 0c57f60e1de6 object-replicator: Partition times: max 0.0003s, min 0.0003s, med 0.0003s
Jun 12 16:33:16 0c57f60e1de6 object-replicator: Object replication complete. (0.00 minutes)
</code>
</pre>
<p>At this point we have a nice little OpenStack Swift install that we could use by linking with other containers.</p>
<h2 id="using-a-data-only-container">Using a data only container</h2>
<p>It would be best to run with a data only container as well, and use that volume on /srv.</p>
<p>So first create a data only container.</p>
<pre>
<code>vagrant@host1:~$ docker run -v /srv --name SWIFT_DATA busybox
vagrant@host1:~$ docker ps --all |grep SWIFT_DATA
6c13b4e27320 busybox:buildroot-2014.02 /bin/sh 7 seconds ago Exit 0 SWIFT_DATA
</code>
</pre>
<p>Now we can create a docker container with “–volumes-from” the SWIFT_DATA container.</p>
<pre>
<code>vagrant@host1:~$ ID=$(docker run -d -p 8080 --volumes-from SWIFT_DATA -t serverascode/swift-onlyone)
</code>
</pre>
<p>And if we inspect that container we can see where the container’s volume is. Sorry that the lines will probably not wrap very nicely.</p>
<pre>
<code>vagrant@host1:~$ docker inspect $ID | grep VolumesFrom
"VolumesFrom": "SWIFT_DATA",
vagrant@host1:~$ docker inspect $ID | grep "\/srv"
"/srv": "/var/lib/docker/vfs/dir/8d437b57f36a2d849cece0752c8316c6916c31ec12fd9049d4203662806d3fe2"
"/srv": true
vagrant@host1:~$ sudo ls /var/lib/docker/vfs/dir/8d437b57f36a2d849cece0752c8316c6916c31ec12fd9049d4203662806d3fe2
sdb1
</code>
</pre>
<p>I think the data only container is an ideomatic way to use Docker.</p>
<h2 id="conclusion">Conclusion</h2>
<p>I’m sure there is a lot that can be done to improve this Dockerfile, so please let me know if you see any issues or have any ideas. I have not done a lot of testing with it yet. But if it does work, then I think this is a nice way to quickly get access to a Swift instance, even if it is a purposely limited one, and hopefully help people move away from the complexity of a DFS when using containers.</p>
<h2 id="issues">Issues</h2>
<ul>
<li>At this time the proxy is not using SSL, nor is there an SSL terminator in front of the proxy, so it’s all plain text. You wouldn’t want to do this in production.</li>
</ul>
Docker and btrfs2014-06-09T00:00:00+00:00http://serverascode.com/2014/06/09/docker-btrfs<h1 id="docker-and-btrfs">Docker and btrfs</h1>
<p>As I write this the first <a href="https://twitter.com/hashtag/dockercon?src=hash">Docker convention</a> is going on in San Francisco (sounds funny to write it was “docker convention” instead of “dockercon”…a convention sounds like a scene from Fear and Loathing in Las Vegas), and Docker has hit 1.0 and been declared <a href="https://twitter.com/solomonstre/status/476036477973831682">production</a> worthy.</p>
<p>Docker has had, for a few versions, the ability to use btrfs as it’s backing driver, instead of aufs.</p>
<h2 id="install-btrfs-on-ubuntu-1404trusty">Install btrfs on Ubuntu 14.04/Trusty</h2>
<p>Before installing docker I’m going to setup btfrs.</p>
<p>In this example I have a disk device called /dev/vdb to use with btrfs. I’ve removed some of the output from the commands.</p>
<pre>
<code>$ sudo su
$ apt-get install btrfs-tools
$ mkfs.btrfs /dev/sdb
$ mkdir /var/lib/docker
$ mount /dev/sdb /var/lib/docker
$ mount | grep btrfs
/dev/sdb on /var/lib/docker type btrfs (rw)
</code>
</pre>
<p>Now that btrfs is installed and a device is formatted and mounted under /var/lib/docker we can install docker.</p>
<h2 id="install-docker">Install docker</h2>
<p>Next we need to install docker. It’s important that we also configure docker to startup with the “-s btrfs” option as well.</p>
<pre>
<code>$ apt-get install docker.io
$ vi /etc/default/docker.io
</code>
</pre>
<p>We need to change the DOCKER_OPTS entry to look like this:</p>
<pre>
<code>$ grep DOCKER_OPTS docker.io
# Use DOCKER_OPTS to modify the daemon startup options.
DOCKER_OPTS="-s btrfs"
</code>
</pre>
<p>Now restart docker.</p>
<pre>
<code>$ service docker.io restart
</code>
</pre>
<p>We should see that docker is running with “-s btrfs”:</p>
<pre>
<code>$ ps ax |grep [d]ocker
10088 ? Sl 0:02 /usr/bin/docker.io -d -s btrfs
</code>
</pre>
<p>If it’s not running with “-s btrfs” then ensure it’s set to do so in /etc/default/docker.io and has been restarted.</p>
<p>I’ve already created several containers and pulled images, actually just the base busybox image which is quite small, so if I run “btrfs subvolume list /var/lib/docker” I should see some subvolumes have been created.</p>
<pre>
<code>vagrant@host1:~$ sudo btrfs subvolume list /var/lib/docker | head -5
ID 258 gen 11 top level 5 path btrfs/subvolumes/511136ea3c5a64f264b78b5433614aec563103b4d4702f3ba7d4d2698e22c158
ID 259 gen 16 top level 5 path btrfs/subvolumes/42eed7f1bf2ac3f1610c5e616d2ab1ee9c7290234240388d6297bc0f32c34229
ID 260 gen 13 top level 5 path btrfs/subvolumes/c120b7cab0b0509fd4de20a57d0f5c17106f3451200dfbfd8c6ab1ccb9391938
ID 261 gen 13 top level 5 path btrfs/subvolumes/d200959a3e91d88e6da9a0ce458e3cdefd3a8a19f8f5e6a1e7f10f268aea5594
ID 262 gen 15 top level 5 path btrfs/subvolumes/120e218dd395ec314e7b6249f39d2853911b3d6def6ea164ae05722649f34b16
</code>
</pre>
<p>And we can see the size of the btrfs file system.</p>
<pre>
<code>$ btrfs filesystem df /var/lib/docker
Data, single: total=1.01GiB, used=337.56MiB
System, DUP: total=8.00MiB, used=16.00KiB
System, single: total=4.00MiB, used=0.00
Metadata, DUP: total=1.00GiB, used=2.72MiB
Metadata, single: total=8.00MiB, used=0.00
$
$ df -h
Filesystem Size Used Avail Use% Mounted on
/dev/sda1 40G 1.2G 37G 4% /
none 4.0K 0 4.0K 0% /sys/fs/cgroup
udev 745M 12K 745M 1% /dev
tmpfs 150M 368K 150M 1% /run
none 5.0M 0 5.0M 0% /run/lock
none 750M 0 750M 0% /run/shm
none 100M 0 100M 0% /run/user
vagrant 233G 185G 49G 80% /vagrant
/dev/sdb 20G 344M 18G 2% /var/lib/docker
$
$ sudo btrfs filesystem show /var/lib/docker
Label: none uuid: c8f11393-9268-475a-82de-cbd697ab3847
Total devices 1 FS bytes used 340.30MiB
devid 1 size 20.00GiB used 3.04GiB path /dev/sdb
Btrfs v3.12
</code>
</pre>
<p>Each image and container has a subvolume.</p>
<p>And, as far as I know at this point, that’s it–we’re now running docker with btrfs.</p>
<h2 id="ansible-playbook">Ansible playbook</h2>
<p>I’ve setup an <a href="https://github.com/ccollicutt/vagrant-docker-btrfs">Ansible playbook</a> with a <a href="http://vagrantup.com">Vagrant</a> file that will setup a virtual machine with docker and btrfs configured in the same way that I describe in this blog post. Vagrant will automatically provision the virtual machine using Ansible.</p>
<pre>
<code>$ git clone https://github.com/ccollicutt/vagrant-docker-btrfs
$ cd vagrant-docker-btrfs
$ vagrant up --provider virtualbox
Bringing machine 'host1' up with 'virtualbox' provider...
==> host1: Importing base box 'trusty64'...
SNIP!
TASK: [add alias for vagrant user docker = docker.io] *************************
changed: [host1]
NOTIFIED: [restart docker] ****************************************************
changed: [host1]
PLAY RECAP ********************************************************************
host1 : ok=17 changed=16 unreachable=0 failed=0
$
</code>
</pre>
<p>Now that that is booted up and configured, we can login and check a couple things.</p>
<pre>
<code>$ vagrant ssh
SNIP!
vagrant@host1:~$ sudo btrfs subvolume list /var/lib/docker
vagrant@host1:~$# none because we have no images or containers
vagrant@host1:~$ mount |grep btrfs
/dev/sdb on /var/lib/docker type btrfs (rw)
vagrant@host1:~$ ps ax |grep [d]ocker
10041 ? Sl 0:00 /usr/bin/docker.io -d -s btrfs
vagrant@host1:~$ docker pull busybox
Pulling repository busybox
a9eb17255234: Download complete
d200959a3e91: Download complete
fd5373b3d938: Download complete
37fca75d01ff: Download complete
511136ea3c5a: Download complete
42eed7f1bf2a: Download complete
f06b02872d52: Download complete
120e218dd395: Download complete
c120b7cab0b0: Download complete
1f5049b3536e: Download complete
vagrant@host1:~$ docker images
REPOSITORY TAG IMAGE ID CREATED VIRTUAL SIZE
busybox buildroot-2013.08.1 d200959a3e91 4 days ago 2.489 MB
busybox ubuntu-14.04 37fca75d01ff 4 days ago 5.609 MB
busybox ubuntu-12.04 fd5373b3d938 4 days ago 5.455 MB
busybox buildroot-2014.02 a9eb17255234 4 days ago 2.433 MB
busybox latest a9eb17255234 4 days ago 2.433 MB
vagrant@host1:~$# now we should have some subvolumes
vagrant@host1:~$ sudo btrfs subvolume list /var/lib/docker
ID 258 gen 12 top level 5 path btrfs/subvolumes/511136ea3c5a64f264b78b5433614aec563103b4d4702f3ba7d4d2698e22c158
ID 259 gen 17 top level 5 path btrfs/subvolumes/42eed7f1bf2ac3f1610c5e616d2ab1ee9c7290234240388d6297bc0f32c34229
ID 260 gen 14 top level 5 path btrfs/subvolumes/f06b02872d5253f5123284edcf49749b352400a1c5880b5ebf2864f5afddeb22
ID 261 gen 14 top level 5 path btrfs/subvolumes/37fca75d01ffc49df7b99aacdbcd4a0ebae39de299787b8f77bb5b6698414308
ID 262 gen 16 top level 5 path btrfs/subvolumes/120e218dd395ec314e7b6249f39d2853911b3d6def6ea164ae05722649f34b16
ID 263 gen 16 top level 5 path btrfs/subvolumes/a9eb172552348a9a49180694790b33a1097f546456d041b6e82e4d7716ddb721
ID 264 gen 19 top level 5 path btrfs/subvolumes/1f5049b3536eb73e7a660a672976ae9c19e8460bf57c2528f9c1e4b2c4bf309f
ID 265 gen 19 top level 5 path btrfs/subvolumes/c120b7cab0b0509fd4de20a57d0f5c17106f3451200dfbfd8c6ab1ccb9391938
ID 266 gen 19 top level 5 path btrfs/subvolumes/d200959a3e91d88e6da9a0ce458e3cdefd3a8a19f8f5e6a1e7f10f268aea5594
ID 267 gen 19 top level 5 path btrfs/subvolumes/fd5373b3d93820744a327e609ee86166e5984d7377987f0fde78daeaa345705d
</code>
</pre>
<h2 id="conclusion">Conclusion</h2>
<p>I haven’t explored much more in terms of using btrfs with docker yet, but this is a good start.</p>
Using Docker with Python and iPython2014-06-05T00:00:00+00:00http://serverascode.com/2014/06/05/docker-python<h1 id="using-docker-with-python-and-ipython">Using Docker with Python and iPython</h1>
<p>Right now <a href="http://docker.io">Docker</a> is one of the hottest projects on the planet, so that means some people aren’t going to like it simply based on that fact alone.</p>
<p>Having said that, I really enjoy the paradigm shift in terms of working with containers, service discovery, and all the interesting new ideas and areas being created. (If you feel like having your mind warped, just read <a href="https://twitter.com/progrium">Jeff Linday’s</a> twitter feed.)</p>
<p>In this post I thought I would take a quick look at using the <a href="https://github.com/dotcloud/docker-py">docker-py</a> module to use Docker containers via Python and, one of my favorite programming applications, <a href="http://ipython.org/">iPython</a>.</p>
<h2 id="install-docker-py">Install docker-py</h2>
<p>First, you need docker-py. Note that in the examples show here I am using Ubuntu Trusty/14.04.</p>
<pre>
<code>$ pip install docker-py
</code>
</pre>
<h2 id="ipython">ipython</h2>
<p>I really like <a href="http://ipython.org/">iPython</a> for exploring Python. It’s kind of an advanced Python shell, but also does much more.</p>
<pre>
<code>$ sudo apt-get install ipython
SNIP!
$ ipython
Python 2.7.6 (default, Mar 22 2014, 22:59:56)
Type "copyright", "credits" or "license" for more information.
IPython 1.2.1 -- An enhanced Interactive Python.
? -> Introduction and overview of IPython's features.
%quickref -> Quick reference.
help -> Python's own help system.
object? -> Details about 'object', use 'object??' for extra details.
In [1]:
</code>
</pre>
<h2 id="install-docker">Install docker</h2>
<p>If docker isn’t already installed, then go ahead and install it.</p>
<pre>
<code>$ sudo apt-get install docker.io
</code>
</pre>
<p>I also alias docker.io to docker.</p>
<pre>
<code>$ alias docker='docker.io'
$ docker version
Client version: 0.9.1
Go version (client): go1.2.1
Git commit (client): 3600720
Server version: 0.9.1
Git commit (server): 3600720
Go version (server): go1.2.1
Last stable version: 0.11.1, please update docker
</code>
</pre>
<p>Docker should now have a socket open that we can connect to.</p>
<pre>
<code>$ ls /var/run/docker.sock
/var/run/docker.sock
</code>
</pre>
<h2 id="pull-an-image">Pull an image</h2>
<p>Let’s download the busybox image.</p>
<pre>
<code>$ docker pull busybox
Pulling repository busybox
71e18d715071: Download complete
98b9fdab1cb6: Download complete
1277aa3f93b3: Download complete
6e0a2595b580: Download complete
511136ea3c5a: Download complete
b6c0d171b362: Download complete
8464f9ac64e8: Download complete
9798716626f6: Download complete
fc1343e2fca0: Download complete
f3c823ac7aa6: Download complete
</code>
</pre>
<p>Now we are ready to use docker-py.</p>
<h2 id="working-with-docker-py">Working with docker-py</h2>
<p>Now that we have docker-py, iPython, Docker, and the busybox image, we can start some containers!</p>
<p>If you’re not familiar with iPython, have a look at the <a href="http://ipython.org/ipython-doc/stable/interactive/tutorial.html">tutorial</a>. iPython is quite powerful.</p>
<p>First, fire up ipython and import docker.</p>
<pre>
<code>$ ipython
Python 2.7.6 (default, Mar 22 2014, 22:59:56)
Type "copyright", "credits" or "license" for more information.
IPython 1.2.1 -- An enhanced Interactive Python.
? -> Introduction and overview of IPython's features.
%quickref -> Quick reference.
help -> Python's own help system.
object? -> Details about 'object', use 'object??' for extra details.
In [1]: import docker
</code>
</pre>
<p>Next we make a connection to Docker.</p>
<pre>
<code>In [2]: c = docker.Client(base_url='unix://var/run/docker.sock',
...: version='1.9',
...: timeout=10)
</code>
</pre>
<p>Now we have a connection to Docker.</p>
<p>iPython offers tab completion. If I type “c.” and then hit the TAB key, ipython will show me what the Docker connection object has to offer.</p>
<pre>
<code>In [3]: c.
c.adapters c.headers c.pull
c.attach c.history c.push
c.attach_socket c.hooks c.put
c.auth c.images c.remove_container
c.base_url c.import_image c.remove_image
c.build c.info c.request
c.cert c.insert c.resolve_redirects
c.close c.inspect_container c.restart
c.commit c.inspect_image c.search
c.containers c.kill c.send
c.cookies c.login c.start
c.copy c.logs c.stop
c.create_container c.max_redirects c.stream
c.create_container_from_config c.mount c.tag
c.delete c.options c.top
c.diff c.params c.trust_env
c.events c.patch c.verify
c.export c.port c.version
c.get c.post c.wait
c.get_adapter c.prepare_request
c.head c.proxies
</code>
</pre>
<p>Let’s look at c.images. I I put a “?” after the object, ipython will provide details about the object.</p>
<pre>
<code>In [5]: c.images?
Type: instancemethod
String Form:<bound method Client.images of <docker.client.Client object at 0x7f3acc731790>>
File: /usr/local/lib/python2.7/dist-packages/docker/client.py
Definition: c.images(self, name=None, quiet=False, all=False, viz=False)
Docstring: <no docstring="">
</code>
</pre>
And grab the busybox image.
<pre>
<code>In [6]: c.images(name="busybox")
Out[6]:
[{u'Created': 1401402591,
u'Id': u'71e18d715071d6ba89a041d1e696b3d201e82a7525fbd35e2763b8e066a3e4de',
u'ParentId': u'8464f9ac64e87252a91be3fbb99cee20cda3188de5365bec7975881f389be343',
u'RepoTags': [u'busybox:buildroot-2013.08.1'],
u'Size': 0,
u'VirtualSize': 2489301},
{u'Created': 1401402590,
u'Id': u'1277aa3f93b3da774690bc4f0d8bf257ff372e23310b4a5d3803c180c0d64cd5',
u'ParentId': u'f3c823ac7aa6ef78d83f19167d5e2592d2c7f208058bc70bf5629d4bb4ab996c',
u'RepoTags': [u'busybox:ubuntu-14.04'],
u'Size': 0,
u'VirtualSize': 5609404},
{u'Created': 1401402589,
u'Id': u'6e0a2595b5807b4f8c109f3c6c5c3d59c9873a5650b51a4480b61428427ab5d8',
u'ParentId': u'fc1343e2fca04a455f803ba66d1865739e0243aca6c9d5fd55f4f73f1e28456e',
u'RepoTags': [u'busybox:ubuntu-12.04'],
u'Size': 0,
u'VirtualSize': 5454693},
{u'Created': 1401402587,
u'Id': u'98b9fdab1cb6e25411eea5c44241561326c336d3e0efae86e0239a1fe56fbfd4',
u'ParentId': u'9798716626f6ae4e6b7f28451c0a1a603dc534fe5d9dd3900150114f89386216',
u'RepoTags': [u'busybox:buildroot-2014.02', u'busybox:latest'],
u'Size': 0,
u'VirtualSize': 2433303}]
</code>
</pre>
Create a container. Note that I'm adding a command to be run, in this example the "env" command.
<pre>
<code>In [8]: c.create_container(image="busybox", command="env")
Out[8]:
{u'Id': u'584459a09e6d4180757cb5c10ac354ca46a32bf8e122fa3fb71566108f330c87',
u'Warnings': None}
</code>
</pre>
Start the container using the Id.
<pre>
<code>In [9]: c.start(container="584459a09e6d4180757cb5c10ac354ca46a32bf8e122fa3fb71566108f330c87")
</code>
</pre>
And we can check the logs, should see the output of the command "env" that we configured when the container was created.
<pre>
<code>In [11]: c.logs(container="584459a09e6d4180757cb5c10ac354ca46a32bf8e122fa3fb71566108f330c87")
Out[11]: 'HOME=/\nPATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin\nHOSTNAME=584459a09e6d\n'
</code>
</pre>
If I run a container with the same options using the dokcer command line, I should see something similar.
<pre>
<code>$ docker run busybox env
HOME=/
PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
HOSTNAME=ce3ad38a52bf
</code>
</pre>
As far as I can tell, docker-py does not have a run option, instead we have to create a container and then start it.
Here's another example:
<pre>
<code>In [17]: busybox = c.create_container(image="busybox", command="echo hi")
In [18]: busybox?
Type: dict
String Form:{u'Id': u'34ede853ee0e95887ea333523d559efae7dcbe6ae7147aa971c544133a72e254', u'Warnings': None}
Length: 2
Docstring:
dict() -> new empty dictionary
dict(mapping) -> new dictionary initialized from a mapping object's
(key, value) pairs
dict(iterable) -> new dictionary initialized as if via:
d = {}
for k, v in iterable:
d[k] = v
dict(**kwargs) -> new dictionary initialized with the name=value pairs
in the keyword argument list. For example: dict(one=1, two=2)
In [19]: c.start(busybox.get("Id"))
In [20]: c.logs(busybox.get("Id"))
Out[20]: 'hi\n'
</code>
</pre>
If you haven't used busybox images with docker yet, I definitely suggest it. I also suggest the debian:jessie image which is only 120MB, quite a bit smaller than, say, the Ubuntu images.
## Conclusion
Docker is a fascinating new system and it's going to be used to build interesting new technologies, especially around cloud services. Using iPython we've explored how to programmatically create docker containers using the docker-py module. Now using python we can create those next generation ideas using docker and containers.
</no></code></pre>
Wordpress with FORCE_SSL_ADMIN behind a reverse proxy2014-05-31T00:00:00+00:00http://serverascode.com/2014/05/31/wordpress-ssl-reverse-proxy<h1 id="wordpress-with-force_ssl_admin-behind-a-reverse-proxy">Wordpress with FORCE_SSL_ADMIN behind a reverse proxy</h1>
<p>This is a pretty specific problem that I have run into a couple of times, both times forgetting the solution and spending an hour or two googling, so I decided to blog it so I can easily find it next time. :)</p>
<p>I am running a wordpress site behind <a href="https://github.com/dotcloud/hipache">hipache</a>, which is also doing ssl termination. So the actual wordpress site is served via plaintext http, and if ssl is required then hipache will provide it. Thus the connection from the client to hipache is ssl, but the connection from hipache to the apache server running wordpress is http.</p>
<p>Further, I want to force logins and access to /wp-admin to be ssl enabled using the wordpress option FORCE_SSL_ADMIN.</p>
<p>The problem is that with FORCE_SSL_ADMIN configured, but no https for apache serving wordpress, connections to wp-login.php or /wp-admin enter into a redirect loop.</p>
<p>The solution is adding an extra bit of configuration code to wp-config.php when using a reverse proxy to terminate ssl. Here is the <a href="http://codex.wordpress.org/Administration_Over_SSL">page</a> that describes what addtional configuration changes to make, which I also show below.</p>
<pre>
<code>define('FORCE_SSL_ADMIN', true);
if ($_SERVER['HTTP_X_FORWARDED_PROTO'] == 'https')
$_SERVER['HTTPS']='on';
</code>
</pre>
<p>With that added to the top of wp-config.php I can now have hipache serve up plain http for all of the wordpress site except wp-login.php and /wp-admin. Hopefully I remember to look here next time… :)</p>
Environment variables with Docker2014-05-29T00:00:00+00:00http://serverascode.com/2014/05/29/environment-variables-with-docker<h1 id="environment-variables-with-docker">Environment variables with Docker</h1>
<p>I’ve been working with <a href="http://docker.io">Docker</a> for a little while, and was wondering how environment variables work, so I took a few minutes to look into it.</p>
<p>Docker supports setting environment variables with the -e switch.</p>
<p>Below is the simplest example. As can be seen, the FOO variable is indeed set to bar within the container.</p>
<pre>
<code># docker run -e FOO=bar busybox env
HOME=/
PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
HOSTNAME=9c6f6cd077b2
FOO=bar
</code>
</pre>
<p>Multiple variables can be added with multiple -e switches.</p>
<pre>
<code># docker run -e FOO=bar -e BAR=foo busybox env
HOME=/
PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
HOSTNAME=6cf2d6e8acb3
FOO=bar
BAR=foo
</code>
</pre>
<h2 id="using-environment-variables-in-a-script-in-a-docker-image">Using environment variables in a script in a docker image</h2>
<p>Below is a simple docker file that adds a script called run.sh to the image.</p>
<pre>
<code># file Dockerfile
FROM busybox
ADD run.sh run.sh
RUN chmod +x run.sh
CMD ./run.sh
</code>
</pre>
<p>This is what is in the run.sh script. If FOO is not set, the container should report “FOO is empty” and otherwise it should print what the variable has been set to.</p>
<pre>
<code># file run.sh
#!/bin/sh
if [ -z "$FOO" ]; then
echo "FOO is empty"
else
echo "FOO is $FOO"
fi
</code>
</pre>
<p>I can now build that Dockerfile.</p>
<pre>
<code># ls
Dockerfile run.sh
# docker build -t testenv .
Uploading context 3.584 kB
Uploading context
Step 0 : FROM busybox
---> 4c0f792ebd1e
Step 1 : ADD run.sh run.sh
---> 6154a355bdd6
Step 2 : RUN chmod +x run.sh
---> Running in 20784036cde1
---> 784a1682769b
Step 3 : CMD ./run.sh
---> Running in d86187fc3a6f
---> 1c952ed5cc6d
Successfully built 1c952ed5cc6d
Removing intermediate container c598898e1706
Removing intermediate container 20784036cde1
Removing intermediate container d86187fc3a6f
</code>
</pre>
<p>Now that the image has been built, I can run a container based off it, and the run.sh script should execute.</p>
<pre>
<code># docker run testenv
FOO is empty
</code>
</pre>
<p>And now adding the FOO environment variable to the docker run command:</p>
<pre>
<code># docker run -e FOO=bar testenv
FOO is bar
# docker run -e FOO=$RANDOM testenv
FOO is 10567
# docker run -e FOO=$RANDOM testenv
FOO is 8898
</code>
</pre>
<p>Awesome. Now with this ability, we could, for example, create one Wordpress container and have it configure wp-config.php with the correct MySQL connection variables, and have that container connect out to the MySQL server with the right user and password, rather than creating an image for each Wordpress site.</p>
Manage docker hosts with shipyard2014-05-25T00:00:00+00:00http://serverascode.com/2014/05/25/docker-shipyard-multihost<h1 id="manage-docker-hosts-with-shipyard">Manage docker hosts with shipyard</h1>
<p><a href="http://www.docker.io">Docker</a> is a container management system. Containers are a form of virtualization, but they are not like typical virtualization that one would achieve with KVM or VMWare. I think it’s best to consider them as modeling processes instead of servers. If you haven’t experimented with Docker yet, <a href="http://blog.thoward37.me/articles/where-are-docker-images-stored/">here is a good blog post</a> on the terminology used which should help to alleviate some of the confusion around what Docker actually does and how.</p>
<p>It’s pretty easy to install docker. Here I install it on Ubuntu Trusty 14.04.</p>
<pre>
<code>vagrant@host1:~$ sudo apt-get install -y docker.io
</code>
</pre>
<p>And that’s it. Once that command completes the server is a docker host.</p>
<p>But what if we want to manage multiple docker hosts using one interface and/or API? What if we want ten docker hosts running and to be able to manage them all as though it’s one container-as-a-service system?</p>
<p>That’s where shipyard comes in.</p>
<h2 id="shipyard">Shipyard</h2>
<p><a href="http://shipyard-project.com/">Shipyard</a> is a project that can manage multiple docker hosts. Quoting from the website:</p>
<blockquote>
<p>Shipyard gives you the ability to manage Docker resources including containers, images, hosts, and more all from a single management interface. Shipyard can manage multiple Docker hosts giving the flexibility to build redundant, highly available applications.</p>
</blockquote>
<p>There are actually several similar systems being worked on right now that can tie together multiple docker hosts. One example is Flynn which has <a href="https://github.com/flynn/flynn-host">flynn-host</a>, another is <a href="https://wiki.openstack.org/wiki/Docker">OpenStack</a> which can manage docker containers, yet another is <a href="https://coreos.com/">CoreOS</a>, <a href="http://www.projectatomic.io/">Project Atomic</a> is new…and there are more out there. Typically these systems will do much more than just manage containers (or jobs) but they will all have that functionality. (Feel free to correct me if I’m wrong.)</p>
<h2 id="setup-the-shipyard-host">Setup the shipyard host</h2>
<p>This is as easy as starting a container. The shipyard project has a pre-created and distributed shipyard docker container. All we have to do is install that image and run it. Note that this will download a few hundred megabytes of images if they do not already exist on the docker host.</p>
<pre>
<code>vagrant@host1:~$ sudo docker.io run -i -t -v /var/run/docker.sock:/docker.sock shipyard/deploy setup
SNIP!
eba9b5f1d1d1: Download complete
08852c160ec2: Download complete
2cbf6e5024d8: Download complete
Shipyard Stack Deployed
You should be able to login with admin:shipyard at http://<docker-host-ip>:8000
You will also need to setup and register the Shipyard Agent.
See http://github.com/shipyard/shipyard-agent for details.
</code>
</pre>
As the output says, the web gui can be accessed on the docker host and port 8000 with the default user/pass of admin/shipyard.
## Shipyard client
Now we need to install the shipyard agent on the docker hosts.
First, make sure Docker is listening on a localhost via tcp. By default--for security reasons--docker will only listen on a local socket.
Change the DOCKER_OPTS in /etc/default/docker to:
<pre>
<code>DOCKER_OPTS="-H tcp://127.0.0.1:4243 -H unix:///var/run/docker.sock"
</code>
</pre>
Then restart docker. Docker should be listening on 4243.
<pre>
<code>vagrant@host1:/etc/default$ netstat -ant |grep 4243
tcp 0 0 127.0.0.1:4243 0.0.0.0:* LISTEN
</code>
</pre>
Now that the shipyard host is up and Docker is listening on a tcp port, we can register an agent. I installed shipyard-agent in /usr/local/bin by downloading the [latest release](https://github.com/shipyard/shipyard-agent/releases).
<pre>
<code>vagrant@host1$ sudo ./shipyard-agent -url http://192.168.5.89:8000 -register
2014/05/25 14:36:37 Using 10.0.2.15 for the Docker Host IP for Shipyard
2014/05/25 14:36:37 If this is not correct or you want to use a different IP, \
please update the host in Shipyard
2014/05/25 14:36:37 Registering at http://192.168.5.89:8000
2014/05/25 14:36:37 Agent Key: b3d356b1294d4a729cd43beac8d7c01c
vagrant@host1$
</code>
</pre>
Once the shipyard-agent with -register is run, it will appear in the shipyard web gui to be activated, but first lets run it with that key.
<pre>
<code>vagrant@host1:/usr/local/bin$ sudo ./shipyard-agent -address="192.168.5.89" \
-url http://192.168.5.89:8000 -key b3d356b1294d4a729cd43beac8d7c01c
2014/05/25 14:50:39 Shipyard Agent (http://192.168.5.89:8000)
2014/05/25 14:50:39 Listening on 192.168.5.89:4500
# it stays in the foreground
</code>
</pre>
(Note that you would normally want to run shipyard-agent out of some kind of process supervisory system.)
host1 now appears in the web gui.
In the web gui we can manually activate the host. Also note that it picked the eth0 IP address which when using Vagrant is not the one we want to use, so I manually set it to the eth1 IP address which in my case is 192.168.5.89. There doesn't seem to be an option at this time to specify the IP.
Once the IP is changed and the host is activated, we can click on containers and get a list of what is running.
Above we can see that the shipyard containers are displayed as running on host1, which is where the shipyard host was installed.
I then went through the same process to add the second host. Now shipyard is managing two docker hosts: host1 and host2.
With shipyard managing the docker hosts, we can do things like pull the busybox image from the docker registry. By clicking on images->import and entering the tag of the docker image and clicking import again, the busybox image will be downloaded to both hosts.
<pre>
<code>vagrant@host1:~$ sudo docker.io images | grep busybox
busybox buildroot-2013.08.1 123fb16d32f8 26 hours ago 2.489 MB
busybox ubuntu-14.04 b9ca777960b9 26 hours ago 5.609 MB
busybox ubuntu-12.04 8ba0d1860bb6 26 hours ago 2.433 MB
busybox buildroot-2014.02 4c0f792ebd1e 38 hours ago 2.433 MB
busybox latest 4c0f792ebd1e 38 hours ago 2.433 MB
</code>
</pre>
And on host2:
<pre>
<code>vagrant@host2:~$ sudo docker.io images | grep busybox
busybox buildroot-2013.08.1 123fb16d32f8 26 hours ago 2.489 MB
busybox ubuntu-14.04 b9ca777960b9 26 hours ago 5.609 MB
busybox ubuntu-12.04 8ba0d1860bb6 26 hours ago 2.433 MB
busybox buildroot-2014.02 4c0f792ebd1e 38 hours ago 2.433 MB
busybox latest 4c0f792ebd1e 38 hours ago 2.433 MB
</code>
</pre>
## Shipyard cli
Most of what I have been showing with regards to shipyard is the web gui. But I'm not a big fan of web guis. I want to use virtual machines and containers programatically, or at the very least from the command line.
Shipyard has a golang [cli](https://github.com/shipyard/shipyard-cli) that is in "active development and has limited functionality," but let's try it out.
<pre>
<code>curtis$ git clone https://github.com/shipyard/shipyard-cli
curtis$ cd shipyard-cli
curtis$ make
github.com/gcmurphy/getpass (download)
github.com/shipyard/shipyard-go (download)
github.com/wsxiaoys/terminal (download)
curtis$ ls
Makefile cli readme.md shipyard
</code>
</pre>
Now that the shipyard binary has been compiled we can use it.
<pre>
<code>curtis$ ./shipyard
NAME:
Shipyard CLI - Command line interface for Shipyard
USAGE:
Shipyard CLI [global options] command [command options] [arguments...]
VERSION:
0.1.1
COMMANDS:
login Login
apps Application Management
containers Container Management
images Image Management
hosts Host Management
config, cfg Show current Shipyard config
info, info Show Shipyard Info
help, h Shows a list of commands or help for one command
GLOBAL OPTIONS:
--username Shipyard API Username
--key Shipyard API Key
--url Shipyard URL
--api-version '1' Shipyard API Version
--config, -c '/Users/curtis/.shipyard.cfg' Config File
--version, -v print the version
--help, -h show help
</code>
</pre>
First we login.
<pre>
<code>curtis$ ./shipyard login
URL: http://192.168.5.89:8000
Username: admin
Password:
Version (default: 1):
Login successful
</code>
</pre>
The login command creates a .shipyard.cfg file for us so that we don't have to "login" again.
<pre>
<code>curtis$ cat ~/.shipyard.cfg
{"Username":"admin","ApiKey":"cc7d9720798af55c05684d240a7b5186405d0e80",\
"Url":"http://192.168.5.89:8000","Version":"1"}
</code>
</pre>
Now we can run commands.
<pre>
<code>curtis$ ./shipyard hosts
host2 (192.168.5.90)
host1 (192.168.5.89)
curtis$ ./shipyard images
8ba0d1860bb6 busybox:ubuntu-12.04
6379130228c2 shipyard/lb:latest
180e6bd6c10d debian:jessie
b48b681ac984 shipyard/redis:latest
123fb16d32f8 busybox:buildroot-2013.08.1
b9ca777960b9 busybox:ubuntu-14.04
4c0f792ebd1e busybox:buildroot-2014.02
590fa59c6dc3 shipyard/router:latest
123fb16d32f8 busybox:buildroot-2013.08.1
8ba0d1860bb6 busybox:ubuntu-12.04
4c0f792ebd1e busybox:buildroot-2014.02
b9ca777960b9 busybox:ubuntu-14.04
626eb587cec1 shipyard/db:latest
bc62aa0fb727 shipyard/deploy:latest
30e0b59613ff shipyard/shipyard:latest
</code>
</pre>
## Conclusion
In the end what we have done here is fairly basic--just install a shipyard host and a couple of clients. Certainly there are other systems that do the same thing and much more, but I think shipyard is a good way to get introduced to the concepts of a multihost docker system.
I'd also like to automate the deployment of shipyard, but have a couple things to figure out, such as how to register the agent automatically, activating the hosts without the web gui, as well as setup some sort of supervisory system for the agent. Also there are a few things that shipyard can do that I haven't touched on, such as the concept of applications.
Hopefully in the next couple of weeks I'll explore more with regards as to how shipyard works and what can be done with it, as well as consider how it compares and contrasts to other systems. I believe that containers are an important technology, and that there is room for simpler tools that can provide containers-as-a-service, perhaps as part of a PaaS system, or just on their own. There are many different and interesting ways to virtualize, compartmentalize, and control mulitihost systems.
</docker-host-ip></code></pre>
Swiftacular - Install OpenStack Swift on Ubuntu Trusty 14.042014-05-24T00:00:00+00:00http://serverascode.com/2014/05/24/swiftacultar-ubuntu-trusty-1404<h1 id="swiftacular---install-openstack-swift-on-ubuntu-trusty-1404">Swiftacular - Install OpenStack Swift on Ubuntu Trusty 14.04</h1>
<p>Recently I updated my <a href="https://github.com/ccollicutt/swiftacular">Swiftacular</a> project to support Ubuntu Trusty 14.04 and OpenStack Icehouse (which Trusty comes with by default).</p>
<p>Swiftacular installs OpenStack Swift using Ansible on CentOS 6.5, Ubuntu 12.04, and Ubuntu 14.04. In CentOS and Ubuntu 12.04 it installs the OpenStack Havana release of Swift, and in Ubuntu 14.04 it uses Icehouse.</p>
<p>This post shows how to install OpenStack Swift Icehouse on Ubuntu 14.04 using Swiftacular.</p>
<h2 id="requirements">Requirements</h2>
<p>Below are the tools required:</p>
<ul>
<li>Git</li>
<li>Ansible</li>
<li>Virtualbox</li>
<li>Vagrant</li>
<li>Internet connection</li>
<li>Enough resources for seven virtual machines</li>
</ul>
<p>Note that I’ve only tested this on OSX Mavericks. But it should be quite easy to adapt to any situation if you don’t mind changing some IP addresses in the group_vars/all file. Another goal I have is to have examples of getting Swiftacular up and running using libvirt + kvm, AWS, Digital Ocean, and other IaaS providers.</p>
<h2 id="setup-openstack-swift-using-swiftacular">Setup OpenStack Swift using Swiftacular</h2>
<p>First, clone the Swiftacular repository and add some libraries. (I should put this all into a make file–it’s on the todo list!)</p>
<pre>
<code>curtis$ git clone https://github.com/ccollicutt/swiftacular.git
curtis$ cd swiftacular
curtis$ git clone https://github.com/openstack-ansible/openstack-ansible-modules library/openstack
</code>
</pre>
<p>Edit the Vagrantfile so that the Ubuntu Trusty box will be used instead of the default Precise box.</p>
<pre>
<code>curtis$ grep config.vm.box Vagrantfile
config.vm.box = "trusty64"
config.vm.box_url = "https://cloud-images.ubuntu.com/vagrant/trusty/current/trusty-server-cloudimg-amd64-vagrant-disk1.box"
#config.vm.box = "centos65"
#config.vm.box_url = "http://puppet-vagrant-boxes.puppetlabs.com/centos-65-x64-virtualbox-nocm.box"
#config.vm.box = "precise64"
#config.vm.box_url = "http://files.vagrantup.com/precise64.box"
</code>
</pre>
<p>Now we can use vagrant to start the virtual machines.</p>
<pre>
<code>curtis$ vagrant up
SNIP!
swift-storage-03: Warning: Remote connection disconnect. Retrying...
==> swift-storage-03: Machine booted and ready!
==> swift-storage-03: Checking for guest additions in VM...
==> swift-storage-03: Setting hostname...
==> swift-storage-03: Configuring and enabling network interfaces...
==> swift-storage-03: Mounting shared folders...
swift-storage-03: /vagrant => /Users/curtis/working/swiftacular
curtis$ # done booting all the vms
</code>
</pre>
<p>Test connectivity using ansible ping.</p>
<pre>
<code>curtis$ ansible -m ping all
192.168.100.100 | success >> {
"changed": false,
"ping": "pong"
}
192.168.100.50 | success >> {
"changed": false,
"ping": "pong"
}
192.168.100.30 | success >> {
"changed": false,
"ping": "pong"
}
192.168.100.200 | success >> {
"changed": false,
"ping": "pong"
}
192.168.100.20 | success >> {
"changed": false,
"ping": "pong"
}
192.168.100.201 | success >> {
"changed": false,
"ping": "pong"
}
192.168.100.202 | success >> {
"changed": false,
"ping": "pong"
}
</code>
</pre>
<p>Good.</p>
<p>We can also use vagrant status to list all the vms. Their names should describe what they do fairly well. The lbssl server is the ssl termination point for the swift proxy. It’s not doing any load balancing in this situation, but could if there were multiple proxy servers.</p>
<pre>
<code>curtis$ vagrant status
SNIP!
swift-package-cache-01 running (virtualbox)
swift-keystone-01 running (virtualbox)
swift-lbssl-01 running (virtualbox)
swift-proxy-01 running (virtualbox)
swift-storage-01 running (virtualbox)
swift-storage-02 running (virtualbox)
swift-storage-03 running (virtualbox)
</code>
</pre>
<p>Now lets set the ansible variables. The default variables should work, but the passwords are set to CHANGEME.</p>
<pre>
<code>curtis$ cp group_vars/all.example group_vars/all
curtis$ # edit the group_vars/all file
</code>
</pre>
<p>Finally we can run ansible-playbook and install OpenStack Swift Icehouse across all the nodes. Depending on your internet connection and disk performance this should only take five or six minutes.</p>
<pre>
<code>curtis$ ansible-playbook site.yml
PLAY [package_cache] **********************************************************
GATHERING FACTS ***************************************************************
ok: [192.168.100.20]
SNIP!
PLAY RECAP ********************************************************************
192.168.100.100 : ok=28 changed=22 unreachable=0 failed=0
192.168.100.20 : ok=22 changed=16 unreachable=0 failed=0
192.168.100.200 : ok=46 changed=37 unreachable=0 failed=0
192.168.100.201 : ok=46 changed=37 unreachable=0 failed=0
192.168.100.202 : ok=46 changed=37 unreachable=0 failed=0
192.168.100.30 : ok=20 changed=17 unreachable=0 failed=0
192.168.100.50 : ok=43 changed=36 unreachable=0 failed=0
</code>
</pre>
<p>If I ssh into the proxy server I can see what OpenStack packages have been installed.</p>
<pre>
<code>curtis$ vagrant ssh swift-proxy-01
SNIP!
vagrant@swift-proxy-01:~$ dpkg --list | grep swift | tr -s " " | cut -f 2,3 -d " "
python-swift 1.13.1-0ubuntu1
python-swiftclient 1:2.0.3-0ubuntu1
swift 1.13.1-0ubuntu1
swift-object 1.13.1-0ubuntu1
swift-plugin-s3 1.7-3
swift-proxy 1.13.1-0ubuntu1
</code>
</pre>
<p>Same with the storage servers.</p>
<pre>
<code>vagrant@swift-storage-01:~$ dpkg --list | grep swift | tr -s " " | cut -f 2,3 -d " "
python-swift 1.13.1-0ubuntu1
python-swiftclient 1:2.0.3-0ubuntu1
swift 1.13.1-0ubuntu1
swift-account 1.13.1-0ubuntu1
swift-container 1.13.1-0ubuntu1
swift-object 1.13.1-0ubuntu1
</code>
</pre>
<p>Now we can run a small test by uploading a text file into a container. I usually run this from the package cache server that is created as part of Swiftacular. But you can run the swift command line client from anywhere that the proxy server can be accessed from.</p>
<pre>
<code>vagrant@swift-package-cache-01:~$ . testrc
vagrant@swift-package-cache-01:~$ echo "swift is cool" > swift.txt
vagrant@swift-package-cache-01:~$ swift upload test_container swift.txt
swift.txt
vagrant@swift-package-cache-01:~$ swift list
test_container
vagrant@swift-package-cache-01:~$ swift list test_container
swift.txt
</code>
</pre>
<p>At this point we have a nice little working test cluster of OpenStack Swift Icehouse release running on Ubuntu Trusty 14.04.</p>
<p>There is still a lot of work I would like to do with Swiftacular. If you have any suggestions, comments, or criticisms please do let me know in the comments or enter an issue into the github repository.</p>
gpg-zip2014-05-04T00:00:00+00:00http://serverascode.com/2014/05/04/gpg-zip<h1 id="gpg-zip">gpg-zip</h1>
<p>I have a dedicated server I use to host a few things, like friends wordpress sites, some personal websites, etc. One of the services the hosting company provides is access to a backup server via ftp, ie. they give me some free space to backup files to.</p>
<p>But I don’t want to just drop backup files there in plaintext–I want them to be encrypted with gpg. Enter gpg-zip!</p>
<p>gpg-zip is handy utility that can tar a directory and then encrypt the resulting file. That file could then be placed anywhere, and, if gpg is working properly, unless someone has access to the private key of the public key that it was encrypted with (or they were set as the recipient), they should not be able to decrypt it. It’s important to note that the encrypted file is only as secure as the private key. Obviously is someone has access to the private key then they can decrypt the file.</p>
<p>First, I have a key that I’m going to use for this example. Creating keys and subkeys securely is a bit beyond the scope of this article. Here’s a good blog post on <a href="http://www.bootc.net/archives/2013/06/07/generating-a-new-gnupg-key/">creating new gpg keys</a>, and another <a href="https://alexcabal.com/creating-the-perfect-gpg-keypair/">here</a>.</p>
<p>Below is the key I will use.</p>
<pre>
<code># gpg --list-keys
/root/.gnupg/pubring.gpg
------------------------
pub 2048R/4FCDA707 2014-05-04
uid curtis <curtis-backups@serverascode.com>
sub 2048R/25AEB942 2014-05-04
</code>
</pre>
<p>It’s important to note that that key is not itself encrypted–it does not have a passphrase set, so it can be used by anyone who has access to a copy of the key. This is not a good thing to do with an important key, but in this case I am going to want to automate this process, and there is no good way, that I’m aware of, to have an automated process decrypt the key without the passphrase also being stored in cleartext. That being said, encrypting the file does not require the password to unlock the private key, but decrypting in an automated fashion would.</p>
<p>Let’s create a test directory with some files in it to gpg-zip.</p>
<pre>
<code># cd /tmp; mkdir test
# for i in $(seq 1 100); do echo "hi $i" > test/$i.txt; done
# ls test | wc -l
100
</code>
</pre>
<p>Now that we have a directory filled with files to backup it can be encrypted with gpg. I’m essentially encrypting the file with myself as the recipient, ie. a message to myself.</p>
<pre>
<code># gpg-zip --encrypt --recipient curtis-backup@serverascode.com test > test.tar.gz.gpg
# file test.tar.gz.gpg
test.tar.gz.gpg: data
</code>
</pre>
<p>I can also use gpg-zip to list the files (but obviously I can only do that if I can decrypt it):</p>
<pre>
<code># gpg-zip --list-archive test.tar.gz.gpg | tail
gpg: encrypted with 2048-bit RSA key, ID 25AEB942, created 2014-05-04
"curtis <curtis-backup@serverascode.com>"
test/57.txt
test/26.txt
test/84.txt
test/6.txt
test/16.txt
test/4.txt
test/18.txt
test/20.txt
test/45.txt
test/76.txt
</code>
</pre>
<p>And I can restore the files as well. I’ll do that in a restore directory.</p>
<pre>
<code># mkdir restore; cd restore
# gpg-zip --decrypt /tmp/test.tar.gz.gpg
gpg: encrypted with 2048-bit RSA key, ID 25AEB942, created 2014-05-04
"curtis <curtis-backup@serverascode.com>"
test/
test/22.txt
test/74.txt
test/47.txt
test/5.txt
SNIP!
</code>
</pre>
<p>Looks good. Now that I have a feeling for how gpg-zip works I can start automating my backups, encrypting them, and shipping them off to the remote ftp server.</p>
<h2 id="conclusion">Conclusion</h2>
<p>gpg-zip is an easy way to encrypt directories. The resulting file can then be shipped across the (unencrypted) wire and stored on a remote system, and I should feel reasonably confident that unless someone surreptitiously accesses my server and steals my gpg keys, that the file will remain secure. There are a few caveats of course, but overall I think this workflow is reasonable.</p>
<p>If you see any mistakes or other issues with this post, please let me know in the comments. :)</p>
First look at Digital Ocean2014-04-26T00:00:00+00:00http://serverascode.com/2014/04/26/first-look-digital-ocean<h1 id="first-look-at-digital-ocean">First look at Digital Ocean</h1>
<p>Even though I have worked a great deal with OpenStack and various virtualization technologies, I haven’t really used infrastructure as a service all that much. Being Canadian has made using Amazon Web Services unlikely as I normally work at organizations that have concerns (justified or not) about their data staying in Canada. Usually that means AWS is off the table. I’ve used Rackspace a bit to test out their Rackspace files product which is based on OpenStack Swift and I’ve also used Heroku to deploy a <a href="https://hubot.github.com/">hubot</a>, but that’s about it.</p>
<h2 id="digital-ocean">Digital Ocean</h2>
<p>Digital Ocean (DO) keeps popping up in my RSS feeds, so I thought I’d give it a shot. From what I’ve read DO is a simplified IaaS provider that also separates itself from the rest of the pack by its use of only solid state drives–no spinning rust here. While I believe Rackspace now provides all SSDs, DO was kind of the first to really market themselves using SSDs (at least the first I was aware of at any rate).</p>
<p>I mention the word “simplified” above. This is another way that I believe DO is distinguishing itself from other IaaS providers–a simplified web interface, possibly a simplified product offering, and easy to understand pricing.</p>
<h2 id="sign-up">Sign-up</h2>
<p>The sign-up is very straight forward. Nothing but an email and a password. I don’t think a second field to verify a password for a new sign-up is necessary, especially given how passwords can usually be reset with a link in an email, so the fact that DO only has one password field seems smart to me. Also the fact that the sign up is on the front page is telling.</p>
<h2 id="credit-card-info">Credit card info</h2>
<p>The first thing I wanted to do is find out what Operating Systems they support for virtual machines. I’m sure they support all the standard OSes, but the sysadmin in me wants to go to that page first. However, as far as I can tell I can’t see that information without putting in a credit card first. So I enter my credit card info.</p>
<h2 id="simple-web-interface">Simple web interface</h2>
<p>I’m definitely enjoying the simple web interface. I think there is a lot of room in IaaS to provide a very simple web gui. I think DO is doing a smart thing here, courting developers, simple web interface, simple usage, relatively low cost, and SSDs. AWS has tons of features and products that are difficult to understand, and what’s more, it’s hard to figure out what your bill is going to be (though again, I haven’t used AWS much).</p>
<p><img src="https://raw.githubusercontent.com/ccollicutt/ccollicutt.github.com/master/img/digital_ocean/webgui.png" alt="" /></p>
<p>There’s not much going on in the sidebar. Just:</p>
<ul>
<li>Create</li>
<li>Droplets</li>
<li>Images</li>
<li>SSH keys</li>
<li>Billing</li>
<li>Support</li>
<li>DNS</li>
<li>API</li>
</ul>
<p>Most of these concepts are going to be in every IaaS provider. Create a virtual machine/instance/droplet. What instances do I already have running? What images can these droplets be based off of? What SSH keys are automatically added to the image when it’s booted? (Most IaaS providers inject an SSH key into the virtual machine and also turn off SSH password access–only access using SSH keys is allowed at first to remove the ability of bots to break the password and login.)</p>
<h2 id="add-an-ssh-key">Add an SSH key</h2>
<p>A big button says “Add SSH key.” It’s calling to me. :)</p>
<p><img src="https://raw.githubusercontent.com/ccollicutt/ccollicutt.github.com/master/img/digital_ocean/sshkey.png" alt="" /></p>
<p>Surprisingly I can’t just upload the file I have to paste it into the text box. Sure. Once I do that it shows my key in the SSH keys list.</p>
<p><img src="https://raw.githubusercontent.com/ccollicutt/ccollicutt.github.com/master/img/digital_ocean/sshkeylist.png" alt="" /></p>
<p>Now I’m going to guess that having entered my CC information, and having uploaded at least one SSH key, I can now boot a droplet/vm/instance.</p>
<p>But I don’t want to do that with the web gui, because I don’t really like to use gui interfaces. Looks like I need to find a command line application that can use the API that DO seems to have…</p>
<h2 id="tugboat">Tugboat</h2>
<p>So I google search for “digital ocean command line” and below are some of the results. Looks like there is an command line app called “tugboat.”</p>
<p><img src="https://raw.githubusercontent.com/ccollicutt/ccollicutt.github.com/master/img/digital_ocean/googlesearch.png" alt="" /></p>
<p>Let’s get that. The <a href="https://github.com/pearkes/tugboat">github README</a> for tugboat says “gem install tugboat.”</p>
<pre>
<code>curtis$ sudo gem install tugboat
SNIP!
10 gems installed
</code>
</pre>
<p>I noticed that during the install a digital_ocean gem was brought down too:</p>
<pre>
<code>curtis$ gem list | grep digital
digital_ocean (1.0.1)
</code>
</pre>
<p>I’m willing to bet that DO provides that gem, and Ruby code can take advantage of it, just like tugboat.</p>
<p>Now I’ve got a tugboat command.</p>
<pre>
<code>curtis$ which tugboat
/usr/bin/tugboat
</code>
</pre>
<p>Here are all the commands tugboat provides:</p>
<pre>
<code>curtis$ tugboat
Commands:
tugboat add-key NAME # Upload an ssh public key.
tugboat authorize # Authorize a DigitalOcean account with tugboat
tugboat create NAME # Create a droplet.
tugboat destroy FUZZY_NAME # Destroy a droplet
tugboat destroy_image FUZZY_NAME # Destroy an image
tugboat droplets # Retrieve a list of your droplets
tugboat halt FUZZY_NAME # Shutdown a droplet
tugboat help [COMMAND] # Describe commands or a specific command
tugboat images # Retrieve a list of your images
tugboat info FUZZY_NAME [OPTIONS] # Show a droplet's information
tugboat info_image FUZZY_NAME [OPTIONS] # Show an image's information
tugboat keys # Show available SSH keys
tugboat password-reset FUZZY_NAME # Reset root password
tugboat rebuild FUZZY_NAME IMAGE_NAME # Rebuild a droplet.
tugboat regions # Show regions
tugboat resize FUZZY_NAME -s, --size=N # Resize a droplet
tugboat restart FUZZY_NAME # Restart a droplet
tugboat sizes # Show available droplet sizes
tugboat snapshot SNAPSHOT_NAME FUZZY_NAME [OPTIONS] # Queue a snapshot of the droplet.
tugboat ssh FUZZY_NAME # SSH into a droplet
tugboat start FUZZY_NAME # Start a droplet
tugboat verify # Check your DigitalOcean credentials
tugboat version # Show version
tugboat wait FUZZY_NAME # Wait for a droplet to reach a state
</code>
</pre>
<p>Oops, looks like I could have added my key with tugboat. Oh well.</p>
<p>The tugboat README says use “tugboat authorized” to setup the API information to allow tugboat to access the DO API using my credentials.</p>
<p>Note that I found my API credentials and keys in the web gui under “API.”</p>
<pre>
<code>curtis$ tugboat authorize
Note: You can get this information from digitalocean.com/api_access
Enter your client key: <REDACTED>
Enter your API key: <REDACTED>
Enter your SSH key path (optional, defaults to ~/.ssh/id_rsa): ~/.ssh/id_dsa
Enter your SSH user (optional, defaults to curtis):
Enter your SSH port number (optional, defaults to 22):
To retrieve region, image, size and key ID's, you can use the corresponding tugboat command, such as `tugboat images`.
Defaults can be changed at any time in your ~/.tugboat configuration file.
Enter your default region ID (optional, defaults to 1 (New York)):
Enter your default image ID (optional, defaults to 350076 (Ubuntu 13.04 x64)):
Enter your default size ID (optional, defaults to 66 (512MB)):
Enter your default ssh key ID (optional, defaults to none): curtis
Enter your default for private networking (optional, defaults to false): true
Enter your default for enabling backups (optional, defaults to false):
Authentication with DigitalOcean was successful.
</code>
</pre>
I set everything as default except put the right location for my local key, and pointed it to the SSH key I already uploaded as default, and also enabled private networking. I know from having read a blog post on DO that they support a form of private networking in certain regions.
Lets see what I get from tugboat.
<pre>
<code>curtis$ tugboat droplets
You don't appear to have any droplets.
Try creating one with `tugboat create`
# so no droplets yet
curtis$ tugboat keys
SSH Keys:
curtis (id: 118429)
</code>
</pre>
What images are available? "--global" means show all images, not just my own images.
<pre>
<code>curtis$ tugboat images --global
My Images:
No images found
Global Images:
CentOS 5.8 x64 (id: 1601, distro: CentOS)
CentOS 5.8 x32 (id: 1602, distro: CentOS)
Debian 6.0 x64 (id: 12573, distro: Debian)
Debian 6.0 x32 (id: 12575, distro: Debian)
Ubuntu 10.04 x64 (id: 14097, distro: Ubuntu)
Ubuntu 10.04 x32 (id: 14098, distro: Ubuntu)
Arch Linux 2013.05 x64 (id: 350424, distro: Arch Linux)
Arch Linux 2013.05 x32 (id: 361740, distro: Arch Linux)
CentOS 6.4 x32 (id: 376568, distro: CentOS)
CentOS 6.4 x64 (id: 562354, distro: CentOS)
Ubuntu 12.04.4 x32 (id: 3100616, distro: Ubuntu)
Ubuntu 12.04.4 x64 (id: 3101045, distro: Ubuntu)
Ubuntu 13.10 x32 (id: 3101580, distro: Ubuntu)
Ubuntu 12.10 x32 (id: 3101888, distro: Ubuntu)
Ubuntu 12.10 x64 (id: 3101891, distro: Ubuntu)
Ubuntu 13.10 x64 (id: 3101918, distro: Ubuntu)
Debian 7.0 x32 (id: 3102384, distro: Debian)
Debian 7.0 x64 (id: 3102387, distro: Debian)
Fedora 19 x32 (id: 3102721, distro: Fedora)
Fedora 19 x64 (id: 3102879, distro: Fedora)
Ubuntu 12.10 x64 Desktop (id: 3104282, distro: Ubuntu)
Docker 0.10 on Ubuntu 13.10 x64 (id: 3104894, distro: Ubuntu)
MEAN on Ubuntu 12.04.4 (id: 3118235, distro: Ubuntu)
GitLab 6.6.5 CE (id: 3118238, distro: Ubuntu)
LAMP on Ubuntu 12.04 (id: 3120115, distro: Ubuntu)
Ghost 0.4.2 on Ubuntu 12.04 (id: 3121555, distro: Ubuntu)
Wordpress on Ubuntu 13.10 (id: 3135725, distro: Ubuntu)
Ruby on Rails on Ubuntu 12.10 (Nginx + Unicorn) (id: 3137635, distro: Ubuntu)
Redmine on Ubuntu 12.04 (id: 3137903, distro: Ubuntu)
Ubuntu 14.04 x32 (id: 3240033, distro: Ubuntu)
Ubuntu 14.04 x64 (id: 3240036, distro: Ubuntu)
CentOS 6.5 x32 (id: 3240847, distro: CentOS)
CentOS 6.5 x64 (id: 3240850, distro: CentOS)
Fedora 20 x32 (id: 3243143, distro: Fedora)
Fedora 20 x64 (id: 3243145, distro: Fedora)
Dokku v0.2.3 on Ubuntu 14.04 (id: 3288841, distro: Ubuntu)
</code>
</pre>
Lots of interesting images there. I can see ghost, wordpress, a basic LAMP stack, things I've never heard of, and more! Docker 0.10 too, that might be interesting to try out. Notice they each have an ID. This is all very similar to OpenStack.
## Spend some money
So now I assume I can create a droplet from the command line. But first lets look at how much this is going to cost me.
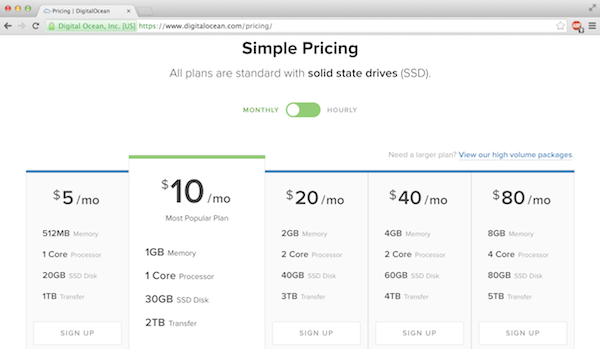
I should have clicked on hourly.
Hourly costs are:
- 512MB - $0.007 per hour
- 1GB - $0.015 per hour
- 2GB - $0.03 per hour
I'm not going to leave these running all the time. I just want to experiment. One note: Rackspace offers billing per minute, whereas DO just has monthly or per hour.
I'm going to boot a Ubuntu 14.04 32 bit image. First I need the image ID.
<pre>
<code>curtis$ tugboat images --global | grep 14.04
Ubuntu 14.04 x32 (id: 3240033, distro: Ubuntu)
Ubuntu 14.04 x64 (id: 3240036, distro: Ubuntu)
Dokku v0.2.3 on Ubuntu 14.04 (id: 3288841, distro: Ubuntu)
</code>
</pre>
Now I can see that the ID is 3240033. I'm going to use that and my default tugboat settings to boot an instance.
<pre>
<code>curtis$ tugboat create tester -i 3240033
Queueing creation of droplet 'tester'...the server responded with status 404!
You specified an invalid region for Droplet creation.
Double-check your parameters and configuration (in your ~/.tugboat file)
</code>
</pre>
Uh oh. Error message.
<pre>
<code>curtis$ tugboat regions
Regions:
San Francisco 1 (id: 3)
New York 2 (id: 4)
Amsterdam 2 (id: 5)
Singapore 1 (id: 6)
</code>
</pre>
Looks like I have New York 1 set, when I need New York 2, which has ID 4.
<pre>
<code>curtis$ tugboat create tester -i 3240033 -r 4
Queueing creation of droplet 'tester'...done
</code>
</pre>
tugboat exits. Guess I'll have to check the status with tugboat droplets.
<pre>
<code>tester (ip: 162.243.253.240, status: new, region: 4, id: 1539322)
# ... few seconds later
curtis$ tugboat droplets
tester (ip: 162.243.253.240, status: active, region: 4, id: 1539322)
</code>
</pre>
Ok, the droplet has status active.
<pre>
<code>curtis$ ping -c 1 162.243.253.240
PING 162.243.253.240 (162.243.253.240): 56 data bytes
64 bytes from 162.243.253.240: icmp_seq=0 ttl=54 time=81.364 ms
--- 162.243.253.240 ping statistics ---
1 packets transmitted, 1 packets received, 0.0% packet loss
round-trip min/avg/max/stddev = 81.364/81.364/81.364/0.000 ms
</code>
</pre>
I can ping it too.
I'm going to try to ssh into the droplet.
<pre>
<code>curtis$ ssh root@162.243.253.240
# hangs, and eventually asks for my password...
</code>
</pre>
Hanging. Wonder why. Check my email while I'm waiting, turns out DO sends and email when a new vm is created. There is a password in the email. Oh no. It says that if I'd prefer not to receive emails with passwords in them then to add an ssh key to DO and also create droplets with that key. I was assuming tugboat was using the default key I set up. Maybe I need to specifically put in the key.
<pre>
<code>curtis$ tugboat help create
Usage:
tugboat create NAME
Options:
-s, [--size=N] # The size_id of the droplet
-i, [--image=N] # The image_id of the droplet
-r, [--region=N] # The region_id of the droplet
-k, [--keys=KEYS] # A comma separated list of SSH key ids to add to the droplet
-p, [--private-networking] # Enable private networking on the droplet
-b, [--backups-enabled] # Enable backups on the droplet
-q, [--quiet]
Create a droplet.
</code>
</pre>
I'll destroy and recreate my droplet.
<pre>
<code>curtis$ tugboat destroy tester
Droplet fuzzy name provided. Finding droplet ID...done, 1539346 (tester)
Warning! Potentially destructive action. Please confirm [y/n]: y
Queuing destroy for 1539346 (tester)...done
</code>
</pre>
Now lets create tester2.
But...first, I realized the API wants an SSH key ID, not key name. I edit ~/.tugboat and set my key to use the ID not the name "curtis."
<pre>
<code>curtis$ tugboat keys
SSH Keys:
curtis (id: 118429)
curtis$ vi ~/.tugboat
# make id change
curtis$ grep ssh_key ~/.tugboat
ssh_key_path: /Users/curtis/.ssh/id_dsa
ssh_key: 118429
# looks good
</code>
</pre>
Ok, let's try that again.
<pre>
<code>curtis$ tugboat create tester2 -i 3240033 -r 4
Queueing creation of droplet 'tester2'...done
curtis$ tugboat droplets
tester2 (ip: 162.243.253.240, status: new, region: 4, id: 1539401)
curtis$ tugboat droplets
tester2 (ip: 162.243.253.240, status: active, region: 4, id: 1539401)
</code>
</pre>
Now it's active. Try ssh one more time...
<pre>
<code>curtis$ ssh root@162.243.253.240
SNIP!
root@tester2:~# ifconfig eth0
eth0 Link encap:Ethernet HWaddr 04:01:17:7d:ad:01
inet addr:162.243.253.240 Bcast:162.243.253.255 Mask:255.255.255.0
inet6 addr: fe80::601:17ff:fe7d:ad01/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:1645 errors:0 dropped:0 overruns:0 frame:0
TX packets:185 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:104117 (104.1 KB) TX bytes:23629 (23.6 KB)
</code>
</pre>
I can login. Nice!
NOTE: It seemed like the IP took awhile to be available, longer than for the vm to become active. Not too sure what to make of that.
Further--DO did *not* send me an email with passwords in it. That suggests I have ssh keys setup properly in tugboat.
(Once the droplet is active and you've sshed in, I would suggest turning off password authentication in /etc/ssh/sshd_config and only use ssh keys to access servers.)
## Private network
DO recently announced that they support [private networks](https://www.digitalocean.com/company/blog/introducing-private-networking/). But they aren't private in the way most would consider...instead it's one big open internal non-routable network. Every droplet that requests a private network can talk to any other droplet. Seems kind of wild-west to me. But that is how it works.
<pre>
<code>root@tester2:~# ifconfig eth1
eth1 Link encap:Ethernet HWaddr 04:01:17:7d:ad:02
inet addr:10.128.183.80 Bcast:10.128.255.255 Mask:255.255.0.0
inet6 addr: fe80::601:17ff:fe7d:ad02/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:133 errors:0 dropped:0 overruns:0 frame:0
TX packets:7 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:5816 (5.8 KB) TX bytes:578 (578.0 B)
</code>
</pre>
If I booted another droplet and it had a private IP I could access it that way. This would be good for things like small clusters, or high availability maybe, and the traffic doesn't count towards your bandwidth limit. It's important to note that if I boot a vm with a private network, and another user does to, technically I can connect to their server on the private network if I know its IP. So it's not a compartmentalized private network for each user or tenant--just one big network! Kind of like the public Internet...
## Destroy!
I'm going to destroy that droplet so I don't leave it up and running and have it cost me. (Though that said, a month of a 512MB droplet isn't much more than a couple coffees at $5.)
<pre>
<code>curtis$ tugboat destroy tester2
Droplet fuzzy name provided. Finding droplet ID...done, 1539401 (tester2)
Warning! Potentially destructive action. Please confirm [y/n]: y
Queuing destroy for 1539401 (tester2)...done
curtis$ tugboat droplets
You don't appear to have any droplets.
Try creating one with `tugboat create`
</code>
</pre>
Create...destroy...it's the DevOps way. :)
## Conclusion
I like the simplicity and ease of getting an account on Digital Ocean; that that aren't a ton of features to get in the way. I like that there is a command line application I can use to create droplets. As well, I think DO is doing smart to target developers. Developers are more important that ever, and part of cloud or utility computing is about making things easy to get going--sign up, input CC information, and boot servers to run code. Also simplifying charges is good too. AWS, Rackspace, etc, often have additional networking charges that are hard to calculate. With DO you get X terabytes of transfer, and moving data over the private network costs nothing. Not too much more to think about unless you hit the bandwidth limit.
One thing I see is that it's not possible to upload an image. I believe I can create a new image based off an existing droplet, but not upload a new image. So if I wanted an OpenBSD droplet I'm out of luck until they support a base OpenBSD image.
As far as disk space--I wonder if at some point they will have to offer volume storage, like what AWS does with EBS and what OpenStack does with Cinder volumes. I do think that EBS is a bit of a problem in that it's hard to offer a service like that without the possibility of it crashing big time--see the CAP theorem for more on that. But at some point users might run out of space, but then they can just move to a larger droplet size, though that will cost more obviously. It will be interesting to see how DO copes with trying to keep it simple while also being profitable, ie. how to make more money without adding more features.
I quite like DO, and I think it's interesting to compare their offering with what OpenStack or AWS provides.
</REDACTED></REDACTED></code></pre>
Adding networks to libvirt2014-04-26T00:00:00+00:00http://serverascode.com/2014/04/26/adding-networks-libvirt<h1 id="adding-networks-to-libvirt">Adding networks to libvirt</h1>
<p>For my <a href="http://github.com/ccollicutt/swiftacular">Swiftacular</a> project I’d like to figure out if I can run some automated tests and create a new Swiftacular cluster using libvirt. My Swiftacular configuration currently has five networks used to create an OpenStack Swift cluster (complete with a separate replication network). My Vagrantfile for Swiftacular sets up those networks, so I need to replicate that configuration using libvirt.</p>
<p>By default with a libvirt host on Ubuntu 12.04 you get one network: the default network.</p>
<pre>
<code># virsh net-list
Name State Autostart
-----------------------------------------
default active yes
</code>
</pre>
<p>That default network comes with a bridge and a dnsmasq server to provide dhcp addresses.</p>
<pre>
<code># ifconfig | grep virbr
virbr0 Link encap:Ethernet HWaddr 52:54:00:a3:05:65
# ps ax |grep dns
4943 ? S 0:02 /usr/sbin/dnsmasq -u libvirt-dnsmasq
SNIP!
</code>
</pre>
<p>Each virtual machine booted using libvirt will have a default network configured. Below is a snippet of the xml defining a virtual machine. Note how the network to use is set to “default.”</p>
<pre>
<code>SNIP!
<interface type="network">
<mac address="fa:16:3e:18:78:ae" />
<source network="default" />
<model type="virtio" />
<address type="pci" domain="0x0000" bus="0x00" slot="0x03" function="0x0" />
</interface>
SNIP!
</code>
</pre>
<p>So first we need to add more networks, and then we need to configure virtual machines xml definition file with the networks, and then ensure that the vms has more interfaces set up.</p>
<h2 id="more-libvirt-networks">More libvirt networks</h2>
<p>In Swiftacular I have five networks:</p>
<ul>
<li>eth0 - default - Used by Vagrant</li>
<li>eth1 - public - 192.168.100.0/24 - The “public” network that users would connect to</li>
<li>eth2 - lbssl - 10.0.10.0/24 - This is the network between the SSL terminator and the Swift Proxy</li>
<li>eth3 - internal - 10.0.20.0/24 - The local Swift internal network</li>
<li>eth4 - replication - 10.0.30.0/24 - The replication network which is a feature of OpenStack Swift starting with the Havana release</li>
</ul>
<p>I’m going to replicate that with libvirt networks, and the eth0 network will be the default network.</p>
<p>Here is an xml definition file for the internal network I would like to add:</p>
<pre>
<code><network>
<name>internal</name>
<forward mode="nat" />
<bridge name="internalbr0" stp="on" delay="0" />
<ip address="10.0.20.1" netmask="255.255.255.0">
<dhcp>
<range start="10.0.20.2" end="10.0.20.254" />
</dhcp>
</ip>
</network>
</code>
</pre>
<p>Now that the xml file has been created, we can use virsh net-define to define it.</p>
<pre>
<code># virsh net-define internal_network.xml
Network internal defined from internal_network.xml
</code>
</pre>
<p>And we can see the network show up in virsh net-list.</p>
<pre>
<code># virsh net-list --all
Name State Autostart
-----------------------------------------
default active yes
internal inactive no
</code>
</pre>
<p>But as can bee seen above, the network is not active, nor set to autostart. So let’s do that.</p>
<pre>
<code># virsh net-start internal
Network internal started
# virsh net-autostart internal
Network internal marked as autostarted
# virsh net-list
Name State Autostart
-----------------------------------------
default active yes
internal active yes
</code>
</pre>
<p>Also we have an internal bridge and a dnsmasq process for that network as well which sets up a leases file.</p>
<pre>
<code># brctl show |grep internal
internalbr0 8000.525400185a02 yes internalbr0-nic
# ls /var/lib/libvirt/dnsmasq/internal.leases
/var/lib/libvirt/dnsmasq/internal.leases
</code>
</pre>
<p>I’m going to setup the rest of my networks in the same fashion.</p>
<pre>
<code># virsh net-list
Name State Autostart
-----------------------------------------
default active yes
internal active yes
lbssl active yes
private active yes
replication active yes
</code>
</pre>
<p>Ok, now we can move onto the other steps.</p>
<h2 id="add-network-interfaces-to-libvirt-vm-definition-file">Add network interfaces to libvirt vm definition file</h2>
<p>In order for those networks to be available to a virtual machine they need to be configured in the xml file that defines the vm.</p>
<pre>
<code>SNIP!
<interface type="network">
<source network="default" />
<model type="virtio" />
</interface>
<interface type="network">
<source network="internal" />
<model type="virtio" />
</interface>
<interface type="network">
<source network="lbssl" />
<model type="virtio" />
</interface>
<interface type="network">
<source network="private" />
<model type="virtio" />
</interface>
<interface type="network">
<source network="replication" />
<model type="virtio" />
</interface>
SNIP!
</code>
</pre>
<p>That snippet would have to be in every vm definition file.</p>
<h2 id="cloud-init-and-user-data">Cloud-init and user-data</h2>
<p>I use <a href="http://cloudinit.readthedocs.org/en/latest/">cloud-init</a> to help configure vms in libvirt.</p>
<p>I have a user-data and meta-data file for each vm which is converted into an image file and connected to the virtual machine.</p>
<p>In my user-data file I configure the files that will setup eth2 to eth4 as dhcp. eth1 is already setup in the image, so I don’t have to configure it with cloud-init.</p>
<pre>
<code>SNIP!
write_files:
- content: |
auto eth1
iface eth1 inet dhcp
path: /etc/network/interfaces.d/eth1.cfg
- content: |
auto eth2
iface eth2 inet dhcp
path: /etc/network/interfaces.d/eth2.cfg
- content: |
auto eth3
iface eth3 inet dhcp
path: /etc/network/interfaces.d/eth3.cfg
- content: |
auto eth4
iface eth4 inet dhcp
path: /etc/network/interfaces.d/eth4.cfg
SNIP!
</code>
</pre>
<p>When the vm boots with a cloud-init image attached, the cloud-init client on the vm will setup the files as configured so that each new interface on the new networks will get an IP from dnsmasq on the corresponding bridge.</p>
<p>Completely going over how cloud-init works is beyond the scope of this blog post, but it is a very important part of any cloud or virtualization platform. Ok, well not every virtualization system. OpenStack too though. :)</p>
<h2 id="boot-a-vm">Boot a vm</h2>
<p>Let’s boot a test vm.</p>
<p>I have a script called generic.sh that creates a custom cloud-init image and configures the image in the libvirt xml file for the vm.</p>
<p>I am using Ubuntu 14.04 as the OS for the virtual machine. This has a different cloud-init version that Ubuntu 12.04 so there may be differences in terms of cloud-init if trying to boot a Precise vm vs a Trusty vm.</p>
<pre>
<code># ./generic.sh trusty testnetworks
Domain testnetworks defined from /tmp/tmp.yJ6w0CO3A2
Domain testnetworks started
</code>
</pre>
<p>Now I have a vm called “testnetworks” running in libvirt. I can check the various dnsmasq lease files in /var/lib/libvirt/dnsmasq/*.leases to see if it got an IP address.</p>
<pre>
<code># virsh list |grep test
40 testnetworks running
# cat /var/lib/libvirt/dnsmasq/internal.leases 1398535697 52:54:00:72:db:0e 10.0.20.68 testnetworks *
</code>
</pre>
<p>And we can see that it did.</p>
<p>Also we can find out the macs that were randomly given to the vm via libvirt using virsh dumpxml.</p>
<pre>
<code># virsh dumpxml testnetworks | grep mac
<type arch="x86_64" machine="pc-1.0">hvm</type>
<mac address="52:54:00:2d:52:8d" />
<mac address="52:54:00:72:db:0e" />
<mac address="52:54:00:93:1b:07" />
<mac address="52:54:00:76:61:ee" />
<mac address="52:54:00:72:79:48" />
</code>
</pre>
<p>If I ssh into the virtual machine I should be able to see all those interfaces and checkout the routing table. I can also get to the Internet via the default gateway.</p>
<pre>
<code># ssh ubuntu@10.0.20.68
SNIP!
ubuntu@testnetworks:~$ ifconfig | grep eth
eth0 Link encap:Ethernet HWaddr 52:54:00:2d:52:8d
eth1 Link encap:Ethernet HWaddr 52:54:00:72:db:0e
eth2 Link encap:Ethernet HWaddr 52:54:00:93:1b:07
eth3 Link encap:Ethernet HWaddr 52:54:00:76:61:ee
eth4 Link encap:Ethernet HWaddr 52:54:00:72:79:48
ubuntu@testnetworks:~$ netstat -rn
Kernel IP routing table
Destination Gateway Genmask Flags MSS Window irtt Iface
0.0.0.0 192.168.122.1 0.0.0.0 UG 0 0 0 eth0
10.0.10.0 0.0.0.0 255.255.255.0 U 0 0 0 eth2
10.0.20.0 0.0.0.0 255.255.255.0 U 0 0 0 eth1
10.0.30.0 0.0.0.0 255.255.255.0 U 0 0 0 eth4
192.168.100.0 0.0.0.0 255.255.255.0 U 0 0 0 eth3
192.168.122.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0
ubuntu@testnetworks:~$ ping -c 1 news.google.com
PING news.l.google.com (74.125.228.100) 56(84) bytes of data.
64 bytes from iad23s08-in-f4.1e100.net (74.125.228.100): icmp_seq=1 ttl=52 time=96.2 ms
--- news.l.google.com ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 96.265/96.265/96.265/0.000 ms
</code>
</pre>
<p>So now I have five networks to play with!</p>
<p>Let’s boot one more to see if we have connectivity between two vms.</p>
<pre>
<code># ./generic.sh trusty testnetworks2
# cat /var/lib/libvirt/dnsmasq/internal.leases
1398535915 52:54:00:84:c2:b9 10.0.20.27 testnetworks2 *
1398535697 52:54:00:72:db:0e 10.0.20.68 testnetworks *
</code>
</pre>
<p>So we should be able to ping 10.0.20.27 from .68.</p>
<pre>
<code>ubuntu@testnetworks:~$ ping -c 1 10.0.20.27
PING 10.0.20.27 (10.0.20.27) 56(84) bytes of data.
64 bytes from 10.0.20.27: icmp_seq=1 ttl=64 time=0.284 ms
--- 10.0.20.27 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 0.284/0.284/0.284/0.000 ms
</code>
</pre>
<p>Yup.</p>
<p>So now we have five networks in libvirt, and virtual machines that can boot up and get a dhcp address on each of those networks. Hopefully this means I can work on automating testing of Swiftacular, probably by creating a custom inventory script.</p>
<p>Please let me know if you see any issues. One question I have is about the forward mode that should be set. I’m not sure it should be nat for my extra networks. Something to look into.</p>
Swiftacular - deploy OpenStack Swift with Ansible on CentOS2014-04-12T00:00:00+00:00http://serverascode.com/2014/04/12/swiftacular-openstack-swift-with-centos<h1 id="swiftacular---deploy-openstack-swift-with-ansible-on-centos">Swiftacular - deploy OpenStack Swift with Ansible on CentOS</h1>
<p><a href="https://github.com/ccollicutt/swiftacular">Swiftacular</a> is a project that can deploy an OpenStack Swift cluster using <a href="http://ansible.com">Ansible</a>. In this post I’ll talk about a recent feature I added which is the ability to deploy to RedHat/CentOS 6.</p>
<h2 id="providers">Providers</h2>
<p>For the most part Swiftacular is used for getting used to how OpenStack <a href="http://docs.openstack.org/developer/swift/">Swift</a> works and is installed, and will usually be deployed using Vagrant and Virtualbox.</p>
<p>One of the features I hope to add is the ability to use multiple provisioners, such as IaaS providers like as Digital Ocean, OpenStack, etc. Having said that, it’s not required to use Vagrant, you could easily change some IPs around in the ansible hosts file, make a couple changes in other spots, and deploy to any servers, whether they are provided by Vagrant, virtual servers or even bare metal.</p>
<p>But for now, Swiftacular uses Vagrant and Virtualbox.</p>
<h2 id="deploying-to-centos">Deploying to CentOS</h2>
<p>By default the Vagrantfile that comes with Swiftacular will use the Ubuntu 12.04 Precise 64bit box that the Vagrant project provides.</p>
<p>But, if you would like to try deploying OpenStack Swift to CentOS 6 Swiftacular supports that as well, and doing so is as easy as changing which box the Vagrantfile points to.</p>
<pre>
<code>#config.vm.box = "centos65"
#config.vm.box_url = "http://puppet-vagrant-boxes.puppetlabs.com/centos-65-x64-virtualbox-nocm.box"
config.vm.box = "precise64"
config.vm.box_url = "http://files.vagrantup.com/precise64.box"
</code>
</pre>
<p>So if you would like to deploy to CentOS, simply make the Vagrantfile look like this:</p>
<pre>
<code>config.vm.box = "centos65"
config.vm.box_url = "http://puppet-vagrant-boxes.puppetlabs.com/centos-65-x64-virtualbox-nocm.box"
#config.vm.box = "precise64"
#config.vm.box_url = "http://files.vagrantup.com/precise64.box"
</code>
</pre>
<p>Then, once vagrant up is run and the virtual machines are created, the site.yml playbook can be run and OpenStack Swift will be deployed using the <a href="http://openstack.redhat.com/Main_Page">RDO packages</a>. The playbooks will detect that it is a RedHat-like operating system and deploy the right packages and files for that operating system.</p>
<h2 id="about-redhat-rdo">About RedHat RDO</h2>
<p>Apparently RDO is a meaningless acronym, but I tend to think of it as “RedHat’s Distribution of OpenStack.”</p>
<p>One thing I found while using RDO is that the rdo-release.repo has a priorities setting. Note the “priority=98” option below.</p>
<pre>
<code>[vagrant@swift-proxy-01 yum.repos.d]$ cat rdo-release.repo
[openstack-havana]
name=OpenStack Havana Repository
baseurl=http://repos.fedorapeople.org/repos/openstack/openstack-havana/epel-6/
enabled=1
skip_if_unavailable=0
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-RDO-Havana
priority=98
</code>
</pre>
<p>This means that it will be used before other repos that don’t have a priority setting (as I believe the default is 99, and the lower the number the higher the priority).</p>
<p>But, this requires the yum priorities plugin to work.</p>
<pre>
<code>[vagrant@swift-proxy-01 yum.repos.d]$ rpm -qa | grep priorities
yum-plugin-priorities-1.1.30-17.el6_5.noarch
</code>
</pre>
<p>Thus that plugin must be installed in order to use the priority setting, otherwise the wrong packages may be installed.</p>
<h2 id="run-swiftacular">Run Swiftacular</h2>
<p>Once the Vagrantfile has been changed to use a CentOS 6 box and vagrant up has been run, swiftacular can install the Swift cluster.</p>
<p>Below I show that the servers are all CentOS 6.5.</p>
<pre>
<code>curtis$ ansible -a "cat /etc/redhat-release" all
192.168.100.20 | success | rc=0 >>
CentOS release 6.5 (Final)
192.168.100.30 | success | rc=0 >>
CentOS release 6.5 (Final)
192.168.100.200 | success | rc=0 >>
CentOS release 6.5 (Final)
192.168.100.100 | success | rc=0 >>
CentOS release 6.5 (Final)
192.168.100.50 | success | rc=0 >>
CentOS release 6.5 (Final)
192.168.100.202 | success | rc=0 >>
CentOS release 6.5 (Final)
192.168.100.201 | success | rc=0 >>
CentOS release 6.5 (Final)
</code>
</pre>
<p>Now to run the site playbook. Note that occasionally I’ve had to run the site playbook twice because of a <a href="https://github.com/ccollicutt/swiftacular/issues/12">bug</a>. So below is on the second run.</p>
<pre>
<code>curtis$ #second run
curtis$ ansible-playbook site.yml
SNIP!
PLAY RECAP ********************************************************************
192.168.100.100 : ok=26 changed=1 unreachable=0 failed=0
192.168.100.20 : ok=22 changed=0 unreachable=0 failed=0
192.168.100.200 : ok=42 changed=3 unreachable=0 failed=0
192.168.100.201 : ok=42 changed=3 unreachable=0 failed=0
192.168.100.202 : ok=45 changed=8 unreachable=0 failed=0
192.168.100.30 : ok=17 changed=2 unreachable=0 failed=0
192.168.100.50 : ok=35 changed=0 unreachable=0 failed=0
</code>
</pre>
<p>Once the Swiftacular playbook has completed successfully, swift is up and running.</p>
<pre>
<code>curtis$ vagrant ssh swift-package-cache-01
working on swift-package-cache-01 with ip of 192.168.100.20
Last login: Sat Apr 12 09:26:12 2014 from 192.168.100.1
Welcome to your Vagrant-built virtual machine.
[vagrant@swift-package-cache-01 ~]$ . testrc
[vagrant@swift-package-cache-01 ~]$ swift list
[vagrant@swift-package-cache-01 ~]$ #nothing there yet, let's add 100 files
[vagrant@swift-package-cache-01 ~]$ mkdir test
[vagrant@swift-package-cache-01 ~]$ for i in $(seq 1 100); do echo "swift $i" > \
test/swift$i.txt; done
[vagrant@swift-package-cache-01 ~]$ swift upload test test
test/swift76.txt
test/swift28.txt
test/swift79.txt
test/swift27.txt
SNIP!
[vagrant@swift-package-cache-01 ~]$ swift list
test
[vagrant@swift-package-cache-01 ~]$ swift list test | head
test/swift1.txt
test/swift10.txt
test/swift100.txt
test/swift11.txt
test/swift12.txt
test/swift13.txt
test/swift14.txt
test/swift15.txt
test/swift16.txt
test/swift17.txt
[vagrant@swift-package-cache-01 ~]$ swift list test |wc -l
100
</code>
</pre>
<p>Now that I’ve uploaded 100 files, and we have replicas set to 2, I can do a little digging around to see where files ended up.</p>
<pre>
<code>curtis$ ansible -m shell -a "sudo find /srv | grep data | wc -l" storage
192.168.100.202 | success | rc=0 >>
0
192.168.100.200 | success | rc=0 >>
100
192.168.100.201 | success | rc=0 >>
100
</code>
</pre>
<p>Above it can be seen that there are 100 files on two of the three servers, which makes sense if we want two copies of each file. Though I still have a lot to learn about what OpenStack Swift is actually doing in the background.</p>
<h2 id="conclusion">Conclusion</h2>
<p>Swiftacular now has the basic ability to deploy OpenStack Swift to RedHat 6 based operating systems using the RDO packages. There is a lot more to be done, but now with Ubuntu 12.04 and RedHat 6 support I can move onto adding other interesting features.</p>
<p>If you have any suggestions or run into errors, please do let me know and I’ll fix them. I’d love to get some testers. :)</p>
Use squid to cache RedHat/CentOS yum repositories2014-03-29T00:00:00+00:00http://serverascode.com/2014/03/29/squid-cache-yum<h1 id="use-squid-to-cache-redhatcentos-yum-repositories">Use squid to cache RedHat/CentOS yum repositories</h1>
<p>Today I began working on adding RedHat/CentOS support to my Ansible based project <a href="https://github.com/ccollicutt/swiftacular">Swiftacular</a> which deploys <a href="http://docs.openstack.org/developer/swift/">OpenStack Swift</a>.</p>
<p>Because, right now, it takes several Vagrant/Virtualbox virtual machines to run swiftacular, I like to make sure that I configure a local package caching server so that I don’t kill my Internet connection by downloading the same package multiple times.</p>
<p>When configuring Ubuntu vms I use apt-cacher-ng. But with RedHat I couldn’t find, at least in a quick google search, a similar system for RedHat. (Though apparently apt-cacher-ng can cache rpms, but I haven’t tried it with Redhat repos.)</p>
<p>I opted just to use squid. Surprisingly I couldn’t find much for blog posts on using squid to proxy yum so I thought I’d post what I did, which is very simple, in case anyone else was trying to do the same thing.</p>
<p>I imagine there are better ways to cache rpms locally, ie. on a laptop, but this is what I did. :)</p>
<h2 id="setup-squid">Setup squid</h2>
<p>First, I installed squid on the package caching server.</p>
<pre>
<code>cache# yum install squid
</code>
</pre>
<p>The one change I have made to the squid configuration file is to set a cache_dir.</p>
<pre>
<code>cache# grep cache_dir /etc/squid/squid.conf
#cache_dir ufs /var/spool/squid 100 16 256
cache_dir ufs /var/spool/squid 7000 16 256
</code>
</pre>
<p>The first uncommented cache_dir is the default, which is not set unless uncommented. The second is my setting, which just has a larger maximum size for the cache directory. You could set that to whatever is appropriate for your environment.</p>
<p>You’ll also have to allow connections to port 3128 via iptables, or just shut iptables down. (Normally I wouldn’t shut iptables down, but this is just for a test system.)</p>
<p>Also note I started squid.</p>
<pre>
<code>cache# netstat -ant | grep 3128
tcp 0 0 :::3128 :::* LISTEN
cache# service iptables stop
SNIP!
cache# service squid start
</code>
</pre>
<p>So far so good.</p>
<h2 id="configure-the-servers-that-will-use-the-package-cache">Configure the servers that will use the package cache</h2>
<p>On all the servers that need to use the cache, I set the proxy configuration in their /etc/yum.conf file to be the cache server on port 3128.</p>
<pre>
<code>server# head -12 yum.conf
[main]
cachedir=/var/cache/yum/$basearch/$releasever
keepcache=0
debuglevel=2
logfile=/var/log/yum.log
exactarch=1
obsoletes=1
gpgcheck=1
plugins=1
installonly_limit=5
proxy=http://192.168.100.20:3128
</code>
</pre>
<p>Also, I commented out the mirrorlist lines in CentOS-Base.repo and uncommented the baseurl, eg.</p>
<pre>
<code>[vagrant@swift-storage-02 yum.repos.d]$ grep "mirrorlist\|baseurl" CentOS-Base.repo
# If the mirrorlist= does not work for you, as a fall back you can try the
# remarked out baseurl= line instead.
#mirrorlist=http://mirrorlist.centos.org/?release=$releasever&arch=$basearch&repo=os
baseurl=http://mirror.centos.org/centos/$releasever/os/$basearch/
#mirrorlist=http://mirrorlist.centos.org/?release=$releasever&arch=$basearch&repo=updates
baseurl=http://mirror.centos.org/centos/$releasever/updates/$basearch/
#mirrorlist=http://mirrorlist.centos.org/?release=$releasever&arch=$basearch&repo=extras
baseurl=http://mirror.centos.org/centos/$releasever/extras/$basearch/
#mirrorlist=http://mirrorlist.centos.org/?release=$releasever&arch=$basearch&repo=centosplus
baseurl=http://mirror.centos.org/centos/$releasever/centosplus/$basearch/
#mirrorlist=http://mirrorlist.centos.org/?release=$releasever&arch=$basearch&repo=contrib
baseurl=http://mirror.centos.org/centos/$releasever/updates/$basearch/
</code>
</pre>
<p>Normally you wouldn’t want to do this, but because of the mirror list there will be many squid cache misses. So baseurl is better, and a closer mirror would be better still.</p>
<p>Next I removed the fastestmirror plugin:</p>
<pre>
<code>server# rm -f /etc/yum/pluginconf.d/fastestmirror.conf
</code>
</pre>
<p>As an example, if I install php-common on one of the servers, then install it on another, it will hit the squid cache and just download it from there. So we only download the package once from the Internet, even if it’s installed on several servers.</p>
<pre>
<code>1396152104.396 10 192.168.100.202 TCP_HIT/200 537778 GET \
http://mirror.centos.org/centos/6/updates/x86_64/Packages/php-common-5.3.3-27.el6_5.x86_64.rpm \
- NONE/- application/x-rpm
</code>
</pre>
<p>That’s all it takes.</p>
<p>One thing I’m not sure about is the cache expiry time. I’m sure there are some other changes I will come across while using squid to cache yum repos, as I’ve only started using it in the last few hours, but I will ensure to come back and edit this post with new information.</p>
<p>If anyone has any comment, questions, concerns, or criticisms, do let me know. :)</p>
<h2 id="ansible">Ansible</h2>
<p>PS. Everything I’m doing above is automated with <a href="http://ansible.com">Ansible</a>.</p>
<h2 id="updates">Updates</h2>
<ul>
<li>Added removing fastestmirror plugin</li>
</ul>
boot2docker on OSX2014-03-26T00:00:00+00:00http://serverascode.com/2014/03/26/boot2docker<h1 id="boot2docker-on-osx">boot2docker on OSX</h1>
<p>Containers are cool. There I said it. LXC is production ready, Docker is a new and very popular project. Containers are hip and that’s Ok with me. (Note that when I say containers I pretty much just mean LXC and systems based on LXC, there are other container systems out there, and have been for some time.)</p>
<p>In this post I’ll look at using boot2docker on OSX. In a previous post I was using <a href="http://serverascode.com/2014/03/13/boot2docker-qemu.html">boot2docker via libvirt and kvm</a>, but now I’ll use it on OSX, mostly because I have an Apple macbook and really need to learn more about docker.</p>
<h2 id="sowhat-is-boot2docker">So…what is boot2docker?</h2>
<p>From the <a href="https://github.com/boot2docker/boot2docker">README.md</a> file:</p>
<blockquote>
<p>boot2docker is a lightweight Linux distribution based on Tiny Core Linux made specifically to run Docker containers. It runs completely from RAM, weighs ~24MB and boots in ~5s (YMMV).</p>
</blockquote>
<p>boot2docker will use virtualbox on OSX to boot a <a href="http://distro.ibiblio.org/tinycorelinux/">tiny core linux</a> based operating system that has docker already installed. Using tiny core to provide access to docker is a really interesting model, and is necessary because OSX doesn’t have a “container”-like system (yet), so in order to use containers locally on an OSX laptop or workstation you need to boot a Linux virtual machine.</p>
<p>Docker is:</p>
<blockquote>
<p>…an open-source project to easily create lightweight, portable, self-sufficient containers from any application. The same container that a developer builds and tests on a laptop can run at scale, in production, on VMs, bare metal, OpenStack clusters, public clouds and more. – <a href="https://www.docker.io/">Docker</a></p>
</blockquote>
<h2 id="install-boot2docker-on-osx">Install boot2docker on OSX</h2>
<p>Thanks to <a href="http://brew.sh/">brew</a>, installation is easy.</p>
<pre>
<code>curtis$ brew update
SNIP!
curtis$ brew install boot2docker
SNIP!
</code>
</pre>
<p>These are the versions I have:</p>
<pre>
<code>curtis$ brew list --versions | grep docker
boot2docker 0.7.0
docker 0.9.0
</code>
</pre>
<p>Thanks brew!</p>
<h2 id="use-boot2docker">Use boot2docker</h2>
<p>Now that boot2docker is installed, we can initialize it.</p>
<pre>
<code>curtis$ boot2docker init
[2014-03-25 17:31:47] Creating VM boot2docker-vm
Virtual machine 'boot2docker-vm' is created and registered.
UUID: 1e60ddea-8794-4c32-b488-ef6b054628e8
Settings file: '/Users/curtis/VirtualBox VMs/boot2docker-vm/boot2docker-vm.vbox'
[2014-03-25 17:31:48] Apply interim patch to VM boot2docker-vm (https://www.virtualbox.org/ticket/12748)
[2014-03-25 17:31:48] Setting VM settings
[2014-03-25 17:31:48] Setting VM networking
[2014-03-25 17:31:48] boot2docker.iso not found.
[2014-03-25 17:31:49] Latest version is v0.7.0, downloading...
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 342 100 342 0 0 508 0 --:--:-- --:--:-- --:--:-- 508
100 24.0M 100 24.0M 0 0 1111k 0 0:00:22 0:00:22 --:--:-- 1332k
[2014-03-25 17:32:11] Done
[2014-03-25 17:32:11] Setting VM disks
[2014-03-25 17:32:11] Creating 40000 Meg hard drive...
Converting from raw image file="stdin" to file="/Users/curtis/.boot2docker/boot2docker-vm.vmdk"...
Creating dynamic image with size 41943040000 bytes (40000MB)...
[2014-03-25 17:32:11] Done.
[2014-03-25 17:32:11] You can now type boot2docker up and wait for the VM to start.
</code>
</pre>
<p>Now we can start the boot2docker vm.</p>
<pre>
<code>curtis$ boot2docker
Usage /usr/local/bin/boot2docker {init|start|up|save|pause|stop|restart|status|info|delete|ssh|download}
curtis$ boot2docker up
[2014-03-25 17:33:58] Starting boot2docker-vm...
[2014-03-25 17:34:18] Started.
To connect the docker client to the Docker daemon, please set:
export DOCKER_HOST=tcp://localhost:4243
</code>
</pre>
<p>Now that the vm is up and running via boot2docker, we can ssh into the vm. For this image, at this time, the password to login is “tcuser.”</p>
<pre>
<code>curtis$ boot2docker ssh
docker@localhost's password: #enter "tcuser" as the password
## .
## ## ## ==
## ## ## ## ===
/""""""""""""""""\___/ ===
~~~ {~~ ~~~~ ~~~ ~~~~ ~~ ~ / ===- ~~~
\______ o __/
\ \ __/
\____\______/
_ _ ____ _ _
| |__ ___ ___ | |_|___ \ __| | ___ ___| | _____ _ __
| '_ \ / _ \ / _ \| __| __) / _` |/ _ \ / __| |/ / _ \ '__|
| |_) | (_) | (_) | |_ / __/ (_| | (_) | (__| < __/ |
|_.__/ \___/ \___/ \__|_____\__,_|\___/ \___|_|\_\___|_|
boot2docker: 0.7.0
docker@boot2docker:~$ ifconfig eth0
eth0 Link encap:Ethernet HWaddr 08:00:27:B8:BB:5C
inet addr:10.0.2.15 Bcast:10.0.2.255 Mask:255.255.255.0
inet6 addr: fe80::a00:27ff:feb8:bb5c/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:88 errors:0 dropped:0 overruns:0 frame:0
TX packets:60 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:10303 (10.0 KiB) TX bytes:8361 (8.1 KiB)
</code>
</pre>
<p>Check it out, there’s the cool docker whale guy.</p>
<p>We’ll do as boot2docker suggests and export the DOCKER_HOST variable.</p>
<pre>
<code>curtis$ export DOCKER_HOST=tcp://localhost:4243
# also put it in my .profile, and add an alias so I don't have to
# type docker all the time :)
curtis$ tail -2 ~/.profile
export DOCKER_HOST=tcp://localhost:4243
alias d='docker'
</code>
</pre>
<p>Now we can user the docker command. Note that I’m running this from OSX.</p>
<pre>
<code># note I'm using my alias d=docker
curtis$ d info
Containers: 0
Images: 0
Driver: aufs
Root Dir: /mnt/sda1/var/lib/docker/aufs
Dirs: 0
Debug mode (server): true
Debug mode (client): false
Fds: 10
Goroutines: 13
Execution Driver: native-0.1
EventsListeners: 0
Kernel Version: 3.13.3-tinycore64
Init Path: /usr/local/bin/docker
</code>
</pre>
<p>Ok, so here it is important to note that we are running the docker command on OSX, but the docker server is running inside a boot2docker based virtual machine created by Vagrant an the boot2docker scripts.</p>
<p>We can also check the status of the boot2docker vm.</p>
<p>NOTE: I have noticed that when I move from home to work sometimes virtual machines network stops working. I haven’t looked into this much, but a couple of times I had to restart the docker virtual machine with “boot2docker stop; boot2docker start.”</p>
<pre>
<code>curtis$ boot2docker status
[2014-03-26 12:51:09] boot2docker-vm is running.
</code>
</pre>
<p>Lets download the busybox image to play with. This is part of the <a href="http://docs.docker.io/en/latest/examples/hello_world/#hello-world">hello world</a> example on the docker documentation website.</p>
<pre>
<code>curtis$ d pull busybox
Pulling repository busybox
769b9341d937: Download complete
511136ea3c5a: Download complete
bf747efa0e2f: Download complete
48e5f45168b9: Download complete
</code>
</pre>
<p>Unfortunately at this point I seem to be running into a bug. When I run a docker command I get a “Coudn’t send EOF: use of a closed network connection” error.</p>
<pre>
<code>curtis$ d run -i -t busybox echo "hi"
hi
# have to hit enter...
[error] client.go:2264 Couldn't send EOF: use of closed network connection
</code>
</pre>
<p>I’ll have to come back to this blog post once I find out more about this bug.</p>
<p>I did find it entered into a <a href="https://github.com/boot2docker/boot2docker/issues/184#issuecomment-38740712">github issue</a> so it should be fixed soon, and once it is I’ll come back and finish up this blog post.</p>
<p>I can still ssh into the boot2docker vm and run commands without that issue, of course.</p>
<pre>
<code>curtis$ boot2docker ssh
SNIP!
docker@boot2docker:~$ docker run -i -t busybox echo "hi"
hi
</code>
</pre>
<p>In reality we haven’t come very far in this blog post, partially because there seems to be a bug in the particular versions of boot2docker and docker I am using, but at least we got boot2docker installed, and are ready to move onto actually using docker straight from OSX. Once I figure out that bug I’ll come back and update this post with some more things I learned about Docker.</p>
Swiftacular - deploy OpenStack Swift with Ansible2014-03-21T00:00:00+00:00http://serverascode.com/2014/03/21/swiftacular-openstack-swift-with-ansible<h1 id="swiftacular---deploy-openstack-swift-with-ansible">Swiftacular - deploy OpenStack Swift with Ansible</h1>
<p>A few months ago I put a good amount of working into learning more about OpenStack Swift and how to deploy it. I used Ansible as my configuration management system, and called the whole project <a href="https://github.com/ccollicutt/swiftacular">Swiftacular</a>.</p>
<p>Recently I realized that I forgot to blog about it, so I decided it was time to fix that. :)</p>
<h2 id="openstack-swift">OpenStack Swift</h2>
<p>OpenStack Swift is an object storage service made up of many components. From their <a href="http://docs.openstack.org/developer/swift/:">documentation</a></p>
<blockquote>
<p>Swift is a highly available, distributed, eventually consistent object/blob store. Organizations can use Swift to store lots of data efficiently, safely, and cheaply.</p>
</blockquote>
<p>In several ways it is analogous to Amazon’s S3 service, which has billions and billions of files/blobs/objects (whatever you want to call them) stored in it.</p>
<p>Most people who use the Internet or smartphones with mobile apps use object storage, they just don’t know it because it’s used in the background by the applications, such as ones that need to store many, many files, like pictures.</p>
<h2 id="new-features-in-swift-replication-network-and-regions">New features in Swift: Replication network and regions</h2>
<p>Swift has a couple new features which are used in Swiftacular. Though I should note that by default Swiftacular only sets up one region.</p>
<p><a href="http://docs.openstack.org/developer/swift/replication_network.html:">Replication network</a></p>
<blockquote>
<p>Swift’s replication process is essential for consistency and availability of data. By default, replication activity will use the same network interface as other cluster operations. However, if a replication interface is set in the ring for a node, that node will send replication traffic on its designated separate replication network interface.</p>
</blockquote>
<p>The idea is that you could do some quality of service on the replication network, or split it off entirely from the standard Swift network, as likely the replication network would go across the link between regions, which are in most cases going to be in different data centers. The link would likely be lower bandwidth and higher latency.</p>
<p><a href="https://www.swiftstack.com/docs/admin/cluster_management/regions.html:">Regions</a></p>
<blockquote>
<p>Whereas Zones are designed to distribute replicas among nodes and drives such that there is no single point of hardware / networking failure, Regions are conceptually designed to distribute those replicas among different geographical areas.</p>
</blockquote>
<p>Regions are great because you can then deploy one large OpenStack Swift cluster across multiple geographically separated data centers. The organization I currently work for is deploying Swift in Calgary, Alberta and Kelowna, B.C. Actually these are in different timezones too!</p>
<h2 id="deploying-openstack-swift-with-ansible">Deploying OpenStack Swift with Ansible</h2>
<p>I like to use Ansible because it’s straightforward to understand and executes over ssh instead of some custom RPC type system requiring a client running on the remote system and certificates. ssh is awesome. Ansible is awesome. Swift is awesome. Radical!</p>
<p>First off, you can find the repository containing all the Ansible playbooks and roles needed to deploy Swift <a href="https://github.com/ccollicutt/swiftacular">here</a>. That repository also contains a README file that will likely be more up to date than this blog post.</p>
<p>Requirements:</p>
<ul>
<li>Vagrant</li>
<li>Virtualbox</li>
<li>Ansible</li>
<li>Internet connection</li>
</ul>
<p>Once you have those requirements, this is how to quickly deploy OpenStack Swift:</p>
<pre>
<code>$ git clone git@github.com:ccollicutt/swiftacular.git
$ cd swiftacular
$ mkdir library
# Checkout some modules to help with managing openstack
$ git clone https://github.com/openstack-ansible/openstack-ansible-modules \
library/openstack
$ vagrant up
$ cp group_vars/all.example group_vars/all
$ vi group_vars/all # ie. edit the CHANGEMEs in the file, if desired
# Source aliases, etc
$ . ansiblerc
# Test connectivity to virtual machines
$ ans -m ping all
# Run the playbook to deploy Swift!
$ pb site.yml
</code>
</pre>
<p>After those commands have completed, you should end up with several virtual machines running.</p>
<pre>
<code>$ vagrant status
SNIP!
swift-package-cache-01 running (virtualbox)
swift-keystone-01 running (virtualbox)
swift-lbssl-01 running (virtualbox)
swift-proxy-01 running (virtualbox)
swift-storage-01 running (virtualbox)
swift-storage-02 running (virtualbox)
swift-storage-03 running (virtualbox)
SNIP!
</code>
</pre>
<p>Those virtual machines comprise an OpenStack Swift cluster. While there is only one region setup by default, the storage servers are setup with a replication network. Both regions and the replication network are new features of OpenStack Swift. In /etc/swift of each of the storage servers there is both a replication configuration file and a standard server configuration.</p>
<pre>
<code>root@swift-storage-01:~# ls /etc/swift/*-server
/etc/swift/account-server:
account-replication.conf account-server.conf
/etc/swift/container-server:
container-replication.conf container-server.conf
/etc/swift/object-server:
object-replication.conf object-server.conf
</code>
</pre>
<p>The replication server configuration file looks like this:</p>
<pre>
<code>root@swift-storage-01:~# cat /etc/swift/object-server/object-replication.conf
[DEFAULT]
devices = /srv/node
bind_ip = 10.0.30.200
workers = 2
[pipeline:main]
pipeline = object-server
[app:object-server]
use = egg:swift#object
replication_server = True
[object-replicator]
[object-updater]
[object-auditor]
</code>
</pre>
<p>As can be seen above the replication server is listening on 10.0.30.200 where 10.0.30.0/24 is the replication network configured. Also the “replication_server” option is set to True.</p>
<p>This is what the regular server config file looks like:</p>
<pre>
<code>root@swift-storage-01:~# cat /etc/swift/object-server/object-server.conf
[DEFAULT]
devices = /srv/node
bind_ip = 10.0.20.200
workers = 2
[pipeline:main]
pipeline = object-server
[app:object-server]
use = egg:swift#object
[object-replicator]
[object-updater]
[object-auditor]
[object-expirer]
</code>
</pre>
<p>It’s listening on 10.0.20.200 and is not setup as a replication only server.</p>
<p>All three of the object, container, and account servers are setup in the same fashion.</p>
<h2 id="using-ansible-delegation-to-setup-the-rings">Using Ansible delegation to setup the rings</h2>
<p>Part of configuring OpenStack Swift involves adding devices to the ring. Thankfully Ansible supports delegating commands. So while some configuration management systems need to have centralized metadata (think PuppetDB) in order to configure all of the devices, with Ansible we can simply use a delegation command, which means that when a storage server is being configured, we can actually delegate a configuration command to run on the proxy server.</p>
<p>That sounds complicated but it’s fairly simple. Maybe a better example is if using Ansible to configure a webserver, and then using a delegation command to add the webserver to a loadbalancer.</p>
<p>As an example, when a storage server is configured we can tell the proxy to add it’s devices to the ring. Below is an Ansible task that is part of Swiftacular that delegates configuration of a ring device when a storage node is being configured. The command actually runs on the Swift proxy.</p>
<p>(Sorry the example swift-ring-builder command below will probably stretch across the screen. It’s long and kinda complicated and is really meant to be invoked programatically.)</p>
<pre>
<code>
- name: build account ring
command: swift-ring-builder account.builder \
add r{{ region }}z{{ zone }}-{{ ansible_eth3.ipv4.address }}:6002R{{ ansible_eth4.ipv4.address }}:6002/{{ disk_prefix }}{{ item }} 100
chdir=/etc/swift
delegate_to: "{{ swift_proxy_server }}"
with_sequence: count={{ disks }}
when: "losetup.rc > 0"
</code>
</pre>
<p>Delegation is very handy, especially with OpenStack Swift where the proxy needs to know what devices each storage server has.</p>
<h2 id="documentation-of-ssltls-in-openstack">Documentation of SSL/TLS in OpenStack</h2>
<p>I don’t know why, but much of the OpenStack documentation, especially around the authentication system Keystone, avoids discussing how to deploy SSL/TLS enabled services. I’m not talking about Swift here specifically, rather the rest of OpenStack–authentication, endpoints, and other services that should be TLS enabled.</p>
<p>On one hand most organizations deploying OpenStack know that there is going to be a layer of TLS termination in front of most services, but on the other it’s not obvious from that general documentation that this layer should exist. The <a href="http://docs.openstack.org/sec/">OpenStack Security Guide</a> goes into more detail about the TLS layer, but don’t go very deep:</p>
<blockquote>
<p>OpenStack endpoints are HTTP services providing APIs to both end-users on public networks and to other OpenStack services within the same deployment operating over the management network. It is highly recommended these requests, both those internal and external, operate over SSL.</p>
</blockquote>
<p>I guess what I’m saying is that it would be good to know how larger OpenStack providers are securing OpenStack services with TLS. :)</p>
<p>Swiftacular sets up Keystone and a loadbalancer with TLS enabled to front swift-proxy. Certainly it’s not setup as you would do it in production (likely with with a dedicated set of TLS termination servers) but it’s a good example. I don’t think the OpenStack documentation should show deploying systems such as Keystone without SSL.</p>
<h2 id="conclusion">Conclusion</h2>
<p>Using the Swiftacular Ansible playbooks and roles, and using the provided Vagrantfile, it’s fairly easy to get a small OpenStack cluster going on a good laptop or workstation. It also includes regions and a replication network setup. This could be a good basis for starting out with OpenStack Swift.</p>
<p>As usual–if you have any questions, concerns, comments or criticism, do let me know. It’s quite likely I’ve made a mistake somewhere here, small or large. :)</p>
<h2 id="updates">Updates</h2>
<ul>
<li>Tried to clarify SSL/TLS section</li>
</ul>
ssh read from socket failed2014-03-20T00:00:00+00:00http://serverascode.com/2014/03/20/ssh-connection-reset-by-peer<h1 id="ssh-read-from-socket-failed">ssh read from socket failed</h1>
<p><em>UPDATE: This is likely because cloud-init is failing to get information from the various sources it can get information from.</em></p>
<p>For the people of the future, the ones who get an error message about connections being reset by peer when trying to ssh into a server, check to see if the server does indeed have server keys in /etc/ssh.</p>
<p>I spent like an hour or more looking into this. I’m not sure why, but an Ubuntu image I was using wouldn’t create the servers ssh keys, though the files were there…they were of zero size.</p>
<p>Below is an example of an attempted connection.</p>
<pre>
<code>root@client# ssh -vvvv ubuntu@192.168.122.217
OpenSSH_5.9p1 Debian-5ubuntu1.1, OpenSSL 1.0.1 14 Mar 2012
debug1: Reading configuration data /root/.ssh/config
debug1: /root/.ssh/config line 1: Applying options for 192.168.122.*
debug1: Reading configuration data /etc/ssh/ssh_config
debug1: /etc/ssh/ssh_config line 19: Applying options for *
debug2: ssh_connect: needpriv 0
debug1: Connecting to 192.168.122.217 [192.168.122.217] port 22.
debug1: Connection established.
debug1: permanently_set_uid: 0/0
debug1: identity file /root/.ssh/id_rsa type -1
debug1: identity file /root/.ssh/id_rsa-cert type -1
debug1: identity file /root/.ssh/id_dsa type -1
debug1: identity file /root/.ssh/id_dsa-cert type -1
debug1: identity file /root/.ssh/id_ecdsa type -1
debug1: identity file /root/.ssh/id_ecdsa-cert type -1
debug1: Remote protocol version 2.0, remote software version OpenSSH_6.5p1 Ubuntu-4
debug1: match: OpenSSH_6.5p1 Ubuntu-4 pat OpenSSH*
debug1: Enabling compatibility mode for protocol 2.0
debug1: Local version string SSH-2.0-OpenSSH_5.9p1 Debian-5ubuntu1.1
debug2: fd 3 setting O_NONBLOCK
debug3: load_hostkeys: loading entries for host "192.168.122.217" from file "/dev/null"
debug3: load_hostkeys: loaded 0 keys
debug1: SSH2_MSG_KEXINIT sent
Read from socket failed: Connection reset by peer
</code>
</pre>
<p>To fix this I regenerated the keys on the server (by logging into the console) and restarted. Then I was able to ssh into the server.</p>
<pre>
<code>root@server# ssh-keygen -q -f /etc/ssh/ssh_host_key -N '' -t rsa1
root@server# ssh-keygen -f /etc/ssh/ssh_host_rsa_key -N '' -t rsa
root@server# ssh-keygen -f /etc/ssh/ssh_host_dsa_key -N '' -t dsa
root@server# service ssh restart
</code>
</pre>
<p>I have no idea why this is happening in this image. Obviously something is broken.</p>
Boot Ubuntu Trusty Tahr 14.04 with libvirt2014-03-17T00:00:00+00:00http://serverascode.com/2014/03/17/trusty-libvirt<h1 id="boot-ubuntu-trusty-tahr-1404-with-libvirt">Boot Ubuntu Trusty Tahr 14.04 with libvirt</h1>
<p>Then next Ubuntu long term service (LTS) operating system, <a href="https://wiki.ubuntu.com/TrustyTahr/ReleaseSchedule">Trusty Tahr or version 14.04</a>, is currently expected to be released on April 27th of 2014, about a month away from the writing of this post. So note that right now it is still beta.</p>
<p>Below I’ll take a quick look at how to deploy the cloud image prepared by Ubuntu with libvirt. We’ll use libvirt + kvm on Ubuntu Precise to boot the Trusty Tahr image. The server running libvirt is Ubuntu 12.04, and is setup in a default manner, which means vms should IPs from dnsmasq and get natted access to the Internet.</p>
<h2 id="download-the-image">Download the image</h2>
<p>First we download the cloud image from Ubuntu’s site. Thankfully Ubuntu provides ready-to-go images.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>root# cd /var/lib/libvirt/images
root# wget https://cloud-images.ubuntu.com/trusty/current/trusty-server-cloudimg-amd64-disk1.img
root# mv trusty-server-cloudimg-amd64-disk1.img trusty-server-cloudimg-amd64-disk1.img.dist
root# qemu-img convert -O qcow2 trusty-server-cloudimg-amd64-disk1.img.dist \
trusty-server-cloudimg-amd64-disk1.img
root# qemu-img resize trusty-server-cloudimg-amd64-disk1.img +8G
</code></pre></div></div>
<p>Above I downloaded the image, converted it from compressed to uncompressed, and then increase it’s size by 8G, making it about a 10G image. If it’s not resized it will be about 2G.</p>
<p>Next create a snapshotted backing file which will allow us to keep the original image pristine.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>root# qemu-img create -f qcow2 -b trusty-server-cloudimg-amd64-disk1.img trusty1.img
</code></pre></div></div>
<p>That’s all it takes to grab a pre-built Ubuntu Trusty Tahr image!</p>
<h2 id="checkout-cloud-localds">Checkout cloud-localds</h2>
<p>We need to get cloud-utils from launchpad which includes a cloud-localds script. Using this script we can easily create an ISO file that can be used locally by the vm with cloud-init to configure the vm.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>root# cd ~
root# bzr branch lp:cloud-utils
root# ls cloud-utils/bin/cloud-localds
cloud-utils/bin/cloud-localds
</code></pre></div></div>
<p>Using that script we can create a user-data image that can be attached to our virtual machine.</p>
<h2 id="create-a-user-data-file">Create a user-data file</h2>
<p>Essentially what this allows us to do is have a local disk file attached to the vm which <a href="http://cloudinit.readthedocs.org/en/latest/">cloud-init</a> can use to setup the system as we would like it, at least by setting a password and/or an ssh key.</p>
<p>I’m not showing my public key below just because it doesn’t fit well on the page. But just paste your public ssh key in after the “-“. The password for the ubuntu user is set to “passw0rd” which is in fact not a good password. It might be better to either not set the password at all and just use and ssh key, or to set a very good password. This is just an example.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>#cloud-config
password: passw0rd
chpasswd: { expire: False }
ssh_pwauth: True
ssh_authorized_keys:
- <enter your public key>
</code></pre></div></div>
<p>Cloud-init has a ton more features and options so I suggest checking out the documentation. That said, it is a rather new and fast moving project.</p>
<h2 id="build-the-user-data-image">Build the user-data image</h2>
<p>Now we convert the user-data file to an ISO file.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>root# ~/cloud-utils/bin/cloud-localds user-data.img user-data
root# cp user-data.img /var/lib/libvirt/images
</code></pre></div></div>
<p>With that file created, we can now setup a libvirt xml file to boot the virtual machine.</p>
<h2 id="prepare-a-libvirtxml-file">Prepare a libvirt.xml file</h2>
<p>Here is an example libvirt xml file, in this case called trusty1.xml.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>root# cat trusty1.xml
<domain type='kvm'>
<name>trusty1</name>
<memory>1048576</memory>
<os>
<type>hvm</type>
<boot dev="hd" />
</os>
<features>
<acpi/>
</features>
<vcpu>1</vcpu>
<devices>
<disk type='file' device='disk'>
<driver type='qcow2' cache='none'/>
<source file='/var/lib/libvirt/images/trusty1.img'/>
<target dev='vda' bus='virtio'/>
</disk>
<disk type='file' device='disk'>
<source file='/var/lib/libvirt/images/user-data.img'/>
<target dev='vdb' bus='virtio'/>
</disk>
<interface type='network'>
<source network='default'/>
<model type='virtio'/>
</interface>
</devices>
</domain>
</code></pre></div></div>
<p>Now that we have a libvirt xml file we can define and start the vm.</p>
<h2 id="define-and-start-the-virtual-machine">Define and start the virtual machine</h2>
<p>Lets define and start the vm based on the images we created and the libvirt xml file.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>root# virsh define trusty1.xml
Domain trusty1 defined from trusty1.xml
root# virsh start trusty1
</code></pre></div></div>
<p>Now that the vm is booted, by default it should get an IP from dnsmasq, and has a random mac address. Figuring out the IP is not that easy with libvirt (if you know a way, let me know) but generally I look at the leases file or would set specific mac addresses to get specific IPs.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>root# cat /var/lib/libvirt/dnsmasq/default.leases
1395108553 52:54:00:6a:f1:c8 192.168.122.103 cloudimg *
</code></pre></div></div>
<p>From dnsmasq know that the instance has the 192.168.122.103 IP, we can ssh in. Note that because I put my ssh public key in I can ssh into the server without a password. I removed some content for brevity.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>root# ssh ubuntu@192.168.122.103
Warning: Permanently added '192.168.122.103' (ECDSA) to the list of known hosts.
Welcome to Ubuntu Trusty Tahr (development branch) (GNU/Linux 3.13.0-14-generic x86_64)
SNIP!
Last login: Sun Mar 16 18:46:59 2014 from 192.168.122.1
ubuntu@cloudimg:~$ cat /etc/lsb-release
DISTRIB_ID=Ubuntu
DISTRIB_RELEASE=14.04
DISTRIB_CODENAME=trusty
DISTRIB_DESCRIPTION="Ubuntu Trusty Tahr (development branch)"
ubuntu@cloudimg:~$ df -h | grep vda1
/dev/vda1 11G 898M 8.7G 10% /
</code></pre></div></div>
<p>That is about the minimum required to get a Trusty image up and running via libvirt. Certainly there are other considerations one might have to make in a production environment, such as passwords and keys, actual production Trusty Tahr image, etc.</p>
<p>Now to explore the new features of Trusty Tahr!</p>
<p>Don’t forget it won’t be officially released until late April of 2014.</p>
boot2docker and libvirt2014-03-13T00:00:00+00:00http://serverascode.com/2014/03/13/boot2docker-qemu<h1 id="boot2docker-and-libvirt">boot2docker and libvirt</h1>
<p><a href="https://www.docker.io">Docker</a> is so hot right now. Well, containers in general are. LXC just hit version 1.0 and the developers have declared it production ready.</p>
<p>Here is part of the LXC 1.0 release announcement:</p>
<blockquote>
<p>LXC 1.0 is the first production ready release of LXC and it comes with a commitment from upstream to maintain it until at least Ubuntu 14.04 LTS reaches end of life in April 2019. That’s slightly over 5 years of support!</p>
</blockquote>
<p>So what is docker? From the website:</p>
<blockquote>
<p>Docker is an open-source project to easily create lightweight, portable, self-sufficient containers from any application. The same container that a developer builds and tests on a laptop can run at scale, in production, on VMs, bare metal, OpenStack clusters, public clouds and more.</p>
</blockquote>
<h2 id="boot2docker">boot2docker</h2>
<p>The idea behind <a href="https://github.com/boot2docker/boot2docker">boot2docker</a> is to be able to use docker quickly, mostly on OSX. But OSX doesn’t support containers (yet, maybe someday), so running docker natively isn’t possible.</p>
<p>To use docker on OSX it has to be done inside a Linux virtual machine running in a hypervisor (like Virtualbox or VMWare Fusion) on top of OSX. This is what boot2docker does–provides a small Linux vm with docker installed, and helps get it all configured and provides a command line interface.</p>
<p>From the github repo for boot2docker:</p>
<blockquote>
<p>boot2docker is a lightweight Linux distribution based on Tiny Core Linux made specifically to run Docker containers. It runs completely from RAM, weighs ~24MB and boots in ~5s (YMMV).</p>
</blockquote>
<p>boot2docker comes with helpful commands and setup to get this running easily and quickly on OSX, but I’m not going to use it on OSX…I’m going to use it with libvirt and KVM.</p>
<h2 id="use-boot2docker-with-libvirt">Use boot2docker with libvirt</h2>
<p>First I downloaded the boot2docker iso from github.</p>
<pre>
<code>root# wget \
https://github.com/boot2docker/boot2docker/releases/download/v0.7.0/boot2docker.iso
</code>
</pre>
<p>Then I created a qemu disk image from that iso.</p>
<pre>
<code>root# qemu-img convert -O qcow2 boot2docker.iso /var/lib/libvirt/images/boot2docker.img
root# file /var/lib/libvirt/images/boot2docker.img: QEMU QCOW Image (v2), 25165824 bytes
</code>
</pre>
<h2 id="boot2docker-boot-script">boot2docker boot script</h2>
<p>Now that I have a base backing file made from the boot2docker ISO file, I can boot virtual machines off it.</p>
<p>I wrote a script that I am still in the process of refining (ie. this is still pretty ugly) but using it I can start several boot2docker based virtual machines from libvirt.</p>
<p>I’ve also added a second drive for each vm and in the script the drive image gets partitioned and ext4 formatted with a label that boot2docker recognizes and mounts automatically.</p>
<p>I’m using sfdisk to partition a second file, and the partitioning may not be setup properly. I haven’t done enough testing, but it’s working so far. :)</p>
<pre>
<code>root# cat boot2docker.sh
#!/bin/bash
vmtype=boot2docker
num_vms=4
backing_image=boot2docker.img
for ((i=1; i<=num_vms; i++)); do
virsh destroy ${vmtype}$i > /dev/null
virsh undefine ${vmtype}$i > /dev/null
rm -f ./${vmtype}0${i}.xml > /dev/null
rm -f /var/lib/libvirt/images/${vmtype}$i.img > /dev/null
rm -f /var/lib/libvirt/images/${vmtype}$i-persist.img > /dev/null
#
# Setup partitions for image
#
cat <<-SFDISKOUT > /var/tmp/sfdisk.out.${vmtype}${i}
# partition table of boot2docker1-persist.img
unit: sectors
${vmtype}${i}-persist.img1 : start= 2048, size= 10483712, Id=83
${vmtype}${i}-persist.img2 : start= 0, size= 0, Id= 0
${vmtype}${i}-persist.img3 : start= 0, size= 0, Id= 0
${vmtype}${i}-persist.img4 : start= 0, size= 0, Id= 0
SFDISKOUT
#
# Create images
#
pushd /var/lib/libvirt/images > /dev/null
qemu-img create -f qcow2 -b ${backing_image} ${vmtype}${i}.img > /dev/null
qemu-img create -f raw ${vmtype}${i}-persist.img 5G
sfdisk --force ${vmtype}${i}-persist.img < /var/tmp/sfdisk.out.${vmtype}${i}
losetup --offset 1048576 /dev/loop0 ${vmtype}${i}-persist.img
mkfs.ext4 -F -L boot2docker-data /dev/loop0
losetup -d /dev/loop0
popd > /dev/null
rm -f /var/tmp/sfdisk.out.${vmtype}${i}
chown libvirt-qemu:kvm /var/lib/libvirt/images/*.img
vm_uuid=`uuid`
#
# Build the libvirt xml file
#
cat <<-LIBVIRTXML > ${vmtype}${i}.xml
<domain type="kvm">
<uuid>${uuid}</uuid>
<name>${vmtype}${i}</name>
<memory>4194304</memory>
<os>
<type>hvm</type>
<boot dev="hd" />
</os>
<features>
<acpi />
</features>
<vcpu>1</vcpu>
<devices>
<disk type="file" device="disk">
<driver type="qcow2" cache="none" />
<source file="/var/lib/libvirt/images/${vmtype}${i}.img" />
<target dev="vda" bus="virtio" />
</disk>
<disk type="file" device="disk">
<driver type="raw" cache="none" />
<source file="/var/lib/libvirt/images/${vmtype}${i}-persist.img" />
<target dev="vdb" bus="virtio" />
</disk>
<interface type="network">
<source network="default" />
<model type="virtio" />
<mac address="fa:16:3e:18:89:0${i}" />
</interface>
</devices>
</domain>
LIBVIRTXML
#
# Define and start the vm
#
virsh define ${vmtype}${i}.xml > /dev/null
if virsh start ${vmtype}${i} > /dev/null; then
echo "${vmtype}${i} started"
fi
sleep 1
done
virsh list --all
exit 0
</code>
</pre>
<h2 id="create-some-boot2docker-virtual-machines">Create some boot2docker virtual machines</h2>
<p>If I run that script, which is a little noisy, I end up with four virtual machines running the boot2docker OS (which is based on Tiny Linux).</p>
<p>The script ends off by listing all the running vms on the box.</p>
<pre>
<code>root# ./boot2docker.sh
SNIP!
boot2docker4 started
Id Name State
----------------------------------
127 boot2docker1 running
128 boot2docker2 running
129 boot2docker3 running
130 boot2docker4 running
</code>
</pre>
<p>The vms are getting IPs from dnsmasq which is configured by default by libvirt.</p>
<pre>
<code>root# cat /var/lib/libvirt/dnsmasq/default.leases
1394830266 fa:16:3e:18:89:04 192.168.122.246 * 01:fa:16:3e:18:89:04
1394830262 fa:16:3e:18:89:03 192.168.122.245 * 01:fa:16:3e:18:89:03
1394830263 fa:16:3e:18:89:02 192.168.122.244 * 01:fa:16:3e:18:89:02
1394830255 fa:16:3e:18:89:01 192.168.122.243 * 01:fa:16:3e:18:89:01
</code>
</pre>
<p>I set the mac adresses in the script to be fa:16:3e:18:89:0X.</p>
<p>Knowing the IPs the vms received from libvirt/dnsmasq, I can ssh into them. (The default user/pass is docker/tcuser.)</p>
<pre>
<code>root# ssh docker@192.168.122.243
Warning: Permanently added '192.168.122.243' (ECDSA) to the list of known hosts.
docker@192.168.122.243's password:
## .
## ## ## ==
## ## ## ## ===
/""""""""""""""""\___/ ===
~~~ {~~ ~~~~ ~~~ ~~~~ ~~ ~ / ===- ~~~
\______ o __/
\ \ __/
\____\______/
_ _ ____ _ _
| |__ ___ ___ | |_|___ \ __| | ___ ___| | _____ _ __
| '_ \ / _ \ / _ \| __| __) / _` |/ _ \ / __| |/ / _ \ '__|
| |_) | (_) | (_) | |_ / __/ (_| | (_) | (__| < __/ |
|_.__/ \___/ \___/ \__|_____\__,_|\___/ \___|_|\_\___|_|
boot2docker: 0.7.0
</code>
</pre>
<p>And we can see that the second device, which is /dev/vdb, has indeed been mounted.</p>
<pre>
<code>docker@boot2docker:~$ df -h
Filesystem Size Used Available Use% Mounted on
rootfs 3.5G 223.4M 3.3G 6% /
tmpfs 1.9G 0 1.9G 0% /dev/shm
/dev/vdb1 4.8G 25.3M 4.5G 1% /mnt/vdb1
cgroup 1.9G 0 1.9G 0% /sys/fs/cgroup
</code>
</pre>
<h2 id="use-docker">Use docker</h2>
<p>We can run docker version to see if it works.</p>
<pre>
<code>docker@boot2docker:~$ docker version
Client version: 0.9.0
Go version (client): go1.2.1
Git commit (client): 2b3fdf2
Server version: 0.9.0
Git commit (server): 2b3fdf2
Go version (server): go1.2.1
Last stable version: 0.9.0
</code>
</pre>
<p>And also run a docker command. The first time we run a container type it’ll have to be downloaded.</p>
<pre>
<code>docker@boot2docker:~$ docker run ubuntu /bin/echo hello world
Unable to find image 'ubuntu' locally
Pulling repository ubuntu
9f676bd305a4: Download complete
9cd978db300e: Download complete
eb601b8965b8: Download complete
5ac751e8d623: Download complete
9cc9ea5ea540: Download complete
511136ea3c5a: Download complete
6170bb7b0ad1: Download complete
1c7f181e78b9: Download complete
f323cf34fd77: Download complete
321f7f4200f4: Download complete
7a4f87241845: Download complete
hello world
</code>
</pre>
<p>With boot2docker we can have many small vms that quickly boot and are ready to run docker right away. Not sure how practical this is, but it’s interesting none-the-less.</p>
<p>Now I need to fix up the script a bit, and also figure out how to setup ssh keys so that I don’t have to enter a password to login.</p>
hipache2014-03-12T00:00:00+00:00http://serverascode.com/2014/03/12/hipache<h1 id="hipache">hipache</h1>
<p>I’ve been trying out using <a href="http://blog.dotcloud.com/announcing-hipache-dotclouds-open-source-websocket-supporting-http-proxy">hipache</a> as a routing web proxy. It uses redis as a configuration store of sorts, so you can add webroutes (not sure what to call them…vhost routes?) without having to reload or restart hipache.</p>
<p>Running it on Ubuntu 12.04 was fairly straight forward, other than I had to install a much newer version of nodejs and npm than what comes with the distro by default.</p>
<h2 id="install-new-npm-nodejs-and-hipache">Install new npm, nodejs, and hipache</h2>
<p>So first, get a recent version of nodejs.</p>
<pre>
<code># get a newer version of node
root# grep DESC /etc/lsb-release
DISTRIB_DESCRIPTION="Ubuntu 12.04.4 LTS"
root# sudo apt-get update
root# sudo apt-get install -y python-software-properties python g++ make
root# sudo add-apt-repository ppa:chris-lea/node.js
root# sudo apt-get update
root# sudo apt-get install nodejs
root# node --version
v0.10.26
</code>
</pre>
<p>Next get a new npm…using npm.</p>
<pre>
<code>root# apt-get install npm
# now update npm using npm
root# npm install npm -g --ca=null
root# npm config set ca=""
root# npm --version
1.3.26
</code>
</pre>
<p>Now install hipache.</p>
<pre>
<code>root# npm install hipache -g
</code>
</pre>
<h2 id="install-redis">Install redis</h2>
<p>hipache uses redis as a data store for webroutes.</p>
<p>I installed version 2.8.7 stable from source.</p>
<pre>
<code>root# wget http://download.redis.io/releases/redis-2.8.7.tar.gz
root# tar zxf redis-2.8.7.tar.gz
root# cd redis-2.8.7
root# make
root# make install
root# cd utils
# Setup redis init stuff
root# ./install_server.sh
</code>
</pre>
<p>At this point I had to edit the /etc/init.d/redis_6379 file because it had a bunch of “\n\n” newlines that weren’t converted for some reason. I’ll have to check into that later on.</p>
<p>The head of that file should look like this.</p>
<pre>
<code>root# head redis_6379
#/bin/sh
#Configurations injected by install_server below....
EXEC=/usr/local/bin/redis-server
CLIEXEC=/usr/local/bin/redis-cli
PIDFILE=/var/run/redis_6379.pid
CONF="/etc/redis/6379.conf"
REDISPORT="6379"
###############
case "$1" in
</code>
</pre>
<p>I configured redis to only to listen on localhost.</p>
<pre>
<code>root# grep bind 6379.conf
# interfaces using the "bind" configuration directive, followed by one or
# bind 192.168.1.100 10.0.0.1
bind 127.0.0.1
</code>
</pre>
<p>Now we can start it.</p>
<h2 id="start-redis">Start redis</h2>
<p>Use service to start redis.</p>
<pre>
<code>root# service redis_6379 start
</code>
</pre>
<p>It’s now listening on 6379.</p>
<pre>
<code>root# netstat -ant |grep 6379 | grep LISTEN
tcp 0 0 127.0.0.1:6379 0.0.0.0:* LISTEN
</code>
</pre>
<h2 id="start-hipache">Start hipache</h2>
<p>Hipache provides an <a href="https://raw.githubusercontent.com/dotcloud/hipache/master/upstart.conf">upstart script</a>.</p>
<pre>
<code># hipache - distributed HTTP and websocket proxy
start on runlevel [2345]
stop on runlevel [06]
respawn
respawn limit 15 5
script
hipache --config /etc/hipache.json
end script
</code>
</pre>
<p>I placed that in /etc/init/hipache.conf</p>
<pre>
<code>root# ls /etc/init/hipache.conf
/etc/init/hipache.conf
</code>
</pre>
<p>Finally we need a hipache config file.</p>
<pre>
<code>root# cat /etc/hipache.json
{
"server": {
"accessLog": "/var/log/hipache_access.log",
"port": 80,
"workers": 5,
"maxSockets": 100,
"deadBackendTTL": 30,
"address": ["127.0.0.1"],
"address6": ["::1"]
},
"redisHost": "127.0.0.1",
"redisPort": 6379,
"redisDatabase": 0,
}
</code>
</pre>
<p>Obviously this is a test config with no password, but it is only listening on localhost.</p>
<p>We can start hipache.</p>
<pre>
<code>root# service hipache start
</code>
</pre>
<h2 id="configure-vhosts">Configure vhosts</h2>
<p>vhosts for hiapche to proxy are entered into redis.</p>
<p>Here’s an example taken from the README:</p>
<pre>
<code>$ redis-cli rpush frontend:www.dotcloud.com mywebsite
(integer) 1
$ redis-cli rpush frontend:www.dotcloud.com http://192.168.0.42:80
(integer) 2
$ redis-cli rpush frontend:www.dotcloud.com http://192.168.0.43:80
(integer) 3
$ redis-cli lrange frontend:www.dotcloud.com 0 -1
1) "mywebsite"
2) "http://192.168.0.42:80"
3) "http://192.168.0.43:80"
</code>
</pre>
<p>Now accessing a hostname/URL that is associated with the IP hipache is listening on will redirect to the backend servers set in redis, assuming the vhost dns name is configured properly, and we can keep adding them and reconfiguring without taking down hipache.</p>
<p>There isn’t a ton of documentation on using hipache, so I’m betting that I’ll eventually run into a wall with it, but for now it’s a pretty interesting project that not only gets me introduced to nodejs but also redis.</p>
<p>Also I should setup an ansible role to do this. Not too happy about the packaging here either, upstart scripts all over the place.</p>
/dev/random, OSX and Yarrow2014-03-04T00:00:00+00:00http://serverascode.com/2014/03/04/yarrow<h1 id="devrandom-osx-and-yarrow">/dev/random, OSX and Yarrow</h1>
<p>I’ve been doing some research on “hardening” or securing workstations–I prefer to call desktops and laptops workstations–specifically OSX Mavericks.</p>
<p>When considering information security cryptography is extremely important. If you subscribe to the CIA triad (confidentiality, integrity, and availability), then cryptography can help with both the “C” and the “I.”</p>
<p>Usually the randomness used in cryptography on workstations comes from /dev/random and /dev/urandom. On Linux /dev/random and /dev/urandom are different devices. If the entropy during cryptographic key creation is not high, then the resulting keys will <a href="https://www.schneier.com/blog/archives/2008/05/random_number_b.html">not be as good</a>.</p>
<blockquote>
<p>When read, the /dev/random device will only return random bytes within the estimated number of bits of noise in the entropy pool. /dev/random should be suitable for uses that need very high quality randomness such as one-time pad or key generation. When the entropy pool is empty, reads from /dev/random will block until additional environmental noise is gathered.
A read from the /dev/urandom device will not block waiting for more entropy. As a result, if there is not sufficient entropy in the entropy pool, the returned values are theoretically vulnerable to a cryptographic attack on the algorithms used by the driver. Knowledge of how to do this is not available in the current unclassified literature, but it is theoretically possible that such an attack may exist. If this is a concern in your application, use /dev/random instead.
If you are unsure about whether you should use /dev/random or /dev/urandom, then probably you want to use the latter. As a general rule,/dev/urandom should be used for everything except long-lived GPG/SSL/SSH keys. NOTE: from man 4 random on Ubuntu 12.04 Precise</p>
</blockquote>
<p>But on OSX they are essentially the same device, and don’t use a hardware random number generator.</p>
<blockquote>
<p>/dev/urandom is a compatibility nod to Linux. On Linux, /dev/urandom will produce lower quality output if the entropy pool drains, while /dev/random will prefer to block and wait for additional entropy to be collected. With Yarrow, this choice and distinction is not necessary, and the two devices behave identically. You may use either. NOTE: from man 4 random on OSX Mavericks</p>
</blockquote>
<p>In fact, the devices use the <a href="https://www.schneier.com/yarrow.html">Yarrow</a> algorithm invented by Bruce Schneier and friends!</p>
<blockquote>
<p>Yarrow is a PRNG; it generates cryptographically secure pseudo-random numbers on a computer. It can also be used as a real random number generator, accepting random inputs from analog random sources. We wrote Yarrow because after analyzing existing PRNGs and breaking our share of them, we wanted to build something secure.</p>
</blockquote>
<p>So on one hand, it’s slightly disappointing that my workstation doesn’t have a hardware random number generator (despite the potential that hrngs have been polluted by various government agencies), but on the other the prng algorithm was created in part by a personal information security hero of mine, Bruce Schneier.</p>
Book Review - The Phoenix Project2014-02-21T00:00:00+00:00http://serverascode.com/2014/02/21/review-the-phoenix-project<h1 id="book-review---the-phoenix-project">Book Review - The Phoenix Project</h1>
<p><em>NOTE: May contain spoilers.</em></p>
<p>Recently I have been reading books about DevOps–its (short) history and (old) influences. That meant reading <em>The Goal</em> by Eliyahu M. Goldratt, which is a business novel about managing a factory using lean manufacturing concepts. <em>The Goal</em> is heavily referenced in <em>The Phoenix Project</em>, and in fact Kim et al’s book mirrors the style and format of Goldratt’s book. (Though it leaves out much of the home life drama of the main character that is included in Goldratt’s book.)</p>
<p>In short the allegorical novel is about Bill Palmer, an IT manager who is suddenly promoted to VP of IT Operations in a large, struggling auto parts manufacturing company. Every IT department and project is a mess and will be familiar to anyone who has worked in the field. The book also uses the same Socratic method as <em>The Goal</em> in that there is an eccentric Guru character, Erik, who helps Bill along the path to success using questions that force critical thinking along the DevOps paradigm.</p>
<p>The first part of the book is about connecting with the reader.</p>
<blockquote>
<p>…the first 170 pages of the book is really designed to create the response of “holy cow, this is me that they’re describing in the book,” regardless of your role in the organization. Why? It’s because it happens everywhere where DevOps practices and culture isn’t embraced. – Gene Kim, <a href="http://www.infoq.com/articles/phoenix-project-book-review">infoq</a></p>
</blockquote>
<p>Coming from an information security background, I was struck by how the Chief Information Security Officer (CISO) was depicted in the book, but I was not surprised, because I’ve also read Kim et al’s book <em>Visible Ops Security</em>, in which statements such as the following are made:</p>
<blockquote>
<p>[P]eople may use the following words to describe information security: hysterical, irrelevant, bureaucratic, bottleneck, difficult to understand, not aligned with the business, immature, shrill, and perpetually focused on irrelevant technical minutiae.</p>
</blockquote>
<p>In the context of the <em>Visible Ops Security</em> book I absolutely agree with the above statement, and have always felt that something needs to change in information security in order for it to become more aligned with the business, and instead of saying no all the time, be able to say yes to new, valuable projects, and to help those projects in achieving reasonable security.</p>
<p>In <em>The Phoenix Project</em> the CISO, John, hits rock bottom after a series of security project failures. In fact there is a scene with him extremely drunk in a bar, with all his belongings packed in a U-haul attached to his Volvo (of course he drives a Volvo). The VP IT Operations gets him a cab home and afterwards John doesn’t come into the office for two weeks. When he finally returns to work he is a “new man,” complete with a shaved head, new attitude, “Euro discotheque” style, and game to implement security in a way that is acceptable to his peers, as well as Erik, the wealthy, eccentric, lean business (and auditing) Guru. While the transformation is a bit obvious, this is an allegorical novel, and the point’s well taken. I assume at some point he sells the Volvo and buys a Porsche.</p>
<p>I don’t think the book is as compelling as Goldratt’s novel. What I do like about <em>The Phoenix Project</em> is its focus on information security, and to a lesser extent auditing. I think there are a lot of improvements that can be made in the way information security practitioners integrate into their organizations culturally, and that this book begins giving examples as to how to accomplish that. However, it does not go far enough down that road, and I would love to read another information security specific book from these authors, one advancing the work done in <em>Visible Ops Security</em> and <em>The Phoenix Project</em>, though I think it will be some time before they can get to it as they are still working on the book <em>The DevOps Cookbook</em>.</p>
<p>In the end, <em>The Phoenix Project</em> is a good read which is differentiated from other business and technical books by its storytelling approach, and it <em>is</em> about DevOps, which likely makes it required reading for anyone in, or wanting to know more about, the difficult to define field.</p>
Deploy Pound with Ansible or Puppet2013-12-20T00:00:00+00:00http://serverascode.com/2013/12/20/deploy-pound-ansible-puppet<h1 id="deploy-pound-with-ansible-or-puppet">Deploy Pound with Ansible or Puppet</h1>
<p>I just thought I would mention that I’ve put up <a href="http://forge.puppetlabs.com/serverascode">Puppet</a> and <a href="https://galaxy.ansibleworks.com/list#/users/10">Ansible</a> modules for deploying the Pound proxy and load-balancer.</p>
<p>I’ve been working on learning Puppet lately, so that is the reason for that module, and then just yesterday AnsibleWorks released their “playbook” site, called <a href="https://galaxy.ansibleworks.com">Galaxy</a>, which performs a similar function to the Puppet Forge, so I thought I would try putting together a playbook/module and uploading it.</p>
<p>So if you use puppet you can download my Pound module with:</p>
<pre>
<code>$ puppet module install serverascode/pound
</code>
</pre>
<p>or if you use ansible you can do:</p>
<pre>
<code>$ ansible-galaxy install serverascode.pound
</code>
</pre>
<p>Next up is looking at SaltStack and then onto figuring out how to do testing of the modules. I’m thinking that testing will be the same with every module, so it should be easy to add that to each one, even if I end up supporting Ansible, Puppet, Chef, and SaltStack.</p>
Deploy Swift All in one with Puppet2013-12-09T00:00:00+00:00http://serverascode.com/2013/12/09/swift-all-in-one-puppet<h1 id="deploy-swift-all-in-one-with-puppet">Deploy Swift All in one with Puppet</h1>
<p>My current employer is deploying <a href="http://docs.openstack.org/developer/swift/">OpenStack Swift object storage</a>. I’m a big fan of object storage, and the deployment we are working on is one that will have two regions in separate timezones, so it’s very interesting in terms of having a geo-replicated Swift cluster.</p>
<p>We would like–or at least some of us would like–to deploy it with the <a href="http://puppetlabs.com">Puppet configuration management system</a>. While I am quite familiar with <a href="http://ansibleworks.com">Ansible</a> I have hardly used Puppet, so in order to deploy our Swift cluster I need to learn how to use it.</p>
<h2 id="learning-puppet">Learning Puppet</h2>
<p>Puppet is a mature configuration management system, which means it has a lot of what I would call “best practices”…things like <a href="http://docs.puppetlabs.com/guides/style_guide.html">style guides</a>, <a href="http://puppetlabs.com/blog/writing-great-modules-an-introduction">blog posts on writing good modules</a>, etc, etc.</p>
<p>The way I decided to get into Puppet was to configure puppet manifests to deploy <a href="http://docs.openstack.org/developer/swift/development_saio.html">OpenStack Swift All-in-one</a>. Swift All-in-one is a way to run the an entire Swift system off of one virtual machine, and to deploy the Swift code from Git.</p>
<h3 id="deploy-swift-all-in-one-with-the-puppet-saio-module">Deploy Swift-all-in-one with the puppet-saio module</h3>
<p>I called the module SAIO and it can be found on the <a href="http://forge.puppetlabs.com/serverascode/saio">Puppet Forge</a>.</p>
<p>Usually I would write a bit about how to use it, but that should all be in the <a href="https://github.com/ccollicutt/puppet-saio/blob/master/modules/saio/README.md">README</a> which should be much more up to date than this blog post.</p>
<h2 id="vagrant">Vagrant</h2>
<p>One part that is not included in the Puppet module on the forge site is that there is also a Vagrant configuration file and some Puppet bootstrapping that will allow a simple <code>vagrant up</code> and a Swift All-in-one virtual machine will be built automatically.</p>
<pre>
<code>$ git checkout https://github.com/ccollicutt/puppet-saio
$ cd puppet-saio
$ vagrant up
SNIP!
Notice: Finished catalog run in 195.17 seconds
$ vagrant ssh
# run remakerings
# then run startmain
</code>
</pre>
<p>At this point you can start testing out Swift.</p>
<h2 id="incremental-puppetism">Incremental puppetism…</h2>
<p>So far I have moved the module from a single <code>init.pp</code> file to breaking it out into a couple of functions, as well as adding <code>params.pp</code> file (which seems to be a best practice). Also I have run <code>puppet-lint</code> on it and fixed most of the warnings, though I have some work to do in my text editor to make sure that it lets me know about code style issues so I can fix them as I’m editing.</p>
<p>Surprisingly, even with a small module (likely less than 400 lines once it fully matures) there is a lot of work in terms of determining order of operations and in breaking it out into ever smaller chunks, both of which are very puppety things to do, and in fact pretty much define the puppet paradigm.</p>
<p>I’m not sure Puppet would be considered officially object oriented but it is certainly object-like, and I have spent more time thinking about order, “chunking”, and best practices than I did writing the tasks. That said, the theory is this will lead to better modules.</p>
apt-cacher-ng2013-11-16T00:00:00+00:00http://serverascode.com/2013/11/16/apt-cacher-ng<h1 id="apt-cacher-ng">apt-cacher-ng</h1>
<p>apt-cacher-ng is an package caching system for apt packages. And I suppose it must be the “next generation” version. :)</p>
<p>I find it to be an indespensible system–especially when I am creating complex multi-virtual machine systems on my laptop–because it allows me to only have to download each package once from the Internet, and every vm can just grab the package from apt-cacher-ng. So if you have one, five or ten vms needing the same package, it’s still only downloaded once from the Internet but many times from your local cache server.</p>
<p>Configuring it is easy!</p>
<pre>
<code>package_cache_srv$ sudo apt-get install apt-cacher-ng
package_cache_srv$ sudo vi /etc/apt-cacher-ng/acng.conf
# edit config, change the bind address to: BindAddress: 0.0.0.0
package_cache_srv$ sudo service apt-cacher-ng restart
</code>
</pre>
<p>Then on each system that you want to use the apt-cache server and a proxy server configuration file for apt:</p>
<pre>
<code>vm_1$ cat /etc/apt/apt.conf.d/01proxy
Acquire::http { Proxy "http://<package_cache_srv IP="" address="">:3142"; };
</code>
</pre>
Now each vm configured with the proxy file will use the apt-cache-ng server to obtain packages.
</package_cache_srv></code></pre>
OpenStack Keystone with SSL2013-11-13T00:00:00+00:00http://serverascode.com/2013/11/13/openstack-keystone-havana-ssl<h1 id="openstack-keystone-with-ssl">OpenStack Keystone with SSL</h1>
<p>In this post I want to quickly go over getting SSL enabled in OpenStack Keystone, specifically the Havana release, and on Ubuntu 12.04. I am going to setup SSL with self-signed certificates for testing.</p>
<p>Havana Ubuntu cloud repo and packages:</p>
<pre>
<code>$ cat /etc/apt/sources.list.d/ubuntu_cloud_archive_canonical_com_ubuntu.list
deb http://ubuntu-cloud.archive.canonical.com/ubuntu precise-updates/havana main
$ dpkg --list | grep keystone
ii keystone 1:2013.2-0ubuntu1~cloud0 OpenStack identity service - Daemons
ii python-keystone 1:2013.2-0ubuntu1~cloud0 OpenStack identity service - Python library
ii python-keystoneclient 1:0.3.2-0ubuntu1~cloud0 Client library for OpenStack Identity API
</code>
</pre>
<p>To create test SSL key file, run this command:</p>
<pre>
<code>$ keystone-manage ssl_setup --keystone-user keystone --keystone-group keystone
</code>
</pre>
<p>Then add an ssl section to the keystone.conf file:</p>
<pre>
<code>[ssl]
enable = True
certfile = /etc/keystone/ssl/certs/keystone.pem
keyfile = /etc/keystone/ssl/private/keystonekey.pem
ca_certs = /etc/keystone/ssl/certs/ca.pem
ca_key = /etc/keystone/ssl/certs/cakey.pem
</code>
</pre>
<p>Setup at least the keystone “Identity Service” publicurl endpoint to use https, eg:</p>
<pre>
<code>https://$keystone_srv:5000/v2.0
</code>
</pre>
<p>Finally, when using the keystone command line client, use the insecure option (again, this is for testing):</p>
<pre>
<code>$ cat adminrc
export OS_SERVICE_ENDPOINT=https://$keystone_srv:5000/v2.0
export OS_SERVICE_TOKEN=$your_admin_token
$ . adminrc
$ keystone --insecure user-list
+----------------------------------+--------+---------+-------+
| id | name | enabled | email |
+----------------------------------+--------+---------+-------+
| d83ff7c66b4a4086b498c960fa3096fe | admin | True | |
+----------------------------------+--------+---------+-------+
</code>
</pre>
<p>The above assumes there is at least the admin user in keystone. Otherwise, with no users it will just complete with no results.</p>
<p>If you don’t use the insecure option you will get this error:</p>
<pre>
<code>$ keystone user-list
<attribute 'message' of 'exceptions.BaseException' objects>
(HTTP Unable to establish connection to https://$keystone_srv/v2.0/users)
</code>
</pre>
<p>Please do let me know if I’ve made any errors by commenting, but so far this is working for me as a basic test of keystone with ssl support.</p>
<p>Finally, note that in most production situations, I believe keystone would be fronted by a separate SSL termination system of some kind (eg. OpenBSD’s <a href="http://www.openbsd.org/cgi-bin/man.cgi?query=relayd&sektion=8&format=html">relayd</a>). So this is just for testing, and perhaps getting to know keystone a bit better.</p>
MetalOps - IPMI serial-over-lan and Supermicro systems2013-11-13T00:00:00+00:00http://serverascode.com/2013/11/13/ipmi-serial-over-lan-supermicro<h1 id="metalops---ipmi-serial-over-lan-and-supermicro-systems">MetalOps - IPMI serial-over-lan and Supermicro systems</h1>
<p>IPMI access is important for people who admister bare metal…which is something that I do from time to time. I administer a small openenstack cluster of eight nodes, based on Dell C6220 chassis, and also a ten node openstack swift cluster based on Supermicro hardware.</p>
<p>Usually people get a console, ie. bios access, via some Java applet. I find that really difficult to use because often the applet only runs on one OS, so it means installing a VM with that OS, firing up a browswer and downloading the applet.</p>
<p>IPMI serial-over-lan is much easier and works with both the Dell and the Supermicro hardware.</p>
<h2 id="getting-to-the-bios-with-sol">Getting to the bios with SOL</h2>
<p>Usually I open two terminals:</p>
<h1 id="terminal-to-use-access-the-sol-console-with">Terminal to use access the SOL console with</h1>
<h1 id="terminal-to-control-the-power-of-the-server">Terminal to control the power of the server</h1>
<p>NOTE: Probably a good idea to change the ADMIN password. :)</p>
<p>First, establish an SOL connection. Below I’m assuming the server has already been setup with it’s IPMI static IP of 10.0.0.10.</p>
<pre>
<code>terminal_1$ ipmitool -I lanplus -H 10.0.0.10 -U ADMIN -P ADMIN sol activate
</code>
</pre>
<p>Next, power down the server.</p>
<pre>
<code>terminal_2$ ipmitool -I lanplus -H 10.0.0.10 -U ADMIN -P ADMIN chassis power off
</code>
</pre>
<p>Then set it to boot into bios. I find this easier then trying to hit a key on startup.</p>
<pre>
<code>terminal_2$ ipmitool -I lanplus -H 10.0.0.10-U ADMIN -P ADMIN chassis bootdev bios
</code>
</pre>
<p>And finally start the server again.</p>
<pre>
<code>terminal_2$ ipmitool -I lanplus -H 10.0.0.10 -U ADMIN -P ADMIN chassis power on
</code>
</pre>
<p>In a few seconds, or a minute perhaps, takes a while for these systems to boot up, you should see the server start to come up in terminal_1, and eventually it will drop you into the text based bios, an example of which you can see in the picture at the very top of this blog post.</p>
<p>To exit, hit enter and then the “~” (tilde) key twice, and finally a “.”. If you just enter one tilde then when you exit you will exit right out of your ssh session to the server that has access to the management network on which the IPMI interfaces are places, assuming that is, you have a secure management network.</p>
<p>Note that IPMI interfaces are notoriously insecure, and using them definitely requires some careful thought and resources, if available, to secure them.</p>
Truncate command and sparse disks2013-11-11T00:00:00+00:00http://serverascode.com/2013/11/11/truncate-and-sparse-disks<h1 id="truncate-command-and-sparse-disks">Truncate command and sparse disks</h1>
<p>Just a quick post on creating sparse disks on Linux.</p>
<p>Currently I am working on deploying <a href="http://docs.openstack.org/developer/swift/">OpenStack Swift</a>. I am using Vagrant and Virtualbox virtual machines to create an <a href="http://ansibleworks.com">Ansible</a> playbook to deploy and manage Swift. To do that I have been using sparse disks to mimic real disks without actually having all the disk space required.</p>
<pre>
<code>$ cd /var/tmp
# Create a sparse file using the truncate command
$ truncate --size 500G sparse_disk1.img
$ ls -la sparse_disk1.img
-rw-rw-r-- 1 vagrant vagrant 536870912000 Nov 11 06:20 sparse_disk1.img
# Check if there is a loop0 already...
$ sudo losetup /dev/loop0
loop: can't get info on device /dev/loop0: No such device or address
# Ok good lets setup the loop device with the sparse disk image
$ sudo losetup /dev/loop0 /var/tmp/sparse_disk1.img
# Make a file system on that loop device
$ sudo mkfs.xfs -i size=1024 /dev/loop0
meta-data=/dev/loop0 isize=1024 agcount=4, agsize=32768000 blks
= sectsz=512 attr=2, projid32bit=0
data = bsize=4096 blocks=131072000, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0
log =internal log bsize=4096 blocks=64000, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
# And mount it
$ sudo mkdir /mnt/sparse_disk1
$ sudo mount -o noatime,nodiratime,nobarrier /dev/loop0 /mnt/sparse_disk1
$ df -h /dev/loop0
Filesystem Size Used Avail Use% Mounted on
/dev/loop0 500G 33M 500G 1% /mnt/sparse_disk1
</code>
</pre>
<p>To unmount/remove…just go in reverse. :)</p>
<pre>
<code>$ sudo umount /mnt/sparse_disk1
$ sudo losetup -d /dev/loop0
$ rm -f /var/tmp/sparse_disk1.img
</code>
</pre>
<p>If you haven’t used Vagrant and configuration management systems such as Chef, Puppet, Ansible, Salt, etc, I highly suggest it. Putting up and tearing down servers and clusters of servers gets addicting.</p>
MetalOps - OpenStack Swift reference hardware2013-11-11T00:00:00+00:00http://serverascode.com/2013/11/11/metalops-swift-reference-hardware<h1 id="metalops---openstack-swift-reference-hardware">MetalOps - OpenStack Swift reference hardware</h1>
<p>I can’t remember where I first heard the phrase metalops but I think it’s an interesting term, much like devops and all the other ops (opops?). Technology rapidly changes, and so must definitions and labels and job titles, etc, etc. Whether these labels are correct or not, they are often useful. (As an aside, I really like the <a href="http://www.gartner.com/technology/research/methodologies/hype-cycle.jsp">Gartner Hype Cycle</a>.)</p>
<p>I think metalops is interesting because it defines an important role in “the cloud” which is that there is always hardware running beneath it, and someone needs to take care of it. Certainly one of the major features of “the cloud” is that the users don’t have to worry about the underlying hardware. But cloud providers do.</p>
<p>My current employer has an interesting role in that while it’s an advocate for the use of “the cloud” (ie. in most cases users <em>not</em> running the physical servers) we also provide several small cloud systems based on OpenStack. This means that we also have to maintain and administer the underlying hardware. Thus, while with one hand I am using devops tools and methodologies, with the other I am trying to figure out where to get smaller hard-drive screws and whether or not serial-over-lan is going to work on the new hardware so that I don’t have to load up a virtual machine and run a GUI java interface. While I can delete a semi-colon I can’t remove 1.5mm of metal from 80 too long hdd screws.</p>
<p>But enough about that, let’s talk OpenStack Swift hardware.</p>
<h2 id="swift-hardware">Swift hardware</h2>
<p>First let me note that we are not yet in production with this hardware. I’ll come back and update this post once we are.</p>
<p>We bought two types of servers:</p>
<h1 id="4x-proxy-nodes">4x proxy nodes</h1>
<h1 id="6x-storage-nodes">6x storage nodes</h1>
<p>We will be deploying the small cluster in two separate geographical areas. We purchased the hardware from <a href="http://www.siliconmechanics.com/">Silicon Mechanics</a> who have been extremely helpful throughout the process, especially with regards to getting us parts (the parts we forgot) fast, usually in a couple of days. Their servers are based on Supermicro gear.</p>
<h3 id="proxy-nodes">Proxy Nodes</h3>
<p>The proxy nodes are simple 1U servers that will act at the front-ends to the Swift system. Each region will have two proxy nodes, and while we haven’t exactly determined how they will be used, each region will likely end up with the pairs being highly available in an active/passive setup, though it’s possible we may change our mind and have them active/active by being load balanced by a third system.</p>
<p>Proxy node hardware:</p>
<ul>
<li>Silicon Mechanics Rackform iServ R335.v3 “Proxy Nodes”</li>
<li>CPU: 1x Intel Xeon E5-2630L, 2.0GHz (6-Core, HT, 15MB Cache, 60W) 32nm</li>
<li>RAM: 64GB (4 x 16GB DDR3-1600 ECC Registered 2R DIMMs) Operating at 1600 MT/s Max</li>
<li>8x 2.5” hot swap drive slots</li>
<li>2x GB on-board NICS and 1x IPMI/BMC shared LAN port</li>
<li>PCIe 3.0 x16 - 2: Intel X520-DA2 10GbE Dual-Port Server Adapter (82599ES) 10GBASE-CR - SFP+ Direct Attach</li>
</ul>
<p>To start we only put one CPU and 64GB of RAM in the proxy nodes, but if we find out they are underpowered we can add a CPU and double the RAM quite easily. We also decided to use a chassis with eight drive slots in case we decide to re-use these servers in the future for a completely different purpose. With eight slots they could easily become OpenStack compute nodes. If they only had four drive slots they might not be as useful.</p>
<h3 id="storage-nodes">Storage nodes</h3>
<p>The storage nodes are interesting beasts. Each 4U box has 36x 3.5” drive slots. There are 24x slots on the front of the server and 12x in the back. This is dense storage.</p>
<p>To start we only loaded each storage node with 10x 3TB drives, so we can add 26x more drives as we require more storage.</p>
<ul>
<li>Silicon Mechanics Swift Storage Node</li>
<li>CPU: 2 x Intel Xeon E5-2630L, 2.0GHz (6-Core, HT, 15MB Cache, 60W) 32nm</li>
<li>RAM: 128GB (8 x 16GB DDR3-1600 ECC Registered 2R DIMMs)</li>
<li>2x GB on-board NICS and 1x IPMI/BMC shared LAN port</li>
<li>Controller: I350 Dual-Port Ethernet, 2 Ports 6Gb/s SATA, and 8 Ports 3Gb/s SATA</li>
<li>LP PCIe 3.0 x16: LSI 9207-8i (8-Port Int, PCIe 3.0)</li>
<li>LP PCIe 3.0 x8 - 1: Intel X520-DA2 10GbE Dual-Port Server Adapter (82599ES) - 10GBASE-CR - SFP+ Direct Attach</li>
<li>Front Drive Set: 10 x 3TB Seagate Constellation CS (6Gb/s, 7.2K RPM, 64MB Cache) 3.5-inch SATA</li>
</ul>
<p>We went with 128GB of memory and lower wattage CPUs that still have 6 cores. We will be using 2x of the hot swap slots for the OS drive. These chassis have 2x internal hard drive slots for OS drives, but getting them out requires pulling the entire server out of the rack to get at them, so we aren’t going to use them.</p>
<p>Silicon Mechanics also offers an SSD cache-drive option, but we aren’t going to deploy Swift using cache drives, though I think some organizations do. Perhaps we will in the future. SSD caching is certainly on our list of technologies to investigate.</p>
<h3 id="metalops-issues">MetalOps Issues</h3>
<p>We did have some issues with these servers, though not due to the vendor whatsoever.</p>
<ul>
<li>We are reusing some 2.5” hard drives from another project as the OS drives for all these servers. I forgot to order 2.5” adapters for the 3.5” hot swap sleds, so we couldn’t install the OS drives.</li>
<li>The hdd screws that come with the 3.5” sleds in the storage nodes and the 2.5” sleds in the proxy nodes are too long for our 2.5” drives. So we had to order smaller screws.</li>
<li>We didn’t order c13-c14 power cables to plugin to the standard rack power. Fortunately our datacenter was able to provide them or we wouldn’t have been able to power up the servers.</li>
<li>The proxy rack rails are identical for the left and right rails. This means that in order to pull the server out of the rack the left rail release has to be pushed up, and the right release down. It took us a few minutes to figure this out. The storage node rails have distinct left and right rails.</li>
</ul>
A year with OpenStack Essex2013-10-21T00:00:00+00:00http://serverascode.com/2013/10/21/year-with-openstack-essex<h1 id="a-year-with-openstack-essex">A year with OpenStack Essex</h1>
<p>I’ve been using an OpenStack Essex installation (cluster? I never know what to call it) for about a year now. OpenStack has gone through several new versions, Essex to Folsom to Grizzly and now Havana was released only a few days ago. But here I am back on Essex. I believe it has been possible to upgrade OpenStack since Folsom, but because I’m running Essex I think upgrading would mean forklift style. My current workplace has a few OpenStack clouds running, and one of them has gone from Folsom to Grizzy and will eventually go to Havana and beyond, but for this one, we’re stuck on Essex.</p>
<p>The system is made up of eight Dell C6220s with one “cloud controller” (ie. not highly available) and seven compute nodes. As of right now we have had almost 3500 virtual machines booted. That’s not bad considering this OpenStack cloud is only used by one application (Apache VCL).</p>
<pre>
<code>mysql> select id from instances order by id DESC limit 1;
+------+
| id |
+------+
| 3355 |
+------+
1 row in set (0.01 sec)
</code>
</pre>
<p></p>
<h2 id="striped-solid-state-drives">Striped solid state drives</h2>
<p>Because we use OpenStack to essentially provide a VDI-lite service, one in which the VMs don’t store any state, and Windows instances are heavy IOPS users, we moved to using striped solid state drives. We’ve been running the compute nodes that way for about three months and so far so good (prior to that they were running on spinning disks).</p>
<pre>
<code>curtis@c2:~$ cat /proc/mdstat
Personalities : [linear] [multipath] [raid0] [raid1] [raid6] [raid5] [raid4] [raid10]
md127 : active raid0 sda5[0] sdc5[2] sdb5[1]
2597588736 blocks super 1.2 256k chunks
md0 : active raid1 sda1[0] sdb1[1]
524224 blocks [2/2] [UU]
md1 : active raid0 sdb3[1] sda3[0] sdc3[2]
106953984 blocks super 1.2 256k chunks
unused devices: <none>
curtis@c2:~$ sudo smartctl -i /dev/sda
smartctl 5.41 2011-06-09 r3365 [x86_64-linux-3.2.0-51-generic] (local build)
Copyright (C) 2002-11 by Bruce Allen, http://smartmontools.sourceforge.net
=== START OF INFORMATION SECTION ===
Device Model: Crucial_CT960M500SSD1
Serial Number: 1324093FD9AB
LU WWN Device Id: 5 00a075 1093fd9ab
Firmware Version: MU02
User Capacity: 960,197,124,096 bytes [960 GB]
Sector Sizes: 512 bytes logical, 4096 bytes physical
Device is: Not in smartctl database [for details use: -P showall]
ATA Version is: 8
ATA Standard is: ATA-8-ACS revision 6
Local Time is: Mon Oct 21 13:57:51 2013 MDT
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
</code>
</pre>
<p></p>
## Issues
So far we have only had a couple issues.
The first is there was a security patch added to the nova package that double checked the virtual size of an image. I updated OpenStack's packages and we couldn't boot Windows images, so I had to roll back to a previous version. I haven't had time to figure out what the issue is, so we have frozen our OpenStack version while I find time to determine the cause. I'm quite sure that this is not an OpenStack issue, rather a configuration issue in terms of the Windows image size.
I also have a problem in which it seems the Windows disk images are mounted via ndb, I assume for some kind of file injection, but then not released. This can cause deleted image files to be hung onto by the file system, so disk space can fill up, but du will not be able to explain why (had to use lsof and look for deleted files).
<pre>
<code>curtis@c2:~$ mount | grep nbd
/dev/mapper/nbd15p1 on /tmp/openstack-disk-mount-tmp0lvNeR type fuseblk
(rw,nosuid,nodev,allow_other,blksize=4096)
/dev/mapper/nbd14p1 on /tmp/openstack-disk-mount-tmpMrUDJF type fuseblk
(rw,nosuid,nodev,allow_other,blksize=4096)
/dev/mapper/nbd13p1 on /tmp/openstack-disk-mount-tmp5p_Jcy type fuseblk
(rw,nosuid,nodev,allow_other,blksize=4096)
/dev/mapper/nbd12p1 on /tmp/openstack-disk-mount-tmpOv9v9X type fuseblk
(rw,nosuid,nodev,allow_other,blksize=4096)
SNIP!
</code>
</pre>
While this does seem like some kind of bug, the held nbd mounts/images are limited to 16 by a configuration option, and while this shouldn't be happening it doesn't seem to be affecting normal operation, at least in our limited use case. This is another issue that needs more investigation. Maybe someone will read this post and let me know what is going on. I did email the OpenStack list about the issue but no one replied. Not sure how many people are using OpenStack Essex with Windows 7.
## Essex has worked great
While I've got a couple issues to look into, OpenStack Essex has worked great. Certainly no major issues to report, but I'm still looking forward to eventually upgrading this system.
</none></code></pre>
Dark days in information security2013-10-18T00:00:00+00:00http://serverascode.com/2013/10/18/dark-days-infosec<h1 id="dark-days-in-information-security">Dark days in information security</h1>
<p>To be honest it’s been a while since I’ve worked in a security conscious environment. When I first started out my career I was extremely interested in security (and I still am) but the organizations I worked in were not as interested in the end-result as much as the process itself–ie. meeting and checking off certain requirements rather than actually being secure.</p>
<p>As my career continued it just became too hard to do the things I thought were required to achieve reasonable information security, so in effect I gave up, and instead of being a security system administrator, or security analyst, whatever the title, I became a plain old systems administrator and started to focus more on storage and research systems, and now “cloud” technology (such as OpenStack), and the devops mindset.</p>
<p>However, I still consider information security my true calling in terms of my IT career, so you can imagine how disappointed I was to read wave after wave of articles and news items regarding the various privacy invasions, alleged illegal spying, etc, etc.</p>
<p>Even though it’s been a few months since the revelations brought on by the leaks made by Edward Snowden and others, and the snowball effect that has created more interest and information around global information security, I find it difficult to properly analyze and discuss the events. It will likely take some time to sort out the damage. Suffice it to say that I hope that as we continue to use more and more technology that politicians, entrepreneurs, teenagers, security experts, government employees, police and security agencies…everyone…takes some time to consider how things are changing and what security, sovereignty, freedom, privacy, patriotism, and democracy really mean to them.</p>
<p>Certainly societal norms can, do, and should change over time, but I think it’s important to occasionally take a step back and try to make sure that we are consciously working towards achieving our true, long term goals as a society. It’s easy to slip into a reactionary posture and make changes that–while seemingly beneficial in the near term–may do more harm than good over a longer period of time. On one hand the future is hard to predict, but on the other…we do make our own future.</p>
Georgia Tech Coursera SDN MOOC2013-08-12T00:00:00+00:00http://serverascode.com/2013/08/12/sdn-mooc<h1 id="georgia-tech-coursera-sdn-mooc">Georgia Tech Coursera SDN MOOC</h1>
<p>Recently I completed the <a href="https://class.coursera.org/sdn-001/wiki/view?page=syllabus">Software Defined Networking</a> (SDN) course presented by Dr. Nick Feamster of the Georgia Institute of Technology. The course was a massive open online course, otherwise known as a MOOC. (Some of the <a href="http://en.wikipedia.org/wiki/Massive_open_online_course#Early_MOOCs">earliest MOOCs</a> were put on by researchers associated with <a href="http://www.athabascau.ca">Athabasca University</a>, an Alberta based post secondary institution specializing in distance learning.)</p>
<h1 id="moocs">MOOCs</h1>
<p>I have a Bachelor of Education which means I could have been a teacher in Alberta. However I went in another direction and have a career in information technology, but one that has been almost entirely spent either working at a university as support staff, or at organizations that support universities in one form or another. Therefore I’m aware–perhaps more than the average person–of MOOCs and how they are affecting, or not affecting, post secondary education. Interestingly, the University of Alberta has just began offering their first class using the Coursera platform: <a href="https://www.coursera.org/course/dino101">DINO 101</a>.</p>
<h2 id="sdn-course">SDN Course</h2>
<p>But what I want to talk about here is the Dr. Feamster’s SDN course. One of the people helping to teach the course wrote <a href="https://class.coursera.org/sdn-001/class/index">this</a> thank you note to the students, and mentioned that it’s a good idea to document <em>the learning</em> in some fashion, so that is what I’m attempting to do in this post.</p>
<blockquote>
<p>I encourage you to document your learning, which is a more insightful way of providing evidence to your learning….I hope you all will try and apply your new knowledge in SDN at work or in your studies.</p>
</blockquote>
<h2 id="what-i-liked">What I liked</h2>
<p>In general, I like the idea of MOOCs. While getting a masters degree of some kind has always been in the back of my mind, I really feel like I am done with school, but being in technology I can never be done with learning. I don’t think I am an <a href="http://en.wikipedia.org/wiki/Autodidacticism">autodidact</a> but learning on my own is something that I do all the time (mostly via articles or blog posts on the Internet), have to do in order to be employable, and enjoy doing, so MOOCs fit in with that style of learning well.</p>
<p>A couple other people at work also took the course at the same time, and we had some discussions about it. I think we all felt that overall the course was a good introduction to SDN, but that it wasn’t in-depth enough for our tastes. Having said that, I don’t see how the team behind the course could have done it differently, as there were so many different people taking the MOOC, from people with little or no networking experience or programming experience, to highly experience networking and programming professionals.</p>
<p>Here are a few things I liked about the class:</p>
<ul>
<li>Learning about new SDN tools</li>
<li>Having a bit of structure around learning a new technology</li>
<li>The professor’s positive attitude</li>
<li>The MOOC being a good overview of SDN, where it came from and (maybe) where it’s going</li>
</ul>
<p>I also enjoyed the interviews though didn’t quite have time to watch all of them. Perhaps at some point I can go back and watch them.</p>
<h2 id="what-i-didnt-like">What I didn’t like</h2>
<p>The most unusual thing, I felt, was the quiz system. Essentially you could take each quiz at least 3 times, most of them more, and you could review your answers, and mistakes, from the previous attempts, and retake the quiz. I’m not sure what the value of doing quizzes in this fashion is, unless you were to take an average of the first quiz and subsequent quizzes, because the easiest thing to do with the quiz is to take it once and even if you score poorly you can simply review your answers and pass the next attempt. Sometimes the question’s changed answers in each attempt, but mostly they did not. I don’t think the quizzes tested students knowledge very well.</p>
<p>Another thing was that the instructions for the assignments were occasionally incorrect, at least in terms of cutting and pasting commands. Because I’ve been using the command line for a long time it was no problem to adjust, but if I was a student with little command line experience, I would imagine cutting and pasting commands would have been frustrating…possibly as difficult as the programming assignments themselves.</p>
<p>If you did cut and paste exactly what was shown, you would still end up having to futz around because you would find yourself in the wrong working directory, and command examples would not execute. I think part of the reason for this was the the assignments would change as the course was ongoing, but the documentation couldn’t keep up.</p>
<p>Also I was never quite sure what mark was required to pass the tests. At least one had to be 100% to pass, I believe, but even now I’m not sure. I think it’s 70% on each quiz to pass. It may very well turn out that I didn’t pass the course. No idea.</p>
<p>Finally, unless I’m mistaken, it wasn’t possible to download the slides used in the video lectures. I would have been great to have access to the slides, and notes as well. Given this is the first MOOC I’ve taken I’m not sure if this is part of the general MOOC design or not. I didn’t enjoy the lectures themselves, mostly because I just don’t like the video-over-slides approach.</p>
<h2 id="what-i-learned">What I learned</h2>
<p>The course covered 6 weeks and 8 modules. There were 10 quizzes and 4 programming assignments.</p>
<p>The modules were:</p>
<ul>
<li>Module 1: History and Evolution of Software Defined Networking</li>
<li>Module 2: Control and Data Plane Separation</li>
<li>Module 3: Virtual Networking</li>
<li>Module 4: SDN Nuts and Bolts - Control Plane</li>
<li>Module 5: SDN Nuts and Bolts - Data Plane</li>
<li>Module 6: Programming SDNs</li>
<li>Module 7: SDN in The Wild</li>
<li>Module 8: The Future of SDN (and Wrap-Up)</li>
</ul>
<p>Mostly I learned about some new and interesting SDN tools. I had used Mininet and Pox, and knew of Nox (related to Pox) and Floodlight, but everything else was new to me.</p>
<ul>
<li><a href="http://osrg.github.io/ryu/">Ryu</a> seems very interesting, is written in Python (my favorite programming language) and is supported in OpenStack. The small OpenStack cloud I run is based on Essex, so there is no Quantum/Neutron networking, but someday we will upgrade and it will be interesting to try out some SDN capabilities. I suppose I should try some out in test, just toss up Devstack and see what I can find out.</li>
<li>One of the people I work with is working on <a href="http://www.opendaylight.org/">Open Daylight</a>. Again, not part of the course, but something that I stumbled on while doing some extra reading.</li>
<li>While <a href="http://trema.github.io/trema/">Trema</a> wasn’t used in the course, one of my co-workers came across it. It’s not in Python, so that is likely why it wasn’t in the course. Instead it’s written in Ruby and some C.</li>
</ul>
<p><a href="https://github.com/trema/trema/wiki/Quick-start:">Interestingly</a></p>
<blockquote>
<p>Don’t be surprised that Trema has an integrated OpenFlow network emulator and you do not need to prepare OpenFlow switches and end-hosts for testing controller applications!</p>
</blockquote>
<p>The above is useful because most of the others work in combination with Mininet, which is an extra step.</p>
<ul>
<li><a href="http://www.read.cs.ucla.edu/click/click">Click</a> modular router project: I’m not clear on what this actually is.</li>
<li><a href="http://netfpga.org/:">NetFGPA project</a> I had come across this before–hardware data plane.</li>
<li><a href="http://frenetic-lang.org/pyretic/:">Pyretic</a> A SDN programming language, or more specifically a domain specific language, aka DSL.</li>
<li><a href="http://resonance.noise.gatech.edu/">Resonance</a></li>
<li><a href="https://class.coursera.org/sdn-001/lecture/53:">Interview with Jennifer Rexford</a> I thought this was a great interview.</li>
</ul>
<h2 id="what-now">What now?</h2>
<p>So, the question is: Now that I have had a good introduction to SDN, where do I go from here?</p>
<p>I don’t really know. It’s unlikely that I will be handed a real network to experiment with, other than perhaps one associated with a small OpenStack cluster, so this means I will have to work with virtualized networks, perhaps using Mininet. Trema is interesting to me because it (apparently) doesn’t require something like Mininet, and can create virtualized networks on its own.</p>
<p>One area I’m interested in doing some more research on is creating broken networks and seeing how that affects systems, especially distributed networking systems.</p>
Deploying a boundary.com meter with ansible2013-06-27T00:00:00+00:00http://serverascode.com/2013/06/27/boundary-meters<h1 id="deploying-a-boundarycom-meter-with-ansible">Deploying a boundary.com meter with ansible</h1>
<p>Lately we have started using <a href="http://boundary.com">Boundary</a> at work. While <a href="https://forge.puppetlabs.com/puppetlabs/boundary">puppet</a> and <a href="https://github.com/boundary/bprobe_cookbook">chef</a> recipes and a <a href="https://github.com/boundary/boundary_scripts">shell script</a> already exist to deploy a boundary meter onto a node/server, there was not a way to easily deploy one using <a href="http://ansibleworks.com">ansible</a>, which is my preferred configuration management and orchestration tool.</p>
<p>Creating a boundary meter on a server is not complicated, but it was not really possible to do it with ansible without simply using ansible to copy a shell script up to the server. And, as ansible’s documentation suggests, if you’re pushing a script up to the server to run it with ansible, then it might be time to turn that bash script into an ansible module.</p>
<p>So, I have written a basic boundary meter module for ansible, and it is currently sitting in the <a href="https://github.com/ansible/ansible/pull/3272">pull request</a> queue waiting to be reviewed, and hopefully added to the many <a href="http://www.ansibleworks.com/docs/modules.html">ansible modules</a> in core.</p>
<p><em>NOTE: Both boundary and ansible move pretty fast, so it’s likely that things will have changed even by the time I post this. :)</em></p>
<h2 id="obtaining-the-capem-file">Obtaining the ca.pem file</h2>
<p><em>NOTE: It seems this file may be in the ubuntu package now, and is installed in /etc/bprobe/ca.pem.dkpg-dist</em></p>
<p>One file that the bprobe package and my ansible module do not provide is the ca.pem file that is necessary for bprobe to contact boundary’s api server.</p>
<p>The easiest way to get that file is to grab it from the bprobe_cookbook github repo.</p>
<pre>
<code>$ wget https://raw.github.com/boundary/bprobe_cookbook/master/files/default/ca.pem
$ md5sum ca.pem
11f809a92ed1cc029c3ac86b42460a10 ca.pem
</code>
</pre>
<p>or I believe it is also available in the official tar.gz release.</p>
<p>That file needs to go into /etc/bprobe and would likely be put there using a configuration management system of some kind, be it chef, ansible, puppet, saltstack, etc… :)</p>
<h2 id="getting-the-bprobe-client">Getting the bprobe client</h2>
<p>While you don’t need the bprobe client to create a meter, you do need bprobe in order to send data. So let’s start by installing bprobe.</p>
<p>I’m installing the bprobe client on ubuntu 12.04. Below I’ll simply show the parts of my ansible playbook that setup the official boundary repository and install bprobe. Even if you don’t use ansible it’s pretty straightforward to understand what’s happening.</p>
<pre>
<code>#Snippet of an ansible playbook
- name: ensure boundary repository is installed
action: apt_repository repo='deb https://apt.boundary.com/ubuntu/ precise universe'
- name: ensure boundary repository gpg key is installed
action: apt_key url=https://apt.boundary.com/APT-GPG-KEY-Boundary state=present
- name: install boundary bprobe
action: apt pkg=bprobe state=installed force=yes
</code>
</pre>
<p>Once those three actions have run, bprobe will be installed.</p>
<pre>
<code>$ which bprobe
/usr/local/bin/bprobe
</code>
</pre>
<h2 id="creating-a-meter">Creating a meter</h2>
<p>In order to start sending data to boundary’s api, that’s all done with a restful api, we need to register a meter. In order to do that with ansible, you’ll need the <a href="https://github.com/ccollicutt/ansible/blob/devel/library/monitoring/boundary_meter">boundary_meter module</a> I (initially) wrote, which by now, if I’m lucky, will be in ansible’s core set of modules.</p>
<p>Once that module is available to ansible, using it to create a meter looks like the below:</p>
<pre>
<code>- name: register boundary meter
action: boundary_meter apikey=AAAAAAA apiid=BBBBBB state=present \
name=${ inventory_hostname }
notify: restart bprobe
handlers:
- name: restart bprobe
action: service name=bprobe state=restarted
</code>
</pre>
<p>where AAAAAA and BBBBBB are your organizations api id and api key for boundary.</p>
<h2 id="monitoring">Monitoring</h2>
<p>Once the meter is registered and bprobe up and running connecting back to boundary’s api server, data should be flowing, and you can login to the boundary web gui and check out the node.</p>
<p>Thanks, and as always, if there are questions, suggestions, comments or criticisms, do let me know. :)</p>
Where to find vagrant boxes2013-04-25T00:00:00+00:00http://serverascode.com/2013/04/25/where-to-find-vagrant-boxes<h1 id="where-to-find-vagrant-boxes">Where to find vagrant boxes</h1>
<p>Update 2: <a href="https://vagrantcloud.com">Vagrant Cloud</a> has launched and I believe is now the best way to find Vagrant boxes.</p>
<p>Update: Added Phusion Passenger url.</p>
<p>This is just a quick post on a couple of places I know to find “vagrant”:htp://vagrantup.com boxes.</p>
<h2 id="ubuntu-cloud-images">Ubuntu cloud images</h2>
<p>Today ubuntu 13.04, aka raring ringtail, was <a href="https://wiki.ubuntu.com/RaringRingtail/ReleaseNotes?action=show&redirect=RaringRingtail%2FTechnicalOverview">released</a> But did you know that ubuntu actually provides vagrant specific boxes, ones that are built every day? They sure do!</p>
<ul>
<li><a href="http://cloud-images.ubuntu.com/vagrant/raring/current/">http://cloud-images.ubuntu.com/vagrant/raring/current/</a></li>
</ul>
<p>So it’s quite simple to try out raring just by using vagrant and ubuntu’s cloud images.</p>
<pre>
<code>$ mkdir raring; cd raring
$ vagrant init
# Edit Vagrantfile and add the below
$ grep box Vagrantfile | grep -v "#"
config.vm.box = "raring"
config.vm.box_url = "http://cloud-images.ubuntu.com/vagrant/raring/current/raring-server-cloudimg-amd64-vagrant-disk1.box"
$ vagrant up
Bringing machine 'default' up with 'virtualbox' provider...
SNIP!
#
# Now we can ssh into the box
#
$ vagrant ssh
Welcome to Ubuntu 13.04 (GNU/Linux 3.8.0-19-generic x86_64)
SNIP!
vagrant@vagrant-ubuntu-raring-64:~$ cat /etc/lsb-release
DISTRIB_ID=Ubuntu
DISTRIB_RELEASE=13.04
DISTRIB_CODENAME=raring
DISTRIB_DESCRIPTION="Ubuntu 13.04"
</code>
</pre>
<p>Nice. That was easy.</p>
<h2 id="vagrantboxes">Vagrantbox.es</h2>
<p>Most vagrant users will know about this site, but I add it here for completeness.</p>
<ul>
<li><a href="http://www.vagrantbox.es/">http://www.vagrantbox.es/</a></li>
</ul>
<p>Obviously for testing/development using these images is just fine, but most shops will want to build their own production images. I think.</p>
<h2 id="opscode-bento">Opscode Bento</h2>
<p>This <a href="https://github.com/opscode/bento">github repo</a> has tons of boxes, and also Packer templates to create your own.</p>
<h2 id="phusion-passenger">Phusion Passenger</h2>
<p>Phusion Passenger also creates and distributes some <a href="https://oss-binaries.phusionpassenger.com/vagrant/boxes/latest/">vagrant boxes</a>.</p>
<h2 id="make-your-own">Make your own</h2>
<p><a href="https://github.com/jedi4ever/veewee">Veewee</a> is a good way to automate image creation. I’ve used it quite a bit, but that was a few months ago. It can take a bit of work to get it up and running.</p>
<p>Puppet labs also <a href="https://github.com/puppetlabs/puppet-vagrant-boxes">publishes</a> some information on creating vagrant boxes, as well as <a href="http://puppet-vagrant-boxes.puppetlabs.com/">several pre-built boxes</a>.</p>
<h2 id="fedora">Fedora</h2>
<p>Unfortunately I can’t seem to find official fedora or redhat vagrant boxes, which is too bad.</p>
<p>But, fedora is working on it!</p>
<ul>
<li><a href="http://fedoraproject.org/wiki/Features/FirstClassCloudImages">http://fedoraproject.org/wiki/Features/FirstClassCloudImages</a></li>
</ul>
<p>I’ll try to update this page as I find more resources. Please feel free to comment with suggestions. :)</p>
More over committing with kvm2013-04-12T00:00:00+00:00http://serverascode.com/2013/04/12/more-overcommitting-kvm<h1 id="more-over-committing-with-kvm">More over committing with kvm</h1>
<p>Previously I wrote about <a href="http://serverascode.com/2013/02/20/overcommitting-with-kvm.html">overcommiting with kvm</a>.</p>
<p>In this post I’m still doing the exact same thing, but now I’m keep track of load and iops.</p>
<h2 id="basic-environment">Basic environment</h2>
<p>What we have is:</p>
<ul>
<li>a single Dell C6220 node</li>
<li>32 threads</li>
<li>128GB of memory</li>
<li>two Intel 520 SSDs in a stripe</li>
<li>ubuntu precise64 cloud image</li>
<li>qcow2 image snapshots</li>
<li>open vSsitch</li>
<li>dnsmasq providing ip addresses</li>
<li>“ansible”:ansible.cc for running stress tests</li>
</ul>
<p>What we’re going to do is boot 300 2GB instances based off the same image.</p>
<h2 id="get-setup">Get setup</h2>
<p>First thing we do is reboot, just to start fresh. It doesn’t really matter, but I like to start with no swap being used, just to show exactly what happens when we boot hundreds of vms.</p>
<p>First set ksm to do more scanning faster.</p>
<pre>
<code>root# echo "20000" > /sys/kernel/mm/ksm/pages_to_scan
root# echo "20" > /sys/kernel/mm/ksm/sleep_millisecs
</code>
</pre>
<p>Next–re-setup vswitch, as I have a kind of <a href="http://serverascode.com/2013/02/21/openvswitch.html">rigged-up configuration</a> going, which needs some care after a reboot, so obviously this is just for testing, not production. :)</p>
<pre>
<code>$ sudo ifconfig br-int
$ sudo ifconfig br-int up
$ sudo ifconfig br-int 192.168.100.10 netmask 255.255.255.0
</code>
</pre>
<p>That ip is what dnsmasq is set to listen on.</p>
<p>I was running into an error where some taps existed already, and the boot script would start failing. I’m not sure why, and I just ended up deleting all the ports in the switch for that particular bridge, br-int.</p>
<pre>
<code>#
# Show/count all the ports
#
$ sudo ovs-vsctl list-ports br-int | wc -l
300
#
# Delete some ports
#
$ sudo for i in $(seq 1 300); do ovs-vsctl del-port br-int tap$i; done
# This takes a while...
</code>
</pre>
<p>Now restart to make sure dnsmasq is listening on 102.168.100.10.</p>
<pre>
<code>$ sudo service dnsmasq stop
* Stopping DNS forwarder and DHCP server dnsmasq
[ OK ]
#
# Now with the right br-int config
#
$ sudo dnsmasq start
</code>
</pre>
<p>Next–time to start hundreds of vms!</p>
<h2 id="start-virtual-machines">Start virtual machines</h2>
<p>Ok, now that we have networking (hopefully) all set up, we’re going to boot 300 vms, 10 seconds apart.</p>
<p>Thankfully these are linux vms so they don’t really cause a boot storm, unlike windows 7.</p>
<p>If I booted 30 (note: 30, not 300) windows 7 vms the server’s load would get so high that the system would grind to a halt. I know because I’ve tried it. Even though this is an ubuntu cloud image, which hopefully is specifically setup to use less iops, and knowing that is perhaps an unfair advantage, I still have no problem saying that windows images use more resources than linux images.</p>
<p>Start instances!</p>
<pre>
<code>root# ./kvm_ubuntu_openvswitch.sh
</code>
</pre>
<p>After that completes there are ~300 vms running.</p>
<pre>
<code>$ ps ax | grep "kvm -drive" | wc -l
301
</code>
</pre>
<p>We can run tests on those vms.</p>
<p><em>NOTE: I haven’t taken the time to tell dnsmasq to send dhcp information for more than a /24, so we only have 240 vms with an ip address.</em></p>
<pre>
<code>$ wc -l /var/lib/misc/dnsmasq.leases
240 /var/lib/misc/dnsmasq.leases
</code>
</pre>
<p>So when I run the stress test with ansible, we can only run it across 240 vms, even though 300 are running, it’s just that 60 of them don’t have ips.</p>
<h2 id="stress-test">Stress test</h2>
<p>In my previous post a commenter suggested running <em>stress</em>, so that’s what I’m doing.</p>
<p>Using ansible, I’ll run this stress command:</p>
<pre>
<code>shell stress --cpu 1 --io 1 --vm 1 --vm-bytes 1024M --timeout 10s
</code>
</pre>
<p>across 20 vms at a time, running over all the vms that are reported by an inventory script that looks at the ips in the dnsmasq.leases file.</p>
<p>Here’s an example of running ansible’s ping module across all those hosts.</p>
<pre>
<code>$ ansible all -c ssh -i ./inventory.py -m ping -u ubuntu
SNIP!
192.168.100.98 | success >> {
"changed": false,
"ping": "pong"
}
192.168.100.99 | success >> {
"changed": false,
"ping": "pong"
}
192.168.100.97 | success >> {
"changed": false,
"ping": "pong"
}
</code>
</pre>
<p>Note that the ips aren’t in order, so .97 is the last host in this run. Suffice it to say that all 240 hosts “ponged” back. :)</p>
<p>Here’s the simple ansible playbook I’ll be running. These vms don’t have access to the internet, and don’t have stress installed, so I’m just copying over the package and installing it “manually”, and then running the stress command.</p>
<pre>
<code>$ cat load.yml
---
- hosts: all
user: ubuntu
sudo: yes
tasks:
- name: check if stress is already installed
action: shell which stress
register: stress_installed
ignore_errors: True
- name: copy stress deb to server
action: copy src=files/stress_1.0.1-1build1_amd64.deb \
dest=/tmp/stress_1.0.1-1build1_amd64.deb
only_if: ${stress_installed.rc} > 0
- name: install stress
action: shell dpkg -i /tmp/stress_1.0.1-1build1_amd64.deb
only_if: ${stress_installed.rc} > 0
- name: run stress
action: shell stress --cpu 1 --io 1 --vm 1 --vm-bytes 1024M --timeout 10s
</code>
</pre>
<p>Let’s run it across 20 vms at a time and see what happens.</p>
<pre>
<code>$ ansible-playbook -u ubuntu -c ssh -i ./inventory.py -f 20 ./load.yml
PLAY [all] *********************
GATHERING FACTS *********************
ok: [192.168.100.110]
ok: [192.168.100.113]
ok: [192.168.100.117]
SNIP!
192.168.100.97 : ok=3 changed=2 unreachable=0 failed=0
192.168.100.98 : ok=3 changed=2 unreachable=0 failed=0
192.168.100.99 : ok=3 changed=2 unreachable=0 failed=0
# Done!
</code>
</pre>
<p>Ansible can be fun. :)</p>
<h2 id="graphs">Graphs</h2>
<p>Below are a rather poor set of graphs. Forgive me as I’m a newbie with gnuplot.</p>
<p>As soon as the load starts going up, that is when the test starts, and as soon as it’s on its way down, that’s when it ends. :)</p>
<p>First run:</p>
<p>!https://raw.github.com/ccollicutt/ccollicutt.github.com/master/img/kvm_overcommitting_load_1.png!</p>
<p>Second run:</p>
<p>!https://raw.github.com/ccollicutt/ccollicutt.github.com/master/img/kvm_overcommitting_load_2.png!</p>
<p>Last load run:</p>
<p>!https://raw.github.com/ccollicutt/ccollicutt.github.com/master/img/kvm_overcommitting_load_3.png!</p>
<p>So with three runs we see a load of about 30, where a load of 32 would be Ok with me, given we have 32 threads in this server.</p>
<p>Also, let’s watch some iops.</p>
<p>I gathered iops data using <em>iostat</em>.</p>
<p>!https://raw.github.com/ccollicutt/ccollicutt.github.com/master/img/kvm_overcommitting_io_1.png!</p>
<p>Ooof, that’s a misleading graph, isn’t it? An increase of one iop is absolutely nothing. A rounding error perhaps.</p>
<p>So–the iops don’t change during the test run, I guess because stress isn’t running any io test, even though we are running with <em>–io 1</em>. That said, I’m not sure what an io setting of 1 with stress does, something to look into. Perhaps running some tests with <a href="http://freecode.com/projects/fio">fio</a> is something to do in the future.</p>
<p>But that graph sure <em>looks</em> like something’s happening, even though the iops only increase by one. I probably shouldn’t include that graph here, but part of what I’m doing is learning about how to display the results of a performance test.</p>
<h2 id="conclusion">Conclusion</h2>
<p>First off, I’m not a scientist, didn’t take statistics, etc. So I’m not sure what kind of conclusions can be made here. All I can say for sure is that fours runs of the stress command across 20 virtual machines in parallel, over a total of 240 vms all running on the same KVM-based host, seems to bring load up to somewhere around 30 to 35, which is acceptable to me.</p>
<p>Mostly this has generated more questions–such as what exactly is stress doing? How do we know when the vms are too unresponsive? What kind of overcommitting numbers do we want? What would happen if we used fio instead of <em>–io 1</em> with stress? Do red lines in a graph make things seem worse? :)</p>
<p>As usual, if anyone has any suggestions, questions, or critiques let me know in the comments!</p>
Vagrant and vmware2013-04-11T00:00:00+00:00http://serverascode.com/2013/04/11/vagrant-and-vmware<h1 id="vagrant-and-vmware">Vagrant and vmware</h1>
<p>After IRC, <a href="http://vagrantup.com">vagrant</a> is probably my most important development tool, mostly because I like to use and investigate openstack, which means using a lot of virtual machines.</p>
<p>Recently Hashicorp released <a href="http://www.hashicorp.com/blog">Vagrant 1.1</a> which introduces the idea of <a href="http://docs.vagrantup.com/v2/providers/index.html">providers</a>. Previously vagrant only supported virtualbox, but now, with 1.1, plugins can be written to support almost any virtualization system that has a command line or API interface of some sort.</p>
<p>For example:</p>
<ul>
<li><a href="http://docs.vagrantup.com/v2/vmware-fusion/index.html">VMWare Fusion</a> (note that this is a paid plugin)</li>
<li><a href="http://gigaom.com/2013/02/13/developers-rejoice-vagrant-finds-a-home-in-the-amazon-cloud/">AWS</a> (<a href="https://github.com/mitchellh/vagrant-aws">github repo</a>)</li>
<li><a href="https://github.com/mitchellh/vagrant-rackspace">RackSpace</a></li>
<li><a href="https://github.com/cloudbau/vagrant-openstack">OpenStack</a> (based on the rackspace plugin)</li>
</ul>
<p>The provider I’m going to focus on here is vmware fusion.</p>
<h2 id="vmware_fusion">vmware_fusion</h2>
<p>One of the things I’ve learned about using brand new technologies is that they often don’t work and/or don’t have any documentation, which frankly are about the same thing to me. That sounds like a kind of grumpy thing to say, but I’m kind of grumpy today. :)</p>
<p>Regardless, I went ahead and bought vmware fusion (which is cheap, BTW, at $49) and also the <a href="http://www.vagrantup.com/vmware">vagrant vmware_fusion plugin</a> (which is $79).</p>
<p>I think this is the first time that I’ve encountered a plugin that was more expensive than the actual application it was plugging into, but I can understand the pricing because Fusion is probably under-valued, or at least under-priced. Plus the $79 goes towards the development of vagrant, which I use <em>a lot</em>.</p>
<p>Recently I deployed <a href="http://serverascode.com/2013/03/13/first-look-packstack.html">packstack</a> via vagrant and <em>virtualbox</em>, and I wanted to do the same with vmware_fusion, but I ran into a few problems, which I’m going to spend the rest of the post detailing.</p>
<p><em>NOTE: I should say that nothing here is the vmware_fusion plugins fault. I’m not blaming the plugin at all. Rather just detailing some of the pain points I’ve encountered, which will no doubt disappear as more people use vmware fusion and vagrant together, and as I get my act together. I’ll try to update this post as I find out new information. :)</em></p>
<h2 id="routes-collide">Routes collide!</h2>
<p>I have both vmware fusion and virtualbox installed on my macbook retina. Unfortunately, virtualbox has an iron grip on its networks.</p>
<blockquote>
<p>VirtualBox hangs on to its network devices (“vboxnet”) for dear life. I haven’t figured out yet how to actually get rid of them except restarting your computer. – <a href="https://groups.google.com/d/msg/vagrant-up/DKxnHU4_aOg/68JzFjJ-14sJ">Mitchell Hashimoto</a></p>
</blockquote>
<p>If you encounter the below error, either change subnets (perhaps in virtualbox, perhaps in the vagrantfile, not sure) or reboot.</p>
<pre>
<code>$ vagrant up apis --provider=vmware_fusion
Bringing machine 'apis' up with 'vmware_fusion' provider...
[apis] Verifying vmnet devices are healthy...
The VMware network device 'vmnet2' can't be started because
its routes collide with another device: 'vboxnet'. Please
either fix the settings of the VMware network device or stop the
colliding device. Your machine can't be started while VMware
networking is broken.
</code>
</pre>
<p>Again, not vmware_fusion’s fault, but still a pain. I can’t simply un-install virtualbox…yet.</p>
<h2 id="vmx-settings">vmx settings</h2>
<p>Often we want to change the settings in the virtual machine, settings such as memory, number of cpus, etc.</p>
<p>Unfortunately vmx is an undocumented format.</p>
<blockquote>
<p>VMX is an undocumented format. You’ll have to google, unfortunately. :) – <a href="https://groups.google.com/d/msg/vagrant-up/DKxnHU4_aOg/68JzFjJ-14sJ">Mitchell Hashimoto</a></p>
</blockquote>
<p>But at the very least here is how to set memory:</p>
<pre>
<code>config.vm.provider :vmware_fusion do |p|
p.vmx['memsize'] = '2048'
end
</code>
</pre>
<p>As more people use vmware_fusion there will be better documentation on vmx settings.</p>
<h2 id="centos6-box">Centos6 box</h2>
<p>While Hashicorp has conveniently provided a <a href="http://files.vagrantup.com/precise64.box">base precise64</a> box for vagrant, there isn’t an official centos box. I have previously tried to create a centos6 box for vagrant, but haven’t had much luck, and that was with vagrant < 1.1 and there is even less documentation on the process now.</p>
<p>Then I noticed that <a href="http://www.vagrantbox.es/">vagrantbox.es</a> (which is a very handy site!) has a centos6 box for vmware_fusion, so I grabbed that:</p>
<ul>
<li><a href="https://dl.dropbox.com/u/5721940/vagrant-boxes/vagrant-centos-6.4-x86_64-vmware_fusion.box">CentOS 6.4 x86_64 Minimal VMware Fusion (VMware Tools, Chef 11.4.0, Puppet 3.1.1)</a></li>
</ul>
<p>Unfortunately it doesn’t seem to work when multiple interfaces are specified in the vagrantfile, so that doesn’t help me much on my quest to run packstack in vmware_fusion. If anyone knows of a good centos6 box, or notices that I’m doing something wrong, please let me know!</p>
<p>Here’s the networking part of the config:</p>
<pre>
<code>config.vm.network :private_network, ip: "172.10.0.200", :netmask => "255.255.0.0"
config.vm.network :private_network, ip: "10.10.0.200", :netmask => "255.255.0.0"
</code>
</pre>
<p>Let’s boot it:</p>
<pre>
<code>$ vagrant up --provider=vmware_fusion
Bringing machine 'default' up with 'vmware_fusion' provider...
[default] Cloning Fusion VM: 'centos65fusion'. This can take some time...
[default] Verifying vmnet devices are healthy...
[default] Preparing network adapters...
[default] Starting the VMware VM...
[default] Waiting for the VM to finish booting...
[default] The machine is booted and ready!
[default] Forwarding ports...
[default] -- 22 => 2222
[default] Configuring network adapters within the VM...
The following SSH command responded with a non-zero exit status.
Vagrant assumes that this means the command failed!
/sbin/ifup eth1 2> /dev/null
</code>
</pre>
<p>Ooops, shouldn’t be seeing the failed command.</p>
<p>What’s the networking like?</p>
<pre>
<code>$ vagrant ssh
[vagrant@vagrant-centos-6 ~]$ ifconfig
eth0 Link encap:Ethernet HWaddr 00:0C:29:24:6A:AD
inet addr:192.168.134.146 Bcast:192.168.134.255 Mask:255.255.255.0
inet6 addr: fe80::20c:29ff:fe24:6aad/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:432 errors:426 dropped:0 overruns:0 frame:0
TX packets:293 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:48690 (47.5 KiB) TX bytes:38046 (37.1 KiB)
Interrupt:19 Base address:0x2024
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
inet6 addr: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:16436 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:0 (0.0 b) TX bytes:0 (0.0 b)
</code>
</pre>
<p>Nope that’s not what I wanted at all.</p>
<p>Ok, now let’s use the exact same vagrantfile but with the offical vmware_fusion ubuntu box.</p>
<pre>
<code>config.vm.box = "precise64"
</code>
</pre>
<p>Vagrant up!</p>
<pre>
<code>#
# Destroy the old one
#
$ vagrant destroy
[default] Stopping the VMware VM...
[default] Deleting the VM...
#
# Edit the vagrantfile to use precise64 basebox
#
$ vi Vagrantfile
#
# Boot it
#
$ vagrant up --provider=vmware_fusion
Bringing machine 'default' up with 'vmware_fusion' provider...
[default] Cloning Fusion VM: 'precise64'. This can take some time...
[default] Verifying vmnet devices are healthy...
[default] Preparing network adapters...
[default] Starting the VMware VM...
[default] Waiting for the VM to finish booting...
[default] The machine is booted and ready!
[default] Forwarding ports...
[default] -- 22 => 2222
[default] Configuring network adapters within the VM...
[default] Enabling and configuring shared folders...
[default] -- vagrant-root: /Users/curtis/working/vagrant/grizzly
#
# SSH into the box...
#
$ vagrant ssh
Welcome to Ubuntu 12.04.1 LTS (GNU/Linux 3.2.0-29-virtual x86_64)
* Documentation: https://help.ubuntu.com/
Last login: Thu Jan 31 13:48:53 2013
vagrant@precise64:~$ ifconfig
eth0 Link encap:Ethernet HWaddr 00:0c:29:29:dc:aa
inet addr:192.168.134.139 Bcast:192.168.134.255 Mask:255.255.255.0
inet6 addr: fe80::20c:29ff:fe29:dcaa/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:375 errors:367 dropped:0 overruns:0 frame:0
TX packets:241 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:41473 (41.4 KB) TX bytes:33220 (33.2 KB)
Interrupt:18 Base address:0x2024
eth1 Link encap:Ethernet HWaddr 00:0c:29:29:dc:b4
inet addr:172.10.0.200 Bcast:172.10.255.255 Mask:255.255.0.0
inet6 addr: fe80::20c:29ff:fe29:dcb4/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:1 errors:1 dropped:0 overruns:0 frame:0
TX packets:6 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:209 (209.0 B) TX bytes:468 (468.0 B)
Interrupt:16 Base address:0x20a4
eth2 Link encap:Ethernet HWaddr 00:0c:29:29:dc:be
inet addr:10.10.0.200 Bcast:10.10.255.255 Mask:255.255.0.0
inet6 addr: fe80::20c:29ff:fe29:dcbe/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:1 errors:1 dropped:0 overruns:0 frame:0
TX packets:6 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:209 (209.0 B) TX bytes:468 (468.0 B)
Interrupt:17 Base address:0x2424
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
inet6 addr: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:16436 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
</code>
</pre>
<p>That’s what I expect to see.</p>
<h2 id="example-vagrantfiles">Example vagrantfiles</h2>
<p><em>UPDATE (April 18th, 2013): This Vagrantfile now doesn’t seem to work with Vagrant 1.2</em></p>
<p>I have been searching for good examples of vagrantfiles that use vmware_fusion.</p>
<p>So far I’ve just found this one:</p>
<ul>
<li><a href="https://github.com/uksysadmin/OpenStackCookBook-1/blob/master/Vagrantfile">https://github.com/uksysadmin/OpenStackCookBook-1/blob/master/Vagrantfile</a></li>
</ul>
<p>But I will keep an eye out for other examples.</p>
<h2 id="update-april-18th-2013-new-network-problem">UPDATE (April 18th, 2013): New network problem</h2>
<p>This is a new one…now this can’t be virtualbox’s fault.</p>
<pre>
<code>$ vagrant up --provider=vmware_fusion
Bringing machine 'percona0' up with 'vmware_fusion' provider...
Bringing machine 'percona1' up with 'vmware_fusion' provider...
Bringing machine 'percona2' up with 'vmware_fusion' provider...
Bringing machine 'haproxy0' up with 'vmware_fusion' provider...
Bringing machine 'haproxy1' up with 'vmware_fusion' provider...
[percona0] Cloning Fusion VM: 'precise64'. This can take some time...
[percona0] Verifying vmnet devices are healthy...
The VMware network device 'vmnet1' can't be started because
its routes collide with another device: 'vmnet13'. Please
either fix the settings of the VMware network device or stop the
colliding device. Your machine can't be started while VMware
networking is broken.
</code>
</pre>
<p>Instructions from Mitchell, edit <em>/Library/Preferences/VMware\ Fusion/networking</em> and:</p>
<p>bq.. Get rid of all the lines in that file <em>except</em> the ones that start with “answer VNET_1<em>” or “answer VNET_8</em>”. We want to keep those, as they’re the default networks that ship with Fusion. After that, open VMware Fusion.app, then run these commands in a separate terminal:</p>
<p>sudo /Applications/VMware\ Fusion.app/Contents/Library/vmnet-cli –stop
sudo /Applications/VMware\ Fusion.app/Contents/Library/vmnet-cli –configure
sudo /Applications/VMware\ Fusion.app/Contents/Library/vmnet-cli –start</p>
<p>Then run</p>
<p>sudo /Applications/VMware\ Fusion.app/Contents/Library/vmnet-cli –status</p>
<p>And tell me the output. Should only have the vmnet1/vmnet8 devices. After
THAT you shoudl be good to go again.</p>
<p>VMware networking is an absolute nightmare. - <a href="https://mail.google.com/mail/u/2/?ui=2&ik=7b53664106&view=om&th=13e1f0d872dd857b">Mitchell</a></p>
<p>It sucks that it’s an edge case, but I still hope that there is some code added to help in situations like this. Thanks to Mitchell for responding on the mailing list, as now I can continue on with other problems. :)</p>
<h2 id="conclusion">Conclusion</h2>
<p>I love vagrant, but am having a heck of a time with vmware_fusion and centos6. Having said that, I <em>KNOW</em> that things are going to get better as I learn and as more people start using vagrant and vmware_fusion.</p>
<p>Hats off to Mitchell for creating a great development tool, one that I use every day!</p>
Vagrant and openstack2013-04-11T00:00:00+00:00http://serverascode.com/2013/04/11/vagrant-and-openstack<h1 id="vagrant-and-openstack">Vagrant and openstack</h1>
<p>Earlier I wrote a post on using <a href="http://serverascode.com/2013/04/11/vagrant-and-vmware.html">vmware fusion and vagrant</a>.</p>
<p>Now I’m going to use vagrant and the vmware_fusion plugin to create a precise64 virtual machine, in which I will install <a href="http://devstack.org">devstack</a>, and then I will use the vagrant and openstack plugin to boot a cirros vm inside the devstack vm. Meta…inception…whatever you want to call it. :)</p>
<p><em>NOTE: Make sure your precise64 vm has more than the default memory of 512–I set mine to 2048. A bit more memory might be nice too, if you’ve got it available.</em></p>
<p><em>NOTE: <a href="http://blog.aaronorosen.com/building-a-multi-tier-application-with-openstack/">Here is a great post</a> to follow on using devstack and grizzly and quantum, much of which I am reusing here.</em></p>
<h2 id="why">Why?</h2>
<p>There is no spoon.</p>
<h2 id="install-devstack">Install devstack</h2>
<p><a href="http://devstack.org">Devstack</a> is a really useful development environment for openstack. If you want to try out the new features in openstack grizzly, this is an easy way.</p>
<pre>
<code>#
# Create the vm
#
$ vagrant up --provider=vmware_fusion
Bringing machine 'default' up with 'vmware_fusion' provider...
SNIP!
#
# Login to the vm
#
$ vagrant ssh
Welcome to Ubuntu 12.04.1 LTS (GNU/Linux 3.2.0-29-virtual x86_64)
* Documentation: https://help.ubuntu.com/
Last login: Thu Apr 11 10:14:43 2013 from 192.168.134.1
vagrant@precise64:~$ sudo apt-get update
Ign http://security.ubuntu.com precise-security InRelease
Ign http://us.archive.ubuntu.com precise InRelease
Ign http://us.archive.ubuntu.com precise-updates InRelease
SNIP!
$ sudo apt-get install git
Reading package lists... Done
Building dependency tree
Reading state information... Done
The following extra packages will be installed:
git-man libcurl3-gnutls liberror-perl librtmp0 rsync
SNIP!
$ git clone git://github.com/openstack-dev/devstack.git
Cloning into 'devstack'...
#
# Setup devstack with a localrc file
#
vagrant@precise64:~$ cd devstack
vagrant@precise64:~/devstack$ cat localrc
ENABLED_SERVICES=g-api,g-reg,key,n-api,n-crt,n-obj,n-cpu,n-sch,n-cauth, \
horizon,mysql,rabbit,sysstat,cinder,c-api,c-vol,c-sch,n-cond,quantum,q-svc, \
q-agt,q-dhcp,q-l3,q-meta,q-lbaas,n-novnc,n-xvnc,q-lbaas
DATABASE_PASSWORD=password
RABBIT_PASSWORD=password
SERVICE_TOKEN=password
SERVICE_PASSWORD=password
ADMIN_PASSWORD=password
#
# Run stack.sh
#
vagrant@precise64:~/devstack$ ./stack.sh
Traceback (most recent call last):
File "<string>", line 2, in <module>
ImportError: No module named netaddr
Traceback (most recent call last):
File "<string>", line 2, in <module>
ImportError: No module named netaddr
SNIP!
# That error doesn't look good...oh well let's continue...
# hit enter a few times
# Go for a walk, get a coffee, do some vacuuming...
Horizon is now available at http://192.168.134.139/
Keystone is serving at http://192.168.134.139:5000/v2.0/
Examples on using novaclient command line is in exercise.sh
The default users are: admin and demo
The password: ed5cb213364bb0fd15a9
This is your host ip: 192.168.134.139
stack.sh completed in 694 seconds.
</code>
</pre>
Now that devstack seems to have completed the install, check and see if basic openstack commands are working.
<pre>
<code>#
# Source the user, password file generated by devstack
#
vagrant@precise64:~/devstack$ source openrc
#
# And lets see what's running and is available
#
vagrant@precise64:~/devstack$ nova list
+----+------+--------+----------+
| ID | Name | Status | Networks |
+----+------+--------+----------+
+----+------+--------+----------+
vagrant@precise64:~/devstack$ nova image-list
+--------------------------------------+---------------------------------+--------+--------+
| ID | Name | Status | Server |
+--------------------------------------+---------------------------------+--------+--------+
| 73f320dd-5769-4ec2-a0e7-e44979070e8c | cirros-0.3.1-x86_64-uec | ACTIVE | |
| 4af449b1-a70b-4857-93ea-9690bc5db779 | cirros-0.3.1-x86_64-uec-kernel | ACTIVE | |
| 017e58df-27bc-4bb4-89d3-f133760a3f0e | cirros-0.3.1-x86_64-uec-ramdisk | ACTIVE | |
+--------------------------------------+---------------------------------+--------+--------+
#
# Oooh, we have quantum too!
#
vagrant@precise64:~$ quantum net-list
+--------------------------------------+---------+--------------------------------------------------+
| id | name | subnets |
+--------------------------------------+---------+--------------------------------------------------+
| 5a39203e-3d83-4d47-a75e-9ec98f5ed595 | private | dae29b88-1562-42e4-8e30-0ecce7b40f47 10.0.0.0/24 |
| a608d79d-ace8-4335-81c3-3490393d7700 | public | cc058059-b342-41d9-8c68-98d6feedcfbd |
+--------------------------------------+---------+--------------------------------------------------+
vagrant@precise64:~$ quantum subnet-list
+--------------------------------------+------+-------------+--------------------------------------------+
| id | name | cidr | allocation_pools |
+--------------------------------------+------+-------------+--------------------------------------------+
| dae29b88-1562-42e4-8e30-0ecce7b40f47 | | 10.0.0.0/24 | {"start": "10.0.0.2", "end": "10.0.0.254"} |
+--------------------------------------+------+-------------+--------------------------------------------+
</code>
</pre>
## Using vagrant with openstack
First, get the vagrant-openstack plugin.
<pre>
<code>$ vagrant plugin install vagrant-openstack
Installing the 'vagrant-openstack' plugin. This can take a few minutes...
Installed the plugin 'vagrant-openstack (0.0.2)'!
$ vagrant plugin list
vagrant-openstack (0.0.2)
vagrant-vmware-fusion (0.4.2)
</code>
</pre>
Before we get too far, let's create a keypair in devstack.
<pre>
<code>vagrant@precise64:~$ source ~/devstack/openrc
vagrant@precise64:~$ nova keypair-add --pub-key ~/.ssh/authorized_keys vagrant
vagrant@precise64:~$ nova keypair-list
+---------+-------------------------------------------------+
| Name | Fingerprint |
+---------+-------------------------------------------------+
| vagrant | dd:3b:b8:2e:85:04:06:e9:ab:ff:a8:0a:c0:04:6e:d6 |
+---------+-------------------------------------------------+
</code>
</pre>
I'm going to create a new local directory to work with vagrant out of.
<pre>
<code>$ cd ~/working/vagrant
$ mkdir vagrant-openstack
$ cd vagrant-openstack
$ vagrant init
$ vi Vagrantfile
# Add config information...
</code>
</pre>
We need to insert some information into the vagrantfile for openstack.
First get the image ID. Devstack automatically adds an image, but each time devstack is run the ID will be different.
<pre>
<code>vagrant@precise64:~$ nova image-list
+--------------------------------------+---------------------------------+--------+--------+
| ID | Name | Status | Server |
+--------------------------------------+---------------------------------+--------+--------+
| 0cf481ad-482e-441c-b8a6-49e792ae0dfb | cirros-0.3.1-x86_64-uec | ACTIVE | |
| 2630cd9e-c375-49d0-81bd-ffbfc638e752 | cirros-0.3.1-x86_64-uec-kernel | ACTIVE | |
| 7375ddbc-51c7-4492-bd2b-de30f10210db | cirros-0.3.1-x86_64-uec-ramdisk | ACTIVE | |
+--------------------------------------+---------------------------------+--------+--------+
</code>
</pre>
In this example we want the _0cf481ad-482e-441c-b8a6-49e792ae0dfb_ image ID.
Also, we probably want to add a smaller flavor for the cirros image. By default the smallest flavor uses 512MB of ram.
<pre>
<code>#
# Default flavors
#
vagrant@precise64:~$ nova flavor-list
+----+-----------+-----------+------+-----------+------+-------+-------------+-----------+-------------+
| ID | Name | Memory_MB | Disk | Ephemeral | Swap | VCPUs | RXTX_Factor | Is_Public | extra_specs |
+----+-----------+-----------+------+-----------+------+-------+-------------+-----------+-------------+
| 1 | m1.tiny | 512 | 0 | 0 | | 1 | 1.0 | True | {} |
| 2 | m1.small | 2048 | 20 | 0 | | 1 | 1.0 | True | {} |
| 3 | m1.medium | 4096 | 40 | 0 | | 2 | 1.0 | True | {} |
| 4 | m1.large | 8192 | 80 | 0 | | 4 | 1.0 | True | {} |
| 5 | m1.xlarge | 16384 | 160 | 0 | | 8 | 1.0 | True | {} |
+----+-----------+-----------+------+-----------+------+-------+-------------+-----------+-------------+
#
# Add a smaller flavor
#
vagrant@precise64:~$ nova-manage flavor create --name=m1.teeny --memory=64 \
--cpu=1 --root_gb=0 --ephemeral_gb=0 --flavor=6 --swap=0 --is_public yes
2013-04-11 11:36:08 DEBUG [nova.openstack.common.lockutils] Got semaphore \
"dbapi_backend" for method "__get_backend"...
m1.teeny created
#
# Now we have a 6th flavor!
#
vagrant@precise64:~$ nova flavor-list
+----+-----------+-----------+------+-----------+------+-------+-------------+-----------+-------------+
| ID | Name | Memory_MB | Disk | Ephemeral | Swap | VCPUs | RXTX_Factor | Is_Public | extra_specs |
+----+-----------+-----------+------+-----------+------+-------+-------------+-----------+-------------+
| 1 | m1.tiny | 512 | 0 | 0 | | 1 | 1.0 | True | {} |
| 2 | m1.small | 2048 | 20 | 0 | | 1 | 1.0 | True | {} |
| 3 | m1.medium | 4096 | 40 | 0 | | 2 | 1.0 | True | {} |
| 4 | m1.large | 8192 | 80 | 0 | | 4 | 1.0 | True | {} |
| 5 | m1.xlarge | 16384 | 160 | 0 | | 8 | 1.0 | True | {} |
| 6 | m1.teeny | 64 | 0 | 0 | | 1 | 1.0 | True | {} |
+----+-----------+-----------+------+-----------+------+-------+-------------+-----------+-------------+
</code>
</pre>
Flavor 6 is what we'll use.
Next, check the OS vars in devstack to see what to put into the vagrantfile:
<pre>
<code>vagrant@precise64:~$ env | grep "^OS"
OS_PASSWORD=password
OS_AUTH_URL=http://192.168.134.139:5000/v2.0
OS_USERNAME=demo
OS_TENANT_NAME=demo
OS_CACERT=/opt/stack/data/CA/int-ca/ca-chain.pem
OS_NO_CACHE=1
</code>
</pre>
Now with all that information we can fill out the vagrantfile. Mine looks like this:
<pre>
<code>$ cat Vagrantfile
# -*- mode: ruby -*-
# vi: set ft=ruby :
Vagrant.configure("2") do |config|
# All Vagrant configuration is done here. The most common configuration
# options are documented and commented below. For a complete reference,
# please see the online documentation at vagrantup.com.
# Every Vagrant virtual environment requires a box to build off of.
config.vm.box = "base"
config.vm.provider :openstack do |os|
os.url = "http://192.168.134.139:5000/v2.0"
os.tenant = "demo"
os.user = "demo"
os.password = "password"
os.flavor = "6"
os.keypair = "vagrant"
os.image = "0cf481ad-482e-441c-b8a6-49e792ae0dfb"
# Not sure why but I feel like calling this vm whitney
os.name = "whitney"
os.ssh_username = "cirros"
os.ssh_private_key = "~/.ssh/id_dsa.pub"
end
end
</code>
</pre>
Using vagrant, boot the vm.
<pre>
<code>#
# Boot it
#
$ vagrant up --provider=openstack
Bringing machine 'default' up with 'openstack' provider...
[default] New VM created 419e5940-e068-42a4-bb28-68ad72f85d8a => whitney
#
# Check status
#
$ vagrant status
Current machine states:
default running (openstack)
The nova instance is running. To stop this machine, you can run
`vagrant halt`. To destroy the machine, you can run `vagrant destroy`.
</code>
</pre>
Let's see what's happening in devstack.
<pre>
<code>#
# What does virsh know?
#
vagrant@precise64:~$ sudo virsh list
Id Name State
----------------------------------
1 instance-00000001 running
#
# And lets ask openstack...
#
vagrant@precise64:~$ source ~/devstack/openrc
vagrant@precise64:~$ nova list
+--------------------------------------+---------+--------+------------------+
| ID | Name | Status | Networks |
+--------------------------------------+---------+--------+------------------+
| 419e5940-e068-42a4-bb28-68ad72f85d8a | whitney | ACTIVE | private=10.0.0.3 |
+--------------------------------------+---------+--------+------------------+
vagrant@precise64:~$ nova show 419e5940-e068-42a4-bb28-68ad72f85d8a
+-----------------------------+----------------------------------------------------------------+
| Property | Value |
+-----------------------------+----------------------------------------------------------------+
| status | ACTIVE |
| updated | 2013-04-11T18:40:43Z |
| OS-EXT-STS:task_state | None |
| private network | 10.0.0.3 |
| key_name | vagrant |
| image | cirros-0.3.1-x86_64-uec (0cf481ad-482e-441c-b8a6-49e792ae0dfb) |
| hostId | cbfc5a689eaff0c72de8f66161efb06270322d48baf6d9120f612c42 |
| OS-EXT-STS:vm_state | active |
| flavor | m1.teeny (6) |
| id | 419e5940-e068-42a4-bb28-68ad72f85d8a |
| security_groups | [{u'name': u'default'}] |
| user_id | 26c0f9a23e9c44f6b660557122119171 |
| name | whitney |
| created | 2013-04-11T18:40:31Z |
| tenant_id | bb54c65c4aba482f8f6d363e0730df95 |
| OS-DCF:diskConfig | MANUAL |
| metadata | {} |
| accessIPv4 | |
| accessIPv6 | |
| progress | 0 |
| OS-EXT-STS:power_state | 1 |
| OS-EXT-AZ:availability_zone | nova |
| config_drive | |
+-----------------------------+----------------------------------------------------------------+
</code>
</pre>
Nice.
Now, unless we give this vm a "public ip" we won't be able to ssh in without hopping into the devstack host first.
But first...one. More. Step.
By default, with devstack, it seems the default security group is pretty restrictive. So we need to add a couple rules.
<pre>
<code>#
# Default secgroup rules
#
vagrant@precise64:~$ nova secgroup-list-rules default
+-------------+-----------+---------+----------+--------------+
| IP Protocol | From Port | To Port | IP Range | Source Group |
+-------------+-----------+---------+----------+--------------+
| | -1 | -1 | | default |
| | -1 | -1 | | default |
+-------------+-----------+---------+----------+--------------+
#
# Add ping
#
vagrant@precise64:~$ nova secgroup-add-rule default icmp -1 -1 0.0.0.0/0
+-------------+-----------+---------+-----------+--------------+
| IP Protocol | From Port | To Port | IP Range | Source Group |
+-------------+-----------+---------+-----------+--------------+
| icmp | -1 | -1 | 0.0.0.0/0 | |
+-------------+-----------+---------+-----------+--------------+
#
# Add ssh
#
vagrant@precise64:~$ nova secgroup-add-rule default tcp 22 22 0.0.0.0/0
+-------------+-----------+---------+-----------+--------------+
| IP Protocol | From Port | To Port | IP Range | Source Group |
+-------------+-----------+---------+-----------+--------------+
| tcp | 22 | 22 | 0.0.0.0/0 | |
+-------------+-----------+---------+-----------+--------------+
#
# New secgroup rules
#
vagrant@precise64:~$ nova secgroup-list-rules default
+-------------+-----------+---------+-----------+--------------+
| IP Protocol | From Port | To Port | IP Range | Source Group |
+-------------+-----------+---------+-----------+--------------+
| | -1 | -1 | | default |
| | -1 | -1 | | default |
| icmp | -1 | -1 | 0.0.0.0/0 | |
| tcp | 22 | 22 | 0.0.0.0/0 | |
+-------------+-----------+---------+-----------+--------------+
#
# And now we should be able to ping and ssh in to whitney
#
vagrant@precise64:~$ ping -c 1 -w 1 10.0.0.3
PING 10.0.0.3 (10.0.0.3) 56(84) bytes of data.
64 bytes from 10.0.0.3: icmp_req=1 ttl=63 time=72.2 ms
--- 10.0.0.3 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 72.261/72.261/72.261/0.000 ms
vagrant@precise64:~$ ssh cirros@10.0.0.3
cirros@10.0.0.3's password: # enter "cubswin:)"
$ uname -a
Linux cirros 3.2.0-37-virtual #58-Ubuntu SMP Thu Jan 24 15:48:03 UTC 2013 x86_64 GNU/Linux
</code>
</pre>
_NOTE: I'm skipping the part about using the authorized_keys file cirros sets up for itself based on the keypair specified. But you can ssh into the cirros instance without a password if everything is setup right, ssh -A, ssh-agent, etc._
## Conclusion
And that concludes our brief look at booting a vm inside of vm, using:
- macbook retina
- vagrant
- vmware fusion
- vagrant-openstack
- devstack
- cirros
- openstack grizzly
Everything works!
We can even delete the vm we just created:
<pre>
<code>$ vagrant destroy
[default] Deleting the instance...
</code>
</pre>
Check in with openstack...
<pre>
<code>#
# vm gone!
#
vagrant@precise64:~$ nova list
+----+------+--------+----------+
| ID | Name | Status | Networks |
+----+------+--------+----------+
+----+------+--------+----------+
</code>
</pre>
</module></string></module></string></code></pre>
Thoughts on "no reliable cloud"2013-04-10T00:00:00+00:00http://serverascode.com/2013/04/10/no-reliable-cloud<h1 id="thoughts-on-no-reliable-cloud">Thoughts on “no reliable cloud”</h1>
<p>Recently <a href="http://blog.hendrikvolkmer.de/about/">Hendrik Volkmer</a> put up a blog post entitled <a href="http://blog.hendrikvolkmer.de/2013/04/03/there-will-be-no-reliable-cloud-part-1/">There will be no reliable cloud</a>. Part of it was based on a <a href="http://engineering.cloudscaling.com/2013/03/service-resiliency-doesnt-always-mean-ha-or-cluster/">presentation</a> I watched at the last OpenStack summit (wish I was going to the Portland summit, but alas is not to be).</p>
<p>The Cloud Scaling presentation was one I enjoyed and considered thought provoking. I wrote a <a href="http://serverascode.com/2012/10/17/openstack-summit-day-3.html">few notes</a> on that presentation last year.</p>
<h2 id="no-reliable-cloud">No reliable cloud</h2>
<p>Here’s a quote from the top of the <a href="http://blog.hendrikvolkmer.de/2013/04/03/there-will-be-no-reliable-cloud-part-1/:">first post</a></p>
<blockquote>
<p>Stop wasting your time trying to [find a reliable cloud]. Stop wasting your time (and money) trying to build one. If you find a service provider that claims that they have it: Maybe question their understanding of cloud - and business.</p>
</blockquote>
<p>I put that there to remind me of the point of the series of posts, and because it essentially defines the attention grabbing headline. :)</p>
<h2 id="tldr">tl;dr</h2>
<p>My thoughts on these posts come down to this:</p>
<ul>
<li>He’s mostly talking web-scale applications</li>
<li>A single zone will not be reliable</li>
<li>But still have to make zones as reasonably reliable as possible (where’s the line?)</li>
<li>We should design reliable applications on top of unreliable zones (but how?)</li>
<li>Contain failure!</li>
<li>HA pairs are probably not the direction to go in to gain reliability</li>
<li>Clustering software often brings in complexity that can destroy reliability gains</li>
<li>Stateless systems are a lot more fun :)</li>
<li>Keep the stateful part of an application or system small</li>
</ul>
<p>Thinking about reliability in a cloud, especially an OpenStack cloud, is an interesting thought experiment. Fortunately, the OpenStack cloud I help to run, which is the back-end for a single application, is actually mostly stateless–except for machine images, the OpenStack database, and the application database. Not a lot of stateful information, except those darn windows images that are many tens of times the size of a standard Linux cloud image.</p>
<h2 id="notes-from-the-part-one-post">Notes from the part one post</h2>
<p>For a <a href="http://blog.hendrikvolkmer.de/2013/04/03/there-will-be-no-reliable-cloud-part-1/">short post</a> it sure goes over a lot of information and links!</p>
<ul>
<li>HA pairs fail catastrophically</li>
<li>HA pairs don’t scale</li>
<li>Classic HA example: NFS + DRBD and clustering, such as Pacemaker…then problems?</li>
<li>HA pairs often end up cheating CAP theorem</li>
<li>Cluster software causes more system outages than hardware failures of software bugs (this I can attend to having used clustered LVM)</li>
<li>Distributed systems
** Eg. Percona Xtradb Cluster</li>
<li>
<p>Availability vs reliability
** HA systems that need to go down for maintenance are a joke</p>
</li>
<li>How to build a reliable cloud</li>
<li>A cloud is a distributed system</li>
<li>Use the stateless (from <a href="http://www.cloudscaling.com/">Cloud Scaling</a> presentation) approach for stateless parts</li>
<li>Distributed data stores for the stateful parts (eg. distributed mysql, distributed file systems such as ceph)</li>
<li>But the distributed stateful part is often what fails (eg. EBS in Amazon)</li>
<li>Notes from blog post comments (notably Randy Bias of Cloud Scaling)</li>
<li>On OpenStack</li>
<li>Move to MySQL Cluster with the NBDEngine running 2-4 mysql instances, and load balancing across them</li>
<li>Or perhaps OpenStack will get rid of the RDBMS and replace with K/V store</li>
<li>Even with 1000s of nodes, metadata use is still low in OpenStack, could be put in memory and persist data using any appropriate back-end</li>
<li>No point in having highly redundant hardware for stateless services</li>
<li>Build reliable applications on unreliable clouds</li>
</ul>
<p>Ok, now on to part two.</p>
<h2 id="notes-from-part-two">Notes from part two</h2>
<p>The <a href="http://blog.hendrikvolkmer.de/2013/04/09/there-will-be-no-reliable-cloud-part-2/">second post</a> builds on the basic information provided in the first.</p>
<blockquote>
<p>Complexity + Scale => Reduced Reliability + Increased Chance of catastrophic failures</p>
</blockquote>
<ul>
<li>Complexity</li>
<li>Complex system fail catastrophically</li>
<li>Failure domains</li>
<li>OpenStack example</li>
<li>Single controller, single cloud (or zone)</li>
<li>HA setup – two controllers in an HA mode of some kind</li>
<li>Single controller, multiple cloud (or multiple zones)</li>
<li>A single zone is unreliable</li>
<li>If both HA nodes fail, still unreliable, and HA is more complex</li>
<li>Two zones is two failure domains, which is more reliable than a single HA-enabled zone</li>
<li>(But of course you should make each zone as reliable as possible)</li>
<li>Reliability engineering (aka math)</li>
<li><a href="http://www.infoq.com/presentations/Reliability-Engineering-Matters-Except-When-It-Doesnt">Reliability engineering matters except when it doesn’t</a></li>
<li>“The higher the number of dependent components => the lower the overall availability and the bigger the impact of failure”</li>
<li>In a cloud with many nodes, adding the ability for live migration will actually decrease reliability, because all nodes are now tied together</li>
<li>Many reliability calculations come from mechanical engineering, which is much different than software engineering</li>
<li>Many complex systems fail by cascading, failure starts small and grows big, until it engulfs the entire system</li>
<li>General approach is to make failure local and contained</li>
<li>Partial failure is desirable</li>
<li>Business side</li>
<li>Software reliability is cheaper</li>
<li>Most web scale applications consist of a large stateless part and a small stateful piece</li>
<li>It does not make business sense to provide a super-reliable cloud</li>
<li>A single compute node or even zone will never be reliable</li>
<li>Best not to consider virtual machines, such as those in EC2, <a href="http://www.jamiebegin.com/why-an-ec2-instance-isnt-a-server/">as servers</a></li>
</ul>
<p>NOTE: There will eventually be a part three post, but as of this writing it’s not up yet.</p>
<h2 id="conclusion">Conclusion</h2>
<p>To me, it boils down to building reliable applications on unreliable clouds, which I think is what a lot of people are doing, and is what seems to come out every time AWS fails.</p>
<p>The first issue that pops into my mind though is RDBMS systems, and how to replicate data between zones, which is often a network concern. Actually, replicating any data between zones could be a problem, which is why, I’m guessing, that he’s (perhaps) suggesting to keep stateful pieces small.</p>
First look at PackStack2013-03-13T00:00:00+00:00http://serverascode.com/2013/03/13/first-look-packstack<h1 id="first-look-at-packstack">First look at PackStack</h1>
<p>I am a big fan, and user, of <a href="http://openstack.org">OpenStack</a>. I also really like the <a href="http://ansible.cc">Ansible</a> configuration management and orchestration system. In fact, I use Ansible to deploy OpenStack, and all kinds of <a href="https://github.com/ccollicutt/ansible_playbooks">other things</a> as well.</p>
<p>Recently on the Ansible mailing list the lead developer (and now CTO of <a href="http://ansibleworks.com">Ansibleworks</a>) <a href="https://groups.google.com/forum/?fromgroups=#!topic/ansible-project/eNlPwjIHGGs">suggested that it was time to bring together</a> everyone who is working, or wants to work with, both Ansible and OpenStack.</p>
<p>One of the suggestions was to follow what <a href="https://github.com/stackforge/packstack">PackStack</a> has done–it’s based on puppet–and port it over to Ansible. (NOTE: I’m not even sure that’s the right git repo, things are moving so fast!)</p>
<p>While I had heard of PackStack before, I had never used it, so I decided it was time I took a look so that I can perhaps help with the OpenStack + Ansible project. Frankly, it was on my list of technology to check out because I always need to have some virtual machines running OpenStack, and it would be nice if there was an easy way to quickly build a multi-host OpenStack install (especially if I would like to contribute code back to the community at some point).</p>
<p>Also–I’m sure Ansible will soon be one of Vagrants supported deployment systems, and when that happens it will be very easy to deploy OpenStack with Vagrant.</p>
<p>So I spent a couple hours creating an <a href="https://github.com/ccollicutt/ansible_playbooks/tree/master/packstack">Ansible playbook</a> that would simply fire off the PackStack command with a generic answer file. So I haven’t ported anything from PackStack to Ansible–I’m simply using Ansible and Vagrant to create an environment for PackStack to do it’s work.</p>
<h2 id="redhatcentos">RedHat/CentOS</h2>
<p>One big note–PackStack currently only supports RedHat/CentOS. I’m using CentOS 6.</p>
<h2 id="host-organization">Host organization</h2>
<p>That repository also contains a Vagrant file, and an Ansible hosts file. I have four virtual machines making up a small OpenStack cluster:</p>
<pre>
<code>$ cat ansible_hosts
[openstack]
apis ansible_ssh_host=192.168.100.130
scheduler ansible_ssh_host=192.168.100.131
compute01 ansible_ssh_host=192.168.100.132
compute02 ansible_ssh_host=192.168.100.133
</code>
</pre>
<p>And all of those IPs and names are reflected in the <code class="language-plaintext highlighter-rouge">PackStack.yml</code>, <code class="language-plaintext highlighter-rouge">files/packstack.cfg</code>, and <code class="language-plaintext highlighter-rouge">Vagrantfile</code> files. I don’t know if they are the most descriptive names, but this is how I’ve currently organized it.</p>
<pre>
<code>$ grep "100\.13" Vagrantfile
apis_config.vm.network :hostonly, "192.168.100.130" # nic3
scheduler_config.vm.network :hostonly, "192.168.100.131" # nic3
compute01_config.vm.network :hostonly, "192.168.100.132" # nic3
compute02_config.vm.network :hostonly, "192.168.100.133" # nic3
</code>
</pre>
<p>The <code class="language-plaintext highlighter-rouge">apis</code> host is going to run horizon (not that I need it) and the front-facing APIs, and the scheduler will run the mysql server and nova-scheduler…and some cinder related services as well (which likely need more investigation as I have really only have experience thus far with OpenStack Essex–but at least I can experiment with other versions of OpenStack now, thanks to PackStack).</p>
<p>For example, here is what nova services are running where:</p>
<pre>
<code>[root@apis packstack(keystone_admin)]$ nova-manage service list
Binary Host Zone Status State Updated_At
nova-scheduler scheduler nova enabled :-) 2013-03-13 21:15:11
nova-cert apis nova enabled :-) 2013-03-13 21:15:15
nova-consoleauth apis nova enabled :-) 2013-03-13 21:15:15
nova-compute compute01 nova enabled :-) 2013-03-13 21:15:13
nova-compute compute02 nova enabled :-) 2013-03-13 21:15:12
</code>
</pre>
<p>Smiley faces are good. :-)</p>
<h2 id="deploying-packstack">Deploying PackStack</h2>
<p>Deploying this specific example only requires a couple of commands (I’m running OSX, and using Virtualbox).</p>
<p>First, tell Vagrant to build the servers.</p>
<p><em>NOTE:</em> You could have IP collisions if you have other virtual machines running–the IPs used here are hard-coded.</p>
<pre>
<code>$ vagrant up
[apis] Importing base box 'centos6'...
[apis] The guest additions on this VM do not match the install version of
VirtualBox! This may cause things such as forwarded ports, shared
folders, and more to not work properly. If any of those things fail on
this machine, please update the guest additions and repackage the
box.
Guest Additions Version: 4.1.6
VirtualBox Version: 4.2.6
[apis] Matching MAC address for NAT networking...
[apis] Clearing any previously set forwarded ports...
[apis] Fixed port collision for 22 => 2222. Now on port 2200.
SNIP!
</code>
</pre>
<p>Once those are built you should have four vms running:</p>
<pre>
<code>$ vagrant status
Current VM states:
apis running
scheduler running
compute01 running
compute02 running
This environment represents multiple VMs. The VMs are all listed
above with their current state. For more information about a specific
VM, run `vagrant status NAME`.
</code>
</pre>
<p>Once that’s done, you can simply run the <code class="language-plaintext highlighter-rouge">packstack.yml</code> playbook.</p>
<pre>
<code>$ ansible-playbook -k -u root PackStack.yml
SSH password: #enter the vagrant password of 'vagrant', just have to do this once
PLAY [openstack] *********************
GATHERING FACTS *********************
ok: [compute01]
ok: [scheduler]
ok: [compute02]
ok: [apis]
SNIP! #Tons of stuff happens here, mostly done by PackStack
TASK: [run PackStack] *********************
skipping: [compute01]
skipping: [compute02]
skipping: [scheduler]
changed: [apis]
PLAY RECAP *********************
apis : ok=13 changed=11 unreachable=0 failed=0
compute01 : ok=7 changed=5 unreachable=0 failed=0
compute02 : ok=7 changed=5 unreachable=0 failed=0
scheduler : ok=7 changed=5 unreachable=0 failed=0
</code>
</pre>
<p>When it completes, there should be a multi-server OpenStack cluster running!</p>
<p>Login to the <code class="language-plaintext highlighter-rouge">apis</code> server:</p>
<pre>
<code>$ ssh root@192.168.100.130
root@192.168.100.130's password: #vagrant password again
Last login: Wed Mar 13 16:34:03 2013 from 192.168.100.1
[root@apis ~]# source keystonerc_admin
[root@apis ~(keystone_admin)]$ nova list
# nothing will appear here, but at least you should get no error messages
</code>
</pre>
<p>Because the Ansible playbook downloaded and installed the Cirros image, @nova image-list@ should give some output:</p>
<pre>
<code>[root@apis ~(keystone_admin)]$ nova image-list
+--------------------------------------+--------+--------+--------+
| ID | Name | Status | Server |
+--------------------------------------+--------+--------+--------+
| 84eebd30-953f-4ffe-b9f9-afb7099f1e75 | cirros | ACTIVE | |
+--------------------------------------+--------+--------+--------+
</code>
</pre>
<p>At any rate, it’s a good start.</p>
<p>Once Vagrant supports Ansible and VMWare Fusion, it will be crazy easy to create a working OpenStack cluster on my laptop.</p>
<h2 id="acknowledgments">Acknowledgments</h2>
<p>Nothing I ever do is novel, and this blog post is no different. I based this work off the following: <a href="https://www.berrange.com/tags/packstack/">Installing a 4 node Fedora 18 OpenStack Folsom cluster with PackStack</a>.</p>
<h2 id="issuescaveatsquestions">Issues/Caveats/Questions</h2>
<ul>
<li>I had at least one problem getting this going…PackStack doesn’t seem to want to install puppet on CentOS 6. I had to make sure the Ansible playbook setup the EPEL repository so that the puppet RPMs were available.</li>
<li>AFAIK, Virtualbox doesn’t support <a href="https://www.virtualbox.org/ticket/4032">nested virtualization</a>, so you won’t be able to boot any <a href="http://www.imdb.com/title/tt1375666/">Inception</a> styled OpenStack instances, ie. vms within vms. Though, again AFAIK, VMWare Fusion on OSX does supported nested virtualization, which is why I’m excited about Vagrant supporting Fusion. I’d prefer to use KVM, but I need to run OSX for work.</li>
<li>Don’t think <a href="https://wiki.openstack.org/wiki/Cinder">Cinder</a> is working.</li>
<li>It can take a good 20 to 30 minutes for this entire build process to complete, mostly because there are a ton of puppet modules to download.</li>
<li>I’m not even sure what version of OpenStack this installs…something to look into. Might have to jump to a more recent version of Fedora to get something like OpenStack Grizzly.</li>
</ul>
<pre>
<code>[root@apis ~(keystone_admin)]$ yum info openstack-nova-common
Loaded plugins: fastestmirror, priorities
Loading mirror speeds from cached hostfile
* base: www.muug.mb.ca
* epel: www.muug.mb.ca
* extras: mirror.its.sfu.ca
* updates: www.muug.mb.ca
Installed Packages
Name : openstack-nova-common
Arch : noarch
Version : 2012.2.2
Release : 1.el6
Size : 115 k
Repo : installed
From repo : epel
Summary : Components common to all OpenStack Nova services
URL : http://openstack.org/projects/compute/
License : ASL 2.0
Description: OpenStack Compute (codename Nova) is open source software designed to
: provision and manage large networks of virtual machines, creating a
: redundant and scalable cloud computing platform. It gives you the
: software, control panels, and APIs required to orchestrate a cloud,
: including running instances, managing networks, and controlling access
: through users and projects. OpenStack Compute strives to be both
: hardware and hypervisor agnostic, currently supporting a variety of
: standard hardware configurations and seven major hypervisors.
:
: This package contains scripts, config and dependencies shared
: between all the OpenStack nova services.
</code>
</pre>
Software defined networking, Openvswitch, and Ubuntu 12.042013-02-21T00:00:00+00:00http://serverascode.com/2013/02/21/openvswitch<h1 id="software-defined-networking-openvswitch-and-ubuntu-1204">Software defined networking, Openvswitch, and Ubuntu 12.04</h1>
<p>Recently I’ve been testing over committing on KVM. Once I started running hundreds of virtual machines (vms) on a single node, I realized that in order to get them to do anything I have to access them over the network to run something like <a href="http://ansible.cc">Ansible</a> playbooks designed to test load.</p>
<p>In order to provide networking resources to the vms, I decided to take a look at <a href="http://openvswitch.org">Openvswitch</a> and what it takes to get it up and running with KVM and Ubuntu 12.04/Precise.</p>
<h2 id="software-defined-networking">Software defined networking</h2>
<p>Like cloud and big-data, <a href="http://en.wikipedia.org/wiki/Software-defined_networking">software defined networking</a> (SDN) is a loaded term. But, like those terms, I feel I need to at least try to get a grasp of what it means.</p>
<blockquote>
<p>“A good working definition of SDN is the separation of the data and control functions of today’s routers and other layer two networking infrastructure with a well-defined programming interface between the two.” – Via <a href="http://arstechnica.com/information-technology/2013/02/100gbps-and-beyond-what-lies-ahead-in-the-world-of-networking/2/">Arstechnica</a></p>
</blockquote>
<p>SDN is a big part of <a href="http://docs.openstack.org/trunk/openstack-network/admin/content/">OpenStack</a> as well. Starting with the <a href="http://www.openstack.org/software/folsom/">Folsom</a> release, networking was split out into it’s own <em>*as-a-Service</em> capability called <a href="https://wiki.openstack.org/wiki/Quantum">Quantum</a>, whereas previously it was a sub-component of Nova. So given I’m a big fan, and user, of OpenStack, it’s important for me to get a good grasp of SDN.</p>
<p><a href="http://www.openflow.org/wk/index.php/OpenFlow_Tutorial">Openflow</a> is also an important technology in SDN that requires some research time.</p>
<p>But, having said all that, basically I’m just going to install and use Openvswitch on a single compute node. :)</p>
<h2 id="building-on-others-work">Building on other’s work</h2>
<p>I followed these blog posts on configuring Openvswitch on Ubuntu 12.04/Precise:</p>
<ul>
<li><a href="http://networkstatic.net/how-to-build-an-sdn-lab-without-needing-openflow-hardware/">How to build a SDN Lab without needing Openflow hardware</a></li>
<li><a href="http://en.community.dell.com/techcenter/networking/w/wiki/3820.openvswitch-openflow-lets-get-started.aspx">Openvswitch and OpenFlow: Let’s get started</a></li>
<li><a href="http://blog.scottlowe.org/2012/08/17/installing-kvm-and-open-vswitch-on-ubuntu/">Installing KVM and Openvswtich on Ubuntu</a></li>
</ul>
<p>I’m not really doing anything new here–though I hope to at some point… :)</p>
<h2 id="installation">Installation</h2>
<p>I put together an <a href="https://github.com/ccollicutt/ansible_playbooks/blob/master/sdn/tasks/setup.yml">ansible playbook</a> to install Openvswitch in Ubuntu 12.04. There is no easy, direct way (that I’m aware of) to install Openvswitch in Precise…unfortunately I just can’t do @apt-get install openvswitch@ and have everything work like magic. I guess building the module is the only unusual thing, and this will disappear in future versions of Ubuntu–perhaps it’s already not necessary in 12.10, not sure, haven’t looked it up.</p>
<p>I’m not going to directly cut and paste my <a href="https://github.com/ccollicutt/ansible_playbooks/blob/master/sdn/tasks/setup.yml">ansible playbook</a> into this post, but suffice it to say that most dependencies can be installed via <code class="language-plaintext highlighter-rouge">apt-get</code>, but there is one step required to build and module.</p>
<pre>
<code># Install these packages:
# - openvswitch-datapath-source
# - bridge-utils
# - module-assistant
# - openvswitch-brcompat
# - openvswitch-common
# - openvswitch-switch
# - linux-headers-3.2.0-23-generic
# - linux-headers-generic-pae
# Then build the module:
$ module-assistant auto-install openvswitch-datapath
</code>
</pre>
<p>Next we set <code class="language-plaintext highlighter-rouge">BRCOMPAT=yes</code> in <code class="language-plaintext highlighter-rouge">/etc/default/openvswitch-switch</code> and restart <code class="language-plaintext highlighter-rouge">openvswitch-switch</code>.</p>
<h2 id="pox">Pox</h2>
<p><a href="http://www.noxrepo.org/pox/about-pox/">Pox</a>, among other things, is an Openflow controller.</p>
<blockquote>
<p>“At its core, it’s a platform for the rapid development and prototyping of network control software using Python. Meaning, at a very basic level, it’s one of a growing number of frameworks…for helping you write an OpenFlow controller.” – Via <a href="http://www.noxrepo.org/pox/about-pox/">Pox website</a></p>
</blockquote>
<p>Hey, it’s Python, it’s Openflow…what else do I need. Sign me up. :)</p>
<pre>
<code>$ cd /usr/local/src
$ git clone http://github.com/noxrepo/pox
$ zdaemon -p 'python /usr/local/src/pox/pox.py \
--no-cli forwarding.l2_learning' -d start
</code>
</pre>
<p>And now Pox should be listening on port 6633:</p>
<pre>
<code>$ netstat -ant | grep 6633
tcp 0 0 0.0.0.0:6633 0.0.0.0:* LISTEN
$ sudo lsof -i | grep 6633
python 34150 root 3u IPv4 39211055 0t0 TCP *:6633 (LISTEN)
</code>
</pre>
<p>More information about pox can be found on the <a href="http://www.openflow.org/wk/index.php/OpenFlow_Tutorial#Controller_Choice:_POX_.28Python.29">Openflow site</a>.</p>
<h2 id="configure-the-bridge">Configure the bridge</h2>
<p>Now we can add a bridge to the openv switch.</p>
<pre>
<code>$ ovs-vsctl add-br br-int
</code>
</pre>
<p>And then configure br-int (or whatever you’ve called the bridge), and I’m using the eth2 interface in this example.</p>
<pre>
<code>$ ovs-vsctl add-port br-int eth2; ifconfig eth2 0; ifconfig br-int <IPv4 Address=""> \
netmask 255.255.255.0
</code>
</pre>
Let's tell Openvswitch to use the Pox controller that is running.
<pre>
<code>$ ovs-vsctl set-controller br-int tcp:<IPv4 Address="">:6633
</code>
</pre>
Finally we need interface up and down scripts.
ifdown:
<pre>
<code>$ cat /sbin/ovs-ifdown
#!/bin/sh
switch='br-int'
/sbin/ifconfig $1 0.0.0.0 down
ovs-vsctl del-port ${switch} $1
</code>
</pre>
ifup:
<pre>
<code>$ cat /sbin/ovs-ifup
#!/bin/sh switch='br-int'
/sbin/ifconfig $1 0.0.0.0 up
ovs-vsctl add-port ${switch} $1
</code>
</pre>
Now we can boot some vms!
## Booting a vm
I'm booting vms via a script, and part of the `kvm` command line options is the network tap, which uses the ifup/ifdown scripts:
<pre>
<code>-net tap,script=/sbin/ovs-ifup,downscript=/sbin/ovs-ifdown
</code>
</pre>
And, here is a running instance:
<pre>
<code>$ ps ax | grep "kvm -drive" | head -1
9831 ? Sl 21:01 kvm -drive if=virtio,file=/mnt/intel/1.img -m 2048 \
-boot a -net nic,macaddr=52:54:00:a1:c0:fd \
-net tap,script=/sbin/ovs-ifup,downscript=/sbin/ovs-ifdown -nographic -vnc :1 \
-chardev file,id=charserial0,path=/mnt/intel/1.console.log \
-device isa-serial,chardev=charserial0,id=serial0 -chardev pty,id=charserial1 \
-device isa-serial,chardev=charserial1,id=serial1 \
-device virtio-balloon-pci,id=balloon0,bus=pci.0,addr=0x5
</code>
</pre>
Right now there's about 300 vms running on this single compute node.
<pre>
<code>$ ps ax |grep "kvm -drive" | wc -l
301
</code>
</pre>
Fun stuff. :)
## What now?
Well, I've achieved my goal of getting Openvswitch up and running to enable networking between vms on a single compute node.
<pre>
<code>ubuntu@ubuntu:~$ ifconfig eth0 | grep 192
inet addr:192.168.100.111 Bcast:192.168.100.255 Mask:255.255.255.0
ubuntu@ubuntu:~$ ping -c 1 192.168.100.23
PING 192.168.100.23 (192.168.100.23) 56(84) bytes of data.
64 bytes from 192.168.100.23: icmp_req=1 ttl=64 time=0.452 ms
--- 192.168.100.23 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 0.452/0.452/0.452/0.000 ms
</code>
</pre>
I think my next step will be to work in multiple virtual machines to see if I can do some of the interesting and useful things that Openflow is capable of, and to find out how I can work with the Pox system to learn more about SDN.
Another important thing to do is to get a test environment of OpenStack Folsom (or Grizzly) up and running to see how Quantum utilizes Openflow and SDN.
I'm hoping to spend the next few days learning about [Pox](http://www.noxrepo.org/pox/about-pox/). Wish me luck. :)
</IPv4></code></pre></IPv4></code></pre>
Over committing with KVM2013-02-20T00:00:00+00:00http://serverascode.com/2013/02/20/overcommitting-with-kvm<h1 id="over-committing-with-kvm">Over committing with KVM</h1>
<p>It’s quite possible to over commit resources with the KVM hypervisor.</p>
<p>I should say first that most of the work I’ve been doing around over committing in KVM is based on a project I am working in where the virtual machines are stateless. This makes over committing easier because if we run out of resources on a compute node and this causes a vm to crash, it’s not the end of the world–the end-user can just restart their session.</p>
<p>To me over committing means having virtual machines running on a node where the total CPU, main memory (ie. ram), and disk that is available to the virtual machines is much larger than the actual physical resources available on the node. Hopefully five or ten times larger.</p>
<h2 id="hardware">Hardware</h2>
<p>I am running these tests on a single Dell C6220 node. It has 32 cores (including hyperthreading), 128GB of main memory, and SSD drives.</p>
<pre>
<code>test_host:~$ cat /proc/cpuinfo | grep processor | wc -l
32
</code>
</pre>
<p>The SSD drive types we are testing with are:</p>
<ul>
<li>2x Standard Dell 300GB SSD</li>
<li>2x Samsung 830 512GB</li>
<li>2x Intel 520 480GB</li>
</ul>
<p>Each of them is in a stripe/RAID0 configuration, so we have three striped devices, md2 (Samsung) and the poorly named md126 (Intel) and md127 (Dell).</p>
<pre>
<code>test_host:~$ cat /proc/mdstat
Personalities : [linear] [multipath] [raid0] [raid1] [raid6] [raid5] [raid4]
[raid10]
md0 : active raid1 sdb1[1] sda1[0]
307136 blocks [2/2] [UU]
md2 : active raid0 sdb5[1] sda5[0]
882155520 blocks super 1.2 512k chunks
md1 : active raid1 sdb2[1] sda2[0]
41910144 blocks super 1.2 [2/2] [UU]
md126 : active raid0 sdd[1] sdc[0]
937702400 blocks super 1.2 512k chunks
md127 : active raid0 sdf[1] sde[0]
586072064 blocks super 1.2 512k chunks
unused devices: <none>
</code>
</pre>
The striped Samsungs are really fast--84K IOPS from the stripe!
## Memory over committing: KSM (not KVM)
KSM, or Kernel Samepage Merging, is a memory de-duplication feature that is present in most Linux systems that support KVM. I wrote a bit about it in a [previous blog post](http://serverascode.com/2012/11/11/ksm-kvm.html). Basically if you up the scanning rate it will de-duplicate more memory. This means if I'm running 300 Ubuntu Precise images there is a lot of memory that can be de-duplicated.
## CPU over committing
I don't have a lot of information on how over committing CPU works in KVM, but there are some best practices documented by a couple organizations, which I have listed below. This is an area I need to do more research in.
- [IBM says:](http://publib.boulder.ibm.com/infocenter/lnxinfo/v3r0m0/index.jsp?topic=%2Fliaat%2Fliaatbpprocmem.htm)
** Target system use at max 80%--ie. each vm shouldn't be using 100% of their CPU, and in fact should max out at 80%
** Allocate minimum VCPUs per vm--ie. if the vm doesn't need four CPUs, rather say, only one, then just give it one
- [RedHat says](https://access.redhat.com/knowledge/docs/en-US/Red_Hat_Enterprise_Linux/6/html/Virtualization_Administration_Guide/sect-Virtualization-Tips_and_tricks-Overcommitting_with_KVM.html:)
** _Virtualized CPUs are over committed best when each guest only has a single VCPU. The Linux scheduler is very efficient with this type of load. KVM should safely support guests with loads under 100% at a ratio of five VCPUs. Over committing single VCPU guests is not an issue._
Notice that RedHat is saying a 5:1 ratio for CPU over committing.
## Disk space over committing
This is straight forward: image snapshots. qcow2 images can be created as snapshots of a backing file.
<pre>
<code>test_host:/mnt/intel$ file 263.img
263.img: QEMU QCOW Image (v2), has backing file
(path /mnt/intel/precise-server-cloudimg-amd64-disk1.qcow2), 2147483648 bytes
</code>
</pre>
This is also how OpenStack handles images. It puts one base image on the compute node and each instance based on that same image is backed by a qcow2 snapshot. I suppose we could do the same with LVM, if desired, using snapshots.
## Can't over commit IOPS
The part that is difficult in terms of running hundreds of vms on a single node is the amount of IOPS each vm takes up. In my experiments the Ubuntu cloud image doesn't really do anything at all in terms of IOPS--maybe one or two IOPS per image when they are idle. So if I'm running 300 images, they don't even use 300 IOPS when idle. Even during boot they hardly do anything. (Of course when they are working they could be using a lot of IOPS.)
But, if I boot 100 Windows 7 images five minutes apart, I need 5000 IOPS.
Yup: *5000 IOPS*.
Six SATA drives in RAID10 are going to barely provide 400 IOPS let alone 5000. So, SSDs, or at least some kind of faster storage, are required. Pretty much any SSD is capable of 5000 IOPS.
IMHO, it's a lot more efficient to run the Ubuntu cloud image than a standard Windows image.
## Load
Right now I have 300 Ubuntu images running, each being given 2048MB of memory.
<pre>
<code>test_host:~$ ps ax | grep "kvm -drive" | wc -l
300
</code>
</pre>
And load and memory usage are just fine. A bit of swapping, but that's Ok.
<pre>
<code>top - 10:58:13 up 8 days, 23:55, 2 users, load average: 1.35, 1.29, 1.92
Tasks: 845 total, 2 running, 843 sleeping, 0 stopped, 0 zombie
Cpu(s): 0.8%us, 3.1%sy, 0.0%ni, 95.9%id, 0.1%wa, 0.0%hi, 0.0%si, 0.0%st
Mem: 131997760k total, 122223236k used, 9774524k free, 142448k buffers
Swap: 33554424k total, 242172k used, 33312252k free, 42323472k cached
SNIP!
</code>
</pre>
They have been running for a few days, and are not using much in terms of IOPS as they are completely idle. Below is the output from [iostat](http://linuxcommand.org/man_pages/iostat1.html). All the vms are running off qcow2 images on the Intel 520 based stripe, md126.
<pre>
<code>avg-cpu: %user %nice %system %iowait %steal %idle
0.67 0.00 3.08 0.05 0.00 96.20
Device: tps MB_read/s MB_wrtn/s MB_read MB_wrtn
sda 16.40 0.00 0.17 0 1
sdb 16.40 0.00 0.17 0 1
sdc 44.70 0.00 0.16 0 1
sde 0.00 0.00 0.00 0 0
sdd 44.20 0.00 0.15 0 1
sdf 0.00 0.00 0.00 0 0
md127 0.00 0.00 0.00 0 0
md126 60.10 0.00 0.31 0 3
md1 35.20 0.00 0.17 0 1
md2 0.00 0.00 0.00 0 0
md0 0.00 0.00 0.00 0 0
dm-0 0.00 0.00 0.00 0 0
nb0 0.00 0.00 0.00 0 0
</code>
</pre>
It would be great to have IOPS usage on a per-process basis, but I couldn't find a tool that would do that. The best I could do is iostat with IOPS per storage device.
## Running tests
Each vm gets its IPs from dnsmasq running on an [Openvswitch](http://openvswitch.org/) bridge (topic of a future blog post). So we have 300 tap devices.
<pre>
<code>test_host:~/performance_testing$ sudo ovs-vsctl show
SNIP!
Port "tap166"
Interface "tap166"
Port "tap0"
Interface "tap0"
ovs_version: "1.4.0+build0"
test_host:~/performance_testing$ ifconfig | grep tap | wc -l
300
</code>
</pre>
I like using the [Ansible](http://ansible.cc) configuration management system. I've written a custom inventory script that pulls the IPs out of the dnsmasq lease file.
<pre>
<code>test_host:~/performance_testing$ ansible all -c ssh -i ./inventory.py \
-m ping -u ubuntu
SNIP 298 hosts!
192.168.100.98 | success >> {
"changed": false,
"ping": "pong"
}
192.168.100.99 | success >> {
"changed": false,
"ping": "pong"
}
</code>
</pre>
Then, using that inventory and Ansible I can run whatever load tests I want across however many virtual instances I want. For example I could run [fio](http://linux.die.net/man/1/fio) tests across 10% of the vms and watch the IOPS usage on the compute node.
If you have any questions, criticisms or concerns, please let me know by posting in the comments. :)
</none></code></pre>
Canadian OpenStack Users Group - CanStack!2013-02-20T00:00:00+00:00http://serverascode.com/2013/02/20/canstack<h1 id="canadian-openstack-users-group---canstack">Canadian OpenStack Users Group - CanStack!</h1>
<p>Recently I have started helping out the <a href="http://www.meetup.com/Canadian-OpenStack-Users-Group/">Canadian OpenStack Users Group</a>. With the support of my employer, I’ve put up a website called <a href="http://canstack.ca">CanStack</a> and a <a href="http://blog.canstack.ca">blog</a> for that site as well. And, of course, the obligatory <a href="http://twitter.com/canstack">twitter account</a>. There is even a github repository for the <a href="http://github.com/canstack/blog_posts">blog posts</a>, so contributing a post is only a git commit away! :)</p>
<p>The fun thing about the website and blog is that the website is hosted in a beta Canadian OpenStack-based cloud, and the blog is hosted in <a href="http://aws.amazon.com/s3/">Amazon S3</a>. I am a big proponent of object storage systems such as S3 and OpenStack Swift, so it was a good experience to get a static blog up on S3.</p>
<p>I use <a href="http://jekyllrb.com">jekyll</a> to generate the blog, just like I do this site, though <a href="http://serverascode.com">serverascode.com</a> is hosted by <a href="http://github.com">github</a>. Thanks github!</p>
<p>My hope with the CanStack website and blog is that they will help to find more members to bring together in our monthly meetings, and that hopefully we can provide some useful information about OpenStack as well.</p>
<p>I just put up a <a href="http://blog.canstack.ca/2013/02/14/vcl-openstack-reference-architecture.html">blog post</a> on how we are using OpenStack in a virtual classroom project, complete with what server and network hardware we are using, and even what data center!</p>
<p>So, if you are interested in what Canadians are doing with OpenStack, <a href="http://canstack.ca">canstack.ca</a> might be a good place to start.</p>
<p>As always, comments, suggestions, and criticisms are welcome. :)</p>
tcpflow2013-02-08T00:00:00+00:00http://serverascode.com/2013/02/08/tcpflow<h1 id="tcpflow">tcpflow</h1>
<p>This is just a quick little post on tcpflow.</p>
<p>I’ve been using <a href="http://graphite.wikidot.com/start">graphite</a> as a a graphing solution for system statistics. I’ve also been using <a href="https://github.com/rcrowley/carbon-relay-ng">carbon-relay-ng</a> to relay packets from different OpenStack projects to a central graphite server.</p>
<p>However, I’ve been having an issue (and am still having an issue actually) with concatenated packets arriving at the graphite server, despite the fact that the clients aren’t sending them.</p>
<p>In order to troubleshoot this I eventually started running tcpflow because it gave me cleaner output than tcpdump did…at least by default anyways. I’m sure that tcpdump can give me pretty much any output I need, but I liked the symplicity of tcpflow, for example:</p>
<pre>
<code>[root@stats ~]# tcpflow -c port 2003
tcpflow[11791]: listening on eth0
010.000.000.001.39216-010.000.000.006.02003: debbuild.cputotals.user 0 1360364000
010.000.000.001.39216-010.000.000.006.02003: debbuild.cputotals.nice 0 1360364000
010.000.000.001.39216-010.000.000.006.02003: debbuild.cputotals.sys 0 1360364000
010.000.000.001.39216-010.000.000.006.02003: debbuild.cputotals.wait 0 1360364000
010.000.000.001.39216-010.000.000.006.02003: debbuild.cputotals.idle 99 1360364000
010.000.000.001.39216-010.000.000.006.02003: debbuild.cputotals.irq 0 1360364000
010.000.000.001.39216-010.000.000.006.02003: debbuild.cputotals.soft 0 1360364000
010.000.000.001.39216-010.000.000.006.02003: debbuild.cputotals.steal 0 1360364000
SNIP!
</code>
</pre>
<p>vs.</p>
<pre>
<code>[root@stats ~]# tcpdump -nnvvXSs 1514 -i eth0 port 2003
tcpdump: listening on eth0, link-type EN10MB (Ethernet), capture size 1514 bytes
22:59:32.650673 IP (tos 0x0, ttl 64, id 41032, offset 0, flags [DF],
proto TCP (6), length 103)
10.0.0.1.39216 > 10.0.0.6.2003: Flags [P.], cksum 0xab18 (correct),
seq 1882211360:1882211411, ack 2847074948, win 115, options
[nop,nop,TS val 804219404 ecr 2428141312], length 51
0x0000: 4500 0067 a048 4000 4006 8642 0a00 0001 E..g.H`.`..B....
0x0010: 0a00 0006 9930 07d3 7030 4420 a9b2 ea84 .....0..p0D.....
0x0020: 8018 0073 ab18 0000 0101 080a 2fef 6a0c ...s......../.j.
0x0030: 90ba 7f00 636f 6c6c 6563 7464 3031 2d63 ....collectd01-c
0x0040: 6c69 656e 742d 7465 7374 2e74 6573 742e lient-test.test.
0x0050: 6669 7273 7420 2033 3530 3420 3133 3630 first..3504.1360
0x0060: 3336 3433 3733 0a 364373.
22:59:32.650750 IP (tos 0x0, ttl 64, id 53955, offset 0, flags [DF],
proto TCP (6), length 52)
10.0.0.6.2003 > 10.0.0.1.39216: Flags [.], cksum 0xc56c (correct),
seq 2847074948, ack 1882211411, win 501, options [nop,nop,TS val
2428143328 ecr 804219404], length 0
0x0000: 4500 0034 d2c3 4000 4006 53fa 0a00 0006 E..4..`.`.S.....
0x0010: 0a00 0001 07d3 9930 a9b2 ea84 7030 4453 .......0....p0DS
0x0020: 8010 01f5 c56c 0000 0101 080a 90ba 86e0 .....l..........
0x0030: 2fef 6a0c /.j.
SNIP!
</code>
</pre>
<p>One thing to note is the -c switch on tcpflow, it means print to the console instead of files in the local directory.</p>
<p>I would love to hear about other uses of tcpflow or ways to alter the output of tcpdump, so please let me know of anything interesting by commenting. :)</p>
Converting VMWare Windows images to OpenStack with virt-v2v2012-11-26T00:00:00+00:00http://serverascode.com/2012/11/26/converting-vmware-windows-to-openstack<h1 id="converting-vmware-windows-images-to-openstack-with-virt-v2v">Converting VMWare Windows images to OpenStack with virt-v2v</h1>
<p>As I’ve mentioned in previous posts, I’m currently working on a project that uses Apache VCL to provide university students with the ability to remotely login to a virtual machine and use specialized software to complete their classwork–a virtual computer lab if you will.</p>
<p>Because we are moving off our current backend to OpenStack, we need to convert Windows images from VMWare to something that will work in OpenStack/KVM.</p>
<h2 id="note-about-windows">Note about Windows…</h2>
<p>Let me note that I am not a “windows guy”–I haven’t really used windows in the last 10 years. Because I have usually been employed as a Unix/Linux admin, I’ve always either ran OpenBSD, Linux, or OSX on my desktop, and literally never had to work with Windows. Until now of course. ;)</p>
<h2 id="moving-the-backend-to-openstack">Moving the backend to OpenStack</h2>
<p>Currently we are in the process of moving the backend of our VCL system from a VMWare ESXi based cluster to OpenStack (Essex to be precise.) There are a lot of reasons for this move, and I won’t get into them here.</p>
<p>Unfortunately you can’t just take an ESXi image and drop it into OpenStack and have it work. Certainly we can actually import the image into glance, as vmdk images are supported, but the OS on the image will not have the virtio drivers for disk and network installed, drivers that OpenStack uses by default.</p>
<p>Neither is it as easy as just installing the drivers into the OS image while it’s running in ESXi. While I believe it’s possible to do this in Windows Server 2008, I don’t believe you can install drivers into Windows 7 without having the actual “hardware” accessible to the image (please correct me if I’m wrong–I’d love to hear that I am), not without some registry and other hacks outside of my purview.</p>
<p>This means we needed to find a way to convert the images from ones that work in VMWare ESXi, to ones that will work in OpenStack + KVM, preferably a way that doesn’t require me to learn anything about the Windows registry. ;)</p>
<h2 id="virt-v2v-to-the-rescue">virt-v2v to the rescue</h2>
<p>Fortunately RedHat provides a system called virt-v2v. This allows the cross-conversion of images for several different types of hypervisors.</p>
<p>The main things I found out about RedHat and virt-v2v are:</p>
<h1 id="some-of-the-packages-are-not-available-in-centos-or-at-least-i-couldnt-find-them-so-you-need-a-redhat-license-if-you-are-converting-images-from-vmware-esxi-to-openstack-then-you-probably-have-enough-money-in-the-project-to-buy-a-redhat-license-">Some of the packages are not available in CentOS, or at least I couldn’t find them, so you need a RedHat license. If you are converting images from VMWare ESXi to OpenStack, then you probably have enough money in the project to buy a RedHat license. ;)</h1>
<h1 id="it-doesnt-work-in-a-virtual-machineit-expects-hardware-virtualization-so-you-need-a-hardware-server-you-dont-need-much-just-enough-to-support-hardware-virtualization-with-kvm">It doesn’t work in a virtual machine–it expects hardware virtualization, so you need a hardware server. You don’t need much, just enough to support hardware virtualization with KVM.</h1>
<h1 id="currently-and-this-might-change-you-have-to-download-the-image-from-the-esxi-server-each-time-you-try-a-conversion-so-if-it-takes-a-long-time-to-download-then-the-conversion-will-also-take-a-long-time-to-finish">Currently, and this might change, you have to download the image from the ESXi server each time you try a conversion, so if it takes a long time to download, then the conversion will also take a long time to finish.</h1>
<p>I’m sure most of the above could be changed with a bit of Perl hacking, but as far as I can tell, without changing any of the RedHat code you do need to meet those requirements.</p>
<p>Note–RedHat has pretty good <a href="https://access.redhat.com/knowledge/docs/en-US/Red_Hat_Enterprise_Virtualization_for_Desktops/2.2/html/Administration_Guide/virt-v2v-scripts.html">documentation</a> on the subject, a few quick google searches will tell you as much as I know. :)</p>
<h2 id="installing-virt-v2v">Installing virt-v2v</h2>
<p>First, as I’ve mentioned, you need a hardware server with RedHat Enterprise 6.x on it.</p>
<pre>
<code>[root@localhost ~]# cat /etc/redhat-release
Red Hat Enterprise Linux Server release 6.3 (Santiago)
</code>
</pre>
<p>It needs to be registered with the RedHat Network and have the “RHEL Server Supplementary” and “RHEL V2VWIN” channels enabled, as per the below image.</p>
<p><img src="https://raw.github.com/ccollicutt/ccollicutt.github.com/master/img/rhn_entitlements_virt-v2v.png" alt="" /></p>
<pre>
<code>[root@localhost ~]# yum repolist
Loaded plugins: product-id, rhnplugin, subscription-manager
Updating certificate-based repositories.
Unable to read consumer identity
repo id repo name status
rhel-x86_64-server-6 Red Hat Enterprise Linux Server (v. 6 for 64-bit x86_64) 8,712
rhel-x86_64-server-supplementary-6 RHEL Server Supplementary (v. 6 64-bit x86_64) 311
rhel-x86_64-server-v2vwin-6 RHEL V2VWIN (v. 6 for 64-bit x86_64) 2
repolist: 9,025
</code>
</pre>
<p>Once those are configured, install the following packages.</p>
<pre>
<code>[root@localhost ~]# yum install virt-v2v virtio-win libguestfs-winsupport libvirt
</code>
</pre>
<p>And then reboot.</p>
<p>Once the server has rebooted, start libvirtd if it isn’t already.</p>
<pre>
<code>[root@localhost ~]# service libvirtd start
</code>
</pre>
<p>Next we need to add a storage pool to libvirt. In this example, just because of the way RHEL defaulted my temporary install, we have a huge /home/images directory in which to put the converted images.</p>
<pre>
<code>[root@localhost ~]# df -h /home
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/VolGroup-lv_home
5.4T 235G 4.9T 5% /home
[root@localhost ~]# cat pool.xml
<pool type="dir">
<name>virtimages</name>
<target>
<path>/home/images</path>
</target>
</pool>
</code>
</pre>
<p>Using that pool.xml file, we’ll configure the pool.</p>
<pre>
<code>[root@localhost ~]# virsh pool-create --file pool.xml
[root@localhost ~]# virsh pool-list
Name State Autostart
-----------------------------------------
virtimages active no
</code>
</pre>
<p>Finally, we configure a .netrc file, obviously entering the proper ESXi host, login, and password.</p>
<pre>
<code>[root@localhost ~]# cat .netrc
machine <esxi host=""> login <login> password <password>
</code>
</pre>
Now we can run virt-v2v!
<pre>
<code>[root@localhost images]# virt-v2v -ic esx://<esxi host="">/?no_verify=1 -o libvirt
-os virtimages <exsi vm="" name="">
<esxi vm="" name="">: 100% [========================]D 0h51m16s
virt-v2v: WARNING: No mapping found for bridge interface public in config file.
The converted guest may not start until its network interface is updated.
virt-v2v: <esxi vm="" name=""> configured with virtio drivers.
</code>
</pre>
I don't worry about the "No mapping" message.
## Bring that image into OpenStack
Now that we have an image in the libvirt pool we configured, it's time to:
# Convert the raw/vmdk image to qcow2 using "qemu-img".
# Import the converted qcow2 image into glance.
# Boot the image once and manually login to finish off virt-v2v's "firstboot" scripts. This means you need an admin login to the image.
# "Set" the hardware, make any changes to the instance such as updating and the like.
# Shut down the instance.
# Create a new OpenStack image from that instance using _nova image-create_.
# Then delete the original image, and instance booted from it, if you want. It's not much use except for archival purposes.
# Boot a new instance from the new image, the one created with _nova image-create_, just to make sure it all works out Ok.
At this point you should, hopefully, have a working Windows image, one that was converted from VMWare ESXi!
</esxi></esxi></exsi></esxi></code></pre></password></login></esxi></code></pre>
KSM and KVM2012-11-11T00:00:00+00:00http://serverascode.com/2012/11/11/ksm-kvm<h1 id="ksm-and-kvm">KSM and KVM</h1>
<p><em>UPDATE: I did some more research and have a better idea of what pages_saved and pages_saving means. So we are saving quite a bit of memory!</em></p>
<p>I recently found out about the <a href="http://www.linux-kvm.org/page/KSM">ksm</a> technology that is in Ubuntu 12.04 + kvm by default. ksm is a memory de-duplication process. As far as I understand it, ksm can allow virtual machines (actually any application, not just virtualization) to share memory pages–it finds all duplicated memory pages and merges them, thereby saving memory in some situations.</p>
<p>One of the projects I am working on is a classroom as a service, or virtual classrooms. Students can login to a web gui and request a reservation to a virtual machine image which they can then access with a RDP client.</p>
<p>In this project all of the images are based on–unfortunately–Windows 7. One would think that if we are running many similar Windows 7 images ksm could do a lot of de-duplication.</p>
<p>I have been doing a few experiments in my spare time to see if ksm can help to over-commit memory. If I can I’d rather be able to run 400 virtual machines than 200. If we can over-commit on memory 1:2 or 1:4 there could be substantial cost savings for the project.</p>
<h2 id="the-test">The Test</h2>
<p>I have a basic Windows 7 image in qcow2 format.</p>
<pre>
<code>root@ksm_test:/mnt/ksm-test$ file win7-base.qcow2
win7-base.qcow2: QEMU QCOW Image (v2), 21474836480 bytes
</code>
</pre>
<p>I am going to run 30 Windows 7 images with four gigs of ram and two virtual cpus each, based off a qcow2 snapshot from the original backing image.</p>
<p>The server I am running this test on is a <a href="http://www.dell.com/us/enterprise/p/poweredge-c6220/pd">Dell c6220</a> with 32 HT cores and 128 gigs of main memory.</p>
<p><em>ASIDE: /mnt/ksm-test is an xfs file system. I found that this test on a ext4 based filesystem used considerably more IOPs than xfs because the jdb2 process was doing a lot of journaling. There are likely some settings I should be using with ext4 to get better performance, but instead I just hopped over to xfs and haven’t gone back to ext4 yet.</em></p>
<p>This is the little script I use to boot the vms:</p>
<pre>
<code>root@ksm_test:~$ cat test_ksm.sh
#!/bin/bash
# How much memory to boot with
MEM=4048
BACKING_DIR=/mnt/ksm-test
BACKING_FILE=win7-base.qcow2
SLEEP=60
pushd $BACKING_DIR
for i in {1..30}; do
echo "====> Starting a new instance..."
# Remove the old backing file
rm -f win7-$i.qcow2
# Create a new backing file that is a qcow2 snapshot of the original file
qemu-img create -f qcow2 -b $BACKING_FILE win7-$i.qcow2
# Actually start the intstance
/usr/bin/kvm \
-M pc-1.0 \
-smp 2,sockets=2,cores=1,threads=1 \
-enable-kvm \
-m $MEM \
-drive file=win7-$i.qcow2,if=virtio \
-boot d \
-net nic,model=virtio \
-net user \
-nographic \
-vnc :$i \
-device virtio-balloon-pci,id=balloon0,bus=pci.0,addr=0x5 \
-daemonize
# Let's just sleep for a few seconds...
echo "====> Sleeping for $SLEEP..."
sleep $SLEEP
done
popd
exit 0
</code>
</pre>
<p>After that script runs we have 30 kvm Win7 instances running:</p>
<pre>
<code>root@ksm_test:/mnt/ksm-test$ ps ax |grep "bin\/kvm" | wc -l
30
</code>
</pre>
<p>For the first while things are a little crazy on the host because 30 Windows 7 vms just booted in 30 minutes. After a few hours, or rather overnight, the vms settle down quite a bit to just doing a few IOPs each.</p>
<p>As far as what these vms are doing–I login to a couple every once and a while just to make sure they are up, but otherwise they are doing nothing but whatever they do by default.</p>
<h2 id="the-defaults">The Defaults</h2>
<p>ksm is enabled in Ubuntu by default when using kvm. However, the defaults are fairly conservative:</p>
<pre>
<code>root@ksm_host:~$ cat /sys/kernel/mm/ksm/pages_to_scan
100
root@ksm_host:~$ cat /sys/kernel/mm/ksm/sleep_millisecs
200
</code>
</pre>
<p>ksm will scan 100 pages, sleep for 200 milliseconds and then scan 100 more, and so on. But with millions of pages it will take a long, long time to scan all of them.</p>
<p>I set the pages_to_scan to 20000 and sleep_millisecs to 20–I’m guessing these are pretty aggressive settings.</p>
<pre>
<code>root@ksm_host:~$ echo "20000" > /sys/kernel/mm/ksm/pages_to_scan
root@ksm_host:~$ echo "20" > /sys/kernel/mm/ksm/sleep_millisecs
</code>
</pre>
<h2 id="the-results">The Results</h2>
<p>I suppose saying “results” sounds scientific. :)</p>
<p>The reality is that I’m really just cutting and pasting the ksm information that has been recorded after several days of running 30 Windows 7 virtual machines that should all be very close in terms of memory use.</p>
<p>From the <a href="http://www.kernel.org/doc/Documentation/vm/ksm.txt">ksm.txt</a> file:</p>
<pre>
<code>A high ratio of pages_sharing to pages_shared indicates good sharing,
but a high ratio of pages_unshared to pages_sharing indicates wasted
effort. pages_volatile embraces several different kinds of activity,
but a high proportion there would also indicate poor use of madvise
MADV_MERGEABLE.
</code>
</pre>
<p>And the results of ksm after a few days of running 30 vms…</p>
<p></pre></p>
<pre>
<code>root@ksm_test:~$ for i in `ls -1 /sys/kernel/mm/ksm`; \
do echo "===> $i"; cat /sys/kernel/mm/ksm/$i; done
===> full_scans
5417
===> pages_shared
443355
===> pages_sharing
26704343
===> pages_to_scan
20000
===> pages_unshared
3164064
===> pages_volatile
183552
===> run
1
===> sleep_millisecs
20
</code>
</pre>
<p>So, if I understand these numbers correctly, pages_shared is the amound of memory ksk is actually using. Thus in this example, ksm is using 1.7GB of memory:</p>
<pre>
<code>root@ksm_test:~$ getconf PAGESIZE
4096
</code>
</pre>
<p>So if we have 443355 pages shared, ksm is using this many bytes:</p>
<pre>
<code>root@ksm_test:~$ echo "443355 * 4096" | bc
1815982080
</code>
</pre>
<p>which is about 1.7GB.</p>
<p>However, saved memory, ie. pages_sharing, is quite high! So this is good. :)</p>
<pre>
<code>root@ksm_test:~$ echo $((26704343*`getconf PAGE_SIZE`/1024/1024/1024)) GB
101 GB
</code>
</pre>
<p>I’m not sure how this equates to all the memory being used on the machine, but as far as ksm is concerned it’s saving us about 100 gigs. Nice.</p>
<pre>
<code>root@ksm_test:~$ free
total used free shared buffers cached
Mem: 131997772 131556896 440876 0 108448 108129628
-/+ buffers/cache: 23318820 108678952
Swap: 41943032 302836 41640196
</code>
</pre>
<p>Update: Now that I have a better understanding of what ksm is doing and what it’s numbers mean, using a modified version of <a href="http://aionica.computerlink.ro/2011/08/ksm-kernel-samepage-merging-status/">this script</a> we can see some interesting results, though in the below example I am running 60 2 gig 1 vcpu instances instead of 30 4 gig 2 vcpu instances like the rest of this post:</p>
<pre>
<code>root@ksm_test:~$ ./ksm_stat.sh
Shared memory is 2071 MB
Saved memory is 95514 MB
Unshared memory is 21336 MB
Volatile memory is 2549 MB
Shared pages usage ratio is 46.11
Unshared pages usage ratio is .22
</code>
</pre>
<p>So thanks for reading, and if you have any suggestions as to what I might be doing incorrectly, be it settings or my math or my general assumptions about ksm :), please let me know in the comments.</p>
OpenStack 2012 Summit Day #42012-10-18T00:00:00+00:00http://serverascode.com/2012/10/18/openstack-summit-day-4<h1 id="openstack-2012-summit-day-4">OpenStack 2012 Summit Day #4</h1>
<h2 id="security-track">Security Track!</h2>
<p>Having been a security administrator at a medium sized University; having taking fairly extensive education in Information Security; having attended security conferences like CanSec West and H.O.P.E I am happy that all of Thursday has a dedicated security track. Unfortunately I can only attend a couple of sessions, but at least I can do that much. :)</p>
<h2 id="creating-an-openstack-security-group">Creating an OpenStack Security Group</h2>
<p>Bryan D. Payne from Neubula and Robert Clark from HP talk about the need for a OpenStack Security Group. The <a href="https://launchpad.net/~openstack-ossg">OSSG</a> is “hiring”, ie. need volunteers especially security engineers, technical writers, and security experts that operate OpenStack clouds.</p>
<p>Computer Security</p>
<ul>
<li>Design for security from the start</li>
<li>Understand your threats</li>
<li>Understand your goals</li>
<li>Pervasive security culture (not just “that paranoid guy has it under control”)</li>
</ul>
<p>Security Challenges for OpenStack</p>
<ul>
<li>Security as an afterthought</li>
<li>Security as silos</li>
<li>Security by non-experts</li>
</ul>
<p>There was some mention of the <a href="https://cloudsecurityalliance.org">Cloud Security Alliance</a> which Bryan is a co-lead on a workgroup for and that the CSA is a more oriented to high-level theory whereas the OSSG will need to be directed at applied security.</p>
<h2 id="delivering-secure-openstack-iaas-for-saas-products">Delivering Secure OpenStack IaaS for SaaS Products</h2>
<p><em>“Everyone has a great plan until they get punched in the mouth”</em>–Mike Tyson</p>
<p>Andrew Hay, is the Chief Evangelist at CloudPassage, Inc. where he serves as the public face of the company and its cloud server security product portfolio.</p>
<p>Three places to “put security” in OpenStack</p>
<ul>
<li>Quantum
** Coolest thing about Quantum is the ability to inject 3rd party products</li>
<li>Keystone</li>
<li>Nova</li>
<li>Security groups/firewalling with iptables</li>
<li>VLANS</li>
<li>Initial configuration of nova</li>
</ul>
<p>Issues in Cloud Security</p>
<ul>
<li>Host security</li>
<li>Security of images
** Network-based security is only so good in multitenant cloud</li>
<li>The ultimate target is the endpoint–so secure it</li>
<li>Cloud servers are more exposed</li>
<li>De-provisioning of servers releases public IPs that might have the wrong firewall rules</li>
</ul>
<p>He then went over some basic host security concepts, quite a few of which I disagree with, or at least he wasn’t able to really go into depth with what he actually meant by them.</p>
<p>Generally speaking I think host security has been reduced mostly because in OpenStack most people use images that have already been provided to them and don’t run any specific configuration management (ie. chef/puppet/<a href="http://ansible.cc/">ansible</a>) “hardening” processes.</p>
<p>Nor do people usually build their own OpenStack images, which I think is an important skill to have. Though if more OS vendors provided base OpenStack images things would be a little easier. As far as I know, at this time, only Ubuntu publishes OpenStack compatible <a href="http://docs.openstack.org/trunk/openstack-compute/admin/content/starting-images.html">cloud</a> <a href="http://cloud-images.ubuntu.com/">images</a>.</p>
<h2 id="sdsc">SDSC</h2>
<p>Unfortunately, or fortunately, depending on your perspective, that was all the OpenStack security talks I was able to attend on Thursday because I had to go to a meeting at the San Digeo Super Computing Center, or the <a href="http://www.sdsc.edu/">SDSC</a>, and wasn’t able to come back to the summit.</p>
<p>I was excited to go to find out more about what they are doing, especially because they have one of the largest <a href="https://cloud.sdsc.edu/hp/index.php">OpenStack Swift installations</a> in the world. I think about five petabytes worth.</p>
<p>They were also very excieted about their new supercomputer <a href="http://www.sdsc.edu/News%20Items/PR030512_gordon.html">Gordon</a>, which has a ton of SSD storage (ie. flash–get it…gordon + flash).</p>
<p>Also they had some old tape systems they were retiring. Tape is not dead yet though!</p>
<p><img src="https://raw.github.com/ccollicutt/ccollicutt.github.com/master/img/sdsc_tape_silo.jpg" alt="" />
<em>(old tape silo being retired; sad to see it go)</em></p>
OpenStack 2012 Summit Day #32012-10-17T00:00:00+00:00http://serverascode.com/2012/10/17/openstack-summit-day-3<h1 id="openstack-2012-summit-day-3">OpenStack 2012 Summit Day #3</h1>
<h2 id="keynotes">Keynotes</h2>
<p>HP says something enterprise business-like. Not too sure. 100s of billions of “spend” available. Capex -> Opex. Many, many slides with business pictographs.</p>
<p><a href="https://twitter.com/troytoman">Troy Toman</a> from Rackspace talks about how proud they are of OpenStack. Brags about how Rackspace’s contribution percentage has actually reduced from 54% in Essex and 30% in Folsom and how that is a good thing, which it is. :)</p>
<p>Notes from Rackspace’s production usage of OpenStack:</p>
<ul>
<li>They have Quantum and <a href="http://wiki.openstack.org/Melange">Melange</a> in production</li>
<li>Glance is backed by Swift</li>
<li>They have deployed the Cells code; at least three cells in each regon</li>
<li>Three regions worldwide</li>
<li>All of the “control” pieces, eg. API servers, are running on a private OpenStack cloud; an internal infrastructure called <em>inova</em></li>
<li>Continuous delivery model for building and deploying to cloud–they pull from trunk at least once a day, and do this in under and hour, and have been deploying this once a week or so.</li>
<li>Fail fast fix fast</li>
<li>Coming soon: block storage and network products</li>
<li>Releasing PHP and Java cloud SDKs</li>
</ul>
<p>Cisco Webex talks about what they do. Lots of open source technologies…puppet, salt, cobbler, etc to run a private cloud so they have “one throat to choke”.</p>
<h2 id="service-resiliency-doesnt-always-mean-ha-or-cluster">Service Resiliency Doesn’t Always mean “HA” or “Cluster”</h2>
<p>The guys from CloudScaling talk about redundancy patterns. This was actually pretty fascinating, and looks like they have taken care of a lot of scale-out redundancy, specifically not “HA-mmer” pairs, all the way up to the DB level, at which part they fall back to MMR MySQL.</p>
<h1 id="ha-pairs-are-not-the-only-type-of-redundancy">“HA” pairs are not the only type of redundancy</h1>
<ul>
<li>Airplanes require seven catastrophic failures to fall out of the sky, whereas with HA pairs you just need one layer to fail</li>
<li>Create small failure domains that don’t propagate = scale up
<h1 id="alternative-redundancy-patterns">Alternative redundancy patterns</h1>
<h1 id="redundancy-patterns-in-open-source-cloud-software">Redundancy patterns in Open Source Cloud Software</h1>
</li>
</ul>
<p>CloudScaling have come up with a methodology for “HA” they call Service Distribution.</p>
<p>Service Distribution</p>
<ul>
<li>Resilient</li>
<li>Stateless</li>
<li>Scale-out</li>
<li>Implementation</li>
<li>OSPF (quagga), Anycast (zebra), Load-balancing proxy (pound)</li>
<li>Perfect for site resiliency</li>
<li>Traditional HA pairs don’t support this</li>
<li>Use ZeroMQ (peer-to-peer) vs RabittMQ and CloudScaling contributed the code back to OpenStack for ZeroMQ</li>
<li>Making data centers look like ISP backbones</li>
</ul>
<p></p>
<h2 id="cirros-cloud-init-the-future-of-cloud-guests">CirrOS, cloud-init: the future of cloud guests</h2>
<p>I think the dev sessions are really about starting conversations that will be finished elsewhere, and if you aren’t fairly deep into the topic there’s not a lot of ways to get your head into the session. I’ve felt the pain of the lack of Cloud-init in Redhat. I’m surprised that there is just one person creating Cirros.</p>
<p>Topics Covered</p>
<ul>
<li>Cirros</li>
<li>Cloud-init</li>
<li>Config drive 2</li>
<li>Execute code from metadata in various ways</li>
</ul>
<h2 id="adding-openvz-support-to-nova">Adding OpenVZ support to Nova</h2>
<p>Rackspace has code that will eventually make it’s way into trunk for using OpenVZ in OpenStack. The session leader, Devananda van der Veen, has created a way to build an OpenVZ kernel on Ubuntu. Rackspace uses OpenVZ to run their cloud database system because they get better performance than using something like KVM for virtualization.</p>
<ul>
<li><a href="https://github.com/openstack-ci/devstack-gate">devstack-gate</a></li>
<li><a href="http://etherpad.openstack.org/grizzly-nova-openvz">Etherpad for this session</a></li>
</ul>
<p>Most of the discussion was about how to get the OpenVZ driver into the OpenStack continuous integration system.</p>
<h2 id="cloud-hosted-desktops-and-openstack">Cloud Hosted Desktops and OpenStack</h2>
<p>Ken Ringdahl, Vice President Engineering, Desktone discusses Desktop as a Service. I’m interested in this topic not because I’m interested in the topic, but because the project I’m currently working on is essentially desktop in the cloud via <a href="https://cwiki.apache.org/VCL/apache-vcl.html">Apache VCL</a> and I’m constantly thinking about how to get off VCL and away from it’s 40k lines of perl, and just use OpenStack with a thin layer on top of it. The reality is that OpenStack has 95% of the code required to implement a service similar to VCL.</p>
<p>So Ken goes through his slides. Mentions VDI and that VDI is hard! Capex, buy more hardware, can’t fit it in their data center, SAN administrators, etc. VDI is tough. But DaaS is not VDI.</p>
<p>The point of the session is that DaaS is a three billion dollar market and is a new business area that OpenStack can access. Further he talks about the fact that running a desktop resource manager/broker on top of OpenStack can create operational and other cost savings. It also allows and organization like Desktone to focus on user experience versus running infrastructure.</p>
<p>Desktops are Different:</p>
<ul>
<li>Storage is key</li>
<li>Random IO</li>
<li>Write intensive IO</li>
<li>Scale: 500 servers is a lot, 500 desktops is not</li>
<li>Optimize OpenStack for DaaS</li>
<li>HA for desktops is different from servers</li>
<li>The future of VDI is non-persistence…nothing stored in VMs</li>
<li>
<h1 id="of-vms-under-management-requires-a-different-approach">of VMs under management requires a different approach</h1>
</li>
<li>Eg. VM and guest state changes</li>
<li>Monitoring is critically important</li>
<li>DaaS encompasses all parts of OpenStack</li>
</ul>
OpenStack 2012 Summit Day #22012-10-16T00:00:00+00:00http://serverascode.com/2012/10/16/openstack-summit-day-2<h1 id="openstack-2012-summit-day-2">OpenStack 2012 Summit Day #2</h1>
<h2 id="keynotes">Keynotes</h2>
<p>The keynotes mostly focused on the increased sized of the OpenStack community and the creation of the foundation that now runs OpenStack. Except Shuttleworth’s in which he used Juju to live upgrade from Essex to Folsom which turned some heads. It’s the first time I’ve heard him speak, and he seemed exactly like the kind of person that can sit in-between business and open source. Chris Kemp was good, and took a couple of shots at VMWare which I always think is fun. ;)</p>
<h2 id="high-availability">High Availability</h2>
<p>Florian Haas of <a href="http://www.hastexo.com/">Hastexo</a> presented an update on high-availability with OpenStack. The company I currently work for has, in the past, contracted Florian/Hastexo to consult on OpenStack deployments and I like the things that he says. He’s the go to person for HA + OpenStack.</p>
<p>He talked at length about <a href="http://clusterlabs.org/wiki/Pacemaker">Pacemaker</a> which is a cluster resource manager. Interestingly he notes that it runs air traffic control systems. Also he mentions that it is extremely friendly to 3rd party functionality via plugins/resource agents,</p>
<p>He also went through the OpenStack High Availability Guide which he was largely responsible for creating, and mentioned that it is in <a href="https://github.com/openstack/openstack-manuals/tree/master/doc/src/docbkx/openstack-ha">source control</a> and thus people can contribute patches.</p>
<p>The slides for this talk are <a href="http://www.hastexo.com//resources/presentations/high-availability-update">online</a>.</p>
<h2 id="frameworks-and-apis-for-advanced-service-insertion">Frameworks and APIs for Advanced Service Insertion</h2>
<p>This was a developer session on the future methodologies of inserting things like firewalls, load balancers and such into Quantum. It was interesting to hear some of the thoughts on the topologies of Quantum and how OpenStack is trying not just to replicate existing networking technologies, but create something new. It was nice to hear the word router with an Italian accent. OpenStack is a global project.</p>
<h2 id="lunch">Lunch</h2>
<p>Not much to say, on this. There was tortilla soup though. :)</p>
<h2 id="the-future-of-infrastructure-automation">The Future of Infrastructure Automation</h2>
<p>This session was not what I thought it was going to be. I didn’t realize it was part of the strategy track until I was sitting down listening, and so before knowing that I figured it would be about what comes after puppet/chef/etc…which it was not.</p>
<p>I don’t have a lot to say about this session, other than the speaker liked <a href="http://www.webhooks.org/">webhooks</a> and push notifications, that it would be nice to for a guest in OpenStack to be able to write metadata instead of just reading, and that some organizations are working on this functionality. I definitely would like to be able to write metadata from guests so that was good to hear.</p>
<h2 id="surviving-your-first-check-in-an-engineers-guide-to-contributing-to-openstack">Surviving your first check-in: An engineers guide to contributing to OpenStack</h2>
<p>This was a great session on lessons learned by an engineer (specifically not a developer), <a href="http://www.colinmcnamara.com/">Collin McNamera</a>, who wanted to contribute code to OpenStack. To get his code into OpenStack he had a ratio of 100:1 in terms of time spent figuring out how to contribute and waiting for answers vs actually coding. That was for his first contribution so the ratio is better now, but it was a tough slog at first.</p>
<p>Lessons learned:</p>
<ul>
<li>Join, or start, a local meetup group</li>
<li>Make sure that according to your employer you can contribute code to OpenSource projects</li>
<li>Execute your OpenStack CLA (contributor license agreement)</li>
<li>Setup your dev environment, probably using virtual machines</li>
<li><a href="http://devstack.org/">Devstack</a></li>
<li>With devstack you can point it to a different OpenStack git repo if you want</li>
<li>Use vm snapshotting to help you keep using your dev environment</li>
<li>Configure git with your name, email, etc and this will save time in the future. Do it right first!</li>
<li>Install git-review</li>
<li>Clone a project, or use the directories that came with Devstack</li>
<li>Add your ssh key to OpenStack Code Review</li>
<li>Create a topic branch</li>
<li>Change code</li>
<li>Test code: run_tests.sh</li>
<li>Commit changes - make sure to put a bug id or blueprint # in the first line</li>
<li>Then give back to the community by teaching others! :)</li>
</ul>
<p>While it’s disappointing to hear how hard it is to contribute code, Collin was a great speaker is obviously passionate about doing good open source work and contributing back to the community.</p>
<h2 id="swift-project-update">Swift Project Update</h2>
<p>As I mentioned in my <a href="http://serverascode.com/2012/10/15/openstack-summit-day-1.html">previous post</a> I am a big fan of object storage, so Swift is an important project to me. :)</p>
<ul>
<li>New features in the last six months</li>
<li>Folsom version of Swift is 1.7.4</li>
<li>Unique-as-possible - Allows more flexible growth, and more harddrives as hand-off nodes</li>
<li>Deep statsd integration - Enables notifications that things like graphite can graph</li>
<li>SSD optimization - It turns out that in large clusters the account and container servers can become limited by IOPs.</li>
<li>Versioned writes - This feature is “almost” there</li>
<li>Moved swift client into it’s own project</li>
</ul>
<p></p>
<ul>
<li>Code golf for the last six months</li>
<li>37 people have contributed</li>
<li>20 have provided their first patch</li>
<li>Three new core developers</li>
<li>170 total commits</li>
<li>17 is the most files touched by a single commit (statsd integration)</li>
<li>3466 is the most lines removed in a single patch (moving swift-client out to a new project)</li>
</ul>
<p></p>
<ul>
<li>What’s next?</li>
<li>Global clusters - ie. Geographic replication, will hopefully be in Grizzly</li>
<li>CORS Support - Better integrate with the browser security model</li>
<li>Optimize concurrent reads</li>
</ul>
<p><img src="https://raw.github.com/ccollicutt/ccollicutt.github.com/master/img/nebula_pool.jpg" alt="" />
<em>(Nebula logo projected on the pool at the club)</em></p>
<h2 id="parties">Parties</h2>
<p>This night I went to both the Rackspace and Nebula parties, though I came back to the hotel pretty early. At the Rackspace party I learned that Miramar, the location of the flight school in Top Gun, is only a few minutes away and actually watched some military jets maneuvering out over the ocean. Surprised no one sang <em>You’ve Lost That Loving Feeling</em>. ;)</p>
<p><img src="https://raw.github.com/ccollicutt/ccollicutt.github.com/master/img/topgun.jpg" alt="" /></p>
ipmitool and BIOS Access2012-10-16T00:00:00+00:00http://serverascode.com/2012/10/16/dell-ipmi-bios<h1 id="ipmitool-and-bios-access">ipmitool and BIOS Access</h1>
<p>When I put my systems administrator hat on one of the things that bothers me is getting remote access to the BIOS. I love to use the command line, and any time I have to fire up a GUI of some kind to do work I get an icky feeling.</p>
<p>So when I had to remotely access some Dell C6220s to turn on virtualization, which is off by default in these Dell servers, I didn’t want to have to go through the rigamarole of getting the right OS configuration that would allow me to remotely access the console via a web-based Java GUI run out of Firefox. Even writing that sentence takes too long. So I thought I would try out serial over lan (SOL) access.</p>
<p>And it works!</p>
<pre>
<code>server2 $ ipmitool -I lanplus -H server1-ipmi -U root -P password sol activate
[SOL Session operational. Use ~? for help]
Ubuntu 12.04.1 LTS server1 ttyS1
server1 login:
</code>
</pre>
<p>If we reboot the server we can see all the usual boot screens and can access them all without having to fire up the Java based console, instead I can just ssh into a second server that has access to the ipmi network and connect with ipmitool.</p>
<p>Here are some of the key mappings that will help to use ipmitool. The main thing to note is how to exit from the SOL session, and to do that you basically hit ENTER the a tilde, then a period. (For some reason this will usually log me not only out of the SOL session, but also the ssh session. Something to look into.)</p>
<pre>
<code>server2 $ ipmitool -I lanplus -H 10.10.10.10 -U username -P password sol activate
[SOL Session operational. Use ~? for help]
Here are some useful commands:
KEY MAPPING FOR CONSOLE REDIRECTION:
Use the <ESC><0> key sequence for <F10>
Use the <ESC><!> key sequence for <F11>
Use the <ESC><@> key sequence for <F12>
Use the <ESC><Ctrl><M> key sequence for <Ctrl><M>
Use the <ESC><Ctrl><H> key sequence for <Ctrl><H>
Use the <ESC><Ctrl><i> key sequence for <Ctrl><i>
Use the <ESC><Ctrl><J> key sequence for <Ctrl><J>
Use the <ESC><X><X> key sequence for <Alt><x>, where x is any letter
key, and X is the upper case of that key
Use the <ESC><R><ESC><r><ESC><R> key sequence for <Ctrl><Alt><del>
Help commands from ~?:
Supported escape sequences:
~. - terminate connection
~^Z - suspend ipmitool
~^X - suspend ipmitool, but don't restore tty on restart
~B - send break
~? - this message
~~ - send the escape character by typing it twice
(Note that escapes are only recognized immediately after newline.)
</code>
</pre>
There are all kinds of things one can do with ipmitool other than terminal based BIOS access, and I won't list all of them here, but one nice thing is the ability to set the boot device, for example setting the boot device to disk and doing so for all future reboots.
<pre>
<code>server2 $ ipmitool -H 10.10.10.10 -U root -P password chassis bootdev disk \
options=persistent
</code>
</pre>
Here are the kernel configs I used to tell Ubuntu to use serial. Note that I added the "\" in the text below, so you can't just cut and paste it; needs to be all on one line.
<pre>
<code>pxeboot-server:/tftp/pxelinux.cfg# cat default
# D-I config version 2.0
DEFAULT server
prompt 0
timeout 1
# serial console
console 0
serial 0 115200 0
LABEL server
kernel ubuntu-installer/amd64/linux
append ramdisk_size=14984 locale=en_US keyboard-configuration/layoutcode=us \
console-keymaps-at/keymap=us locale=en_US console-setup/layoutcode=en_US \
netcfg/wireless_wep= netcfg/choose_interface=eth0 netcfg/get_hostname=c01-07 \
url=http://10.10.10.10/node.preseed vga=normal \
initrd=ubuntu-installer/amd64/initrd.gz -- \
console=ttyS1,115200 earlyprint=serial,ttyS1,115200
</code>
</pre>
Finally I'll show a screenshot of a text install happening, and I am watching that via text-based SOL access.
So give SOL a shot, and let me know if I've made any mistakes in this post, or if there are other interesting things that can be done with ipmitool. :)
</del></Alt></Ctrl></R></ESC></r></ESC></R></ESC></x></Alt></X></X></ESC></J></Ctrl></J></Ctrl></ESC></i></Ctrl></i></Ctrl></ESC></H></Ctrl></H></Ctrl></ESC></M></Ctrl></M></Ctrl></ESC></F12></ESC></F11></ESC></F10></ESC></code></pre>
OpenStack 2012 Summit Day #12012-10-15T00:00:00+00:00http://serverascode.com/2012/10/15/openstack-summit-day-1<h1 id="openstack-2012-summit-day-1">OpenStack 2012 Summit Day #1</h1>
<p>This week I’m at the OpenStack 2012 Summit. It’s by far the biggest conference I’ve been to. Usually I go to conferences on security, such as <a href="http://en.wikipedia.org/wiki/Hackers_on_Planet_Earth">H.O.P.E</a> or <a href="http://cansecwest.com/">CanSec</a> or even smaller library related conferences. Given that OpenStack is one of the fastest growing open source projects of all time, it’s no surprise to find out that the conference has grown from 75 people a couple years ago, to about 1300 this year, up from 700 only a year ago. It’s massive and it’s growing.</p>
<h2 id="tldr">tl;dr</h2>
<ul>
<li>Need to get into Ceph</li>
<li>Database as a service too</li>
<li>Upgrading is a big issue in OpenStack</li>
<li>San Diego is nice</li>
<li>OpenStack is kinda a big deal</li>
</ul>
<h2 id="opening-keynote">Opening “keynote”</h2>
<p>Not much to say here, some summit housekeeping with trippy techno rave music to wake me up. :)</p>
<h2 id="open-compute">Open Compute</h2>
<p>The first session I attended was by <a href="https://twitter.com/coleinthecloud">Cole Crawford</a> of the <a href="http://opencompute.org/">Open Compute Foundation</a>. Basically this was an overview of the history of things like the 19” rack (it came from waaaaay back from the train system) and how we need to change our standards to allow things like interoperability and other good stuff.</p>
<p>I was hoping to find out how a small organization–like the one that I work for–could be involved in Open Compute, specifically how we could access similar hardware as Facebook and others are using. I didn’t quite get that out of the presentation, but hopefully in the future I will be able to get us into Open Compute hardware in some fashion or another.</p>
<p>At the very least I signed up for the mailing list. :)</p>
<h2 id="intercloud-object-storage-colony">Intercloud Object Storage: Colony</h2>
<p>The <a href="https://github.com/nii-cloud/colony">Colony</a> session was lead by Shigetoshi Yokoyama of the <a href="http://www.nii.ac.jp/en/">Japan National Institute of Informatics</a> and there is a copy of the slides <a href="http://www.slideshare.net/shigetoshi-yokoyama/openstack-design-summit-colony-session-12603753">online</a>. Colony is described as “federated swifts” for intercloud object storage services.</p>
<p>Having worked in a world class library that was interested in running petabytes of storage, I’m enthralled with object storage. It’s an important storage paradigm, and surprisingly, for reasons unknown, one that doesn’t seem to get a lot of attention in Canada. Perhaps it’s because startups and other organizations just use S3 and haven’t run into any privacy issues as of yet. Speaking of Amazon S3: it has a trillion+ objects stored now.</p>
<p>I think that in situations where we need to store a lot of replicated data–such as what a library or researcher would like to, or rather <em>should</em> like to store–object storage such as swift is a great way to go. (Though that said, perhaps systems like <a href="http://aws.amazon.com/glacier/">Amazon’s Glacier</a> make more sense for those use cases, but maybe not.) I was at a presentation by the then <a href="http://webdocs.cs.ualberta.ca/~jonathan/">CIO of the University of Alberta</a> who figured there was three to five petabytes of research data on campus that needs to be preserved. That’s a lot of storage, especially when factoring in replication, and it really needs to happen at some point–and it can’t just be a huge tape system.</p>
<p>Further, considering that libraries and researchers (ie. their respective Universities and organizations), are supposed to work together it would make sense to be able to have some kind of interoperability between object storage clouds, private or otherwise, even if it’s just for some geographic separation.</p>
<p>Certainly Colonly is going to be a project to keep an eye on as object storage evolves and we try to do it across data centers and organizations.</p>
<h2 id="operating-your-openstack-private-cloud">Operating your OpenStack Private Cloud</h2>
<p>The next session I attended was <a href="http://www.openstack.org/summit/san-diego-2012/openstack-summit-sessions/">Operating your OpenStack Private Cloud</a>, which is good because that is one of the things that I do. I manage a small, eight node, OpenStack cluster that will eventually backend a <a href="https://cwiki.apache.org/VCL/apache-vcl.html">Apache VCL</a> setup for virtual classrooms. So a very small private cloud, but I’ve still hit a few “pain points” that larger installations do.</p>
<p>A few points the speaker made:</p>
<ul>
<li>Monitoring: statsd, graphite, etc</li>
<li>Operations tools don’t exist for OpenStack (yet)–we need better ops tools so he wrote <a href="https://github.com/JCallicoat/pulsar">Pulsar</a></li>
<li>Would be nice to see an operations dashboard (perhaps in horizon)</li>
<li>Eg. can’t get a list of all instances on a node and their IP addresses</li>
<li>Some tools need hostnames and some need ids…why</li>
<li>DSH for Ubuntu, PSH for Redhat?</li>
<li>Don’t forget your bashfu; still working with Linux :)</li>
<li>Database backups</li>
<li><a href="http://hollandbackup.org/">Holland</a></li>
<li>Performance and scale considerations</li>
<li>Block storage solution of some kind (cinder, or cinder + some vendor)</li>
<li>Local disk - raw image is only slightly faster than qcow2, but qcow2 may make better business sense</li>
<li>IO will degrade on local disks when glance copies images between machines</li>
<li>Scheduling</li>
<li>CFQ made the most sense</li>
<li>You have the power to change all this! You have the power to change your scheduler! Benchmark workloads and plan accordingly.</li>
<li>Lots of things you can do with glance performance-wise</li>
<li>Image caching</li>
<li>If you’re using qcow2 it doesn’t have to move the whole image (something to check into)</li>
<li>Don’t want swift to become unbalanced</li>
<li>They use chef for automated deployment</li>
<li>controller in 15 minutes</li>
<li>compute in two</li>
<li>Day to day tasks</li>
<li>Made up of mostly dealing with new issues</li>
<li>Eg. resizing</li>
<li>Hardware failures…still have all this hardware</li>
<li>Don’t forget–it’s not (always) you, it’s a bug</li>
<li>Nice thing about a private cloud is you can pick the architecture that matches your requirements</li>
<li>OpenStack/We need to provide an upgrade path (I hear this 20 times today)</li>
<li>Metrics</li>
<li>Load average is actually quite telling</li>
<li>How long does an API call take?</li>
</ul>
<h2 id="lunch">Lunch!</h2>
<p>Lunch was Ok. There are so many people here it’s tough to move around. And given OpenStack gave out giant bags, everyone (like me) has their own personal giant bag, plus the one they got from OpenStack (though I gave mine back). Giant bags galore!</p>
<p>Then I had a beer at the bar downstairs:</p>
<p><img src="https://raw.github.com/ccollicutt/ccollicutt.github.com/master/img/openstack_summit_2012_bar.jpg" alt="" /></p>
<h2 id="database-as-a-service">Database as a Service</h2>
<p>This session is specifically about <a href="http://wiki.openstack.org/DatabaseAsAService">RedDwarf</a>. RedDwarf is taking MySQL and treating it like a “first class citizen” in OpenStack. It’s a managed MySQL database service.</p>
<p>I believe that SQL databases should be separated out from compute. That said, there are many people that would disagree with me. There’s a theory out there that storage and compute should be together on the same nodes, and if that’s the case then I assume so would database. Right now I would prefer to separate out storage, compute, and database. Maybe it doesn’t fit perfectly with the cloud paradigm, but sometimes you have to apply technology not just theorize about it. SQL isn’t going anywhere, and neither is its unique workload.</p>
<p>HP and Rackspace have slightly different implementations of RedDwarf, and both of their services are in production. Each are trying to keep their system compatible with OpenStack, and have committed themselves to using the same CLI: <a href="https://github.com/hub-cap/python-reddwarfclient">python-reddwarfclient</a>. Further, they are both using OpenStack-common and Swift for securely storing database snapshots.</p>
<p>The team has a desire to bring RedDwarf forward, and they want to involve more community usage and get it into incubation in OpenStack and at that point a lot of doors open, such as a GUI in Horizon.</p>
<p>You can get a test install using the below commands, and it will “fake” a nova backend.</p>
<pre>
<code>$ git clone https://github.com/hub-cap/reddwarf_lite
$ ./reddwarf_lite/bin/start_server.sh
</code>
</pre>
<p>There was also a lot of discussion as to the fact that RedDwarf could be used to build <em>Other Things as a Service</em> and also the fact that they are running it on top of OpenVZ versus another virtualization hypervisor and did so for performance reasons (up to 30% better was a number mentioned).</p>
<h2 id="extending-openstack-for-fun-and-profit-creating-new-functionality-with-the-enhancements-api">Extending OpenStack for Fun and Profit: Creating New Functionality with the Enhancements API</h2>
<p>This session is about having two sides–one side is OpenStack, and the other side is “your innovation”. It’s about getting OpenStack and your innovation to talk to one another; about getting your innovation to market and make money.</p>
<p>The speaker, Tim Smith, is the <a href="http://www.gridcentric.com/company/management/">co-founder</a> of GridCentric which has essentially implemented <em>fork()</em> for virtual machines. The main idea is spin up replica instances quickly and efficiently. They are reinventing boot, and in order to do that they need to extend Nova. GridCentric’s code for their extension is up on <a href="https://github.com/gridcentric/openstack">github</a> and would be a good example to work from. (I’ve looked at GridCentric’s offerings before in relation to virtual classrooms–ie. not having a bootstorm when a bunch of students startup instances for a class. With something like GridCentric’s technology you don’t have to boot the instance.)</p>
<p>Nova is a framework providing:</p>
<ul>
<li>A standardized API</li>
<li>Messaging/RPC</li>
<li>Database-backed ORM</li>
</ul>
<p>Nova can be extended by:</p>
<ul>
<li>API extensions</li>
<li>Custom “services”</li>
<li>Nova CLI extensions</li>
<li>Dashboard extensions</li>
</ul>
<p>Tim suggests that there are a few business challenges such as the fast evolution of OpenStack but generally seems positive about extending OpenStack. Certainly GridCentric has based some of their business on OpenStack.</p>
<p>A commenter noted that there are actually pre-action and post-action boot hooks in Folsom which may help to extend Nova.</p>
<h2 id="storing-vms-with-cinder-and-ceph-rbd">Storing VMs with Cinder and Ceph RBD</h2>
<p>Considering how interested I am in storage, this project, <a href="http://ceph.com/">Ceph</a>, is one of the most important I know of. So when Josh from Inktank talks about Ceph, I’m here to listen. As a note, this room is standing room only for this session!</p>
<p>Ceph is designed for scalability–it has no single point of failure, and you don’t have to be locked into a single hardware vendor. It’s software based and self-managing. There is also the ability to run custom functions on the storage node–such as create a thumbnail from an image file.</p>
<p><a href="http://ceph.com/wiki/Custom_data_placement_with_CRUSH">CRUSH</a> is basically what sets Ceph apart from other storage systems. It’s a pseudo-random placement algorithm and it ensures even distribution across the cluster and has a rules-based system. Basically it avoids look up tables, which eventually kill distributed storage. Further, unlike RAID the entire cluster can recover in parallel.</p>
<p>RBD, the Rados Block Device, is the part of Ceph used to access block storage. KVM has a native driver for RBD. They are thin-provisioned, striped across nodes, and support snapshots and cloning. With RBD you can spin up thousands of virtual machines with the same base image.</p>
<p>Why use block storage in OpenStack?</p>
<ul>
<li>Persistent</li>
<li>Not tied to a single host–decouple storage from compute</li>
<li>Enables live migration</li>
</ul>
<p>Now with Folsom, Cinder has learned how to talk to Glance, which can respond with Images–ie. boot from volume. But still involves a large copy from Glance. However, images can be stored in RBD, and have been able to for some time! So we can skip the copy and just use RBD directly.</p>
<p>That said, it isn’t quite perfect yet. There are enhancements being made in Grizzly. Eg. is not in Horizon, but is in the API and CLI.</p>
<p>NOTES:</p>
<ul>
<li>The Ceph file system is not recommended for production, but everything else is, such as RBD. If you don’t use the Ceph file system you don’t need metadata servers.</li>
<li>According to Josh, in terms of running OSDs on the same node as the hypervisor, as long as you have enough memory you should be Ok. Everything is running in userspace. This runs a bit counterintuitive to me, and also is contrary to one of the positive points made about block storage–decoupling. But it’s a valid use case.</li>
</ul>
<h2 id="from-folsom-to-grizzy-a-devops-upgrade-pattern">From Folsom to Grizzy: A DevOps Upgrade Pattern</h2>
<p>This was the last session of the day, and I was quite tired, so apologies. Suffice it to say: <em>Even imagining upgrading OpenStack is difficult and requires a lot of bullet points</em>.</p>
<h2 id="misc-notes-from-the-day">Misc Notes from the Day</h2>
<p></p>
<ul>
<li>There’s free sunshine and <em>stout</em> outside on the balcony</li>
<li><a href="http://www.buildcloudstorage.com/2012/08/is-openstack-swift-reliable-enough-for.html">Probability of data loss in Swift</a> (this is not to say it’s high, rather an analysis)</li>
<li>Infiniband doesn’t have a lot of traction in OpenStack AFAIK, need to look into this</li>
<li>San Diego has basically the same weather all the time</li>
<li>Japan’s summers are very hot and humid</li>
<li>!https://fbcdn-sphotos-e-a.akamaihd.net/hphotos-ak-ash4/430171_10150245244739982_1571995757_n.jpg!</li>
</ul>
My OpenBSD Lab2012-06-13T00:00:00+00:00http://serverascode.com/2012/06/13/openbsd-lab<h1 id="my-openbsd-lab">My OpenBSD Lab</h1>
<p>Above you can see my little OpenBSD lab. For some reason my workplace has several different kinds of small form factor servers, such as the big silver Netcom box, a couple of <a href="http://soekris.com">Soekris</a> boxes, and I can’t even tell what make/model the little blue boxes are. They are all essentially small, fanless servers with at least two ethernet ports. Since they weren’t being used for anything and I needed to setup a few test installs of OpenBSD, I went to work. :)</p>
<p>The “lab” is comprised of two <a href="http://www.openbsd.org/faq/pf/carp.html">carped</a> firewalls (the blue boxes; note the red cable between them is a cross over cable for pfsync traffic), a couple of cheap desktop switches, and the square silver thing is an OpenBSD bridge that goes in between the two switches. The carped firewalls are connected to another part of my test network, which eventually leads out to the Internet. I also have a couple of OpenBSD virtual machines running on my RHEL 5 xen dom0. One of them provides an OpenBSD pxe boot solution to install OpenBSD onto systems like the Soekris that can’t boot from USB.</p>
<p>When testing I plug my laptop into the internal switch (the green cable), so that in order to get out to the Internet it has to go over the bridge and through the firewalls. “Over the Bridge and through the Firewall”…sounds like a book Hemingway would have written if he was a Unix security administrator. ;)</p>
<p>Using this little lab I can test out all kinds of interesting OpenBSD functionality such as packet filtering with pf, virtual IP address failover with carp, bridging, and network authentication using authpf, along with anything else that I need to work on or try out in the OpenBSD world, or just try to stay familiar with OpenBSD in general.</p>
<p>Bridge up!</p>
<pre>
<code>$ ifconfig bridge0 up
</code>
</pre>
36 hot swappable hard-drive bay Supermicro server specs2012-06-07T00:00:00+00:00http://serverascode.com/2012/06/07/36-hot-swappable-day-supermicro-chassis<h1 id="36-hot-swappable-hard-drive-bay-supermicro-server-specs">36 hot swappable hard-drive bay Supermicro server specs</h1>
<p><img src="https://github.com/ccollicutt/ccollicutt.github.com/raw/master/img/supermicro_stack_small.jpg" alt="" /></p>
<p>The above is the front of four Supermicro 36-bay chassis servers racked but not completely filled with drives.</p>
<p><img src="https://github.com/ccollicutt/ccollicutt.github.com/raw/master/img/supermicro_back_small.jpg" alt="" /></p>
<p>This is the back of the server. As you can see, there are 12 hot swappable slots in the back. The motherboard has room for seven low profile boards of varying PCIe speeds.</p>
<p>Sorry for the poor picture quality–I don’t get paid enough to have a phone with a good camera. ;)</p>
<p>This is output from the bottom server that has four drives lit up:</p>
<pre>
<code># ls /dev/sd?
/dev/sda /dev/sdb /dev/sdc /dev/sdd /dev/sde /dev/sdf
</code>
</pre>
<p>so with the two internal hard-drives that makes six, which is what we see above. If the server was filled up with drives, there would be 38.</p>
<h2 id="first-things-first-the-specs">First things First: The Specs</h2>
<p>Why not get this out of the way? That’s what you’re here for, isn’t it? :) The below would be for one server:</p>
<table>
<tbody>
<tr>
<td><em>Item</em></td>
<td><em>Part or Part #</em></td>
<td><em>Quantity</em></td>
</tr>
<tr>
<td>4U 36 bay Chassis</td>
<td>SM <a href="http://www.supermicro.com/products/chassis/4u/847/sc847e16-r1400lp.cfm">SC847E16-R1400LPB</a></td>
<td>1</td>
</tr>
<tr>
<td>iPass cable</td>
<td>SM CBL-0281L</td>
<td>1</td>
</tr>
<tr>
<td>iPass cable</td>
<td>SM 0108L-02</td>
<td>1</td>
</tr>
<tr>
<td>Internal HD Brackets</td>
<td>SM MCP-220-84701-0N</td>
<td>2</td>
</tr>
<tr>
<td>Motherboard</td>
<td>SM X8DT6-F</td>
<td>1</td>
</tr>
<tr>
<td>CPU</td>
<td>Xeon E5645 (6 cores)</td>
<td>2</td>
</tr>
<tr>
<td>Heat Sink/CPU Fan</td>
<td>Dynatron G666</td>
<td>2</td>
</tr>
<tr>
<td>Kingston 24GB Pack</td>
<td>SM KVR1066D3Q8R7SK3/24G</td>
<td>2</td>
</tr>
<tr>
<td>SATA power splitter</td>
<td>SM CBL-0082L</td>
<td>1</td>
</tr>
</tbody>
</table>
<p><br />
The total cost for the above is around <em>$4000</em>.</p>
<p>What you get is one 4U, dual CPU server (24 cores counting hyperthreading), with 48GB of RAM, the MB supports up to 196GB I believe, and room for 36 hot swappable drives, PLUS two internal OS drives that are actually bracketed deep inside the chassis, ie. difficult to get out.</p>
<p>%{color:blue}Note:% I’ve done my best to make sure the above is correct, and I do have exactly that hardware, but don’t base your business on those specs without doing some testing. Order one server and see how it goes before ordering a dozen+.</p>
<p>%{color:blue}Note:% You would need to find a local vendor to put the pieces together, or you could do it yourself–but I don’t recommend that. I’d put 5% of the total cost aside for professional assembly. We were lucky enough that our vendor was willing to put them together for free–at least on the first order. :)</p>
<p><img src="https://github.com/ccollicutt/ccollicutt.github.com/raw/master/img/supermicro_internal_hard_drive_small.jpg" alt="" /></p>
<p>(Terrible image…but you can kind of see the two internal hard-drives.)</p>
<p>So with those two internal slots, plus 24 bays in the front, and 12 in the back is a total of 38 3.5” slots, 36 of them hot swappable. Or, put another way, if using 3TB SATA drives…114TB of raw storage. (Also I think you can fit four 2.5” drives internally instead of two 3.5” drives. But don’t quote me on that.)</p>
<h2 id="bulk-storage-costs">Bulk storage costs</h2>
<p>The amount of data an organization has to store never seems to go down, only up up UP!–probably at least 50% per year. High-end, “enterprise storage”, can cost between $50K-$100K per terabyte, where K is thousands.</p>
<p>I’m not kidding. It’s <em>really</em> that much, and there are few organizations that can afford to have their storage increase by 50% per year at that cost. Everywhere I’ve worked has started out with a large Enterprise SAN and quickly realized they can’t afford it.</p>
<p>Of course, there are reasons why enterprise storage costs so much. It’s not easy to design and build a large, production, high-performance SAN, and in most cases trying to replicate one with commodity hardware is not a good idea, and could cost people their jobs. Not a nice thought, but it’s true.</p>
<p>But in some specialized cases, such as bulk data storage, <em>not</em> using an Enterprise SAN might be an option. However, unless you work at Facebook, or another company that somehow has access to hardware based on Open Compute’s <a href="http://opencompute.org/project_category/storage-technology/">Open Vault</a>, what do you do for bulk storage hardware?</p>
<p>One possibility is the above 36-bay Supermicro chassis based server. I know there are people out there using them. <em>Lots</em> of them.</p>
<h2 id="now-you-can-afford-test-infrastructure">Now you can afford test infrastructure</h2>
<p>One note I feel important to make is that when you purchase cost effective hardware there is often money on the table to buy more hardware for test. I always like to have test hardware running so that I don’t have to worry about “trying something out” in production. When running production systems I never want to be afraid to make a change, and the way to do that is to have test infrastructure to experiment and…test with.</p>
<p>If your enterprise hardware is so expensive that test infrastructure is completely out of the question, then I wonder how easy it will be to try things out; to make changes without fear of brining down the production system?</p>
<p>To me there is massive value in test hardware.</p>
<p>Also, test hardware can be moved from test to production in case of failure.</p>
<h2 id="support">Support</h2>
<p>Obviously if you spec your own hardware, versus say buying from a tier one vendor, support means that if it breaks you pull a new part off the shelf or out of test and replace it in production yourself.</p>
<p>Further, tier one vendors will usually certify their hardware for particular operating systems and applications. You won’t have that if you spec your own. But you certainly can start small (and inexpensively) and test out your specs/OS/applications, then go bigger when you know it all works well together.</p>
<p>Personally, I don’t like spending 3 hours on the phone with the tier one support, going through generic call scripts with someone who doesn’t care about my problem in the least, and then having the local support tech either be a “cell phone with hands” or cancel four times in a row before simply replacing the whole motherboard because they have no idea what is actually wrong. I suppose that sounds kind of negative, but those are real anecdotes. :) PS. We have lots of tier one vendor servers…</p>
<h2 id="bonus">Bonus</h2>
<p>The Java IPMI remote console gui works great on Linux! Some tier one vendors don’t…and they make you pay extra to actually use the remote console. (<em>cough</em> HP <em>cough</em>)</p>
<p>That said…don’t look at how they store passwords in the ssh interface. Just don’t.</p>
<h2 id="conclusion">Conclusion</h2>
<p>I feel that in specialized applications systems like this supermicro server can be very effective. Especially if it leaves money on the table for test infrastructure. I’d rather have twelve (nine production, three in test) of these boxes than two four-socket tier one servers.</p>
<p>I recommend using 5% of the budget for parts to go on the shelf, and 5%-25% for test.</p>
<p>If you have any questions/concerns, please comment.</p>
Installing IBM high-iops FusionIO Cards in Redhat/Centos 62012-05-23T00:00:00+00:00http://serverascode.com/2012/05/23/installing-ibm-fusionio-rhel_centos6<h1 id="installing-ibm-high-iops-fusionio-cards-in-redhatcentos-6">Installing IBM high-iops FusionIO Cards in Redhat/Centos 6</h1>
<p>In a previous <a href="http://serverascode.com/serverascode/storage/2011/06/27/fusionio-drives-on-redhat-enterprise-5.html">post</a> I had described how I deployed a IBM branded FusionIO drive on Redhat Enterprise 5.</p>
<p>I am now running that same card on CentOS 6, and am using the new version (2.2.3) of <a href="http://www-947.ibm.com/support/entry/portal/docdisplay?lndocid=MIGR-5085137">IBM’s version of the driver</a>.</p>
<p>Actually I think there is a <a href="http://www.mysqlperformanceblog.com/2012/05/07/testing-fusion-io-iodrive-now-with-driver-3-1/">new-new</a> version (3) of the driver now out for some people. I’m not sure if IBM has put out this driver or not for their high-iops cards.</p>
<p>CentOS version:</p>
<pre>
<code>[root@srv ~]# cat /etc/redhat-release
CentOS release 6.2 (Final)
</code>
</pre>
<p>The kernel I am running is stock RHEL 6:</p>
<pre>
<code>[root@srv ~]# uname -a
Linux example.com 2.6.32-220.17.1.el6.x86_64 #1 \
SMP Wed May 16 00:01:37 BST 2012 x86_64 x86_64 x86_64 GNU/Linux
</code>
</pre>
<p>This is what I see in terms of PCI devices for the FusionIO cards:</p>
<pre>
<code>[root@srv ~]# lspci | grep -i fusion
8f:00.0 Mass storage controller: Fusion-io ioDimm3 (rev 01)
90:00.0 Mass storage controller: Fusion-io ioDimm3 (rev 01)
</code>
</pre>
<p>So the card is physically installed in the server, but the driver has not been loaded, so they are not usable at this point. Also should note that one 640GB cards actually looks like 2x 320GB devices to the OS.</p>
<p>First, we download the zip file containing the RPMs from IBM.</p>
<p>%{color:red}Warning:% These drivers are for the IBM version of the FusionIO cards. If you are not running the IBM version you probably need different drivers and RPMs.</p>
<pre>
<code># wget ftp://download2.boulder.ibm.com/ecc/sar/CMA/XSA/ibm_dd_highiop_ssd-2.2.3_rhel6_x86-64.zip
SNIP!
</code>
</pre>
<p>Inside that zip are several RPMs:</p>
<pre>
<code>[root@srv tmp]# mkdir fio
[root@srv tmp]# cd fio/
[root@srv fio]# unzip ../ibm_dd_highiop_ssd-2.2.3_rhel6_x86-64.zip
Archive: ../ibm_dd_highiop_ssd-2.2.3_rhel6_x86-64.zip
inflating: rhel6/fio-common-2.2.3.66-1.0.el6.x86_64.rpm
inflating: rhel6/fio-firmware-highiops-101583.6-1.0.noarch.rpm
inflating: rhel6/fio-snmp-agentx-1.1.1.5-1.0.el6.x86_64.rpm
inflating: rhel6/fio-sysvinit-2.2.3.66-1.0.el6.x86_64.rpm
inflating: rhel6/fio-util-2.2.3.66-1.0.el6.x86_64.rpm
inflating: rhel6/high_iops-gui-2.3.1.1874-1.1.noarch.rpm
inflating: rhel6/iomemory-vsl-2.2.3.66-1.0.el6.el6.src.rpm
inflating: rhel6/iomemory-vsl-2.6.32-71.el6.x86_64-2.2.3.66-1.0.el6.el6.x86_64.rpm
inflating: rhel6/libfio-2.2.3.66-1.0.el6.x86_64.rpm
inflating: rhel6/libfusionjni-1.1.1.5-1.0.el6.x86_64.rpm
</code>
</pre>
<p>So far when I’ve been running these servers I haven’t installed all of those RPMs, only a subset.</p>
<p>So lets install those RPMs:</p>
<pre>
<code>[root@srv rhel6]# yum localinstall --nogpg \
fio-common-2.2.3.66-1.0.el6.x86_64.rpm \
libfio-2.2.3.66-1.0.el6.x86_64.rpm fio-util-2.2.3.66-1.0.el6.x86_64.rpm \
fio-sysvinit-2.2.3.66-1.0.el6.x86_64.rpm \
fio-firmware-highiops-101583.6-1.0.noarch.rpm \
iomemory-vsl-2.6.32-71.el6.x86_64-2.2.3.66-1.0.el6.el6.x86_64.rpm
SNIP!
Transaction Test Succeeded
Running Transaction
Installing : fio-util-2.2.3.66-1.0.el6.x86_64 1/6
Installing : fio-common-2.2.3.66-1.0.el6.x86_64 2/6
Installing : iomemory-vsl-2.6.32-71.el6.x86_64-2.2.3.66-1.0.e 3/6
Installing : libfio-2.2.3.66-1.0.el6.x86_64 4/6
Installing : fio-sysvinit-2.2.3.66-1.0.el6.x86_64 5/6
Installing : fio-firmware-highiops-101583.6-1.0.noarch 6/6
Installed:
fio-common.x86_64 0:2.2.3.66-1.0.el6
fio-firmware-highiops.noarch 0:101583.6-1.0
fio-sysvinit.x86_64 0:2.2.3.66-1.0.el6
fio-util.x86_64 0:2.2.3.66-1.0.el6
iomemory-vsl-2.6.32-71.el6.x86_64.x86_64 0:2.2.3.66-1.0.el6.el6
libfio.x86_64 0:2.2.3.66-1.0.el6
</code>
</pre>
<p>As you can see the sysvinit RPM contains a couple of init.d files.</p>
<pre>
<code>[root@srv rhel6]# rpm -qpl fio-sysvinit-2.2.3.66-1.0.el6.x86_64.rpm
/etc/init.d/iomemory-vsl
/etc/sysconfig/iomemory-vsl
</code>
</pre>
<p>Let’s <em>chkconfig</em> this on permanently.</p>
<pre>
<code>[root@srv rhel6]# chkconfig iomemory-vsl on
</code>
</pre>
<p>We <em>also</em> need to enable <em>iomemory-vsl</em> in <em>/etc/sysconfig/iomemory-vsl</em>.</p>
<pre>
<code>[root@srv init.d]# cd /etc/sysconfig
[root@srv sysconfig]# grep ENABLED iomemory-vsl
# If ENABLED is not set (non-zero) then iomemory-vsl init script will not be
#ENABLED=1
[root@srv sysconfig]# vi iomemory-vsl
[root@srv sysconfig]# grep ENABLED iomemory-vsl
# If ENABLED is not set (non-zero) then iomemory-vsl init script will not be
ENABLED=1
[root@srv sysconfig]#
</code>
</pre>
<p>And we can start or restart iomemory-vsl:</p>
<pre>
<code>[root@srv sysconfig]# service iomemory-vsl restart
Stopping iomemory-vsl:
Unloading module iomemory-vsl
[FAILED]
Starting iomemory-vsl:
Loading module iomemory-vsl
Attaching: [ ] ( 0%) /Attaching:
[
Attaching: [====================] (100%) \
fioa
Attaching: [====================] (100%)
fiob
[ OK ]
</code>
</pre>
<p>At this point I’m going to <em>reboot</em> the server as well, just to make sure everything is going to get loaded if the server spontaneously restarts, which they have been known to do. ;)</p>
<pre>
<code>[root@srv sysconfig]# reboot
</code>
</pre>
<p>Now after the reboot there are a couple more block storage devices on this server:</p>
<pre>
<code>[root@srv ~]# ls /dev/fio?
/dev/fioa /dev/fiob
</code>
</pre>
<p>We want to create a lvm physical volume (pv) on that block device:</p>
<pre>
<code>[root@srv ~]# pvcreate /dev/fioa
Device /dev/fioa not found (or ignored by filtering).
</code>
</pre>
<p>Ooops. Error message. What went wrong? Well, the “or ignored by filtering” is where to start looking. <a href="https://support.fusionio.com/kb/enabling-an-iomemory-device-for-lvm-use/">This</a> FusionIO knowledge base entry (which you have to login to see, how annoying is that) shows that we need to add an entry to the <em>lvm.conf</em> on the server:</p>
<pre>
<code>Locate and edit the /etc/lvm/lvm.conf configuration file.
Add an entry similar to the following to that file:
types = [ "fio", 16 ]
</code>
</pre>
<p>That is precisely what I will do.</p>
<pre>
<code>[root@srv lvm]# grep types lvm.conf
# List of pairs of additional acceptable block device types found
# types = [ "fd", 16 ]
types = [ "fio", 16 ]
</code>
</pre>
<p>And now:</p>
<pre>
<code># let's see if the types were loaded
[root@srv ~]# lvm dumpconfig | grep types
types=["fio", 16]
[root@srv ~]# pvcreate /dev/fioa
Physical volume "/dev/fioa" successfully created
[root@srv ~]# pvcreate /dev/fiob
Physical volume "/dev/fiob" successfully created
</code>
</pre>
<p>And create a volume group and add the pvs to it.</p>
<pre>
<code>[root@srv ~]# vgcreate hiops /dev/fioa
Volume group "hiops" successfully created
[root@srv ~]# vgextend hiops /dev/fiob
Volume group "hiops" successfully extended
[root@srv ~]# vgs
VG #PV #LV #SN Attr VSize VFree
hiops 2 0 0 wz--n- 504.91g 504.91g
system 1 9 0 wz--n- 58.56g 36.66g
vm 1 11 2 wz--n- 1.31t 228.09g
</code>
</pre>
<p>I should note at this point that there is only 504g in the hiops volume group when there should be about 600g.</p>
<p>Previously, using the fio-format command, I had formatted these drives to only 80% capacity. But that was on another server, and I’m not sure it’s really necessary to do that unless you are looking for extreme performance or perhaps additional reliability.</p>
<p>I believe that in some cases with SSD, PCIe or otherwise, it’s not a bad idea to use less than 100% of the drive. That said, if you are looking to max out these drives performance-wise, I’d suggest talking to your vendor rather than just listening to me. :)</p>
<p>(AFAIK, these cards can actually take an external power source to increase performance even more. But we don’t use that functionality.)</p>
<p>So I’m going to reformat these drives to 100% usage. Just for fun. Why not get back that 100g because the performance/endurance at 100% is going to be fine for our usage.</p>
<p>%{color:blue}Note:% Brand new drives won’t have to be formatted. I’m only doing this because I had formatted the drives when they were in the other server.</p>
<p>%{color:red}Warning:% Reformatting will obviously delete any data on these drives!</p>
<pre>
<code># first detach the /dev/fioa
[root@srv ~]# fio-detach /dev/fct0
Detaching: [====================] (100%) -
[root@srv ~]# fio-format -s 100% /dev/fct0
Creating a device of size 322.55GBytes (300.40GiBytes).
Using block (sector) size of 512 bytes.
WARNING: Formatting will destroy any existing data on the device!
Do you wish to continue [y/n]? y
Formatting: [====================] (100%) \
Formatting: [====================] (100%)
Format successful.
# then attach...
[root@srv ~]# fio-attach /dev/fct0
Attaching: [====================] (100%) -
fioa
</code>
</pre>
<p>And we can add that device back with <em>pvcreate</em> and then we should see a larger drive:</p>
<pre>
<code>[root@srv ~]# pvcreate /dev/fioa
Physical volume "/dev/fioa" successfully created
[root@srv ~]# pvs /dev/fioa
PV VG Fmt Attr PSize PFree
/dev/fioa hiops lvm2 a- 300.40g 300.40g
</code>
</pre>
<p>I reformatted the other side of the drive back to 100% as well. (With new drives this shouldn’t be necessary.)</p>
<p>And the fio-status now is:</p>
<pre>
<code>[root@srv ~]# fio-status
Found 2 ioDrives in this system with 1 ioDrive Duo
Fusion-io driver version: 2.2.3 build 66
Adapter: ioDrive Duo
IBM 640GB High IOPS MD Class PCIe Adapter, Product Number:68Y7381 SN:XXXXX
External Power: NOT connected
PCIE Power limit threshold: 24.75W
Sufficient power available: Unknown
Connected ioDimm modules:
fct0: IBM 640GB High IOPS MD Class PCIe Adapter, Product Number:68Y7381 SN:XXXXX
fct1: IBM 640GB High IOPS MD Class PCIe Adapter, Product Number:68Y7381 SN:XXXXX
fct0 Attached as 'fioa' (block device)
IBM 640GB High IOPS MD Class PCIe Adapter, Product Number:68Y7381 SN:XXXXX
Alt PN:68Y7382
Located in slot 0 Upper of ioDrive Duo SN:XXXXX
PCI:8f:00.0
Firmware v5.0.6, rev 101583
322.55 GBytes block device size, 396 GBytes physical device size
Sufficient power available: Unknown
Internal temperature: avg 50.2 degC, max 51.2 degC
Media status: Healthy; Reserves: 100.00%, warn at 10.00%
fct1 Attached as 'fiob' (block device)
IBM 640GB High IOPS MD Class PCIe Adapter, Product Number:68Y7381 SN:XXXXX
Alt PN:68Y7382
Located in slot 1 Lower of ioDrive Duo SN:XXXXX
PCI:90:00.0
Firmware v5.0.6, rev 101583
322.55 GBytes block device size, 396 GBytes physical device size
Sufficient power available: Unknown
Internal temperature: avg 46.3 degC, max 46.8 degC
Media status: Healthy; Reserves: 100.00%, warn at 10.00%
</code>
</pre>
<p>Finally we can create a logical volume (lv) to use.</p>
<pre>
<code>[root@srv ~]# vgs hiops
VG #PV #LV #SN Attr VSize VFree
hiops 1 0 0 wz--n- 300.40g 300.40g
[root@srv ~]# lvcreate -n test -L10.0G /dev/hiops
Logical volume "test" created
</code>
</pre>
<p>If you have any corrections or other comments, please let me know!</p>
Bottle, Elixir, Bootstrap and Datatables - Instant Admin Backend2012-05-15T00:00:00+00:00http://serverascode.com/2012/05/15/instant-admin-backend<h1 id="bottle-elixir-bootstrap-and-datatables---instant-admin-backend">Bottle, Elixir, Bootstrap and Datatables - Instant Admin Backend</h1>
<p><em>UPDATE: I’ve recently stopped using Elixir and have moved to using straight SQLAlchemy.</em></p>
<p>Recently I have been working on a web-based administrative backend, and have found doing so unusually easy, mostly because of the combination of <a href="http://bottlepy.org/">Bottle</a>, a python micro-framework, <a href="http://elixir.ematia.de/">Elixir</a>, a wrapper over top of <a href="http://www.sqlalchemy.org/">SQLAlchemy</a> (which is itself an SQL toolkit and <a href="http://en.wikipedia.org/wiki/Object-relational_mapping">ORM</a>), Twitter’s <a href="http://twitter.github.com/bootstrap/">bootstrap</a>, scaffolding for websites, and finally <a href="http://datatables.net/">Datatables</a>, which enables advanced interactions with HTML tables.</p>
<p>The only difficulty I had, and it was slight, was integrating bootstrap and datatables together, but this <a href="http://datatables.net/blog/Twitter_Bootstrap_2">post</a> helped out quite a bit.</p>
<p>I would certainly suggest to anyone looking to create an administrative backend, or any web application really, to look into these four technologies, as it would take very little time to create a <a href="http://en.wikipedia.org/wiki/Minimum_viable_product">minimum viable product</a>, or a demo, using a combination of Bottle, Elixir, Bootstrap, and Datatables.</p>
<p>In future posts I will present an example application.</p>
OCZ Z-Drive R4 Installation and Performance2012-05-08T00:00:00+00:00http://serverascode.com/2012/05/08/ocz-zdrive-r4-installation-performance<h1 id="ocz-z-drive-r4-installation-and-performance">OCZ Z-Drive R4 Installation and Performance</h1>
<p>In a previous <a href="http://serverascode.com/2012/04/13/11-ocz-zdrive-r4s">post</a> I mentioned how we had purchased 11 300GB <a href="http://www.oczenterprise.com/ssd-products/z-drive-c-series.html">OCZ Z-Drive R4 PCIe-SSD cards</a>. (Please note that this was a special case purchase–the cards didn’t meet any specific requirements we had other than that they were easily available, PCIe-SSD, and low profile.)</p>
<p>We bought the low profile version because these drives are going into the <a href="http://www.supermicro.com/products/chassis/4U/847/SC847E1-R1400LP.cfm">Supermicro SC847E16-R1400LPB</a> chassis (the subject of future posts), which have room for seven low profile cards. I believe the full height zdrive R4s are faster, so this is a compromise.</p>
<h2 id="installation">Installation</h2>
<p>Each of our servers is going to get one zdrive. I placed them in a x8 slot.</p>
<p>Once the OS is up and installed (these cards are not bootable, ie. the OS can’t be installed onto the cards) the <a href="http://www.oczenterprise.com/drivers.html">proprietary kernel module</a> needs to be loaded.</p>
<p>There is an <a href="http://www.oczenterprise.com/downloads/solutions/z-driver4-installation-guide.pdf">installation guide</a>.</p>
<p>I’m running Centos 6.2 on these servers.</p>
<pre>
<code># cat /etc/redhat-release
CentOS release 6.2 (Final)
# uname -a
Linux ocz_server 2.6.32-220.el6.x86_64 #1 SMP Tue Dec 6 19:48:22 GMT 2011 x86_64 x86_64 x86_64 GNU/Linux
</code>
</pre>
<p>I’m using the:</p>
<pre>
<code>Red Hat Enterprise Linux 6.x, CentOS 6.x 64-bit 1.0.0.1480 Mar 2, 2012
</code>
</pre>
<p>version of the driver.</p>
<p>When that tar file is downloaded and unzipped all there is inside is the <em>ocz10xx.ko</em> kernel module.</p>
<pre>
<code># wget http://www.oczenterprise.com/files/drivers/OCZ%20RHEL-Centos_6.x_64-Bit_r1480.tar.gz
--2012-05-08 21:40:23-- http://www.oczenterprise.com/files/drivers/OCZ%20RHEL-Centos_6.x_64-Bit_r1480.tar.gz
Resolving www.oczenterprise.com... 74.52.187.58
Connecting to www.oczenterprise.com|74.52.187.58|:80... connected.
HTTP request sent, awaiting response... 200 OK
Length: 4072553 (3.9M) [application/x-gzip]
Saving to: “OCZ RHEL-Centos_6.x_64-Bit_r1480.tar.gz”
100%[======================================>] 4,072,553 1.03M/s in 4.0s
2012-05-08 21:40:27 (991 KB/s) - “OCZ RHEL-Centos_6.x_64-Bit_r1480.tar.gz” saved [4072553/4072553]
# tar zxvf OCZ\ RHEL-Centos_6.x_64-Bit_r1480.tar.gz
ocz10xx.ko
</code>
</pre>
<p>which can be loaded by:</p>
<pre>
<code># insmod ocz10xx.ko
# lsmod | grep ocz
ocz10xx 479350 1
</code>
</pre>
<p>When that module is loaded the following is reported to dmesg:</p>
<pre>
<code>ocz10xx: module license 'Proprietary' taints kernel.
Disabling lock debugging due to kernel taint
ocz10xx module is older than RHEL 6.2 ... applying fixups
alloc irq_desc for 26 on node -1
alloc kstat_irqs on node -1
ocz10xx 0000:07:00.0: PCI INT A -> GSI 26 (level, low) -> IRQ 26
ocz10xx 0000:07:00.0: setting latency timer to 64
OCZ Storage Controller is found, using IRQ 26, driver version 2.0.0.1480.
OCZ Linux driver ocz10xx, driver version 2.0.0.1480.
OCZ DRIVE LEVEL=OCZ_FAST, STATE=ONLINE
scsi5 : OCZ Storage Controller
scsi 5:0:126:0: Direct-Access ATA OCZ Z-DRIVE R4 C 2.15 PQ: 0 ANSI: 5
sd 5:0:126:0: Attached scsi generic sg8 type 0
sd 5:0:126:0: [sdg] 586135549 512-byte logical blocks: (300 GB/279 GiB)
sd 5:0:126:0: [sdg] Write Protect is off
sd 5:0:126:0: [sdg] Mode Sense: 41 00 00 00
sd 5:0:126:0: [sdg] Write cache: enabled, read cache: enabled, doesn't support DPO or FUA
sdg: unknown partition table
sd 5:0:126:0: [sdg] Attached SCSI disk
</code>
</pre>
<p>and I now have a <em>/dev/sdg</em> to use.</p>
<h2 id="loading-the-kernel-module-at-boot">Loading the kernel module at boot</h2>
<p>First, let me say that I don’t have a lot of experience with kernel modules. I’m hoping that if I’ve made a mistake that someone will alert me in the comments. Or perhaps I missed where this is documented by OCZ.</p>
<p>Running <em>insmod</em> is great for the first time one tries out the zdrive, but what happens after a reboot?</p>
<p>Usually kernel modules go in <em>/lib/modules/<code class="language-plaintext highlighter-rouge">uname -r</code></em> but this module doesn’t seem to be tied to a particular kernel version. While I could put it in that directory, each time I get a new kernel I’d have to move it. This would not be good for maintainability. Assuming the module works with all 6.x kernels–which is what the OCZ drivers page suggests–it should be Ok to put this module in a more permanent location.</p>
<p>What I did was build and RPM with three files:</p>
<pre>
<code># rpm -qf /etc/depmod.d/ocz-zdrive-r4.conf
ocz-zdrive-r4-r1480-2.el6.x86_64
# rpm -qf /etc/modprobe.d/ocz-zdrive-r4.conf
ocz-zdrive-r4-r1480-2.el6.x86_64
# rpm -qf /usr/share/ocz-zdrive-r4/module/ocz10xx.ko
ocz-zdrive-r4-r1480-2.el6.x86_64
</code>
</pre>
<p>The <em>.conf</em> files contain:</p>
<pre>
<code># cat /etc/depmod.d/ocz-zdrive-r4.conf
search /usr/share/ocz-zdrive-r4/module
# cat /etc/modprobe.d/ocz-zdrive-r4.conf
alias ocz10xx ocz
</code>
</pre>
<p>which will ensure that the <em>ocz10xx.ko</em> module is loaded with all the other kernel modules, so that you can put file systems on the zdrive into fstab and have them mounted at boot:</p>
<pre>
<code># uptime
23:05:24 up 15 min, 2 users, load average: 0.00, 0.02, 0.00
# lsmod | grep ocz
ocz10xx 479350 1
# mount | grep ocz
/dev/mapper/ocz-test on /mnt/ocz-xfs-test type xfs (rw)
# cat /etc/fstab | grep ocz
/dev/mapper/ocz-test /mnt/ocz-xfs-test xfs defaults 1
</code>
</pre>
<p>Please let me know if there is something wrong with the methodology. :)</p>
<h2 id="performance-testing">Performance testing</h2>
<p>As I’ve said before, good performance testing is hard to do. All I can really do at this point is run the same tests that <a href="https://support.fusionio.com/kb/verifying-linux-system-performance/">FusionIO</a> (GAH! Behind a support login now! Bad FusionIO, bad!) suggests running on their drives.</p>
<p>%{color:red}WARNING:% The write tests will destroy data on the drive!</p>
<p>%{color:blue}NOTE:% A little bird told me that you need to run the write tests first, otherwise the flash drive–if it’s empty–may (depending on the vendor, perhaps) know it’s empty and return zeroes and you’ll be testing RAM instead of the card.</p>
<h3 id="write-bandwidth-test">Write bandwidth test</h3>
<pre>
<code># fio --filename=/dev/sdg --direct=1 --rw=randwrite --bs=1m \
--size=5G --numjobs=4 --runtime=10 --group_reporting --name=file1
file1: (g=0): rw=randwrite, bs=1M-1M/1M-1M, ioengine=sync, iodepth=1
...
file1: (g=0): rw=randwrite, bs=1M-1M/1M-1M, ioengine=sync, iodepth=1
fio 2.0.7
Starting 4 processes
Jobs: 4 (f=4): [wwww] [100.0% done] [0K/1021M /s] [0 /974 iops] [eta 00m:00s]
file1: (groupid=0, jobs=4): err= 0: pid=2444
write: io=9281.0MB, bw=948572KB/s, iops=926 , runt= 10019msec
clat (usec): min=679 , max=81086 , avg=4111.26, stdev=4974.85
lat (usec): min=848 , max=81251 , avg=4313.21, stdev=4974.67
clat percentiles (usec):
| 1.00th=[ 1704], 5.00th=[ 1928], 10.00th=[ 2064], 20.00th=[ 2672],
| 30.00th=[ 2736], 40.00th=[ 2800], 50.00th=[ 2960], 60.00th=[ 3408],
| 70.00th=[ 3568], 80.00th=[ 3760], 90.00th=[ 4960], 95.00th=[ 9664],
| 99.00th=[35584], 99.50th=[36608], 99.90th=[38144], 99.95th=[38656],
| 99.99th=[81408]
bw (KB/s) : min=139912, max=273338, per=25.14%, avg=238498.74, stdev=28729.62
lat (usec) : 750=0.09%, 1000=0.03%
lat (msec) : 2=8.60%, 4=76.87%, 10=9.69%, 20=2.80%, 50=1.90%
lat (msec) : 100=0.03%
cpu : usr=4.53%, sys=2.98%, ctx=9287, majf=0, minf=120
IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued : total=r=0/w=9281/d=0, short=r=0/w=0/d=0
Run status group 0 (all jobs):
WRITE: io=9281.0MB, aggrb=948572KB/s, minb=948572KB/s, maxb=948572KB/s, mint=10019msec, maxt=10019msec
Disk stats (read/write):
sdg: ios=83/18421, merge=578/0, ticks=13/69730, in_queue=69712, util=99.21%
</code>
</pre>
<h3 id="read-iops-test">Read IOPS test</h3>
<pre>
<code># fio --filename=/dev/sdg --direct=1 --rw=randread --bs=4k \
--size=5G --numjobs=64 --runtime=10 --group_reporting --name=file1
file1: (g=0): rw=randread, bs=4K-4K/4K-4K, ioengine=sync, iodepth=1
...
file1: (g=0): rw=randread, bs=4K-4K/4K-4K, ioengine=sync, iodepth=1
fio 2.0.7
Starting 64 processes
Jobs: 64 (f=64): [rrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrr
Jobs: 64 (f=64): [rrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrr
Jobs: 64 (f=64): [rrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrr
Jobs: 64 (f=64): [rrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrr
Jobs: 64 (f=64): [rrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrr
Jobs: 64 (f=64): [rrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrr
Jobs: 64 (f=64): [rrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrr
Jobs: 64 (f=64): [rrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrr
Jobs: 64 (f=64): [rrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrr]
[100.0% done] [374.1M/0K /s] [91.4K/0 iops] [eta 00m:00s]
file1: (groupid=0, jobs=64): err= 0: pid=2465
read : io=3589.4MB, bw=367442KB/s, iops=91860 , runt= 10003msec
clat (usec): min=100 , max=283036 , avg=693.42, stdev=1539.29
lat (usec): min=101 , max=283036 , avg=693.61, stdev=1539.29
clat percentiles (usec):
| 1.00th=[ 262], 5.00th=[ 378], 10.00th=[ 438], 20.00th=[ 506],
| 30.00th=[ 556], 40.00th=[ 604], 50.00th=[ 652], 60.00th=[ 700],
| 70.00th=[ 756], 80.00th=[ 828], 90.00th=[ 948], 95.00th=[ 1064],
| 99.00th=[ 1400], 99.50th=[ 1592], 99.90th=[ 2288], 99.95th=[ 2832],
| 99.99th=[56064]
bw (KB/s) : min= 816, max= 7032, per=1.55%, avg=5706.40, stdev=599.67
lat (usec) : 250=0.81%, 500=17.90%, 750=50.29%, 1000=23.77%
lat (msec) : 2=7.05%, 4=0.16%, 10=0.01%, 20=0.01%, 50=0.01%
lat (msec) : 100=0.01%, 250=0.01%, 500=0.01%
cpu : usr=0.56%, sys=6.49%, ctx=919527, majf=0, minf=2240
IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued : total=r=918880/w=0/d=0, short=r=0/w=0/d=0
Run status group 0 (all jobs):
READ: io=3589.4MB, aggrb=367441KB/s, minb=367441KB/s, maxb=367441KB/s, mint=10003msec, maxt=10003msec
Disk stats (read/write):
sdg: ios=914696/0, merge=0/0, ticks=612829/0, in_queue=607382, util=98.84%
</code>
</pre>
<h3 id="read-bandwidth-test">Read bandwidth test</h3>
<pre>
<code># fio --filename=/dev/sdg --direct=1 --rw=randread --bs=1m --size=5G \
--numjobs=4 --runtime=10 --group_reporting --name=file1
file1: (g=0): rw=randread, bs=1M-1M/1M-1M, ioengine=sync, iodepth=1
...
file1: (g=0): rw=randread, bs=1M-1M/1M-1M, ioengine=sync, iodepth=1
fio 2.0.7
Starting 4 processes
Jobs: 4 (f=4): [rrrr] [100.0% done] [1599M/0K /s] [1524 /0 iops] [eta 00m:00s]
file1: (groupid=0, jobs=4): err= 0: pid=2543
read : io=16475MB, bw=1647.2MB/s, iops=1647 , runt= 10002msec
clat (usec): min=828 , max=79515 , avg=2423.79, stdev=1154.98
lat (usec): min=828 , max=79515 , avg=2424.04, stdev=1154.98
clat percentiles (usec):
| 1.00th=[ 1528], 5.00th=[ 1768], 10.00th=[ 1912], 20.00th=[ 2064],
| 30.00th=[ 2160], 40.00th=[ 2256], 50.00th=[ 2320], 60.00th=[ 2416],
| 70.00th=[ 2544], 80.00th=[ 2736], 90.00th=[ 2992], 95.00th=[ 3280],
| 99.00th=[ 3856], 99.50th=[ 4128], 99.90th=[ 6176], 99.95th=[13120],
| 99.99th=[78336]
bw (KB/s) : min=369211, max=526336, per=25.10%, avg=423322.49, stdev=33254.52
lat (usec) : 1000=0.18%
lat (msec) : 2=14.73%, 4=84.40%, 10=0.63%, 20=0.04%, 100=0.02%
cpu : usr=0.19%, sys=5.89%, ctx=16488, majf=0, minf=1151
IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued : total=r=16475/w=0/d=0, short=r=0/w=0/d=0
Run status group 0 (all jobs):
READ: io=16475MB, aggrb=1647.2MB/s, minb=1647.2MB/s, maxb=1647.2MB/s, mint=10002msec, maxt=10002msec
Disk stats (read/write):
sdg: ios=32621/0, merge=0/0, ticks=71360/0, in_queue=71316, util=99.09%
</code>
</pre>
<h3 id="write-iops-test">Write IOPS test</h3>
<pre>
<code># fio --filename=/dev/sdg --direct=1 --rw=randwrite --bs=4k --size=5G \
--numjobs=64 --runtime=10 --group_reporting --name=file
file: (g=0): rw=randwrite, bs=4K-4K/4K-4K, ioengine=sync, iodepth=1
...
file: (g=0): rw=randwrite, bs=4K-4K/4K-4K, ioengine=sync, iodepth=1
fio 2.0.7
Starting 64 processes
Jobs: 64 (f=64): [wwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwJobs:
64 (f=64): [wwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwJobs: 64
(f=64): [wwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwJobs: 64
(f=64): [wwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwJobs: 64
(f=64): [wwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwJobs: 64
(f=64): [wwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwJobs: 64
(f=64): [wwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwJobs: 64
(f=64): [wwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwJobs: 64
(f=64): [wwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwww]
[100.0% done] [0K/408.8M /s] [0 /99.8K iops] [eta 00m:00s]
file: (groupid=0, jobs=64): err= 0: pid=2556
write: io=3670.1MB, bw=374777KB/s, iops=93694 , runt= 10030msec
clat (usec): min=40 , max=302579 , avg=677.08, stdev=1765.33
lat (usec): min=40 , max=302580 , avg=678.03, stdev=1765.34
clat percentiles (usec):
| 1.00th=[ 117], 5.00th=[ 390], 10.00th=[ 450], 20.00th=[ 506],
| 30.00th=[ 548], 40.00th=[ 580], 50.00th=[ 620], 60.00th=[ 652],
| 70.00th=[ 692], 80.00th=[ 748], 90.00th=[ 820], 95.00th=[ 892],
| 99.00th=[ 1064], 99.50th=[ 1144], 99.90th=[31616], 99.95th=[32640],
| 99.99th=[33536]
bw (KB/s) : min= 2208, max= 9448, per=1.56%, avg=5834.54, stdev=562.51
lat (usec) : 50=0.25%, 100=0.58%, 250=1.49%, 500=16.44%, 750=62.05%
lat (usec) : 1000=16.98%
lat (msec) : 2=1.91%, 4=0.06%, 10=0.09%, 20=0.02%, 50=0.11%
lat (msec) : 100=0.01%, 250=0.01%, 500=0.01%
cpu : usr=0.68%, sys=6.54%, ctx=942753, majf=0, minf=2070
IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued : total=r=0/w=939753/d=0, short=r=0/w=0/d=0
Run status group 0 (all jobs):
WRITE: io=3670.1MB, aggrb=374776KB/s, minb=374776KB/s, maxb=374776KB/s, mint=10030msec, maxt=10030msec
Disk stats (read/write):
sdg: ios=609/926539, merge=2759/0, ticks=337/599297, in_queue=594561, util=99.08%
</code>
</pre>
<h2 id="conclusion">Conclusion</h2>
<p>From a cursory look these drives seem to perform well. At least when they are brand new. :) We’ll see how they perform over time.</p>
<p>If anyone would like to see specific tests, please let me know.</p>
What 11 OCZ Z-Drive R4 Cards Look Like2012-04-13T00:00:00+00:00http://serverascode.com/2012/04/13/11-ocz-zdrive-r4s<h1 id="what-11-ocz-z-drive-r4-cards-look-like">What 11 OCZ Z-Drive R4 Cards Look Like</h1>
<p><img src="https://github.com/ccollicutt/ccollicutt.github.com/raw/master/img/Photo0128.jpg" alt="" /></p>
<p>…in one big box.</p>
<p>Recently we picked up 11 <a href="http://www.oczenterprise.com/ssd-products/z-drive-c-series.html">300GB OCZ Z-Drive PCIe SSD</a> cards to put in some new servers we bought. Don’t ask me to explain what and why because this was somewhat of an unusual purchase, but suffice it to say we’re going to be running a lot of fast VMs on top of this storage. I would have liked to get the full height cards, but because of the servers they are going in we have to use the half-height version.</p>
<p>Look for some performance and configuration posts in the future, along with updates on using FusionIO on RHEL 6 as I’ve updated the server those are installed in to RHEL 6.</p>
Deploying Ruby-on-Rails applications using RPM packaging2012-01-17T00:00:00+00:00http://serverascode.com/2012/01/17/Deploying-ruby-on-rails-applications-via-rpm-packaging<h1 id="deploying-ruby-on-rails-applications-using-rpm-packaging">Deploying Ruby-on-Rails applications using RPM packaging</h1>
<p>It’s been a long time between posts but the time has come!</p>
<p>In this post I hope to take a good look at one way to deploy a working ruby on rails (RoR) application by packaging it in an RPM.</p>
<p>In this example all of the gems the application requires are downloaded and built/compiled at the same time the RPM is, and thus the RPM contains all the required gems (100+ in this example). The best way to deploy an application, in my opinion, would be to standardize on a set of gems that is available at the OS level–so the RPM would not contain <em>any</em> gems, rather would require the general OS level gems.</p>
<p>Unfortunately, for many reasons, which I won’t get into, that is just not possible for me at this time. Maybe in the future when all gems can easily be built into RPMs, and also when internal developers can agree on a set of gems. Someday…</p>
<h2 id="environment">Environment</h2>
<p>We’re deploying to a specific RHEL6 server environment.</p>
<h3 id="ruby-version">Ruby version</h3>
<p>We’ll be deploying the RoR application to <a href="http://distrowatch.com/table.php?distribution=redhat">Redhat Enterprise 6</a> (RHEL6) virtual machine which has, <em>and likely always will have</em>, @ruby 1.8.7@ (with backported security patches of course!).</p>
<pre>
<code>[root@RoR-TEST ~]# ruby -v
ruby 1.8.7 (2010-06-23 patchlevel 299) [x86_64-linux]
[root@RoR-TEST ~]# cat /etc/redhat-release
Red Hat Enterprise Linux Server release 6.1 (Santiago)
</code>
</pre>
<p>This will likely be a problem in the future, as it seems that Rails 3.2 will be the last version that supports ruby 1.8.X (where X seems to be 7+ as 1.8.6 is specifially not supported). At some point the dev team may want to go to a Rails version that will not run on Ruby 1.8.7.</p>
<h3 id="apache-and-passenger">Apache and passenger</h3>
<p>We’ll also be deploying the RoR app using apache and passenger.</p>
<h2 id="requirements">Requirements</h2>
<p>A few things are required to build and deploy an RPM.</p>
<h1 id="the-application-code-in-some-kind-of-version-control-system-and-hopefully-that-vcs-supports-taggingsvn-mercurial-and-git-all-support-tags">The application code in some kind of version control system and hopefully that VCS supports tagging…svn, mercurial, and git all support tags.</h1>
<h1 id="a-build-server-that-is-the-same-as-os-and-arch-as-the-production-server-being-deployed-to-in-this-case-rhel6-and-x86_64">A build server that is the same as OS and arch as the production server being deployed to. In this case, RHEL6 and X86_64.</h1>
<p>** A spec file for the application.
** This build server needs <code class="language-plaintext highlighter-rouge">bundle</code> and <code class="language-plaintext highlighter-rouge">gem</code> available in the binary PATH because currently the example spec file needs it to be there.
** A working rpmbuild environment, configured as appropriate.</p>
<h1 id="a-test-server-to-test-the-rpm-deployment-ie-a-place-to-actually-install-the-rpm-into">A test server to test the RPM deployment, ie. a place to actually install the RPM into.</h1>
<h2 id="the-spec-file">The spec file</h2>
<p>Building a RPM requires, among other things, a spec file. This file is the heart of a RoR RPM deployment.</p>
<p>I have put an example spec file up on <a href="https://github.com/ccollicutt/Ruby-on-Rails-Example-RPM-Deployment-spec-file">github</a> to peruse and abuse. Again, it’s not going to work out of the box, but it’s a good example, or will be at some point. :)</p>
<p>The build portion of the spec file is what is interesting in terms of deploying a RoR app with RPM.</p>
<p>Prior to the build section the code has been pulled out of a git repository into a local build directory by the rpmbuild process.</p>
<p>In the build section, which I’m cutting and pasting examples out of, we are going to cd into that checked out repository and use bundle to <em>compile and install</em> all the gems into <code class="language-plaintext highlighter-rouge">./vendor/bundle</code>.</p>
<pre>
<code>%build
pushd %{name}
# Install all required gems into ./vendor/bundle using the handy bundle commmand
bundle install --deployment
</code>
</pre>
<p>Once that has completed, which could be quite a long process depending on the number and complexity of the gems required, we remove the assets and recompile them.</p>
<pre>
<code># Compile assets, this only has to be done once AFAIK, so in the RPM is fine
rm -rf ./public/assets/*
bundle exec rake assets:precompile
</code>
</pre>
<p>Then we need to also build bundler into the RPM as well, which requires a smidge of trickery:</p>
<pre>
<code># For some reason bundler doesn't install itself, this is probably right,
# but I guess it expects bundler to be on the server being deployed to
# already. But the rails-helloworld app crashes on passenger looking for
# bundler, so it would seem to me to be required. So, I used gem to install
# bundler after bundle deployment. :) And the app then works under passenger.
PWD=`pwd`
cat > gemrc <<EOGEMRC
gemhome: $PWD/vendor/bundle/ruby/1.8
gempath:
- $PWD/vendor/bundle/ruby/1.8
EOGEMRC
#gem --source %{gem_source} --config-file ./gemrc install bundler
gem --config-file ./gemrc install bundler
# Don't need the gemrc any more...
rm ./gemrc
</code>
</pre>
<p>Finally, it seems that some of the gems have a funny location for ruby set, which we need to change because the rpmbuild process will mark that as a requirement. This issue may be fixed now.</p>
<pre>
<code># Some of the files in here have /usr/local/bin/ruby set as the bang
# but that won't work, and makes the rpmbuild process add /usr/local/bin/ruby
# to the dependencies. So I'm changing that here. Either way it prob won't
# work. But at least this rids us of the dependencie that we can never meet.
for f in `grep -ril "\/usr\/local\/bin\/ruby" ./vendor`; do
sed -i "s|/usr/local/bin/ruby|/usr/bin/ruby|g" $f
head -1 $f
done
popd
</code>
</pre>
<p>Basically, three major things happen in the build section:</p>
<h1 id="use-the-handy-bundler-application-to-install-all-the-required-gems">Use the handy bundler application to install all the required gems</h1>
<h1 id="also-install-bundler-itself">Also install bundler itself</h1>
<h1 id="work-around-other-issues-as-found">Work around other issues as found</h1>
<p>Once that is done, we have a nice spec file that can be built and then installed!</p>
<h2 id="rpmbuild">rpmbuild</h2>
<p>Now we build our RPM. In this example I’m building a RoR application called <code class="language-plaintext highlighter-rouge">special_collections</code>. <code class="language-plaintext highlighter-rouge">rhel6b</code> is my RHEL6 build server/environment.</p>
<pre>
<code>[curtis@rhel6b SPECS]$ rpmbuild -ba special_collections.spec
Executing(%prep): /bin/sh -e /var/tmp/rpm-tmp.J1hbLc
+ umask 022
+ cd /home/curtis/rpmbuild/BUILD
+ rm -rf ./special_collections
+ git clone https://code.example.com/git/special_collections
Initialized empty Git repository in /home/curtis/rpmbuild/BUILD/special_collections/.git/
SNIP!
Checking for unpackaged file(s): /usr/lib/rpm/check-files /home/curtis/rpmbuild/BUILDROOT/special_collections-0.1.4-1.el6.ualib.x86_64
Wrote: /home/curtis/rpmbuild/SRPMS/special_collections-0.1.4-1.el6.ualib.src.rpm
Wrote: /home/curtis/rpmbuild/RPMS/x86_64/special_collections-0.1.4-1.el6.ualib.x86_64.rpm
Executing(%clean): /bin/sh -e /var/tmp/rpm-tmp.VOkPMU
+ umask 022
+ cd /home/curtis/rpmbuild/BUILD
+ rm -rf /home/curtis/rpmbuild/BUILDROOT/special_collections-0.1.4-1.el6.ualib.x86_64
+ exit 0
</code>
</pre>
<p><em>NOTES:</em></p>
<ul>
<li>The above rpmbuild could take a long time depending on the number of gems that the application requires. It’s important to rembember that in this process all the gems are being downloaded from <a href="http://rubygems.org">rubygems.org</a> and then also <em>compiled</em> on the build server, each and every time the rpm is built. So it’s slow. There are some things I’m looking at doing to reduce the time it takes to build the RPM, but that’s where it is right now. Maybe someone will read this blog and give me some comments on what I can be doing better!</li>
<li>The resulting RPM is quite large…in this case about 80MB <em>compressed</em>. This is because it has 100+ gems in it.</li>
</ul>
<h2 id="installing-the-rpm-on-a-brand-new-server">Installing the RPM on a brand new server</h2>
<p>I have a brand new server all ready for this ruby application to be deployed. It’s a minimal install.</p>
<pre>
<code>[root@RoR-TEST ~]# rpm -qa | grep -i "apache\|ruby\|passenger"
[root@RoR-TEST ~]#
# Nothing! No ruby, passenger, or apache currently installed.
[root@RoR-TEST ~]# rpm -qa | wc -l
293
# And only 293 RPMs!
</code>
</pre>
<p>Normally I install a RPM from a custom yum repository, but in this example I will use @yum localinstall@ so I copy the RPM from the build server to the new server.</p>
<p>Note that I have several 3rd party repositories configured on this server, including epel, rpmforge, and the passenger repository. Obviously one has to trust a 3rd party repository to use it. Configuring yum priorities might be a good idea as well to try to avoid unwanted collisions.</p>
<p>So, to install:</p>
<pre>
<code>[root@RoR-TEST tmp]# yum localinstall special_collections-0.1.4-1.el6.ualib.x86_64.rpm
SNIP!
rubygem-passenger-native-libs x86_64 1:3.0.11-1.el6_1.8.7.352 passenger 29 k
rubygem-rack noarch 1:1.1.0-2.el6 epel 446 k
rubygem-rake noarch 0.8.7-2.1.el6 optional 403 k
rubygems noarch 1.3.7-1.el6 optional 206 k
sgml-common noarch 0.6.3-32.el6 base 43 k
Transaction Summary
========================================================================================================================
Install 73 Package(s)
Total size: 234 M
Total download size: 74 M
Installed size: 413 M
Is this ok [y/N]: y
SNIP!
rubygem-daemon_controller.noarch 0:0.2.6-1.el6 rubygem-fastthread.x86_64 0:1.0.7-2.el6
rubygem-passenger.x86_64 1:3.0.11-1.el6 rubygem-passenger-native.x86_64 1:3.0.11-1.el6
rubygem-passenger-native-libs.x86_64 1:3.0.11-1.el6_1.8.7.352 rubygem-rack.noarch 1:1.1.0-2.el6
rubygem-rake.noarch 0:0.8.7-2.1.el6 rubygems.noarch 0:1.3.7-1.el6
sgml-common.noarch 0:0.6.3-32.el6
Complete!
</code>
</pre>
<p><br /></p>
<h2 id="configure-the-application">Configure the application</h2>
<p>Currently the RPM will create a directory in <code class="language-plaintext highlighter-rouge">/etc/</code> that contains the <code class="language-plaintext highlighter-rouge">database.yml</code> file for the rails app:</p>
<pre>
<code>[root@RoR-TEST special_collections]# pwd
/etc/railsapps/special_collections
[root@RoR-TEST special_collections]# ls
database.yml
</code>
</pre>
<p>Edit that to set the proper database information.</p>
<h2 id="configure-apache">Configure apache</h2>
<p>Now that apache has been installed because it is required by the custom RPM it needs to be configured.</p>
<p>First let’s make sure it’ll start on a reboot. Don’t want to have to login on the weekend three months from now after a spontaneous reboot now do we? :)</p>
<pre>
<code>[root@RoR-TEST yum.repos.d]# chkconfig httpd on
</code>
</pre>
<p>Now to setup the apache rails environment for this particular application. Note that in this case, we’re doing one RoR app per virtual host. It’s just easier for me because there are some variables that need to be set in the virtual host config file.</p>
<p>I also always configure a <code class="language-plaintext highlighter-rouge">/etc/httpd/conf.d/vhost.d</code> directory for virtual host files, and tell httpd to check there for <code class="language-plaintext highlighter-rouge">*.conf</code> files.</p>
<pre>
<code>[root@RoR-TEST vhost.d]# grep vhost.d /etc/httpd/conf/httpd.conf
Include conf.d/vhost.d/*.conf
</code>
</pre>
<p>The vhost config file looks like this:</p>
<pre>
<code>[root@RoR-TEST vhost.d]# cat specialcollections.example.com.conf
<VirtualHost *:80>
ServerName specialcollections.example.com
DocumentRoot /usr/share/railsapps/special_collections/public
# Because of the way we're deploying rails apps, ie. by using bundler during the rpm
# build process to install all the required gems into $RAILSAPP/$NAME/vendor/bundle/ruby/1.8
# this has to be set here. Otherwise the app will not have the required gems to run.
SetEnv GEM_HOME /usr/share/railsapps/special_collections/vendor/bundle/ruby/1.8/
<Directory /usr/share/railsapps/special_collections/public>
Options -MultiViews
</Directory>
</VirtualHost>
</code>
</pre>
<p>Startup apache:</p>
<pre>
<code>[root@RoR-TEST vhost.d]# service httpd configtest
[root@RoR-TEST vhost.d]# service httpd start
</code>
</pre>
<p>Done with apache.</p>
<h2 id="rake">Rake</h2>
<p>Now to configure the initial database.</p>
<p>First, the paths need to be setup. I create a file called <code class="language-plaintext highlighter-rouge">special_collectionsrc</code> that has path information setup. Note that this rc file is someting I created specifically for this application because each rails app will have it’s own paths <em>and</em> gems. Then, when wanting to use rake with the specific application that file is sourced to ensure the correct rake and other gems are used.</p>
<pre>
<code>[root@RoR-TEST ~]# which rake
/usr/bin/rake
# oops not the right one!
[root@RoR-TEST ~]# which bundle
/usr/bin/which: no bundle in (/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/root/bin)
# oops isn't on the path!
[root@RoR-TEST ~]# cat special_collectionsrc
#!/bin/bash
export GEM_HOME=/usr/share/railsapps/special_collections/vendor/bundle/ruby/1.8
PATH=/usr/share/railsapps/special_collections/vendor/bundle/ruby/1.8/bin:$PATH
export RAILS_ENV=production
</code>
</pre>
<p>Once that file is sourced, we should be able to find rake on the path:</p>
<pre>
<code>[root@RoR-TEST ~]# source special_collectionsrc
[root@RoR-TEST ~]# which rake
/usr/share/railsapps/special_collections/vendor/bundle/ruby/1.8/bin/rake
[root@RoR-TEST ~]# which bundle
/usr/share/railsapps/special_collections/vendor/bundle/ruby/1.8/bin/bundle
</code>
</pre>
<p>cd to <code class="language-plaintext highlighter-rouge">/usr/share/railsapps/special_collections/</code> and load the db:</p>
<pre>
<code>[root@RoR-TEST special_collections]# rake db:load
/usr/share/railsapps/special_collections/vendor/bundle/ruby/1.8/gems/curb-0.7.16/lib/curb_core.so: warning: already initialized constant CURL_SSLVERSION_DEFAULT
-- create_table("collections", {:force=>true})
-> 0.4194s
-- create_table("gallery_images", {:force=>true})
-> 0.0040s
-- initialize_schema_migrations_table()
-> 0.0077s
-- assume_migrated_upto_version(20111104163654, ["db/migrate"])
-> 0.0048s
</code>
</pre>
<p>Whenever working with this particular RoR app the rc file should be sourced.</p>
<p>Done raking.</p>
<h2 id="thatsit">That’s…it</h2>
<p>At this point the rails app should be available at the virtual host URL that was configured in the vhost. :)</p>
<p>While it’s a long process to get that intial spec file and rpmbuild working, once it’s done the application can be deployed in a few minutes, and now the developers can simply worry about commiting and tagging code, and let the sysadmin deal with deploying the actual application in a replicable manner. Of course there will be some back and forth, new gems might not compile, etc, but the general structure is in place. Further, the deployment is quite automatable–a new tag could mean a new RPM build and deployment to test.</p>
Quickly building command line apps to create files from templates in python2011-10-13T00:00:00+00:00http://serverascode.com/2011/10/13/quickly-building-command-line-apps-to-create-files-from-templates-in-python<h1 id="quickly-building-command-line-apps-to-create-files-from-templates-in-python">Quickly building command line apps to create files from templates in python</h1>
<p>First, let me say that I am not an expert in Python. :) That said, I have been working on a <a href="http://github.com/ccollicutt/kicker">script</a> for a while now that creates a kickstart file from a command line application that uses:</p>
<h1 id="a-configuration-file-to-get-defaults">a configuration file to get defaults,</h1>
<h1 id="command-line-options-to-add-or-override-options-and">command line options to add or override options, and</h1>
<h1 id="cheetah-template-files"><a href="http://www.cheetahtemplate.org/">cheetah template</a> files.</h1>
<p>I think I finally have a good system for doing this, and could see it being useful to others in terms of writing their own quick application to generate some kind of text file from a command line application using the above three points, and what I have done is commited a set of <a href="https://github.com/ccollicutt/cli-template-generator">skeleton files</a> so that you could do this yourself very easily.</p>
<h2 id="dependencies">Dependencies</h2>
<p><code class="language-plaintext highlighter-rouge">cli-template-generator</code> was written to run on RHEL5 which means python 2.4.3.</p>
<p>It also requires <code class="language-plaintext highlighter-rouge">python-argparse</code> and <code class="language-plaintext highlighter-rouge">python-cheetah</code> if you are on RHEL5.</p>
<p>I think it will work in later python versions.</p>
<h2 id="using-the-cli-template-generator">Using the cli-template-generator</h2>
<p>First, clone the <code class="language-plaintext highlighter-rouge">cli-template-generator</code> repository.</p>
<pre>
<code>$ git clone git@github.com:ccollicutt/cli-template-generator.git
Cloning into cli-template-generator...
remote: Counting objects: 8, done.
remote: Compressing objects: 100% (6/6), done.
remote: Total 8 (delta 0), reused 8 (delta 0)
Receiving objects: 100% (8/8), done.
$ cd cli-template-generator/
$ ls
README skeleton.conf skeleton.py skeleton.tpl
</code>
</pre>
<p>There are three files that work together to create a text file from a template: skeleton.{conf,py,tpl}.</p>
<p>The tpl file contains the Cheetah template information:</p>
<pre>
<code>$ cat skeleton.tpl
Hello $hello
</code>
</pre>
<p>Which means the <code class="language-plaintext highlighter-rouge">hello</code> variable will be replaced with the string it’s set to in either the config file or the command line argument.</p>
<p>The conf file holds the default configuration option(s).</p>
<pre>
<code>$ cat skeleton.conf
[default]
#
# Add default configuration options in this file
# Eg.
# Key: Value
hello: World!
</code>
</pre>
<p>By default, the skeleton.conf file sets the variable <code class="language-plaintext highlighter-rouge">hello</code> to the string <code class="language-plaintext highlighter-rouge">World!</code>. So if we run <code class="language-plaintext highlighter-rouge">skeleton.py</code> we will see:</p>
<pre>
<code>$ ./skeleton.py
Hello World!
</code>
</pre>
<p>Also by default we have one command line configuration option, <code class="language-plaintext highlighter-rouge">--hello</code>, that we can set to whatever we want. We can see what options are available using <code class="language-plaintext highlighter-rouge">--help</code>.</p>
<pre>
<code>$ ./skeleton.py --help
usage: skeleton.py [-h] [-c CONFIGFILE] [--hello HELLO]
optional arguments:
-h, --help show this help message and exit
-c CONFIGFILE, --config-file CONFIGFILE
Use a different config file than ./skeleton.conf
--hello HELLO Who are you saying hello to?
</code>
</pre>
<p>So if we run <code class="language-plaintext highlighter-rouge">skeleton.py</code> with the <code class="language-plaintext highlighter-rouge">--hello</code> option we should get different results.</p>
<pre>
<code>$ ./skeleton.py --hello Curtis!
Hello Curtis!
</code>
</pre>
<p>So, as you can see, it should be fairly easy to copy the skeleton files, replace some of the default locations for the files, add some configuration options to the configuration file and also to the parser in the py file, and edit the template so that it uses your new variables.</p>
<p>Bam! You have a custom cli text file generator! Given the amount of text files in Unix/Linux, there could be a lot of good uses for this.</p>
Getting the number of commits in mercurial, git, and svn2011-09-28T00:00:00+00:00http://serverascode.com/2011/09/28/Getting-the-number-of-hg-git-svn-commits<h1 id="getting-the-number-of-commits-in-mercurial-git-and-svn">Getting the number of commits in mercurial, git, and svn</h1>
<p>This is a short post on one way to get the number of commits in hg, git, and svn.</p>
<p>One of the things that I wanted to graph with Cacti is the number of commits that happen in our git, mercurial, and svn repositories. Yup we use all three.</p>
<p>I know that the number of commits isn’t the best metric in terms of figuring out how much our repos are being used, but it’s certainly one of the numbers to look at, and it’s easy to start with. I’m aware of things like churn in hg, but haven’t looked into them fully. Obviously one could make one large commit, or many smaller ones. I prefer many smaller ones, but that’s just me. Basically I’m saying I’ll add more metrics later.</p>
<p>In order to graph the number of commits, I need to find the number of commits.</p>
<p>At this point I’m most interested in the number of commits that happened in the last 24 hours, one day ago, or yesterday, which I’m aware are not necessarily all the same thing. ;) I’ll run the cronjob that checks commits just after midnight, so the numbers should be kinda accurate.</p>
<p><em>hg</em></p>
<pre>
<code>$ cd some_hg_repo
$ hg log --template '{rev}:{node|short}\n' --date -1 | wc -l
</code>
</pre>
<p><em>git</em></p>
<pre>
<code>$ cd some_git_repo
$ git log --since="24 hours ago" | grep "^commit" | wc -l
</code>
</pre>
<p><em>svn</em></p>
<notextile>
<pre>
<code>$ cd some_svn_repo
# and SVN_REPO=`pwd` or something like that
# Where YESTERDAY=`date --date yesterday +\{\%Y-\%m-\%d\}`
$ svn log -q -r $YESTERDAY file:///$SVN_REPO | grep "^r" | wc -l
</code>
</pre>
</notextile>
<p>Note that with svn, if there hasn’t been a commit in since <code class="language-plaintext highlighter-rouge">YESTERDAY</code> it will return that last commit before that–could be two days ago or more–so unless there are no commits, the number of commits will be at least one, which may not be what you are expecting.</p>
OpenBSD pf and set limit states2011-09-12T00:00:00+00:00http://serverascode.com/2011/09/12/openbsd-pf-set-limit-states<h1 id="openbsd-pf-and-set-limit-states">OpenBSD pf and set limit states</h1>
<p>So you have a OpenBSD firewall. Actually you have at least two because you are doing <a href="http://www.openbsd.org/faq/pf/carp.html">carp</a> for high availability (not load balancing but HA), right?</p>
<p>Awesome! It’s fun isn’t it? I suppose I have to admit it’s more fun testing it in a lab environment than in production. <em>:)</em></p>
<p>One thing I noticed when doing a bit of <em>non-scientific</em> load testing on a pair of small carped firewalls is that in OpenBSD the size of the state table is limited to 10000 entries by default. I would imagine that most people won’t run into the limit, but I was surprised at how easy it was to hit 10000 sessions using something like <a href="http://www.joedog.org/index/siege-home">siege</a>.</p>
<p>Using a client laptop–an older core 2 duo with 4 gigs of ram and a 60 gig SSD drive (a Lenovo T61 specifically) on one side of the firewall and a virtualized web server with 512MB of RAM and one CPU on the other–I was able to hit the state limit in a couple of seconds with a command such as:</p>
<pre>
<code>laptop$ siege -b -c 40 -r 100 http://testserver/testpage
</code>
</pre>
<p>where the resulting test page looks like:</p>
<pre>
<code><html>
<body>
hi there
</body>
</html>
</code>
</pre>
<p>When the <code class="language-plaintext highlighter-rouge">siege</code> command is run I watch the state tables on the OpenBSD firewalls with a command such as:</p>
<pre>
<code>openbsd_fw{1,2}# while true; do pfctl -s info; sleep 1; done
</code>
</pre>
<p>With nothing happening the result of that command looks about like this:</p>
<pre>
<code>openbsd_fw1$ pfctl -s info
Status: Enabled for 0 days 00:22:05 Debug: err
State Table Total Rate
current entries 38
searches 215881 162.9/s
inserts 30364 22.9/s
removals 46342 35.0/s
Counters
match 30804 23.2/s
bad-offset 0 0.0/s
fragment 0 0.0/s
short 362 0.3/s
normalize 0 0.0/s
memory 0 0.0/s
bad-timestamp 0 0.0/s
congestion 0 0.0/s
ip-option 0 0.0/s
proto-cksum 0 0.0/s
state-mismatch 0 0.0/s
state-insert 0 0.0/s
state-limit 0 0.0/s
src-limit 0 0.0/s
synproxy 0 0.0/s
</code>
</pre>
<p>We can see that the current limit is 10000:</p>
<pre>
<code>openbsd_fw1$ pfctl -sm
states hard limit 10000
src-nodes hard limit 10000
frags hard limit 5000
tables hard limit 1000
table-entries hard limit 200000
</code>
</pre>
<p>So lets fire up that <code class="language-plaintext highlighter-rouge">siege</code> command and see what happens by watching the current entries on the firewall that has the master carp IP. (Note that with <code class="language-plaintext highlighter-rouge">pfsync</code> all the states will be transferred to the backup firewall as well, but for simplicity let’s focus on the master.)</p>
<pre>
<code>openbsd_fw1$ ifconfig | grep -i master
carp: MASTER carpdev fxp2 vhid 1 advbase 1 advskew 0
status: master
carp: MASTER carpdev fxp0 vhid 2 advbase 1 advskew 0
status: master
openbsd_fw1$ while true; do pfctl -s info | grep "current entries"; sleep 1; done
current entries 17
current entries 15
current entries 13
current entries 12
current entries 12
# siege starts up here
current entries 4820
current entries 10000
current entries 10000
current entries 10000
current entries 10000
current entries 10000
^C
</code>
</pre>
<p>So you can see it only takes a couple seconds to hit that limit.</p>
<p>Let’s up it to 200000 and see what happens.</p>
<pre>
<code>openbsd_fw1$ grep "set limit" /etc/pf.conf
set limit states 200000
openbsd_fw1$ pfctl -nf /etc/pf.conf
openbsd_fw1$ pfctl -f /etc/pf.conf
openbsd_fw1$ pfctl -sm
states hard limit 200000
src-nodes hard limit 10000
frags hard limit 5000
tables hard limit 1000
table-entries hard limit 200000
</code>
</pre>
<p>Run the siege command on the client:</p>
<pre>
<code>openbsd_fw1$ while true; do pfctl -s info | grep "current entries"; sleep 1; done
current entries 40
current entries 40
current entries 40
current entries 40
# siege starts up here
current entries 560
current entries 6686
current entries 12480
current entries 17728
current entries 23060
current entries 27116
current entries 28332
current entries 29498
current entries 29884
current entries 29884
current entries 29884
current entries 29884
current entries 29884
current entries 29884
current entries 29884
current entries 29884
^C
</code>
</pre>
<p>And looks like we max out the <code class="language-plaintext highlighter-rouge">siege</code> command now at about 30k sessions. Nice!</p>
<p>To conclude, this was just a quick look at session limits on OpenBSD. If you’re running a pf firewall it may be something to consider looking at to make sure you’re not hitting the limit which would reduce the effectiveness of your firewall.</p>
<p>Note that I haven’t shown any memory usage from the firewall, but the small boxes have 512MB of RAM and even at 200K sessions the memory usage only went up very slightly so I don’t think it’s constrained for memory reasons.</p>
Cacti, Better Cacti Graphs, and SSH Original Command2011-09-12T00:00:00+00:00http://serverascode.com/2011/09/12/better-cacti-graphs-and-ssh-original-command<h1 id="cacti-better-cacti-graphs-and-ssh-original-command">Cacti, Better Cacti Graphs, and SSH Original Command</h1>
<p>So you’re at the point where you want to monitor your servers performance. Actually let’s take it a step further and you want to do this with <a href="http://www.cacti.net">Cacti</a>. Actually let’s take <em>another</em> step and say that you’re going to use Cacti and <a href="http://code.google.com/p/mysql-cacti-templates/">Better Cacti Graphs</a> (BCG)…and ssh.</p>
<p>We’re getting pretty specific here aren’t we?</p>
<p>So you setup Cacti, RPM up old BCG, and you configure <a href="http://code.google.com/p/mysql-cacti-templates/wiki/SSHBasedTemplates">ssh logins</a> for BCG so that it can grab stats off the client system.</p>
<p><em>But</em>, and here’s the kicker–you want to make sure that you limit what the cacti user can do with a ssh login. (Possibly because your security analyst wants it to be “more secure” and yet has never actually used ssh.)</p>
<p>Well, there is fairly little known functionality built into OpenSSH that will allow you to lock down what the user can do with a ssh key based login. The best thing to do at this point to learn more about this functionality would be to google <a href="http://lmgtfy.com/?q=SSH_ORIGINAL_COMMAND">SSH_ORIGINAL_COMMAND</a>. Sorry, can’t help but use <a href="http://lmgtry.com">lmgtfy.com</a>, no offense intended. <em>:)</em> It’s just fun to say.</p>
<p>The point is that there are many (little known) options that can be put in a <code class="language-plaintext highlighter-rouge">authorized_keys</code> file to limit what the user can do with they login with that key.</p>
<p>eg. The beginning of the key that I put in the cacti user’s <code class="language-plaintext highlighter-rouge">authorized_keys</code> file on the client server:</p>
<pre>
<code>command="/usr/share/cacti-ssh-auth/ssh_commands_check.sh",from="SOME_IP_ADDRESS",
no-port-forwarding,no-X11-forwarding ssh-dss SNIP_REST_OF_KEY!
</code>
</pre>
<p>What this setting does is:</p>
<ul>
<li>Only allows the user to run the script that comes after command, meaning they can <em>only</em> run <code class="language-plaintext highlighter-rouge">ssh_commands_check.sh</code>, and it runs by default.</li>
<li>Only allow logins from SOME_IP_ADDRESS (eg. 10.0.4.30 or something), ie. the monitoring server where cacti is installed. Authentication via IP addresses isn’t the best idea, but why not.</li>
<li>Disable port forwarding and X11 forwarding for the session, always.</li>
</ul>
<p>The contents of the <code class="language-plaintext highlighter-rouge">ssh_commands_check.sh</code> script look like this:</p>
<pre>
<code>#!/bin/sh
# When using $SSH_ORIGINAL_COMMAND to watch what commands we get out
# of better-cacti-graphs, this is what we see:
# cat /proc/diskstats
# cat /proc/stat
# wget -U Cacti/1.0 -q -O - -T 5 "http://localhost/server-status?auto"
# uptime
# free -ob
case "$SSH_ORIGINAL_COMMAND" in
'cat /proc/diskstats')
cat /proc/diskstats
;;
'wget -U Cacti/1.0 -q -O - -T 5 http://localhost/server-status?auto')
wget -U Cacti/1.0 -q -O - -T 5 "http://localhost/server-status?auto"
;;
'uptime')
uptime
;;
'free -ob')
free -ob
;;
*)
# Then essentially do nothing b/c only the above
# commands are allowed to run. :)
# I don't really want to echo the actual command
# until I can find some way to escape anything
# malicious. For another day!
logger -i "$0 ERROR: disallowed command attempted"
;;
esac
</code>
</pre>
<p>Great you say. But how did you find out <em>exactly</em> what commands cacti is trying to run? Well SSH_ORIGINAL_COMMAND to the rescue!</p>
<p>I used something like:</p>
<pre>
<code>command="echo $SSH_ORIGINAL_COMMAND >> /var/tmp/ssh_check_cmd.txt; $SSH_ORIGINAL_COMMAND",
from="SOME_IP_ADDRESS",no-port-forwarding,no-X11-forwarding ssh-dss SNIP_REST_OF_KEY!
</code>
</pre>
<p>and then @tail -f /var/tmp/ssh_check_cmd.txt@ and saw this:</p>
<pre>
<code>client_server$ tail -f ssh_orig_cmd.txt
cat /proc/diskstats
cat /proc/stat
wget -U Cacti/1.0 -q -O - -T 5 "http://localhost/server-status?auto"
uptime
free -ob
</code>
</pre>
<p>so we can be fairly sure that those are the commands the cacti monitor server is asking the client to run.</p>
<p><em>NOTE</em> that I would suggest checking what commands the ssh cacti scripts are running and not blindly using the ones I put above because things could have changed since I put up this post. And in fact could be completely wrong. It will take a bit of time to figure this out.</p>
<p>Also you can review the <a href="http://code.google.com/p/mysql-cacti-templates/source/browse/trunk/scripts/ss_get_by_ssh.php">code</a> for BCG’s use of ssh to find out exactly what commands are running, but note that bash/ect might interpret things differently, so it’s best to check with SSH_ORIGINAL_COMMAND.</p>
Packaging code is about sharing2011-08-18T00:00:00+00:00http://serverascode.com/2011/08/18/packaging-code-is-about-sharing<h1 id="packaging-code-is-about-sharing">Packaging code is about sharing</h1>
<p>I have been packaging code into RPMs for internal use for about five years now. I’m not going to say I’m an expert at it–I’m still learning–but I’m getting better at it and I think that’s a good thing.</p>
<p>Recently I packaged a <a href="https://wiki.umiacs.umd.edu/adapt/index.php/Ace:Main">piece of software</a> that didn’t have an existing RPM (AFAIK). I was then able to share that RPM, and installation instructions, with a partner institution so that they could easily install the software as well–in fact with one command. :)</p>
<p>From one perspective it’s obvious that packaging software is about sharing. But often I spend so much time just getting the RPM built, which can mean the gruelling process of pulling requirements out of developers who think packaging is…not important or even <em>intrusive</em>, that I forget how it’s not just about easing sysadmin maintenance of servers; that it’s about being able to <em>share</em> systems and software with peers.</p>
<p>I often wonder where some Linux users think packages come from. Certainly not a big white stork in the middle of the night. Dedicated volunteers (and I don’t mean me) are building thousands of packages every day! So hat tip to all those volunteers. Licensing is important, but so is packaging. :)</p>
Booting partitions bigger than 2TB on a HP DL160 G6 with RHEL52011-08-09T00:00:00+00:00http://serverascode.com/2011/08/09/dl160-g6-2tb-partitions<h1 id="booting-partitions-bigger-than-2tb-on-a-hp-dl160-g6-with-rhel5">Booting partitions bigger than 2TB on a HP DL160 G6 with RHEL5</h1>
<p>Yesterday I was working on a HP DL160 G6 server. Originally it had two 160GB hard-drives, but of course, I wanted more storage…a lot more. :) So we ordered four 2TB drives to put in it. Then I realized the backplane would only support two drives, so I had to order a backplane that can support four drives.</p>
<p>Once all the parts arrived I replaced the backplane and put the four drives in. It was fairly simple actually. Then when I booted the server with the new backplane and disks the P410 RAID card noticed the new drives, and suggested configuring RAID 1+0, a suggestion I accepted. That leaves me with about 4TB usable.</p>
<p>By default, the system creates one large drive of 4TB, which Redhat Enterprise 5 sees as <code class="language-plaintext highlighter-rouge">/dev/sda</code>.</p>
<p><em>However</em>, mbr, the default partition type on RHEL5, cannot boot partitions larger than 2TB. So, after the first install via kickstart I was missing 2TB. Not cool! Well, actually it’s fine, the computer did what it was told, but I wanted to use the rest.</p>
<p>The solution? It was actually fairly easy. Maybe too easy. But it’s working.</p>
<p>Because, it seems, the HP BIOS in this server supports UEFI/EFI/GPT/whatever, in the <code class="language-plaintext highlighter-rouge">%pre</code> section of the kickstart we can create a gpt partition.</p>
<pre>
<code>%pre
# B/c sda on this server is 4.0TB we need to try to use gpt instead of mdr.
/usr/sbin/parted -s /dev/sda mklabel gpt
</code>
</pre>
<p>Also make sure that if you have a <code class="language-plaintext highlighter-rouge">clearpart</code> command in your kickstart to comment it out or delete it.</p>
<pre>
<code># Removing b/c of the parted in %pre
#clearpart --drives=sda --all --initlabel
</code>
</pre>
<p>Then run your kickstart as usual and hopefully your system will boot with whatever partitions you configured. In my case, I created two partitions, one 60GB for the system and the rest for virtual machines, and placed logical volumes over top:</p>
<pre>
<code>4TB_RAID10_SERVER$ pvs
PV VG Fmt Attr PSize PFree
/dev/sda2 system lvm2 a- 58.56g 36.66g
/dev/sda3 vm lvm2 a- 3.58t 3.58t
</code>
</pre>
<p>And running <code class="language-plaintext highlighter-rouge">parted</code> we can see that it is indeed a gpt layout:</p>
<pre>
<code>4TB_RAID10_SERVER$ parted /dev/sda print
Model: HP LOGICAL VOLUME (scsi)
Disk /dev/sda: 4001GB
Sector size (logical/physical): 512B/512B
Partition Table: gpt
Number Start End Size File system Name Flags
1 1049kB 525MB 524MB ext4 boot
2 525MB 63.4GB 62.9GB lvm
3 63.4GB 4001GB 3937GB lvm
</code>
</pre>
<p>So now I can create that rsync backup server I’ve always wanted, and I have up to 3.58TB to store the backups on. Good times and I’m glad it all worked out. Now if only they were 3TB drives… <em>;)</em></p>
ksplice bought out by Oracle, RHEL desupported2011-07-21T00:00:00+00:00http://serverascode.com/2011/07/21/oracle-buys-ksplice<h1 id="ksplice-bought-out-by-oracle-rhel-desupported">ksplice bought out by Oracle, RHEL desupported</h1>
<p>I am <em>extremely</em> saddened to see that <a href="http://ksplice.com">ksplice</a> has been <a href="http://www.oracle.com/us/corporate/acquisitions/ksplice/customer-letter-430127.html">bought out</a> by Oracle and will no longer be supporting Redhat Enterprise. I can only hope that the Linux community can find a way to provide this service outside of the limited confines of Oracle Corp.</p>
Basic infrastructure to support production linux servers2011-07-20T00:00:00+00:00http://serverascode.com/2011/07/20/basic-linux-infrastructure<h1 id="basic-infrastructure-to-support-production-linux-servers">Basic infrastructure to support production linux servers</h1>
<p>Every IT group providing Linux servers will require some infrastructure services. What I mean by that is that there are services that Linux sysadmins need that help them to run their servers in a efficient, scalable way.</p>
<p>Production services need support from <strong>infrastructure services</strong>.</p>
<p>This post lists a basic collection of services that a Linux sysadmin might require. For me, this would be the <em>minimum</em> services required to run a group of Linux servers, be it 10 or 1000.</p>
<p>Notes:</p>
<h1 id="i-mention-specific-solutions-but-there-are-many-different-ways-to-obtain-the-same-basic-infrastructure">I mention specific solutions, but there are many different ways to obtain the same basic infrastructure.</h1>
<h1 id="most-of-what-i-discuss-below-is-geared-towards-redhat-servers-but-is-also-completely-applicable-to-any-linux-disto-that-has-a-packaging-system-which-is-pretty-much-all-of-them">Most of what I discuss below is geared towards Redhat servers, but is also completely applicable to any Linux disto that has a packaging system, which is pretty much all of them.</h1>
<p><em>1. Write documentation with mediawiki</em></p>
<p>One of the most important things a sysadmin does is document what they did so that they can take a relaxing, rejuvenating vacation. By this I mean that they have documented their systems so that the other admins taking over can use it to fix things, to understand what is installed, where it is, what it does, who owns it, ect, when the primary sysadmin is unavailable because he/she is in downtown Tokyo and is having a hard time connecting to the local wireless because they can’t read Japanese.</p>
<p>Documentation is also important so you can remember what you did six months ago to get iscsi working, or how to configure a xen dom0 to use a bridge that comes from a vlan, or that command to dd a logical volume from one server to another over ssh without having to figure it out all over again. I suppose you could <a href="http://serverascode.com">blog</a> about it too. <em>:)</em></p>
<p>Regardless of what is being documented, usually the system I will use is a <a href="http://www.mediawiki.org">Mediawiki</a> instance. Mediawiki supports searching (also full text searching if you use <a href="http://sphinxsearch.com/">sphinx</a> and the <a href="http://www.mediawiki.org/wiki/Extension:SphinxSearch">sphinx search plugin</a> so that you can search in pre tags too), file uploads, categories, and many, many other features, especially via the diverse plugin/extension community.</p>
<p>When people don’t want to use mediawiki I ask them what they want to do, how they want to work, and inevitably mediawiki can do it.</p>
<p><em>2. Serve packages using mrepo</em></p>
<p>Most Linux distros use <em>some</em> form of package management to install software. For example, in Debian/Ubuntu a deb file and in Redhat it’s an rpm.</p>
<p>These packages, somewhat akin to an advanced zip file, contain all the files, requirements, metadata, ect, for a particular piece of software or service. The @./configure; make; make install@ dance is only done on the build servers.</p>
<p>In most of the environments I work in, we strive to <em>package all code</em>. This means that all software and applications are installed on a server in a package. Configuration can be done by hand, or via a centralized configuration management system, but the code is actually installed via a package. This goes for Perl CPAN modules too. :) <em>EVERYTHING</em>.</p>
<p>The <em>package server</em> provides a central spot that the servers obtain packages from, eg. a <a href="http://dag.wieers.com/home-made/mrepo/">mrepo</a> server.</p>
<p>The packages server will do three major things:</p>
<p>** Download RPM packages from external repositories, eg. the official Redhat repositories, EPEL, RPMForge, ect.
Also it will allow us to store our own <em>custom packages</em>.
This means our servers don’t go to the internet to get updates, they go to the packages server.</p>
<p>** Serve those packages to all of our Linux servers.</p>
<p>** Allow for the ability to “freeze” the repositories so that we can install software updates in test environments, test them, and then install the exact same version of the packages/software in production, thus being a <em>somewhat</em> more sure that everything is going to work OK after the update.</p>
<p><em>3. Centralize syslogging with rsyslog</em></p>
<p>There should be a central syslog server somewhere in your infrastucture, and all production servers should send syslog packets to that server.</p>
<p>This will allow for a central spot for gathering syslog messages from all servers. We can then run scripts/processes to analyze these logs looking for issues.</p>
<p>Also, should a server get <em>hacked</em> the first thing <em>malicious users</em> usually do is (try) to delete logs. But, if the logs have been sent to a central log server then they (probably) can’t do that.</p>
<p>I usually replace, when possible, syslog with <a href="http://www.rsyslog.com/">rsyslog</a> and at minimum use TCP delivery instead of UDP.</p>
<p><em>4. Centralize root email with sendmail or postfix and dovecot</em></p>
<p>There are many scripts on servers that will send email to root if something breaks, eg. cron or logwatch. So all of these emails should be sent to a central email address that sysadmins have access to.</p>
<p>I’m not a huge fan of what is essentially logging over email, but it’s nearly impossible to avoid.</p>
<p>Currently I configure each server’s root alias to email a central address which is delivered to a Maildir and serve that up over IMAPS with <a href="http://www.dovecot.org">dovecot</a>. Dovecot is pretty great.</p>
<p>(Note that while sendmail is default on RHEL5, postfix is default on RHEL6!)</p>
<p><em>5. Serve kickstarts over http</em></p>
<p>The kickstart server is simply a plain http server that serves kickstart files, and in conjunction with the packaging server allows for rapid, repeatable installation of Redhat/CentOS. Or you could do it over nfs, or pop it on the USB key. I always use a web server to serve up the kickstarts.</p>
<p><code class="language-plaintext highlighter-rouge">ks=http://example.com/ks/newserver.ks</code> if you know what I mean. :)</p>
<p><em>6. Centralize configuration management</em></p>
<p>This is a central server that can be used to access all the Linux/Unix servers via ssh and to try automate with custom scripts or things like <a href="https://code.google.com/p/pdsh/">pdsh</a>, <a href="http://www.opscode.com/chef/">chef</a>, <a href="http://www.puppetlabs.com/">puppet</a>, <a href="http://www.fabfile.org">fabric</a>, ect.</p>
<p>Also stores a copy of every Linux servers RPM database so that if a server gets hacked you can check what files have changed, if any, on the hacked server. (Though that should be in backups too.)</p>
<p><em>7. Build packages with rpmbuild</em></p>
<p>To create custom RPM packages a build server for each OS and architecture is required. So if you run RHEL5 and RHEL 6 on x86_64 then you’ll need two build servers, one for each OS and arch.</p>
<p>This is where @rpmbuild -ba some.spec@ will be run to build a RPM. Then the RPM will be copied to the packaging server.</p>
<p><em>8. Login from anywhere securely with ssh</em></p>
<p>(Of course with ssh!)</p>
<p>Linux/Unix admins should be able to access a ssh gateway from the Internet to be able to access servers and possibly their workstations or just the central management server.</p>
<p>Only public key authentication would be allowed to this server (meaning no password based authentication) which makes it very secure in terms of auth.</p>
<p>Some workplaces will want to put this behind a commercial VPN. Try to avoid this…IMHO ssh is one of the, if <em>not the</em>, most secure network applications on the planet–certainly better than some million <a href="https://secure.wikimedia.org/wikipedia/en/wiki/Source_lines_of_code">SLOC</a> ssl “vpn”.</p>
<p>PS. Did you know you can create a ssh-based vpn with something like <a href="https://github.com/apenwarr/sshuttle?">sshuttle</a> If you did sysadmin 2pts for you! <em>:)</em></p>
<p><em>9. Monitor uptime with nagios</em></p>
<p>Essentially a <a href="http://www.nagios.org">Nagios</a> server, or similar, that monitors production services and servers and will let you know when they go down. I have also used hobbit, which is apparently called <a href="http://sourceforge.net/projects/xymon/">Xymon</a> now.</p>
<p>(But they won’t go down, right? In fact, the monitoring system will go down more than the production serivces, won’t it. <em>:)</em> I’ve always thought that was the hard part of uptime monitoring.)</p>
<p><em>10. Manage code with version control systems</em></p>
<p>Every IT workplace should have a central code repository. Sure, hg and git are distributed, but I still think it’s nice to have a central location. “Github”:github.com seems to be successful at centralizing distributed revision control, so I think centralizing a local git or hg instance (with hgweb.cgi for example) will work for most workplaces as well. :)</p>
<p>I have a github account and have used svn and hg at work. Use whatever you want–just do it now!</p>
<p><em>11. Backup with rdiff-backup</em></p>
<p>This would be a server used to rsync snapshot-type backups over ssh to disk for rapid restores. I like <a href="http://www.nongnu.org/rdiff-backup/">rdiff-backup</a></p>
<p>It would likely compliment that huge Netbackup, or Commvault (calmvault?), or other backup system you have that doesn’t work half the time and requires the installation of a gigantic root-running tarball or monolithic 600MB RPM which doubles the size of your 500MB minimal Redhat OS install. Good times in commercial backup land.</p>
<p><em>12. Test with jmeter</em></p>
<p>If you have dev, test, production environments then you should also automate testing. This would be the service that helps you do that, running Jmeter and/or Selenium for example; do everything from one location, perhaps when a RPM/package is built then it’s automatically tested from here. Wouldn’t that be nice!?</p>
<p><em>13. Monitor performance with cacti</em></p>
<p>Everyone wants performance. Or do they? How does one know how much performance one needs? You have to do performance testing, and you have to monitor performance. You can’t just buy performance, you have to put some work in.</p>
<p>That said, for monitoring performance I usually use either <a href="http://www.nagios.org">Nagios</a> or something like <a href="http://www.cacti.net">Cacti</a> using snmp with some custom scripts.</p>
<p><em>14. Secure remote bios level access via a remote KVM or IPMI</em></p>
<p>By this I mean the secure network you attach your remote KVM to the hardware dom0 servers, and/or to the IPMI interfaces that most teir 1 servers come with (not that I endorse only tier 1 vendors) so that you don’t have to hang out in that cold, loud, unfriendly server room.</p>
Using fusion-io drives on Redhat Enterprise 52011-06-27T00:00:00+00:00http://serverascode.com/2011/06/27/fusionio-drives-on-redhat-enterprise-5<h1 id="using-fusion-io-drives-on-redhat-enterprise-5">Using fusion-io drives on Redhat Enterprise 5</h1>
<p>%{color:red}Update:% Please note that this post is getting a bit old. Currently I am running these IBM FusionIO drives on RHEL 6. I’ll be posting about that and a few other PCIe-SSD subjects in the next short while. - 24 Apr 2012</p>
<h2 id="fusionio-iodrive-overview">FusionIO IODrive Overview</h2>
<p>So at work we have a rather large <a href="http://www-03.ibm.com/systems/x/hardware/enterprise/x3850x5/">IBM x3850 x5</a> server. It has 4 sockets each with six cores and hyperthreading (not that I’m necessarily a fan of hyperthreading–really I haven’t done enough research to make up my mind) which ends up with RHEL5 seeing 48 CPUS.</p>
<pre>
<code>$ cat /proc/cpuinfo | grep proc | wc -l
48
</code>
</pre>
<p>Fun.</p>
<p>But the important part of this post is that this server also has three 640GB <a href="http://www.fusionio.com/products/iodrive-duo/">fusion-io drives</a> which I have installed and configured as a volume group called <code class="language-plaintext highlighter-rouge">fio</code></p>
<pre>
<code>$ ls /dev/fio
fio/ fioa fiob fioc fiod fioe fiof
$ vgs fio
VG #PV #LV #SN Attr VSize VFree
fio 6 4 0 wz--n- 1.76T 1.08T
</code>
</pre>
<p>and where the <code class="language-plaintext highlighter-rouge">fio[a,b,c,d,e,f]</code> are the drives, with each 640 gig card actually appearing as 2 320 gig disks.</p>
<pre>
<code>$ dmesg |grep -i "found device"
fioinf IBM 640GB High IOPS MD Class PCIe Adapter 0000:89:00.0: Found device 0000:89:00.0
fioinf IBM 640GB High IOPS MD Class PCIe Adapter 0000:8a:00.0: Found device 0000:8a:00.0
fioinf IBM 640GB High IOPS MD Class PCIe Adapter 0000:93:00.0: Found device 0000:93:00.0
fioinf IBM 640GB High IOPS MD Class PCIe Adapter 0000:94:00.0: Found device 0000:94:00.0
fioinf IBM 640GB High IOPS MD Class PCIe Adapter 0000:98:00.0: Found device 0000:98:00.0
fioinf IBM 640GB High IOPS MD Class PCIe Adapter 0000:99:00.0: Found device 0000:99:00.0
</code>
</pre>
<h2 id="resources">Resources</h2>
<p>The most important resource for using these FusionIO drives is the <a href="http://kb.fusionio.com/KB/c4/linux-specific.aspx">official knowledge base</a> which has several articles specifically for linux. I would suggest reading all of them. :)</p>
<h2 id="install">Install</h2>
<p>Once the cards were put into the server, which is somewhat harrowing given their individual cost, and the server was booted, the software drivers that were downloaded from the IBM website were installed. This server runs RHEL5</p>
<pre>
<code>$ cat /etc/redhat-release
Red Hat Enterprise Linux Server release 5.6 (Tikanga)
</code>
</pre>
<p>as that RHEL version that is what IBM supports for drivers.</p>
<pre>
<code>$ rpm -i iodrive-driver-1.2.7.5-1.0_2.6.18_164.el5.x86_64.rpm \
iodrive-firmware-1.2.7.6.43246-1.0.noarch.rpm \
iodrive-jni-1.2.7.5-1.0.x86_64.rpm \
iodrive-snmp-1.2.7.5-1.0.x86_64.rpm \
iodrive-util-1.2.7.5-1.0.x86_64.rpm \
</code>
</pre>
<p>Currently I am using the drivers as they were downloaded, which means using a specific matching kernel to match. The drivers do come with a source RPM so that you can rebuild them for your latest kernel, but I have opted not to do that yet. So install the matching kernel</p>
<pre>
<code>$ yum install kernel-2.6.18-164.el5
</code>
</pre>
<p>and reboot.</p>
<p>However, I am also using the amazing <a href="http://ksplice.com">ksplice</a> service to ensure that depsite the fact that I am using a rather old kernel to match the FusionIO drivers that the kernel is still up to date in terms of security issues:</p>
<pre>
<code>$ uptrack-uname -r
2.6.18-238.12.1.el5
$ uname -r
2.6.18-164.el5
</code>
</pre>
<p>The @uptrack-uname -r@ command asks uptrack what security equivalent version of the kernel is. Great stuff that kslplice.</p>
<p>Once the drivers are installed we can load the modules</p>
<pre>
<code>$ modprobe fio-driver
</code>
</pre>
<p>and now we can see the drives</p>
<pre>
<code>$ ls /dev/fio*
fioa fiob fioc fiod fioe fiof
</code>
</pre>
<p>and at this point we can configure the drives.</p>
<h2 id="worker-processes">Worker processes</h2>
<p>Once the drivers are installed there is a <code class="language-plaintext highlighter-rouge">/etc/init.d/iodrive</code> startup script. One of the things this script does is startup some <code class="language-plaintext highlighter-rouge">worker</code> processes which I believe are used to move data around the FusionIO drives to ensure their performance and longevity.</p>
<pre>
<code>$ chkconfig --list iodrive
iodrive 0:off 1:on 2:on 3:on 4:on 5:on 6:off
</code>
</pre>
<p><br /></p>
<pre>
<code>$ ps ax | grep worker
5271 ? S< 1169:51 [fct0-worker]
5588 ? S< 1168:07 [fct1-worker]
5593 ? S< 359:01 [fct2-worker]
5598 ? R< 206:02 [fct3-worker]
5603 ? S< 203:15 [fct4-worker]
5608 ? S< 203:12 [fct5-worker]
20921 pts/2 S+ 0:00 grep worker
</code>
</pre>
<p>These processes will take up some CPU time. Frankly, because there are 48 CPUs in this server, using up one to run these workers is OK. But it was a little confusing at first seeing all this activity–one worker process for each card.</p>
<h2 id="configuration">Configuration</h2>
<p>Given that we are going to manage the FusionIO drives via LVM, we will need to configure LVM to allow it. See this <a href="http://kb.fusionio.com/KB/a36/enabling-the-iodrive-for-lvm-use.aspx">knowledge base article</a>.</p>
<pre>
<code>$ grep fio /etc/lvm/lvm.conf
types = [ "fio", 16 ]
</code>
</pre>
<p>Then add each <code class="language-plaintext highlighter-rouge">/dev/fio*</code> drive as a phyical volume and then add them to a volume group.</p>
<pre>
<code>$ pvs | grep fio
/dev/fioa fio lvm2 a- 300.31G 320.00M
/dev/fiob fio lvm2 a- 300.31G 100.31G
/dev/fioc fio lvm2 a- 300.31G 100.31G
/dev/fiod fio lvm2 a- 300.31G 300.31G
/dev/fioe fio lvm2 a- 300.31G 300.31G
/dev/fiof fio lvm2 a- 300.31G 300.31G
$ vgs fio
VG #PV #LV #SN Attr VSize VFree
fio 6 4 0 wz--n- 1.76T 1.08T
</code>
</pre>
<p><br /></p>
<h2 id="fio-status">fio-status</h2>
<p>Useful way to check the status of the FusionIO drives.</p>
<pre>
<code>$ fio-status
Found 6 ioDrives in this system with 3 ioDrive Duos
Fusion-io driver version: 1.2.7.5
Adapter: ioDrive Duo
IBM 640GB High IOPS MD Class PCIe Adapter, Product Number:68Y7381 SN:59518
PCIE Power limit threshold: 24.75W
Connected ioDimm modules:
fct0: IBM 640GB High IOPS MD Class PCIe Adapter, Product Number:68Y7381 SN:77479
fct1: IBM 640GB High IOPS MD Class PCIe Adapter, Product Number:68Y7381 SN:77478
fct0 Attached as 'fioa' (block device)
IBM 640GB High IOPS MD Class PCIe Adapter, Product Number:68Y7381 SN:77479
Alt PN:68Y7382
Located in 0 Upper slot of ioDrive Duo SN:59518
Firmware v43246
322.46 GBytes block device size, 396 GBytes physical device size
Internal temperature: avg 56.6 degC, max 59.6 degC
Media status: Healthy; Reserves: 100.00%, warn at 10%
fct1 Attached as 'fiob' (block device)
IBM 640GB High IOPS MD Class PCIe Adapter, Product Number:68Y7381 SN:77478
Alt PN:68Y7382
Located in 1 Lower slot of ioDrive Duo SN:59518
Firmware v43246
322.46 GBytes block device size, 396 GBytes physical device size
Internal temperature: avg 61.0 degC, max 63.0 degC
Media status: Healthy; Reserves: 100.00%, warn at 10%
Adapter: ioDrive Duo
IBM 640GB High IOPS MD Class PCIe Adapter, Product Number:68Y7381 SN:59507
PCIE Power limit threshold: 24.75W
Connected ioDimm modules:
fct2: IBM 640GB High IOPS MD Class PCIe Adapter, Product Number:68Y7381 SN:77143
fct3: IBM 640GB High IOPS MD Class PCIe Adapter, Product Number:68Y7381 SN:77144
fct2 Attached as 'fioc' (block device)
IBM 640GB High IOPS MD Class PCIe Adapter, Product Number:68Y7381 SN:77143
Alt PN:68Y7382
Located in 0 Upper slot of ioDrive Duo SN:59507
Firmware v43246
322.46 GBytes block device size, 396 GBytes physical device size
Internal temperature: avg 62.0 degC, max 65.5 degC
Media status: Healthy; Reserves: 100.00%, warn at 10%
fct3 Attached as 'fiod' (block device)
IBM 640GB High IOPS MD Class PCIe Adapter, Product Number:68Y7381 SN:77144
Alt PN:68Y7382
Located in 1 Lower slot of ioDrive Duo SN:59507
Firmware v43246
322.46 GBytes block device size, 396 GBytes physical device size
Internal temperature: avg 64.0 degC, max 66.4 degC
Media status: Healthy; Reserves: 100.00%, warn at 10%
Adapter: ioDrive Duo
IBM 640GB High IOPS MD Class PCIe Adapter, Product Number:68Y7381 SN:100366
PCIE Power limit threshold: 24.75W
Connected ioDimm modules:
fct4: IBM 640GB High IOPS MD Class PCIe Adapter, Product Number:68Y7381 SN:77344
fct5: IBM 640GB High IOPS MD Class PCIe Adapter, Product Number:68Y7381 SN:77345
fct4 Attached as 'fioe' (block device)
IBM 640GB High IOPS MD Class PCIe Adapter, Product Number:68Y7381 SN:77344
Alt PN:68Y7382
Located in 0 Upper slot of ioDrive Duo SN:100366
Firmware v43246
322.46 GBytes block device size, 396 GBytes physical device size
Internal temperature: avg 68.9 degC, max 71.9 degC
Media status: Healthy; Reserves: 100.00%, warn at 10%
fct5 Attached as 'fiof' (block device)
IBM 640GB High IOPS MD Class PCIe Adapter, Product Number:68Y7381 SN:77345
Alt PN:68Y7382
Located in 1 Lower slot of ioDrive Duo SN:100366
Firmware v43246
322.46 GBytes block device size, 396 GBytes physical device size
Internal temperature: avg 63.0 degC, max 66.0 degC
Media status: Healthy; Reserves: 100.00%, warn at 10%
</code>
</pre>
<h2 id="xfs">XFS</h2>
<p>Prior to finding out about the official knowledge base, I had decided to purchase a subscription from Redhat for the XFS file system. Then, upon reading this <a href="http://kb.fusionio.com/KB/a43/filesystem-tuning.aspx">kb article</a>, I found that they heavily recommend XFS as the file system to run on top of a FusionIO drive</p>
<pre>
<code>XFS is currently the recommended filesystem. It can achieve up to 3x
the performance of a tuned ext2/ext3 solution. At this time, there is
no know additional tuning for running XFS in a single- or multi-ioDrive
configuration
</code>
</pre>
<p>so that is the file system we use.</p>
<pre>
<code>$ mount | grep fio
/dev/mapper/fio-vault1 on /var/lib/vault1 type xfs (rw)
</code>
</pre>
<p><br /></p>
<h2 id="mounting-drives-after-a-reboot">Mounting drives after a reboot</h2>
<p>I’ll admit I hadn’t thought of this during the initial installation. After a few days we moved the server to a new location which thus required a power down and restart.</p>
<p>While the server was restarting, and I was standing in the cold, loud server room because the new room didn’t have any networking for IPMI (which is not good), I noticed it took a very long time to get past the udev portion of the boot, and in fact the FusionIO drives failed to mount from fstab. Of course there is a logical reason for that–read about it <a href="http://kb.fusionio.com/KB/a64/loading-the-driver-via-udev-or-init-script-for-md-and-lvm.aspx">here</a>.</p>
<p>Because we are using the 1.2 driver, I followed the straight forward instructions <a href="http://kb.fusionio.com/KB/a64/loading-the-driver-via-udev-or-init-script-for-md-and-lvm.aspx#Using_Init_Scripts_to_Load_the_1.2.x">here</a>.</p>
<h2 id="performance-testing">Performance testing</h2>
<p>Performance testing is hard. Maybe it’s just me. But testing superdisk like these FusionIO drives on a server with 48 CPUS and 64 gigs of main memory is not easy. Again I will admit I took a shot at benchmarking the FusionIO disk having not read the kb. I messed around with Bonnie++, io-whatever, but nothing quite came out right, partially because I didn’t put a lot of time into it, and because the server has so much memory that it makes it hard to beat the cache (I did try to reduce the memory the OS could see via kernel configuration, but didn’t have a lot of luck with that).</p>
<p>Finally I read this kb article which suggested using the <a href="http://freshmeat.net/projects/fio">fio utility</a> (which I don’t believe is a utility put out by FusionIO, rather just aptly named).</p>
<p>The fio tool is not in the RHEL repositories but it is in rpmforge/repoforge.</p>
<pre>
<code>$ cd /var/tmp
$ wget http://pkgs.repoforge.org/rpmforge-release/rpmforge-release-0.5.2-2.el5.rf.x86_64.rpm
$ rpm -Uvh rpmforge-release-0.5.2-2.el5.rf.x86_64.rpm
$ yum repolist | grep forge
rpmforge RHEL 5Server - RPMforge.net - enabled: 10,636
$ yum search fio | grep -i benchmark
fio.x86_64 : I/O benchmark and stress/hardware verification tool
</code>
</pre>
<p>Here are a couple of example runs. Please note that at this point I do not know much about fio. Benchmarking disk is a highly technical thing to do, and getting tests right would take a lot of research and consideration, which I have not done.</p>
<p>It seems that the <code class="language-plaintext highlighter-rouge">fio</code> benchmark utility suports <code class="language-plaintext highlighter-rouge">direct=1</code> which means use non-buffered-io, thereby skipping memory cacheing and going straight to the disk.</p>
<pre>
<code>$ cat fio-randwrite.fio
[randwrite[
direct=1
rw=randwrite
bs=1m
size=5G
numjobs=4
runtime=10
group_reporting
directory=/mnt/fio-test-xfs
$ fio fio-randwrite.fio
randwrite: (g=0): rw=randwrite, bs=1M-1M/1M-1M, ioengine=sync, iodepth=1
...
randwrite: (g=0): rw=randwrite, bs=1M-1M/1M-1M, ioengine=sync, iodepth=1
fio 1.55
Starting 4 processes
randwrite: Laying out IO file(s) (1 file(s) / 5120MB)
randwrite: Laying out IO file(s) (1 file(s) / 5120MB)
randwrite: Laying out IO file(s) (1 file(s) / 5120MB)
randwrite: Laying out IO file(s) (1 file(s) / 5120MB)
Jobs: 4 (f=4): [wwww] [100.0% done] [0K/522.8M /s] [0 /510 iops] [eta 00m:00s]
randwrite: (groupid=0, jobs=4): err= 0: pid=28487
write: io=4556.0MB, bw=466161KB/s, iops=455 , runt= 10008msec
clat (msec): min=1 , max=1692 , avg= 9.83, stdev=22.04
lat (msec): min=1 , max=1692 , avg= 9.84, stdev=22.04
bw (KB/s) : min= 559, max=264126, per=24.79%, avg=115540.55, stdev=20377.90
cpu : usr=0.10%, sys=14.85%, ctx=59071, majf=0, minf=92
IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued r/w/d: total=0/4556/0, short=0/0/0
lat (msec): 2=0.53%, 4=1.27%, 10=97.17%, 20=0.59%, 50=0.09%
lat (msec): 100=0.18%, 250=0.15%, 2000=0.02%
Run status group 0 (all jobs):
WRITE: io=4556.0MB, aggrb=466161KB/s, minb=477349KB/s, maxb=477349KB/s,
mint=10008msec, maxt=10008msec
Disk stats (read/write):
dm-11: ios=0/158802, merge=0/0, ticks=0/55956241, in_queue=55915327,
util=66.05%, aggrios=0/159667, aggrmerge=0/0, aggrticks=0/55932489,
aggrin_queue=55785218, aggrutil=65.96%
fioc: ios=0/159667, merge=0/0, ticks=0/55932489, in_queue=55785218,
util=65.96%
</code>
</pre>
<p>And then a similar test using RAID10 SAS disk formated ext3.</p>
<pre>
<code>$ cat fio-randwrite.fio
[randwrite[
direct=1
rw=randwrite
bs=1m
size=5G
numjobs=4
runtime=10
group_reporting
directory=/mnt/sas-test
$ fio fio-randwrite.fio
randwrite: (g=0): rw=randwrite, bs=1M-1M/1M-1M, ioengine=sync, iodepth=1
...
randwrite: (g=0): rw=randwrite, bs=1M-1M/1M-1M, ioengine=sync, iodepth=1
fio 1.55
Starting 4 processes
randwrite: Laying out IO file(s) (1 file(s) / 5120MB)
randwrite: Laying out IO file(s) (1 file(s) / 5120MB)
randwrite: Laying out IO file(s) (1 file(s) / 5120MB)
randwrite: Laying out IO file(s) (1 file(s) / 5120MB)
Jobs: 4 (f=4): [wwww] [1200.0% done] [0K/0K /s] [0 /0 iops] [eta
1158050441d:07h:00m:05sJobs: 4 (f=4): [wwww] [inf% done] [0K/0K /s]
[0 /0 iops] [eta 1158050441d:07h:00m:04s] Jobs: 4 (f=4): [wwww]
[1300.0% done] [0K/0K /s] [0 /0 iops] [eta 1158050441d:07h:00m:04sJobs:
4 (f=4): [wwww] [inf% done] [0K/0K /s] [0 /0 iops]
[eta 1158050441d:07h:00m:03s] Jobs: 1 (f=1): [___w] [66.1% done]
[0K/0K /s] [0 /0 iops] [eta 00m:19s]
randwrite: (groupid=0, jobs=4): err= 0: pid=28586
write: io=4096.0KB, bw=112369 B/s, iops=0 , runt= 37326msec
clat (usec): min=12140K, max=37183K, avg=32696578.04, stdev= 0.00
lat (usec): min=12140K, max=37183K, avg=32696579.88, stdev= 0.00
bw (KB/s) : min= 27, max= 83, per=31.61%, avg=34.46, stdev= 0.00
cpu : usr=0.00%, sys=51.90%, ctx=9598, majf=0, minf=102
IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued r/w/d: total=0/4/0, short=0/0/0
lat (msec): >=2000=100.00%
Run status group 0 (all jobs):
WRITE: io=4096KB, aggrb=109KB/s, minb=112KB/s, maxb=112KB/s,
mint=37326msec, maxt=37326msec
Disk stats (read/write):
dm-12: ios=128/4721384, merge=0/0, ticks=5582/602531980, in_queue=602926524,
util=97.85%, aggrios=129/87424, aggrmerge=0/4634618, aggrticks=5631/10828734,
aggrin_queue=10826088, aggrutil=98.01%
sdb: ios=129/87424, merge=0/4634618, ticks=5631/10828734, in_queue=10826088,
util=98.01%
</code>
</pre>
<p>That’s a pretty big difference: <code class="language-plaintext highlighter-rouge">io=4556.0MB</code> for the FusionIO drives versus <code class="language-plaintext highlighter-rouge">io=4096.0KB</code> for the SAS RAID10. I’m going to have to look into this more! :)</p>
<p>PS. I found this <a href="https://secure.wikimedia.org/wikipedia/en/wiki/List_of_device_bandwidths">list</a> of device bandwidths interesting.</p>
Installing chef on Centos 52011-05-11T00:00:00+00:00http://serverascode.com/2011/05/11/Installing-chef-on-centos-5<h1 id="installing-chef-on-centos-5">Installing chef on Centos 5</h1>
<h2 id="mirroring-the-frameos-rpm-repository">Mirroring the FrameOS RPM repository</h2>
<p>Installing Chef is pretty easy given that FrameOS has created all of the RPMs for us. See this <a href="http://blog.frameos.org/2011/04/14/announcing-rbel-frameos-org/">blog post</a> for more information.</p>
<p>I mirror their repository on a local, centralized server using mrepo. Below is an example of my configuration.</p>
<pre>
<code>[root@repos etc]# cd /etc/mrepo.conf.d/
[root@repos mrepo.conf.d]# cat chef.conf
[chef]
# FRAMEOS builds RPMS for chefhere:
# http://blog.frameos.org/2011/04/14/announcing-rbel-frameos-org/
#
# This might also be a good repo to use:
# - http://download.elff.bravenet.com/5/x86_64/
name = FrameOS rbel Chef RPMs $release ($arch)
release = 5
#arch = x86_64 i386
arch = x86_64
metadata = repomd repoview yum
### Additional repositories
chef = http://rbel.frameos.org/stable/el$release/$arch/
</code>
</pre>
<p>This repo is then available to my servers at <code class="language-plaintext highlighter-rouge">http://repos/mrepo/chef-x86_64/RPMS.chef/</code>.</p>
<h2 id="installing-chef-server">Installing chef-server</h2>
<p>Then I created a CentOS 5 virtual machine called <code class="language-plaintext highlighter-rouge">chef-server</code>. I enabled the repo I mention above on that server, and then ran:</p>
<notextile>
<pre>
<code>[root@chef-server yum.repos.d]# yum install rubygem-chef-server
Loaded plugins: fastestmirror
Loading mirror speeds from cached hostfile
* extras: ftp.telus.net
* updates: repos
Setting up Install Process
Resolving Dependencies
--> Running transaction check
SNIP!
</code>
</pre>
<br />
I added these iptables rules to /etc/sysconfig/iptables.
<pre>
<code># Chef
# -- web interface
-A RH-Firewall-1-INPUT -m state --state NEW -m tcp -p tcp --dport 4040 -j ACCEPT
# -- chef-server
-A RH-Firewall-1-INPUT -m state --state NEW -m tcp -p tcp --dport 4000 -j ACCEPT
# -- amqp server
-A RH-Firewall-1-INPUT -m state --state NEW -m multiport -p tcp --dport 5672,4369,50229 -j ACCEPT
# -- search indexes (solr)
-A RH-Firewall-1-INPUT -m state --state NEW -m tcp -p tcp --dport 8983 -j ACCEPT
# data store (couchdb)
-A RH-Firewall-1-INPUT -m state --state NEW -m tcp -p tcp --dport 5984 -j ACCEPT
</code>
</pre>
<br />
And then ran the setup script (after taking a look at what it does :) ).
<pre>
<code>[root@chef-server sbin]# setup-chef-server.sh
Checking RabbitMQ...
RabbitMQ not running. Starting...
Starting rabbitmq-server: SUCCESS
rabbitmq-server.
Configuring RabbitMQ default Chef user...
Starting CouchDB...
Starting couchdb: [ OK ]
Enabling Chef Services...
Starting Chef Services...
Starting chef-server: [ OK ]
Starting chef-server-webui: [ OK ]
Starting chef-solr: [ OK ]
Starting chef-expander: [ OK ]
</code>
</pre>
</notextile>
<p>At which point I had a chef-server running, to which I can add clients and nodes.</p>
<h2 id="installing-chef-client">Installing chef-client</h2>
<p>Installing chef-client is also easily done with the provided rpms. I created another CentOS 5 virtual machine, called chef-client. (Actually I created many of them. It’s fun once you get it automated. :) )</p>
<pre>
<code>[root@chef-client ~]# yum install chef-client
</code>
</pre>
<p>(Note that this may not be the preferred way to bootstrap a chef-client, but it has been working for me.)</p>
<p>Then create a <code class="language-plaintext highlighter-rouge">client.rb</code> file in <code class="language-plaintext highlighter-rouge">/etc/chef</code>, where chef-server.example.com is the fqdn of your chef-server and is accessible on port 4000 from your chef-client.</p>
<pre>
<code>[root@chef-client2 chef]# cat client.rb
log_level :info
log_location STDOUT
chef_server_url 'http://chef-server.example.com:4000'
</code>
</pre>
<p>Next, copy the <code class="language-plaintext highlighter-rouge">validation.pem</code> file from the chef-server to <code class="language-plaintext highlighter-rouge">/etc/chef</code> on the chef-client, likely using scp (or, do it when the server is built in a kickstart file :) ).</p>
<pre>
<code>[root@chef-client2 chef]# ls
client.rb validation.pem
</code>
</pre>
<p>Then start <code class="language-plaintext highlighter-rouge">chef-client</code>.</p>
<pre>
<code>[root@chef-client2 chef]# service chef-client start
</code>
</pre>
<p><em>But</em> in the /var/log/chef/client.log you will see an error that says client.pem is not present. This is good–chef-client will create the client.pem file.</p>
<pre>
<code># Logfile created on [Date] 1 by logger.rb/22285
INFO: Daemonizing..
INFO: Forked, in 1762. Priveleges: 0 0
INFO: *** Chef 0.10.0 ***
INFO: Client key /etc/chef/client.pem is not present - registering
WARN: Failed to read the private key /etc/chef/validation.pem: #<Errno::ENOENT: No such file or directory - /etc/chef/validation.pem>
ERROR: Chef::Exceptions::PrivateKeyMissing: I cannot read /etc/chef/validation.pem, which you told me to use to sign requests!
FATAL: Stacktrace dumped to /var/chef/cache/chef-stacktrace.out
ERROR: Sleeping for 1800 seconds before trying again
FATAL: SIGTERM received, stopping
</code>
</pre>
<p>Now, restart chef-client so that new client.pem file can be used in conjuncation with the validation.pem file to register the node/client with the chef-server.</p>
<pre>
<code>[root@chef-client2 chef]# service chef-client restart
</code>
</pre>
<p>As long as the client.pem is there, the validation.pem is there, and the networking is OK, you should connect:</p>
<pre>
<code> INFO: *** Chef 0.10.0 ***
INFO: Run List is []
INFO: Run List expands to []
INFO: Starting Chef Run for chef-client2.example.com
INFO: Loading cookbooks []
WARN: Node chef-client2.example.com has an empty run list.
INFO: Chef Run complete in 6.815418 seconds
INFO: Running report handlers
INFO: Report handlers complete
FATAL: SIGTERM received, stopping
INFO: Daemonizing..
INFO: Forked, in 2032. Priveleges: 0 0
</code>
</pre>
<p>And now the client should appear in the node and client lists. (Note that I have not detailed how to add a user/client to the chef system, you’ll have to do that to use knife.)</p>
<pre>
<code>[someuser@chef-server ~]$ knife node list
chef-client2.example.com
SNIP!
[someuser@chef-server ~]$ knife client list
chef-client2.example.com
SNIP!
</code>
</pre>
<p>(The SNIP!s mean I’ve removed some items for brevity.)</p>
<p>Finally, run @chkconfig chef-client on@ on the chef-client to ensure the service starts at boot.</p>
<h2 id="installing-chef-client-from-a-kickstart-file">Installing chef-client from a kickstart file</h2>
<p>When building new vms I install chef-client from a kickstart file. This is also easily done!</p>
<p>The first important option in the kickstart file is the <code class="language-plaintext highlighter-rouge">repo</code> option.</p>
<pre>
<code>repo --name=chef --baseurl=http://your_repo_server/mrepo/chef-x86_64/RPMS.chef/
</code>
</pre>
<p>and then, in the <code class="language-plaintext highlighter-rouge">%packages</code> section simply add:</p>
<pre>
<code>rubygem-chef
</code>
</pre>
<p>which will be installed from the chef repo configured in the repo option.</p>
<p>Also, enable the service:</p>
<pre>
<code>services --enabled chef-client
</code>
</pre>
<p>Finally, in the <code class="language-plaintext highlighter-rouge">%post</code> section I add the below. Note the [PASTE THE CONTENTS OF YOUR VALIDATION.PEM HERE!!!] portion–that means put the results of @cat /etc/chef/validation.pem@ there, not that actual phrase. :)</p>
<pre>
<code>%post
# chef-client
if [ ! -e /etc/chef ]; then
mkdir /etc/chef
fi
cat > /etc/chef/client.rb << EOCLRB
log_level :info
log_location STDOUT
chef_server_url 'http://chef-server.example.com:4000'
EOCLRB
chmod 600 /etc/chef/client.rb
cat > /etc/chef/validation.pem << EOVALPEM
[PASTE THE CONTENTS OF YOUR VALIDATION.PEM HERE!!!]
EOVALPEM
chmod 600 /etc/chef/validation.pem
</code>
</pre>
<p>When the server built from this kickstart boots chef-client will startup. However, it will fail the first time it starts up because the client.pem had to be generated. But, the next time it starts up it will connect to the chef-server and register. If you want it to register right away, then ssh into the server and run @service chef-client restart@ and it should register.</p>
Installing Jekyll on Ubuntu 10.042011-05-09T00:00:00+00:00http://serverascode.com/2011/05/09/Installing-jekyll-on-ubuntu-10-04<h1 id="installing-jekyll-on-ubuntu-1004">Installing Jekyll on Ubuntu 10.04</h1>
<p>Another small post…given that I’ve recently changed jobs and thus have new workstation(s) to install and configure as I like them, <em>and</em> that I recently purchased a used Lenovo T61 laptop (which BTW is running very well on Ubuntu 10.04/Lucid, perhaps fodder for another post) I’ve repeated a several software installations lately on Lucid, including getting jekyll running locally so I can review blog posts before I send them up to <a href="http://github.com">github</a> to run <a href="http://serverascode.com">serverascode.com</a>.</p>
<p>When you run @gem install jekyll@ on Lucid, you will recieve this error message:</p>
<pre>
<code>$ grep -i release /etc/lsb-release
DISTRIB_RELEASE=10.04
$ gem install jekyll
ERROR: Error installing jekyll:
liquid requires RubyGems version >= 1.3.7
</code>
</pre>
<p>Lucid comes with @gem 1.3.5@ which is not the version that Jekyll’s gem requires. When searching for the error message I found <a href="http://help.rubygems.org/discussions/problems/350-installing-rubygems-137-and-jekyll-on-ubuntu-1004#comment_3175741">this</a> post which describes one way of getting jekyll running on lucid, which is to install the gem package from Ubuntu 10.10. Now, obviously installing a package from what essentially is a different version of Ubuntu isn’t usually a recommended way to go, it’s certainly a quick and easy one (duh! :) ). I downloaded the <a href="http://packages.ubuntu.com/maverick/all/rubygems1.8/download">rubygems1.8_1.3.7-2</a> package and installed it. Then I was able to run @gem install jekyll@ and then run jekyll:</p>
<pre>
<code>$ jekyll --server --auto
Configuration from /ccollicutt.github.com/_config.yml
Auto-regenerating enabled: /ccollicutt.github.com -> ccollicutt.github.com/_site
[2011-04-20 13:20:25] regeneration: 12 files changed
[2011-04-20 13:20:25] INFO WEBrick 1.3.1
[2011-04-20 13:20:25] INFO ruby 1.8.7 (2010-01-10) [x86_64-linux]
[2011-04-20 13:20:30] INFO WEBrick::HTTPServer#start: pid=7082 port=4000
SNIP!
</code>
</pre>
<p>It remains to be seen if I’ll run into issues with having the <code class="language-plaintext highlighter-rouge">gem</code> from Ubuntu 10.10 running on Ubuntu 10.04. I’ll update this post if I do. <em>:)</em></p>
Using LVM hosttags2011-04-13T00:00:00+00:00http://serverascode.com/2011/04/13/using-lvm-hosttags<h1 id="using-lvm-hosttags">Using LVM hosttags</h1>
<p>This is a somewhat minor post, but I thought it would be worthwhile to take a peek at using LVM hosttags to manage dom0 access to logical volumes on top of SAN LUNs because there doesn’t seem to be a lot of documentation on using hosttags online. Perhaps that’s because no one is doing it this way.</p>
<p>While it’s not my favorite way of managing SAN disks across servers (I like <a href="http://docs.redhat.com/docs/en-US/Red_Hat_Enterprise_Linux/6/html/Logical_Volume_Manager_Administration/LVM_Cluster_Overview.html">clvmd</a> but it brings considerable complexity), hosttags are certainly one way to do it. Hosttags are a relatively simple method, and better than LVM filters IMHO. The point of using LVM hosttags is to ensure that only one server is ever writing to a SAN LUN at a time (unless you have something like GFS or similar in use, which is managing that process of multiple writers, and in that case what are you doing here? :) ).</p>
<p>In this example we have three Redhat Enterprise 5.x dom0 servers connected to a large–and expensive–storage area network. We’ll call them <code class="language-plaintext highlighter-rouge">vmhost1</code>, <code class="language-plaintext highlighter-rouge">vmhost2</code>, and <code class="language-plaintext highlighter-rouge">vmhost3</code>. The LUNs are provided to the vmhosts via the SANs configuration software. The vmhosts see them as regular disk, but they <em>aren’t</em> regular disk because each of the servers can see them, where see means read and write. (Note that I may be using terms incorrectly, but by SAN LUN I mean the slice of SAN disk provided to the server over fibre channel.)</p>
<pre>
<code>[root@vmhost1 ~]# multipath -l | grep 00000002
mpath3 (877880e80144455000001445500000002) dm-12 HITACHI,OPEN-V*4
[root@vmhost2 ~]# multipath -l | grep 00000002
mpath3 (877880e80144455000001445500000002) dm-11 HITACHI,OPEN-V*4
[root@vmhost3 ~]# multipath -l | grep 00000002
mpath3 (877880e80144455000001445500000002) dm-11 HITACHI,OPEN-V*4
</code>
</pre>
<p>As is shown in the above output, each of the hosts can see the same SAN LUN: <code class="language-plaintext highlighter-rouge">877880e80144455000001445500000002</code> which in each case is also called <code class="language-plaintext highlighter-rouge">mpath3</code>. But I don’t really care about what names the disk is given because I run LVM on top of those disks.</p>
<pre>
<code>[root@vmhost2 ~]# pvs | grep mpath3
/dev/mapper/mpath3 some_volume_group LVM2 a- 96.62G 16.62G
</code>
</pre>
<p>So, we have a SAN LUN, a physical volume (PV) made from that LUN, and a volume group (VG) called <code class="language-plaintext highlighter-rouge">some_volume_group</code> created from that PV.</p>
<p>So it sort of looks like this in terms of hierarchy:</p>
<ul>
<li>Fibre Channel SAN LUN</li>
<li>multipathd</li>
<li>PV</li>
<li>VG</li>
<li>Logical volume (LV) which has hosttags assigned</li>
</ul>
<h2 id="using-hosttags">Using hosttags</h2>
<p>First we make sure we have hosttags configured on each of the vmhosts.</p>
<pre>
<code>[root@vhmost2 lvm]# pwd
/etc/lvm
[root@vmohost2 lvm]# grep hosttags lvm.conf
tags { hosttags = 1 }
</code>
</pre>
<p>Obviously because I run using LVM hosttags in production, I already have hosttags configured and being used to control vmhost access to LVs.</p>
<pre>
<code>[root@vmohost2 lvm]# uname -n
xmhost2.example.com
[root@vmhost2 lvm]# lvdisplay @`uname -n` | grep "LV Name"
SNIP!
lv Name /dev/some_logical_volume/test
</code>
</pre>
<p>If I want to create a LV on a vmhost, and that VG is configured to use hosttags, then it has to be done properly. This is an example that will fail because the host does not have permission, ie. the LV is not available because of the lack of a hosttag attribute on the LV that names the @uname -n@ host specifically.</p>
<pre>
<code>[root@vmhost2 ~]# lvcreate -n test2 -L10.0G /dev/some_volume_group
# Will fail out with error message
</code>
</pre>
<p>But this <em>next</em> command will work, because we are saying create a LV and assign a hosttag to it which is the same as the hostname that is creating it. The vmhost can’t create a LV if it’s not made available via a hosttag.</p>
<pre>
<code>[root@vmhost2 ~]# uname -a
vmhost2.example.com
[root@vmhost2 ~]# lvcreate --addtag @vmhost2.example.com -n test2 \
-L10.0G /dev/some_volume_group
</code>
</pre>
<p>Now, on <code class="language-plaintext highlighter-rouge">vmhost1</code> we can see that the LV appears in the list, but it is not available:</p>
<pre>
<code>[root@vmhost1 ~]# lvs some_volume_group | grep test2
test2 some_volume_group -wi--- 10.00G
</code>
</pre>
<p>But it’s available on vmhost2, where it was created, and where it has a hosttag attribute of <code class="language-plaintext highlighter-rouge">vmhost2.example.com</code>.</p>
<pre>
<code>[root@vmhost2 ~]# lvs some_volume_group | grep test2
test2 some_volume_group -wi-a- 10.00G
</code>
</pre>
<p>And, if you use @lvdisplay @<code class="language-plaintext highlighter-rouge">uname -n</code>@ you can see what LVs have the servers @uname -n@ tag:</p>
<pre>
<code>[root@vmhost2 ~]# lvdisplay @vmhost2.example.com | grep "LV Name"
LV Name /dev/some_volume_group/test2
</code>
</pre>
<p>whereas <code class="language-plaintext highlighter-rouge">vmhost1</code> does not see that LV:</p>
<pre>
<code>[root@vmhost1 ~]# lvdisplay @vmhost1.example.com | grep "LV Name"
# Nothing returns, as expected
</code>
</pre>
<p>So, while this sounds complicated, it really isn’t. Essentially for a LV to be available to a server that can see the same LUNs as other servers, in terms of LVM, it must have its hosttag added to the LVs metadata. Otherwise, it’s not available and can’t be used on that host.</p>
<p>While all three hosts can see the LV, it’s only available to those vmhosts that have had their hostname added to the specific LVs tags. It adds complexity to the vmhost setup and use, but it’s better to do this than to end up having two virtual machines writing to the same LV. Other options include using filtering in LVM, or even going all the way and using <a href="http://docs.redhat.com/docs/en-US/Red_Hat_Enterprise_Linux/6/html/Logical_Volume_Manager_Administration/LVM_Cluster_Overview.html">clvmd</a>, which I have done, <em>but that’s another story…</em> :)</p>
What is serverascode.com?2011-04-11T00:00:00+00:00http://serverascode.com/2011/04/11/what-is-serverascode_com<h1 id="what-is-serverascodecom">What is serverascode.com?</h1>
<p>serverascode.com has two major functions: 1) to document how I am working through the process of learning to treat servers as code, and 2) to be my systems administration resume.</p>
<p>Starting with #2, I believe that in my line of work–Unix/Linux systems administration–in todays “market”, a two page traditional resume will not get me the job I’m looking for. The only thing that will is a good set of open source contributions; that if servers are code, then much of what I do as a systems administrator should be available on-line in a source code repository. As I write this post, I only have a few lines of code available at <a href="https://github.com/ccollicutt/kicker">github</a> but as time goes on that will increase.</p>
<p>As far as #1, I love to read about the latest way systems administrator are working; how they are being successful leveraging technology to manage large numbers of often diverse, highly interconnected systems while still ensuring they are highly operational and secure. I read sites like Hacker News and other blogs that describe a sort of “new age” methodology to systems administration; so called “devops” or “agile sysadmin” or just plain 2010+ systems administration. However, I have not had an opportunity to apply those concepts, and I would like to use this blog, and services like github, to begin treating a @server as code@.</p>
<p>For better or for worse, systems administration has changed greatly–and will continue to change–especially with the recent trend in virtualization. I believe at the core of this change is the concept of treating server(s) as code. My feeling is that in 2010+ we don’t admin a server, we code it. From procurement to deployment to maintenance to decommissioning–it’s all code now.</p>
<p>On top of every Linux distribution, which can perhaps now be a called a OS framework, comes configuration conventions, and a packaging system. Then, over top of the framework, we add a centralized management server instance (perhaps the only server I should be logging into) which runs configuration management software, such as chef, puppet, and others, which control installation and configuration of applications, alerting things such as change management, and other systems I have not yet determined.</p>
<p>Suffice it to say that I am looking forward to working towards treating @servers as code@ and documenting that process in blog posts and, hopefully more-so, as code!</p>